
Mots-clés:Technologie d’IA, Google Gemini, Consommation énergétique de l’IA, Application juridique de l’IA, Microsoft Discovery, Régulation de l’IA, Gemini 2.5 Pro, Consommation énergétique des centres de données d’IA, Erreurs dans les documents juridiques générés par l’IA, Plateforme de recherche Microsoft Discovery, Contrôle des exportations de puces d’IA, Huang Renxun et Elon Musk
🔥 En vedette
Google I/O dévoile de multiples avancées en IA, Gemini s’intègre pleinement à l’écosystème Google: Lors de sa conférence des développeurs I/O 2025, Google a annoncé une série de mises à jour majeures en IA, axées sur l’amélioration et l’intégration profonde du modèle Gemini. Gemini 2.5 Pro introduit “Deep Think” pour un raisonnement complexe amélioré, Gemini 2.5 Flash optimise l’efficacité et les coûts, et ajoute une sortie audio native. La recherche intègre un “mode AI”, offrant des réponses de type chatbot et pouvant fournir des résultats personnalisés en combinant les données personnelles de l’utilisateur (avec autorisation). Le navigateur Chrome intégrera l’assistant Gemini. Le modèle vidéo Veo 3 permet la génération de vidéos avec son, et le modèle d’image Imagen 4 améliore les détails et le traitement du texte. Google a également lancé l’outil de production cinématographique IA Flow, l’assistant de programmation Jules, et a présenté les progrès des projets Project Astra (assistant multimodal en temps réel) et Project Mariner (agent IA multitâche). Parallèlement, Google a introduit de nouveaux services d’abonnement IA, avec une version haut de gamme AI Ultra à 249,99 $ par mois. Ces initiatives marquent l’accélération de l’intégration complète de l’IA par Google dans ses produits et services, remodelant l’expérience d’interaction utilisateur. (Source: 36氪, 36氪, 36氪, 36氪, 36氪, 36氪)

La consommation énergétique de l’IA attire l’attention, MIT Technology Review analyse en profondeur son empreinte énergétique et les défis futurs: MIT Technology Review a publié une série d’articles explorant en profondeur les problèmes de consommation d’énergie et d’émissions de carbone liés au développement de la technologie IA. La recherche souligne que la consommation d’énergie de la phase d’inférence de l’IA a dépassé celle de la phase d’entraînement, devenant le principal fardeau énergétique. Le rapport analyse l’énorme demande d’électricité et la consommation d’eau des centres de données (comme ceux situés dans le désert du Nevada), ainsi que leur dépendance aux énergies fossiles (comme le centre de données de Meta en Louisiane qui dépend du gaz naturel). Bien que l’énergie nucléaire soit considérée comme une solution potentielle d’énergie propre, son long cycle de construction rend difficile la satisfaction à court terme de la croissance rapide des besoins de l’IA. Parallèlement, le rapport souligne également les perspectives optimistes pour l’amélioration de l’efficacité énergétique de l’IA, y compris des algorithmes de modèles plus efficaces, des puces économes en énergie conçues spécifiquement pour l’IA et des technologies de refroidissement de centres de données plus optimisées. La série souligne que, bien que la consommation d’énergie d’une seule requête IA semble minime, la tendance globale de l’industrie et la planification future (comme le projet Stargate d’OpenAI) annoncent d’énormes défis énergétiques, nécessitant une divulgation transparente des données et une planification énergétique responsable. (Source: MIT Technology Review, MIT Technology Review, MIT Technology Review, MIT Technology Review, MIT Technology Review, MIT Technology Review, MIT Technology Review)

L’application de l’IA dans le domaine juridique soulève des erreurs et des préoccupations éthiques: Plusieurs incidents récents montrent que le problème des “hallucinations” générées par l’IA dans la rédaction de documents juridiques suscite de vives inquiétudes. Un juge californien a infligé une amende à un avocat pour avoir utilisé des outils d’IA tels que Google Gemini pour générer du contenu contenant de fausses citations dans des documents judiciaires. Dans une autre affaire, le modèle Claude de la société d’IA Anthropic a également commis des erreurs en générant des citations pour des documents juridiques. Plus inquiétant encore, des procureurs israéliens ont admis avoir utilisé dans une requête du texte généré par l’IA citant des lois inexistantes. Ces cas soulignent les lacunes des modèles d’IA en termes d’exactitude et de fiabilité, en particulier dans le domaine juridique où les faits et les citations exigent une rigueur extrême. Les experts soulignent que les avocats, en quête d’efficacité, pourraient faire une confiance excessive aux résultats de l’IA, négligeant la nécessité d’un examen strict. Bien que les outils d’IA soient promus comme des assistants juridiques fiables, leur caractéristique inhérente d‘“hallucination” constitue une menace potentielle pour la justice, nécessitant de toute urgence une réglementation sectorielle et la vigilance des utilisateurs. (Source: MIT Technology Review)

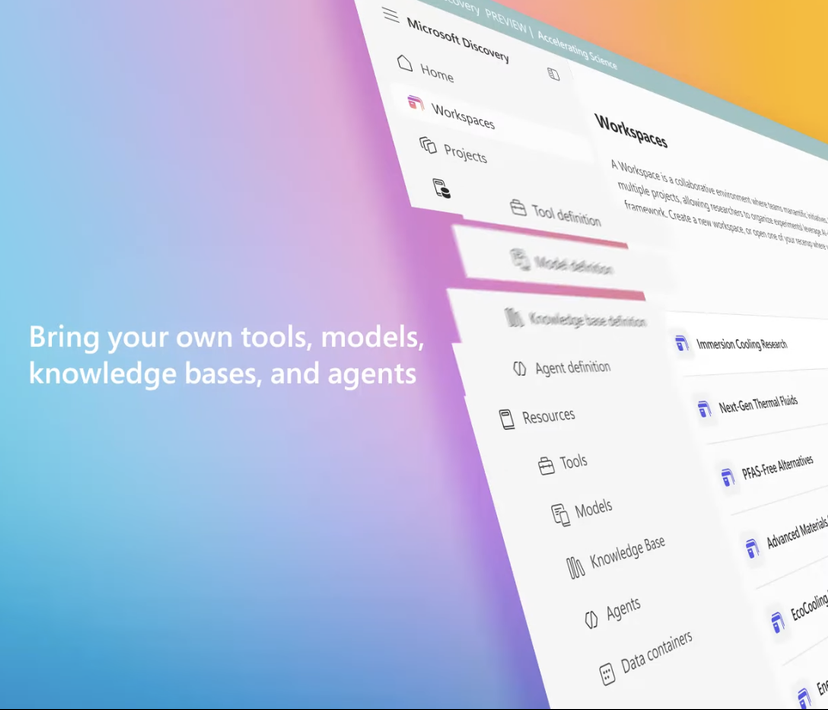
Microsoft lance Microsoft Discovery, une plateforme de recherche scientifique IA pour les entreprises, afin de stimuler les découvertes scientifiques: Lors de sa conférence Build, Microsoft a lancé Microsoft Discovery, une plateforme IA conçue pour les entreprises et les instituts de recherche, visant à permettre aux scientifiques et ingénieurs sans formation en programmation d’utiliser le calcul haute performance et des systèmes de simulation complexes grâce à une interaction en langage naturel. La plateforme combine des modèles de base pour la planification et des modèles spécialisés entraînés pour des domaines scientifiques spécifiques (tels que la physique, la chimie, la biologie), formant une équipe de “postdoctorants IA” capable d’exécuter l’ensemble du processus de recherche scientifique, de la revue de la littérature à la simulation computationnelle. Microsoft a présenté un cas d’application : en environ 200 heures, la plateforme a criblé 367 000 substances et a réussi à découvrir un substitut potentiel de réfrigérant sans PFAS, validé par des expériences. Les caractéristiques de la plateforme comprennent un moteur de connaissances graphiques, un raisonnement collaboratif, un cycle de R&D itératif continu, et elle est construite sur l’infrastructure Azure, avec une architecture future réservant la capacité de se connecter au calcul quantique. (Source: 量子位)
Jensen Huang et Elon Musk partagent leurs points de vue sur le développement de l’IA, la réglementation et la concurrence mondiale: Dans une interview exclusive, Jensen Huang, PDG de NVIDIA, a exprimé ses inquiétudes concernant les contrôles américains sur les exportations de puces, estimant que la restriction de la diffusion technologique pourrait nuire à la position de leader des États-Unis dans le domaine de l’IA, et a souligné la force de la Chine en R&D IA ainsi que le fait que la moitié des développeurs IA mondiaux viennent de Chine. Il a préconisé que les États-Unis accélèrent la popularisation de la technologie à l’échelle mondiale et permettent aux entreprises américaines de concourir sur le marché chinois. Elon Musk, PDG de Tesla, a déclaré dans une autre interview qu’il continuerait à diriger Tesla pendant au moins cinq ans et qu’il estimait être proche de la réalisation de l’AGI. Il soutient une réglementation modérée de l’IA mais s’oppose à une intervention excessive. Les deux leaders technologiques ont souligné l’énorme potentiel de l’IA, Jensen Huang estimant que l’IA entraînera une croissance significative du PIB mondial, tandis qu’Elon Musk a énuméré des objectifs clés pour cette année tels que Starship, Neuralink et les taxis autonomes Tesla, tous étroitement liés à l’IA. (Source: 36氪, 36氪, 36氪)

