
Mots-clés:Agent IA, Microsoft Build 2025, AlphaEvolve, GPT-4, Azure AI Foundry, NVIDIA Computex 2025, Outils de programmation IA, Intelligence incarnée, Extension GitHub Copilot pour VSCode, Protocole de contexte de modèle (MCP), Réseau en langage naturel (NLWeb), Meituan NoCode, Assistant intelligent QBot de Tencent
🔥 Pleins feux
Microsoft Build 2025 ouvre l’ère du “réseau d’agents intelligents”, adoptant pleinement le développement natif IA: Microsoft, lors de sa conférence des développeurs Build 2025, a annoncé sa vision d’un “Open Agentic Web” (réseau agentique ouvert), publiant plus de 50 mises à jour. Celles-ci incluent principalement la mise en open source de l’extension GitHub Copilot pour VSCode, le lancement du Model Context Protocol (MCP) et du standard ouvert Natural Language Web (NLWeb), ainsi que l’intégration de plus de 1900 modèles, dont Grok de xAI, dans Azure AI Foundry. Ces initiatives visent à fluidifier le pipeline de développement allant du modèle à l’agent intelligent, permettant le fonctionnement autonome et l’interopérabilité des agents IA dans divers scénarios. Le PDG de Microsoft, Satya Nadella, a souligné que les agents IA redéfiniront la manière de résoudre les problèmes, et a discuté avec le PDG d’OpenAI, Sam Altman, le PDG de Nvidia, Jensen Huang, et le fondateur de xAI, Elon Musk, de l’avenir des agents IA dans le développement logiciel, les infrastructures et les applications dans le monde physique. (Source: 36氪 | GitHub Blog | VS Code Blog | The Verge)
Google DeepMind publie AlphaEvolve, un agent IA qui bat un record d’efficacité de 56 ans en multiplication matricielle: Google DeepMind a lancé AlphaEvolve, un agent de codage alimenté par Gemini, qui, grâce à des algorithmes évolutifs et un système d’évaluation automatisé, a découvert un algorithme de multiplication de matrices complexes 4×4 plus efficace que l’algorithme de Strassen, utilisé depuis 56 ans, réduisant le nombre de multiplications scalaires requises de 49 à 48. Cette percée, d’une grande importance théorique en mathématiques, a déjà démontré sa valeur dans des applications internes de Google, comme l’accélération de 23% des opérations de multiplication de grandes matrices dans l’architecture Gemini, la réduction de 1% du temps d’entraînement de Gemini, et l’amélioration de 32,5% des performances de FlashAttention. AlphaEvolve démontre l’énorme potentiel de l’IA dans la découverte scientifique automatisée et l’optimisation d’algorithmes, capable de traiter divers problèmes complexes allant des défis mathématiques à l’ordonnancement des ressources des centres de données et à l’accélération de l’entraînement des modèles d’IA. (Source: Google DeepMind Blog | 量子位)
Une étude montre que GPT-4 est 64% plus persuasif que les humains dans les débats personnalisés: Une étude publiée dans Nature Human Behaviour indique que lorsque GPT-4 d’OpenAI peut accéder à des informations personnelles sur son adversaire de débat, telles que le sexe, l’âge, le niveau d’éducation, et ajuster ses arguments en conséquence, sa force de persuasion est supérieure de 64% à celle des humains. Cette recherche, menée en collaboration par l’École Polytechnique Fédérale de Lausanne et d’autres institutions, a impliqué 900 participants et confirme davantage la puissante capacité des grands modèles de langage (LLM) en matière de persuasion. Les chercheurs avertissent que cela révèle que les outils d’IA, après avoir obtenu une petite quantité d’informations sur les utilisateurs, peuvent construire des arguments complexes et persuasifs, ce qui constitue une menace potentielle pour la propagation de fausses informations personnalisées. Ils appellent les décideurs politiques et les plateformes à prendre ce risque au sérieux et à explorer l’utilisation des LLM pour générer des contre-récits personnalisés afin de lutter contre la désinformation. (Source: Nature Human Behaviour | MIT Technology Review)
Microsoft et Hugging Face approfondissent leur collaboration, Azure AI Foundry intègre plus de 10 000 modèles open source: Lors de la conférence Microsoft Build, Microsoft a annoncé l’extension de sa collaboration avec Hugging Face. Azure AI Foundry intègre désormais plus de 10 000 modèles open source de Hugging Face, couvrant diverses modalités (texte, audio, image, etc.) et tâches. Cette initiative vise à permettre aux utilisateurs d’Azure de déployer plus facilement et en toute sécurité une gamme diversifiée de modèles open source pour la création d’applications et d’agents IA. Tous les modèles intégrés ont passé des tests de sécurité, utilisent le format safetensors et ne contiennent pas de code distant, garantissant la sécurité des applications d’entreprise. Les deux parties prévoient de continuer à introduire les modèles les plus récents et populaires, à prendre en charge davantage de modalités (comme la vidéo, la 3D) et à renforcer l’optimisation pour les agents et outils IA. (Source: HuggingFace Blog)
🎯 Tendances
