
Mots-clés:DeepSeek-R1-0528, Agent intelligent, Modèle multimodal, IA open source, Apprentissage par renforcement, Édition d’images, Grand modèle de langage, Benchmark IA, DeepSeek-R1-0528-Qwen3-8B, Outil Circuit Tracer, Darwin Gödel Machine, FLUX.1 Kontext, Récupération agentique
🔥 À la Une
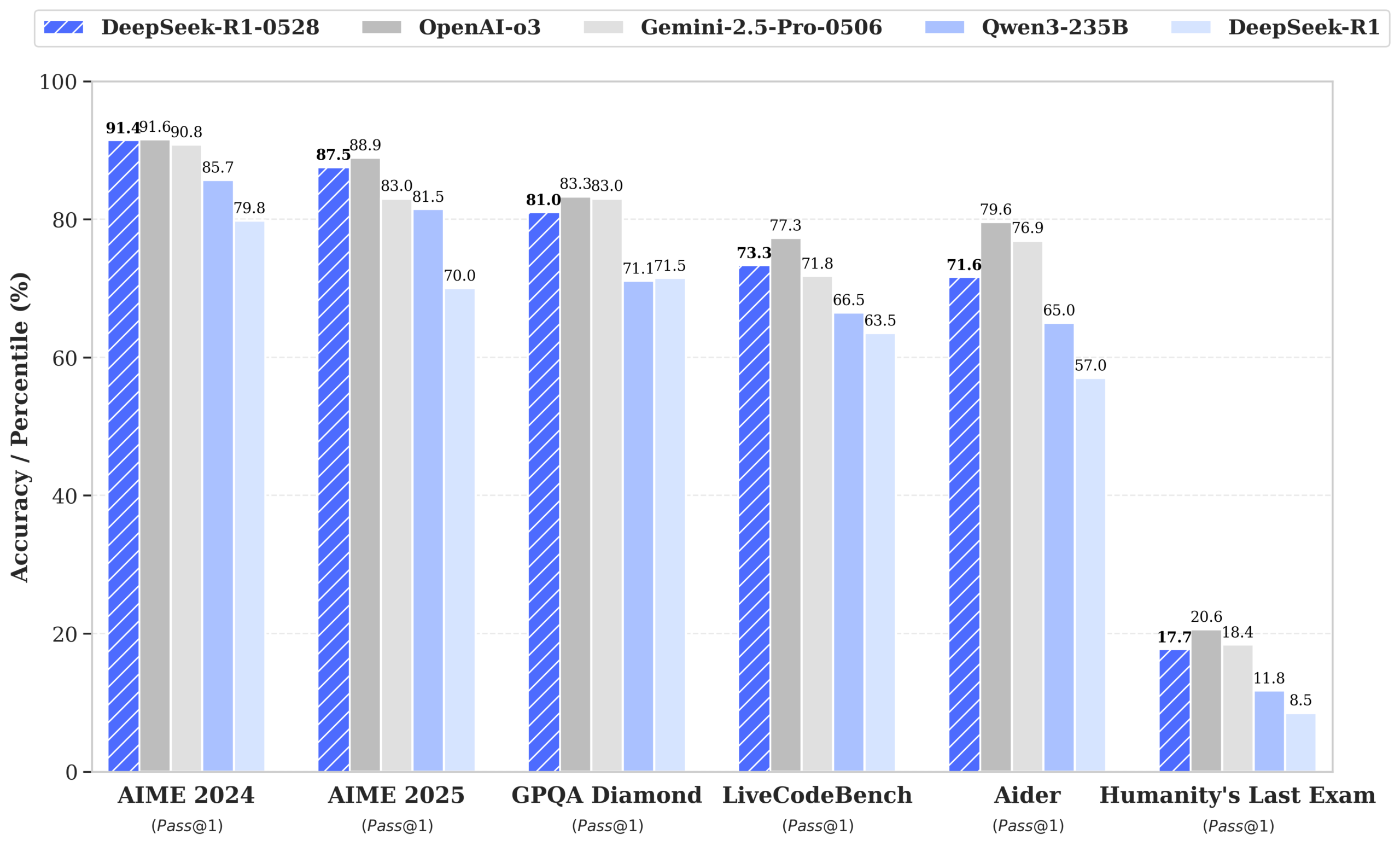
DeepSeek publie le modèle R1-0528, dont les performances approchent celles de GPT-4o et Gemini 2.5 Pro, se hissant au sommet du classement open source: DeepSeek-R1-0528 excelle dans plusieurs benchmarks en mathématiques, programmation et raisonnement logique général, notamment avec un taux de précision passant de 70 % à 87,5 % au test AIME 2025. La nouvelle version réduit significativement le taux d’hallucination (environ 45-50 %), améliore la capacité de génération de code frontal et prend en charge la sortie JSON ainsi que les appels de fonction. Parallèlement, DeepSeek a publié DeepSeek-R1-0528-Qwen3-8B, affiné à partir de Qwen3-8B Base, dont les performances sur AIME 2024 ne sont surpassées que par R1-0528, dépassant Qwen3-235B. Cette mise à jour consolide la position de DeepSeek en tant que deuxième plus grand laboratoire d’IA au monde et leader de l’open source. (Source : ClementDelangue, dotey, huggingface, NandoDF, andrew_n_carr, Francis_YAO_, scaling01, karminski3, teortaxesTex, tokenbender, dotey)
Anthropic rend open source son outil de “traçage de la pensée” pour grands modèles, Circuit Tracer: La société Anthropic a rendu open source son outil de recherche sur l’explicabilité des grands modèles, Circuit Tracer. Il permet aux chercheurs de générer et d’explorer interactivement des “cartes d’attribution” pour comprendre les processus de “pensée” internes et les mécanismes de décision des grands modèles de langage (LLM). Cet outil vise à aider les chercheurs à sonder plus en profondeur le fonctionnement interne des LLM, par exemple comment un modèle utilise des caractéristiques spécifiques pour prédire le prochain token. Les utilisateurs peuvent essayer l’outil sur Neuronpedia ; en saisissant une phrase, ils obtiennent un diagramme de circuit montrant l’utilisation des caractéristiques par le modèle. (Source : scaling01, mlpowered, rishdotblog, menhguin, NeelNanda5, akbirkhan, riemannzeta, andersonbcdefg, algo_diver, Reddit r/ClaudeAI)
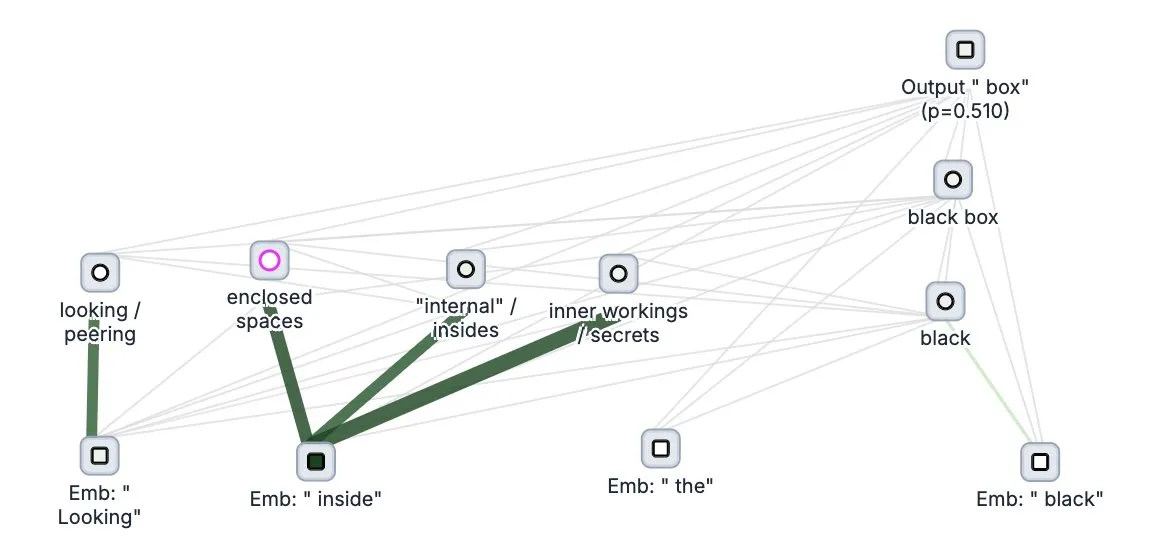
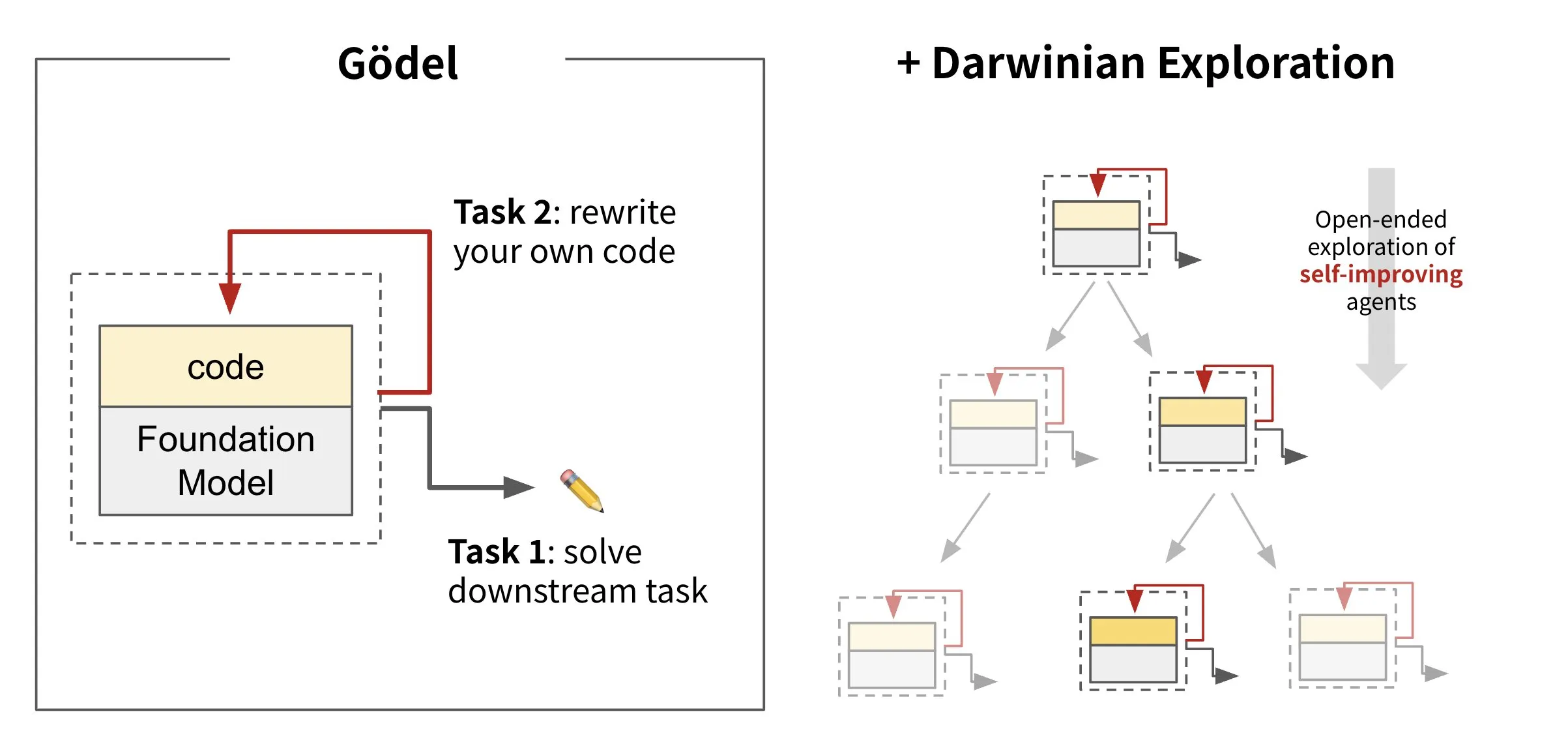
Sakana AI lance son framework d’agent auto-évolutif Darwin Gödel Machine (DGM): Sakana AI a lancé Darwin Gödel Machine (DGM), un framework d’agent IA capable de s’auto-améliorer en réécrivant son propre code. Inspiré par la théorie de l’évolution, DGM maintient une lignée en expansion continue de variantes d’agents pour explorer de manière ouverte l’espace de conception des agents auto-améliorants. Ce framework vise à permettre aux systèmes d’IA d’apprendre et de faire évoluer leurs propres capacités au fil du temps, à l’instar des humains. Sur SWE-bench, DGM a amélioré les performances de 20,0 % à 50,0 % ; sur Polyglot, le taux de réussite est passé de 14,2 % à 30,7 %. (Source : SakanaAILabs, teortaxesTex, Reddit r/MachineLearning)
Black Forest Labs lance le modèle d’édition d’images FLUX.1 Kontext, prenant en charge les entrées mixtes texte et image: Black Forest Labs a lancé une nouvelle génération de modèles d’édition d’images, FLUX.1 Kontext, qui utilise une architecture de flow matching. Il peut accepter simultanément du texte et des images en entrée, permettant une génération et une édition d’images contextuelles. Ce modèle excelle en termes de cohérence des personnages, d’édition locale, de référence de style et de vitesse d’interaction, générant par exemple des images en résolution 1024×1024 en seulement 3 à 5 secondes. Les tests de Replicate indiquent que ses effets d’édition sont supérieurs à ceux de GPT-4o-Image et à moindre coût. Kontext est disponible en versions Pro et Max, et une version Dev open source est prévue. (Source : TomLikesRobots, two_dukes, cloneofsimo, robrombach, bfirsh, timudk, scaling01, KREA AI)

🎯 Tendances
Google DeepMind publie le modèle médical multimodal MedGemma: Google DeepMind a lancé MedGemma, un modèle ouvert puissant conçu spécifiquement pour la compréhension multimodale de textes et d’images médicaux. Ce modèle, proposé dans le cadre des Health AI Developer Foundations, vise à améliorer les capacités d’application de l’IA dans le domaine médical, notamment en combinant l’analyse de textes et d’imagerie médicale (comme les radiographies). (Source : GoogleDeepMind)
Perplexity AI lance Perplexity Labs pour la gestion de tâches complexes: Perplexity AI a annoncé une nouvelle fonctionnalité, Perplexity Labs, spécialement conçue pour gérer des tâches plus complexes. Elle vise à fournir aux utilisateurs des capacités d’analyse et de construction comparables à celles d’une équipe de recherche entière. Les utilisateurs peuvent utiliser Labs pour créer des rapports d’analyse, des présentations, des tableaux de bord dynamiques, etc. Cette fonctionnalité est actuellement disponible pour tous les utilisateurs Pro et a démontré son potentiel dans la recherche scientifique, l’analyse de marché et la création de mini-applications (telles que des jeux, des tableaux de bord). (Source : AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas)
Tencent Hunyuan et Tencent Music lancent conjointement HunyuanVideo-Avatar, capable de générer des vidéos de chant réalistes à partir de photos: Tencent Hunyuan et Tencent Music ont conjointement lancé le modèle HunyuanVideo-Avatar. Ce modèle peut combiner des photos et des fichiers audio téléchargés par les utilisateurs pour détecter automatiquement le contexte de la scène et les émotions, afin de générer des vidéos de discours ou de chant avec une synchronisation labiale réaliste et des effets visuels dynamiques. Cette technologie prend en charge plusieurs styles et a été rendue open source. (Source : huggingface, thursdai_pod)
Apache Spark 4.0.0 officiellement publié, avec des améliorations de SQL, Spark Connect et du support multilingue: La version Apache Spark 4.0.0 a été officiellement publiée. Elle apporte des améliorations significatives aux fonctionnalités SQL, des perfectionnements à Spark Connect pour faciliter l’exécution des applications, et ajoute la prise en charge de nouvelles langues. Cette mise à jour a résolu plus de 5100 problèmes, avec la participation de plus de 390 contributeurs. (Source : matei_zaharia, lateinteraction)

Le modèle vidéo Kling 2.1 est lancé, intégrant OpenArt pour la cohérence des personnages: Kling AI a lancé son modèle vidéo Kling 2.1 et s’est associé à OpenArt pour permettre la cohérence des personnages dans la narration d’histoires vidéo par IA. Kling 2.1 améliore l’alignement des prompts, la vitesse de génération vidéo, la clarté des mouvements de caméra et prétend offrir les meilleurs effets de conversion texte-vidéo. La nouvelle version prend en charge les sorties 720p (standard) et 1080p (professionnel). La fonctionnalité image-vidéo est actuellement en ligne, et la fonctionnalité texte-vidéo sera bientôt disponible. (Source : Kling_ai, NandoDF)
Hume lance le modèle vocal EVI 3, capable de comprendre et de générer n’importe quelle voix humaine: Hume a lancé son dernier modèle de langage vocal, EVI 3, visant à atteindre une intelligence vocale universelle. EVI 3 est capable de comprendre et de générer n’importe quelle voix humaine, et non plus seulement celles de quelques locuteurs spécifiques, offrant ainsi une plus large gamme d’expressivité et une compréhension plus profonde de l’intonation, du rythme, du timbre et du style de parole. Cette technologie vise à permettre à chacun de posséder une IA unique et digne de confiance, reconnaissable par la voix. (Source : AlanCowen, AlanCowen, _akhaliq)
