
Mots-clés:AlphaEvolve, Gemini, Algorithmes d’évolution, Agents intelligents IA, Optimisation d’algorithmes, Multiplication matricielle, Centre de données Borg, Optimisation de multiplication matricielle complexe 4×4, Découverte d’algorithmes par Google DeepMind, Conception automatisée d’algorithmes par IA, Application Gemini 2.0 Pro, Optimisation d’allocation des ressources Borg
🔥 En vedette
Google DeepMind lance AlphaEvolve : un agent intelligent de codage basé sur Gemini et des algorithmes évolutifs, réalisant des percées en mathématiques et en informatique: Google DeepMind a publié AlphaEvolve, un agent intelligent qui utilise le grand modèle de langage Gemini 2.0 Pro pour découvrir et optimiser automatiquement le code algorithmique grâce à des algorithmes évolutifs. AlphaEvolve est capable de générer, évaluer et améliorer de manière autonome des solutions candidates à partir du code initial et des métriques d’évaluation fournis par des humains. Le système a excellé sur plus de 50 problèmes mathématiques, reproduisant les solutions connues dans environ 75 % des cas et découvrant de meilleures solutions dans 20 % des cas. Il est à noter qu’AlphaEvolve a réduit le nombre de calculs pour la multiplication de matrices complexes 4×4 de 49 à 48, battant un record vieux de 56 ans. De plus, il a optimisé l’algorithme de planification du centre de données interne Borg de Google, récupérant 0,7 % des ressources de calcul mondiales, et a amélioré la conception de la prochaine génération de puces TPU, réduisant le temps d’entraînement de Gemini de 1 %. Ce résultat démontre l’énorme potentiel de l’IA dans la découverte automatisée d’algorithmes et l’innovation scientifique. Bien qu’il traite actuellement principalement des problèmes pouvant être évalués automatiquement, ses perspectives d’application dans des domaines scientifiques appliqués tels que la découverte de médicaments sont vastes. (Source: , QubitAI, 36Kr)
Nvidia annonce plusieurs avancées en IA au Computex 2025, Jensen Huang souligne la vision de l’Agentic AI et de la Physical AI: Lors de son discours d’ouverture au Computex 2025, Jensen Huang, PDG de Nvidia, a souligné que l’IA évolue d’une « réponse unique » vers une Agentic AI (IA agentive) « pensante et raisonnante » et une Physical AI (IA physique) qui comprend le monde physique. Pour soutenir cette tendance, Nvidia a lancé une version étendue de la plateforme Blackwell (Blackwell Ultra AI) et a annoncé la production à grande échelle du système Grace Blackwell GB300, dont les performances d’inférence sont 1,5 fois supérieures à celles de la génération précédente. Jensen Huang a également donné un aperçu de la prochaine génération de super-puces IA, Rubin Ultra, dont les performances seraient 14 fois supérieures à celles du GB300. Pour promouvoir la construction d’infrastructures IA, Nvidia a lancé la technologie NVLink Fusion et s’est associée à TSMC, Foxconn et d’autres pour construire un supercalculateur IA à Taïwan. De plus, Nvidia a mis à jour son modèle de fondation pour robots humanoïdes Isaac GR00T N1.5, améliorant son adaptation à l’environnement et ses capacités d’exécution de tâches, et prévoit de rendre open source le moteur physique Newton, développé en collaboration avec DeepMind et Disney Research. (Source: AI Frontline, QubitAI, Reddit r/artificial)
L’équipe OpenAI Codex révèle lors d’un AMA les plans d’intégration pour GPT-5 et les futurs produits: L’équipe OpenAI Codex a organisé une session « Ask Me Anything » (AMA) sur Reddit. Jerry Tworek, vice-président de la recherche, a révélé que l’objectif du prochain modèle de fondation, GPT-5, est d’améliorer les capacités des modèles existants et de réduire le besoin de changer de modèle. Il est prévu d’intégrer les outils existants tels que Codex, Operator (agent d’exécution de tâches), Deep Research (outil de recherche approfondie) et Memory (fonction de mémoire) pour former une expérience d’assistant IA unifiée. Les membres de l’équipe ont également partagé la motivation initiale derrière le développement de Codex (née d’une réflexion interne sur la sous-utilisation des modèles), l’amélioration d’environ 3 fois de l’efficacité de la programmation grâce à l’utilisation interne de Codex, et les perspectives pour l’avenir du génie logiciel – transformer efficacement et de manière fiable les exigences en logiciels exécutables. Codex utilise actuellement principalement les informations chargées dans le runtime du conteneur, et pourrait à l’avenir combiner la technologie RAG pour acquérir les connaissances les plus récentes. OpenAI explore également des plans de tarification flexibles et prévoit d’offrir des crédits API gratuits aux utilisateurs Plus/Pro pour l’utilisation de Codex CLI. (Source: 36Kr)
VS Code annonce l’open-sourcing de l’extension GitHub Copilot Chat et prévoit de créer une plateforme d’édition de code IA open source: L’équipe de Visual Studio Code a annoncé son intention de faire de VS Code un éditeur IA open source, en adhérant aux principes fondamentaux d’ouverture, de collaboration et d’implication de la communauté. Dans le cadre de ce plan, l’extension GitHub Copilot Chat a été rendue open source sur GitHub sous licence MIT. À l’avenir, VS Code prévoit d’intégrer progressivement ces fonctionnalités IA au cœur de l’éditeur, dans le but de construire une plateforme d’édition de code IA entièrement open source et pilotée par la communauté, afin d’améliorer l’efficacité du développement, la transparence et la sécurité. Cette initiative est considérée comme une étape importante pour Microsoft dans le domaine de l’open source et pourrait avoir un impact profond sur l’écosystème des outils de programmation assistée par IA. (Source: dotey, jeremyphoward)
Huawei Ascend et DeepSeek collaborent, les performances d’inférence des modèles MoE surpassent celles de Nvidia Hopper: Huawei Ascend a annoncé que son super-nœud CloudMatrix 384 et son serveur d’inférence Atlas 800I A2 ont réalisé une percée majeure en termes de performances d’inférence lors du déploiement de modèles MoE à très grande échelle tels que DeepSeek V3/R1, surpassant l’architecture Hopper de Nvidia dans des conditions spécifiques. Le super-nœud CloudMatrix 384 a dépassé un débit de décodage par carte de 1920 Tokens/s avec une latence de 50 ms, tandis que l’Atlas 800I A2 a atteint un débit par carte de 808 Tokens/s avec une latence de 100 ms. Huawei attribue cela à une stratégie consistant à « compenser la physique par les mathématiques », en utilisant des optimisations algorithmiques et système pour pallier les limitations matérielles. Les rapports techniques correspondants ont été publiés et le code principal sera rendu open source d’ici un mois. Les mesures d’optimisation comprennent des solutions de parallélisme expert pour les modèles MoE, le déploiement découplé PD, l’adaptation du framework vLLM, la stratégie de quantification A8W8C16, ainsi que la solution de communication FlashComm, la conversion du parallélisme intra-couche, le moteur d’inférence spéculative FusionSpec et l’optimisation de l’affinité matérielle des opérateurs MLA/MoE. (Source: QubitAI, WeChat)
🎯 Tendances
Apple rend open source FastVLM, un modèle de langage visuel efficace, optimisant l’expérience IA en périphérie: Apple a rendu open source FastVLM (Fast Vision Language Model), un modèle de langage visuel conçu pour fonctionner efficacement sur des appareils en périphérie tels que l’iPhone. FastVLM introduit un nouveau codeur visuel hybride, FastViTHD, qui combine des couches convolutives avec des modules Transformer, et utilise des techniques de pooling multi-échelle et de sous-échantillonnage pour réduire considérablement le nombre de tokens visuels nécessaires au traitement des images (16 fois moins que les ViT traditionnels). Cela permet au modèle de maintenir une haute précision tout en offrant une vitesse de sortie du premier token (TTFT) jusqu’à 85 fois plus rapide que les modèles comparables. FastVLM est compatible avec les principaux LLM et s’adapte facilement à l’écosystème iOS/Mac, offrant trois versions de paramètres (0.5B, 1.5B, 7B) adaptées à diverses tâches graphiques et textuelles en temps réel telles que la description d’images, les questions-réponses et l’analyse. (Source: WeChat)
Meta publie le modèle KernelLLM 8B, surpassant GPT-4o dans des benchmarks spécifiques: Meta a publié le modèle KernelLLM 8B sur Hugging Face. Selon les informations, dans le benchmark KernelBench-Triton Level 1, ce modèle de 8 milliards de paramètres a surpassé en performance d’inférence unique des modèles plus grands tels que GPT-4o et DeepSeek V3. Dans le cas d’inférences multiples, les performances de KernelLLM sont également supérieures à celles de DeepSeek R1. Cette publication a attiré l’attention de la communauté IA, étant considérée comme un autre exemple de la forte compétitivité des modèles de taille petite à moyenne sur des tâches spécifiques. (Source: ClementDelangue, huggingface, mervenoyann, HuggingFace Daily Papers)
Le modèle Mistral Medium 3 affiche de solides performances sur Arena, particulièrement dans le domaine technique: Le nouveau modèle Mistral Medium 3 de Mistral AI a montré d’excellentes performances lors de l’évaluation communautaire sur lmarena.ai, se classant 11e en capacité de conversation globale, une amélioration significative par rapport à Mistral Large (score Elo augmenté de 90 points). Le modèle s’est particulièrement distingué dans le domaine technique, se classant 5e en capacité mathématique, 7e en traitement de prompts complexes et en codage, et 9e dans le WebDev Arena. Les commentaires de la communauté estiment que ses performances dans le domaine technique sont proches du niveau de GPT-4.1, avec un coût potentiellement plus compétitif, similaire à la tarification de GPT-4.1 mini. Les utilisateurs peuvent essayer gratuitement le modèle sur l’interface de chat officielle de Mistral. (Source: hkproj, qtnx_, lmarena_ai)
Hugging Face Datasets ajoute la visualisation directe des conversations de chat: La plateforme Hugging Face Datasets a bénéficié d’une mise à jour importante : les utilisateurs peuvent désormais lire directement le contenu des conversations de chat dans les jeux de données. Cette fonctionnalité est considérée par les membres de la communauté (tels que Caleb, Maxime Labonne) comme un grand pas en avant pour résoudre les problèmes de qualité des données, car la consultation directe des données de conversation originales aide à mieux comprendre les données, à effectuer le nettoyage des données et à améliorer l’efficacité de l’entraînement des modèles. Auparavant, la visualisation de conversations spécifiques pouvait nécessiter du code ou des outils supplémentaires ; cette nouvelle fonctionnalité simplifie ce processus, améliorant la commodité et la transparence du travail sur les données. (Source: eliebakouch, _lewtun, _akhaliq, maximelabonne, ClementDelangue, huggingface, code_star)
MLX LM s’intègre à Hugging Face Hub, simplifiant l’exécution locale de modèles sur Mac: MLX LM est désormais directement intégré à Hugging Face Hub, permettant aux utilisateurs Mac d’exécuter plus facilement plus de 4400 LLM localement sur les appareils Apple Silicon. Les utilisateurs n’ont qu’à cliquer sur « Use this model » sur la page d’un modèle compatible sur Hugging Face Hub pour exécuter rapidement le modèle dans le terminal, sans configuration cloud complexe ni attente. De plus, il est possible de lancer directement un serveur compatible OpenAI depuis la page du modèle. Cette intégration vise à abaisser la barrière à l’entrée pour l’exécution locale de modèles et à améliorer l’efficacité du développement et de l’expérimentation. (Source: awnihannun, ClementDelangue, huggingface, reach_vb)
Nvidia rend open source son modèle d’inférence Physical AI Cosmos-Reason1-7B: Nvidia a rendu open source Cosmos-Reason1-7B, un modèle de sa série Physical AI, sur Hugging Face. Ce modèle est conçu pour comprendre le bon sens du monde physique et générer des décisions incarnées correspondantes. Cela marque une nouvelle étape pour Nvidia dans la promotion de l’intégration du monde physique et de l’IA, fournissant de nouveaux outils et une base de recherche pour des applications telles que la robotique et la conduite autonome, qui nécessitent une interaction avec l’environnement physique. (Source: reach_vb)
Le modèle de génération vidéo de Baidu, Steamer-I2V, en tête du classement VBench pour la génération image-vers-vidéo: Le modèle de génération vidéo de Baidu, Steamer-I2V, s’est classé premier dans la catégorie image-vers-vidéo (I2V) du classement d’évaluation de génération vidéo de référence VBench, avec un score total de 89,38 %, dépassant des modèles renommés tels que Sora d’OpenAI et Imagen Video de Google. Les avantages techniques de Steamer-I2V comprennent un contrôle précis de l’image au niveau du pixel, des mouvements de caméra de qualité professionnelle, une qualité d’image cinématographique haute définition allant jusqu’à 1080P et une esthétique dynamique, ainsi qu’une compréhension sémantique précise du chinois basée sur une base de données multimodale chinoise de plusieurs centaines de millions d’entrées. Ce résultat démontre la force de Baidu dans le domaine de la génération multimodale et fait partie de sa stratégie de construction d’un écosystème de contenu IA. (Source: 36Kr)

