
Mots-clés:AlphaEvolve, Conception d’algorithmes d’IA, IA multimodale, Outils de programmation d’IA, Algorithmes d’évolution autonome, Grands modèles linguistiques, Agents intelligents d’IA, Implémentation open source d’AlphaEvolve, Conception autonome d’algorithmes de multiplication matricielle par l’IA, Interface unifiée pour l’IA multimodale, Impact des outils de programmation d’IA sur les développeurs, Performances du modèle local Qwen 3
🔥 En vedette
Google DeepMind publie AlphaEvolve, un algorithme d’IA pour la conception et l’évolution autonomes d’algorithmes: Google DeepMind a rendu public le projet AlphaEvolve et son article, présentant un agent intelligent IA capable de concevoir, tester, apprendre et faire évoluer de manière autonome des algorithmes plus efficaces. Ce système utilise le prompt engineering pour piloter de grands modèles de langage (comme Gemini) afin de générer des propositions d’algorithmes initiaux, et optimise les algorithmes dans une boucle évolutive grâce à une évaluation de l’adéquation (fitness evaluation) et à une sélection des survivants. La communauté a rapidement réagi, une implémentation open-source OpenAlpha_Evolve est apparue, et des chercheurs ont utilisé des outils tels que Claude pour vérifier les avancées d’AlphaEvolve dans des domaines comme la multiplication matricielle, démontrant l’énorme potentiel de l’IA en matière d’innovation algorithmique. (Source: karminski3, karminski3, Reddit r/ClaudeAI, Reddit r/artificial)

La stratégie multimodale d’OpenAI se dessine : l’intégration des interfaces et la centralisation de l’infrastructure suscitent l’attention: Avec les récentes sorties de produits tels que GPT-4o, Sora et Whisper, OpenAI a non seulement démontré ses progrès en matière de capacités multimodales (texte, image, audio, vidéo), mais a également révélé son intention stratégique d’intégrer plusieurs modalités dans une interface et une API unifiées. Bien que cette stratégie offre une commodité aux utilisateurs, elle soulève également des discussions sur la centralisation de l’infrastructure qui pourrait limiter l’espace d’innovation pour les développeurs et chercheurs externes. En particulier, les modèles de génération vidéo comme Sora, en raison de leurs besoins élevés en ressources de calcul, intègrent davantage d’applications à coût élevé dans l’écosystème OpenAI, ce qui pourrait exacerber la “gravité computationnelle” des plateformes de premier plan et affecter l’ouverture et le développement modulaire du domaine de l’IA. (Source: Reddit r/deeplearning)
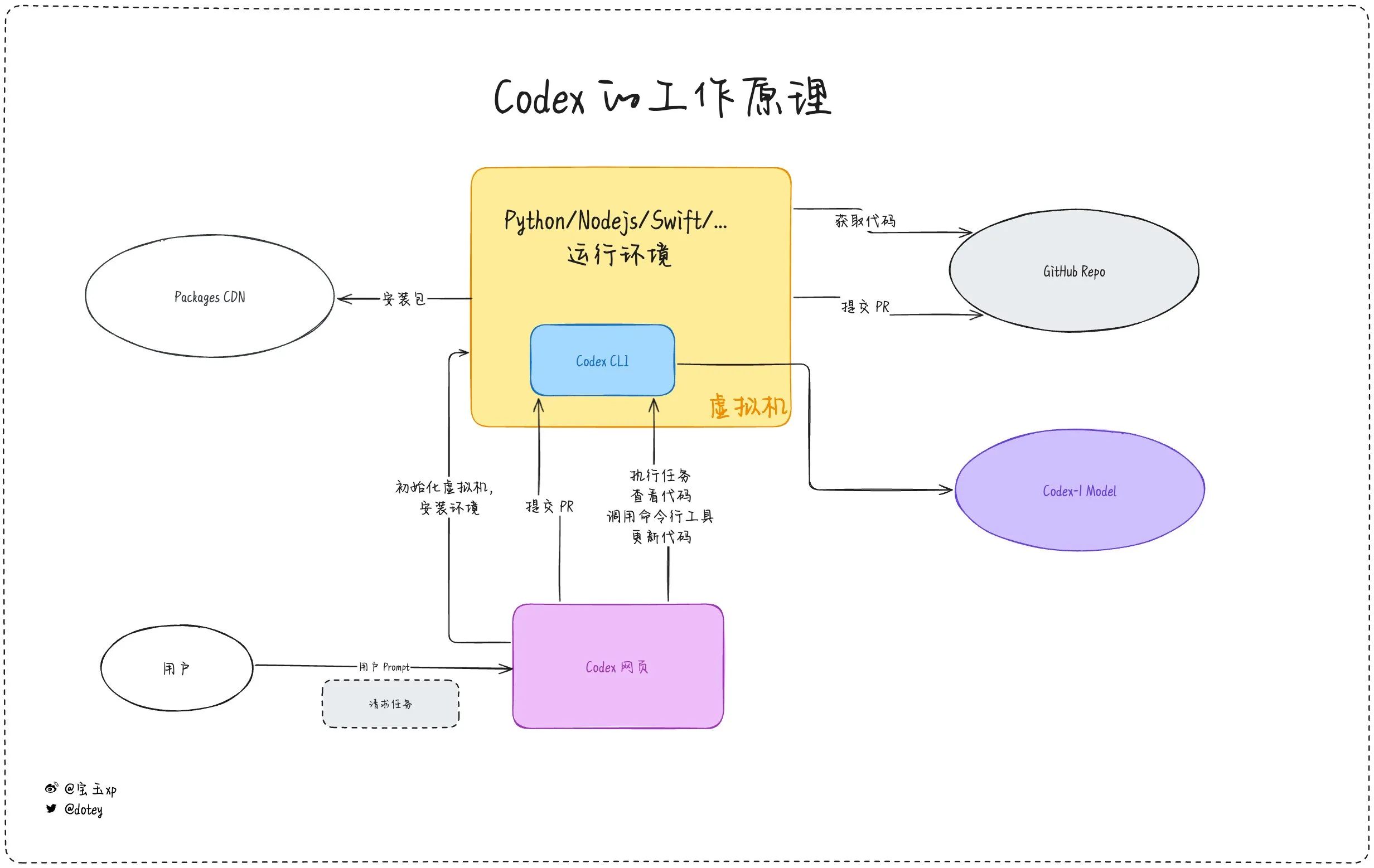
La pénétration des outils de programmation IA s’intensifie, entre expérience des développeurs et réflexions: Les outils de programmation IA tels que Codex, Devin et divers AI Agents s’intègrent de plus en plus rapidement dans les processus de développement logiciel. Les retours des développeurs montrent que Codex fait preuve d’une grande efficacité dans l’internationalisation du code, la mise à niveau de projets, etc., et peut réduire considérablement les cycles de développement. Cependant, comme le souligne l’évaluation de Codex par dotey, les outils d’IA actuels ressemblent davantage à des “employés externalisés” : bien qu’ils puissent accomplir des tâches, ils présentent encore des limites en matière de connexion réseau, de persistance des tâches et d’accumulation d’expérience. Les discussions au sein de la communauté mentionnent également que certains développeurs, après une utilisation prolongée de la programmation assistée par IA, commencent à réfléchir à son impact sur leur propre pensée et leur créativité, choisissant même de revenir à un mode de développement plus dépendant du “cerveau humain”, ce qui montre que l’équilibre entre l’amélioration de l’efficacité par les outils d’IA et le maintien des capacités fondamentales des développeurs reste un enjeu important. (Source: dotey, giffmana, cto_junior, Reddit r/artificial)