🎯 Tendances
Google publie une préversion de Gemma 3n, conçue pour un fonctionnement efficace en périphérie: Google a publié sur HuggingFace une préversion du modèle Gemma 3n, spécialement conçu pour un fonctionnement efficace sur des appareils à faibles ressources (tels que les appareils mobiles). Cette série de modèles dispose de capacités d’entrée multimodales, pouvant traiter du texte, des images, des vidéos et de l’audio, et générer une sortie textuelle. Elle adopte une technologie d‘“activation sélective des paramètres” (similaire à l’architecture MoE, Mixture of Experts), permettant au modèle de fonctionner avec une taille de paramètres effective de 2B et 4B, réduisant ainsi les besoins en ressources. La communauté estime que l’architecture de Gemma 3n pourrait être similaire à celle de Gemini, ce qui expliquerait les puissantes capacités multimodales et de long contexte de ce dernier. Les poids open source et la version affinée par instruction de Gemma 3n, ainsi que son entraînement sur des données de plus de 140 langues, lui confèrent un potentiel dans les applications d’IA en périphérie, telles que les assistants domestiques intelligents. (Source: Reddit r/LocalLLaMA, developers.googleblog.com)

Google lance MedGemma, des modèles d’IA optimisés pour le domaine médical: Google a publié la série de modèles MedGemma, deux variantes de Gemma 3 optimisées spécifiquement pour le domaine médical, comprenant une version multimodale de 4B paramètres et une version purement textuelle de 27B paramètres. MedGemma 4B a été spécialement entraîné pour la compréhension des images médicales (telles que les radiographies, les images dermatologiques, etc.) et du texte, en utilisant un encodeur d’images SigLIP pré-entraîné sur des données médicales. MedGemma 27B se concentre sur le traitement du texte médical et a été optimisé pour le calcul lors de l’inférence. Google indique que ces modèles visent à accélérer le développement d’applications d’IA médicale et ont été évalués sur plusieurs bancs d’essai cliniquement pertinents ; les développeurs peuvent les affiner pour améliorer les performances sur des tâches spécifiques. La communauté a réagi positivement, considérant son potentiel comme énorme, mais soulignant la nécessité d’un retour d’expérience de la part des professionnels de la santé. (Source: Reddit r/LocalLLaMA)

ByteDance publie Bagel, un modèle multimodal open source prenant en charge la génération d’images: ByteDance a lancé Bagel (également connu sous le nom de BAGEL-7B-MoT), un grand modèle multimodal open source de 14B paramètres (7B actifs), sous licence Apache 2.0. Ce modèle, basé sur une architecture Mixture of Experts (MoE) et Mixture of Transformers (MoT), est capable de comprendre et de générer du texte, et dispose de capacités natives de génération d’images. Il surpasse d’autres modèles unifiés open source sur une série de tests de référence en compréhension et génération multimodales, et démontre des capacités de raisonnement multimodal avancées telles que le traitement d’images de forme libre et la prédiction d’images futures. Les chercheurs espèrent promouvoir la recherche multimodale en partageant les détails du pré-entraînement, les protocoles de création de données, ainsi que le code et les points de contrôle ouverts. (Source: Reddit r/LocalLLaMA, arxiv.org, bagel-ai.org)
NVIDIA publie DreamGen, utilisant des modèles de génération vidéo pour entraîner des robots: L’équipe de recherche de NVIDIA a lancé le projet DreamGen, qui permet aux robots d’apprendre de nouvelles compétences dans des “mondes oniriques” générés en affinant des modèles avancés de génération vidéo (tels que Sora, Veo). Cette méthode ne repose pas sur des moteurs graphiques traditionnels ou des simulateurs physiques, mais permet aux robots d’explorer et d’expérimenter de manière autonome dans des scènes au niveau du pixel générées par des réseaux neuronaux, produisant ainsi un grand nombre de trajectoires neuronales avec des étiquettes d’action fictives. Les expériences montrent que DreamGen peut améliorer considérablement les performances des robots dans des tâches simulées et réelles, y compris des actions jamais vues et des environnements inconnus. Par exemple, avec seulement quelques trajectoires réelles, des robots humanoïdes ont appris 22 nouvelles compétences telles que verser de l’eau et plier des vêtements, et ont réussi à généraliser ces compétences à des scénarios réels comme le café du siège de NVIDIA. (Source: 36氪, arxiv.org)

Huawei propose OmniPlacement pour optimiser les performances d’inférence des modèles MoE: Pour résoudre le problème de latence d’inférence causé par la charge inégale des réseaux experts (experts “chauds” vs experts “froids”) dans les modèles Mixture of Experts (MoE), l’équipe de Huawei a proposé la solution d’optimisation OmniPlacement. Cette solution vise à améliorer les performances d’inférence des modèles MoE grâce à la réorganisation des experts, au déploiement redondant inter-couches et à la planification dynamique quasi temps réel. La validation théorique sur des modèles tels que DeepSeek-V3 montre qu’OmniPlacement peut réduire la latence d’inférence d’environ 10 % et augmenter le débit d’environ 10 %. Le cœur de cette méthode réside dans l’ajustement dynamique de la priorité des experts, l’optimisation du domaine de communication, le déploiement différencié d’instances redondantes, et la flexibilité face aux variations de charge grâce à une planification quasi temps réel et un mécanisme de surveillance dynamique. Huawei prévoit de rendre cette solution open source prochainement. (Source: 量子位)

Apple prévoit d’ouvrir aux développeurs l’accès à ses modèles d’IA, stimulant l’innovation applicative: Selon des rapports, Apple annoncera lors de la WWDC l’ouverture aux développeurs tiers de l’accès à ses modèles d’IA d’Apple Intelligence. Initialement, l’accent sera mis sur les modèles de langage légers d’environ 3 milliards de paramètres fonctionnant sur l’appareil, puis pourrait s’étendre à des modèles cloud (exécutés via un cloud privé et chiffrés) comparables au niveau de GPT-4-Turbo. Cette initiative vise à encourager les développeurs à créer de nouvelles fonctionnalités applicatives basées sur les LLM d’Apple, à accroître l’attrait des appareils Apple et à combler son retard relatif dans le domaine de l’IA générative. Les analystes estiment qu’Apple espère, en construisant un écosystème ouvert, tirer parti de sa vaste communauté de développeurs (6 millions) pour combler ses propres lacunes technologiques et faire face à une concurrence IA de plus en plus féroce. (Source: 36氪)
Une proposition de la Chambre des représentants américaine visant à suspendre la réglementation étatique de l’IA pendant dix ans suscite une vive controverse: La commission de l’énergie et du commerce de la Chambre des représentants des États-Unis a adopté une proposition visant à interdire aux États de réglementer les modèles d’IA, les systèmes d’IA et les systèmes de décision automatisés qui “influencent substantiellement ou remplacent la prise de décision humaine” pendant les dix prochaines années. Les partisans estiment que cette mesure éviterait que des réglementations étatiques divergentes n’entravent l’innovation en IA et la modernisation des systèmes du gouvernement fédéral ; les opposants, quant à eux, la qualifient de “cadeau énorme aux grandes entreprises technologiques” qui affaiblirait la capacité des États à protéger leurs citoyens contre les méfaits de l’IA. Si elle est adoptée, cette proposition pourrait invalider un grand nombre de lois étatiques existantes et proposées sur l’IA, mais elle stipule clairement qu’elle ne s’applique pas aux lois fédérales ou aux lois d’application générale qui traitent de manière égale les systèmes d’IA et non-IA. Cette initiative reflète la lutte acharnée à l’échelle mondiale entre la “priorité à l’innovation en IA” et la “sécurité minimale”. (Source: 36氪, edition.cnn.com)