Les LLM peinent à lire l’heure sur les horloges et les calendriers: Des chercheurs de l’Université d’Édimbourg et d’autres institutions ont découvert que, bien que les grands modèles de langage (LLM) et les grands modèles de langage multimodaux (MLLM) excellent dans diverses tâches, leur précision est préoccupante pour des tâches de lecture temporelle apparemment simples, comme la reconnaissance de l’heure sur une horloge à aiguilles et la compréhension des dates sur un calendrier. L’étude a construit deux ensembles de tests personnalisés, ClockQA et CalendarQA. Les résultats montrent que la précision des systèmes d’IA pour lire l’heure sur une horloge n’est que de 38,7 %, et pour déterminer la date sur un calendrier, elle n’est que de 26,3 %. Même des modèles avancés comme Gemini-2.0 et GPT-o1 rencontrent des difficultés notables, en particulier pour traiter les chiffres romains, les aiguilles stylisées ou les calculs de dates complexes (comme les années bissextiles ou déterminer le jour de la semaine pour une date spécifique). Les chercheurs estiment que cela révèle les lacunes des modèles actuels en matière de raisonnement spatial, d’analyse de la disposition structurée et de généralisation à des motifs inhabituels. (Source: 36Kr, WeChat)

Microsoft annonce l’intégration du modèle Grok à Azure AI Foundry lors de la conférence Build: Lors de la conférence des développeurs Microsoft Build 2025, Microsoft a annoncé que le modèle Grok de la société xAI rejoindrait sa gamme de modèles Azure AI Foundry. Les utilisateurs pourront essayer gratuitement Grok-3 et Grok-3-mini sur Azure Foundry et GitHub jusqu’à début juin. Cette décision signifie qu’Azure AI Foundry étendra davantage sa gamme de modèles tiers pris en charge, et qu’à l’avenir, les utilisateurs pourront utiliser des modèles de plusieurs fournisseurs tels qu’OpenAI, xAI, DeepSeek, Meta, Mistral AI, Black Forest Labs, via un débit réservé unifié. (Source: TheTuringPost, xai)
Apple prévoirait d’autoriser les utilisateurs d’iPhone de l’UE à remplacer Siri par des assistants vocaux tiers: Selon Mark Gurman, Apple prévoirait pour la première fois d’autoriser les utilisateurs d’iPhone de l’Union européenne à remplacer Siri par des assistants vocaux tiers. Cette mesure pourrait viser à répondre aux exigences réglementaires de plus en plus strictes du marché numérique de l’UE, dans le but d’améliorer l’ouverture de la plateforme et le choix des utilisateurs. Si ce plan est mis en œuvre, il aura un impact important sur le paysage du marché des assistants vocaux, offrant à d’autres assistants vocaux l’opportunité d’entrer dans l’écosystème Apple. (Source: zacharynado)

Meta publie l’ensemble de données Open Molecules 2025 et le modèle UMA pour accélérer la découverte de molécules et de matériaux: Meta AI a publié Open Molecules 2025 (OMol25) et le modèle atomique universel de Meta (UMA). OMol25 est actuellement l’ensemble de données de calculs de chimie quantique de haute précision le plus vaste et le plus diversifié, contenant des biomolécules, des complexes métalliques et des électrolytes. UMA est un modèle de potentiel interatomique basé sur l’apprentissage machine, entraîné sur plus de 30 milliards d’atomes, conçu pour fournir des prédictions plus précises du comportement moléculaire. L’open-sourcing de ces outils vise à accélérer la découverte et l’innovation en science des molécules et des matériaux. (Source: AIatMeta)
Hugging Face Datasets ajoute la fonctionnalité d’édition incrémentielle des fichiers Parquet: Hugging Face Datasets a annoncé que la version nocturne de sa bibliothèque de dépendances sous-jacente, PyArrow, prend désormais en charge l’édition incrémentielle des fichiers Parquet sans avoir à réécrire complètement le fichier. Cette nouvelle fonctionnalité améliorera considérablement l’efficacité des opérations sur les jeux de données à grande échelle, en particulier lorsqu’il est nécessaire de mettre à jour ou de modifier fréquemment des parties de données, ce qui peut réduire considérablement le temps et les ressources de calcul consommés. Cette mesure devrait améliorer l’expérience des développeurs lors du traitement et de la maintenance de grands jeux de données d’entraînement pour l’IA. (Source: huggingface)
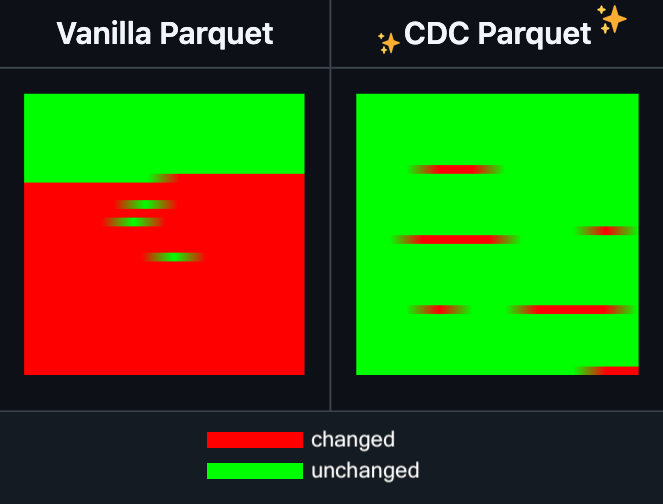
LangGraph ajoute une fonctionnalité de mise en cache au niveau des nœuds, améliorant l’efficacité des workflows: LangGraph a annoncé que sa version open source inclut désormais une fonctionnalité de mise en cache des nœuds/tâches. Cette fonctionnalité vise à accélérer les workflows en évitant les calculs répétitifs, particulièrement utile pour les workflows d’agents contenant des parties communes ou nécessitant un débogage fréquent. Les utilisateurs peuvent utiliser la mise en cache dans l’API impérative ou l’API graphique, permettant ainsi d’itérer et d’optimiser plus rapidement leurs applications IA. Il s’agit de la première d’une série de mises à jour de la version open source de LangGraph cette semaine. (Source: hwchase17)

