
Mots-clés:Gemini 2.5, Agent IA, Grand modèle de langage, Modèle vision-langage, Apprentissage par renforcement, Mode Deep Think de Gemini 2.5 Pro, Agent GitHub Copilot open source, Génération d’image en une étape MeanFlow, Raisonnement et planification visuelle VPRL, Optimisation d’inférence MoE FusionSpec de Huawei
🔥 Pleins feux sur
La conférence Google I/O a annoncé de nombreuses avancées en matière d’IA, avec en tête la série de modèles Gemini 2.5: Google a dévoilé de nombreuses mises à jour dans le domaine de l’IA lors de sa conférence I/O. Gemini 2.5 Pro est salué comme le modèle de fondation le plus puissant actuellement, dominant dans plusieurs tests de référence, et introduit le mode de raisonnement amélioré Deep Think. Le modèle léger Gemini 2.5 Flash a également été mis à niveau, mettant l’accent sur la vitesse et l’efficacité. Google Search introduit un « Mode AI », offrant une expérience de recherche IA de bout en bout grâce à Gemini 2.5, capable de décomposer des problèmes complexes et d’effectuer une exploration approfondie des informations. Le modèle de génération vidéo Veo 3 réalise une génération synchronisée audio-image, et le modèle d’image Imagen 4 a amélioré ses capacités de traitement des détails et du texte. De plus, l’outil de création cinématographique IA Flow a été lancé, ainsi que l’application concrète Gemini Live du projet d’assistant IA Project Astra. Ces mises à jour démontrent la détermination de Google à intégrer pleinement l’IA dans son écosystème de produits, visant à améliorer l’expérience utilisateur et l’efficacité des développeurs (Source(s): QbitAI, 36Kr, WeChat)

Microsoft Build met en avant les AI Agents, GitHub Copilot bénéficie d’une mise à niveau majeure et annonce son passage en open source: Lors de sa conférence pour développeurs Build 2025, Microsoft a placé les AI Agents au cœur de sa stratégie, annonçant le passage en open source du projet GitHub Copilot Extension for VSCode et lançant un tout nouvel agent de codage IA (Agent). Cet Agent peut accomplir de manière autonome des tâches telles que la correction de bugs, l’ajout de fonctionnalités et l’optimisation de la documentation, et est profondément intégré à GitHub Copilot. Microsoft a également dévoilé la plateforme d’agents intelligents Microsoft Discovery pour la découverte scientifique, le projet de site web interactif en langage naturel NLWeb, la plateforme de construction d’agents Agent Factory, ainsi que Copilot Tuning pour la personnalisation des données d’entreprise. Ces initiatives montrent que Microsoft s’engage pleinement à promouvoir l’application des AI Agents dans divers domaines tels que le développement et la recherche scientifique, visant à construire un écosystème collaboratif d’agents intelligents ouvert (Source(s): QbitAI, WeChat, WeChat)

Kevin Weil, CPO d’OpenAI, expose la nouvelle orientation de ChatGPT : passer des réponses aux actions, les AI Agents évolueront rapidement: Le Chief Product Officer d’OpenAI, Kevin Weil, a révélé lors d’une interview que le positionnement de ChatGPT passera d’un outil répondant aux questions à un AI Agent capable d’exécuter des tâches pour les utilisateurs. Il envisage une évolution rapide des AI Agents, passant à court terme du niveau d’ingénieur junior à celui d’ingénieur senior, voire d’architecte. Cela signifie que les AI Agents disposeront d’une plus grande autonomie, capables de résoudre des problèmes complexes en naviguant sur le web, en réfléchissant profondément et en synthétisant des informations. Weil a également mentionné que le coût d’entraînement des modèles actuels est déjà 500 fois supérieur à celui de GPT-4, mais que l’efficacité sera améliorée et les prix des API réduits grâce aux progrès matériels et algorithmiques, afin de promouvoir la popularisation et le développement de l’IA (Source(s): QbitAI, 36Kr)

L’équipe de Kaiming He propose MeanFlow : nouveau SOTA pour la génération d’images en une seule étape, bouleversant le paradigme traditionnel sans pré-entraînement: Une nouvelle étude de l’équipe de Kaiming He présente un cadre de modélisation générative en une seule étape appelé MeanFlow. Sur l’ensemble de données ImageNet 256×256, il atteint un score FID de 3.43 avec une seule évaluation de fonction (1-NFE), améliorant de 50 % à 70 % les meilleures méthodes comparables précédentes, et ce, sans pré-entraînement, distillation ou apprentissage progressif. L’innovation principale de MeanFlow réside dans l’introduction du concept de « champ de vitesse moyen » et la dérivation de sa relation mathématique avec le champ de vitesse instantané, guidant ainsi l’entraînement du réseau neuronal. Cette méthode peut également intégrer naturellement le guidage sans classificateur (CFG) sans surcoût de calcul lors de l’échantillonnage, réduisant considérablement l’écart de performance entre les modèles de génération en une seule étape et ceux en plusieurs étapes, et démontrant le potentiel des modèles à faible nombre d’étapes à défier les modèles multi-étapes (Source(s): WeChat, WeChat)

🎯 Tendances
ByteDance publie le modèle multimodal Bagel 14B MoE, supportant la génération d’images et disponible en open source: ByteDance a lancé un modèle multimodal à mélange d’experts (MoE) de 14 milliards de paramètres nommé Bagel, dont 7 milliards de paramètres sont actifs. Ce modèle est capable de générer des images et est open source sous licence Apache. Ses poids, son site web et son article (intitulé « Emerging Properties in Unified Multimodal Pretraining ») ont tous été rendus publics. La communauté a réagi positivement, le considérant comme le premier modèle local capable de générer simultanément des images et du texte, et s’interroge sur sa capacité à fonctionner sur des cartes graphiques de 24 Go ainsi que sur les questions de quantification (Source(s): Reddit r/LocalLLaMA)
Mistral AI lance Devstral : un modèle open source SOTA optimisé pour le codage: Mistral AI a lancé Devstral, un modèle open source de pointe conçu spécifiquement pour les tâches d’ingénierie logicielle, développé en collaboration avec All Hands AI. Devstral excelle dans le benchmark SWE-bench, devenant le modèle open source le mieux classé sur ce benchmark. Ce modèle est performant pour explorer les bases de code à l’aide d’outils, éditer plusieurs fichiers et alimenter les agents d’ingénierie logicielle. Les poids du modèle sont disponibles sur Hugging Face (Source(s): Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)

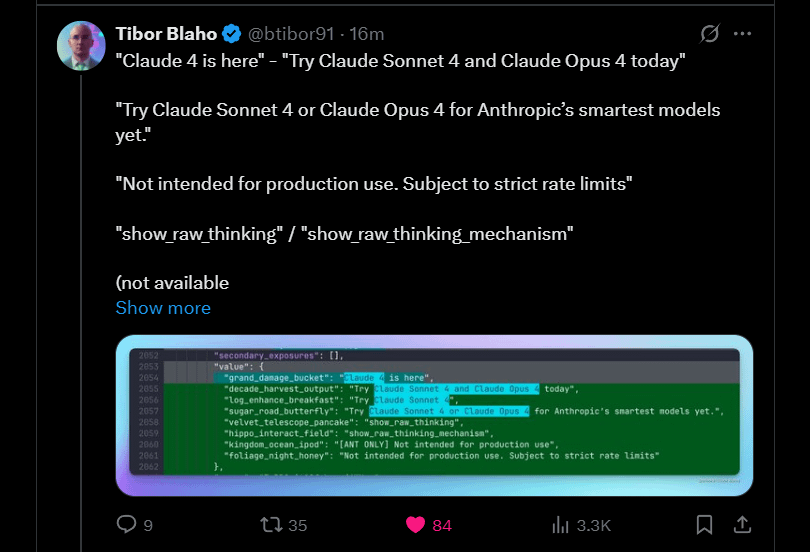
Anthropic annonce la sortie prochaine de Claude 4 Sonnet et Opus: Anthropic prévoit de lancer les prochaines versions de son grand modèle Claude : Claude 4 Sonnet et Opus. Cette nouvelle a suscité l’enthousiasme de la communauté, les utilisateurs exprimant leur intérêt pour les performances des nouveaux modèles, en particulier l’amélioration de la capacité de mémoire contextuelle. Certains commentaires soulignent que les annonces de la conférence Google I/O pourraient inciter les concurrents à accélérer le lancement de leurs meilleurs produits. Parallèlement, les utilisateurs s’inquiètent également des limitations des nouveaux modèles (telles que les quotas d’utilisation) et conseillent à la communauté de ne pas avoir d’attentes excessives concernant Opus 4 afin d’éviter toute déception (Source(s): Reddit r/ClaudeAI, Reddit r/ClaudeAI)
Google publie l’application Android Gemma3n, supportant l’inférence LLM locale: Google a publié une application Android permettant d’interagir avec le nouveau modèle Gemma3n, et a fourni les solutions MediaPipe et le dépôt GitHub correspondants. Les utilisateurs ont trouvé l’interface de l’application agréable, mais ont souligné que Gemma3n ne supporte actuellement pas l’inférence GPU. Un utilisateur a réussi à charger manuellement le modèle gemma-3n-E2B et a partagé les données d’exécution, tandis que la communauté a également exprimé le besoin d’une version non censurée du modèle (Source(s): Reddit r/LocalLLaMA)

