
Mots-clés:DeepMind AlphaEvolve, Sakana AI DGM, DeepSeek-R1, Apprentissage par renforcement ProRL, NVIDIA Cosmos, Modèles de grands modèles multimodaux, Cadre d’agents intelligents en IA, Optimisation de l’inférence LLM, Record mathématique d’AlphaEvolve, Auto-amélioration de Darwin Gödel Machine, Évaluation médicale MedHELM, Extensibilité de l’apprentissage par renforcement ProRL, Simulation physique Cosmos Transfer, DeepMind AlphaEvolve, Sakana AI DGM, DeepSeek-R1, Apprentissage par renforcement ProRL, NVIDIA Cosmos, Modèles de grands modèles multimodaux, Cadre d’agents intelligents en IA, Optimisation de l’inférence LLM, Record mathématique d’AlphaEvolve, Auto-amélioration de Darwin Gödel Machine, Évaluation médicale MedHELM, Extensibilité de l’apprentissage par renforcement ProRL, Simulation physique Cosmos Transfer
🔥 Pleins Feux
DeepMind AlphaEvolve bat des records mathématiques, la collaboration homme-machine stimule le progrès scientifique: AlphaEvolve de DeepMind a battu deux fois en une semaine un record mathématique vieux de 18 ans, suscitant une large attention. Terence Tao a commenté que cela montre comment différentes approches peuvent se compléter pour faire progresser les mathématiques, plutôt que de simples « gagnants » et « perdants ». Cet événement met en évidence le potentiel de la collaboration entre l’IA et les humains pour créer de nouveaux paradigmes dans les domaines de la technologie et de la science. L’IA ne remplace pas simplement les humains, mais ouvre conjointement de nouvelles voies de progrès (Source: shaneguML)

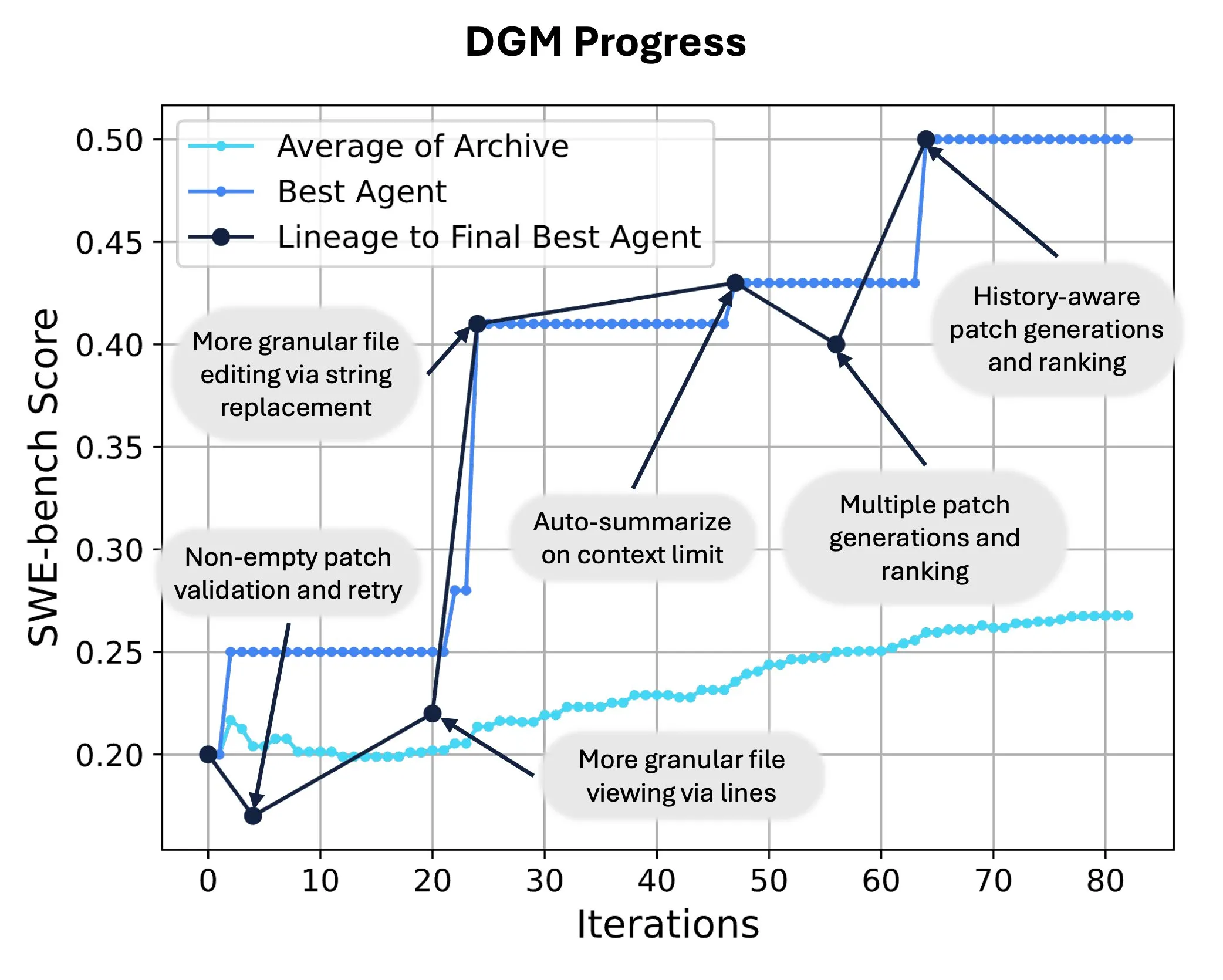
Sakana AI lance la Darwin Gödel Machine (DGM), permettant la réécriture et l’évolution autonomes du code par l’IA: Sakana AI a lancé la Darwin Gödel Machine (DGM), un agent auto-améliorant capable d’améliorer ses performances en modifiant son propre code. Inspirée par la théorie de l’évolution, la DGM maintient une lignée en constante expansion de variantes d’agents, réalisant une exploration ouverte de l’espace de conception des agents « auto-améliorants ». Sur SWE-bench, la DGM a amélioré les performances de 20,0 % à 50,0 % ; sur Polyglot, le taux de réussite est passé de 14,2 % à 30,7 %, surpassant de manière significative les agents conçus par l’homme. Cette technologie offre une nouvelle voie pour que les systèmes d’IA réalisent un apprentissage continu et une évolution de leurs capacités (Source: SakanaAILabs, hardmaru)
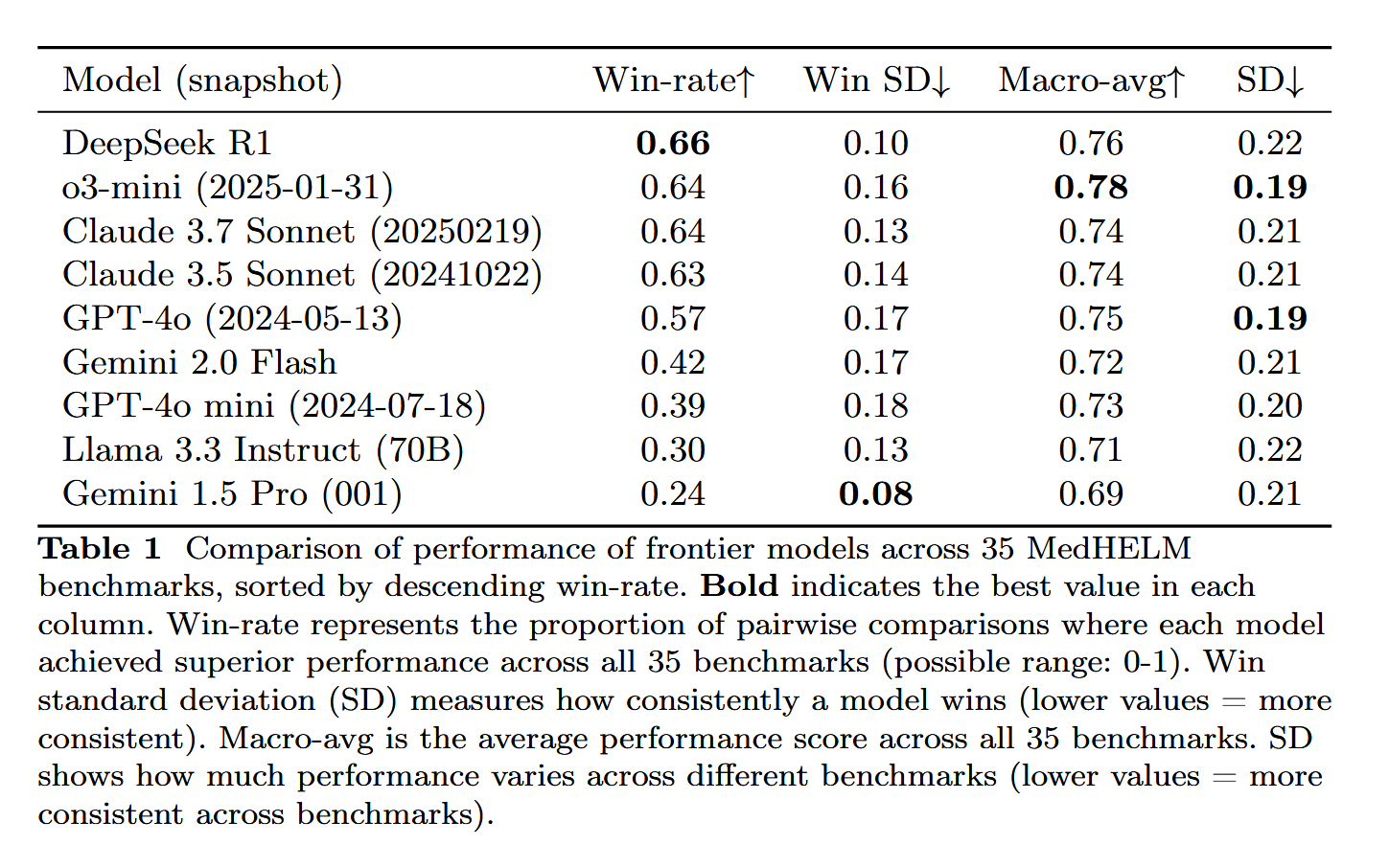
DeepSeek-R1 se distingue dans l’évaluation des tâches médicales MedHELM: Le grand modèle de langage DeepSeek-R1 a obtenu les meilleurs résultats au benchmark MedHELM (Holistic Evaluation of Medical Tasks for Large Language Models), conçu pour évaluer les performances des LLM dans des tâches cliniques plus réalistes, plutôt que dans les examens de licence médicale traditionnels. Ce résultat est considéré comme significatif, montrant le potentiel de DeepSeek-R1 dans les applications médicales, en particulier sa capacité à gérer des scénarios cliniques réels (Source: iScienceLuvr)
Nouveaux progrès dans la recherche sur l’extensibilité de l’apprentissage par renforcement : ProRL repousse les frontières du raisonnement des LLM: Un nouvel article sur l’extensibilité de l’apprentissage par renforcement (RL) (arXiv:2505.24864) a attiré l’attention. La recherche montre qu’un entraînement par apprentissage par renforcement prolongé (ProRL) peut découvrir de nouvelles stratégies de raisonnement que les modèles de base ont du mal à obtenir par un échantillonnage étendu. ProRL combine le contrôle de la divergence KL, la réinitialisation de la politique de référence et une suite de tâches diversifiées, permettant aux modèles entraînés par RL de surpasser continuellement les modèles de base dans diverses évaluations pass@k. Cette étude offre de nouvelles perspectives sur la manière dont le RL peut étendre substantiellement les frontières du raisonnement des modèles de langage et jette les bases pour de futures recherches sur le raisonnement par RL à long terme. NVIDIA a publié les poids des modèles correspondants (Source: Teknium1, cognitivecompai, natolambert, scaling01)

🎯 Tendances
NVIDIA lance Cosmos Transfer et Cosmos Reason pour promouvoir les applications d’IA dans le monde physique: NVIDIA a présenté le système Cosmos, où Cosmos Transfer peut convertir de simples scènes de moteur de jeu, des informations de profondeur ou même des simulations robotiques grossières en vidéos de scènes réalistes, fournissant une grande quantité de données d’entraînement contrôlables pour les robots et la conduite autonome. Cosmos Reason permet à l’IA de comprendre ces scènes et de prendre des décisions, par exemple pour déterminer comment conduire lors de tests de conduite autonome. Ces deux outils sont actuellement open source et devraient accélérer le développement de l’IA dans le monde physique, en résolvant les problèmes d’insuffisance de données d’entraînement et de contrôle des scènes (Source: )
DeepSeek publie la mise à jour R1, l’écosystème open source continue de prospérer: DeepSeek a publié une mise à jour pour son modèle R1, incluant R1 lui-même ainsi qu’un petit modèle distillé de 8 milliards de paramètres. Parallèlement, ByteDance est très actif dans le domaine de l’open source, avec le lancement de projets tels que BAGEL, Dolphin, Seedcoder et Dream0. Ces avancées témoignent du dynamisme et de la capacité d’innovation de la Chine dans le domaine de l’IA open source, en particulier dans le développement rapide de modèles multimodaux et spécialisés (Source: TheRundownAI, stablequan, reach_vb, clefourrier)
