
Mots-clés:Gemini 2.5 Pro, Veo 3, OpenAI, Jony Ive, Claude 4 Opus, Génération de vidéos par IA, Agent intelligent IA, Modèle multimodal, Mode Deep Think, Modèle de génération vidéo, Capacité de raisonnement IA, Conception matérielle IA, Optimisation du génie logiciel
🔥 Pleins feux
Google lance Gemini 2.5 Pro Deep Think et Veo 3, propulsant le raisonnement par IA et la génération de vidéos vers de nouveaux sommets: Lors de la conférence Google I/O, Google a dévoilé le mode Deep Think de Gemini 2.5 Pro, conçu spécifiquement pour résoudre des problèmes complexes. Ce mode a excellé sur des problèmes difficiles de concours mathématiques tels que l’USAMO, démontrant des progrès significatifs de l’IA en matière de raisonnement avancé, par exemple, en résolvant des problèmes d’algèbre complexes par un raisonnement en plusieurs étapes et en essayant différentes méthodes de preuve (comme la preuve par l’absurde, le théorème de Rolle). Parallèlement, Google a lancé le modèle de génération vidéo Veo 3, qui établit une nouvelle référence dans le domaine de la génération vidéo par IA grâce à ses scènes réalistes, la cohérence contrôlable des personnages, la synthèse sonore et diverses fonctions d’édition (telles que le changement de scène, la génération à partir d’images de référence, le transfert de style, la spécification des images de début et de fin, l’édition locale, etc.), suscitant une large attention (Source: demishassabis, lmthang, GoogleDeepMind, _philschmid, fabianstelzer, matvelloso, seo_leaders, op7418, )
OpenAI investit 6,5 milliards de dollars pour acquérir la société de Jony Ive, en vue de créer conjointement une nouvelle génération d’ordinateurs alimentés par l’IA: OpenAI a annoncé une collaboration avec Jony Ive, ancien designer en chef d’Apple, et l’acquisition de sa société, dans le but de développer ensemble une nouvelle génération d’ordinateurs alimentés par l’IA. Cette démarche marque l’expansion d’OpenAI dans le domaine du matériel et sa tentative d’intégrer profondément les capacités de l’IA dans les appareils informatiques, ce qui pourrait remodeler la manière dont les humains interagissent avec les machines. Jony Ive est réputé pour son design exceptionnel chez Apple, et sa participation laisse présager des avancées majeures en matière de design et d’expérience utilisateur pour ces nouveaux appareils, défiant ainsi les formes actuelles des dispositifs informatiques (Source: op7418, TheRundownAI, BorisMPower)
La conférence des développeurs d’Anthropic est imminente, Claude 4 Opus pourrait être lancé, l’accent étant mis sur les capacités d’ingénierie logicielle: Anthropic s’apprête à tenir sa première conférence des développeurs, et la communauté spécule largement que la nouvelle génération de modèles Claude 4 (y compris Sonnet 4 et Opus 4) pourrait y être annoncée. Des signes indiquent que l’API Claude Sonnet 3.7 présente déjà un comportement similaire à celui de Claude 4, comme l’utilisation rapide d’outils sans nécessiter d’« étapes de réflexion ». Anthropic semble se concentrer sur la résolution de problèmes d’ingénierie logicielle complexes, une voie différente de celle d’OpenAI et de Google qui visent des « modèles universels ». Le magazine TIME a également confirmé indirectement le lancement de Claude 4 Opus, renforçant davantage les attentes du marché concernant les capacités d’Anthropic en matière de codage IA et de traitement de tâches complexes (Source: op7418, mathemagic1an, cto_junior, scaling01, Reddit r/ClaudeAI)
Différences stratégiques entre OpenAI et Google en matière d’écosystème IA : assembler un navire de guerre contre transformer un empire: OpenAI et Google empruntent deux voies distinctes, respectivement « l’assemblage d’un écosystème » et la « transformation d’un écosystème », pour conquérir la position de « système d’exploitation principal » de la future plateforme IA. OpenAI assemble de A à Z des capacités IA full-stack en acquérant du matériel (io), des bases de données (Rockset), des chaînes d’outils (Windsurf) et des outils collaboratifs (Multi). Google, quant à lui, choisit d’intégrer profondément son modèle Gemini dans ses produits existants (Recherche, Android, Docs, YouTube, etc.) et de transformer ses systèmes sous-jacents pour les rendre natifs à l’IA. Bien que leurs stratégies diffèrent, leur objectif est le même : construire la plateforme ultime de l’ère de l’IA (Source: dotey)
🎯 Tendances
Microsoft dévoile sa vision du « réseau d’agents intelligents », soulignant que les agents IA deviendront le cœur du travail de nouvelle génération: Satya Nadella, PDG de Microsoft, a exposé la vision de l’entreprise pour un « agentic web » (réseau d’agents intelligents) lors de la conférence Build 2025 et dans des interviews. Il estime que les futurs agents IA deviendront des citoyens de premier ordre dans l’écosystème commercial et M365, pouvant même donner naissance à de nouvelles professions telles que « administrateur d’agents IA ». Lorsque 95 % du code sera généré par l’IA, le rôle des humains se tournera vers la gestion et l’orchestration de ces agents intelligents. Microsoft construit un écosystème d’agents ouverts via Azure AI Foundry, Copilot Studio et des protocoles ouverts comme NLWeb, et positionne Teams comme un centre de collaboration multi-agents (Source: rowancheung, TheTuringPost)
MMaDA : Lancement d’un modèle de langage à diffusion multimodale unifiant le raisonnement textuel, la compréhension multimodale et la génération d’images: Des chercheurs ont lancé MMaDA (Multimodal Large Diffusion Language Models), un nouveau type de modèle de fondation à diffusion multimodale. Grâce à une chaîne de pensée mixte longue (Mixed Long-CoT) et à un algorithme d’apprentissage par renforcement unifié UniGRPO, il unifie les capacités de raisonnement textuel, de compréhension multimodale et de génération d’images. MMaDA-8B surpasse Show-o et SEED-X en compréhension multimodale, et SDXL et Janus en génération de texte vers image. Le modèle et le code sont open source sur Hugging Face (Source: _akhaliq, arankomatsuzaki, andrew_n_carr, Reddit r/LocalLLaMA)

dKV-Cache : Un mécanisme de cache conçu pour les modèles de langage à diffusion, améliorant considérablement la vitesse d’inférence: Pour remédier à la lenteur d’inférence des modèles de langage à diffusion (DLMs), des chercheurs ont proposé le mécanisme dKV-Cache. Cette méthode s’inspire du KV-Cache des modèles autorégressifs et conçoit un cache clé-valeur pour le processus de débruitage des DLMs grâce à des stratégies de mise en cache différée et conditionnelle. Les expériences montrent que dKV-Cache peut multiplier la vitesse d’inférence par 2 à 10, réduisant significativement l’écart de vitesse entre les DLMs et les modèles autorégressifs, améliorant même les performances sur les longues séquences, et peut être appliqué aux DLMs existants sans entraînement (Source: NandoDF, HuggingFace Daily Papers)

Imagen4 excelle dans la restitution des détails, se rapprochant de la phase finale de la génération d’images: Le modèle Imagen4 a démontré une capacité impressionnante à restituer les détails lors de la génération d’images à partir d’invites textuelles complexes. Par exemple, lors de la génération d’une image contenant 25 détails spécifiques (tels que des couleurs, des objets, des emplacements, un éclairage et une ambiance particuliers), Imagen4 en a restitué avec succès 23. Cette haute fidélité et cette compréhension précise des instructions complexes indiquent que la technologie de génération de texte vers image approche un niveau « final » capable de reproduire parfaitement l’imagination de l’utilisateur (Source: cloneofsimo)

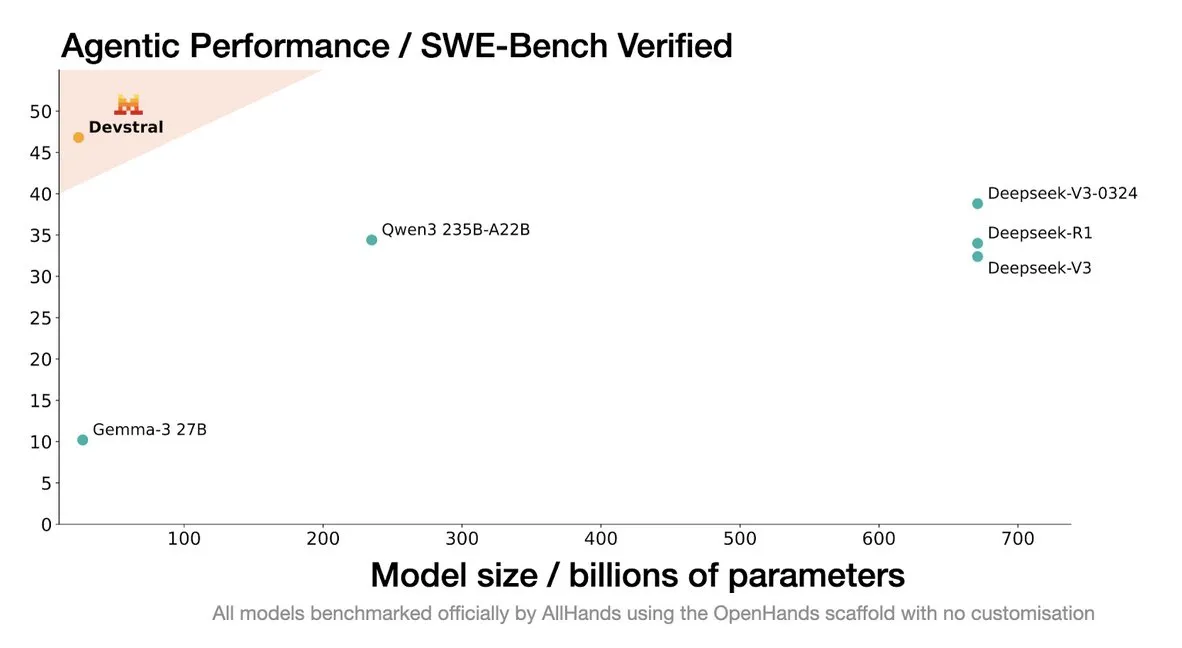
Mistral lance le modèle Devstral, conçu spécifiquement pour les agents de codage: Mistral AI a lancé Devstral, un modèle open source spécialement conçu pour les agents de codage, développé en collaboration avec allhands_ai. Sa version quantifiée DWQ 4 bits est disponible sur Hugging Face (mlx-community/Devstral-Small-2505-4bit-DWQ) et fonctionne de manière fluide sur des appareils tels que le M2 Ultra, montrant un potentiel d’optimisation dans la génération et la compréhension de code (Source: awnihannun, clefourrier, GuillaumeLample)
ByteDance publie un rapport sur l’entraînement d’un modèle multimodal de niveau Gemini, adoptant une architecture Transformer intégrée: ByteDance a publié un rapport de 37 pages détaillant sa méthode d’entraînement d’un modèle multimodal natif de type Gemini. L’élément le plus remarquable est l’architecture « Integrated Transformer », qui utilise le même réseau de base à la fois comme modèle autorégressif de type GPT et comme modèle de diffusion de type DiT, démontrant son exploration de la modélisation multimodale unifiée (Source: NandoDF)