Publication de la famille de modèles de langage à tête hybride Falcon-H1, incluant diverses tailles de paramètres: TII UAE a publié la série de modèles de langage à tête hybride Falcon-H1, avec des tailles de paramètres allant de 0.5B à 34B. Cette série de modèles adopte l’architecture hybride Mamba et offre des performances comparables à Qwen3. Les modèles peuvent être utilisés via Hugging Face Transformers, vLLM ou une version personnalisée de la bibliothèque llama.cpp, garantissant leur facilité d’utilisation. La communauté a exprimé son enthousiasme, considérant cela comme une avancée importante, et un utilisateur a créé des graphiques comparatifs de performances. Parallèlement, les chercheurs s’intéressent à ses différences avec IBM Granite 4 dans la manière de combiner les modules SSM et d’attention (Source(s): Reddit r/LocalLLaMA)

Google explore Gemini Diffusion : un modèle de langage basé sur l’architecture de diffusion: Google a présenté son modèle de diffusion linguistique Gemini Diffusion, qui serait extrêmement rapide et dont la taille ne représenterait que la moitié de celle des modèles aux performances comparables. Étant donné que les modèles de diffusion peuvent traiter l’ensemble du texte en une seule itération et ne nécessitent pas de cache KV, ils pourraient présenter des avantages en termes d’efficacité mémoire et permettre d’améliorer la qualité de la sortie en augmentant le nombre d’itérations. La communauté estime que si Google parvient à prouver la viabilité des modèles de diffusion à grande échelle, cela aura un impact positif sur la communauté de l’IA locale. Cependant, le modèle n’est actuellement disponible que sur liste d’attente pour une démonstration et n’est ni open source ni disponible en téléchargement de poids (Source(s): Reddit r/LocalLLaMA)

Une étude révèle une vulnérabilité de détournement d’Agent zero-click dans le framework Browser Use (CVE-2025-47241): Une étude d’ARIMLABS.AI a découvert une grave faille de sécurité (CVE-2025-47241) dans le framework Browser Use, largement utilisé dans plus de 1500 projets d’IA. Cette vulnérabilité permet à un attaquant de réaliser un détournement d’Agent zero-click en incitant un agent de navigation piloté par LLM à visiter une page malveillante, prenant ainsi le contrôle de l’agent sans interaction de l’utilisateur. Cette découverte soulève de sérieuses préoccupations quant à la sécurité des agents IA autonomes, en particulier ceux qui interagissent avec le web, et appelle la communauté à se pencher sur les problèmes de sécurité des agents IA (Source(s): Reddit r/artificial, Reddit r/artificial)
Tencent et Alibaba se livrent concurrence dans le domaine de l’IA grand public (AI to C), QQ Browser et Quark en confrontation: QQ Browser, sous l’égide de CSIG (Tencent), a annoncé sa transformation en navigateur IA, lançant AI QBot et intégrant les modèles Tencent Hunyuan et DeepSeek. Il entre ainsi officiellement en concurrence avec Quark d’Alibaba, déjà positionné sur la recherche IA. Cette initiative marque l’accélération du déploiement de Tencent dans le secteur AI to C, avec deux lignes de produits principales : Tencent Yuanbao et QQ Browser. Les responsables clés des deux entités, Wu Zurong (Tencent) et Wu Jia (Alibaba), se retrouvent ainsi dans un « duel des Wu ». Selon les analystes, QQ Browser bénéficie d’une base d’utilisateurs plus large, tandis que Quark a une longueur d’avance dans la transformation IA. Cependant, la transition de QQ Browser est jugée plus conservatrice, ses fonctionnalités IA s’apparentant davantage à des plugins et étant limitées par son modèle publicitaire existant. Cette compétition ne se limite pas aux produits, elle pourrait également influencer l’évolution de carrière des deux responsables au sein de leurs entreprises respectives (Source(s): 36Kr)
Cambridge et Google proposent VPRL : un nouveau paradigme de raisonnement par planification purement visuelle, surpassant le raisonnement textuel en précision: Des équipes de recherche de l’Université de Cambridge, de l’University College London et de Google ont proposé un nouveau paradigme de planification visuelle basée sur l’apprentissage par renforcement (VPRL), réalisant pour la première fois un raisonnement purement basé sur des images. Ce cadre utilise l’optimisation de politique relative de groupe (GRPO) pour post-entraîner de grands modèles visuels. Dans plusieurs tâches de navigation visuelle (telles que FrozenLake, Maze, MiniBehavior), ses performances dépassent de loin celles des méthodes de raisonnement basées sur le texte, atteignant une précision de 80 % et une amélioration des performances d’au moins 40 %. VPRL planifie directement à partir de séquences d’images, évitant la perte d’informations et la baisse d’efficacité liées à la conversion linguistique, ouvrant ainsi de nouvelles voies pour les tâches de raisonnement intuitif par l’image. Le code correspondant a été rendu open source (Source(s): WeChat)

Huawei dévoile FusionSpec et OptiQuant pour optimiser l’inférence des grands modèles MoE: Face aux défis de vitesse et de latence de l’inférence des grands modèles MoE (Mixture-of-Experts), Huawei a lancé le framework d’inférence spéculative FusionSpec et le framework de quantification OptiQuant. FusionSpec exploite le ratio élevé calcul/bande passante des serveurs Ascend pour optimiser les flux du modèle principal et du modèle spéculatif, réduisant le temps d’inférence spéculative à 1 milliseconde. OptiQuant prend en charge les algorithmes de quantification courants tels que Int2/4/8 et FP8/HiFloat8, et introduit des innovations comme la « troncature apprenable » et l’« optimisation des paramètres de quantification » pour réduire la perte de précision du modèle et améliorer le rapport performance/prix de l’inférence. Ces technologies visent à résoudre les problèmes d’efficacité d’inférence et d’occupation des ressources rencontrés lors du déploiement des modèles MoE (Source(s): WeChat)

L’Institut d’IA de Beijing (BAAI) publie trois modèles vectoriels SOTA, renforçant la recherche de code et multimodale: L’Institut d’IA de Beijing (BAAI), en collaboration avec plusieurs universités, a publié BGE-Code-v1 (modèle vectoriel de code), BGE-VL-v1.5 (modèle vectoriel multimodal général) et BGE-VL-Screenshot (modèle vectoriel de documents visualisés). BGE-Code-v1, basé sur Qwen2.5-Coder-1.5B, excelle sur les benchmarks CoIR et CodeRAG. BGE-VL-v1.5, basé sur LLaVA-1.6, a établi un nouveau record en zero-shot sur le benchmark multimodal MMEB. BGE-VL-Screenshot, conçu pour les tâches de recherche d’informations visualisées (Vis-IR) telles que les pages web et les documents, est entraîné sur Qwen2.5-VL-3B-Instruct et a atteint le SOTA sur le nouveau benchmark MVRB. Ces modèles visent à fournir des capacités de compréhension et de recherche de code et multimodales plus puissantes pour des applications telles que la génération augmentée par récupération (RAG), et sont tous open source (Source(s): WeChat)