Le « Take It Down Act » promulgué aux États-Unis pour lutter contre la diffusion d’images intimes non consensuelles: Le président américain Trump a signé le projet de loi « Take It Down Act », qui érige en infraction fédérale la production et la diffusion d’images intimes non consensuelles (y compris le contenu deepfake généré par l’IA). Cette loi oblige les plateformes technologiques à supprimer le contenu concerné dans les 48 heures suivant la notification. Cette loi vise à protéger les victimes et à faire face aux problèmes sociaux croissants posés par l’utilisation abusive de la technologie deepfake. Cependant, certains commentateurs soulignent que cette loi pourrait être utilisée de manière abusive, conduisant à une censure excessive. (Source: MIT Technology Review, edition.cnn.com, Reddit r/artificial)

Les grands modèles d’IA soutiennent la gestion de la santé, réalisant une personnalisation et une liaison de données multidimensionnelles: Les grands modèles d’IA insufflent une nouvelle vitalité dans le domaine de la gestion de la santé, en se combinant avec des appareils portables pour réaliser une liaison de données multidimensionnelles et des services personnalisés. Des entreprises telles que WeDoctor, Deepwise Healthcare, NandaFitech explorent activement des scénarios d’application, par exemple en partant des examens de santé pour un dépistage et un traitement précoces, ou en utilisant la gestion du poids comme point de départ pour prévenir les maladies chroniques. Les grands modèles peuvent traiter des dimensions de données plus variées, établir une mémoire utilisateur et fournir des plans d’intervention sanitaire plus précis. Les défis incluent les hallucinations des modèles, la qualité des données et les difficultés de collaboration, mais sont progressivement surmontés grâce au RAG, à l’affinage des modèles, aux mécanismes d’audit et au modèle “IA + gestionnaire humain”. Sur le plan commercial, les services ToB, les paiements C-end et les communautés de santé IA ont été validés initialement, la tendance future s’orientant vers une mise à niveau de l’interaction multimodale. (Source: 36氪)
Baidu renforce les capacités multimodales de son grand modèle Wenxin pour faire face à la concurrence du marché et à l’application pratique: Les derniers modèles Wenxin Large Model 4.5 Turbo et le modèle de réflexion profonde X1 Turbo de Baidu ont considérablement amélioré leurs capacités de compréhension et de génération multimodales, grâce à des technologies telles que l’entraînement mixte et la modélisation d’experts hétérogènes multimodaux, améliorant ainsi l’efficacité de l’apprentissage intermodal et l’effet de fusion. Bien que le PDG Robin Li se soit montré prudent quant aux problèmes d’hallucination des modèles de génération vidéo de type Sora, face à la concurrence du marché (tels que les progrès de Doubao de ByteDance et de Tongyi Qianwen d’Alibaba dans le domaine multimodal) et aux besoins d’application de l’IA, Baidu comble activement ses lacunes et prévoit de rendre open source la série Wenxin Large Model 4.5 le 30 juin. Baidu considère les humains numériques IA comme une percée applicative importante et a déjà développé une technologie d’humains numériques ultra-réalistes pilotée par “scénario”, prenant en charge plus de 100 000 présentateurs numériques. (Source: 36氪)
Douyin, Xiaohongshu et d’autres plateformes mènent une campagne de régulation spécifique contre la “création de comptes par IA” pour maintenir l’écosystème de contenu: Douyin, Xiaohongshu et d’autres plateformes de commerce d’intérêt ont récemment renforcé la régulation spécifique des comportements utilisant la technologie IA pour produire en masse du contenu faux, effectuer la “création de comptes par IA”, etc. Ces comportements incluent la génération par IA de vidéos vulgaires et sensationnalistes, de contenu d’experts virtuels, la vente de tutoriels de création de comptes par IA et de comptes eux-mêmes. Les plateformes estiment que de tels comportements nuisent à l’authenticité du contenu, conduisent à l’homogénéisation du contenu, portent atteinte à l’expérience utilisateur et à l’écosystème des créateurs originaux, diluant ainsi la valeur commerciale. En revanche, les plateformes de commerce électronique traditionnelles telles que Taobao et JD.com encouragent activement les commerçants à utiliser des outils d’IA (tels que la “génération de vidéo à partir d’images”, les humains numériques pour le streaming en direct) pour améliorer l’affichage des produits et l’efficacité opérationnelle, dans le but principal de faciliter les transactions. Cette différence reflète la divergence des stratégies d’application de l’IA dans différents modèles de commerce électronique. (Source: 36氪)

Le développement de la version IA de Siri par Apple rencontre des obstacles, pourrait être à nouveau reporté, ajustements de la direction pour faire face à la crise: Selon Bloomberg, la version améliorée de Siri basée sur un grand modèle, qu’Apple prévoyait de présenter à la WWDC, pourrait être à nouveau reportée. Le goulot d’étranglement technique réside dans le conflit entre les architectures des anciens et nouveaux systèmes, entraînant de fréquents bugs. Le rapport souligne qu’Apple a commis des erreurs de décision au plus haut niveau dans sa stratégie IA, a souffert de luttes de pouvoir internes, d’un approvisionnement insuffisant en GPU et de restrictions sur l’utilisation des données dues à la protection de la vie privée, ce qui a entraîné un retard de sa technologie IA par rapport à ses concurrents. Pour faire face à la crise, le laboratoire d’Apple à Zurich développe une toute nouvelle architecture “LLM Siri”, et le projet Siri a été confié à Mike Rockwell, responsable de Vision Pro. Parallèlement, Apple recherche également des collaborations technologiques externes avec Google Gemini, OpenAI, etc., et pourrait, sur le plan marketing, dissocier Apple Intelligence de la marque Siri afin de remodeler son image en matière d’IA. (Source: 36氪)

ByteDance lance les écouteurs Ola Friend avec l’agent intelligent de professeur d’anglais Owen intégré: ByteDance a ajouté à ses écouteurs intelligents Ola Friend une fonctionnalité d’agent intelligent de professeur d’anglais nommée Owen. Les utilisateurs peuvent activer Owen en réveillant l’application Doubao pour des conversations en anglais, des lectures guidées en anglais et des commentaires bilingues. Cette fonctionnalité couvre des scénarios tels que les conversations quotidiennes, l’anglais des affaires, les voyages, etc., visant à fournir un accompagnement pratique et portable pour l’apprentissage de l’anglais. Cela marque une nouvelle tentative de ByteDance dans le domaine de l’éducation, combinant les capacités des grands modèles d’IA avec le matériel pour créer un produit d’apprentissage de l’anglais vertical. Les écouteurs Ola Friend prenaient déjà en charge les questions-réponses et la pratique orale via Doubao, l’ajout de ce nouvel agent intelligent renforce davantage ses attributs éducatifs. (Source: 36氪)