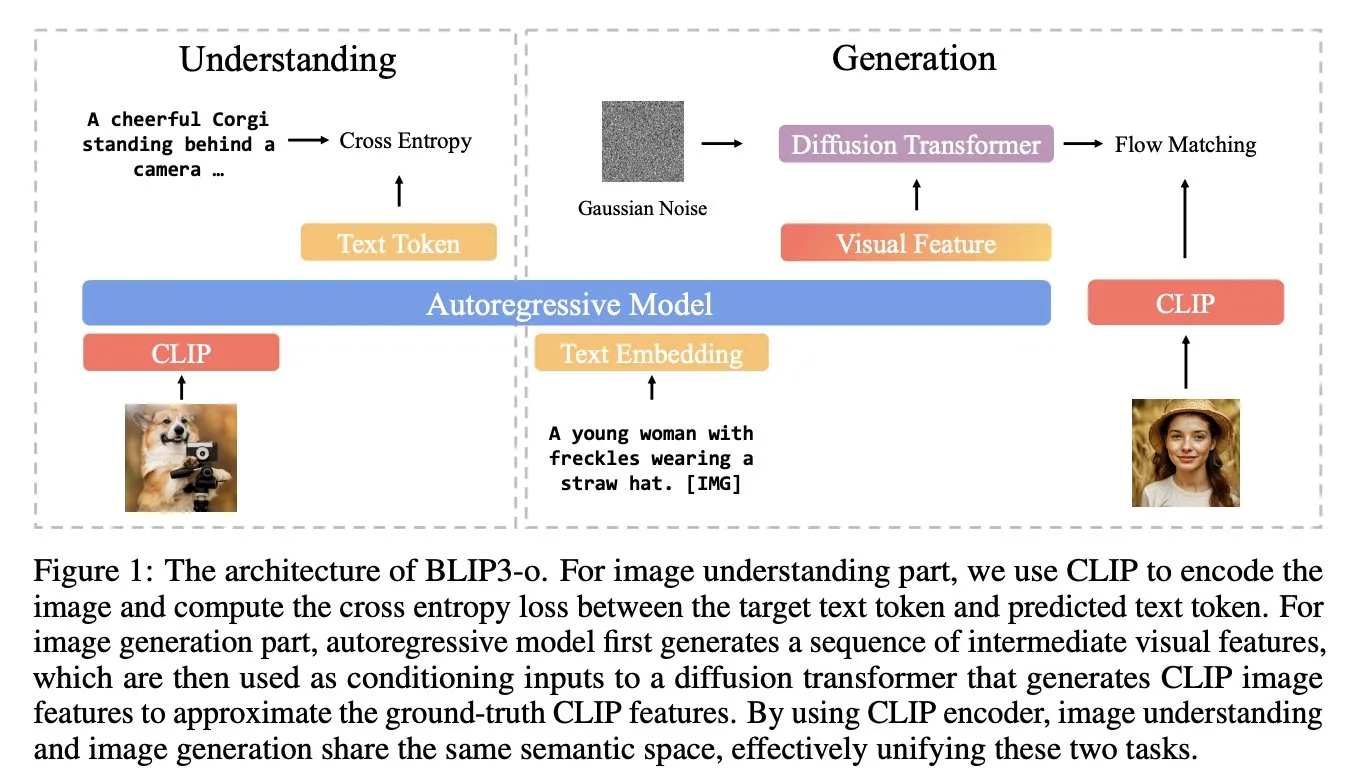
BLIP3-o : Salesforce lance une série de modèles multimodaux unifiés entièrement open source, débloquant des capacités de génération d’images de niveau GPT-4o: L’équipe de recherche de Salesforce a publié la série de modèles BLIP3-o, un ensemble de modèles multimodaux unifiés entièrement open source, visant à débloquer des capacités de génération d’images similaires à GPT-4o. Ce projet ne se contente pas de rendre les modèles open source, mais publie également un jeu de données de pré-entraînement contenant 25 millions d’entrées, favorisant l’ouverture de la recherche multimodale (Source: arankomatsuzaki)
Google lance une version préliminaire de Gemma 3n E4B, un modèle multimodal conçu pour les appareils à faibles ressources: Google a publié le modèle Gemma 3n E4B-it-litert-preview sur Hugging Face. Ce modèle est conçu pour traiter des entrées textuelles, imagées, vidéo et audio, et générer des sorties textuelles ; la version actuelle prend en charge les entrées textuelles et visuelles. Gemma 3n utilise une nouvelle architecture Matformer, permettant d’imbriquer plusieurs modèles et d’activer efficacement 2B ou 4B paramètres, optimisée spécifiquement pour un fonctionnement efficace sur les appareils à faibles ressources. Le modèle est entraîné sur environ 11 trillions de tokens de données multimodales, avec des connaissances à jour jusqu’en juin 2024 (Source: Tim_Dettmers, Reddit r/LocalLLaMA)
Une étude révèle le phénomène de la connaissance spécifique à la langue (LSK) dans les grands modèles: Une nouvelle étude explore le phénomène de la « Language Specific Knowledge » (LSK) dans les modèles linguistiques, c’est-à-dire que le modèle peut mieux performer dans certaines langues non anglaises que dans l’anglais lorsqu’il traite de certains sujets ou domaines. L’étude a révélé que les performances du modèle peuvent être améliorées en effectuant un raisonnement en chaîne de pensée dans une langue spécifique (même une langue à faibles ressources). Cela suggère que les textes spécifiques à une culture sont plus abondants dans la langue correspondante, de sorte que des connaissances spécifiques peuvent n’exister que dans les langues « expertes ». Les chercheurs ont conçu la méthode LSKExtractor pour mesurer et exploiter cette LSK, améliorant la précision relative moyenne de 10 % sur plusieurs modèles et ensembles de données (Source: HuggingFace Daily Papers)
Les effets de génération vidéo de DeepMind Veo 3 sont stupéfiants, les détails réalistes suscitent l’attention: Le modèle de génération vidéo Veo 3 de Google DeepMind a démontré de puissantes capacités de génération vidéo, notamment le changement de scène, la génération pilotée par image de référence, le transfert de style, la cohérence des personnages, la spécification des images de début et de fin, le zoom vidéo, l’ajout d’objets et le contrôle des actions. Le réalisme des vidéos générées et la compréhension des instructions complexes ont émerveillé les utilisateurs quant à la rapidité du développement de la technologie de génération vidéo par IA, certains l’utilisant même pour créer des publicités dont l’effet rivalise avec des productions professionnelles (Source: demishassabis, , Reddit r/ChatGPT)
Le modèle de langage visuel Moondream lance une version quantifiée 4 bits, réduisant considérablement la VRAM et augmentant la vitesse: Le modèle de langage visuel (VLM) Moondream a publié une version quantifiée 4 bits, réalisant une réduction de 42 % de l’occupation de la VRAM et une augmentation de 34 % de la vitesse d’inférence, tout en maintenant une précision de 99,4 %. Cette optimisation rend ce VLM petit mais puissant plus facile à déployer et à utiliser pour des tâches telles que la détection d’objets, et a été bien accueillie par les développeurs (Source: Sentdex, vikhyatk)
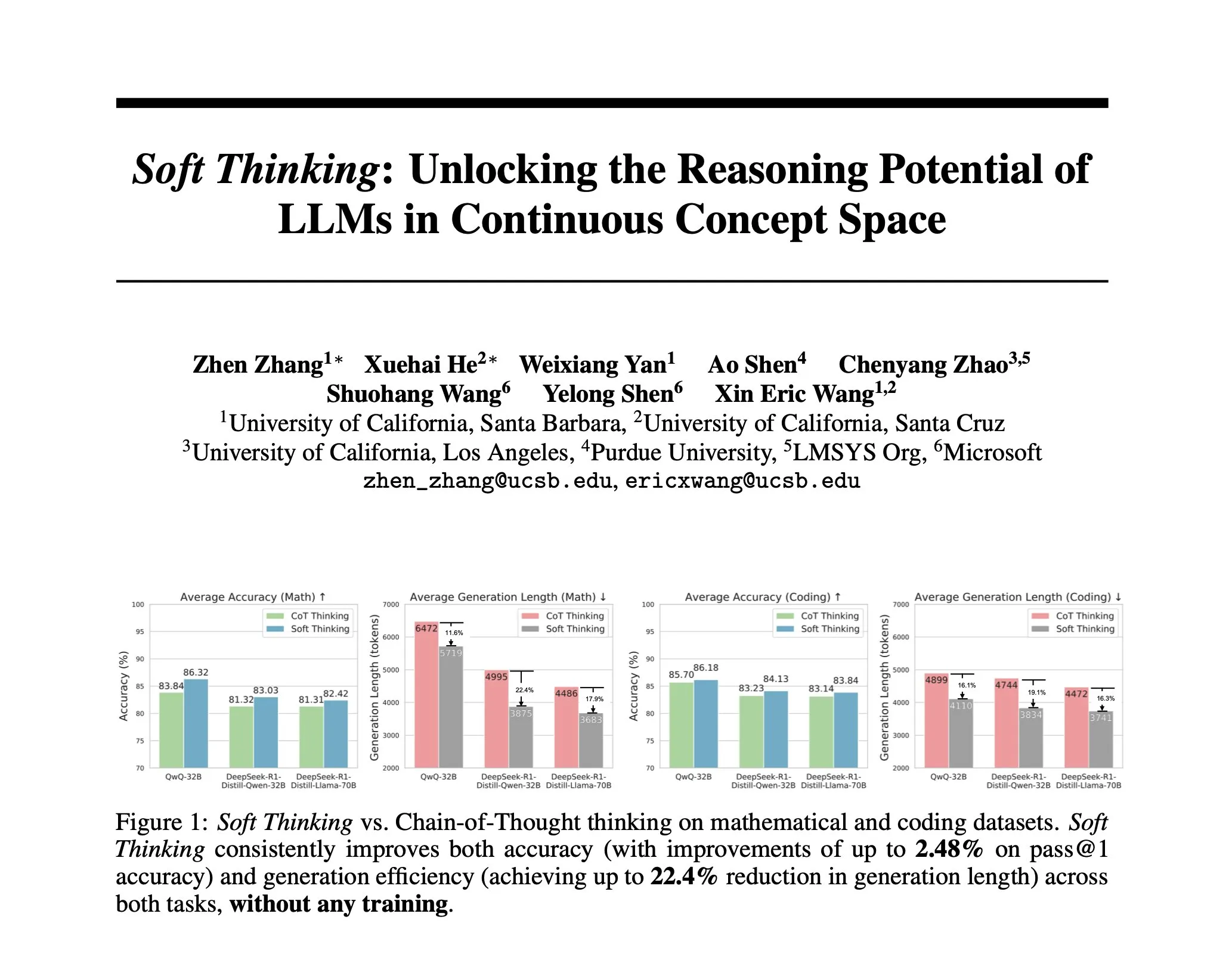
Une étude propose Soft Thinking : une méthode sans entraînement simulant le raisonnement « souple » humain: Pour rapprocher le raisonnement de l’IA de la pensée fluide humaine, non limitée par des tokens discrets, des chercheurs ont proposé la méthode Soft Thinking. Cette méthode ne nécessite aucun entraînement supplémentaire et génère des tokens conceptuels continus et abstraits. Ces tokens fusionnent en douceur plusieurs significations grâce à un mélange d’enchâssements pondérés par probabilité, permettant ainsi des représentations plus riches et une exploration transparente de différentes voies de raisonnement. Les expériences montrent que cette méthode améliore la précision jusqu’à 2,48 % (pass@1) dans les tests de référence mathématiques et de code, tout en réduisant l’utilisation de tokens jusqu’à 22,4 % (Source: arankomatsuzaki)
Framework IA-T2I : Utilisation d’Internet pour améliorer la capacité des modèles de génération texte-image à traiter les connaissances incertaines: Pour remédier aux lacunes des modèles de génération texte-image (T2I) existants dans le traitement des invites textuelles contenant des connaissances incertaines (telles que des événements récents, des concepts rares), le framework IA-T2I (Internet-Augmented Text-to-Image Generation) a été proposé. Ce framework détermine s’il faut référencer des images via un module de récupération active, utilise un module de sélection d’images hiérarchique pour choisir les images les plus appropriées parmi les résultats renvoyés par les moteurs de recherche afin d’améliorer le modèle T2I, et évalue et optimise en continu les images générées via un mécanisme d’auto-réflexion. Sur l’ensemble de données Img-Ref-T2I spécialement conçu, IA-T2I surpasse GPT-4o d’environ 30 % (évaluation humaine) (Source: HuggingFace Daily Papers)
MoI (Mixture of Inputs) améliore la qualité de la génération autorégressive et les capacités de raisonnement: Pour résoudre le problème de la perte d’informations sur la distribution des tokens lors du processus de génération autorégressive standard, les chercheurs ont proposé la méthode Mixture of Inputs (MoI). Cette méthode ne nécessite aucun entraînement supplémentaire. Après avoir généré un token, elle mélange le token discret généré avec la distribution des tokens précédemment rejetés pour construire une nouvelle entrée. En utilisant l’estimation bayésienne, la distribution des tokens est considérée comme un a priori, le token échantillonné comme une observation, et l’espérance a posteriori continue remplace le vecteur one-hot traditionnel comme nouvelle entrée du modèle. MoI a constamment amélioré les performances de plusieurs modèles tels que Qwen-32B et Nemotron-Super-49B sur des tâches de raisonnement mathématique, de génération de code et de questions-réponses de niveau doctoral (Source: HuggingFace Daily Papers)
ConvSearch-R1 : Optimisation de la réécriture de requêtes dans la recherche conversationnelle par apprentissage par renforcement: Pour résoudre les problèmes d’ambiguïté, d’omission et de référence des requêtes dépendantes du contexte dans la recherche conversationnelle, le framework ConvSearch-R1 a été proposé. Ce framework adopte pour la première fois une approche auto-dirigée, utilisant l’apprentissage par renforcement pour optimiser directement la réécriture des requêtes en utilisant les signaux de récupération, éliminant complètement la dépendance à la supervision externe de la réécriture (telle que l’annotation manuelle ou les grands modèles). Sa méthode en deux étapes comprend un préchauffage de la stratégie auto-dirigée et un apprentissage par renforcement guidé par la récupération (utilisant un mécanisme de récompense incitative basé sur le classement). Les expériences montrent que ConvSearch-R1 surpasse de manière significative les méthodes SOTA précédentes sur les ensembles de données TopiOCQA et QReCC (Source: HuggingFace Daily Papers)
Le framework ASRR permet un raisonnement auto-adaptatif efficace pour les grands modèles de langage: Pour résoudre le problème des coûts de calcul excessifs dus au raisonnement redondant des grands modèles de raisonnement (LRM) sur des tâches simples, les chercheurs ont proposé le framework de raisonnement auto-adaptatif auto-récupérateur (Adaptive Self-Recovery Reasoning, ASRR). Ce framework, en révélant le « mécanisme interne d’auto-récupération » du modèle (complétant implicitement le raisonnement lors de la génération de la réponse), supprime le raisonnement inutile et introduit un ajustement de la récompense de longueur sensible à la précision, allouant de manière adaptative l’effort de raisonnement en fonction de la difficulté de la question. Les expériences montrent qu’ASRR peut réduire considérablement le budget de raisonnement et améliorer le taux d’innocuité sur les benchmarks de sécurité avec une perte de performance minimale (Source: HuggingFace Daily Papers)
