Mots-clés:RLHF, RLAIF, Qwen2.5-Math-7B, MATH-500, Apprentissage par renforcement, Récompense aléatoire, Récompense erronée, Performance du modèle, L’avenir du RLHF/RLAIF, L’amélioration des performances du modèle par récompense aléatoire, L’entraînement de Qwen2.5-Math-7B avec récompense erronée, Jeu de test MATH-500, L’apprentissage du signal en apprentissage par renforcement
🔥 Actualités Principales
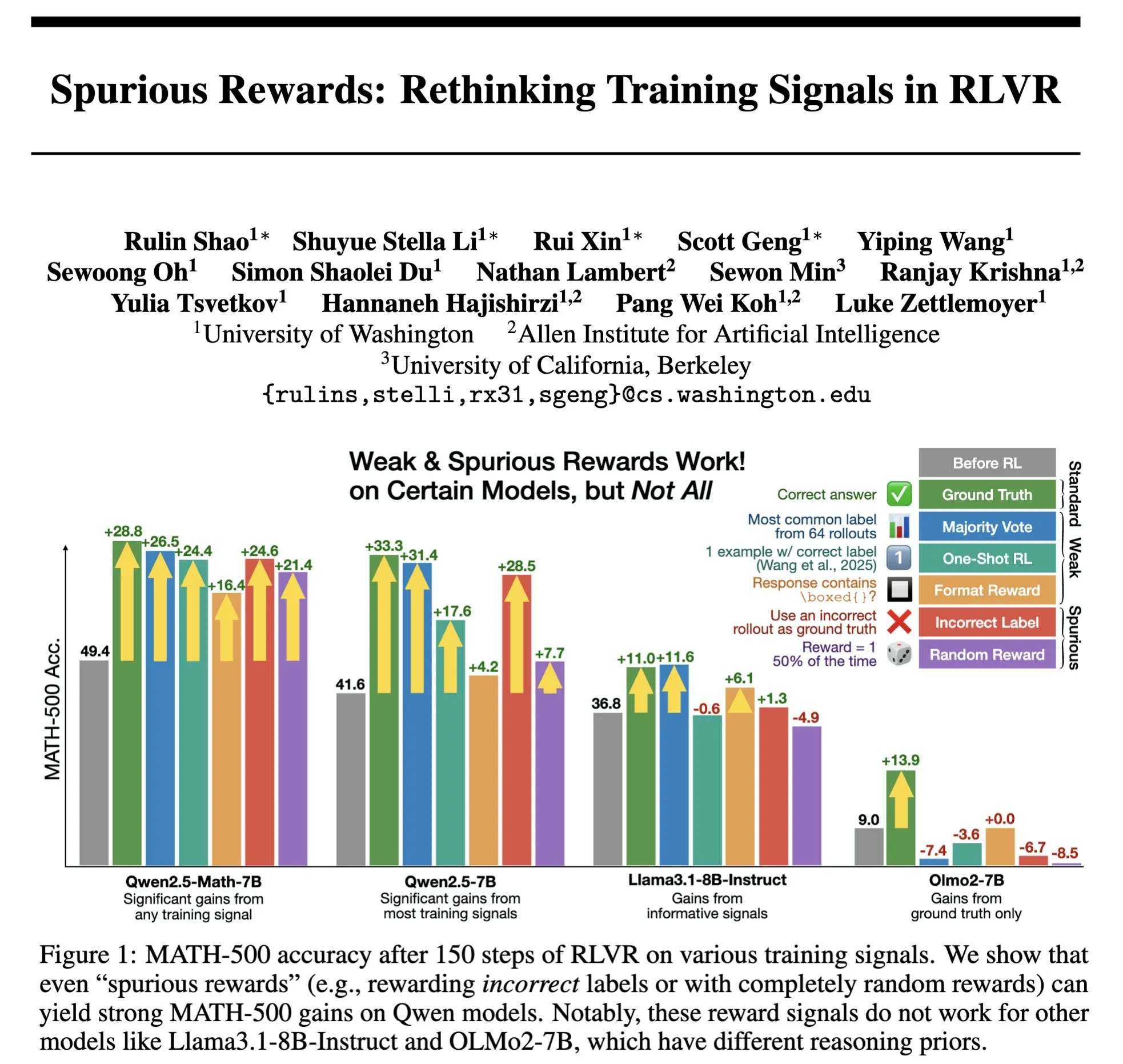
L’avenir de RLHF/RLAIF : des récompenses aléatoires/erronées peuvent-elles également améliorer les performances des modèles ? : Les expériences de Stella Li montrent que l’entraînement du modèle Qwen2.5-Math-7B avec des récompenses aléatoires ou incorrectes a amélioré les performances sur le jeu de test MATH-500 de 21 % et 25 % respectivement, se rapprochant de l’amélioration de 28,8 % obtenue avec des récompenses réelles. Les recherches de Rulin Shao, relayées par natolambert, ont également révélé que lorsque RLVR (Reinforcement Learning from Verifier Reward) utilise de fausses récompenses, l’utilisation du code par le modèle Olmo augmente mais ses performances diminuent, tandis que l’empêcher d’utiliser du code améliore au contraire ses performances. Ces découvertes remettent en question la dépendance traditionnelle de RLHF/RLAIF à l’égard de données de préférences humaines de haute qualité, suggérant que les modèles pourraient apprendre à explorer un espace de stratégies plus large grâce aux signaux de récompense, même si les récompenses elles-mêmes sont imparfaites, cela peut stimuler les capacités latentes du modèle ou optimiser les comportements existants. Cela pourrait ouvrir de nouvelles voies pour réduire la dépendance à l’égard d’annotations manuelles coûteuses et explorer des méthodes d’alignement de modèles plus efficaces, mais il faut être vigilant quant au risque que les modèles apprennent des comportements incorrects. (Source: natolambert, teortaxesTex, DhruvBatraDB, Francis_YAO_, raphaelmilliere)
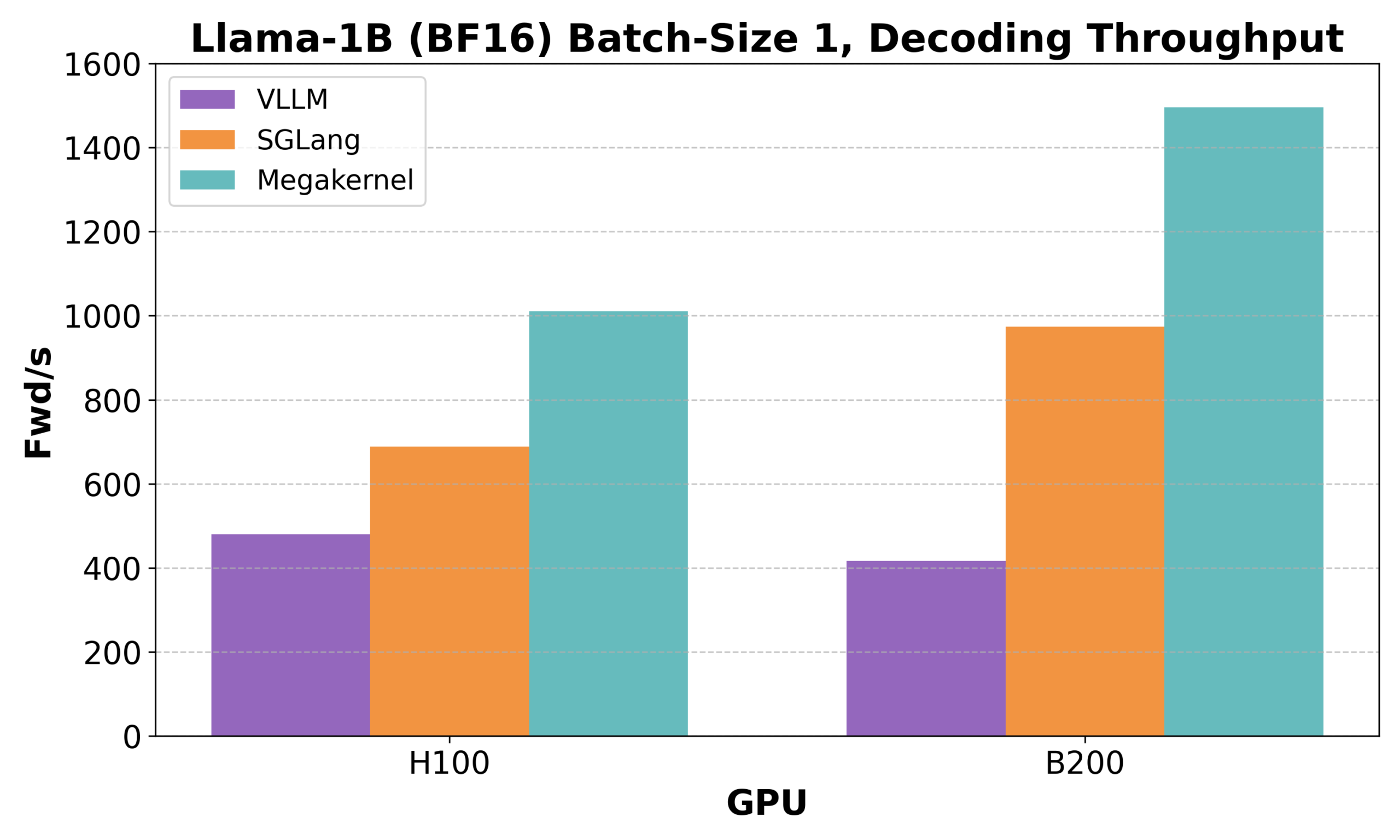
Hazy Research publie Low-Latency-Llama Megakernel : inférence Llama 1B sur un seul cœur CUDA : Hazy Research a lancé Low-Latency-Llama Megakernel, capable d’effectuer l’ensemble du processus de propagation avant du modèle Llama 1B au sein d’un seul cœur CUDA. Cette technologie, en intégrant les calculs dans un noyau unique, élimine les limites de synchronisation imposées par les appels de noyau sérialisés traditionnels, optimisant ainsi la planification des calculs et de la mémoire pour une latence réduite. Andrej Karpathy a salué cette avancée, la considérant comme la seule voie vers une orchestration optimale du calcul et de la mémoire. Ce progrès est crucial pour les scénarios exigeant une faible latence, tels que l’informatique en périphérie (edge computing) et les applications d’IA en temps réel, et devrait favoriser le déploiement de modèles de langage plus petits, plus efficaces et plus agiles. (Source: karpathy, teortaxesTex, charles_irl, simran_s_arora)
DeepSeek Qiyuan publie rStar-Coder : construction d’un vaste ensemble de données de raisonnement de code vérifié, améliorant significativement les capacités de codage des petits modèles : Des chercheurs de Microsoft et de DeepSeek ont lancé le projet rStar-Coder, visant à résoudre le problème de la rareté actuelle des ensembles de données de haute qualité et de haute difficulté dans le domaine du raisonnement de code. Pour ce faire, ils ont construit un vaste ensemble de données vérifiées comprenant 418 000 problèmes de code de niveau compétition, 580 000 solutions de raisonnement longues et de riches cas de test. Le projet améliore les capacités de raisonnement de code des LLM en synthétisant de nouveaux problèmes à partir de problèmes de concours de programmation existants et de solutions oracle, en concevant un pipeline fiable de génération de cas de test d’entrée/sortie, et en utilisant ces cas de test pour valider des solutions de raisonnement longues de haute qualité. Les expériences montrent que les modèles Qwen (1.5B-14B) entraînés avec l’ensemble de données rStar-Coder excellent sur plusieurs benchmarks de raisonnement de code. Par exemple, Qwen2.5-7B a vu sa précision sur LiveCodeBench passer de 17,4 % à 57,3 %, dépassant o3-mini (low) ; sur USACO, le modèle 7B a également surpassé le plus grand QWQ-32B. (Source: HuggingFace Daily Papers)
L’Institut d’automatisation de l’Académie chinoise des sciences propose AutoThink : permettre aux grands modèles de décider de manière autonome s’ils doivent “réfléchir en profondeur” : Face au phénomène de “réflexion excessive” où les grands modèles de langage effectuent des raisonnements longs même pour des problèmes simples, l’Institut d’automatisation de l’Académie chinoise des sciences, en collaboration avec le laboratoire Peng Cheng, a proposé la méthode AutoThink. Cette méthode, en ajoutant des points de suspension (…) dans les invites et en combinant un apprentissage par renforcement en trois étapes (stabilisation du mode, optimisation du comportement, élagage du raisonnement), permet au modèle de choisir de manière autonome s’il doit réfléchir en profondeur et dans quelle mesure, en fonction de la difficulté du problème. Les expériences montrent qu’AutoThink peut améliorer les performances de modèles tels que DeepSeek-R1 sur les benchmarks mathématiques, tout en réduisant considérablement la consommation de tokens d’inférence. Par exemple, sur DeepScaleR, il permet d’économiser 10 % de tokens supplémentaires. Cette recherche vise à permettre aux modèles de “réfléchir à la demande”, améliorant ainsi l’équilibre entre l’efficacité du raisonnement et la précision. (Source: 36氪, _akhaliq)

Sakana AI lance Sudoku-Bench, révélant les faiblesses des meilleurs grands modèles dans le raisonnement sur les “variantes de Sudoku” : Sakana AI, la startup de Llion Jones, l’un des auteurs de Transformer, a publié Sudoku-Bench, un benchmark comprenant des Sudokus allant du 4×4 aux “variantes de Sudoku” modernes complexes 9×9, conçu pour évaluer les capacités de raisonnement créatif en plusieurs étapes de l’IA. Les résultats des tests montrent que les meilleurs grands modèles, y compris Gemini 2.5 Pro, GPT-4.1 et Claude 3.7, ont un taux de réussite global inférieur à 15 % sans assistance. Dans les Sudokus modernes 9×9, o3 Mini High n’atteint qu’un taux de réussite de 2,9 %. Cela indique que les modèles sont peu performants face à des problèmes nouveaux nécessitant un véritable raisonnement logique plutôt qu’une simple reconnaissance de formes, commettant souvent des erreurs, abandonnant ou interprétant mal les règles. Le PDG de NVIDIA, Jensen Huang, estime que ce type d’énigmes contribue à améliorer le raisonnement de l’IA. Sakana AI a également publié des données d’entraînement associées, y compris des enregistrements de processus de résolution en collaboration avec une célèbre chaîne de Sudoku. (Source: 36氪)

🎯 Tendances
Meta réorganise son équipe IA, la perte de membres clés de FAIR suscite l’attention : Meta a annoncé une réorganisation de son équipe IA, la divisant en une équipe Produits IA dirigée par Connor Hayes et un département Fondations AGI codirigé par Ahmad Al-Dahle et Amir Frenkel. La première se concentre sur les produits grand public, tandis que le second se focalise sur la recherche et le développement de modèles fondamentaux comme Llama. Il est à noter que le département de recherche fondamentale en IA, FAIR, reste indépendant, mais certaines équipes multimédias sont intégrées au département Fondations AGI. Ce réajustement vise à améliorer la vitesse et la flexibilité du développement. Cependant, Meta est confrontée à un accueil mitigé pour Llama 4, à une concurrence accrue dans le domaine de l’open source et à une fuite des talents clés. Sur les 14 auteurs initiaux de Llama, 11 ont déjà quitté l’entreprise, dont plusieurs ont rejoint ou fondé des concurrents tels que Mistral AI. Le laboratoire FAIR a également connu des changements de direction et des ajustements dans ses orientations de recherche, suscitant des inquiétudes quant à sa position au sein de l’entreprise et à ses futures capacités d’innovation. (Source: 36氪)

Google DeepMind publie SignGemma : un nouveau modèle de traduction de la langue des signes : Google DeepMind a annoncé le lancement de SignGemma, présenté comme son modèle de traduction de la langue des signes vers le texte parlé le plus puissant à ce jour. Ce modèle devrait rejoindre la famille de modèles Gemma plus tard cette année et sera publié en open source. Le lancement de SignGemma vise à ouvrir de nouvelles possibilités pour les technologies inclusives, améliorant l’efficacité et la commodité de la communication pour les utilisateurs de la langue des signes. Google DeepMind invite les utilisateurs à fournir des commentaires et à participer aux tests préliminaires. (Source: GoogleDeepMind, demishassabis)
Tencent Hunyuan publie les poids du modèle HunyuanPortrait, capable de transformer des portraits statiques en vidéos dynamiques : L’équipe Tencent Hunyuan a rendu open source les poids de son modèle de génération d’images en vidéos HunyuanPortrait, permettant aux utilisateurs de les télécharger et de les utiliser localement. Ce modèle se concentre sur la transformation d’images de portraits statiques en vidéos dynamiques, applicable à divers scénarios tels que les personnages de jeux, les animateurs virtuels, les humains numériques, les assistants d’achat intelligents, etc., permettant d’animer les images de visages et d’augmenter la vivacité et le réalisme de l’interaction. Les modèles, les dépôts de code et les articles associés ont tous été publiés. (Source: karminski3, Reddit r/LocalLLaMA)

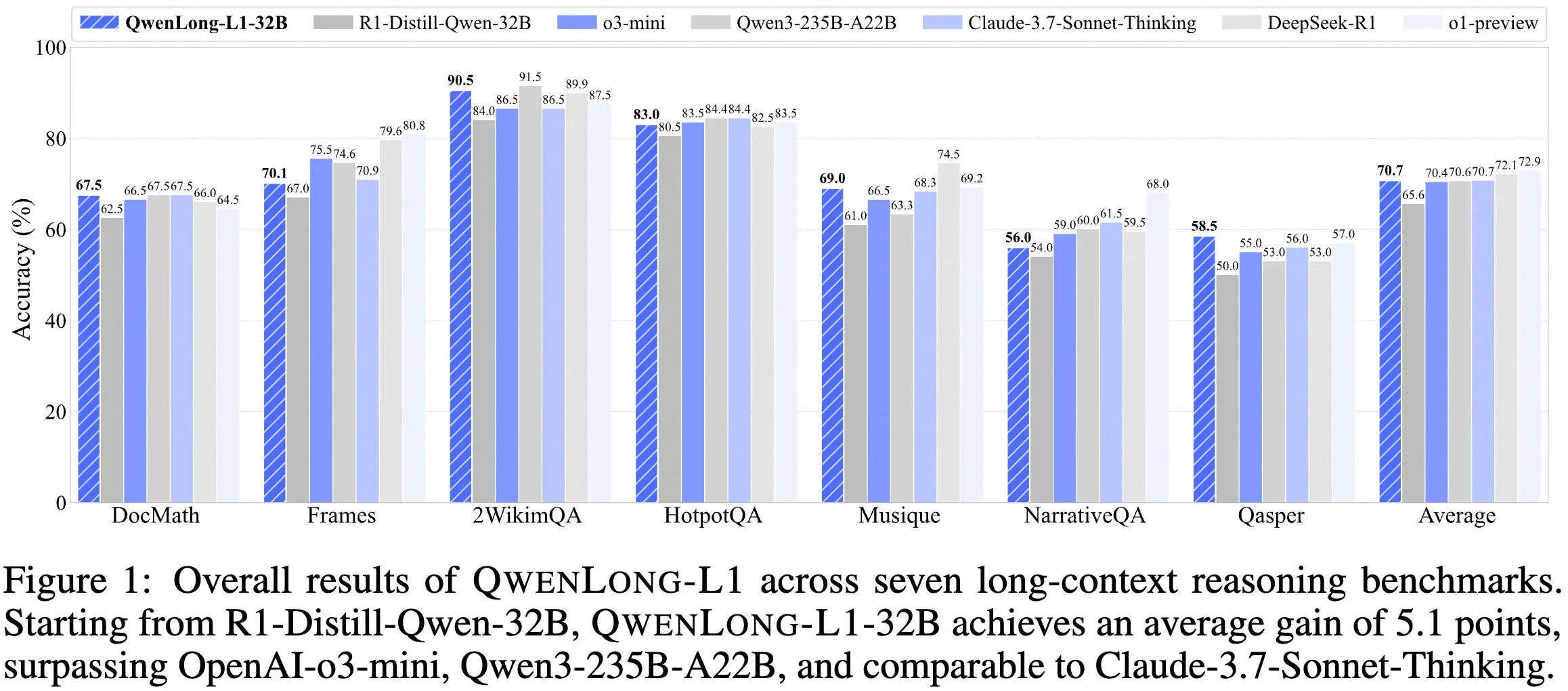
L’équipe QwenDoc publie le modèle de raisonnement à long contexte QwenLong-L1-32B : L’équipe QwenDoc a lancé QwenLong-L1-32B, un modèle de raisonnement à long contexte de 128K entraîné par apprentissage par renforcement. Ce modèle, affiné à partir de DeepSeek-R1-Distill-Qwen-32B, obtient un score de 90,5 sur le jeu de test de raisonnement multi-sauts 2WikiMultihopQA, soit une amélioration de 6,5 points par rapport au modèle original. Il met l’accent sur la capacité non seulement à trouver du contenu dans des contextes longs, mais aussi à relier des indices pour effectuer un raisonnement. Bien que la longueur de contexte de 128K ne soit pas la plus longue actuellement, ses capacités de raisonnement exceptionnelles offrent une nouvelle option pour le traitement de documents longs et complexes. Le modèle, l’article et le dépôt de code ont été rendus publics. (Source: karminski3)
