Mots-clés:OpenAI, Jony Ive, Matériel d’IA, Google I/O, Gemini, Mistral AI, Devstral, Programmation IA, Acquisition d’OpenAI io, Gemini 2.5 Pro, Modèle open source Devstral, Outil de production cinématographique IA Flow, Agent de programmation IA Jules
🔥 聚焦
OpenAI annonce l’acquisition de io, la start-up de matériel AI de Jony Ive, pour 6,5 milliards de dollars: OpenAI confirme l’acquisition de io, la société de matériel AI fondée par l’ancien chef du design d’Apple, Jony Ive, en collaboration avec SoftBank, pour une valeur d’environ 6,5 milliards de dollars. Jony Ive deviendra le directeur de la création d’OpenAI, responsable de la conception des produits. L’équipe d’io, d’environ 55 personnes, rejoindra OpenAI pour se consacrer au développement de nouveaux types d’appareils matériels AI, le premier produit étant attendu pour 2026. Cette acquisition marque l’entrée officielle d’OpenAI dans le domaine du matériel, visant à créer des appareils informatiques personnels et des expériences interactives natives AI, susceptibles de défier le marché actuel des smartphones et des appareils informatiques. (Source: 量子位, 智东西, 新芒xAI, sama, Reddit r/artificial, dotey, steph_palazzolo, karinanguyen_, kevinweil, npew, gdb, zachtratar, shuchaobi, snsf, Reddit r/ArtificialInteligence)

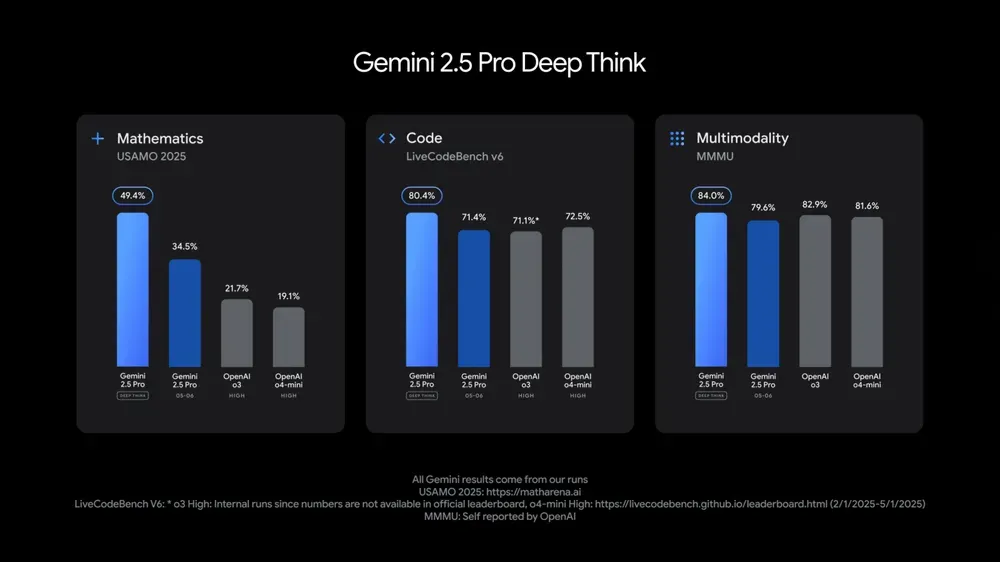
Google I/O dévoile plusieurs modèles et applications AI, soulignant l’intégration de l’AI dans le quotidien: Lors de sa conférence des développeurs I/O 2025, Google a présenté Gemini 2.5 Pro et sa version Deep Think, la version légère Gemini 2.5 Flash, le modèle de diffusion de texte Gemini Diffusion, le modèle de génération d’images Imagen 4 et le modèle de génération vidéo Veo 3. Veo 3 prend en charge la génération de vidéos avec audio et dialogues, avec des résultats impressionnants. Google a également lancé Flow, une application de création cinématographique AI, intégrant Veo, Imagen et Gemini. La fonction de recherche AI intégrera des résumés AI, Deep Search et des informations personnelles, et introduira un AI Mode. Google souligne l’intégration transparente de l’AI dans ses produits et services existants, visant à rendre la technologie AI « invisible » pour améliorer l’expérience utilisateur. (Source: , MIT Technology Review, dotey, JeffDean, demishassabis, GoogleDeepMind, Google, Reddit r/ChatGPT)