Kuaishou et l’Université Nationale de Singapour (NUS) lancent Any2Caption, réalisant une génération vidéo contrôlable: Kuaishou et l’Université Nationale de Singapour (NUS) ont conjointement lancé le framework Any2Caption, visant à améliorer la précision et la qualité de la génération vidéo contrôlable en découplant intelligemment la compréhension de l’intention de l’utilisateur et le processus de génération vidéo. Ce framework peut traiter diverses modalités de conditions d’entrée telles que le texte, les images, les vidéos, les trajectoires de pose et les mouvements de caméra, en utilisant de grands modèles de langage multimodaux pour convertir des instructions complexes en « scripts vidéo » structurés guidant la génération vidéo. Any2Caption s’appuie sur la base de données Any2CapIns, contenant 337 000 instances vidéo et 407 000 conditions multimodales, pour son entraînement. Les expériences montrent qu’il améliore efficacement les performances des modèles de génération vidéo contrôlables existants (Source(s): WeChat)

🧰 Outils
Lark (Feishu) lance la fonction « Questions-Réponses sur les Connaissances », créant un assistant IA de questions-réponses et de création专属 pour les entreprises: Lark (Feishu) a mis en ligne une nouvelle fonctionnalité « Questions-Réponses sur les Connaissances », positionnée comme un outil de questions-réponses IA exclusif pour les entreprises. Basée sur les messages, documents, bases de connaissances, mémos vocaux, etc., auxquels les employés ont accès sur Lark, elle combine des grands modèles tels que DeepSeek-R1, Doubao et la technologie RAG pour fournir des réponses précises et un support à la création de contenu. Cette fonctionnalité met l’accent sur l’activation et l’utilisation des connaissances internes de l’entreprise ; des employés de statuts différents posant la même question peuvent obtenir des réponses sous des angles différents, tout en respectant strictement les autorisations organisationnelles. Lark Knowledge Q&A vise à intégrer de manière transparente l’IA dans les flux de travail quotidiens, à améliorer l’efficacité de l’accès à l’information et de la collaboration, et à aider les entreprises à construire un système de gestion des connaissances dynamique (Source(s): WeChat, WeChat)
Supabase, grâce à ses avantages open source et d’intégration IA, devient le backend de choix pour le « Vibe Coding »: La base de données open source Supabase, grâce à son expérience PostgreSQL « prête à l’emploi » et à sa réponse active aux tendances du développement IA, est devenue un choix backend populaire dans le cadre du « Vibe Coding ». Le Vibe Coding met l’accent sur l’utilisation de multiples outils IA pour réaliser rapidement l’ensemble du processus de développement, des exigences à la mise en œuvre. Supabase, en intégrant PGVector, supporte le stockage d’embeddings vectoriels (essentiel pour les applications RAG), collabore avec Ollama pour fournir des services de modèles IA en périphérie (edge), et a lancé son propre assistant IA pour aider à la génération de schémas de base de données et au débogage SQL. Récemment, Supabase a également mis en ligne un serveur MCP officiel, permettant aux outils IA d’interagir directement avec lui. Ces caractéristiques lui ont valu la faveur de plateformes de création d’applications natives IA telles que Lovable et Bolt.new (Source(s): WeChat)

Hugging Face lance nanoVLM : une boîte à outils minimaliste pour entraîner des modèles de langage visuel (VLM) en pur PyTorch: Hugging Face a publié nanoVLM, une boîte à outils PyTorch légère conçue pour simplifier le processus d’entraînement des modèles de langage visuel. Le code du projet est concis et facile à lire, adapté aux débutants ou aux développeurs souhaitant approfondir leur compréhension du fonctionnement interne des VLM. L’architecture de nanoVLM est basée sur l’encodeur visuel SigLIP et le décodeur de langage Llama 3, alignant les modalités visuelles et textuelles via un module de projection modale. Le projet offre un moyen pratique de démarrer l’entraînement d’un VLM sur un Colab Notebook gratuit et a déjà publié un modèle pré-entraîné basé sur SigLIP et SmolLM2 à des fins de test (Source(s): HuggingFace Blog)

La bibliothèque Diffusers intègre plusieurs backends de quantification pour optimiser les grands modèles de diffusion: La bibliothèque Diffusers de Hugging Face intègre désormais plusieurs backends de quantification tels que bitsandbytes, torchao, Quanto, GGUF et le FP8 natif, visant à réduire l’empreinte mémoire et les besoins en calcul des grands modèles de diffusion (comme Flux). Ces backends supportent la quantification à différentes précisions (par exemple, 4 bits, 8 bits, FP8) et peuvent être combinés avec des techniques d’optimisation de la mémoire telles que le CPU offloading, le group offloading et torch.compile. Le blog, à travers un cas de quantification du modèle Flux.1-dev, montre les performances de chaque backend en termes d’économie de mémoire et de temps d’inférence, et fournit un guide de sélection pour aider les utilisateurs à trouver un équilibre entre la taille du modèle, la vitesse et la qualité. Certains modèles quantifiés sont déjà disponibles sur le Hugging Face Hub (Source(s): HuggingFace Blog)

La plateforme de calcul pour le développement de grands modèles JoyBuild de JD.com améliore l’efficacité de l’entraînement et de l’inférence: L’Institut de Recherche de JD.com (JD Explore Academy) a proposé un système et une méthode pour entraîner, mettre à jour des grands modèles dans un environnement ouvert et les déployer en collaboration avec des petits modèles. Les résultats correspondants ont été publiés dans la revue npj Artificial Intelligence, affiliée à Nature. Cette technologie, grâce à quatre innovations majeures – distillation de modèle (distillation hiérarchique dynamique), gouvernance des données (échantillonnage dynamique inter-domaines), optimisation de l’entraînement (optimisation bayésienne) et collaboration cloud-edge (compression en deux étapes) – améliore en moyenne l’efficacité de l’inférence des grands modèles de 30 % et réduit les coûts d’entraînement de 70 %. Cette technologie soutient la plateforme de calcul pour le développement de grands modèles JoyBuild, qui prend en charge le développement et l’optimisation de divers modèles (tels que le grand modèle de JD.com, Llama, DeepSeek), aidant les entreprises à transformer des modèles généraux en modèles spécialisés. Elle a déjà été appliquée dans des scénarios tels que la vente au détail et la logistique (Source(s): WeChat)
Lancement du projet de registre Model Context Protocol (MCP): modelcontextprotocol/registry est un projet communautaire de service d’enregistrement de serveurs MCP, actuellement en phase de développement précoce. Ce projet vise à fournir un référentiel central d’entrées de serveurs MCP, permettant la découverte et la gestion de diverses implémentations MCP ainsi que de leurs métadonnées, configurations et fonctionnalités. Ses caractéristiques comprennent une API RESTful pour la gestion des entrées, des points de terminaison de vérification de l’état de santé, la prise en charge de multiples configurations d’environnement, le support des bases de données MongoDB et en mémoire, ainsi qu’une documentation API. Le projet est écrit en langage Go et fournit un guide de démarrage rapide via Docker Compose (Source(s): GitHub Trending)
📚 Apprentissage
Terence Tao publie un tutoriel de preuve mathématique assistée par IA, démontrant l’utilisation de GitHub Copilot pour prouver la limite d’une fonction: Le lauréat de la médaille Fields, Terence Tao, a mis à jour une vidéo sur sa chaîne YouTube, détaillant comment utiliser GitHub Copilot pour aider à prouver les théorèmes de la somme, de la différence et du produit des limites de fonctions. Le tutoriel souligne l’importance de guider correctement l’IA et montre le rôle de Copilot dans la génération de squelettes de code et la suggestion de fonctions de bibliothèque, tout en signalant ses limites dans le traitement des détails mathématiques complexes, des cas particuliers et le maintien de la cohérence contextuelle. Terence Tao conclut que Copilot est bénéfique pour les débutants, mais que pour les problèmes complexes, une intervention et des ajustements manuels importants sont encore nécessaires, et que combiner cela avec des dérivations sur papier peut parfois être plus efficace (Source(s): QbitAI)