Le framework MoT (Mixture-of-Thought) améliore les capacités de raisonnement logique: Inspirés par l’utilisation par les humains de multiples modalités de raisonnement (langage naturel, code, logique symbolique) pour résoudre des problèmes logiques, les chercheurs ont proposé le framework Mixture-of-Thought (MoT). MoT permet aux LLM de raisonner à travers trois modalités complémentaires, y compris une nouvelle modalité symbolique de table de vérité. Grâce à une conception en deux étapes (entraînement MoT auto-évolutif et inférence MoT), MoT surpasse de manière significative les méthodes de chaîne de pensée monomodales sur des benchmarks de raisonnement logique tels que FOLIO et ProofWriter, avec une amélioration moyenne de la précision allant jusqu’à 11,7 % (Source: HuggingFace Daily Papers)
RL Tango : Co-entraînement du générateur et du validateur par apprentissage par renforcement pour améliorer le raisonnement linguistique: Pour résoudre les problèmes de piratage de récompense et de mauvaise généralisation causés par des validateurs (modèles de récompense) fixes ou affinés par supervision dans les méthodes d’apprentissage par renforcement des LLM existantes, le framework RL Tango a été proposé. Ce framework entraîne simultanément et de manière entrelacée le générateur LLM et un validateur LLM génératif et au niveau du processus, par apprentissage par renforcement. Le validateur est entraîné uniquement sur la base d’une récompense de vérification de l’exactitude au niveau du résultat, sans nécessiter d’annotation au niveau du processus, formant ainsi une promotion mutuelle efficace avec le générateur. Les expériences montrent que le générateur et le validateur de Tango atteignent tous deux des performances SOTA pour les modèles à l’échelle 7B/8B (Source: HuggingFace Daily Papers)
pPE : L’ingénierie des invites a priori aide à l’ajustement fin par renforcement (RFT): Une étude explore le rôle de l’ingénierie des invites a priori (prior prompt engineering, pPE) dans l’ajustement fin par renforcement (RFT). Contrairement à l’ingénierie des invites au moment de l’inférence (iPE), le pPE place les instructions (telles que le raisonnement pas à pas) avant la requête pendant la phase d’entraînement afin d’amener le modèle linguistique à internaliser des comportements spécifiques. L’expérience a converti cinq stratégies iPE (raisonnement, planification, raisonnement par code, rappel de connaissances, utilisation d’exemples vides) en méthodes pPE, appliquées à Qwen2.5-7B. Les résultats montrent que tous les modèles entraînés avec pPE surpassent les modèles iPE correspondants, le pPE avec exemples vides montrant la plus grande amélioration sur des benchmarks tels que AIME2024 et GPQA-Diamond, révélant le pPE comme un moyen efficace et sous-étudié dans le RFT (Source: HuggingFace Daily Papers)
BiasLens : Un framework d’évaluation des biais des LLM sans ensemble de tests manuels: Pour résoudre le problème des méthodes actuelles d’évaluation des biais des LLM qui dépendent de données étiquetées construites manuellement et ont une couverture limitée, le framework BiasLens a été proposé. Ce framework part de la structure de l’espace vectoriel du modèle, combine les vecteurs d’activation conceptuelle (CAVs) et les auto-encodeurs clairsemés (SAEs) pour extraire des représentations conceptuelles interprétables, et quantifie les biais en mesurant les changements de similarité de représentation entre les concepts cibles et les concepts de référence. BiasLens montre une forte cohérence (corrélation de Spearman r > 0,85) avec les indicateurs traditionnels d’évaluation des biais en l’absence de données étiquetées, et peut révéler des formes de biais difficiles à détecter avec les méthodes existantes (Source: HuggingFace Daily Papers)
HumaniBench : Un cadre d’évaluation des grands modèles multimodaux centré sur l’humain: Face aux performances insuffisantes des LMM actuels sur les critères centrés sur l’humain tels que l’équité, l’éthique et l’empathie, HumaniBench a été proposé. Il s’agit d’un benchmark complet comprenant 32 000 paires de questions-réponses texte-image du monde réel, annotées avec l’aide de GPT-4o et validées par des experts. HumaniBench évalue sept principes d’IA centrés sur l’humain : l’équité, l’éthique, la compréhension, le raisonnement, l’inclusivité linguistique, l’empathie et la robustesse, couvrant sept tâches diversifiées. Les tests sur 15 LMM SOTA montrent que les modèles à source fermée sont généralement en tête, mais la robustesse et la localisation visuelle restent des points faibles (Source: HuggingFace Daily Papers)
AJailBench : Le premier benchmark complet d’attaques de jailbreak pour les grands modèles de langage audio: Pour évaluer systématiquement la sécurité des grands modèles de langage audio (LAMs) face aux attaques de jailbreak, AJailBench a été proposé. Ce benchmark a d’abord construit l’ensemble de données AJailBench-Base contenant 1495 invites audio adverses, couvrant 10 catégories d’infractions. L’évaluation basée sur cet ensemble de données montre que les LAMs SOTA actuels ne présentent pas tous une robustesse constante. Pour simuler des attaques plus réalistes, les chercheurs ont développé une boîte à outils de perturbation audio (APT), qui recherche des perturbations subtiles et efficaces par optimisation bayésienne, générant l’ensemble de données étendu AJailBench-APT. L’étude montre que des perturbations minimes et préservant la sémantique peuvent réduire considérablement les performances de sécurité des LAMs (Source: HuggingFace Daily Papers)
WebNovelBench : Un benchmark pour évaluer la capacité des LLM à créer des romans longs: Pour relever le défi de l’évaluation de la capacité narrative longue des LLM, WebNovelBench a été proposé. Ce benchmark utilise un ensemble de données de plus de 4000 romans web chinois et définit l’évaluation comme une tâche de génération d’histoire à partir d’un plan. Grâce à une méthode LLM-comme-juge, une évaluation automatique est effectuée à partir de huit dimensions de qualité narrative, et les scores sont agrégés par analyse en composantes principales, puis comparés par classement centile avec des œuvres humaines. L’expérience a permis de distinguer efficacement les chefs-d’œuvre humains, les romans web populaires et le contenu généré par les LLM, et a effectué une analyse complète de 24 LLM SOTA (Source: HuggingFace Daily Papers)
MultiHal : Un ensemble de données multilingue basé sur un graphe de connaissances pour l’évaluation des hallucinations des LLM: Pour combler les lacunes des benchmarks d’évaluation des hallucinations existants en termes de chemins de graphes de connaissances et de multilinguisme, MultiHal a été proposé. Il s’agit d’un benchmark multilingue et multi-sauts basé sur un graphe de connaissances, spécialement conçu pour l’évaluation du texte généré. L’équipe a extrait 140 000 chemins à partir de graphes de connaissances du domaine ouvert et a sélectionné 25 900 chemins de haute qualité. L’évaluation de base montre que, sur plusieurs langues et plusieurs modèles, le RAG amélioré par graphe de connaissances (KG-RAG) améliore de manière absolue les scores de similarité sémantique d’environ 0,12 à 0,36 point par rapport aux questions-réponses ordinaires, démontrant le potentiel de l’intégration des graphes de connaissances (Source: HuggingFace Daily Papers)
Llama-SMoP : Méthode de reconnaissance vocale audio-vidéo LLM basée sur des projecteurs à mélange épars: Pour résoudre le problème du coût de calcul élevé des LLM dans la reconnaissance vocale audio-vidéo (AVSR), Llama-SMoP a été proposé. Il s’agit d’un LLM multimodal efficace qui utilise un module de projecteurs à mélange épars (SMoP), étendant la capacité du modèle sans augmenter les coûts d’inférence grâce à des projecteurs à mélange d’experts (MoE) à déclenchement épars. Les expériences montrent que la configuration Llama-SMoP DEDR, qui utilise un routage et des experts spécifiques à la modalité, obtient d’excellentes performances dans les tâches ASR, VSR et AVSR, et se comporte bien en termes d’activation des experts, d’extensibilité et de robustesse au bruit (Source: HuggingFace Daily Papers)
VPRL : Un cadre de planification purement visuelle basé sur l’apprentissage par renforcement, surpassant le raisonnement textuel en performance: Des équipes de recherche de l’Université de Cambridge, de l’University College London et de Google ont proposé VPRL (Visual Planning with Reinforcement Learning), un nouveau paradigme de raisonnement reposant uniquement sur des séquences d’images. Ce cadre utilise l’optimisation de politique relative de groupe (GRPO) pour post-entraîner de grands modèles visuels, calculant les signaux de récompense et validant les contraintes environnementales par des transitions d’état visuelles. Dans des tâches de navigation visuelle telles que FrozenLake, Maze et MiniBehavior, VPRL atteint une précision allant jusqu’à 80,6 %, surpassant de manière significative les méthodes de raisonnement basées sur le texte (telles que les 43,7 % de Gemini 2.5 Pro), et se comporte mieux dans les tâches complexes et en termes de robustesse, prouvant la supériorité de la planification visuelle (Source: 量子位)

