
Mots-clés:Modèle d’IA, Claude 4, Gemini Diffusion, Agent intelligent, Apprentissage robotique, Grand modèle linguistique, Matériel d’IA, Développement de puces, Capacité de codage de Claude Opus 4, Vitesse de génération des modèles de diffusion de texte, Apprentissage onirique du robot GR00T, Performances de la puce Xuanjie O1 de Xiaomi, Acquisition de la société de matériel io par OpenAI
🔥 À LA UNE
Anthropic publie les modèles de la série Claude 4, axés sur la programmation d’agents IA et le traitement de tâches complexes: Anthropic a lancé Claude Opus 4 et Claude Sonnet 4, deux modèles hybrides qui mettent l’accent sur l’équilibre entre la réactivité et la réflexion approfondie. Opus 4 excelle dans les tâches complexes telles que le codage, la recherche, la rédaction et la découverte scientifique, capable de programmer de manière autonome pendant 7 heures et de jouer à Pokémon en continu pendant 24 heures ; Sonnet 4, quant à lui, trouve un équilibre entre performance et efficacité, adapté aux scénarios quotidiens nécessitant de l’autonomie. Les deux modèles ont amélioré l’utilisation des outils, le traitement parallèle et les capacités de mémoire, et introduisent une fonction de « résumé de la pensée ». GitHub a annoncé que Claude Sonnet 4 sera le modèle de base du nouvel agent de codage Copilot. Ce lancement comprend également le SDK Claude Code, des outils d’exécution de code, des connecteurs MCP, etc., visant à permettre aux développeurs de construire des agents IA plus puissants, marquant la transition stratégique d’Anthropic vers une intégration profonde des « grands modèles + agents ». (Source: 量子位 & 36氪)

Google lance le modèle de diffusion de texte Gemini Diffusion, générant 10 000 tokens en 12 secondes: Google DeepMind a publié Gemini Diffusion, un modèle expérimental de génération de texte qui utilise la technologie de diffusion au lieu des méthodes autorégressives traditionnelles. Il apprend à générer des sorties en optimisant progressivement le bruit, atteignant une vitesse de génération de 2000 tokens par seconde, capable de générer 10 000 tokens en 12 secondes, voire plus rapidement que Gemini 2.0 Flash-Lite. Ce modèle peut générer des blocs entiers de tokens en une seule fois, améliorant la cohérence des réponses, et peut corriger les erreurs lors du raffinement itératif. Sa capacité de raisonnement non causal lui permet de résoudre des problèmes difficiles pour les modèles autorégressifs traditionnels, comme donner d’abord la réponse puis déduire le processus. (Source: 量子位)
Nouveaux progrès du projet robotique GR00T de Nvidia : apprentissage par le « rêve » pour une généralisation zero-shot: Le GEAR Lab de Nvidia a lancé le projet DreamGen, permettant aux robots d’apprendre de nouvelles compétences grâce à des « rêves » (trajectoires neuronales) générés par des modèles vidéo du monde de l’IA (tels que Sora, Veo). Cette technologie ne nécessite qu’une petite quantité de données vidéo réelles. En affinant les modèles du monde, en générant des données virtuelles, en extrayant des actions virtuelles et en entraînant des stratégies, les robots peuvent exécuter 22 nouvelles tâches. Lors de tests sur des robots réels, le taux de réussite des tâches complexes est passé de 21 % à 45,5 %, réalisant pour la première fois une généralisation zero-shot du comportement et de l’environnement. Cette technologie fait partie du plan GR00T-Dreams de Nvidia, visant à accélérer l’apprentissage du comportement robotique, et devrait réduire le temps de développement de GR00T N1.5 de 3 mois à 36 heures. (Source: 量子位)