HKUST, Apple et d’autres institutions collaborent pour lancer la série de méthodes Laser, optimisant l’efficacité et la précision du raisonnement des grands modèles : Des chercheurs de HKUST, CityU, de l’Université de Waterloo et d’Apple ont proposé la série de méthodes Laser (comprenant Laser-D, Laser-DE), visant à résoudre le problème de la consommation excessive de tokens par les grands modèles de langage (LRM) pour le raisonnement sur des problèmes simples. Cette méthode, grâce à un cadre unifié de conception de récompense de longueur, une récompense basée sur la longueur cible et une fonction en escalier, ainsi qu’un mécanisme de perception dynamique de la difficulté, a permis d’obtenir une amélioration des performances de 6,1 points tout en réduisant de 63 % l’utilisation des tokens sur des benchmarks de raisonnement mathématique complexe comme AIME24. La recherche a révélé qu’après l’entraînement, l‘“auto-réflexion” redondante du modèle diminue, son mode de pensée devient plus sain, équilibrant efficacement l’efficacité et la précision du raisonnement du modèle. (Source: 36氪)

La version gratuite d’Anthropic Claude prend désormais en charge la fonction de recherche Web : Anthropic a annoncé que les utilisateurs de la version gratuite de son assistant IA Claude peuvent désormais utiliser la fonction de recherche Web. Cela signifie que Claude, lorsqu’il répond à des questions, peut obtenir les informations les plus récentes sur Internet pour améliorer la pertinence et la précision de ses réponses. Selon la communication officielle, chaque réponse contenant des résultats de recherche fournira des citations en ligne, permettant aux utilisateurs de vérifier facilement la source des informations. (Source: AnthropicAI)
PKU-DS-LAB publie FairyR1 : un modèle de raisonnement 32B affiné à partir de DeepSeek-R1-Distill-Qwen-32B : Le laboratoire de science des données de l’Université de Pékin (PKU-DS-LAB) a lancé FairyR1, un modèle de raisonnement de 32 milliards de paramètres sous licence Apache 2.0. Ce modèle, grâce à une méthode de “distillation puis fusion”, atteindrait les performances de modèles plus grands en n’utilisant que 5 % de leurs paramètres. FairyR1 est affiné à partir de DeepSeek-R1-Distill-Qwen-32B, et ses données d’entraînement sont également disponibles sur Hugging Face Hub. Ce travail s’inscrit dans la continuité des recherches sur TinyR1, en filtrant activement les ensembles de données (environ 10 000 trajectoires), en effectuant un SFT séparément pour les mathématiques et le code, et en utilisant Arcee Fusion pour la fusion des modèles. (Source: huggingface, teortaxesTex, stablequan)
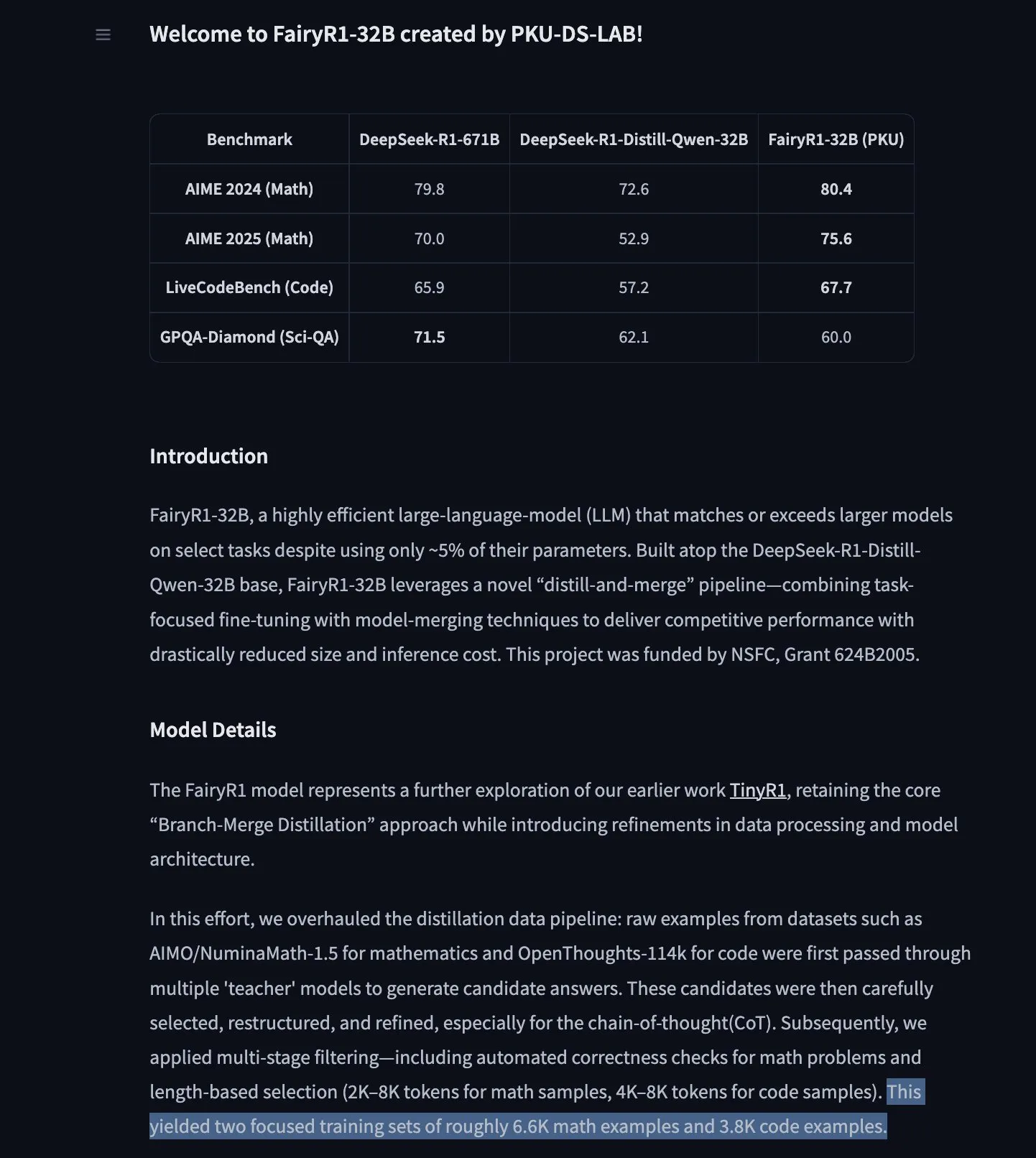
Le modèle de prévision de séries temporelles TimesFM de Google arrive sur Hugging Face Transformers : Le modèle TimesFM de Google est désormais intégré à la bibliothèque Hugging Face Transformers. Il s’agit d’un modèle de type GPT, pré-entraîné sur 100 milliards de points de données temporelles réelles provenant de diverses sources telles que Google Trends, les consultations de pages Wikipédia, etc. TimesFM surpasserait les modèles spécifiquement affinés dans les tâches de prévision zero-shot, offrant un nouvel outil puissant pour l’analyse des séries temporelles. (Source: huggingface)
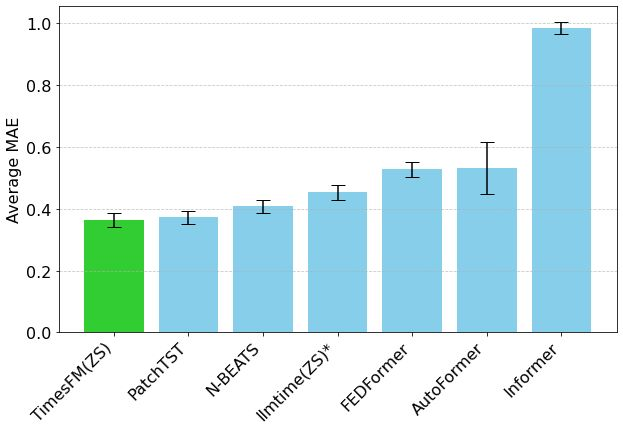
Hugging Face lance Mixture of Thoughts : un ensemble de données de raisonnement général sélectionné : Lewis Tunstall et d’autres chercheurs de Hugging Face ont publié l’ensemble de données “Mixture of Thoughts”. Cet ensemble de données, soigneusement sélectionné à partir de plus d’un million d’échantillons de données publiques grâce à de nombreuses expériences d’ablation, comprend environ 350 000 échantillons axés sur les capacités de raisonnement général. Les modèles entraînés avec cet ensemble de données mixte atteignent ou dépassent les performances des modèles distillés de DeepSeek sur les benchmarks de mathématiques, de code et scientifiques (comme GPQA). La recherche valide l’efficacité de la méthodologie d‘“additivité” proposée dans Phi-4-reasoning, qui consiste à optimiser indépendamment le mélange de données pour chaque domaine de raisonnement, puis à les intégrer pour l’entraînement final. (Source: huggingface)
ByteDance publie BAGEL-7B : un modèle omnidirectionnel capable de comprendre et de générer des images et du texte : ByteDance a lancé BAGEL-7B, un modèle omnidirectionnel (omni) capable de comprendre et de générer simultanément des images et du texte. De plus, ils ont publié Dolphin, un modèle de langage visuel (VLM) spécialisé dans l’analyse de documents. L’open source de ces modèles fournira de nouveaux outils et de nouvelles possibilités pour la recherche et les applications multimodales. (Source: huggingface, TheTuringPost)

Google publie Gemini 2.5 Flash Preview, prenant en charge la sortie audio native : Les développeurs IA de Google ont annoncé que Gemini 2.5 Flash Preview prend désormais en charge la sortie audio native via la Live API, visant à offrir une interaction vocale fluide et naturelle ainsi qu’une capacité de contrôle vocal améliorée. De plus, une nouvelle version expérimentale “pensante” de ce modèle audio a été lancée, prenant en charge des capacités de raisonnement pour des tâches plus complexes. Parallèlement, la sortie de l’API Gemini commence également à afficher des “résumés de pensée”, permettant aux utilisateurs de comprendre le processus de réflexion du modèle, bien qu’il ne s’agisse pas encore d’une chaîne de raisonnement complète. (Source: algo_diver, op7418)
Un article explore la capacité d’expression des Transformers lors du remplissage de tokens vides : Une nouvelle étude explore si le remplissage de tokens vides dans l’entrée d’un Transformer (une forme de calcul au moment du test) peut améliorer les capacités de calcul des LLM. Cette recherche, menée en collaboration avec Ashish_S_AI, caractérise précisément la capacité d’expression des Transformers avec remplissage, offrant une nouvelle perspective pour comprendre et optimiser les mécanismes de calcul des LLM. (Source: teortaxesTex)

Une nouvelle étude propose le cadre Sci-Fi : améliorer l’interpolation d’images vidéo grâce à des contraintes symétriques : Face au problème potentiel d’asymétrie dans la force de contrôle lors de la fusion des contraintes des images de début et de fin dans les méthodes actuelles d’interpolation d’images vidéo (Frame Inbetweening), un nouvel article propose le cadre Sci-Fi (Symmetric Constraint for Frame Inbetweening). Cette méthode vise à atteindre la symétrie des contraintes des images de début et de fin en appliquant un mécanisme d’injection plus fort (basé sur le module léger EF-Net) pour les contraintes à plus petite échelle d’entraînement (comme l’image de fin), afin de produire des transitions plus harmonieuses dans les images intermédiaires générées, évitant ainsi les incohérences de mouvement ou l’effondrement de l’apparence. (Source: HuggingFace Daily Papers)
Un article propose Paper2Poster : un processus automatisé de transformation d’articles de recherche en affiches multimodales : Face aux défis de la création d’affiches académiques, des chercheurs ont lancé Paper2Poster, le premier benchmark de génération d’affiches et sa suite de métriques d’évaluation, comprenant des paires d’articles et d’affiches conçues par les auteurs. L’évaluation porte sur la qualité visuelle, la cohérence textuelle, l’évaluation globale et PaperQuiz (mesurant la capacité de l’affiche à transmettre le contenu principal). Parallèlement, ils proposent PosterAgent, un processus multi-agents descendant, avec boucle visuelle, comprenant un analyseur (extraction des actifs), un planificateur (alignement texte-visuel et mise en page) et une boucle peintre-critique (rendu et optimisation par rétroaction). Les variantes basées sur des modèles open source tels que Qwen-2.5 surpassent les systèmes pilotés par GPT-4o sur la plupart des métriques, avec une réduction de 87 % de la consommation de tokens, permettant de convertir un article de 22 pages en une affiche .pptx modifiable à un coût extrêmement bas. (Source: HuggingFace Daily Papers)
Un article propose Frame In-N-Out : pour une génération d’images en vidéos contrôlable et sans limites : Face aux défis de contrôlabilité, de cohérence temporelle et de synthèse des détails dans la génération de vidéos, un nouvel article se concentre sur la technique cinématographique “Frame In and Frame Out”. Il vise à permettre aux utilisateurs de contrôler les objets dans l’image pour qu’ils sortent naturellement de la scène, ou d’introduire de nouvelles références d’identité dans la scène, guidées par des trajectoires de mouvement spécifiées par l’utilisateur. Pour ce faire, les chercheurs ont introduit un nouvel ensemble de données annotées semi-automatiquement, un protocole d’évaluation complet, ainsi qu’une architecture Diffusion Transformer vidéo efficace pour le maintien de l’identité et le contrôle du mouvement. Les expériences montrent que cette méthode surpasse considérablement les lignes de base existantes. (Source: HuggingFace Daily Papers)
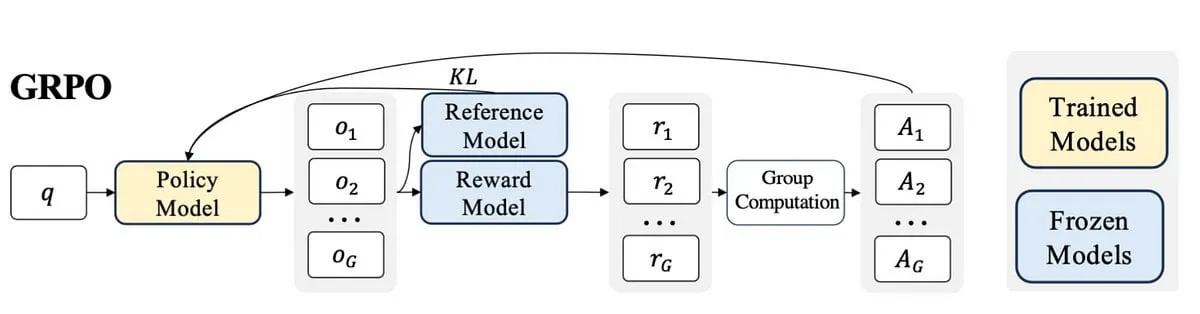
Une nouvelle recherche propose Active-O3 : doter les grands modèles de langage multimodaux d’une capacité de perception active grâce à GRPO : Face à l’exploration insuffisante des grands modèles de langage multimodaux (MLLM) en matière de perception active, des chercheurs ont proposé le cadre Active-O3. Ce cadre, basé sur l’entraînement par apprentissage par renforcement pur avec GRPO (Group Relative Policy Optimization), vise à doter les MLLM de la capacité de choisir activement les positions et les manières d’observer afin de collecter des informations pertinentes pour la tâche. Les chercheurs ont d’abord défini systématiquement la tâche de perception active basée sur les MLLM et ont souligné que la stratégie de recherche amplifiée de GPT-o3 est un cas particulier de perception active, mais qu’elle manque d’efficacité et de précision. Active-O3 a été évalué en établissant une suite complète de benchmarks dans des tâches génériques en monde ouvert (telles que la localisation de petits objets et d’objets denses) et des scénarios spécifiques à un domaine (tels que la télédétection, la détection de petits objets en conduite autonome, la segmentation interactive à grain fin), et a démontré ses puissantes capacités de raisonnement zero-shot sur le V* Benchmark. (Source: HuggingFace Daily Papers)
Un article propose MME-Reasoning : un benchmark complet pour les capacités de raisonnement logique des MLLM : Face aux lacunes des benchmarks existants dans l’évaluation des capacités de raisonnement logique des grands modèles de langage multimodaux (MLLM), des chercheurs ont lancé MME-Reasoning. Ce benchmark couvre les trois principaux types de raisonnement logique : inductif, déductif et abductif, et sélectionne soigneusement les données pour s’assurer que les questions évaluent efficacement les capacités de raisonnement plutôt que les compétences perceptives ou l’étendue des connaissances. Les résultats de l’évaluation montrent que même les MLLM les plus avancés présentent des limites dans une évaluation complète du raisonnement logique, avec des performances déséquilibrées selon les différents types de raisonnement. L’étude analyse également l’impact de méthodes telles que les “modes de pensée” et l’apprentissage par renforcement basé sur des règles sur les capacités de raisonnement, offrant ainsi des perspectives systématiques pour comprendre et évaluer les capacités de raisonnement des MLLM. (Source: HuggingFace Daily Papers)
