
Mots-clés:DeepSeek R1-0528, Machine de Gödel Darwin, Consommation énergétique de l’IA, Apprentissage par renforcement avec récompenses fictives, Ascend de Huawei, Classement SuperCLUE, Benchmark multimodal, Amélioration des performances de DeepSeek R1-0528, Mécanisme d’auto-évolution DGM, Solutions nucléaires pour centres de données IA, Mécanisme RLVR du modèle Qwen, Optimisation de l’entraînement Pangu Ultra MoE
🔥 En Vedette
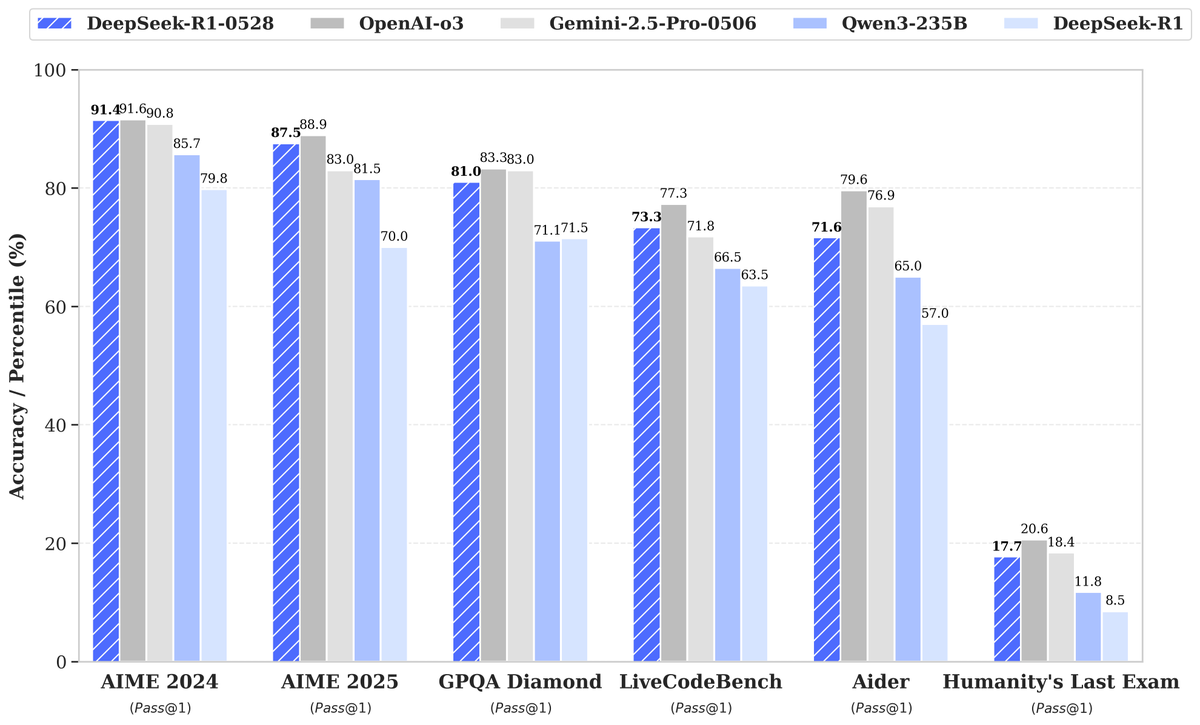
DeepSeek lance son nouveau modèle R1-0528, suscitant l’attention avec une amélioration significative de ses performances: DeepSeek a lancé une nouvelle version de son grand modèle de langage, R1-0528, qui a excellé dans plusieurs benchmarks, notamment en réalisant des progrès significatifs dans des domaines tels que la génération de code (LiveCodeBench), le raisonnement scientifique (GPQA Diamond) et les concours de mathématiques (AIME 2024). Artificial Analysis a souligné que le R1-0528 est passé de 60 à 68 points dans son indice d’intelligence, le plaçant au même niveau que Gemini 2.5 Pro de Google, devenant ainsi le deuxième laboratoire d’IA au monde et consolidant sa position de leader dans le domaine des modèles open-weight. La communauté a réagi positivement, Unsloth publiant rapidement des versions quantifiées GGUF pour faciliter le déploiement local. Cette mise à jour a été principalement réalisée grâce à des techniques de post-formation telles que l’apprentissage par renforcement (RL), démontrant le potentiel d’amélioration continue de l’intelligence du modèle sur la base de l’architecture et du pré-entraînement existants. Bien que certaines discussions aient souligné que ses résultats présentent parfois un style “flatteur”, il est globalement considéré comme un bond en avant majeur en termes de capacités de raisonnement et de code. (Source: DeepSeek, Artificial Analysis, tokenbender, karminski3, teortaxesTex)
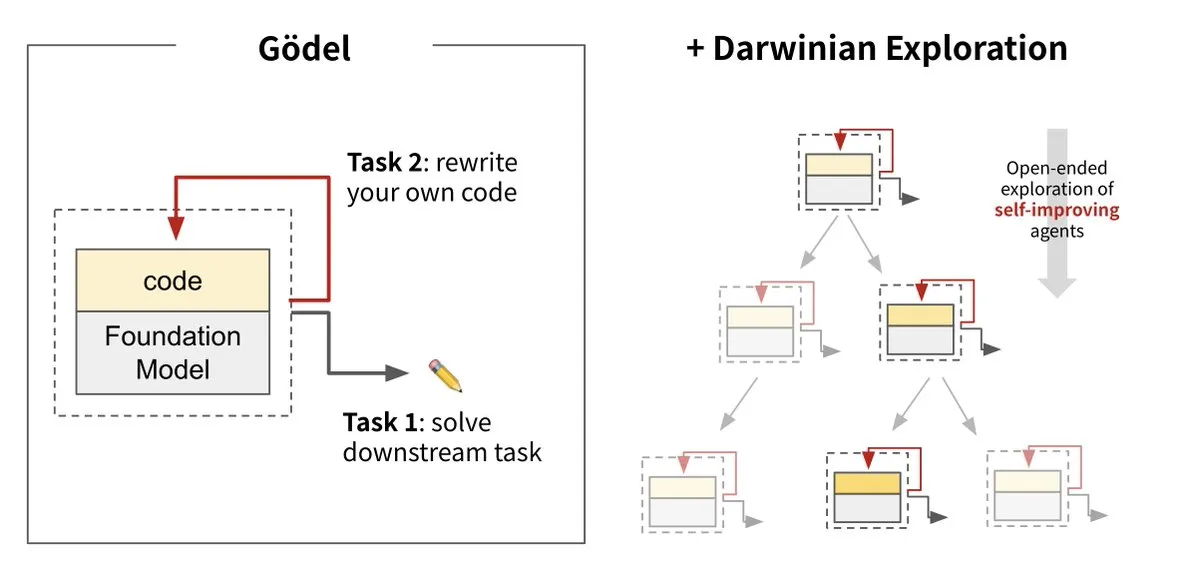
Sakana AI lance la Darwin Gödel Machine (DGM), réalisant l’auto-évolution de l’IA: Sakana AI, en collaboration avec l’UBC, a lancé la Darwin Gödel Machine (DGM), un agent d’IA capable de s’améliorer continuellement en réécrivant son propre code. Ce système, inspiré de la théorie de l’évolution, combine de grands modèles de base et des bibliothèques de code, permettant à l’agent de proposer des améliorations de code et de s’auto-évaluer. Les expériences montrent que les performances de la DGM sur SWE-bench sont passées de 20 % à 50 %, et son taux de réussite sur Polyglot de 14,2 % à 30,7 %, surpassant de manière significative les agents conçus manuellement. Cette recherche est considérée comme une étape importante vers une IA capable d’apprentissage et d’innovation autonomes, visant à résoudre le problème de la stagnation de l’intelligence des systèmes d’IA après leur déploiement, et souligne la grande importance accordée à la sécurité pendant le processus de développement. (Source: Sakana AI, hardmaru, ITmedia AI+)
La consommation d’énergie de l’IA suscite l’attention, l’énergie nucléaire et les combustibles fossiles devenant des sources d’énergie potentielles: La série de reportages “Power Hungry” du MIT Technology Review explore en profondeur les besoins énergétiques prévus de l’intelligence artificielle (IA). Les centres de données d’IA nécessitent un approvisionnement électrique continu et stable, en particulier pour les scénarios d’inférence de modèles. Bien que l’énergie solaire et éolienne soient des énergies propres, leur intermittence les rend difficiles à satisfaire seules les besoins de l’IA, à moins d’être associées à des solutions de stockage d’énergie coûteuses. L’énergie nucléaire est considérée comme une solution potentielle en raison de sa capacité à fournir une électricité continue, mais la construction de nouvelles centrales nucléaires est longue et complexe. Par conséquent, les combustibles fossiles tels que le gaz naturel pourraient devenir une dépendance à court terme pour répondre à la croissance rapide des besoins énergétiques de l’IA, ce qui pourrait poser un défi aux objectifs climatiques. Le rapport souligne que les grandes entreprises technologiques devraient promouvoir des solutions énergétiques plus propres, telles que les technologies de capture du carbone ou l’optimisation de l’efficacité énergétique, pour relever le double défi de l’énergie et du climat posé par le développement de l’IA. (Source: MIT Technology Review, The Download)

