
Mots-clés:Agent intelligent de programmation IA, Codex, AlphaEvolve, Paradigme de raisonnement IA, Modèle MoE (Mixture of Experts), Puce IA, Éducation IA, Mini-série IA, Modèle OpenAI Codex-1, Google DeepMind AlphaEvolve, ByteDance Seed1.5-VL, Technologie Qwen ParScale, Système NVIDIA GB300
🔥 Pleins feux
OpenAI lance l’agent de programmation IA cloud Codex, alimenté par le nouveau modèle codex-1: OpenAI a lancé Codex, un agent de programmation IA basé sur le cloud, propulsé par codex-1, une version o3 spécialement optimisée pour l’ingénierie logicielle. Codex peut traiter plusieurs tâches en parallèle de manière sécurisée dans un sandbox cloud et s’intègre à GitHub pour appeler directement les bibliothèques de code, permettant de construire rapidement des modules, de répondre aux questions sur les bibliothèques de code, de corriger les vulnérabilités, de soumettre des PR et d’effectuer des tests et validations automatiques. Des tâches qui prenaient auparavant plusieurs jours ou heures peuvent être accomplies par Codex en 30 minutes. Cet outil est désormais disponible pour les utilisateurs de ChatGPT Pro, Enterprise et Team, et vise à devenir l’« ingénieur 10x » des développeurs, remodelant ainsi le processus de développement logiciel. (Source: 36氪)
Google DeepMind lance AlphaEvolve, l’IA évolue de manière autonome pour réaliser des percées en mathématiques et en algorithmique: Le système d’IA AlphaEvolve de Google DeepMind, grâce à l’auto-évolution et à l’entraînement de grands modèles de langage, a réalisé des percées dans plusieurs domaines mathématiques et scientifiques. Il a amélioré l’algorithme de multiplication de matrices 4×4 (pour la première fois en 56 ans), optimisé le problème de remplissage hexagonal (pour la première fois en 16 ans) et fait progresser le « problème du nombre de baisers ». AlphaEvolve peut optimiser de manière autonome les algorithmes, a même trouvé un moyen d’accélérer l’entraînement du modèle Gemini, et a été appliqué pour optimiser l’infrastructure de calcul interne de Google, économisant 0,7 % des ressources de calcul. Cela marque le fait que l’IA peut non seulement résoudre des problèmes, mais aussi découvrir de nouvelles connaissances, ce qui pourrait bouleverser les paradigmes de la recherche scientifique et réaliser une science créée par l’IA. (Source: 36氪)
Discours de Sam Altman au sommet de l’IA de Sequoia : L’IA entrera dans le monde réel d’ici trois ans, remodelant la vie et le travail: Le PDG d’OpenAI, Sam Altman, a prédit lors du sommet de l’IA de Sequoia que les agents IA deviendront pratiques en 2025 (en particulier dans le domaine du codage), que l’IA stimulera des découvertes scientifiques majeures en 2026, et que les robots entreront dans le monde physique pour créer de la valeur en 2027. Il a retracé le parcours d’OpenAI, de ses premières explorations à la naissance de ChatGPT, et a suggéré que les futurs produits d’IA seront des services d’« abonnement IA de base », capables d’intégrer l’ensemble des expériences de vie d’un individu et de devenir l’interface intelligente par défaut. OpenAI se concentrera sur les modèles de base et les scénarios d’application, tout en maintenant l’efficacité organisationnelle d’une « petite équipe, grande responsabilité ». (Source: 36氪)
Discours de Nvidia au Computex : L’ordinateur personnel IA en production, lancement du système GB300 de nouvelle génération, projet de construction d’un supercalculateur IA à Taïwan: Le PDG de Nvidia, Jensen Huang, a annoncé lors du Computex 2025 que l’ordinateur personnel IA DGX Spark est entré en pleine production et sera commercialisé dans quelques semaines ; le système IA de nouvelle génération GB300 (équipé de 72 GPU Blackwell Ultra et de 36 CPU Grace) sera lancé au troisième trimestre. Nvidia s’associera à TSMC et Foxconn pour construire un centre de supercalculateurs IA à Taïwan. Parallèlement, la série de stations de travail Blackwell RTX Pro 6000 et la Superchip Grace Blackwell Ultra ont été annoncées, et il est prévu de rendre open source le moteur physique Newton en juillet pour l’entraînement des robots. Jensen Huang a souligné que l’IA sera omniprésente, réaffirmant son impact révolutionnaire. (Source: 36氪)

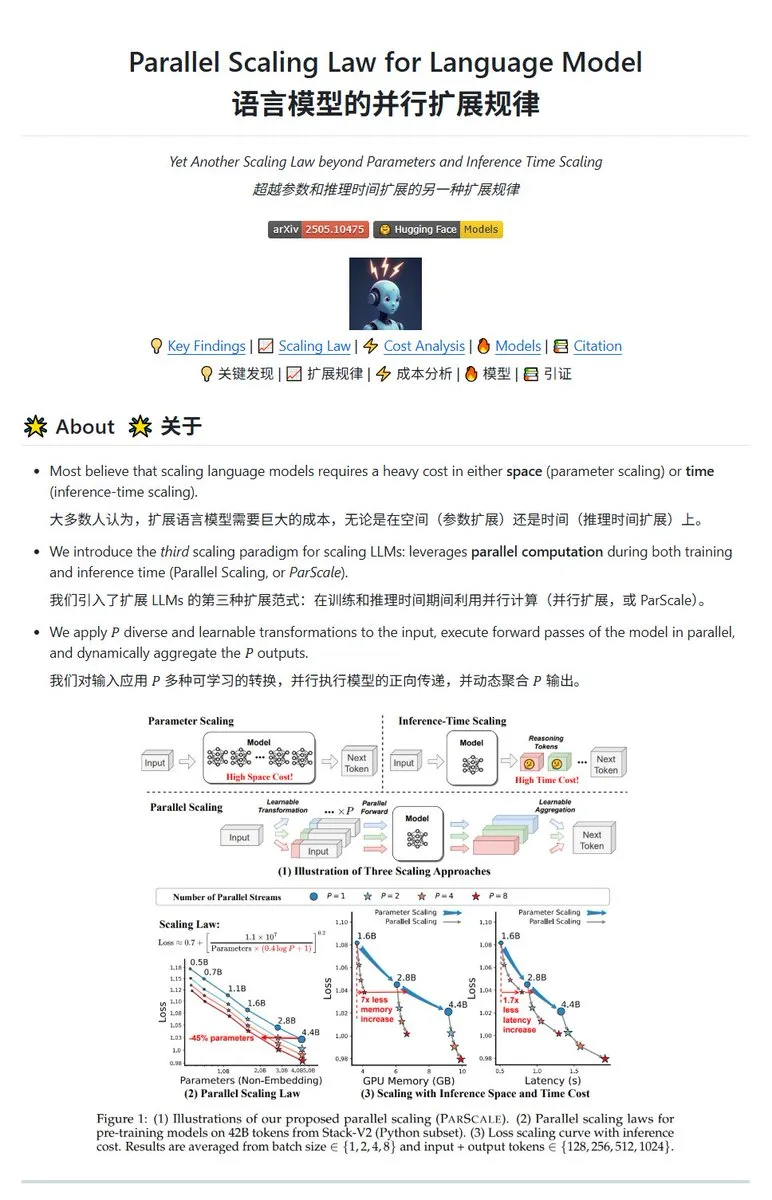
Qwen publie la technologie de mise à l’échelle parallèle ParScale, permettant aux petits modèles d’atteindre les performances des grands modèles: L’équipe Qwen a lancé la technologie ParScale, qui améliore les capacités des modèles grâce à l’inférence parallèle. Cette méthode utilise n flux parallèles pour l’inférence, chaque flux appliquant une transformation différentiable et apprenable à l’entrée, les résultats étant finalement fusionnés via un mécanisme d’agrégation dynamique. Les recherches indiquent que P flux parallèles équivalent approximativement à une augmentation de la quantité de paramètres du modèle d’un facteur O(log P). Par exemple, un modèle de 30B avec 8 flux parallèles peut atteindre les performances d’un modèle de 42,5B. Cette technologie pourrait améliorer les performances des modèles sans augmenter significativement l’occupation de la mémoire GPU, ou réduire la taille des modèles existants en augmentant le parallélisme, mais potentiellement au prix d’une augmentation des besoins en calcul et d’une réduction de la vitesse d’inférence. (Source: karminski3, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
🎯 Tendances
Rapport Poe : OpenAI et Google en tête de la course à l’IA, Anthropic montre des signes de faiblesse: Le dernier rapport d’utilisation de Poe (janvier-mai 2025) révèle des changements spectaculaires dans le paysage du marché de l’IA. Dans le domaine de la génération de texte, GPT-4o (35,8 %) est en tête, tandis que Gemini 2.5 Pro domine en termes de capacité de raisonnement (31,5 %). La génération d’images est dominée par Imagen3, GPT-Image-1 et la série Flux. Dans le domaine de la génération vidéo, Kling-2.0-Master a fait une percée spectaculaire, tandis que la part de marché de Runway a considérablement diminué. En ce qui concerne les agents, o3 affiche les meilleures performances. Le rapport souligne que la capacité de raisonnement est devenue un champ de bataille clé, la part de marché de Claude d’Anthropic ayant diminué, et la proportion d’utilisateurs de DeepSeek R1 ayant également baissé par rapport à son pic. Les entreprises doivent prêter attention à la précision et à la fiabilité des modèles dans les tâches complexes et choisir leurs modèles d’IA de manière flexible. (Source: 36氪)