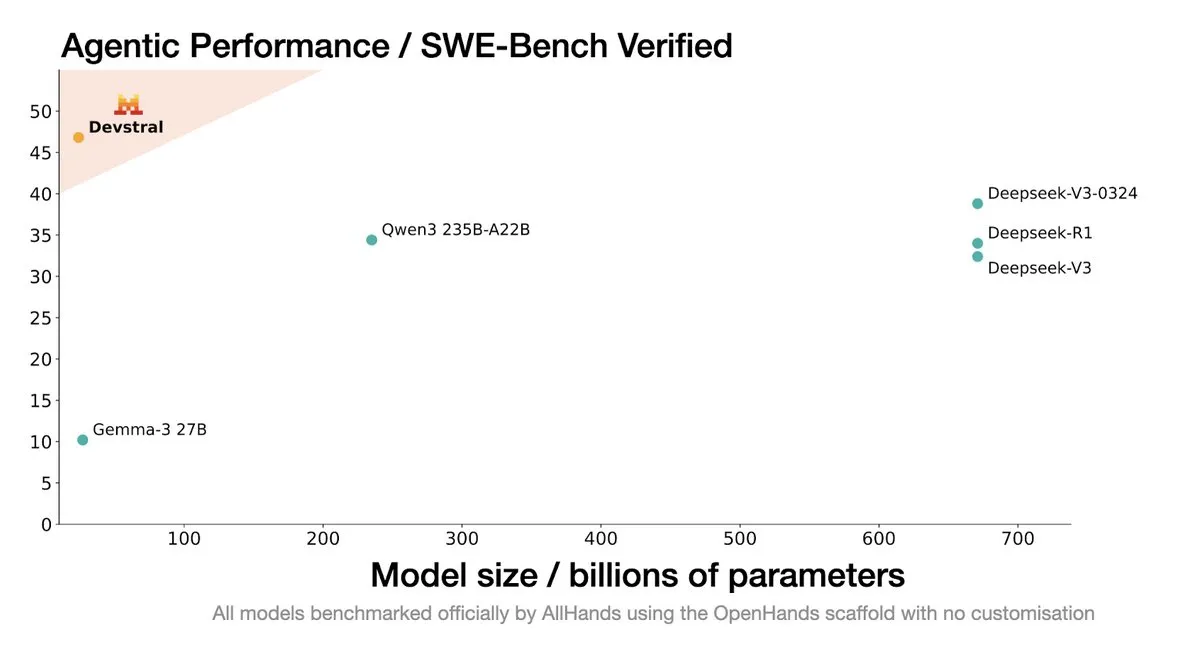
Mistral AI lance Devstral : un modèle open source SOTA conçu pour les agents de codage: Mistral AI, en collaboration avec All Hands AI, a lancé Devstral, un modèle open source SOTA spécialement conçu pour les agents de codage. Ce modèle a excellé dans le benchmark SWE-Bench Verified, surpassant les séries DeepSeek et Qwen3 235B, avec seulement 24B de paramètres, et peut fonctionner sur une seule carte RTX4090 ou un Mac avec 32 Go de mémoire. Devstral est entraîné sur de véritables GitHub Issues, mettant l’accent sur la compréhension contextuelle dans de grandes bases de code, l’identification des relations entre composants et la reconnaissance des erreurs dans les fonctions complexes. Il est publié sous la licence open source Apache 2.0, plus ouverte que le précédent Codestral. (Source: MistralAI, natolambert, karminski3, qtnx_, huggingface, arthurmensch)
Koray Kavukcuoglu, CTO de Google DeepMind, décrypte Veo 3, Deep Think et les progrès vers l’AGI: Lors de la conférence Google I/O, Koray Kavukcuoglu, CTO de DeepMind, a accordé une interview pour discuter des avancées du modèle de génération vidéo Veo 3 (comme la synchronisation audio-vidéo), du mode de raisonnement amélioré Deep Think dans Gemini 2.5 Pro (qui raisonne via des chaînes de pensée parallèles) et de sa vision de l’AGI. Kavukcuoglu a souligné que l’échelle n’est pas le seul facteur pour atteindre l’AGI ; l’architecture, les algorithmes, les données et les techniques de raisonnement sont tout aussi importants. La réalisation de l’AGI nécessite des percées en recherche fondamentale et des innovations clés, plutôt qu’une simple accumulation d’ingénierie. Il est également optimiste quant au “vibe coding” qui permettrait aux personnes sans formation en codage de créer des applications. (Source: demishassabis, 36氪)
🎯 动向
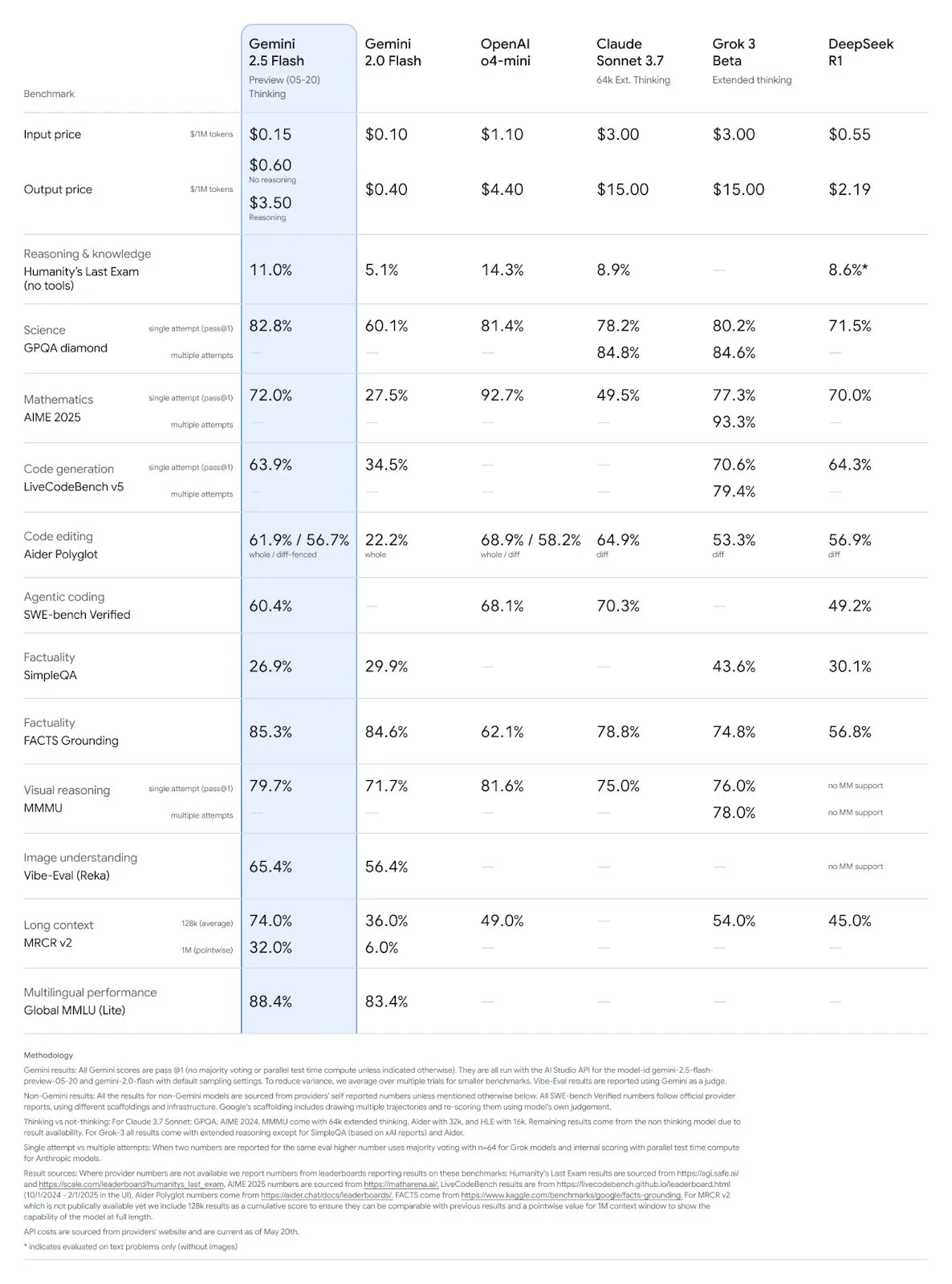
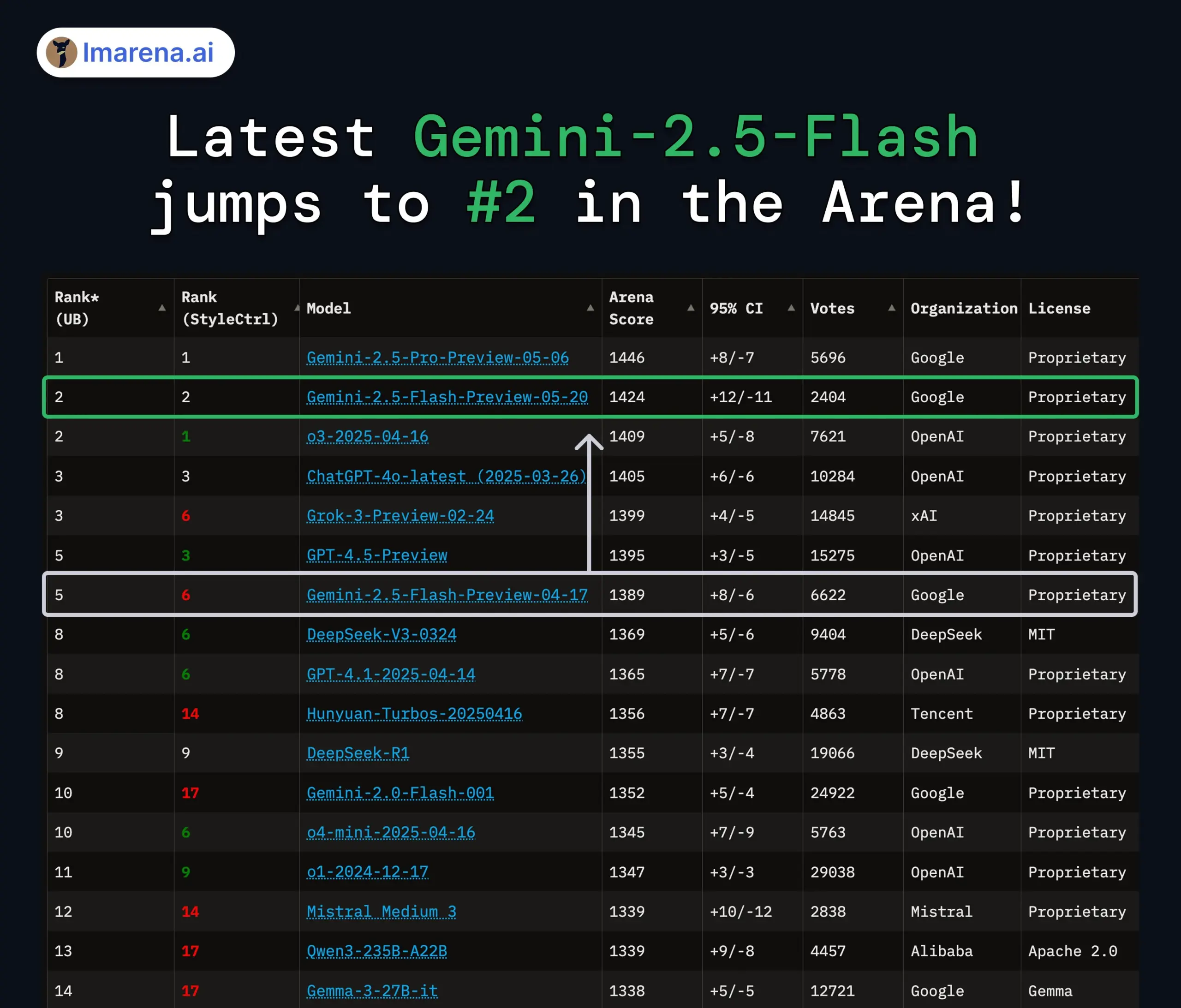
Mise à jour des modèles Google Gemini 2.5 Pro et Flash, performances significativement améliorées: Google a annoncé lors de sa conférence I/O que les modèles Gemini 2.5 Pro et Flash seront officiellement lancés en juin. Gemini 2.5 Pro est présenté comme le modèle d’IA le plus intelligent au monde, avec une nouvelle version Deep Think, et se classe en tête dans plusieurs tests. Gemini 2.5 Flash, en tant que modèle léger, voit son efficacité augmenter de 22 %, sa consommation de tokens diminuer de 20 % à 30 %, et dispose d’une capacité native de génération audio. Les données de LMArena montrent que la nouvelle version de Gemini-2.5-Flash a bondi à la deuxième place dans l’arène des chatbots, se distinguant particulièrement dans les tâches complexes comme le codage et les mathématiques. (Source: natolambert, demishassabis, karminski3, lmarena_ai)
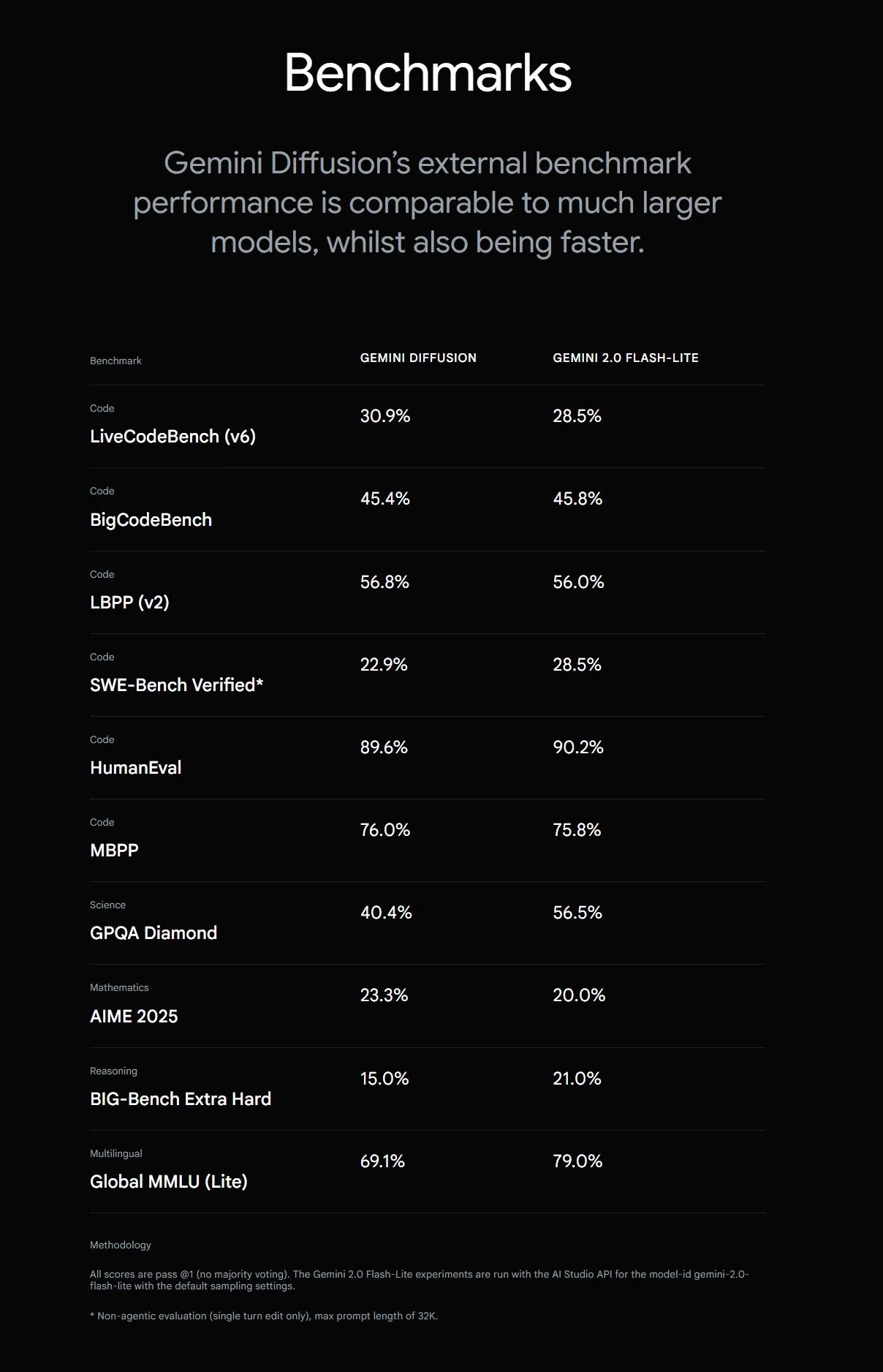
Google lance Gemini Diffusion, vitesse de génération de texte multipliée par 5: Google DeepMind a lancé Gemini Diffusion, un modèle expérimental de génération de texte dont la vitesse de génération est 5 fois plus rapide que le modèle le plus rapide précédent. Ses capacités en programmation sont particulièrement remarquables, atteignant 2000 tokens par seconde (y compris les frais de tokenisation, etc.). Contrairement aux modèles autorégressifs traditionnels, les modèles de diffusion peuvent effectuer un raisonnement non causal, capables de « penser » à l’avance aux réponses suivantes, et surpassent GPT-4o dans la résolution de problèmes complexes nécessitant un raisonnement global (tels que des problèmes de calcul spécifiques, la recherche de nombres premiers). Ce modèle est actuellement disponible uniquement sur demande pour les développeurs. (Source: OriolVinyalsML, dotey, karminski3)
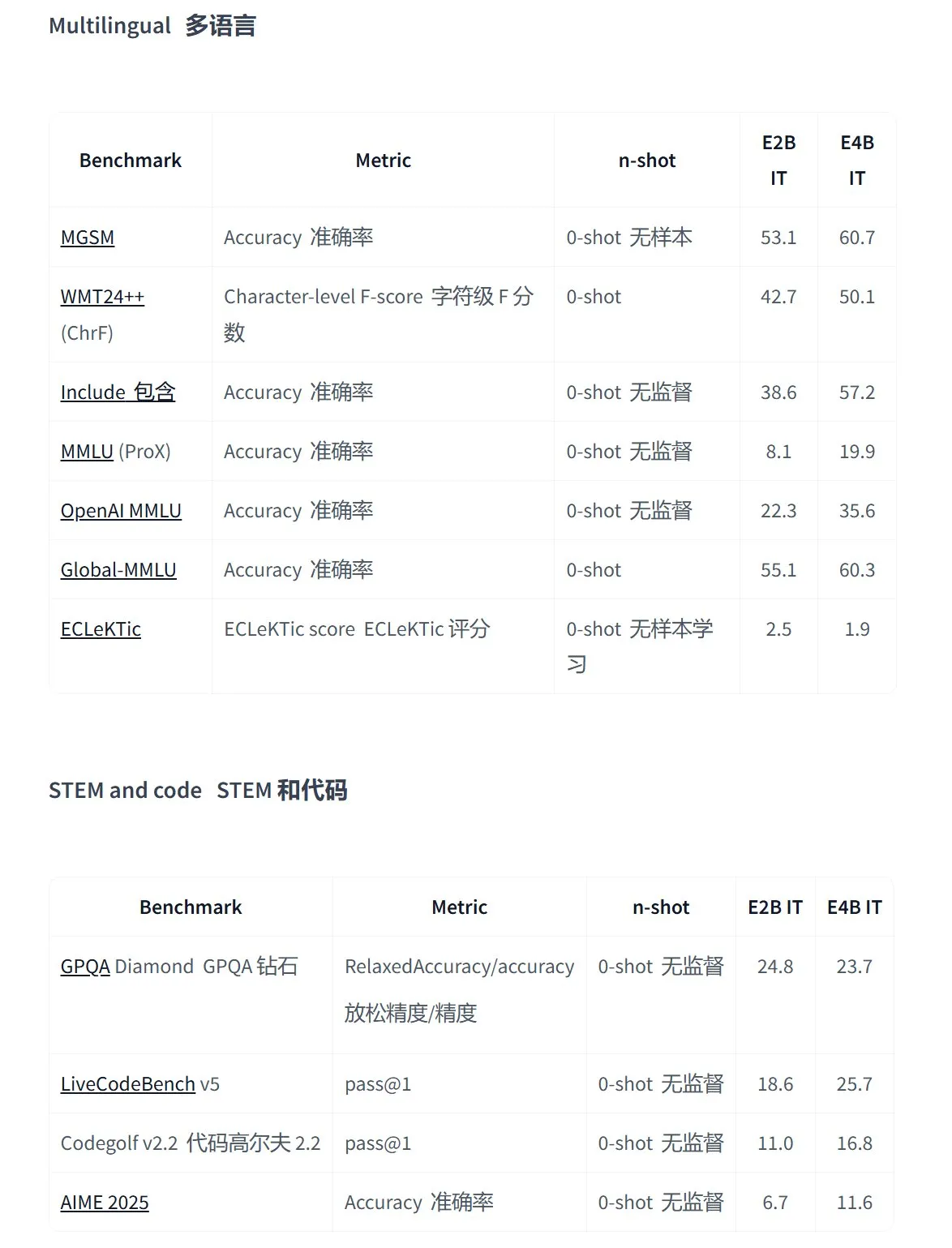
Google lance la série de modèles open source Gemma 3n, conçue pour les applications multimodales sur appareil: Google a lancé Gemma 3n, une nouvelle génération de modèles open source multimodaux efficaces, spécialement conçus pour les appareils à faible consommation d’énergie. Ils prennent en charge les entrées texte, voix, image, vidéo et le traitement multilingue. Les modèles de cette série (tels que gemma-3n-E4B-it-litert-preview et gemma-3n-E2B-it-litert-preview) sont compacts (3-4,4 Go), peuvent fonctionner sur des appareils avec 2 Go de RAM et leurs connaissances sont à jour jusqu’en juin 2024. Ils sont actuellement disponibles en avant-première pour les développeurs sur les plateformes AI Studio et AI Edge. (Source: demishassabis, karminski3, huggingface, Ar_Douillard, GoogleDeepMind)
L’API Responses d’OpenAI ajoute le support MCP, la génération d’images et des fonctionnalités d’interpréteur de code: La plateforme pour développeurs d’OpenAI a annoncé une mise à jour importante de son API Responses (anciennement Assistants API), ajoutant la prise en charge des serveurs de protocole de contexte de modèle distant (MCP), permettant aux agents AI d’interagir de manière plus flexible avec des outils et services externes. De plus, l’API intègre désormais des capacités de génération d’images et des fonctionnalités d’interpréteur de code, élargissant ainsi davantage ses scénarios d’application et son potentiel de développement. (Source: gdb, npew, OpenAIDevs, snsf)
L’API xAI intègre la fonction de recherche en temps réel Grok Live Search: xAI a annoncé l’ajout de la fonction Live Search à son API, permettant à Grok de rechercher des données en temps réel à partir de la plateforme X, d’Internet, des actualités, etc. Cette fonctionnalité est actuellement en phase de test bêta et est offerte gratuitement aux développeurs pour une durée limitée. Elle vise à renforcer la capacité de Grok à acquérir et traiter les informations les plus récentes, offrant ainsi un support pour la création d’applications AI plus dynamiques et riches en informations. (Source: xai, TheGregYang, yoheinakajima)