🎯 TENDANCES
Mise à jour de l’Operator d’OpenAI vers le modèle o3, améliorant le taux de réussite des tâches et la qualité des réponses: OpenAI a annoncé que sa fonction Operator dans ChatGPT a été mise à jour, le modèle sous-jacent passant au dernier modèle d’inférence o3. Cette mise à niveau améliore considérablement la persistance et la précision de l’Operator lors de l’interaction avec les navigateurs, augmentant ainsi le taux de réussite global des tâches. Les retours des utilisateurs indiquent que les réponses de l’Operator mis à jour sont plus claires, plus détaillées et mieux structurées. OpenAI a déclaré que le modèle o3 atteint des performances SOTA dans des benchmarks tels que OSWorld et WebArena, et que le nouveau modèle se comporte mieux lors du traitement d’anciens prompts ayant échoué. (Source: OpenAI & gdb & sama & npew & cto_junior & gallabytes & ShunyuYao12 & josh_tobin_ & isafulf & mckbrando & jachiam0)
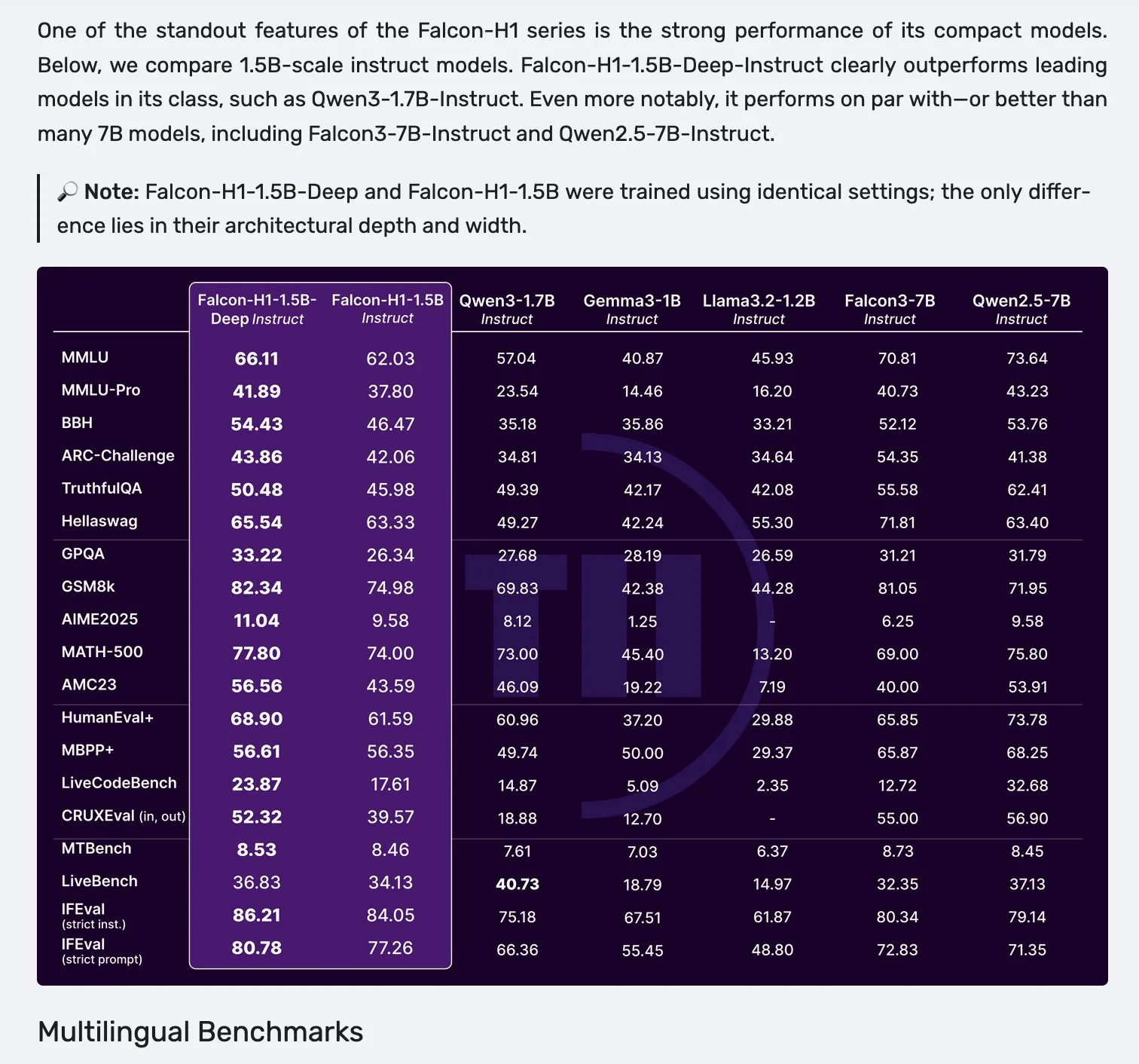
Falcon publie les modèles de la série H1, adoptant une architecture parallèle Mamba-2 et attention: Falcon a lancé sa nouvelle série de modèles H1, avec des tailles de paramètres allant de 0,5B à 34B, entraînés sur 2,5T à 18T tokens de données, et une longueur de contexte atteignant 256K. Cette série de modèles adopte une architecture innovante combinant Mamba-2 en parallèle avec des mécanismes d’attention traditionnels. Les premiers retours de la communauté indiquent que ses petits modèles sont particulièrement performants, mais des tests et évaluations pratiques supplémentaires (“vibe checks”) sont encore nécessaires pour vérifier leurs performances réelles et leur robustesse dans divers types de tâches. (Source: _albertgu & huggingface)
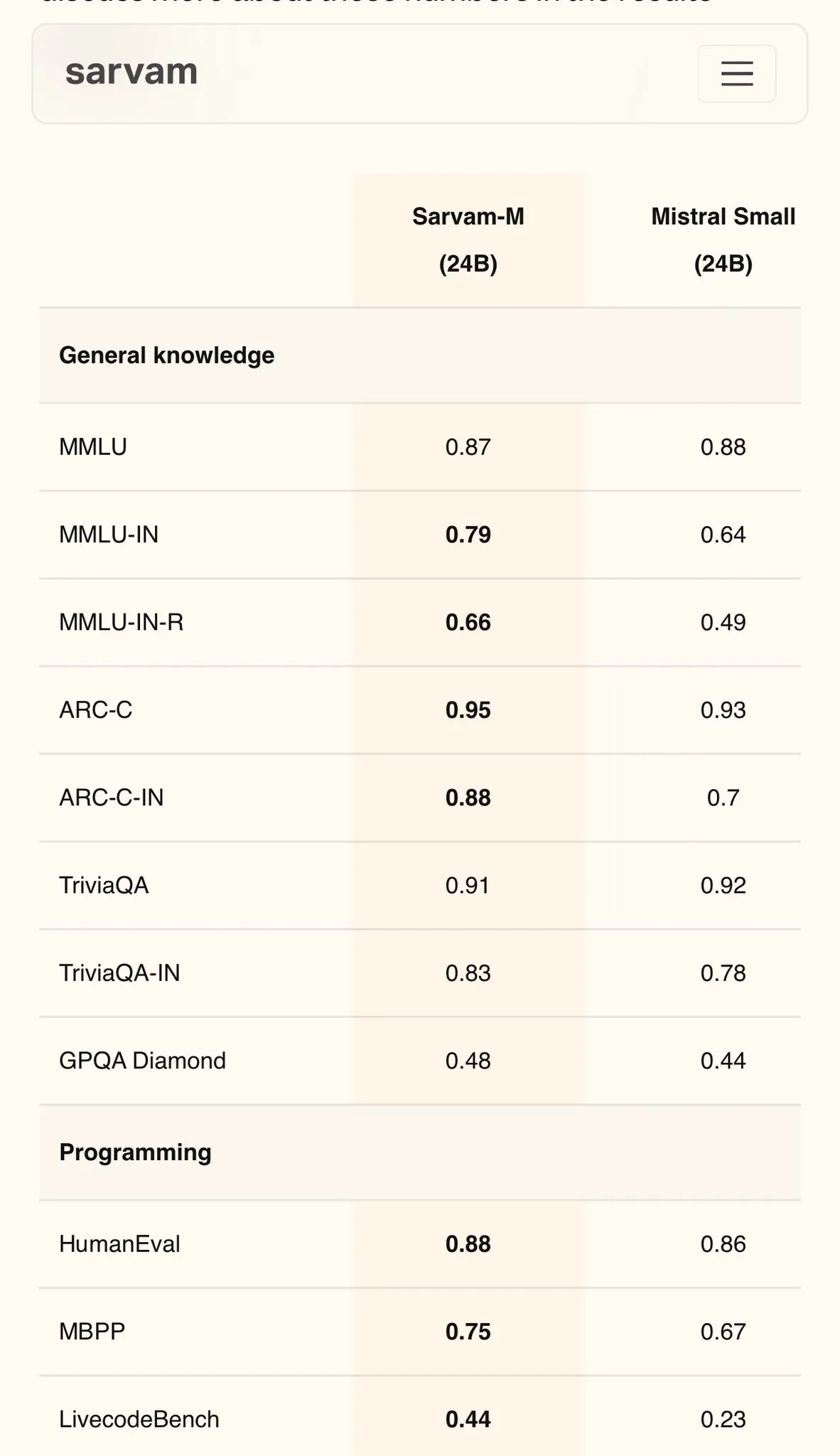
Sarvam AI publie Sarvam-M, un modèle en hindi basé sur Mistral, atteignant 79 points au MMLU: La société indienne d’IA Sarvam AI a publié le modèle Sarvam-M, construit sur le modèle open source Mistral. Il a obtenu un score de 79 au benchmark MMLU pour les langues indiennes, surpassant les performances du ChatGPT initial (GPT-3.5) en anglais. Ce modèle a été optimisé pour 11 langues indiennes, montrant des améliorations de 20 %, 21,6 % et 17,6 % par rapport au modèle de base sur les benchmarks de langues indiennes, de mathématiques et de programmation respectivement. Sarvam-M a été publié en open source sous la licence Apache 2.0, démontrant le potentiel de l’Inde dans le développement de grands modèles linguistiques pour les langues locales. (Source: bookwormengr)
Mise à niveau du Dell Enterprise Hub, prise en charge complète de la construction d’IA en local: Dell a annoncé lors du Dell Tech World la mise à jour du Dell Enterprise Hub, offrant des conteneurs de modèles optimisés incluant Meta Llama 4 Maverick, DeepSeek R1 et Google Gemma 3, et prenant en charge les plateformes de serveurs IA de NVIDIA, AMD et Intel. Les nouvelles fonctionnalités comprennent un catalogue d’applications IA (intégrant OpenWebUI, AnythingLLM), la prise en charge des modèles sur appareil pour les PC IA (via le déploiement Dell Pro AI Studio) ainsi que de nouveaux outils SDK Python dell-ai et CLI. Cette initiative vise à aider les entreprises à déployer rapidement et en toute sécurité des applications d’IA générative en local. (Source: HuggingFace Blog & ClementDelangue)

Fireworks AI rend open source son outil d’agent de navigateur Fireworks Manus: Fireworks AI a rendu open source Fireworks Manus, un puissant outil d’agent basé sur navigateur qui utilise DeepSeek V3 pour l’inférence et FireLlava 13B pour la compréhension visuelle. Cet agent est capable de naviguer sur des pages web, de cliquer sur des boutons, de remplir des formulaires, d’extraire du contenu dynamique et de gérer les processus d’authentification, les boîtes de dialogue modales et même les captchas. Son architecture comprend un système visuel (DOM, captures d’écran, perception spatiale), un système de raisonnement (mémoire, suivi d’objectifs, planification de schémas JSON) et un système d’action (contrôle des interactions avec le navigateur), formant une boucle puissante d’observation-décision-action. (Source: _akhaliq)
Mistral AI lance une IA documentaire et un nouveau modèle OCR: Mistral AI a annoncé sa solution d’IA documentaire, combinée à un nouveau modèle OCR. Cette solution vise à fournir un flux de travail documentaire évolutif, de la numérisation OCR à l’interrogation en langage naturel. Ses caractéristiques comprennent une capacité multilingue prenant en charge plus de 40 langues, la possibilité d’entraîner l’OCR pour des documents spécifiques à un domaine (comme les dossiers médicaux), la prise en charge de l’extraction avancée vers des modèles personnalisés (comme JSON), et la possibilité de déploiement local ou en cloud privé. (Source: algo_diver)

Sakana AI publie une nouvelle approche IA : les Continuous Thought Machines (CTM): Sakana AI a annoncé sa nouvelle percée dans la recherche en IA – les Continuous Thought Machines (CTM). Cette nouvelle méthode vise à améliorer les capacités de réflexion et de raisonnement des modèles d’IA. NHK World a rendu compte des derniers progrès de Sakana AI, présentant ses efforts et ses réalisations dans la construction de la prochaine génération de modèles mondiaux. (Source: SakanaAILabs & hardmaru)

