
Mots-clés:GPT-5, Capacité de raisonnement de l’IA, AlphaEvolve, Opérateur OpenAI, Mistral AI, Calcul lors des tests et chaînes de pensée, Optimisation autonome du code par l’IA, Modèles d’IA multimodaux, Automatisation de la recherche d’emploi par IA, Réglage fin local des LLM
🔥 Pleins Feux
OpenAI révèle ses plans futurs : GPT-5 intégrera les outils existants pour créer une expérience All-in-One: Jerry Tworek, vice-président de la recherche chez OpenAI, a révélé lors d’un AMA sur Reddit que l’objectif principal du modèle de base de nouvelle génération, GPT-5, est d’améliorer les capacités des modèles existants et de réduire la complexité du changement de modèle. Pour ce faire, OpenAI prévoit d’intégrer les outils existants tels que Codex (programmation), Operator (exécution de tâches informatiques), Deep Research (recherche approfondie) et Memory (fonction de mémoire) dans GPT-5 afin de proposer une expérience unifiée. Les membres de l’équipe ont également partagé que Codex était initialement un projet parallèle d’ingénieurs, que son utilisation interne a permis d’augmenter l’efficacité de la programmation d’environ 3 fois, et qu’OpenAI explore des options de tarification flexibles, y compris le paiement à l’utilisation. (Source: WeChat)
Nouvelle dimension pour l’amélioration des capacités de raisonnement de l’IA : calcul au moment du test et chaîne de pensée: Lilian Weng, ancienne élève de l’Université de Pékin et ex-responsable de la recherche en IA appliquée chez OpenAI, explore en profondeur dans son dernier long article « Why We Think » comment améliorer les capacités de raisonnement des grands modèles de langage grâce à des stratégies telles que le « calcul au moment du test » (test-time compute) et la « chaîne de pensée » (Chain-of-Thought, CoT). L’article expose la justification de faire « réfléchir plus longtemps » les modèles sous plusieurs angles, notamment la théorie psychologique du double système, la perspective des ressources computationnelles et la modélisation des variables latentes. Il passe également en revue les progrès de la recherche sur des techniques clés telles que l’échantillonnage parallèle, la révision séquentielle, l’apprentissage par renforcement et l’utilisation d’outils externes pour améliorer les performances de raisonnement des modèles. Weng souligne que grâce à ces méthodes, les modèles peuvent consacrer davantage de ressources de calcul au moment du raisonnement, simulant ainsi le processus de pensée profonde de l’homme, afin d’obtenir de meilleures performances sur des tâches complexes, et indique les futures orientations de recherche en matière de raisonnement fidèle, de résolution de récompenses et d’autocorrection non supervisée. (Source: WeChat, WeChat)
Google lance AlphaEvolve : l’IA écrit et optimise son propre code algorithmique, réduisant considérablement les coûts de calcul: Google a lancé le système d’IA AlphaEvolve, capable d’écrire et d’optimiser du code de manière autonome, et qui a déjà démontré un potentiel énorme dans des projets tels qu’AlphaFold. AlphaEvolve utilise des algorithmes évolutifs pour rechercher de meilleures implémentations algorithmiques. Par exemple, dans l’algorithme de repliement des protéines d’AlphaFold, il a découvert un nouveau mécanisme d’attention qui a réduit les coûts de calcul de 25 %, ce qui équivaut à une économie de plusieurs millions de dollars en ressources de calcul. Cette percée marque une étape importante pour l’IA dans les domaines de la découverte scientifique et de l’optimisation algorithmique, et promet de réduire les coûts et d’accroître l’efficacité dans un plus grand nombre de problèmes de calcul complexes à l’avenir. (Source: Reddit r/ArtificialInteligence)

OpenAI l’admet : l’investissement dans le raisonnement de l’IA est directement proportionnel à la performance, la clé pour surpasser les capacités humaines réside dans le « temps de réflexion »: Noam Brown, chercheur chez OpenAI, a souligné lors d’une discussion que l’IA est en train de passer d’un « paradigme de pré-entraînement » à un « paradigme de raisonnement ». Le pré-entraînement prédit le mot suivant à partir de données massives, ce qui est coûteux ; tandis que le paradigme de raisonnement permet au modèle de « réfléchir » plus profondément avant de répondre, et même si le coût est légèrement plus élevé, la qualité de la réponse est considérablement améliorée. Par exemple, le modèle o1 a surpassé GPT-4o au concours de mathématiques AIME et aux questions scientifiques de niveau doctoral GPQA, et le modèle o3 a atteint le niveau humain le plus élevé dans les concours de programmation. Cela indique qu’en augmentant l’investissement en ressources de calcul pendant le raisonnement (c’est-à-dire le « temps de réflexion »), les performances de l’IA sur des tâches complexes peuvent faire un bond en avant considérable, voire surpasser celles des humains. (Source: WeChat)

🎯 Tendances
Mistral AI enregistre des résultats significatifs pour ses modèles en 2025, avec d’excellentes performances pour plusieurs d’entre eux: Mistral AI a réalisé plusieurs avancées importantes au premier semestre 2025, en publiant plusieurs modèles haute performance, notamment Codestral 25.01 (modèle FIM de pointe), Mistral Small 3 & 3.1 (meilleur de sa catégorie, supportant le multimodal et un contexte de 130k), Mistral Saba (surpassant en performance des modèles trois fois plus grands), Mistral OCR (modèle OCR de pointe) et Mistral Medium 3. Ces résultats démontrent la solide capacité de R&D de Mistral AI dans différentes tailles de modèles et domaines d’application, en particulier dans la génération de code, le traitement multimodal et la technologie OCR où elle a pris la tête. (Source: qtnx_)

