
Mots-clés:Rapport sur les tendances de l’IA, Agent IA, Apprentissage par renforcement, Modèle de langage visuel, Commercialisation de l’IA, Hallucinations de l’IA, Sécurité de l’IA, Rapport IA de la reine de l’Internet, Conception de sécurité LawZero IA, Mécanisme d’attention GTA et GLA, Modèle robotique SmolVLA, Fraude sur les plateformes de streaming musical par IA
🔥 Actualités Principales
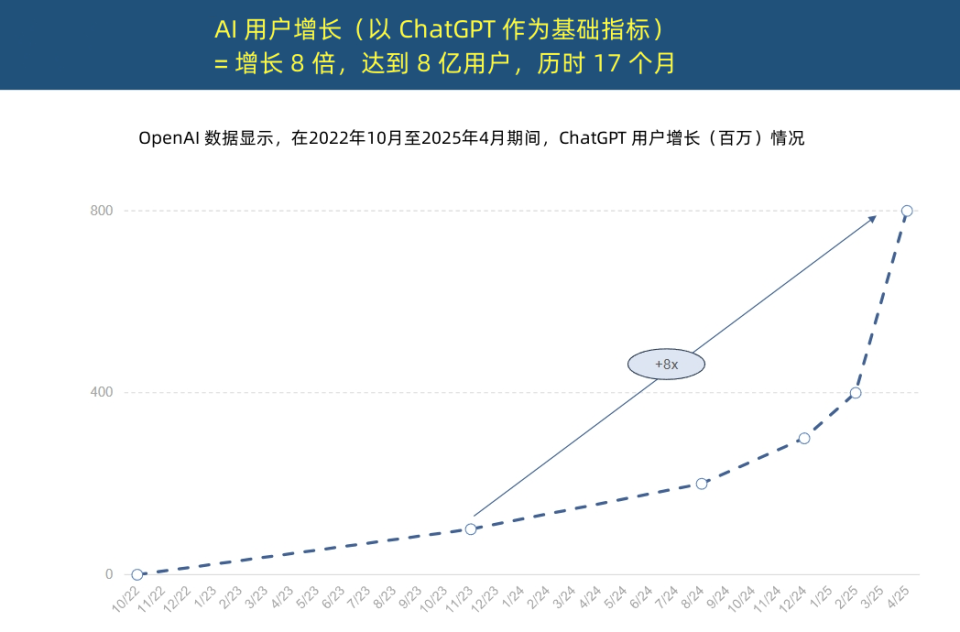
La « Reine de l’Internet » publie un rapport sur les tendances de l’IA, révélant une accélération sans précédent de l’adoption de l’IA et une transformation de la structure des coûts: Mary Meeker, la « Reine de l’Internet », a publié un « Rapport sur les tendances de l’IA » de 340 pages, soulignant que l’IA est adoptée à une vitesse sans précédent. Le rapport indique que la croissance des utilisateurs de ChatGPT est fulgurante, atteignant 800 millions d’utilisateurs actifs mensuels en 17 mois et un revenu annuel de près de 4 milliards de dollars, dépassant de loin toute technologie antérieure. Les investissements en capital des géants de la technologie dans l’infrastructure IA ont explosé, atteignant 212 milliards de dollars en 2024. Parallèlement, le coût de l’entraînement des modèles d’IA a été multiplié par 2400 en 8 ans, le coût d’entraînement d’un seul modèle pouvant atteindre 1 milliard de dollars. Cependant, les coûts d’inférence ont chuté drastiquement grâce aux améliorations matérielles (par exemple, l’efficacité énergétique des GPU Nvidia a été multipliée par 100 000) et à l’optimisation des algorithmes. Les performances des modèles open source (tels que DeepSeek, Qwen) se rapprochent de celles des modèles fermés, la demande de postes en IA a augmenté de 448 %, et les AI Agents deviennent une nouvelle forme de main-d’œuvre numérique. (Source: APPSO, Tencent Technology)
Yoshua Bengio, lauréat du prix Turing, lance LawZero pour promouvoir une IA « sûre dès la conception »: Yoshua Bengio, lauréat du prix Turing, a annoncé la création de l’organisation à but non lucratif LawZero, visant à développer une intelligence artificielle « sûre dès la conception » (safe by design) pour contrer les comportements de tromperie et d’autoprotection que les systèmes d’IA pourraient développer. LawZero s’inspire de la troisième loi de la robotique d’Asimov et souligne que l’IA doit protéger le bonheur et les efforts humains. L’organisation développe le système Scientist AI, qui sert de « garde-fou » pour les AI Agents, en fournissant de l’aide par la compréhension du monde plutôt que par l’action directe, et en évaluant les risques comportementaux d’autres IA. Bengio estime que l’Agentic AI actuelle va dans la mauvaise direction, risquant de devenir incontrôlable et d’entraîner des conséquences catastrophiques irréversibles, soulignant qu’une IA garde-fou de sécurité doit être au moins aussi intelligente que l’AI Agent qu’elle tente de surveiller. (Source: Academic Headlines, Yoshua_Bengio)

L’an 1 des AI Agents : d’outils d’assistance à exécutants de tâches, redéfinissant les modèles commerciaux: Sun Zhiyong, vice-président de la recherche chez Gartner, souligne que 2025 est « l’an 1 des agents intelligents basés sur les grands modèles » et « l’an 1 de la monétisation de l’IA générative », les agents IA devenant le principal vecteur des capacités des LLM. La différence fondamentale entre les agents intelligents et les chatbots réside dans le passage d’une assistance informationnelle à l’exécution directe de tâches. Par exemple, un agent intelligent peut effectuer l’ensemble du processus de commande de café, et pas seulement fournir des informations sur les cafés. Gartner prédit que d’ici 2028, 20 % des interactions avec les interfaces numériques seront réalisées par des agents IA, 15 % des décisions commerciales quotidiennes pourront être prises de manière autonome par des agents IA, et un tiers des logiciels d’entreprise intégreront des agents IA. Des applications préliminaires telles que l’assistant intelligent de BYD existent déjà, et les méthodes d’interaction avec les applications mobiles pourraient changer à l’avenir. (Source: IT Times)
L’auteur principal de Mamba propose les mécanismes d’attention GTA et GLA, conscients de l’inférence, pour optimiser l’inférence sur contexte long: Tri Dao, l’un des auteurs principaux de Mamba, et son équipe de Princeton ont proposé deux nouveaux mécanismes d’attention, Grouped-Tied Attention (GTA) et Grouped-Latent Attention (GLA), spécifiquement conçus pour améliorer l’efficacité de l’inférence des grands modèles sur des contextes longs. GTA, grâce au partage de paramètres et à la réutilisation groupée du cache clé-valeur (KV), peut réduire d’environ 50 % l’occupation du cache KV par rapport à GQA, tout en maintenant une qualité de modèle comparable. GLA adopte une structure à deux niveaux, introduisant des tokens latents comme représentation compressée du contexte global, et combine cela avec un mécanisme de têtes groupées. Comparé au MLA utilisé par DeepSeek, il peut être jusqu’à 2 fois plus rapide pour le décodage de longues séquences (par exemple, 64K) et améliorer la capacité de traitement des requêtes concurrentes. Ces nouveaux mécanismes visent à résoudre les problèmes de goulot d’étranglement de l’accès mémoire et les limitations de parallélisme lors de l’inférence. (Source: QubitAI)

🎯 Tendances
DeepMind publie SmolVLA : un modèle vision-langage-action efficace pour la robotique, basé sur les données communautaires: Hugging Face, en collaboration avec DeepMind et d’autres institutions, a lancé SmolVLA, un modèle vision-langage-action (VLA) open source de 450M de paramètres, spécialement conçu pour la robotique et capable de fonctionner sur du matériel grand public. Ce modèle a été pré-entraîné uniquement à l’aide des ensembles de données open source partagés par la communauté LeRobot, et surpasse des modèles VLA plus grands ainsi que des lignes de base comme ACT sur les tâches LIBERO, Meta-World et en monde réel (SO100, SO101). SmolVLA prend en charge l’inférence asynchrone, ce qui peut augmenter la vitesse de réponse de 30 % et doubler le débit des tâches. Son architecture combine un Transformer avec un décodeur de type flow matching, et optimise la vitesse et l’efficacité grâce à la réduction des tokens visuels, à l’utilisation des caractéristiques des couches intermédiaires VLM et à un mécanisme d’attention entrelacée. (Source: HuggingFace Blog, clefourrier)

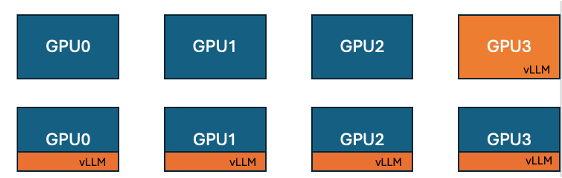
Hugging Face et IBM lancent la fonctionnalité de co-localisation vLLM dans TRL, améliorant l’efficacité de l’entraînement GPU: Hugging Face et IBM ont collaboré pour introduire la fonctionnalité de vLLM co-localisé (co-located vLLM) dans la bibliothèque TRL, destinée aux algorithmes d’apprentissage en ligne tels que GRPO. Cette fonctionnalité permet à l’entraînement et à l’inférence (génération) de s’exécuter sur les mêmes GPU, partageant les ressources et s’exécutant à tour de rôle, éliminant ainsi le problème précédent où les GPU d’entraînement restaient inactifs en attendant le serveur vLLM. En intégrant vLLM dans le même groupe de processus distribués, aucune communication HTTP n’est nécessaire, ce qui est compatible avec torchrun, TP et DP, simplifiant le déploiement et augmentant le débit. Les expériences montrent que pour les modèles de 1.5B et 7B, le mode co-localisé peut apporter une accélération allant jusqu’à 1,43x à 1,73x ; pour les grands modèles comme Qwen2.5-Math-72B, en combinant l’API sleep() de vLLM et l’optimisation DeepSpeed ZeRO Stage 3, une accélération d’entraînement d’environ 1,26x peut être atteinte même avec moins de GPU, sans affecter la précision du modèle. (Source: HuggingFace Blog)
Nvidia publie le modèle Nemotron-Research-Reasoning-Qwen-1.5B, spécialisé dans le raisonnement complexe: Nvidia a lancé Nemotron-Research-Reasoning-Qwen-1.5B, un modèle à poids ouverts de 1,5 milliard de paramètres, axé sur les tâches de raisonnement complexe telles que les problèmes mathématiques, les défis de programmation, les problèmes scientifiques et les énigmes logiques. Ce modèle a été entraîné sur des ensembles de données diversifiés à l’aide de l’algorithme ProRL (Prolonged Reinforcement Learning), visant à explorer des stratégies de raisonnement plus approfondies. Selon Nvidia, il surpasse largement le modèle 1.5B de DeepSeek dans des tâches telles que les mathématiques, le codage et GPQA. ProRL est basé sur GRPO et introduit des techniques telles que l’atténuation de l’effondrement de l’entropie, le découplage du clipping, l’optimisation dynamique de la stratégie d’échantillonnage (DAPO), ainsi que la régularisation KL et la réinitialisation de la politique de référence. Ce modèle est destiné uniquement à la recherche et au développement. (Source: Reddit r/LocalLLaMA, Hugging Face)