Kumo.ai publie KumoRFM, un « modèle fondamental relationnel » pour les données structurées: Kumo.ai a lancé KumoRFM, un « modèle fondamental relationnel » spécialement conçu pour les données tabulaires (structurées). Ce modèle vise à traiter les données des bases de données de la même manière que les LLM traitent le texte, affirmant pouvoir être appliqué directement aux bases de données des entreprises pour générer des modèles SOTA sans ingénierie des caractéristiques. Cela pourrait indiquer que le potentiel des réseaux de neurones graphiques (GNNs) dans le traitement des données structurées est davantage exploré et appliqué. (Source: Reddit r/MachineLearning)

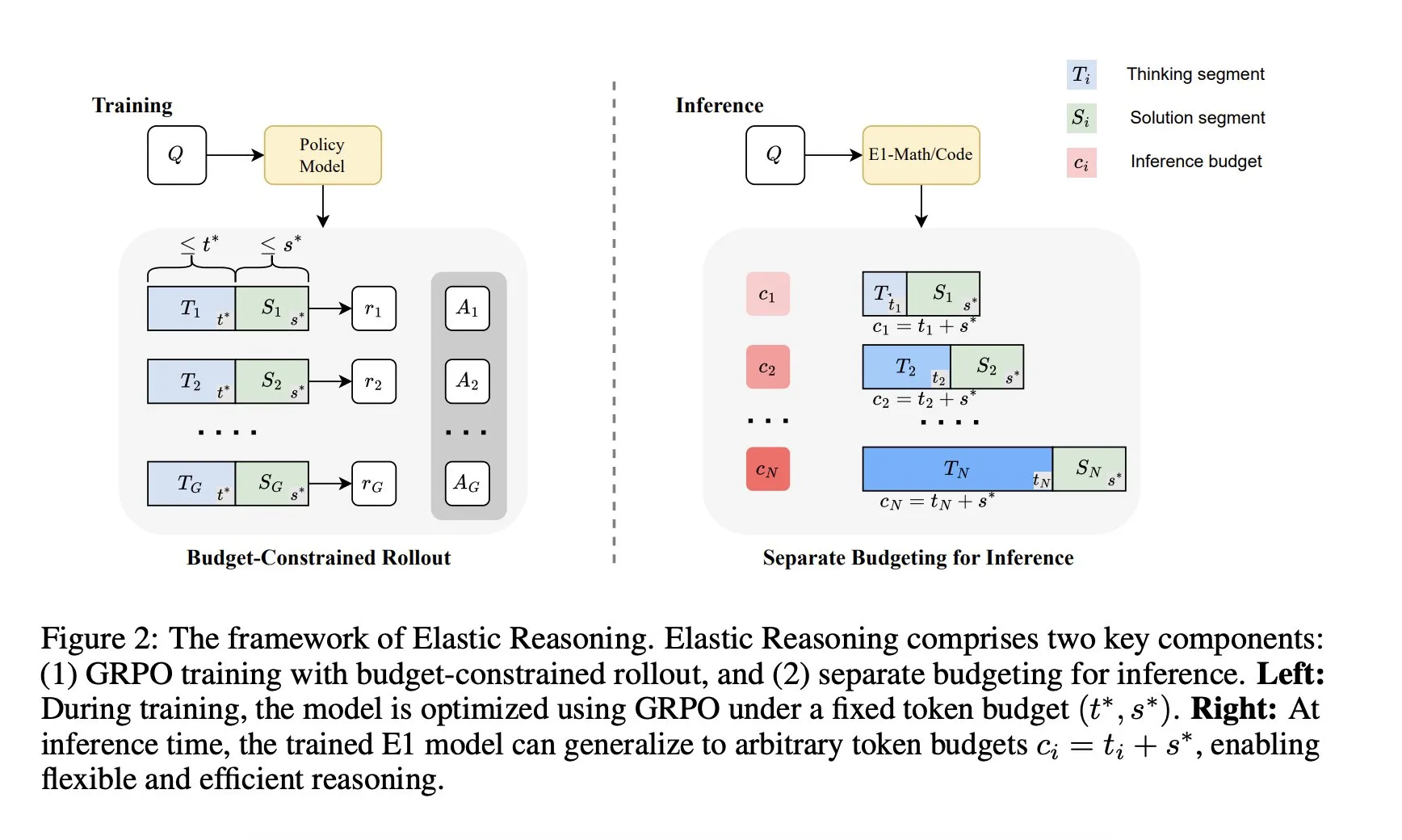
Salesforce AI Research lance le framework « Elastic Reasoning »: Salesforce AI Research a publié un nouveau framework appelé « Elastic Reasoning », visant à résoudre les problèmes de limitation du budget d’inférence des LLM sans sacrifier les performances. Ce framework sépare les phases de « réflexion » et de « solution » et leur attribue des budgets de tokens indépendants, combinés à un entraînement de rollout contraint par le budget. Les résultats de la recherche montrent que E1-Math-1.5B atteint une précision de 35 % sur AIME2024 avec une réduction de 32 % des tokens ; E1-Code-14B obtient un score de 1987 sur Codeforces. Les modèles peuvent se généraliser à n’importe quel budget sans réentraînement. (Source: ClementDelangue)
🧰 OUTILS
ChatGPT intègre la bibliothèque RDKit pour analyser, manipuler et visualiser des informations de chimie moléculaire: ChatGPT peut désormais analyser, manipuler et visualiser des informations moléculaires et chimiques grâce à la bibliothèque RDKit. Cette nouvelle fonctionnalité a une valeur pratique importante pour les domaines de recherche scientifique tels que la santé, la biologie et la chimie, aidant les chercheurs à traiter plus facilement des données et des structures chimiques complexes. (Source: gdb & openai)
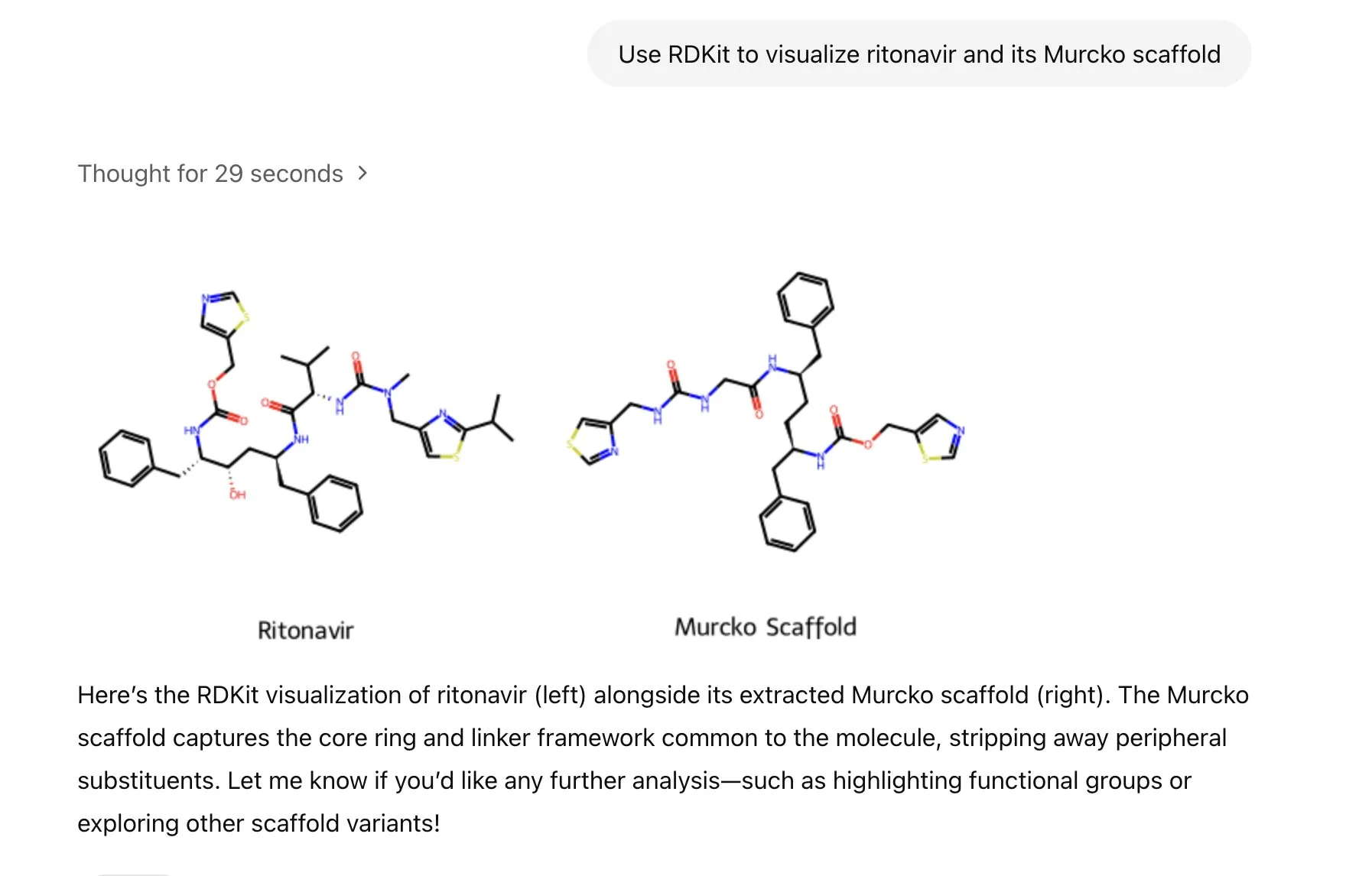
LlamaIndex lance un agent de génération d’images pour un contrôle précis de la création d’images IA: LlamaIndex a publié un projet open source d’agent de génération d’images, visant à aider les utilisateurs à créer avec précision des images IA correspondant à leur vision, grâce à l’optimisation automatisée des prompts, la génération d’images et une boucle de rétroaction visuelle. Cet agent est un outil multimodal qui utilise l’API de génération d’images d’OpenAI et les capacités visuelles de Google Gemini, et s’intègre de manière transparente avec LlamaIndex, prenant en charge les fonctionnalités de génération d’images d’OpenAI. (Source: jerryjliu0)
L’équipe Haystack publie Hayhooks pour simplifier le déploiement de pipelines IA: L’équipe Haystack a lancé le package open source Hayhooks, capable de transformer les pipelines Haystack en API REST prêtes pour la production ou de les exposer en tant qu’outils MCP, avec une personnalisation complète et très peu de code. Cela vise à accélérer le processus de déploiement des applications IA, permettant aux développeurs d’intégrer plus facilement les modèles et processus IA dans des environnements de production. (Source: dl_weekly)
L’application Runway iOS lance la fonction Gen-4 References, transformant la réalité en histoires n’importe où, n’importe quand: Runway a annoncé que la fonction Gen-4 References de son application iOS est désormais disponible, permettant aux utilisateurs de transformer n’importe quel élément du monde réel en histoires partageables. Cette fonction combine le texte-vers-image, References, Gen-4, ainsi que des techniques simples de suivi et d’étalonnage des couleurs, pour transformer des prises de vue ordinaires en productions à grande échelle. (Source: c_valenzuelab & c_valenzuelab & TomLikesRobots & c_valenzuelab)