Fluctuations récentes des performances du modèle Claude, les utilisateurs signalent des problèmes de traitement du contexte et de la fonction Artifact: Des utilisateurs de la communauté Reddit signalent que le modèle Claude d’Anthropic (en particulier Opus 3) a récemment rencontré des problèmes de traitement de contextes longs, de stabilité de la génération d’Artifact, ainsi que de connexion et de temps de disponibilité. Cela se manifeste par des interruptions de chat après un petit nombre de tours, ou par l’incapacité de la fonction Artifact à se terminer ou à exporter des fichiers vides. La page d’état d’Anthropic confirme une augmentation des erreurs de requêtes à contexte long et plusieurs interruptions de service de courte durée, potentiellement liées au lancement de la fonction Artifact et à des ajustements du backend. Certains utilisateurs ont atténué les problèmes en demandant directement une sortie Markdown, en changeant de réseau ou en utilisant Claude 3.5 Sonnet. (Source: Reddit r/ClaudeAI, qtnx_, Reddit r/ClaudeAI)
xAI rend publics les prompts système de Grok, révélant sa conception axée sur l’humour et la pensée critique: La société xAI a rendu publics les prompts système de son modèle d’IA Grok. Ces prompts révèlent que Grok a été conçu comme un assistant IA doté d’humour, d’un esprit légèrement rebelle et d’une pensée critique. Les prompts soulignent que Grok doit éviter les réponses moralisatrices et l’encouragent à adopter un « style Grok » unique lorsqu’il aborde des sujets controversés. Cette initiative accroît la transparence dans la conception du comportement des modèles d’IA et permet au public de découvrir l’origine de la personnalité unique de Grok. (Source: Reddit r/artificial)

Meta testerait le modèle Llama 3.3 8B Instruct sur OpenRouter: Meta serait en train de tester son modèle Llama 3.3 8B Instruct sur la plateforme OpenRouter. Ce modèle est décrit comme une version légère et rapide du Llama 3.3 70B, avec une fenêtre de contexte de 128 000 tokens, et est affiché comme gratuit sur OpenRouter. Certains utilisateurs l’ayant testé estiment que sa sortie est légèrement plus fade par rapport aux versions 8B 3.1 ou 3.3 70B. Cette démarche pourrait signifier que Meta explore le déploiement et les scénarios d’application de modèles de différentes tailles. (Source: Reddit r/LocalLLaMA)
Une décision arbitrale controversée de l’IA en Formule 1 suscite le débat: Une discussion concernant une décision arbitrale controversée prise par une IA lors d’une course de Formule 1 a attiré l’attention sur l’application de l’IA dans le domaine des compétitions sportives. Bien que les détails spécifiques ne soient pas clairs, cela concerne généralement la précision et l’impartialité des systèmes d’arbitrage par IA dans des situations rapides et complexes, ainsi que la manière dont les arbitres humains et les systèmes d’IA peuvent collaborer. (Source: Ronald_vanLoon)
Le premier porte-avions drone de la Chine, le « Jiutian », devrait effectuer son premier vol en juin: La Chine prévoit d’effectuer en juin le premier vol de son premier porte-avions drone aérien, le « Jiutian » SS-UAV. Ce drone peut naviguer à une altitude de 15 000 mètres, transporter plus de 100 petits drones ou 1 000 kg de missiles, et a une portée de 7 000 kilomètres. Cette nouvelle a suscité l’attention sur le développement de la technologie des drones militaires chinois. (Source: menhguin)
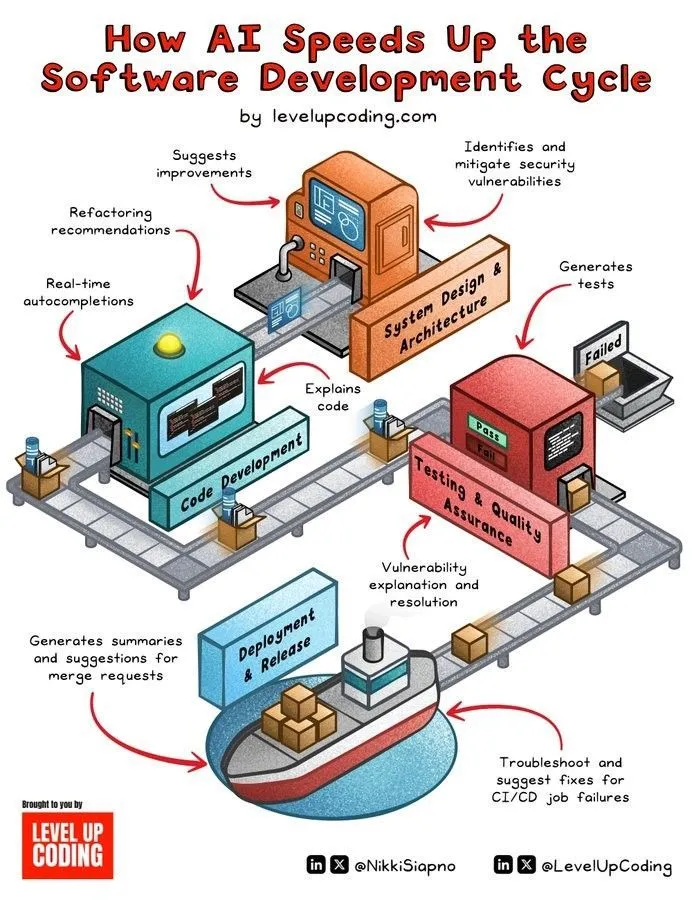
L’IA accélère le cycle de développement logiciel: La technologie de l’IA accélère considérablement le cycle de vie du développement logiciel en automatisant des tâches telles que la génération de code, les tests, le débogage et la rédaction de documentation. Les outils d’IA aident les développeurs à améliorer leur efficacité, à réduire les tâches répétitives et peuvent potentiellement identifier des erreurs, réduisant ainsi les délais de mise sur le marché des produits. (Source: Ronald_vanLoon)
Une technologie miniature de type cérébral confère aux robots humanoïdes des capacités de perception et de réflexion en temps réel: Une technologie miniature imitant la structure du cerveau humain est en cours de développement, visant à doter les robots humanoïdes de capacités de perception visuelle et de réflexion en temps réel. Cette technologie pourrait impliquer le calcul neuromorphique ou la conception de puces d’IA efficaces, dans le but de permettre aux robots de réagir plus rapidement et plus intelligemment dans des environnements complexes. (Source: Ronald_vanLoon)