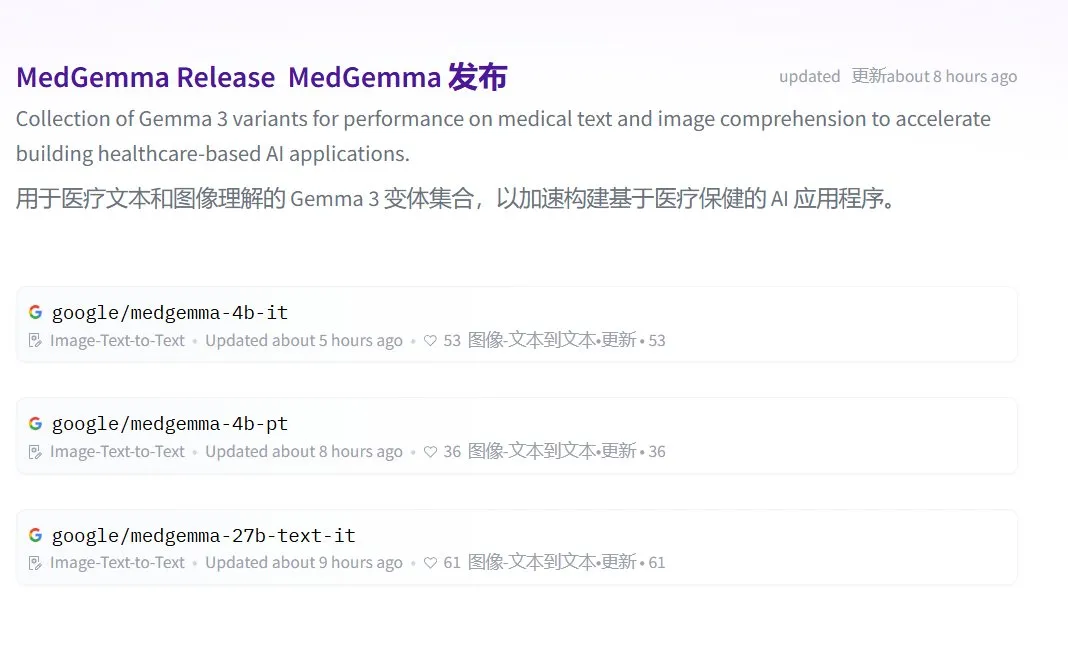
Google lance la série MedGemma de grands modèles médicaux open source: Google a lancé MedGemma, une série de modèles médicaux open source basés sur l’architecture Gemma 3. Elle comprend medgemma-4b-pt (modèle de base), medgemma-4b-it (multimodal, pour le diagnostic par imagerie médicale) et medgemma-27b-text-it (texte uniquement, pour les consultations et dossiers médicaux). Ces modèles ont été spécifiquement entraînés pour la compréhension de textes et d’images médicales, visant à améliorer les capacités d’application de l’IA dans le domaine médical, telles que l’aide au diagnostic, l’analyse de dossiers médicaux, etc. Les modèles sont disponibles sur Hugging Face. (Source: JeffDean, karminski3)
Mise à niveau de plusieurs produits du grand modèle Hunyuan de Tencent, lancement d’une plateforme ouverte d’agents intelligents: Tencent Hunyuan a annoncé la mise à niveau itérative de son modèle phare à réflexion rapide TurboS et de son modèle à réflexion profonde T1. TurboS se classe désormais parmi les dix meilleurs au monde en termes de capacités de codage et de mathématiques. De nouveaux modèles ont été lancés : le modèle de raisonnement visuel profond T1-Vision et le modèle d’appel vocal de bout en bout Hunyuan Voice. L’ancien moteur de connaissances a été mis à niveau pour devenir la “Plateforme de développement d’agents intelligents Tencent Cloud”, intégrant les capacités RAG et Agent. Hunyuan Image 2.0, 3D v2.5 et les modèles de génération visuelle pour jeux ont également été mis à jour, et il est prévu de continuer à rendre open source les modèles de base multimodaux et les plugins. (Source: 36氪)

