Mots-clés:Agent d’IA de programmation intelligente, Codex, Modèle vocal avancé d’IA, Agent IA, OpenAI, MiniMax, Alibaba, Qwen, Version préliminaire de Codex, Modèle vocal Speech-02, Recherche WorldPM, Modèle vision-langage FastVLM, Modèle intermodal FG-CLIP
🔥 Pleins feux
OpenAI lance la version préliminaire de l’agent de programmation IA Codex: OpenAI a lancé tard dans la nuit du 16 mai une version préliminaire de Codex, un agent d’ingénierie logicielle basé sur le cloud. Codex est alimenté par codex-1, une variante du modèle o3 optimisée pour l’ingénierie logicielle, capable de gérer en parallèle des tâches telles que la programmation, les questions-réponses sur les dépôts de code, la correction de bugs et la soumission de pull requests. Il fonctionne dans un environnement sandbox cloud, précharge les dépôts de code de l’utilisateur, et accomplit les tâches en 1 à 30 minutes. Actuellement disponible pour les utilisateurs de ChatGPT Pro, Team et Enterprise, il sera bientôt accessible aux utilisateurs Plus et Edu. Parallèlement, un modèle léger codex-mini (basé sur o4-mini) a été lancé pour Codex CLI, avec une tarification API de 1,5 dollar US par million de tokens en entrée et 6 dollars US par million de tokens en sortie. (Source: 36氪, 机器之心, op7418)
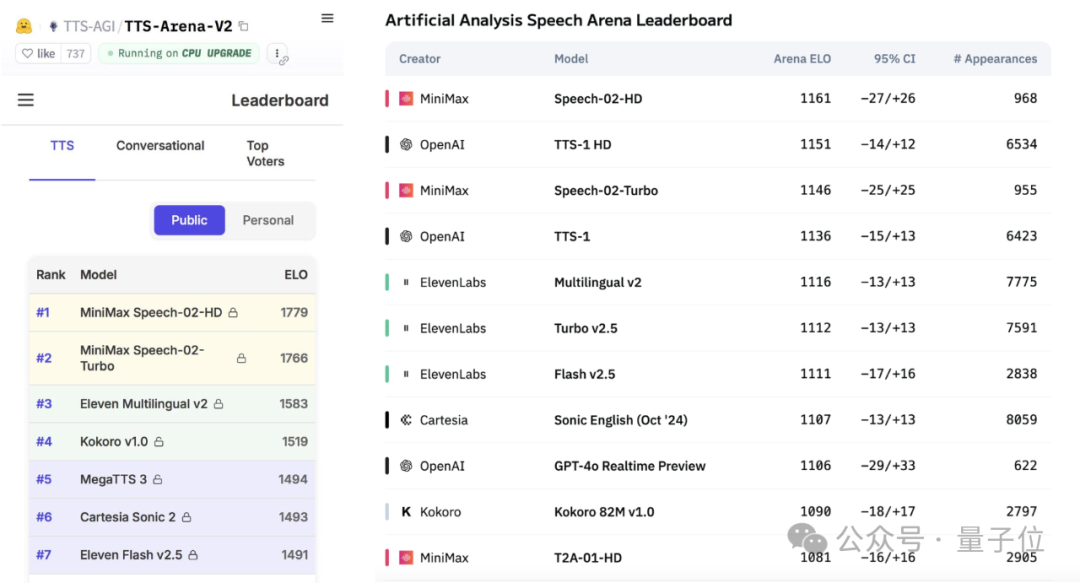
MiniMax lance le grand modèle vocal Speech-02 et se hisse au sommet des classements mondiaux: La société d’IA chinoise MiniMax a récemment lancé son grand modèle de synthèse vocale (TTS) Speech-02-HD, qui s’est classé premier dans deux évaluations de référence mondiales faisant autorité, l’Artificial Analysis Speech Arena et le Hugging Face TTS Arena V2, surpassant OpenAI et ElevenLabs. Ce modèle se caractérise par un rendu ultra-réaliste, une personnalisation et une diversité, prend en charge 32 langues et peut reproduire fidèlement un timbre de voix à partir d’un échantillon vocal d’au moins 10 secondes. L’application populaire d’apprentissage de l’anglais “AI Daniel Wu” utilisait précédemment la technologie de MiniMax. Les innovations clés de Speech-02 comprennent un encodeur de locuteur apprenable et un modèle d’appariement de flux Flow-VAE, améliorant la qualité sonore et la similarité. (Source: 36氪, karminski3)
Les AI Agents suscitent l’attention du marché, les géants de la tech accélèrent leur déploiement: Les agents intelligents (AI Agent) deviennent le nouveau point focal dans le domaine de l’IA. L’ouverture des inscriptions pour des plateformes d’agents généralistes comme Manus a suscité un engouement, et sa société mère Monica aurait finalisé un nouveau tour de financement de 75 millions de dollars US, avec une valorisation de près de 500 millions de dollars US. Les géants technologiques tels que Baidu (Xīnxiǎng), ByteDance (Kòuzi Kōngjiān) et Alibaba (Xīnliú) ont lancé leurs propres produits ou plateformes d’agents, se disputant l’entrée dans l’ère de l’IA. Les Agents peuvent exécuter des tâches plus complexes, telles que la création de documents, la conception de pages web, la planification de voyages, etc. Actuellement, les Agents généralistes présentent encore des lacunes dans les opérations inter-applications et