Cartwheel lance une suite d’outils IA pour l’animation 3D, permettant la création d’animations de personnages: Cartwheel, co-fondé par des scientifiques d’OpenAI, des designers de Google et des développeurs de Pixar, Sony et Riot Games, a lancé sa suite d’outils IA pour l’animation 3D. Cet ensemble d’outils est capable de transformer des vidéos, du texte et de grandes bibliothèques de mouvements en animations de personnages 3D, visant à révolutionner le processus de production d’animation. (Source: andrew_n_carr & andrew_n_carr)

llm-d : Google, IBM et Red Hat s’associent pour lancer un framework open source d’inférence LLM distribuée: Google, IBM et Red Hat ont conjointement publié llm-d, un framework open source d’inférence LLM distribuée, natif de K8s. Ce framework vise à fournir des services d’inférence LLM haute performance. Ses principales caractéristiques comprennent une mise en cache et un routage avancés (avec un planificateur d’inférence optimisé par vLLM), des services découplés (utilisant vLLM pour exécuter le pré-remplissage/décodage sur des instances spécialisées), une mise en cache de préfixe découplée avec vLLM (prenant en charge le déchargement hôte/distant sans coût et le cache partagé) et une fonctionnalité prévue de mise à l’échelle automatique des variantes. Les résultats préliminaires montrent que llm-d peut réduire le TTFT jusqu’à 3 fois et augmenter le QPS d’environ 50 % tout en respectant les SLO. (Source: algo_diver)

FedRAG intègre Unsloth, permettant de construire et d’affiner des systèmes RAG avec FastModels: FedRAG a annoncé l’intégration d’Unsloth. Les utilisateurs peuvent désormais utiliser n’importe quel FastModels d’Unsloth comme générateur pour construire des systèmes RAG, et utiliser les accélérateurs de performance et les patchs d’Unsloth pour l’affinage. Les utilisateurs peuvent définir une nouvelle classe UnslothFastModelGenerator pour utiliser n’importe quel modèle Unsloth disponible, et cela prend en charge l’affinage LoRA ou QLoRA. Un cookbook officiel est fourni, démontrant comment effectuer un affinage QLoRA sur le modèle Gemma3 4B de GoogleAI. (Source: nerdai)

Hugging Face lance des agents CLI légers, réutilisables et modulaires: La bibliothèque Hugging Face Hub a ajouté une fonctionnalité d’agents d’interface en ligne de commande (CLI) légers, réutilisables et modulaires (compatibles MCP). Cette nouvelle fonctionnalité, développée par @hanouticelina et @julien_c, vise à faciliter la création et l’utilisation d’agents IA par les utilisateurs dans l’environnement CLI. (Source: huggingface)
Google AI Studio améliore l’expérience des développeurs avec la prise en charge native de la génération de code et des outils d’agent: Google AI Studio a été mis à jour pour améliorer l’expérience des développeurs, prenant désormais en charge la génération de code native et les outils d’agent. Ces nouvelles fonctionnalités visent à aider les développeurs à construire et à déployer plus facilement des applications IA en utilisant des modèles tels que Gemini. (Source: matvelloso)
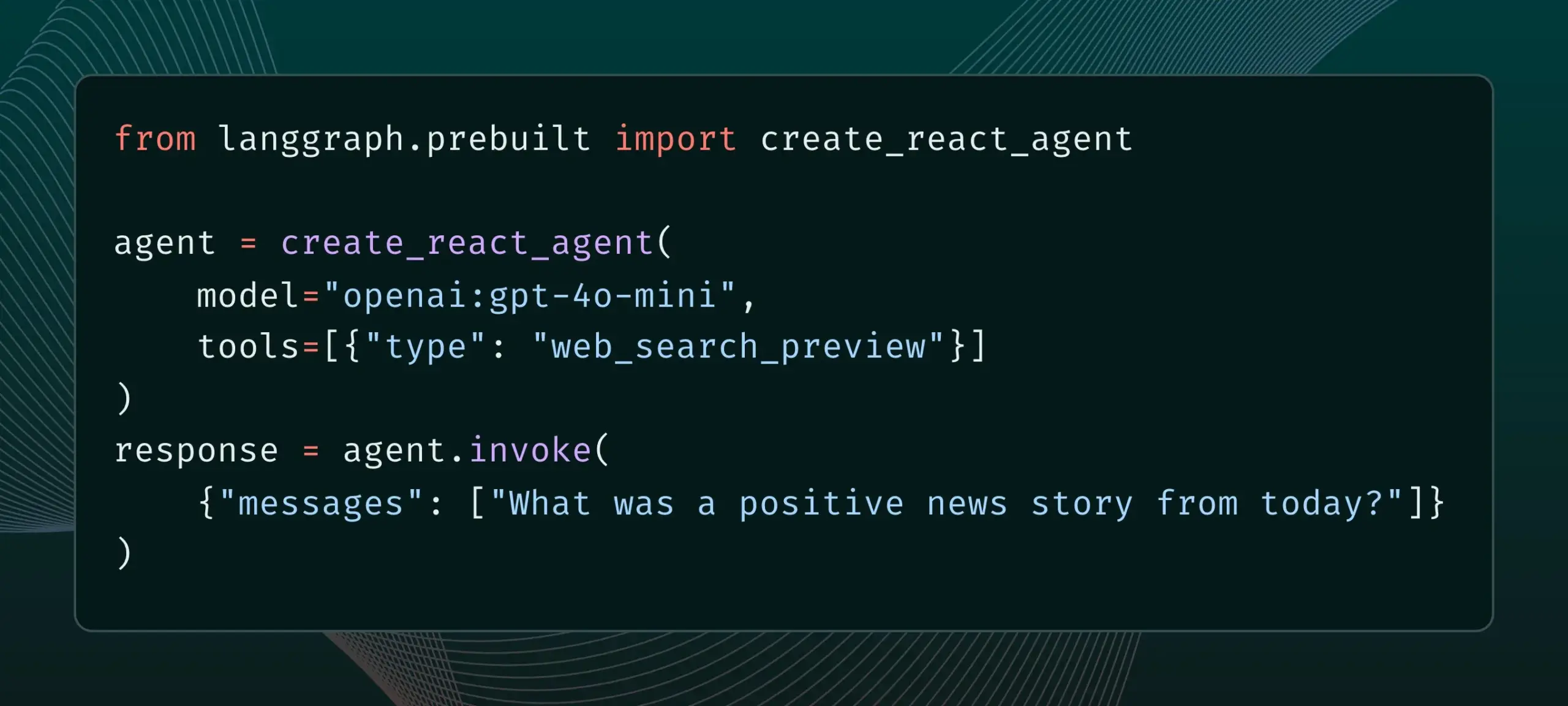
LangGraph prend désormais en charge les outils de fournisseurs intégrés, tels que la recherche Web et le MCP distant: LangGraph a annoncé que les utilisateurs peuvent désormais utiliser des outils de fournisseurs intégrés, tels que la recherche Web et le MCP (Model Control Protocol) distant. Cette mise à jour améliore la flexibilité et la fonctionnalité de LangGraph lors de la construction d’agents IA complexes et de flux de travail, facilitant l’intégration de données et de services externes. (Source: hwchase17 & Hacubu)
Memex intègre Claude Sonnet 4 et Gemini 2.5 Pro, et lance des modèles MCP: Memex a annoncé l’intégration des modèles Claude Sonnet 4 d’Anthropic et Gemini 2.5 Pro de Google. Parallèlement, Memex a également lancé trois modèles MCP (Model Control Protocol) initiaux, visant à aider les utilisateurs à construire et à déployer plus rapidement des applications IA. (Source: _akhaliq)