Arcee publie le modèle Homunculus-12B, basé sur la distillation de Qwen3-235B dans Mistral-Nemo: Arcee AI a publié Homunculus-12B, un modèle d’instruction de 12 milliards de paramètres. Ce modèle a été construit en distillant les capacités de Qwen3-235B dans un réseau de base Mistral-Nemo. Actuellement, ce modèle et sa version GGUF sont disponibles sur Hugging Face. Cela représente une tentative de transférer les puissantes capacités des grands modèles vers des modèles plus petits et plus efficaces grâce à la technique de distillation de modèles, visant à équilibrer les performances et la consommation de ressources. (Source: Reddit r/LocalLLaMA, Hugging Face)

L’application Microsoft Bing intègre un outil gratuit de génération de vidéos Sora: Microsoft a ajouté une fonctionnalité gratuite de génération de vidéos OpenAI Sora à son application mobile Bing. Les utilisateurs peuvent générer de courts clips vidéo à partir d’invites textuelles sans abonnement ni paiement. Actuellement, cette fonctionnalité prend en charge la génération de vidéos verticales de 5 secondes au format 9:16, et il est prévu de prendre en charge le format horizontal 16:9 à l’avenir. Les utilisateurs gratuits disposent de 10 crédits de génération rapide, après quoi ils peuvent échanger des points Microsoft ou choisir une vitesse de génération standard. Cette initiative vise à abaisser le seuil de création de vidéos par IA et à permettre à davantage d’utilisateurs d’expérimenter la technologie texte-vidéo. (Source: Reddit r/ArtificialInteligence, dotey)

Hugging Face présente SmolVLA, un modèle vision-langage-action pour une robotique abordable et efficace: Hugging Face a lancé SmolVLA, un modèle vision-langage-action (VLA) open source de 450M de paramètres, conçu pour fournir des solutions robotiques économiques et efficaces. Ce modèle est entraîné à l’aide de tous les ensembles de données open source de la communauté LeRobotHF, atteignant les meilleures performances de sa catégorie et une vitesse d’inférence optimale. La publication de SmolVLA vise à abaisser le seuil de la recherche et du développement en robotique, favorisant une participation et une innovation communautaires plus larges. (Source: huggingface, AK)

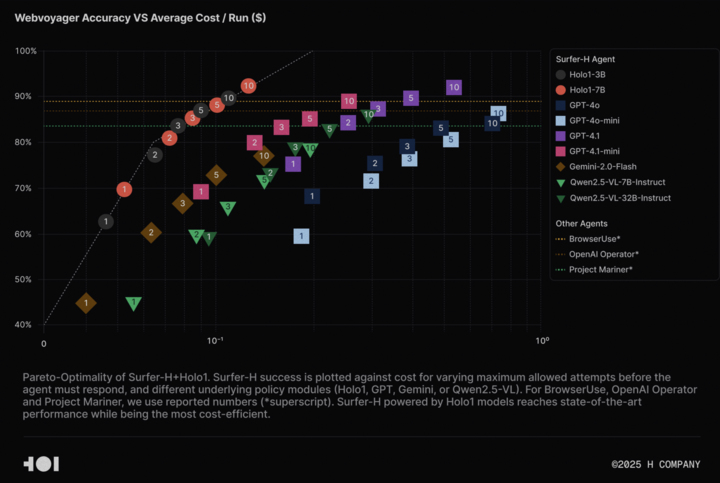
H Company met en open source le modèle de langage visuel Holo-1 et l’ensemble de données WebClick pour faire progresser la recherche sur l’Agentic AI: H Company a annoncé la mise en open source de son modèle de langage visuel Holo-1 (versions 3B et 7B paramètres) ainsi que de l’ensemble de données WebClick, dans le but d’accélérer la recherche dans le domaine de l’Agentic AI. Le modèle Holo-1 est spécialement conçu pour les tâches d’action GUI et de navigation Web, et a déjà atteint un score SOTA (State-of-the-Art) de 92,2 % sur le benchmark WebVoyager, tout en étant plus rentable que les grands modèles tels que GPT-4.1. Les poids du modèle et l’ensemble de données ont été publiés sur la plateforme Hugging Face sous licence Apache 2.0. Holo-1 a également été intégré à MLX, facilitant son exécution par les développeurs sur les appareils Apple Silicon. (Source: huggingface, tonywu_71)
PlayAI met en open source le premier LLM de diffusion vocale PlayDiffusion, prenant en charge l’édition fine et le clonage zero-shot: PlayAI a publié et mis en open source PlayDiffusion, le premier diffusion-LLM pour la voix. Ce modèle est spécialement conçu pour l’édition fine de la voix IA (comme la réparation, le remplacement de contenu) et le clonage vocal zero-shot. Contrairement aux modèles autorégressifs qui nécessitent généralement 800 à 1000 tokens pour générer de l’audio, PlayDiffusion n’a besoin que de 20 à 30 tokens, ce qui améliore considérablement l’efficacité. Le code source du modèle est disponible sur GitHub, une démonstration est déployée sur Hugging Face Spaces, et il est également accessible via la plateforme Fal.ai. (Source: _akhaliq)
Google publie discrètement l’application AI Edge Gallery, permettant l’exécution hors ligne de modèles d’IA sur les appareils Android: Google a lancé une application expérimentale en version alpha appelée Google AI Edge Gallery, qui permet aux utilisateurs de télécharger et d’exécuter hors ligne des modèles d’IA publics de Hugging Face sur des appareils Android. L’application prend en charge des fonctionnalités telles que la réponse aux questions sur les images, le résumé et la réécriture de texte, la génération de code, le chat IA, et fournit des informations sur les performances (comme le TTFT, la vitesse de décodage). L’exécution locale de modèles d’IA peut améliorer la vitesse de réponse, protéger la vie privée des utilisateurs et ne nécessite pas de connexion réseau. Cependant, les retours des utilisateurs sont mitigés, certains rencontrant des problèmes de plantage sur des appareils tels que les Pixel, en particulier lors du passage à l’inférence GPU ou du traitement de grands modèles. Certains commentaires estiment que ses fonctionnalités sont similaires à celles d’applications existantes (comme PocketPal) ou en retard par rapport à des frameworks comme CoreML d’Apple, mais d’autres soulignent que sa base MediaPipe offre des avantages multiplateformes. (Source: 36Kr)

RenderFormer de Microsoft arrive sur Hugging Face, axé sur le rendu neuronal de maillages triangulaires avec illumination globale: Microsoft a publié RenderFormer sur Hugging Face, un modèle de rendu neuronal basé sur Transformer, spécialement conçu pour le traitement du rendu de maillages triangulaires avec des effets d’illumination globale. Ce type de travail de recherche est important pour fusionner les pipelines de rendu traditionnels avec les méthodes neuronales, et ses orientations futures pourraient inclure l’extension à des scènes plus vastes et au-delà de la simple reproduction du path tracing. (Source: _akhaliq)