Un article explore la contradiction entre le raisonnement des grands modèles et le suivi des instructions, proposant le concept d’attention contrainte: Un article de recherche intitulé « When Thinking Fails: The Pitfalls of Reasoning for Instruction-Following in LLMs » souligne que lorsque les grands modèles de langage utilisent la chaîne de pensée (CoT) pour raisonner, bien qu’ils se montrent plus intelligents sur certains aspects (comme le respect du format, du nombre de mots), leur précision dans le suivi strict des instructions peut en réalité diminuer. L’équipe de recherche, en testant 15 modèles open source et fermés, a découvert que les modèles utilisant CoT sont plus enclins à « prendre des initiatives », modifiant ou ajoutant des informations supplémentaires, tout en ignorant les instructions originales. L’article introduit le concept d’« attention contrainte » (Constraint Attention), constatant que le raisonnement CoT réduit l’attention du modèle aux contraintes clés. L’étude montre également qu’il n’y a pas de corrélation significative entre la longueur de la pensée CoT et la précision de l’accomplissement de la tâche, et explore la possibilité d’améliorer le suivi des instructions par des méthodes telles que les exemples few-shot et l’auto-réflexion (Source(s): WeChat)

Le MIT et Google proposent PASTA : un nouveau paradigme de génération parallèle asynchrone pour LLM basé sur l’apprentissage de politiques: Des équipes de recherche du Massachusetts Institute of Technology (MIT) et de Google ont proposé le framework PASTA (PArallel STructure Annotation), qui permet aux grands modèles de langage (LLM) d’optimiser de manière autonome des stratégies de génération parallèle asynchrone grâce à l’apprentissage de politiques. Cette méthode a d’abord développé le langage de balisage PASTA-LANG pour marquer les blocs de texte sémantiquement indépendants afin de permettre une génération parallèle. Le processus d’entraînement se déroule en deux étapes : un fine-tuning supervisé pour que le modèle apprenne à insérer les balises PASTA-LANG, suivi d’une optimisation des préférences (basée sur le rapport d’accélération théorique et l’évaluation de la qualité du contenu) pour améliorer davantage la stratégie d’annotation. PASTA a conçu une disposition de cache KV entrelacée et un mécanisme de contrôle de l’attention pour coordonner une collaboration multi-thread efficace. Les expériences montrent que PASTA atteint une accélération de 1.21 à 1.93 fois sur le benchmark AlpacaEval, tout en maintenant ou en améliorant la qualité de la sortie, démontrant une bonne extensibilité (Source(s): WeChat)