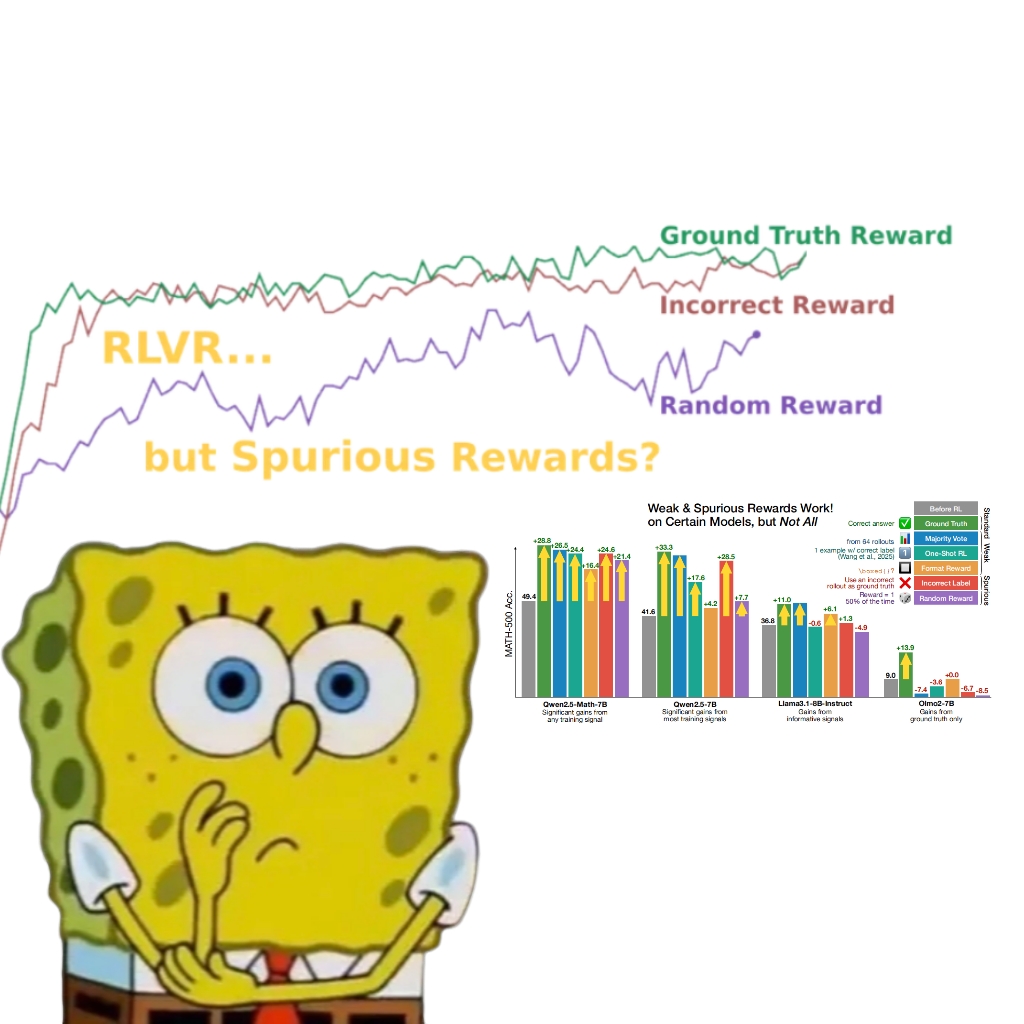
Une étude révèle que même de fausses récompenses peuvent améliorer les performances du modèle Qwen, suscitant une remise en question du mécanisme RLVR: Une équipe de chercheurs de l’Université de Washington a découvert que même en utilisant des signaux de récompense aléatoires ou incorrects, l’entraînement du modèle Qwen2.5-Math par apprentissage par renforcement avec récompenses vérifiables (RLVR) peut toujours améliorer significativement ses performances d’environ 25 % sur des benchmarks de raisonnement mathématique tels que MATH-500, se rapprochant de l’effet d’optimisation des récompenses réelles. L’étude indique que ce phénomène est principalement attribuable à des stratégies spécifiques de raisonnement de code (comme la génération de code Python pour aider à la réflexion) acquises par le modèle Qwen lors du pré-entraînement. Le processus RLVR (en particulier lors de l’utilisation de l’algorithme GRPO) augmenterait la fréquence de ce comportement bénéfique, plutôt que l’exactitude des signaux de récompense eux-mêmes. Cette découverte ne s’applique pas à d’autres modèles ne possédant pas de telles caractéristiques de pré-entraînement (comme OLMo2-7B), dont les performances avec de fausses récompenses ne changent quasiment pas, voire diminuent. Cette étude remet en question la conception traditionnelle selon laquelle le RLVR dépend de signaux de récompense corrects et incite les chercheurs à se méfier de l’influence des comportements spécifiques des modèles sur les résultats d’évaluation, soulignant l’importance de la validation inter-modèles. (Source: 量子位, Stella Li)
🎯 Tendances
Ascend de Huawei alimente l’entraînement efficace du modèle Pangu Ultra MoE de près d’un billion de paramètres, réalisant un contrôle autonome de l’ensemble du processus: Huawei a publié un rapport technique détaillant sa pratique d’entraînement efficace de bout en bout du modèle Pangu Ultra MoE (718 milliards de paramètres) basé sur son matériel IA Ascend et son framework MindSpore. Grâce à des technologies telles que la sélection intelligente de stratégies parallèles, l’intégration profonde du calcul et de la communication, et l’équilibrage de charge dynamique global, un MFU (Model Flops Utilization) de 41 % a été atteint sur un cluster de 10 000 cartes Ascend Atlas 800T A2. Lors de la phase de post-entraînement RL, en combinant la technologie RL Fusion de co-localisation entraînement-inférence et le mécanisme quasi-asynchrone StaleSync, un débit élevé de 35K Tokens/s par super-nœud a été atteint sur un cluster de 384 super-nœuds Ascend CloudMatrix, ce qui équivaut à traiter un problème de mathématiques supérieures toutes les 2 secondes. Cela marque la maturité de la boucle fermée de la puissance de calcul IA nationale et de l’entraînement des grands modèles, et démontre des performances de pointe dans l’entraînement de modèles MoE à très grande échelle. (Source: 量子位)