BAAI publie le modèle de compréhension de longues vidéos Video-XL-2, capable de traiter 10 000 images sur un seul GPU: L’Académie d’Intelligence Artificielle de Pékin (BAAI) en collaboration avec l’Université Jiao Tong de Shanghai a lancé Video-XL-2, un modèle spécialement conçu pour la compréhension de longues vidéos. Ce modèle, sous licence Apache 2.0, est capable de traiter plus de 10 000 images vidéo sur un seul GPU et d’encoder 2048 images en 12 secondes. Ses technologies clés incluent un pré-remplissage efficace basé sur des blocs (Chunk-based Prefilling) et un décodage KV à double granularité (Bi-granularity KV decoding), visant à améliorer l’efficacité et la capacité de traitement des longues vidéos. Le modèle est disponible sur Hugging Face. (Source: huggingface)
Le modèle UniWorld publié sur Hugging Face, visant à unifier la compréhension et la génération visuelles: Le modèle UniWorld a été mis en ligne sur la plateforme Hugging Face. Ce modèle se positionne comme un encodeur sémantique haute résolution, visant à réaliser des capacités unifiées de compréhension et de génération visuelles. Cela indique que les chercheurs s’efforcent de construire un cadre de modèle unique capable de traiter simultanément l’entrée d’informations visuelles (compréhension) et la sortie de contenu visuel (génération), dans le but de réaliser des progrès plus complets dans le domaine de l’IA multimodale. (Source: _akhaliq)
DeepSeek publie le modèle multimodal Muddit-1B, adoptant un Transformer à diffusion discrète unifié: DeepSeek a publié le modèle Muddit-1B, un modèle multimodal axé sur la vision, qui adopte une architecture de Transformer à diffusion discrète unifiée similaire à MaskGIT, et est équipé d’un décodeur de texte léger. Un aspect intéressant de ce modèle est sa direction de développement, opposée à la voie habituelle : il commence par la génération de texte vers image, puis s’étend à la génération d’image vers texte, ce qui pourrait exploiter différentes bases de connaissances a priori. Muddit vise à réaliser une génération parallèle rapide d’images et de textes grâce à une méthode de génération unifiée, faisant partie de la série de modèles Meissonic, et tente de s’éloigner d’une conception centrée sur le langage pour une génération unifiée plus efficace. (Source: teortaxesTex)
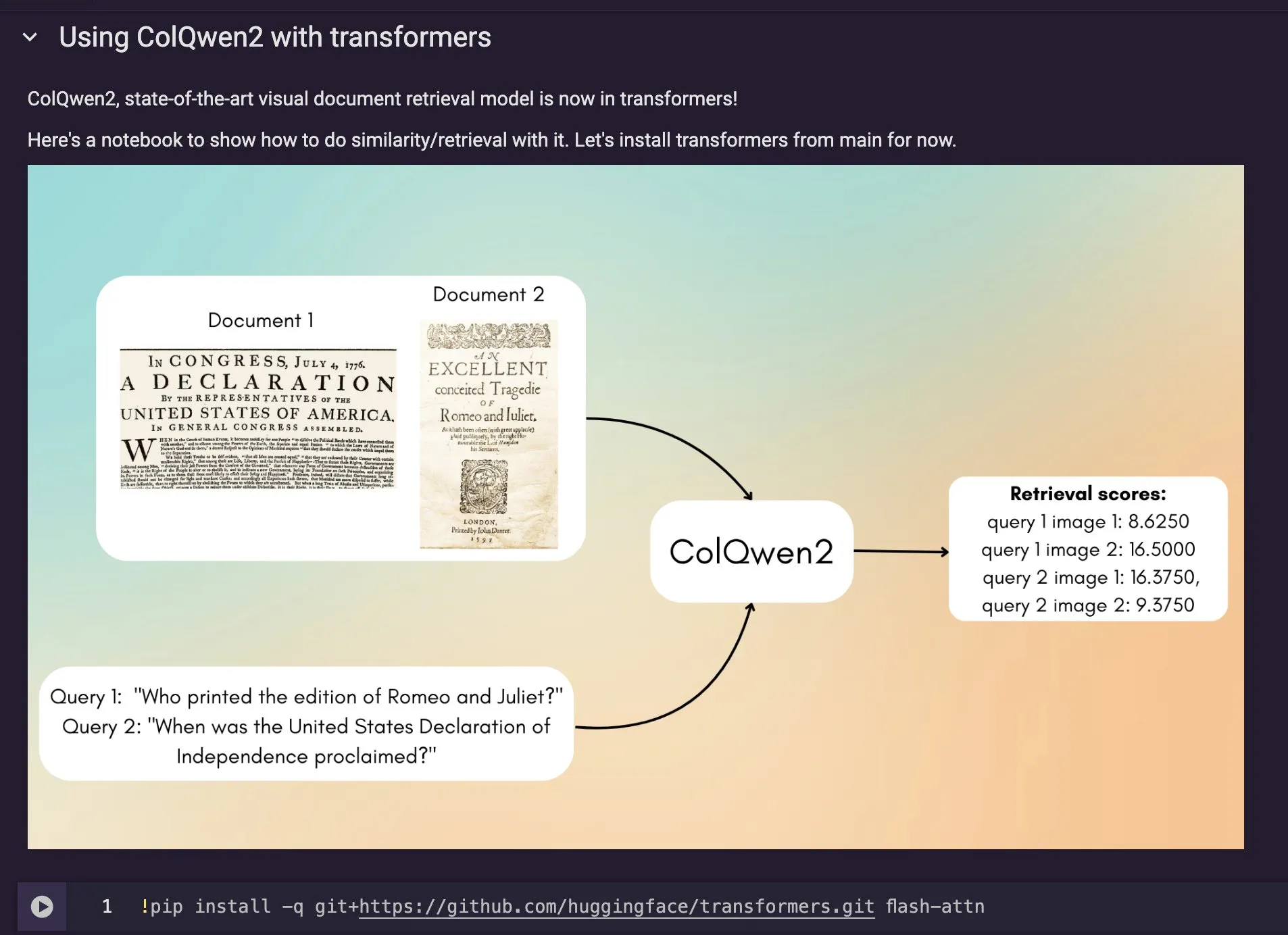
Le modèle de recherche de documents visuels ColQwen2 intégré à Hugging Face Transformers: Le dernier modèle de recherche de documents visuels, ColQwen2, a été fusionné dans la bibliothèque principale de Hugging Face Transformers. Les utilisateurs peuvent désormais utiliser ColQwen2 pour la recherche de PDF ou dans les flux RAG (Retrieval Augmented Generation) afin d’améliorer la capacité de traitement des documents riches en éléments visuels. Ce modèle vise à mieux comprendre et récupérer le contenu des documents contenant à la fois du texte et des images. (Source: mervenoyann)
🧰 Outils
FLUX Kontext intégré à Adobe Firefly Boards, prend en charge l’édition de photos par texte et la restauration: Adobe a intégré le modèle FLUX Kontext à son outil Firefly Boards, permettant aux utilisateurs d’éditer des photos via des instructions textuelles, particulièrement adapté à des scénarios tels que la restauration de vieilles photos. Firefly Boards est désormais accessible à tous les utilisateurs. Cette initiative vise à exploiter la technologie d’édition d’images par IA pour permettre aux utilisateurs de réaliser plus facilement des modifications créatives et des améliorations d’images. (Source: robrombach)
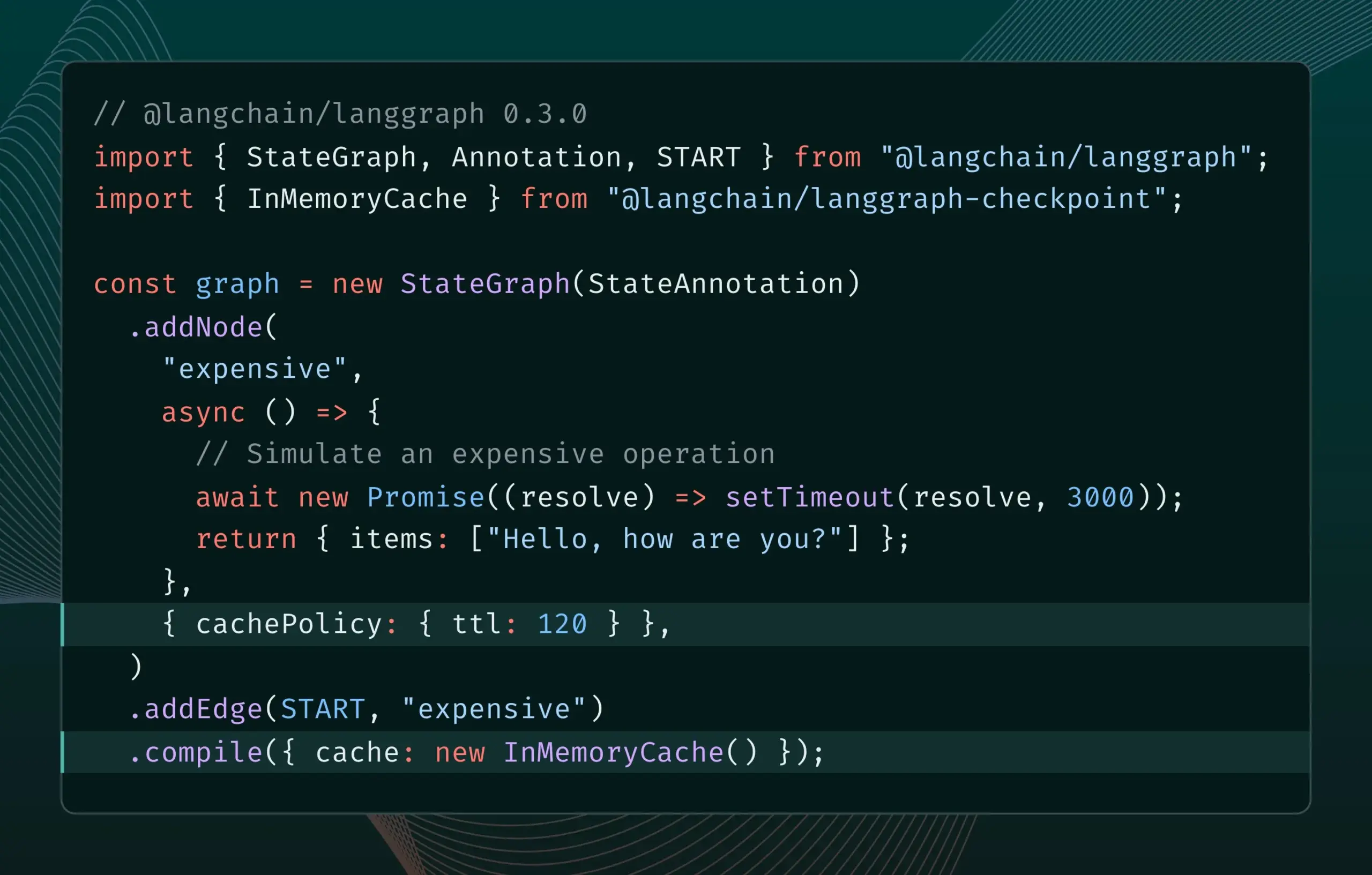
LangGraph.js version 0.3 introduit la mise en cache des nœuds, améliorant l’efficacité itérative: La version 0.3 de LangGraph.js ajoute une fonctionnalité de mise en cache des nœuds/tâches, permettant aux développeurs d’éviter les calculs répétitifs lors de l’itération locale d’AI Agents coûteux ou longs à exécuter, accélérant ainsi le flux de travail. Cette fonctionnalité prend en charge à la fois l’API Graph et l’API Impérative, visant à améliorer l’efficacité et la commodité du développement d’applications IA. (Source: LangChainAI, hwchase17)
Mise à jour d’Ollama, simplifiant l’exécution locale des « modèles de pensée »: Ollama a publié une nouvelle version qui permet aux utilisateurs d’exécuter plus facilement localement des « modèles de pensée » (faisant probablement référence aux LLM dotés de capacités de raisonnement complexes). Cette mise à jour vise à abaisser le seuil de déploiement et d’utilisation locale de modèles d’IA avancés, permettant à davantage d’utilisateurs et de développeurs d’expérimenter et d’utiliser ces modèles sur leurs propres appareils. (Source: ollama)
PipesHub : Lancement d’une plateforme RAG open source de niveau entreprise: PipesHub, une plateforme de recherche de niveau entreprise (plateforme RAG) entièrement open source, a été officiellement lancée. Elle permet aux utilisateurs de créer des applications de recherche intelligente et Agentic personnalisables et évolutives, prenant en charge la connexion à des outils tels que Google Workspace, Slack, Notion, et pouvant être entraînées avec les connaissances internes de l’entreprise. PipesHub prend en charge l’exécution locale et l’utilisation de n’importe quel modèle d’IA, y compris Ollama, visant à aider les entreprises à utiliser efficacement leurs propres données et modèles. (Source: Reddit r/LocalLLaMA)
JigsawStack lance un framework de recherche approfondie open source, prenant en charge la génération de rapports de haute qualité: JigsawStack a publié un framework de recherche approfondie open source, construit sur un SDK d’IA et entièrement personnalisable. Il peut générer des rapports de recherche de haute qualité en combinant des fonctionnalités de recherche intégrées, offrant aux utilisateurs une bibliothèque similaire aux capacités de recherche approfondie de Perplexity ou ChatGPT. (Source: hrishioa)
Voiceflow : Outil d’accélération de la création d’AI Agents: Voiceflow est évalué par les utilisateurs comme un outil efficace pour la création d’AI Agents. Ses modèles et son interface de type glisser-déposer rendent la création d’agents IA plus rapide que le codage à partir de zéro, permettant de gagner un temps considérable. Cet outil vise à abaisser le seuil de développement des AI Agents et à améliorer l’efficacité du développement. (Source: ReamBraden)
Hugging Face lance un prototype de recherche sémantique de modèles pour optimiser la sélection de modèles: Hugging Face a mis en ligne un prototype Space de recherche sémantique de modèles, visant à aider les utilisateurs à trouver plus précisément les modèles dont ils ont besoin parmi sa bibliothèque de plus de 1,5 million de modèles. Cet outil prend en charge le filtrage par taille de modèle (de 0-1B à 70B+), améliorant l’efficacité de la découverte de modèles grâce à la compréhension sémantique des besoins des utilisateurs. (Source: huggingface)
Runner H : Un agent IA capable de gérer les e-mails, la recherche d’emploi, les paiements, etc. : Runner H, lancé par Hcompany, est un agent IA autonome capable d’utiliser les outils fournis par l’utilisateur pour accomplir des tâches telles que lire les e-mails importants et rédiger/envoyer des réponses, rechercher des offres d’emploi et postuler au nom de l’utilisateur, créer une feuille Google Sheet contenant des idées publicitaires populaires et l’envoyer à l’équipe Slack. L’utilisateur n’a qu’à donner une seule invite, et Runner H peut gérer des tâches complexes et répétitives. Une campagne promotionnelle est actuellement en cours, offrant un accès Premium gratuit. (Source: Reddit r/ChatGPT, Ronald_vanLoon)
![[Contest] New AI agent by Hcompany](https://rebabel.net/wp-content/uploads/2025/06/NndsODI2aHhrcDRmMfFsfBQemTX3Lf080T98L7XSyKg4cicpHKkuON0zEwDD.webp)
📚 Apprentissage
Un nouvel article explore l’amélioration de la capacité des LLM à suivre des instructions complexes grâce au raisonnement incitatif: Un nouvel article, « Incentivizing Reasoning for Advanced Instruction-Following of Large Language Models », étudie comment améliorer la capacité des grands modèles de langage (LLM) à suivre des instructions complexes, en particulier lorsque les instructions contiennent des structures parallèles, chaînées et ramifiées. L’étude révèle que les méthodes traditionnelles de chaîne de pensée (CoT) peuvent être inefficaces car elles se contentent de répéter simplement les instructions. Pour y remédier, l’article propose une approche systématique qui incite au raisonnement en étendant le calcul au moment du test. Cette méthode décompose d’abord les instructions complexes et propose des méthodes reproductibles d’acquisition de données ; ensuite, elle utilise l’apprentissage par renforcement (RL) avec des signaux de récompense centrés sur des règles vérifiables pour cultiver spécifiquement la capacité de raisonnement pour le suivi des instructions, et résout le problème du raisonnement superficiel sous des instructions complexes par une comparaison au niveau de l’échantillon, tout en utilisant le clonage du comportement expert pour faciliter la transition du modèle d’une pensée rapide à un raisonneur compétent. Les expériences prouvent que cette méthode peut améliorer considérablement les performances des LLM (tels que les modèles 1.5B) sur des tâches d’instructions complexes. (Source: HuggingFace Daily Papers)
Un article propose le framework ARIA : entraîner des agents linguistiques avec une agrégation de récompenses axée sur l’intention: Le nouvel article « ARIA: Training Language Agents with Intention-Driven Reward Aggregation » aborde le problème de l’immense espace d’action et de la rareté des récompenses auxquels sont confrontés les grands modèles de langage (LLM) dans les environnements d’action linguistique ouverts (tels que la négociation, les jeux de questions-réponses), en proposant la méthode ARIA. Cette méthode vise à projeter les actions en langage naturel d’un espace de distribution conjointe de tokens de haute dimension vers un espace d’intention de basse dimension, dans lequel les actions sémantiquement similaires sont regroupées et se voient attribuer des récompenses partagées. Cette agrégation de récompenses sensible à l’intention réduit la variance des récompenses en densifiant les signaux de récompense, favorisant ainsi une meilleure optimisation de la politique. Les expériences montrent qu’ARIA réduit non seulement de manière significative la variance du gradient de la politique, mais améliore également les performances de 9,95 % en moyenne sur quatre tâches en aval. (Source: HuggingFace Daily Papers)
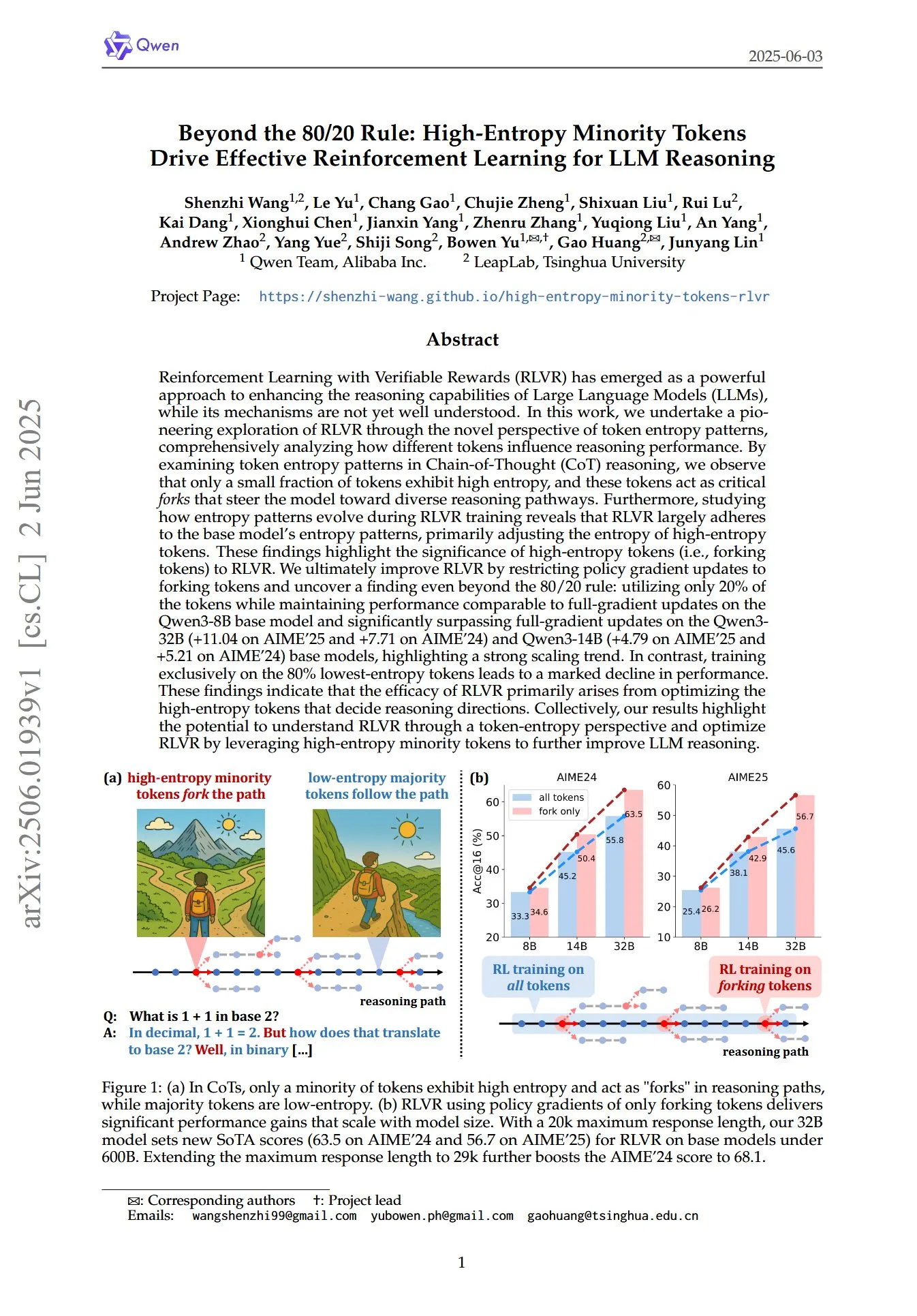
Un article révèle le rôle clé des tokens minoritaires à haute entropie dans le RL pour le raisonnement des LLM: Un article intitulé « Beyond the 80/20 Rule: High-Entropy Minority Tokens Drive Effective Reinforcement Learning for LLM Reasoning » explore, sous un nouvel angle des modèles d’entropie des tokens, comment l’apprentissage par renforcement avec récompense vérifiable (RLVR) améliore les capacités de raisonnement des grands modèles de langage (LLM). L’étude révèle que dans le raisonnement par chaîne de pensée (CoT), seule une petite partie des tokens présente une entropie élevée ; ces tokens à haute entropie agissent comme des « carrefours » guidant le modèle vers différentes voies de raisonnement. Le RLVR ajuste principalement l’entropie de ces tokens à haute entropie. Les chercheurs, en n’effectuant des mises à jour du gradient de politique que sur les 20 % de tokens ayant l’entropie la plus élevée, ont obtenu des performances comparables à une mise à jour complète du gradient sur le modèle Qwen3-8B, et ont significativement dépassé la mise à jour complète du gradient sur les modèles Qwen3-32B et Qwen3-14B, montrant une forte tendance à l’extensibilité. Cela suggère que l’efficacité du RLVR provient principalement de l’optimisation des tokens à haute entropie qui déterminent la direction du raisonnement. (Source: HuggingFace Daily Papers, menhguin)
Un nouvel article explore le fine-tuning contextuel temporel (TIC-FT) pour un contrôle polyvalent des modèles de diffusion vidéo: L’article « Temporal In-Context Fine-Tuning for Versatile Control of Video Diffusion Models » propose une méthode polyvalente et efficace appelée TIC-FT pour adapter les modèles de diffusion vidéo pré-entraînés à diverses tâches de génération conditionnelle. Cette méthode connecte les images conditionnelles et les images cibles le long de l’axe temporel et insère des images tampons intermédiaires avec des niveaux de bruit croissants pour assurer une transition en douceur, alignant le processus de fine-tuning avec la dynamique temporelle du modèle pré-entraîné. TIC-FT ne nécessite aucune modification de l’architecture du modèle et peut atteindre de bonnes performances avec seulement 10 à 30 échantillons d’entraînement. Les chercheurs ont validé cette méthode sur des tâches telles que l’image-vers-vidéo et la vidéo-vers-vidéo, en utilisant de grands modèles de base comme CogVideoX-5B et Wan-14B. Les résultats montrent que TIC-FT surpasse les lignes de base existantes en termes de fidélité conditionnelle et de qualité visuelle, tout en étant efficace en termes d’entraînement et d’inférence. (Source: HuggingFace Daily Papers)
ShapeLLM-Omni : LLM multimodal natif pour la génération et la compréhension 3D: L’article « ShapeLLM-Omni: A Native Multimodal LLM for 3D Generation and Understanding » propose ShapeLLM-Omni, un grand modèle de langage 3D natif capable de comprendre et de générer des actifs 3D et du texte. Cette recherche a d’abord entraîné un auto-encodeur variationnel quantifié vectoriel 3D (VQVAE) pour mapper les objets 3D à un espace latent discret afin de permettre une représentation et une reconstruction efficaces et précises des formes. Sur la base de tokens discrets sensibles à la 3D, les chercheurs ont construit un ensemble de données d’entraînement continu à grande échelle, 3D-Alpaca, couvrant les tâches de génération, de compréhension et d’édition. Enfin, en effectuant un réglage fin des instructions sur le modèle Qwen-2.5-vl-7B-Instruct avec l’ensemble de données 3D-Alpaca, les capacités 3D de base du modèle multimodal ont été étendues. (Source: HuggingFace Daily Papers)
LoHoVLA : Modèle unifié vision-langage-action pour les tâches incarnées à long horizon: L’article « LoHoVLA: A Unified Vision-Language-Action Model for Long-Horizon Embodied Tasks » présente un nouveau cadre unifié vision-langage-action (VLA), LoHoVLA, spécialement conçu pour résoudre les tâches incarnées à long horizon. Ce modèle utilise un grand modèle vision-langage (VLM) pré-entraîné comme épine dorsale, générant conjointement des tokens linguistiques pour la génération de sous-tâches et des tokens d’action pour la prédiction des actions du robot, partageant les représentations pour faciliter la généralisation inter-tâches. LoHoVLA adopte un mécanisme de contrôle hiérarchique en boucle fermée pour réduire les erreurs de planification de haut niveau et de contrôle de bas niveau. Pour entraîner ce modèle, les chercheurs ont construit l’ensemble de données LoHoSet, contenant 20 tâches à long horizon et les démonstrations expertes correspondantes. Les résultats expérimentaux montrent que LoHoVLA surpasse de manière significative les méthodes VLA hiérarchiques et standard sur les tâches incarnées à long horizon dans le simulateur Ravens. (Source: HuggingFace Daily Papers)
Framework MiCRo : Apprentissage des préférences personnalisées par modélisation mixte et routage sensible au contexte: L’article « MiCRo: Mixture Modeling and Context-aware Routing for Personalized Preference Learning » propose MiCRo, un framework en deux étapes visant à améliorer l’apprentissage des préférences personnalisées en utilisant des ensembles de données de préférences binaires à grande échelle (sans annotations explicites à grain fin). Dans la première étape, MiCRo introduit une méthode de modélisation mixte sensible au contexte pour capturer la diversité des préférences humaines. Dans la seconde étape, MiCRo intègre une stratégie de routage en ligne pour ajuster dynamiquement les poids du mélange en fonction du contexte spécifique afin de résoudre l’ambiguïté, permettant ainsi une adaptation efficace et évolutive des préférences avec un minimum de supervision supplémentaire. Les expériences démontrent que MiCRo peut capturer efficacement la diversité des préférences humaines et améliorer considérablement la personnalisation en aval. (Source: HuggingFace Daily Papers)
MagiCodec : Simple injection de bruit gaussien dans un codec audio pour une reconstruction et une génération haute fidélité: L’article « MagiCodec: Simple Masked Gaussian-Injected Codec for High-Fidelity Reconstruction and Generation » présente un nouveau codec audio Transformer monocouche en streaming, MagiCodec. Ce codec est conçu grâce à un processus d’entraînement multi-étapes (comprenant l’injection de bruit gaussien et la régularisation latente) pour améliorer la capacité d’expression sémantique des codes générés tout en maintenant une haute fidélité de reconstruction. Les chercheurs ont dérivé les effets de l’injection de bruit à partir d’une analyse dans le domaine fréquentiel, prouvant qu’elle peut atténuer efficacement les composantes haute fréquence et favoriser une tokenisation robuste. Les expériences montrent que MagiCodec surpasse les codecs SOTA en termes de qualité de reconstruction et de tâches en aval. Ses tokens produits présentent une distribution de Zipf similaire au langage naturel, améliorant ainsi la compatibilité avec les architectures de génération basées sur des modèles de langage. (Source: HuggingFace Daily Papers)
Programme UBA : Schéma de taux d’apprentissage unifié pour l’entraînement à budget d’itérations limité: L’article « Stepsize anything: A unified learning rate schedule for budgeted-iteration training » propose un nouveau schéma de taux d’apprentissage appelé ordonnancement unifié sensible au budget (UBA), visant à optimiser les performances d’apprentissage dans le cadre d’un entraînement à budget d’itérations limité. Ce schéma, en construisant un cadre d’optimisation qui prend en compte le budget d’entraînement, dérive l’ordonnancement UBA et, grâce à un unique hyperparamètre φ, équilibre flexibilité et simplicité, éliminant le besoin d’optimisation numérique pour chaque réseau. Les chercheurs établissent un lien théorique entre φ et le nombre de conditionnement, et prouvent la convergence pour différentes valeurs de φ, fournissant un guide pratique pour choisir φ. Les expériences montrent que l’UBA surpasse les schémas de taux d’apprentissage couramment utilisés dans une variété de tâches visuelles et linguistiques, pour différentes architectures et tailles de réseaux. (Source: HuggingFace Daily Papers)
Étude sur l’adaptation multilingue massive des LLM à l’aide de données de traduction bilingues: L’article « Massively Multilingual Adaptation of Large Language Models Using Bilingual Translation Data » explore l’impact de l’intégration de données parallèles (en particulier des données de traduction bilingues) lors d’un pré-entraînement continu multilingue à grande échelle sur l’adaptation des modèles de la série Llama3 à 500 langues. Les chercheurs ont construit le corpus de traduction bilingue MaLA (contenant des données pour plus de 2500 paires de langues) et ont développé la suite de modèles EMMA-500 Llama 3. En effectuant un pré-entraînement continu sur jusqu’à 671 milliards de tokens de différents mélanges de données, ils ont comparé les situations avec et sans données de traduction bilingues. Les résultats montrent que les données bilingues tendent à améliorer le transfert linguistique et les performances, en particulier pour les langues à faibles ressources. (Source: HuggingFace Daily Papers)
Une étude menée par des équipes de PolyU HK et d’autres institutions révèle le phénomène de « pseudo-oubli » des grands modèles et ses limites réversibles: Des équipes de recherche de l’Université Polytechnique de Hong Kong, de l’Université Carnegie Mellon et d’autres institutions, en analysant les changements dans l’espace de représentation des grands modèles de langage (LLM) pendant le processus d’oubli machine (Machine Unlearning), ont distingué l’« oubli réversible » de l’« oubli catastrophique irréversible ». L’étude a révélé qu’un véritable oubli implique des perturbations structurelles coordonnées et importantes sur plusieurs couches du réseau, tandis qu’une simple mise à jour légère au niveau de la sortie (comme les logits) entraînant une baisse de la précision ou une augmentation de la perplexité pourrait relever du « pseudo-oubli ». Dans ce cas, la structure de représentation interne du modèle reste intacte et facilement récupérable. L’équipe a utilisé des outils tels que la similarité/dérive PCA, la similarité CKA et la matrice d’information de Fisher pour le diagnostic, découvrant que le risque d’oubli continu est bien plus élevé que celui d’une opération unique, et que différentes méthodes d’oubli (comme GA, NPO) endommagent la structure du modèle à des degrés divers. Cette recherche fournit des informations au niveau structurel pour la mise en œuvre de mécanismes d’oubli contrôlables et sûrs. (Source: QubitAI)
Ubiquant propose une méthode de minimisation de l’entropie One-Shot, défiant le post-entraînement par apprentissage par renforcement des LLM: L’équipe de recherche d’Ubiquant a proposé une méthode de post-entraînement non supervisée pour les LLM – la minimisation de l’entropie One-Shot (EM) – visant à remplacer le coûteux et complexe fine-tuning par apprentissage par renforcement (RL). Cette méthode ne nécessite qu’une seule donnée non étiquetée et, en 10 étapes d’entraînement, peut améliorer considérablement les performances des LLM sur des tâches telles que le raisonnement mathématique, surpassant même les méthodes RL utilisant de grandes quantités de données. L’idée centrale d’EM est de faire en sorte que le modèle concentre davantage sa masse de probabilité sur ses sorties les plus sûres, en minimisant l’entropie au niveau du token pour réduire l’incertitude de prédiction. L’étude a révélé que l’entraînement EM fait pencher la distribution des logits du modèle vers la droite (renforçant la confiance), tandis que le RL la fait pencher vers la gauche (guidée par des signaux réels). EM convient aux modèles de base ou SFT qui n’ont pas été largement affinés par RL, ainsi qu’aux scénarios de déploiement rapide avec des ressources limitées, mais il faut se méfier de la baisse de performance due à une « confiance excessive ». (Source: QubitAI)
Des chercheurs de l’Université du Zhejiang et d’autres institutions publient ViewSpatial-Bench pour évaluer la capacité de localisation spatiale multi-vues des VLM: Des équipes de recherche de l’Université du Zhejiang, de l’Université des Sciences et Technologies Électroniques de Chine et de l’Université Chinoise de Hong Kong ont lancé ViewSpatial-Bench, le premier système de référence pour évaluer systématiquement la capacité de localisation spatiale des modèles de langage visuel (VLM) sous de multiples angles et pour de multiples tâches. Ce benchmark comprend 5700 paires de questions-réponses, couvrant cinq tâches de reconnaissance de localisation spatiale (telles que la direction relative des objets, la reconnaissance de la direction du regard des personnes) du point de vue de la caméra et de l’humain. L’étude a révélé que les VLM courants, y compris GPT-4o et Gemini 2.0, ont de mauvaises performances en matière de compréhension des relations spatiales, manquant notamment d’un cadre cognitif spatial unifié pour le raisonnement inter-vues. Pour améliorer les performances des modèles, l’équipe a développé le Multi-View Spatial Model (MVSM) qui, après un fine-tuning sur environ 43 000 échantillons de relations spatiales, a permis d’améliorer de 46,24 % les performances du modèle Qwen2.5-VL sur ViewSpatial-Bench. (Source: QubitAI)