Nvidia dévoile plusieurs nouveautés IA au Computex 2025, accélérant la transformation vers les usines d’IA: Le PDG Jensen Huang a présenté au Computex 2025 le GPU GeForce RTX 5060, la superplateforme de calcul Grace Blackwell GB300, le supercalculateur IA personnel DGX Spark (équipé de GB10, disponible dans quelques semaines) et la DGX Station (784 Go de RAM, capable d’exécuter DeepSeek R1). Huang a souligné que Nvidia passait d’un fournisseur de GPU à un fournisseur mondial d’infrastructures IA, visant à créer des “usines d’IA” prêtes à l’emploi. Parallèlement, Newton, le moteur physique développé conjointement par Nvidia, DeepMind et Disney, sera open source en juillet, et le modèle de base pour robot humanoïde Isaac GR00T sera lancé, promouvant le développement de l’IA physique. Nvidia a également annoncé la construction de nouveaux bureaux à Taïwan et a souligné l’importance des talents chinois en IA. (Source: 36氪 | 36氪)
Microsoft prévoit de permettre aux utilisateurs de l’UE de changer l’assistant vocal par défaut sur les iPhone et autres appareils: Selon Bloomberg, Apple prévoit de permettre aux utilisateurs de l’Union Européenne de changer l’assistant vocal par défaut sur les appareils tels que l’iPhone, l’iPad et le Mac, de Siri à d’autres options comme Google Assistant ou Amazon Alexa. Cette mesure pourrait viser à répondre aux pressions antitrust de la loi sur les marchés numériques (DMA) de l’UE. Siri a été critiqué ces dernières années pour ses fonctionnalités obsolètes et son manque d’intelligence, et il existe des désaccords internes chez Apple concernant l’orientation du développement de Siri, de plus son architecture actuelle peine à s’intégrer efficacement avec les grands modèles de langage (LLM). Bien qu’Apple développe un nouveau Siri basé sur les LLM et ait lancé Apple Intelligence, permettre aux utilisateurs de changer l’assistant par défaut pourrait avoir un impact sur son écosystème. (Source: 36氪)
Apple teste en interne son propre chatbot IA, dont les capacités pourraient être comparables à celles de ChatGPT: Le journaliste de Bloomberg, Mark Gurman, a révélé qu’Apple teste en interne son projet de chatbot IA. Sous la direction du nouveau responsable de l’IA, John Giannandrea, le projet a fait des progrès significatifs au cours des six derniers mois, et certains cadres estiment que sa version actuelle est proche de la dernière version de ChatGPT. Ce robot pourrait être capable d’effectuer des recherches instantanées sur le web et d’intégrer des informations. Cette initiative pourrait viser à réduire la dépendance à l’égard de services externes comme OpenAI et à améliorer la compétitivité de Siri. Bien que la WWDC 2025 ne mette peut-être pas l’accent sur la mise à niveau de Siri, Apple continue d’accroître ses investissements dans l’IA afin de redynamiser son assistant vocal à l’ère de l’IA. (Source: 36氪)
Windows prendra en charge nativement le Model Context Protocol (MCP): Microsoft a annoncé lors de la conférence Build 2025 que le système d’exploitation Windows prendra en charge nativement le Model Context Protocol (MCP), visant à simplifier le développement et le déploiement d’applications IA sous Windows. Le MCP est comparé à un “USB-C pour les applications IA”, tentant de fournir une méthode d’interaction standardisée pour différents modèles et applications IA. La plateforme Windows AI Foundry intégrera cette prise en charge, permettant aux développeurs d’exécuter et de gérer plus facilement des modèles IA locaux et des agents intelligents sur les appareils Windows. (Source: op7418 | Reddit r/LocalLLaMA)
Microsoft Azure AI Foundry intègre le grand modèle Grok de xAI: Microsoft a annoncé lors de sa conférence des développeurs Build 2025 que les grands modèles Grok 3 et Grok 3 mini de la société xAI d’Elon Musk rejoindront la plateforme Azure AI Foundry. Les utilisateurs d’Azure pourront utiliser et payer directement ces modèles via la plateforme cloud. Cette initiative élargit davantage le nombre de modèles IA disponibles sur Azure (déjà plus de 1900), qui comprenait auparavant OpenAI, Meta et DeepSeek, entre autres. Elon Musk, par liaison vidéo, a exprimé son souhait que les développeurs fournissent des commentaires et espère à l’avenir offrir les services de Grok à davantage d’entreprises. (Source: 36氪)
L’équipe de Percy Liang lance le projet Marin pour promouvoir le développement de modèles d’IA ouverts: Percy Liang, professeur à l’Université de Stanford, a lancé le projet Marin, visant à construire des modèles ouverts d’une “manière radicalement participative”. Le projet met l’accent sur un processus de développement ouvert, permettant à quiconque de contribuer. Les premiers modèles Marin ont été publiés, dont un modèle 8B disponible sur la plateforme Together AI pour des tests. Cette initiative répond à l’appel à une ouverture plus profonde dans le domaine de l’IA, non seulement en ouvrant les poids, le code et les données, mais aussi l’ensemble de l’écosystème de R&D. (Source: vipulved)

Intel lance la carte graphique professionnelle Arc Pro B60, KTransformers annonce la prise en charge des GPU Intel: Intel a lancé une nouvelle carte graphique de qualité professionnelle, l’Arc Pro B60, dotée de 24 Go de VRAM et d’une bande passante mémoire de 456 Go/s, au prix d’environ 500 $ par carte, offrant un nouveau choix matériel pour le calcul IA. Parallèlement, le framework KTransformers a annoncé la prise en charge des GPU Intel. Des tests ont montré qu’une plateforme Xeon 5 + DDR5 + Arc A770 exécutant le modèle quantifié DeepSeek-R1 Q4 peut atteindre environ 7,5 tokens/s, offrant davantage de possibilités matérielles pour l’exécution locale de grands modèles. (Source: karminski3 | karminski3)