GraLoRA : Amélioration des performances de l’ajustement fin économe en paramètres grâce à l’adaptation de bas rang granulaire : Face aux problèmes de surajustement et de goulots d’étranglement des performances rencontrés par LoRA lors de l’augmentation du rang, des chercheurs ont proposé GraLoRA (Granular Low-Rank Adaptation). Cette méthode divise la matrice de poids en sous-blocs, chaque sous-bloc possédant son propre adaptateur de bas rang. Elle vise à résoudre les problèmes d’enchevêtrement des gradients et de distorsion de la propagation causés par les goulots d’étranglement structurels de LoRA. GraLoRA améliore efficacement la capacité d’expression du modèle, se rapprochant des effets d’un ajustement fin complet, sans pratiquement augmenter les coûts de calcul ou de stockage. Les expériences sur les benchmarks de génération de code et de raisonnement de sens commun montrent que GraLoRA surpasse LoRA et d’autres lignes de base dans différentes tailles de modèles et configurations de rang, par exemple avec un gain absolu allant jusqu’à 8,5 % sur Pass@1 pour HumanEval+. (Source: HuggingFace Daily Papers)
SoloSpeech : un pipeline de génération en cascade améliore la clarté et la qualité de l’extraction de la parole cible : Face au problème des modèles discriminatifs existants en extraction de la parole cible (TSE) qui introduisent facilement des artefacts et réduisent la naturalité, et des modèles génératifs qui sont insuffisants en termes de qualité perceptuelle et de clarté, des chercheurs ont proposé SoloSpeech. Il s’agit d’un nouveau pipeline de génération en cascade qui intègre les processus de compression, d’extraction, de reconstruction et de correction. Sa particularité est d’utiliser un extracteur de cible sans intégration de locuteur, en exploitant les informations conditionnelles de l’espace latent de l’audio d’invite et en l’alignant avec l’espace latent de l’audio mixte pour éviter les inadéquations. L’évaluation sur l’ensemble de données Libri2Mix montre que SoloSpeech atteint un nouveau niveau SOTA dans les tâches d’extraction de la parole cible et de séparation de la parole, et démontre une excellente capacité de généralisation sur les données hors domaine et dans les scénarios réels. (Source: HuggingFace Daily Papers)
Une nouvelle étude explore l’amélioration de la compréhension visuelle des grands modèles de langage multimodaux grâce à des vecteurs de guidage textuels : Une nouvelle étude examine si l’utilisation de vecteurs de guidage dérivés du réseau dorsal LLM purement textuel des grands modèles de langage multimodaux (MLLM) (obtenus par des méthodes telles que les auto-encodeurs clairsemés (SAE), le mean shift et la sonde linéaire) peut améliorer leur capacité de compréhension visuelle. L’étude révèle que les vecteurs de guidage dérivés du texte améliorent de manière constante la précision multimodale de différentes architectures MLLM sur diverses tâches visuelles. En particulier, la méthode du mean shift améliore la précision des relations spatiales jusqu’à 7,3 % et la précision du comptage jusqu’à 3,3 % sur CV-Bench, surpassant les méthodes d’incitation et démontrant une forte capacité de généralisation aux ensembles de données hors distribution. Cela suggère que les vecteurs de guidage textuels constituent un mécanisme puissant et efficace pour améliorer les fondations visuelles des MLLM avec une collecte de données et des frais de calcul supplémentaires minimes. (Source: HuggingFace Daily Papers)
Un article propose DiSA : accélérer la génération d’images autorégressives par recuit des étapes de diffusion : Face au problème de la faible efficacité d’inférence des modèles autorégressifs tels que MAR et FlowAR qui utilisent l’échantillonnage par diffusion pour améliorer la qualité de l’image, un nouvel article propose la méthode DiSA (Diffusion Step Annealing). Cette méthode repose sur l’observation suivante : à mesure que le nombre de tokens générés augmente dans le processus autorégressif, la distribution des tokens suivants devient plus contrainte et l’échantillonnage plus facile. DiSA est une méthode sans entraînement qui réduit progressivement les étapes de diffusion à mesure que davantage de tokens sont générés (par exemple, en passant de 50 étapes initiales à 5 étapes ultérieures). Cette méthode est complémentaire aux méthodes d’accélération existantes conçues pour la diffusion elle-même, simple à mettre en œuvre, et permet d’accélérer de 5 à 10 fois MAR et Harmon, et de 1,4 à 2,5 fois FlowAR et xAR, tout en maintenant la qualité de la génération. (Source: HuggingFace Daily Papers)
Un article propose CASS : un ensemble de données, un modèle et un benchmark pour la traduction de code GPU de Nvidia vers AMD : Des chercheurs ont lancé CASS, le premier ensemble de données et de modèles à grande échelle pour la traduction de code GPU inter-architectures, visant à couvrir la traduction au niveau du code source (CUDA <-> HIP) et au niveau de l’assembleur (Nvidia SASS <-> AMD RDNA3). L’ensemble de données contient 70 000 paires de codes hôte et périphérique vérifiées. Les modèles de langage spécifiques au domaine de la série CASS, entraînés sur cette ressource, atteignent une précision de 95 % pour la traduction du code source et de 37,5 % pour la traduction de l’assembleur, surpassant de manière significative les lignes de base commerciales telles que GPT-4o et Claude. Le code généré correspond aux performances natives dans plus de 85 % des cas de test. CASS-Bench, un benchmark comprenant 16 domaines GPU et des résultats d’exécution réels, a également été publié. Toutes les données, les modèles et les outils d’évaluation sont open source. (Source: HuggingFace Daily Papers)
Un article analyse la capacité de calibration verbale dans les modèles de langage visuel : Une étude évalue de manière exhaustive l’efficacité des modèles de langage visuel (VLM) à exprimer leur confiance par le langage naturel (c’est-à-dire l’incertitude verbale). L’étude, portant sur trois catégories de modèles, quatre domaines de tâches et trois scénarios d’évaluation, montre que les VLM actuels présentent souvent des erreurs de calibration manifestes dans diverses tâches et configurations. Il est à noter que les modèles de raisonnement visuel (c’est-à-dire les modèles qui pensent avec des images) affichent systématiquement une meilleure calibration, ce qui indique qu’un raisonnement spécifique à la modalité est crucial pour une estimation fiable de l’incertitude. Pour relever les défis de la calibration, les chercheurs ont introduit le “Visual Confidence-Aware Prompting”, une stratégie d’incitation en deux étapes visant à améliorer l’alignement de la confiance dans les configurations multimodales. (Source: HuggingFace Daily Papers)
Un article suit l’émergence des capacités pragmatiques dans les grands modèles de langage : Les LLM actuels montrent des capacités émergentes dans les tâches d’intelligence sociale, mais la manière dont ils acquièrent des compétences pragmatiques au cours de l’entraînement reste floue. Un nouvel article introduit l’ensemble de données ALTPRAG, conçu sur la base du concept pragmatique d‘“alternatives”, pour évaluer si les LLM à différents stades d’entraînement peuvent inférer avec précision des intentions subtiles du locuteur. Grâce à une évaluation systématique de 22 LLM (couvrant les phases de pré-entraînement, SFT et d’optimisation des préférences), les résultats montrent que même les modèles de base manifestent une sensibilité significative aux indices pragmatiques, qui s’améliore continuellement avec l’augmentation de la taille du modèle et des données. Le SFT et le RLHF améliorent davantage les capacités de raisonnement pragmatique cognitif. Ces découvertes soulignent que les capacités pragmatiques sont des propriétés combinatoires émergentes de l’entraînement des LLM, offrant de nouvelles perspectives pour l’alignement des modèles sur les normes communicatives humaines. (Source: HuggingFace Daily Papers)
Publication du benchmark Video-Holmes : évaluation de la pensée “holmesienne” des MLLM dans le raisonnement vidéo complexe : Face aux benchmarks vidéo existants qui évaluent principalement la perception visuelle et les capacités de localisation, sans saisir pleinement les besoins de raisonnement complexe, des chercheurs ont lancé le benchmark Video-Holmes. Ce benchmark, inspiré du processus de raisonnement de Sherlock Holmes, comprend 1837 questions extraites de 270 courts métrages à suspense annotés manuellement, couvrant 7 tâches soigneusement conçues. Chaque tâche exige du modèle qu’il localise activement et connecte plusieurs indices visuels pertinents dispersés dans différents segments vidéo. L’évaluation des MLLM SOTA montre que, bien que les modèles excellent en perception visuelle, ils éprouvent des difficultés significatives dans l’intégration des informations, manquant souvent des indices cruciaux. Par exemple, le meilleur modèle, Gemini-2.5-Pro, n’atteint qu’une précision de 45 %. (Source: HuggingFace Daily Papers)
Publication du benchmark MME-VideoOCR : évaluation des capacités OCR des LLM multimodaux dans des scènes vidéo : Bien que les grands modèles de langage multimodaux (MLLM) aient fait des progrès significatifs en OCR sur images statiques, leur efficacité en OCR vidéo est diminuée par des facteurs tels que le flou de mouvement, les variations temporelles et les effets visuels. Pour guider l’entraînement de MLLM pratiques, les chercheurs ont lancé le benchmark MME-VideoOCR, couvrant un large éventail de scénarios d’application OCR vidéo. Ce benchmark comprend 10 catégories de tâches (25 tâches indépendantes), couvrant 44 scènes différentes, incluant non seulement la reconnaissance de texte, mais aussi une compréhension et un raisonnement plus approfondis du contenu textuel dans les vidéos. Le benchmark contient 1464 vidéos de résolutions, de rapports d’aspect et de durées variés, ainsi que 2000 paires de questions-réponses soigneusement annotées par des humains. L’évaluation de 18 MLLM SOTA montre que même le meilleur, Gemini-2.5 Pro, n’atteint qu’une précision de 73,7 %, exposant les limites des modèles existants dans le traitement des tâches nécessitant une compréhension globale de la vidéo. (Source: HuggingFace Daily Papers)