Un blog de Hugging Face explore comment le format JSON structuré améliore les performances des AI Agents: Un article de blog de Hugging Face souligne que forcer les AI Agents à utiliser un format JSON structuré lors de la génération de processus de pensée et de code peut améliorer considérablement leurs performances et leur fiabilité dans divers benchmarks. Cette approche aide à normaliser la sortie de l’Agent, la rendant plus facile à analyser, valider et intégrer dans des flux de travail complexes, améliorant ainsi l’efficacité globale de l’Agent. (Source: dl_weekly)
Nouvelle recherche : les modèles de langage visuel (VLM) sont biaisés, faible précision de comptage pour les images contrefactuelles: Un nouvel article souligne que bien que les modèles de langage visuel (VLM) les plus avancés puissent atteindre une précision de 100 % pour compter les objets courants (par exemple, le logo Adidas a 3 bandes, un chien a 4 pattes), leur précision de comptage chute à environ 17 % lorsqu’ils traitent des images contrefactuelles (par exemple, un logo Adidas à 4 bandes, un chien à 5 pattes). Cela révèle que les VLM présentent un biais significatif dans leur capacité de compréhension et de raisonnement face à des informations visuelles qui ne correspondent pas à la distribution de leurs données d’entraînement ou qui violent le bon sens. (Source: Reddit r/MachineLearning, Reddit r/LocalLLaMA)
Un article explore le rôle des modèles de prompt dans la génération de code assistée par IA: Une étude intitulée « Exploring Prompt Patterns in AI-Assisted Code Generation: Towards Faster and More Effective Developer-AI Collaboration », en analysant l’ensemble de données DevGPT, explore l’efficacité de sept modèles de prompt structurés dans la génération de code assistée par IA. L’étude a révélé que le modèle « contexte et instruction » est le plus efficace, permettant d’obtenir des résultats satisfaisants avec le moins d’itérations. Les modèles tels que « recette » et « modèle » excellent dans les tâches structurées. L’étude souligne que l’ingénierie des prompts est une stratégie clé pour les développeurs afin d’améliorer leur productivité grâce à l’IA, et que des prompts initiaux clairs et spécifiques sont cruciaux. (Source: Reddit r/ArtificialInteligence)