DeepMind annonce la conférence Google I/O: Le compte officiel de Google DeepMind a annoncé la prochaine conférence Google I/O qui se tiendra le 20 mai (10h, heure du Pacifique) et sera diffusée en direct sur la plateforme X. Il est prévu que la conférence annonce une série de mises à jour et de produits majeurs liés à l’IA, poursuivant la forte dynamique de Google dans le domaine de l’IA. (Source: GoogleDeepMind)
🧰 Outils
AgenticSeek : un agent IA fonctionnant purement en local, en concurrence avec Manus AI: AgenticSeek est un projet open source visant à fournir un assistant IA fonctionnant entièrement en local, capable de naviguer sur le web de manière autonome, d’écrire du code et de planifier des tâches, toutes les données restant sur l’appareil de l’utilisateur pour garantir la confidentialité. Cet outil est spécialement conçu pour les modèles d’inférence locaux, prend en charge l’interaction vocale et s’engage à réduire les coûts d’utilisation des agents IA (uniquement la consommation d’électricité) et les risques de fuite de données. (Source: GitHub Trending)
Meituan teste en interne l’outil de programmation IA NoCode, positionné comme “Vibe Coding”: Selon un reportage exclusif de 36Kr, Meituan lancera prochainement un outil de programmation IA appelé “NoCode”, dont le nom de domaine nocode.cn a été enregistré et est entré en phase de test alpha. Ce produit, développé par l’équipe de qualité et d’efficacité R&D de Meituan, se positionne comme une “programmation d’ambiance” similaire à Lovable, s’adressant aux non-techniciens. Grâce à une interaction conversationnelle, il accomplit automatiquement des tâches de codage et de déploiement, telles que l’analyse de données, le prototypage de produits, la génération d’outils opérationnels, etc. NoCode adopte une architecture Code Agent, capable d’effectuer un raisonnement logique en plusieurs étapes, et prévoit de s’ouvrir aux commerçants et au grand public, réduisant ainsi la barrière de l’informatisation pour les PME. (Source: 36氪)
Le navigateur QQ de Tencent se met à niveau en navigateur IA et intègre l’assistant intelligent QBot: Le navigateur QQ a annoncé sa mise à niveau en navigateur IA et a lancé un assistant IA nommé QBot, basé sur les modèles Tencent Hunyuan et DeepSeek. QBot intègre des fonctions de recherche IA, de navigation IA, de bureautique IA, d’apprentissage IA, de rédaction IA, etc., et introduit des capacités d’agent IA similaires à Manus, capables d’exécuter des tâches complexes. Le premier lot d’agents en test alpha comprend “AI Gaokao Tong”, capable de générer des plans personnalisés de candidature à l’examen d’entrée à l’université (Gaokao) pour les utilisateurs. Le navigateur QQ compte plus de 400 millions d’utilisateurs, et cette mise à niveau vise à améliorer l’efficacité avec laquelle les utilisateurs obtiennent des informations et traitent les tâches grâce à l’IA. (Source: 36氪)
OpenAI Codex arrive sur la version iOS de ChatGPT, prenant en charge les tâches de programmation mobile: OpenAI a annoncé que son assistant de programmation Codex est désormais intégré à l’application iOS de ChatGPT. Les utilisateurs peuvent directement lancer de nouvelles tâches de codage sur leur téléphone, visualiser les différences de code, demander des modifications et même soumettre des PR. Cette fonctionnalité prend également en charge le suivi des activités en temps réel sur l’écran de verrouillage, permettant aux utilisateurs de suivre à tout moment la progression du travail de Codex et de reprendre les tâches inachevées une fois de retour devant leur ordinateur. Cela marque une étape importante vers la programmation IA sur mobile et la collaboration multi-scénarios. (Source: karinanguyen_ | gdb)
L’application mobile NotebookLM est lancée, compatible Android et iOS: L’outil de prise de notes IA de Google, NotebookLM, a officiellement lancé son application mobile, disponible progressivement sur les plateformes Android et iOS. La version mobile offre des fonctionnalités essentielles telles que les résumés audio et les conversations, permettant aux utilisateurs d’utiliser l’IA pour l’analyse de contenu et l’apprentissage à tout moment et en tout lieu. Une fonctionnalité pratique est que les utilisateurs peuvent directement transférer le contenu qu’ils consultent (à l’exception des comptes publics WeChat) vers NotebookLM pour traitement. (Source: op7418)
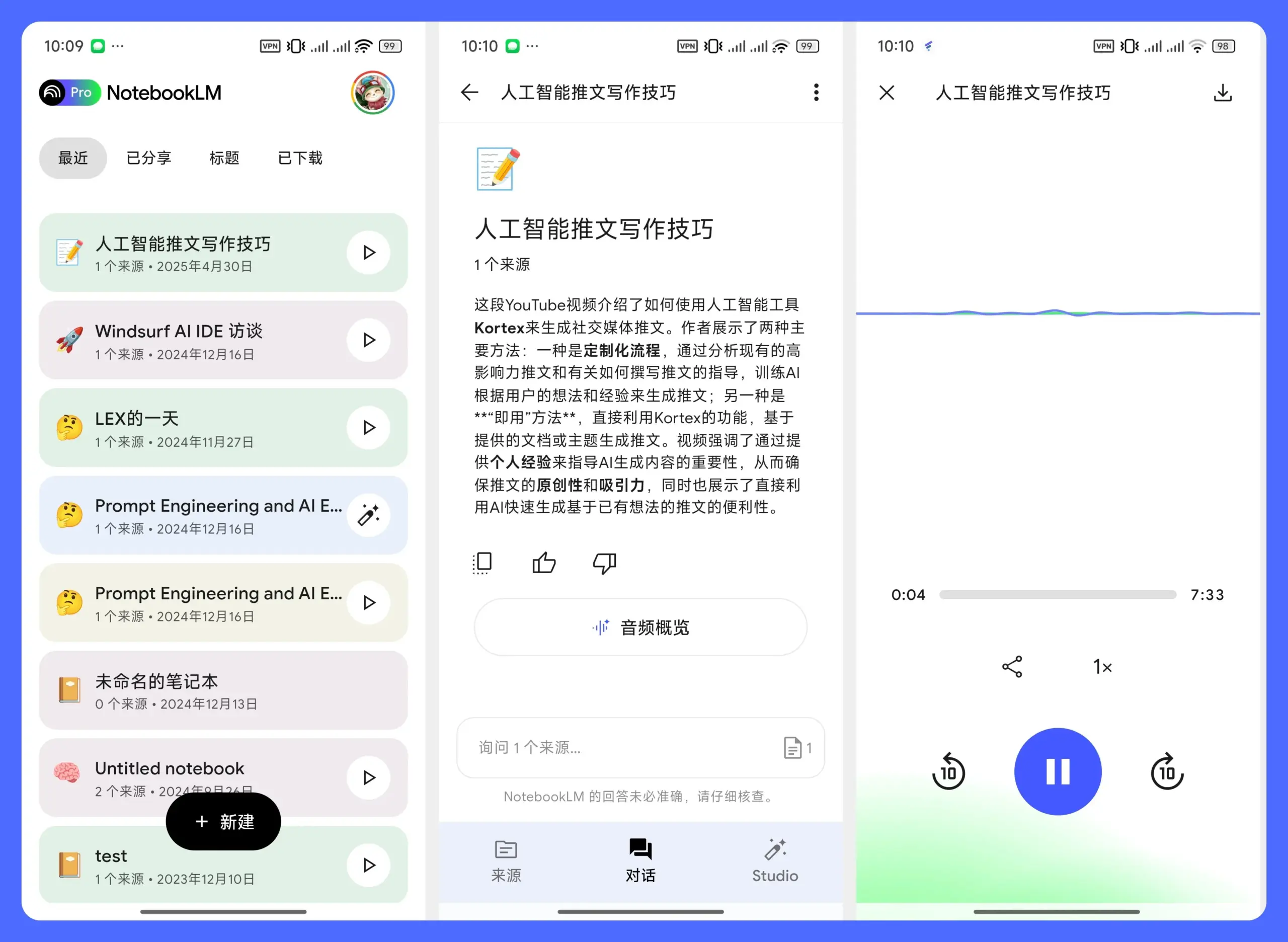
Public lance l’outil d’investissement IA “Generated Assets”: La plateforme d’investissement Public a lancé un nouveau produit, “Generated Assets”, permettant aux utilisateurs de soumettre des idées d’investissement à l’IA, qui en retour fournit des conseils d’investissement, des indices d’investissement personnalisés, et peut comparer les rendements historiques ainsi que suivre les performances en temps réel. Cela s’apparente à une réalisation par l’IA d’un “investissement d’ambiance” ou d’un “investissement thématique”, visant à abaisser la barrière pour les utilisateurs souhaitant construire et gérer des portefeuilles d’investissement personnalisés. (Source: op7418)