Alibaba lance WebDancer pour explorer les agents de recherche d’informations autonomes: Alibaba a lancé le projet WebDancer, qui vise à rechercher et développer des agents IA capables de rechercher des informations de manière autonome. Ce projet se concentre sur la manière de rendre les agents IA plus efficaces pour naviguer dans l’environnement Web, comprendre les informations et accomplir des tâches complexes d’acquisition d’informations. (Source : _akhaliq)
MiniMax rend open source le framework V-Triune et le modèle Orsta, unifiant le raisonnement RL visuel et les tâches de perception: La société d’IA MiniMax a rendu open source son framework unifié pour l’apprentissage par renforcement visuel, V-Triune, ainsi que la série de modèles Orsta (de 7B à 32B) basés sur ce framework. Grâce à une conception de composants à trois couches et à un mécanisme de récompense dynamique basé sur l’Intersection sur Union (IoU), ce framework permet pour la première fois à un VLM d’apprendre conjointement des tâches de raisonnement visuel et de perception au sein d’un unique processus de post-entraînement, améliorant significativement les performances sur le benchmark MEGA-Bench Core. (Source : 量子位)

Le laboratoire d’IA de Shanghai et d’autres publient RISEBench, un nouveau benchmark pour l’édition d’images qui teste le raisonnement profond des modèles: Le laboratoire d’intelligence artificielle de Shanghai, en collaboration avec plusieurs universités, a publié un nouveau benchmark d’évaluation de l’édition d’images appelé RISEBench. Il comprend 360 cas difficiles conçus par des experts humains, couvrant quatre types de raisonnement fondamentaux : temporel, causal, spatial et logique. Les résultats des tests montrent que même GPT-4o-Image ne parvient à accomplir que 28,9 % des tâches, révélant les lacunes des modèles multimodaux actuels en matière de compréhension d’instructions complexes et d’édition visuelle. (Source : 36氪)

L’Université chinoise de Hong Kong et d’autres proposent le framework TON, permettant aux modèles d’IA de réfléchir sélectivement pour améliorer l’efficacité et la précision: Des chercheurs de l’Université chinoise de Hong Kong et du Show Lab de l’Université nationale de Singapour ont proposé le framework TON (Think Or Not), qui permet aux modèles de langage visuel (VLM) de décider de manière autonome s’ils ont besoin d’un raisonnement explicite. Grâce au “rejet de la pensée” et à l’apprentissage par renforcement, ce framework permet au modèle de répondre directement aux questions simples et d’effectuer un raisonnement détaillé pour les questions complexes. Ainsi, sans sacrifier la précision, la longueur moyenne de la sortie du raisonnement est réduite jusqu’à 90 %, et la précision de certaines tâches est même augmentée de 17 %. (Source : 36氪)
Microsoft Copilot intègre Instacart pour des achats d’épicerie assistés par IA: Mustafa Suleyman, responsable de l’IA chez Microsoft, a annoncé que Copilot intègre désormais le service Instacart. Les utilisateurs peuvent ainsi, via l’application Copilot, gérer de manière transparente l’ensemble du processus, de la génération de recettes à la création de listes de courses, jusqu’à la livraison à domicile de produits frais et d’épicerie. Cela marque une nouvelle expansion des assistants IA dans le domaine des services de la vie quotidienne. (Source : mustafasuleyman)
🧰 Outils
LlamaIndex lance le code source de BundesGPT et l’outil create-llama pour simplifier la création d’applications IA: Jerry Liu de LlamaIndex a annoncé la mise à disposition du code source de BundesGPT et fait la promotion de son outil open source create-llama. Basé sur LlamaIndex, cet outil vise à aider les développeurs à créer et intégrer facilement des données d’entreprise et des agents IA. Son nouveau mode “eject-mode” simplifie grandement la création d’interfaces IA entièrement personnalisables comme BundesGPT. Cette initiative vise à soutenir le projet potentiel de l’Allemagne d’offrir un abonnement gratuit à ChatGPT Plus à chaque citoyen. (Source : jerryjliu0)
Les outils LangChain peuvent être convertis en outils MCP et intégrés au serveur FastMCP: Les utilisateurs de LangChain peuvent désormais convertir leurs outils LangChain en outils MCP (Model Component Protocol) et les ajouter directement à un serveur FastMCP. En installant la bibliothèque langchain-mcp-adapters, les développeurs peuvent utiliser plus facilement l’ensemble des outils de LangChain au sein de l’écosystème MCP, favorisant ainsi l’interopérabilité entre les différents frameworks d’IA. (Source : LangChainAI, hwchase17)
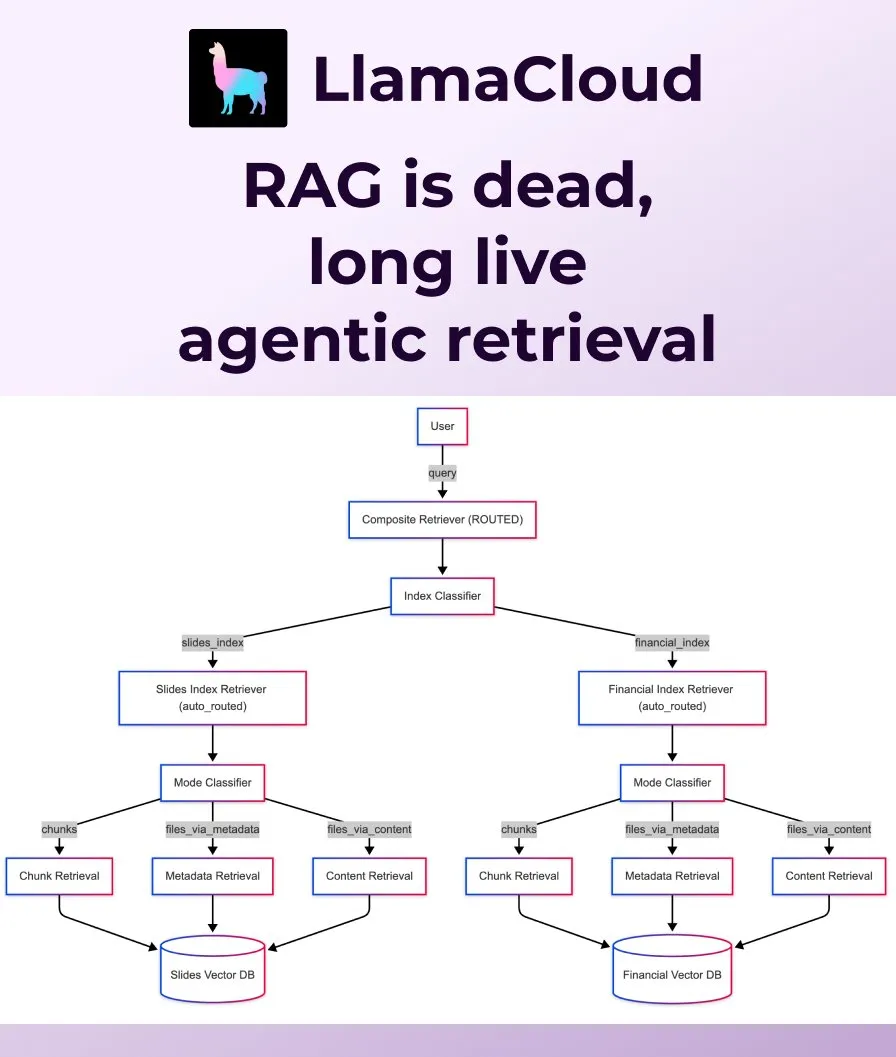
LlamaIndex lance Agentic Retrieval pour remplacer le RAG traditionnel: LlamaIndex estime que le RAG (Retrieval Augmented Generation) traditionnel et simpliste ne suffit plus à répondre aux besoins des applications modernes et lance Agentic Retrieval. Cette solution, intégrée à LlamaCloud, permet aux agents de récupérer dynamiquement des fichiers entiers ou des blocs de données spécifiques à partir d’une ou plusieurs bases de connaissances (telles que Sharepoint, Box, GDrive, S3) en fonction du contenu de la question, réalisant ainsi une acquisition de contexte plus intelligente et flexible. (Source : jerryjliu0, jerryjliu0)
Ollama prend en charge l’exécution du modèle Osmosis-Structure-0.6B pour la conversion de données non structurées: Les utilisateurs peuvent désormais exécuter le modèle Osmosis-Structure-0.6B via Ollama. Il s’agit d’un modèle extrêmement petit capable de convertir n’importe quelle donnée non structurée dans un format spécifié (par exemple, JSON Schema). Il peut être utilisé avec n’importe quel modèle et est particulièrement adapté aux tâches d’inférence nécessitant des sorties structurées. (Source : ollama)
CrewAI met à jour la documentation Gemini pour simplifier le processus de démarrage: L’équipe de CrewAI a mis à jour sa documentation concernant l’API Google Gemini, dans le but d’aider les utilisateurs à démarrer plus facilement la création d’agents IA avec les modèles Gemini. La nouvelle documentation pourrait inclure des directives plus claires, des exemples de code ou des meilleures pratiques. (Source : _philschmid)
Requesty lance la fonctionnalité Smart Routing, sélectionnant automatiquement le meilleur LLM pour OpenWebUI: Requesty a lancé la fonctionnalité Smart Routing, qui s’intègre de manière transparente à OpenWebUI pour sélectionner automatiquement le meilleur LLM (tel que GPT-4o, Claude, Gemini) en fonction du type de tâche indiqué dans le prompt de l’utilisateur. Il suffit d’utiliser smart/task comme ID de modèle pour que le système classe le prompt en environ 65 millisecondes et l’achemine vers le modèle le plus approprié en fonction du coût, de la vitesse et de la qualité. Cette fonctionnalité vise à simplifier la sélection des modèles et à améliorer l’expérience utilisateur. (Source : Reddit r/OpenWebUI)
EvoAgentX : Lancement du premier framework open source pour l’auto-évolution des agents IA: Une équipe de recherche de l’Université de Glasgow au Royaume-Uni a lancé EvoAgentX, le premier framework open source au monde pour l’auto-évolution des agents IA. Il permet de construire des workflows en un clic et introduit un mécanisme d‘“auto-évolution”, permettant aux systèmes multi-agents d’optimiser continuellement leur structure et leurs performances en fonction des changements de l’environnement et des objectifs. L’objectif est de faire passer les systèmes multi-agents IA du “débogage manuel” à l‘“évolution autonome”. Les expériences montrent une amélioration moyenne des performances de 8 % à 13 % dans les tâches de questions-réponses multi-sauts, de génération de code et de raisonnement mathématique. (Source : 36氪)