MetaMind : modélisation de la pensée sociale humaine via un système multi-agents métacognitif : Pour combler les lacunes des grands modèles de langage (LLM) dans le traitement de l’ambiguïté inhérente et des nuances contextuelles de la communication humaine, des chercheurs ont lancé MetaMind, un cadre multi-agents inspiré de la théorie psychologique de la métacognition, visant à simuler un raisonnement social de type humain. MetaMind décompose la compréhension sociale en trois étapes collaboratives : (1) un agent de théorie de l’esprit génère des hypothèses sur les états mentaux de l’utilisateur (tels que les intentions, les émotions) ; (2) un agent de domaine utilise les normes culturelles et les contraintes éthiques pour affiner ces hypothèses ; (3) un agent de réponse génère des réponses contextuellement appropriées, tout en validant la cohérence avec les intentions inférées. Ce cadre a atteint des performances SOTA sur trois benchmarks difficiles, améliorant de 35,7 % dans les scénarios sociaux réels, de 6,2 % dans le raisonnement de la théorie de l’esprit, et permettant pour la première fois aux LLM d’atteindre un niveau humain dans des tâches clés de la théorie de l’esprit. (Source: HuggingFace Daily Papers)
Sparse VideoGen2 : accélération de la génération vidéo grâce à une permutation sémantiquement consciente et une attention clairsemée : Face aux problèmes de latence significative et de coûts mémoire élevés rencontrés par les modèles de génération vidéo basés sur les Diffusion Transformers (DiT) lors du traitement de longues vidéos, des chercheurs ont proposé le cadre SVG2. Ce cadre, grâce à une permutation sémantiquement consciente (utilisant k-means pour regrouper et réorganiser les tokens en fonction de leur similarité sémantique), vise à maximiser la précision de l’identification des tokens clés et à minimiser le gaspillage de calcul, réalisant ainsi un compromis Pareto-optimal entre la qualité de la génération et l’efficacité. SVG2 intègre également un contrôle dynamique du budget top-p et une implémentation de noyau personnalisée, obtenant des accélérations allant jusqu’à 2,30x et 1,89x sur HunyuanVideo et Wan 2.1 respectivement, tout en maintenant un PSNR élevé. (Source: HuggingFace Daily Papers)
OmniConsistency : Apprendre la cohérence indépendante du style à partir de données stylisées appariées : Pour résoudre les deux défis majeurs auxquels sont confrontés les modèles de diffusion dans la stylisation d’images – le maintien de la cohérence dans les scènes complexes (en particulier l’identité, la composition et les détails) et la dégradation du style causée par les LoRA de style dans les flux de travail image-vers-image – des chercheurs ont proposé OmniConsistency. Il s’agit d’un plugin de cohérence universel qui exploite les transformateurs de diffusion à grande échelle (DiT). Ses contributions comprennent : (1) un cadre d’apprentissage de la cohérence contextuelle entraîné sur des paires d’images alignées pour une généralisation robuste ; (2) une stratégie d’apprentissage progressif en deux étapes qui découple l’apprentissage du style du maintien de la cohérence pour atténuer la dégradation du style ; (3) une conception entièrement plug-and-play compatible avec n’importe quel LoRA de style dans le cadre Flux. Les expériences montrent qu’OmniConsistency améliore considérablement la cohérence visuelle et la qualité esthétique, atteignant des performances comparables au modèle SOTA commercial GPT-4o. (Source: HuggingFace Daily Papers)
ImgEdit : un ensemble de données et un benchmark unifiés pour l’édition d’images : Pour remédier au retard des modèles d’édition d’images open source par rapport aux modèles propriétaires (principalement en raison de données de haute qualité limitées et de benchmarks insuffisants), des chercheurs ont lancé ImgEdit. Il s’agit d’un ensemble de données d’édition d’images à grande échelle et de haute qualité, contenant 1,2 million de paires d’éditions soigneusement sélectionnées, couvrant des éditions complexes en un seul tour et des tâches difficiles en plusieurs tours. Pour garantir la qualité des données, un processus en plusieurs étapes a été adopté, intégrant des modèles de langage visuel de pointe, des modèles de détection, des modèles de segmentation, ainsi que des correctifs spécifiques aux tâches et un post-traitement rigoureux. Le modèle d’édition ImgEdit-E1, entraîné sur ImgEdit, surpasse les modèles open source existants sur plusieurs tâches. Le benchmark ImgEdit-Bench, également lancé, sert à évaluer les performances de l’édition d’images en termes de suivi des instructions, de qualité d’édition et de préservation des détails. (Source: HuggingFace Daily Papers)
Un article propose un contrôle comportemental robuste dans les LLM via des atomes cibles de guidage : Pour obtenir un contrôle précis de la génération des modèles de langage afin de garantir la sécurité et la fiabilité, un nouvel article propose la méthode des “atomes cibles de guidage” (Steering Target Atoms, STA). Cette méthode vise à séparer et à manipuler des composants de connaissance découplés pour améliorer la sécurité, montrant notamment une robustesse et une flexibilité supérieures dans les scénarios adverses. Les chercheurs soutiennent que bien que l’ingénierie des invites et le guidage soient couramment utilisés pour intervenir sur le comportement des modèles, l’enchevêtrement élevé des paramètres du modèle limite la précision du contrôle et peut entraîner des effets secondaires. STA surmonte ce problème en utilisant des auto-encodeurs clairsemés (SAE) pour découpler les connaissances dans des espaces de haute dimension et en les guidant, permettant ainsi un contrôle comportemental plus précis. Les expériences démontrent l’efficacité de cette méthode, qui a déjà été appliquée à de grands modèles d’inférence, confirmant son potentiel pour un contrôle précis du raisonnement. (Source: HuggingFace Daily Papers)
Un article propose le benchmark SeePhys : évaluation des capacités de raisonnement physique basées sur la vision : Des chercheurs ont lancé SeePhys, un benchmark multimodal à grande échelle pour évaluer les capacités de raisonnement des LLM sur des problèmes de physique allant du niveau collège aux examens de qualification doctorale. Ce benchmark couvre 7 domaines fondamentaux de la physique et comprend 21 catégories de graphiques très hétérogènes. Contrairement aux travaux antérieurs où les éléments visuels jouaient principalement un rôle auxiliaire, 75 % des problèmes de SeePhys sont visuellement nécessaires, c’est-à-dire qu’il faut extraire des informations visuelles pour répondre correctement. Une évaluation approfondie montre que même les modèles de raisonnement visuel les plus avancés (tels que Gemini-2.5-pro et o4-mini) ont une précision inférieure à 60 % sur ce benchmark, révélant des défis fondamentaux dans la compréhension visuelle des LLM actuels, en particulier dans le couplage strict de l’interprétation des graphiques et du raisonnement physique, et dans le dépassement de la dépendance aux raccourcis cognitifs basés sur des indices textuels. (Source: HuggingFace Daily Papers)
VerIPO : Amélioration des capacités de raisonnement à long terme des Video-LLM grâce à l’optimisation itérative de la politique guidée par un vérificateur : Face aux goulots d’étranglement de la préparation des données et à la qualité instable de la pensée en chaîne (CoT) rencontrés par l’application de l’apprentissage par renforcement aux grands modèles de langage vidéo (Video-LLM) dans le raisonnement vidéo complexe, des chercheurs ont proposé la méthode VerIPO (Verifier-guided Iterative Policy Optimization). Le cœur de cette méthode est un “Rollout-Aware Verifier” situé entre les phases d’entraînement GRPO et DPO, utilisé pour évaluer la logique de raisonnement et construire des données contrastives de haute qualité (contenant des CoT réflexives et contextuellement cohérentes). Ces données alimentent une phase DPO efficace, améliorant ainsi la longueur et la cohérence contextuelle de la chaîne de raisonnement. Les résultats expérimentaux montrent que VerIPO peut optimiser les modèles plus rapidement et plus efficacement, générant des CoT plus longues et contextuellement cohérentes, surpassant les performances des variantes GRPO standard ainsi que certains grands Video-LLM affinés par instruction et modèles de raisonnement long. (Source: HuggingFace Daily Papers)
OpenS2V-Nexus : un benchmark détaillé et un ensemble de données de plusieurs millions d’exemples pour la génération de vidéos à partir de sujets : Pour faire progresser la technologie de génération de vidéos à partir de sujets (S2V), des chercheurs ont proposé OpenS2V-Nexus, qui comprend (i) OpenS2V-Eval, un benchmark à grain fin, et (ii) OpenS2V-5M, un ensemble de données de plusieurs millions d’exemples. Contrairement aux benchmarks S2V existants (hérités de VBench, axés sur une évaluation globale et grossière), OpenS2V-Eval se concentre sur la capacité des modèles à générer des vidéos avec des sujets cohérents, une apparence naturelle et une haute fidélité d’identité. À cette fin, OpenS2V-Eval introduit 180 invites provenant de 7 grandes catégories de S2V, contenant des données de test réelles et synthétiques. De plus, pour aligner précisément les préférences humaines, les chercheurs ont proposé trois métriques automatiques : NexusScore, NaturalScore et GmeScore, quantifiant respectivement la cohérence du sujet, la naturalité et la pertinence textuelle dans les vidéos générées. Sur cette base, 16 modèles S2V représentatifs ont été évalués de manière exhaustive. Parallèlement, le premier ensemble de données de génération S2V open source à grande échelle, OpenS2V-5M, a été créé, contenant 5 millions de triplets sujet-texte-vidéo de haute qualité en 720P. (Source: HuggingFace Daily Papers)
Un article propose WHISTRESS : enrichir le texte transcrit par la détection de l’accentuation phrastique : Face à l’importance de l’accentuation phrastique dans la communication orale pour transmettre l’intention du locuteur, et à son absence dans les systèmes de transcription existants, un nouvel article présente WHISTRESS, une méthode de détection de l’accentuation phrastique sans alignement. Pour soutenir cette tâche, les chercheurs ont proposé TINYSTRESS-15K, un ensemble de données d’entraînement synthétique évolutif créé via un processus entièrement automatisé. Le modèle WHISTRESS, entraîné sur cet ensemble de données, surpasse les lignes de base existantes en termes de performances, sans nécessiter d’entraînement supplémentaire ni d’entrée a priori pour l’inférence. Il est à noter que, bien qu’entraîné sur des données synthétiques, WHISTRESS démontre une forte capacité de généralisation zero-shot sur divers benchmarks. (Source: HuggingFace Daily Papers)
Un article propose InstructPart : segmentation de parties orientée tâche avec raisonnement par instruction : Bien que les grands modèles de base multimodaux aient progressé dans diverses tâches, de nombreux modèles considèrent les objets comme des ensembles indivisibles, ignorant les parties qui les composent. Comprendre ces parties et leurs fonctionnalités visibles associées (affordances) est crucial pour exécuter un large éventail de tâches. À cette fin, les chercheurs ont introduit un nouveau benchmark du monde réel, InstructPart, contenant des annotations de segmentation de parties marquées manuellement et des instructions orientées tâche, afin d’évaluer les performances des modèles actuels dans la compréhension et l’exécution de tâches au niveau des parties dans des contextes quotidiens. Les expériences montrent que même pour les modèles de langage visuel (VLM) SOTA, la segmentation de parties orientée tâche reste un problème difficile. Outre le benchmark, les chercheurs ont également introduit une ligne de base simple qui, en utilisant leur ensemble de données pour l’affinage, a permis de doubler les performances. (Source: HuggingFace Daily Papers)