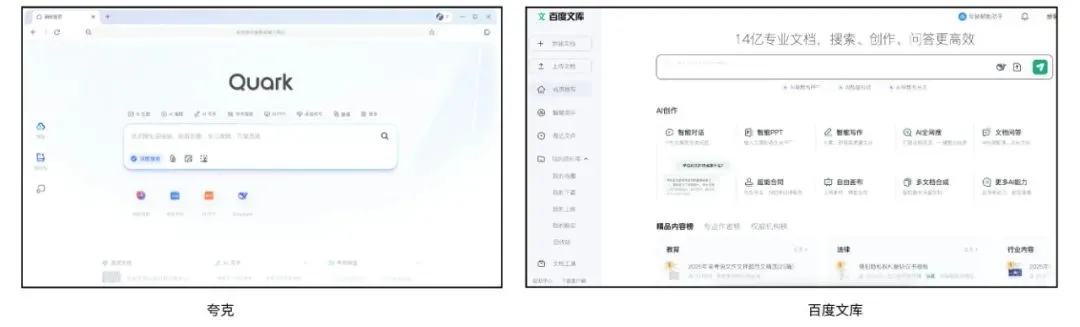
Quark et Baidu Wenku rivalisent pour devenir des super-applications IA, intégrant recherche, outils et services de contenu: Quark, filiale d’Alibaba, et Baidu Wenku, filiale de Baidu, se transforment en applications “super-cadre” centrées sur l’IA, intégrant la conversation IA, la recherche approfondie, les outils IA (tels que la rédaction, la génération de PPT, l’assistant santé, etc.) ainsi que les services de stockage en ligne et de documents, dans le but de devenir des portails IA uniques pour les utilisateurs C-end. Quark, fort de sa recherche sans publicité et de sa base d’utilisateurs jeunes, atteint déjà 149 millions d’utilisateurs actifs mensuels et se monétise via un système d’abonnement. Baidu Wenku, s’appuyant sur ses vastes ressources documentaires et sa base d’utilisateurs payants, a lancé “Cangzhou OS” pour intégrer l’AI Agent, renforçant ainsi l’ensemble de la chaîne de création et de consommation de contenu. Les deux sont confrontés aux défis de l’homogénéisation des fonctionnalités, de la surcharge applicative et de l’équilibre à trouver entre les besoins généraux et les services spécialisés. (Source: 36氪)
Zhipu Qingyan, Kimi et 33 autres applications signalées pour collecte illégale de données personnelles: Le Centre national de notification des informations sur la cybersécurité et la sécurité de l’information a publié un avis indiquant que Zhipu Qingyan (version 2.9.6) pour “collecte réelle de données personnelles dépassant le cadre de l’autorisation de l’utilisateur”, et Kimi (version 2.0.8) pour “collecte réelle de données personnelles sans lien direct avec les fonctions commerciales”, ainsi que 33 autres applications, ont été répertoriées comme présentant des cas de collecte et d’utilisation illégales et non conformes de données personnelles. Ces deux applications d’IA populaires, toutes deux développées par des équipes issues de l’Université Tsinghua, ont récemment bénéficié d’un financement et d’une attention considérables sur le marché. Cette notification, portant sur la période de détection du 16 avril au 15 mai 2025, met en évidence les défis de conformité des données auxquels sont confrontées les applications d’IA dans leur développement rapide. (Source: 36氪)
🧰 Outils
OpenEvolve : Implémentation open source d’AlphaEvolve de DeepMind, utilisant des LLM pour faire évoluer des bases de code: Des développeurs ont rendu open source le projet OpenEvolve, une implémentation du système AlphaEvolve de Google DeepMind. Le framework OpenEvolve fait évoluer des bases de code entières grâce à un processus itératif de LLM (génération de code, évaluation, sélection) pour découvrir de nouveaux algorithmes ou optimiser ceux existants. Il prend en charge tout LLM compatible avec l’API OpenAI, peut intégrer plusieurs modèles (comme une combinaison de Gemini-Flash-2.0 et Claude-Sonnet-3.7), supporte l’optimisation multi-objectifs et l’évaluation distribuée. Le projet a réussi à reproduire les cas d’empilement de cercles et de minimisation de fonctions de l’article AlphaEvolve, démontrant sa capacité à faire évoluer des méthodes simples vers des algorithmes d’optimisation complexes (comme scipy.minimize et le recuit simulé). (Source: Reddit r/LocalLLaMA, Reddit r/MachineLearning)

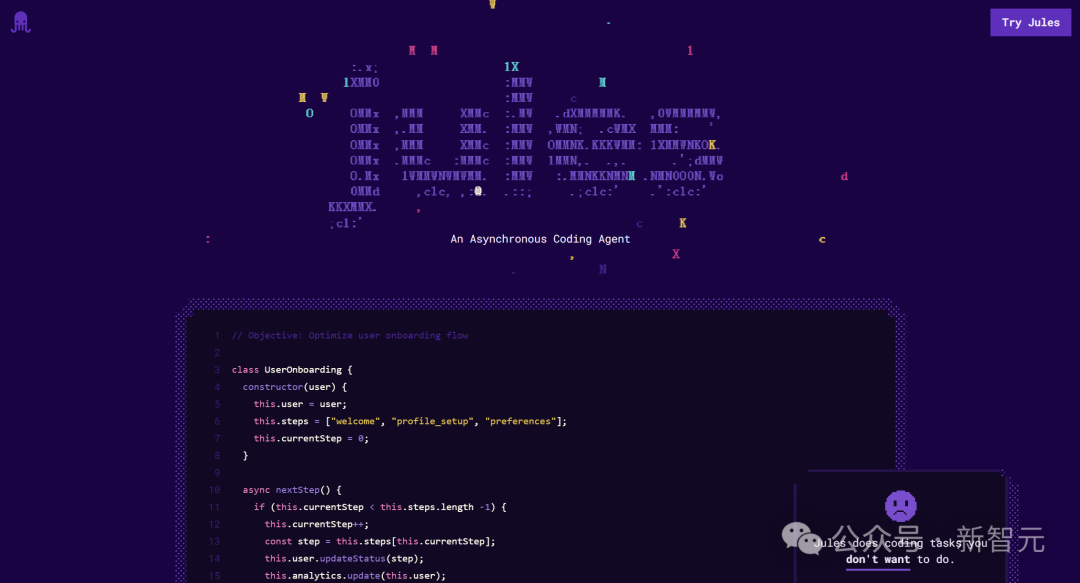
Google lance Jules, un agent de programmation IA prenant en charge les tâches de code automatisées: Google a lancé Jules, un agent de programmation IA, actuellement en phase de test mondial, les utilisateurs pouvant exécuter gratuitement 5 tâches par jour. Jules est basé sur le modèle multimodal Gemini 2.5 Pro, capable de comprendre des bases de code complexes, d’exécuter des tâches telles que la correction de bugs, la mise à jour de versions, l’écriture de tests, l’implémentation de nouvelles fonctionnalités, et prend en charge Python et JavaScript. Il peut se connecter à GitHub pour créer des pull requests (PR), valider le code dans des machines virtuelles cloud, et fournir un plan d’exécution détaillé que les développeurs peuvent examiner et modifier. Jules vise à s’intégrer profondément dans le flux de travail des développeurs, à améliorer l’efficacité de la programmation, et lancera à l’avenir la fonctionnalité Codecast (résumé audio de l’activité de la base de code) ainsi qu’une version entreprise. (Source: 36氪)
Feishu lance “Feishu Knowledge Q&A”, créant un outil de questions-réponses IA exclusif pour les entreprises: Feishu s’apprête à lancer un nouveau produit IA, “Feishu Knowledge Q&A”, positionné comme un outil de questions-réponses IA exclusif basé sur les connaissances de l’entreprise. Les utilisateurs pourront l’appeler depuis la barre latérale de Feishu pour poser des questions relatives à leur travail. L’outil pourra accéder à tous les messages, documents, bases de connaissances, fichiers, etc. de Feishu relevant des autorisations de l’utilisateur, et fournir des réponses précises directement basées sur ce “contexte”. Sa gestion des autorisations est alignée sur le système d’autorisations de Feishu lui-même, garantissant la sécurité des informations. Le produit a déjà été testé en interne par des dizaines de milliers d’utilisateurs, la version web (ask.feishu.cn) est en ligne et prend en charge le téléchargement de données personnelles ainsi que l’appel aux modèles DeepSeek ou Doubao pour poser des questions. Cette initiative s’inscrit dans la tendance de combiner les bases de connaissances d’entreprise avec l’IA, visant à améliorer l’efficacité du travail et les capacités de gestion des connaissances. (Source: 36氪)
Manus : La plateforme d’agents intelligents IA ouvre ses inscriptions, la société mère lève un financement important: La plateforme d’agents intelligents IA Manus a annoncé l’ouverture des inscriptions aux utilisateurs étrangers, supprimant la liste d’attente et offrant des tâches gratuites quotidiennes. Manus, grâce à sa technologie de “raisonnement collaboratif multi-modèles à architecture hybride”, peut exécuter des tâches telles que la génération automatique de PPT et l’organisation de factures. Sa société mère, Butterfly Effect, a récemment levé 75 millions de dollars, portant sa valorisation à 3,6 milliards de dollars. Le succès de Manus est considéré comme une manifestation de la “vitesse d’itération chinoise × la pensée produit de la Silicon Valley”, coordonnant les agents de planification, d’exécution et de validation pour permettre à l’IA de passer de la “réflexion et suggestion” à l‘“exécution en boucle fermée”. (Source: 36氪)