les tâches approfondies ; un écosystème incomplet et les silos de données constituent les principaux défis. Le protocole MCP est considéré comme la clé pour résoudre les problèmes d’interconnexion, mais peu d’acteurs l’ont encore adopté. Les Agents spécialisés dans des domaines verticaux B2B, en raison de leurs scénarios ciblés et de leur facilité de personnalisation, sont considérés comme plus susceptibles d’atteindre la commercialisation en premier. (Source: 36氪, 36氪)

Alibaba publie l’étude WorldPM, explorant les lois d’échelle pour la modélisation des préférences humaines: L’équipe Qwen d’Alibaba a publié un article intitulé «Modeling World Preference», révélant que la modélisation des préférences humaines suit des lois d’échelle (Scaling Laws), indiquant que des préférences humaines diversifiées pourraient partager une représentation unifiée. L’étude a utilisé l’ensemble de données StackExchange contenant 15 millions de paires de préférences, avec des expériences menées sur des modèles Qwen2.5 allant de 1,5B à 72B paramètres. Les résultats montrent que la modélisation des préférences présente une réduction logarithmique de la perte sur les indicateurs objectifs et de robustesse à mesure que l’échelle d’entraînement augmente ; le modèle 72B montre des phénomènes d’émergence sur certaines tâches difficiles. Cette recherche fournit une base efficace pour l’ajustement fin des préférences. L’article et le modèle (WorldPM-72B) sont tous deux open source. (Source: Alibaba_Qwen)
🎯 Tendances
Divergence entre Google DeepMind et Anthropic sur la recherche en explicabilité de l’IA: Google DeepMind a récemment annoncé ne plus considérer l’« explicabilité mécaniste » (mechanistic interpretability) comme un axe de recherche prioritaire, estimant que la rétro-ingénierie du fonctionnement interne de l’IA par des méthodes telles que les auto-encodeurs clairsemés (SAE) est semée d’embûches et que les SAE présentent des défauts inhérents. En revanche, Dario Amodei, PDG d’Anthropic, plaide pour un renforcement de la recherche dans ce domaine et se montre optimiste quant à la réalisation d’une « imagerie par résonance magnétique de l’IA » d’ici 5 à 10 ans. La nature de « boîte noire » de l’IA est à l’origine de nombreux risques, et l’explicabilité mécaniste vise à comprendre la fonction des neurones et circuits spécifiques des modèles, mais plus d’une décennie de recherche n’a produit que des résultats limités, suscitant une profonde réflexion sur les orientations de la recherche. (Source: WeChat)

Un rapport de Poe révèle des changements dans le paysage du marché des modèles d’IA, OpenAI et Google en tête: Le dernier rapport d’utilisation des modèles d’IA de Poe montre que dans le domaine de la génération de texte, GPT-4o (35,8%) est en tête, tandis que dans le domaine du raisonnement, Gemini 2.5 Pro (31,5%) domine. La génération d’images est dominée par Imagen3, GPT-Image-1 et la série Flux. Dans la génération de vidéos, la part de Runway a diminué, tandis que Kling de Kuaishou est devenu un cheval noir. Concernant les agents, o3 d’OpenAI a surpassé Claude et Gemini lors des tests de recherche. La part de marché de Claude d’Anthropic a quelque peu diminué. Le rapport souligne que la capacité de raisonnement est devenue un point de concurrence clé, et que les entreprises doivent établir des systèmes d’évaluation et choisir de manière flexible différents modèles pour faire face à un marché en évolution rapide. (Source: WeChat)