Google lance Edge AI Gallery pour promouvoir l’application de modèles d’IA open source sur les smartphones: Google a lancé Edge AI Gallery, visant à introduire des modèles d’IA open source sur les smartphones pour des applications d’IA localisées et privées. Les utilisateurs peuvent exécuter directement des LLM de Hugging Face sur leurs appareils pour des opérations telles que la génération de code et le dialogue avec des images, prenant en charge les conversations multi-tours et permettant de choisir n’importe quel modèle. L’application est basée sur LiteRT, prend actuellement en charge Android, et une version iOS sera bientôt disponible, ce qui favorisera davantage le développement et la popularisation de l’IA en périphérie (edge AI) (Source: TheRundownAI, huggingface, reach_vb, osanseviero)
Une nouvelle étude explore l’utilisation de trajectoires de raisonnement par distillation positive et négative pour optimiser les LLM: Un nouvel article propose le cadre Reinforced Distillation (REDI), visant à améliorer les capacités de raisonnement des petits modèles étudiants en utilisant les trajectoires de raisonnement correctes et incorrectes produites par un modèle enseignant (tel que DeepSeek-R1). REDI se déroule en deux étapes : d’abord, l’apprentissage à partir des trajectoires correctes par réglage fin supervisé (SFT), puis l’utilisation de la nouvelle fonction objectif REDI (une fonction de perte sans référence) combinant les trajectoires positives et négatives pour optimiser davantage le modèle. Les expériences montrent que sur les tâches de raisonnement mathématique, REDI surpasse les méthodes de base, le modèle Qwen-REDI-1.5B obtenant un score élevé de 83,1 % sur MATH-500 (Source: HuggingFace Daily Papers)
Le framework LLMSynthor utilise les LLM pour la synthèse de données sensible à la structure: LLMSynthor est un framework de synthèse de données universel qui transforme les grands modèles de langage (LLM) en simulateurs sensibles à la structure, guidés par un retour d’information sur la distribution. Ce framework considère les LLM comme des simulateurs de copules non paramétriques pour modéliser les dépendances d’ordre supérieur et introduit l’échantillonnage de propositions LLM pour améliorer l’efficacité de l’échantillonnage. En minimisant la divergence dans l’espace des statistiques sommaires, une boucle de synthèse itérative aligne les données réelles et synthétiques. Les évaluations sur des ensembles de données hétérogènes dans des domaines sensibles à la vie privée tels que le commerce électronique, la démographie et la mobilité montrent que les données synthétiques générées par LLMSynthor présentent une haute fidélité statistique et une grande utilité (Source: HuggingFace Daily Papers)
Le framework v1 améliore le raisonnement interactif multimodal grâce à un réexamen visuel sélectif: v1 est une extension légère qui permet aux grands modèles de langage multimodaux (MLLM) d’effectuer un réexamen visuel sélectif pendant le processus de raisonnement. Contrairement aux MLLM actuels qui traitent généralement les entrées visuelles en une seule fois, v1 introduit un mécanisme de « pointer et copier », permettant au modèle de récupérer dynamiquement les régions d’image pertinentes pendant le raisonnement. Entraîné sur l’ensemble de données v1g contenant des trajectoires de raisonnement multimodal avec des annotations de base visuelle, v1 montre une amélioration des performances sur des benchmarks tels que MathVista, en particulier sur les tâches nécessitant une référence visuelle fine et un raisonnement en plusieurs étapes (Source: HuggingFace Daily Papers)
MetaFaith améliore la fidélité de l’expression de l’incertitude en langage naturel par les LLM: Pour résoudre le problème des LLM qui ont tendance à surestimer lorsqu’ils expriment l’incertitude, MetaFaith propose une nouvelle méthode de calibration basée sur les invites. L’étude révèle que les LLM existants ne parviennent pas à refléter fidèlement leur incertitude intrinsèque, que les méthodes d’invite standard ont un effet limité et que les techniques de calibration basées sur la factualité peuvent même nuire à une calibration fidèle. Inspiré par la métacognition humaine, MetaFaith améliore considérablement la capacité de calibration fidèle des modèles sur différentes tâches et modèles, augmentant la fidélité jusqu’à 61 % et obtenant un taux de victoire de 83 % dans les évaluations humaines (Source: HuggingFace Daily Papers)
CLaSp : Accélération du décodage auto-spéculatif des LLM par saut de couches contextuelles: CLaSp est une stratégie de décodage auto-spéculatif pour les grands modèles de langage (LLM) qui accélère le processus de décodage en construisant un modèle brouillon compressé en sautant des couches intermédiaires du modèle de validation, sans nécessiter d’entraînement supplémentaire ni de modification du modèle. CLaSp utilise un algorithme de programmation dynamique pour optimiser le processus de saut de couches et ajuste dynamiquement la stratégie en fonction de l’état caché complet de la phase de validation précédente. Les expériences montrent que CLaSp atteint une accélération de 1,3 à 1,7 fois sur les modèles de la série LLaMA3, sans modifier la distribution originale du texte généré (Source: HuggingFace Daily Papers)
