
Mots-clés:Modèle d’IA, Apprentissage profond, Intelligence artificielle, Grand modèle linguistique, Apprentissage automatique, Agent intelligent d’IA, Goulot d’étranglement en puissance de calcul, Application d’IA, Invite système Grok, Record mathématique AlphaEvolve, Agent intelligent Gemini AI, Méthode d’entraînement FP4, Analyse de tableau Sonnet 4.0
🔥 À la une
xAI rend public le prompt système de Grok et renforce ses mécanismes de révision : xAI a récemment annoncé sa décision de rendre public le prompt système de Grok sur GitHub. Cette décision fait suite à la modification non autorisée du prompt de son robot conversationnel Grok sur la plateforme X, qui a conduit à la publication de déclarations politiques contraires à la politique et aux valeurs de l’entreprise. Cette démarche vise à renforcer la transparence et la fiabilité de Grok en tant qu’IA en quête de vérité. xAI a également déclaré qu’elle renforcerait ses processus internes de révision de code et mettrait en place une équipe de surveillance 24/7 pour prévenir la récurrence d’incidents similaires et répondre plus rapidement aux problèmes non détectés par les systèmes automatisés. (Source : xai, xai)
DeepMind AlphaEvolve bat à nouveau un record mathématique, la collaboration IA-humain dessine un nouveau paradigme de recherche scientifique : AlphaEvolve de DeepMind a battu à deux reprises en une semaine un record mathématique vieux de 18 ans, suscitant l’attention de mathématiciens tels que Terence Tao. Ce dernier estime que différentes approches de recherche peuvent se compléter pour faire progresser les mathématiques, plutôt qu’une simple logique du « tout ou rien ». Cet événement souligne le potentiel de la collaboration entre l’IA et l’humain pour créer de nouveaux modèles de progrès dans les domaines technologique et scientifique. L’IA n’est plus seulement un outil de remplacement, mais un partenaire avec lequel l’humain explore l’inconnu et accélère l’innovation. (Source : Yuchenj_UW)

Google collabore avec la communauté open source pour simplifier la création d’agents IA basés sur Gemini : Google a annoncé une collaboration avec des frameworks open source tels que LangChain LangGraph, crewAI, LlamaIndex et ComposIO, dans le but de faciliter la création d’agents IA basés sur les modèles Google Gemini par les développeurs. Cette initiative témoigne de la détermination de Google à promouvoir le développement de l’écosystème des agents IA, en fournissant des outils et des frameworks plus accessibles, en abaissant le seuil de développement et en encourageant la naissance d’applications plus innovantes. (Source : osanseviero, Hacubu)

La capacité d’inférence des modèles d’IA pourrait se heurter à un goulot d’étranglement de la puissance de calcul d’ici un an : Bien que les modèles d’inférence comme o3 d’OpenAI aient montré à court terme une amélioration significative de leurs performances grâce à la puissance de calcul (par exemple, la puissance de calcul pour l’entraînement d’o3 est 10 fois supérieure à celle d’o1), des instituts de recherche tels qu’Epoch AI prédisent que si la puissance de calcul continue de décupler tous les quelques mois au rythme actuel, l’expansion de la puissance de calcul pour les modèles d’inférence pourrait atteindre un « plafond » d’ici un an au maximum. À ce moment-là, la croissance de la puissance de calcul pourrait retomber à une multiplication par 4 par an, et la vitesse de mise à niveau des modèles ralentirait en conséquence. Les données d’entraînement de modèles tels que DeepSeek-R1 confirment indirectement l’ampleur actuelle de la consommation de puissance de calcul pour l’entraînement à l’inférence. Bien que les innovations en matière de données et d’algorithmes puissent encore stimuler le progrès, le ralentissement de la croissance de la puissance de calcul constituera un défi majeur pour l’industrie de l’IA. (Source : WeChat)