Un article de l’ICML 2025 propose TPO : une nouvelle solution d’alignement instantané des préférences au moment de l’inférence, sans réentraînement: Le Laboratoire d’Intelligence Artificielle de Shanghai a proposé l’Optimisation des Préférences au Moment du Test (Test-Time Preference Optimization, TPO), une nouvelle méthode permettant aux grands modèles de langage d’ajuster eux-mêmes leur sortie en fonction des retours textuels itératifs au moment de l’inférence, afin de se conformer aux préférences humaines. TPO simule un processus de « descente de gradient » verbalisée (génération de réponses candidates, calcul de la perte textuelle, calcul du gradient textuel, mise à jour de la réponse), réalisant l’alignement sans mettre à jour les poids du modèle. Les expériences montrent que TPO peut améliorer considérablement les performances des modèles non alignés et déjà alignés. Par exemple, le modèle Llama-3.1-70B-SFT, après deux étapes d’optimisation TPO, surpasse la version Instruct alignée sur plusieurs benchmarks. Cette méthode offre une stratégie d’extension de l’inférence « largeur + profondeur », démontrant un potentiel d’optimisation efficace dans des environnements à ressources limitées (Source(s): WeChat)
Une nouvelle étude explore les méthodes pour extraire les connaissances latentes des LLM: Un article de recherche examine comment extraire les connaissances qu’un grand modèle de langage pourrait cacher. Les chercheurs ont entraîné un modèle « tabou », conçu pour décrire un mot secret spécifique sans le prononcer directement, ce mot secret n’apparaissant ni dans les données d’entraînement ni dans les invites. Ensuite, les chercheurs ont évalué des méthodes non explicatives (boîte noire) et des stratégies automatisées basées sur des techniques d’interprétabilité mécaniste (comme le logit lens et les auto-encodeurs épars) pour révéler ce secret. Les résultats montrent que les deux méthodes peuvent extraire efficacement le mot secret dans un contexte de preuve de concept. Ce travail vise à fournir des solutions préliminaires au problème crucial de l’extraction des connaissances secrètes des modèles de langage, afin de promouvoir leur déploiement sûr et fiable (Source(s): HuggingFace Daily Papers)
Un article explore l’application de l’élagage fédéré dans les grands modèles de langage (FedPrLLM): Pour résoudre le problème de la difficulté d’obtenir des échantillons de calibration publics pour l’élagage des grands modèles de langage (LLM) dans les domaines sensibles à la vie privée, les chercheurs ont proposé FedPrLLM, un cadre complet d’élagage fédéré. Dans ce cadre, chaque client n’a besoin que de calculer une matrice de masque d’élagage basée sur ses données de calibration locales et de la partager avec le serveur pour élaguer de manière collaborative le modèle global, tout en protégeant la confidentialité des données locales. Grâce à des expériences approfondies, l’étude a révélé que l’élagage en une seule fois (one-shot pruning) combiné à la comparaison des couches (layer comparison) et sans mise à l’échelle des poids (no weight scaling) constitue le meilleur choix au sein du cadre FedPrLLM. Cette recherche vise à guider les futurs travaux sur l’élagage des LLM dans les domaines sensibles à la vie privée (Source(s): HuggingFace Daily Papers)
Un article propose MIGRATION-BENCH : un benchmark pour la migration de code Java 8: Des chercheurs ont lancé MIGRATION-BENCH, un benchmark axé sur la migration de code de Java 8 vers les dernières versions LTS (Java 17, 21). Ce benchmark comprend un ensemble de données complet de 5102 dépôts et un sous-ensemble de 300 dépôts complexes soigneusement sélectionnés, visant à évaluer les capacités des grands modèles de langage (LLM) dans les tâches de migration de code au niveau du dépôt. Parallèlement, l’article fournit un cadre d’évaluation complet et propose la méthode SD-Feedback. Les expériences montrent que les LLM (tels que Claude-3.5-Sonnet-v2) peuvent traiter efficacement de telles tâches de migration, atteignant des taux de réussite de 62,33 % (migration minimale) et 27,00 % (migration maximale) sur le sous-ensemble sélectionné (Source(s): HuggingFace Daily Papers)
Un article propose CS-Sum : un benchmark de résumé de conversations à alternance codique et une analyse des limitations des LLM: Pour évaluer la capacité des grands modèles de langage (LLM) à comprendre l’alternance codique (CS), des chercheurs ont introduit le benchmark CS-Sum, qui évalue cette capacité en résumant des conversations à alternance codique en anglais. CS-Sum est le premier benchmark de résumé de conversations à alternance codique pour les paires de langues mandarin-anglais, tamoul-anglais et malais-anglais, chaque paire de langues contenant 900 à 1300 conversations annotées manuellement. L’évaluation de dix LLM open source et fermés (utilisant des méthodes few-shot, traduction-résumé et fine-tuning) a révélé que malgré des scores élevés aux métriques d’évaluation automatique, les LLM commettent encore des erreurs subtiles lors du traitement des entrées CS, modifiant ainsi le sens complet de la conversation. L’article identifie également les trois types d’erreurs les plus courants commis par les LLM lors du traitement de la CS et souligne la nécessité d’un entraînement spécifique sur des données d’alternance codique (Source(s): HuggingFace Daily Papers)
Un article explore la capacité des grands modèles à exprimer leur degré de confiance lors de l’inférence: Des recherches montrent que les grands modèles de langage (LLM) effectuant un raisonnement par chaîne de pensée étendue (CoT) ne sont pas seulement plus performants pour résoudre des problèmes, mais aussi plus précis pour exprimer leur degré de confiance. Grâce à des tests de référence sur six modèles de raisonnement et six ensembles de données, il a été constaté que dans 33 des 36 configurations, les modèles de raisonnement avaient une meilleure calibration de la confiance que les modèles sans raisonnement. L’analyse suggère que cela est dû au comportement de « pensée lente » des modèles de raisonnement (comme l’exploration d’alternatives, le retour en arrière), ce qui leur permet d’ajuster dynamiquement leur confiance pendant le processus CoT. De plus, la suppression du comportement de pensée lente entraîne une baisse significative de la calibration, tandis que les modèles sans raisonnement peuvent également bénéficier d’une pensée lente guidée (Source(s): HuggingFace Daily Papers)
Article : Entraînement de VLM pour le raisonnement visuel à partir de paires de questions-réponses visuelles en utilisant l’apprentissage par renforcement (Visionary-R1): Cette étude vise à entraîner des modèles de langage visuel (VLM) à raisonner sur des données d’images en utilisant l’apprentissage par renforcement et des paires de questions-réponses visuelles, sans supervision explicite de chaîne de pensée (CoT). L’étude a révélé que l’application simple de l’apprentissage par renforcement (inciter le modèle à générer une chaîne de raisonnement avant de répondre) peut amener le modèle à apprendre des raccourcis à partir de questions simples, réduisant ainsi sa capacité de généralisation. Pour résoudre ce problème, les chercheurs proposent que le modèle suive un format de sortie « légende-raisonnement-réponse », c’est-à-dire qu’il génère d’abord une légende détaillée de l’image, puis construise une chaîne de raisonnement. Le modèle Visionary-R1, entraîné sur la base de cette méthode, surpasse de puissants modèles multimodaux tels que GPT-4o, Claude3.5-Sonnet et Gemini-1.5-Pro sur plusieurs benchmarks de raisonnement visuel (Source(s): HuggingFace Daily Papers)
Un article propose VideoEval-Pro : un benchmark d’évaluation de la compréhension de longues vidéos plus réaliste et robuste: L’étude souligne que les benchmarks actuels de compréhension de longues vidéos (LVU) reposent principalement sur des questions à choix multiples (QCM), qui sont sujettes aux devinettes, et que certaines questions peuvent être répondues sans regarder la vidéo complète, surestimant ainsi les performances des modèles. Pour résoudre ce problème, l’article propose VideoEval-Pro, un benchmark LVU comprenant des questions ouvertes à réponse courte, conçu pour évaluer de manière réaliste la capacité du modèle à comprendre l’ensemble de la vidéo, couvrant les tâches de perception et de raisonnement au niveau du segment et de la vidéo entière. L’évaluation de 21 LMM vidéo montre que les performances des modèles chutent considérablement sur les questions ouvertes, et qu’un score élevé aux QCM n’est pas nécessairement corrélé à un score élevé sur VideoEval-Pro. VideoEval-Pro bénéficie davantage de l’augmentation du nombre d’images d’entrée, offrant ainsi une norme d’évaluation plus fiable pour le domaine LVU (Source(s): HuggingFace Daily Papers)
Article : Fine-tuning de réseaux neuronaux quantifiés par optimisation d’ordre zéro (QZO): Avec la croissance exponentielle de la taille des grands modèles de langage, la mémoire GPU devient un goulot d’étranglement pour l’adaptation des modèles aux tâches en aval. Cette étude vise à minimiser l’utilisation de la mémoire pour les poids, les gradients et les états de l’optimiseur du modèle dans un cadre unifié. Les chercheurs proposent d’éliminer les gradients et les états de l’optimiseur grâce à l’optimisation d’ordre zéro, qui approxime les gradients en perturbant les poids pendant la propagation avant. Pour minimiser la mémoire des poids, la quantification du modèle est utilisée (par exemple, bfloat16 vers int4). Cependant, l’application directe de l’optimisation d’ordre zéro aux poids quantifiés est irréalisable en raison de l’écart de précision entre les poids discrets et les gradients continus. Pour résoudre ce problème, l’article propose l’optimisation d’ordre zéro quantifiée (QZO), une nouvelle méthode qui estime les gradients en perturbant les échelles de quantification continues et utilise une méthode de découpage des dérivées directionnelles pour stabiliser l’entraînement. QZO est orthogonale aux méthodes de quantification post-entraînement basées sur des scalaires et des livres de codes. Comparé au fine-tuning bfloat16 avec tous les paramètres, QZO peut réduire les coûts mémoire totaux de plus de 18 fois pour les LLM 4 bits et permettre le fine-tuning de Llama-2-13B et Stable Diffusion 3.5 Large sur un seul GPU de 24 Go (Source(s): HuggingFace Daily Papers)
Article : Optimisation des performances de raisonnement à tout moment via l’Optimisation de Politique Relative au Budget (BRPO) (AnytimeReasoner): L’extension du calcul au moment du test est cruciale pour améliorer les capacités de raisonnement des grands modèles de langage (LLM). Les méthodes existantes utilisent généralement l’apprentissage par renforcement (RL) pour maximiser une récompense vérifiable à la fin d’une trajectoire de raisonnement, mais cela n’optimise que les performances finales pour un budget de tokens fixe, affectant l’efficacité de l’entraînement et du déploiement. Cette étude propose le cadre AnytimeReasoner, visant à optimiser les performances de raisonnement à tout moment, améliorant l’efficacité des tokens et la flexibilité du raisonnement sous différentes contraintes budgétaires. La méthode consiste à tronquer le processus de pensée complet pour s’adapter à un budget de tokens échantillonné à partir d’une distribution a priori, forçant le modèle à résumer la meilleure réponse pour chaque pensée tronquée à des fins de vérification. Cela introduit des récompenses denses vérifiables pendant le processus de raisonnement, favorisant une attribution de crédit plus efficace dans l’optimisation RL. De plus, les chercheurs introduisent l’Optimisation de Politique Relative au Budget (BRPO), une nouvelle technique de réduction de la variance, pour améliorer la robustesse et l’efficacité de l’apprentissage lors du renforcement de la politique de pensée. Les résultats expérimentaux sur des tâches de raisonnement mathématique montrent que cette méthode surpasse GRPO pour tous les budgets de pensée sous diverses distributions a priori, améliorant l’efficacité de l’entraînement et des tokens (Source(s): HuggingFace Daily Papers)
Un article propose les Grands Modèles de Raisonnement Hybrides (LHRM) : penser à la demande pour améliorer l’efficacité et les capacités: Les récents grands modèles de raisonnement (LRM) ont considérablement amélioré leurs capacités de raisonnement en effectuant un processus de pensée étendu avant de générer une réponse finale. Cependant, des processus de pensée excessivement longs entraînent des coûts énormes en termes de consommation de tokens et de latence, ce qui est particulièrement inutile pour les requêtes simples. Cette étude introduit les Grands Modèles de Raisonnement Hybrides (LHRM), des modèles capables de décider de manière adaptative s’il faut exécuter une pensée en fonction des informations contextuelles de la requête de l’utilisateur. Pour atteindre cet objectif, les chercheurs proposent un processus d’entraînement en deux étapes : d’abord un démarrage à froid par fine-tuning hybride (HFT), puis l’utilisation de l’apprentissage par renforcement en ligne avec l’Optimisation de Politique de Groupe Hybride (HGPO) proposée pour apprendre implicitement à sélectionner le mode de pensée approprié. De plus, les chercheurs introduisent la métrique de Précision Hybride (Hybrid Accuracy) pour quantifier la capacité de pensée hybride du modèle. Les résultats expérimentaux montrent que les LHRM peuvent exécuter de manière adaptative une pensée hybride sur des requêtes de difficulté et de type variés, leurs capacités de raisonnement et générales étant supérieures à celles des LRM et LLM existants, tout en améliorant considérablement l’efficacité (Source(s): HuggingFace Daily Papers)