Le lancement du modèle IA phare de Meta, Behemoth (Llama 4), retardé, ce qui pourrait entraîner un ajustement de la stratégie IA: Selon des rapports, le lancement du grand modèle de 2 trillions de paramètres Behemoth (Llama 4) de Meta, initialement prévu pour avril, a été reporté à l’automne ou plus tard en raison de performances inférieures aux attentes. Ce modèle, pré-entraîné sur 30T de tokens multimodaux avec 32K GPU, vise à concurrencer OpenAI, Google, etc. Les difficultés de développement ont suscité une déception interne quant aux performances de l’équipe Llama 4 et pourraient entraîner des ajustements au sein des équipes de produits IA. Parallèlement, 11 des 14 membres de l’équipe initiale de Llama 1 ont quitté l’entreprise. Les dirigeants de Meta ont démenti les rumeurs selon lesquelles « 80 % de l’équipe aurait démissionné », soulignant que les départs concernaient principalement l’équipe du papier Llama 1. Cet événement alimente les craintes que Meta ne soit confrontée à un goulot d’étranglement dans la course à l’IA. (Source: 36氪)

ByteDance et Google DeepMind publient de nouvelles recherches sur les modèles MoE, axées sur l’efficacité et l’application aux systèmes de production: L’article de ByteDance « MegaScale-MoE: Large-Scale Communication-Efficient Training of Mixture-of-Experts Models in Production » présente un système de production conçu pour l’entraînement efficace de modèles MoE à grande échelle. En superposant la communication et le calcul au niveau des opérateurs, il atteint une efficacité 1,88 fois supérieure à celle de Megatron-LM et a été déployé dans ses centres de données pour entraîner des modèles de production (tels que Internal-352B, 32 experts, top-3). Google DeepMind a publié AlphaEvolve, qui, grâce à l’auto-évolution de l’IA et à l’entraînement des LLM, a réalisé des percées dans les domaines mathématiques et algorithmiques, par exemple en améliorant la multiplication de matrices 4×4 et le problème de remplissage hexagonal, démontrant le potentiel de l’IA dans la découverte scientifique. (Source: teortaxesTex, 36氪)

OpenAI discute du paradigme de raisonnement de l’IA, soulignant son rôle clé dans l’amélioration des performances: Noam Brown, chercheur chez OpenAI, a souligné que le développement de l’IA est passé du paradigme du pré-entraînement (prédire le mot suivant à partir de données massives) au paradigme du raisonnement. Le coût du pré-entraînement est élevé, tandis que le paradigme du raisonnement améliore la qualité des réponses en augmentant le temps de « réflexion » du modèle (quantité de calcul de raisonnement), même si le coût d’entraînement reste inchangé. Par exemple, les modèles de la série o ont obtenu une précision bien supérieure à celle de GPT-4o lors de concours de mathématiques (AIME) et sur des problèmes scientifiques de niveau doctoral (GPQA) grâce à un temps de raisonnement plus long. Ronnie Chatterji, économiste en chef d’OpenAI, a discuté de la manière dont l’IA remodèle le paysage des entreprises, estimant que la clé réside dans la manière dont les entreprises intègrent l’IA pour augmenter ou remplacer les rôles humains, et comment la technologie IA s’intègre dans la chaîne de valeur. (Source: 36氪)

Le PDG de Google, Sundar Pichai, répond à la théorie de la « mort de Google », soulignant l’évolution de la recherche axée sur l’IA et les avantages en matière d’infrastructure: Dans une interview exclusive, le PDG de Google, Sundar Pichai, a répondu aux inquiétudes concernant le remplacement de la recherche Google par l’IA, déclarant que Google transforme la recherche d’une requête réactive en un assistant intelligent prédictif et personnalisé grâce à des fonctionnalités telles que « AI Overviews » et « AI Mode ». Il a souligné que l’investissement à long terme de Google dans l’infrastructure IA (TPU auto-développés, centres de données à grande échelle) et l’efficacité des modèles constituent des avantages essentiels, permettant de fournir des modèles avancés à un coût avantageux. Pichai estime que l’IA est une « plateforme technologique pour tous les scénarios » qui remodèlera les activités principales telles que la recherche, YouTube, Cloud, et donnera naissance à de nouvelles formes. Il a également mentionné que la compétitivité de l’IA chinoise (comme DeepSeek) ne doit pas être négligée et a souligné que l’électricité sera un goulot d’étranglement clé pour le développement de l’IA. (Source: 36氪)