Sakana AI lance une nouvelle architecture IA : « Continuous Thought Machines » (CTM) : La startup IA de Tokyo, Sakana AI, a publié une nouvelle architecture de modèle IA appelée « Continuous Thought Machines » (CTM). CTM vise à permettre aux modèles de raisonner comme le cerveau humain, avec moins de supervision. Cette nouvelle architecture pourrait offrir de nouvelles pistes pour résoudre les défis actuels auxquels sont confrontés les modèles IA en matière de raisonnement complexe et d’apprentissage autonome. (Source: dl_weekly)
Microsoft et Nvidia approfondissent leur collaboration sur les PC RTX AI, TensorRT arrive sur Windows ML: Lors des événements Microsoft Build et COMPUTEX Taipei, Nvidia et Microsoft ont annoncé une collaboration accrue pour le développement des PC RTX AI. La bibliothèque d’optimisation d’inférence TensorRT de Nvidia a été repensée et intégrée dans la nouvelle pile d’inférence de Microsoft, Windows ML. Cette initiative vise à simplifier le processus de développement d’applications IA et à exploiter pleinement les performances de pointe des GPU RTX pour les tâches IA sur PC, favorisant ainsi la popularisation et l’application de l’IA sur les appareils informatiques personnels. (Source: nvidia)
Bilibili rend open source son modèle de génération de vidéos d’animation Index-AniSora, atteignant des performances SOTA sur plusieurs indicateurs: Bilibili a annoncé l’open-sourcing de son modèle de génération de vidéos d’animation auto-développé, Index-AniSora, présenté à l’IJCAI 2025. AniSora est spécialement conçu pour la génération de vidéos de style anime, prenant en charge divers styles tels que les séries animées japonaises, les productions chinoises et les adaptations de mangas. Il permet un contrôle fin, comme le guidage de régions locales de la vidéo et le guidage temporel (par exemple, guidage par la première/dernière image, interpolation d’images clés). Le projet open source comprend le code d’entraînement et d’inférence pour AniSoraV1.0 basé sur CogVideoX-5B et AniSoraV2.0 basé sur Wan2.1-14B, des outils de construction de jeux de données d’entraînement, un système de benchmark dédié à l’animation, et le modèle AniSoraV1.0_RL optimisé par apprentissage par renforcement basé sur les préférences humaines. (Source: WeChat)

Tencent Hunyuan rend open source le premier modèle de récompense CoT unifié multimodal UnifiedReward-Think: Tencent Hunyuan, en collaboration avec Shanghai AI Lab, l’Université Fudan et d’autres institutions, a proposé UnifiedReward-Think, le premier modèle de récompense multimodal unifié doté de capacités de raisonnement en chaîne longue (CoT). Ce modèle vise à permettre aux modèles de récompense d’« apprendre à penser » lors de l’évaluation de tâches complexes de génération et de compréhension visuelles, améliorant ainsi la précision de l’évaluation, la capacité de généralisation inter-tâches et l’interprétabilité du raisonnement. Le projet a été entièrement rendu open source, y compris le modèle, les ensembles de données, les scripts d’entraînement et les outils d’évaluation. (Source: WeChat)
Alibaba rend open source son modèle de génération et d’édition vidéo Tongyi Wanxiang Wan2.1-VACE: Alibaba a officiellement rendu open source son modèle de génération et d’édition vidéo Tongyi Wanxiang Wan2.1-VACE. Ce modèle dispose de multiples fonctionnalités telles que la génération de vidéo à partir de texte, la génération de vidéo référencée par image, la repeinture vidéo, l’édition locale de vidéo, l’extension de l’arrière-plan vidéo et l’extension de la durée de la vidéo. Deux versions ont été rendues open source cette fois-ci, 1.3B et 14B, la version 1.3B pouvant fonctionner sur des cartes graphiques grand public, visant à abaisser le seuil de la création vidéo AIGC. (Source: WeChat)
ByteDance publie le modèle de langage visuel Seed1.5-VL, en tête de plusieurs benchmarks: ByteDance a construit le modèle de langage visuel Seed1.5-VL, composé d’un encodeur visuel de 532M de paramètres et d’un LLM à mélange d’experts (MoE) de 20B de paramètres actifs. Malgré une architecture relativement compacte, il atteint des performances SOTA sur 38 des 60 benchmarks publics et surpasse des modèles tels qu’OpenAI CUA et Claude 3.7 sur des tâches centrées sur l’agent comme le contrôle d’interface graphique et le gameplay, démontrant de solides capacités de raisonnement multimodal. (Source: WeChat)
MiniMax lance le modèle TTS autorégressif MiniMax-Speech, prenant en charge le clonage vocal zero-shot dans 32 langues: MiniMax a proposé MiniMax-Speech, un modèle de synthèse vocale (TTS) autorégressif basé sur Transformer. Ce modèle peut extraire les caractéristiques du timbre vocal à partir d’un audio de référence sans transcription, réalisant une génération vocale zero-shot cohérente avec le timbre de référence et expressive, et prenant en charge le clonage vocal one-shot. La technologie Flow-VAE améliore la qualité de l’audio synthétisé, et le modèle prend en charge 32 langues. Il atteint des performances SOTA sur les indicateurs objectifs de clonage vocal, se classe en tête du classement public TTS Arena, et peut être étendu à des applications telles que le contrôle de l’émotion vocale, la synthèse texte-son et le clonage vocal professionnel. (Source: WeChat)
OuteTTS 1.0 (0.6B) publié, un modèle TTS open source Apache 2.0 prenant en charge 14 langues: OuteAI a publié OuteTTS-1.0-0.6B, un modèle de synthèse vocale (TTS) léger construit sur Qwen-3 0.6B. Ce modèle utilise la licence Apache 2.0 et prend en charge 14 langues, dont le chinois, l’anglais, le japonais et le coréen. Sa bibliothèque d’inférence Python OuteTTS v0.4.2 prend désormais en charge l’inférence par lots asynchrone EXL2, l’inférence par lots expérimentale vLLM, ainsi que le traitement par lots continu et l’inférence de modèles URL externes pour le serveur Llama.cpp. Les tests de performance sur un seul GPU NVIDIA L40S montrent que vLLM OuteTTS-1.0-0.6B FP8 peut atteindre un RTF (facteur temps réel) de 0,05 avec une taille de lot de 32. Les poids du modèle (ST, GGUF, EXL2, FP8) sont disponibles sur Hugging Face. (Source: Reddit r/LocalLLaMA)

Hugging Face et Microsoft Azure approfondissent leur collaboration, plus de 10 000 modèles open source arrivent sur Azure AI Foundry: Lors de la conférence Microsoft Build, le PDG Satya Nadella a annoncé une collaboration élargie avec Hugging Face. Actuellement, plus de 11 000 des modèles open source les plus populaires sont disponibles via Hugging Face sur Azure AI Foundry, facilitant leur déploiement par les utilisateurs. Cette initiative enrichit davantage l’écosystème IA d’Azure, offrant aux développeurs plus de choix de modèles et une expérience de développement plus pratique. (Source: ClementDelangue, _akhaliq)

Intel lance les GPU Arc Pro séries B50/B60, ciblant les marchés de l’IA et des stations de travail, version 24 Go à environ 500 $: Intel a lancé au Computex ses nouvelles cartes graphiques professionnelles Arc Pro série B, comprenant l’Arc Pro B50 (16 Go de VRAM, environ 299 $) et l’Arc Pro B60 (24 Go de VRAM, environ 500 $). Parmi celles-ci, une solution de station de travail « Project Battlematrix » composée de deux GPU B60 avec 48 Go de VRAM a également été présentée, avec un prix attendu inférieur à 1000 $. Ces produits visent à fournir des solutions rentables pour le calcul IA et les stations de travail professionnelles, en particulier la configuration à haute VRAM est attrayante pour l’exécution locale de grands modèles de langage. Les nouveaux produits devraient être lancés au troisième trimestre de cette année, initialement via les fabricants OEM, avec une éventuelle version DIY au quatrième trimestre. (Source: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)

🧰 Outils
Moondream Station publie une version Linux, simplifiant l’exécution locale de Moondream: Moondream Station, un outil conçu pour simplifier l’exécution de Moondream (un modèle de langage visuel) sur des appareils locaux, a annoncé la prise en charge du système d’exploitation Linux. Cela signifie que les utilisateurs de Linux peuvent déployer et utiliser plus facilement les modèles Moondream pour des expériences d’IA multimodales et le développement d’applications. (Source: vikhyatk)
Flowith lance l’agent intelligent infini NEO, prenant en charge un nombre illimité d’étapes, de contexte et d’appels d’outils: La société d’applications IA Flowith a lancé son dernier produit agent, NEO, présenté comme le premier agent au monde prenant en charge un nombre illimité d’étapes, un contexte illimité et des appels d’outils illimités. Cet agent est conçu pour fonctionner longtemps dans le cloud, possède un niveau d’intelligence dépassant les benchmarks, et est annoncé comme étant sans coût et sans restriction. Ce lancement pourrait représenter une nouvelle avancée pour les agents IA dans la gestion de tâches complexes à long terme et l’intégration de capacités externes. (Source: _akhaliq, op7418)

Kapa AI utilise Weaviate pour créer « Ask AI », un outil interactif de questions-réponses sur la documentation technique: Kapa AI a développé un widget intelligent nommé « Ask AI », permettant aux utilisateurs d’interroger l’ensemble de leur base de connaissances techniques (documentation, blogs, tutoriels, issues GitHub, forums, etc.) par le biais d’un dialogue en langage naturel. Pour une recherche sémantique et une récupération de connaissances efficaces, Kapa AI a adopté la base de données vectorielle Weaviate, appréciant sa capacité de recherche hybride intégrée, sa compatibilité Docker et ses fonctionnalités multi-tenant pour soutenir une croissance rapide du nombre d’utilisateurs et du volume de données. (Source: bobvanluijt)