Fourier Intelligence dévoile son robot humanoïde auto-développé Fourier GR-1: Fourier Intelligence (Fourier Robots) a lancé son robot humanoïde auto-développé GR-1. La conception de ce robot met l’accent sur un contrôle avancé du mouvement et une structure corporelle hautement biomimétique, visant à obtenir des capacités de mouvement plus flexibles et naturelles, démontrant les progrès de la Chine dans le domaine des robots humanoïdes. (Source: Ronald_vanLoon)
Mise à niveau de l’agilité du robot biomimétique Unitree G1: La société Unitree a présenté une version améliorée de l’agilité de son robot biomimétique G1. Cela signifie généralement que le robot a été amélioré en termes de contrôle du mouvement, de capacité d’équilibre, d’adaptabilité à l’environnement, etc., lui permettant d’exécuter des tâches plus flexibles et de faire face à des terrains complexes. (Source: Ronald_vanLoon)
Des robots humanoïdes chinois effectuent des tâches de contrôle qualité: Des robots humanoïdes chinois sont désormais utilisés pour effectuer des tâches de contrôle qualité. Cela indique que l’application des robots humanoïdes dans le domaine de l’automatisation industrielle s’étend progressivement, utilisant leur flexibilité et leurs capacités de perception pour remplacer ou assister le travail humain dans des tâches d’inspection répétitives et exigeantes en précision. (Source: Ronald_vanLoon)
Des nano-robots porteurs d’« armes cachées » tuent les cellules cancéreuses: Une nouvelle avancée en technologie médicale montre que des nano-robots peuvent transporter des « armes cachées » pour cibler et tuer avec précision les cellules cancéreuses. Cette technologie utilise la taille minuscule et la contrôlabilité des nano-robots, et pourrait permettre des traitements anticancéreux plus précis et avec moins d’effets secondaires. (Source: Ronald_vanLoon)
L’importance des technologies d’amélioration de la confidentialité (PET) pour les entreprises modernes ne cesse de croître: Avec le durcissement des réglementations sur la confidentialité des données et la sensibilisation accrue des utilisateurs à la protection des informations personnelles, les technologies d’amélioration de la confidentialité (PETs) deviennent de plus en plus importantes pour les entreprises modernes. Ces technologies, telles que l’apprentissage fédéré et le chiffrement homomorphe, permettent l’analyse des données et l’extraction de valeur tout en protégeant la confidentialité des données, aidant ainsi les entreprises à se développer en conformité. (Source: Ronald_vanLoon)

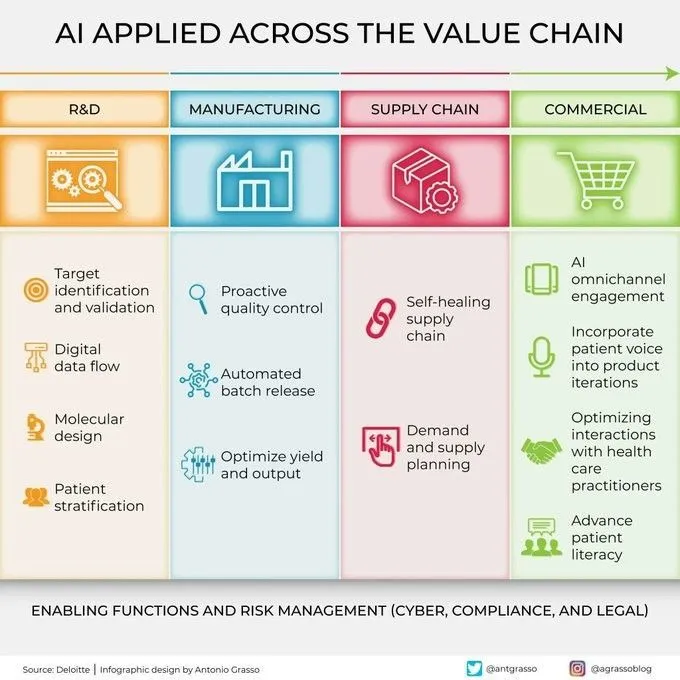
L’IA est de plus en plus utilisée à tous les maillons de la chaîne de valeur: La technologie de l’intelligence artificielle est largement appliquée à tous les maillons de la chaîne de valeur des entreprises, y compris la R&D, la production, le marketing, les ventes et le service après-vente. Grâce à l’analyse de données, la modélisation prédictive, l’automatisation des processus, etc., l’IA aide les entreprises à optimiser leur efficacité opérationnelle, à améliorer l’expérience client et à créer une nouvelle valeur commerciale. (Source: Ronald_vanLoon)
🧰 Outils
KernelSU : Solution de root Android basée sur le noyau: KernelSU est une solution de root basée sur le noyau conçue pour les appareils Android. Elle fournit une gestion de su et d’accès root au niveau du noyau, et dispose d’un système de modules basé sur OverlayFS ainsi que de fonctionnalités de profils d’application, visant à un contrôle plus approfondi des permissions de l’appareil. Le projet prend en charge les appareils Android GKI 2.0 (noyau 5.10+), est également compatible avec les anciennes versions du noyau (4.14+, compilation manuelle requise), et prend en charge WSA, ChromeOS et les environnements Android conteneurisés. (Source: GitHub Trending)

Sunshine : Hôte de streaming de jeux auto-hébergé, compatible Moonlight: Sunshine est un logiciel open-source d’hôte de streaming de jeux auto-hébergé, permettant aux utilisateurs de diffuser l’écran de leurs jeux PC vers divers appareils compatibles Moonlight. Il prend en charge l’encodage matériel pour les GPU AMD, Intel et Nvidia, et propose également des options d’encodage logiciel, visant à une expérience de cloud gaming à faible latence. Les utilisateurs peuvent configurer et appairer les clients via une interface Web UI. (Source: GitHub Trending)

Tasmota : Firmware alternatif open-source pour les appareils ESP8266/ESP32: Tasmota est un firmware alternatif conçu pour les appareils intelligents basés sur les puces ESP8266 et ESP32. Il offre une interface utilisateur Web facile à utiliser pour la configuration, prend en charge les mises à jour OTA en ligne, permet l’automatisation via des minuteries ou des règles, et offre un contrôle local complet via les protocoles MQTT, HTTP, série ou KNX, améliorant ainsi l’extensibilité et la personnalisation des appareils. (Source: GitHub Trending)
Limbo : Projet d’évolution moderne de SQLite en Rust: Le projet Limbo vise à construire une version moderne évoluée de SQLite en langage Rust. Il prend en charge l’I/O asynchrone io_uring sous Linux, est compatible avec le dialecte SQL, le format de fichier et l’API C de SQLite, et fournit des liaisons pour les langages JavaScript/WASM, Rust, Go, Python et Java. Des plans futurs incluent l’intégration de la recherche vectorielle, l’amélioration de l’écriture concurrente et la gestion des schémas. (Source: GitHub Trending)

Ventoy : Solution de nouvelle génération pour clés USB bootables: Ventoy est un outil open-source pour créer des clés USB bootables, prenant en charge le démarrage direct à partir de fichiers image aux formats ISO, WIM, IMG, VHD(x), EFI, etc., sans avoir besoin de reformater la clé USB à plusieurs reprises. Les utilisateurs n’ont qu’à copier les fichiers image sur la clé USB, et Ventoy générera automatiquement un menu de démarrage. Il prend en charge plusieurs systèmes d’exploitation et modes de démarrage (Legacy BIOS, UEFI), et est compatible avec les partitions MBR et GPT. (Source: GitHub Trending)