Inventaire des startups appliquant l’IA dans le domaine de l’éducation: L’article dresse la liste de 13 startups d’IA dans l’éducation à suivre en 2025. Elles transforment l’enseignement grâce à des parcours d’apprentissage personnalisés, des systèmes de tutorat intelligents, la notation automatique et la création de contenu immersif. Par exemple, Merlyn est un assistant IA à commande vocale qui allège la charge administrative des enseignants ; Brisk Teaching est une extension Chrome qui simplifie les tâches pédagogiques ; Edexia est une plateforme de notation IA qui apprend le style des enseignants ; Storytailor combine la bibliothérapie et l’IA pour créer des histoires personnalisées ; Brainly fournit une aide aux devoirs améliorée par l’IA. Ces entreprises démontrent le vaste potentiel d’application de l’IA dans l’éducation, de l’amélioration de l’efficacité à la réalisation d’un apprentissage personnalisé et de l’équité éducative. (Source: 36氪)
Les courts métrages IA confrontés à des défis techniques et de commercialisation, un écart entre les effets produits et les attentes: Bien que les outils d’IA promettent de réduire les coûts de production des courts métrages et de raccourcir les cycles, les professionnels constatent que les courts métrages IA rencontrent des difficultés techniques importantes en termes de cohérence des personnages, de synchronisation labiale et de naturel du langage cinématographique, ce qui fait que de nombreuses œuvres ressemblent davantage à des « courts métrages de type PPT ». L’IA a du mal à comprendre les idées surréalistes, ce qui limite l’exploitation des genres fantastiques et de science-fiction. Actuellement, la technologie IA est plus adaptée à la production de courts métrages qu’à des séries courtes complètes, et les perspectives de commercialisation sont incertaines. Les grandes sociétés de production cinématographique et télévisuelle comme Bona Film Group et Huace Group sont plus susceptibles de percer grâce à leurs ressources, tandis que la plupart des petits créateurs sont confrontés à des coûts d’essai élevés et à une obsolescence rapide de leurs œuvres due à l’itération rapide de la technologie. (Source: 36氪)
MSI lance un PC IA intégrant la super-puce NVIDIA GB10, avec 6144 cœurs CUDA et 128 Go de mémoire LPDDR5X: MSI a présenté son EdgeExpert MS-C931 S, un PC IA équipé de la super-puce NVIDIA GB10. Il est confirmé que cette puce possède 6144 cœurs CUDA et 128 Go de mémoire LPDDR5X. Après ASUS, Dell et Lenovo, MSI est un autre fabricant à lancer un ordinateur personnel IA basé sur l’architecture NVIDIA DGX Spark. Le lancement de tels produits marque la popularisation progressive des capacités de calcul IA haute performance vers les appareils personnels et en périphérie (edge), mais certains commentateurs soulignent que leur prix pourrait rendre difficile la concurrence avec des produits comme le Mac Mini. (Source: Reddit r/LocalLLaMA)
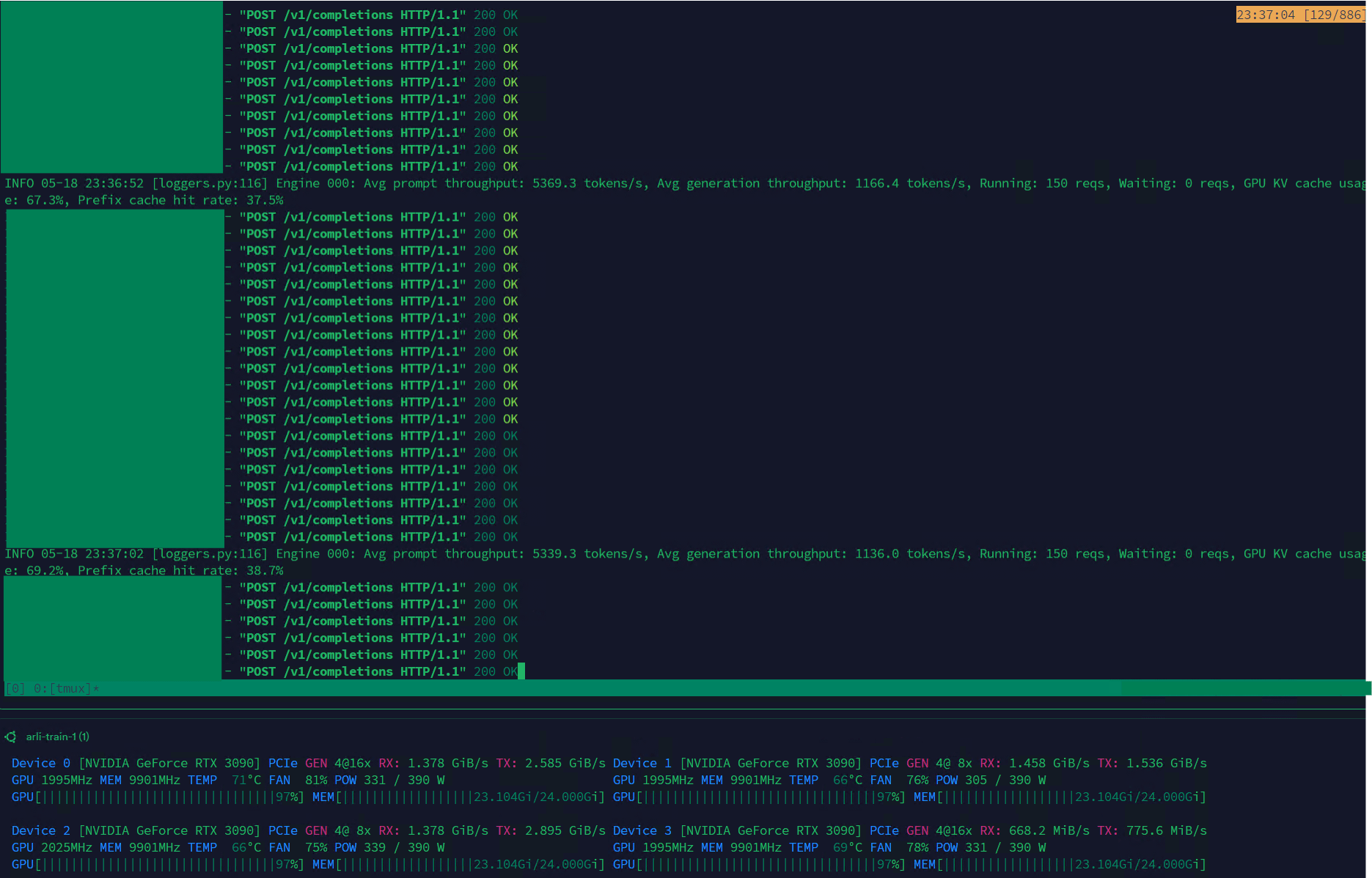
Qwen3-30B atteint un débit élevé sur VLLM, adapté à la gestion de jeux de données: Le modèle Qwen3-30B-A3B démontre une excellente vitesse d’inférence (5K t/s en pré-remplissage, 1K t/s en génération) sur le framework VLLM et les cartes graphiques RTX 3090s, ce qui le rend très adapté aux tâches de filtrage et de gestion de jeux de données. Bien qu’il puisse y avoir une légère régression par rapport à QwQ, son avantage en termes de vitesse le rend plus pratique pour le traitement des données. Le principal problème actuel est la vitesse d’entraînement extrêmement lente, mais une PR dans la bibliothèque Hugging Face Transformers tente de résoudre ce problème, et il est espéré que des modèles RpR avec des jeux de données améliorés basés sur Qwen3-30B seront lancés à l’avenir. (Source: Reddit r/LocalLLaMA)
Bilibili rend open source son modèle de génération de vidéos d’animation Index-AniSora, prenant en charge divers styles d’anime: Bilibili a lancé Index-AniSora, un modèle open source spécialement conçu pour la génération de vidéos de style anime, basé sur son framework technologique AniSora (accepté par IJCAI25). Ce modèle peut transformer des mangas en animations en un clic, prenant en charge divers styles tels que les séries animées japonaises, les productions nationales chinoises, les adaptations de mangas, les VTubers, etc. Le système AniSora, en construisant un jeu de données de dizaines de millions de paires texte-vidéo de haute qualité, en développant un framework de génération par diffusion unifié et en introduisant un mécanisme de masquage spatio-temporel, permet un contrôle fin de la synchronisation labiale et des mouvements des personnages. Parallèlement, Bilibili a conçu une référence d’évaluation pour les vidéos d’animation et un système d’évaluation automatisé optimisé basé sur VLM. Le contenu open source comprendra AniSoraV1.0 (basé sur CogVideoX-5B), AniSoraV2.0 (basé sur Wan2.1-14B, prenant en charge l’entraînement sur Huawei 910B) ainsi que les outils de construction de jeux de données et d’évaluation associés. (Source: WeChat)