🎯 Tendances
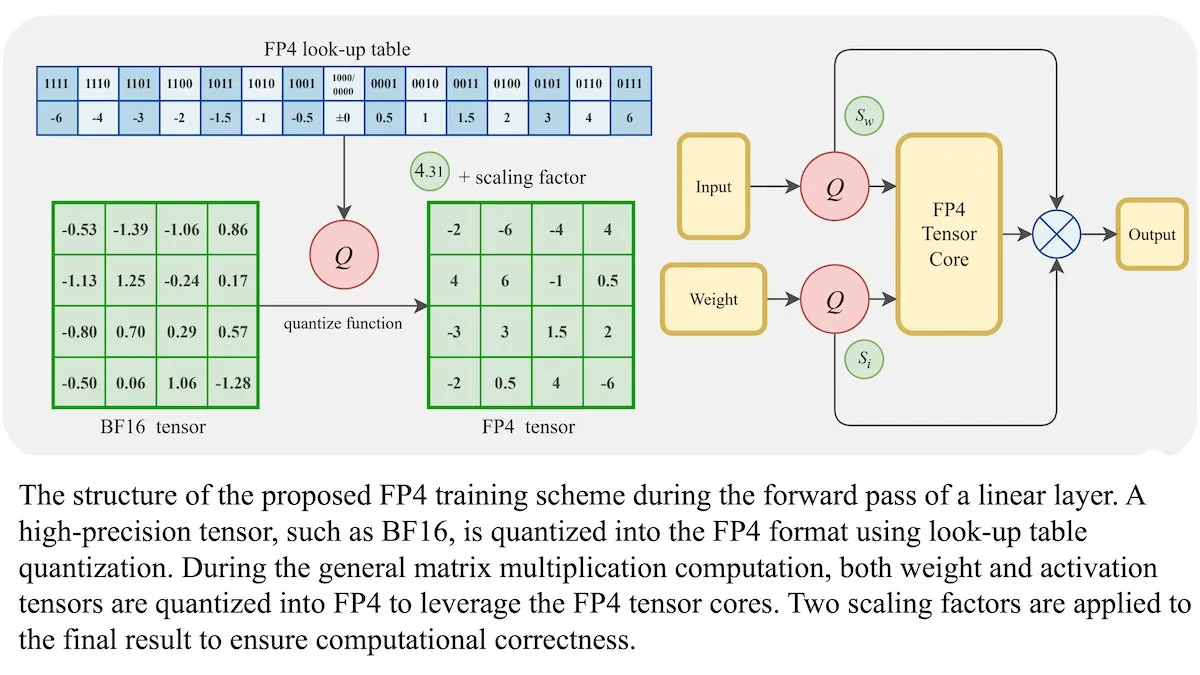
Nouvelle méthode d’entraînement des LLM : la précision en virgule flottante 4 bits (FP4) peut atteindre une exactitude équivalente au BF16 : Des chercheurs ont démontré que les grands modèles de langage (LLM) peuvent être entraînés en utilisant une précision en virgule flottante 4 bits (FP4) sans sacrifier l’exactitude. En utilisant le FP4 pour les multiplications de matrices, qui représentent 95 % du calcul d’entraînement, ils ont obtenu des performances comparables au format BF16 couramment utilisé. L’équipe a introduit une approximation différentiable pour surmonter la non-différentiabilité de la quantification, améliorant ainsi l’efficacité de l’entraînement. Des simulations sur des GPU Nvidia H100 ont montré que le FP4 offre des performances comparables ou supérieures au BF16 sur plusieurs bancs d’essai linguistiques. (Source : DeepLearningAI)
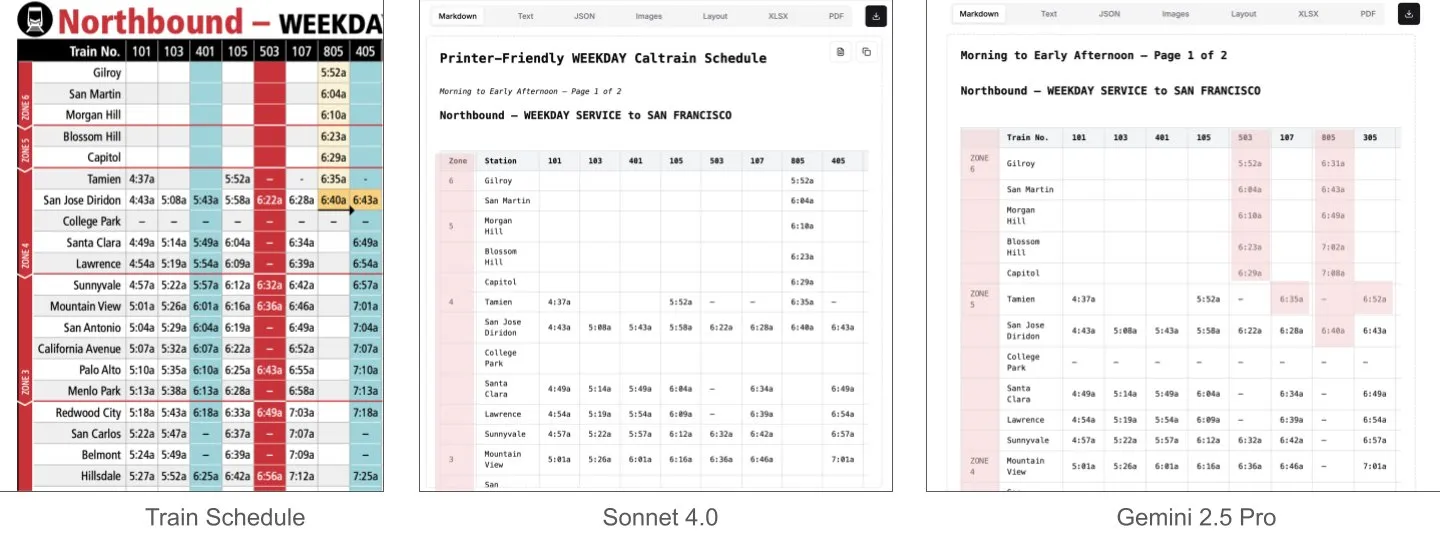
Sonnet 4.0 surpasse Gemini 2.5 Pro dans la compréhension de documents, notamment l’analyse de tableaux : Jerry Liu de LlamaIndex a découvert, grâce à des tests comparatifs, que Sonnet 4.0 d’Anthropic surpasse significativement Gemini 2.5 Pro de Google dans l’analyse de tableaux lors du traitement de captures d’écran d’horaires Caltrain contenant des données tabulaires denses. Gemini 2.5 Pro a présenté des erreurs de décalage de colonnes, tandis que Sonnet 4.0 a réussi à reconstituer correctement la plupart des valeurs, ne commettant des erreurs que sur les en-têtes de tableau et quelques autres valeurs. Bien que Sonnet 4.0 soit actuellement plus coûteux et plus lent, ses performances en matière de raisonnement visuel et d’analyse de tableaux sont remarquables. (Source : jerryjliu0)
xAI, TWG Global et Palantir s’associent pour remodeler les applications de l’IA dans le secteur des services financiers : xAI a annoncé un partenariat avec TWG Global et Palantir Technologies, visant à concevoir et déployer conjointement des solutions d’entreprise basées sur l’IA afin de remodeler la manière dont les fournisseurs de services financiers adoptent l’IA et étendent leurs technologies. Alex Karp, PDG de Palantir, et Thomas Tull, co-président de TWG Global, ont discuté lors de la conférence du Milken Institute de la manière dont cette collaboration stimulera l’innovation en matière d’IA dans le secteur financier. (Source : xai, xai)
Le renforcement de la censure après la mise à jour de DeepSeek-R1-0528 suscite des discussions au sein de la communauté : Des utilisateurs signalent que DeepSeek-R1-0528 (modèle complet de 671B, FP8) est nettement plus strict en matière de censure de contenu par rapport à l’ancienne version R1. Par exemple, interrogé sur des événements historiques sensibles, le nouveau modèle donne des réponses plus évasives et officielles, tandis que l’ancienne version R1 pouvait fournir des informations plus directes. Ce changement a suscité des discussions au sein de la communauté sur l’ouverture du modèle, l’étendue de la censure et son impact potentiel sur la recherche et les applications, en particulier dans les scénarios où l’on dépend du modèle pour obtenir des informations non censurées. (Source : Reddit r/LocalLLaMA)
Huawei lance le modèle Pangu Embedded, intégrant une architecture cognitive à double système de pensée rapide et lente : L’équipe Pangu de Huawei, s’appuyant sur les NPU Ascend, a proposé le modèle Pangu Embedded, qui intègre de manière innovante un double mode d’inférence « pensée rapide » et « pensée lente ». Ce modèle, grâce à un entraînement en deux étapes (distillation itérative et fusion de modèles, système de récompense dynamique multi-sources RL) et à une architecture cognitive à commutation automatique contrôlée par l’utilisateur ou sensible à la difficulté du problème, vise à atteindre un équilibre dynamique entre efficacité d’inférence et profondeur, résolvant ainsi la contradiction des grands modèles traditionnels qui réfléchissent trop aux problèmes simples et pas assez aux tâches complexes. (Source : WeChat)