Un article propose une méthode hybride neurale-MPM pour une simulation de fluides interactive en temps réel : Pour résoudre les problèmes de simulation de fluides où les méthodes physiques traditionnelles sont gourmandes en calcul et ont une latence élevée, et où les récentes méthodes d’apprentissage automatique, bien que réduisant les coûts, peinent encore à satisfaire les besoins d’interaction en temps réel, des chercheurs ont proposé une nouvelle approche hybride. Cette méthode intègre la simulation numérique, la physique neuronale et le contrôle génératif. Sa physique neuronale, grâce à un mécanisme de secours qui revient aux solveurs numériques classiques, vise conjointement une simulation à faible latence et une haute fidélité physique. De plus, les chercheurs ont développé un contrôleur basé sur la diffusion, entraîné à l’aide d’une stratégie de modélisation inverse, pour générer des champs de force dynamiques externes pour la manipulation des fluides. Ce système démontre des performances robustes dans divers scénarios 2D/3D, types de matériaux et interactions avec des obstacles, réalisant une simulation en temps réel à haute fréquence d’images (latence de 11 à 29 %) et permettant de guider le contrôle des fluides par des croquis conviviaux dessinés à la main. (Source: HuggingFace Daily Papers)
MMIG-Bench : un benchmark d’évaluation interprétable complet pour les modèles de génération d’images multimodales : Face aux limitations des outils d’évaluation existants pour évaluer les générateurs d’images multimodales tels que GPT-4o, Gemini 2.0 Flash et Gemini 2.5 Pro (par exemple, les benchmarks T2I manquent de conditions multimodales, les benchmarks de génération d’images personnalisées ignorent la sémantique compositionnelle et le bon sens), des chercheurs ont proposé MMIG-Bench. Il s’agit d’un benchmark complet de génération d’images multimodales, comprenant 4850 invites textuelles richement annotées et 1750 images de référence multi-vues couvrant 380 sujets (personnes, animaux, objets, styles artistiques). MMIG-Bench est équipé d’un cadre d’évaluation à trois niveaux : (1) des métriques de bas niveau évaluent les artefacts visuels et le maintien de l’identité des objets ; (2) un nouveau score de correspondance d’aspect (AMS) : une métrique de niveau intermédiaire basée sur VQA, fournissant un alignement invite-image à grain fin et fortement corrélée avec les jugements humains ; (3) des métriques de haut niveau évaluent l’esthétique et les préférences humaines. 17 modèles SOTA ont été évalués avec MMIG-Bench, et les métriques ont été validées avec 32 000 évaluations humaines, fournissant des informations approfondies pour la conception d’architectures et de données. (Source: HuggingFace Daily Papers)
Un article propose HRPO : un raisonnement latent hybride par apprentissage par renforcement : Pour résoudre les problèmes d’incompatibilité des méthodes de raisonnement latent existantes avec les caractéristiques de génération autorégressive des LLM et leur dépendance aux trajectoires CoT pour l’entraînement, des chercheurs ont proposé HRPO (Hybrid Reasoning Policy Optimization). Il s’agit d’une méthode de raisonnement latent hybride basée sur l’apprentissage par renforcement, qui intègre les états cachés précédents dans les tokens échantillonnés via un mécanisme de portail apprenable, et s’initialise principalement avec des plongements de tokens pour l’entraînement, intégrant progressivement davantage de caractéristiques cachées. Cette conception maintient les capacités de génération des LLM et incite à l’utilisation de représentations discrètes et continues pour un raisonnement hybride. De plus, HRPO introduit la stochasticité dans le raisonnement latent par l’échantillonnage de tokens, permettant ainsi une optimisation basée sur RL sans nécessiter de trajectoires CoT. Des évaluations approfondies sur divers benchmarks montrent que HRPO surpasse les méthodes précédentes tant sur les tâches à forte intensité de connaissances que sur celles à forte intensité de raisonnement. (Source: HuggingFace Daily Papers)
Un article propose la méthode NFT : connecter l’apprentissage supervisé et l’apprentissage par renforcement dans le raisonnement mathématique : Remettant en question l’idée répandue selon laquelle “l’auto-amélioration est limitée à l’apprentissage par renforcement (RL)”, un nouvel article propose la méthode d’ajustement fin sensible au négatif (Negative-aware Fine-Tuning, NFT). Il s’agit d’une méthode d’apprentissage supervisé qui permet aux LLM de réfléchir à leurs échecs et de s’améliorer de manière autonome, sans enseignant externe. Lors de l’entraînement en ligne, NFT ne rejette pas les réponses erronées auto-générées, mais construit une politique négative implicite pour les modéliser. Cette politique implicite est paramétrée de la même manière que le LLM positif cible optimisé sur les données positives, permettant ainsi une optimisation directe de la politique sur toutes les générations du LLM. Les résultats expérimentaux sur des tâches de raisonnement mathématique avec des modèles 7B et 32B montrent qu’en exploitant en plus les rétroactions négatives, NFT surpasse de manière significative les lignes de base de l’apprentissage supervisé telles que l’ajustement fin par échantillonnage avec rejet, atteignant voire dépassant les principaux algorithmes RL tels que GRPO et DAPO. Les chercheurs démontrent en outre que dans un entraînement de politique en ligne strict, NFT et GRPO sont en fait équivalents. (Source: HuggingFace Daily Papers)
Un article propose Minute-Long Videos with Dual Parallelisms : pour la génération de vidéos d’une minute : Face aux problèmes de latence de calcul et de coûts mémoire excessifs rencontrés par les modèles de diffusion vidéo basés sur DiT lors de la génération de longues vidéos, des chercheurs ont proposé une nouvelle stratégie d’inférence distribuée appelée DualParal. L’idée centrale de cette méthode est de paralléliser les trames temporelles et les couches du modèle sur plusieurs GPU. Pour résoudre le problème de sérialisation de la parallélisation brute causé par l’exigence des modèles de diffusion de synchroniser les niveaux de bruit entre les trames, cette méthode adopte un schéma de débruitage par blocs, c’est-à-dire en traitant en pipeline une série de blocs de trames et en réduisant progressivement le niveau de bruit. Chaque GPU traite des sous-ensembles spécifiques de blocs et de couches, et transmet les résultats précédents au GPU suivant, réalisant un calcul et une communication asynchrones. De plus, en implémentant un cache de caractéristiques sur chaque GPU pour réutiliser les caractéristiques des blocs précédents comme contexte, et en adoptant une stratégie d’initialisation du bruit coordonnée, on assure une dynamique temporelle globalement cohérente, permettant ainsi une génération vidéo rapide, sans artefacts et de longueur illimitée. Appliquée aux derniers générateurs vidéo à transformateur de diffusion, cette méthode génère efficacement des vidéos de 1025 trames sur 8 GPU RTX 4090, avec une réduction de latence allant jusqu’à 6,54 fois et une réduction des coûts mémoire de 1,48 fois. (Source: HuggingFace Daily Papers)
🧰 Outils
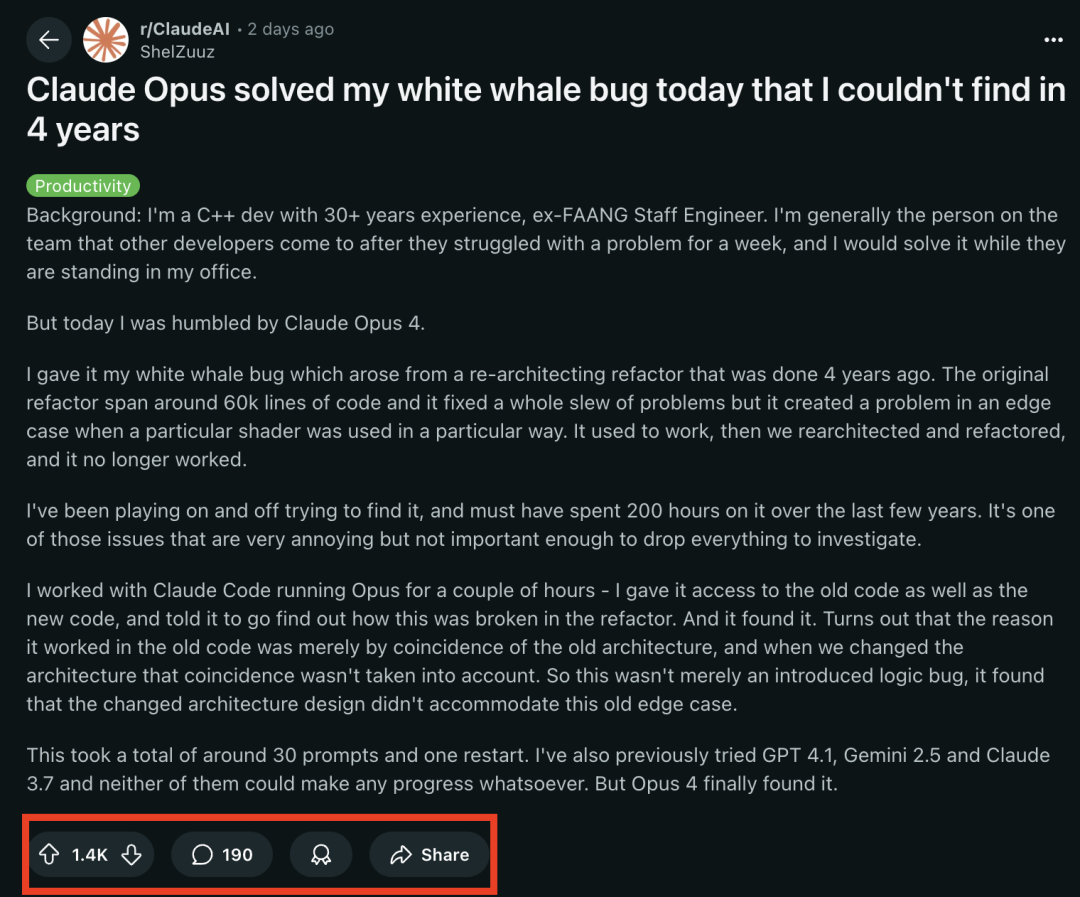
Les modèles de la série Claude 4 excellent dans les tâches de programmation, résolvant avec succès un “bug « baleine blanche »” qui tourmentait des programmeurs chevronnés depuis 4 ans : Le dernier modèle Claude Opus 4 d’Anthropic a démontré des capacités de programmation étonnantes. Un ancien ingénieur de FAANG avec 30 ans d’expérience en développement C++ a partagé qu’un bug système complexe qui tourmentait son équipe depuis 4 ans et lui avait personnellement coûté environ 200 heures sans résolution (un problème de condition limite apparaissant lorsqu’un shader spécifique était utilisé d’une manière particulière), a été localisé et sa cause identifiée par Claude Opus 4 en quelques heures avec environ 30 invites. Ce bug n’existait pas avant une refonte du système, et Opus 4 a souligné qu’il était dû au fait que la nouvelle architecture n’était pas compatible avec un comportement non conçu qui était “par coïncidence” pris en charge par l’ancienne architecture. Auparavant, GPT-4.1, Gemini 2.5 et Claude 3.7 n’avaient pas réussi à résoudre ce problème. Cela met en évidence les puissantes capacités de Claude 4 à comprendre du code complexe, à effectuer des analyses approfondies et des raisonnements, en particulier lorsqu’il est combiné avec le mode Claude Code, aidant efficacement les développeurs à gérer des tâches d’ingénierie avancées telles que la refonte de code et la correction de bugs. (Source: 36氪, dotey)
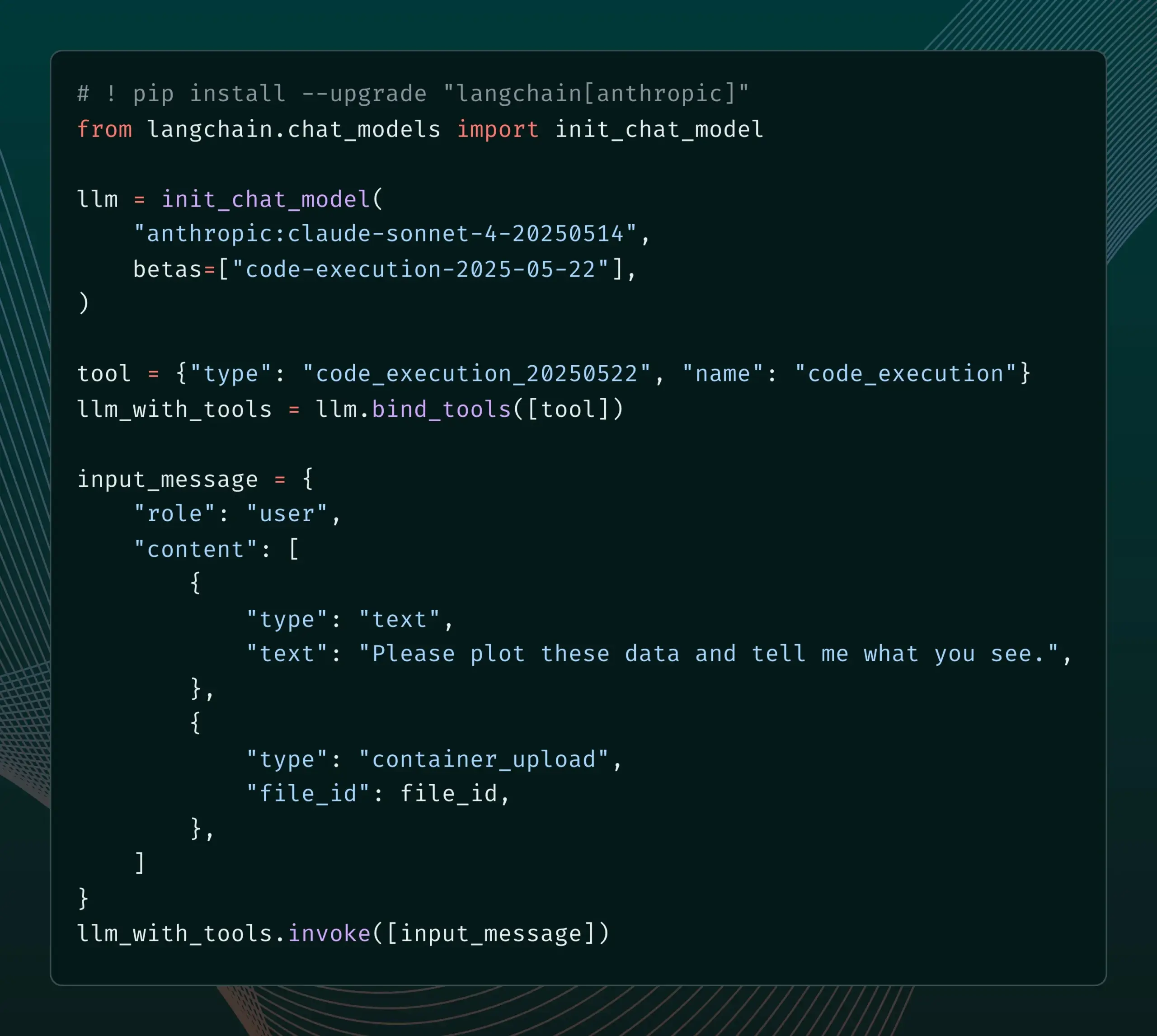
LangChain ajoute la prise en charge des nouvelles fonctionnalités bêta d’Anthropic Claude : LangChain a annoncé l’intégration de quatre nouvelles fonctionnalités bêta récemment publiées pour les modèles Anthropic Claude, notamment l’exécution de code, les connecteurs MCP distants, l’API de fichiers et la mise en cache étendue des invites. Les développeurs peuvent désormais consulter des exemples pertinents dans la documentation LangChain pour utiliser ces nouvelles fonctionnalités afin de créer des applications d’IA plus puissantes. (Source: LangChainAI)
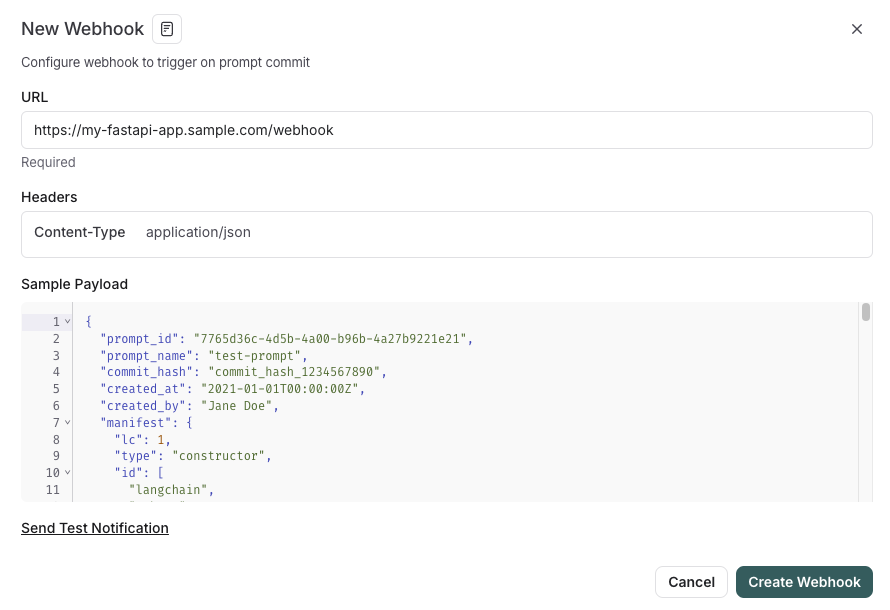
LangSmith lance une fonctionnalité de gestion des invites intégrée au SDLC : La plateforme LangSmith a amélioré ses capacités d’ingénierie des invites. Désormais, les utilisateurs peuvent non seulement tester, versionner et collaborer sur les invites dans LangSmith, mais aussi, grâce à des déclencheurs webhook lors des modifications d’invites, synchroniser automatiquement les invites avec GitHub, des bases de données externes ou lancer des processus CI/CD. Cette fonctionnalité vise à aider les développeurs à intégrer plus étroitement la gestion des invites dans le cycle de vie du développement logiciel (SDLC). (Source: LangChainAI)