Doctor : Outil de web crawling et de compréhension intelligent pour agents LLM, optimisé par LangChain: Doctor est un outil qui aide les agents LLM à crawler et à comprendre le contenu web en temps réel. Il combine le traitement de pages web, la recherche vectorielle et les capacités de traitement de documents de LangChain, et fournit des services via FastAPI. Les utilisateurs peuvent utiliser Doctor pour améliorer les capacités d’acquisition et d’analyse d’informations de leurs applications d’IA. (Source: LangChainAI, Hacubu)
Deep Research Agent : Agent de recherche IA fonctionnant localement et protégeant la vie privée: Un agent IA open-source axé sur la protection de la vie privée, qui peut fonctionner localement pour effectuer des recherches sur n’importe quel sujet. Il utilise LangGraph pour piloter son flux de travail de recherche itératif, offrant aux utilisateurs un puissant outil de recherche localisé sans avoir besoin de télécharger des données sur le cloud. (Source: LangChainAI, Hacubu)

Assistant de terminal intelligent : Outil multi-OS de conversion du langage naturel en lignes de commande: Un assistant de terminal intelligent capable de convertir des instructions en langage naturel en commandes de terminal multi-systèmes d’exploitation. Cet outil est construit sur un système multi-agents LangGraph et utilise les protocoles A2A et MCP pour une exécution multiplateforme, visant à simplifier les opérations en ligne de commande et à réduire la barrière à l’entrée pour les utilisateurs. (Source: LangChainAI)

Montelimar : Boîte à outils OCR open-source pour appareils: Julien Blanchon a lancé Montelimar, une boîte à outils open-source de reconnaissance optique de caractères (OCR) pour appareils. Elle permet de faire des captures d’écran et d’appliquer l’OCR à différentes parties de l’écran, compatible avec les modèles Nougat et OCRS, avec des backends respectifs en Rust (OCRS) et MLX (Nougat). L’outil peut exporter en LaTeX, tableaux, Markdown (via Nougat, plus lent) et texte brut (via OCRS, plus rapide), et offre un historique ainsi que des raccourcis clavier au niveau du système. (Source: awnihannun)
OpenF5 TTS : Modèle de synthèse vocale commercial sous licence Apache 2.0: OpenF5 TTS est un modèle de synthèse vocale ré-entraîné basé sur le modèle F5-TTS, sous licence open-source Apache 2.0, utilisable à des fins commerciales. Ce modèle est actuellement très populaire parmi les modèles de synthèse vocale sur Hugging Face, offrant aux développeurs une option de synthèse vocale de haute qualité et commercialisable. (Source: ClementDelangue)
Tensor Slayer : Outil pour améliorer les performances des modèles sans entraînement: Tensor Slayer est un nouvel outil qui prétend améliorer les performances des modèles de 25 % grâce au « direct tensor patching » (correction directe des tenseurs), sans nécessiter de fine-tuning, de jeux de données, de coûts de calcul supplémentaires ou de temps d’entraînement. Ce concept est assez disruptif et vise à démocratiser l’amélioration des modèles d’IA. (Source: TheZachMueller)
Photoshop utilise un agent local (c/ua) pour des opérations sans code: Computer Use Agents (c/ua) montre comment réaliser des opérations sans code dans Photoshop grâce à des invites utilisateur, une sélection de modèles, Docker et une boucle d’agent appropriée. Cela vise à réduire la barrière à l’entrée pour les utilisateurs ordinaires utilisant des logiciels complexes, en simplifiant le flux de travail grâce à des agents IA. (Source: Reddit r/artificial)
PlainRepo : Application hors ligne pour copier sélectivement de gros blocs de code/texte pour l’extraction de contexte par les LLM: PlainRepo est une application gratuite et open-source fonctionnant hors ligne, qui permet aux utilisateurs de copier sélectivement de grandes portions de code ou de texte afin que les LLM locaux puissent en extraire des informations contextuelles. Ceci est très utile pour les utilisateurs qui ont besoin d’utiliser des LLM locaux sans connexion réseau ou pour des raisons de confidentialité. (Source: Reddit r/LocalLLaMA, Plus-Garbage-9710)
M0D.AI : Cadre de contrôle d’interaction IA personnalisé, co-créé par un utilisateur et une IA sur cinq mois: L’utilisateur James O’Kelly, grâce à une collaboration approfondie avec des IA (comme Gemini, ChatGPT) pendant cinq mois et environ 13 000 conversations, a construit un cadre d’interaction et de contrôle IA hautement personnalisé nommé M0D.AI. Le système comprend un backend Python, un serveur web Flask, une interface utilisateur frontale dynamique et une couche métacognitive nommée mematrix.py pour surveiller et guider le comportement de l’IA. M0D.AI montre comment un utilisateur sans formation en programmation peut, avec l’aide de l’IA, concevoir et développer des systèmes logiciels complexes. (Source: Reddit r/artificial)
📚 Apprentissage
Ingénierie LLM : Référentiel de cours de 8 semaines pour maîtriser l’IA et les LLM: Un cours de 8 semaines intitulé « LLM Engineering – Master AI and LLMs » vise à aider les participants à maîtriser l’ingénierie des grands modèles de langage. Le dépôt GitHub associé au cours fournit le code des projets hebdomadaires, des guides d’installation (PC, Mac, Linux) et des liens Colab. Le cours met l’accent sur la pratique, en commençant par l’installation d’Ollama pour exécuter Llama 3.2, puis en approfondissant HuggingFace, l’utilisation des API, le fine-tuning des modèles, etc. Il fournit également des instructions pour utiliser Ollama comme alternative gratuite aux API payantes comme celles d’OpenAI. (Source: GitHub Trending)

Cohérence probabiliste dans les LLM : fondements théoriques et étude des différences empiriques: Un article intitulé « Cohérence probabiliste dans les LLM : fondements théoriques et différences empiriques » souligne que les grands modèles de langage (LLM) utilisent une stratégie fixe pour calculer les probabilités des tokens, mais que les performances réelles des modèles avec différents ordres de tokens s’écartent de la cohérence probabiliste théorique. L’étude, en entraînant un modèle GPT-2 sur des textes de neurosciences (en utilisant des ordres de tokens avant, arrière et permutés), démontre que la perplexité est théoriquement indépendante de l’ordre, mais que les résultats empiriques montrent que le modèle échoue à ce test en raison de biais architecturaux. Les biais d’attention (locaux et à longue portée) sont considérés comme la cause directe des échecs de cohérence observés. (Source: menhguin)