🎯 Tendances
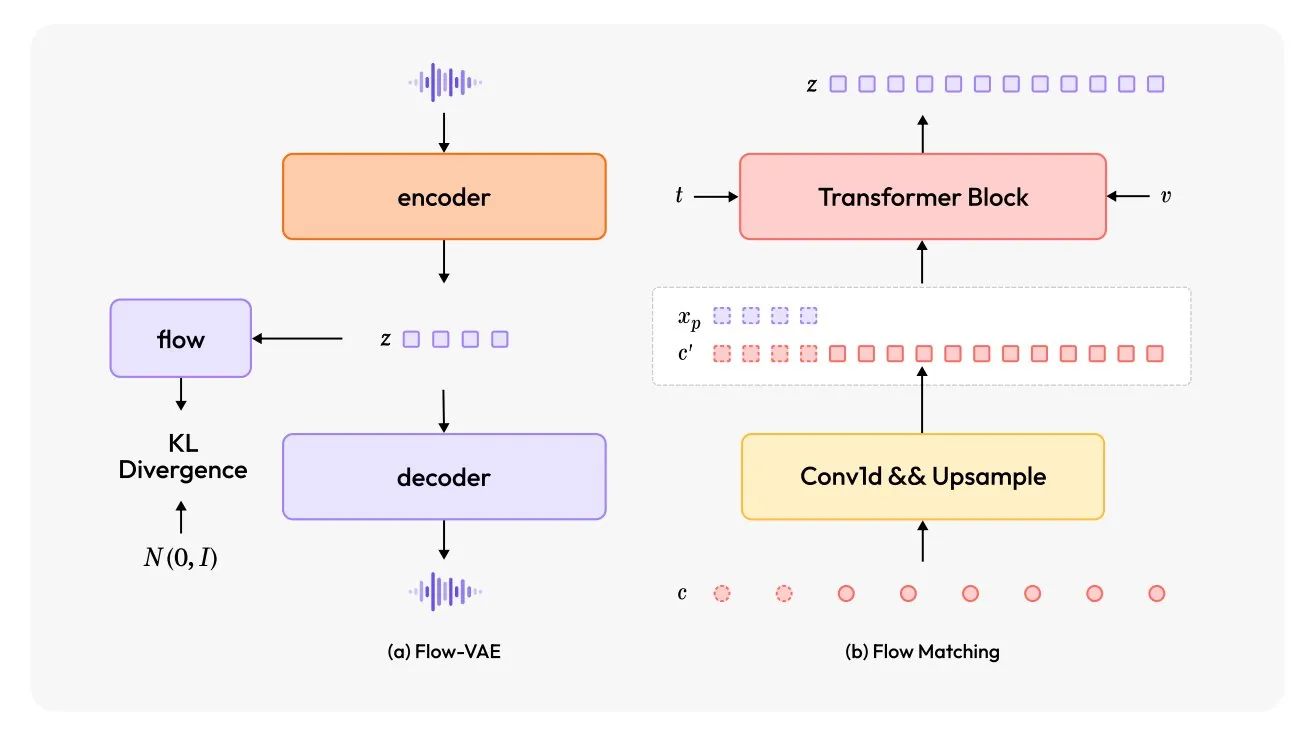
MiniMax-Speech : Lancement d’un nouveau modèle TTS multilingue: TheTuringPost a présenté MiniMax-Speech, un nouveau modèle de synthèse vocale (TTS). Ce modèle adopte deux innovations majeures : un encodeur de locuteur apprenable capable de capturer le timbre vocal à partir de courts extraits audio, et un module Flow-VAE pour améliorer la qualité audio. MiniMax-Speech prend en charge 32 langues et peut être utilisé pour ajouter des émotions à la voix, générer de la parole à partir de descriptions textuelles ou effectuer un clonage vocal zero-shot, démontrant son potentiel en matière de synthèse vocale personnalisée et de haute qualité. (Source: TheTuringPost, TheTuringPost)
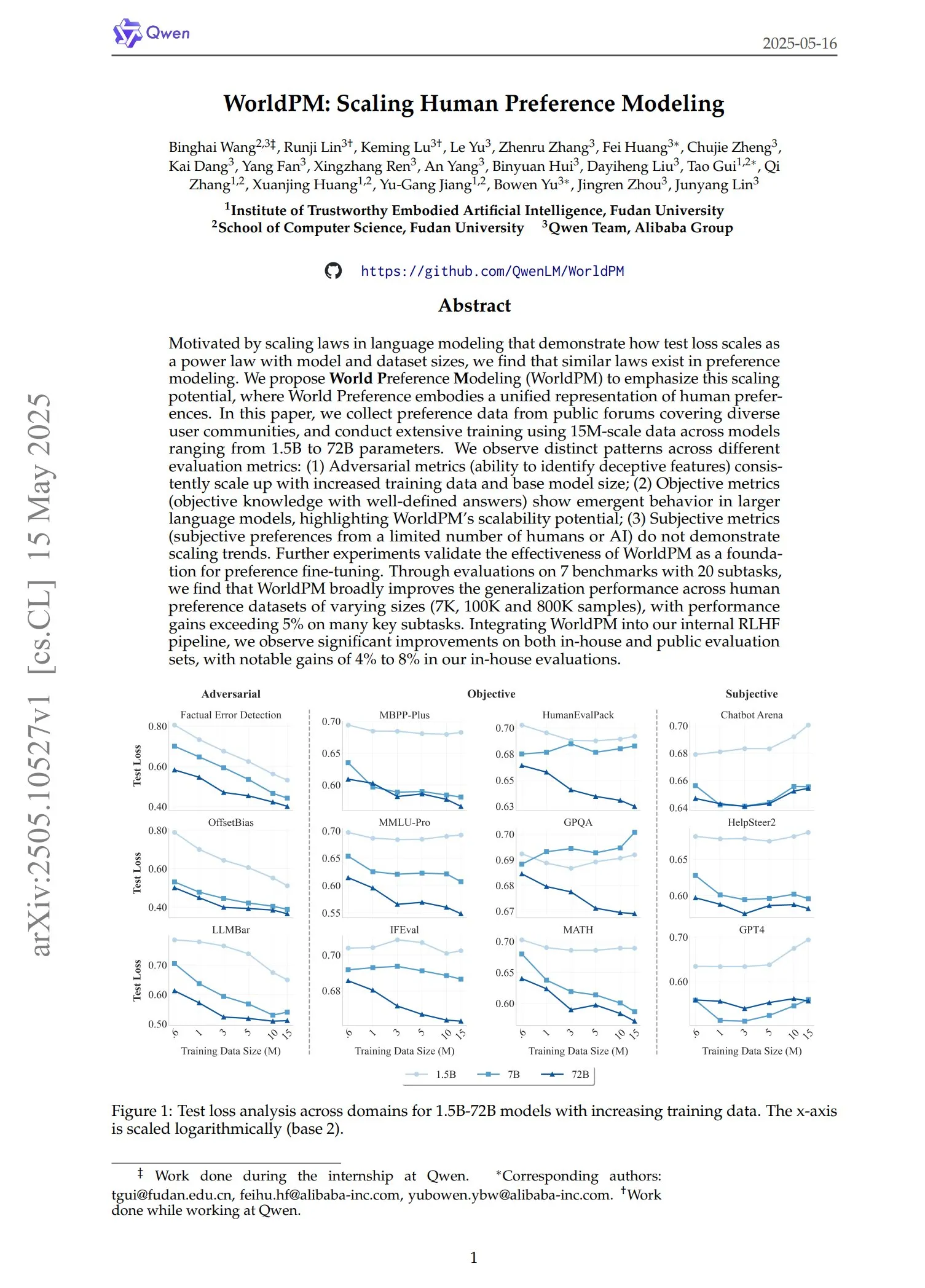
Qwen publie la série de modèles de préférence WorldPM: L’équipe Qwen a lancé quatre nouveaux modèles de modélisation des préférences : WorldPM-72B, WorldPM-72B-HelpSteer2, WorldPM-72B-RLHFLow et WorldPM-72B-UltraFeedback. Ces modèles sont principalement utilisés pour évaluer la qualité des réponses d’autres modèles et pour assister le processus d’apprentissage supervisé. Selon les déclarations officielles, l’utilisation de ces modèles de préférence pour l’entraînement permet d’obtenir de meilleurs résultats que l’entraînement à partir de zéro. Les articles de recherche correspondants ont également été publiés. (Source: karminski3)
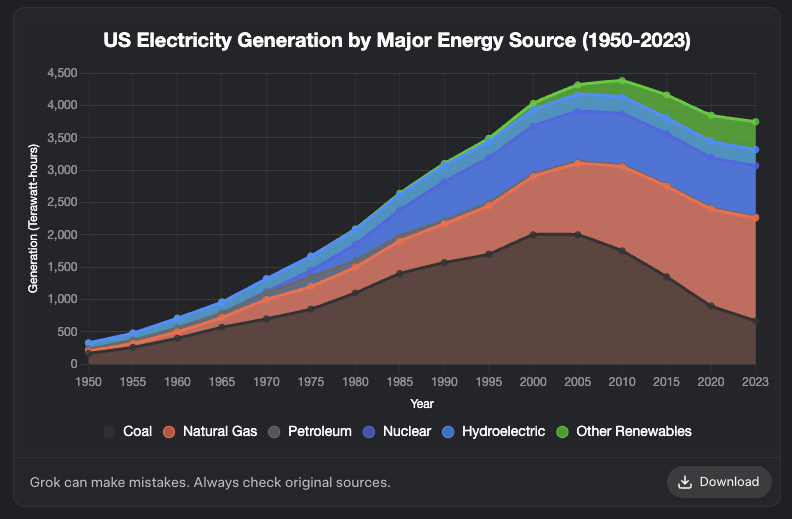
Grok ajoute une fonctionnalité de génération de graphiques: Le modèle Grok de XAI prend désormais en charge la génération de graphiques. Les utilisateurs peuvent créer des graphiques via Grok dans leur navigateur, et cette fonctionnalité devrait être étendue à d’autres plateformes dans les prochains jours. Cette mise à jour améliore les capacités de Grok en matière de visualisation de données et de présentation d’informations. (Source: grok, Yuhu_ai_, TheGregYang)
DeepRobotics lance le robot quadrupède de taille moyenne Lynx: La société DEEP Robotics a présenté son nouveau robot quadrupède de taille moyenne, Lynx. Ce robot a démontré sa capacité à se déplacer de manière stable sur des terrains complexes, reflétant les progrès de l’entreprise en matière de contrôle du mouvement robotique et de technologie de perception. Il peut être utilisé dans divers scénarios tels que l’inspection et la logistique. (Source: Ronald_vanLoon)
Sanctuary AI intègre de nouveaux capteurs tactiles à son robot à usage général: Sanctuary AI a annoncé que son robot à usage général a intégré une nouvelle technologie de capteurs tactiles. Cette amélioration vise à renforcer les capacités de perception et de manipulation d’objets du robot, lui permettant d’interagir plus finement avec son environnement, ce qui constitue une étape importante vers des robots d’intelligence artificielle générale plus performants. (Source: Ronald_vanLoon)
Le robot Unitree démontre des capacités de démarche avancées: Le robot Go2 d’Unitree Robotics a démontré plusieurs démarches avancées, notamment la marche en équilibre sur les mains, le retournement adaptatif et le franchissement d’obstacles. La réalisation de ces capacités marque une amélioration significative des algorithmes de contrôle du mouvement et de l’adaptabilité à l’environnement de ses chiens robots. (Source: Ronald_vanLoon)