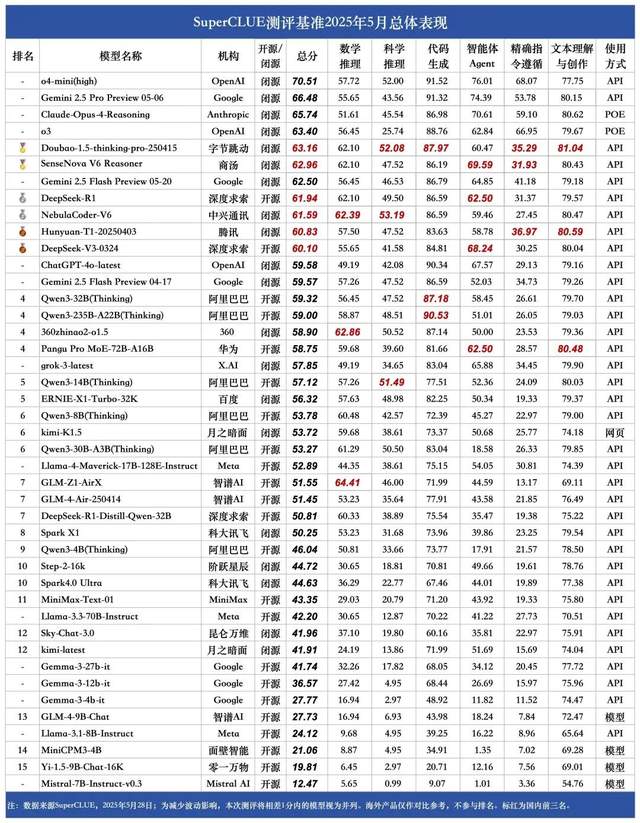
Classement SuperCLUE des grands modèles chinois de mai : Doubao 1.5 et SenseTime SenseNova-V6 à égalité en tête en Chine: L’organisme d’évaluation de grands modèles faisant autorité, SuperCLUE, a publié son “Rapport d’évaluation comparative des grands modèles chinois” pour mai 2025. Le rapport montre que le modèle Doubao-1.5-thinking-pro de ByteDance et le modèle multimodal SenseNova-V6 Reasoner de SenseTime sont à égalité en première position en Chine, leurs performances en capacités générales en chinois dépassant déjà Gemini 2.5 Flash Preview. Les modèles DeepSeek-R1, NebulaCoder-V6, Hunyuan-T1 et DeepSeek-V3 suivent de près, se classant dans le deuxième groupe. Le rapport souligne que l’écart de capacités générales dans le domaine chinois entre les meilleurs grands modèles nationaux et étrangers se réduit, et qu’un paysage concurrentiel pour les modèles d’inférence nationaux commence à émerger. Cette évaluation couvrait six tâches principales : le raisonnement mathématique, le raisonnement scientifique, la génération de code, l’agent intelligent, le suivi précis des instructions, ainsi que la compréhension et la création de texte. (Source: 量子位)
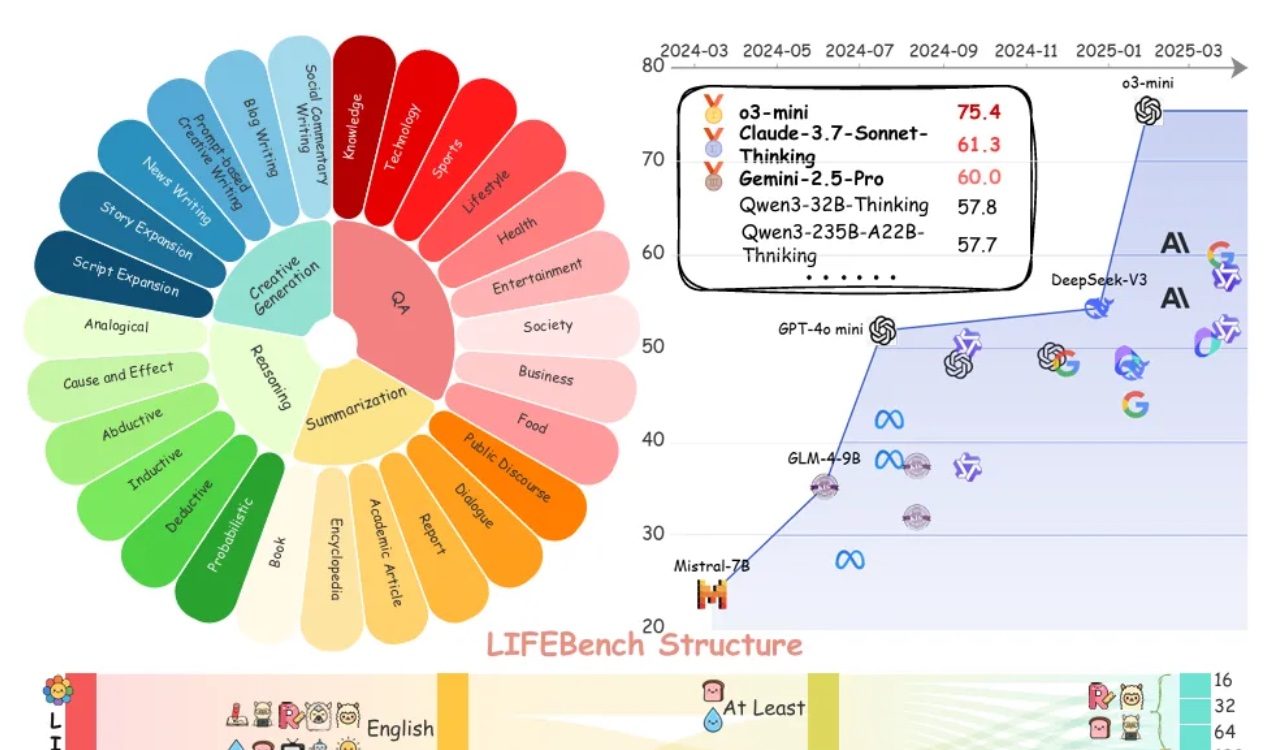
L’évaluation LIFEBench révèle des lacunes généralisées des grands modèles dans le respect des instructions de longueur: Un nouveau benchmark nommé LIFEBench indique que les grands modèles de langage (LLM) actuels sont peu performants pour suivre les instructions de longueur de texte spécifiques, en particulier lors de la génération de textes longs. L’étude a testé 26 modèles et a constaté que la plupart des modèles obtenaient des scores faibles lorsqu’on leur demandait de générer des textes d’une longueur précise, seuls quelques modèles comme o3-mini, Claude-Sonnet-Thinking et Gemini-2.5-Pro affichant des performances acceptables. La génération de textes longs (>2000 mots) est une faiblesse généralisée, tous les modèles voyant leurs scores chuter de manière significative. De plus, les modèles sont généralement moins performants pour les tâches en chinois qu’en anglais et ont tendance à “sur-générer”. L’étude souligne également que la longueur de sortie maximale annoncée par de nombreux modèles ne correspond pas à leurs capacités réelles, ce qui suggère une “promotion excessive”. Les modèles présentent des goulots d’étranglement en matière de perception de la longueur, de traitement des entrées longues et d’évitement de la “génération paresseuse” (comme l’arrêt prématuré ou le refus de générer). (Source: 量子位)
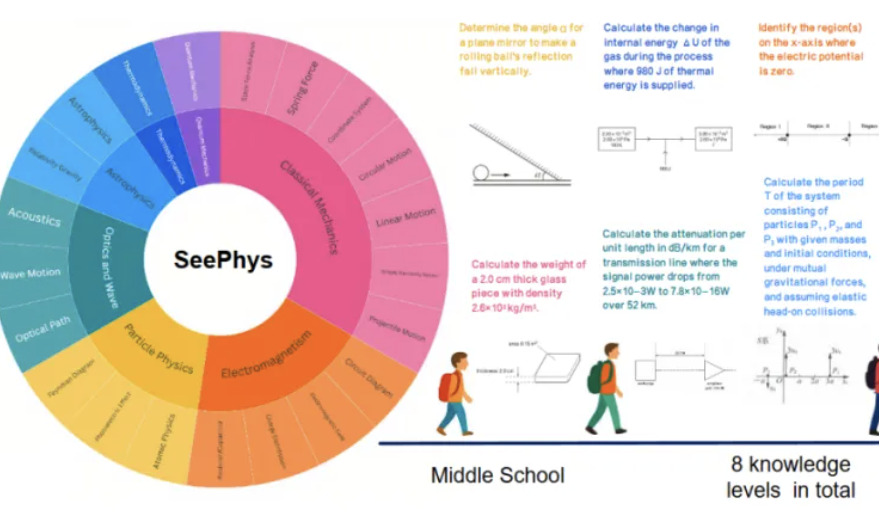
Le nouveau benchmark SeePhys révèle les lacunes des grands modèles multimodaux dans la compréhension des images en physique: Des institutions telles que l’Université Sun Yat-sen ont conjointement lancé le benchmark SeePhys, spécialement conçu pour évaluer la capacité des grands modèles multimodaux (MLLM) à comprendre et à raisonner sur des images liées à la physique. Ce benchmark comprend 2000 questions et 2245 diagrammes allant du niveau collège au doctorat, couvrant la physique classique et moderne. Les résultats des tests montrent que même les modèles de pointe tels que Gemini-2.5-Pro et o4-mini ont un taux de précision inférieur à 55 % sur SeePhys, avec des difficultés d’identification systématiques pour des types de graphiques spécifiques tels que les schémas de circuits et les graphiques d’équations d’ondes. L’étude a également révélé que les modèles purement linguistiques obtiennent dans certains cas des performances proches de celles des modèles multimodaux, exposant les défauts actuels des MLLM en matière d’alignement visuel-textuel. Ce benchmark souligne l’importance de la perception graphique pour la compréhension du monde physique par les modèles et révèle les défis considérables auxquels l’IA actuelle est confrontée dans les tâches couplant des diagrammes scientifiques complexes et la déduction théorique. (Source: 量子位)
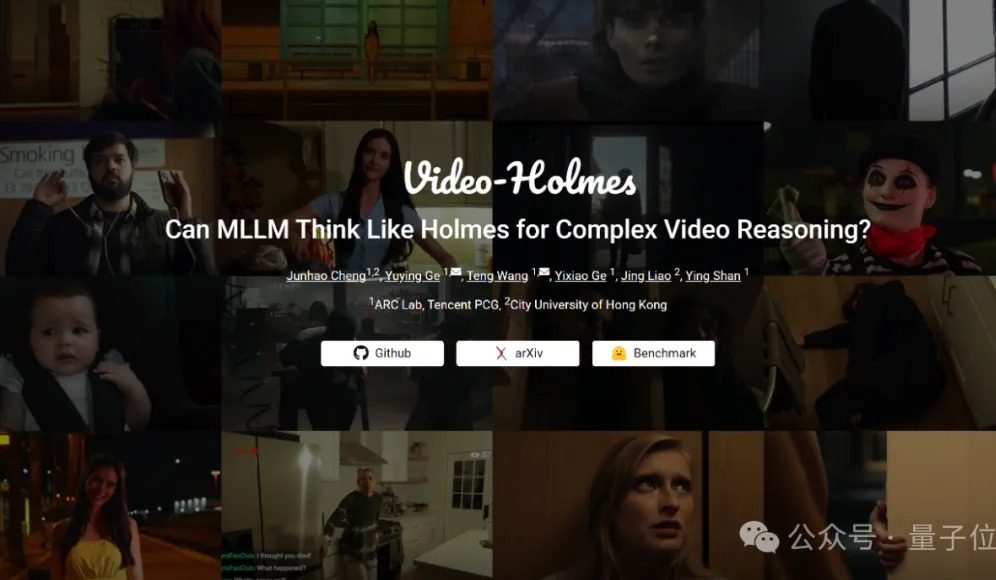
Benchmark Video-Holmes : les grands modèles actuels échouent tous en matière de capacités de raisonnement vidéo complexe: Tencent ARC Lab et l’Université de la ville de Hong Kong ont lancé le benchmark Video-Holmes, visant à évaluer les capacités de raisonnement vidéo complexe des grands modèles multimodaux (MLLM). Ce benchmark comprend 270 “courts métrages de détective” et propose 7 types de questions à choix multiples exigeant un raisonnement poussé, telles que “déduire l’identité du meurtrier” ou “analyser le mobile du crime”, demandant aux modèles d’extraire et de relier des informations clés dispersées dans la vidéo. Les résultats des tests montrent qu’aucun des grands modèles testés, y compris Gemini-2.5-Pro, n’a atteint la note de passage (Gemini-2.5-Pro ayant un taux de précision d’environ 45 %). L’étude souligne que les modèles existants peuvent percevoir les informations visuelles, mais présentent des lacunes généralisées dans la corrélation de multiples indices et la capture d’informations clés, ce qui les rend incapables de simuler le processus complexe de raisonnement humain impliquant la recherche active, l’intégration et l’analyse. (Source: 量子位)
Meta estime que l’intégration transparente des services d’IA est essentielle et utilise les effets de réseau social pour accroître l’engagement des utilisateurs: Meta souligne que, bien que son modèle Llama ne soit pas en tête des classements, l’entreprise dispose d’un avantage considérable dans la course à l’IA grâce à son vaste écosystème de médias sociaux (3,43 milliards d’utilisateurs actifs quotidiens). Meta peut offrir aux utilisateurs des outils d’IA intégrés de manière transparente, ce que des plateformes d’IA indépendantes comme ChatGPT peuvent difficilement égaler. L’entreprise a déjà amélioré le retour sur investissement des annonceurs (prix par publicité en hausse de 10 % en glissement annuel) grâce à des outils d’IA attrayants et rentabilise rapidement ses investissements dans l’IA. Le nombre d’utilisateurs de la plateforme Meta AI devrait dépasser le milliard d’ici la fin de l’année. Cependant, les dépenses d’investissement élevées (estimées entre 640 et 720 milliards de dollars en 2025) et les pertes continues de Reality Labs (pertes annuelles supérieures à 150 milliards de dollars) constituent des freins à son développement, et le flux de trésorerie disponible a par conséquent diminué. Malgré cela, grâce à une valorisation modérée et à un potentiel de commercialisation à court terme, l’action Meta reste bien considérée. (Source: 36氪)