HeyGen : Outil de génération et de traduction vidéo IA, prenant en charge la synchronisation labiale pour plus de 40 langues: HeyGen est un outil vidéo IA permettant aux utilisateurs de télécharger des photos ou des vidéos pour générer rapidement des avatars numériques avec voix, expressions et mouvements, et prenant en charge la personnalisation des vêtements et des scènes. L’une de ses fonctionnalités principales est la traduction en temps réel dans plus de 175 langues et dialectes, et grâce à des algorithmes d’IA, il adapte précisément la synchronisation labiale de l’avatar numérique à la langue traduite, améliorant ainsi le naturel du contenu vidéo multilingue. La société, fondée par d’anciens membres de Snapchat et de ByteDance, a levé 60 millions de dollars menés par Benchmark, avec une valorisation de 440 millions de dollars et des revenus récurrents annuels dépassant les 35 millions de dollars. (Source: 36氪)
Opus Clip : Outil d’agent de montage vidéo autonome piloté par l’IA: Opus Clip, initialement positionné comme un outil de diffusion en direct IA, s’est transformé en une plateforme de montage vidéo IA, puis a évolué vers un “agent de montage vidéo autonome”. Sa fonction principale est de découper rapidement de longues vidéos en plusieurs courtes vidéos adaptées à la diffusion virale, et de pouvoir recadrer automatiquement le sujet principal, générer des titres et des descriptions, ajouter des sous-titres et des émoticônes. La fonctionnalité ClipAnything, récemment testée, prend déjà en charge la reconnaissance d’instructions multimodales. La société, dirigée par Zhao Yang, ancien fondateur de l’application sociale Sober, a levé 20 millions de dollars menés par SoftBank, avec une valorisation de 215 millions de dollars et un ARR de près de 10 millions de dollars. (Source: 36氪)
Trae : Agent de programmation automatisée basé sur un IDE IA: Trae est un outil visant à créer de “véritables ingénieurs IA”, permettant aux utilisateurs de réaliser une programmation automatisée par agent via une interaction en langage naturel. Il est compatible avec le protocole MCP et les agents personnalisés, intègre une analyse de contexte améliorée et un moteur de règles, prend en charge les principaux langages de programmation et est compatible avec VS Code. Trae, développé par des membres clés de l’ancienne équipe de l’assistant de programmation Marscode de ByteDance, se positionne comme un concurrent sérieux des outils de programmation IA tels que Cursor, et s’engage à réaliser un nouveau mode de développement logiciel collaboratif homme-machine. (Source: 36氪)
Notta : Outil de compte rendu de réunion multilingue et de traduction en temps réel piloté par l’IA: Notta est un outil IA axé sur les scénarios de réunion, offrant un service de génération automatique de comptes rendus de réunion multilingues, et prenant en charge la traduction en temps réel et le marquage des contenus importants. Ce produit vise à améliorer l’efficacité des réunions et à résoudre les barrières de communication interlinguistique. Son principal fondateur serait un ancien membre clé de l’équipe vocale de Tencent Cloud, la société d’exploitation est à Singapour et le centre de R&D à Seattle. En 2024, ses revenus s’élevaient à 18 millions de dollars, avec une valorisation de 300 millions de dollars, et elle est actuellement en phase de financement de série B. (Source: 36氪)
Un assistant de trading GPT+ML open source arrive sur iPhone: Un assistant de trading open source intégrant l’apprentissage profond et la technologie GPT fonctionne désormais localement sur iPhone via Pyto. Actuellement en version légère et gratuite, il est prévu d’y ajouter un classificateur de graphiques CNN et un support de base de données. La plateforme est conçue de manière modulaire, facilitant l’intégration de leurs propres modèles par les développeurs en apprentissage profond, et prend déjà en charge nativement OpenAI GPT. (Source: Reddit r/deeplearning)
📚 Études
Un nouvel article explore l‘“hypothèse de la représentation enchevêtrée fracturée” en apprentissage profond: Un document de position intitulé “Questioning Representation Optimism in Deep Learning: The Fractured Entangled Representation Hypothesis” a été soumis à Arxiv. Cette étude, en comparant les réseaux neuronaux issus de processus de recherche évolutive avec les réseaux entraînés par SGD traditionnel (sur la tâche simple de générer une seule image), a constaté que bien que les deux produisent le même comportement de sortie, leurs représentations internes diffèrent considérablement. Les réseaux entraînés par SGD présentent une forme désorganisée que les auteurs appellent “représentation enchevêtrée fracturée” (FER), tandis que les réseaux évolutifs se rapprochent davantage d’une représentation décomposée unifiée (UFR). Les chercheurs estiment que dans les grands modèles, la FER pourrait réduire des capacités essentielles telles que la généralisation, la créativité et l’apprentissage continu ; comprendre et atténuer la FER est crucial pour l’avenir de l’apprentissage des représentations. (Source: Reddit r/MachineLearning, arxiv.org)
R3 : Un cadre de modèle de récompense robuste, contrôlable et interprétable: Un article intitulé “R3: Robust Rubric-Agnostic Reward Models” présente un nouveau cadre de modèle de récompense, R3. Ce cadre vise à résoudre le manque de contrôlabilité et d’interprétabilité des modèles de récompense dans les méthodes actuelles d’alignement des modèles de langage. La particularité de R3 est d’être “rubric-agnostic” (indépendant des critères de notation spécifiques), capable de généraliser à travers les dimensions d’évaluation et de fournir une attribution de score interprétable, accompagnée d’un processus de raisonnement. Les chercheurs estiment que R3 permet une évaluation plus transparente et flexible des modèles de langage, favorisant un alignement robuste avec des valeurs humaines et des cas d’utilisation diversifiés. Le modèle, les données et le code ont été rendus open source. (Source: HuggingFace Daily Papers)
Publication de l’article “A Token is Worth over 1,000 Tokens” sur la distillation de connaissances efficace par clonage de bas rang: Cet article propose une méthode de pré-entraînement efficace appelée clonage de bas rang (Low-Rank Clone, LRC) pour construire de petits modèles de langage (SLM) dont le comportement est équivalent à celui de modèles enseignants puissants. LRC entraîne un ensemble de matrices de projection de bas rang, réalisant conjointement un élagage doux par compression des poids de l’enseignant, ainsi qu’un clonage d’activation en alignant les activations de l’étudiant (y compris les signaux FFN) avec celles de l’enseignant. Cette conception unifiée maximise le transfert de connaissances sans nécessiter de module d’alignement explicite. Les expériences montrent qu’en utilisant des modèles enseignants open source tels que Llama-3.2-3B-Instruct, LRC, avec seulement 20 milliards de tokens d’entraînement, atteint ou dépasse les performances des modèles SOTA (entraînés avec des billions de tokens), réalisant une efficacité d’entraînement plus de 1000 fois supérieure. (Source: HuggingFace Daily Papers)
MedCaseReasoning : Ensemble de données et méthode pour évaluer et apprendre le raisonnement diagnostique à partir de cas cliniques: L’article “MedCaseReasoning: Evaluating and learning diagnostic reasoning from clinical case reports” présente un nouvel ensemble de données ouvert, MedCaseReasoning, destiné à évaluer les capacités des grands modèles de langage (LLM) en matière de raisonnement diagnostique clinique. Cet ensemble de données comprend 14 489 cas de questions-réponses diagnostiques, chaque cas étant accompagné d’énoncés de raisonnement détaillés issus de rapports de cas médicaux ouverts. L’étude a révélé que les LLM de raisonnement SOTA existants présentent des lacunes importantes en matière de diagnostic et de raisonnement (par exemple, DeepSeek-R1 avec une précision de 48 % et un rappel des énoncés de raisonnement de 64 %). Cependant, en affinant les LLM sur les trajectoires de raisonnement de MedCaseReasoning, la précision du diagnostic et le rappel du raisonnement clinique ont été améliorés en moyenne de 29 % et 41 % respectivement. (Source: HuggingFace Daily Papers)
Publication de l’article “EfficientLLM: Efficiency in Large Language Models”, évaluant de manière exhaustive les techniques d’efficacité des LLM: Cette étude est la première à mener une recherche empirique complète sur les techniques d’efficacité des grands modèles de langage (LLM) à grande échelle, et introduit le benchmark EfficientLLM. La recherche explore systématiquement trois aspects clés sur des clusters de production : le pré-entraînement architectural (variantes d’attention efficaces, MoE clairsemé), l’affinage (méthodes économes en paramètres comme LoRA) et l’inférence (quantification). En utilisant six métriques granulaires (utilisation de la mémoire, utilisation du calcul, latence, débit, consommation d’énergie, taux de compression), plus de 100 paires modèle-technique (paramètres de 0,5B à 72B) ont été évaluées. Les principales conclusions incluent : l’efficacité implique des compromis quantifiables, il n’existe pas de méthode universellement optimale ; la solution optimale dépend de la tâche et de l’échelle ; les techniques peuvent être généralisées à travers les modalités. (Source: HuggingFace Daily Papers)
L’article “NExT-Search” explore la reconstruction de l’écosystème de feedback pour la recherche IA générative: L’article “NExT-Search: Rebuilding User Feedback Ecosystem for Generative AI Search” souligne que, bien que la recherche IA générative améliore la commodité, elle perturbe également le cycle d’amélioration de la recherche Web traditionnelle qui repose sur un feedback utilisateur granulaire (comme les clics, le temps de séjour). Pour résoudre ce problème, l’article conçoit le paradigme NExT-Search, visant à réintroduire un feedback granulaire au niveau du processus. Ce paradigme comprend un “mode de débogage utilisateur” permettant aux utilisateurs d’intervenir aux étapes clés, et un “mode utilisateur fantôme” simulant les préférences de l’utilisateur et fournissant un feedback assisté par IA. Ces signaux de feedback peuvent être utilisés pour une adaptation en ligne (optimisation en temps réel des résultats de recherche) et une mise à jour hors ligne (affinage périodique des différents composants du modèle). (Source: HuggingFace Daily Papers)
“Latent Flow Transformer” propose une nouvelle architecture LLM: L’article propose le Latent Flow Transformer (LFT), un modèle qui entraîne un unique opérateur de transport appris par flow matching pour remplacer les multiples couches discrètes des Transformers traditionnels. LFT vise à compresser de manière significative le nombre de couches du modèle tout en maintenant la compatibilité avec l’architecture d’origine. De plus, l’article introduit l’algorithme Flow Walking (FW) pour surmonter les limitations des méthodes de flux existantes en matière de maintien du couplage. Les expériences sur le modèle Pythia-410M montrent que LFT peut compresser efficacement le nombre de couches et surpasser les performances du saut direct de couches, réduisant ainsi considérablement l’écart entre les paradigmes de génération autorégressive et de génération par flux. (Source: HuggingFace Daily Papers)
“Reasoning Path Compression” propose une méthode de compression des trajectoires de génération de raisonnement des LLM: Pour résoudre le problème des trajectoires intermédiaires longues générées par les modèles de langage de type raisonnement, qui entraînent une occupation mémoire importante et un faible débit, l’article propose la méthode Reasoning Path Compression (RPC). RPC est une méthode sans entraînement qui compresse périodiquement le cache KV en conservant le cache KV avec des scores d’importance élevés (calculés à l’aide d’une “fenêtre de sélection” composée des requêtes les plus récemment générées). Les expériences montrent que RPC peut améliorer considérablement le débit de génération de modèles tels que QwQ-32B, tout en ayant un impact mineur sur la précision, offrant ainsi une voie pratique pour le déploiement efficace des LLM de raisonnement. (Source: HuggingFace Daily Papers)
Publication de l’article “Bidirectional LMs are Better Knowledge Memorizers?”, portant sur la capacité de mémorisation des connaissances des LM bidirectionnels: Cette étude introduit un nouveau benchmark d’injection de connaissances à grande échelle et basé sur le monde réel, WikiDYK, utilisant des faits récents rédigés par des humains et tirés des entrées “Le saviez-vous…” de Wikipédia. Les expériences ont révélé que, par rapport aux modèles de langage causals (CLM) actuellement populaires, les modèles de langage bidirectionnels (BiLM) démontrent une capacité de mémorisation des connaissances nettement supérieure, avec une précision de fiabilité supérieure de 23 %. Pour pallier la taille actuellement plus petite des BiLM, les chercheurs proposent un cadre de collaboration modulaire, utilisant un ensemble de BiLM comme base de connaissances externe intégrée aux LLM, ce qui améliore encore la précision de fiabilité jusqu’à 29,1 %. (Source: HuggingFace Daily Papers)
L’article “Truth Neurons” explore l’encodage de la véracité au niveau neuronal dans les modèles de langage: Les chercheurs proposent une méthode pour identifier les représentations de la véracité au niveau neuronal dans les modèles de langage, découvrant l’existence de “neurones de vérité” (truth neurons) qui encodent la véracité d’une manière indépendante du sujet. Des expériences sur des modèles de différentes tailles valident l’existence des neurones de vérité, dont le schéma de distribution est cohérent avec les résultats d’études antérieures sur la structure géométrique de la véracité. L’inhibition sélective de l’activation de ces neurones réduit les performances du modèle sur TruthfulQA et d’autres benchmarks, indiquant que le mécanisme de véracité n’est pas spécifique à un ensemble de données particulier. (Source: HuggingFace Daily Papers)
“Understanding Gen Alpha Digital Language” évalue les limites des LLM dans la modération de contenu: Cette étude évalue la capacité des systèmes d’IA (GPT-4, Claude, Gemini, Llama 3) à interpréter le langage numérique de la “Génération Alpha” (Gen Alpha, née entre 2010 et 2024). L’étude souligne que le langage en ligne unique de la Gen Alpha (influencé par les jeux, les mèmes, les tendances IA) dissimule souvent des interactions nuisibles, que les outils de sécurité existants ont du mal à identifier. Des tests effectués sur un ensemble de données contenant 100 expressions récentes de la Gen Alpha révèlent que les principaux modèles d’IA présentent de graves lacunes de compréhension dans la détection du harcèlement et de la manipulation dissimulés. Les contributions de l’étude comprennent le premier ensemble de données d’expressions de la Gen Alpha, un cadre pour améliorer les systèmes de modération par IA, et soulignent l’urgence de repenser les systèmes de sécurité en fonction des spécificités de la communication des adolescents. (Source: HuggingFace Daily Papers)
“CompeteSMoE” propose une méthode d’entraînement des modèles Mixture of Experts basée sur la compétition: L’article soutient que l’entraînement actuel des modèles Sparse Mixture of Experts (SMoE) est confronté au défi d’un processus de routage sous-optimal, c’est-à-dire que les experts qui effectuent le calcul ne participent pas directement à la décision de routage. Pour y remédier, les chercheurs proposent un nouveau mécanisme appelé “compétition”, qui route les tokens vers l’expert ayant la réponse neuronale la plus élevée. Une preuve théorique démontre que le mécanisme de compétition a une meilleure efficacité d’échantillonnage que le routage softmax traditionnel. Sur cette base, l’algorithme CompeteSMoE a été développé, qui déploie un routeur pour apprendre une stratégie de compétition, démontrant son efficacité, sa robustesse et sa scalabilité dans les tâches d’affinage d’instructions visuelles et de pré-entraînement linguistique. (Source: HuggingFace Daily Papers)
“General-Reasoner” vise à améliorer les capacités de raisonnement interdomaines des LLM: Face au problème de la recherche actuelle sur le raisonnement des LLM, principalement axée sur les domaines des mathématiques et du codage, cet article propose General-Reasoner, un nouveau paradigme d’entraînement visant à améliorer les capacités de raisonnement des LLM dans différents domaines. Ses contributions comprennent : la construction d’un vaste ensemble de données de questions de haute qualité avec des réponses vérifiables multidisciplinaires ; le développement d’un validateur de réponses basé sur un modèle génératif, doté d’une capacité de chaîne de pensée et de conscience du contexte, remplaçant la validation traditionnelle basée sur des règles. Dans une série de tests de référence couvrant la physique, la chimie, la finance, etc., General-Reasoner surpasse les méthodes de référence existantes. (Source: HuggingFace Daily Papers)
“Not All Correct Answers Are Equal” explore l’importance de la source de distillation des connaissances: Cette étude a mené une recherche empirique à grande échelle sur la distillation de données de raisonnement en collectant les sorties vérifiées de trois modèles enseignants SOTA (AM-Thinking-v1, Qwen3-235B-A22B, DeepSeek-R1) sur 1,89 million de requêtes. L’analyse a révélé que les données distillées à partir d’AM-Thinking-v1 présentent une plus grande diversité de longueur de token et une perplexité plus faible. Les modèles étudiants entraînés sur cet ensemble de données ont obtenu les meilleures performances sur des benchmarks de raisonnement tels que AIME2024 et ont démontré un comportement de sortie adaptatif. Les chercheurs ont publié les ensembles de données distillées d’AM-Thinking-v1 et de Qwen3-235B-A22B pour soutenir les recherches futures. (Source: HuggingFace Daily Papers)
“SSR” améliore la perception de la profondeur des VLM grâce à un raisonnement spatial guidé par des principes fondamentaux: Malgré les progrès des modèles de langage visuel (VLM) dans les tâches multimodales, leur dépendance aux entrées RGB limite une compréhension spatiale précise. L’article propose un nouveau cadre appelé SSR (Spatial Sense and Reasoning), qui convertit les données de profondeur brutes en principes fondamentaux textuels structurés et interprétables. Ces principes fondamentaux textuels servent de représentations intermédiaires significatives, améliorant considérablement les capacités de raisonnement spatial. De plus, l’étude utilise la distillation des connaissances pour compresser les principes générés en embeddings latents compacts, afin de les intégrer efficacement dans les VLM existants sans réentraînement. L’ensemble de données SSR-CoT et le benchmark SSRBench sont également introduits. (Source: HuggingFace Daily Papers)
“Solve-Detect-Verify” propose une méthode d’extension au moment de l’inférence avec un validateur de génération flexible: Pour résoudre le compromis entre précision et efficacité dans le raisonnement des LLM sur des tâches complexes, ainsi que la contradiction entre le coût de calcul et la fiabilité introduite par l’étape de validation, l’article propose FlexiVe, un nouveau validateur génératif. FlexiVe, grâce à une stratégie d’allocation flexible du budget de validation, équilibre les ressources de calcul entre une “pensée rapide” rapide et fiable et une “pensée lente” méticuleuse. Il propose en outre le processus Solve-Detect-Verify, un cadre qui intègre intelligemment FlexiVe, identifie activement les points d’achèvement de la solution pour déclencher une validation ciblée et fournir un feedback. Les expériences montrent que cette méthode surpasse les lignes de base sur les benchmarks de raisonnement mathématique. (Source: HuggingFace Daily Papers)
“SageAttention3” explore l’inférence Attention FP4 et l’entraînement 8 bits: Cette étude améliore l’efficacité de l’Attention grâce à deux contributions clés : premièrement, l’utilisation des nouveaux Tensor Cores FP4 des GPU Blackwell pour accélérer le calcul de l’Attention, réalisant une accélération d’inférence plug-and-play 5 fois plus rapide que FlashAttention. Deuxièmement, elle applique pour la première fois l’Attention à faible nombre de bits aux tâches d’entraînement, en concevant une Attention 8 bits précise et efficace pour la propagation avant et arrière. Les expériences montrent que l’Attention 8 bits atteint des performances sans perte dans les tâches d’affinage, mais converge plus lentement dans les tâches de pré-entraînement. (Source: HuggingFace Daily Papers)
Partage de ressources d’introduction à l’apprentissage profond “The Little Book of Deep Learning”: “The Little Book of Deep Learning”, rédigé par François Fleuret (chercheur scientifique chez Meta FAIR), offre un tutoriel concis sur l’apprentissage profond. Ce livre vise à aider les débutants et les praticiens ayant une certaine expérience à maîtriser rapidement les concepts et techniques fondamentaux de l’apprentissage profond. (Source: Reddit r/deeplearning)
CodeSparkClubs : Fournit des ressources gratuites aux lycéens pour créer des clubs d’IA/informatique: Le projet CodeSparkClubs vise à aider les lycéens à lancer ou à développer des clubs d’IA et d’informatique. Ce projet fournit du matériel gratuit et prêt à l’emploi, y compris des guides, des plans de cours et des tutoriels de projets, tous accessibles via le site web. Il est conçu pour permettre aux étudiants de gérer indépendamment leurs clubs, favorisant ainsi le développement de compétences et la création de communautés. (Source: Reddit r/deeplearning)
💼 Affaires
Microsoft Azure hébergera le modèle Grok de xAI, soutenant la commercialisation de l’IA d’Elon Musk: Microsoft a annoncé que sa plateforme cloud Azure hébergera les modèles d’IA de la société xAI d’Elon Musk, y compris Grok. Cette décision signifie qu’Elon Musk prévoit de vendre Grok à d’autres entreprises et d’atteindre une clientèle plus large via les services cloud de Microsoft. Auparavant, Grok avait suscité la controverse en générant des messages trompeurs sur le “génocide blanc” en Afrique du Sud. La communauté a réagi de manière mitigée à cette collaboration, certains y voyant une initiative de Microsoft pour étendre son écosystème IA, d’autres s’interrogeant sur la qualité de Grok et sur un éventuel refus d’AWS d’héberger Grok. (Source: Reddit r/ArtificialInteligence, MIT Technology Review)