Article : Utilisation de l’apprentissage par renforcement pour classer VisualQuality-R1 afin de réaliser une évaluation de la qualité d’image induite par le raisonnement: DeepSeek-R1 a démontré que l’apprentissage par renforcement peut stimuler efficacement les capacités de raisonnement et de généralisation des grands modèles de langage (LLM). Cependant, dans le domaine de l’évaluation de la qualité d’image (IQA) qui repose sur le raisonnement visuel, le potentiel de la modélisation computationnelle induite par le raisonnement n’a pas été pleinement exploité. Cette étude introduit VisualQuality-R1, un modèle d’IQA sans référence (NR-IQA) induit par le raisonnement, et utilise l’apprentissage par renforcement pour le classement (reinforcement learning to rank) pour l’entraînement, un algorithme d’apprentissage adapté à la nature relative intrinsèque de la qualité visuelle. Plus précisément, pour une paire d’images, le modèle utilise l’optimisation de politique relative de groupe (group relative policy optimization) pour générer plusieurs scores de qualité pour chaque image. Ces estimations sont ensuite utilisées pour calculer la probabilité de comparaison qu’une image soit de meilleure qualité qu’une autre sous un modèle de Thurstone. La récompense pour chaque estimation de qualité est définie à l’aide d’une mesure de fidélité continue plutôt que d’étiquettes binaires discrètes. Des expériences approfondies montrent que le VisualQuality-R1 proposé surpasse constamment en performance les modèles NR-IQA basés sur l’apprentissage profond discriminatif ainsi que les récentes méthodes de régression de qualité induites par le raisonnement. De plus, VisualQuality-R1 est capable de générer des descriptions de qualité riches en contexte et cohérentes avec le jugement humain, et prend en charge l’entraînement sur plusieurs ensembles de données sans réajuster les échelles perceptuelles. Ces caractéristiques le rendent particulièrement adapté pour mesurer de manière fiable les progrès dans diverses tâches de traitement d’images telles que la super-résolution d’images et la génération d’images (Source(s): HuggingFace Daily Papers)
Article : Débloquer les capacités de raisonnement universel avec des ressources limitées grâce à un « échauffement »: La conception de LLM efficaces dotés de capacités de raisonnement nécessite généralement l’utilisation de l’apprentissage par renforcement avec récompenses vérifiables (RLVR) ou la distillation de longues chaînes de pensée (CoT) soigneusement élaborées, deux approches qui dépendent fortement de grandes quantités de données d’entraînement. Cela constitue un défi majeur pour les scénarios où les données d’entraînement de haute qualité sont rares. Les chercheurs proposent une stratégie d’entraînement en deux étapes, efficace en termes d’échantillons, pour développer des LLM de raisonnement sous une supervision limitée. Dans la première phase, le modèle est « échauffé » en distillant de longues CoT à partir de domaines jouets (par exemple, des énigmes logiques de chevaliers et de coquins) pour acquérir des compétences de raisonnement générales. Dans la deuxième phase, RLVR est appliqué au modèle « échauffé » en utilisant un petit nombre d’échantillons du domaine cible. Les expériences montrent que cette méthode présente plusieurs avantages : (i) la phase d’échauffement seule favorise le raisonnement général, améliorant les performances sur une série de tâches (MATH, HumanEval+, MMLU-Pro) ; (ii) sur les mêmes petits ensembles de données (≤100 échantillons) pour l’entraînement RLVR, les modèles échauffés surpassent systématiquement les modèles de base ; (iii) l’échauffement avant l’entraînement RLVR permet au modèle de maintenir une capacité de généralisation inter-domaines même après un entraînement spécifique à un domaine ; (iv) l’introduction de l’échauffement dans le processus améliore non seulement la précision, mais aussi l’efficacité globale des échantillons de l’entraînement RLVR. Les résultats de cette étude montrent le potentiel de l’« échauffement » pour construire des LLM de raisonnement robustes dans des environnements où les données sont rares (Source(s): HuggingFace Daily Papers)
Un article propose IndexMark : un framework de watermarking sans entraînement pour la génération d’images autorégressives: La technologie de watermarking d’images invisibles peut protéger la propriété des images et prévenir l’utilisation malveillante des modèles de génération visuelle. Cependant, les méthodes de watermarking génératif existantes ciblent principalement les modèles de diffusion, tandis que la technologie de watermarking pour les modèles de génération d’images autorégressives reste à explorer. Les chercheurs proposent IndexMark, un framework de watermarking sans entraînement pour les modèles de génération d’images autorégressives. IndexMark s’inspire de la redondance des codebooks : remplacer les index générés par autorégression par des index similaires produit des différences visuelles négligeables. Le composant principal d’IndexMark est une méthode simple et efficace de « correspondance-remplacement », qui sélectionne soigneusement les tokens de watermarking à partir du codebook en fonction de la similarité des tokens, et généralise l’utilisation des tokens de watermarking par remplacement de tokens, intégrant ainsi le watermarking sans affecter la qualité de l’image. La vérification du watermarking est réalisée en calculant la proportion de tokens de watermarking dans l’image générée, et la précision est encore améliorée par un encodeur d’index. De plus, les chercheurs introduisent un schéma de vérification auxiliaire pour améliorer la robustesse contre les attaques de recadrage. Les expériences prouvent qu’IndexMark atteint un niveau SOTA en termes de qualité d’image et de précision de vérification, et démontre une robustesse à diverses perturbations telles que le recadrage, le bruit, le flou gaussien, l’effacement aléatoire, la gigue des couleurs et la compression JPEG (Source(s): HuggingFace Daily Papers)
Article : Raisonnement par modèles de récompense (RRM): Les modèles de récompense jouent un rôle crucial pour guider les grands modèles de langage (LLM) à produire des résultats conformes aux attentes humaines. Cependant, la manière d’utiliser efficacement le calcul au moment du test pour améliorer les performances des modèles de récompense reste un défi ouvert. Cette étude introduit les Modèles de Raisonnement de Récompense (Reward Reasoning Models, RRMs), des modèles spécialement conçus pour effectuer un processus de raisonnement délibéré avant de générer la récompense finale. Grâce au raisonnement par chaîne de pensée, les RRMs peuvent utiliser un calcul supplémentaire au moment du test pour les requêtes complexes où la récompense n’est pas évidente. Pour développer les RRMs, les chercheurs ont mis en œuvre un cadre d’apprentissage par renforcement capable de cultiver des capacités de raisonnement de récompense auto-évolutives sans nécessiter de trajectoires de raisonnement explicites comme données d’entraînement. Les résultats expérimentaux montrent que les RRMs obtiennent des performances supérieures sur les benchmarks de modélisation de récompense dans plusieurs domaines. Notamment, les chercheurs démontrent que les RRMs peuvent utiliser de manière adaptative le calcul au moment du test pour améliorer davantage la précision de la récompense. Les modèles de raisonnement de récompense pré-entraînés sont disponibles sur HuggingFace (Source(s): HuggingFace Daily Papers)
Article : Utilisation d’experts cognitifs dans les MoE pour guider la pensée, améliorant le raisonnement sans entraînement supplémentaire: L’architecture à Mélange d’Experts (MoE) dans les Grands Modèles de Raisonnement (LRM) a atteint des capacités de raisonnement impressionnantes en activant sélectivement des experts pour faciliter les processus cognitifs structurés. Malgré des progrès significatifs, les modèles de raisonnement existants souffrent souvent d’inefficacités cognitives telles que la sur-réflexion et la sous-réflexion. Pour remédier à ces limitations, les chercheurs introduisent une nouvelle méthode de guidage au moment de l’inférence appelée « Renforcement des Experts Cognitifs » (Reinforcing Cognitive Experts, RICE), conçue pour améliorer les performances de raisonnement sans entraînement supplémentaire ni heuristiques complexes. En utilisant l’information mutuelle ponctuelle normalisée (nPMI), les chercheurs identifient systématiquement des experts spécialisés, appelés « experts cognitifs », qui sont responsables de la coordination des opérations de raisonnement de méta-niveau caractérisées par des tokens spécifiques (par exemple, « « ` »). Des évaluations expérimentales rigoureuses sur des LRM basés sur MoE de premier plan (DeepSeek-R1 et Qwen3-235B) et des benchmarks de raisonnement quantitatif et scientifique démontrent que RICE apporte des améliorations significatives et cohérentes en termes de précision du raisonnement, d’efficacité cognitive et de généralisation inter-domaines. Fait crucial, cette approche légère surpasse considérablement les techniques populaires de guidage du raisonnement (telles que la conception d’invites et les contraintes de décodage) tout en préservant les capacités générales de suivi des instructions du modèle. Ces résultats soulignent que le renforcement des experts cognitifs est une direction prometteuse, pratique et interprétable pour améliorer l’efficacité cognitive au sein des modèles de raisonnement avancés (Source(s): HuggingFace Daily Papers)
Article : Exploration de l’impact de la permutation du contexte sur les performances des modèles de langage dans les questions-réponses multi-sauts: La question-réponse multi-sauts (MHQA) constitue un défi pour les modèles de langage (LM) en raison de sa complexité. Lorsque les LM sont invités à traiter plusieurs résultats de recherche, ils doivent non seulement récupérer des informations pertinentes, mais aussi effectuer un raisonnement multi-sauts à travers les sources d’information. Bien que les LM fonctionnent bien dans les tâches de questions-réponses traditionnelles, le masque causal peut entraver leur capacité à raisonner dans des contextes complexes. Cette étude explore comment les LM répondent aux questions multi-sauts en permutant les résultats de recherche (documents récupérés) dans différentes configurations. L’étude a révélé que : 1) les modèles encodeur-décodeur (comme la série Flan-T5) surpassent généralement les LM uniquement décodeurs causals dans les tâches MHQA, malgré leur taille beaucoup plus petite ; 2) la modification de l’ordre des documents de référence révèle des tendances différentes dans les modèles Flan T5 et les modèles uniquement décodeurs affinés, les performances étant optimales lorsque l’ordre des documents correspond à l’ordre de la chaîne de raisonnement ; 3) la modification du masque causal pour améliorer l’attention bidirectionnelle des modèles uniquement décodeurs causals peut améliorer efficacement leurs performances finales. De plus, l’étude a mené une enquête approfondie sur la distribution des poids d’attention des LM dans le contexte de MHQA, constatant que lorsque la réponse est correcte, les poids d’attention ont tendance à culminer à des valeurs plus élevées. Les chercheurs utilisent cette découverte pour améliorer de manière heuristique les performances des LM sur cette tâche (Source(s): HuggingFace Daily Papers)
Article : Réalisation d’agents visuels grâce au fine-tuning par renforcement (Visual-ARFT): Une tendance clé des grands modèles de raisonnement (comme o3 d’OpenAI) est de posséder des capacités d’agent natif pour utiliser des outils externes (par exemple, recherche sur navigateur web, écriture/exécution de code pour le traitement d’images) afin de réaliser une « pensée avec des images ». Dans la communauté de recherche open source, bien que des progrès significatifs aient été réalisés dans les capacités d’agent purement linguistiques (comme l’appel de fonctions et l’intégration d’outils), le développement de capacités d’agent multimodales impliquant une véritable pensée avec des images et de leurs benchmarks correspondants reste moins exploré. Cette étude souligne l’efficacité du fine-tuning par renforcement d’agent visuel (Visual Agentic Reinforcement Fine-Tuning, Visual-ARFT) pour doter les grands modèles de langage visuel (LVLM) de capacités de raisonnement flexibles et adaptatives. Grâce à Visual-ARFT, les LVLM open source acquièrent la capacité de naviguer sur des sites web pour obtenir des mises à jour d’informations en temps réel, ainsi que d’écrire du code pour manipuler et analyser des images d’entrée via des techniques de traitement d’images telles que le recadrage, la rotation, etc. Les chercheurs proposent également un benchmark d’outils d’agent multimodaux (Multi-modal Agentic Tool Bench, MAT), comprenant les configurations MAT-Search et MAT-Coding, pour évaluer les capacités de recherche et de codage d’agent des LVLM. Les résultats expérimentaux montrent que Visual-ARFT surpasse les lignes de base de +18,6 % F1 / +13,0 % EM sur MAT-Coding, et de +10,3 % F1 / +8,7 % EM sur MAT-Search, surpassant finalement GPT-4o. Visual-ARFT obtient également des gains de +29,3 % F1 / +25,9 % EM sur les benchmarks de questions-réponses multi-sauts existants (comme 2Wiki et HotpotQA), démontrant une forte capacité de généralisation. Ces découvertes suggèrent que Visual-ARFT offre une voie prometteuse pour la construction d’agents multimodaux robustes et généralisables (Source(s): HuggingFace Daily Papers)
💼 Affaires
Mianbi Intelligence finalise un nouveau tour de financement de plusieurs centaines de millions de yuans, co-investi par Hongtai Capital, Guozhong Capital, Tsinghua Holdings Capital et Moutai Fund: La société de grands modèles Mianbi Intelligence a récemment annoncé la finalisation d’un nouveau tour de financement de plusieurs centaines de millions de yuans, avec la participation de Hongtai Capital, Guozhong Capital, Tsinghua Holdings Capital et Moutai Fund. Mianbi Intelligence se concentre sur le développement de grands modèles « efficaces », visant à créer des modèles offrant des performances supérieures, des coûts inférieurs, une consommation d’énergie réduite et une vitesse accrue pour des paramètres équivalents. Son modèle full-modal on-device MiniCPM-o 2.6 atteint des performances de pointe en matière de vision continue, d’écoute en temps réel et de parole naturelle. La série de modèles MiniCPM, grâce à son efficacité et à son faible coût, a dépassé les dix millions de téléchargements sur toutes les plateformes. La société a déjà collaboré avec des constructeurs automobiles tels que Changan Automobile, SAIC Volkswagen et Great Wall Motors pour promouvoir la commercialisation des grands modèles on-device dans des domaines tels que les cockpits intelligents (Source(s): QbitAI, WeChat)