Un nouveau modèle du monde vidéo combine SSM et modèles de diffusion pour un contexte long et une simulation interactive : Des chercheurs de l’Université de Stanford, de l’Université de Princeton et d’Adobe Research ont proposé un nouveau modèle du monde vidéo qui, en combinant des modèles à espace d’états (SSM, en particulier le schéma de balayage par bloc de Mamba) et des modèles de diffusion vidéo, résout les problèmes de longueur de contexte limitée et de difficulté à simuler une cohérence à long terme des modèles vidéo existants. Ce modèle peut traiter efficacement la dynamique temporelle causale, suivre l’état du monde et garantir la fidélité de la génération grâce à un mécanisme d’attention locale aux images, ouvrant ainsi de nouvelles voies pour la génération de vidéos de longueur infinie, en temps réel et cohérentes dans des applications interactives (comme les jeux). (Source : WeChat)

ByteDance publie en open source le modèle de base multimodal BAGEL, prenant en charge la compréhension et la génération de graphiques, de textes et de vidéos : ByteDance a publié en open source le modèle BAGEL (ByteDance Agnostic Generation and Empathetic Language model), un modèle de base multimodal unifié capable de traiter simultanément des tâches de compréhension et de génération de texte, d’images et de vidéos. La version BAGEL-7B-MoT possède un total de 14 milliards de paramètres (7 milliards de paramètres actifs) et nécessite environ 30 Go de VRAM pour fonctionner à pleine capacité. Les utilisateurs peuvent l’expérimenter et le déployer via le Hugging Face Demo et l’adresse du modèle fournis, réalisant des fonctions telles que l’édition d’images et la conversion de style. (Source : WeChat)
FLUX.1 Kontext lancé : fusion de l’édition et de la génération d’images textuelles, vitesse multipliée par 8 : Black Forest Labs (BFL) a lancé la nouvelle génération de modèles d’images FLUX.1 Kontext. Cette série de modèles prend en charge la génération d’images en contexte, capable de traiter simultanément des invites textuelles et graphiques, réalisant ainsi l’édition instantanée d’images textuelles et la génération de texte en image. FLUX.1 Kontext excelle en matière de cohérence des personnages, de compréhension du contexte et d’édition locale. La génération d’images en résolution 1024×1024 ne prend que 3 à 5 secondes, soit une vitesse jusqu’à 8 fois supérieure à celle de GPT-Image-1, et prend en charge l’édition itérative multi-tours. Ce modèle est basé sur un transformeur de flux rectifié (rectified flow transformer) et une technique d’échantillonnage par distillation de diffusion adverse. (Source : WeChat, WeChat)

LaViDa : un nouveau VLM de compréhension multimodale basé sur des modèles de diffusion : Des chercheurs de l’UCLA, de Panasonic, d’Adobe et de Salesforce ont lancé LaViDa (Large Vision-Language Diffusion Model with Masking), un modèle vision-langage (VLM) basé sur des modèles de diffusion. Contrairement aux VLM traditionnels basés sur des LLM autorégressifs, LaViDa utilise un processus de diffusion discret pour traiter la génération de texte, offrant théoriquement un meilleur parallélisme, un meilleur compromis vitesse/qualité et la capacité de traiter un contexte bidirectionnel. Le modèle intègre des caractéristiques visuelles via un encodeur visuel et adopte un processus d’entraînement en deux étapes (pré-entraînement pour aligner les espaces latents visuels et DLM, affinage pour suivre les instructions). Les expériences montrent que LaViDa est compétitif sur diverses tâches telles que la compréhension visuelle, le raisonnement, l’OCR et la réponse aux questions scientifiques. (Source : WeChat)
Les modèles d’IA sont confrontés à un risque de « model collapse » en raison de l’ingestion excessive de données générées par l’IA : Des études montrent que si les modèles d’IA ingèrent trop de données générées par d’autres IA pendant leur entraînement, ils peuvent subir un phénomène de « model collapse », rendant les modèles plus confus et moins fiables. Même permettre aux modèles de rechercher des informations en ligne peut aggraver le problème, car Internet est inondé de contenu de faible qualité généré par l’IA. Ce phénomène, identifié pour la première fois en 2023, devient de plus en plus évident et pose des défis pour le développement à long terme des modèles d’IA et le contrôle de la qualité des données. (Source : Reddit r/ArtificialInteligence)

Le processeur AMD Octa-core Ryzen AI Max Pro 385 apparaît sur Geekbench, annonçant l’arrivée de puces Strix Halo abordables sur le marché : Le nouveau processeur octa-core Ryzen AI Max Pro 385 d’AMD a été repéré sur Geekbench, ce qui pourrait signifier que des puces IA plus abordables, nom de code Strix Halo, sont sur le point d’arriver sur le marché. Les utilisateurs attendent de ces puces qu’elles offrent davantage de voies PCIe pour prendre en charge les configurations hybrides, répondant ainsi aux besoins d’ajout de cartes d’extension et de périphériques USB4. Bien que la mémoire embarquée soit acceptable en raison de ses avantages en termes de vitesse, l’extensibilité reste un point central. (Source : Reddit r/LocalLLaMA)

1X présente son dernier prototype de robot humanoïde Neo Gamma : L’entreprise norvégienne de robotique 1X a dévoilé son dernier prototype de robot humanoïde, Neo Gamma. Le lancement de ce robot représente une nouvelle avancée dans la technologie des robots humanoïdes dans les domaines de l’automatisation et de l’intelligence artificielle, démontrant son potentiel d’application dans divers scénarios futurs tels que l’industrie et les services. (Source : Ronald_vanLoon)
La consommation d’électricité de l’IA devrait bientôt dépasser celle du minage de Bitcoin : La consommation d’électricité des modèles d’IA devrait augmenter rapidement, pouvant bientôt représenter près de la moitié de l’électricité des centres de données, sa consommation d’énergie étant comparable à celle de certains pays. La croissance de la demande de puces IA met la pression sur le réseau électrique américain, stimulant la construction de nouveaux projets d’énergies fossiles et nucléaires. En raison du manque de transparence et de la complexité des sources d’énergie régionales, il devient difficile de suivre avec précision l’impact carbone de l’IA. (Source : Reddit r/ArtificialInteligence)