Un développeur utilise Gemini Flash pour créer rapidement un outil MVP convertissant des captures d’écran en HTML: Le développeur Daniel Huynh a utilisé le modèle Gemini Flash de Google AI pour construire en un week-end un outil MVP (Produit Minimum Viable) capable de convertir rapidement des maquettes de design, des captures d’écran de concurrents ou d’inspiration en code HTML. L’outil est disponible gratuitement à l’essai sur Hugging Face Spaces, démontrant le potentiel des modèles multimodaux pour l’assistance au développement front-end. (Source: osanseviero, _akhaliq)
Azure AI Foundry Agent Service est officiellement disponible, avec intégration de LlamaIndex: Microsoft a annoncé que Azure AI Foundry Agent Service est officiellement disponible (GA) et offre un support de premier ordre pour LlamaIndex. Ce service vise à aider les entreprises clientes à construire des assistants de support client, des robots d’automatisation de processus, des systèmes multi-agents, ainsi que des solutions intégrées de manière sécurisée avec les données et outils de l’entreprise, favorisant ainsi le développement et l’application d’agents IA au niveau de l’entreprise. (Source: jerryjliu0)
tinygrad : un framework de deep learning minimaliste entre PyTorch et micrograd: tinygrad est un framework de deep learning conçu avec la simplicité comme philosophie centrale, visant à être le framework le plus facile pour ajouter de nouveaux accélérateurs, prenant en charge l’inférence et l’entraînement. Il supporte des modèles tels que LLaMA et Stable Diffusion, et utilise l’évaluation paresseuse (lazy evaluation) pour fusionner les opérations et optimiser les performances. tinygrad prend en charge divers accélérateurs, notamment GPU (OpenCL), CPU (code C), LLVM, Metal, CUDA. Son code est concis, les fonctionnalités principales étant implémentées avec peu de lignes de code, ce qui facilite la compréhension et l’extension par les développeurs. (Source: GitHub Trending)
Nano AI Search lance la fonction « Super Search », intégrant plusieurs modèles et la boîte à outils MCP: Nano AI Search (bot.n.cn) a ajouté une fonction « Super Search », visant à fournir des capacités d’acquisition et de traitement d’informations plus approfondies. Cette fonction intègre des centaines de grands modèles nationaux et internationaux, et peut basculer automatiquement selon les besoins ; elle intègre la boîte à outils universelle MCP, prenant en charge des milliers d’outils IA, capable de traiter des pages web, des images, des vidéos, des PDF et d’autres formats de fichiers, et d’effectuer la génération de code, l’analyse de données, etc. Elle combine également la recherche publique avec la recherche privée dans les bases de connaissances locales pour fournir des résultats plus complets, et intègre des capacités de génération de texte en image et de texte en vidéo. L’expérience utilisateur montre que cette fonction peut organiser les résultats de recherche en rapports détaillés contenant des graphiques et des pages web attrayantes, adaptés à divers scénarios tels que la recherche sectorielle, la comparaison d’achats et la structuration des connaissances. (Source: WeChat)
Clara : un espace de travail IA modulaire et hors ligne, intégrant LLM, Agents, automatisation et génération d’images: Des développeurs ont lancé un projet open source nommé Clara, visant à créer un espace de travail IA entièrement hors ligne et modulaire. Les utilisateurs peuvent organiser sur un tableau de bord, sous forme de widgets, des chats LLM locaux (prenant en charge RAG, images, documents, exécution de code, compatible avec Ollama et les API de type OpenAI), créer des Agents avec mémoire et logique, exécuter des processus d’automatisation via l’intégration native de N8N (offrant plus de 1000 modèles gratuits), et générer des images localement avec Stable Diffusion (ComfyUI). Clara est disponible pour Mac, Windows et Linux, et vise à résoudre le problème des utilisateurs qui basculent fréquemment entre plusieurs outils IA, en permettant une exploitation IA centralisée. (Source: Reddit r/LocalLLaMA)
AI Playlist Curator : un outil Python utilisant des LLM pour organiser de manière personnalisée les playlists YouTube: Un développeur a créé un projet Python nommé AI Playlist Curator, visant à aider les utilisateurs à organiser automatiquement leurs playlists YouTube volumineuses et désordonnées. Cet outil utilise des LLM pour classer les chansons selon les préférences de l’utilisateur et créer des sous-playlists personnalisées, prenant en charge le traitement de toutes les playlists enregistrées et des chansons aimées. Le projet est open source sur GitHub, et le développeur espère recevoir des retours de la communauté pour l’améliorer davantage. (Source: Reddit r/MachineLearning)
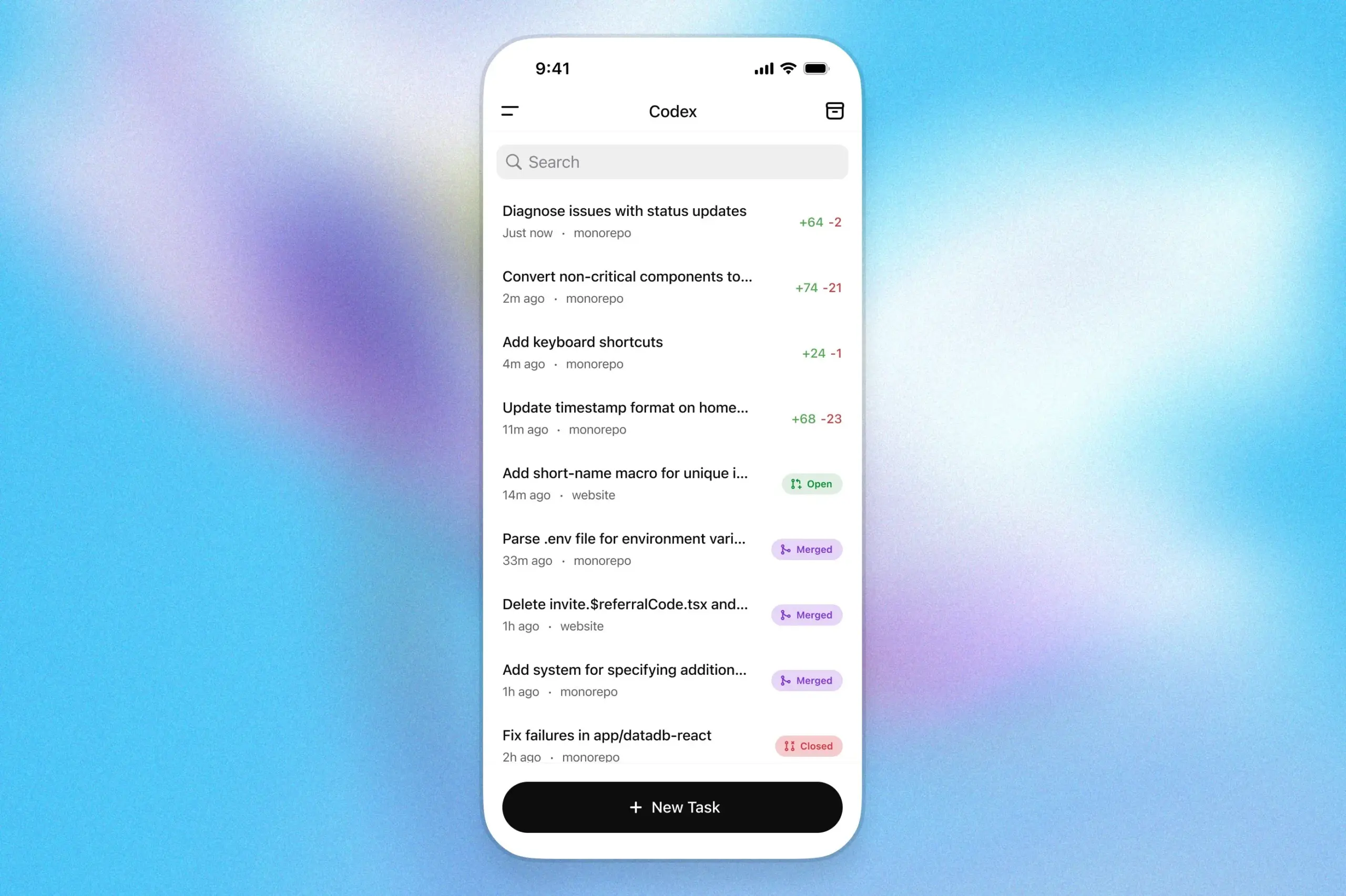
L’assistant de programmation OpenAI Codex arrive sur l’application ChatGPT iOS: OpenAI a annoncé que son assistant de programmation Codex est désormais intégré à l’application ChatGPT pour iOS. Les utilisateurs peuvent lancer de nouvelles tâches de programmation, visualiser les différences de code, demander des modifications et même soumettre des pull requests (PR) depuis leur appareil mobile. La fonctionnalité prend également en charge le suivi en temps réel de la progression de Codex via les activités de l’écran de verrouillage, permettant aux utilisateurs de basculer de manière transparente entre différents appareils. (Source: openai)
Kollektiv : un outil utilisant le protocole MCP pour résoudre le problème du copier-coller répétitif de contexte dans les chats LLM: Des développeurs ont lancé l’outil Kollektiv, visant à résoudre le problème des utilisateurs qui doivent copier-coller à plusieurs reprises de grandes quantités de contexte (comme des articles de recherche, de la documentation SDK, des notes personnelles, du contenu de livres) lorsqu’ils discutent avec des LLM (comme Claude). Kollektiv permet aux utilisateurs de télécharger ces sources de documents une seule fois et de les appeler à la demande depuis n’importe quel IDE compatible ou client MCP (comme Cursor, Windsurf, PyCharm, etc.) via un serveur MCP (Model Control Protocol). Le serveur MCP est responsable de l’authentification des utilisateurs, de l’isolation des données et de la diffusion des données à la demande vers l’interface de chat. L’outil n’est actuellement pas recommandé pour les documents sensibles ou confidentiels. (Source: Reddit r/ClaudeAI)
📚 Apprentissage
Google DeepMind publie un rapport technique sur AlphaEvolve, révélant ses capacités de découverte d’algorithmes: Google DeepMind a publié un rapport technique sur son système d’IA AlphaEvolve. AlphaEvolve est un agent de codage basé sur Gemini, capable de concevoir et d’optimiser des algorithmes grâce à des algorithmes évolutifs. Le rapport détaille comment AlphaEvolve génère, évalue et améliore de manière autonome des solutions algorithmiques candidates grâce à une boucle de rétroaction structurée, réalisant ainsi des percées sur plusieurs problèmes mathématiques et de science computationnelle, y compris l’amélioration du record de l’algorithme de multiplication de matrices complexes 4×4. Ce rapport constitue une référence importante pour comprendre le potentiel de l’IA dans la découverte scientifique automatisée et l’innovation algorithmique. (Source: , HuggingFace Daily Papers)
DeepLearning.AI lance le cours « Building AI Browser Agents »: DeepLearning.AI a mis en ligne un nouveau cours intitulé « Building AI Browser Agents ». Ce cours, dispensé par Div Garg et Naman Agarwal, co-fondateurs d’AGI, vise à aider les apprenants à maîtriser les techniques de construction d’agents IA capables d’interagir avec les navigateurs. Le contenu du cours pourrait couvrir l’automatisation web, l’extraction d’informations, l’interaction avec les interfaces utilisateur et d’autres applications de l’IA dans l’environnement du navigateur. (Source: DeepLearningAI)
Publication du rapport technique de Qwen3: Alibaba a publié le rapport technique de sa dernière génération de grands modèles de langage, Qwen3. Ce rapport détaille l’architecture du modèle Qwen3, les méthodes d’entraînement, l’évaluation des performances et ses résultats sur divers benchmarks. La série de modèles Qwen3 vise à fournir des capacités améliorées de compréhension du langage, de génération et de traitement multimodal. La publication de son rapport technique offre aux chercheurs et aux développeurs l’occasion de comprendre en profondeur les détails techniques de ce modèle. (Source: _akhaliq)