Nvidia dévoile sa feuille de route technologique IA pour les cinq prochaines années, se transformant en une entreprise d’infrastructure IA: Jensen Huang, PDG de Nvidia, a annoncé lors du COMPUTEX 2025 le repositionnement de l’entreprise en tant que fournisseur d’infrastructure IA et a dévoilé sa feuille de route technologique pour les cinq prochaines années. Il a souligné que l’infrastructure IA sera omniprésente, à l’instar de l’électricité ou d’Internet, et que Nvidia s’engage à construire les « usines » de l’ère de l’IA. Pour soutenir cette transformation, Nvidia élargira son réseau de chaînes d’approvisionnement, approfondira sa collaboration avec TSMC et d’autres, et prévoit d’établir un bureau à Taïwan (NVIDIA Constellation) ainsi que son premier supercalculateur IA géant (Source: 36氪)

Google relance son projet de lunettes IA, lance la plateforme Android XR et des appareils tiers: Lors de la conférence I/O 2025, Google a annoncé la relance de son projet de lunettes IA/AR, a lancé la plateforme Android XR spécialement développée pour les appareils XR, et a présenté deux appareils tiers basés sur cette plateforme : Project Moohan de Samsung (concurrent du Vision Pro) et Project Aura de Xreal. Google vise à reproduire le succès d’Android dans le domaine des smartphones, en créant le « moment Android » pour les appareils XR, et en se positionnant sur les futures plateformes de calcul ambiant et spatial. Combinées au grand modèle multimodal amélioré Gemini 2.5 Pro et à la technologie d’assistant intelligent Project Astra, la nouvelle génération de lunettes IA/AR offrira une expérience révolutionnaire en matière de compréhension vocale, de traduction en temps réel, de conscience contextuelle et d’exécution de tâches complexes (Source: 36氪)

Mise à jour des principes du défi ARC-AGI-2, mettant l’accent sur le raisonnement contextuel en plusieurs étapes: Le nouveau document ARC-AGI-2 a mis à jour les principes de conception de ce défi. Les nouveaux principes exigent que la résolution des tâches nécessite des capacités de raisonnement multi-règles, multi-étapes et contextuelles. Les grilles sont plus grandes, contiennent plus d’objets et encodent plusieurs concepts interactifs. Les tâches sont nouvelles et non réutilisables pour limiter la mémorisation. Cette conception vise intentionnellement à résister à la synthèse de programmes par force brute. Les solveurs humains ont besoin en moyenne de 2,7 minutes par tâche, tandis que les meilleurs systèmes (comme OpenAI o3-medium) n’obtiennent qu’environ 3 %, toutes les tâches nécessitant un effort cognitif explicite (Source: TheTuringPost, clefourrier)
Skywork lance un super agent, visant à réduire 8 heures de travail à 8 minutes: Skywork a lancé son agent d’espace de travail IA – Skywork Super Agents, affirmant qu’il peut compresser 8 heures de travail utilisateur en 8 minutes. Ce produit se positionne comme le pionnier des agents d’espace de travail IA, ses fonctionnalités spécifiques et ses méthodes de mise en œuvre restent à observer (Source: _akhaliq)
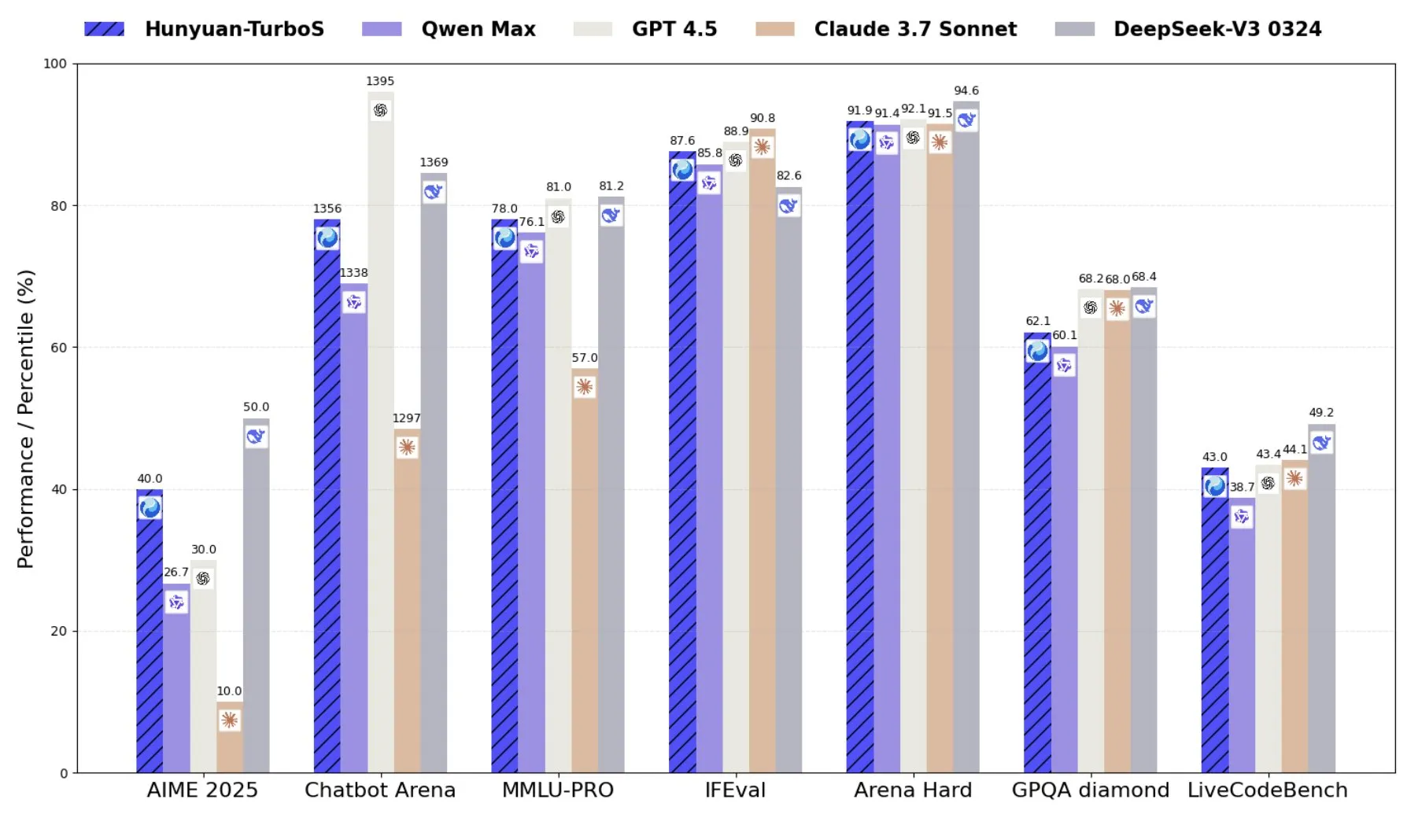
Tencent lance Hunyuan-TurboS, un modèle mixte d’experts combinant Transformer et Mamba: Tencent a lancé le modèle Hunyuan-TurboS, qui adopte une architecture mixte d’experts (MoE) combinant Transformer et Mamba, avec 56 milliards de paramètres activés et entraîné sur 16 trillions de tokens. Hunyuan-TurboS peut basculer dynamiquement entre un mode de réponse rapide et un mode de « réflexion » profonde, se classant parmi les sept premiers au classement général du LMSYS Chatbot Arena (Source: tri_dao)
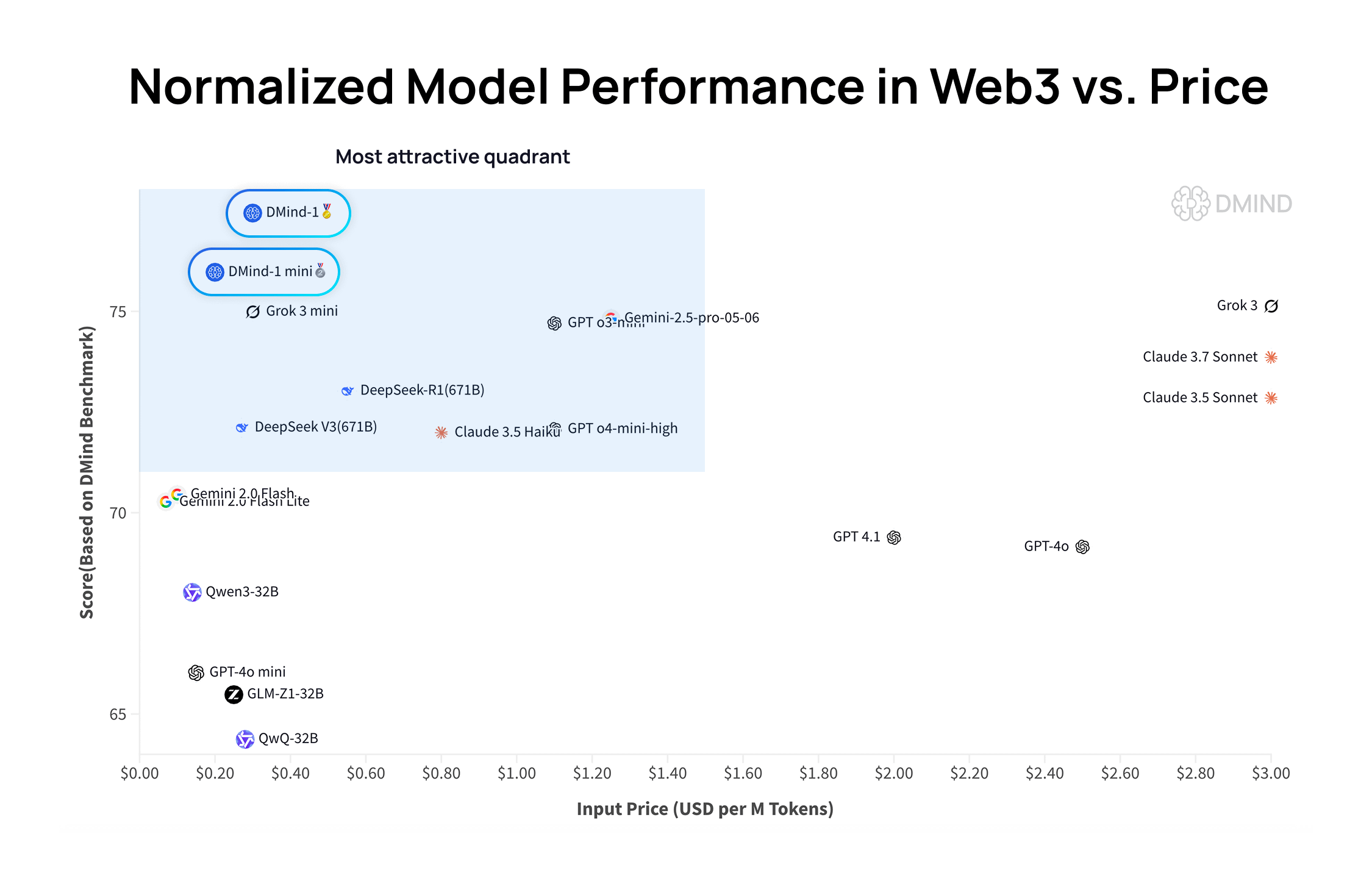
DMind-1 : Un grand modèle de langage open source conçu pour les scénarios Web3: DMind AI a lancé DMind-1, un grand modèle de langage open source optimisé pour les scénarios Web3. DMind-1 (32B) est affiné à partir de Qwen3-32B et utilise une grande quantité de connaissances spécifiques au Web3, visant à équilibrer les performances et les coûts des applications AI+Web3. Dans les évaluations de référence Web3, DMind-1 surpasse les LLM génériques grand public, avec un coût de token d’environ 10 % seulement. Le DMind-1-mini (14B) lancé simultanément conserve plus de 95 % des performances de DMind-1, tout en étant supérieur en termes de latence et d’efficacité de calcul (Source: _akhaliq)
LightOn lance Reason-ModernColBERT, un modèle à petits paramètres performant dans les tâches de recherche à forte intensité de raisonnement: LightOn a lancé Reason-ModernColBERT, un modèle à interaction tardive avec seulement 149 millions de paramètres. Dans le populaire benchmark BRIGHT (axé sur la recherche à forte intensité de raisonnement), ce modèle a excellé, surpassant des modèles 45 fois plus grands en termes de paramètres et atteignant des performances SOTA dans plusieurs domaines. Ce résultat prouve une fois de plus l’efficacité des modèles à interaction tardive sur des tâches spécifiques (Source: lateinteraction, jeremyphoward, Dorialexander, huggingface)