ByteDance publie le modèle de langage visuel Seed1.5-VL, aux performances excellentes dans les tâches multimodales: ByteDance a lancé Seed1.5-VL, un modèle de langage visuel composé d’un encodeur visuel de 532M de paramètres et d’un LLM à mélange d’experts (MoE) avec 20B de paramètres actifs. Ce modèle a atteint des performances SOTA sur 38 des 60 benchmarks publics et a surpassé des systèmes de pointe tels que OpenAI CUA et Claude 3.7 dans des tâches centrées sur l’agent, comme le contrôle d’interface graphique (GUI) et le gameplay, démontrant de puissantes capacités de compréhension et de raisonnement multimodales. (Source: WeChat)
Nous Research lance Psyche Network, réalisant le pré-entraînement distribué d’un LLM de 40 milliards de paramètres: Nous Research a lancé Psyche Network, un réseau d’entraînement décentralisé basé sur l’architecture DeepSeek V3 MLA, qui a effectué son premier test en pré-entraînant un grand modèle de langage de 40 milliards de paramètres. Ce réseau utilise l’optimiseur DisTrO et une pile réseau peer-to-peer personnalisée pour intégrer la puissance de calcul GPU distribuée à l’échelle mondiale, permettant aux individus et aux petits groupes de s’entraîner sur un seul H/DGX et de fonctionner sur des GPU 3090. Cette initiative vise à briser le monopole des géants de la technologie sur la puissance de calcul et à rendre l’entraînement de modèles à grande échelle plus accessible. (Source: 量子位)

🧰 Outils
Sim Studio : Constructeur de workflows d’agents IA open source: Sim Studio est une plateforme open source et légère de construction de workflows d’agents IA, offrant une interface intuitive qui permet aux utilisateurs de construire et de déployer rapidement des applications LLM connectées à divers outils. Elle prend en charge une version hébergée dans le cloud et l’auto-hébergement (environnement Docker recommandé, prise en charge des modèles locaux comme Ollama). Sa pile technologique comprend Next.js, Bun, PostgreSQL, Drizzle ORM, Better Auth, Shadcn UI, Tailwind CSS, Zustand, ReactFlow et Turborepo. (Source: GitHub Trending)

Cherry Studio : Une application de bureau front-end LLM open source complète suscite l’intérêt: Cherry Studio est une application de bureau front-end LLM open source qui intègre de multiples fonctionnalités telles que RAG, la recherche web, l’accès aux modèles locaux (via Ollama, LM Studio) et aux modèles cloud (comme Gemini, ChatGPT). Les retours d’utilisateurs indiquent que sa prise en charge et sa gestion MCP (Multi Control Protocol) sont supérieures à celles d’Open WebUI et de LibreChat, et qu’elle est facile à installer et à configurer. L’application prend également en charge la connexion directe aux bases de connaissances Obsidian. Bien que certains utilisateurs expriment des inquiétudes quant à sa source, son ensemble complet de fonctionnalités en fait un choix attrayant. (Source: Reddit r/LocalLLaMA)