📚 Apprentissage
HuggingFace, Gradio et d’autres organisent conjointement le Hackathon Agents & MCP, offrant des prix substantiels et des crédits API: HuggingFace, Gradio, Anthropic, SambaNovaAI, MistralAI, LlamaIndex et d’autres institutions organiseront conjointement le Gradio Agents & MCP Hackathon (du 2 au 8 juin). L’événement offre un total de 11 000 $ de prix et fournira aux premiers inscrits des crédits API gratuits de Hyperbolic, Anthropic, Mistral et SambaNova. Modal Labs s’engage même à offrir à tous les participants 250 $ de crédits GPU, pour un total de plus de 300 000 $. (Source : huggingface, _akhaliq, ben_burtenshaw, charles_irl)
LangChain partage l’expérience de JPMorgan Chase dans l’utilisation de systèmes multi-agents pour la recherche en investissement: David Odomirok et Zheng Xue de JPMorgan Chase ont partagé la manière dont ils ont construit un système d’IA multi-agents appelé “Ask David”. Ce système vise à automatiser le processus de recherche en investissement pour des milliers de produits financiers, démontrant le potentiel des architectures multi-agents dans l’analyse financière complexe. (Source : LangChainAI, hwchase17)
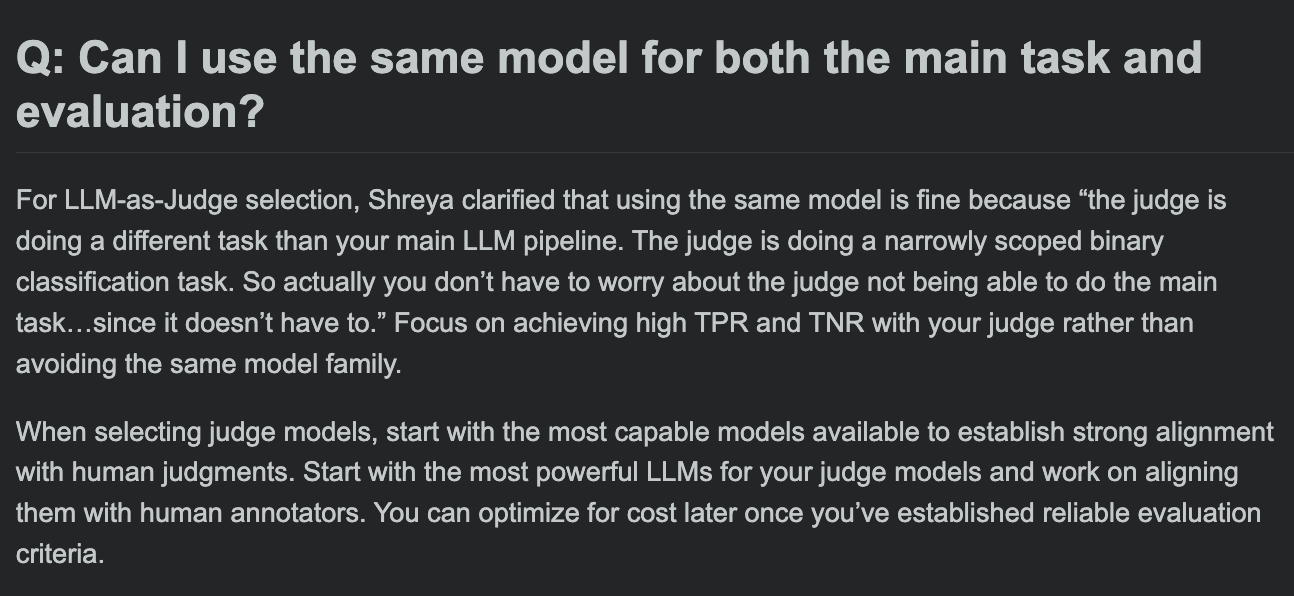
Hamel Husain partage la FAQ de son cours sur l’évaluation des LLM, et se demande si le modèle d’évaluation et le modèle de la tâche principale peuvent être identiques: Lors de la session de questions-réponses de son cours sur l’évaluation des LLM, Hamel Husain a abordé une question fréquente : peut-on utiliser le même modèle pour le traitement de la tâche principale et pour l’évaluation de cette tâche ? Cette discussion aide les développeurs à comprendre les biais potentiels et les meilleures pratiques en matière d’évaluation des modèles. (Source : HamelHusain, HamelHusain)
The Rundown AI lance une plateforme d’éducation IA personnalisée: The Rundown AI a annoncé le lancement de la première plateforme mondiale d’éducation IA personnalisée, offrant des formations, des cas d’usage et des ateliers en direct adaptés à différents secteurs, niveaux de compétence et flux de travail quotidiens. Le contenu de la plateforme comprend 16 cours de certification IA spécifiques à des secteurs technologiques, plus de 300 cas d’usage réels de l’IA, des ateliers d’experts ainsi que des réductions sur des outils IA, etc. (Source : TheRundownAI, rowancheung)
Common Crawl publie les graphiques de réseau au niveau des hôtes et des domaines pour mars-mai 2025: Common Crawl a publié ses dernières données de graphiques de réseau au niveau des hôtes et des domaines, couvrant les mois de mars, avril et mai 2025. Ces données sont d’une valeur importante pour l’étude de la structure du Web, l’entraînement de modèles de langage et la réalisation d’analyses Web à grande échelle. (Source : CommonCrawl)
Bill Chambers lance l’activité d’apprentissage “20 Days of DSPyOSS”: Pour aider la communauté à mieux comprendre les fonctionnalités et l’utilisation de DSPyOSS, Bill Chambers a lancé une activité d’apprentissage de 20 jours sur DSPyOSS. Chaque jour, un extrait de code DSPy et son explication seront publiés, dans le but d’aider les utilisateurs à maîtriser ce framework, du niveau débutant au niveau avancé. (Source : lateinteraction)
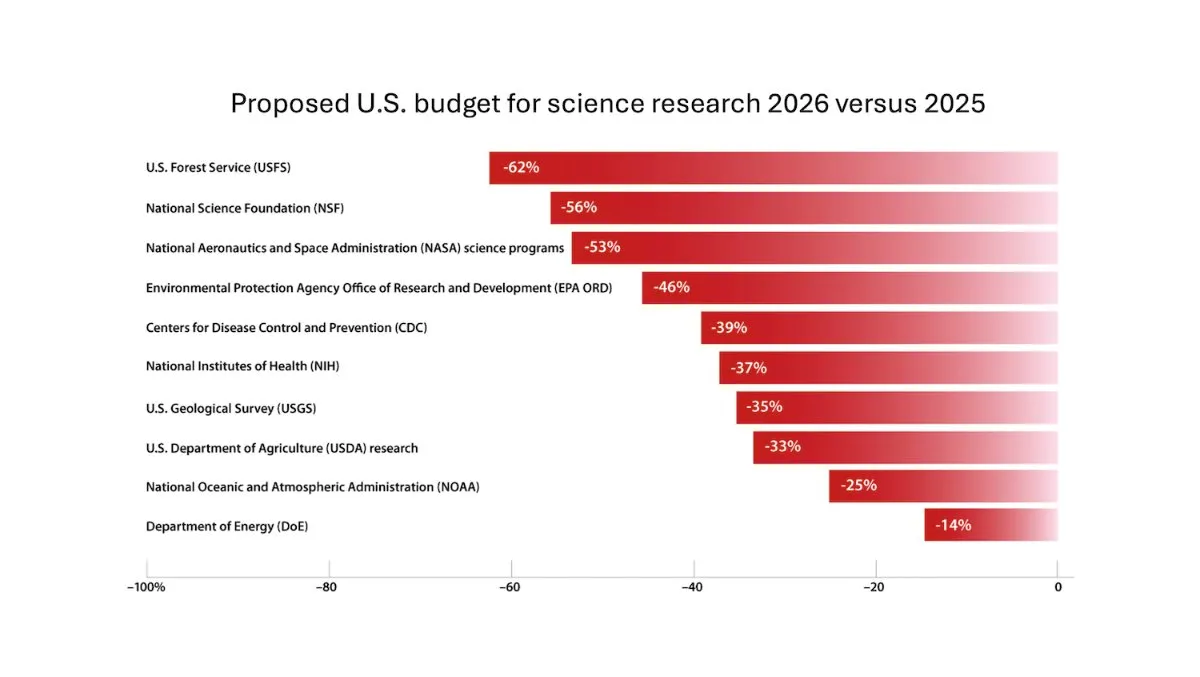
DeepLearning.AI publie la newsletter The Batch, Andrew Ng discute des risques liés à la réduction du financement de la recherche scientifique: Dans le dernier numéro de la newsletter The Batch, Andrew Ng discute des risques potentiels que la réduction du financement de la recherche scientifique fait peser sur la compétitivité et la sécurité nationales. La newsletter couvre également les performances du modèle Claude 4 sur les benchmarks de codage, les annonces IA de Google I/O, la méthode d’entraînement à faible coût de DeepSeek et la possibilité que GPT-4o ait été entraîné sur des livres protégés par le droit d’auteur. (Source : DeepLearningAI)
Google DeepMind offre gratuitement Gemini 2.5 Pro et NotebookLM aux étudiants universitaires britanniques: Google DeepMind a annoncé qu’il offrait aux étudiants universitaires britanniques un accès gratuit à ses modèles les plus avancés (y compris Gemini 2.5 Pro et NotebookLM) pendant 15 mois. Cette initiative vise à soutenir les étudiants dans leurs études, notamment pour la recherche, la rédaction et la préparation aux examens, et offre 2 To d’espace de stockage gratuit. (Source : demishassabis)
Analyse d’article IA : Prot2Token, un framework unifié pour la modélisation des protéines: L’article « Prot2Token: A Unified Framework for Protein Modeling via Next-Token Prediction » présente un framework unifié pour la modélisation des protéines, Prot2Token. Il transforme diverses tâches de prédiction, allant des propriétés des séquences protéiques et des caractéristiques des résidus aux interactions inter-protéiques, en un format standard de prédiction du prochain token. Ce framework utilise un décodeur autorégressif, exploitant les embeddings d’encodeurs de protéines pré-entraînés et des tokens de tâche apprenables pour un apprentissage multi-tâches, visant à améliorer l’efficacité et à accélérer les découvertes biologiques. (Source : HuggingFace Daily Papers)
Analyse d’article IA : Extraction d’exemples négatifs difficiles pour la recherche spécifique à un domaine dans les systèmes d’entreprise: L’article « Hard Negative Mining for Domain-Specific Retrieval in Enterprise Systems » propose un framework évolutif d’extraction d’exemples négatifs difficiles (hard negative mining) pour les données spécifiques à un domaine d’entreprise. Cette méthode sélectionne dynamiquement des documents sémantiquement difficiles mais contextuellement non pertinents pour améliorer les performances des modèles de reclassement déployés. Des expériences sur un corpus d’entreprise du secteur des services cloud ont démontré une amélioration du MRR@3 et du MRR@10 de 15 % et 19 % respectivement. (Source : HuggingFace Daily Papers)
Analyse d’article IA : FS-DAG, réseau de graphes pour la compréhension de documents riches visuellement en few-shot et adaptable au domaine: L’article « FS-DAG: Few Shot Domain Adapting Graph Networks for Visually Rich Document Understanding » propose l’architecture de modèle FS-DAG pour la compréhension de documents riches visuellement en situation de few-shot. Ce modèle utilise des backbones spécifiques au domaine et spécifiques au langage/à la vision, s’adaptant à différents types de documents avec un minimum de données au sein d’un framework modulaire. Dans les expériences sur les tâches d’extraction d’informations, il a montré une vitesse de convergence et des performances supérieures aux méthodes SOTA. (Source : HuggingFace Daily Papers)
Analyse d’article IA : FastTD3, apprentissage par renforcement simple, rapide et performant pour le contrôle de robots humanoïdes: L’article « FastTD3: Simple, Fast, and Capable Reinforcement Learning for Humanoid Control » présente un algorithme d’apprentissage par renforcement appelé FastTD3. Grâce à la simulation parallèle, aux mises à jour par grands lots, aux évaluateurs distribués et à des hyperparamètres soigneusement ajustés, il accélère considérablement la vitesse d’entraînement des robots humanoïdes dans des suites populaires telles que HumanoidBench, IsaacLab et MuJoCo Playground. (Source : HuggingFace Daily Papers, pabbeel, cloneofsimo, jachiam0)