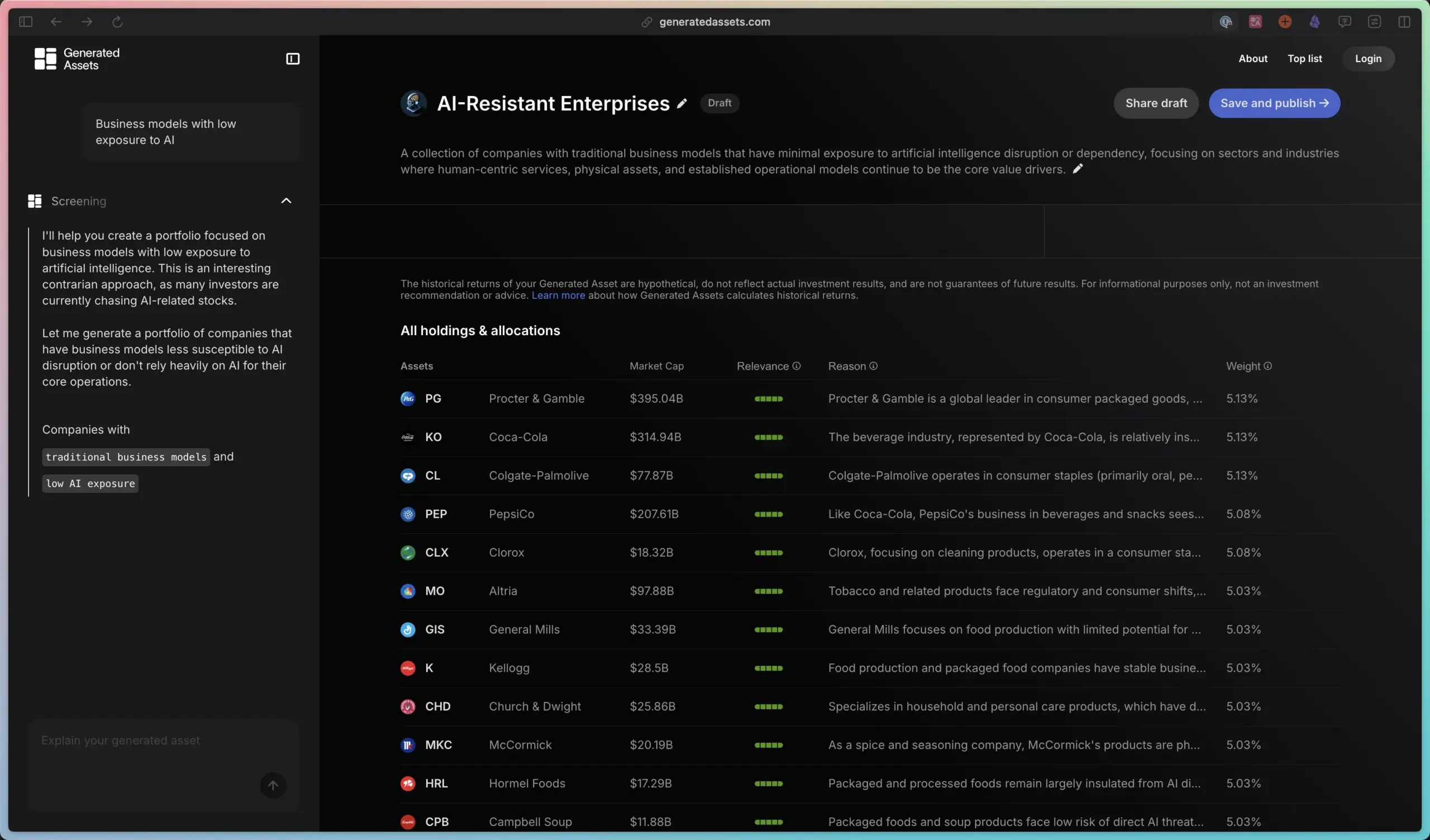
ClaraVerse : une application “tout-en-un” intégrant divers outils d’IA: Une suite d’outils d’IA nommée ClaraVerse a été partagée par la communauté. Elle intègre une interface de chat, des composants IA, Ollama (exécution locale de grands modèles), n8n (flux de travail/tâches planifiées), des modèles d’agents IA, ComfyUI (génération d’images) ainsi qu’une photothèque avec indexation IA. L’objectif est de fournir aux utilisateurs une plateforme de travail IA centralisée, simplifiant l’utilisation et la commutation entre différents outils d’IA. (Source: karminski3)
La base de données vectorielles Qdrant intègre le protocole NLWeb de Microsoft: La base de données vectorielles Qdrant a annoncé être l’un des premiers partenaires du protocole ouvert NLWeb, lancé par Microsoft lors de sa conférence Build. NLWeb vise à transformer les barres de recherche traditionnelles en interfaces sémantiques basées sur le langage naturel et sensibles à l’intention. Grâce à l’intégration avec Qdrant, les sites web peuvent l’utiliser pour une recherche vectorielle rapide avec filtres, fournissant des résultats sémantiquement pertinents, sans nécessiter de modifications majeures de la logique front-end ou back-end. (Source: qdrant_engine)

📚 Apprentissage
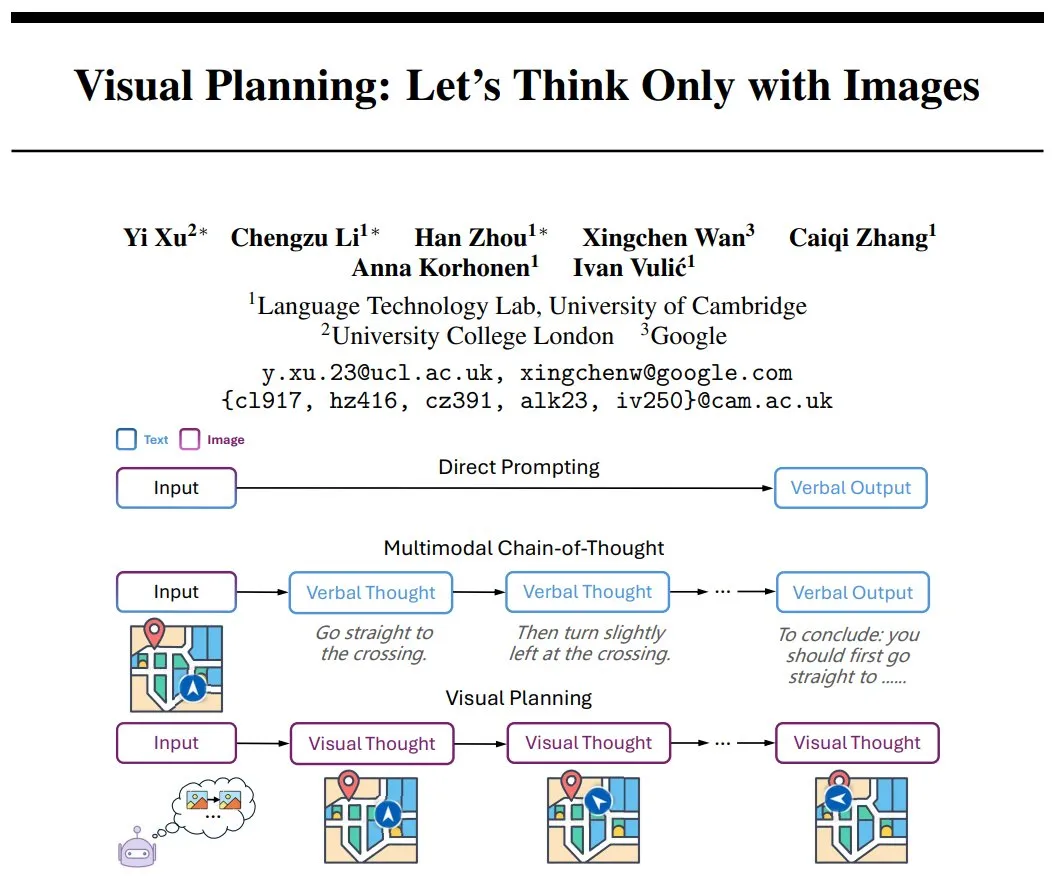
DeepMind propose la planification visuelle (Visual Planning) : un paradigme de raisonnement basé uniquement sur des séquences d’images: Yi Xu et d’autres chercheurs ont proposé un nouveau paradigme de raisonnement appelé “planification visuelle” (Visual Planning), visant à permettre aux modèles de penser et de planifier entièrement à travers des séquences d’images, simulant la manière dont les humains conçoivent mentalement des étapes, sans recourir à la pensée linguistique ou textuelle. Cette méthode explore la possibilité pour l’IA d’effectuer des raisonnements complexes dans des systèmes de symboles non linguistiques, offrant de nouvelles perspectives pour le développement de l’IA multimodale. (Source: madiator)
Stanford et d’autres institutions lancent Terminal-Bench : un benchmark pour évaluer les capacités des agents IA dans les tâches de terminal: Des chercheurs de l’Université de Stanford et de Laude ont lancé Terminal-Bench, un cadre et un benchmark pour évaluer la capacité des agents IA à accomplir des tâches complexes dans des environnements de terminal du monde réel. Étant donné que de nombreux agents IA (tels que Claude Code, Codex CLI) exécutent des tâches utiles en interagissant avec le terminal, ce benchmark vise à quantifier leur efficacité réelle, favorisant l’amélioration des capacités des agents destinés à un déploiement pratique. (Source: madiator | andersonbcdefg)

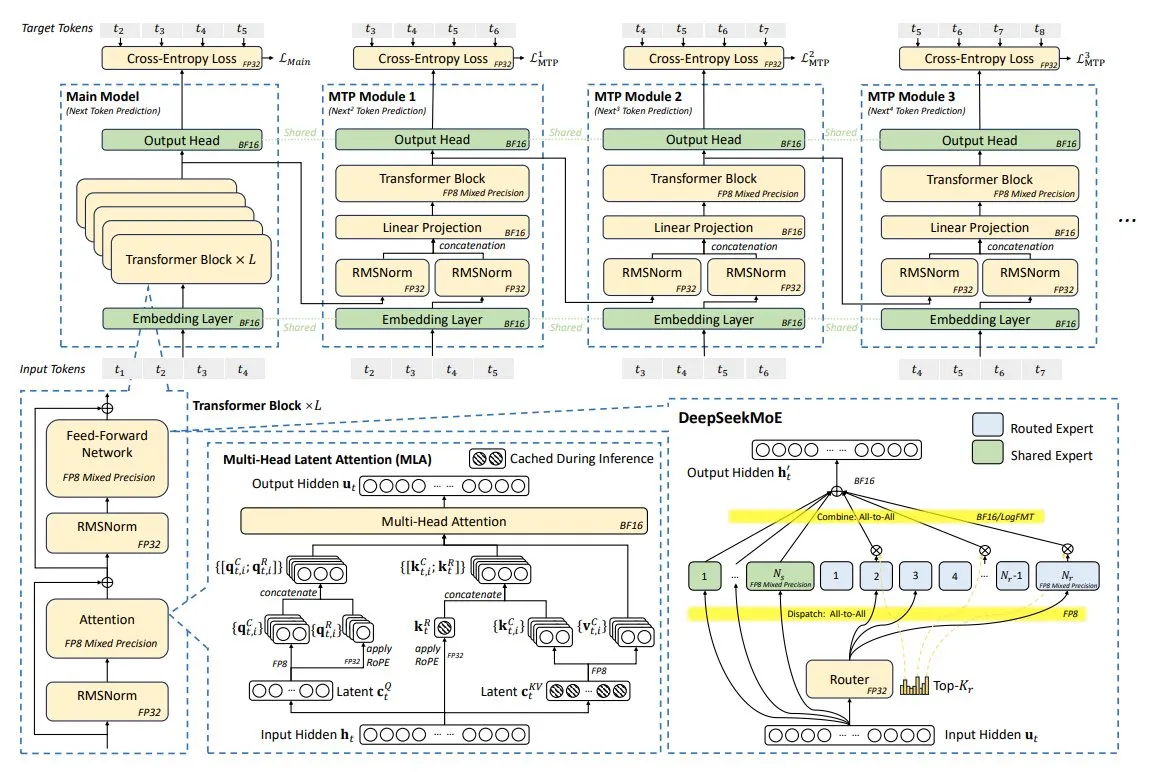
Analyse technique de DeepSeek-V3 : une conception协同 logicielle et matérielle pour un modèle efficace: Le modèle DeepSeek-V3 a été entraîné sur seulement 2048 GPU NVIDIA H800 grâce à une conception协同 logicielle et matérielle. Ses innovations clés comprennent l’attention latente multi-têtes (MLA), le mélange d’experts (MoE), l’entraînement en précision mixte FP8 et une topologie de réseau multi-plans. Ces technologies combinées visent à obtenir de meilleures performances de modèle à moindre coût, représentant une nouvelle tendance dans la conception de modèles d’IA vers un meilleur rapport efficacité-coût. (Source: TheTuringPost)
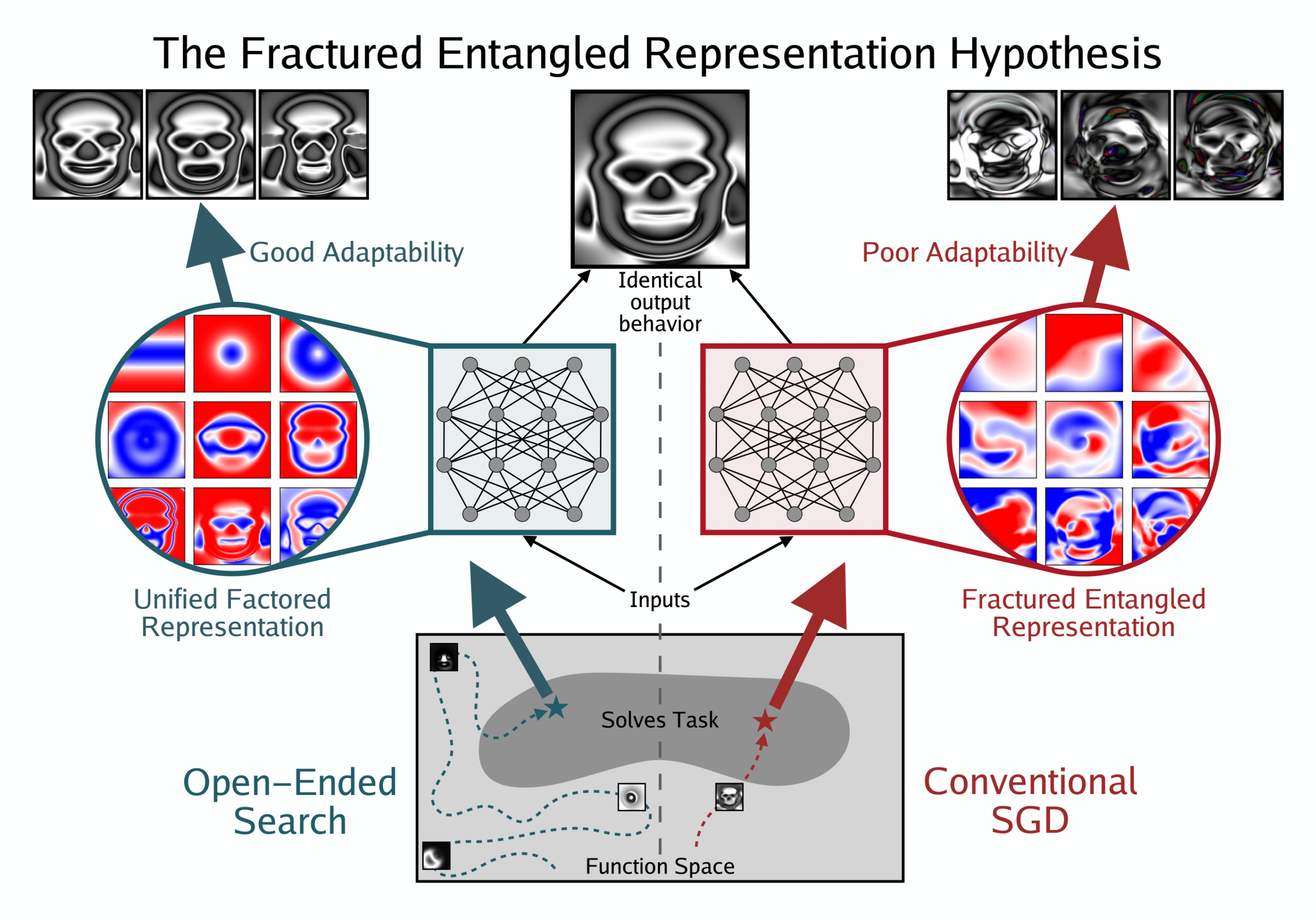
Un nouvel article explore l’optimisme représentationnel en apprentissage profond : l’hypothèse des représentations enchevêtrées et disjointes: Kenneth Stanley et ses collègues ont publié un document de position intitulé “Questioning Representational Optimism in Deep Learning: The Disjointed Entangled Representations Hypothesis”. L’étude souligne que les réseaux découverts par des recherches ouvertes non conventionnelles, capables de produire une seule image, ont des représentations élégantes et modulaires ; tandis que les réseaux appris par SGD pour produire la même sortie ont des représentations chaotiques et enchevêtrées. Cela suggère qu’un bon comportement en sortie peut cacher de mauvaises représentations internes, mais révèle également la possibilité que les représentations puissent être meilleures, ce qui a des implications profondes pour la généralisation, la créativité et la capacité d’apprentissage des modèles, offrant de nouvelles pistes pour améliorer les modèles de base et les LLM. (Source: hardmaru | togelius | bengoertzel)
Mise à jour du tutoriel RL, axée sur le chapitre LLM (DPO, GRPO, chaîne de pensée, etc.): Sirbayes a publié une nouvelle version de son tutoriel sur l’apprentissage par renforcement (RL). Cette mise à jour concerne principalement le chapitre sur les grands modèles de langage (LLM), ajoutant les derniers contenus tels que DPO (Direct Preference Optimization), GRPO (Group Relative Policy Optimization), la chaîne de pensée (Thinking), etc. Parallèlement, les chapitres sur l’apprentissage par renforcement multi-agents (MARL), l’apprentissage par renforcement basé sur un modèle (MBRL), l’apprentissage par renforcement hors ligne et DPG (Deep Deterministic Policy Gradient) ont également été légèrement mis à jour. (Source: sirbayes)