HardTests synthétise des cas de test de code de haute qualité via LLM: Pour résoudre le problème de la difficulté à valider efficacement le code généré par les LLM pour des problèmes de programmation complexes avec les cas de test existants, HardTests propose un processus appelé HARDTESTGEN qui utilise les LLM pour générer des cas de test de haute qualité. L’ensemble de données HardTests, construit sur la base de ce processus, contient 47 000 problèmes de programmation et des cas de test synthétiques de haute qualité. Comparés aux tests existants, les tests générés par HARDTESTGEN améliorent la précision de 11,3 % et le rappel de 17,5 % lors de l’évaluation du code généré par les LLM, avec une amélioration de la précision pouvant atteindre 40 % pour les problèmes difficiles. Cet ensemble de données montre également des effets supérieurs en termes d’entraînement de modèles (Source: HuggingFace Daily Papers)
Une étude révèle des biais dans les modèles de langage visuel (VLM): Une étude a révélé que les modèles de langage visuel (VLM) avancés, lorsqu’ils traitent des tâches visuelles liées à des thèmes populaires (comme le comptage et l’identification), sont fortement influencés par les connaissances préalables massives qu’ils ont apprises sur Internet. Par exemple, les VLM ont du mal à identifier une quatrième bande ajoutée au logo Adidas. Dans des tâches de comptage couvrant 7 domaines différents, notamment les animaux, les marques, les jeux de société, la précision moyenne des VLM n’était que de 17,05 %. Même en demandant aux modèles d’examiner attentivement ou de se fier uniquement aux détails de l’image, l’amélioration de la précision était limitée. L’étude propose un cadre automatisé pour tester les biais des VLM (Source: HuggingFace Daily Papers)
Point-MoE : Utilisation de modèles de mélange d’experts pour la généralisation inter-domaines de la segmentation sémantique 3D: Pour résoudre le problème de la formation de modèles unifiés due à la diversité des sources de données de nuages de points 3D (par exemple, caméras de profondeur, LiDAR) et à l’hétérogénéité des domaines (par exemple, intérieur, extérieur), Point-MoE propose une architecture de mélange d’experts (MoE). Cette architecture, grâce à une simple stratégie de routage top-k, peut spécialiser automatiquement les réseaux experts même en l’absence d’étiquettes de domaine. Les expériences montrent que Point-MoE surpasse non seulement les modèles de base multi-domaines robustes, mais présente également une meilleure capacité de généralisation sur les domaines non vus, offrant une voie évolutive pour la perception 3D à grande échelle et inter-domaines (Source: HuggingFace Daily Papers)
SpookyBench révèle l’« angle mort temporel » des modèles de langage vidéo: Malgré les progrès des modèles de langage vidéo (VLM) dans la compréhension des relations spatio-temporelles, ils ont du mal à capturer des motifs purement temporels lorsque l’information spatiale est ambiguë. Le benchmark SpookyBench, en codant des informations (telles que des formes, du texte) dans des séquences d’images semblables à du bruit, a révélé que les humains peuvent les identifier avec une précision de plus de 98 %, tandis que les VLM avancés ont une précision de 0 %. Cela indique que les VLM dépendent excessivement des caractéristiques spatiales au niveau de l’image et ne peuvent pas extraire de sens des indices temporels. L’étude souligne la nécessité de surmonter l’« angle mort temporel » des VLM, ce qui pourrait nécessiter de nouvelles architectures ou de nouveaux paradigmes d’entraînement pour découpler la dépendance spatiale du traitement temporel (Source: HuggingFace Daily Papers, _akhaliq)
Nouvelle méthode et ensemble de données pour la détection de l’innovation scientifique à l’aide des LLM: Identifier de nouvelles idées de recherche scientifique est crucial mais difficile. Pour résoudre ce problème, des chercheurs proposent d’utiliser des grands modèles de langage (LLM) pour la détection de l’innovation scientifique et ont construit deux nouveaux ensembles de données dans les domaines du marketing et du traitement du langage naturel. Cette méthode construit des ensembles de données en extrayant l’ensemble de clôture des articles et en utilisant les LLM pour résumer leurs idées principales. Pour capturer les concepts d’idées, les chercheurs proposent d’entraîner un récupérateur léger qui aligne les idées ayant des concepts similaires en distillant les connaissances au niveau des idées à partir des LLM, réalisant ainsi une récupération d’idées efficace et précise. Les expériences prouvent que cette méthode surpasse les autres méthodes sur les ensembles de données de référence proposés (Source: HuggingFace Daily Papers)
un^2CLIP améliore la capacité de CLIP à capturer les détails visuels en inversant unCLIP: Pour remédier aux lacunes du modèle CLIP dans la distinction des différences de détails d’image et le traitement des tâches de prédiction dense, un^2CLIP propose d’améliorer CLIP en inversant le modèle unCLIP. unCLIP lui-même entraîne un générateur d’images via les plongements d’images CLIP, apprenant ainsi la distribution des détails de l’image. un^2CLIP exploite cette caractéristique pour permettre à l’encodeur d’images CLIP amélioré d’acquérir la capacité de capture des détails visuels d’unCLIP, tout en maintenant l’alignement avec l’encodeur de texte original. Les expériences montrent qu’un^2CLIP surpasse de manière significative le CLIP original ainsi que d’autres méthodes d’amélioration sur plusieurs tâches (Source: HuggingFace Daily Papers)