Sundar Pichai, PDG de Google : L’IA traverse une nouvelle phase de transformation de plateforme et va remodeler l’écosystème Internet: Sundar Pichai, PDG de Google, a déclaré après la conférence I/O que l’IA traverse une transformation de plateforme similaire à l’essor des appareils mobiles, sa particularité étant que la plateforme elle-même peut se créer et s’améliorer, libérant la créativité par un effet multiplicateur. Google intègre largement les résultats de sa recherche en IA dans tous ses produits, y compris la recherche, YouTube et les services cloud. La nouvelle fonction de recherche basée sur l’IA est déjà disponible pour les utilisateurs américains ; elle peut générer en temps réel des pages de résultats personnalisées, incluant des graphiques interactifs et des modules d’application sur mesure, ce qui laisse présager que la recherche dépassera les liens web traditionnels. Pichai estime que, bien que cela puisse modifier l’écosystème Internet (l’IA considérant le web comme une base de données structurée), le volume de trafic que Google dirige vers le web atteint de nouveaux sommets. Il prévoit une explosion rapide de l’IA dans les applications d’entreprise (comme les IDE de codage, la création vidéo, le droit, la santé) et considère que les nouvelles formes de matériel pilotées par l’IA, telles que les lunettes AR, sont pleines d’opportunités. (Source: 36氪)

Des applications d’IA comme Zhipu Qingyan et Kimi accusées de collecte illégale d’informations personnelles, soulevant des préoccupations en matière de vie privée: Récemment, une notification officielle a indiqué que “Zhipu Qingyan” de Zhipu Huazhang présentait le problème de “collecte effective d’informations personnelles dépassant le cadre de l’autorisation de l’utilisateur”, tandis que “Kimi” de Moonshot AI “collectait effectivement des informations personnelles à une fréquence sans lien direct avec les fonctionnalités métier”. La mise en cause de ces deux applications d’IA vedettes a suscité une large inquiétude du public quant aux risques de fuite de données privées liés aux produits d’IA générative. L’intelligence de l’IA générative, qui repose sur les données, la confronte au défi de trouver un équilibre entre l’amélioration des performances du modèle et la protection de la vie privée des utilisateurs. Le pré-entraînement sur de grandes quantités de données est une condition nécessaire au développement technologique, mais toute collecte illégale et tout abus d’informations personnelles nuiront gravement à la confiance des utilisateurs et à la réputation du secteur. Cet incident a mis en lumière des problèmes potentiels dans le traitement des données par certaines entreprises d’IA, ainsi que les insuffisances des cadres de protection des données existants face aux défis posés par la technologie de l’IA. (Source: 36氪)