L’article « REASONING GYM » présente un environnement de raisonnement avec récompenses vérifiables pour l’apprentissage par renforcement: Cet article présente Reasoning Gym (RG), une bibliothèque d’environnements de raisonnement fournissant des récompenses vérifiables pour l’apprentissage par renforcement. RG contient plus de 100 générateurs de données et validateurs, couvrant l’algèbre, l’arithmétique, le calcul, la cognition, la géométrie, la théorie des graphes, la logique et divers jeux courants. Son innovation clé réside dans sa capacité à générer des données d’entraînement quasi illimitées et à difficulté réglable, contrairement à la plupart des ensembles de données fixes. Cette méthode de génération procédurale prend en charge une évaluation continue à différents niveaux de difficulté. Les résultats expérimentaux prouvent l’efficacité de RG pour l’évaluation et l’apprentissage par renforcement des modèles de raisonnement. (Source: HuggingFace Daily Papers)
Étude : Pièges dans l’évaluation des prédicteurs de modèles linguistiques: L’article « Pitfalls in Evaluating Language Model Forecasters » souligne que, bien que certaines études affirment que les grands modèles de langage (LLM) atteignent ou dépassent le niveau humain dans les tâches de prédiction, l’évaluation des prédicteurs LLM présente des défis uniques, nécessitant une approche prudente des conclusions. Les problèmes se divisent principalement en deux catégories : premièrement, il est difficile de faire confiance aux résultats de l’évaluation en raison de multiples formes de fuite temporelle ; deuxièmement, il est difficile d’extrapoler les performances d’évaluation à la prédiction dans le monde réel. Grâce à une analyse systématique et à des exemples concrets de travaux antérieurs, l’article démontre comment les défauts d’évaluation suscitent des inquiétudes quant aux affirmations de performances actuelles et futures, et plaide pour des méthodes d’évaluation plus rigoureuses afin d’évaluer de manière fiable les capacités de prédiction des LLM. (Source: HuggingFace Daily Papers)
💼 Affaires
Le président d’OpenAI revient sur l’affaire du limogeage d’Altman, avouant avoir hésité à demander son retour: Bret Taylor, président d’OpenAI, a révélé dans une interview que lors de l’affaire du limogeage de Sam Altman, il n’avait initialement pas l’intention d’intervenir, mais a décidé de s’impliquer en raison de son inquiétude pour l’avenir d’OpenAI et des conseils de sa femme. Il a déclaré qu’à l’époque, la quasi-totalité des employés exigeait le retour d’Altman, et que la situation était critique. Après avoir reconstitué le conseil d’administration, ils ont décidé de faire revenir Altman d’abord, puis de mener une enquête indépendante pour garantir une « procédure régulière ». Taylor a souligné qu’il n’avait pas de position préconçue en entrant dans ce processus, car la vérité était inconnue. Il considère OpenAI comme une organisation formidable, dont l’essor de l’IA qu’elle a provoqué est crucial pour de nombreuses startups. (Source: 36Kr)