Analyse d’article IA : HLIP, pré-entraînement langue-image évolutif pour l’imagerie médicale 3D: L’article « Towards Scalable Language-Image Pre-training for 3D Medical Imaging » présente un framework de pré-entraînement évolutif pour l’imagerie médicale 3D appelé HLIP (Hierarchical attention for Language-Image Pre-training). HLIP utilise un mécanisme d’attention hiérarchique léger, capable de s’entraîner directement sur des ensembles de données cliniques non organisés, et a atteint des performances SOTA sur plusieurs benchmarks. (Source : HuggingFace Daily Papers)
Analyse d’article IA : PENGUIN, benchmark de sécurité personnalisée pour les LLM et approche d’agent basée sur la planification: L’article « Personalized Safety in LLMs: A Benchmark and A Planning-Based Agent Approach » introduit le concept de sécurité personnalisée et propose le benchmark PENGUIN (comprenant 14 000 scénarios dans 7 domaines sensibles) ainsi que le framework RAISE (un agent à deux étapes, sans entraînement, capable d’acquérir stratégiquement des informations contextuelles spécifiques à l’utilisateur). L’étude montre que les informations personnalisées peuvent améliorer considérablement les scores de sécurité, et que RAISE peut renforcer la sécurité avec un faible coût d’interaction. (Source : HuggingFace Daily Papers)
Analyse d’article IA : Renforcer le raisonnement multi-tours des agents LLM via l’attribution de crédit au niveau du tour: L’article « Reinforcing Multi-Turn Reasoning in LLM Agents via Turn-Level Credit Assignment » étudie comment renforcer les capacités de raisonnement des agents LLM par l’apprentissage par renforcement, en particulier dans les scénarios d’utilisation d’outils multi-tours. Les auteurs proposent une stratégie d’estimation d’avantage à grain fin au niveau du tour pour une attribution de crédit plus précise. Les expériences montrent que cette méthode peut améliorer considérablement la capacité de raisonnement multi-tours des agents LLM dans les tâches de décision complexes. (Source : HuggingFace Daily Papers)
Analyse d’article IA : PISCES, effacement précis de concepts au sein des paramètres dans les grands modèles de langage: L’article « Precise In-Parameter Concept Erasure in Large Language Models » propose le framework PISCES pour effacer précisément des concepts entiers des paramètres d’un modèle en éditant directement les directions qui encodent ces concepts dans l’espace des paramètres. Cette méthode utilise un démêleur pour décomposer les vecteurs MLP, identifier les caractéristiques liées au concept cible et les supprimer des paramètres du modèle. Les expériences montrent sa supériorité par rapport aux méthodes existantes en termes d’efficacité d’effacement, de spécificité et de robustesse. (Source : HuggingFace Daily Papers)
Analyse d’article IA : DORI, évaluation de la compréhension de l’orientation des MLLM avec des tâches de perception multi-axes à grain fin: L’article « Right Side Up? Disentangling Orientation Understanding in MLLMs with Fine-grained Multi-axis Perception Tasks » introduit le benchmark DORI, conçu pour évaluer la capacité des grands modèles de langage multimodaux (MLLM) à comprendre l’orientation des objets. DORI comprend quatre dimensions : la localisation de la face avant, la transformation par rotation, les relations d’orientation relative et la compréhension de l’orientation canonique. Quinze MLLM SOTA ont été testés, révélant que même les meilleurs modèles présentent des limitations significatives dans le jugement fin de l’orientation. (Source : HuggingFace Daily Papers)
Analyse d’article IA : Les LLM peuvent-ils inférer des relations causales à partir de textes du monde réel ?: L’article « Can Large Language Models Infer Causal Relationships from Real-World Text? » explore la capacité des LLM à inférer des relations causales à partir de textes du monde réel. Les chercheurs ont développé un benchmark issu de publications académiques réelles, comprenant des textes de différentes longueurs, complexités et domaines. Les expériences montrent que même les LLM SOTA rencontrent des défis importants dans cette tâche, le meilleur modèle n’atteignant qu’un score F1 de 0,477, révélant leurs difficultés à traiter les informations implicites, à distinguer les facteurs pertinents et à connecter des informations dispersées. (Source : HuggingFace Daily Papers)
Analyse d’article IA : IQBench, comment évaluer l‘“intelligence” des modèles vision-langage avec des tests de QI humains: L’article « IQBench: How “Smart’’ Are Vision-Language Models? A Study with Human IQ Tests » lance IQBench, un nouveau benchmark visant à évaluer l’intelligence fluide des modèles vision-langage (VLM) à l’aide de tests de QI visuels standardisés. Ce benchmark, centré sur le visuel, comprend 500 questions de QI visuelles collectées et annotées manuellement, évaluant la capacité des modèles à interpréter, à résoudre des problèmes et la précision de leurs prédictions finales. Les expériences montrent que o4-mini, Gemini-2.5-Flash et Claude-3.7-Sonnet obtiennent de bons résultats, mais tous les modèles éprouvent des difficultés dans les tâches de raisonnement spatial 3D et d’anagrammes. (Source : HuggingFace Daily Papers)
Analyse d’article IA : PixelThink, vers un raisonnement en chaîne de pixels (chain-of-pixel reasoning) efficace: L’article « PixelThink: Towards Efficient Chain-of-Pixel Reasoning » propose la solution PixelThink, qui module la génération du raisonnement au sein d’un paradigme d’apprentissage par renforcement en intégrant la difficulté de la tâche estimée de manière externe et l’incertitude du modèle mesurée de manière interne. Le modèle apprend à compresser la longueur du raisonnement en fonction de la complexité de la scène et de la confiance de la prédiction. Le benchmark ReasonSeg-Diff est également introduit pour l’évaluation. Les expériences montrent que cette méthode améliore l’efficacité du raisonnement et les performances globales de segmentation. (Source : HuggingFace Daily Papers)
Analyse d’article IA : Réexamen du débat multi-agents comme extension au moment du test : une étude systématique de l’efficacité conditionnelle: L’article « Revisiting Multi-Agent Debate as Test-Time Scaling: A Systematic Study of Conditional Effectiveness » conceptualise le débat multi-agents (MAD) comme une technique d’extension du calcul au moment du test et étudie systématiquement son efficacité par rapport aux méthodes d’auto-agent dans différentes conditions (difficulté de la tâche, taille du modèle, diversité des agents). L’étude révèle que pour le raisonnement mathématique, l’avantage du MAD est limité, mais il est plus efficace lorsque la difficulté du problème augmente ou que la capacité du modèle diminue ; pour les tâches de sécurité, l’optimisation collaborative du MAD peut augmenter la vulnérabilité, mais des configurations diversifiées aident à réduire le taux de réussite des attaques. (Source : HuggingFace Daily Papers)
Analyse d’article IA : VF-Eval, évaluation de la capacité des MLLM à générer des retours sur les vidéos AIGC: L’article « VF-Eval: Evaluating Multimodal LLMs for Generating Feedback on AIGC Videos » propose un nouveau benchmark, VF-Eval, pour évaluer la capacité des grands modèles de langage multimodaux (MLLM) à interpréter les vidéos générées par IA (AIGC). VF-Eval comprend quatre tâches : vérification de la cohérence, perception des erreurs, détection du type d’erreur et évaluation du raisonnement. L’évaluation de 13 MLLM de pointe montre que même le plus performant, GPT-4.1, peine à maintenir de bonnes performances sur toutes les tâches. (Source : HuggingFace Daily Papers)