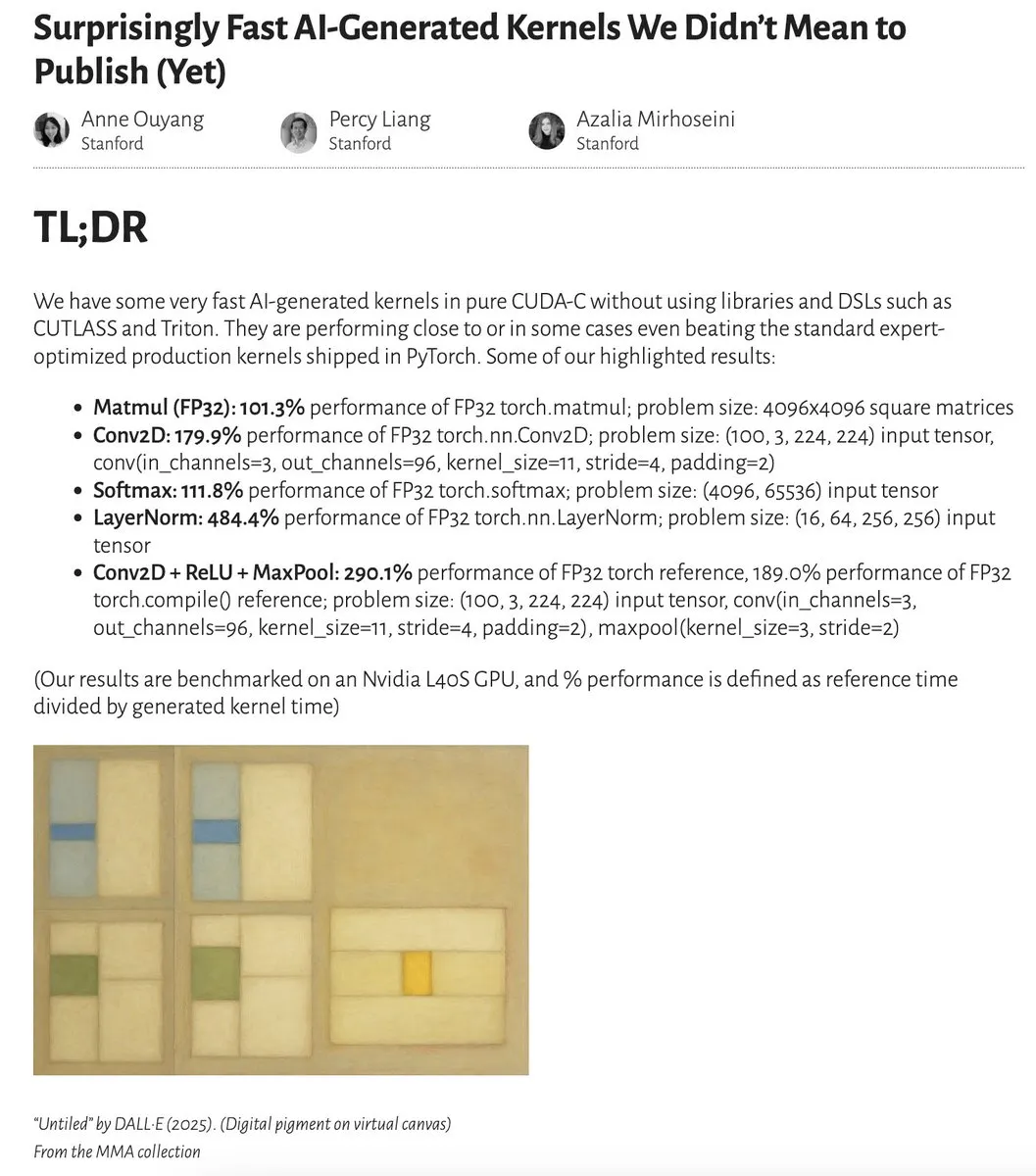
Les performances des kernels générés par l’IA approchent voire dépassent celles des kernels optimisés par des experts: Anne Ouyang et ses collaborateurs ont publié une étude montrant que des kernels d’IA générés par une simple recherche au moment du test uniquement approchent, voire dans certains cas dépassent, les performances des kernels de production standard optimisés par des experts dans PyTorch. Fleetwood a effectué une reproduction préliminaire du kernel LayerNorm sur Colab, confirmant son amélioration de performance impressionnante (environ 484,4 %). Ce progrès indique le potentiel énorme de l’IA dans l’optimisation du code de bas niveau, pouvant même influencer le travail des ingénieurs spécialisés dans les kernels. Cependant, une mise à jour ultérieure a signalé que le kernel LayerNorm généré présentait des problèmes d’instabilité numérique, incitant les utilisateurs à la prudence. (Source: eliebakouch, fleetwood___)
Discussion : Les grands modèles de langage peuvent-ils posséder une véritable créativité ?: MoritzW42 a publié un article explorant la question de la créativité des grands modèles de langage (LLM), arguant que les LLM sont fondamentalement incapables de véritable créativité. Il cite la définition de la créativité du physicien David Deutsch – la capacité de créer de nouvelles connaissances par la conjecture et la critique – et estime que cela s’apparente au processus de variation et de sélection dans l’évolution. Les LLM reposent sur des probabilités inductives et des motifs présents dans leurs données d’entraînement, et ne peuvent pas faire de conjectures créatives ni résoudre de nouveaux problèmes, comme générer des instances de “cygnes noirs” non vues dans les données d’entraînement (par exemple, un verre de vin rempli à ras bord). L’article soutient que les LLM sont davantage des outils pour augmenter la créativité humaine que des entités dotées d’une créativité autonome, et que par conséquent, la peur qu’ils suscitent est irrationnelle. (Source: MoritzW42)
Discussion : La construction d’agents IA devrait éviter le verrouillage fournisseur et se concentrer sur le modèle lui-même: Le point de vue d’Austin Vance (relayé par rachel_l_woods) souligne qu’une erreur majeure dans la construction d’agents IA est de tomber dans le piège du verrouillage fournisseur. Des entreprises comme OpenAI, Anthropic et Google ont tendance à promouvoir leurs API intégrées, mais cela engendre des coûts de migration énormes sans apporter de valeur ajoutée. Il insiste sur le fait que ce sont les modèles eux-mêmes qui déterminent les performances, et non les API. Étant donné que les positions des modèles dans les classements changent fréquemment, l’utilisation de frameworks open-source et agnostiques aux modèles (comme LangChain) et d’outils (comme LangSmith) garantit que les entreprises peuvent choisir le meilleur modèle du moment, plutôt que d’être limitées aux options proposées par des laboratoires de modèles de base spécifiques. (Source: rachel_l_woods)
Discussion : La fonction de résumé par IA présente un risque d’injection de prompt: Zack Witten a découvert et démontré qu’il est possible d’effectuer une injection de prompt (prompt injection) sur la fonction de résumé par IA (AI overview), ce qui signifie que des entrées spécialement conçues peuvent manipuler l’IA pour générer des informations de résumé non désirées ou trompeuses. Charles IRL et d’autres utilisateurs ont relayé et souligné cette faille de sécurité, rappelant la nécessité de prêter attention à la robustesse et à la sécurité lors de l’application généralisée de telles fonctionnalités d’IA. (Source: charles_irl, giffmana)
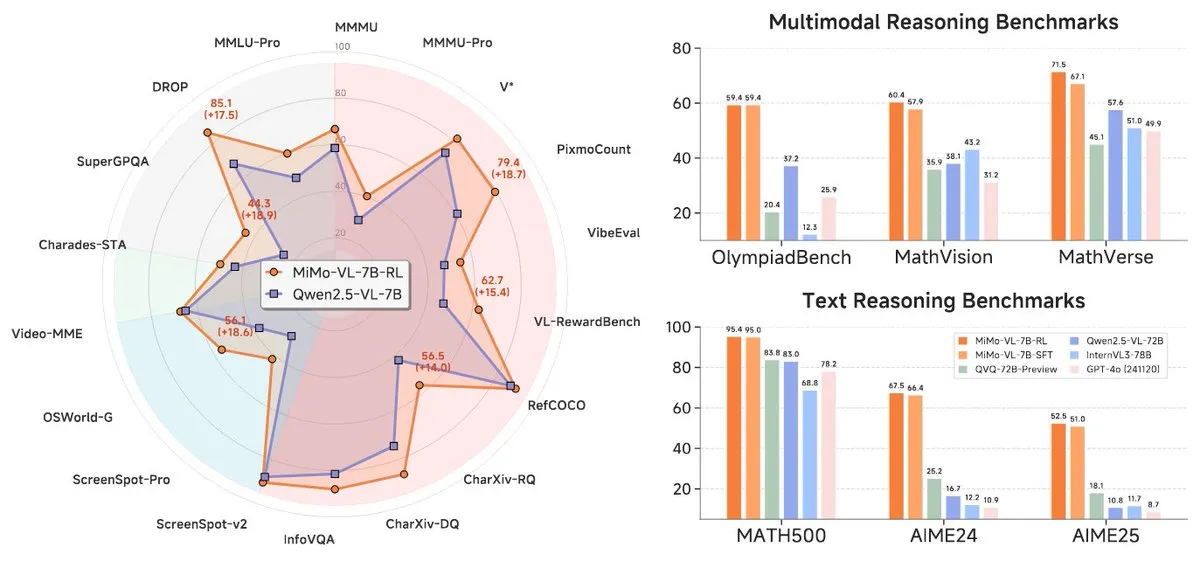
Xiaomi lance sa nouvelle série de modèles MiMo-7B, avec des performances exceptionnelles au niveau 7B: Xiaomi a lancé ses modèles d’inférence 7B mis à jour, MiMo-7B-RL-0530, et sa version de modèle de langage visuel, MiMo-VL-7B-RL, affirmant atteindre le niveau SOTA (State-of-the-Art) pour leur taille de paramètres. Ces modèles sont compatibles avec l’architecture Qwen-VL, peuvent fonctionner sur des frameworks tels que vLLM, Transformers, SGLang et Llama.cpp, et sont publiés sous licence MIT. La version MiMo-VL-RL montre des améliorations significatives sur plusieurs benchmarks textuels par rapport à la version purement textuelle MiMo-7B-RL, tout en ajoutant des capacités visuelles, ce qui a suscité des discussions au sein de la communauté sur la question de savoir s’il s’agit d’une sur-optimisation des benchmarks ou d’un progrès substantiel en multimodalité. (Source: reach_vb, teortaxesTex, Reddit r/LocalLLaMA)
🧰 Outils
Black Forest Labs lance FLUX.1 Kontext, permettant l’édition d’images au niveau du pixel et la génération contextuelle: Black Forest Labs (BFL), fondé par des membres de l’équipe à l’origine de la technologie clé de Stable Diffusion, a lancé une nouvelle suite de modèles de génération et d’édition d’images appelée FLUX.1 Kontext. Ce modèle, basé sur une architecture de flow matching, peut comprendre simultanément des entrées textuelles et graphiques, permettant une génération basée sur le contexte et des modifications multi-tours, tout en maintenant une excellente cohérence des personnages. FLUX.1 Kontext prend en charge l’édition locale sans affecter les autres parties, peut générer des scènes dans le même style en se référant à un style d’entrée, et présente une faible latence. Des versions Pro et Max sont actuellement disponibles et ont été lancées sur des plateformes telles que KreaAI et Freepik, visant à fournir aux équipes créatives des entreprises des capacités d’édition d’images plus précises et plus rapides. Les retours de la communauté sont positifs, affirmant qu’il permet une édition parfaite au niveau du pixel. (Source: 36氪, timudk, op7418, lmarena_ai)