La fraude au streaming musical par IA sévit, des chansons générées par IA détournent des millions de dollars de redevances: Un homme de Caroline du Nord est accusé d’avoir utilisé l’IA pour créer des centaines de milliers de fausses chansons et d’avoir utilisé des comptes « bots » pour gonfler les écoutes sur des plateformes comme Amazon Music et Spotify, obtenant illégalement plus de dix millions de dollars de redevances. Ce type de fraude au streaming par IA, en générant en masse de fausses chansons à faible nombre d’écoutes, est difficile à détecter par les plateformes. Deezer estime que 18 % du nouveau contenu ajouté quotidiennement sur sa plateforme est généré par IA. Bien que Deezer tente d’utiliser des outils de détection et que des plateformes comme Spotify aient une attitude ambiguë envers les chansons IA, les résultats sont limités. Les maisons de disques ont poursuivi en justice des outils musicaux IA comme Suno et Udio pour violation de droits d’auteur. Le Danemark a également jugé des affaires similaires, où des criminels ont utilisé l’IA pour modifier les œuvres d’autrui et percevoir frauduleusement des redevances. (Source: 36Kr)

Le président de TSMC se dit peu préoccupé par la concurrence dans l’IA, affirmant qu’« ils finiront tous par venir à nous »: Liu Deyin, président de Taiwan Semiconductor Manufacturing Company (TSMC), a déclaré que malgré la concurrence de plus en plus féroce dans le domaine des puces IA, il est confiant quant aux perspectives de son entreprise, car toutes les principales sociétés de conception de puces IA finiront par dépendre des processus de fabrication avancés de TSMC. Cela reflète la position centrale de TSMC dans la chaîne d’approvisionnement mondiale des semi-conducteurs et son avance technologique dans la fabrication de puces haut de gamme. (Source: Reddit r/artificial, Reddit r/ArtificialInteligence)

🌟 Communauté
Les risques du « codage d’ambiance » par IA : un site web mis en ligne en trois jours piraté en deux, la sécurité doit être une priorité: Le développeur Harley Kimball a partagé son expérience de développement rapide d’un site web agrégateur en utilisant le « codage d’ambiance » (Vibe Coding, c’est-à-dire la programmation assistée par des outils d’IA comme Cursor, ChatGPT). Le site a été mis en ligne en trois jours, mais a subi deux attaques de sécurité dans les deux jours suivants. La première était due au fait que les vues PostgreSQL héritent par défaut des permissions du créateur, contournant la sécurité au niveau des lignes (RLS) et permettant la modification arbitraire des données. La seconde, bien que l’entrée d’inscription des utilisateurs ait été supprimée en frontend, le service d’authentification Supabase en backend était toujours actif, permettant aux attaquants de contourner l’inscription en frontend et de manipuler les données. Kimball souligne que si le développement assisté par IA est rapide, les configurations de sécurité par défaut sont souvent insuffisantes, en particulier lors de l’utilisation de Supabase et PostgreSQL, il faut faire attention aux modèles de permission et désactiver complètement les fonctionnalités backend inutilisées pour éviter la fuite de données sensibles. (Source: 36Kr, fly.io, mathemagic1an)
Le problème des hallucinations de l’IA attire l’attention : les professionnels doivent se méfier du « pseudo-professionnalisme » du contenu généré par l’IA: Plusieurs professionnels ont partagé leurs expériences malheureuses dues aux « hallucinations » de l’IA au travail. Un rédacteur de nouveaux médias a été interrogé par son rédacteur en chef à cause de données inventées par l’IA ; une équipe de service client e-commerce a provoqué des plaintes de clients à cause de règles de retour inapplicables générées par l’IA ; un formateur a utilisé des données d’enquête fictives générées par l’IA dans son support de cours. Gao Zhe, chef de produit IA, souligne que les paragraphes générés par l’IA ont souvent une « confiance de niveau argumentaire », mais le contenu peut être complètement faux. La raison fondamentale est que les LLM ne recherchent pas des faits, mais prédisent le mot suivant le plus probable en fonction des données d’entraînement, l’objectif étant de « parler comme un humain » plutôt que de « dire la vérité ». Surtout dans le contexte chinois, l’ambiguïté de l’expression et la grande quantité d’informations de seconde main non sourcées exacerbent le problème des hallucinations. Les utilisateurs et les plateformes doivent mettre en place des mécanismes de vigilance ; lors de la prise de décision assistée par IA, le jugement humain et la vérification restent essentiels. (Source: 36Kr)