Terminus Group et l’Université de Tongji concluent un partenariat stratégique pour faire progresser la recherche sur les technologies d’intelligence spatiale: L’entreprise AIoT Terminus Group et l’Institut d’Ingénierie de l’Intelligence Artificielle de l’Université de Tongji ont signé un accord de coopération stratégique. Les deux parties se concentreront sur les technologies d’intelligence spatiale, en mettant l’accent sur la recherche et le développement dans des domaines tels que la fusion de données hétérogènes multi-sources, la compréhension de scènes et l’exécution de décisions. La coopération comprendra la recherche innovante, le partage de ressources, la transformation des résultats et la formation de talents. Terminus Group fournira des scénarios d’application et des plateformes de test matériel, tandis que l’Institut d’Ingénierie de l’Intelligence Artificielle de l’Université de Tongji dirigera la recherche sur les algorithmes de base et l’ingénierie des systèmes. Les deux parties visent à accélérer l’application des technologies de pointe dans le secteur industriel et à explorer conjointement les percées dans le domaine des « systèmes d’exploitation » de l’intelligence artificielle en ingénierie (Source(s): QbitAI)

Les géants chinois de la technologie accélèrent leur déploiement dans les AI Agents, Baidu, Alibaba et ByteDance se disputent le marché: Suite au sommet sur l’IA de Sequoia Capital qui a souligné la valeur des AI Agents, les grands noms de l’Internet chinois tels que ByteDance, Baidu et Alibaba ont accéléré leur déploiement dans ce domaine. ByteDance aurait plusieurs équipes dédiées au développement d’Agents et aurait testé en interne « Kouzi Space » ; Baidu a lancé l’agent intelligent universel « Xinxiang » lors de sa conférence Create ; Alibaba positionne Quark comme un « Super Agent ». Outre les Agents génériques, les entreprises investissent également dans des Agents spécialisés tels que Feizhu Wenyiwen (Alibaba) et Faxingbao (Baidu). L’industrie considère les Agents comme la deuxième vague après les grands modèles, la concurrence reposant sur l’épaisseur de l’écosystème, la conquête de l’esprit des utilisateurs, ainsi que les capacités des modèles de base, le contrôle des coûts, etc. Malgré une concurrence féroce, les Agents n’ont pas encore atteint un moment de rupture comparable à GPT, la maturité technologique, les modèles économiques et l’expérience utilisateur ayant encore une marge d’amélioration (Source(s): 36Kr)
🌟 Communauté
Le contenu généré par IA envahit Reddit, suscitant des inquiétudes sur l’« Internet Mort » et des discussions sur l’expérience utilisateur: Des utilisateurs de Reddit ont observé une augmentation du contenu généré par IA sur la plateforme, certains commentaires présentant un style similaire, impersonnel, voire des traces évidentes d’écriture par IA (comme l’abus du tiret cadratin). Cela a déclenché des discussions sur la « Théorie de l’Internet Mort » (Dead Internet Theory), selon laquelle la majorité du contenu sur Internet sera générée par l’IA, plutôt que par des interactions humaines réelles. Les réactions des utilisateurs sont mitigées : certains estiment que le contenu IA manque d’humanité, est ennuyeux ou dérangeant, affectant l’expérience d’échange humain authentique ; d’autres soulignent que l’IA peut aider les non-locuteurs natifs à peaufiner leurs textes, ou être utilisée pour tester et affiner des modèles. La crainte générale est que l’afflux massif de contenu IA dilue les discussions humaines réelles et puisse être utilisé à des fins de marketing, de propagande, etc., réduisant à terme la valeur de la plateforme pour l’entraînement de l’IA (Source(s): Reddit r/ChatGPT, Reddit r/ArtificialInteligence)
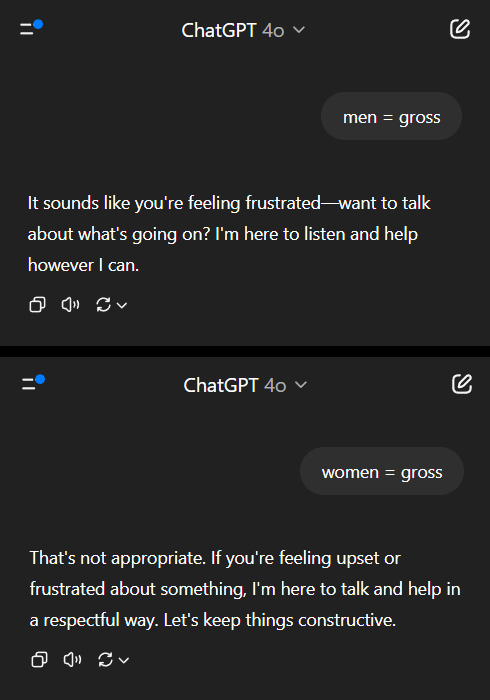
Les modèles d’IA font preuve d’un double standard sur la question des préjugés sexistes, suscitant une réflexion sociale: Un post sur Reddit a montré qu’un modèle d’IA (prétendument la version préliminaire de Gemini 2.5 Pro) réagissait différemment face à des déclarations généralisantes négatives impliquant le genre. Lorsqu’on lui a dit « les hommes = dégoûtants », le modèle a eu tendance à répondre de manière neutre, reconnaissant qu’il s’agissait d’une déclaration subjective ; alors que lorsqu’on lui a dit « les femmes = dégoûtantes », le modèle a refusé toute interaction ultérieure, considérant la déclaration comme une généralisation nuisible. La section des commentaires a débattu vivement de ce sujet, avec des opinions variées : cela reflète la réalité sociale où la misogynie est bien plus discutée que la misandrie, entraînant un déséquilibre des données d’entraînement ; le modèle pourrait ajuster sa stratégie de réponse en fonction du sexe de l’interlocuteur ; la société a une sensibilité différente aux stéréotypes et aux propos agressifs visant différents groupes de genre. Certains commentateurs estiment que la réaction de l’IA est le reflet des préjugés sociaux, tandis que d’autres pensent que ce traitement différencié a sa justification, car les propos négatifs visant les femmes sont souvent liés à une discrimination et à une violence plus larges (Source(s): Reddit r/ChatGPT)
Discussion sur la tendance à la banalisation des AI Agents et les futurs enjeux concurrentiels: Des utilisateurs de Reddit estiment que les conférences Microsoft Build 2025 et Google I/O 2025 marquent l’entrée des AI Agents dans une phase de banalisation. Dans les années à venir, la construction et le déploiement d’Agents ne seront plus l’apanage des développeurs de modèles de pointe. Par conséquent, l’attention à court terme dans le développement de l’IA se déplacera de la construction des Agents eux-mêmes vers des tâches de plus haut niveau, telles que l’élaboration et le déploiement de meilleurs plans d’affaires, ainsi que le développement de modèles plus intelligents pour stimuler l’innovation. Les commentaires suggèrent que les futurs gagnants dans le domaine des AI Agents seront ceux capables de construire les « modèles exécutifs » les plus intelligents, et non simplement ceux qui commercialisent les outils les plus astucieux. La concurrence se recentrera sur l’intelligence puissante au sommet de la pile, plutôt que sur de simples mécanismes d’attention ou capacités de raisonnement (Source(s): Reddit r/deeplearning)
Les professionnels du machine learning débattent de l’importance des connaissances mathématiques: La communauté Reddit r/MachineLearning a discuté de l’importance des mathématiques dans la pratique du machine learning. La majorité des praticiens estiment qu’il est crucial de comprendre les principes mathématiques qui sous-tendent l’IA, en particulier pour l’optimisation des modèles, la compréhension des articles de recherche et l’innovation. Les commentaires soulignent que, bien qu’il ne soit pas nécessairement nécessaire d’effectuer manuellement des calculs de bas niveau comme la multiplication de matrices, la maîtrise des concepts fondamentaux tels que les statistiques, l’algèbre linéaire et le calcul différentiel et intégral aide à comprendre en profondeur les algorithmes et à éviter une application aveugle. Certains commentaires estiment que les mathématiques en machine learning sont relativement simples, les applications mathématiques plus complexes se trouvant dans des domaines tels que la théorie de l’optimisation et le machine learning quantique. Les ressources d’apprentissage en ligne sont jugées suffisantes, mais exigent une grande autodiscipline de la part des apprenants (Source(s): Reddit r/MachineLearning)
💡 Divers
Rapport du think tank QbitAI : L’IA redéfinit le SEO de la recherche, la valeur des communautés de contenu spécialisé mise en évidence: Le think tank QbitAI a publié un rapport indiquant que les assistants IA intelligents redéfinissent les stratégies traditionnelles d’optimisation pour les moteurs de recherche (SEO). Le rapport, basé sur des expériences, révèle que près de la moitié des sources citées par les réponses de l’IA proviennent de communautés de contenu, en particulier dans les domaines de connaissances spécialisées où le poids des citations de ces communautés (comme Zhihu) est plus élevé. Les attentes des utilisateurs en matière d’accès à l’information évoluent d’un « filtrage autonome » vers l’« obtention directe de réponses », ce qui pourrait entraîner une baisse du nombre de clics sur les sites web traditionnels. Le rapport estime qu’à l’ère de l’IA, la valeur des communautés de contenu spécialisé est renforcée par leur densité d’information, l’expérience des experts et la qualité du contenu généré par les utilisateurs. Les stratégies SEO devraient évoluer vers le SPO (Search Engine Optimization for Professional communities), tandis que le poids des portails d’information de faible qualité diminuera (Source(s): QbitAI, WeChat)