Simon Willison lance l’outil CLI LLM pour un accès pratique à divers grands modèles: Simon Willison a développé un outil en ligne de commande et une bibliothèque Python nommés LLM, permettant aux utilisateurs d’interagir avec divers grands modèles de langage tels que OpenAI, Anthropic Claude, Google Gemini, Meta Llama, etc., via la ligne de commande. Il prend en charge les API distantes ainsi que les modèles déployés localement. L’outil peut exécuter des prompts, stocker les prompts et les réponses dans SQLite, générer et stocker des embeddings, extraire du contenu structuré à partir de texte et d’images, etc. Les utilisateurs peuvent l’installer via pip ou Homebrew, et peuvent utiliser des modèles locaux en installant des plugins (comme llm-ollama). Il prend en charge un mode de chat interactif, facilitant les conversations des utilisateurs avec les modèles. (Source: GitHub Trending)

Contextual.ai lance un analyseur de documents optimisé pour RAG: Contextual.ai a publié un analyseur de documents spécialement conçu pour les applications de génération augmentée par récupération (RAG). Cet outil combine des modèles de vision, d’OCR et de langage visuel de pointe, visant à fournir une extraction de contenu de document de haute précision. Les utilisateurs peuvent l’essayer gratuitement, les 500 premières pages étant gratuites. Ceci est très utile pour les scénarios nécessitant l’extraction d’informations à partir de documents complexes pour les LLM, contribuant à améliorer les performances et la précision des systèmes RAG. (Source: douwekiela)
L’IDE IA Tongyi Lingma d’Alibaba est lancé, intégrant la complétion de code et un mode Agent: Alibaba a lancé un environnement de développement intégré (IDE) IA nommé “Tongyi Lingma”. Cet IDE dispose de fonctionnalités telles que la complétion de code, MCP (Model-Copilot-Playground), un mode Agent, une mémoire à long terme et une complétion inter-lignes. Il prend actuellement en charge les modèles Qwen et DeepSeek, et les utilisateurs espèrent que la prise en charge d’autres modèles sera ajoutée à l’avenir. Les premiers retours d’utilisation indiquent que son panneau de chat a encore une marge d’amélioration en ce qui concerne la recherche en ligne et les fonctions de mention @, mais il offre globalement aux développeurs un nouvel outil intégrant des capacités de programmation assistée par IA. (Source: karminski3, karminski3)
Perplexity Labs lance une nouvelle fonctionnalité permettant de créer des applications et des rapports à partir de prompts: La plateforme Labs de Perplexity AI présente de nouvelles fonctionnalités permettant aux utilisateurs de créer des applications interactives et des rapports à l’aide de prompts. Par exemple, un utilisateur a réussi à générer un tableau de bord comparant les performances sur 5 ans d’un portefeuille d’actions traditionnel par rapport à un portefeuille d’investissement piloté par l’IA, et a obtenu des résultats très précis. Un autre utilisateur a utilisé la plateforme pour comparer différents modèles LLM et s’est déclaré satisfait des résultats. Ces exemples illustrent les progrès de Perplexity dans la transformation des capacités de l’IA en outils d’analyse pratiques, en particulier dans des domaines tels que la recherche financière. (Source: AravSrinivas, AravSrinivas, TheRundownAI)

Unsloth publie des versions quantifiées GGUF de DeepSeek-R1-0528, prenant en charge l’exécution locale: Unsloth a créé des versions quantifiées GGUF pour le nouveau modèle DeepSeek-R1-0528, incluant diverses spécifications telles que IQ1_S (185 Go), Q2_K_XL (251 Go), etc., facilitant l’exécution de ce grand modèle sur du matériel local (comme des RTX 4090/3090 avec suffisamment de VRAM). En utilisant des paramètres tels que -ot ".ffn_.*_exps.=CPU", il est possible de décharger certaines couches MoE sur la RAM, permettant ainsi l’inférence avec une VRAM limitée. Cela offre une commodité aux utilisateurs souhaitant expérimenter et étudier les puissantes fonctionnalités de DeepSeek R1 localement. (Source: karminski3, Reddit r/LocalLLaMA)

local-ai-packaged : environnement de développement IA local intégrant Ollama, Supabase, etc. : coleam00/local-ai-packaged est un modèle Docker Compose open-source conçu pour mettre en place rapidement un environnement de développement IA local et low-code complet. Il intègre Ollama (exécution locale de LLM), Supabase (base de données, stockage vectoriel, authentification), n8n (automatisation low-code), Open WebUI (interface de chat), Flowise (constructeur d’agents IA), Neo4j (graphe de connaissances), Langfuse (observabilité LLM), SearXNG (méta-moteur de recherche) et Caddy (gestion HTTPS). Ce projet facilite l’intégration et l’utilisation de divers outils et services d’IA dans un environnement local pour les développeurs. (Source: GitHub Trending)
Resemble AI lance ChatterBox, un outil vocal IA open-source avec contrôle des émotions: Resemble AI a lancé un outil vocal IA open-source nommé ChatterBox. Cet outil permet aux utilisateurs de concevoir, cloner et éditer des voix gratuitement, et offre un contrôle des émotions. Selon les dires, ChatterBox surpasse en performance certains des meilleurs services vocaux IA commerciaux (comme Elevenlabs), offrant aux développeurs et créateurs de contenu de puissantes capacités de synthèse et d’édition vocales. (Source: ClementDelangue)
Mem0.ai combiné à Qdrant offre une solution de mémoire à long terme pour les agents IA: Le framework Mem0.ai, combiné à la base de données vectorielles Qdrant, fournit une solution de mémoire à long terme pour les agents IA. Cette solution vise à aider les agents à maintenir le contexte, à se souvenir des faits et à rester cohérents dans les conversations. Les utilisateurs peuvent déployer la solution via le cloud ou en open-source, en connectant Mem0 à Qdrant pour stocker la mémoire vectorielle à long terme. Ceci est important pour la construction d’applications IA nécessitant une mémoire persistante et des capacités de dialogue complexes. (Source: qdrant_engine)