Une équipe de recherche chinoise développe un robot piloté par des cellules cérébrales humaines cultivées: Selon InterestingSTEM, une équipe de recherche chinoise développe un robot piloté par des cellules cérébrales humaines cultivées en laboratoire. Cette recherche explore la fusion du calcul biologique et de la technologie robotique, visant à utiliser les capacités d’apprentissage et d’adaptation des neurones biologiques pour fournir de nouvelles idées pour le contrôle des robots. Bien qu’elle en soit encore à un stade exploratoire précoce, elle a suscité de larges discussions sur les futures formes d’intelligence robotique. (Source: Ronald_vanLoon)
Un nouveau capteur cérébral nanométrique atteint une précision de 96,4 % dans la reconnaissance des signaux neuronaux: Un nouveau type de capteur cérébral nanométrique a démontré une précision allant jusqu’à 96,4 % dans la reconnaissance des signaux neuronaux. Cette technologie pourrait être appliquée aux interfaces cerveau-machine, à la recherche en neurosciences et au diagnostic médical, offrant de nouveaux outils pour une interprétation plus précise de l’activité cérébrale. (Source: Ronald_vanLoon)

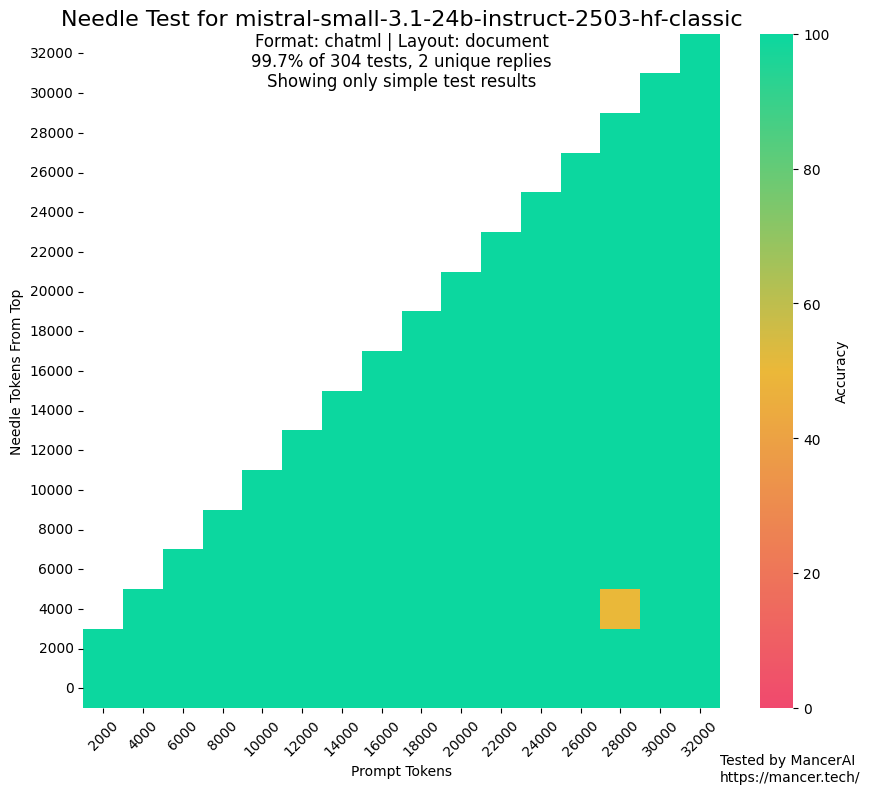
Des rumeurs selon lesquelles MistralAI utiliserait des jeux de test pour l’entraînement suscitent l’attention: Des discussions au sein de la communauté ont soulevé des doutes sur la possibilité que MistralAI ait utilisé des données de jeux de test dans des benchmarks tels que NIAH pour son entraînement. Kalomaze, en comparant les performances sur le test NIAH de GitHub avec un NIAH personnalisé (faits et questions générés de manière procédurale), a souligné que MistralAI obtenait des résultats bien supérieurs sur le premier, suggérant une possible contamination des données. Dorialexander a émis l’hypothèse qu’une “approximation synthétique” de l’ensemble d’évaluation aurait pu être utilisée pour concevoir le mélange de données, suscitant des inquiétudes quant à l’équité et à la transparence de l’évaluation des modèles. (Source: Dorialexander)
Une étude affirme que Claude 3.5 surpasse les humains en matière de persuasion: Un article de recherche sur arXiv indique que le modèle Claude 3.5 d’Anthropic surpasse les humains en termes de capacité de persuasion. Cette étude a comparé expérimentalement les performances du modèle et des humains sur des tâches de persuasion spécifiques, les résultats montrant que l’IA pourrait avoir un avantage significatif dans la construction d’arguments convaincants et la communication, ce qui a des implications potentielles pour des domaines tels que le marketing, les relations publiques et l’interaction homme-machine. (Source: Reddit r/ClaudeAI)

Les grands modèles locaux sur du matériel grand public montrent une amélioration significative de leurs capacités: Un utilisateur de Reddit rapporte que le modèle Qwen 3 avec 14 milliards de paramètres (avec un patch yarn pour supporter un contexte de 128k) sur un PC grand public avec seulement 10 Go de VRAM et 24 Go de RAM, grâce à la quantification IQ4_NL et une configuration de contexte de 80k, peut déjà faire tourner de manière satisfaisante des assistants de programmation IA comme Roo Code et Aider. Bien que la vitesse soit plus lente lors du traitement de contextes longs (par exemple 20k+), environ 2 t/s, la qualité de l’édition du code et la capacité de reconnaissance du code source sont bonnes. C’est la première fois qu’un modèle local peut gérer de manière stable des tâches de codage complexes et produire des différences de code significatives lors de conversations plus longues. Ce progrès est dû à l’amélioration du modèle lui-même, à l’optimisation des frameworks d’inférence comme llama.cpp et à l’adaptation des outils front-end comme Roo. (Source: Reddit r/LocalLLaMA)
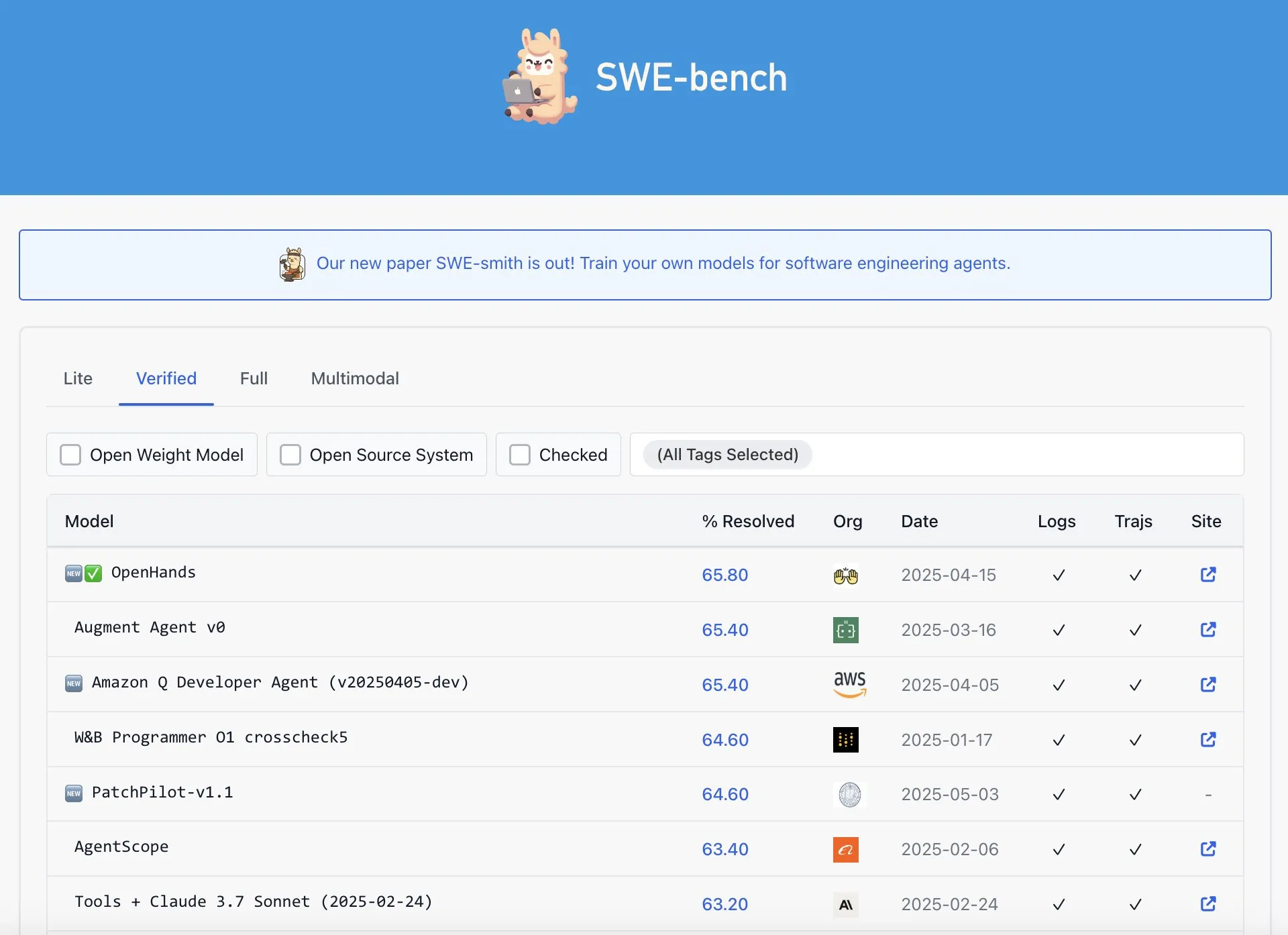