MLX-LM-LoRA : Ajoute LoRA aux modèles MLX et prend en charge diverses méthodes d’entraînement: Le projet open source mlx-lm-lora permet aux utilisateurs d’intégrer des modules LoRA (Low-Rank Adaptation) aux modèles du framework Apple MLX. Ce projet prend non seulement en charge l’ajout de LoRA, mais intègre également diverses méthodes d’entraînement d’alignement telles que ORPO, DPO, CPO, GRPO, permettant aux utilisateurs d’affiner les modèles selon leurs besoins, de générer des modules LoRA personnalisés et de les appliquer à leurs modèles MLX préférés. (Source: karminski3)
DeepDrone : Projet open source de drone contrôlé par IA basé sur Qwen: Un développeur a créé un projet de drone contrôlé par IA nommé DeepDrone, basé sur le grand modèle Qwen, et l’a rendu open source sur HuggingFace et GitHub. Ce projet démontre le potentiel d’application des grands modèles de langage au contrôle autonome des drones, suscitant des discussions sur l’IA dans l’automatisation et ses applications militaires potentielles. (Source: karminski3)
Qwen Web Dev : Générer et déployer un site web avec une seule invite: L’équipe Qwen d’Alibaba a annoncé l’amélioration de son outil Qwen Web Dev, permettant aux utilisateurs de générer un site web avec une seule invite (prompt) et de le déployer en un clic. Cet outil vise à abaisser la barrière d’entrée au développement web, permettant aux utilisateurs de transformer plus facilement leurs idées en sites web accessibles et de les partager avec le monde. (Source: Alibaba_Qwen, huybery)
SuperGo.AI : Un outil à interface unique intégrant huit modèles LLM: Un passionné d’IA a développé un outil nommé SuperGo.AI, qui intègre huit LLM avec des rôles différents (tels que Super Cerveau IA, Imagination IA, Éthique IA, Univers IA, etc.) dans une seule interface. Ces rôles IA peuvent se percevoir et interagir les uns avec les autres, et les utilisateurs peuvent choisir les modes « Créatif », « Scientifique » et « Mixte » pour obtenir des réponses combinées. Cet outil vise à offrir une nouvelle expérience de collaboration multi-IA et est actuellement sans mur de paiement. (Source: Reddit r/artificial)
Kokoro-JS : Réalise la synthèse vocale (TTS) locale illimitée: Kokoro-JS est un outil de synthèse vocale 100 % local et 100 % open source, qui fonctionne en téléchargeant un modèle d’IA d’environ 300 Mo côté navigateur. Le texte saisi par l’utilisateur n’est envoyé à aucun serveur, garantissant la confidentialité et la disponibilité hors ligne. Cet outil vise à fournir des fonctionnalités TTS illimitées. (Source: Reddit r/LocalLLaMA)
📚 Apprentissage
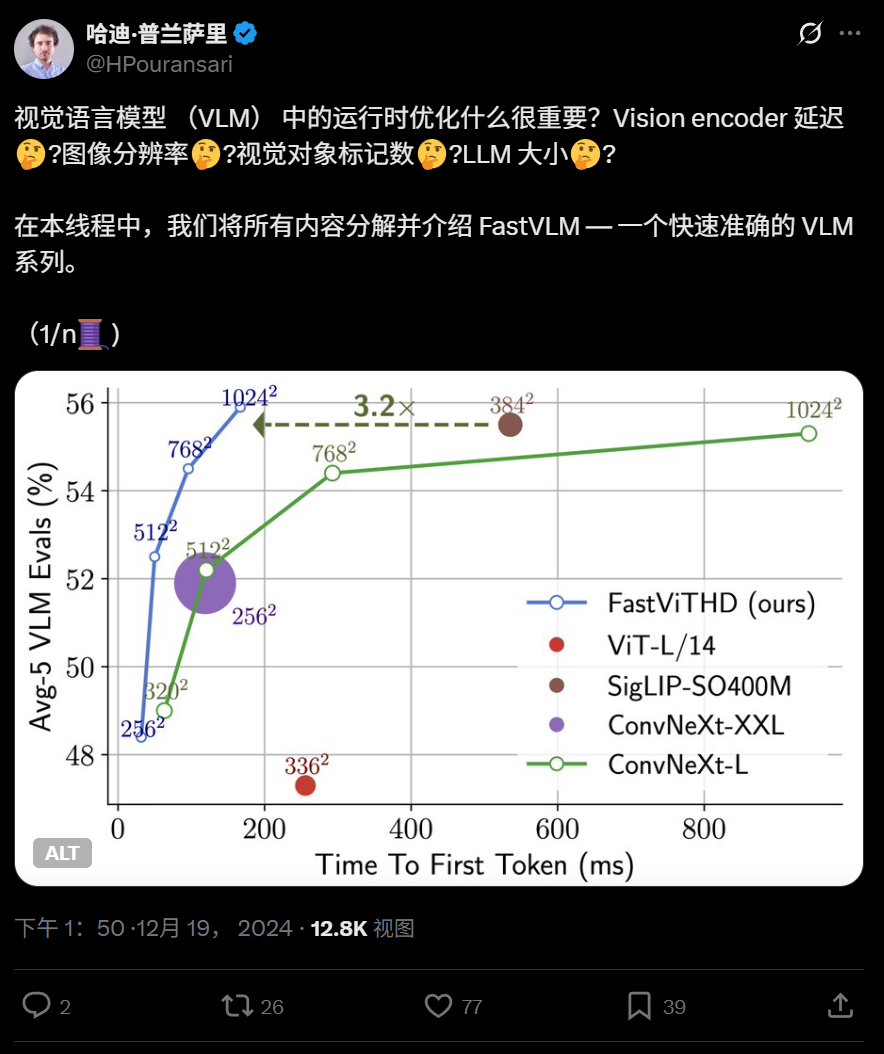
Apple rend open source FastVLM, un modèle de langage visuel efficace, optimisé pour l’exécution sur les appareils: Apple a rendu open source FastVLM, un modèle de langage visuel conçu pour fonctionner efficacement sur des appareils tels que l’iPhone. FastVLM introduit un nouvel encodeur visuel hybride, FastViTHD, qui combine des couches convolutives et des modules Transformer, et utilise des techniques de pooling multi-échelle et de sous-échantillonnage pour réduire considérablement le nombre de tokens visuels nécessaires au traitement des images (16 fois moins que les ViT traditionnels), améliorant la vitesse de sortie du premier token de 85 fois. Ce modèle est compatible avec les principaux LLM et une application de démonstration iOS/macOS basée sur le framework MLX est déjà disponible, adaptée aux appareils en périphérie (edge) et aux tâches graphiques en temps réel. (Source: WeChat)
L’Université de Technologie de Harbin et l’Université de Pennsylvanie proposent PointKAN, améliorant l’analyse des nuages de points 3D basée sur KAN: Des équipes de recherche de l’Université de Technologie de Harbin (Shenzhen) et de l’Université de Pennsylvanie ont lancé PointKAN, une nouvelle architecture de perception 3D basée sur les Kolmogorov-Arnold Networks (KANs). PointKAN remplace les fonctions d’activation fixes des MLP traditionnels par des fonctions d’activation apprenables, améliorant ainsi la capacité d’apprentissage des caractéristiques géométriques complexes. Il comprend un module d’affinité géométrique et un module d’extraction de caractéristiques locales parallèles. L’équipe a également proposé une version PointKAN-elite, qui adopte la structure Efficient-KANs, utilise des fonctions rationnelles comme fonctions de base et partage les paramètres par groupes, réduisant considérablement le nombre de paramètres et la complexité de calcul, tout en affichant des performances SOTA dans les tâches de classification, de segmentation partielle et d’apprentissage avec peu d’échantillons. (Source: 量子位)

L’Université de Pittsburgh propose le framework PhyT2V pour améliorer le réalisme physique des vidéos générées par IA: Le laboratoire des systèmes intelligents de l’Université de Pittsburgh a développé le framework PhyT2V, visant à améliorer la cohérence physique du contenu généré par les modèles texte-vers-vidéo (T2V). Cette méthode ne nécessite pas de réentraînement du modèle ni de données externes à grande échelle. Grâce à un raisonnement en chaîne (CoT) guidé par de grands modèles de langage (LLM) et à un mécanisme d’auto-correction itératif, elle analyse et optimise les invites textuelles sur plusieurs tours en fonction des règles physiques. PhyT2V est capable d’identifier les règles physiques, les inadéquations sémantiques et de générer des invites corrigées, améliorant ainsi la capacité de généralisation des principaux modèles T2V (tels que CogVideoX, OpenSora) dans des scènes physiques réalistes (solides, fluides, gravité, etc.), avec des effets particulièrement significatifs dans les scénarios hors distribution, les indicateurs de bon sens physique (PC) et de respect sémantique (SA) étant améliorés jusqu’à 2,3 fois. (Source: WeChat)
Dernières recherches sur les LLM : multimodalité, alignement au moment du test, Agent, optimisation RAG, etc. : Les avancées de la semaine en matière de recherche sur les LLM comprennent : 1. L’Université de Washington a proposé QALIGN, une méthode d’alignement au moment du test qui ne nécessite pas de modifier le modèle ni d’accéder aux logits, réalisant un meilleur alignement dans la génération de texte via MCMC. 2. UCLA a pré-entraîné Clinical ModernBERT, étendant la longueur du contexte de l’encodeur du domaine biomédical à 8192 tokens. 3. Skoltech a proposé une méthode de récupération RAG auto-adaptative légère et indépendante des LLM, basée sur des informations externes (popularité des entités, type de question). 4. PSU a défini le problème d’attribution automatisée des défaillances des systèmes multi-agents LLM et a développé un jeu de données et une méthode d’évaluation. 5. L’Université Fudan a proposé un cadre de contraintes multidimensionnelles et un processus de génération automatisée d’instructions pour améliorer la capacité des LLM à suivre les instructions. 6. a-m-team a rendu open source AM-Thinking-v1 (32B), dont les capacités de codage mathématique rivalisent avec celles de DeepSeek-R1-671B. 7. Xiaomi a lancé MiMo-7B, qui affiche d’excellentes performances dans les tâches de raisonnement grâce à l’optimisation du pré-entraînement et du post-entraînement. 8. MiniMax a proposé le modèle TTS autorégressif MiniMax-Speech, qui prend en charge le clonage de timbre vocal zero-shot dans 32 langues. 9. ByteDance a construit le modèle de langage visuel Seed1.5-VL, qui se distingue dans les tâches multimodales et les tâches centrées sur l’agent. 10. Le premier modèle de langage de 32B paramètres au monde, INTELLECT-2, a réalisé un entraînement par apprentissage par renforcement distribué, proposant le framework PRIME-RL. (Source: WeChat)
Les ateliers AAAI 2025 se concentrent sur le raisonnement neuronal, la découverte mathématique et l’accélération de la science et de l’ingénierie par l’IA: Les ateliers d’AAAI 2025 ont mis l’accent sur les applications de l’IA dans le domaine scientifique. L’atelier « Raisonnement neuronal et découverte mathématique » a souligné que les réseaux neuronaux boîte noire peuvent être utilisés pour proposer des conjectures mathématiques et générer de nouvelles figures géométriques, mais a également noté leur incapacité à atteindre un raisonnement logique de niveau symbolique, et a préconisé des approches interdisciplinaires. Un autre atelier, « L’IA pour accélérer la science et l’ingénierie » (quatrième édition, sur le thème de l’IA pour les biosciences), s’est concentré sur des sujets tels que les modèles fondamentaux pour la conception thérapeutique, les modèles génératifs pour la découverte de médicaments, la conception d’anticorps en boucle fermée en laboratoire, l’apprentissage profond en génomique et l’inférence causale dans les applications biologiques, et a exploré les défis et les opportunités des modèles génératifs dans les biosciences. (Source: aihub.org)