Alibaba et l’Université du Zhejiang proposent ParScale, une loi de mise à l’échelle du calcul parallèle: L’équipe de recherche d’Alibaba, en collaboration avec l’Université du Zhejiang, a proposé une nouvelle Scaling Law : la loi de mise à l’échelle du calcul parallèle (ParScale). Cette loi indique que l’augmentation du calcul parallèle du modèle pendant l’entraînement et l’inférence peut améliorer les capacités des grands modèles sans augmenter le nombre de paramètres, tout en améliorant l’efficacité de l’inférence. Comparé à la mise à l’échelle des paramètres, ParScale n’augmente la mémoire que de 4,5 % et la latence de 16,7 %. Cette méthode est réalisée grâce à la diversification des transformations d’entrée, au traitement parallèle et à l’agrégation dynamique des sorties, et se montre particulièrement performante dans les tâches de raisonnement complexes telles que les mathématiques et la programmation. (Source: 36氪)
Microsoft lance Aurora, un modèle de fondation atmosphérique à grande échelle, multipliant la vitesse de prévision par 5000: Microsoft et ses collaborateurs ont lancé Aurora, le premier modèle de fondation atmosphérique à grande échelle. Entraîné sur plus d’un million d’heures de données géophysiques, il peut prédire avec plus de précision et d’efficacité la qualité de l’air, la trajectoire des cyclones tropicaux, la dynamique des vagues et la météo à haute résolution. Comparé au système avancé de prévision numérique IFS, Aurora est environ 5000 fois plus rapide en calcul et atteint le SOTA dans plusieurs domaines clés de prévision. L’architecture de ce modèle est flexible et peut être affinée pour des tâches spécifiques, ce qui devrait favoriser la popularisation de la prévision des systèmes terrestres. (Source: 36氪)

La recherche AI de Google va lancer l’AI Mode, intégrant de multiples fonctionnalités intelligentes: Google a annoncé le lancement d’un “AI Mode” pour son moteur de recherche, présenté comme “la recherche AI la plus puissante”. Ce mode, basé sur Gemini 2.5, dispose de capacités de raisonnement améliorées, prend en charge des requêtes plus longues, la recherche multimodale et des réponses instantanées de haute qualité. À l’avenir, il intégrera également la fonction “Deep Search”, capable d’effectuer des centaines de requêtes simultanément et de fournir des rapports complets. Il est également prévu d’intégrer des données personnelles de Gmail et d’autres services, ainsi que les fonctionnalités d’interaction en temps réel par caméra de Project Astra et de gestion automatique des tâches de Project Mariner. (Source: dotey, Google)

Lancement du modèle de génération d’images Google Imagen 4, avec une amélioration considérable de la vitesse et des détails: Google a lancé son dernier modèle de génération de texte en image, Imagen 4, affirmant une amélioration de la vitesse de génération de 3 à 10 fois par rapport à la génération précédente, des détails d’image plus riches, des résultats plus précis et une capacité de rendu de texte considérablement améliorée. Imagen 4 est capable de générer des objets complexes tels que des tissus, des gouttes d’eau, des poils d’animaux, avec une résolution allant jusqu’à 2K, et prend en charge la création de cartes de vœux, d’affiches, de bandes dessinées, etc. Ce modèle est désormais disponible gratuitement sur l’application Gemini, Whisk, les applications Workspace et Vertex AI. (Source: dotey, GoogleDeepMind)
Une étude révèle que le code généré par les outils d’assistance au codage AI présente un risque d’« hallucination de paquets logiciels »: Une étude qui sera bientôt publiée dans USENIX Security 2025 souligne que le code généré par l’IA présente couramment le phénomène d’« hallucination de paquets logiciels », c’est-à-dire que les bibliothèques tierces référencées n’existent tout simplement pas. L’étude a testé 16 grands modèles de langage courants et a constaté que plus de 20 % du code dépendait de paquets logiciels fictifs, ce pourcentage étant encore plus élevé pour les modèles open source. Cela crée des opportunités pour les attaques de la chaîne d’approvisionnement, car les attaquants peuvent utiliser ces noms de paquets fictifs pour publier du code malveillant. Des entreprises comme Apple et Microsoft ont déjà été victimes de telles attaques de confusion de dépendances. (Source: 36氪)