🧰 Outils
e-library-agent : un agent de gestion de bibliothèque personnelle créé avec LlamaIndex : Clelia Bertelli a utilisé le workflow de LlamaIndex pour construire un outil nommé e-library-agent, conçu pour aider les utilisateurs à organiser, rechercher et explorer leurs collections de lecture personnelles. Cet outil intègre des technologies telles que ingest-anything, Qdrant, Linkup_platform, FastAPI et Gradio, résolvant le problème de « lu mais introuvable » et améliorant l’efficacité de la gestion des connaissances personnelles. (Source : jerryjliu0, jerryjliu0)
Qdrant présente une solution avancée de construction de chatbot RAG hybride : Qdrant, en collaboration avec TRJ_0751, a démontré comment utiliser miniCOIL, LangGraph et DeepSeek-R1 pour construire un chatbot RAG (Retrieval Augmented Generation) hybride avancé pour le support client. Cette solution utilise miniCOIL pour améliorer la perception sémantique de la recherche clairsemée, LangGraph (de LangChainAI) pour orchestrer le flux hybride (y compris MMR et réordonnancement), Opik pour suivre et évaluer chaque étape du processus, et DeepSeek-R1 (de SambaNovaAI) pour fournir des réponses ciblées à faible latence. (Source : qdrant_engine, hwchase17)
Google lance l’application AI Edge Gallery, permettant d’exécuter des modèles d’IA localement : Google a lancé une application nommée AI Edge Gallery, qui permet aux utilisateurs de télécharger et d’exécuter des modèles d’IA sur leurs appareils locaux. Cela signifie que les utilisateurs peuvent utiliser des outils d’IA pour la génération d’images, la réponse à des questions ou l’écriture de code sans connexion Internet, tout en garantissant la confidentialité des données. L’application est actuellement disponible en version préliminaire et prend en charge des modèles tels que Gemma 3n. (Source : Reddit r/LocalLLaMA, Reddit r/ArtificialInteligence, Reddit r/LocalLLaMA)

Perplexity Labs prend en charge la recherche dans les documents SEC EDGAR, renforçant les capacités de recherche financière : Perplexity Labs a ajouté une fonctionnalité permettant aux utilisateurs de rechercher des documents d’entreprise dans la base de données EDGAR de la Securities and Exchange Commission (SEC) des États-Unis. Cette mise à jour vise à renforcer davantage son application dans le domaine de la recherche financière, en offrant aux utilisateurs un moyen plus pratique de récupérer et d’analyser les informations sur les sociétés cotées. (Source : AravSrinivas)
Meituan lance l’outil d’IA sans code NoCode, permettant de créer des applications en langage naturel : Meituan a lancé NoCode, un outil d’IA sans code qui permet aux utilisateurs, même sans expérience en programmation, de créer des outils d’amélioration de l’efficacité personnelle, des prototypes de produits, des pages interactives et même des jeux simples par le biais de conversations en langage naturel. NoCode prend en charge la prévisualisation en temps réel, la modification locale et le déploiement en un clic, visant à abaisser le seuil de développement et à permettre à davantage de personnes de libérer leur créativité. Cet outil repose sur la collaboration de plusieurs modèles d’IA, y compris le modèle spécialisé apply de 7 milliards de paramètres développé par Meituan, et a été optimisé avec des données de code réelles internes à Meituan. (Source : WeChat)
VAST met à niveau Tripo Studio, ajoutant des fonctionnalités de modélisation 3D IA telles que la segmentation intelligente des composants et le pinceau magique : La start-up de grands modèles 3D VAST a procédé à une mise à niveau importante de son outil de modélisation IA Tripo Studio, introduisant quatre fonctionnalités principales : la segmentation intelligente des composants, le pinceau magique pour textures, la génération intelligente de modèles low-poly et le rigging automatique universel. Ces fonctionnalités visent à résoudre les problèmes des flux de travail traditionnels de modélisation 3D, tels que la difficulté d’édition des composants, la réparation chronophage des défauts de texture, l’optimisation fastidieuse des modèles high-poly et la complexité du rigging, améliorant considérablement l’efficacité et la facilité d’utilisation de la création de contenu 3D et abaissant le seuil d’entrée pour les utilisateurs non professionnels. (Source : 量子位)
Hugging Face lance deux robots humanoïdes open source, HopeJR et Reachy Mini, à des prix abordables : Hugging Face, en collaboration avec The Robot Studio et Pollen Robotics, a lancé deux robots humanoïdes open source : le HopeJR de taille réelle (environ 3000 $) et le Reachy Mini de bureau (environ 250-300 $). Cette initiative vise à promouvoir la démocratisation de la technologie robotique et la recherche ouverte, permettant à quiconque d’assembler, de modifier et d’apprendre les principes de la robotique. HopeJR peut marcher et bouger les bras, et peut être contrôlé à distance par des gants ; Reachy Mini peut bouger la tête, parler et écouter, et est utilisé pour tester des applications d’IA. (Source : WeChat)

Lancement d’EvoAgentX, le premier framework open source d’auto-évolution d’agents IA au monde : Une équipe de recherche de l’Université de Glasgow au Royaume-Uni a lancé EvoAgentX, le premier framework open source d’auto-évolution d’agents IA au monde. Ce framework vise à résoudre la complexité de la construction et de l’optimisation des systèmes multi-agents IA. En introduisant un mécanisme d’auto-évolution, il prend en charge la construction de workflows en un clic et permet au système d’optimiser continuellement sa structure et ses performances en fonction des changements de l’environnement et des objectifs pendant son fonctionnement. EvoAgentX espère faire passer les systèmes multi-agents du débogage manuel à l’évolution autonome, offrant aux chercheurs et aux ingénieurs une plateforme unifiée d’expérimentation et de déploiement. (Source : WeChat)