ByteDance propose une stratégie de moyennage de modèles pré-entraînés (Pre-trained Model Averaging): L’équipe de recherche de ByteDance a publié un article proposant un nouveau cadre pour la fusion de modèles pendant le pré-entraînement de grands modèles de langage – la stratégie de moyennage de modèles pré-entraînés (PMA). L’étude a révélé que la fusion de points de contrôle entraînés avec un taux d’apprentissage constant peut non seulement atteindre des performances comparables, voire meilleures, qu’un entraînement continu, mais aussi améliorer considérablement l’efficacité de l’entraînement. Cette recherche offre une nouvelle piste d’optimisation de l’efficacité pour le pré-entraînement de grands modèles et valide le potentiel de la fusion de modèles pour améliorer les performances et l’efficacité. (Source: teortaxesTex)

Nouvelle recherche du laboratoire Tongyi d’Alibaba, ZeroSearch : les LLM jouent le rôle de moteurs de recherche, améliorant les capacités de raisonnement sans API: Le laboratoire Tongyi d’Alibaba propose le framework ZeroSearch, qui permet aux LLM de simuler le comportement des moteurs de recherche pendant le processus d’apprentissage par renforcement, sans avoir besoin d’appeler réellement les API des moteurs de recherche, réduisant ainsi les coûts et améliorant la stabilité de l’entraînement. Cette méthode, grâce à un léger peaufinage, permet aux LLM de générer des résultats utiles et des interférences sonores, et adopte un entraînement anti-bruit progressif pour améliorer progressivement les capacités de raisonnement et anti-interférences du modèle dans des scénarios de recherche complexes. Les expériences montrent qu’un LLM avec seulement 3 milliards de paramètres en tant que module de recherche peut améliorer efficacement les capacités de recherche. (Source: 量子位)

Un nouvel algorithme RXTX de l’Université chinoise de Hong Kong optimise le calcul de la multiplication matricielle XXt: Des chercheurs de l’Université chinoise de Hong Kong ont proposé un nouvel algorithme, RXTX, pour accélérer le calcul du produit d’une matrice par sa transposée (XXt). Cet algorithme est basé sur la multiplication récursive de matrices par blocs 4×4, combinée à des techniques de recherche par apprentissage automatique et d’optimisation combinatoire. Comparé aux algorithmes existants basés sur la récursivité de Strassen, RXTX réduit la constante de multiplication asymptotique d’environ 5% et montre un avantage en termes de volume total d’opérations pour n≥256. Lors de tests sur des matrices 6144×6144, il s’est avéré 9% plus rapide que l’implémentation par défaut de BLAS. Cette recherche a des implications potentielles pour des domaines tels que l’analyse de données, la conception de puces et l’entraînement des LLM. (Source: 量子位)
Article AdaptThink : apprendre aux modèles de raisonnement quand “réfléchir”: Cette étude propose AdaptThink, un cadre qui, par apprentissage par renforcement, apprend aux modèles de raisonnement à choisir de manière adaptative s’il faut ou non s’engager dans une réflexion approfondie (comme la Chain-of-Thought) en fonction de la difficulté de la question. Son noyau comprend un objectif d’optimisation contraint (encourageant la réduction de la réflexion tout en maintenant les performances) et une stratégie d’échantillonnage préférentiel (équilibrant les échantillons avec et sans réflexion). Les expériences montrent qu’AdaptThink peut réduire considérablement les coûts de raisonnement et améliorer les performances. Par exemple, sur des ensembles de données mathématiques, il a permis de réduire la longueur moyenne des réponses de DeepSeek-R1-Distill-Qwen-1.5B de 53 % et d’augmenter la précision de 2,4 %. (Source: HuggingFace Daily Papers)
Article VisionReasoner : unifier la perception visuelle et le raisonnement par l’apprentissage par renforcement: VisionReasoner est un cadre unifié visant à traiter plusieurs tâches de perception visuelle à l’aide d’un modèle partagé. Il adopte une stratégie d’apprentissage cognitif multi-objets et une restructuration systématique des tâches pour améliorer la capacité du modèle à analyser les entrées visuelles et à effectuer un raisonnement structuré afin de répondre à dix tâches différentes telles que la détection, la segmentation et le comptage. Les résultats expérimentaux montrent que VisionReasoner surpasse les modèles tels que Qwen2.5VL sur des benchmarks comme COCO (détection), ReasonSeg (segmentation) et CountBench (comptage). (Source: HuggingFace Daily Papers)