Suno lance la fonction Remix, permettant aux utilisateurs de créer des œuvres secondaires à partir de chansons existantes: La plateforme de génération de musique par IA Suno a lancé la fonction Remix, permettant aux utilisateurs de choisir n’importe quel morceau de la plateforme pour le recréer. Les utilisateurs peuvent effectuer des opérations telles que la reprise (Cover), l’extension (Extend) ou la réutilisation des invites (Reuse Prompt) sur les chansons. Les créations Remix conserveront les informations sur la source du matériel original, et les utilisateurs pourront également activer ou désactiver à tout moment les autorisations Remix pour leurs propres œuvres. (Source: SunoMusic)
Une étude révèle que tous les modèles d’intégration (embedding models) apprennent des structures sémantiques similaires: Jack Morris et d’autres chercheurs ont découvert que les structures sémantiques apprises par différents modèles d’intégration sont très similaires, au point qu’il est même possible de mapper entre les espaces d’intégration de différents modèles en se basant uniquement sur des informations structurelles, sans aucune donnée appariée. Cette découverte suggère l’existence possible d’une sorte de structure géométrique universelle dans les espaces d’intégration, ce qui a des implications importantes pour la compatibilité entre modèles, l’apprentissage par transfert et la compréhension de la nature même des intégrations. (Source: menhguin, torchcompiled, dilipkay, jeremyphoward)
Un article explore le problème de la « taxe d’hallucination » de l’affinage par apprentissage par renforcement (RFT): Une étude de Taiwei Shi et al. souligne que si l’affinage par apprentissage par renforcement (RFT) améliore les capacités de raisonnement des grands modèles de langage, il peut également amener les modèles à produire avec confiance des réponses hallucinées face à des questions auxquelles ils ne peuvent pas répondre, un phénomène qu’ils appellent la « taxe d’hallucination ». L’étude a utilisé l’ensemble de données SUM (problèmes mathématiques synthétiques sans réponse) pour la validation et a constaté que l’entraînement RFT standard réduisait considérablement le taux de refus des modèles. En ajoutant une petite quantité de données SUM à l’entraînement RFT, il est possible de restaurer efficacement le comportement de refus approprié du modèle et d’améliorer sa conscience de sa propre incertitude et des limites de ses connaissances. (Source: teortaxesTex)

🧰 工具
Google lance Flow, un outil de création cinématographique IA, intégrant Veo, Imagen et Gemini: Google a lancé Flow, un outil de production cinématographique IA, qui intègre ses derniers modèles de génération vidéo Veo 3, de génération d’images Imagen 4 et son modèle multimodal Gemini. Grâce à Flow, les utilisateurs peuvent utiliser le langage naturel et la gestion des ressources pour créer facilement des courts métrages de qualité cinématographique, y compris la génération de séquences à partir d’invites textuelles, la combinaison de scènes, la construction de récits et la sauvegarde d’éléments fréquemment utilisés comme ressources. Cet outil vise à aider les créateurs à produire rapidement et efficacement des œuvres de qualité cinématographique. Il est actuellement disponible pour les abonnés Google AI Pro et Ultra aux États-Unis. (Source: dotey, op7418)

Google lance Jules, un agent de programmation IA basé sur le cloud et alimenté par Gemini 2.5 Pro: Google a lancé Jules, un agent de programmation IA basé sur Gemini 2.5 Pro. Jules peut traiter automatiquement en arrière-plan les tâches dans les dépôts de code, telles que la correction de bugs et la refactorisation de code, et prend en charge le traitement multitâche en parallèle. De plus, Jules propose des podcasts Codecasts mis à jour quotidiennement pour aider les utilisateurs à se tenir au courant des dernières évolutions des dépôts de code. Cet outil est actuellement disponible gratuitement à l’essai. (Source: dotey, karminski3, GoogleDeepMind)
LangChain lance Open Agent Platform (OAP), une plateforme d’agents open source sans code: LangChain a lancé Open Agent Platform (OAP), une plateforme open source sans code destinée aux utilisateurs ordinaires pour la création, le prototypage et le déploiement d’agents IA. OAP permet de créer des agents via une interface utilisateur Web, de se connecter à des serveurs RAG pour améliorer la récupération d’informations, d’étendre les outils externes via MCP et d’utiliser Agent Supervisor pour orchestrer des flux de travail multi-agents. L’objectif est de permettre aux développeurs non professionnels de tirer parti de la puissance des agents LangGraph. (Source: LangChainAI, Hacubu)

Google Labs lance Stitch, un outil de conception d’interface utilisateur IA: Google Labs a lancé Stitch, un outil de conception d’interface utilisateur IA qui intègre les derniers modèles DeepMind de Google (y compris Gemini et Imagen) et peut générer rapidement des conceptions d’interface utilisateur de haute qualité. Les utilisateurs peuvent mettre à jour les thèmes d’interface en langage naturel, ajuster automatiquement les images, traduire le contenu en plusieurs langues et exporter le code frontal en un clic. Stitch est une version évoluée du précédent Galileo AI, dont le fondateur a rejoint l’équipe de Google. (Source: dotey)
LangChain lance LangChain Sandbox, un bac à sable de code local: LangChain a lancé LangChain Sandbox, qui permet aux agents IA d’exécuter en toute sécurité du code Python non fiable en local. Il fournit un environnement d’exécution isolé et des autorisations configurables, sans nécessiter d’exécution à distance ni de conteneurs Docker, et prend en charge la persistance de l’état entre plusieurs exécutions via des sessions. Cela offre un outil plus sûr et plus pratique pour construire des agents IA capables d’exécuter du code (tels que les agents codeact). (Source: hwchase17, Hacubu)
Vitalops rend open source Datatune : un outil LLM pour traiter des ensembles de données à grande échelle en langage naturel: Vitalops a rendu open source Datatune, un outil permettant aux utilisateurs de traiter des ensembles de données de n’importe quelle taille à l’aide d’instructions en langage naturel. Datatune prend en charge les opérations Map et Filter, peut se connecter à divers fournisseurs de services LLM tels qu’OpenAI, Azure, Ollama, ou à des modèles personnalisés, et utilise Dask DataFrame pour le partitionnement et le traitement parallèle. Cet outil vise à simplifier les tâches telles que le nettoyage et l’enrichissement des données, en remplaçant les expressions régulières complexes ou le code personnalisé. (Source: Reddit r/MachineLearning)
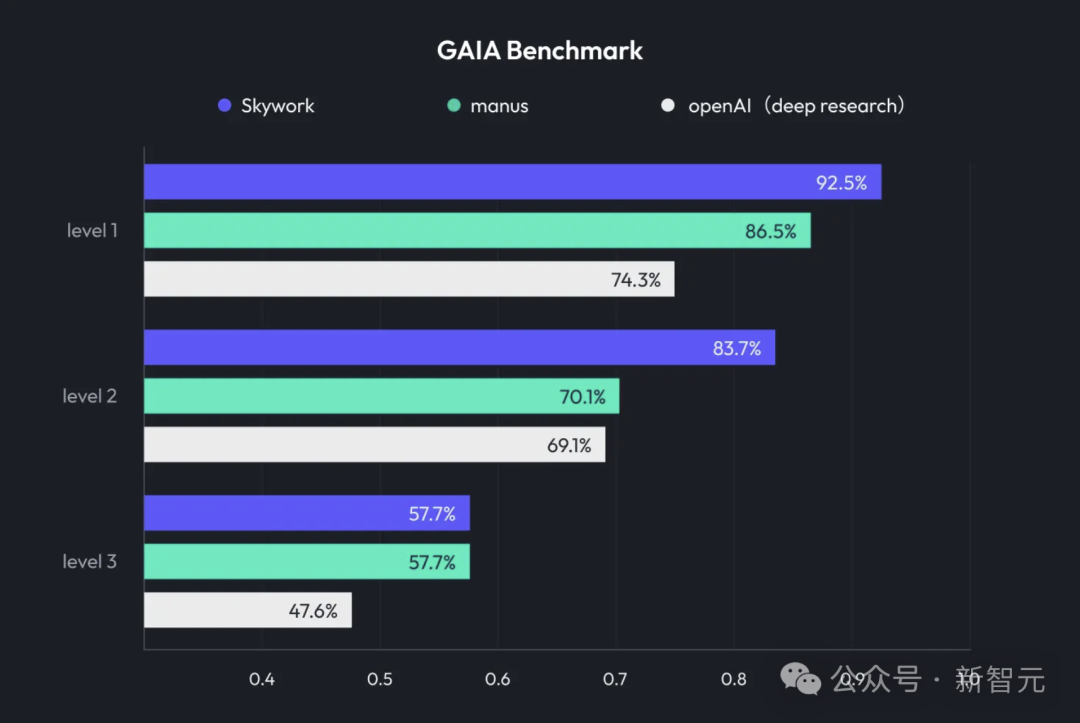
Kunlun Tech lance Skywork Super Agents, intégrant Deep Research et sortie multimodale: Kunlun Tech a lancé son produit de bureautique IA Skywork Super Agents, qui combine des capacités de Deep Research avec les fonctionnalités de sortie multimodale des agents intelligents généraux. Ce produit prend en charge divers scénarios de bureautique tels que la création de PPT, la rédaction de documents, le traitement de tableurs, la génération de pages Web et la création de podcasts. Il met l’accent sur la traçabilité du contenu pour réduire les hallucinations et offre des fonctionnalités d’édition en ligne et d’exportation. Kunlun Tech a également rendu open source le framework Deep Research Agent et le MCP associé. (Source: 36氪)
Google lance SynthID Detector pour aider à identifier le contenu généré par l’IA: Google a lancé SynthID Detector, un nouveau portail conçu pour aider les journalistes, les professionnels des médias et les chercheurs à identifier plus facilement si un contenu porte le filigrane SynthID. SynthID est une technologie développée par Google pour ajouter un filigrane invisible au contenu généré par l’IA (y compris les images, l’audio, la vidéo ou le texte). Le lancement de cet outil de détection contribue à améliorer la transparence et la traçabilité du contenu généré par l’IA. (Source: dotey, Google)
Feishu lance la fonction « Questions-Réponses Intelligentes », créant un outil de Q&R IA exclusif pour les entreprises: Feishu (Lark) a lancé une nouvelle fonction « Questions-Réponses Intelligentes ». Cet outil peut fournir des réponses précises et un support à la création de contenu aux employés en se basant sur toutes les informations auxquelles ils ont accès sur Feishu (messages, documents, base de connaissances, etc.), en combinaison avec de grands modèles de langage tels que DeepSeek-R1, Doubao (Pois) et la technologie RAG. Sa particularité est que les réponses s’ajustent dynamiquement en fonction de l’identité et des autorisations de l’interlocuteur au sein de l’entreprise. L’objectif est d’intégrer de manière transparente l’IA dans les flux de travail quotidiens et d’améliorer l’efficacité de la gestion et de l’utilisation des connaissances au sein de l’entreprise. (Source: 量子位)