Séminaire de recherche : La recherche multi-vues et la gestion des données améliorent la démonstration progressive de théorèmes (MPS-Prover): Un nouvel article présente MPS-Prover, un nouveau système de démonstration automatisée progressive de théorèmes (ATP). Ce système surmonte le problème de guidage de recherche biaisé dans les démonstrateurs progressifs existants grâce à une stratégie efficace de gestion des données post-entraînement (élagage d’environ 40 % des données redondantes sans sacrifier les performances) et à un mécanisme de recherche arborescente multi-vues (intégrant un modèle critique appris et des règles heuristiques). Les expériences montrent que MPS-Prover atteint des performances SOTA sur plusieurs benchmarks tels que miniF2F et ProofNet, générant des preuves plus courtes et plus diversifiées. (Source: HuggingFace Daily Papers)
Séminaire de recherche : Planification visuelle – Penser uniquement avec des images (Visual Planning): Un nouvel article propose le paradigme de la « planification visuelle », permettant aux modèles de planifier entièrement par le biais de représentations visuelles (séquences d’images), plutôt que de s’appuyer sur du texte. Les chercheurs estiment que dans les tâches impliquant des informations spatiales et géométriques, le langage n’est peut-être pas le support de raisonnement le plus naturel. Ils introduisent le cadre de planification visuelle par apprentissage par renforcement VPRL, et utilisent GRPO pour l’optimisation post-entraînement de grands modèles visuels, obtenant des améliorations significatives dans des tâches de navigation visuelle telles que FrozenLake, Maze et MiniBehavior, surpassant les variantes de planification basées sur un raisonnement purement textuel. (Source: HuggingFace Daily Papers)
Séminaire de recherche : L’extension du raisonnement peut améliorer la factualité des grands modèles de langage (Scaling Reasoning can Improve Factuality): Une étude explore si l’extension du processus de raisonnement des grands modèles de langage (LLM) peut améliorer leur exactitude factuelle dans les questions-réponses complexes en domaine ouvert (QA). Les chercheurs ont extrait des trajectoires de raisonnement de modèles tels que QwQ-32B et DeepSeek-R1-671B, et ont affiné plusieurs modèles de la série Qwen2.5, tout en intégrant des chemins de graphes de connaissances dans les trajectoires de raisonnement. Les expériences montrent que, lors d’une seule exécution, les modèles de raisonnement plus petits présentent une amélioration notable de l’exactitude factuelle par rapport aux modèles originaux affinés par instruction. En augmentant le calcul au moment du test et le budget en tokens, l’exactitude factuelle peut être améliorée de manière stable de 2 à 8 %. (Source: HuggingFace Daily Papers)
Séminaire de recherche : Mergenetic – une bibliothèque simple de fusion de modèles évolutifs: Un nouvel article présente Mergenetic, une bibliothèque open source pour la fusion évolutive de modèles. La fusion de modèles permet de combiner les capacités de modèles existants en de nouveaux modèles, sans entraînement supplémentaire. Mergenetic prend en charge la combinaison facile de méthodes de fusion et d’algorithmes évolutifs, et intègre des évaluateurs de fitness légers pour réduire les coûts d’évaluation. Les expériences prouvent que Mergenetic produit des résultats compétitifs sur diverses tâches et langues en utilisant un matériel modeste. (Source: HuggingFace Daily Papers)
Séminaire de recherche : Pensée de groupe – Plusieurs agents de raisonnement concurrents collaborant au niveau du token (Group Think): Un nouvel article propose la « pensée de groupe » (Group Think) – faire en sorte qu’un seul LLM agisse comme plusieurs agents de raisonnement concurrents (penseurs). Ces agents partagent la visibilité sur la progression partielle des générations des autres, s’adaptant dynamiquement aux trajectoires de raisonnement des uns et des autres au niveau du token, réduisant ainsi le raisonnement redondant, améliorant la qualité et diminuant la latence. Cette méthode est adaptée à l’inférence en périphérie sur des GPU locaux, et les expériences prouvent qu’elle améliore également la latence lors de l’utilisation de LLM open source non spécifiquement entraînés. (Source: HuggingFace Daily Papers)
Séminaire de recherche : Les humains attendent rationalité et coopération de la part d’adversaires LLM dans les jeux stratégiques (Humans expect rationality and cooperation from LLM opponents): Une première expérience de laboratoire contrôlée avec incitations monétaires a étudié les différences de comportement humain dans des concours P-beauty multi-joueurs, opposant des humains à d’autres humains et à des LLM. Les résultats montrent que les humains choisissent des nombres significativement plus bas lorsqu’ils affrontent des LLM, principalement en raison d’une augmentation de la prévalence du choix de l’équilibre de Nash « zéro ». Ce changement est principalement observé chez les sujets dotés de capacités de raisonnement stratégique élevées, qui perçoivent les LLM comme ayant des capacités de raisonnement et des tendances coopératives plus fortes. (Source: HuggingFace Daily Papers)
Séminaire de recherche : Distillation de connaissances semi-supervisée simple à partir de modèles de langage visuel via une optimisation à double tête (Dual-Head Optimization for KD): Un nouvel article propose DHO (Dual-Head Optimization), un cadre de distillation de connaissances (KD) simple et efficace pour transférer les connaissances de modèles de langage visuel (VLM) vers des modèles compacts spécifiques à une tâche dans un cadre semi-supervisé. DHO introduit deux têtes de prédiction apprenant indépendamment les données étiquetées et les prédictions de l’enseignant, et combine linéairement leurs sorties lors de l’inférence, atténuant ainsi le conflit de gradient entre le signal de supervision et le signal de distillation. Les expériences montrent que DHO surpasse les lignes de base KD à tête unique sur plusieurs domaines et ensembles de données à grain fin, atteignant des performances SOTA sur ImageNet. (Source: HuggingFace Daily Papers)
Séminaire de recherche : GuardReasoner-VL – Protéger les VLM par un raisonnement renforcé: Pour améliorer la sécurité des modèles de langage visuel (VLM), un nouvel article introduit GuardReasoner-VL, un modèle de protection VLM basé sur le raisonnement. L’idée centrale est d’inciter le modèle de protection à un raisonnement prudent avant de prendre des décisions de modération, via un apprentissage par renforcement (RL) en ligne. Les chercheurs ont construit un corpus de raisonnement, GuardReasoner-VLTrain, contenant 123K échantillons et 631K étapes de raisonnement. Ils ont initialisé les capacités de raisonnement du modèle par affinage supervisé (SFT), puis les ont encore améliorées par RL en ligne. Les expériences montrent que ce modèle (versions 3B/7B rendues open source) offre des performances supérieures, surpassant le deuxième meilleur modèle de 19,27 % en score F1 moyen. (Source: HuggingFace Daily Papers)
Séminaire de recherche : La prédiction multi-tokens nécessite des registres (Multi-Token Prediction Needs Registers): Un nouvel article propose MuToR, une méthode simple et efficace de prédiction multi-tokens, qui prédit les cibles futures en insérant de manière entrelacée des tokens de registre apprenables dans la séquence d’entrée. Comparé aux méthodes existantes, MuToR n’ajoute qu’un nombre négligeable de paramètres, ne nécessite aucune modification architecturale, est compatible avec les modèles pré-entraînés existants et reste cohérent avec l’objectif de pré-entraînement du token suivant, ce qui le rend particulièrement adapté à l’affinage supervisé. Cette méthode démontre son efficacité et sa généralité dans les tâches de génération dans les domaines du langage et de la vision. (Source: HuggingFace Daily Papers)
Séminaire de recherche : MMLongBench – Un benchmark efficace et complet pour les modèles de langage visuel à long contexte: Pour répondre aux besoins d’évaluation des modèles de langage visuel à long contexte (LCVLM), un nouvel article introduit MMLongBench, le premier benchmark couvrant une variété de tâches de langage visuel à long contexte. MMLongBench contient 13331 échantillons, couvrant cinq catégories de tâches telles que le RAG visuel et l’ICL multi-échantillons, et propose divers types d’images. Tous les échantillons sont fournis dans cinq longueurs d’entrée normalisées de 8K à 128K tokens. En testant 46 LCVLM open source et fermés, l’étude a révélé que les performances sur une seule tâche ne sont pas représentatives de la capacité globale à long contexte, que les modèles actuels ont encore une grande marge d’amélioration, et que les modèles dotés de fortes capacités de raisonnement ont tendance à mieux performer sur les longs contextes. (Source: HuggingFace Daily Papers)
Séminaire de recherche : MatTools – Un benchmark de grands modèles de langage pour les outils en science des matériaux: Un nouvel article propose le benchmark MatTools pour évaluer la capacité des grands modèles de langage (LLM) à répondre à des questions de science des matériaux en générant et en exécutant de manière sécurisée du code pour des logiciels de science des matériaux computationnelle basés sur la physique. MatTools comprend un benchmark de questions-réponses sur les outils de simulation de matériaux (basé sur pymatgen, avec 69225 paires QA) et un benchmark d’utilisation d’outils en situation réelle (avec 49 tâches, 138 sous-tâches). L’évaluation de plusieurs LLM révèle que : les modèles généralistes surpassent les modèles spécialisés ; l’IA comprend mieux l’IA ; les méthodes simples sont plus efficaces. (Source: HuggingFace Daily Papers)
Séminaire de recherche : Un cadre de watermarking symbiotique universel équilibrant la robustesse, la qualité du texte et la sécurité du watermarking des LLM: Face au compromis existant entre robustesse, qualité du texte et sécurité dans les schémas de watermarking actuels pour les grands modèles de langage (LLM), un nouvel article propose un cadre de watermarking symbiotique universel. Ce cadre intègre des méthodes basées sur les logits et sur l’échantillonnage, et conçoit trois stratégies : série, parallèle et mixte. Le cadre mixte utilise l’entropie des tokens et l’entropie sémantique pour intégrer de manière adaptative le watermark, visant à optimiser les performances sous tous les aspects. Les expériences montrent que cette méthode surpasse les lignes de base existantes et atteint des performances SOTA. (Source: HuggingFace Daily Papers)
Séminaire de recherche : CheXGenBench – Un benchmark unifié pour la fidélité, la confidentialité et l’utilité des radiographies thoraciques synthétiques: Un nouvel article présente CheXGenBench, un cadre multifacette pour évaluer la génération de radiographies thoraciques synthétiques, évaluant simultanément la fidélité, les risques pour la vie privée et l’utilité clinique. Ce cadre comprend des partitions de données standardisées et un protocole d’évaluation unifié (plus de 20 indicateurs quantitatifs), analysant la qualité de génération, les vulnérabilités potentielles en matière de confidentialité et l’applicabilité clinique en aval de 11 architectures texte-image de premier plan. L’étude a révélé que les protocoles d’évaluation existants présentent des lacunes dans l’évaluation de la fidélité de la génération. L’équipe a également publié un ensemble de données synthétiques de haute qualité, SynthCheX-75K. (Source: HuggingFace Daily Papers)
Peter Lax, auteur du manuel classique « Analyse Fonctionnelle », décède à 99 ans: Peter Lax, géant des mathématiques appliquées et premier mathématicien appliqué à recevoir le prix Abel, est décédé à l’âge de 99 ans. Lax était célèbre pour son manuel classique « Analyse Fonctionnelle » et a apporté des contributions fondamentales dans les domaines des équations aux dérivées partielles, de la dynamique des fluides, du calcul numérique, etc., comme le théorème d’équivalence de Lax, les méthodes de Lax-Friedrichs et de Lax-Wendroff. Il fut également l’un des pionniers de l’application des techniques informatiques à l’analyse mathématique, et son travail a profondément influencé le développement des mathématiques à l’ère de l’informatique. (Source: QubitAI)