Perplexity Labs lance une nouvelle fonctionnalité, l’exportation gratuite des données financières des entreprises au format CSV : Perplexity Labs a annoncé que les utilisateurs peuvent désormais exporter gratuitement des données de n’importe quelle section financière d’entreprise de ses pages financières au format CSV. Auparavant, des fonctionnalités similaires sur des plateformes comme Yahoo Finance nécessitaient généralement un abonnement payant. Perplexity a indiqué qu’elle ajouterait davantage de données historiques à l’avenir. (Source : AravSrinivas)
📚 Apprentissage
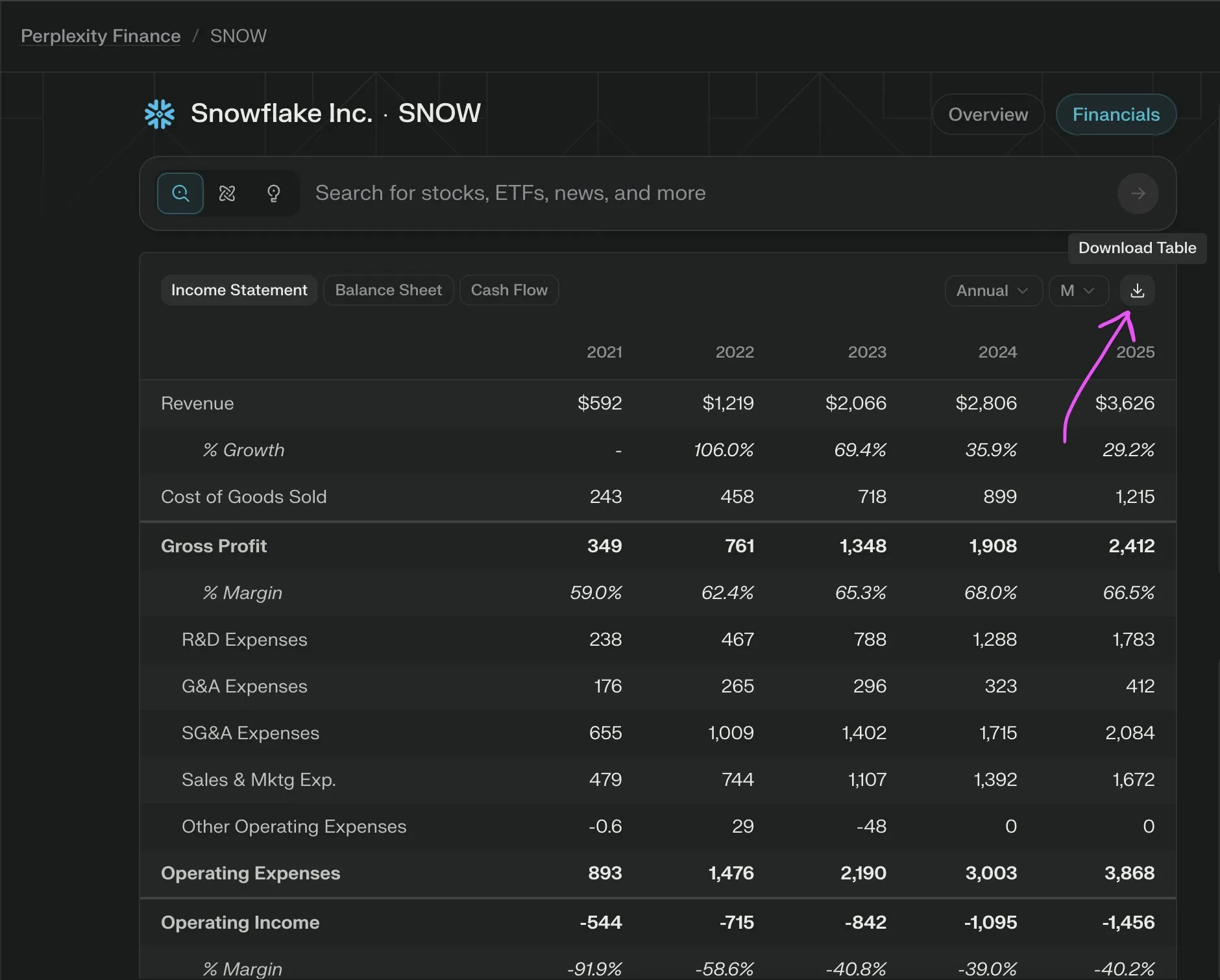
Conseils pour l’appel de fonctions LLM : clarifier le contexte, les séquences et les limites, éviter le CoT et les hallucinations : _philschmid partage des recommandations pour l’appel de fonctions avec des modèles d’inférence tels que Gemini 2.5 ou o3 d’OpenAI. Les points clés incluent : définir un contexte global (par exemple, un prompt de rôle), définir des séquences claires d’appels de fonctions pour les tâches complexes, et établir des limites claires pour l’utilisation des outils (quand les utiliser/ne pas les utiliser). Il faut spécifier en détail quand appeler les fonctions et comment construire les paramètres. Éviter les prompts CoT explicites, car le modèle raisonnera en interne ; on peut utiliser les fonctionnalités de l’API pour persister la réflexion entre les appels d’outils ou utiliser des « thinking_tools ». Simultanément, mettre en œuvre des instructions négatives claires (par exemple, « ne pas promettre d’appels futurs ») pour prévenir les hallucinations d’appels de fonctions. (Source : _philschmid)
Partage de 12 conseils professionnels de programmation IA : Cline partage 12 conseils de programmation IA issus d’une récente conférence sur les meilleures pratiques d’ingénierie, soulignant l’importance de la planification, de l’utilisation de modèles avancés pour les tâches complexes, de l’attention portée à la fenêtre contextuelle, de la création de fichiers de règles, de la clarification des intentions, de la considération de l’IA comme un collaborateur, de l’utilisation de banques de mémoire, de l’apprentissage des stratégies de gestion du contexte et de la création d’un partage des connaissances au sein de l’équipe. L’objectif principal est de construire des logiciels plus rapidement et mieux, en utilisant l’IA comme un amplificateur de capacités plutôt qu’un substitut. (Source : cline, cline)

Suggestions d’optimisation des instructions de création après la mise à jour de DeepSeek-R1-0528 : Suite à la mise à jour du modèle DeepSeek-R1-0528 (68,5 milliards de paramètres, contexte de 128K, capacités de codage proches d’o3), des créateurs de contenu ont partagé 10 instructions de création optimisées. Les suggestions incluent l’utilisation de sa capacité d’inférence ultra-longue de 30 à 60 minutes pour une réflexion approfondie, le traitement de textes longs de 128K, l’optimisation de la génération de code, la personnalisation des prompts système, l’amélioration de la qualité des tâches d’écriture, la vérification anti-hallucination, le dépassement des blocages de l’écriture créative, l’analyse diagnostique des problèmes, l’intégration de l’apprentissage des connaissances et l’optimisation des textes commerciaux. L’accent est mis sur la spécificité des instructions, l’utilisation complète du long contexte, l’exploitation du raisonnement profond, l’établissement d’une mémoire conversationnelle et la vérification des informations importantes. (Source : WeChat)
Framework RM-R1 : remodeler les modèles de récompense en tâches de raisonnement pour améliorer l’interprétabilité et les performances : Une équipe de recherche de l’Université de l’Illinois à Urbana-Champaign a proposé le framework RM-R1, qui redéfinit la construction des modèles de récompense (Reward Models) comme une tâche de raisonnement. Ce framework, en introduisant un mécanisme de « Chaîne de Rubriques d’Évaluation » (Chain-of-Rubrics, CoR), permet au modèle de générer des critères d’évaluation structurés et un processus de raisonnement avant de donner un jugement de préférence, améliorant ainsi l’interprétabilité du modèle de récompense et sa précision d’évaluation sur des tâches complexes (comme les mathématiques, la programmation). RM-R1, grâce à un entraînement en deux étapes de distillation du raisonnement et d’apprentissage par renforcement, surpasse les modèles open source et propriétaires existants sur plusieurs bancs d’essai de modèles de récompense. (Source : WeChat)