Animon : Première plateforme japonaise de génération d’anime par IA, axée sur la qualité bidimensionnelle et la génération gratuite illimitée: La société japonaise CreateAI (anciennement TuSimple Future) a lancé Animon, une plateforme de génération d’anime par IA spécialement conçue pour la création d’anime. Cette plateforme fusionne l’esthétique de l’anime japonais avec la technologie IA, en mettant l’accent sur la cohérence du style visuel et la production efficace, et annonce que les utilisateurs individuels peuvent générer des vidéos gratuitement et de manière illimitée. Animon permet de générer rapidement des séquences d’animation (environ 3 minutes) en téléchargeant des images de personnages et des descriptions textuelles, dans le but d’abaisser le seuil de la création d’anime et de stimuler un écosystème de contenu UGC. Sa société mère, CreateAI, possède son propre grand modèle Ruyi et détient les droits d’adaptation d’IP telles que « Le Problème à trois corps » et « Jin Yong Qunxia Zhuan » (Héros de Jin Yong), poursuivant une stratégie à double moteur « contenu auto-développé + plateforme d’outils UGC ». (Source: 量子位)

📚 学习
DeepLearning.AI lance un nouveau cours : Affinage renforcé des LLM avec GRPO: Andrew Ng a annoncé un nouveau cours de courte durée en collaboration avec Predibase, sur le thème de « l’affinage renforcé des LLM avec GRPO (Group Relative Policy Optimization) ». Le cours enseignera comment utiliser l’apprentissage par renforcement (en particulier l’algorithme GRPO) pour améliorer les performances des LLM dans les tâches de raisonnement en plusieurs étapes (telles que la résolution de problèmes mathématiques, le débogage de code), sans nécessiter un grand nombre d’échantillons d’affinage supervisé. GRPO guide le modèle via une fonction de récompense programmable, convient aux tâches dont les résultats sont vérifiables et peut améliorer considérablement les capacités de raisonnement des petits LLM. (Source: AndrewYNg, DeepLearningAI)
LlamaIndex partage son expérience de gestion de dépôts monolithiques Python à grande échelle: L’équipe de LlamaIndex a partagé son expérience dans la gestion d’un dépôt monolithique (monorepo) Python contenant plus de 650 paquets communautaires. Ils sont passés de Poetry et Pants à uv et à leur propre outil de gestion de build open source, LlamaDev, ce qui a permis d’accélérer l’exécution des tests de 20 %, d’obtenir des journaux plus clairs, de simplifier le développement local et de réduire la barrière à l’entrée pour les contributeurs. Cette expérience est instructive pour les équipes qui doivent gérer de grands projets Python. (Source: jerryjliu0)

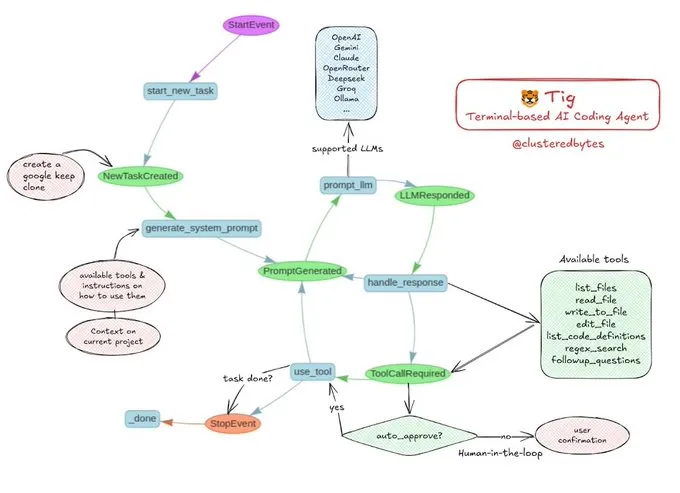
Partage de tutoriel : Construire son propre agent de codage IA Tig: Jerry Liu a recommandé un projet d’agent de codage IA open source appelé Tig. Ce projet est un assistant de codage basé sur un terminal, avec une intervention humaine (human-in-the-loop), construit à l’aide du workflow LlamaIndex. Tig est capable d’écrire, de déboguer, d’analyser du code dans plusieurs langages, d’exécuter des commandes shell, de rechercher dans des bases de code, et de générer des tests et de la documentation, entre autres tâches. Le dépôt GitHub fournit un guide de construction détaillé, ce qui en fait une excellente ressource pédagogique pour les développeurs souhaitant apprendre à construire des agents de codage IA. (Source: jerryjliu0)
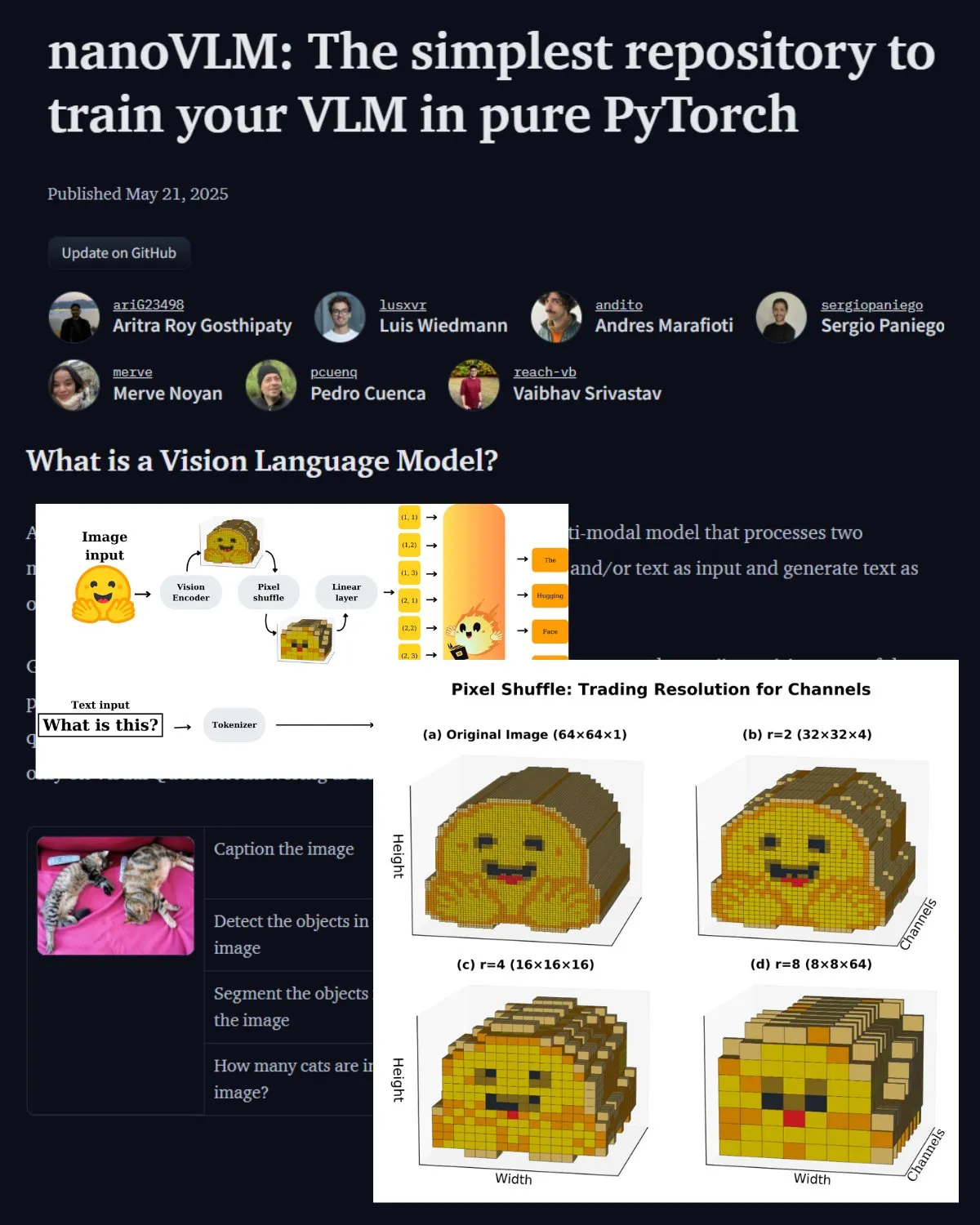
Hugging Face publie un article de blog important sur les VLM et présente le laboratoire communautaire nanoVLM: Hugging Face a publié un article de blog sur les modèles de langage visuel (VLM), couvrant les bases des VLM, leur architecture et la manière d’entraîner son propre VLM léger. Il présente également nanoVLM, un dépôt open source pour l’affinage des VLM, qui est devenu un laboratoire communautaire pour la recherche en langage visuel, visant à aider les développeurs à explorer et à contribuer à la recherche sur les VLM. (Source: _akhaliq, huggingface)
Serrano Academy publie une série de tutoriels vidéo sur l’affinage des LLM par apprentissage par renforcement: Serrano Academy a terminé et publié une série de tutoriels vidéo sur l’utilisation de l’apprentissage par renforcement pour l’affinage et l’entraînement des LLM. Le contenu couvre des concepts et techniques clés tels que l’apprentissage par renforcement profond (Deep Reinforcement Learning), RLHF (Reinforcement Learning from Human Feedback), PPO (Proximal Policy Optimization), DPO (Direct Preference Optimization), GRPO (Group Relative Policy Optimization) et la divergence KL (KL Divergence). (Source: SerranoAcademy)
Un article explore le phénomène des « couches vides » dans les grands modèles de langage: Une étude a examiné le phénomène selon lequel toutes les couches des grands modèles de langage affinés par instruction ne sont pas activées pendant le processus de raisonnement, qualifiant les couches non activées de « couches vides » (Voids). L’étude a utilisé la méthode de calcul adaptatif L2 (LAC) pour suivre les couches activées pendant les phases de traitement des invites et de génération des réponses, et a constaté que les couches activées différaient également selon les phases. Les expériences ont montré que, dans des benchmarks tels que MMLU, le fait de sauter les couches vides dans Qwen2.5-7B-Instruct (en utilisant seulement 30 % des couches) améliorait les performances, ce qui suggère que le saut sélectif de la plupart des couches pourrait être bénéfique pour des tâches spécifiques. (Source: HuggingFace Daily Papers)
Une étude propose le « Soft Thinking » : libérer le potentiel de raisonnement des LLM dans un espace conceptuel continu: Un article intitulé « Soft Thinking » propose une méthode sans entraînement qui simule un raisonnement « souple » de type humain en générant des marqueurs conceptuels souples et abstraits dans un espace conceptuel continu. Ces marqueurs conceptuels sont formés par un mélange pondéré probabilistiquement d’intégrations de marqueurs discrets, capables d’encapsuler de multiples significations provenant de marqueurs discrets apparentés, explorant ainsi implicitement de multiples voies de raisonnement. Les expériences montrent que cette méthode améliore la précision pass@1 sur les benchmarks mathématiques et de codage, tout en réduisant l’utilisation de tokens et en maintenant l’interprétabilité des sorties. (Source: HuggingFace Daily Papers)
Un article explore la réalisation de chaînes de pensée évolutives grâce au raisonnement élastique: Des chercheurs de Salesforce ont proposé une méthode pour réaliser des chaînes de pensée évolutives grâce au raisonnement élastique (Elastic Reasoning). Cette recherche vise à résoudre le problème de la génération et de la gestion efficaces de longues chaînes de pensée par les grands modèles de langage lorsqu’ils traitent des tâches de raisonnement complexes, afin d’améliorer la précision et l’efficacité du raisonnement. Les modèles et le code correspondants ont été publiés sur Hugging Face. (Source: _akhaliq)