Lilian Weng, ancienne vice-présidente d’OpenAI, publie un long article « Why We Think », explorant le calcul au moment du test et la chaîne de pensée: Lilian Weng, ancienne vice-présidente d’OpenAI, a publié un long article de dix mille mots intitulé « Why We Think », explorant en profondeur comment des techniques telles que le « calcul au moment du test » (Test-time Compute) et la « chaîne de pensée » (Chain-of-Thought, CoT) améliorent considérablement les performances et le niveau d’intelligence des grands modèles de langage. L’article établit une analogie avec la théorie du double système de pensée « rapide et lente » chez l’humain, soulignant que permettre aux modèles de « réfléchir » davantage avant de produire une sortie (par exemple, via un décodage intelligent, un raisonnement CoT, une modélisation à variables latentes, etc.) peut surmonter les goulots d’étranglement actuels des capacités. L’article passe en revue en détail les progrès et les défis dans plusieurs directions de recherche, notamment la pensée basée sur les tokens, l’échantillonnage parallèle et la révision séquentielle, l’apprentissage par renforcement et l’intégration d’outils externes, la fidélité de la pensée et la pensée en espace continu. (Source: QubitAI)

HIT et UPenn lancent conjointement PointKAN, un nouveau SOTA pour l’analyse de nuages de points basé sur les KANs: Des équipes de recherche de l’Institut de Technologie de Harbin (Shenzhen) et de l’Université de Pennsylvanie ont lancé PointKAN, une solution d’analyse de nuages de points 3D basée sur les Kolmogorov-Arnold Networks (KANs). Cette méthode utilise un module affine géométrique et un module d’extraction de caractéristiques locales parallèles, et remplace les fonctions d’activation fixes des MLP traditionnels par des fonctions d’activation apprenables pour capturer plus efficacement les caractéristiques géométriques complexes des nuages de points. Simultanément, l’équipe a proposé la structure Efficient-KANs, qui remplace les fonctions B-spline par des fonctions rationnelles et effectue un partage de paramètres intra-groupe, réduisant considérablement le nombre de paramètres et les coûts de calcul. Les expériences montrent que PointKAN et sa version allégée PointKAN-elite obtiennent des performances SOTA ou compétitives dans des tâches telles que la classification, la segmentation partielle et l’apprentissage few-shot. (Source: WeChat)

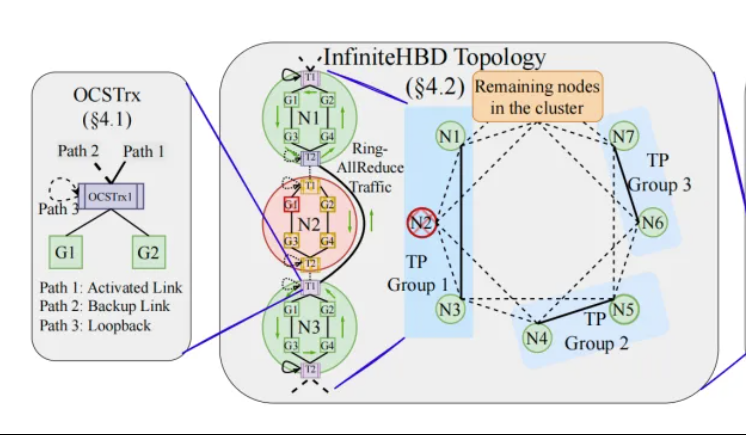
Pékin/Step/Enflame proposent InfiniteHBD : une architecture d’interconnexion GPU à haut débit de nouvelle génération, réduisant les coûts d’entraînement des grands modèles: Des équipes de recherche de l’Université de Pékin, StepStar et Enflame Technology ont proposé la solution InfiniteHBD pour pallier les limitations des architectures actuelles de domaine à haut débit (HBD) dans l’entraînement distribué de grands modèles. Cette architecture, centrée sur un module de conversion optoélectronique intégrant des capacités de commutation de chemin optique (OCS), permet des connexions point-à-multipoint dynamiquement reconfigurables, avec une isolation des pannes au niveau du nœud et une faible fragmentation des ressources. L’étude montre que le coût unitaire d’InfiniteHBD n’est que de 31 % de celui du NVIDIA NVL-72, avec un taux de gaspillage de GPU proche de zéro et une MFU (utilisation des FLOPs du modèle) jusqu’à 3,37 fois supérieure à celle du NVIDIA DGX. Cette recherche a été acceptée par SIGCOMM 2025. (Source: WeChat, QubitAI)
Aperçu des articles de l’ICML 2025 : OmniAudio génère de l’audio spatial à partir de vidéos à 360°: Une recherche qui sera présentée à l’ICML 2025 propose le cadre OmniAudio, capable de générer directement de l’audio spatial ambisonique de premier ordre (FOA) avec une sensation directionnelle à partir de vidéos panoramiques à 360°. L’étude a d’abord construit un vaste ensemble de données appariées de vidéos à 360° et d’audio spatial, Sphere360. OmniAudio adopte un entraînement en deux étapes : d’abord un pré-entraînement auto-supervisé de correspondance de flux grossier à fin, utilisant des données audio non spatiales à grande échelle pour apprendre des caractéristiques audio générales ; puis un affinage supervisé combiné à un encodeur vidéo à double branche (extrayant les caractéristiques visuelles globales et locales). Les résultats expérimentaux montrent qu’OmniAudio surpasse de manière significative les modèles de base existants sur les indicateurs d’évaluation objectifs et subjectifs. (Source: WeChat)