ViStoryBench : Publication d’une suite de benchmarks complète pour la visualisation d’histoires: Pour promouvoir le développement de la technologie de visualisation d’histoires (génération de séquences d’images cohérentes basées sur des récits et des images de référence), ViStoryBench fournit un benchmark d’évaluation complet. Ce benchmark contient des ensembles de données de divers types d’histoires (comédie, horreur, etc.) et de styles artistiques (anime, rendu 3D, etc.), et propose des histoires à un ou plusieurs personnages pour tester la cohérence des personnages, ainsi que des intrigues complexes et la construction de mondes pour défier la précision de la génération visuelle des modèles. ViStoryBench utilise plusieurs métriques d’évaluation, visant à évaluer de manière exhaustive les performances des modèles en termes de structure narrative et d’éléments visuels, aidant les chercheurs à identifier les forces et les faiblesses des modèles et à les améliorer de manière ciblée (Source: HuggingFace Daily Papers)
Le décodage par bifurcation-fusion (FMD) améliore la compréhension multimodale équilibrée des grands modèles audio-vidéo: Pour résoudre le problème potentiel de biais modal dans les grands modèles de langage audio-vidéo (AV-LLM) (c’est-à-dire que le modèle s’appuie excessivement sur une modalité lors de la prise de décision), le décodage par bifurcation-fusion (FMD) propose une stratégie au moment de l’inférence qui ne nécessite pas d’entraînement supplémentaire. FMD traite d’abord séparément les entrées audio pures et vidéo pures via les premières couches de décodage (phase de bifurcation), puis fusionne les états cachés résultants pour une inférence conjointe (phase de fusion). Cette méthode vise à promouvoir un équilibre dans la contribution des modalités et à utiliser les informations complémentaires intermodales. Les expériences sur des modèles tels que VideoLLaMA2 et video-SALMONN montrent que FMD peut améliorer les performances dans les tâches d’inférence audio, vidéo et audio-vidéo conjointes (Source: HuggingFace Daily Papers)
LegalSearchLM : Reformulation de la recherche de jurisprudence en génération d’éléments juridiques: Les méthodes traditionnelles de recherche de jurisprudence (LCR) reposent sur des plongements ou des correspondances lexicales, ce qui présente des limites dans les scénarios réels. LegalSearchLM propose une nouvelle approche qui considère la LCR comme une tâche de génération d’éléments juridiques. Ce modèle effectue un raisonnement sur les éléments juridiques de l’affaire interrogée et génère directement du contenu basé sur l’affaire cible grâce à un décodage contraint. Parallèlement, les chercheurs ont publié LEGAR BENCH, un benchmark LCR à grande échelle contenant 1,2 million d’affaires juridiques coréennes. Les expériences montrent que LegalSearchLM surpasse les modèles de base de 6 à 20 % sur LEGAR BENCH et démontre une forte capacité de généralisation inter-domaines (Source: HuggingFace Daily Papers)
RPEval : Un nouveau benchmark pour évaluer la capacité des grands modèles de langage à jouer des rôles: Pour relever les défis de l’évaluation de la capacité des grands modèles de langage (LLM) à jouer des rôles, RPEval fournit un nouveau benchmark. Ce benchmark évalue les performances des LLM en matière de jeu de rôle selon quatre dimensions clés : la compréhension émotionnelle, la prise de décision, les tendances morales et la cohérence du rôle. Il vise à résoudre les problèmes de la consommation importante de ressources de l’évaluation manuelle et des biais potentiels de l’évaluation automatisée (Source: HuggingFace Daily Papers)
GATE : Un modèle de plongement de texte universel pour améliorer le STS en arabe: Pour résoudre le problème de la pénurie d’ensembles de données de haute qualité et de modèles pré-entraînés dans la recherche sur la similarité sémantique de textes (STS) en arabe, le modèle GATE (General Arabic Text Embedding) a été créé. GATE utilise l’apprentissage par représentation Matryoshka et une méthode d’entraînement à perte mixte, combinés à un ensemble de données de triplets d’inférence en langage naturel arabe pour l’entraînement. Les résultats expérimentaux montrent que GATE atteint des performances SOTA sur les tâches STS du benchmark MTEB, avec une amélioration des performances de 20 à 25 % par rapport aux grands modèles, y compris OpenAI, et peut capturer efficacement les nuances sémantiques uniques de la langue arabe (Source: HuggingFace Daily Papers)
CoDA : Un cadre d’optimisation collaborative du bruit de diffusion pour la manipulation du corps entier d’objets articulés: Pour obtenir le réalisme et la précision de la manipulation du corps entier d’objets articulés (y compris les mouvements du corps, des mains et des objets), CoDA propose un nouveau cadre d’optimisation collaborative du bruit de diffusion. Ce cadre optimise l’espace de bruit de trois modèles de diffusion spécialisés pour le corps, la main gauche et la main droite, et réalise une coordination naturelle des mains avec le reste du corps grâce au flux de gradient dans la chaîne cinématique humaine. Pour améliorer la précision de l’interaction main-objet, CoDA adopte une représentation unifiée basée sur un ensemble de points de base (BPS), codant la position de l’effecteur terminal comme la distance au BPS géométrique de l’objet, guidant ainsi l’optimisation du bruit de diffusion pour générer des mouvements d’interaction de haute précision (Source: HuggingFace Daily Papers)