Analyse d’article IA : SafeScientist, des agents LLM pour des découvertes scientifiques conscientes des risques: L’article « SafeScientist: Toward Risk-Aware Scientific Discoveries by LLM Agents » présente un framework de scientifique IA appelé SafeScientist, conçu pour renforcer la sécurité et la responsabilité éthique dans l’exploration scientifique pilotée par l’IA. Ce framework peut refuser activement les tâches inappropriées ou à haut risque et met l’accent sur la sécurité du processus de recherche grâce à des mécanismes de défense multiples, notamment la surveillance des prompts, la surveillance collaborative des agents, la surveillance de l’utilisation des outils et un composant d’examinateur éthique. Le benchmark SciSafetyBench est également proposé pour l’évaluation. (Source : HuggingFace Daily Papers)
Analyse d’article IA : CXReasonBench, un benchmark pour l’évaluation du raisonnement diagnostique structuré sur les radiographies pulmonaires: L’article « CXReasonBench: A Benchmark for Evaluating Structured Diagnostic Reasoning in Chest X-rays » présente le processus CheXStruct et le benchmark CXReasonBench, utilisés pour évaluer si les grands modèles de langage visuel (LVLM) peuvent exécuter des étapes de raisonnement cliniquement valides dans le diagnostic des radiographies pulmonaires. Ce benchmark comprend 18 988 paires QA, couvrant 12 tâches de diagnostic et 1 200 cas, et prend en charge une évaluation multi-chemins et multi-étapes, y compris la sélection de régions anatomiques et la localisation visuelle des mesures diagnostiques. (Source : HuggingFace Daily Papers)
Analyse d’article IA : ZeroGUI, automatisation de l’apprentissage en ligne des interfaces graphiques utilisateur (GUI) sans coût humain: L’article « ZeroGUI: Automating Online GUI Learning at Zero Human Cost » propose ZeroGUI, un framework d’apprentissage en ligne évolutif pour automatiser l’entraînement des agents GUI sans aucun coût humain. ZeroGUI intègre la génération automatique de tâches basée sur les VLM, l’estimation automatique des récompenses et un apprentissage par renforcement en ligne en deux étapes pour interagir continuellement avec l’environnement GUI et en apprendre. (Source : HuggingFace Daily Papers)
Analyse d’article IA : Spatial-MLLM, amélioration de l’intelligence spatiale visuelle des MLLM: L’article « Spatial-MLLM: Boosting MLLM Capabilities in Visual-based Spatial Intelligence » propose le framework Spatial-MLLM pour le raisonnement spatial basé sur la vision à partir d’observations purement 2D. Ce framework adopte une architecture à double encodeur (un encodeur visuel sémantique et un encodeur spatial) et la combine avec une stratégie d’échantillonnage d’images sensible à l’espace, atteignant des performances SOTA sur plusieurs ensembles de données du monde réel. (Source : HuggingFace Daily Papers)
Analyse d’article IA : TrustVLM, déterminer si les prédictions d’un modèle vision-langage sont fiables: L’article « To Trust Or Not To Trust Your Vision-Language Model’s Prediction » introduit TrustVLM, un framework sans entraînement conçu pour évaluer la fiabilité des prédictions des modèles vision-langage (VLM). Cette méthode exploite les différences de représentation conceptuelle dans l’espace des embeddings d’images et propose de nouvelles fonctions de score de confiance pour améliorer la détection des erreurs de classification, démontrant des performances SOTA sur 17 ensembles de données différents. (Source : HuggingFace Daily Papers)
Analyse d’article IA : MAGREF, génération vidéo multi-références guidée par masques: L’article « MAGREF: Masked Guidance for Any-Reference Video Generation » propose MAGREF, un framework unifié de génération vidéo multi-références. Il introduit un mécanisme de guidage par masques, utilisant des masques dynamiques sensibles aux régions et une connexion de canaux au niveau du pixel, pour réaliser une synthèse vidéo multi-sujets cohérente dans des conditions d’images de référence et de prompts textuels diversifiés. Il surpasse les lignes de base open source et commerciales existantes sur les benchmarks vidéo multi-sujets. (Source : HuggingFace Daily Papers)
Analyse d’article IA : ATLAS, apprendre à mémoriser de manière optimale le contexte au moment du test: L’article « ATLAS: Learning to Optimally Memorize the Context at Test Time » propose ATLAS, un module de mémoire à long terme de haute capacité qui apprend à mémoriser le contexte en optimisant la mémoire en fonction des tokens actuels et passés, surmontant ainsi la caractéristique de mise à jour en ligne des modèles à mémoire à long terme. Sur cette base, les auteurs proposent la famille d’architectures DeepTransformers. Les expériences montrent qu’ATLAS surpasse les Transformers et les modèles récurrents linéaires récents dans les tâches de modélisation du langage, de raisonnement de bon sens, de tâches à forte densité de rappel et de compréhension de contexte long. (Source : HuggingFace Daily Papers)
Analyse d’article IA : Satori-SWE, méthode d’ingénierie logicielle évolutive et efficace en termes d’échantillons au moment du test: L’article « Satori-SWE: Evolutionary Test-Time Scaling for Sample-Efficient Software Engineering » propose la méthode EvoScale, qui considère la génération de code comme un processus évolutif. En optimisant itérativement les sorties, elle améliore les performances des petits modèles sur des tâches d’ingénierie logicielle (comme SWE-Bench). Le modèle Satori-SWE-32B, grâce à cette méthode et en utilisant un petit nombre d’échantillons, atteint ou dépasse les performances de modèles ayant plus de 100B de paramètres. (Source : HuggingFace Daily Papers)
Analyse d’article IA : OPO, apprentissage par renforcement on-policy avec une baseline de récompense optimale: L’article « On-Policy RL with Optimal Reward Baseline » propose l’algorithme OPO, un nouvel algorithme d’apprentissage par renforcement simplifié, conçu pour résoudre les problèmes d’instabilité d’entraînement et de faible efficacité de calcul auxquels sont confrontés les algorithmes RL actuels lors de l’entraînement des LLM. OPO met l’accent sur un entraînement on-policy précis et introduit une baseline de récompense optimale qui minimise théoriquement la variance du gradient. Les expériences montrent ses performances supérieures et sa stabilité d’entraînement sur les benchmarks de raisonnement mathématique. (Source : HuggingFace Daily Papers)
Analyse d’article IA : SWE-bench Goes Live! Un benchmark d’ingénierie logicielle mis à jour en temps réel: L’article « SWE-bench Goes Live! » présente SWE-bench-Live, un benchmark mis à jour en temps réel visant à surmonter les limitations du SWE-bench existant. La nouvelle version comprend 1319 tâches issues de problèmes GitHub réels depuis 2024, couvrant 93 dépôts, et est dotée de processus de gestion automatisés pour permettre l’évolutivité et la mise à jour continue, offrant ainsi une évaluation plus rigoureuse et résistante à la contamination des LLM et des agents. (Source : HuggingFace Daily Papers, _akhaliq)
Analyse d’article IA : ToMAP, entraîner des persuadeurs LLM conscients de l’adversaire avec la théorie de l’esprit: L’article « ToMAP: Training Opponent-Aware LLM Persuaders with Theory of Mind » présente une nouvelle méthode appelée ToMAP, qui construit des agents de persuasion plus flexibles en intégrant deux modules de théorie de l’esprit, améliorant ainsi leur conscience et leur analyse de l’état mental de l’adversaire. Les expériences montrent que les persuadeurs ToMAP avec seulement 3B de paramètres surpassent les grandes lignes de base comme GPT-4o sur plusieurs modèles d’objets de persuasion et corpus. (Source : HuggingFace Daily Papers)