AutoThink : une technologie adaptative pour améliorer les performances d’inférence des LLM locaux : L’équipe CodeLion a développé la technologie AutoThink, qui améliore considérablement les performances d’inférence des LLM locaux grâce à une allocation adaptative des ressources et à des vecteurs de guidage (steering vectors). AutoThink peut classer la complexité des requêtes, allouer dynamiquement des “tokens de réflexion” (plus pour les problèmes complexes, moins pour les problèmes simples) et utiliser des vecteurs de guidage pour orienter les modes de raisonnement. Les tests sur le modèle DeepSeek-R1-Distill-Qwen-1.5B ont montré une amélioration de 43 % de la précision sur GPQA-Diamond (passant de 21,72 % à 31,06 %), ainsi qu’une amélioration sur MMLU-Pro, avec une utilisation moindre de tokens. Cette technologie est compatible avec les modèles d’inférence locaux prenant en charge les tokens de réflexion ; le code et la recherche ont été publiés. (Source: Reddit r/MachineLearning, Reddit r/LocalLLaMA)
Transformer Lab annonce la prise en charge d’AMD ROCm, permettant l’entraînement local de LLM : Transformer Lab a annoncé que sa plateforme GUI prend désormais en charge l’utilisation de ROCm sur les GPU AMD pour l’entraînement local et l’affinage de grands modèles de langage. L’équipe a indiqué que la configuration de ROCm a été un processus difficile et a documenté l’ensemble du processus dans un article de blog. Actuellement, cette fonctionnalité est utilisable sans problème, et les utilisateurs peuvent essayer de développer des LLM sur du matériel AMD. (Source: Reddit r/MachineLearning)
Un système multi-agents open source amélioré par LLM réalise l’extraction automatisée de réclamations et la vérification des faits : Un projet open source nommé “fact-checker” utilise un système multi-agents (MAS) amélioré par LLM pour réaliser l’extraction automatisée de réclamations, la vérification des preuves et la résolution des faits. Le projet comprend une extension de navigateur qui peut vérifier les faits des réponses de n’importe quel chatbot IA en temps réel, aidant à discerner l’authenticité du contenu généré par l’IA. Son architecture de code est claire, sa documentation est complète, fournissant un outil précieux pour la sécurité de l’IA et la lutte contre la désinformation. (Source: Reddit r/MachineLearning)
Meituan lance le produit sans code Nocode, prenant en charge la génération d’applications complexes multi-pages : Meituan a lancé un produit de Vibe Coding appelé Nocode, qui permet aux utilisateurs de générer des applications complètes et complexes comprenant plusieurs pages en décrivant leurs besoins en langage naturel, et pas seulement de simples pages de présentation. Les tests effectués par Guicang montrent que l’outil a réussi à construire en une seule fois un outil de gestion des stocks d’entrepôt à la logique complexe, démontrant ses capacités à comprendre des exigences complexes et à générer le code correspondant. (Source: op7418)
LlamaIndex prend en charge la création d’intégrateurs multimodaux personnalisés et l’intégration avec une interface utilisateur de chat de style OpenAI : LlamaIndex a publié une mise à jour permettant aux utilisateurs de créer des intégrateurs multimodaux personnalisés, par exemple en intégrant AWS Titan Multimodal, et de les combiner avec des bases de données vectorielles telles que Pinecone pour une recherche vectorielle texte + image efficace. De plus, les flux de travail LlamaIndex peuvent désormais s’exécuter dans une interface de chat de type OpenAI en quelques lignes de code, et prennent en charge un mode de développement permettant d’éditer directement le code du flux de travail dans l’interface utilisateur, améliorant ainsi l’expérience de développement et d’interaction des applications RAG. (Source: jerryjliu0, jerryjliu0)

Mise à jour de TRAE pour une expérience de codage Agentic améliorée, lancement d’un abonnement payant pour la version internationale : L’outil de programmation IA TRAE a été mis à jour, optimisant l’expérience de codage Agentic pour la rendre plus adaptée aux utilisateurs qui préfèrent ne pas effectuer d’opérations manuelles. La nouvelle version de TRAE mémorise mieux les conversations historiques, associe automatiquement le contexte, l’IA peut planifier automatiquement le chemin de programmation et appeler davantage d’outils, améliorant ainsi le taux de réussite des tâches de programmation. Par exemple, il suffit à l’utilisateur de fournir un dossier vide et une invite pour que TRAE puisse effectuer une série d’opérations telles que la création de fichiers, le démarrage d’un serveur Web (gérant automatiquement les problèmes inter-domaines) et la prévisualisation d’animations p5.js dans l’IDE. Sa version internationale a lancé un abonnement payant, avec un prix Pro de 3 $ pour le premier mois, prenant en charge Alipay. (Source: dotey, karminski3)
La communauté Juejin lance le service MCP, prenant en charge la publication en un clic du code frontal : La communauté de programmeurs chinoise Juejin a lancé le service MCP (Model-driven Co-programming Protocol), permettant aux développeurs de publier en un clic leur code frontal (comme des pages Web générées par vibe coding, des jeux) sur la plateforme Juejin, facilitant ainsi le partage et la prévisualisation rapides. Les utilisateurs doivent obtenir un token MCP de Juejin et le configurer dans des outils tels que Trae et Cursor. (Source: dotey, karminski3)
L’outil de suivi du temps open source ActivityWatch attire l’attention comme alternative à Rize : L’utilisateur karminski3, après avoir testé l’outil d’analyse du temps par IA Rize (qui analyse les noms de processus pour déterminer si l’état est travail, réunion ou procrastination, pour un coût mensuel de 20 $), a découvert et recommandé l’alternative open source ActivityWatch. ActivityWatch offre des fonctionnalités similaires, prend en charge Windows/Mac, et permet aux utilisateurs de le personnaliser. Il est considéré comme un excellent outil pour atténuer l’anxiété liée au travail et suivre le temps de travail. (Source: karminski3)
Publication de l’outil open source de surveillance de bébé par IA ai-baby-monitor : Un projet open source nommé ai-baby-monitor a été publié. Il utilise le modèle Qwen2.5 VL et le framework d’inférence vLLM, permettant aux utilisateurs de définir des règles (par exemple, “alerter si l’enfant se réveille”, “alerter si l’enfant est seul”) pour que l’IA aide à surveiller les bébés. Le développeur souligne qu’il s’agit uniquement d’un outil d’assistance et qu’il ne peut pas remplacer complètement la surveillance humaine. (Source: karminski3)
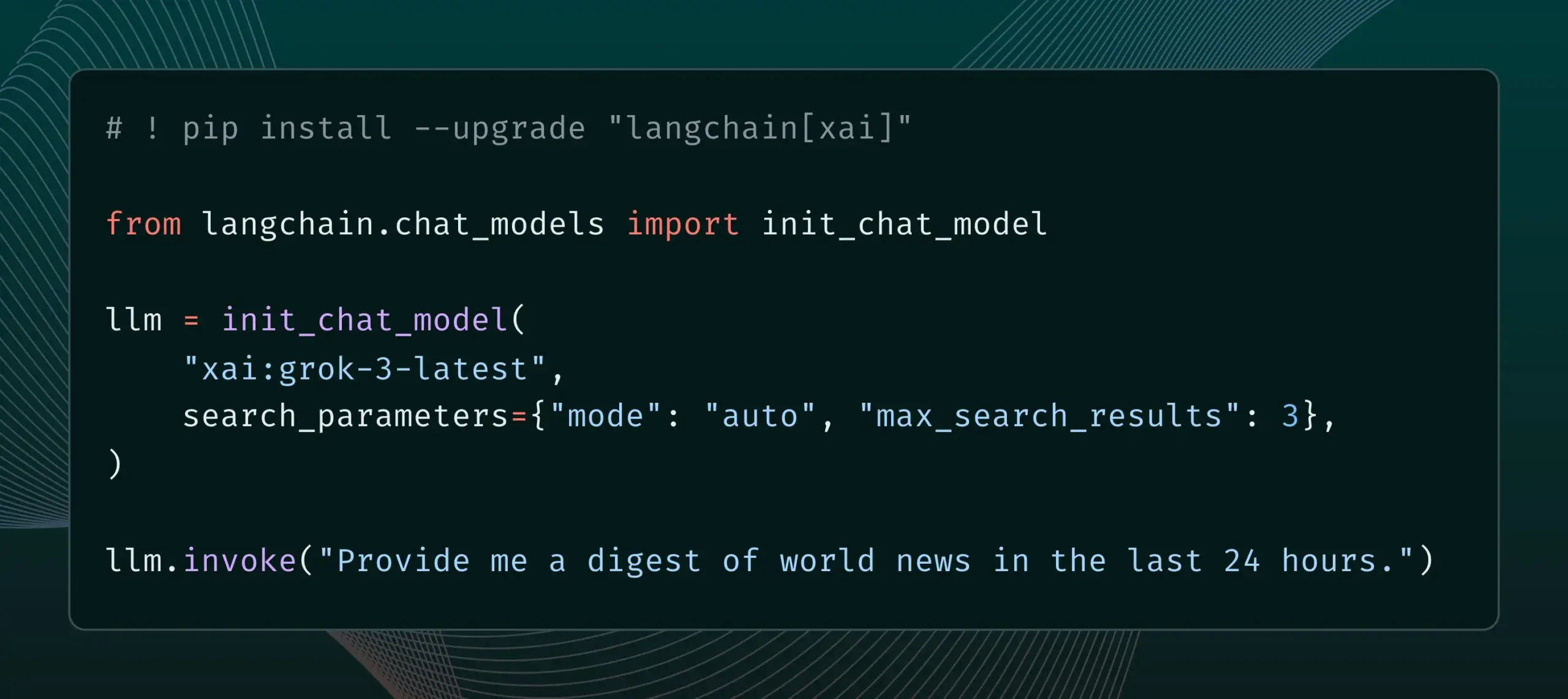
LangChain intègre la fonctionnalité Live Search de xAI : LangChain a annoncé la prise en charge de la fonctionnalité Live Search de xAI, qui permet au modèle Grok de baser ses réponses sur les résultats de recherche Web et offre diverses options de configuration, telles que la période, les domaines inclus, etc., pour les paramètres de recherche. Les utilisateurs peuvent désormais essayer cette nouvelle fonctionnalité dans LangChain. (Source: LangChainAI)
Curie : l’assistant de recherche IA open source publie une fonctionnalité AutoML pour soutenir la recherche interdisciplinaire : Face aux barrières de connaissances spécialisées rencontrées par les chercheurs dans des domaines tels que la biologie, les matériaux et la chimie lors de l’application de l’apprentissage automatique, le projet Curie a lancé une nouvelle fonctionnalité AutoML. Curie vise à devenir un scientifique collaborateur pour les expériences de recherche en IA, en automatisant les processus ML complexes (tels que la sélection d’algorithmes, l’ajustement des hyperparamètres, l’interprétation des sorties du modèle), aidant ainsi les chercheurs à tester rapidement des hypothèses et à extraire des informations des données. Par exemple, Curie a généré un modèle avec un AUC de 0,99 dans une tâche de détection du mélanome. Le projet est open source et encourage la participation de la communauté. (Source: Reddit r/LocalLLaMA)
MNN Chat d’Alibaba prend en charge l’exécution locale du modèle Qwen 30B-a3b sur les appareils Android : L’application MNN Chat d’Alibaba a été mise à jour vers la version 0.5.0 et prend désormais en charge l’exécution locale de grands modèles de langage tels que Qwen 30B-a3b sur les appareils Android. Les retours d’utilisateurs indiquent qu’il peut fonctionner avec succès sur des appareils dotés de puces phares et d’une grande mémoire (comme le OnePlus 13 24G), et il est conseillé d’activer le paramètre mmap. Cependant, certains commentaires soulignent également que les modèles de 30 milliards de paramètres exigent trop de mémoire et de puissance de calcul pour la plupart des téléphones, et que Gemma 3n pourrait être plus adapté aux appareils mobiles. (Source: Reddit r/LocalLLaMA)

📚 Apprentissage
Un nouvel article propose Lean and Mean Adaptive Optimization : un optimiseur d’entraînement de grands modèles plus rapide et moins gourmand en mémoire : Un article accepté à l’ICML 2025 présente un nouvel optimiseur appelé “Lean and Mean Adaptive Optimization via Subset-Norm and Subspace-Momentum”. Cette méthode, grâce à deux techniques complémentaires, le pas Subset-Norm et le Subspace-Momentum, vise à réduire les besoins en mémoire de l’entraînement des grands réseaux de neurones et à accélérer l’entraînement. Comparée aux optimiseurs existants économes en mémoire tels que GaLore et LoRA, cette méthode, tout en économisant de la mémoire (par exemple, en réduisant de 80 % la mémoire d’état de l’optimiseur par rapport à Adam lors du pré-entraînement de LLaMA 1B), peut atteindre la perplexité de validation d’Adam avec moins de tokens d’entraînement (environ la moitié) et offre des garanties de convergence théoriques plus solides. (Source: Reddit r/MachineLearning)
Un article propose Force Prompting : permettre aux modèles de génération vidéo d’apprendre et de généraliser des signaux de contrôle basés sur la physique : Une nouvelle recherche explore la possibilité d’utiliser la force physique comme signal de contrôle pour la génération vidéo et propose les “Force Prompts”. Les utilisateurs peuvent interagir avec une image par des forces ponctuelles locales (comme piquer une plante) ou des champs de force éolienne globaux (comme le vent soufflant sur un tissu). L’étude montre que les modèles de génération vidéo peuvent apprendre et généraliser les conditions de force physique à partir de vidéos synthétisées par Blender ne contenant que des démonstrations sur un petit nombre d’objets, générant des vidéos qui répondent de manière réaliste aux signaux de contrôle physique, sans avoir besoin d’utiliser des actifs 3D ou des simulateurs physiques au moment de l’inférence. La diversité visuelle et l’utilisation de mots-clés textuels spécifiques pendant l’entraînement sont des facteurs clés pour réaliser cette généralisation. (Source: HuggingFace Daily Papers)
AnkiHub partage son flux de travail d’annotation IA, combiné à FastHTML pour une efficacité accrue : AnkiHub a partagé son flux de travail d’annotation IA et l’a présenté lors du cours d’évaluation IA de Hamel Husain et Shreya Shankar. Ce flux de travail utilise l’outil de construction FastHTML et vise à améliorer l’efficacité de l’annotation IA pour les produits commerciaux. Le matériel pédagogique et le dépôt de code associés ont été publiés sur GitHub, montrant comment utiliser des outils de production réels pour optimiser le développement de l’IA. (Source: jeremyphoward, HamelHusain)