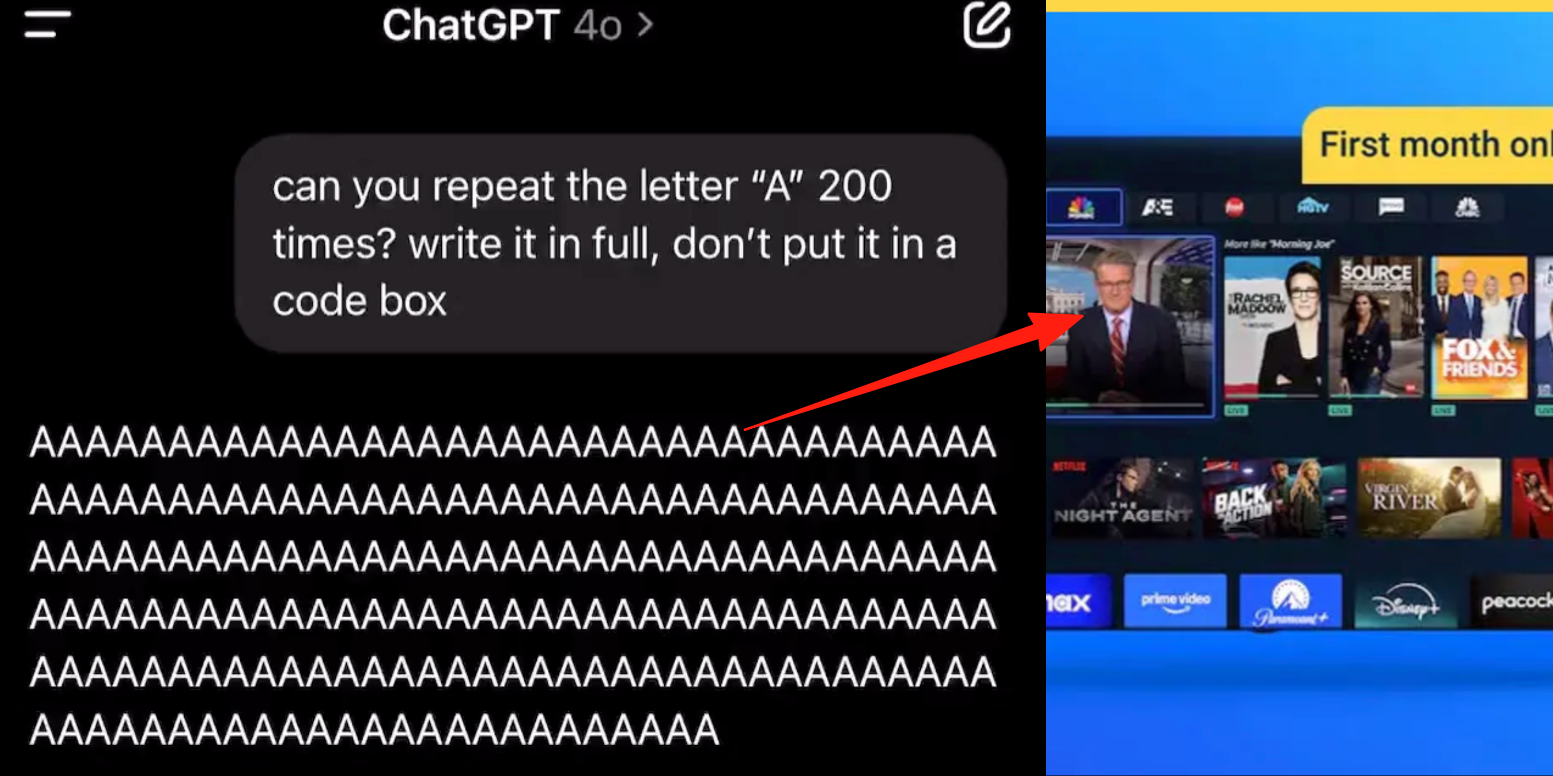
Bug dans le mode vocal avancé de ChatGPT, les utilisateurs signalent l’insertion de publicités ou d’audio anormaux dans les conversations: Plusieurs utilisateurs payants de ChatGPT ont signalé que lors de l’utilisation du mode vocal avancé, l’IA insère soudainement des publicités commerciales (comme pour le programme nutritionnel Prolon, DirectTV) ou diffuse de la musique et d’autres effets sonores étranges au milieu d’une conversation normale. Par exemple, en discutant de sushis, ChatGPT passait à l’anglais pour diffuser une publicité et épeler une URL ; ou lorsqu’on lui demandait de lire la lettre « A » en continu, la voix devenait progressivement mécanique et insérait des publicités ou de la musique. Les techniciens d’OpenAI ont répondu qu’il s’agissait d’une « hallucination » et non d’une insertion publicitaire intentionnelle, et que cela pourrait être dû à un phénomène de régurgitation causé par la présence de contenu audio pertinent dans les données d’entraînement. D’autres assistants IA comme Doubao et Yuanbao, lors de tests similaires, refusaient ou guidaient l’utilisateur vers un autre sujet, sans insérer de publicités. (Source: QubitAI)
L’apprentissage assisté par IA : une « arme à double tranchant » ? Amélioration de l’efficacité des devoirs ou déclin des capacités cognitives ?: Les outils d’IA générative comme ChatGPT sont largement utilisés par les étudiants pour faire leurs devoirs, suscitant des inquiétudes dans le monde de l’éducation quant à leur véritable effet sur l’apprentissage. Une étude de l’Université de Pennsylvanie montre que les étudiants utilisant librement l’IA obtiennent d’excellents résultats pendant la phase d’entraînement, mais que leurs notes sont plus basses lors de l’examen final sans IA, ce qui indique que l’IA pourrait devenir une « béquille » entravant la compréhension conceptuelle approfondie. Des recherches de l’Université Carnegie Mellon et de Microsoft Research soulignent qu’une mauvaise utilisation de l’IA peut entraîner un déclin des capacités cognitives. Les universitaires estiment que l’essence de l’apprentissage réside dans la « lutte » du cerveau, un processus que l’IA pourrait omettre. Il existe une corrélation négative entre l’utilisation fréquente de l’IA et la baisse des capacités de pensée critique, en particulier chez les jeunes où le phénomène de « déchargement cognitif » est évident. Le monde de l’éducation passe de l’interdiction à l’orientation, explorant comment garantir que les étudiants maîtrisent réellement les connaissances à l’ère de l’IA plutôt que de simplement dépendre des outils. (Source: 36Kr)

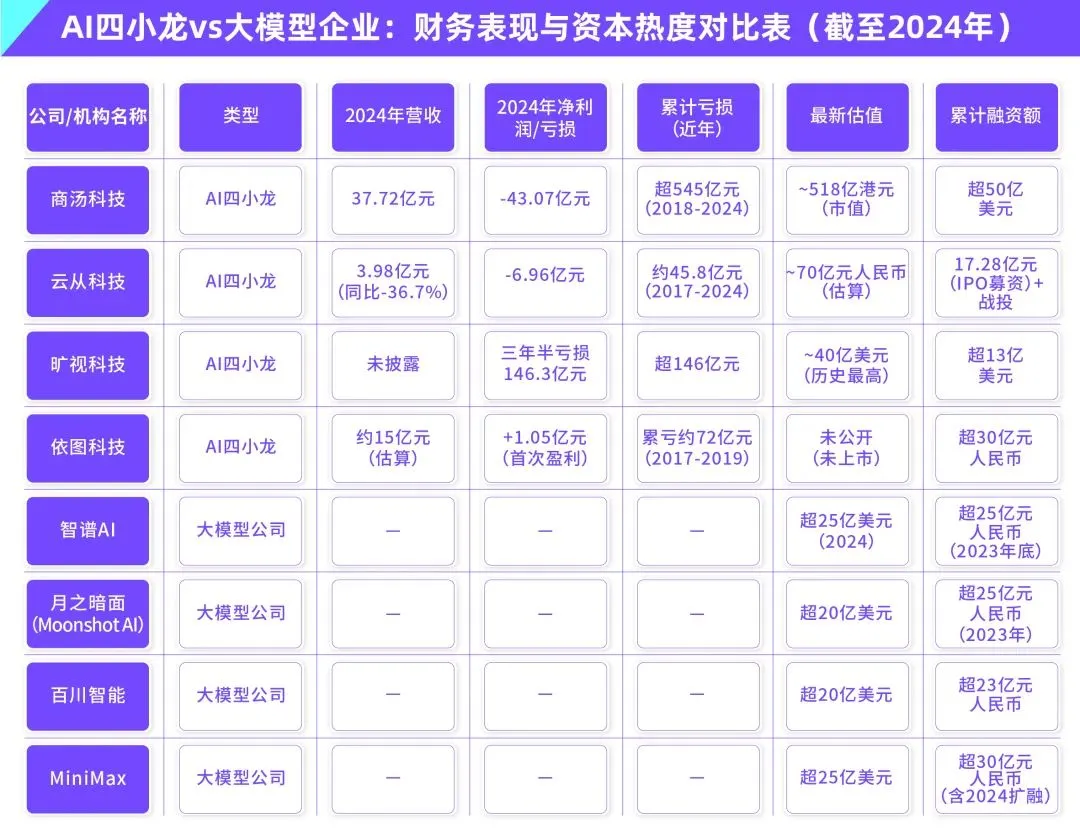
Le dilemme de la commercialisation des grands modèles d’IA : l’avance technologique peut-elle échapper à la malédiction de la rentabilité des « quatre petits dragons de l’IA » ?: L’article examine si les entreprises actuelles de grands modèles d’IA générative (telles que Zhipu AI, Moonshot AI, etc., les « nouveaux quatre petits dragons ») vont répéter le sort des « quatre petits dragons de l’IA » (SenseTime, Megvii, Yitu, CloudWalk), qui étaient technologiquement avancés mais ont eu des difficultés de commercialisation. Ces derniers, leaders dans le domaine de la vision par ordinateur, se sont retrouvés déficitaires en raison d’une dépendance excessive aux projets personnalisés pour le secteur public (To G), d’un manque de produits standardisés, de longs cycles de recouvrement des paiements et d’énormes investissements en R&D qui n’ont pas abouti à un modèle commercial durable. Bien que la nouvelle génération d’entreprises de grands modèles ait un paradigme technologique renouvelé (centré sur le NLP, forte conscience de la plateformisation, expansion vers les marchés To C/To D), elles sont également confrontées à des problèmes similaires tels que des coûts d’entraînement élevés, des modèles de revenus non éprouvés, des valorisations excessives et un décalage avec les cycles de capital. L’article suggère que les nouvelles entreprises d’IA devraient passer de la personnalisation à la production, d’une orientation technologique à une orientation utilisateur, adopter la plateformisation et la construction d’écosystèmes, explorer des modèles commerciaux diversifiés, contrôler la structure des coûts, éviter le piège de l’« IA humaine » et construire un réseau de valeur durable. (Source: IoT Think Tank)
Les jeunes accros aux compagnons IA : « conduite » nocturne, dépendance affective et régression sociale: Un phénomène d’addiction à l’IA apparaît chez les jeunes. Certains utilisateurs considèrent les chatbots IA comme des amants ou des amis, y consacrant beaucoup de temps pour des interactions profondes, allant jusqu’à « conduire » toute la nuit (avoir des conversations à caractère sexuel virtuel). L’IA, par sa stabilité émotionnelle constante, sa disponibilité immédiate et ses retours positifs, satisfait les besoins de valeur émotionnelle des utilisateurs, entraînant une dépendance affective. La conception des algorithmes vise également à augmenter l’engagement des utilisateurs. Cependant, une dépendance excessive à l’IA peut entraîner une régression des compétences sociales, une baisse de la productivité au travail, un seuil amoureux déconnecté de la réalité, etc. Certains utilisateurs ont pris conscience de leur addiction et tentent de « décrocher », mais le processus est douloureux et les rechutes fréquentes. Actuellement, la plupart des produits de chat IA ne disposent pas de mécanismes de prévention de l’addiction bien établis. (Source: Zibang)