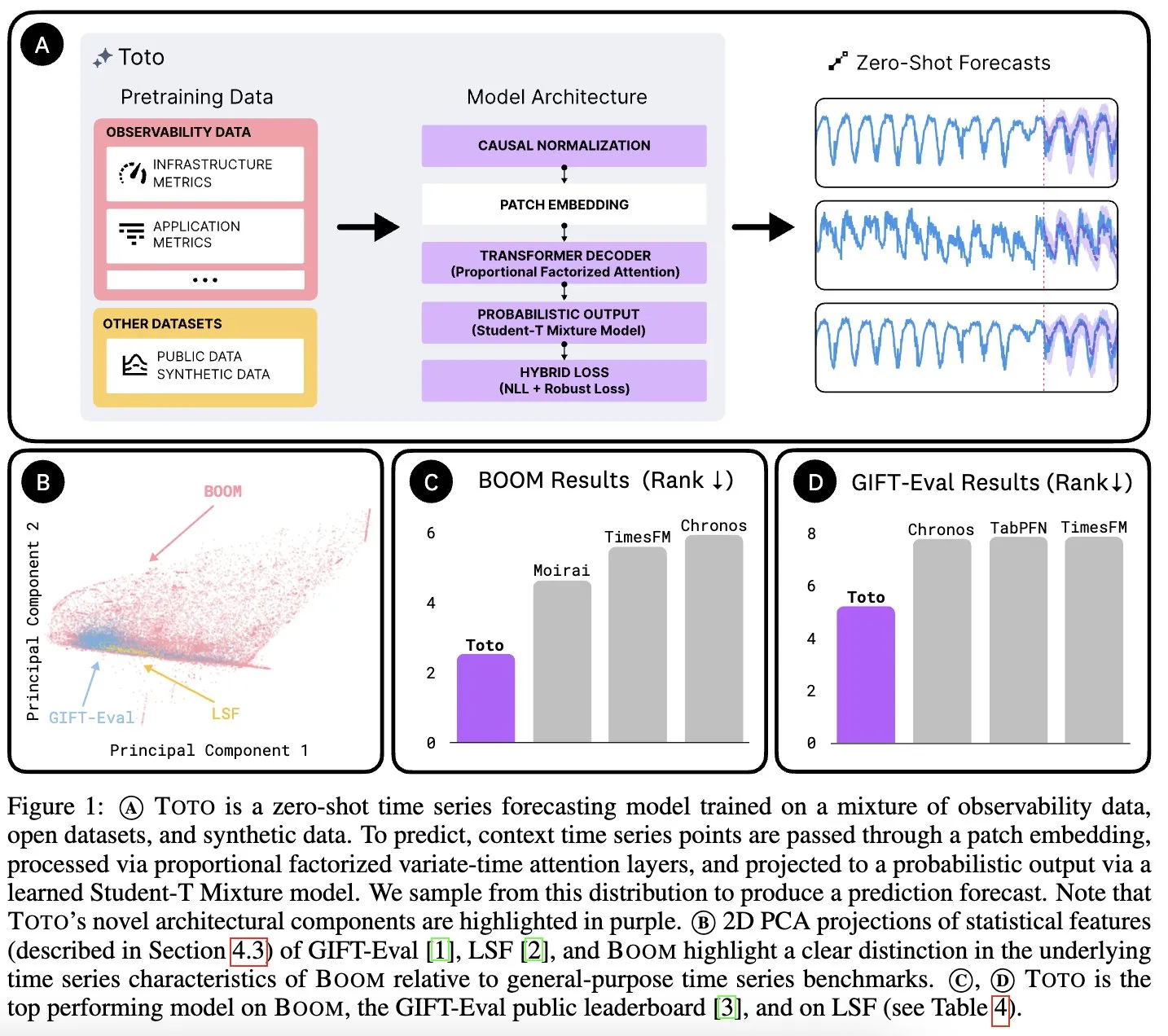
Datadog AI Research lance le modèle de base de séries temporelles Toto et le benchmark d’indicateurs d’observabilité BOOM: Datadog AI Research a lancé Toto, un nouveau modèle de base de séries temporelles, qui devance largement les modèles SOTA existants dans les benchmarks pertinents. Parallèlement, BOOM a été lancé, qui est actuellement le plus grand benchmark d’indicateurs d’observabilité. Tous deux sont open source sous licence Apache 2.0, visant à promouvoir la recherche et l’application dans les domaines de l’analyse des séries temporelles et de l’observabilité (Source: jefrankle, ClementDelangue)
TII lance la série de modèles hybrides Transformer-SSM Falcon-H1: L’Institut d’Innovation Technologique (TII) des Émirats Arabes Unis a lancé la série de modèles Falcon-H1, un ensemble de modèles de langage à architecture hybride combinant les mécanismes d’attention Transformer et les têtes de modèle d’état-espace (SSM) Mamba2. Cette série de modèles a des tailles de paramètres allant de 0,5B à 34B, prend en charge des longueurs de contexte allant jusqu’à 256K, et surpasse ou égale les meilleurs modèles Transformer tels que Qwen3-32B et Llama4-Scout dans plusieurs benchmarks, montrant notamment des avantages en multilinguisme (prise en charge native de 18 langues) et en efficacité. Les modèles ont été intégrés à vLLM, Hugging Face Transformers et llama.cpp (Source: Reddit r/LocalLLaMA)