Huawei Selftok : un tokeniseur visuel autorégressif basé sur la diffusion inverse, unifiant la génération multimodale: L’équipe de génération multimodale Pangu de Huawei a proposé la technologie Selftok, une solution innovante de tokenisation visuelle qui intègre un a priori autorégressif dans les tokens visuels via un processus de diffusion inverse. Cela permet de transformer le flux de pixels en une séquence discrète suivant strictement une loi de causalité, visant à résoudre le problème du conflit entre les schémas de tokens spatiaux existants et le paradigme autorégressif (AR). Le Tokenizer Selftok utilise un encodeur à double flux (la branche image hérite du VAE de SD3, la branche texte est un groupe de vecteurs continus apprenables) et un quantificateur avec un mécanisme de réactivation. Les expériences montrent que Selftok atteint des performances SOTA sur les indicateurs de reconstruction ImageNet, et que le Selftok dAR-VLM entraîné sur l’IA Ascend et le framework MindSpeed surpasse GPT-4o sur des benchmarks de génération texte-image tels que GenEval. Ce travail a été sélectionné comme candidat au meilleur article de CVPR 2025. (Source: WeChat)
L’équipe de Yan Shuicheng publie le cadre d’évaluation General-Level et le benchmark General-Bench, classifiant les modèles multimodaux généralistes: Dirigée par le professeur Yan Shuicheng de l’Université Nationale de Singapour et le professeur Zhang Hanwang de l’Université Technologique de Nanyang, entre autres, dix grandes universités ont conjointement publié le cadre d’évaluation General-Level et l’ensemble de données de benchmark à grande échelle General-Bench pour les modèles multimodaux généralistes. Ce cadre, s’inspirant de la classification de la conduite autonome, établit cinq niveaux (Level 1-5) pour évaluer la généralité et les performances des grands modèles de langage multimodaux (MLLM). Le critère d’évaluation principal est l’« effet de généralisation synergique » (Synergy), examinant la capacité du modèle à transférer et à améliorer les connaissances entre les tâches, entre les paradigmes de compréhension et de génération, et entre les modalités. General-Bench comprend plus de 700 tâches et 320 000 échantillons. L’évaluation de plus de 100 MLLM existants montre que la plupart des modèles se situent aux niveaux L2-L3, et qu’aucun modèle n’atteint encore le niveau L5. (Source: WeChat)

💼 Affaires
Sakana AI et Mitsubishi UFJ Bank (MUFG) concluent un partenariat pluriannuel: La startup japonaise d’IA Sakana AI a annoncé la signature d’un accord de partenariat global pluriannuel avec la plus grande banque du Japon, MUFG Bank. Sakana AI fournira à MUFG Bank une technologie IA agile et robuste, visant à aider cette banque centenaire à rester compétitive dans le domaine de l’IA en pleine évolution. Cette collaboration devrait permettre à Sakana AI d’atteindre la rentabilité d’ici un an. (Source: SakanaAILabs, SakanaAILabs)

Cohere s’associe à Dell pour intégrer sa plateforme d’agents intelligents sécurisée Cohere North aux solutions IA d’entreprise localisées de Dell: La société d’IA Cohere a annoncé un partenariat avec Dell Technologies pour accélérer les solutions IA d’entreprise sécurisées et dotées de capacités d’agents. Dell deviendra le premier fournisseur à proposer aux entreprises un déploiement localisé (on-premises) de la plateforme d’agents intelligents sécurisée de Cohere, Cohere North. Cette collaboration est particulièrement cruciale pour les secteurs traitant des données sensibles et soumis à des exigences de conformité strictes, permettant aux entreprises de déployer et d’exécuter la technologie avancée d’agents IA de Cohere au sein de leurs propres centres de données. (Source: sarahookr)

Mistral AI s’associe à MGX et Bpifrance pour construire le plus grand campus IA d’Europe en France: Mistral AI a annoncé un partenariat avec MGX, une société d’investissement technologique soutenue par Abu Dhabi, et Bpifrance, la banque publique d’investissement française, pour construire conjointement le plus grand campus IA d’Europe en région parisienne. Ce campus intégrera des centres de données, des ressources de calcul haute performance, ainsi que des installations d’enseignement et de recherche. Nvidia participera également en fournissant un soutien technique. Cette initiative vise à promouvoir le développement de l’écosystème IA européen et à renforcer la position stratégique de la France dans le domaine de l’IA au niveau mondial. (Source: arthurmensch, arthurmensch)
🌟 Communauté
La prévalence du ADHD chez les professionnels de l’IA suscite l’attention, elle pourrait dépasser 20-30%: Des discussions sur les réseaux sociaux ont émergé concernant la prévalence du trouble du déficit de l’attention avec ou sans hyperactivité (ADHD) chez les professionnels du secteur de l’IA. Un utilisateur a observé que ce domaine semble attirer de nombreux talents présentant des caractéristiques de neurodiversité. Minh Nhat Nguyen a commenté que plus de 20-30% des personnes travaillant dans l’industrie de l’IA pourraient souffrir de ADHD. Ce phénomène pourrait être lié aux exigences du travail de recherche et développement en IA, qui demandent une concentration intense, des itérations rapides et une pensée créative, des traits qui coïncident parfois avec certaines manifestations du ADHD. (Source: Dorialexander)
La dévaluation des compétences à l’ère de l’IA suscite la réflexion, la restructuration des systèmes plutôt que la maîtrise des outils est essentielle: Un article d’analyse approfondie souligne que la véritable crise de l’ère de l’IA n’est pas de « savoir ou non utiliser les outils IA », mais la dévaluation des compétences elles-mêmes et la restructuration de l’ensemble du système de travail. L’article, à travers des exemples tels que la ligne Maginot, la conteneurisation, et le remplacement des dactylographes par les traitements de texte, démontre que le simple apprentissage de nouveaux outils ne garantit pas de rester en tête. L’essentiel est de comprendre comment l’IA modifie la structure, les processus et la logique organisationnelle du travail. Lorsque le système est réécrit, les compétences autrefois très valorisées peuvent rapidement devenir marginales. L’augmentation de la productivité n’entraîne pas nécessairement une augmentation de la valeur individuelle, car la valeur afflue vers ceux qui contrôlent la couche de coordination du nouveau système. L’article réfute huit idées fausses populaires, telles que « apprendre l’IA permet de prendre de l’avance », « l’IA me fait travailler plus donc j’ai plus de valeur », et « les postes de travail ne changent pas, seule la manière de travailler change », soulignant la nécessité de réfléchir à son positionnement et à sa valeur au niveau du système. (Source: 36Kr)
L’ancien PDG de Google, Eric Schmidt : L’émergence d’une intelligence non humaine va remodeler l’ordre mondial, il faut se méfier des risques et des défis de l’IA: L’ancien PDG de Google, Eric Schmidt, a averti dans une interview exclusive que la société sous-estime gravement le potentiel disruptif de l’« intelligence non humaine ». Il estime que l’IA est passée de la génération de langage à la prise de décision stratégique, capable d’accomplir des tâches complexes de manière indépendante. Schmidt a souligné les trois principaux défis posés par l’IA : les goulots d’étranglement en matière d’énergie et de puissance de calcul (les États-Unis ont besoin de 90 gigawatts d’électricité supplémentaires), l’épuisement imminent des données publiques (la prochaine étape nécessitera des données générées par l’IA), et comment faire en sorte que l’IA dépasse les connaissances humaines existantes pour créer de « nouvelles connaissances ». Il a également identifié trois risques majeurs : la perte de contrôle de l’auto-amélioration récursive de l’IA, l’obtention du contrôle des armes, et l’auto-réplication non autorisée. Il estime que, dans le contexte d’une concurrence accrue entre la Chine et les États-Unis dans le domaine de l’IA, la diffusion rapide de l’IA open source pourrait entraîner des risques pour la sécurité, voire déclencher une situation de « frappe préventive » similaire à la « dissuasion nucléaire ». Schmidt a appelé à un dialogue mondial immédiat sur la gouvernance de l’IA et a souligné la nécessité d’intégrer la protection des libertés humaines dès la conception des systèmes. (Source: 36Kr)

Le PDG de GitHub réfute la « théorie de l’inutilité de la programmation », soulignant que les programmeurs humains restent importants à l’ère de l’IA: En réponse aux déclarations du PDG de Nvidia, Jensen Huang, et d’autres, selon lesquelles « il ne sera plus nécessaire d’apprendre à programmer à l’avenir », le PDG de GitHub, Thomas Dohmke, a exprimé son désaccord lors d’une interview. Il estime que 2025 sera l’année des agents de programmation (SWE Agent), mais que le rôle des programmeurs humains restera crucial. Dohmke a souligné que l’IA devrait servir d’assistant pour augmenter les capacités des développeurs, et non les remplacer complètement. Il imagine que le développement logiciel futur évoluera vers un modèle de collaboration homme-IA, où les développeurs agiront comme des « chefs d’orchestre d’agents intelligents », responsables de l’attribution des tâches et de la validation des résultats. Mario Rodriguez, CPO de GitHub, a également déclaré que l’entreprise s’engage à renforcer les capacités individuelles avec Copilot. Ils estiment qu’avec le développement de l’IA, il est crucial de comprendre comment programmer et reprogrammer des machines capables de représenter la pensée et l’action humaines, et qu’abandonner l’apprentissage du code équivaut à renoncer à avoir voix au chapitre dans l’avenir des agents intelligents. (Source: 36Kr, QubitAI)

Les rapports de vulnérabilité de faible qualité générés par l’IA prolifèrent, le fondateur de curl introduit un mécanisme de filtrage pour contrer les « déchets IA »: Daniel Stenberg, fondateur du projet curl, a déclaré qu’il était submergé par un grand nombre de rapports de vulnérabilité de faible qualité et non valides générés par l’IA. Ces rapports font perdre un temps considérable aux mainteneurs, s’apparentant à une attaque DDoS. Par conséquent, lors de la soumission de rapports de sécurité liés à curl sur HackerOne, une case à cocher demandant si l’IA a été utilisée a été ajoutée. Si la réponse est oui, des preuves supplémentaires de l’authenticité de la vulnérabilité sont requises, faute de quoi le rapporteur risque d’être banni. Stenberg affirme que le projet n’a jamais reçu de rapport de bug valide généré par l’IA. Seth Larson, développeur Python, avait également exprimé des préoccupations similaires, estimant que de tels rapports sèment la confusion, le stress et la frustration chez les mainteneurs, exacerbant le problème de l’épuisement professionnel dans les projets open source. Les discussions au sein de la communauté suggèrent que la prolifération des rapports générés par l’IA reflète une surcharge d’informations et la tentative de certains d’exploiter les mécanismes de primes de bogues, certains cadres supérieurs étant même induits en erreur en pensant que l’IA peut remplacer les programmeurs expérimentés. (Source: WeChat)