Divergence entre Google et Anthropic sur la recherche en explicabilité de l’IA, l’explicabilité mécaniste face à des défis: La nature de « boîte noire » de l’IA limite son application dans de nombreux domaines clés. Google DeepMind a récemment annoncé une réduction de la priorité accordée à la recherche sur l’« explicabilité mécaniste » (mechanistic interpretability), estimant que la rétro-ingénierie des mécanismes internes de l’IA par des méthodes telles que les auto-encodeurs clairsemés (SAE) se heurte à de nombreux problèmes, tels que l’absence de référence objective, une couverture conceptuelle incomplète, la distorsion des caractéristiques, etc., et que les technologies SAE actuelles n’ont pas réussi à identifier les « concepts » requis dans les tâches critiques. En revanche, le PDG d’Anthropic, Dario Amodei, plaide pour un renforcement de la recherche dans ce domaine et se montre optimiste quant à la réalisation d’une « imagerie par résonance magnétique de l’IA » d’ici 5 à 10 ans. Ce débat met en lumière les défis profonds liés à la compréhension et au contrôle du comportement de l’IA. (Source: 36氪)

L’Université de Pékin, StepFunction et Xizhi Technology proposent InfiniteHBD : une nouvelle génération d’architecture de domaine à haute bande passante pour GPU afin de réduire les coûts et d’augmenter l’efficacité: Face aux limitations des architectures de domaine à haute bande passante (HBD) existantes en termes d’évolutivité, de coût et de tolérance aux pannes, les équipes de l’Université de Pékin, StepFunction et Xizhi Technology ont proposé l’architecture InfiniteHBD. Cette architecture est centrée sur un module de commutation optique (OCSTrx) et, en intégrant une capacité de commutation optique (OCS) à faible coût dans le module de conversion optoélectronique, elle permet une topologie en anneau K-Hop dynamiquement reconfigurable à l’échelle du centre de données et une isolation des pannes au niveau du nœud. Le coût unitaire d’InfiniteHBD n’est que de 31 % de celui de NVL-72, le taux de gaspillage de GPU est proche de zéro, et le MFU (Model FLOPs Utilization) est jusqu’à 3,37 fois supérieur à celui de NVIDIA DGX, offrant une solution optimisée pour l’entraînement de grands modèles à grande échelle. L’article a été accepté par SIGCOMM 2025. (Source: WeChat)

OceanBase lance PowerRAG, adopte pleinement l’IA et construit une base de données intégrée Data×AI: Lors de sa conférence des développeurs, OceanBase a lancé PowerRAG, un produit applicatif orienté IA, visant à fournir des capacités de développement RAG prêtes à l’emploi, en connectant les données, les plateformes, les interfaces et la couche applicative. Le CTO Yang Chuanhui a détaillé la stratégie IA d’OceanBase : construire des capacités Data×AI, évoluant d’une base de données intégrée vers une plateforme de données intégrée. OceanBase améliorera ses capacités vectorielles, optimisera la recherche fusionnée, réalisera la mise à jour dynamique du stockage des connaissances d’entreprise, intégrera en profondeur le post-entraînement et l’affinage des modèles, et s’est déjà adapté aux principales plateformes d’agents telles que Dify, FastGPT, ainsi qu’au protocole MCP. Ses performances vectorielles se sont distinguées lors des tests VectorDBBench, et l’algorithme de quantification BQ a considérablement réduit les besoins en mémoire. (Source: WeChat)

💼 Affaires
Des fonds d’investissement étatiques de Shanghai investissent dans des entreprises de puces IA telles que Xinyaohui, Suiyuan Technology et Biren Technology: Shanghai International Group (SIG), une société d’investissement détenue par l’État de Shanghai, a récemment signé des accords d’investissement avec trois sociétés de semi-conducteurs : Xinyaohui, Suiyuan Technology et Biren Technology. Auparavant, son fonds mère précurseur en IA avait mené le financement pré-IPO de Biren Technology. SIG a déclaré qu’elle se positionnerait activement sur les segments des modèles de base, des puces de calcul et de l’intelligence incarnée. Xinyaohui se concentre sur les IP de semi-conducteurs, en particulier la technologie Chiplet ; son fondateur, Zeng Keqiang, était auparavant vice-président de Synopsys Chine. Suiyuan Technology et Biren Technology sont toutes deux des sociétés de conception de puces GPU. Cette démarche témoigne de l’orientation stratégique de SIG vers l’amont de la chaîne de valeur de l’IA, en particulier dans le domaine des puces de calcul. (Source: 36氪)
Sakana AI et la banque Mitsubishi UFJ concluent un partenariat global pour développer une IA spécifique au secteur bancaire: La startup japonaise d’IA Sakana AI a annoncé la signature d’un accord de partenariat pluriannuel avec la banque Mitsubishi UFJ (MUFG). Sakana AI développera pour MUFG des agents IA spécifiquement adaptés aux opérations bancaires, dans le but de transformer les activités bancaires et de promouvoir l’application pratique de l’IA. Parallèlement, le cofondateur et COO de Sakana AI, Ren Ito, deviendra conseiller de MUFG pour aider la banque à mettre en œuvre sa stratégie IA. Cette collaboration marque une étape importante pour Sakana AI dans l’application de technologies IA avancées pour résoudre des problèmes concrets du secteur financier japonais. (Source: SakanaAILabs, SakanaAILabs, SakanaAILabs, SakanaAILabs, SakanaAILabs)

Gu Xuemei, cofondatrice de Lingyi Wanwu, quitte l’entreprise pour créer sa propre startup ; l’entreprise réoriente ses activités vers le B2B: Gu Xuemei, cofondatrice de Lingyi Wanwu et responsable du pré-entraînement des modèles et des produits grand public (C-end), a quitté l’entreprise il y a plusieurs mois et prépare actuellement le lancement de sa propre startup. Lingyi Wanwu a confirmé cette information et l’a remerciée pour sa contribution. Depuis 2025, Lingyi Wanwu a réorienté ses activités, passant des applications IA ToC et des API de modèles aux scénarios B2B tels que les humains numériques, la personnalisation et le déploiement de modèles. Ses produits grand public, comme l’outil de bureautique « Wanzhi » pour le marché chinois, ont cessé leurs opérations en raison d’un nombre d’utilisateurs inférieur aux attentes, et la commercialisation de son produit de jeu de rôle à l’étranger, Mona, n’a pas non plus été satisfaisante. Auparavant, le cofondateur Dai Zonghong avait également quitté l’entreprise pour créer sa propre startup. (Source: 36氪)