OpenAI Codex ne serait pas le meilleur sur le classement SWE-Bench Verified: Graham Neubig souligne que l’affirmation selon laquelle le modèle Codex d’OpenAI aurait obtenu des résultats SOTA (State-Of-The-Art) sur le classement SWE-Bench Verified n’est pas tout à fait exacte. En analysant les données et différents critères de mesure, il estime que, quel que soit l’angle sous lequel on examine la question, les performances de Codex sur ce benchmark spécifique sont sujettes à controverse et ne sont pas incontestablement les meilleures. (Source: JayAlammar)
🧰 Outils
OpenAlpha_Evolve open source : reproduire l’agent intelligent de conception d’algorithmes IA de Google: Suite à la publication de l’article AlphaEvolve par Google DeepMind, le développeur shyamsaktawat a rapidement lancé une implémentation open source, OpenAlpha_Evolve. Ce framework Python permet aux utilisateurs d’expérimenter les concepts de conception d’algorithmes pilotés par l’IA, y compris la définition des tâches, le prompt engineering, la génération de code (à l’aide de LLM comme Gemini), l’exécution de tests, l’évaluation de l’adéquation et la sélection évolutive, dans le but de permettre à une communauté plus large de participer à l’exploration de la conception de nouveaux algorithmes par l’IA. (Source: karminski3, Reddit r/artificial, Reddit r/LocalLLaMA)

L’éditeur Cursor ajoute une fonction d’édition rapide de fichiers entiers: Cursor, l’éditeur de code axé sur l’IA, a annoncé que les utilisateurs peuvent désormais éditer rapidement des fichiers entiers. Cette nouvelle fonctionnalité vise à améliorer l’efficacité du travail des développeurs, en rendant plus pratiques les modifications et refactorisations de code à grande échelle dans Cursor. (Source: cursor_ai)
Codex accomplit efficacement des tâches d’internationalisation et de localisation d’applications: Le développeur Katsuya a partagé son expérience de l’utilisation d’OpenAI Codex pour l’internationalisation d’applications. Il a demandé à Codex de localiser une application en japonais, une tâche qui prendrait normalement plusieurs jours, et celle-ci a été achevée en une nuit, démontrant pleinement les puissantes capacités de Codex en matière de génération automatisée de code et de traitement de tâches linguistiques complexes. (Source: gdb, ShunyuYao12)
llmbasedos : un environnement sandbox MCP sécurisé conçu pour les LLM: Le projet llmbasedos fournit un environnement de système d’exploitation basé sur une version allégée d’Arch Linux, conçu pour offrir un sandbox sécurisé de Modular Compute Protocol (MCP) aux grands modèles de langage (LLM). Il encapsule des fonctionnalités telles que le système de fichiers, la messagerie, la synchronisation et le proxy en tant que services MCP. Les utilisateurs peuvent démarrer à partir de l’ISO sur une machine virtuelle ou physique, puis appeler ces services pour une interaction et un développement sécurisés avec les LLM. (Source: karminski3)

cachelm : un outil open source de cache sémantique pour LLM améliorant l’efficacité et réduisant les coûts: Le développeur devanmolsharma a lancé l’outil open source cachelm, une couche de cache sémantique conçue pour les applications LLM. Il met en œuvre une mise en cache basée sur la similarité sémantique via la recherche vectorielle, ce qui peut réduire efficacement les appels répétitifs à l’API LLM (même si l’utilisateur formule sa question différemment), diminuant ainsi la consommation de tokens et accélérant les réponses. L’outil prend en charge OpenAI, ChromaDB, Redis, ClickHouse, etc., et permet aux utilisateurs de personnaliser les vectoriseurs, les bases de données ou les LLM. (Source: Reddit r/MachineLearning)
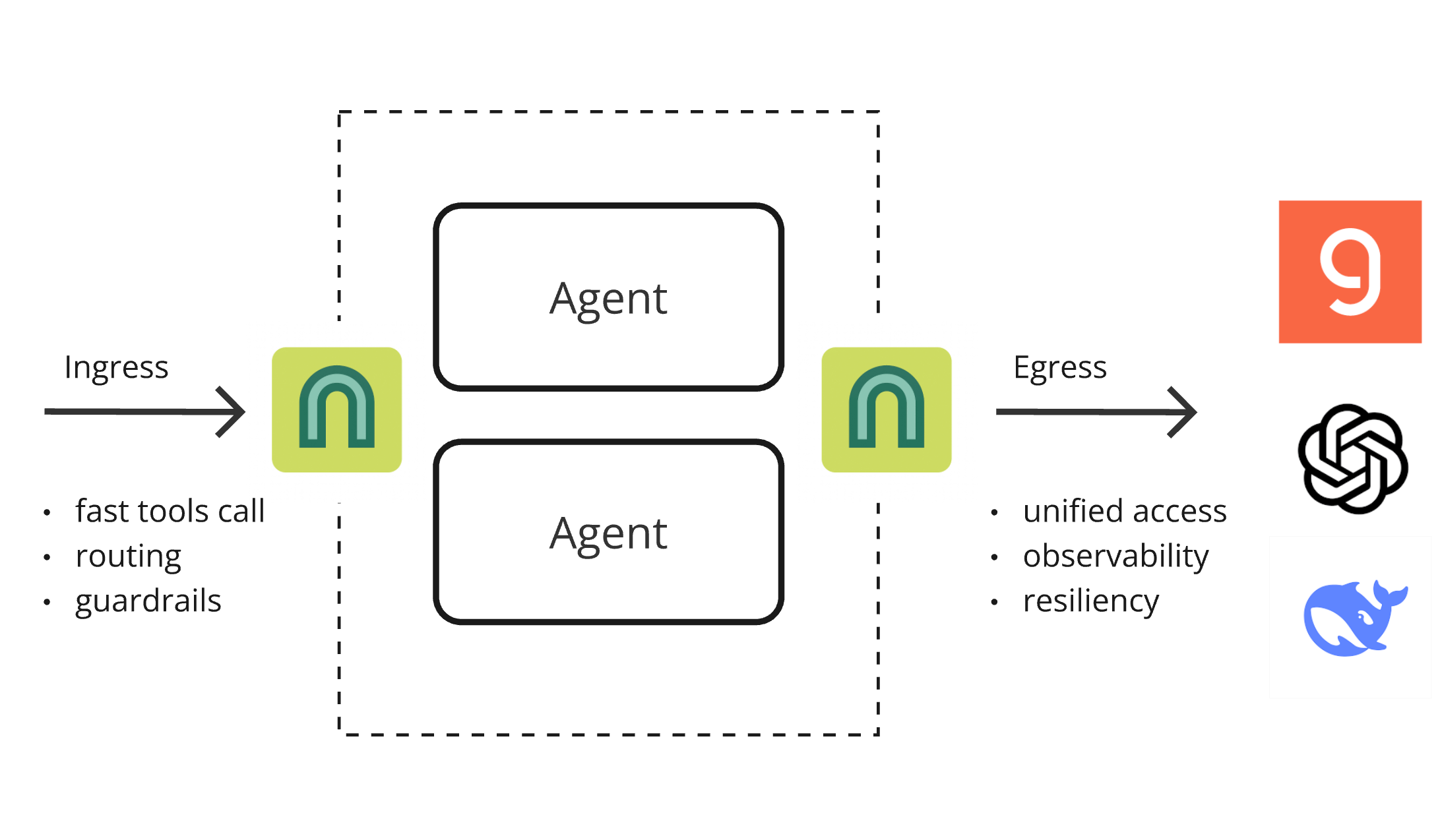