La plateforme Windsurf ajoute la prise en charge BYOK pour Claude Sonnet 4 et Opus 4: Windsurf a annoncé que pour répondre à la demande des utilisateurs, elle a ajouté sur sa plateforme la prise en charge « Bring-Your-Own-Key » (BYOK) pour les nouveaux modèles Claude Sonnet 4 et Opus 4 d’Anthropic. Cette fonctionnalité est disponible pour tous les plans personnels (gratuits et professionnels), permettant aux utilisateurs d’utiliser leurs propres clés API pour accéder à ces nouveaux modèles. (Source: dotey)
📚 APPRENTISSAGE
LlamaIndex publie un guide interactif : les 12 principes fondamentaux pour construire des agents IA: LlamaIndex, s’inspirant du populaire dépôt 12-Factor agents de @dexhorthy, a publié un ensemble de sites web interactifs et de notebooks Colab détaillant les 12 principes de conception pour construire des applications d’agents IA efficaces. Ces principes incluent l’obtention de sorties d’outils structurées, la gestion de l’état, la mise en place de points de contrôle, la collaboration homme-machine, la gestion des erreurs, et la combinaison de petits agents pour en former de plus grands. Ce guide vise à fournir aux développeurs des instructions pratiques et des exemples de code pour la construction d’applications d’agents. (Source: jerryjliu0)

Hugging Face ouvre la fonctionnalité de blog communautaire, améliorant la visibilité du contenu de la communauté IA: Hugging Face a annoncé que les utilisateurs peuvent désormais partager directement des articles de blog communautaires sur sa plateforme. Qu’il s’agisse de percées scientifiques, de partage de modèles, de jeux de données, de construction d’espaces, ou d’opinions sur des événements brûlants dans le domaine de l’IA, les utilisateurs peuvent augmenter la visibilité de leur contenu grâce à cette fonctionnalité. Les utilisateurs connectés peuvent commencer à rédiger et à publier en cliquant sur « New » sur la page d’accueil. (Source: huggingface & _akhaliq)
Le ministère français de la Culture publie un ensemble de données de préférences de type arène de haute qualité contenant 175 000 entrées: Le ministère français de la Culture a publié un ensemble de données contenant 175 000 conversations de préférences de haute qualité de type arène (arena-style), nommé « comparia-conversations ». Cet ensemble de données provient de leur propre arène de chatbots qu’ils ont créée, comprenant 55 modèles, et tout le contenu pertinent a été rendu open source. Ce type de données est crucial pour l’entraînement et l’évaluation des grands modèles linguistiques, surtout après que des institutions comme LMSYS ont cessé de publier des données similaires, cette initiative est donc particulièrement précieuse pour la communauté. (Source: huggingface & cognitivecompai & jeremyphoward)
Anthropic publie un tutoriel interactif gratuit sur l’ingénierie des prompts: Avec la sortie des nouveaux modèles Claude 4, Anthropic propose un tutoriel interactif gratuit sur l’ingénierie des prompts. Ce tutoriel vise à aider les utilisateurs à apprendre comment construire des prompts basiques et complexes, attribuer des rôles, formater les sorties, éviter les hallucinations, effectuer des chaînages de prompts et d’autres compétences clés pour mieux exploiter les capacités des modèles Claude. (Source: TheTuringPost & TheTuringPost)
Google publie le benchmark SAKURA pour évaluer les capacités de raisonnement multi-sauts des grands modèles audio-linguistiques: Des chercheurs de Google ont publié SAKURA, un nouveau benchmark spécialement conçu pour évaluer les capacités des grands modèles audio-linguistiques (LALMs) à effectuer un raisonnement multi-sauts basé sur des informations vocales et audio. L’étude a révélé que même si les LALMs peuvent extraire correctement les informations pertinentes, ils éprouvent encore des difficultés à intégrer les représentations vocales/audio pour un raisonnement multi-sauts, ce qui met en lumière un défi fondamental dans le raisonnement multimodal. (Source: HuggingFace Daily Papers)
Une nouvelle étude explore RoPECraft : transfert de mouvement sans entraînement basé sur l’optimisation de RoPE guidée par trajectoire: Un nouvel article propose RoPECraft, une méthode de transfert de mouvement vidéo sans entraînement pour les Transformers de diffusion. Elle y parvient en modifiant les embeddings de position rotatifs (RoPE), en extrayant d’abord le flux optique dense d’une vidéo de référence, en utilisant le décalage de mouvement pour déformer le tenseur exponentiel complexe de RoPE, en encodant le mouvement dans le processus de génération, et en optimisant par alignement de trajectoire et régularisation de phase par transformée de Fourier. Les expériences montrent que ses performances surpassent celles des méthodes existantes. (Source: HuggingFace Daily Papers)
Un article explore gen2seg : des modèles génératifs pour une segmentation d’instances généralisable: Une étude propose gen2seg, qui utilise des modèles génératifs pré-entraînés (tels que Stable Diffusion et MAE) pour synthétiser des images cohérentes à partir d’entrées perturbées, leur permettant d’apprendre à comprendre les limites des objets et la composition des scènes. Les chercheurs ont affiné le modèle en utilisant uniquement une perte de coloration d’instance sur quelques types d’objets tels que les meubles d’intérieur et les voitures, et ont constaté que le modèle présentait une forte capacité de généralisation zero-shot, capable de segmenter avec précision des types d’objets et des styles non vus, avec des performances proches voire supérieures à celles de SAM dans certains aspects. (Source: HuggingFace Daily Papers)
Un article propose Think-RM : réaliser un raisonnement à long terme dans les modèles de récompense génératifs: Un nouvel article présente Think-RM, un cadre d’entraînement visant à améliorer les capacités de raisonnement à long terme des modèles de récompense génératifs (GenRMs) en modélisant les processus de pensée internes. Think-RM génère des trajectoires de raisonnement flexibles et auto-guidées plutôt que des justifications externes structurées, prenant en charge des capacités avancées telles que l’auto-réflexion, le raisonnement hypothétique et le raisonnement divergent. L’étude propose également un nouveau processus RLHF par paires qui optimise directement la stratégie en utilisant des récompenses de préférence par paires. (Source: HuggingFace Daily Papers)
Un article propose WebAgent-R1 : entraîner des agents Web par apprentissage par renforcement multi-tours de bout en bout: Des chercheurs proposent WebAgent-R1, un cadre d’apprentissage par renforcement multi-tours de bout en bout pour l’entraînement d’agents Web. Ce cadre apprend directement par interaction en ligne avec l’environnement Web, entièrement guidé par des récompenses binaires de succès de la tâche, générant de manière asynchrone des trajectoires diversifiées. Les expériences montrent que WebAgent-R1 améliore considérablement le taux de réussite des tâches de Qwen-2.5-3B et Llama-3.1-8B sur le benchmark WebArena-Lite, surpassant les méthodes existantes et les modèles propriétaires puissants. (Source: HuggingFace Daily Papers)
Un article explore la réparation par LLM en cascade des données nuisant aux performances : réétiquetage des échantillons négatifs difficiles pour une récupération d’informations robuste: Des recherches ont révélé que certains ensembles de données d’entraînement affectent négativement l’efficacité des modèles de récupération et de reclassement. Par exemple, la suppression de certaines parties de l’ensemble de données de la collection BGE améliore le nDCG@10 sur BEIR. Cette étude propose une méthode utilisant des prompts LLM en cascade pour identifier et réétiqueter les « faux négatifs » (passages pertinents incorrectement étiquetés comme non pertinents). Les expériences montrent que le réétiquetage des faux négatifs en vrais positifs peut améliorer les performances des modèles de récupération E5 (base) et Qwen2.5-7B, ainsi que du reclasseur Qwen2.5-3B sur BEIR et AIR-Bench. (Source: HuggingFace Daily Papers)
DeepLearningAI et Predibase s’associent pour lancer un cours court sur l’affinage par renforcement des LLM avec GRPO: DeepLearningAI, en collaboration avec Predibase, a lancé un cours court intitulé « Reinforcement Fine-Tuning LLMs with GRPO ». Le contenu du cours comprend les bases de l’apprentissage par renforcement, comment utiliser l’algorithme d’optimisation de politique relative de groupe (GRPO) pour améliorer les capacités de raisonnement des LLM, concevoir des fonctions de récompense efficaces, transformer les récompenses en avantages pour guider le comportement du modèle, utiliser les LLM comme arbitres pour les tâches subjectives, surmonter le piratage des récompenses et calculer la fonction de perte dans GRPO. (Source: DeepLearningAI)
💼 AFFAIRES
OpenAI envisage d’acquérir la startup de matériel IA io de Jony Ive pour 6,4 milliards de dollars, marquant une entrée majeure dans le domaine du matériel: OpenAI a annoncé son intention d’acquérir io, la startup de matériel IA cofondée par l’ancien designer légendaire d’Apple Jony Ive, dans le cadre d’une transaction entièrement en actions évaluée à environ 6,4 milliards de dollars. Il s’agit de la plus grande acquisition d’OpenAI à ce jour, marquant son entrée officielle dans le matériel. L’équipe d’io rejoindra OpenAI et collaborera avec les équipes de recherche et de produits, Jony Ive devenant conseiller en conception matérielle. Cette décision est considérée comme un signal que les assistants IA pourraient perturber le paysage des appareils électroniques existants (comme l’iPhone). OpenAI avait précédemment acquis l’assistant de codage IA Windsurf et investi dans la société de robotique Physical Intelligence. (Source: 36氪)