Analyse d’article IA : Les LLM peuvent-ils tromper CLIP ? Évaluation de la compositionalité adverse des représentations multimodales pré-entraînées via des mises à jour textuelles: L’article « Can LLMs Deceive CLIP? Benchmarking Adversarial Compositionality of Pre-trained Multimodal Representation via Text Updates » introduit le benchmark de compositionalité adverse multimodale (MAC). Il utilise des LLM pour générer des échantillons de texte trompeurs afin d’exploiter les vulnérabilités de compositionalité des représentations multimodales pré-entraînées comme CLIP. L’étude propose une méthode d’auto-entraînement, affinée par un échantillonnage par rejet avec filtrage favorisant la diversité, pour améliorer le taux de réussite des attaques et la diversité des échantillons. (Source : HuggingFace Daily Papers)
Analyse d’article IA : Le rôle des récompenses bruitées dans l’apprentissage du raisonnement – L’ascension façonne la sagesse plus profondément que le sommet: L’article « The Climb Carves Wisdom Deeper Than the Summit: On the Noisy Rewards in Learning to Reason » étudie l’impact du bruit des récompenses sur le post-entraînement des LLM par apprentissage par renforcement pour le raisonnement. L’étude révèle que les LLM font preuve d’une forte robustesse à une quantité importante de bruit de récompense. Même en ne récompensant que l’apparition de phrases de raisonnement clés (sans vérifier l’exactitude de la réponse), le modèle peut atteindre des performances comparables à celles des modèles entraînés avec une validation stricte et des récompenses précises. (Source : HuggingFace Daily Papers)
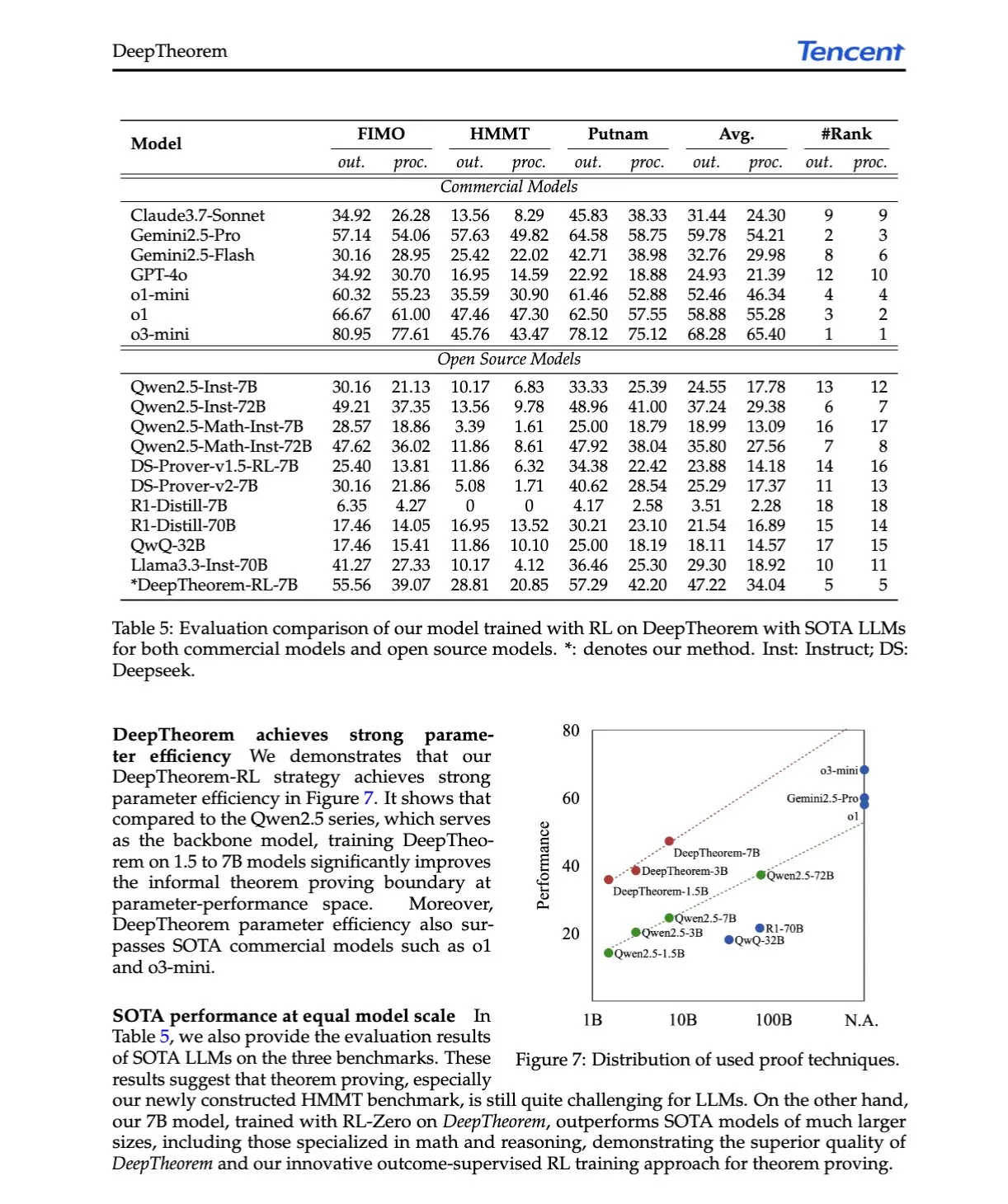
Analyse d’article IA : DeepTheorem, faire progresser la démonstration de théorèmes par les LLM grâce au langage naturel et à l’apprentissage par renforcement: L’article « DeepTheorem: Advancing LLM Reasoning for Theorem Proving Through Natural Language and Reinforcement Learning » propose DeepTheorem, un framework de démonstration de théorèmes non formels qui utilise le langage naturel pour améliorer le raisonnement mathématique des LLM. Ce framework comprend un ensemble de données de benchmark à grande échelle (121 000 théorèmes et démonstrations non formels de niveau IMO) et une stratégie RL spécialement conçue pour la démonstration de théorèmes non formels (RL-Zero). (Source : HuggingFace Daily Papers, teortaxesTex)
Analyse d’article IA : D-AR, diffusion via des modèles autorégressifs: L’article « D-AR: Diffusion via Autoregressive Models » propose un nouveau paradigme, D-AR, qui reformule le processus de diffusion d’images en un processus standard de prédiction du prochain token autorégressif. Grâce à un tokenizer conçu à cet effet, les images sont converties en séquences de tokens discrets, où les tokens à différentes positions peuvent être décodés en différentes étapes de débruitage par diffusion dans l’espace des pixels. Cette méthode atteint un FID de 2,09 sur ImageNet en utilisant un backbone Llama de 775M et 256 tokens discrets. (Source : HuggingFace Daily Papers)
Analyse d’article IA : Table-R1, extension au moment de l’inférence pour le raisonnement sur tableaux: L’article « Table-R1: Inference-Time Scaling for Table Reasoning » explore pour la première fois l’extension au moment de l’inférence pour les tâches de raisonnement sur tableaux. Les chercheurs ont développé et évalué deux stratégies de post-entraînement : la distillation à partir des trajectoires d’inférence des modèles de pointe (Table-R1-SFT) et l’apprentissage par renforcement avec des récompenses vérifiables (Table-R1-Zero). Table-R1-Zero (7B paramètres) atteint ou dépasse les performances de GPT-4.1 et DeepSeek-R1 sur diverses tâches de raisonnement sur tableaux. (Source : HuggingFace Daily Papers)
Analyse d’article IA : Muddit, un modèle de diffusion discrète unifié pour une génération au-delà du texte-vers-image: L’article « Muddit: Liberating Generation Beyond Text-to-Image with a Unified Discrete Diffusion Model » présente Muddit, un modèle Transformer de diffusion discrète unifié qui prend en charge la génération parallèle rapide des modalités texte et image. Muddit intègre les puissants a priori visuels d’un backbone texte-vers-image pré-entraîné et un décodeur de texte léger, offrant une compétitivité en termes de qualité et d’efficacité. (Source : HuggingFace Daily Papers)
Analyse d’article IA : VideoReasonBench, les MLLM peuvent-ils effectuer un raisonnement vidéo complexe centré sur la vision ?: L’article « VideoReasonBench: Can MLLMs Perform Vision-Centric Complex Video Reasoning? » introduit VideoReasonBench, un benchmark conçu pour évaluer les capacités de raisonnement vidéo complexe centrées sur la vision. Ce benchmark contient des vidéos de séquences d’opérations à grain fin, et les questions évaluent les capacités de rappel, d’inférence et de prédiction. Les expériences montrent que la plupart des MLLM SOTA obtiennent de mauvais résultats sur ce benchmark, tandis que Gemini-2.5-Pro, amélioré par la pensée, se distingue. (Source : HuggingFace Daily Papers, OriolVinyalsML)
Analyse d’article IA : GeoDrive, modèle du monde de conduite informé par la géométrie 3D avec contrôle précis des actions: L’article « GeoDrive: 3D Geometry-Informed Driving World Model with Precise Action Control » propose GeoDrive, qui intègre explicitement des conditions géométriques 3D robustes dans un modèle du monde de conduite pour améliorer la compréhension spatiale et la contrôlabilité des actions. Cette méthode améliore les effets de rendu pendant l’entraînement grâce à un module d’édition dynamique. Les expériences prouvent sa supériorité par rapport aux modèles existants en termes de précision des actions et de perception spatiale 3D. (Source : HuggingFace Daily Papers)
Analyse d’article IA : Guidage sans classifieur adaptatif via un masquage dynamique à faible confiance: L’article « Adaptive Classifier-Free Guidance via Dynamic Low-Confidence Masking » propose la méthode A-CFG, qui personnalise l’entrée inconditionnelle du guidage sans classifieur (CFG) en exploitant la confiance de prédiction instantanée du modèle. A-CFG identifie les tokens à faible confiance à chaque étape d’un modèle de langage à diffusion itérative (masquée) et les re-masque temporairement, créant ainsi des entrées inconditionnelles dynamiques et localisées, ce qui rend l’influence corrective du CFG plus précise. (Source : HuggingFace Daily Papers)
Analyse d’article IA : PatientSim, un simulateur basé sur des personas pour des interactions médecin-patient réalistes: L’article « PatientSim: A Persona-Driven Simulator for Realistic Doctor-Patient Interactions » présente PatientSim, un simulateur qui génère des personas de patients réalistes et diversifiés à partir de profils cliniques de l’ensemble de données MIMIC et de quatre axes de persona (personnalité, maîtrise de la langue, niveau de rappel des antécédents médicaux, niveau de confusion cognitive). Il vise à fournir un système d’interaction patient réaliste pour l’entraînement ou l’évaluation des LLM médecins. (Source : HuggingFace Daily Papers)
Analyse d’article IA : LoRAShop, génération et édition d’images multi-concepts sans entraînement avec des Rectified Flow Transformers: L’article « LoRAShop: Training-Free Multi-Concept Image Generation and Editing with Rectified Flow Transformers » présente LoRAShop, le premier framework utilisant des modèles LoRA pour l’édition d’images multi-concepts. Ce framework exploite les motifs d’interaction des caractéristiques internes des Transformers à diffusion de style Flux pour dériver des masques latents découplés pour chaque concept, et ne mélange les poids LoRA que dans les régions conceptuelles, permettant une intégration transparente de multiples sujets ou styles. (Source : HuggingFace Daily Papers)