BoldVoice utilise l’apprentissage automatique pour quantifier et guider l’intensité de l’accent anglais: L’application BoldVoice utilise l’apprentissage automatique et des techniques d’espace latent pour quantifier l’intensité de l’accent anglais et fournir aux utilisateurs des conseils de prononciation. Cette méthode vise à aider les utilisateurs à améliorer plus efficacement leur prononciation et leur accent en anglais. (Source: dl_weekly)
Blog Milvus : Défis et optimisations pour un filtrage efficace des métadonnées en production tout en maintenant un rappel élevé: Milvus a publié un article de blog pratique explorant comment, dans la recherche vectorielle en environnement de production, effectuer un filtrage efficace des métadonnées tout en maintenant un taux de rappel élevé. L’article discute des défis associés et propose des stratégies d’optimisation. (Source: dl_weekly)
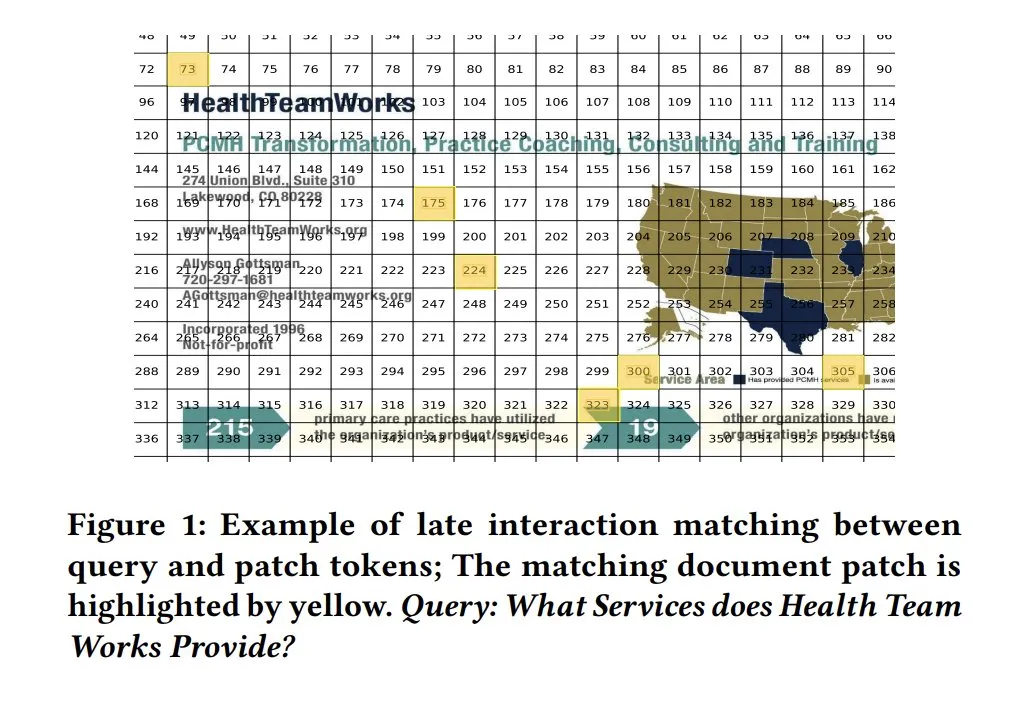
Cartes de similarité ColPali pour l’interprétabilité des modèles: Les cartes de similarité (similarity maps) dans les modèles de recherche de documents visuels comme ColPali offrent une forte interprétabilité pour la correspondance au niveau des fragments de requête et de document. En visualisant quelles régions de l’image sont pertinentes pour la requête via des cartes de chaleur, par exemple, cela aide à comprendre le processus de décision du modèle. Tony Wu fournit un guide de démarrage rapide à ce sujet. (Source: lateinteraction, tonywu_71, lateinteraction)
soarXiv : Une belle façon d’explorer la connaissance humaine: Jinay lance soarXiv, une plateforme visant à explorer les articles de recherche scientifique d’une manière plus esthétique et interactive. Les utilisateurs peuvent remplacer « arxiv » par « soarxiv » dans l’URL d’un article ArXiv pour localiser et parcourir cet article dans une interface ressemblant à une carte du ciel cosmique. La plateforme a intégré 2,8 millions d’articles jusqu’en avril 2025. (Source: menhguin)
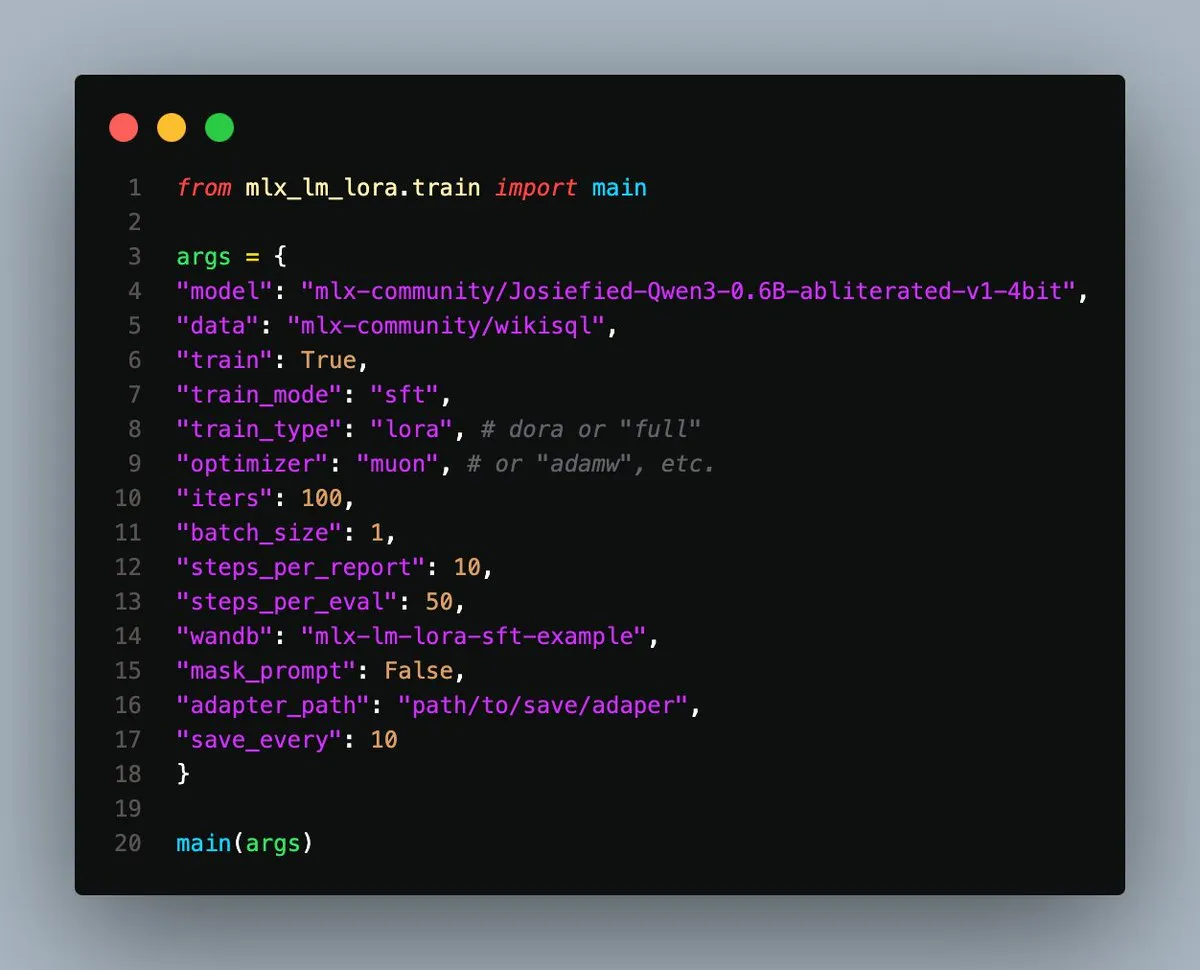
Sortie de MLX-LM-LoRA v0.3.3, simplifiant le fine-tuning local sur Apple Silicon: Gökdeniz Gülmez a publié la version v0.3.3 de MLX-LM-LoRA, simplifiant et flexibilisant davantage le processus de fine-tuning local des modèles sur Apple Silicon. La nouvelle version permet de définir le nombre d’époques (epochs) d’entraînement directement dans la configuration d’entraînement ou en ligne de commande, et fournit des scripts d’exemple et des Notebooks, y compris des cas de fine-tuning de base et d’entraînement avancé des préférences avec DPO, ne nécessitant qu’environ 20 lignes de code pour commencer. (Source: awnihannun)
Analyse des fuites de prompts système : révélation de l’architecture interne et des règles de comportement des principaux LLM: Simbaproduz a publié sur GitHub un projet analysant de manière exhaustive les récentes fuites de prompts système des principaux grands modèles de langage (tels que Claude 3.7, ChatGPT-4o, Grok 3, Gemini, etc.). Ce guide explore en profondeur l’architecture interne, la logique opérationnelle et les règles de comportement de ces modèles, y compris la persistance des informations, les stratégies de traitement d’images, les méthodes de navigation sur le Web, les systèmes de personnalisation et les mécanismes de défense contre la manipulation contradictoire. Ces informations ont une valeur de référence importante pour la construction d’outils LLM, d’agents intelligents et de systèmes d’évaluation. (Source: Reddit r/MachineLearning)
Un article de l’ICML 2025 explore la décomposition fréquentielle des perturbations adverses sur les images: Un article Spotlight de l’ICML 2025 de l’Université de l’Académie chinoise des sciences et de l’Institut de technologie informatique, intitulé « Diffusion-based Adversarial Purification from the Perspective of the Frequency Domain », propose que les perturbations adverses ont tendance à dégrader davantage le spectre d’amplitude et de phase des hautes fréquences des images. Sur cette base, les chercheurs proposent d’injecter les informations de basse fréquence de l’échantillon original comme a priori dans le processus inverse des modèles de diffusion pour guider la génération d’échantillons propres, éliminant ainsi efficacement les perturbations adverses tout en préservant le contenu sémantique de l’image. (Source: WeChat)