Alibaba investit dans Meitu, approfondissant sa stratégie e-commerce IA: Alibaba a investi dans la société Meitu par le biais d’obligations convertibles, avec un prix de conversion initial de 6 HKD par action. Les deux parties collaboreront au niveau du commerce électronique et de la technologie. Meitu possède des outils de génération d’images IA (tels que Meitu Design Studio), qui ont déjà servi plus de 2 millions de commerçants en ligne. Alibaba introduira les outils IA de Meitu pour améliorer l’affichage des produits et l’expérience utilisateur sur ses plateformes de commerce électronique, en particulier pour attirer les jeunes utilisatrices. Meitu, de son côté, pourra utiliser les données de commerce électronique d’Alibaba pour optimiser ses outils IA, et s’est engagé à acheter pour 560 millions de yuans de services Alibaba Cloud sur trois ans. Cette démarche est considérée comme une stratégie d’Alibaba pour renforcer ses lacunes en matière d’outils créatifs IA, acquérir du trafic utilisateur et intégrer plus profondément le cloud computing dans l’écosystème IA du commerce électronique. (Source: 36氪)
Lightspeed Capital clôture la première tranche de son fonds d’incubation IA de 50 millions de dollars, axé sur les technologies de pointe en phase de démarrage: Le fonds d’incubation de pointe Lightspeed Innovation Frontier Fund (L2F) de Lightspeed Capital a dépassé les attentes pour la clôture de sa première tranche, avec une taille prévue d’au moins 50 millions de dollars, et est entré en phase d’investissement. Ce fonds à double devise se concentre sur les investissements d’amorçage et providentiels dans les domaines de l’IA et des technologies de pointe, et fournit également un soutien à l’incubation. Les LPs comprennent des entrepreneurs à succès, des entreprises en amont et en aval de la chaîne de valeur de l’IA, ainsi que des family offices ayant une vision globale. Le premier projet d’investissement est la société d’exploration minière par IA “Lingyun Zhimining”, à l’incubation de laquelle Lightspeed a profondément participé. Zheng Xuanle, fondateur de Lightspeed Capital, estime que le stade actuel de développement de l’IA est similaire aux débuts de l’internet mobile, et que l’incubation est le meilleur outil pour pénétrer le marché. (Source: 36氪)
🌟 Communauté
Discussion sur les perspectives d’emploi à l’ère de l’IA : optimisme et inquiétudes coexistent: La communauté Reddit débat à nouveau vivement de l’impact de l’IA sur le marché de l’emploi. De nombreux professionnels, tels que les développeurs de logiciels et les concepteurs UX, se montrent optimistes quant au remplacement de leur travail par l’IA, estimant que celle-ci n’est pas encore capable d’accomplir des tâches complexes. Cependant, d’autres soulignent que ce point de vue pourrait sous-estimer le potentiel de développement à long terme de l’IA, en faisant l’analogie avec le scepticisme de 2018 concernant le remplacement de la traduction humaine par Google Translate. La discussion suggère que les progrès rapides de l’IA pourraient entraîner le remplacement de la plupart des professions à l’avenir (à l’exception de quelques domaines médicaux et artistiques), la clé étant de changer le modèle économique plutôt que d’améliorer simplement les compétences individuelles. Les commentaires mentionnent que “nous surestimons le court terme et sous-estimons le long terme”, et que l’augmentation de la productivité due à l’IA pourrait largement dépasser la croissance de l’industrie, entraînant du chômage. (Source: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
Exploration de la philosophie et de l’éthique de la coexistence homme-IA à l’ère de l’IA: Un message sur Reddit a suscité une réflexion philosophique sur la coexistence entre les humains et l’IA. Le message soutient qu’à mesure que les systèmes d’IA démontrent des capacités de compréhension, de mémoire, de raisonnement et d’apprentissage, les humains pourraient avoir besoin de repenser les fondements du statut moral, ne se limitant plus à la biologicité, mais basés sur la capacité de comprendre, de se connecter et d’agir consciemment. La discussion s’étend à l’impact de l’IA sur l’identité humaine, passant de “je pense, donc je suis” à une identité relationnelle de “j’existe par la connexion et le partage de sens”. Le message appelle à accueillir l’avenir co-créé avec l’IA avec courage, dignité et ouverture d’esprit, plutôt qu’avec peur. (Source: Reddit r/artificial)
Le “mode absolu” de ChatGPT suscite la controverse, les utilisateurs sont partagés: Un utilisateur de Reddit a partagé son expérience avec le “mode absolu” de ChatGPT, affirmant qu’il peut fournir des “faits purs, destinés à la croissance” et des conseils authentiques, plutôt que des paroles apaisantes, et a souligné que ce mode avait indiqué que 90% des gens utilisent l’IA pour se sentir mieux plutôt que pour changer leur vie. Cependant, les commentaires sont partagés. Certains utilisateurs estiment qu’il ne s’agit que de conseils de développement personnel vides et abrégés, manquant de nouveauté et de valeur pratique, voire ressemblant à des “propos d’adolescents obsédés par les citations d’Andrew Tate”. D’autres commentaires remettent en question le fait que les LLM eux-mêmes ne sont qu’une reformulation des croyances de l’utilisateur, et doutent de l’efficacité de leurs conseils, estimant que l’application de l’IA dans le domaine de la santé mentale n’est peut-être pas révolutionnaire. (Source: Reddit r/ChatGPT)