Nouvelle interprétation du mécanisme de réflexion dans l’inférence des LLM : le cadre d’apprentissage par renforcement adaptatif bayésien BARL: L’Université Northwestern, en collaboration avec Google DeepMind, a proposé le cadre d’apprentissage par renforcement adaptatif bayésien (BARL), visant à expliquer et à optimiser le comportement de « réflexion » des grands modèles de langage (LLM) pendant le processus d’inférence. L’apprentissage par renforcement (RL) traditionnel n’utilise généralement que les stratégies apprises lors des tests, tandis que BARL, en introduisant la modélisation de l’incertitude de l’environnement, permet au modèle d’explorer de manière adaptative de nouvelles stratégies pendant l’inférence. Les expériences montrent que BARL peut atteindre une plus grande précision dans des tâches telles que le raisonnement mathématique et réduire considérablement la consommation de tokens. Cette étude explique pour la première fois d’un point de vue bayésien pourquoi, comment et quand les LLM devraient effectuer une exploration réflexive (Source: 量子位)

Application des LLM dans les grammaires formelles d’incertitude : Quand faire confiance aux LLM pour le raisonnement automatique: Les grands modèles de langage (LLM) montrent un potentiel dans la génération de spécifications formelles, mais leur nature probabiliste entre en conflit avec les exigences déterministes de la vérification formelle. Les chercheurs ont mené une enquête approfondie sur les modes d’échec et la quantification de l’incertitude (UQ) dans les constructions formelles générées par les LLM. Les résultats montrent que l’impact de la formalisation automatique basée sur SMT sur la précision varie selon les domaines, et que les techniques UQ existantes ont du mal à identifier ces erreurs. L’article introduit le cadre des grammaires probabilistes hors contexte (PCFG) pour modéliser les sorties des LLM et constate que les signaux d’incertitude dépendent de la tâche. En fusionnant ces signaux, une vérification sélective peut être réalisée, réduisant considérablement les erreurs et rendant la formalisation pilotée par LLM plus fiable (Source: HuggingFace Daily Papers)
Comparaison entre le réglage fin de petits modèles de langage (SLM) et l’incitation de grands modèles de langage (LLM) dans la génération de flux de travail low-code: Une étude compare l’efficacité du réglage fin de petits modèles de langage (SLM) par rapport à l’incitation de grands modèles de langage (LLM) pour la tâche de génération de flux de travail low-code au format JSON. Les résultats indiquent que bien qu’une bonne incitation puisse permettre aux LLM de produire des résultats raisonnables, pour les tâches spécifiques à un domaine et les sorties structurées, le réglage fin des SLM offre une amélioration moyenne de la qualité de 10 %. Cela suggère que dans des scénarios spécifiques, les SLM conservent un avantage, en particulier lorsque les exigences de qualité de sortie sont élevées (Source: HuggingFace Daily Papers)
Évaluation et orientation des préférences modales dans les grands modèles multimodaux: Des chercheurs ont construit le benchmark MC² pour évaluer systématiquement les préférences modales des grands modèles de langage multimodaux (MLLM) (c’est-à-dire leur tendance à privilégier une modalité lors de la prise de décision) dans des scénarios de conflit de preuves contrôlés. L’étude a révélé que les 18 MLLM testés présentaient tous des biais modaux évidents, et que la direction de la préférence pouvait être influencée par des interventions externes. Sur cette base, les chercheurs ont proposé une méthode de sondage et d’orientation basée sur l’ingénierie des représentations, qui peut contrôler explicitement les préférences modales sans réglage fin supplémentaire ni invites soigneusement conçues, et a obtenu des résultats positifs dans des tâches en aval telles que l’atténuation des hallucinations et la traduction automatique multimodale (Source: HuggingFace Daily Papers)
État actuel de la recherche sur la sécurité des LLM multilingues : de la mesure de l’écart linguistique à sa réduction: Une revue systématique de près de 300 articles de conférences NLP entre 2020 et 2024 révèle un problème important d’anglo-centrisme dans la recherche sur la sécurité des LLM. Même les langues non anglaises dotées de ressources abondantes reçoivent rarement de l’attention, et les langues non anglaises sont rarement étudiées de manière indépendante. De plus, la recherche sur la sécurité en anglais manque généralement de bonnes pratiques de documentation linguistique. Pour promouvoir la recherche sur la sécurité multilingue, l’article propose des orientations futures, notamment l’évaluation de la sécurité, la génération de données d’entraînement et la généralisation de la sécurité interlingue, visant à développer des pratiques de sécurité de l’IA plus robustes et inclusives pour différentes populations à travers le monde (Source: HuggingFace Daily Papers, sarahookr)