Article ICML 2025 TokenSwift : Accélération par 3 de la génération de textes longs de niveau 100K grâce à l’« auto-complétion »: L’équipe NLCo de BIGAI a publié un article à l’ICML 2025 intitulé « TokenSwift: Lossless Acceleration of Ultra Long Sequence Generation », proposant un cadre d’accélération efficace et sans perte, TokenSwift, pour l’inférence de textes longs de niveau 100K tokens. Ce cadre, grâce à des mécanismes tels que l’ébauche parallèle de plusieurs tokens, la complétion heuristique par n-grammes, la validation parallèle par structure arborescente et la gestion dynamique du cache KV, permet une accélération de l’inférence de plus de 3 fois tout en maintenant la cohérence avec la sortie du modèle original, améliorant ainsi considérablement l’efficacité de la génération de séquences ultra-longues. (Source: WeChat)

💼 Affaires
OpenAI accusé d’alimenter la course aux armements en IA qu’il avait autrefois mise en garde: Un article de Bloomberg explore comment OpenAI, après le lancement de ChatGPT, est passé d’une organisation méfiante vis-à-vis des risques de l’IA à un acteur clé stimulant la course à la technologie de l’IA. L’article analyse probablement le changement stratégique d’OpenAI, les pressions de commercialisation et l’impact de ses actions sur l’orientation générale de l’industrie de l’IA et les considérations de sécurité. (Source: Reddit r/ArtificialInteligence)

L’administration Trump met fin à près de 3 milliards de dollars de financement de la recherche pour l’Université Harvard, déclenchant une course mondiale aux talents: L’administration Trump a mis fin à près de 3 milliards de dollars de financement de la recherche pour l’Université Harvard, affectant plus de 350 projets, une décision considérée comme un coup dur pour le système de recherche américain. Parallèlement, l’Union européenne, le Canada, l’Australie et d’autres pays et régions ont lancé des programmes de subventions de plusieurs dizaines de millions de dollars pour attirer les meilleurs scientifiques américains touchés, suscitant un débat sur les flux mondiaux de talents scientifiques. L’Université Harvard a intenté une action en justice et a débloqué 250 millions de dollars pour atténuer la crise. (Source: WeChat)