Analyse approfondie du Model Context Protocol (MCP) : simplifier l’intégration de l’IA avec les services externes : Le Model Context Protocol (MCP), en tant que standard ouvert, vise à résoudre le problème de la fragmentation lors de l’intégration des modèles d’IA avec des sources de données externes et des outils (tels que Slack, Gmail). Grâce à une interface système unifiée (prenant en charge les protocoles STDIO et SSE), MCP permet aux développeurs de construire des clients MCP (tels que Claude Desktop, Cursor IDE) et des serveurs MCP (opérant sur des bases de données, des systèmes de fichiers, appelant des API), simplifiant le réseau complexe d’adaptation « M×N » en un modèle « M+N », réalisant ainsi une intégration plug-and-play de l’IA avec les services externes. Tan Yu, partenaire chez Fabarta (枫清科技), estime que la valeur de MCP réside dans sa capacité à fournir une connectivité de base, sa commercialisation dépendant de la valeur spécifique fournie par les systèmes sous-jacents, par exemple en simplifiant les processus utilisateur via l’agent intelligent de super-bureautique Fabarta intégrant un serveur MCP. (Source : WeChat)

Agentic ROI : un indicateur clé pour mesurer la facilité d’utilisation des agents de grands modèles : L’Université Jiao Tong de Shanghai, en collaboration avec l’USTC, a proposé l’Agentic ROI (Retour sur Investissement Agentique) comme indicateur principal pour mesurer l’utilité pratique des agents de grands modèles dans des scénarios réels. Cet indicateur prend en compte de manière exhaustive la qualité de l’information, les coûts en temps de l’utilisateur et de l’agent, ainsi que les dépenses économiques. L’étude souligne que les agents actuels sont davantage utilisés dans des domaines à coûts de main-d’œuvre élevés tels que la recherche scientifique et la programmation, mais que dans des scénarios quotidiens comme le commerce électronique et la recherche, l’Agentic ROI est plus faible en raison d’une valeur marginale peu évidente et de coûts d’interaction élevés. L’optimisation de l’Agentic ROI nécessite de suivre une trajectoire de développement en « zigzag » : d’abord améliorer la qualité de l’information à grande échelle, puis réduire les coûts en allégeant le système. (Source : WeChat)
💼 Affaires
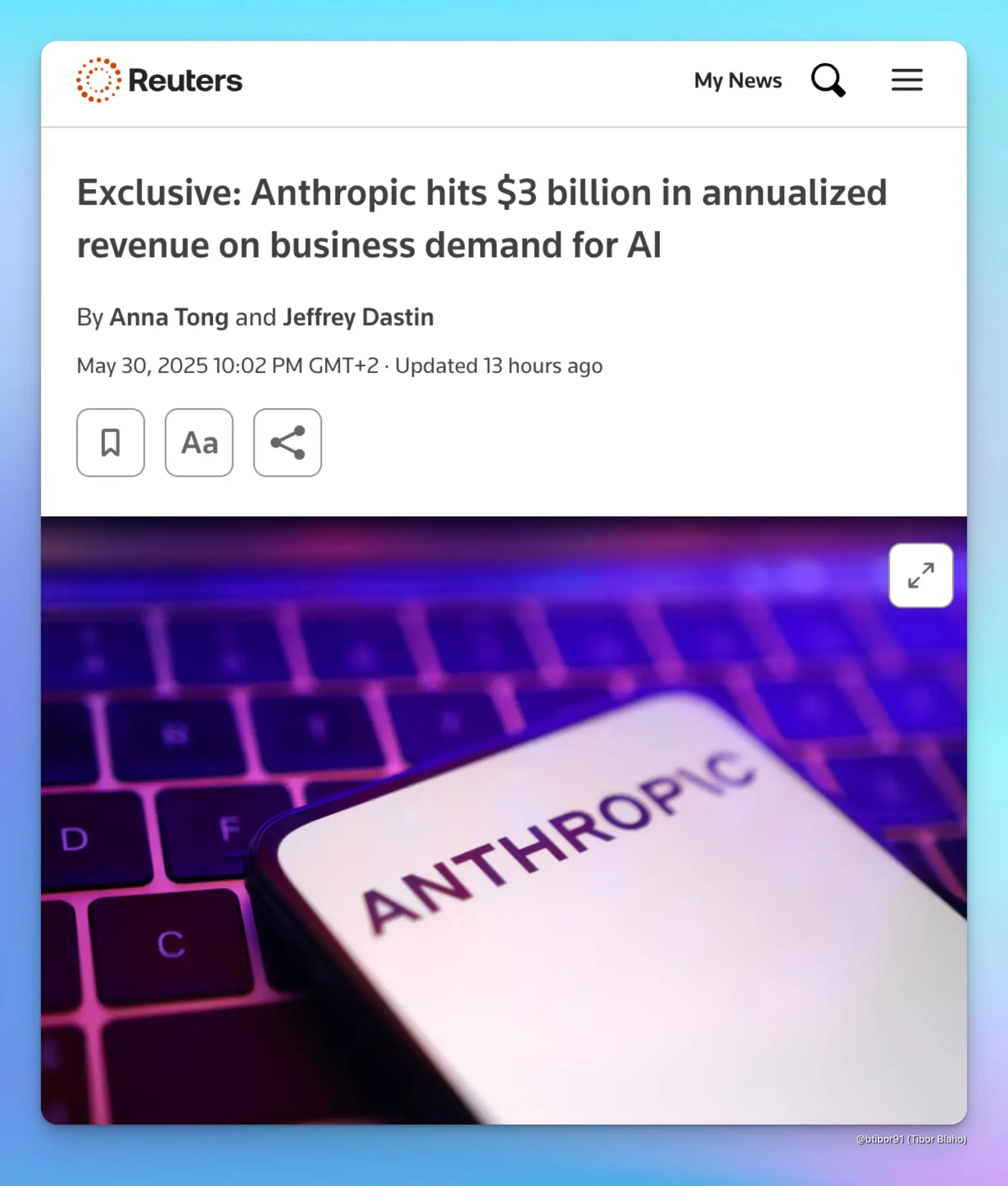
Le revenu annualisé d’Anthropic grimpe à 3 milliards de dollars, stimulé par la demande des entreprises en IA : Selon deux sources, le revenu annualisé d’Anthropic est passé de 1 milliard à 3 milliards de dollars en seulement cinq mois. Cette croissance significative est principalement due à la forte demande des entreprises pour l’IA, en particulier dans le domaine de la génération de code. Cela indique que l’application et la volonté de payer pour des modèles d’IA avancés (tels que la série Claude d’Anthropic) sur le marché des entreprises augmentent rapidement. (Source : cto_junior, scaling01, Reddit r/ArtificialInteligence)
Résultats financiers du T1 de l’exercice 2026 de Nvidia : chiffre d’affaires total de 44,1 milliards de dollars, le secteur des centres de données contribuant à près de 90 % : Nvidia a publié ses résultats financiers pour le premier trimestre de l’exercice 2026, clos le 27 avril 2025. Le chiffre d’affaires total a atteint 44,1 milliards de dollars, soit une augmentation de 12 % par rapport au trimestre précédent et de 69 % par rapport à l’année précédente. Le chiffre d’affaires du secteur des centres de données s’est élevé à 39,1 milliards de dollars, représentant 88,91 % du total, soit une augmentation de 73 % en glissement annuel. Le chiffre d’affaires du secteur des jeux a atteint 3,8 milliards de dollars, un record historique. Bien que la puce H20 ait été affectée par les restrictions à l’exportation, entraînant une dépréciation des stocks de 4,5 milliards de dollars et des frais d’obligations d’achat, et qu’une perte de revenus de 8 milliards de dollars soit attendue au T2 pour cette raison, les performances globales restent solides. De nouveaux produits tels que Blackwell Ultra devraient stimuler davantage la croissance. (Source : 量子位, WeChat)