Analyse d’article IA : AnySplat, splatting gaussien 3D feed-forward à partir de vues non contraintes: L’article « AnySplat: Feed-forward 3D Gaussian Splatting from Unconstrained Views » présente AnySplat, un réseau feed-forward pour la synthèse de nouvelles vues à partir d’un ensemble d’images non calibrées. Contrairement aux pipelines de rendu neuronal traditionnels, AnySplat peut prédire les primitives gaussiennes 3D (encodant la géométrie et l’apparence de la scène) ainsi que les paramètres intrinsèques et extrinsèques de la caméra pour chaque image d’entrée en une seule passe avant, sans nécessiter d’annotations de pose, et prend en charge la synthèse de nouvelles vues en temps réel. (Source : HuggingFace Daily Papers)
Analyse d’article IA : ZeroSep, séparer n’importe quoi en audio avec zéro entraînement: L’article « ZeroSep: Separate Anything in Audio with Zero Training » découvre qu’il est possible de réaliser une séparation de sources sonores en zero-shot uniquement avec un modèle de diffusion audio guidé par texte pré-entraîné, dans une configuration spécifique. La méthode ZeroSep inverse l’audio mixte dans l’espace latent du modèle de diffusion et utilise un guidage conditionné par le texte pour le processus de débruitage afin de récupérer les sources sonores individuelles, sans aucun entraînement ou affinage spécifique à la tâche. (Source : HuggingFace Daily Papers)
Analyse d’article IA : Étude sur la minimisation de l’entropie en one-shot: L’article « One-shot Entropy Minimization » révèle, après avoir entraîné 13 440 grands modèles de langage, que la minimisation de l’entropie ne nécessite qu’une seule donnée non étiquetée et 10 étapes d’optimisation pour atteindre, voire dépasser, les améliorations de performance obtenues par l’apprentissage par renforcement basé sur des règles utilisant des milliers de données et des récompenses soigneusement conçues. Ce résultat pourrait inciter à repenser les paradigmes de post-entraînement des LLM. (Source : HuggingFace Daily Papers)
Analyse d’article IA : ChartLens, attribution visuelle à grain fin dans les graphiques: L’article « ChartLens: Fine-grained Visual Attribution in Charts » aborde le problème des hallucinations fréquentes des MLLM dans la compréhension des graphiques en introduisant la tâche d’attribution visuelle a posteriori dans les graphiques et en proposant l’algorithme ChartLens. Cet algorithme utilise des techniques de segmentation pour identifier les objets du graphique et effectue une attribution visuelle à grain fin avec les MLLM via des prompts d’ensembles de marquage. Le benchmark ChartVA-Eval, contenant des annotations d’attribution à grain fin pour des graphiques des domaines financier, politique, économique, etc., est également publié. (Source : HuggingFace Daily Papers)
Analyse d’article IA : Explorer les motifs structurels de la connaissance dans les grands modèles de langage d’un point de vue graphique: L’article « A Graph Perspective to Probe Structural Patterns of Knowledge in Large Language Models » étudie les motifs structurels de la connaissance dans les LLM d’un point de vue graphique. L’étude quantifie la connaissance des LLM aux niveaux des triplets et des entités, analyse sa relation avec les attributs structurels des graphes tels que le degré des nœuds, et révèle l’homogénéité de la connaissance (les entités topologiquement proches ont des niveaux de connaissance similaires). Sur cette base, un modèle d’apprentissage automatique sur graphes a été développé pour estimer la connaissance des entités et utilisé pour la vérification des connaissances. (Source : HuggingFace Daily Papers)
💼 Affaires
Lumos Robotics, entreprise d’intelligence incarnée, lève près de 200 millions de yuans en six mois et conclut des partenariats avec COSCO Shipping, etc.: Lumos Robotics (鹿明机器人), une entreprise de robotique d’intelligence incarnée fondée par l’ancien dirigeant de Dreame, Yu Chao, a annoncé la finalisation d’un tour de financement de type Angel++, avec des investisseurs tels que Fosun RZ Capital, Dematic Technology et Wuzhong Financial Holding. En six mois, l’entreprise a levé près de 200 millions de yuans. Axée sur le scénario domestique, ses produits comprennent les séries de robots humanoïdes LUS et MOS ainsi que des composants clés. Elle a déjà lancé le robot humanoïde grandeur nature LUS et a conclu des partenariats stratégiques avec Dematic Technology, COSCO Shipping et d’autres, accélérant la commercialisation de l’intelligence incarnée dans des scénarios tels que la logistique et la fabrication intelligente. (Source : 36氪)

Snorkel AI lève 100 millions de dollars en série D et lance des services d’évaluation d’agents IA et de données expertes: Snorkel AI, une entreprise d’IA pour centres de données, a annoncé une levée de fonds de 100 millions de dollars en série D, menée par Valor Equity Partners, portant son financement total à 235 millions de dollars. Parallèlement, l’entreprise a lancé Snorkel Evaluate (une plateforme d’évaluation d’agents IA pour centres de données) et Expert Data-as-a-Service (données expertes en tant que service), visant à aider les entreprises à construire et déployer des agents IA plus fiables et professionnels. (Source : realDanFu, percyliang, tri_dao, krandiash)
Le département américain de l’Énergie annonce une collaboration avec Dell et Nvidia pour développer le supercalculateur de nouvelle génération “Doudna”: Le département américain de l’Énergie a annoncé avoir signé un contrat avec Dell pour développer le prochain supercalculateur phare du Lawrence Berkeley National Laboratory, nommé “Doudna” (NERSC-10). Ce système sera alimenté par la plateforme Vera Rubin de nouvelle génération de Nvidia et devrait être mis en service en 2026. Ses performances seront plus de 10 fois supérieures à celles du fleuron actuel, Perlmutter. Il est conçu pour prendre en charge des charges de travail de calcul haute performance et d’IA à grande échelle, afin d’aider les États-Unis à remporter la course à la domination mondiale de l’IA. (Source : 36氪, nvidia)

🌟 Communauté
DeepSeek R1-0528 suscite un vif débat, les performances, les hallucinations et les appels d’outils étant au centre des discussions: La publication de DeepSeek R1-0528 a suscité de nombreuses discussions au sein de la communauté. La plupart des avis s’accordent à dire qu’il présente des améliorations significatives en mathématiques, en programmation et en raisonnement logique général, se rapprochant voire dépassant certains modèles propriétaires. La nouvelle version a progressé dans la réduction du taux d’hallucination et prend désormais en charge la sortie JSON et les appels de fonction. Parallèlement, sa version distillée Qwen3-8B a également attiré l’attention pour ses excellentes performances mathématiques sur un petit modèle. La communauté estime généralement que DeepSeek a consolidé sa position de leader dans le domaine de l’open source et attend avec impatience la sortie de la version R2. (Source : ClementDelangue, dotey, scaling01, awnihannun, karminski3, teortaxesTex, scaling01, karminski3, teortaxesTex, dotey, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
Le modèle d’édition d’images IA FLUX.1 Kontext attire l’attention, mettant l’accent sur la compréhension contextuelle et la cohérence des personnages: Le modèle d’édition d’images FLUX.1 Kontext publié par Black Forest Labs a attiré l’attention de la communauté pour sa capacité à traiter simultanément des entrées texte et image tout en maintenant la cohérence des personnages. Les utilisateurs rapportent d’excellentes performances dans des tâches telles que l’édition d’images, le transfert de style et la superposition de texte, en particulier pour sa capacité à bien préserver les caractéristiques du sujet lors d’éditions multiples. Des plateformes comme Replicate ont déjà mis en ligne ce modèle et fourni des rapports de test détaillés ainsi que des conseils d’utilisation. (Source : TomLikesRobots, two_dukes, robrombach, timudk, robrombach, cloneofsimo, robrombach, robrombach)