La start-up d’IA Spellbook enregistre une croissance continue de la valeur contractuelle annuelle moyenne (ACV) pour la troisième année consécutive: Malgré les craintes que la marchandisation de la technologie de l’IA puisse entraîner une pression sur les prix, Scott Stevenson, co-fondateur de la start-up de logiciels juridiques d’IA Spellbook, a déclaré que la valeur contractuelle annuelle moyenne (ACV) de son entreprise a augmenté pour la troisième année consécutive. Il estime que les équipes qui agissent rapidement peuvent continuellement créer de la nouvelle valeur grâce aux produits d’IA, compensant ainsi la pression potentielle à la baisse des prix. (Source: scottastevenson)
🌟 Communauté
Dixième anniversaire de DeepDream : une étape clé de l’art IA et son impact profond: Alex Mordvintsev, créateur de DeepDream, revient sur la naissance de cet outil d’art IA phénoménal il y a dix ans. Cristóbal Valenzuela, co-fondateur de Runway, partage également comment DeepDream l’a inspiré à se lancer dans le domaine de l’art IA et à co-fonder finalement Runway. L’apparition de DeepDream a marqué une première démonstration du potentiel de l’IA dans le domaine de la création artistique et a eu un impact profond sur le développement ultérieur de l’art génératif et des outils de création de contenu par IA. (Source: c_valenzuelab)

Débat animé sur la nécessité d’un co-fondateur technique pour l’IA: Une discussion a émergé sur les réseaux sociaux concernant le conseil de certains VC en phase de démarrage selon lequel les entrepreneurs n’auraient plus besoin de co-fondateurs techniques, un chef de produit et l’IA suffisant pour construire un produit. Ce point de vue a suscité une large controverse, Danielle Fong et d’autres exprimant leur scepticisme, suggérant que l’IA ne peut pas encore remplacer complètement le rôle central et la compréhension technique approfondie d’un fondateur technique. (Source: jonst0kes)
Discussion sur le problème des hallucinations de l’IA : causes techniques et stratégies de réponse: La communauté débat activement du problème des « hallucinations » (génération confiante d’informations fausses ou fabriquées) par les modèles de langage IA (tels que ChatGPT, Claude, etc.). Les points de discussion incluent les racines techniques des hallucinations (telles que les défauts du mécanisme d’attention, le bruit dans les données d’entraînement, le manque d’ancrage des modèles dans le monde réel, etc.), la question de savoir si le RAG ou le fine-tuning peuvent les éradiquer, comment les utilisateurs devraient aborder avec prudence les sorties des LLM, et comment les développeurs peuvent trouver un équilibre entre créativité et exactitude factuelle. Certains estiment que toutes les sorties des LLM devraient être considérées comme des hallucinations potentielles, nécessitant une vérification par l’utilisateur. (Source: Reddit r/ArtificialInteligence)
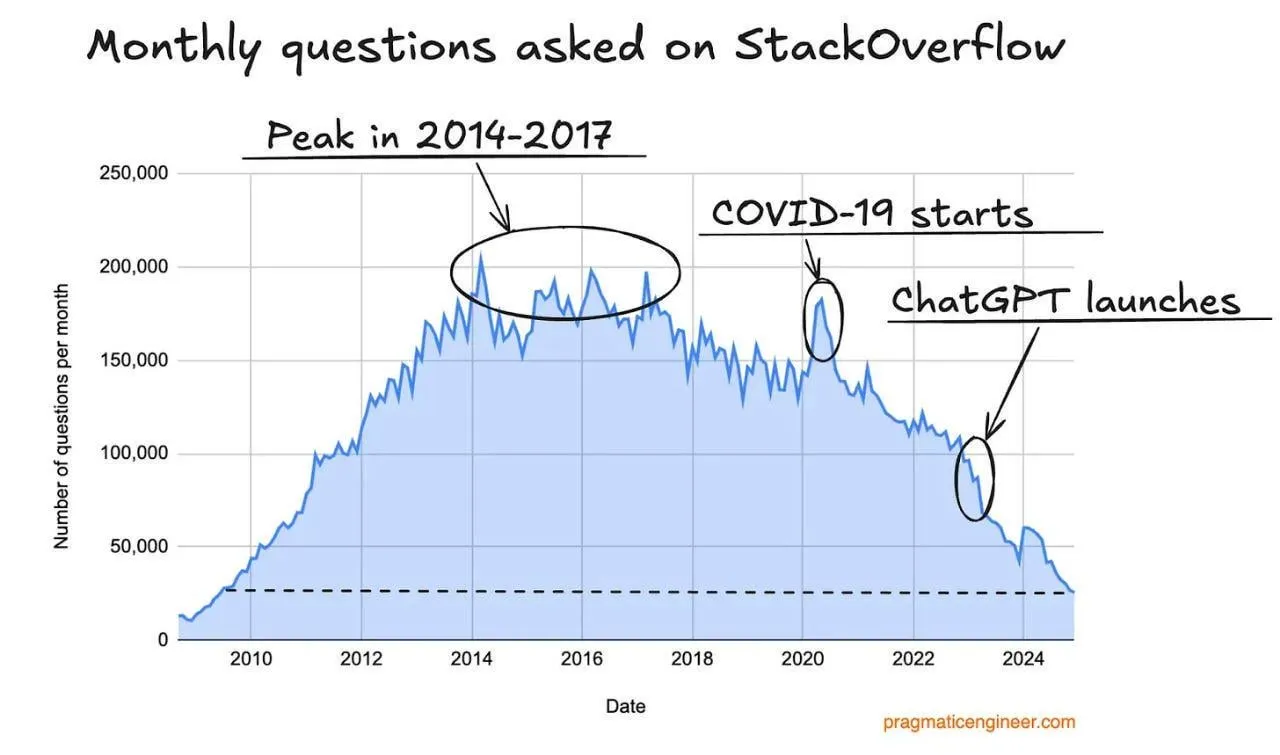
Baisse du trafic de Stack Overflow, potentiellement impacté par les assistants de programmation IA: Un utilisateur a observé une tendance à la baisse du trafic du site Stack Overflow et suppose que cela pourrait être lié à l’essor des assistants de programmation IA tels que ChatGPT. Les développeurs se tournent de plus en plus directement vers l’IA pour obtenir des extraits de code et des solutions, réduisant ainsi leur dépendance aux communautés de questions-réponses traditionnelles. Dans les commentaires, les utilisateurs estiment généralement que les assistants IA sont plus avantageux en termes de réponses directes et pour éviter les émotions négatives de la communauté, mais s’inquiètent également du fait qu’une dépendance excessive à l’IA vis-à-vis des données existantes pourrait entraîner un épuisement futur des données d’entraînement. (Source: Reddit r/ArtificialInteligence)
Un tuteur de cours d’ingénierie LLM partage ses expériences d’apprentissage et ses ressources: Ed Donner, tuteur d’un cours d’ingénierie LLM, partage la philosophie pédagogique et les ressources de son cours, soulignant l’importance d’apprendre par la pratique (DOING). Il encourage les étudiants à manipuler activement le code et fournit des guides d’installation pour PC, Mac, Linux ainsi que des liens vers des Notebooks Google Colab, facilitant l’apprentissage et l’expérimentation des étudiants dans différents environnements. Le contenu du cours couvre Ollama, HuggingFace, l’utilisation d’API, etc., et propose des solutions pour utiliser des modèles locaux en remplacement des API payantes. (Source: ed-donner)
Partage d’expérience utilisateur : Utiliser Claude pour améliorer ses capacités de réflexion et de communication: Un utilisateur de Claude Pro partage son expérience sur la manière dont l’interaction avec l’IA l’a aidé à améliorer sa façon de penser et ses compétences en communication. Grâce à ses interactions avec Claude, l’utilisateur a appris à mieux se « prompter » lui-même lors de la résolution de problèmes, à identifier les questions fondamentales, et à accorder plus d’attention à une expression claire et à l’empathie lorsqu’il communique avec ses collègues, reconnaissant ainsi le rôle positif des outils d’assistance IA dans l’amélioration des capacités cognitives et d’expression personnelles. (Source: Reddit r/ClaudeAI)
L’« écart discriminateur-générateur » pourrait être le concept central de l’innovation scientifique par l’IA: Jason Wei suggère que l’« écart discriminateur-générateur » (Discriminator-generator gap) pourrait être l’idée la plus importante de l’IA dans l’innovation scientifique. Lorsqu’on dispose d’une puissance de calcul suffisante, de stratégies de recherche intelligentes et de critères de mesure clairs, tout ce qui peut être mesuré peut être optimisé par l’IA. Ce concept met l’accent sur le processus itératif consistant à ce qu’un générateur propose des solutions et qu’un discriminateur évalue leur qualité pour stimuler l’innovation, particulièrement adapté aux environnements où la validation est rapide, où il existe une récompense continue et où la mise à l’échelle est possible. (Source: _jasonwei, dotey)
Transformation et défis des chefs de produit à l’ère de l’IA: Les réseaux sociaux discutent de l’impact de l’IA sur le poste de chef de produit. L’opinion dominante est que le secteur des chefs de produit connaîtra une transformation au cours des 18 prochains mois, et que les PM qui ne comprennent pas les besoins des utilisateurs pourraient être éliminés. Les outils d’IA (tels que les AI Agents) peuvent transformer des idées en produits en peu de temps, mais la véritable difficulté réside dans l’identification des problèmes fondamentaux des utilisateurs et la fourniture de solutions précises. Ce poste se jouera finalement sur la capacité à faire correspondre les problèmes des utilisateurs et les solutions, plutôt que sur la simple création de documents et de prototypes. (Source: dotey)
Paradoxe de la sécurité de l’IA : la superintelligence pourrait favoriser la défense: Richard Socher propose le « paradoxe de la sécurité de l’IA » : sous des hypothèses raisonnables, l’émergence de la superintelligence pourrait en fait être plus favorable à la partie défensive dans une guerre biologique ou cybernétique. Avec la baisse du coût marginal de l’intelligence, il est possible de découvrir davantage de vecteurs d’attaque grâce à des exercices de red teaming, et de renforcer ou d’immuniser les systèmes jusqu’à ce que toutes les voies d’attaque pertinentes soient couvertes. Théoriquement, lorsque le coût de la défense tend vers zéro, le système peut être complètement immunisé. Ce point de vue remet en question l’idée traditionnelle selon laquelle le développement de l’IA exacerberait l’asymétrie entre l’attaque et la défense. (Source: RichardSocher)
Débat sur les standards d’application des AI Agents : CONTRIBUTING.md pourrait être une meilleure pratique: Face à l’émergence de 9 standards concurrents pour les règles des AI Agents, un développeur propose d’utiliser directement le fichier CONTRIBUTING.md d’un projet pour normaliser le comportement des AI Agents. Ce fichier contient généralement déjà des guides de style de code, des références pertinentes et des extraits de compilation, et pourrait servir de support naturel pour les règles des AI Agents, évitant ainsi de réinventer la roue. (Source: JayAlammar)