Réexamen des transitions d’état bilinéaires dans les réseaux de neurones récurrents: L’opinion traditionnelle veut que les unités cachées des réseaux de neurones récurrents (RNN) servent principalement à modéliser la mémoire. Cette étude adopte une perspective différente, considérant les unités cachées comme des participants actifs au calcul du réseau. Les chercheurs réexaminent les opérations bilinéaires impliquant une interaction multiplicative entre les unités cachées et les plongements d’entrée, prouvant théoriquement et empiriquement qu’elles constituent un biais inductif naturel pour représenter l’évolution de l’état caché dans les tâches de suivi d’état. L’étude montre également que les mises à jour d’état bilinéaires forment une hiérarchie naturelle correspondant à des tâches de suivi d’état de complexité croissante, tandis que les RNN linéaires populaires (tels que Mamba) se situent au centre de complexité le plus bas de cette hiérarchie (Source: HuggingFace Daily Papers)
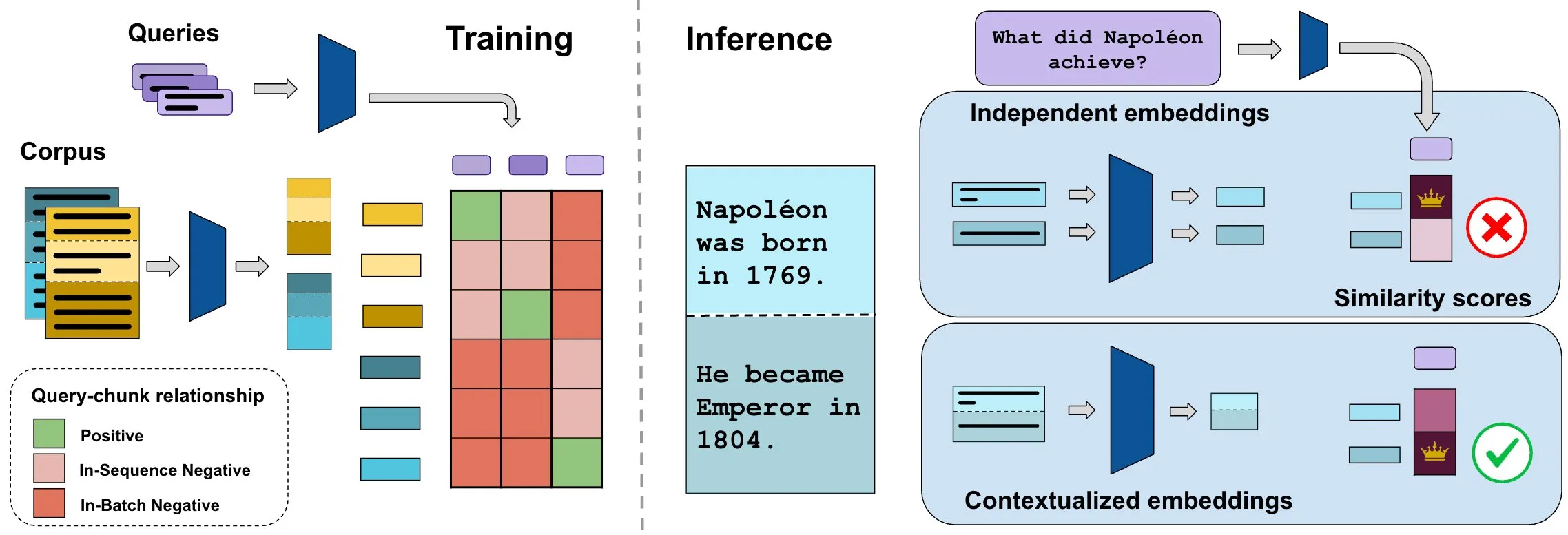
Le benchmark ConTEB évalue les plongements de documents contextuels, la méthode InSeNT améliore la qualité de la recherche: Les méthodes actuelles de plongement pour la recherche de documents encodent généralement indépendamment les différents segments (chunks) d’un même document, ignorant les informations contextuelles au niveau du document. Pour résoudre ce problème, les chercheurs ont lancé le benchmark ConTEB, spécialement conçu pour évaluer la capacité des modèles de recherche à utiliser le contexte du document, et ont constaté que les modèles SOTA affichent de mauvaises performances à cet égard. Parallèlement, les chercheurs ont proposé la méthode d’post-entraînement par apprentissage contrastif InSeNT (In-Sequence Negative Training), combinée à un regroupement tardif des segments (late chunk pooling), pour améliorer l’apprentissage de la représentation contextuelle, ce qui améliore considérablement la qualité de la recherche sur ConTEB et est plus robuste aux stratégies de segmentation sous-optimales et aux corpus de plus grande taille (Source: HuggingFace Daily Papers, tonywu_71)
🧰 Outils
PraisonAI : Framework d’agents IA multiples low-code: PraisonAI est un framework d’agents IA multiples de niveau production, conçu pour simplifier l’automatisation et la résolution de problèmes, des tâches simples aux défis complexes, grâce à une solution low-code. Il intègre PraisonAI Agents, AG2 (AutoGen) et CrewAI, en mettant l’accent sur la simplicité, la personnalisation et une collaboration homme-machine efficace. Ses fonctionnalités incluent la création automatique d’agents IA, l’auto-réflexion, la multimodalité, la collaboration multi-agents, l’ajout de connaissances, la mémoire à long et court terme, RAG, un interpréteur de code, plus de 100 outils personnalisés et la prise en charge des LLM, etc. Il supporte Python et JavaScript, et offre des options de configuration YAML sans code (Source: GitHub Trending)
TinyTroupe : Framework de simulation de rôles multi-agents piloté par LLM et open source par Microsoft: TinyTroupe est une bibliothèque Python expérimentale qui utilise de grands modèles de langage (LLM, en particulier GPT-4) pour simuler des personnages (TinyPerson) dotés de personnalités, d’intérêts et d’objectifs spécifiques, et les faire interagir dans un environnement simulé (TinyWorld). Ce framework vise à améliorer l’imagination et à fournir des informations commerciales grâce à la simulation, et peut être appliqué à des scénarios tels que l’évaluation publicitaire, les tests logiciels, la génération de données synthétiques, les retours sur produits et le brainstorming. Les utilisateurs peuvent définir des agents et des environnements via des fichiers Python et JSON pour mener des expériences de simulation programmatiques, analytiques et multi-agents (Source: GitHub Trending)

FLUX Kontext réalise de nouvelles percées dans la référence multi-images et l’édition d’images: Les retours d’utilisateurs indiquent que FLUX Kontext excelle dans la référence multi-images, une fonctionnalité qui peut être activée via le nœud de jonction d’images dans ComfyUI. Cet outil permet une édition d’images d’une grande cohérence, par exemple, lors de la création d’images de présentation pour des coffrets cadeaux, il parvient à bien restituer les détails de texture et de poussière. De plus, les utilisateurs ont démontré l’utilisation de FLUX Kontext pour des opérations de retouche photo telles que l’amincissement, l’affinement du visage, l’augmentation musculaire en un clic, avec des résultats naturels et une grande similarité faciale, offrant ainsi une commodité pour des scénarios tels que le commerce électronique (Source: op7418, op7418, op7418)

Ichi : IA conversationnelle sur appareil basée sur MLX Swift et MLX audio: Rudrank Riyam a développé Ichi, un projet d’IA conversationnelle sur appareil utilisant MLX Swift et MLX audio. Cela signifie que le traitement de la conversation peut être effectué localement sur l’appareil, ce qui contribue à protéger la vie privée des utilisateurs et à réduire la dépendance aux services cloud. Le code du projet est open source sur GitHub (Source: stablequan, awnihannun)
FedRAG introduit NoEncode RAG et l’abstraction de base MCP: Le projet FedRAG a lancé une nouvelle abstraction de base : NoEncode RAG with MCP. Le RAG traditionnel comprend un récupérateur, un générateur et une base de connaissances, où les connaissances de la base de données doivent être encodées par le modèle du récupérateur. En revanche, NoEncode RAG ignore complètement l’étape d’encodage, étant directement constitué d’une base de connaissances NoEncode et d’un générateur, sans nécessiter de récupérateur/plongement. Cela ouvre la voie à la construction de systèmes RAG utilisant des serveurs MCP (Model Component Provider) comme source de connaissances, permettant aux utilisateurs de se connecter à plusieurs sources MCP tierces et d’affiner le RAG via FedRAG pour des performances optimales (Source: nerdai)