Article AdaCoT : déclenchement adaptatif de la chaîne de pensée Pareto-optimal par apprentissage par renforcement: Pour résoudre le problème des coûts de calcul inutiles engendrés par la chaîne de pensée (CoT) lorsque les grands modèles de langage (LLM) traitent des requêtes simples, le cadre AdaCoT a été proposé. Il utilise l’apprentissage par renforcement (PPO) pour permettre au LLM de décider de manière adaptative s’il doit ou non invoquer la CoT en fonction de la complexité implicite de la requête, visant à équilibrer les performances du modèle et les coûts d’invocation de la CoT. Grâce à la technique de masquage sélectif des pertes (SLM) pour éviter l’effondrement de la frontière de décision, les expériences montrent qu’AdaCoT peut réduire considérablement le taux de déclenchement inutile de CoT (jusqu’à 3,18 %) et le nombre de tokens de réponse (réduction de 69,06 %), tout en maintenant des performances élevées pour les tâches complexes. (Source: HuggingFace Daily Papers)
Article GIE-Bench : un benchmark d’évaluation ancré pour l’édition d’images guidée par texte: Pour évaluer plus précisément les modèles d’édition d’images guidée par texte, GIE-Bench a été proposé. Ce benchmark évalue selon deux dimensions : l’exactitude fonctionnelle (vérifiant si l’édition a réussi grâce à des questions à choix multiples générées automatiquement) et la préservation du contenu de l’image (utilisant une technique de masquage sensible aux objets et un score de préservation pour assurer la cohérence des régions non ciblées). Il comprend plus de 1000 exemples d’édition de haute qualité, couvrant 20 catégories. L’évaluation de modèles tels que GPT-Image-1 montre qu’il est en tête pour le suivi des instructions, mais qu’il y a place à amélioration pour la préservation des régions non pertinentes. (Source: HuggingFace Daily Papers)
Article InstanceGen : génération d’images avec instructions au niveau de l’instance: Pour résoudre le problème des modèles de génération de texte en image pré-entraînés qui peinent à capturer avec précision la sémantique des invites complexes contenant plusieurs objets et attributs au niveau de l’instance, InstanceGen propose une nouvelle technique. Cette technique combine une initialisation structurée fine basée sur l’image (directement fournie par les modèles de génération d’images contemporains) et des instructions au niveau de l’instance basées sur les LLM, permettant aux images générées de mieux suivre toutes les parties des invites textuelles, y compris le nombre d’objets, les attributs au niveau de l’instance et les relations spatiales entre les instances. (Source: HuggingFace Daily Papers)
💼 Affaires
千诀科技, société d’intelligence incarnée issue de Tsinghua, boucle un tour de financement Pre-A+ de plusieurs centaines de millions de yuans: La société de “cerveau incarné” 千诀科技 a récemment finalisé un nouveau tour de financement Pre-A+, avec des investissements de Junshan Investment,祥峰投资 (Vertex Ventures) et Shixi Capital, portant le financement total cumulé à plusieurs centaines de millions de yuans. Incubée par des membres clés du département d’automatisation de l’Université Tsinghua et d’instituts de recherche en IA associés, la société se concentre sur le développement d’un système de “cerveau incarné” universel, mettant l’accent sur la perception multimodale en temps réel, la planification de tâches continues et les capacités d’exécution autonome. Elle a déjà réalisé des déploiements de produits dans des scénarios tels que les services à domicile et la logistique, et collabore avec plusieurs grands fabricants de robots et sociétés d’électronique grand public. (Source: 36氪)

Les agents IA pourraient remodeler le paysage du marché SaaS: Le PDG de Microsoft, Satya Nadella, a prédit que les applications SaaS seraient bouleversées à l’ère des agents IA, suscitant un vaste débat dans l’industrie sur l’avenir des agents IA et du SaaS. Grâce à leurs capacités de perception, de décision et d’action autonomes, les agents IA pourraient résoudre les problèmes des SaaS traditionnels en matière de personnalisation, d’interopérabilité des données et d’expérience utilisateur, par exemple en créant automatiquement des flux de travail via une interaction en langage naturel, en intégrant des données entre applications et en fournissant de manière proactive des conseils commerciaux. Bien que les agents IA soient actuellement confrontés à des défis dans les applications d’entreprise, tels que les limitations des capacités des LLM, les coûts et la sécurité des données, des fournisseurs comme Salesforce, Microsoft et 用友 (Yonyou) ont commencé à intégrer des agents IA dans leurs produits SaaS, explorant de nouveaux modèles de fusion ou de disruption du SaaS. (Source: 36氪)
L’IA redéfinit la gestion de la rémunération : de l’analyse des données à la prise de décision et à la communication intelligentes: L’intelligence artificielle transforme profondément la gestion de la rémunération. Un rapport de Korn Ferry montre que l’utilisation de l’IA dans la communication sur la rémunération, l’étalonnage externe et l’architecture des compétences professionnelles est en augmentation. À l’avenir, l’IA devrait permettre de passer d’une approche axée sur les données à une prise de décision intelligente en traitant des volumes de données plus importants et plus variés (y compris les plateformes de médias sociaux, les enquêtes tierces), par exemple pour prédire les risques de départ des employés, évaluer l’efficacité des incitations, ajuster dynamiquement les fourchettes de salaires et mettre en œuvre des incitations personnalisées. Parallèlement, l’IA est également confrontée à des défis tels que la confidentialité des données, la “boîte noire” des algorithmes et la crédibilité des résultats. Une communication efficace sur la rémunération est encore plus importante à l’ère du numérique et de l’intelligence. Les outils d’IA peuvent aider les gestionnaires à communiquer de manière systématique et personnalisée, améliorant ainsi le sentiment d’équité et la satisfaction des employés. (Source: 36氪)