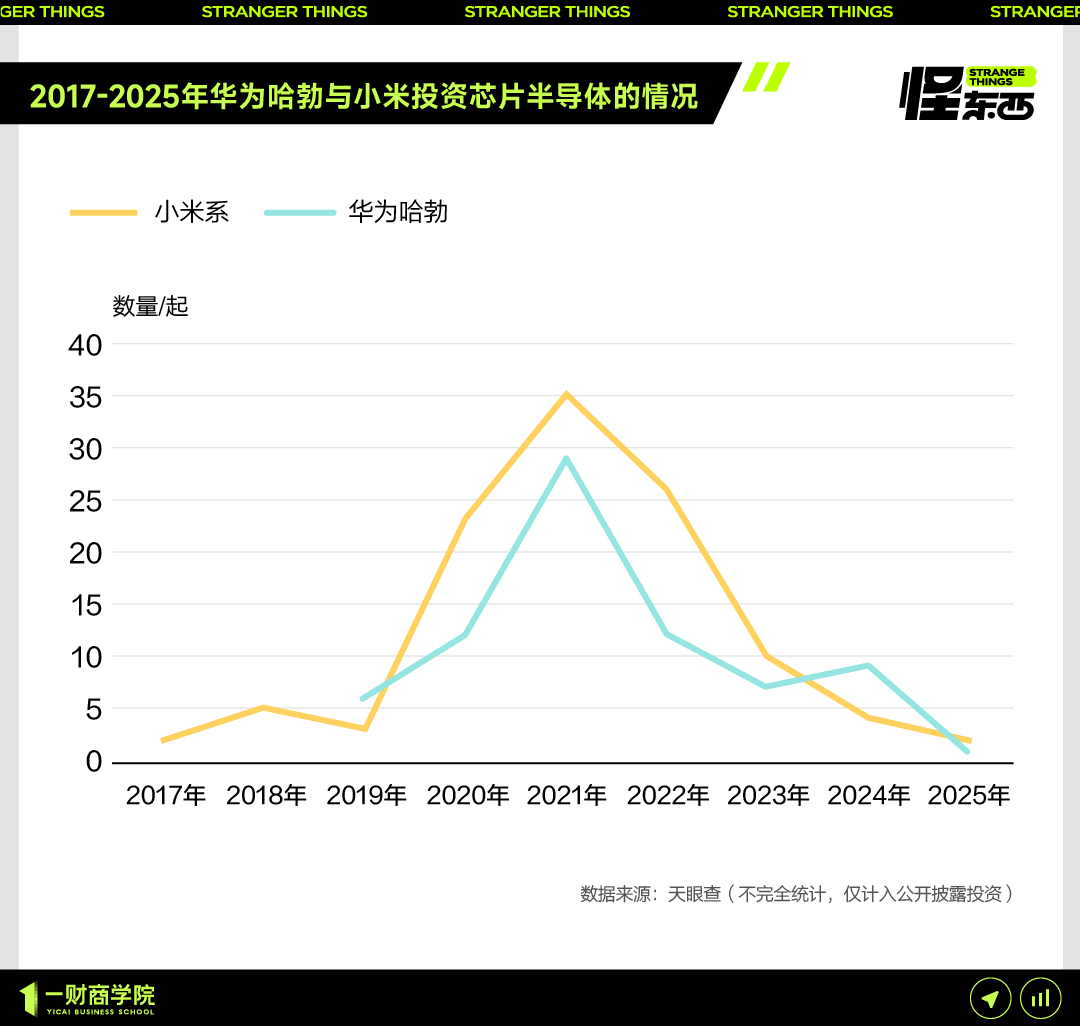
Xiaomi lance sa puce Xuanjie O1 3nm développée en interne et une série de nouveaux produits, continuant d’investir massivement dans les puces: Lors de sa conférence du 15e anniversaire, Xiaomi a officiellement lancé sa puce SoC développée en interne, la Xuanjie O1. Utilisant un processus de 3nm de deuxième génération et intégrant 19 milliards de transistors, ses performances CPU multicœurs dépasseraient celles de l’Apple A18 Pro. La Xuanjie O1 équipe déjà le téléphone Xiaomi 15S Pro, la tablette Xiaomi Pad 7 Ultra et la montre Xiaomi Watch S4. Xiaomi a lancé sa R&D sur les puces en 2014 et, en 8 ans, a investi dans 110 projets de semi-conducteurs via des entités telles que le Xiaomi Changjiang Industrial Fund, se concentrant sur les maillons intermédiaires de la chaîne industrielle et les projets en phase initiale. Lei Jun a annoncé que les investissements en R&D pour les cinq prochaines années devraient atteindre 200 milliards de yuans, visant à promouvoir la montée en gamme des produits grâce à des puces développées en interne et à construire un « écosystème complet homme-voiture-maison ». (Source: 36氪 & 量子位)
JD.com investit dans Zhiyuan Robot, la société de robotique de « Zhihuijun », approfondissant sa stratégie en matière d’intelligence incarnée: 36Kr a appris en exclusivité que Zhiyuan Robot est sur le point de finaliser un nouveau tour de financement, avec des investisseurs incluant JD.com et le Shanghai Embodied Intelligence Fund, certains actionnaires existants participant également. Zhiyuan Robot a été fondée en 2023 par l’ancien « jeune prodige » de Huawei, Peng Zhihui (Zhihuijun), et a déjà lancé les robots humanoïdes des séries Yuanzheng A1 et A2. JD.com avait précédemment investi dans la société de robots de service Xianglu Technology et lancé son grand modèle Yanxi ainsi que son modèle industriel Joy industrial. Cet investissement dans Zhiyuan Robot marque un approfondissement de sa stratégie dans le domaine de l’intelligence incarnée, en particulier pour des applications potentielles dans ses activités principales de commerce électronique et de logistique. (Source: 36氪)