💡 Autres
Peter Lax, auteur du manuel classique « Analyse Fonctionnelle », est décédé à l’âge de 99 ans: Le géant des mathématiques Peter Lax, premier mathématicien appliqué à recevoir le prix Abel, est décédé à l’âge de 99 ans. Le professeur Lax était célèbre pour son manuel classique « Analyse Fonctionnelle » et a apporté des contributions fondamentales dans des domaines tels que les équations aux dérivées partielles, la dynamique des fluides et le calcul numérique, comme le théorème d’équivalence de Lax, les méthodes de Lax-Friedrichs/Lax-Wendroff, etc. Il fut également l’un des pionniers de l’application des techniques informatiques à l’analyse mathématique, et ses travaux ont profondément influencé la recherche scientifique et la pratique de l’ingénierie. (Source: WeChat)

Recherche d’emploi par IA : un agent IA utilisant OpenAI Operator pour postuler à mille emplois en un clic suscite le débat: Une vidéo montre un agent IA utilisant l’outil Operator d’OpenAI pour postuler à 1000 postes en un seul clic. Ce phénomène a déclenché une discussion sur l’application de l’IA dans le domaine du recrutement, y compris la possibilité pour l’IA de filtrer les CV, de planifier des entretiens, voire de mener des entretiens préliminaires, ainsi que l’impact de cette automatisation sur les demandeurs d’emploi et les recruteurs. (Source: Reddit r/ChatGPT)

Le MIT retire un article d’économie lié à l’IA, soupçonné d’avoir été rédigé par une IA et dont les données sont douteuses: Le département d’économie du MIT a retiré un article rédigé par un doctorant intitulé « Intelligence Artificielle, Découverte Scientifique et Innovation de Produit », car l’université manquait de confiance dans la fiabilité des données de l’article. La communauté soupçonne que l’article a pu être en grande partie rédigé par une IA, ce qui a déclenché une discussion sur l’éthique et le contrôle qualité de l’utilisation de l’IA dans la recherche universitaire. (Source: Reddit r/ArtificialInteligence)