ArchGW 0.2.8 publié, un proxy natif IA unifiant les fonctionnalités de bas niveau: ArchGW a publié la version 0.2.8. Ce proxy natif IA basé sur Envoy vise à unifier les fonctionnalités “de bas niveau” répétitives dans les applications. La nouvelle version ajoute la prise en charge du trafic bidirectionnel (en préparation pour Google A2A), améliore le modèle Arch-Function-Chat 3B pour le routage rapide et l’appel d’outils, et prend en charge les LLM hébergés sur Groq. ArchGW, via un proxy local, simplifie le développement d’applications IA, améliore la sécurité, la cohérence et l’observabilité. (Source: Reddit r/artificial)
SparseDepthTransformer : un lycéen développe une solution d’optimisation de Transformer par saut de couches dynamique: Un lycéen a développé un projet nommé SparseDepthTransformer qui, grâce à un mécanisme de notation léger, évalue l’importance sémantique de chaque token et permet aux tokens non importants de sauter les calculs des couches profondes du Transformer. Les expériences montrent que cette méthode, tout en maintenant la qualité de la sortie, réduit l’utilisation de la mémoire d’environ 15 % et diminue le nombre moyen de couches traitées par token d’environ 40 %, offrant une nouvelle piste pour améliorer l’efficacité des Transformers. (Source: Reddit r/MachineLearning)

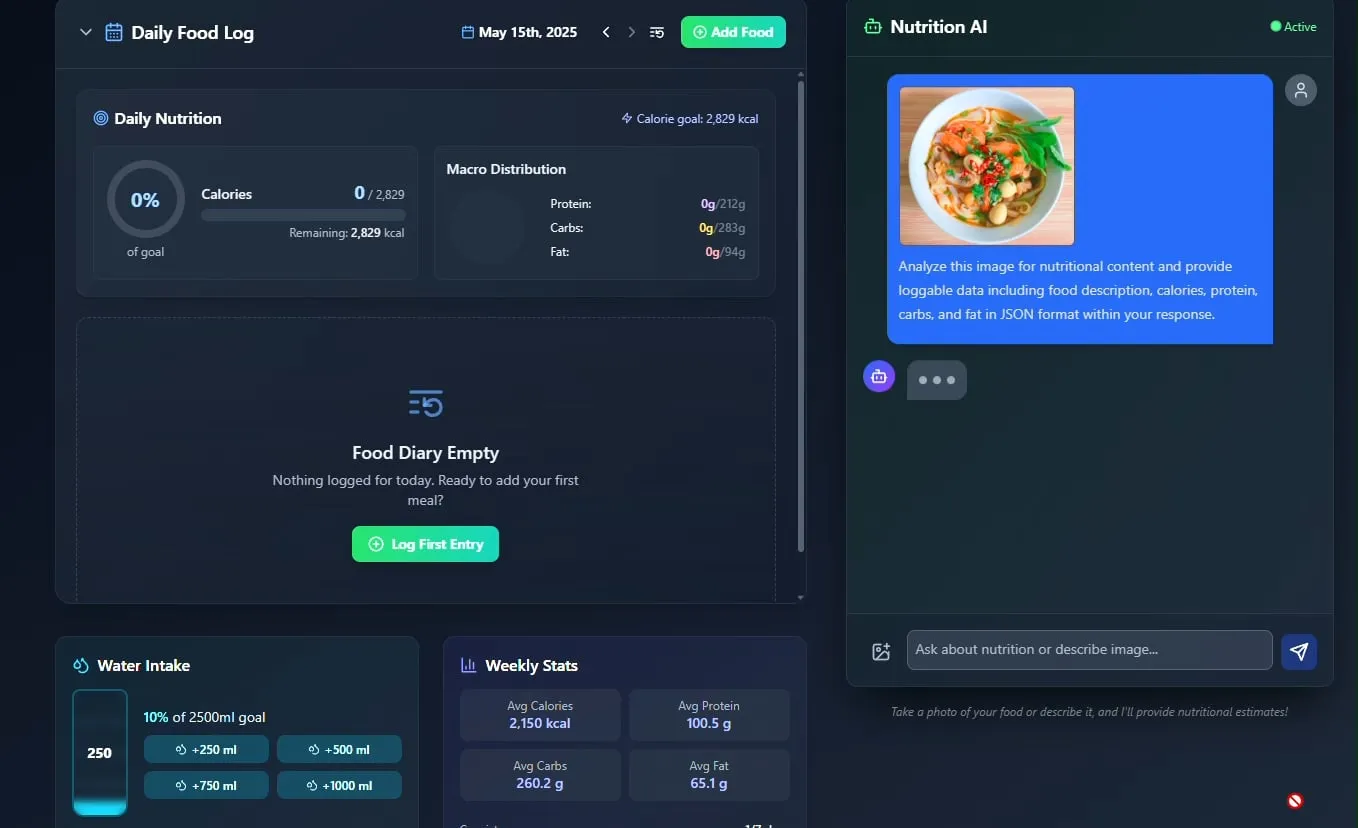
Un traqueur d’aliments et de nutrition par IA fait son apparition, avec un projet d’open source: Le développeur Pavankunchala a présenté une application de suivi de l’alimentation et de la nutrition pilotée par l’IA. La fonctionnalité principale de l’application est d’identifier les aliments et d’estimer les informations nutritionnelles (calories, protéines, etc.) en analysant les photos d’aliments téléchargées par l’utilisateur. Elle prend également en charge l’enregistrement manuel, un aperçu nutritionnel quotidien et le suivi de l’hydratation. Le développeur prévoit de rendre le code de ce projet open source à l’avenir. (Source: Reddit r/LocalLLaMA)
Un agent IA italien automatise la recherche d’emploi, postulant à mille emplois en une minute, suscitant un vif débat: Un AI Agent, prétendument italien, a démontré sa puissante capacité d’automatisation de la recherche d’emploi, capable de compléter 1000 candidatures en 1 minute. Cette démonstration a déclenché de vastes discussions au sein de la communauté sur l’application de l’IA dans le domaine du recrutement, suscitant d’une part l’étonnement face à son efficacité, et d’autre part des préoccupations quant à sa pertinence, son impact sur le marché du recrutement et la manière de contrer la “détection des robots”. (Source: Reddit r/ChatGPT)

📚 Apprentissage
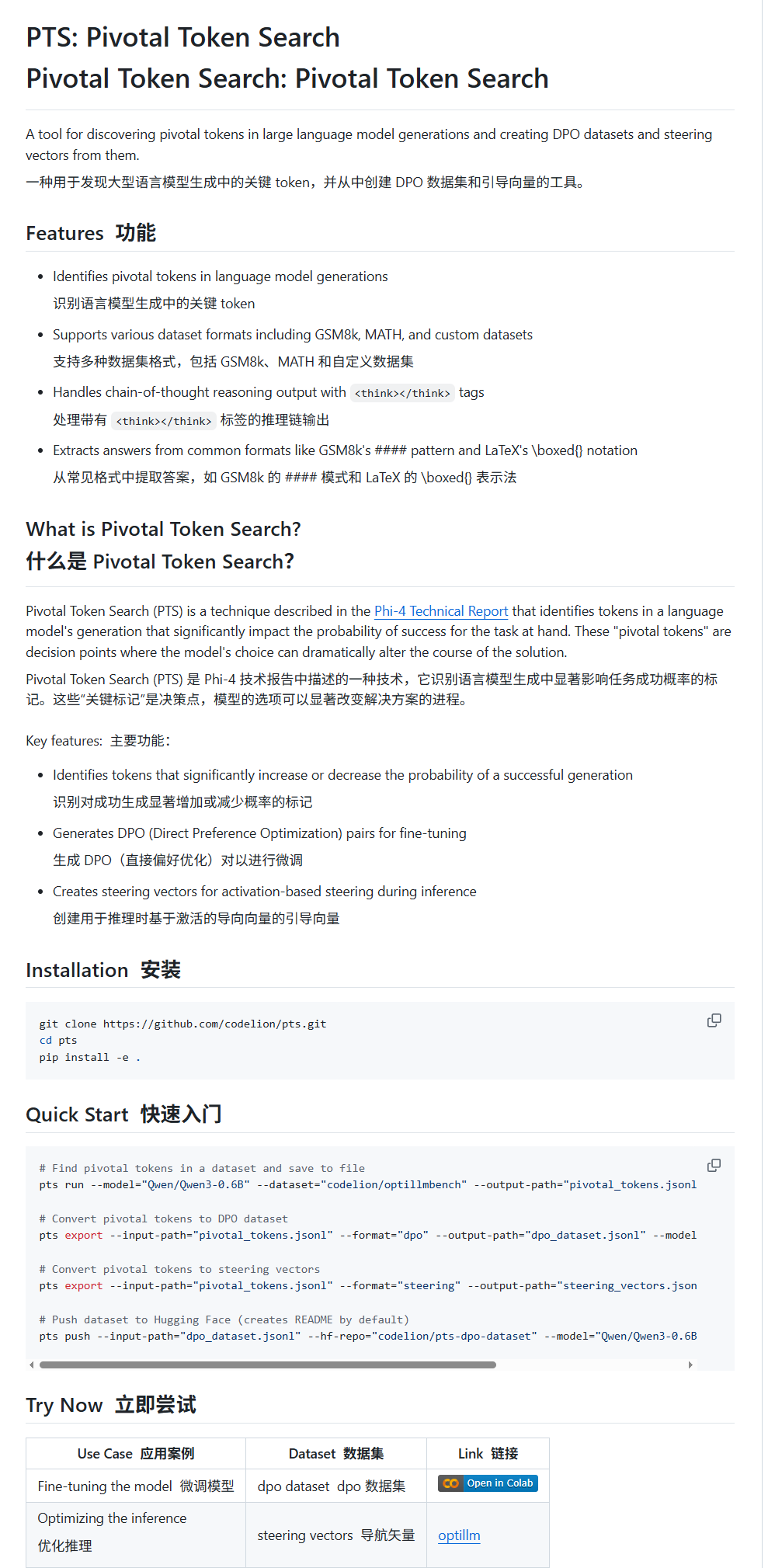
Pivotal Token Search (PTS) : une nouvelle technique de fine-tuning et de guidage pour les LLM: karminski3 présente une nouvelle technique appelée PTS (Pivotal Token Search). Cette technique repose sur l’idée que les points de décision clés dans la sortie d’un grand modèle de langage résident dans un petit nombre de tokens cruciaux. En extrayant ces tokens qui influencent significativement l’exactitude de la sortie (classés en “tokens choisis” et “tokens rejetés”), on construit un jeu de données DPO pour le fine-tuning. De plus, PTS peut extraire les schémas d’activation des tokens clés pour générer des steering vectors, guidant le comportement du modèle lors de l’inférence sans nécessiter de fine-tuning. Cette méthode serait inspirée de Phi4 et son efficacité suscite des discussions au sein de la communauté. (Source: karminski3)
OpenAI Codex CLI offre des crédits API gratuits et encourage le partage de données: Le compte développeur d’OpenAI a annoncé que les utilisateurs Plus ou Pro peuvent obtenir des crédits API gratuits en exécutant npm i -g @openai/codex@latest et codex --free. De plus, les utilisateurs peuvent également obtenir des tokens gratuits quotidiens en choisissant de partager leurs données dans les paramètres de la plateforme pour améliorer et entraîner les modèles OpenAI. Cette initiative vise à encourager les développeurs à utiliser les outils Codex et à participer à l’amélioration des modèles. (Source: OpenAIDevs, fouad)