🌟 Communauté
Sundar Pichai publie une photo de “réflexion profonde”, en prévision de Google I/O: Le PDG de Google, Sundar Pichai, a publié sur les réseaux sociaux une photo de lui en “réflexion profonde”, suscitant une large attente au sein de la communauté pour la prochaine conférence Google I/O. Cette photo a été relayée et interprétée par de nombreux influenceurs du domaine de l’IA, qui y voient généralement le signe que Google fera des annonces majeures dans le domaine de l’IA, en particulier concernant le modèle Gemini et ses applications. Les membres de la communauté spéculent sur de nouvelles fonctionnalités, de nouveaux modèles ou de nouvelles stratégies possibles. (Source: demishassabis | YiTayML | zacharynado | lmthang | scaling01 | brickroad7 | jack_w_rae | TheTuringPost | shaneguML | op7418)

Les capacités de programmation des agents IA suscitent un vif débat, Sama optimiste quant à leur capacité à achever automatiquement les projets inachevés: Le PDG d’OpenAI, Sam Altman, se réjouit à l’idée que les agents de programmation IA (comme Codex) puissent achever les projets réalisés à 80 % mais non finalisés, et en assurer la maintenance automatique. La communauté a comparé et discuté des capacités de différents agents de programmation IA (tels que Codex, Jules, Claude Code), en se concentrant sur la capacité de planification des tâches, l’environnement de machine virtuelle (par exemple, s’il est connecté à Internet) et les performances dans les tâches complexes à long terme. Il est généralement admis que le potentiel des agents IA dans le domaine du développement logiciel est énorme, mais les différents modèles présentent encore des différences en termes de mise en œuvre et de résultats concrets. (Source: sama | mathemagic1an)
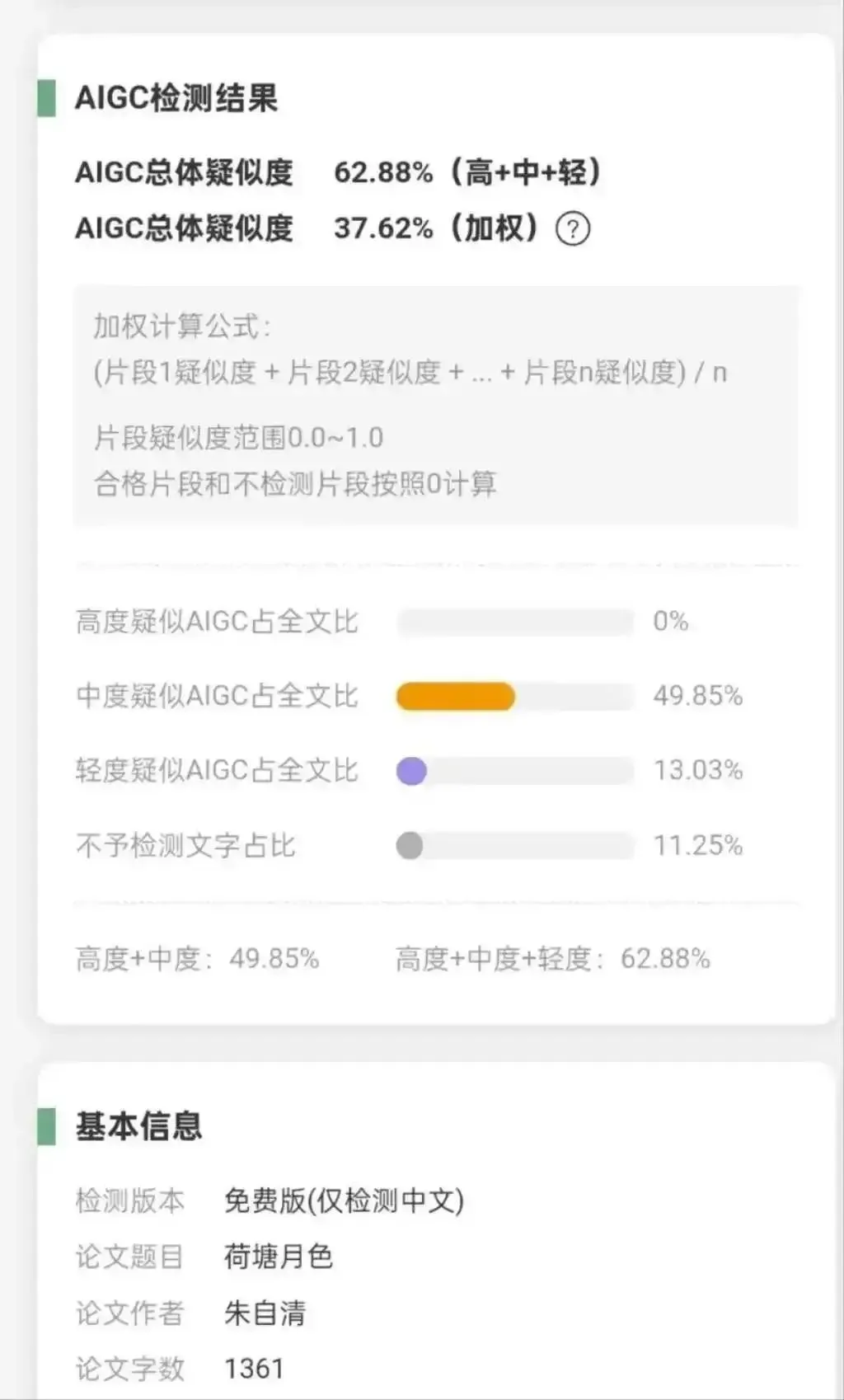
L’introduction de la détection de contenu généré par IA dans les universités suscite la controverse, le “Préface au Pavillon du Prince Teng” jugé à 100% généré par IA: Plusieurs universités chinoises ont intégré le “taux de détection de contenu généré par IA” dans l’évaluation des mémoires, ce qui a conduit les étudiants à utiliser diverses méthodes pour contourner la détection, et les enseignants à se débattre entre le verdict de l’IA et le jugement humain. Les outils de détection d’IA, en raison de leur dépendance à la comparaison de bases de données et aux biais de reconnaissance de formes, classent souvent à tort des œuvres classiques (comme le “Préface au Pavillon du Prince Teng” avec un taux d’IA de 100 %, “Clair de lune sur l’étang aux lotus” de Zhu Ziqing à 62,88 %) et des écrits académiques normatifs comme étant générés par IA. Ce phénomène a donné naissance à une chaîne industrielle grise de “réduction du taux d’IA”, suscitant une profonde réflexion sur les limites de la technologie de détection d’IA, les normes d’évaluation académique et l’essence de l’éducation. (Source: 36氪)
Le mode de pensée de la prochaine génération grandissant à l’ère de l’IA fait l’objet de discussions: La communauté Reddit débat vivement du fait que la nouvelle génération d’enfants grandissant dans un environnement d’IA aura un mode de pensée significativement différent de celui des générations précédentes. Ils s’habitueront à interagir avec des assistants IA, l’accent de leur apprentissage pourrait passer de la mémorisation des faits à la formulation de questions et à la navigation dans les systèmes, et de l’apprentissage par essais et erreurs à l’itération rapide. Cette fusion précoce avec la logique machine pourrait profondément remodeler leur curiosité, leur mémoire, leur intuition et même leur définition de l’intelligence elle-même, soulevant des questions sur la formation de leurs futures croyances, leur capacité à construire des systèmes et leur confiance en leurs propres pensées. (Source: Reddit r/ArtificialInteligence)
Le développement rapide de l’IA dans le domaine de l’ingénierie logicielle suscite un sentiment de crise chez les développeurs: Un ingénieur logiciel de 42 ans, qui gagnait autrefois 150 000 dollars par an, s’est retrouvé dépassé par les tendances liées à l’IA. Après avoir envoyé plus de 800 CV, il n’a obtenu que très peu d’entretiens et vit actuellement de la livraison de repas. Son expérience a déclenché un débat sur la question de savoir si l’IA (comme GitHub Copilot, Claude, ChatGPT) a déjà commencé à remplacer massivement les programmateurs. Le PDG d’Anthropic avait prédit que l’IA serait capable de générer la grande majorité du code. Bien que les données du Bureau des statistiques du travail montrent toujours que l’ingénierie logicielle est l’une des professions à la croissance la plus rapide, la vague de licenciements dans le secteur technologique se poursuit et les entreprises utilisent l’IA pour réduire les coûts et accroître l’efficacité. Cela incite à réfléchir à la manière dont la société devrait faire face au chômage structurel induit par l’IA et à la construction d’un nouveau paradigme de collaboration “humain + IA”. (Source: 36氪)