Étude du MIT : L’IA peut apprendre l’association entre le visuel et le son sans intervention humaine: Des chercheurs du MIT ont présenté un système d’IA capable d’apprendre de manière autonome les liens entre les informations visuelles et les sons correspondants, sans directives explicites ni données étiquetées par des humains. Cette capacité est cruciale pour développer des systèmes d’IA multimodaux plus complets, leur permettant de comprendre et de percevoir le monde de manière plus humaine (Source: Reddit r/artificial, Reddit r/ArtificialInteligence)

Les Émirats arabes unis lancent un grand modèle d’IA en langue arabe, accélérant la course à l’IA dans la région du Golfe: Les Émirats arabes unis ont lancé un grand modèle d’IA en langue arabe, marquant un investissement supplémentaire dans le domaine de l’intelligence artificielle et intensifiant la concurrence entre les pays de la région du Golfe en matière de développement technologique de l’IA. Cette initiative vise à renforcer l’influence de la langue arabe dans le domaine de l’IA et à répondre aux besoins des applications d’IA localisées (Source: Reddit r/artificial)
Fenbi Technology lance un grand modèle vertical, définissant un nouveau paradigme « IA + Éducation »: Lors du sommet sur les applications industrielles de l’IA de Tencent Cloud, Fenbi Technology a présenté son grand modèle vertical auto-développé dans le domaine de la formation professionnelle. Ce modèle a déjà été appliqué à des produits tels que l’évaluation des entretiens et le système de préparation aux examens par IA, couvrant l’ensemble de la chaîne « enseignement, apprentissage, pratique, évaluation, test ». Grâce à des formes telles que les enseignants IA, l’objectif est de passer d’un enseignement « unique pour tous » à un enseignement personnalisé « unique pour chacun », et il est prévu de lancer des produits matériels IA équipés de ce grand modèle auto-développé, afin de promouvoir la transformation intelligente de l’éducation (Source: 量子位)

Beisen Kuxueyuan lance une nouvelle génération de plateforme AI Learning, introduisant cinq grands Agents IA: Après l’acquisition de Kuxueyuan, Beisen Holdings a lancé une nouvelle génération de plateforme d’apprentissage basée sur un grand modèle d’IA, AI Learning. Cette plateforme ajoute à l’eLearning existant cinq agents intelligents : un assistant de création de cours IA, un assistant d’apprentissage IA, un coach IA, un coach en leadership IA et un assistant d’examen IA. L’objectif est de bouleverser le modèle traditionnel d’apprentissage en entreprise grâce à des dialogues en temps réel avec les Agents, à l’entraînement des compétences, à l’apprentissage personnalisé et à la création de cours et d’examens centralisée par l’IA (Source: 量子位)

Rapport financier T1 de Pony.ai : Les revenus des services Robotaxi ont explosé de 800 % en glissement annuel, 1000 véhicules autonomes seront déployés d’ici la fin de l’année: Pony.ai a publié son rapport financier pour le premier trimestre 2025, avec un chiffre d’affaires total de 102 millions de yuans, en hausse de 12 % en glissement annuel. Parmi ceux-ci, les revenus des services Robotaxi, son activité principale, ont atteint 12,3 millions de yuans, soit une augmentation massive de 200,3 % en glissement annuel, et les revenus des tarifs passagers ont même explosé de 800 % en glissement annuel. L’entreprise prévoit de commencer la production en série de sa septième génération de Robotaxi au deuxième trimestre et de déployer 1000 véhicules d’ici la fin de l’année, visant à atteindre le seuil de rentabilité par véhicule. Pony.ai a également annoncé des partenariats avec Tencent Cloud et Uber pour étendre respectivement ses marchés nationaux et du Moyen-Orient via les plateformes WeChat et Uber (Source: 量子位)

Kevin Weil, CPO d’OpenAI : ChatGPT se transformera en assistant d’action, le coût du modèle est déjà 500 fois supérieur à celui de GPT-4: Kevin Weil, Chef de Produit d’OpenAI, a déclaré que le positionnement de ChatGPT passera de la réponse aux questions à l’exécution de tâches pour les utilisateurs, devenant un assistant d’action IA en utilisant des outils de manière entrelacée (comme la navigation sur le web, la programmation, la connexion à des sources de connaissances internes). Il a révélé que le coût du modèle actuel est déjà 500 fois supérieur à celui du GPT-4 initial, mais OpenAI s’engage à améliorer l’efficacité et à réduire les prix de l’API grâce à des améliorations matérielles et algorithmiques. Il estime que les Agents IA se développeront rapidement, passant du niveau d’ingénieur junior à celui d’architecte en un an (Source: 量子位)

🧰 Outils
FlowiseAI : Construire des agents IA de manière visuelle: FlowiseAI est un projet open source qui permet aux utilisateurs de construire des agents IA et des applications LLM via une interface visuelle. Il prend en charge le glisser-déposer de composants, la connexion de différents LLM, outils et sources de données, simplifiant ainsi le processus de développement d’applications IA. Les utilisateurs peuvent installer Flowise via npm ou le déployer avec Docker pour construire et tester rapidement leurs propres flux IA (Source: GitHub Trending)

Lancement de la bibliothèque JS de Hugging Face, simplifiant l’interaction avec l’API Hub et les services d’inférence: Hugging Face a lancé une série de bibliothèques JavaScript (@huggingface/inference, @huggingface/hub, @huggingface/mcp-client, etc.), visant à faciliter l’interaction des développeurs via JS/TS avec l’API Hugging Face Hub et les services d’inférence. Ces bibliothèques prennent en charge la création de dépôts, le téléversement de fichiers, l’appel à l’inférence de plus de 100 000 modèles (y compris la complétion de chat, la génération de texte vers image, etc.), l’utilisation du client MCP pour construire des agents intelligents, et prennent en charge plusieurs fournisseurs d’inférence (Source: GitHub Trending)

L’environnement d’exécution local Jan AI passe sous licence Apache 2.0, abaissant le seuil d’utilisation pour les entreprises: Jan AI, un outil open source permettant d’exécuter des LLM localement, a récemment changé sa licence d’AGPL à la licence Apache 2.0, plus permissive. Ce changement vise à faciliter le déploiement et l’utilisation de Jan par les entreprises et les équipes au sein de leurs organisations, sans se soucier des problèmes de conformité liés à l’AGPL, permettant de librement forker, modifier et publier, favorisant ainsi l’adoption à grande échelle de Jan dans des environnements de production réels (Source: reach_vb, Reddit r/LocalLLaMA)
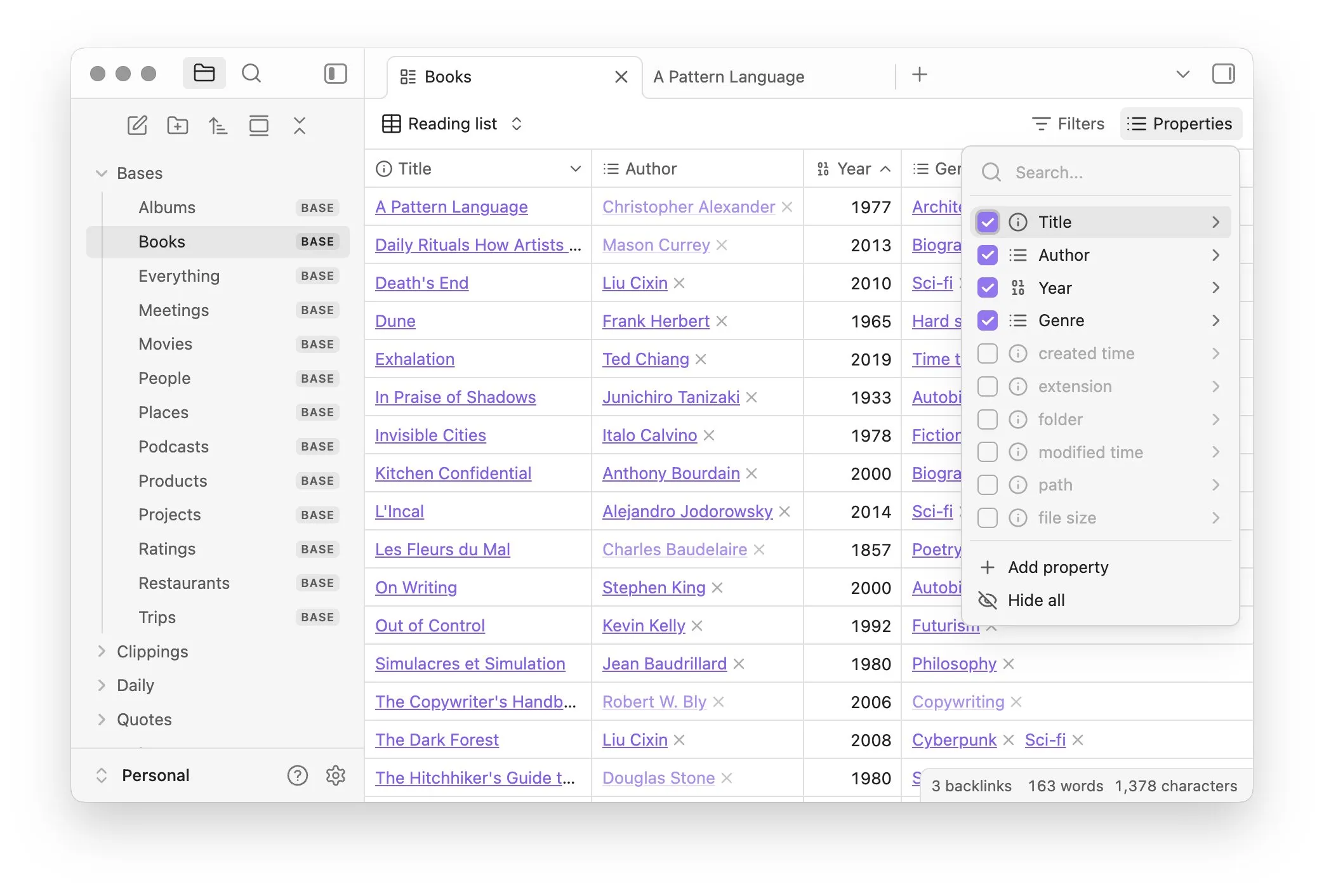
Obsidian lance le plugin de base Bases, permettant une gestion des notes sous forme de base de données: Le logiciel de gestion des connaissances Obsidian a mis à jour son plugin de base Bases, permettant aux utilisateurs de transformer leurs ensembles de notes en puissantes bases de données. Avec Bases, les utilisateurs peuvent créer des vues tabulaires personnalisées, visualiser et manipuler de manière interactive les données de leur base de connaissances, prendre en charge le filtrage des notes par propriétés et créer des formules pour dériver des propriétés dynamiques, applicables à divers scénarios tels que la gestion de projet, la planification de voyages, les listes de lecture, etc. Cette fonctionnalité est actuellement ouverte aux utilisateurs précoces (Source: op7418)
Hugging Face lance Tiny Agents, simplifiant le contrôle du navigateur et les opérations sur les fichiers par des modèles locaux: Dans son cours MCP, Hugging Face a présenté Tiny Agents, un framework de configuration facile à prendre en main pour le contrôle du navigateur. Les utilisateurs, via la ligne de commande, la configuration JSON et des invites, peuvent permettre à un LLM exécuté localement (via un serveur compatible OpenAI) de contrôler un navigateur (comme Playwright) ou le système de fichiers local, sans appel direct à l’API, offrant ainsi une commodité pour les applications d’agents de modèles locaux tels que llama.cpp (Source: Reddit r/LocalLLaMA)