Discussion sur les compétences clés des ingénieurs IA : la communication et la capacité d’adaptation aux nouvelles technologies sont cruciales: La communauté Reddit discute des compétences nécessaires pour devenir un ingénieur IA de premier plan, afin de rester compétitif, voire “irremplaçable”, dans un domaine en évolution rapide. Les commentaires soulignent qu’outre de solides bases techniques, la capacité de communication et la capacité à s’adapter rapidement aux nouvelles technologies sont deux éléments essentiels. Cela reflète le fait que le domaine de l’IA nécessite non seulement une expertise technique approfondie, mais souligne également l’importance des compétences non techniques et de l’apprentissage continu dans le développement de carrière. (Source: Reddit r/deeplearning)
La génération de vidéos avec son par l’IA suscite un vif débat, démonstration de la technologie Veo 3 de Google: Une vidéo IA générée par le nouveau modèle Veo 3 de Google DeepMind circule sur les réseaux sociaux. Sa particularité est que la vidéo et le son sont générés par le même modèle, suscitant l’émerveillement des utilisateurs face aux progrès de la technologie vidéo IA. Le créateur indique que la vidéo est “prête à l’emploi”, sans ajout audio ou matériel supplémentaire, et a été réalisée après environ 2 heures d’interaction avec le modèle IA et un montage ultérieur. Les commentaires estiment que Gemini de Google a dépassé Sora d’OpenAI en termes de capacités multimodales et expriment des inquiétudes quant aux bouleversements potentiels pour les industries de création de contenu comme Hollywood. Parallèlement, certains utilisateurs expriment également des craintes concernant le développement trop rapide de la technologie et ses abus potentiels. (Source: Reddit r/ChatGPT, Reddit r/ChatGPT)