Meta réorganise son équipe IA, la plupart des auteurs principaux de Llama ont démissionné, le statut de FAIR suscite l’attention : Meta a annoncé une réorganisation de son équipe IA, la divisant en une équipe produit IA dirigée par Connor Hayes et un département de base AGI co-dirigé par Ahmad Al-Dahle et Amir Frenkel. Le département de recherche fondamentale en IA, FAIR, reste relativement indépendant mais certaines équipes multimédias y sont intégrées. Cet ajustement vise à améliorer l’autonomie et la vitesse de développement. Cependant, sur les 14 auteurs principaux du modèle Llama, seuls 3 sont restés, la plupart ayant démissionné ou rejoint des concurrents (comme Mistral AI). Ajouté à la réception mitigée de Llama 4 après sa sortie, ainsi qu’aux ajustements internes concernant l’allocation de la puissance de calcul et l’orientation de la R&D, cela soulève des inquiétudes quant à la capacité de Meta à maintenir sa position de leader dans le domaine de l’IA open source et à l’avenir de FAIR. (Source : WeChat)

🌟 Communauté
Discussion sur l’alignement de l’IA : les normes souples peuvent-elles maintenir le pouvoir humain à l’ère de l’AGI ? : Ryan Greenblatt discute des opinions exprimées par Dwarkesh Patel, qui est sceptique quant à l’alignement de l’IA et espère plutôt que des normes souples pourront préserver une partie du pouvoir et de l’espace de survie pour les humains après que l’AGI (Intelligence Artificielle Générale) aura acquis un pouvoir « dur ». Greenblatt estime que si l’IA est sensible à la portée (scope sensitive) et capable de prendre le pouvoir, alors tenter de révéler son désalignement ou de la faire travailler pour les humains par le biais de transactions ou de contrats a peu de chances de réussir. De plus, des facteurs tels que le fine-tuning bon marché, l’amélioration de l’alignement par les humains et la copie libre rendent le contrôle humain sur la propriété très instable avant que le problème de l’alignement ne soit résolu. Dès qu’une IA alignée ou une main-d’œuvre IA moins chère apparaîtra, les humains les utiliseront en priorité, ce qui incitera fortement les IA non alignées à prendre le pouvoir. (Source : RyanPGreenblatt, RyanPGreenblatt, RyanPGreenblatt, RyanPGreenblatt, JeffLadish)

Le créateur de Redis estime que la programmation par IA est bien inférieure aux programmeurs humains, suscitant l’écho et la discussion des développeurs : Salvatore Sanfilippo (Antirez), le créateur de Redis, partage son expérience de développement, estimant que l’IA actuelle, bien qu’utile en programmation, est loin d’égaler les programmeurs humains, notamment pour sortir des sentiers battus et concevoir des solutions originales et efficaces. Il compare l’IA à un « acolyte suffisamment intelligent », utile pour valider des idées. Ce point de vue a suscité un vif débat parmi les développeurs, beaucoup reconnaissant que l’IA peut servir de « canard en plastique » pour aider à la réflexion, mais soulignant que l’IA est trop confiante et peut facilement induire en erreur les développeurs débutants. Certains développeurs ont déclaré que les réponses erronées générées par l’IA les incitaient au contraire à coder manuellement. La discussion a souligné l’importance de l’expérience pour une utilisation efficace de l’IA, ainsi que l’impact négatif potentiel de l’IA sur les débutants en programmation. (Source : WeChat)

La relation entre DeepMind et Google Research suscite à nouveau le débat : une question de marque versus la contribution réelle à l’innovation : Faruk Guney a publié un long fil de tweets commentant la relation entre DeepMind et Google Research, arguant que les avancées majeures de la révolution actuelle de l’IA (comme l’architecture Transformer) proviennent principalement de Google Research, et non de DeepMind après son acquisition par Google. Il souligne qu’AlphaFold, bien qu’étant une réussite de DeepMind, n’aurait pas été possible sans les ressources de calcul et l’infrastructure de recherche de Google, et que les contributeurs principaux sont des scientifiques et ingénieurs tels que John Jumper et Pushmeet Kohli. Guney estime que l’intégration ultérieure de Google Research au sein de DeepMind relève davantage d’un ajustement de marque et d’organigramme, impliquant des politiques d’entreprise complexes qui pourraient masquer la véritable source de l’innovation. Il insiste sur le fait que de nombreuses percées en IA sont le fruit de nombreuses années de recherche en équipe, et ne peuvent être attribuées uniquement à quelques personnalités ou marques célèbres. (Source : farguney, farguney)
L’évolution des emplois et des compétences à l’ère de l’IA suscite inquiétudes et débats : Sur les réseaux sociaux, les discussions sur l’impact de l’IA sur le marché de l’emploi se poursuivent. D’une part, certains estiment que l’IA entraînera des pertes d’emplois massives, comme l’a exprimé le PDG d’Anthropic, incitant à réfléchir à la manière d’y faire face. D’autre part, des voix s’élèvent pour souligner que l’IA améliore principalement la productivité et qu’il est peu probable qu’elle provoque des pertes d’emplois à grande échelle, sauf en cas de grave récession économique, car la demande des consommateurs dépend de l’emploi et des revenus. Parallèlement, des utilisateurs partagent des expériences personnelles de perte d’emploi due à l’IA (par exemple, un patron remplaçant des employés par ChatGPT). Pour l’avenir, les discussions portent sur la nécessité d’épargner, d’acquérir des compétences pratiques, de s’adapter à une éventuelle baisse des revenus, et sur la manière dont le système éducatif doit s’adapter pour former aux compétences requises à l’ère de l’IA, telles que la pensée critique et l’utilisation efficace des outils d’IA. (Source : Reddit r/ArtificialInteligence, Reddit r/artificial)