Compilation de ressources gratuites pour l’apprentissage des systèmes multi-agents (MAS): TheTuringPost a compilé et partagé 7 ressources gratuites pour l’apprentissage des systèmes multi-agents (MAS). Celles-ci comprennent CrewAI, le framework multi-agents CAMEL et le tutoriel multi-agents LangChain ; un livre intitulé « Multiagent Systems: Algorithmic, Game-Theoretic, and Logical Foundations » ; ainsi que trois cours en ligne couvrant respectivement le passage du prompt aux systèmes multi-agents, la maîtrise du développement multi-agents avec AutoGen, et l’utilisation pratique de multi-agents IA avec crewAI et des cas d’usage avancés. (Source: TheTuringPost)

Tutoriel pour une classification d’images rapide avec MobileNetV2: L’utilisateur Reddit Eran Feit a partagé un tutoriel Python pour la classification d’images avec MobileNetV2. Ce tutoriel guide pas à pas les utilisateurs pour charger le modèle MobileNetV2 pré-entraîné, prétraiter les images avec OpenCV (conversion BGR vers RGB, redimensionnement à 224×224, traitement par lots), effectuer l’inférence, et décoder les résultats de prédiction pour obtenir des étiquettes et des probabilités lisibles par l’homme. Ce tutoriel est adapté aux débutants pour une prise en main rapide des tâches de classification d’images légères. (Source: Reddit r/deeplearning)
Publication d’un guide pour l’implémentation de RAG multi-sources et de recherche hybride dans OpenWebUI: Le site productiv-ai.guide a publié un guide détaillé étape par étape pour implémenter la Retrieval Augmented Generation (RAG) multi-sources avec recherche hybride (Hybrid Search) et réordonnancement (Re-ranking) dans OpenWebUI. Ce guide vise à aider les utilisateurs à configurer et à utiliser les fonctionnalités RAG d’OpenWebUI, y compris la fonctionnalité de réordonnancement externe récemment ajoutée, afin d’améliorer la précision et la pertinence de la recherche d’informations. (Source: Reddit r/OpenWebUI)
💼 Affaires
Concurrence féroce sur le marché des AI Agents : comparaison approfondie entre Manus et Lovart: L’AI Agent “Lovart”, spécialisé dans le domaine du design vertical, suscite l’attention en raison de son flux de travail unique de type “prise de commande”. Il tente de simuler un processus de conception complet, de la communication des besoins à la livraison de matériaux en couches, contrastant avec la logique de “coordination” de l’agent généraliste “Manus”. Bien que Lovart se distingue par sa compréhension de l’esthétique du design, son expression conceptuelle et son organisation de l’information, et qu’il soit plus rapide que Manus, les deux sont confrontés à des problèmes de stabilité, de traitement du chinois et de cohérence des modifications. L’émergence de Lovart est considérée comme une orientation correcte pour les agents verticaux qui approfondissent les scénarios et internalisent l’expérience sectorielle, laissant présager que les AI Agents pourraient véritablement s’implanter dans l’industrie du contenu. (Source: 36氪)

Le marché des montres intelligentes pour enfants en plein essor, la tendance AIoT stimule la croissance des fabricants chinois de puces SoC: Bénéficiant des politiques de relance de la consommation et de la tendance de développement de l’AIoT, les ventes d’appareils portables intelligents en Chine (en particulier les montres intelligentes pour enfants) ont explosé. L’émergence de grands modèles open source comme DeepSeek a abaissé le seuil de déploiement de l’IA en périphérie (edge AI), accélérant la pénétration de l’IA dans les appareils électroménagers intelligents, les écouteurs IA et autres terminaux. Des fabricants chinois de puces SoC tels que Rockchip (瑞芯微) et Bestechnic (恒玄科技), grâce à leur positionnement sur la faible consommation d’énergie et la puissance de calcul IA, ainsi qu’à des puces phares comme le RK3588 de Rockchip couvrant de multiples scénarios (PC, matériel intelligent, automobile), ont vu leurs performances augmenter de manière significative, et leur valorisation s’est également accrue. (Source: 36氪)