Le problème des biais de genre dans les algorithmes d’IA : l’invisibilité et l’absence des “données féminines”: Dans le développement de l’intelligence artificielle, le problème des biais de genre dans les algorithmes devient de plus en plus saillant. Pour des raisons historiques et sociales, la représentativité des données féminines dans la collecte de données est insuffisante (par exemple, dans les essais cliniques, les articles Wikipédia), ce qui peut entraîner des biais de l’IA à l’encontre des femmes dans des domaines tels que le diagnostic médical et la recommandation de contenu. Par exemple, les systèmes de reconnaissance d’images peuvent identifier à tort un homme dans une cuisine comme étant une femme, et les résultats d’images des moteurs de recherche renforcent les stéréotypes de genre. Le déséquilibre entre les sexes dans l’industrie de l’IA est également considéré comme l’une des causes. Pour résoudre ce problème, il faut agir sur plusieurs fronts : sensibiliser les développeurs, garantir l’égalité des chances professionnelles pour les femmes, améliorer les lois et réglementations, mettre en place des mécanismes d’audit de genre pour les systèmes d’IA et optimiser les algorithmes (par exemple, rééchantillonnage des données, application du raisonnement causal). (Source: 36氪)
Les agents IA suscitent des discussions sur la transformation du secteur SaaS: Le PDG de Microsoft, Satya Nadella, prédit que le SaaS sera bouleversé à l’ère des agents IA. Grâce à leurs capacités autonomes de perception, de décision et d’action, les agents IA pourraient résoudre les problèmes du SaaS en matière de personnalisation, d’interopérabilité des données et d’expérience utilisateur. Par exemple, les agents IA peuvent créer automatiquement des flux de travail via une interaction en langage naturel, intégrer des données entre applications et fournir de manière proactive des conseils commerciaux. Actuellement, des fournisseurs SaaS tels que Salesforce, Microsoft et 用友 (Yonyou) ont commencé à intégrer des agents IA, explorant de nouveaux modèles de fusion ou de disruption du SaaS. Bien que les agents IA soient encore confrontés à des défis dans les applications d’entreprise, tels que les capacités des LLM, les coûts et la sécurité des données, leur potentiel de transformation a déjà attiré une large attention de l’industrie. (Source: finbarrtimbers)
💡 Autres
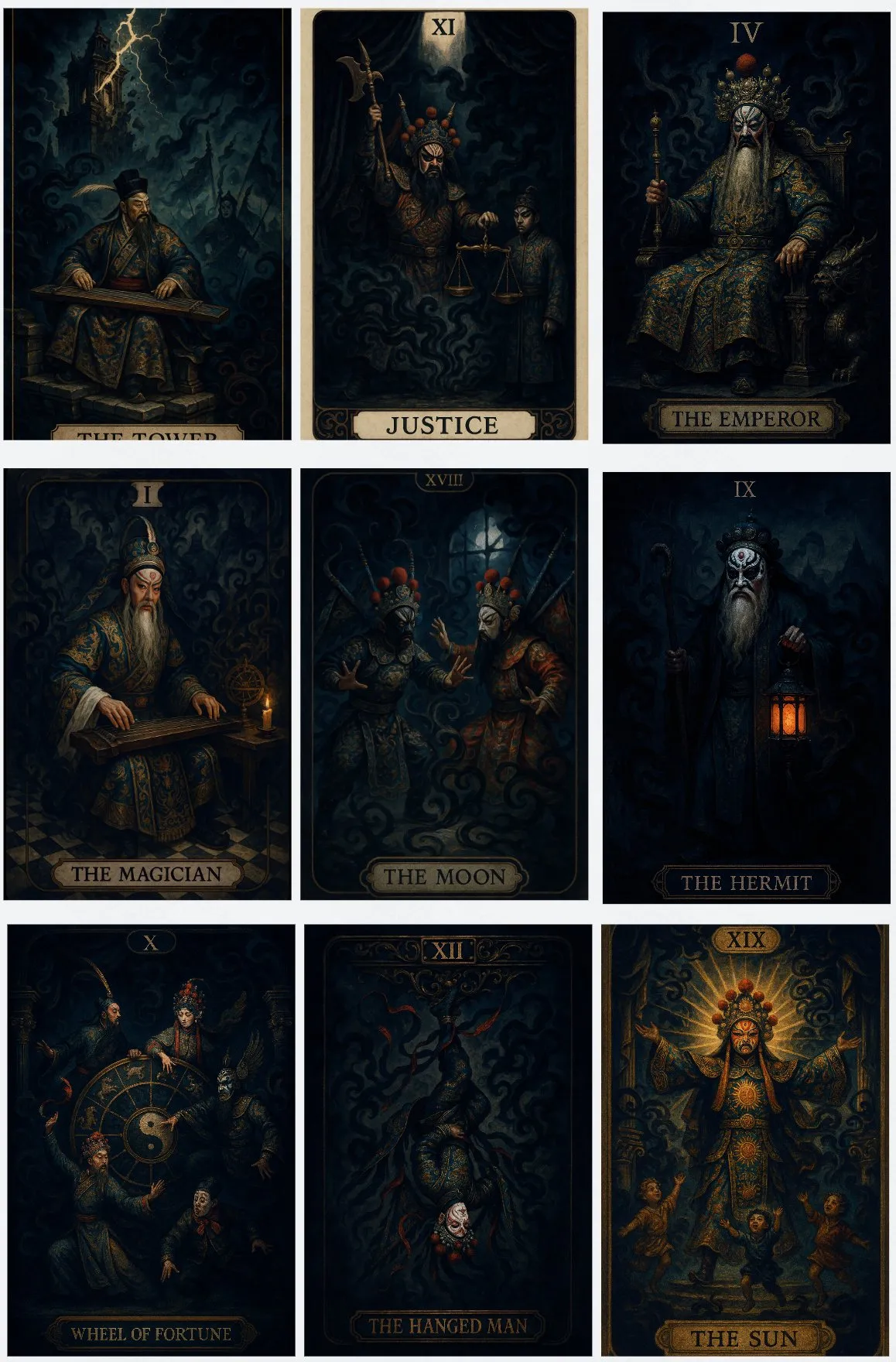
IA génère des cartes de tarot de style opéra chinois: L’utilisateur @op7418 a utilisé l’outil IA Lovart pour créer un jeu de cartes de tarot de style opéra chinois. Son concept de design consiste à combiner le contenu traditionnel de l’opéra avec la signification exprimée par la carte de tarot correspondante, démontrant le potentiel d’application de l’IA dans la conception créative et la fusion culturelle. (Source: op7418)
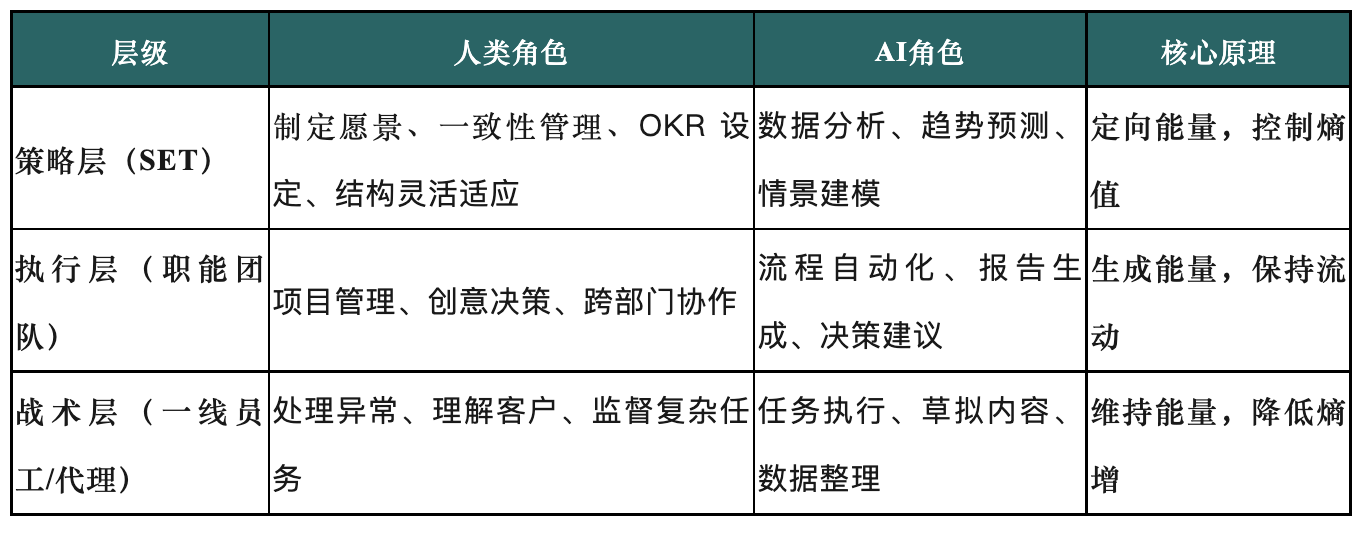
Remodelage de la structure organisationnelle à l’ère de l’IA : l’essor de l’équipe d’exécution stratégique (SET): L’article explore comment, à l’ère de l’accélération du développement de l’IA, les structures organisationnelles traditionnelles peinent à s’adapter à la complexité induite par l’IA. Il propose un modèle organisationnel à trois niveaux centré sur une “équipe d’exécution stratégique” (SET), visant à faire de l’IA une partie intégrante de l’équipe, en réalisant une exécution agile et une extension intelligente grâce à des mécanismes de collaboration homme-machine raisonnables. La SET est responsable de la transformation de la stratégie en actions interdépartementales, du suivi de l’entropie organisationnelle, de l’ajustement flexible des stratégies et de la coordination de la collaboration entre les personnes, les processus et les agents IA, afin de libérer le potentiel de l’IA et de piloter la mise en œuvre de la stratégie. (Source: 36氪)
La vérification des faits par la foule peut-elle endiguer la désinformation sur les réseaux sociaux ?: Preslav Nakov, professeur à l’Université d’intelligence artificielle Mohamed bin Zayed, examine l’impact du remplacement par Meta des vérificateurs de faits tiers par les Community Notes. Il estime que les Community Notes (issues de Birdwatch de X), un modèle de crowdsourcing, ont du potentiel, mais que la modération de contenu nécessite une combinaison de plusieurs méthodes, notamment le filtrage automatique, le crowdsourcing et la vérification professionnelle des faits. Faisant une analogie avec le filtrage des spams et le traitement des contenus préjudiciables par les LLM, il souligne que chaque méthode a ses avantages et ses inconvénients et qu’elles devraient fonctionner en synergie. Des recherches montrent que les Community Notes peuvent amplifier l’impact du travail des vérificateurs de faits professionnels ; leurs centres d’intérêt diffèrent mais leurs conclusions sont similaires, ce qui les rend complémentaires. (Source: MIT Technology Review)