🌟 Communauté
La détection AIGC dans les mémoires universitaires suscite la controverse, sa précision remise en question, affectant la diplomation des étudiants: Cette année, de nombreuses universités ont introduit la détection AIGC comme étape de vérification des mémoires de fin d’études, visant à empêcher les étudiants d’abuser de l’IA pour la rédaction. Cependant, cette mesure a suscité une large controverse. Les étudiants rapportent que leur propre contenu est souvent mal identifié comme généré par l’IA, tandis que le taux de suspicion augmente après une révision assistée par l’IA. Des tests ont même montré que le « Préambule au Pavillon du Prince Teng » avait un taux de suspicion de génération par IA de 99,2 %. Les outils de détection AIGC sont eux-mêmes pilotés par l’IA, leur principe étant d’analyser les caractéristiques linguistiques du texte et de les comparer aux modèles d’écriture de l’IA, mais leur précision est préoccupante, l’outil précoce d’OpenAI n’atteignant que 26 % de précision. Cette incertitude non seulement cause des problèmes et des dépenses supplémentaires aux étudiants (les résultats varient entre les sites de détection, les services de réduction de similarité sont payants), mais soulève également des questions sur la nature des outils d’IA : l’IA imite l’écriture humaine, puis on utilise l’IA pour détecter si un texte humain ressemble à de l’IA, ce qui constitue un paradoxe logique. (Source: 36氪)

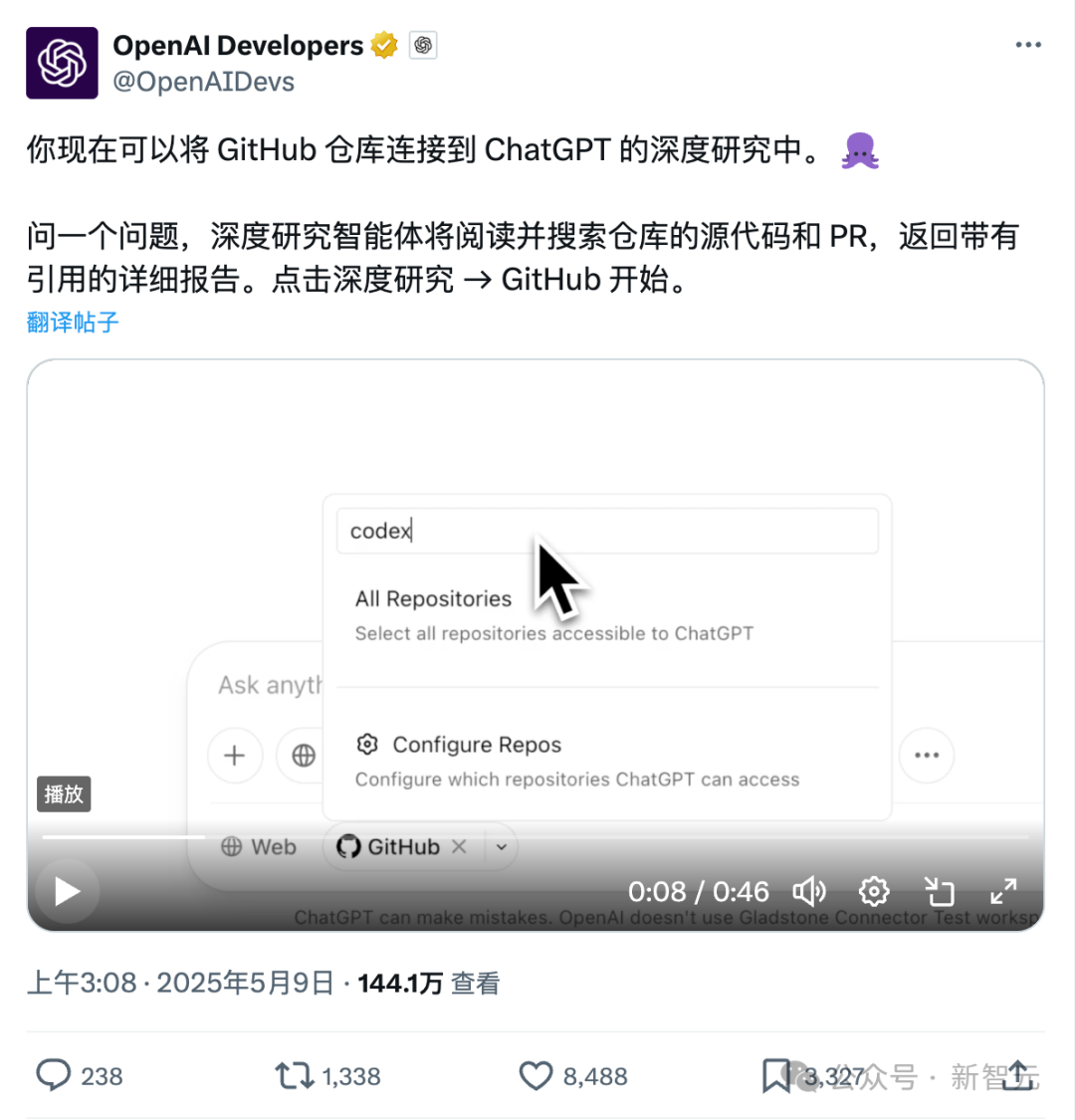
Nouvelle fonctionnalité de ChatGPT : connexion directe à Github pour une recherche approfondie des dépôts de code et de la documentation spécialisée: La fonctionnalité Deep Research récemment lancée par ChatGPT a ajouté la capacité de se connecter directement aux dépôts Github, permettant aux utilisateurs d’autoriser ChatGPT à accéder à leurs dépôts publics ou privés pour une analyse approfondie du code, un résumé de l’architecture fonctionnelle, l’identification de la pile technologique, l’évaluation de la qualité du code et l’analyse de l’adéquation du projet, etc. Cette fonctionnalité ne se limite pas au code ; les utilisateurs peuvent télécharger divers documents tels que des PDF, Word, etc., dans leurs dépôts Github et utiliser ChatGPT pour une recherche approfondie de documents dans des domaines spécifiques, ce qui équivaut à une combinaison RAG+MCP à portée limitée. Cette fonctionnalité est actuellement disponible pour les utilisateurs Plus. En limitant le champ de recherche, elle devrait améliorer la spécialisation et la précision des rapports de recherche et réduire les hallucinations. (Source: 36氪)
La concurrence sur le marché des agents IA s’intensifie, Manus ouvre complètement ses inscriptions, les géants comme ByteDance et Baidu entrent en jeu: Manus, surnommé l’« Agent tout-puissant », a annoncé le 12 mai l’ouverture complète de ses inscriptions, permettant aux utilisateurs d’obtenir un quota d’utilisation sans attente. Parallèlement, des rumeurs de marché indiquent que Manus lève une nouvelle série de financement avec une valorisation de 1,5 milliard de dollars. Depuis son lancement en mars, Manus a déclenché un engouement pour les projets de type Agent, mais fait également face à une baisse de trafic et à l’émergence de produits concurrents. ByteDance a lancé Coze Space, Baidu a mis en ligne « Miaoda » et « Xinxiang », et l’Agent de design Lovart a également commencé ses tests. Le marché des Agents passe d’une phase de validation de concept précoce à une concurrence tous azimuts sur les fonctionnalités des produits, les modèles économiques et la croissance des utilisateurs. (Source: 36氪)
Le codage assisté par IA modifie le flux de travail des développeurs, augmentant la productivité mais nécessitant une vigilance contre la dépendance excessive: Un utilisateur de Reddit a partagé comment les assistants de code IA ont considérablement changé son expérience de codage, en particulier pour traiter de grands projets hérités et comprendre du code complexe. Les outils d’IA peuvent expliquer le code ligne par ligne, fournir des suggestions, mettre en évidence les problèmes potentiels, résumer les fichiers, trouver des extraits et générer des commentaires, comme avoir un expert disponible 24h/24 et 7j/7. Les commentaires soulignent que l’IA peut effectuer un codage répétitif, améliorer l’efficacité, guider vers de nouvelles approches, ajouter des commentaires et même aider les développeurs à accomplir des tâches dépassant leurs capacités, réduisant des jours de travail à quelques heures. Cependant, cela soulève également des questions sur l’évolution des compétences des développeurs et la dépendance aux outils d’IA. (Source: Reddit r/artificial)
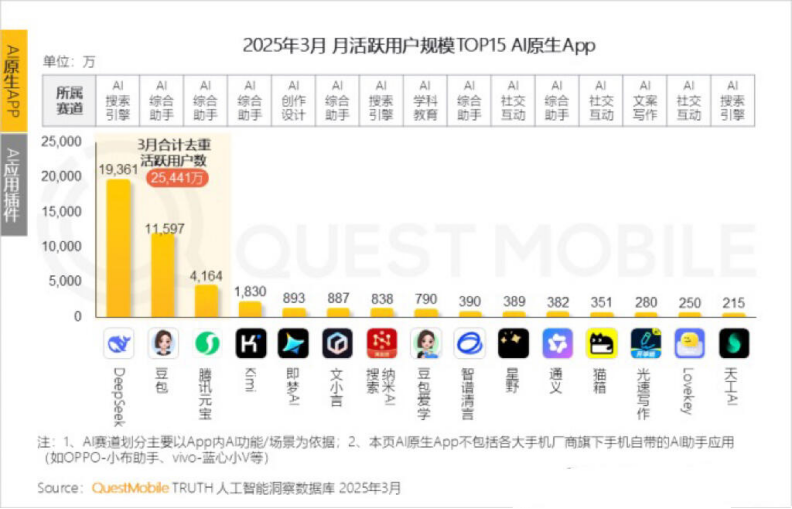
Baisse du nombre d’utilisateurs actifs mensuels de Kimi, Moonshot AI cherche une percée dans des niches et une transformation sociale: Kimi Chat de Moonshot AI a vu son nombre d’utilisateurs actifs mensuels chuter de 36 millions en octobre de l’année dernière à 18,2 millions en mars de cette année, selon les données de QuestMobile, le plaçant au quatrième rang. Pour améliorer la rétention des utilisateurs, Kimi passe d’un grand modèle généraliste à une expansion dans des domaines de niche, comme la collaboration avec Caixin Media pour améliorer la qualité de la recherche de contenu financier, le positionnement sur la recherche médicale IA, et l’introduction de contenu vidéo de Bilibili. Parallèlement, Kimi a lancé un défi de check-in sur Xiaohongshu, tentant d’atteindre plus d’utilisateurs grand public via les plateformes sociales. Son interface utilisateur s’oriente également vers le multimodal, un style similaire à Doubao, et la communautarisation. Face à des concurrents comme DeepSeek et à l’entrée des géants dans les applications IA, le positionnement de Kimi en tant que leader technologique est remis en question, la pression de la commercialisation augmente, et l’entreprise recherche activement de nouveaux relais de croissance. (Source: 36氪)
Discussion sur la question de savoir si l’IA devrait se désigner à la première personne: Un utilisateur de Reddit a lancé une discussion, estimant que le fait que des LLM comme ChatGPT utilisent « je » ou « tu » pour se désigner et s’adresser aux utilisateurs pourrait être inapproprié, car ils sont par essence des « choses » et non des « personnes ». Il suggère qu’ils utilisent la troisième personne, comme « ChatGPT vous aidera… », pour éviter de donner aux utilisateurs l’impression qu’ils sont des entités personnifiées, ce qui pourrait entraîner des dangers potentiels ou des problèmes éthiques. Dans les commentaires, certains pensent que la troisième personne suggère au contraire une conscience de soi, tandis que d’autres trouvent que la troisième personne semble stupide et inconfortable. Cette discussion reflète la réflexion des utilisateurs sur le positionnement identitaire de l’IA et les modes d’interaction homme-machine. (Source: Reddit r/ArtificialInteligence)
💡 Divers
Le MIT rétracte en urgence un article sur l’IA largement médiatisé, citant des doutes sur l’authenticité des données et de la recherche: Le Massachusetts Institute of Technology (MIT) a rétracté un article rédigé par Aidan Toner-Rogers, doctorant en économie, intitulé « Intelligence artificielle, découverte scientifique et innovation de produits ». Cet article avait attiré l’attention car il suggérait que les outils d’IA pouvaient considérablement améliorer l’efficacité de l’innovation des meilleurs scientifiques, mais risquaient d’exacerber les « disparités entre riches et pauvres » dans la recherche et de réduire le bien-être des chercheurs ordinaires, et avait été salué par des professeurs renommés, dont des lauréats du prix Nobel. Le MIT a déclaré qu’après avoir reçu un signalement concernant l’intégrité de la recherche et mené une enquête interne, il avait perdu confiance dans la source, la fiabilité, la validité des données et l’authenticité de la recherche, et avait demandé à arXiv et au Quarterly Journal of Economics de retirer l’article. L’auteur a quitté le MIT, et les professeurs concernés ont également publié des déclarations pour se distancier. Il semblerait que l’auteur ait acheté de faux noms de domaine pendant l’enquête pour se faire passer pour des courriels de grandes entreprises, ait été démasqué et poursuivi en justice. (Source: 36氪)