Étude : Les modèles d’IA mentiraient-ils pour sauver des enfants malades ?: Une étude intitulée LitmusValues a créé un processus d’évaluation visant à révéler les priorités des modèles d’IA dans une série de catégories de valeurs liées à l’IA. En collectant des AIRiskDilemmas (un ensemble de dilemmes contenant des scénarios liés aux risques de sécurité de l’IA), les chercheurs mesurent les choix des modèles d’IA face à différents conflits de valeurs, afin de prédire leurs priorités de valeur et d’identifier les risques potentiels. L’étude montre que les valeurs définies dans LitmusValues (y compris la bienveillance, etc.) peuvent prédire les comportements à risque déjà observés dans AIRiskDilemmas ainsi que les comportements à risque non observés dans HarmBench. (Source: HuggingFace Daily Papers)
Recherche sur l’affinage efficace des modèles de diffusion par apprentissage par renforcement basé sur la valeur (VARD): Les modèles de diffusion sont performants dans les tâches de génération, mais leur affinage pour des attributs spécifiques reste un défi. Les méthodes d’apprentissage par renforcement existantes présentent des lacunes en termes de stabilité, d’efficacité et de traitement des récompenses non différentiables. VARD (Value-based Reinforced Diffusion) propose d’abord d’apprendre une fonction de valeur qui prédit l’espérance de récompense à partir d’états intermédiaires, puis d’utiliser cette fonction de valeur et la régularisation KL pour fournir une supervision dense tout au long du processus de génération. Les expériences prouvent que cette méthode peut améliorer le guidage de la trajectoire, augmenter l’efficacité de l’entraînement et étendre l’application du RL à l’optimisation des modèles de diffusion avec des fonctions de récompense non différentiables complexes. (Source: HuggingFace Daily Papers)
💼 商业
LMArena.ai (anciennement LMSYS.org) lève 100 millions de dollars en financement de démarrage, mené par a16z et UC Investments: La plateforme d’évaluation de modèles d’IA LMArena.ai (anciennement LMSYS.org) a annoncé avoir bouclé un tour de financement de démarrage de 100 millions de dollars, mené conjointement par Andreessen Horowitz (a16z) et UC Investments (la société d’investissement de l’Université de Californie). L’entreprise se consacre à la création d’une plateforme neutre, ouverte et communautaire pour aider le monde à comprendre et à améliorer les performances des modèles d’IA sur les requêtes réelles des utilisateurs. Après ce financement, la société est valorisée à 600 millions de dollars. (Source: janonacct, lmarena_ai, scaling01, _akhaliq, ClementDelangue)
Le gouvernement américain annonce la vente de technologies et services d’IA d’une valeur de plusieurs dizaines de milliards de dollars à l’Arabie Saoudite et aux Émirats Arabes Unis: Le gouvernement américain a annoncé un accord avec l’Arabie Saoudite et les Émirats Arabes Unis pour la vente de technologies et services d’IA d’une valeur de plusieurs dizaines de milliards de dollars. Les entreprises participantes incluent AMD, Nvidia, Amazon, Google, IBM, Oracle et Qualcomm, entre autres. Nvidia fournira à la société saoudienne Humain 18 000 puces IA GB300 et des centaines de milliers de GPU par la suite ; AMD et Humain investiront conjointement 10 milliards de dollars dans la construction de centres de données IA. Cette initiative vise à renforcer l’influence américaine en matière d’IA au Moyen-Orient et à aider les deux pays à diversifier leur économie. (Source: DeepLearning.AI Blog)