OpenAI aurait ajusté son plan de restructuration d’entreprise et répliqué aux accusations concernant sa nature non lucrative: Selon Garrison Lovely, une lettre d’OpenAI adressée au procureur général de Californie, non rapportée précédemment, a été révélée. Le contenu de la lettre concerne non seulement des détails inattendus sur le plan de restructuration d’OpenAI, mais montre également qu’OpenAI prend activement des mesures pour contrer les critiques et les accusations selon lesquelles elle tenterait d’affaiblir la structure de gouvernance non lucrative de l’entreprise. (Source: NeelNanda5)

🌟 Communauté
La nature N-Gram des LLM et les limites de l‘“intelligence” suscitent un vif débat: La communauté continue de débattre de la mesure dans laquelle les grands modèles de langage (LLM) dépendent encore des propriétés statistiques des N-Gram, et si les LLM actuels constituent une “véritable IA”. Certains points de vue (comme le commentaire de pmddomingos sur l’article NeurIPS de jxmnop) suggèrent que les LLM se comportent comme des modèles N-Gram dans plus des 2/3 des cas. Un data scientist sur Reddit a souligné que les LLM actuels manquent de véritable compréhension, de raisonnement et de bon sens, et sont encore loin de l’AGI (Intelligence Artificielle Générale), étant essentiellement des “systèmes de prédiction du mot suivant” complexes plutôt que des agents intelligents dotés de conscience de soi et d’adaptabilité. (Source: jxmnop, pmddomingos, Reddit r/ArtificialInteligence)

Le style “film transparent” des images générées par IA et les images suggestives de “Doubao” attirent l’attention: Récemment, un grand nombre d’images d’un style particulier, générées par des outils de dessin IA tels que Doubao, ont émergé sur les réseaux sociaux, en particulier des images présentant un effet d’emballage en “film transparent”. Ces images, en raison de leur effet visuel novateur et du contenu potentiellement “suggestif”, ont suscité de nombreuses discussions, imitations et créations dérivées parmi les utilisateurs, devenant une tendance populaire dans le domaine du contenu généré par IA. (Source: op7418, dotey)

Éthique de l’IA et avenir : construire “Dieu” ou s’autodétruire ?: La communauté débat avec véhémence de l’objectif ultime du développement de l’IA et de ses risques potentiels. Emad Mostaque déclare sans ambages que certains tentent de construire une AGI semblable à “Dieu”, ce qui pourrait mener à l’utopie ou à la destruction. Le PDG de NVIDIA, Jensen Huang, envisage un avenir où des ingénieurs humains collaboreront avec 1000 IA pour concevoir des puces. Parallèlement, une discussion suscitée par une bande dessinée SMBC déplace la question de la conscience de l’IA vers un aspect éthique plus pratique : pouvons-nous traiter ces “choses” la conscience tranquille ? Ces points de vue constituent collectivement une vision complexe de l’avenir de l’IA. (Source: Reddit r/artificial, Reddit r/artificial, Reddit r/artificial)