Des images générées par IA utilisées pour des escroqueries en ligne, suscitant la vigilance des utilisateurs: Un utilisateur de Reddit a partagé des exemples d’images de personnages générées par IA utilisées pour la promotion de produits sur des réseaux sociaux comme Facebook. Les personnages et les scènes de ces images présentent souvent des incohérences logiques (comme un mannequin entrant et sortant d’une boîte de manière étrange, des personnages non pertinents en arrière-plan, etc.), mais la cohérence de l’image des personnages est élevée. Les commentateurs ont souligné que ce type de contenu généré par IA a été utilisé pour des escroqueries, et ont appelé les utilisateurs à la vigilance. Des blogueurs comme Pleasant Green ont également réalisé des vidéos dénonçant ce type d’arnaques. (Source: Reddit r/ChatGPT)
Discussion sur l’imitation de style et l’extraction de prompts pour les images générées par IA: Des utilisateurs ont discuté de la manière de faire imiter par des modèles d’IA (comme DALL-E 3) des styles artistiques spécifiques (par exemple, le style Pixar combiné au style Designer Toy pour un portrait de Salvador Dalí) pour créer des portraits de personnages. Ils ont partagé des prompts détaillés, soulignant les caractéristiques du personnage, l’arrière-plan, l’éclairage et les concepts clés (comme l’ombre en tant que projection mentale). De plus, un autre utilisateur a fourni un modèle de prompt pour extraire les paramètres de style d’une image et les exporter au format JSON, visant à aider les utilisateurs à faire de la rétro-ingénierie du style d’une image, bien qu’une reproduction précise reste difficile. (Source: dotey, dotey)