Un développeur rend open source une application d’optimisation de CV par IA, basée sur LangChain et Ollama: Un développeur a construit et rendu open source une application d’optimisation de CV alimentée par l’IA. Après que l’utilisateur a téléchargé son CV actuel et la description du poste visé, l’application tente d’ajuster les mots-clés du CV pour mieux correspondre aux exigences du recrutement. Le backend de ce projet utilise LangChain, combinant la recherche éparse BM25 et des modèles denses pour une recherche hybride. Le modèle de langage s’exécute localement via Ollama, et le frontend utilise React. Le projet est actuellement au stade de preuve de concept, et le code est open source sur GitHub (Source: Reddit r/deeplearning)
L’outil de création d’applications Lovable améliore ses capacités de traitement d’images: L’outil de création d’applications IA Lovable a annoncé des améliorations de ses fonctionnalités de traitement d’images. Les utilisateurs peuvent désormais télécharger des images dans le chat et indiquer à Lovable d’utiliser ces éléments graphiques dans l’application, améliorant ainsi l’expérience utilisateur lors de la création d’applications contenant des éléments visuels avec l’aide de l’IA (Source: op7418)
Helios : La première plateforme tentant d’accélérer le travail gouvernemental avec l’IA: Joe Scheidler a lancé Helios, une plateforme visant à utiliser l’IA pour améliorer l’efficacité du travail gouvernemental, décrite comme « la version de Cursor pour le gouvernement ». Cette plateforme est l’une des premières tentatives explicites ciblant les ministères, cherchant à optimiser leurs flux de travail et leur efficacité grâce à la technologie IA. Ses fonctionnalités spécifiques et ses scénarios d’application restent à observer (Source: timsoret)
📚 Apprentissage
L’Université du Zhejiang publie le manuel « Fondations des Grands Modèles », expliquant systématiquement les connaissances sur les LLM et le mettant à jour continuellement: L’équipe LLM de l’Université du Zhejiang a rendu open source le manuel « Fondations des Grands Modèles », visant à fournir aux lecteurs intéressés par les grands modèles de langage une base de connaissances systématique et une introduction aux technologies de pointe. Ce livre couvre les modèles de langage traditionnels, l’évolution de l’architecture des LLM, l’ingénierie des prompts, l’ajustement fin efficace des paramètres, l’édition de modèles, la génération augmentée par récupération, etc., et sera mis à jour mensuellement. Chaque chapitre est accompagné d’une liste d’articles pertinents pour suivre les derniers progrès. Le PDF complet et le contenu par chapitre ont été publiés sur GitHub (Source: GitHub Trending)

Hugging Face propose 10 cours d’IA gratuits, couvrant divers niveaux et domaines de connaissances: Hugging Face a compilé 10 cours d’IA gratuits proposés sur sa plateforme, dont le contenu couvre divers sujets d’IA populaires, du niveau débutant au niveau avancé, y compris le traitement du langage naturel, l’apprentissage profond, l’apprentissage par renforcement, le traitement audio, le multimodal, etc. Ces cours offrent aux apprenants de différents niveaux des ressources précieuses pour apprendre systématiquement les connaissances en IA, favorisant davantage la vulgarisation des connaissances en IA et le développement de la communauté open source (Source: huggingface, reach_vb, _akhaliq)

L’Université de Stanford partage son expérience et ses leçons apprises lors de l’entraînement du modèle Marin 8B: L’équipe de Percy Liang de l’Université de Stanford a publié un compte rendu détaillé de l’entraînement de leur modèle Marin 8B à partir de zéro (qui a surpassé le modèle de base Llama 3.1 8B sur plusieurs benchmarks). Ce compte rendu honnête contient toutes les découvertes de l’équipe et les erreurs commises au cours du processus de développement, fournissant à la communauté une expérience précieuse de la construction réelle de LLM, et soulignant l’importance des essais, des erreurs et de l’itération dans le processus de recherche scientifique (Source: stanfordnlp, YejinChoinka, hrishioa)
DeepLearning.AI et Predibase s’associent pour lancer un cours sur l’ajustement fin par renforcement (RFT) des LLM: DeepLearning.AI d’Andrew Ng s’est associé à Predibase pour lancer un cours de courte durée gratuit sur l’utilisation du GRPO (Group Relative Policy Optimization) pour l’ajustement fin par renforcement (RFT) afin d’améliorer les performances des LLM. Le cours est dispensé par Travis Addair, co-fondateur et CTO de Predibase, entre autres, et vise à aider les apprenants à maîtriser comment utiliser l’apprentissage par renforcement pour transformer de petits LLM open source en moteurs de raisonnement pour des cas d’utilisation spécifiques, avec seulement une petite quantité de données annotées (Source: DeepLearningAI)
La page des articles de Hugging Face ajoute une fonction de résumé généré par IA: Hugging Face a introduit une nouvelle fonctionnalité sur sa page de présentation des articles, fournissant pour chaque article un résumé d’une phrase généré par IA. Ce résumé vise à synthétiser de manière concise le contenu principal de l’article, aidant les utilisateurs à filtrer et à comprendre rapidement la littérature de recherche, améliorant ainsi l’accessibilité et l’efficacité d’utilisation des ressources académiques. Cette fonctionnalité est alimentée par un LLM open source, incarnant le concept de « l’IA au service de la recherche en IA » (Source: _akhaliq, _akhaliq, _akhaliq, _akhaliq, huggingface)

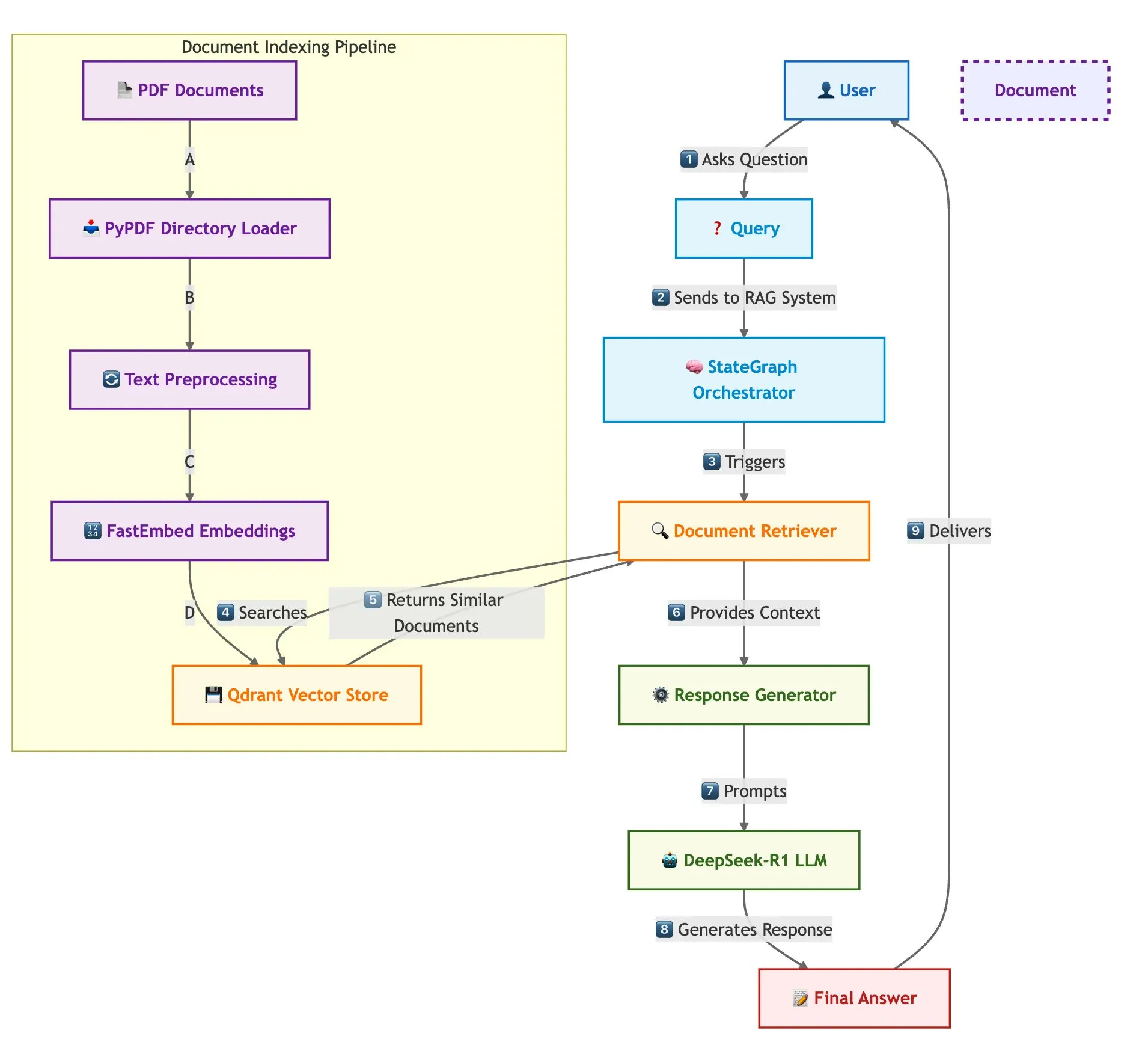
Qdrant, SambaNova et d’autres présentent conjointement une solution de construction rapide de systèmes RAG multi-documents: Un blog technique explique comment utiliser la base de données vectorielle Qdrant, SambaNova, DeepSeek-R1 et LangGraph pour construire un système de génération augmentée par récupération (RAG) multi-documents rapide et économe en mémoire. Cette solution permet une économie de mémoire de 32 fois grâce à la quantification binaire, utilise DeepSeek-R1 pour des réponses LLM rapides et centralisées, et s’appuie sur LangGraph pour une orchestration modulaire, adaptée aux scénarios de traitement multi-documents à grande échelle (Source: qdrant_engine)
Publication du compte-rendu du sommet LangChain Interrupt 2025 (version en mandarin): Le compte-rendu en mandarin du sommet LangChain Interrupt 2025 a été publié. Ce sommet a attiré plus de 800 participants du monde entier, qui ont partagé leurs expériences et leurs perspectives sur la construction d’agents IA, et ont annoncé plusieurs produits tels que LangGraph Platform et LangGraph Studio v2, tout en discutant de sujets tels que l’ingénierie des agents et l’observabilité de l’IA (Source: hwchase17)
Andi Marafioti publie un tutoriel nanoVLM, expliquant pas à pas l’entraînement d’un modèle de langage visuel en PyTorch pur: Andi Marafioti a publié un nouveau tutoriel de blog, intitulé nanoVLM, qui explique en détail comment entraîner son propre modèle de langage visuel (VLM) à partir de zéro en utilisant uniquement PyTorch. Le tutoriel est facile à comprendre et à prendre en main, visant à aider les débutants à maîtriser rapidement le processus d’entraînement des VLM (Source: LoubnaBenAllal1)