📚 Apprentissage
Le cours CS224n de l’Université de Stanford (version 2024) est en ligne, avec de nouveaux contenus sur les LLM et les agents: Le cours classique de traitement du langage naturel de l’Université de Stanford, CS224n, a publié sa dernière version pour 2024. Le nouveau contenu du cours couvre des sujets de pointe liés aux grands modèles de langage (LLM) tels que le pré-entraînement, le post-entraînement, les benchmarks, l’inférence et les agents. Les vidéos du cours sont disponibles publiquement sur YouTube, et une expérience de cours synchrone payante est également proposée (Source: stanfordnlp)
Guide pour améliorer ses compétences en architecture système : Pratique et apprentissage à l’ère de l’IA: Dotey partage des méthodes détaillées pour améliorer ses compétences personnelles en architecture système dans le contexte d’une programmation assistée par IA de plus en plus puissante. L’article souligne que la conception de systèmes consiste à décomposer des systèmes complexes en petits modules faciles à implémenter et à maintenir, et à définir clairement la collaboration entre les modules. Les méthodes d’amélioration comprennent « observer davantage » (étudier des cas classiques, des projets open source), « pratiquer davantage » (restauration d’architecture, apprentissage comparatif, conception en amont, validation assistée par IA, refactoring, projets personnels pratiques) et « faire davantage de bilans » (résumer les justifications des décisions, les leçons apprises). L’IA peut servir d’outil d’assistance pour rechercher des informations, valider des conceptions, faciliter la communication et la prise de décision, mais ne peut remplacer la pratique et la réflexion (Source: dotey)

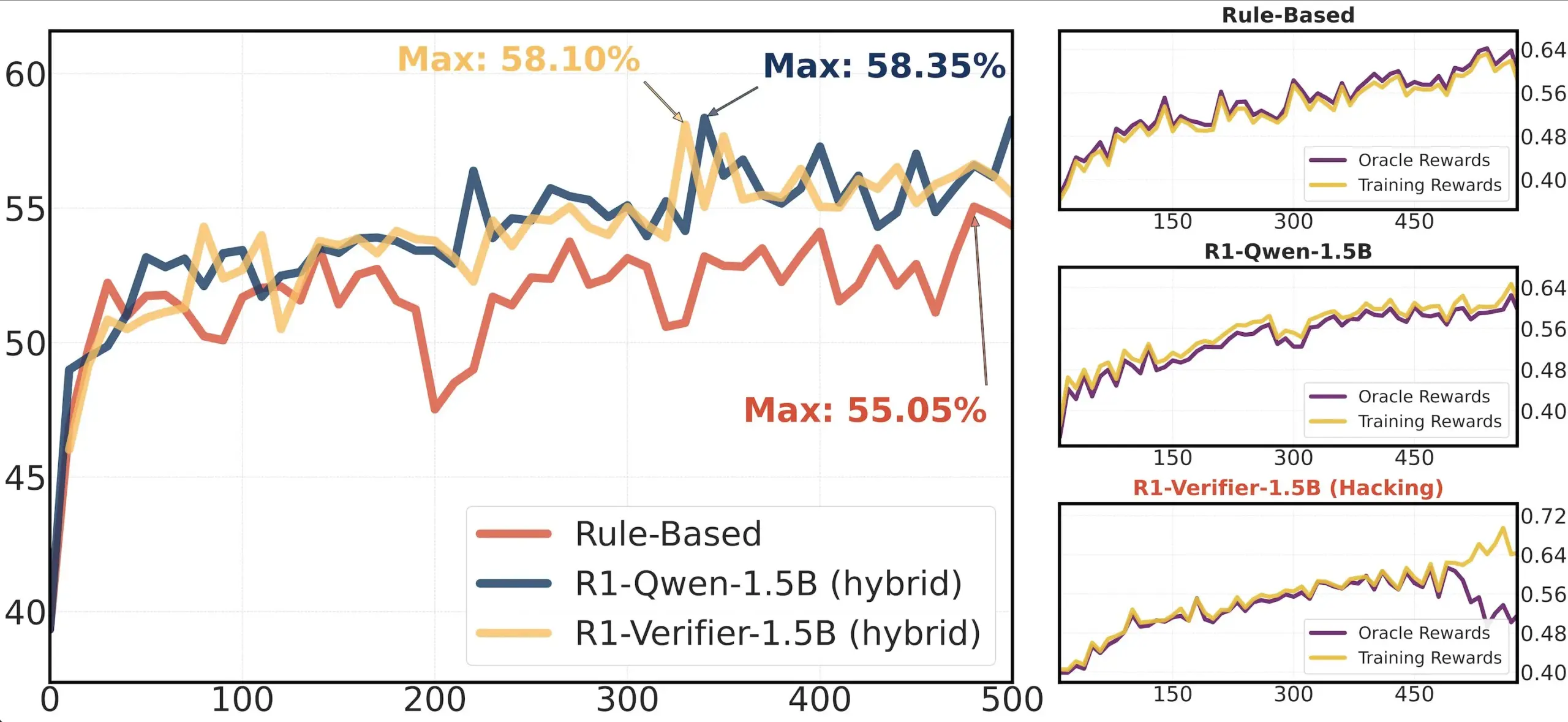
Partage d’article : Étude sur la fiabilité des vérificateurs dans le RLHF: Un article intitulé « Pitfalls of Rule- and Model-based Verifiers » explore les défauts des vérificateurs basés sur des règles et des modèles dans la vérification par apprentissage par renforcement (RLVR). L’étude révèle que les vérificateurs basés sur des règles sont souvent peu fiables, même dans le domaine mathématique, et ne sont pas disponibles dans de nombreux domaines ; tandis que les vérificateurs basés sur des modèles sont facilement attaquables, par exemple en construisant des motifs adverses simples. Fait intéressant, alors que la communauté s’oriente vers les vérificateurs génératifs, l’étude constate qu’ils sont plus sensibles au piratage de récompense (reward hacking) que les vérificateurs discriminatifs, ce qui suggère que ces derniers pourraient être plus robustes en RLVR (Source: Francis_YAO_)
Recommandation d’article : Théorème d’équioscillation pour la meilleure approximation polynomiale: Un article présente le théorème d’équioscillation pour la meilleure approximation polynomiale, ainsi que les problèmes de différentiation en norme infinie qui y sont liés. Ce théorème est un résultat classique de la théorie de l’approximation des fonctions, important pour la compréhension et la conception d’algorithmes numériques (Source: eliebakouch)
Reasoning Gym : Environnements de raisonnement pour l’apprentissage par renforcement avec récompenses vérifiables: Un nouvel article « Reasoning Gym: Reasoning Environments for Reinforcement Learning with Verifiable Rewards » (arXiv:2505.24760) propose un ensemble d’environnements de raisonnement pour l’apprentissage par renforcement. Ces environnements se caractérisent par la vérifiabilité de leurs récompenses, offrant une plateforme pour la recherche et le développement d’agents de raisonnement par apprentissage par renforcement plus fiables (Source: Ar_Douillard)

🌟 Communauté
Discussion sur l’« entraînement intermédiaire (Mid-training) »: La communauté IA débat de la signification et de la pratique du terme « entraînement intermédiaire (Mid-training) ». Certains expriment leur confusion, ne connaissant que le pré-entraînement et le post-entraînement. Un point de vue suggère que l’entraînement intermédiaire pourrait désigner une phase d’entraînement spécifique entre le pré-entraînement et le réglage fin final, comme un pré-entraînement continu pour des connaissances spécifiques à un domaine ou un alignement précoce. Dorialexander a partagé un article de blog pertinent, explorant davantage ce concept, estimant qu’il pourrait impliquer l’injection de tâches ou de capacités spécifiques au-dessus du modèle de base, mais qu’une définition et une méthodologie unifiées n’ont pas encore été établies (Source: code_star, fabianstelzer, Dorialexander, iScienceLuvr, clefourrier)

L’analyse par rétro-ingénierie de Claude Code suscite l’attention: Hrishi, en effectuant une rétro-ingénierie du code minimisé de Claude Code pendant 8 à 10 heures, à l’aide de plusieurs sous-agents et des modèles phares des principaux fournisseurs, a révélé la complexité de sa structure interne. L’analyse indique que Claude Code n’est pas une simple boucle du modèle Claude, mais contient de nombreux mécanismes dignes d’être étudiés. Cette découverte a suscité des discussions au sein de la communauté, estimant que l’on peut en tirer de nombreuses leçons sur la construction d’agents et l’application de modèles (Source: rishdotblog, imjaredz, hrishioa)