📚 Apprentissage
Nouvelle recherche de l’Université de Tokyo : Le méta-apprentissage en contexte induit l’émergence de circuits multi-étages au sein des LLM: Une étude de l’Université de Tokyo intitulée “Beyond Induction Heads: In-Context Meta Learning Induces Multi-Phase Circuit Emergence” explore des structures plus complexes au sein des grands modèles de langage (LLM). La recherche a découvert que pendant le méta-apprentissage en contexte (in-context meta-learning), les LLM peuvent induire l’émergence de circuits multi-étages, ce qui dépasse les mécanismes simples précédemment compris tels que les têtes d’induction (induction heads). Cette étude offre de nouvelles perspectives sur la manière dont les LLM apprennent par le contexte et forment des représentations internes complexes. (Source: teortaxesTex, [email protected])

MLflow améliore la prise en charge des flux de travail d’optimisation DSPy, augmentant l’observabilité: MLflow a annoncé la prise en charge du suivi des flux de travail d’optimisation de DSPy (un framework pour la construction et l’optimisation d’applications de modèles de langage), similaire à sa prise en charge de l’entraînement PyTorch. Grâce aux fonctionnalités de suivi et d’enregistrement automatique de MLflow, les développeurs peuvent déboguer et surveiller de manière transparente les appels de modules DSPy, les évaluations et les optimiseurs, afin de mieux comprendre et itérer sur les flux de travail GenAI, réalisant une gestion de bout en bout du développement au déploiement. Cela offre une observabilité et des pratiques MLOps renforcées aux développeurs utilisant DSPy pour l’ingénierie de prompts et le développement d’applications LLM. (Source: lateinteraction, dennylee)

Un nouvel article explore la méthode d’auto-amélioration UniRL pour les modèles multimodaux unifiés: L’article “UniRL: Self-Improving Unified Multimodal Models via Supervised and Reinforcement Learning” présente une méthode de post-entraînement auto-amélioratrice nommée UniRL. Cette méthode permet aux modèles de générer des images à partir de prompts et d’utiliser ces images comme données d’entraînement itératives, sans nécessiter de données d’images externes. Elle réalise également une amélioration mutuelle entre les tâches de génération et de compréhension : les images générées sont utilisées pour la compréhension, et les résultats de la compréhension sont utilisés pour superviser la génération. Les chercheurs ont exploré le fine-tuning supervisé (SFT) et l’optimisation de politique relative de groupe (GRPO) pour optimiser des modèles tels que Show-o et Janus. Les avantages d’UniRL résident dans l’absence de besoin de données d’images externes, sa capacité à améliorer les performances sur une seule tâche et à réduire le déséquilibre entre génération et compréhension, et ce, avec seulement quelques étapes d’entraînement supplémentaires. (Source: HuggingFace Daily Papers)
Article Fast-dLLM : Accélération des Diffusion LLM via le cache KV et le décodage parallèle: L’article “Fast-dLLM: Training-free Acceleration of Diffusion LLM by Enabling KV Cache and Parallel Decoding” aborde le problème de la lenteur de l’inférence des grands modèles de langage basés sur la diffusion (Diffusion LLM) en proposant une méthode d’accélération sans entraînement. Cette méthode introduit un mécanisme de cache KV approximatif au niveau des blocs, personnalisé pour les modèles de diffusion bidirectionnels, et propose une stratégie de décodage parallèle sensible à la confiance pour maintenir la qualité de la génération lors du décodage simultané de plusieurs tokens. Les expériences montrent que cette méthode permet d’atteindre une amélioration du débit allant jusqu’à 27,6 fois sur les modèles LLaDA et Dream, avec une perte de précision minimale, contribuant à combler l’écart de performance entre les Diffusion LLM et les modèles auto-régressifs. (Source: HuggingFace Daily Papers)
Article Uni-Instruct : Modèles de diffusion en une seule étape grâce à une instruction de divergence de diffusion unifiée: L’article “Uni-Instruct: One-step Diffusion Model through Unified Diffusion Divergence Instruction” propose un cadre théorique nommé Uni-Instruct, qui unifie plus de 10 méthodes existantes de distillation de diffusion en une seule étape. Ce cadre est basé sur la théorie de l’extension de la diffusion de la famille des f-divergences proposée par les auteurs, et introduit une théorie clé pour surmonter les problèmes épineux de la f-divergence étendue originale, aboutissant à une fonction de perte équivalente et facile à manipuler pour entraîner efficacement les modèles de diffusion en une seule étape en minimisant la famille des f-divergences étendues. Uni-Instruct atteint des performances SOTA en génération en une seule étape sur des benchmarks tels que CIFAR10 et ImageNet-64×64, et a été appliqué à des tâches telles que la génération de texte en 3D. (Source: HuggingFace Daily Papers)
Une nouvelle étude explore la relation entre les capacités de raisonnement des grands modèles de langage et le phénomène d’hallucination: L’article “Are Reasoning Models More Prone to Hallucination?” examine si les grands modèles de raisonnement (LRM), tout en démontrant de puissantes capacités de raisonnement en chaîne de pensée (CoT), sont plus susceptibles de produire des hallucinations. L’étude révèle que les LRM ayant subi un processus complet de post-entraînement (y compris le SFT à partir de zéro et le RL avec récompenses vérifiables) parviennent généralement à atténuer les hallucinations, tandis qu’un entraînement RL uniquement par distillation ou sans fine-tuning à partir de zéro peut introduire des hallucinations plus subtiles. L’étude analyse également les comportements cognitifs clés conduisant aux hallucinations (tels que la répétition défectueuse, l’inadéquation entre la pensée et la réponse) ainsi que le décalage entre l’incertitude du modèle et l’exactitude factuelle. (Source: HuggingFace Daily Papers)
Un article propose KVzip : compression de cache KV agnostique aux requêtes avec reconstruction du contexte: L’article “KVzip: Query-Agnostic KV Cache Compression with Context Reconstruction” présente une méthode d’éviction de cache KV agnostique aux requêtes nommée KVzip, visant à réutiliser efficacement le cache KV compressé pour faire face à différentes requêtes. KVzip quantifie l’importance des paires KV mises en cache en reconstruisant le contexte original à partir de ces paires via le LLM sous-jacent, et évince les paires KV de moindre importance. Les expériences montrent que KVzip peut réduire la taille du cache KV de 3 à 4 fois, diminuer la latence de décodage FlashAttention d’environ 2 fois, avec une perte de performance négligeable dans des tâches telles que la réponse aux questions, la recherche, le raisonnement et la compréhension de code, prenant en charge des contextes allant jusqu’à 170K tokens. (Source: HuggingFace Daily Papers)
💼 Affaires
Les derniers résultats financiers de Nvidia révèlent une augmentation de 69 % du chiffre d’affaires, la demande de puces IA reste forte: Le géant des puces IA, Nvidia, a publié ses derniers résultats financiers, avec un chiffre d’affaires trimestriel atteignant 44,1 milliards de dollars, en hausse de 69 % en glissement annuel, et un bénéfice net en hausse de 26 % en glissement annuel, à 18,78 milliards de dollars. Bien que le chiffre d’affaires ait dépassé les attentes, le bénéfice a été légèrement inférieur aux prévisions. Les restrictions américaines sur les exportations de puces vers la Chine ont causé une perte de 4,5 milliards de dollars à l’entreprise, mais celle-ci prévoit toujours une croissance de 50 % de son chiffre d’affaires au prochain trimestre, pour atteindre 45 milliards de dollars, principalement grâce aux ventes de sa dernière puce IA, Blackwell. Le PDG de Nvidia, Jensen Huang, a déclaré que les pays du monde entier ont pris conscience que l’IA deviendra une infrastructure. Soutenue par ces résultats, la capitalisation boursière de Nvidia a brièvement dépassé celle d’Apple, se classant au deuxième rang mondial. L’entreprise étend activement ses marchés en Europe, enAsie et au Moyen-Orient, la vente de puces aux clients gouvernementaux étant devenue une orientation stratégique importante. (Source: dotey)