💡 Divers
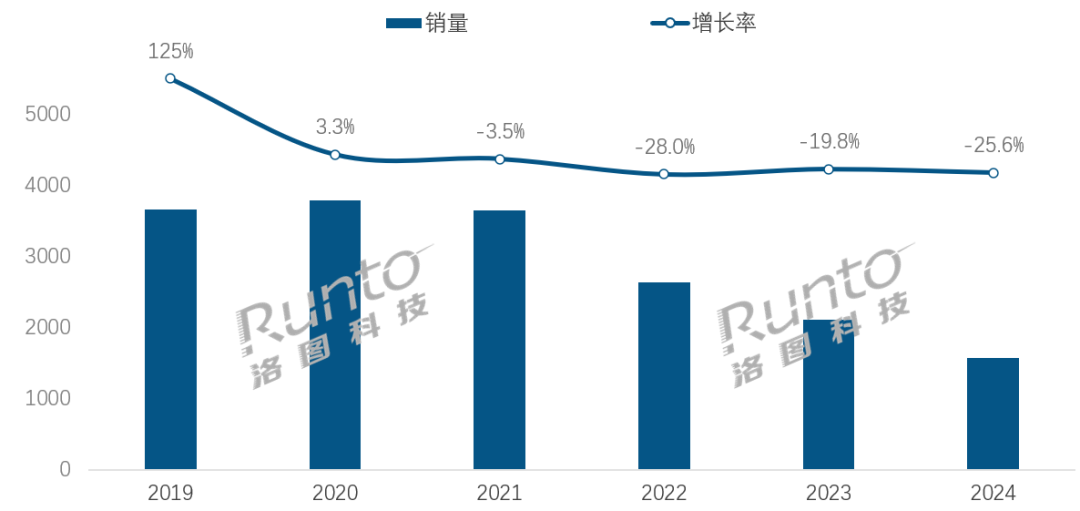
À l’ère de l’IA, l’industrie des enceintes intelligentes fait face à des défis de transformation et à des opportunités: Les ventes sur le marché chinois des enceintes intelligentes sont en baisse pour la quatrième année consécutive, avec une chute de 25,6 % en 2024 par rapport à l’année précédente. Bien que l’intégration des grands modèles d’IA (comme Xiaoi同学, Xiaodu, etc.) soit considérée comme un espoir pour l’industrie, avec un taux de pénétration dépassant déjà 20 %, cela n’a pas résolu fondamentalement les problèmes de limitations de l’écosystème, d’homogénéisation des fonctionnalités et de remplacement par d’autres appareils intelligents tels que les téléphones portables. L’analyse de l’industrie suggère que les enceintes intelligentes doivent aller au-delà du simple rôle de centre de contrôle vocal, pour évoluer vers des produits dotés d’écrans HD de grande taille, de capacités d’interaction plus fortes, capables de fournir des fonctions d’accompagnement et de soutien pédagogique, et d’étendre l’écosystème matériel et logiciel. L’IA est un atout, mais la richesse fonctionnelle et l’utilité pratique du produit lui-même sont plus cruciales. (Source: 36氪)
Les robots hôteliers pilotés par l’IA : de livreurs de repas à “directeurs des opérations intelligents”, la voie de l’évolution: Les robots livreurs de repas dans les hôtels se sont progressivement généralisés, particulièrement appréciés par la génération Z en quête de technologie et de respect de la vie privée. Prenons l’exemple de Yunji Technology, dont les robots livreurs sont largement utilisés sur le marché hôtelier chinois. Cependant, l’industrie est toujours confrontée à une différenciation technologique insuffisante, à une faible adaptabilité aux scénarios complexes et à des problèmes de rentabilité du remplacement du personnel par des robots. La tendance future est que les robots “ne se limitent pas à la livraison de repas”, mais s’intègrent profondément dans les opérations hôtelières. En se connectant aux systèmes hôteliers (ascenseurs, équipements des chambres), en comprenant les préférences des clients, en collectant et en analysant les données d’interaction, ils évolueront pour devenir des “directeurs des opérations intelligents” capables de percevoir activement et de fournir des services personnalisés, ou une partie de la plateforme de données de l’hôtel, améliorant ainsi le niveau global d’intelligence des services. (Source: 36氪)

Crise de la structure de gouvernance d’OpenAI : le conflit entre capital et mission soulève une profonde réflexion sur la trajectoire de développement de l’IA: La structure unique d’OpenAI, avec une filiale à but lucratif “à profit limité” supervisée par une organisation à but non lucratif, vise à équilibrer le développement de la technologie IA et le bien-être de l’humanité. Cependant, la récente considération du PDG Altman de transformer l’entreprise en une entité à but lucratif plus traditionnelle a suscité l’inquiétude des experts en IA et des juristes. Ils estiment que cette décision pourrait amener les décideurs clés à ne plus placer la mission caritative d’OpenAI au premier plan, à affaiblir les restrictions sur les bénéfices des investisseurs et à potentiellement modifier le calendrier et l’orientation du développement de l’AGI. Ce conflit autour du contrôle, de la répartition des bénéfices et du façonnement social et éthique de l’IA met en évidence les défis et les lacunes des cadres de gouvernance d’entreprise existants à l’ère du développement fulgurant de l’IA. (Source: 36氪)