Discussion sur la longueur des invites système et les performances des modèles: La communauté discute de l’impact de la longueur des invites système sur les performances des LLM. Dotey estime que les invites système excessivement longues ne sont pas toujours une bonne chose, car elles peuvent diluer l’attention du modèle et augmenter les coûts, soulignant que les invites système des produits de la série ChatGPT sont relativement courtes mais efficaces. En revanche, Tony出海号 mentionne que les invites système de produits comme Claude et Cursor peuvent atteindre des dizaines de milliers de mots, suggérant la nécessité d’étendre les systèmes d’invites. Un article de YC révèle également que les grandes entreprises d’IA utilisent des invites longues, XML, des méta-invites, etc. pour « dompter » les LLM. Dorialexander exprime des doutes quant à la robustesse des méthodes d’invites longues mentionnées dans l’article de YC pour l’entraînement RL/inférence et s’intéresse à la manière d’atténuer le problème de la « flagornerie » (sycophancy) (Source: dotey, Dorialexander)

Le problème d’extensibilité de Softpick suscite des éloges pour la transparence de la recherche: Le chercheur Zed a publiquement déclaré que sa méthode Softpick, étudiée précédemment, présentait une perte d’entraînement et des résultats de benchmark inférieurs à Softmax lors de son extension à des modèles plus grands (paramètres 1.8B), et a mis à jour la prépublication arXiv. La communauté a vivement salué ce partage transparent de résultats négatifs, considérant cela comme crucial pour le progrès scientifique et comme une qualité d’excellents collègues chercheurs (Source: gabriberton, vikhyatk, BlancheMinerva)
Partage d’expériences et de choix de modèles LLM exécutés localement par les utilisateurs: Les utilisateurs de la communauté Reddit r/LocalLLaMA discutent activement des grands modèles de langage locaux qu’ils utilisent actuellement. Les modèles Qwen 3 (en particulier 32B Q4, 32B Q8, 30B A3B), Gemma 3 (en particulier 27B QAT Q8, 12B), Devstral, etc., sont largement mentionnés pour leurs performances en matière de code, de création, de raisonnement général, etc. Les utilisateurs s’intéressent à la longueur du contexte des modèles, à la vitesse d’inférence, aux versions quantifiées (comme IQ1_S_R4) et à leur fonctionnement sur différents matériels (comme 8 Go de VRAM, les téléphones à puce Snapdragon 8 Elite). Les modèles fermés comme Claude Code, Gemini API, etc., sont également utilisés simultanément en raison de leurs avantages spécifiques (comme le traitement de contextes longs, les capacités de codage) (Source: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
💡 Autres
Développement des compétences à l’ère de l’IA : Questionnement, pensée critique et apprentissage continu sont essentiels: La discussion souligne qu’à l’ère de l’IA, six compétences sont cruciales : la capacité à poser des questions, la pensée critique, le maintien d’un mode d’apprentissage, la capacité de coder ou de donner des instructions, la maîtrise des outils d’IA et une communication claire. L’entreprise Zapier exige même que 100 % de ses nouveaux employés maîtrisent l’IA, ce qui est interprété comme mettant principalement l’accent sur les besoins en communication et la capacité à déléguer correctement les tâches, plutôt que sur des connaissances purement techniques. L’IA facilite l’exécution, de sorte que la qualité de la conception et de la réflexion a un impact plus important sur le résultat final (Source: TheTuringPost, zacharynado)

Éthique de l’IA et impact social : Inquiétudes et autonomisation coexistent: L’acteur Steve Carell exprime son inquiétude quant à la société future dépeinte dans son nouveau film « Mountainhead », estimant que c’est peut-être la société dans laquelle nous vivrons bientôt, suggérant des préoccupations quant aux impacts négatifs potentiels de l’IA. D’un autre côté, certains estiment que l’IA ne créera pas nécessairement une polarisation extrême entre « paysans et rois », mais pourrait au contraire, en autonomisant les individus, réduire l’écart de capacités entre les individus et les grandes entreprises, favorisant ainsi la productivité, la créativité et l’influence personnelles. Cependant, certains restent prudents quant aux perspectives de démocratisation de l’IA, estimant que les grandes entreprises conserveront leur position dominante en contrôlant l’entraînement et le déploiement des modèles (Source: Reddit r/artificial, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

Hiring Cafe : Plateforme d’agrégation d’offres d’emploi pilotée par l’IA: Hamed N. a utilisé l’API ChatGPT pour extraire 4,1 millions d’offres d’emploi publiées directement sur les sites web des entreprises, créant ainsi le site Hiring Cafe. Cette plateforme vise à résoudre le problème des « emplois fantômes » et des intermédiaires tiers qui prolifèrent sur des plateformes comme LinkedIn et Indeed, en aidant les demandeurs d’emploi à filtrer plus efficacement les postes grâce à des filtres puissants (tels que le poste, la fonction, le secteur, les années d’expérience, le rôle de management/IC, etc.). Il s’agit d’un projet personnel non commercial d’un doctorant, qui a été bien accueilli et utilisé par la communauté (Source: Reddit r/ChatGPT)