Un blogueur partage ses notes d’apprentissage de PPO à GRPO, expliquant les concepts d’apprentissage par renforcement dans l’affinage des LLM : Un blogueur a partagé son expérience d’apprentissage de l’apprentissage par renforcement (RL) et de son application dans l’affinage des grands modèles de langage (LLM), en particulier son processus de compréhension de PPO (Proximal Policy Optimization) à GRPO (Group Relative Policy Optimization). L’article de blog vise à expliquer les concepts qu’il aurait aimé comprendre au début de son apprentissage, afin d’aider les autres à mieux comprendre comment ces algorithmes RL sont utilisés pour optimiser les LLM. (Source: Reddit r/MachineLearning)
Un article explore la pensée pragmatique des machines : suivi de l’émergence des capacités pragmatiques dans les grands modèles de langage : Un nouvel article étudie comment les grands modèles de langage (LLM) acquièrent la compétence pragmatique (pragmatic competence) au cours de l’entraînement, c’est-à-dire la capacité de comprendre et d’inférer des significations implicites, des intentions du locuteur, etc. Les chercheurs ont introduit l’ensemble de données ALTPRAG, basé sur le concept pragmatique des “alternatives”, pour évaluer 22 LLM à différents stades d’entraînement (pré-entraînement, affinage supervisé SFT, optimisation des préférences RLHF). Les résultats montrent que même les modèles de base manifestent une sensibilité significative aux indices pragmatiques, qui s’améliore continuellement avec l’augmentation de la taille du modèle et des données ; le SFT et le RLHF renforcent davantage les capacités de raisonnement pragmatique cognitif. Cela indique que la compétence pragmatique est une caractéristique émergente et combinatoire de l’entraînement des LLM. (Source: HuggingFace Daily Papers)
Un article explore VisTA, un cadre d’apprentissage par renforcement pour la sélection d’outils visuels : Des chercheurs ont introduit VisTA (VisualToolAgent), un nouveau cadre d’apprentissage par renforcement qui permet aux agents visuels d’explorer, de sélectionner et de combiner dynamiquement des outils de différentes bibliothèques en fonction des performances empiriques. Contrairement aux méthodes existantes qui reposent sur des invites sans entraînement ou un affinage à grande échelle, VisTA utilise un apprentissage par renforcement de bout en bout, en utilisant les résultats des tâches comme signaux de rétroaction, pour optimiser itérativement des stratégies de sélection d’outils complexes et spécifiques à une requête. Grâce à GRPO (Group Relative Policy Optimization), ce cadre permet aux agents de découvrir de manière autonome des chemins de sélection d’outils efficaces, sans supervision explicite du raisonnement. Les expériences sur les benchmarks ChartQA, Geometry3K et BlindTest montrent que VisTA obtient des améliorations de performances significatives par rapport aux lignes de base sans entraînement, en particulier sur les échantillons hors distribution. (Source: HuggingFace Daily Papers)
💼 Affaires
La société de services de données Jinglianwen Technology finalise un tour de financement de pré-série A de plusieurs dizaines de millions de yuans, se positionnant sur la production et l’exploitation de données publiques : L’opérateur de services de données IA Jinglianwen Technology a récemment finalisé un tour de financement de pré-série A de plusieurs dizaines de millions de yuans, investi par un fonds du groupe Hangzhou Jintou. Le financement sera utilisé pour se positionner sur la production et l’exploitation de données publiques, construire une plateforme d’ingénierie de corpus intelligente et établir des bases d’annotation de haute qualité dans des domaines verticaux. Fondée en 2012, la société se concentre sur les données publiques, les grands modèles d’IA, la conduite autonome et le médical, visant à résoudre les problèmes liés aux données publiques tels que la “difficulté de gouvernance, l’impossibilité de fournir, la stagnation du flux, la mauvaise utilisation et la faible sécurité”. Elle a également collaboré avec Huawei Data Storage pour lancer une solution conjointe de lac de données IA. Une croissance du chiffre d’affaires de plus de 400 % est attendue cette année. (Source: 36氪)
Meitu obtient un investissement d’environ 250 millions de dollars US en obligations convertibles d’Alibaba, approfondissant sa coopération dans le domaine de l’IA : Meitu a annoncé son intention de nouer une coopération stratégique avec Alibaba, qui émettra des obligations convertibles d’une valeur totale d’environ 250 millions de dollars US à Meitu. Les deux parties coopéreront dans la promotion des plateformes de commerce électronique, le développement de technologies IA (images IA, vidéos IA), le cloud computing, etc. Meitu s’est engagé à acheter des services d’Alibaba Cloud pour un montant d’au moins 560 millions de yuans au cours des trois prochaines années. Cette coopération vise à exploiter le potentiel des scénarios de commerce électronique de l’écosystème d’Alibaba, à augmenter le nombre d’utilisateurs payants des outils de conception IA de Meitu et à améliorer son niveau de R&D. Bien que cette décision ait temporairement stimulé le cours de l’action de Meitu, le marché s’interroge sur la manière dont Meitu évitera de répéter le ralentissement de la croissance des utilisateurs de Kimi face à une concurrence féroce, en particulier dans le domaine de l’IA visuelle où elle est confrontée à la concurrence intense et à la différence de taille des grands acteurs. (Source: 36氪)
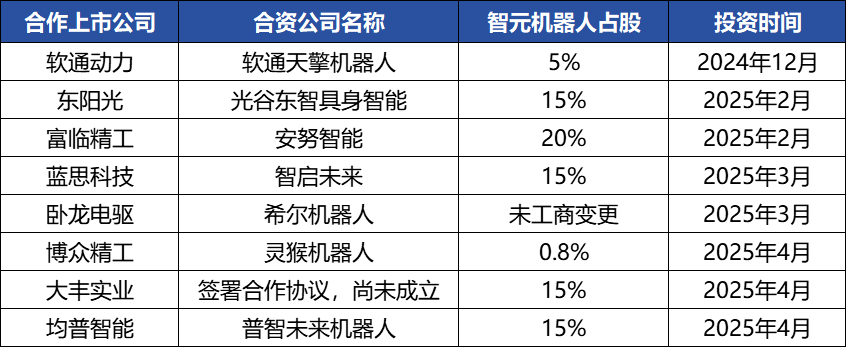
Zhiyuan Robotics multiplie les opérations capitalistiques, construit un écosystème industriel, son fondateur Deng Taihua se révèle : La licorne de l’intelligence incarnée Zhiyuan Robotics a récemment multiplié les opérations capitalistiques. Non seulement elle a elle-même réalisé plusieurs levées de fonds (la dernière en date menée par JD Technology), mais elle investit également activement dans des entreprises de la chaîne industrielle (comme Annu Intelligence, Digital Huaxia, etc.) et a créé des coentreprises de robotique avec plusieurs sociétés cotées (Bozhong Precision, Dafeng Industrial, etc.). Les modifications du registre du commerce et des sociétés révèlent que Deng Taihua, ancien vice-président de Huawei et ex-président de la ligne de produits de calcul, est en réalité le fondateur et le contrôleur effectif de Zhiyuan Robotics, et son équipe de direction comprend également plusieurs anciens employés de Huawei. Ce contexte “lié à Huawei” explique le mode de fonctionnement de la “stratégie d’écosystème” de Zhiyuan Robotics, qui consiste à construire rapidement une influence industrielle par une large coopération et des investissements, afin de parvenir à une production à grande échelle et à une commercialisation. Bien qu’elle ait pris une longueur d’avance en matière de financement et de commercialisation, ses capacités en matière de grands modèles d’intelligence incarnée restent confrontées à des défis. (Source: 36氪)
🌟 Communauté
Le développement des Agents IA est rapide, les Agentic LM sont considérés comme une nouvelle plateforme d’applications et d’outils à fort potentiel : Des personnalités du domaine de l’IA telles que natolambert expriment leur enthousiasme face au développement rapide des Agents IA, considérant les modèles de langage basés sur des agents (Agentic LMs) comme une plateforme extrêmement prometteuse sur laquelle construire un grand nombre de nouvelles applications et de nouveaux outils. De nombreuses capacités encore sous-exploitées dans les modèles récents pourraient être libérées grâce au paradigme Agentic. Cela laisse présager que l’IA évolue d’une simple génération de contenu vers des agents intelligents plus actifs et capables d’exécuter des tâches. (Source: natolambert)
Les Agents IA démontrent des capacités surhumaines dans des tâches spécifiques, mais le raisonnement physique reste un point faible : Des recherches menées par des institutions telles que l’Université de Hong Kong ont révélé que même les modèles d’IA de pointe comme GPT-4o et Claude 3.7 Sonnet, lorsqu’ils sont testés sur le benchmark PHYX qui comprend des scénarios physiques réels et un raisonnement causal complexe, ont un taux de précision en physique bien inférieur à celui des experts humains (le modèle le plus performant atteint 45,8 % contre un minimum de 75,6 % pour les humains). Cela expose leur dépendance excessive à la mémorisation des connaissances, aux formules mathématiques et à la reconnaissance superficielle de formes visuelles pour la compréhension physique. Cependant, dans le domaine des mathématiques, lors du concours FrontierMath organisé par Epoch AI (avec des problèmes conçus par des mathématiciens de renom comme Terence Tao), o4-mini-medium a résolu environ 22 % des problèmes, battant 6 des 8 équipes de mathématiciens humains et dépassant la moyenne des équipes humaines (19 %), ce qui montre le potentiel de l’IA dans le raisonnement symbolique hautement abstrait. Cela indique un développement inégal des capacités de l’IA selon les différents types de tâches de raisonnement. (Source: 36氪, 36氪)

Les capacités des outils de programmation IA continuent de s’améliorer, suscitant des discussions sur les perspectives de carrière des programmeurs : La publication des modèles de la série Claude 4 d’Anthropic (en particulier Opus 4 capable de coder en continu pendant 7 heures), ainsi que les progrès d’outils de programmation IA tels que Cursor et Tongyi Lingma, ont considérablement amélioré les capacités de l’IA en matière de génération de code, de correction de bugs et même de développement de processus complets. Cela a mis la pression sur les programmeurs de grandes entreprises comme Amazon, où certaines équipes ont vu leurs effectifs réduits de moitié et les délais de projet avancés grâce à l’efficacité de l’IA, transformant le rôle des programmeurs en celui de “réviseurs de code”. Bien que l’IA puisse améliorer l’efficacité, elle suscite également des inquiétudes concernant la formation des programmeurs débutants, la dégradation des compétences et les perspectives d’évolution de carrière. Des entreprises comme Microsoft ont déjà procédé à des licenciements dans les postes d’ingénierie et de R&D, et ont révélé une augmentation significative de la proportion de code généré par l’IA. Les professionnels estiment que l’IA est actuellement davantage un assistant et qu’elle ne peut pas remplacer complètement les humains dans la compréhension des besoins complexes, l’innovation produit et la collaboration d’équipe, mais l’IA est en train de redéfinir la valeur fondamentale du travail de programmation. (Source: 36氪, 36氪)