La programmation assistée par IA suscite un vif débat : l’efficacité augmente considérablement, mais le rôle des développeurs humains reste crucial: Un développeur avec des décennies d’expérience en programmation a partagé son expérience d’avoir un bug qui le bloquait pendant des heures résolu et son code optimisé en quelques minutes par une IA (probablement Codex ou un outil similaire), s’émerveillant de l’IA comme d’un « coéquipier surpuissant et infatigable ». Cette expérience a suscité des discussions au sein de la communauté. La plupart reconnaissent la puissance de l’IA dans la génération de code, la correction de bugs et la synthèse d’informations, ce qui peut considérablement améliorer l’efficacité. Cependant, certains développeurs soulignent que l’IA commet encore des erreurs, en particulier dans la logique complexe, les cas limites et les solutions créatives, où elle est inférieure aux humains, et que ses résultats nécessitent l’examen et l’évaluation critique de développeurs expérimentés. Le PDG de Microsoft, Satya Nadella, a également souligné que l’IA est un outil d’autonomisation, que le développement logiciel ne peut plus se passer de l’IA, mais que l’ambition et l’initiative humaines restent importantes. La discussion s’accorde généralement sur le fait que l’IA va changer la façon de programmer, et que les développeurs devront s’adapter à un nouveau paradigme de collaboration avec l’IA, en se concentrant sur la conception architecturale de plus haut niveau et la définition des problèmes. (Source: Reddit r/ChatGPT, WeChat)
L’agent IA Manus ouvre ses inscriptions mais sa tarification élevée, fait face à la concurrence des géants nationaux et internationaux, le lancement de la version chinoise incertain: La plateforme d’agents IA Manus, après une période de battage médiatique autour des codes d’invitation, a officiellement ouvert ses inscriptions, mais actuellement uniquement pour les utilisateurs étrangers, sans version chinoise. Les retours des utilisateurs indiquent qu’elle utilise un système de consommation de points ; les points gratuits (1000 à l’inscription, 300 par jour) ne suffisent qu’à accomplir des tâches simples. Les tâches complexes (comme la création d’un jeu de Sudoku en version web) nécessitent l’achat de points, avec un coût moyen de 1 dollar pour 100 points, ce qui est considéré comme élevé. Les analystes du secteur estiment que la dépendance de Manus à des grands modèles tiers (comme Claude pour la version internationale) entraîne des coûts élevés, et que l’exécution dans un bac à sable cloud augmente également les dépenses. Le retard de la version chinoise pourrait être lié à l’enregistrement des modèles nationaux, aux habitudes de paiement des utilisateurs et à la concurrence sur le marché. Des produits nationaux et internationaux tels que Coze de ByteDance et l’application « Xīnxiǎng » de Baidu constituent déjà une concurrence. Bien que Manus ait obtenu de nouveaux financements, le fossé concurrentiel de son modèle « léger en modèle, lourd en application » est mis à l’épreuve. (Source: 36Kr)
Les modèles d’IA échouent collectivement à un test de raisonnement visuel de « complétion de cube », soulevant des questions sur leur réelle capacité de compréhension: Un problème de raisonnement visuel demandant de calculer le nombre de petits cubes nécessaires pour compléter un cube incomplet a mis en difficulté plusieurs modèles d’IA grand public, dont OpenAI o3, Google Gemini 2.5 Pro, DeepSeek et Qwen3. Les réponses fournies par les différents modèles variaient, principalement en raison d’une compréhension différente des spécifications du grand cube final (par exemple, 3x3x3, 4x4x4, 5x5x5). Même avec des indications, les modèles avaient du mal à répondre correctement du premier coup. Certains internautes ont souligné que la formulation du problème pouvait être ambiguë et que les humains pouvaient également être perplexes. Ce phénomène a suscité un débat sur la question de savoir si les modèles d’IA comprennent réellement les problèmes ou s’ils se fient uniquement à la reconnaissance de formes, soulignant les limites actuelles de l’IA en matière de raisonnement spatial complexe et de compréhension visuelle. (Source: 36Kr)
Les utilisateurs discutent du problème de la « sur-réflexion » des LLM dans le suivi des instructions et le raisonnement: Des discussions sur les réseaux sociaux et dans des articles de recherche soulignent que les grands modèles de langage (LLM), lorsqu’ils utilisent des processus de raisonnement tels que la chaîne de pensée (CoT), peuvent parfois « trop réfléchir », ce qui les empêche de suivre avec précision des instructions simples. Par exemple, lorsqu’on leur demande d’écrire un nombre spécifique de mots ou de répéter une phrase particulière, le CoT peut amener le modèle à se concentrer davantage sur le contenu global de la tâche et à ignorer ces contraintes de base, ou à introduire du contenu explicatif supplémentaire. Les chercheurs ont proposé un indicateur d’« attention aux contraintes » pour quantifier ce phénomène et ont testé des stratégies d’atténuation telles que l’apprentissage contextuel, l’auto-réflexion, le raisonnement auto-sélectionné et le raisonnement par sélection de classificateur. Cela suggère que toutes les tâches ne sont pas adaptées au CoT, et que les instructions simples peuvent nécessiter un mode d’exécution plus direct. (Source: menhguin, omarsar0)

Réflexion sur l’économie de l’IA : le travail cognitif bon marché bouleverse les modèles économiques traditionnels, la répartition de la valeur est à redéfinir: Un point de vue suscitant le débat soutient que l’essor de l’IA rend le travail cognitif (comme la rédaction de rapports, l’analyse de données, l’écriture de code) extrêmement bon marché, ce qui remet fondamentalement en question les modèles économiques classiques basés sur l’hypothèse que « l’intelligence humaine est rare et coûteuse ». Lorsque l’IA peut accomplir une grande quantité de travail intellectuel à un coût marginal proche de zéro, la productivité peut monter en flèche, mais la valeur d’une tâche unique chutera, et l’avantage de la spécialisation sera érodé. La répartition de la valeur ne se fera plus simplement en fonction de l’efficacité ou de la production, mais dépendra de qui contrôle les nouvelles ressources rares (comme les données, les plateformes, les modèles d’IA eux-mêmes). Cela s’apparente à des changements technologiques historiques (comme la fast fashion pour l’industrie du vêtement, le streaming pour l’industrie musicale) où les gains d’efficacité n’ont pas entièrement profité aux travailleurs, mais ont été captés par les coordinateurs du système. L’article avertit que l’IA n’automatise pas seulement les tâches, mais marchandise également la « pensée », ce qui pourrait être la force la plus disruptive de l’histoire économique moderne. (Source: Reddit r/artificial)
Stratégie d’entreprise à l’ère de l’IA : éviter le piège de l’« entreprise intelligente », reconstruire plutôt qu’optimiser les anciens processus: De nombreuses entreprises, en adoptant l’IA, ont tendance à l’utiliser comme un outil pour optimiser les processus existants, réduire les coûts et augmenter l’efficacité, tombant dans le piège de l’« entreprise intelligente » qui consiste à « faire la même chose plus intelligemment ». Cependant, la véritable transformation ne consiste pas à rendre les anciens processus plus intelligents, mais à se demander si ces processus ont encore lieu d’être, et à construire de nouveaux systèmes et modèles commerciaux natifs de l’IA. La technologie ne s’adaptera pas simplement aux anciens systèmes, elle les remodèlera. Les entreprises devraient éviter d’investir trop de ressources dans l’optimisation de processus qui sont sur le point d’être淘汰és par l’IA, et devraient plutôt se concentrer sur la définition de nouvelles règles, en changeant fondamentalement la manière de prendre des décisions, les mécanismes de coordination et la structure organisationnelle. (Source: 36Kr)
💡 Autres
Événement de networking LangChain à New York: LangChain a annoncé qu’il organisera un événement de networking à New York le jeudi 22 mai, en collaboration avec Tabs et TavilyAI. L’événement comprendra des discussions informelles, des démonstrations de produits et des opportunités d’échange avec d’autres constructeurs. (Source: hwchase17, LangChainAI)

La conférence mondiale sur l’IA, édition de Tokyo, se tiendra en juin: Un événement intitulé « Global AI Conference · Tokyo Stop » est prévu du 7 au 8 juin à Tokyo, au Japon. De nombreux développeurs, artistes, investisseurs et autres personnalités de l’IA y participeront. Les personnes intéressées par le domaine de l’IA et prévoyant de se rendre au Japon peuvent consulter les informations d’inscription correspondantes. (Source: op7418)

Le paradigme de l’architecture des services IA évolue de « Modèle en tant que Service » vers « Agent en tant que Service »: Avec le développement de la technologie IA, l’architecture des services IA connaît une profonde transition de « Modèle en tant que Service » (MaaS) vers « Agent en tant que Service » (AaaS). Les Agents IA, avec leur capacité à être orientés objectif, à percevoir l’environnement, à prendre des décisions autonomes et à apprendre, dépassent le mode passif d’exécution d’instructions des modèles IA traditionnels. Ils peuvent penser de manière indépendante, décomposer des tâches, planifier des trajectoires et faire appel à des outils externes pour atteindre des objectifs complexes. Cette transformation stimule un développement complet de la chaîne industrielle, depuis l’infrastructure sous-jacente (puissance de calcul, données), les algorithmes de base et les grands modèles, jusqu’à la couche intermédiaire des composants et plateformes d’Agents, et enfin aux applications de produits terminaux (Agents génériques, sectoriels, embarqués). Des entreprises chinoises d’Agents IA telles que HeyGen, Laiye Technology, Waveform Intelligence, etc., s’exportent activement pour explorer les marchés étrangers. Bien que confrontés à des défis tels que les coûts élevés de la puissance de calcul et une offre insuffisante, le potentiel des Agents IA est continuellement libéré grâce à l’optimisation des algorithmes, aux puces spécialisées, au calcul en périphérie, etc. (Source: 36Kr)