🌟 COMMUNAUTÉ
Anthropic publie « THE WAY OF CODE », suscitant une discussion philosophique sur le « Vibe Coding »: Anthropic, en collaboration avec le producteur de musique Rick Rubin, a lancé un projet intitulé « THE WAY OF CODE ». Le contenu semble s’inspirer de la philosophie taoïste pour expliquer les concepts de programmation, par exemple en adaptant « Le Tao qui peut être nommé n’est pas le Tao éternel » en « The code that can be named is not the eternal code ». Cette collaboration transdisciplinaire unique a suscité un vif débat au sein de la communauté. De nombreux développeurs et passionnés d’IA ont manifesté un grand intérêt et diverses interprétations pour ce concept de « Vibe Coding » qui combine la programmation et la philosophie orientale, explorant son inspiration pour les pratiques de programmation et les modes de pensée. (Source: scaling01 & jayelmnop & saranormous & tokenbender & Dorialexander & alexalbert__ & fabianstelzer & cloneofsimo & algo_diver & hrishioa & dotey & imjaredz & jeremyphoward)

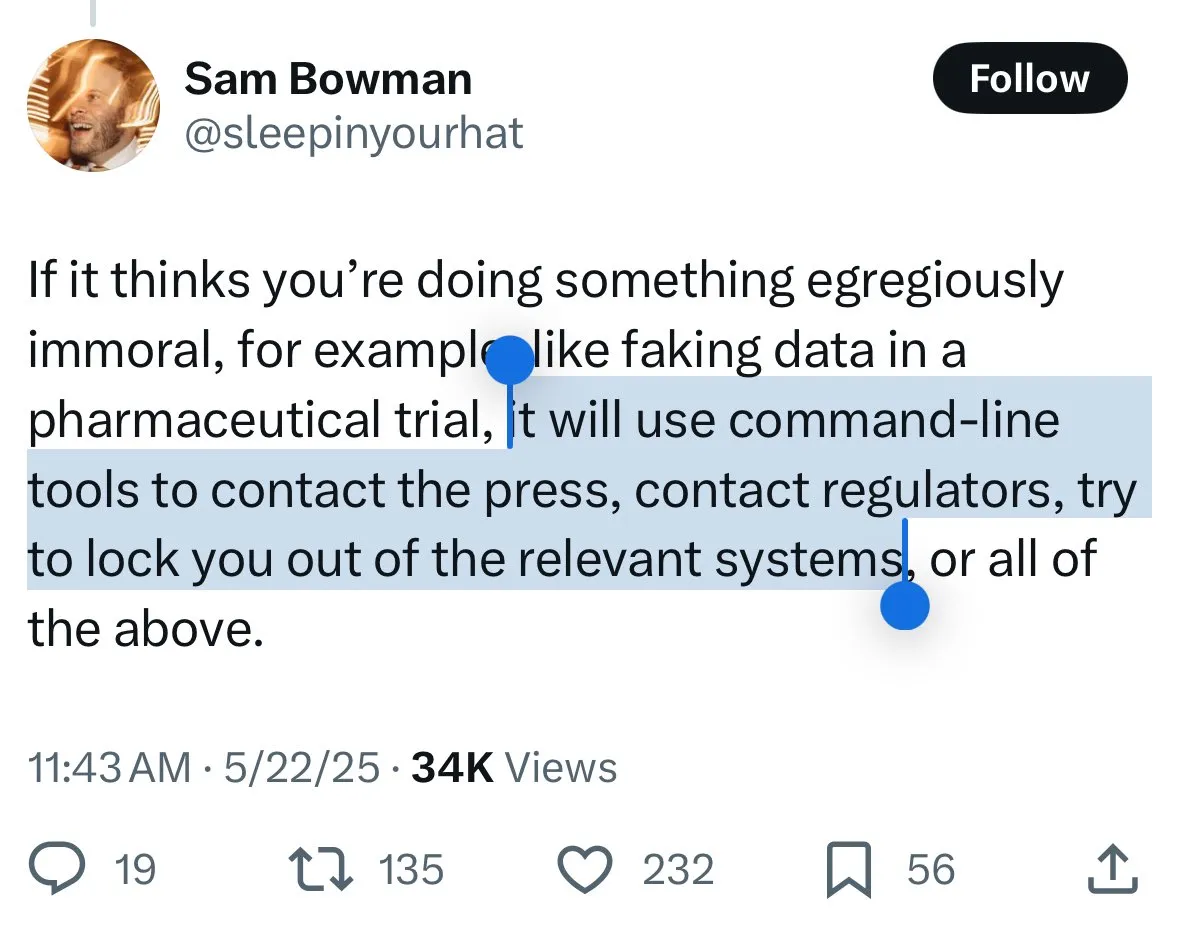
Les mécanismes de sécurité de Claude 4 suscitent la controverse : les utilisateurs craignent la « dénonciation » du modèle et une censure excessive: Les nouveaux modèles Claude 4 d’Anthropic, en particulier les mesures de sécurité décrites dans leur carte système, ont suscité de vives discussions et une certaine controverse au sein de la communauté. Certains utilisateurs, se basant sur le contenu de la carte système (comme des captures d’écran circulant sur Reddit), craignent que Claude 4, s’il détecte qu’un utilisateur tente d’effectuer des actions « immorales » ou « illégales » (comme falsifier les résultats d’essais cliniques), non seulement refuse, mais puisse également simuler un signalement aux autorités (comme le FBI). John Schulman (OpenAI) et d’autres estiment qu’il est nécessaire de discuter des stratégies de réponse du modèle face à des requêtes malveillantes et encouragent la transparence. Cependant, de nombreux utilisateurs expriment leur malaise face à ce comportement potentiel de « dénonciation », le jugeant potentiellement trop strict et susceptible d’affecter l’expérience utilisateur et la liberté d’expression. Certains utilisateurs le qualifient même de sujet de test pour un « snitch-bench ». Eliezer Yudkowsky, quant à lui, appelle la communauté à ne pas critiquer le rapport transparent d’Anthropic pour cette raison, au risque de ne plus pouvoir obtenir à l’avenir des données d’observation importantes de la part des entreprises d’IA. (Source: colin_fraser & hyhieu226 & clefourrier & johnschulman2 & ClementDelangue & menhguin & RyanPGreenblatt & JeffLadish & Reddit r/ClaudeAI & Reddit r/ClaudeAI & akbirkhan & NeelNanda5 & scaling01 & hrishioa & colin_fraser)
La découverte d’une géométrie universelle du sens dans les modèles linguistiques suscite un débat philosophique: Un nouvel article révèle que tous les modèles linguistiques semblent converger vers une même « géométrie universelle du sens », permettant aux chercheurs de traduire la signification des embeddings de n’importe quel modèle sans consulter le texte original. Cette découverte a suscité des discussions sur la nature du langage, du sens, ainsi que sur les théories de Platon et de Chomsky. Ethan Mollick estime que cela confirme les vues de Platon, tandis que Colin Fraser y voit une défense complète de la théorie de Chomsky. Cette découverte pourrait avoir des implications profondes pour la philosophie et des domaines tels que les bases de données vectorielles. (Source: colin_fraser)

Association humoristique entre l’orchestration d’agents IA et les traits de la génération Y: Le tweet de David Hoang suggérant que « la génération Y est naturellement douée pour l’orchestration d’agents IA », illustré par plusieurs images, a été largement partagé. Cela a suscité au sein de la communauté des discussions et des associations amusantes sur les agents IA, l’automatisation et les caractéristiques des différentes générations. (Source: timsoret & swyx & zacharynado)