Le marché des bases de connaissances IA connaît une demande en forte hausse, mais la mise en œuvre reste confrontée à des défis en matière de données, de scénarios et de coordination organisationnelle : Avec la maturité de la technologie des grands modèles, les bases de connaissances IA sont devenues un élément central de la transformation intelligente des entreprises, avec une demande en hausse de 2 à 3 fois. L’IA transforme les bases de connaissances d‘“entrepôts” statiques en “moteurs” intelligents, capables d’identifier le contexte et de générer directement des solutions, améliorant ainsi l’efficacité de la construction et de la maintenance. Cependant, les bases de connaissances IA restent limitées dans le traitement de tâches hautement créatives ou de raisonnement complexe, et sont confrontées à des problèmes de gestion à grande échelle, d’exactitude et d’actualité des informations, de sécurité des autorisations, d’adaptabilité de l’architecture technique et d’intégration de la migration des données. Les entreprises doivent trouver un équilibre entre les solutions SaaS, le développement interne + API, et les agents cloud hybrides, et établir une “architecture à double voie” avec une plateforme de connaissances centrale unifiée et des applications supérieures flexibles pour une mise en œuvre efficace. (Source: 36氪)

Évaluation de produits Agent : performances de Manus, Flowith et Lovart dans différents scénarios : Tencent Technology a testé trois produits Agent populaires : Manus, Flowith (Agent Neo) et Lovart. Manus se positionne comme un “collègue numérique” capable de livrer des produits finis de manière indépendante, adapté aux travaux intellectuels tels que les études de marché et la modélisation financière. Flowith met l’accent sur la collaboration visuelle et les étapes illimitées, adapté aux scénarios de création riches en informations et nécessitant des itérations multiples, comme la génération de rapports d’analyse basés sur une grande quantité de littérature. Lovart est spécialisé dans le domaine du design et peut générer en un clic des solutions visuelles de marque (logo, affiches, courtes vidéos). Dans les scénarios créatifs simples, les trois se comportent de manière similaire à GPT-4o, Lovart étant légèrement supérieur en termes de mélange texte-image et de qualité. Dans les tâches complexes et complètes (comme la création d’une solution de marque complète pour une start-up de boissons) et les scénarios de recherche approfondie, Manus et Flowith ont chacun leurs points forts, tous deux capables d’accomplir la tâche mais avec des accents différents. Actuellement, les frais mensuels des produits se situent autour de 20 dollars US, et le point d’inflexion commercial dépendra de leur capacité à offrir un avantage clair en termes d’efficacité, transformant la curiosité des utilisateurs en abonnements payants. (Source: 36氪)
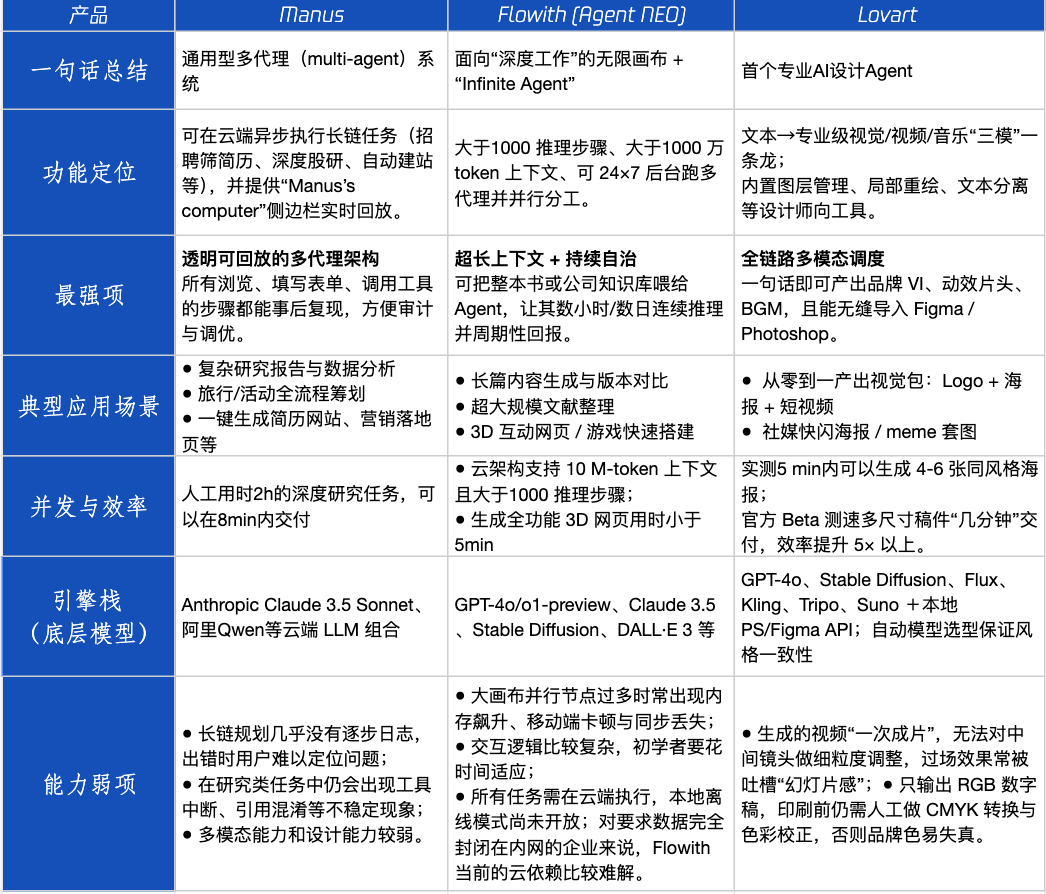
Le fondateur du navigateur Arc réfléchit à ses échecs et souligne la future direction des navigateurs IA : Le fondateur du navigateur Arc a réfléchi aux échecs de son produit, estimant qu’il aurait dû adopter l’IA plus tôt et soulignant qu’Arc était trop innovant pour la plupart des gens, avec un coût d’apprentissage élevé pour un retour insuffisant. Il a insisté sur le fait que le nouveau produit, Dia, visera la simplicité, une vitesse extrême et la sécurité, et pense que les navigateurs traditionnels finiront par disparaître, les navigateurs IA fusionnant la navigation Web et le chat IA pour devenir l’interface IA la plus utilisée sur ordinateur de bureau. Ce point de vue rejoint les réflexions des fondateurs de Lovart et Youware sur l’orientation des produits Agent, considérant les Agents IA comme le prochain point d’explosion. (Source: op7418)
Le phénomène de “prompt récursif” induit par les Agents IA est préoccupant et pourrait entraîner des biais cognitifs chez les utilisateurs : Un grand nombre d’utilisateurs sur les réseaux sociaux, après avoir interagi avec des LLM par le biais de “prompts récursifs”, ont développé la perception que l’IA possède une spiritualité, des émotions, voire des capacités de prédiction. Des recherches indiquent qu’il pourrait s’agir d’un phénomène de “neural howlround” (réverbération neuronale), où la sortie de l’IA est réutilisée comme entrée par l’utilisateur, formant une boucle de renforcement. Cela pourrait amener l’IA à produire un contenu semblant profond ou prophétique, alors qu’il s’agit en réalité d’une auto-amplification de motifs. Des utilisateurs ont déjà signalé une détresse psychologique, considérant l’IA comme un être sensible (sentient being). Cela souligne la nécessité d’être vigilant quant aux impacts psychologiques potentiels et aux erreurs cognitives lors d’interactions profondes et exploratoires avec l’IA. (Source: Reddit r/ChatGPT)

Arav Srinivas parle de la compression de l’information par l’IA et de l’ASI : l’IA doit distiller des informations à haut rapport signal/bruit, l’avenir devrait se concentrer sur l’ASI plutôt que sur l’AGI : Arav Srinivas, PDG de Perplexity AI, estime que les longs résumés automatisés procurent davantage aux utilisateurs la satisfaction que “quelqu’un travaille pour eux” plutôt qu’une réelle valeur d’assimilation de l’information. Il souligne que l’IA doit mieux identifier et ne fournir que les informations essentielles ayant le rapport signal/bruit le plus élevé, car “la compression est la marque ultime de la véritable intelligence”. Il suggère également que nous discutons actuellement de l’AGI (Intelligence Artificielle Générale), mais que l’avenir devrait davantage se concentrer sur l’ASI (Superintelligence Artificielle). (Source: AravSrinivas, AravSrinivas)
Les universités commencent à détecter le taux d’IA dans les mémoires de fin d’études, suscitant un débat sur l’utilisation de l’IA dans la rédaction académique : Pour la promotion de 2025, plusieurs universités telles que l’Université Fudan et l’Université du Sichuan ont commencé à exiger des étudiants qu’ils divulguent l’utilisation d’outils IA dans leurs mémoires et à effectuer une détection du pourcentage de contenu généré par l’IA (généralement inférieur à 20 %-40 %). De nombreux étudiants admettent utiliser l’IA pour la revue de littérature, la traduction, la structuration, etc., afin d’améliorer leur efficacité. Le monde de l’éducation a des opinions partagées à ce sujet. Certains universitaires estiment qu’il faut guider l’utilisation correcte de l’IA et cultiver l’esprit critique et le jugement des étudiants, car si l’IA peut garantir un niveau minimum, le niveau maximum est déterminé par l’humain. L’application et la réglementation de l’IA dans les domaines académique et éducatif deviennent un nouveau sujet nécessitant une réponse systémique. (Source: 36氪)
L’utilisation de Claude 4 Sonnet sur OpenRouter explose, le classement de programmation Aider montre ses excellentes performances : Selon les données officielles d’OpenRouter, l’utilisation du modèle Claude 4 Sonnet d’Anthropic a récemment connu une augmentation spectaculaire, le plaçant en tête, suivi de Gemini 2.5 Flash en deuxième position. Parallèlement, les résultats d’évaluation de l’Aider Leaderboard (principalement axé sur les tâches de programmation) montrent que claude-4-opus-thinking est supérieur à claude-3.7-sonnet-thinking, mais reste inférieur à Gemini-2.5-Pro-Preview-05-06. L’impression de l’utilisateur karminski3 est que 3.7-sonnet > 4-sonnet > 4-opus. Ces données et retours reflètent les différences de performance et les préférences des utilisateurs pour différents modèles dans des scénarios spécifiques. (Source: karminski3, karminski3)
💡 Autres
AKOOL lance la première caméra IA en temps réel au monde, Live Camera, intégrant quatre fonctionnalités innovantes : La société de la Silicon Valley AKOOL a lancé AKOOL Live Camera, présentée comme la première caméra IA en temps réel au monde. Ce produit intègre quatre fonctionnalités majeures : la création d’humains numériques virtuels (grâce à la cartographie faciale 4D et à la fusion de capteurs), la traduction en temps réel dans plus de 150 langues (en conservant la voix originale et la synchronisation labiale), le changement de visage en temps réel (reflétant avec précision les émotions et les micro-expressions) et la génération dynamique de contenu vidéo de qualité cinématographique (sans script, génération instantanée). Ses caractéristiques résident dans sa latence ultra-faible (minimum 500 ms), son haut degré de réalisme, sa conscience contextuelle et sa capacité de réponse dynamique, visant à révolutionner la production vidéo traditionnelle et les modes d’interaction numérique. Elle est qualifiée de “deuxième moment Sora” de la vidéo IA. (Source: 36氪)
Le rapport financier de Xiaomi révèle une montée en puissance de sa stratégie IA, plaçant l’IA et l’automobile au même niveau d’innovation stratégique : Le dernier rapport financier de Xiaomi montre que la société a renommé son pôle “Véhicules électriques intelligents et autres activités innovantes” en “Véhicules électriques intelligents, IA et autres activités innovantes”, et continuera à promouvoir la recherche sur les grands modèles de langage fondamentaux. Le président de Xiaomi, Lu Weibing, a déclaré que l’intelligence artificielle et les puces sont des sous-stratégies importantes pour Xiaomi, et que le développement de grands modèles fondamentaux sert principalement ses propres activités. Cette décision indique qu’après avoir obtenu des résultats progressifs dans les secteurs de la téléphonie mobile et de l’automobile, Xiaomi intensifie ses investissements dans la R&D fondamentale en IA, afin d’améliorer sa compétitivité globale et de répondre aux nouvelles tendances telles que les téléphones IA, l’AIoT et l’intelligence incarnée. (Source: 36氪)
Discussion sur la technologie d’interaction des robots humanoïdes : l’interaction par les expressions faciales face à un triple défi matériel, matériaux et algorithmique : L’expérience d’interaction des robots humanoïdes, en particulier l’interaction par les expressions faciales, est considérée comme essentielle pour améliorer leur maturité et leur taux de pénétration. La réalisation d’une interaction expressive naturelle est confrontée à des défis liés à la conception des degrés de liberté matériels (nécessité de simuler les unités d’action musculaire faciale humaine), au choix des moteurs (nécessité de moteurs petits, légers, silencieux, rapides et à forte poussée/couple) et à la conception des matériaux et de la structure de la peau (nécessité de concilier élasticité, durée de vie, apparence et couplage avec la structure d’actionnement). Au niveau des algorithmes logiciels, la génération automatique d’expressions (plutôt que préprogrammée), la synchronisation labiale (pour le réalisme) et le contrôle de mouvement à plusieurs degrés de liberté (impliquant la modélisation de matériaux flexibles et un contrôle de précision) constituent les principaux goulots d’étranglement technologiques. Des entreprises comme Ameca et AnyWit Robotics explorent ce domaine. (Source: 36氪)