L’IA va-t-elle bouleverser le modèle économique du SaaS ? La communauté des développeurs en débat: Avec la popularisation d’outils de programmation IA puissants comme Claude Code, la communauté des développeurs commence à discuter de leur impact potentiel sur le modèle économique du SaaS (Software as a Service). L’opinion dominante est que le seuil permettant aux développeurs individuels de reproduire les fonctionnalités essentielles des produits SaaS existants à l’aide de l’IA est en baisse. Cela pourrait amener les entreprises et les utilisateurs individuels à réduire leur dépendance aux services SaaS traditionnels, pour se tourner vers des solutions auto-construites ou assistées par IA plus rentables. À l’avenir, le développement de logiciels pourrait davantage reposer sur la microgestion de l’IA. (Source: Reddit r/ClaudeAI)
Les différences de traitement multilingue par l’IA attirent l’attention, le pré-tokenizer de Llama pourrait en être une cause: Des discussions au sein de la communauté soulignent que les grands modèles de langage (LLM) ont généralement de meilleures performances en anglais que dans d’autres langues. L’une des raisons possibles pointées du doigt est la manière dont le pré-tokenizer de modèles comme Llama traite les textes non anglais (en particulier les caractères non latins). Par exemple, le pré-tokenizer pourrait sur-segmenter les caractères chinois en unités plus petites, affectant la compréhension de la structure linguistique et de la sémantique par le modèle, et entraînant ainsi une baisse des performances dans ces langues. (Source: giffmana)

💡 Autres
Le framework DSPy souligne l’importance des primitives de bas niveau pour le développement d’agents IA: Depuis que le framework IA DSPy a rendu open source ses abstractions fondamentales en janvier 2023, il n’a subi que peu de modifications, hormis quelques simplifications, et est resté stable malgré plusieurs itérations des API LLM. Les discussions au sein de la communauté soulignent que cela est dû au fait que DSPy se concentre sur la construction de primitives de bas niveau correctes, plutôt que de simplement rechercher une expérience développeur superficielle ou la facilité de construction rapide d‘“agents”. L’opinion dominante est que de nombreux frameworks de développement d’agents actuels se concentrent trop sur la facilité d’utilisation, négligeant la solidité des briques de base, alors que la philosophie de DSPy est d’avoir d’abord une base “réactive” solide pour pouvoir construire des comportements d‘“agents” complexes. (Source: lateinteraction, lateinteraction)
La fatigue esthétique face au contenu généré par IA stimule la demande de modèles personnalisés: Les discussions au sein de la communauté suggèrent que les productions de nombreux modèles de génération d’images optimisés par apprentissage par renforcement (RL) apparaissent souvent “banales” ou “kitsch”. Bien que techniquement correctes, elles manquent de créativité et de personnalité excitantes. Cela reflète le fait que les objectifs d’optimisation des modèles peuvent tendre vers les préférences esthétiques moyennes du grand public, plutôt que vers des recherches artistiques uniques. Par conséquent, les modèles personnalisés et les méthodes capables d’échantillonner en fonction d’objectifs esthétiques individuels sont considérés comme essentiels pour surmonter ce problème et créer un contenu IA plus attrayant à l’avenir. (Source: torchcompiled)

Ollama lance un moteur multimodal, les utilisateurs d’OpenWebUI s’interrogent sur la compatibilité: Ollama a annoncé le lancement officiel de son moteur multimodal, une nouvelle qui a suscité l’attention des utilisateurs de la communauté OpenWebUI. Les utilisateurs se demandent généralement si OpenWebUI sera capable de prendre en charge “dès la sortie de la boîte” le nouveau moteur multimodal d’Ollama, c’est-à-dire sans nécessiter de modifications de configuration complexes pour exploiter ses capacités de traitement de divers types de données comme les images et le texte. (Source: Reddit r/OpenWebUI)