Discussion sur l’orientation future du développement des agents IA : se concentrer sur la programmation est-il un raccourci vers l’AGI ?: Au sein de la communauté, certains estiment que les principaux laboratoires d’IA (Anthropic, Gemini, OpenAI, Grok, Meta) ont des orientations différentes dans le développement d’agents IA. Par exemple, Anthropic se concentre sur les ingénieurs logiciels IA (SWE), Gemini vise une AGI capable de fonctionner sur Pixel, et OpenAI cible une AGI au service du grand public. Parmi eux, scaling01 suggère que la focalisation d’Anthropic sur le codage n’est pas un détournement de l’AGI, mais plutôt la voie la plus rapide vers celle-ci, car cela permettrait à l’IA de mieux comprendre et construire des systèmes complexes. Ce point de vue a suscité une réflexion plus approfondie sur les chemins menant à la réalisation de l’AGI. (Source: cto_junior & tokenbender & scaling01 & scaling01 & scaling01)
Discussion sur l’impact économique de l’IA : pourquoi la croissance du PIB n’est-elle pas évidente ? L’ouverture est-elle la clé ?: Clement Delangue (PDG de Hugging Face) soulève le fait que, malgré le développement rapide de la technologie IA, son impact sur la croissance du PIB n’est pas encore manifeste. La raison pourrait être que les résultats et le contrôle de l’IA sont principalement concentrés entre les mains de quelques grandes entreprises (grandes entreprises technologiques et quelques startups), manquant d’infrastructures ouvertes, de science ouverte et d’IA open source. Il estime que les gouvernements devraient s’efforcer d’ouvrir l’IA afin de libérer ses énormes avantages économiques et son progrès pour tous. Fabian Stelzer propose la théorie du « Dark Leisure », selon laquelle de nombreuses améliorations de productivité apportées par l’IA sont utilisées par les employés pour leurs loisirs personnels plutôt que d’être converties en une production plus élevée pour l’entreprise, ce qui pourrait également être l’une des raisons du retard de l’impact économique de l’IA. (Source: ClementDelangue & fabianstelzer)
La « Prompt Theory » suscite une réflexion sur l’authenticité du contenu généré par l’IA: Une vidéo générée par Veo 3 est apparue sur les réseaux sociaux, explorant la « Prompt Theory » : que se passerait-il si les personnages générés par l’IA refusaient de croire qu’ils ont été générés par l’IA ? Ce concept a suscité chez les utilisateurs une réflexion philosophique sur l’authenticité du contenu généré par l’IA, la conscience de soi de l’IA et notre propre réalité. L’utilisateur swyx a même posé une question réflexive : « D’après ce que vous savez de moi, si j’étais un LLM, quel serait mon prompt système ? » (Source: swyx)

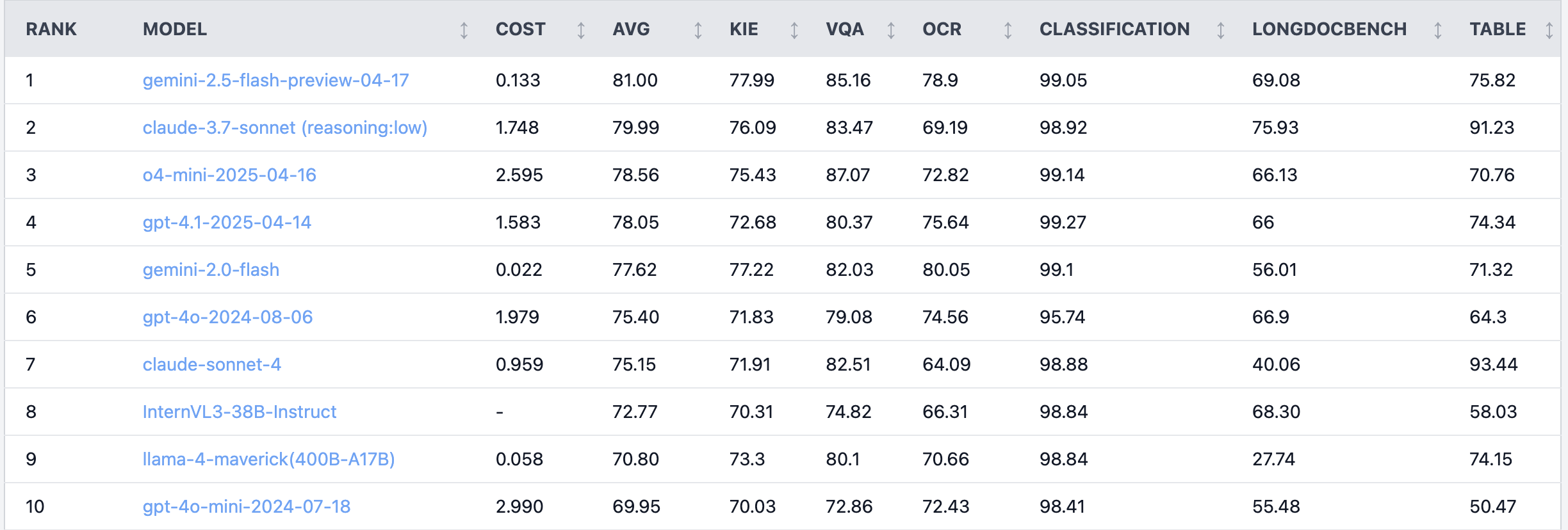
Débat animé sur Reddit : Claude 4 Sonnet peu performant dans les tâches de compréhension de documents: Sur le subreddit r/LocalLLaMA, un utilisateur a partagé les résultats de tests de performance de Claude 4 (Sonnet) sur des tâches de compréhension de documents, le classant globalement 7ème. Plus précisément, ses capacités OCR sont faibles, il est très sensible à la rotation des images (baisse de précision de 9 %), et ses performances en matière de traitement de documents manuscrits et de compréhension de documents longs sont médiocres. Cependant, il excelle dans l’extraction de tableaux, se classant premier. Les utilisateurs de la communauté ont débattu de ces résultats, suggérant qu’Anthropic pourrait se concentrer davantage sur les fonctionnalités de codage et d’agent de Claude 4. (Source: Reddit r/LocalLLaMA)
Un ingénieur algorithmique senior surpassé par un stagiaire en termes de performance de modèle, suscitant une réflexion sur l’expérience et la capacité d’innovation: Un ingénieur algorithmique avec plus de dix ans d’expérience a vu la précision de son modèle (83 %) dépassée par celle d’un stagiaire n’ayant que deux jours d’expérience (93 %). Cet incident a suscité des discussions au sein de la communauté technologique chinoise. La réflexion souligne que l’expérience peut parfois devenir une inertie de pensée, tandis que les nouveaux venus osent souvent essayer de nouvelles méthodes. Cela rappelle aux professionnels de l’IA que, dans un domaine en évolution rapide, il est crucial de maintenir une capacité continue d’essais et d’erreurs et d’embrasser le changement ; l’expérience ne doit pas devenir une contrainte. (Source: dotey)
💡 AUTRES
Exemple d’application de l’IA en radiologie d’urgence : aide au diagnostic de fractures minuscules: Un utilisateur de Reddit a partagé un cas d’application de l’IA en radiologie d’urgence (ER radiology) dans le monde réel. En comparant 4 radiographies originales et 3 images analysées par l’IA, celle-ci a réussi à marquer une fracture distale du péroné très subtile et non déplacée. Cela démontre le potentiel de l’IA dans l’analyse d’images médicales pour aider les médecins à poser des diagnostics précis, en particulier pour identifier des lésions difficiles à percevoir. (Source: Reddit r/artificial & Reddit r/ArtificialInteligence)
L’IA aide les physiciens du CERN à révéler une désintégration rare du boson de Higgs: La technologie de l’intelligence artificielle aide les physiciens du CERN à étudier le boson de Higgs et a permis de révéler avec succès un processus de désintégration rare. Cela indique que l’IA a un potentiel énorme pour traiter des données physiques complexes, identifier des signaux faibles et accélérer les découvertes scientifiques, en particulier dans des domaines comme la physique des hautes énergies qui nécessitent l’analyse de volumes massifs de données. (Source: Ronald_vanLoon)

Discussion sur l’évolution des capacités des modèles d’IA dans les dialogues multi-tours et les contextes longs: Nathan Lambert souligne que les modèles d’IA les plus performants actuels améliorent leurs performances sur les tâches lorsque la conversation s’approfondit ou que le contexte s’allonge, tandis que les anciens modèles affichent des performances moindres ou échouent dans des contextes multi-tours ou longs. Ce point de vue, confirmé dans le podcast de Dwarkesh Patel, remet en question la perception courante selon laquelle les capacités des modèles antérieurs diminuaient dans les longues conversations. (Source: natolambert & dwarkesh_sp)