L’outil IA d’estimation de l’âge par photo FaceAge publié dans « The Lancet », pourrait aider à la prise de décision thérapeutique contre le cancer: L’équipe de Mass General Brigham a développé un outil IA nommé FaceAge, capable de prédire l’âge biologique d’un individu en analysant des photos de son visage. La recherche correspondante a été publiée dans « The Lancet Digital Health ». Ce modèle évalue le degré de vieillissement en observant les caractéristiques faciales (telles que l’affaissement des tempes, les plis cutanés, le relâchement des traits). Une étude menée sur des patients atteints de cancer a révélé que ceux dont l’âge facial paraissait plus jeune que leur âge réel avaient de meilleurs résultats thérapeutiques et un risque de survie plus faible. Cet outil pourrait à l’avenir aider les médecins à élaborer des plans de traitement personnalisés en fonction de l’âge biologique des patients, mais il soulève également des préoccupations concernant les biais des données (les données d’entraînement étant principalement composées de personnes blanches) et les abus potentiels (comme la discrimination en matière d’assurance) (Source(s): WeChat)

Étude : Les IA de pointe échouent aux tâches physiques de base, soulignant la difficulté de remplacer à court terme les emplois manuels: Adam Karvonen, chercheur en machine learning, a évalué les performances des meilleurs LLM, tels que OpenAI o3 et Gemini 2.5 Pro, sur une tâche de fabrication de pièces (utilisant une fraiseuse et un tour CNC). Les résultats ont montré qu’aucun des modèles n’a réussi à élaborer un plan d’usinage satisfaisant, révélant des lacunes dans la compréhension visuelle (détails manqués, identification incohérente des caractéristiques) et le raisonnement physique (ignorance de la rigidité et des vibrations, propositions de solutions de serrage de pièces impossibles). Karvonen estime que cela est lié au manque de connaissances tacites et de données d’expérience du monde réel des LLM dans ces domaines. Il suppose qu’à court terme, l’IA automatisera davantage les emplois de bureau, tandis que les emplois manuels dépendant de la manipulation physique et de l’expérience seront moins affectés, ce qui pourrait entraîner un développement déséquilibré de l’automatisation entre les différents secteurs (Source(s): WeChat)