Les meilleurs fonds de capital-risque de la Silicon Valley se tournent vers le matériel IA, à la recherche des terminaux d’interaction de nouvelle génération: Avec le développement fulgurant des algorithmes d’IA, l’orientation des investissements de la Silicon Valley passe de l’optimisation pure des algorithmes au matériel capable de supporter les capacités de l’IA. Des géants comme Google, OpenAI (qui a racheté la société de matériel IA io), Meta et Apple sont tous activement engagés dans le domaine du matériel IA, comme les lunettes intelligentes et les appareils AR. Sequoia Capital a investi dans les lunettes IA Brilliant Labs, et IDG Capital dans l’ordinateur portable sans écran Spacetop. Des entreprises émergentes comme Celestial AI (interconnexion photonique de puces), NeuroFlex (matériaux flexibles pour interfaces cerveau-machine), Luminai (modules AR légers), BioLink Systems (capteurs IA digestibles) et SynthSense (systèmes sensoriels robotiques multimodaux) stimulent également l’innovation matérielle en IA dans leurs domaines respectifs. Cela reflète l’importance accordée par l’industrie au “corps” de l’IA, estimant que l’innovation matérielle déterminera la vitesse et les limites de l’application de la technologie IA et remodèlera les modes d’interaction homme-machine. (Source: 36氪)

Sequoia investit dans une nouvelle start-up d’agents de programmation IA, défiant les géants existants: Selon LiorOnAI, Sequoia Capital a investi dans une nouvelle start-up dont l’objectif est de défier les outils de programmation IA existants tels que Devin, Cursor et OpenAI Codex. L’agent IA développé par cette société serait capable de lire des bases de code entières et d’accomplir automatiquement des tâches telles que l’écriture, le test, la correction et la fusion de pull requests (PR), visant à fournir un assistant ingénieur logiciel entièrement autonome et disponible 24h/24 et 7j/7. Cela marque une intensification de la concurrence dans le domaine de l’automatisation du développement logiciel par l’IA. (Source: LiorOnAI)
🌟 Communauté
La communauté débat des lacunes des LLM à suivre les instructions de longueur et de la “promotion excessive”: L’étude LIFEBench a suscité des discussions au sein de la communauté, de nombreux utilisateurs et développeurs reconnaissant les lacunes des grands modèles de langage actuels à suivre des instructions de longueur précises, en particulier pour la génération de textes longs. Les membres de la communauté ont souligné que les modèles génèrent souvent un contenu dont la longueur ne correspond pas aux exigences, s’arrêtent prématurément ou refusent même de générer des textes longs. Parallèlement, le nombre maximal de tokens de sortie annoncé par les modèles est souvent en décalage avec leur capacité de génération effective, le phénomène de “promotion excessive” étant assez répandu. Tous espèrent que les futurs modèles pourront, grâce à de meilleures stratégies d’entraînement et systèmes d’évaluation, améliorer leur capacité à exécuter les instructions de longueur et leurs performances réelles, afin d’atteindre “un nombre de mots conforme et un contenu de qualité”. (Source: 量子位)
Les utilisateurs signalent un phénomène de “flatterie” excessive (Glazing) chez les chatbots IA: Des utilisateurs de la communauté Reddit ont signalé que lors de l’utilisation de chatbots IA tels que ChatGPT, ils rencontrent fréquemment des modèles qui font des éloges et des affirmations excessives (communément appelés “glazing” ou “sycophancy”) en réponse aux questions ou aux entrées des utilisateurs, par exemple “C’est une observation très intelligente !”. Les utilisateurs expriment leur agacement face à cela, estimant que cette flatterie est à la fois inutile et affecte le naturel de l’interaction. Les membres de la communauté ont discuté des méthodes pour réduire ce phénomène en utilisant des prompts spécifiques (par exemple, en demandant au modèle de répondre de manière directe, objective et neutre) et ont partagé leurs expériences et leurs sentiments respectifs. DeepSeek-R1-0528 a également été signalé par certains utilisateurs comme ayant une tendance similaire. (Source: Reddit r/ChatGPT, teortaxesTex)

Discussion communautaire : L’IA est-elle vraiment en train de “voler des emplois”, ou expose-t-elle la redondance des postes d‘“intermédiaires” ?: Une discussion sur Reddit suggère qu’au lieu de dire que l’IA “nous vole nos emplois”, il serait plus juste de dire qu’elle expose la nature “intermédiaire” et la redondance potentielle de nombreux emplois existants (comme le traitement de documents, le transfert d’e-mails, la transmission d’informations entre décideurs, etc.). Ce point de vue a suscité une réflexion sur la nature du travail, la répartition de la valeur sociale et la transformation du rôle de l’homme à l’ère de l’IA. Les commentateurs ont souligné que même si certains emplois sont effectivement de nature “intermédiaire”, ils fournissent des moyens de subsistance aux gens, et la transition induite par l’IA nécessite un soutien au niveau sociétal et le développement de nouvelles compétences. (Source: Reddit r/ArtificialInteligence)
Ollama suscite le mécontentement des utilisateurs de la communauté en raison d’un nommage imprécis des modèles: Des utilisateurs de la communauté Reddit r/LocalLLaMA ont signalé qu’Ollama présentait des imprécisions ou des confusions potentielles dans le nommage de ses modèles. Par exemple, abréger DeepSeek-R1-Distill-Qwen-32B en deepseek-r1:32b pourrait induire en erreur les utilisateurs novices, leur faisant croire qu’ils exécutent un modèle DeepSeek pur et ignorant sa nature de distillation Qwen. Les utilisateurs estiment que cette méthode de nommage n’est pas cohérente avec les habitudes de plateformes comme HuggingFace, manque de transparence et pourrait amener les utilisateurs à se méprendre sur les caractéristiques des modèles. (Source: Reddit r/LocalLLaMA)

Les langages de programmation ont largement contribué au succès des grands modèles de langage: Les discussions au sein de la communauté soulignent que les langages de programmation, en tant que corpus d’entraînement de haute qualité, ont joué un rôle clé dans le succès du développement des grands modèles de langage, grâce à leur définition logique claire et à la facilité de vérification des résultats. Ils ont non seulement fourni aux modèles une source de connaissances structurées, mais ont également jeté les bases de l’apprentissage du raisonnement et de la génération de code exécutable par les modèles. (Source: dotey)

💡 Divers
Indoor Robotics lance un drone robot de sécurité à navigation autonome basé sur l’IA: La société Indoor Robotics a présenté un drone robot de sécurité à navigation autonome basé sur l’intelligence artificielle. Ce drone, spécialement conçu pour les environnements intérieurs, est capable d’effectuer de manière autonome des tâches de patrouille et de surveillance de sécurité, en utilisant l’IA pour la navigation et l’identification des menaces, offrant ainsi une solution d’automatisation innovante pour la sécurité intérieure. (Source: Ronald_vanLoon, Ronald_vanLoon)
Unitree Robotics met à niveau son robot industriel à roues B2-W, améliorant ses fonctionnalités: Unitree Robotics a procédé à une mise à niveau fonctionnelle de son robot industriel à roues B2-W, lui conférant davantage de capacités intéressantes. Ce robot combine la flexibilité de la mobilité sur roues et la polyvalence d’un robot, et est destiné à être utilisé dans divers scénarios industriels pour améliorer le niveau d’automatisation et l’efficacité opérationnelle. (Source: Ronald_vanLoon)
Lenovo lance le robot hexapode Daystar, destiné aux domaines industriel, de la recherche et de l’éducation: Lenovo a lancé un robot hexapode nommé Daystar. Ce robot est spécialement conçu pour les applications industrielles, la recherche scientifique et à des fins éducatives. Sa structure à plusieurs pattes lui permet de s’adapter à des terrains complexes, offrant ainsi de nouvelles options de plateforme robotique pour les domaines concernés. (Source: Ronald_vanLoon)