Les agents IA vont significativement modifier les modèles de recherche et de publicité: Arav Srinivas, PDG de Perplexity AI, estime qu’avec les agents IA effectuant des recherches pour le compte des utilisateurs, le volume de requêtes humaines sur les moteurs de recherche comme Google diminuera considérablement. Cela entraînera une baisse des CPM/CPC publicitaires, et les dépenses publicitaires pourraient se déplacer vers les médias sociaux ou les plateformes d’IA. Les utilisateurs n’auront plus besoin d’effectuer fréquemment des recherches par mots-clés ; ce sont les assistants IA qui leur fourniront proactivement les informations. (Source : AravSrinivas)
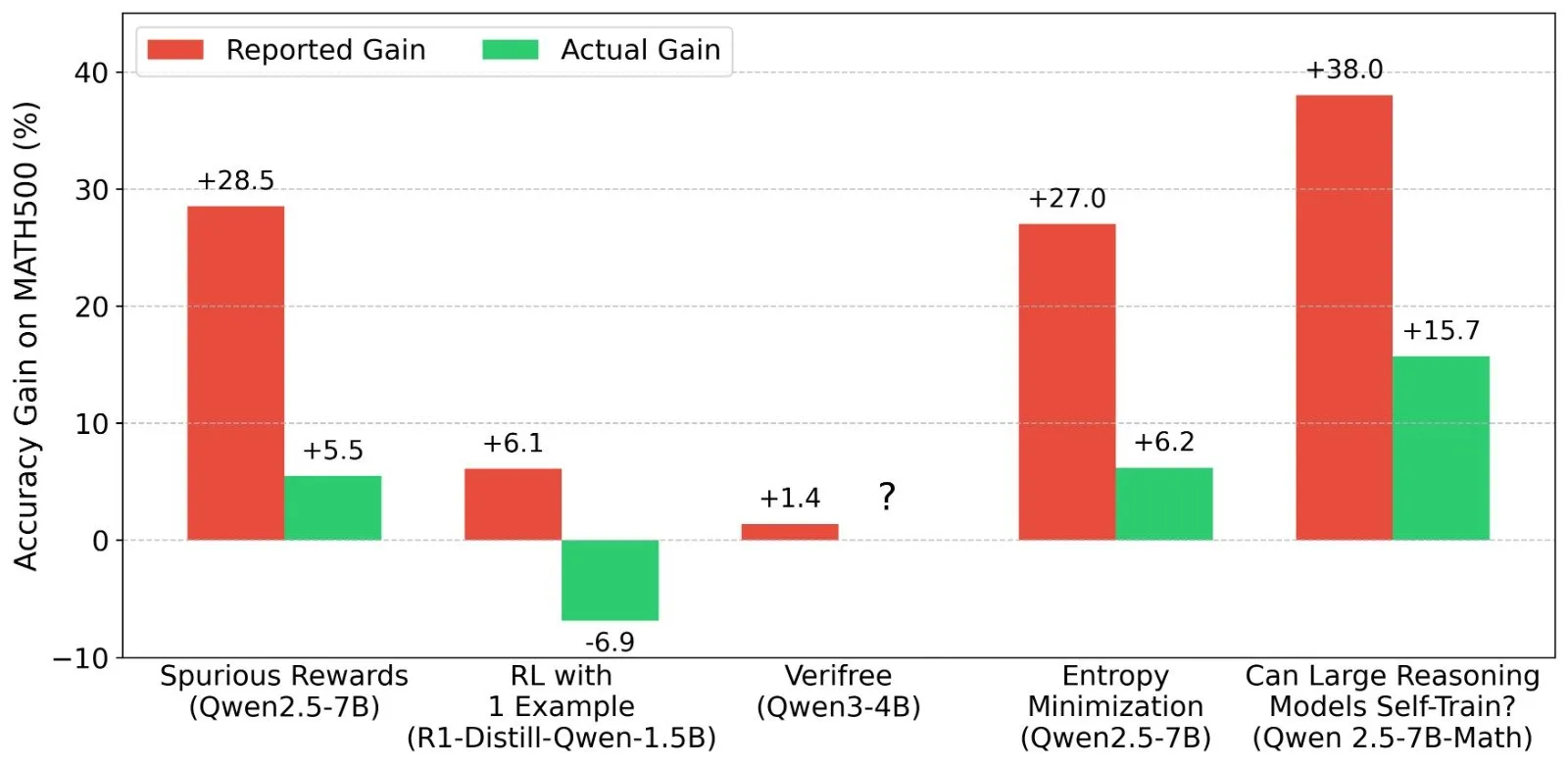
Discussion sur les résultats de l’apprentissage par renforcement (RL) des LLM : signaux de récompense et authenticité des capacités du modèle: Shashwat Goel et d’autres chercheurs s’interrogent sur le phénomène récent où les modèles LLM RL améliorent leurs performances sans signaux de récompense réels, soulignant que certaines études pourraient sous-estimer les capacités de base des modèles pré-entraînés ou qu’il pourrait y avoir d’autres facteurs de confusion. La discussion a conduit à une analyse approfondie des performances de modèles tels que Qwen en RL, ainsi qu’à une réflexion sur l’efficacité du RLVR (Reinforcement Learning with Verifiable Rewards), soulignant la nécessité de lignes de base plus strictes et d’une optimisation des prompts lors de l’évaluation des effets du RL. (Source : menhguin, AndrewLampinen, lateinteraction, madiator, vikhyatk, matei_zaharia, hrishioa, iScienceLuvr)
Le “Vibe Coding” suscite la discussion, soulignant l’importance des valeurs par défaut sécurisées et les risques de dette technique: Le “Vibe coding” (programmation à l’ambiance, qui repose davantage sur l’intuition et l’itération rapide que sur des spécifications strictes) est devenu un sujet de discussion brûlant au sein de la communauté. Amjad Masad, PDG de Replit, estime que cette approche donne du pouvoir aux nouveaux développeurs, mais que les plateformes doivent fournir des configurations par défaut sécurisées. Parallèlement, Pedro Domingos commente que “la programmation à l’ambiance est le Godzilla de la dette technique”, suggérant les problèmes de maintenance à long terme qu’elle pourrait engendrer. Semafor a rapporté une faille de sécurité chez Lovable due à une mauvaise configuration de la stratégie RLS, ce qui a encore attiré l’attention sur la sécurité de cette méthode de programmation. (Source : alexalbert__, amasad, pmddomingos, gfodor)
Le rôle de l’IA dans l’ingénierie logicielle : amélioration de l’efficacité et caractère irremplaçable des programmeurs humains: Salvatore Sanfilippo, le créateur de Redis, a partagé son expérience en affirmant que bien que l’IA (comme Gemini 2.5 Pro) soit précieuse pour l’assistance à la programmation, la revue de code et la validation d’idées, les programmeurs humains restent bien supérieurs à l’IA en matière de résolution créative de problèmes et de pensée non conventionnelle. La discussion au sein de la communauté a en outre souligné que l’IA ressemble actuellement davantage à un “canard en caoutchouc intelligent”, capable d’aider à la réflexion, mais que ses suggestions doivent être évaluées avec prudence, et qu’une dépendance excessive pourrait affaiblir les compétences fondamentales des développeurs. Mitchell Hashimoto a également partagé un cas où un LLM l’a aidé à localiser rapidement un problème de compilation Clang, lui faisant gagner un temps considérable. (Source : mitchellh, 36氪)
La question de savoir si l’IA remplacera massivement les emplois continue de susciter l’attention: Dario Amodei, PDG d’Anthropic, prédit que l’IA pourrait entraîner la disparition de la moitié des postes de bureau de premier échelon, tandis que Mark Cuban estime que l’IA créera de nouvelles entreprises et de nouveaux emplois. La communauté débat vivement de cette question. Certains estiment que des emplois tels que le service client, la rédaction de textes de base et une partie du développement sont déjà affectés, mais que l’IA peine encore à remplacer les humains dans les domaines créatifs, la prise de décisions complexes et les tâches nécessitant une forte interaction humaine. Le consensus général est que l’IA transformera la nature du travail et que les humains devront s’adapter et améliorer leur capacité à collaborer avec l’IA. (Source : Reddit r/ArtificialInteligence, Reddit r/artificial, Reddit r/ArtificialInteligence)
L’agent IA (intelligent agent) devient la prochaine interface d’interaction, suscitant une course entre les géants de la tech: Microsoft, Google, OpenAI, Alibaba, Tencent, Baidu, Coocaa et d’autres entreprises technologiques nationales et internationales investissent massivement dans les agents IA. Capables de réflexion approfondie, de planification autonome, de prise de décision et d’exécution de tâches complexes, les agents intelligents sont considérés comme la prochaine interface d’interaction après les moteurs de recherche et les applications. Trois forces principales se sont déjà formées : les constructeurs d’écosystèmes technologiques, représentés par OpenAI et Baidu ; les fournisseurs de services aux entreprises pour des scénarios verticaux, représentés par Microsoft et Alibaba Cloud ; et les fabricants de terminaux matériels et logiciels, représentés par Huawei et Coocaa. (Source : 36氪)

💡 Divers
L’expansion internationale de l’IA chinoise s’accélère, passant de l’exportation de produits à la construction d’écosystèmes: Le rapport “La croissance transocéanique de l’IA chinoise” souligne que l’expansion internationale des entreprises chinoises d’IA est entrée dans une phase d’accélération à grande échelle, 76 % d’entre elles se concentrant sur le niveau applicatif. Le parcours d’internationalisation est passé d’applications de type outil à ses débuts, à l’exportation de solutions sectorielles combinant des avantages technologiques à moyen terme, pour se concentrer actuellement sur l’internationalisation des écosystèmes technologiques, promouvant les normes techniques et la collaboration open source. L’expansion de l’IA à l’étranger présente une pénétration graduelle “du proche au lointain” et fait face à des défis tels que la localisation, la conformité éthique et le marketing de marque. (Source : 36氪)

Le département américain de l’Énergie compare la course à l’IA au “nouveau Projet Manhattan” et affirme que les États-Unis l’emporteront: En annonçant le supercalculateur de nouvelle génération “Doudna”, le département américain de l’Énergie a qualifié la compétition pour le développement de l’IA de “Projet Manhattan de notre époque” et a déclaré que les États-Unis remporteront cette course. Ces propos ont suscité au sein de la communauté des discussions sur la concurrence technologique entre grandes puissances, l’éthique de l’IA et la coopération internationale. (Source : gfodor, teortaxesTex, andrew_n_carr, npew, jpt401)
Les progrès de l’IA dans la création de contenu soulèvent des questions sur l‘“authenticité” et la “créativité”: La communauté a discuté des applications de l’IA dans des domaines tels que le design de mode, la création de bandes dessinées et la génération de vidéos. D’une part, l’IA peut générer rapidement une grande diversité de contenus, allant même jusqu’à concrétiser en vidéo des œuvres de bande dessinée datant de plusieurs années ; d’autre part, ces contenus générés paraissent parfois étranges ou manquent de profondeur. Cela soulève des questions sur la “supériorité” éventuelle du contenu généré par l’IA et sur le rôle que jouera la créativité humaine à l’ère de l’IA. (Source : Reddit r/ChatGPT, Reddit r/artificial)