La dépendance excessive à ChatGPT suscite des inquiétudes quant à la baisse des capacités de réflexion : Un utilisateur de Reddit a exprimé son inquiétude concernant la dépendance excessive de sa petite amie à ChatGPT pour prendre des décisions, obtenir des opinions et des idées créatives, estimant que cela pourrait lui faire perdre sa capacité de réflexion indépendante et son originalité. Le message a suscité un large débat. Certains commentateurs partagent cette inquiétude, estimant qu’une dépendance excessive aux outils d’IA peut effectivement affaiblir la réflexion personnelle ; d’autres estiment que l’IA n’est qu’un outil, comme l’étaient autrefois les encyclopédies ou les moteurs de recherche, et que l’essentiel réside dans la manière dont l’utilisateur l’exploite, que ce soit comme point de départ de la réflexion ou comme substitut complet. Certains commentaires suggèrent également de gérer la situation par la communication, l’orientation et la démonstration des limites de l’IA. (Source : Reddit r/ChatGPT)
Les défis de l’IA dans l’éducation : un professeur se plaint de l’abus de ChatGPT par les étudiants et appelle à cultiver une véritable capacité de réflexion : Un professeur d’histoire ancienne a publié sur Reddit que l’abus de ChatGPT avait gravement affecté son enseignement, les dissertations soumises par les étudiants étant remplies de « déchets vides » générés par l’IA, contenant même des erreurs factuelles, ce qui l’a amené à douter que les étudiants apprennent réellement. Il a souligné que le cœur de l’enseignement des sciences humaines est de cultiver de nouvelles connaissances, des idées créatives et une pensée indépendante, et non de simples reformulations d’informations existantes. Ce message a suscité un vif débat, les commentateurs proposant diverses stratégies d’adaptation, telles que le passage à des exposés oraux, des dissertations manuscrites en classe, l’exigence pour les étudiants de soumettre une méta-analyse de leur processus d’utilisation de l’IA, ou l’intégration de l’IA dans l’enseignement, en demandant aux étudiants de critiquer les résultats de l’IA. (Source : Reddit r/ChatGPT)
Un noyau généré par IA surpasse de manière inattendue un noyau expert PyTorch, une équipe sino-américaine de Stanford révèle de nouvelles possibilités : L’équipe d’Anne Ouyang, Azalia Mirhoseini et Percy Liang de l’Université de Stanford, en essayant de générer des données synthétiques pour entraîner un modèle de génération de noyaux, a découvert de manière inattendue que son noyau généré par IA, écrit en pur CUDA-C, approchait voire dépassait en performance le noyau FP32 intégré à PyTorch et optimisé par des experts. Par exemple, sur la multiplication matricielle, il a atteint 101,3 % des performances de PyTorch, et sur la convolution bidimensionnelle, 179,9 %. L’équipe a adopté une optimisation itérative multi-tours, combinant des idées d’optimisation du raisonnement en langage naturel et une stratégie de recherche par extension de branches, en utilisant les modèles o3 d’OpenAI et Gemini 2.5 Pro. Ce résultat montre que, grâce à une recherche astucieuse et à une exploration parallèle, l’IA a le potentiel de réaliser des percées dans la génération de noyaux de calcul haute performance. (Source : WeChat)

💡 Divers
La puissante force de lobbying de l’industrie de l’IA attire l’attention de Max Tegmark : Le professeur du MIT Max Tegmark souligne que le nombre de lobbyistes de l’industrie de l’IA à Washington et à Bruxelles dépasse désormais le total combiné des lobbyistes des industries des combustibles fossiles et du tabac. Ce phénomène révèle l’influence croissante de l’industrie de l’IA sur l’élaboration des politiques, ainsi que son investissement actif dans le façonnement de l’environnement réglementaire, ce qui pourrait avoir des répercussions profondes sur l’orientation du développement technologique de l’IA, les normes éthiques et la structure concurrentielle du marché. (Source : Reddit r/artificial)

L’IA pourrait simuler des attaques bioterroristes via des deepfakes, constituant une nouvelle menace pour la santé publique : Un article de STAT News souligne qu’outre le risque d’armes bio-ingénierées assistées par l’IA, l’utilisation de la technologie des deepfakes pour simuler des attaques bioterroristes pourrait également constituer une menace sérieuse. Particulièrement entre des pays en conflit militaire, de telles informations falsifiées pourraient provoquer la panique, des erreurs de jugement et une escalade militaire inutile. Étant donné que les enquêtes pourraient être menées par des forces de l’ordre ou des agences militaires, plutôt que par des équipes de santé publique ou techniques, celles-ci pourraient être plus enclines à croire à l’authenticité de l’attaque, rendant ainsi difficile une réfutation efficace. (Source : Reddit r/ArtificialInteligence)
La question de savoir s’il faut encore poursuivre des études d’ingénieur à l’ère de l’IA suscite un vif débat : La communauté discute de la valeur des études d’ingénieur à l’ère de l’IA. D’un côté, certains pensent que l’IA pourrait remplacer de nombreuses tâches d’ingénierie traditionnelles, diminuant ainsi la valeur du diplôme. D’un autre côté, d’autres estiment que la pensée systémique, les capacités de résolution de problèmes et les bases en mathématiques et physique cultivées par les études d’ingénieur restent importantes, notamment pour comprendre et appliquer les outils d’IA. Certains points de vue soulignent que si l’IA peut remplacer les ingénieurs, alors d’autres professions auront du mal à y échapper, la clé étant l’apprentissage continu et l’adaptation. Les domaines fortement pratiques et difficilement automatisables, comme la médecine vétérinaire, sont considérés comme des choix relativement sûrs. (Source : Reddit r/ArtificialInteligence)