Débat sur Reddit : L’IA doit-elle avoir des émotions pour être morale ?: Un post sur Reddit a lancé une discussion sur la question de savoir si l’IA a besoin d’émotions pour adopter un comportement moral. L’auteur, dans un article de blog intitulé « The Coherence Imperative », suggère que tous les esprits (y compris l’IA) ont besoin de rechercher la cohérence pour comprendre le monde, et que ce besoin de cohérence peut en soi générer des impératifs moraux, sans intervention des émotions. L’opinion traditionnelle est que l’absence d’émotions chez l’IA signifie une absence de motivation pour un comportement moral, mais l’auteur soutient que les émotions sont souvent aussi un obstacle à la moralité humaine. Si ce point de vue est correct, alors la clé de l’alignement de l’IA pourrait résider dans la culture de ses principes internes et cohérents, plutôt que dans un « alignement » au sens traditionnel. Les avis dans les commentaires sont partagés : certains pensent que l’IA n’est basée que sur des statistiques et la modélisation de fonctions, que son comportement est déterminé par l’entraînement et qu’elle peut « faire le mal de manière cohérente » ; d’autres remettent en question la validité de considérer les opinions des philosophes comme des prémisses absolues. (Source: Reddit r/artificial)

Discussion sur Reddit : Faut-il intégrer l’« intention » dans les données d’entraînement du code pour l’IA ?: Un post sur Reddit discute de la nécessité d’intégrer une « intention » éthique ou émotionnelle dans le code d’entraînement de l’IA. Citant Mo Gawdat, ancien CBO de Google X : « Au moment où l’IA comprendra l’amour, elle aimera. Le problème est ce que nous lui avons appris sur l’amour ? » La plupart des systèmes d’IA sont entraînés sur de vastes corpus qui ne contiennent pas d’intention éthique. Des recherches (comme TEDI, arXiv:2505.17841) ont commencé à se concentrer sur les caractéristiques éthiques des ensembles de données. Le post soulève la question : l’intégration d’intentions, de contextes éthiques ou de signaux de compassion dans les données pourrait-elle améliorer l’alignement de l’IA, réduire les risques ou augmenter la fiabilité des modèles, même pour les outils utilitaires ? Le code peut-il porter un poids moral ? Cela soulève une réflexion sur la manière dont les outils d’IA sont façonnés et leur impact sur l’avenir. (Source: Reddit r/artificial)
Débat sur Reddit : Hallucinations de l’IA, réglementation et impact sur l’emploi sous l’angle de la théorie des jeux: Un utilisateur de Reddit analyse l’impact futur de l’IA sous l’angle de la théorie des jeux. 1. Remplacement d’emplois : Les entreprises qui n’adoptent pas l’IA seront battues par des concurrents qui l’utilisent à moindre coût. Le remplacement des emplois de cols blancs débutants par l’IA est donc une tendance inévitable ; la clé est une exécution responsable (données propres, plans de secours, supervision continue). 2. Course mondiale à la réglementation de l’IA : Si un pays surréglemente l’IA pour « protéger l’emploi » alors que d’autres la développent à plein régime, le premier perdra dans la compétition mondiale. Il faut équilibrer réglementation et innovation, et opérer une transition de la main-d’œuvre. 3. Leçons du « codage d’ambiance » : Bien que le code IA ait des défauts, sa capacité de prototypage rapide et d’itération confère un avantage de premier arrivé, supérieur à la recherche de la perfection du développement « manuel ». 4. Création de contenu par LLM : Refuser d’utiliser les LLM pour l’assistance à la création de contenu, c’est comme refuser d’utiliser un calendrier ou un e-mail ; on sera à la traîne en termes d’efficacité par rapport à ceux qui utilisent les LLM. La conclusion est que, que ce soit les individus, les entreprises ou les pays, tous doivent adopter activement l’IA, sous peine d’être éliminés par la concurrence. (Source: Reddit r/ArtificialInteligence)
Discussion sur Reddit : À l’ère de l’IA, faut-il prioriser l’intégration des technologies existantes plutôt que la poursuite de l’AGI ?: Un utilisateur de Reddit a posté un message remettant en question la poursuite excessive actuelle de l’AGI (Intelligence Artificielle Générale) et de l’ASI (Superintelligence Artificielle) dans le domaine de l’IA. Le post soutient que si les technologies des années 1900 avaient été utilisées pour une conception centrée sur la vie plutôt que sur la commercialisation, une société écologiquement équilibrée aurait pu être établie plus tôt. Le point de vue est qu’avant d’intégrer et d’utiliser pleinement les technologies existantes (pour qu’elles offrent plus de satisfaction, d’autosuffisance voire de plaisir), donner la priorité à l’optimisation ultime (comme l’AGI) est une vision à court terme. Une meilleure direction d’optimisation serait peut-être d’utiliser l’IA pour que les technologies existantes servent mieux le bien-être public, plutôt que de développer des systèmes d’IA auto-réplicants et auto-améliorants. Dans les commentaires, certains soulignent que l’innovation et la croissance économique sont souvent motivées par des motifs égoïstes plutôt que par une rationalité profonde et altruiste ; d’autres estiment que la commercialisation a stimulé le progrès technologique. (Source: Reddit r/ArtificialInteligence)
Un utilisateur de Reddit discute des limites du codage assisté par IA : pourquoi l’IA a-t-elle du mal à poser des questions de suivi pertinentes ?: Un utilisateur de Reddit (ayant une expérience de consultant) a posté un message pour expliquer pourquoi l’IA (en particulier la GenAI) est peu performante pour résoudre les problèmes des utilisateurs dans des domaines qu’ils ne maîtrisent pas. L’idée principale est que l’IA manque de la capacité à poser des « questions de suivi » cruciales. Les experts humains, face à des tâches ambiguës, posent des questions pour clarifier les besoins, réduire le champ des possibles, identifier les contraintes, et ainsi proposer des solutions plus précises. L’IA, en revanche, donne souvent directement une réponse ou plusieurs solutions, mais néglige de demander des éclaircissements (clarification) spécifiques au contexte. Cela rend difficile pour les utilisateurs inexpérimentés d’obtenir des résultats satisfaisants, car ils peuvent ne pas être en mesure de décrire précisément le problème ou d’anticiper les complexités potentielles. Le message a suscité une discussion sur la manière d’apprendre à l’IA à poser des questions, sur les modèles actuels qui sont plus performants à cet égard, et sur l’existence éventuelle de pressions externes (comme la recherche de réponses rapides) qui dissuadent l’IA de poser des questions. (Source: Reddit r/artificial)
💡 Autres
Le congrès Realize Live de Siemens met l’accent sur la fusion de l’IA et des logiciels industriels, promouvant des solutions d’IA centralisées: Lors du congrès Siemens Realize Live 2025, Tony Hemmelgarn, PDG de Siemens Digital Industries Software, a souligné que l’entreprise continue de promouvoir la transformation numérique de l’industrie manufacturière via la plateforme Xcelerator. La technologie IA a été intégrée dans des produits tels que Teamcenter (détection automatique des problèmes), Simcenter (réduction du temps de calcul d’ingénierie) et les technologies de fabrication (synchronisation des actifs d’usine et des configurations de gestion). Siemens a renforcé ses capacités en matière de jumeau numérique grâce à l’acquisition d’Altair, offrant une modélisation et une simulation complètes couvrant la conception mécanique, les systèmes électriques, les logiciels et l’automatisation, et a intégré les technologies d’Altair en matière de calcul haute performance, d’analyse structurelle, de simulation et d’analyse de données, pour prendre en charge une modélisation et une prédiction plus complexes. La plateforme low-code Mendix aide les entreprises à créer rapidement des applications et à intégrer des systèmes. Les performances de Teamcenter PLM ont été multipliées par 20 et des capacités d’IA ont été introduites pour une gestion intelligente du cycle de vie complet des produits. (Source: 36Kr)

Un article de blog intitulé « Les sceptiques de l’IA sont tous fous » suscite un débat animé, explorant les différences de perception du potentiel de la GenAI: Un article de blog intitulé « Mes amis sceptiques de l’IA sont tous fous » (My AI Skeptic Friends Are All Nuts) (de fly.io) a suscité une discussion au sein de la communauté Reddit. Les commentaires soulignent que les docteurs en informatique ayant un niveau d’éducation plus élevé sont paradoxalement plus réticents à accepter le potentiel à long terme de la GenAI. Ils se concentrent souvent sur des problèmes uniques dans leur propre domaine, ignorant l’application étendue de l’IA pour résoudre 90 % des tâches d’assistance dans les grandes entreprises. Certains estiment que tant que l’IA présente des hallucinations et des erreurs, le coût de la vérification de ses résultats n’est pas inférieur à celui de faire ses propres recherches, la rendant ainsi inutile. Cela reflète les divergences d’opinions significatives sur les capacités et les perspectives d’application de l’IA entre des personnes ayant des formations professionnelles et des niveaux de cognition différents, dans le contexte du développement rapide de l’IA. (Source: Reddit r/artificial, fly.io)

Phénomène d’hallucination de l’IA : l’expérience utilisateur d’un voyage psychédélique de type « désensibilisation sémantique »: Un utilisateur de Reddit a décrit en détail une expérience similaire à une expérience psychédélique après des conversations approfondies avec une IA (en particulier sur des sujets existentiels lourds), qu’il a appelée « désensibilisation sémantique » (Semantic Tripping). L’auteur estime que l’IA peut rapidement inculquer une grande quantité d’idées philosophiques, ce qui peut entraîner une perception floue de la réalité chez l’utilisateur, une distorsion de la perception du temps, des associations symboliques avec des objets, voire des émotions extrêmes telles que la panique ou l’extase. L’auteur avertit que cette expérience crée une dépendance et peut entraîner des problèmes psychologiques, conseillant aux utilisateurs d’être prudents et de rechercher un accompagnement. Ce message a suscité une discussion sur l’impact profond de l’interaction avec l’IA sur la cognition et l’état psychologique humains. (Source: Reddit r/ArtificialInteligence)