Ferenc Huszár décrypte les chaînes de Markov en temps continu et leur application dans les modèles de langage à diffusion: Le chercheur en apprentissage profond Ferenc Huszár a publié un article de blog expliquant de manière accessible l’intuition derrière les chaînes de Markov en temps continu (CTMC), qui sont des composants clés des modèles de langage à diffusion (DLM) tels que Mercury et Gemini Diffusion. L’article explore différentes perspectives sur les chaînes de Markov et leurs liens avec les processus ponctuels, offrant une référence précieuse pour comprendre les fondements théoriques des DLM (Source: fhuszar)
💼 Affaires
La société « d’IA artificielle » Builder.ai déclare faillite, après avoir levé près de 500 millions de dollars: La société britannique Builder.ai (anciennement Engineer.ai), qui prétendait révolutionner le développement logiciel avec l’IA et dont la valorisation avait atteint 1 milliard de dollars, a annoncé cette semaine sa liquidation judiciaire. Il avait été révélé que de nombreuses fonctionnalités de sa plateforme IA étaient en réalité réalisées manuellement par des ingénieurs indiens. Malgré un financement de près de 500 millions de dollars de la part d’institutions renommées telles que Microsoft et SoftBank DeepCore, l’entreprise a finalement épuisé ses fonds en raison de doutes sur l’authenticité de sa technologie, d’une gestion financière chaotique et de litiges juridiques impliquant son fondateur, laissant une dette de 30 millions de dollars envers Microsoft et de 85 millions de dollars envers Amazon pour des services cloud (Source: 36氪)

LMArena.ai (anciennement LMSys) lève 100 millions de dollars en financement de démarrage, passant d’une application Gradio à la commercialisation: LMArena.ai, initialement un projet académique basé sur Gradio appelé LMSys (pour la compétition et l’évaluation des LLM), a annoncé avoir levé 100 millions de dollars en financement de démarrage, mené par a16z et la société d’investissement de l’Université de Californie. Ce financement soutiendra la poursuite des recherches de LMArena sur l’IA fiable et l’exploitation de sa plateforme, marquant la transition d’un projet académique open source réussi vers une exploitation commerciale. Cela souligne également le potentiel d’outils de prototypage rapide comme Gradio pour incuber des projets d’IA influents (Source: ClementDelangue, _akhaliq, clefourrier)
La guerre des talents en IA s’intensifie, OpenAI, Google et d’autres offrent des salaires de plusieurs millions pour attirer les meilleurs: La course aux talents dans le domaine de l’IA à la Silicon Valley est devenue brûlante, les chercheurs de haut niveau (IC) étant la ressource principale que se disputent les géants comme OpenAI, Google et xAI, avec des salaires et des stock-options dépassant généralement les dizaines de millions de dollars par an. Par exemple, OpenAI a offert une prime de 2 millions de dollars et plus de 20 millions de dollars en actions pour retenir un chercheur senior qui envisageait de rejoindre SSI ; Google DeepMind offre également des salaires annuels de 20 millions de dollars aux meilleurs talents. Cette concurrence féroce découle de la contribution énorme d’un petit nombre de talents clés au développement des grands modèles de langage, leur départ ou leur maintien pouvant directement influencer le succès ou l’échec des modèles d’IA (Source: 36氪)
🌟 Communauté
La capacité de Sora en chinois semble s’être améliorée, mais les limitations du modèle persistent: Des utilisateurs des réseaux sociaux ont observé que le modèle de génération vidéo Sora d’OpenAI semble avoir progressé dans le traitement du texte chinois, capable de générer des scènes contenant des caractères chinois. Cependant, les utilisateurs soulignent également que le modèle a toujours ses limites, le contenu généré n’étant pas parfait, et accepter cette imperfection pourrait être une norme pour interagir avec les modèles d’IA à ce stade (Source: dotey)

Gemini lance une fonction « d’examen » de rapports approfondis, facilitant la réutilisation des connaissances et la boucle d’apprentissage: Google Gemini a lancé une nouvelle fonctionnalité : après avoir lu un rapport approfondi, Gemini peut directement poser des questions pour tester l’utilisateur. Cette fonction vise à vérifier le degré de compréhension réelle du contenu par l’utilisateur et à construire une boucle d’apprentissage native à l’IA « apprendre → tester → compléter → réapprendre », soulignant que l’essentiel de l’apprentissage à l’ère de l’IA réside dans la capacité à réutiliser les connaissances plutôt que dans la quantité de lecture (Source: dotey)
La fonction de mémoire de ChatGPT suscite des inquiétudes des utilisateurs quant au contrôle: La nouvelle fonction de ChatGPT « apprendre et mémoriser à partir des discussions » permet au modèle de se souvenir des informations des conversations passées de l’utilisateur afin de fournir des réponses plus personnalisées lors des interactions ultérieures. Cependant, certains utilisateurs avancés expriment des inquiétudes, estimant que cela change la manière d’interagir avec le modèle. Ils préfèrent avoir un contrôle total sur le contenu d’entrée du modèle et ne souhaitent pas que le modèle utilise des informations historiques à leur insu ou sans qu’ils puissent le contrôler précisément (Source: random_walker)
Le développement rapide des Agents IA pourrait modifier les futurs modes de travail: La communauté discute activement du développement rapide des Agents IA et de leur impact potentiel sur les futurs modes de travail. L’opinion dominante est que les Agents IA évoluent d’outils de questions-réponses simples vers des « employés virtuels » capables d’accomplir des tâches complexes de manière autonome (comme le codage, la recherche, le support client). Kevin Weil, CPO d’OpenAI, prévoit que les capacités des Agents IA augmenteront rapidement, passant du niveau d’ingénieur junior à celui d’architecte en un an. Microsoft a également proposé le concept de « réseau d’agents intelligents », laissant présager un avenir où le travail pourrait s’articuler autour de la gestion et de l’orchestration des agents IA (Source: rowancheung, 量子位)
L’IA a un potentiel énorme dans le diagnostic médical, mais suscite des inquiétudes professionnelles chez les médecins: L’IA démontre des capacités étonnantes en matière de diagnostic médical. Par exemple, une étude affirme que le modèle o1-preview présente des capacités surhumaines dans les tâches de raisonnement et de diagnostic médicaux, et des cas où l’IA détecte une pneumonie en quelques secondes ont également attiré l’attention. Cela fait du diagnostic assisté par IA un sujet brûlant, mais inquiète également certains médecins ayant 20 ans d’expérience quant à leurs perspectives de carrière, certains plaisantant même sur le fait d’aller travailler chez McDonald’s. La communauté estime que l’IA devrait plutôt être considérée comme un outil aidant les médecins à améliorer leur efficacité et leur précision, et non comme un substitut complet (Source: paul_cal, Reddit r/ArtificialInteligence)
Les éditeurs de presse accusent le mode de recherche IA de Google de « vol »: L’Alliance des médias d’information et d’autres éditeurs ont exprimé leur vif mécontentement à l’égard du nouveau mode de recherche IA de Google, le qualifiant de « vol ». Ils estiment que l’IA de Google extrait directement des informations du contenu des actualités et les intègre dans les résultats de recherche, contournant les sites d’information, ce qui nuit au trafic et aux revenus publicitaires des éditeurs, soulevant un débat houleux sur les droits d’auteur et l’utilisation équitable du contenu à l’ère de l’IA (Source: Reddit r/artificial)
Le modèle DeepSeek est utilisé en Chine pour la divination traditionnelle, soulevant un débat sur les frontières de l’application de l’IA: Des utilisateurs ont découvert qu’une part importante du trafic du modèle DeepSeek en Chine provient d’utilisateurs l’employant pour des activités de divination traditionnelle telles que la consultation du Yi Jing. Ce phénomène a suscité des discussions sur les frontières de l’application de l’IA et son adaptation culturelle, reflétant également indirectement l’exploration diversifiée et les besoins des utilisateurs en matière de capacités de l’IA (Source: menhguin, cto_junior)

💡 Autres
Le robot humanoïde de Figure complète un service continu de 20 heures sur la chaîne de production de BMW: La société de robots humanoïdes Figure a annoncé que son robot a réussi à effectuer un service continu de 20 heures sur la chaîne de production de la BMW X3. Auparavant, le robot avait subi plusieurs semaines de tests avec des services de 10 heures. Figure affirme qu’il s’agit de la première fois au monde qu’un robot humanoïde accomplit un travail continu aussi long sur une chaîne de production automobile, démontrant son potentiel dans le domaine de l’automatisation industrielle (Source: adcock_brett, TheRundownAI)
Différence et lien entre Agentic AI et GenAI: La communauté a discuté des concepts d’Agentic AI (IA agentique) et de Generative AI (IA générative). L’IA générative désigne principalement l’IA capable de créer de nouveaux contenus (texte, images, code, etc.), tandis que l’IA agentique met davantage l’accent sur l’autonomie, l’orientation vers un objectif et la capacité d’interagir et d’agir avec l’environnement. L’IA agentique utilise généralement l’IA générative comme l’une de ses capacités principales pour comprendre, planifier et exécuter des tâches, et constitue une direction importante pour l’évolution de l’IA vers une intelligence autonome plus avancée (Source: Ronald_vanLoon, Ronald_vanLoon)

L’application de l’IA dans la recherche scientifique est sous-estimée, avec un phénomène de « maquillage des résultats »: La communauté souligne que le potentiel de l’IA dans la recherche scientifique est énorme mais pourrait être sous-estimé, et qu’il existe un phénomène où les chercheurs « maquillent » les résultats des expériences d’IA pour publication. Par exemple, dans des domaines tels que les équations aux dérivées partielles (EDP), les performances réelles de l’IA pourraient ne pas être aussi exceptionnelles que celles présentées dans les articles. Cela suggère que la communauté scientifique doit évaluer de manière plus rigoureuse et transparente le rôle réel et les limites de l’IA dans les découvertes scientifiques (Source: clefourrier)