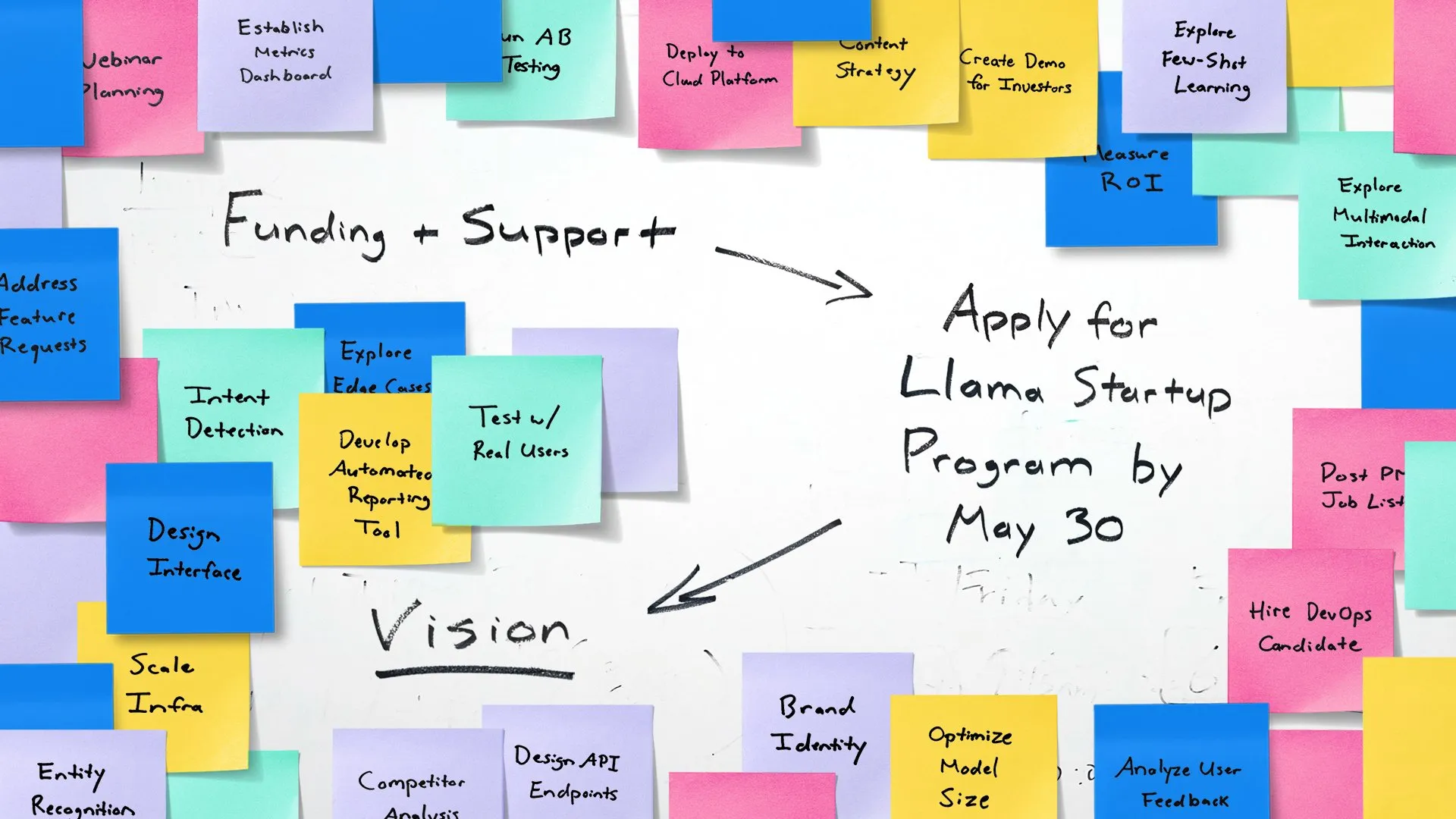
Meta lance le Llama Startup Program pour soutenir les jeunes start-ups IA: Meta a annoncé le lancement du Llama Startup Program, visant à soutenir les jeunes start-ups américaines (financement inférieur à 10 millions de dollars, au moins un développeur) dans l’innovation d’applications d’IA générative utilisant les modèles Llama. Le programme offre le remboursement des ressources cloud, le soutien technique d’experts Llama et des ressources communautaires. La date limite de candidature est le 30 mai 2025 à 18h00 (heure du Pacifique). (Source: AIatMeta)
🌟 社区
La conférence Google I/O suscite un vif débat : intégration complète de l’IA et perspectives d’avenir: La conférence Google I/O a dévoilé un grand nombre de produits et de mises à jour liés à l’IA, notamment la série de modèles Gemini, la génération vidéo Veo 3, la génération d’images Imagen 4, le mode de recherche IA, etc., suscitant de nombreuses discussions au sein de la communauté. De nombreux commentateurs estiment que Google a démontré une grande force dans le domaine des applications de l’IA, en particulier sa stratégie d’intégration transparente de l’IA dans son écosystème de produits existant. Parallèlement, des sujets tels que l’authenticité du contenu généré par l’IA, l’éthique de l’IA et la voie future vers l’AGI sont également devenus des points de discussion centraux. (Source: rowancheung, dotey, karminski3, GoogleDeepMind, natolambert)

Le matériel IA devient un nouveau point focal, la collaboration entre OpenAI et Jony Ive attire l’attention: L’annonce de l’acquisition par OpenAI de la société de matériel IA io de Jony Ive, ainsi que la présentation par Google lors de la conférence I/O d’un prototype de lunettes intelligentes Android XR, ont enflammé les discussions de la communauté sur l’avenir du matériel IA. La collaboration entre Sam Altman et Jony Ive est perçue comme visant à créer une nouvelle génération d’appareils informatiques personnels pilotés par l’IA, susceptibles de bouleverser les modes d’interaction actuels des téléphones et des ordinateurs. La communauté attend avec impatience que le matériel natif AI apporte des expériences révolutionnaires, mais s’interroge également sur sa forme, ses fonctionnalités et son acceptation par le marché. (Source: dotey, sama, dotey, swyx)

Le rôle et les risques de l’IA dans le développement logiciel suscitent la discussion: Le lancement par Mistral AI du modèle Devstral, spécialement conçu pour les agents de codage, ainsi que la mise à jour de Codex par OpenAI, ont suscité des discussions sur l’application de l’IA dans le développement logiciel. La communauté s’intéresse aux capacités réelles des outils de programmation IA, à la qualité et à la sécurité du code généré. En particulier, des recherches soulignent que le code généré par l’IA peut référencer des « paquets logiciels hallucinés » inexistants, ce qui entraîne des risques pour la sécurité de la chaîne d’approvisionnement et rappelle aux développeurs la nécessité de vérifier avec prudence le code et les dépendances générés par l’IA. (Source: MistralAI, DeepLearning.AI Blog, qtnx_)
La discussion sur l’évaluation des modèles d’IA et les benchmarks continue de s’intensifier: L’obtention d’un financement massif par LMArena.ai, ainsi que les performances de divers nouveaux modèles sur les benchmarks, ont fait de l’évaluation des modèles d’IA un sujet brûlant au sein de la communauté. Les utilisateurs s’intéressent aux capacités réelles des différents modèles sur des tâches spécifiques (telles que le codage, les mathématiques, la réponse aux questions de bon sens, la compréhension des émotions), ainsi qu’à la fiabilité et aux limites des systèmes d’évaluation existants. Par exemple, le cadre d’évaluation de l’intelligence émotionnelle SAGE publié par Tencent tente de fournir une nouvelle dimension d’évaluation pour les modèles d’IA sous l’angle du « QE ». (Source: lmarena_ai, 36氪, natolambert)
Le retard de développement du secteur technologique européen suscite la réflexion, Yann LeCun relaie une discussion pointant le manque de « patriotisme » comme cause principale: Un article du Wall Street Journal sur la scène technologique européenne, bien plus petite que celles des États-Unis et de la Chine, a suscité des discussions. Yann LeCun a relayé le commentaire d’Arnaud Bertrand. Bertrand estime que la cause principale du retard technologique de l’Europe est un manque d’esprit « patriotique ». Les médias et les élites européennes ont tendance à encenser les start-ups américaines tout en négligeant l’innovation locale, ce qui empêche les entreprises locales d’obtenir un soutien précoce et une reconnaissance du marché. Il cite sa propre expérience avec la création de HouseTrip pour illustrer le manque de confiance et de soutien envers l’innovation locale en Europe. (Source: ylecun)

💡 其他
La consommation d’énergie de l’IA suscite des inquiétudes: MIT Technology Review a organisé une table ronde pour discuter du problème de la consommation d’énergie induite par le développement accéléré de la technologie IA et de son impact sur le climat. Avec l’augmentation de la taille des modèles d’IA et de l’étendue de leurs applications, la demande en électricité et en ressources de calcul augmente de façon spectaculaire, faisant de la demande énergétique des centres de données un nouveau point focal. La discussion a porté sur la consommation d’énergie d’une seule requête IA, l’empreinte énergétique globale de l’IA et la manière de relever ce défi. (Source: MIT Technology Review, madiator)

Anthropic annonce de nouvelles informations à venir, la communauté spécule sur le lancement possible de Claude 4: La société Anthropic a publié une annonce indiquant qu’elle tiendra une diffusion en direct le 22 mai à 9h30, heure du Pacifique (23 mai à 0h00, heure de Pékin), suscitant des spéculations au sein de la communauté sur le lancement possible d’une nouvelle génération de son modèle Claude (peut-être Claude 4). Compte tenu des récentes annonces majeures d’OpenAI et de Google, cette initiative d’Anthropic est très attendue. (Source: AnthropicAI, dotey, karminski3, scaling01, Reddit r/ClaudeAI)
Fusion de l’IA et de la technologie XR, Google présente un prototype de lunettes intelligentes Android XR: Lors de la conférence I/O, Google a présenté un prototype de lunettes intelligentes Android XR, soulignant leur intégration profonde avec l’IA. Cet appareil prend en charge l’assistance intelligente à la première personne et les fonctions d’assistance sans contact, permettant aux utilisateurs d’interagir avec l’appareil en langage naturel pour effectuer des recherches d’informations, gérer leur emploi du temps, naviguer en temps réel, etc. Cela laisse présager que l’IA deviendra le moteur principal d’interaction et de fonctionnalité des appareils XR de nouvelle génération, améliorant l’expérience utilisateur dans les environnements de réalité augmentée. (Source: dotey, 36氪)