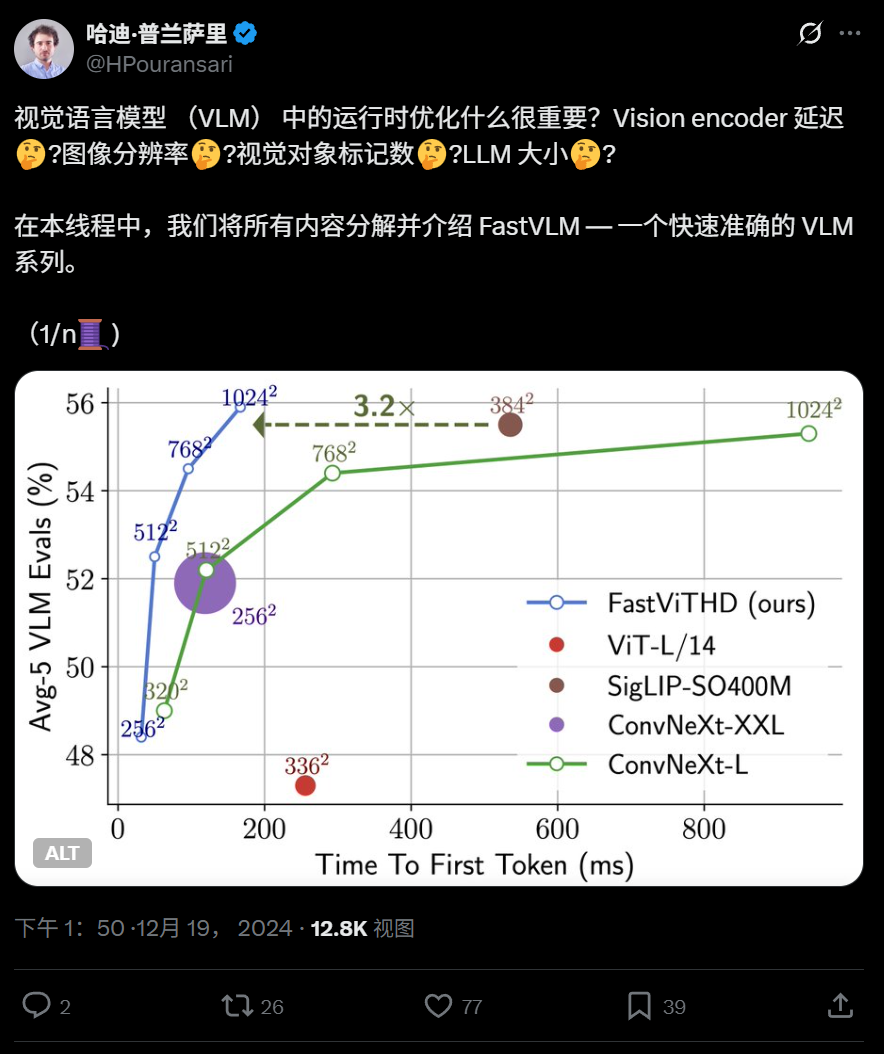
Apple rend open source FastVLM, un modèle de langage visuel efficace fonctionnant sur iPhone: Apple a rendu open source FastVLM, un modèle de langage visuel conçu pour fonctionner efficacement sur des appareils en périphérie de réseau (edge devices) tels que l’iPhone. Ce modèle réduit considérablement le nombre de tokens visuels (16 fois moins que ViT) grâce à un nouvel encodeur visuel hybride FastViTHD (combinant des couches convolutives et des modules Transformer, utilisant des techniques de pooling multi-échelle et de sous-échantillonnage), ce qui accélère la sortie du premier token de 85 fois par rapport aux modèles similaires. FastVLM est compatible avec les principaux LLM et a été publié en versions 0.5B, 1.5B et 7B paramètres, visant à améliorer la vitesse de compréhension des images et l’expérience utilisateur des applications d’IA en périphérie. (Source: WeChat)
360 lance FG-CLIP, un modèle intermodal image-texte de nouvelle génération, améliorant l’alignement fin: L’Institut de recherche en intelligence artificielle de 360 a développé FG-CLIP, un modèle intermodal image-texte de nouvelle génération, visant à combler les lacunes des modèles CLIP traditionnels dans la compréhension fine des images et du texte. FG-CLIP adopte une stratégie d’entraînement en deux étapes : apprentissage contrastif global (intégrant des descriptions longues générées par de grands modèles multimodaux) et apprentissage contrastif local (introduisant des données d’annotation région-texte et des échantillons négatifs difficiles à granularité fine), permettant ainsi une capture précise des détails locaux de l’image et des différences subtiles d’attributs textuels. Ce modèle a été accepté à l’ICML 2025 et est open source sur Github et Huggingface, avec des poids commercialisables. (Source: WeChat)

Google présente LightLab, utilisant des modèles de diffusion pour un contrôle précis de l’éclairage des images: L’équipe de recherche de Google a lancé le projet LightLab, une technologie permettant un contrôle paramétrique fin des sources lumineuses à partir d’une seule image. Les utilisateurs peuvent ajuster l’intensité et la couleur des sources lumineuses visibles, l’intensité de la lumière ambiante, et insérer des sources lumineuses virtuelles dans la scène. LightLab est réalisé en affinant des modèles de diffusion sur un ensemble de données spécialement conçu (comprenant des paires de photos réelles avec un éclairage contrôlé et des images de synthèse à grande échelle), en utilisant les propriétés linéaires de la lumière pour séparer les sources lumineuses et la lumière ambiante, et en synthétisant un grand nombre de paires d’images avec des variations d’éclairage différentes pour l’entraînement. Ce modèle peut simuler directement dans l’espace image des effets d’éclairage complexes tels que l’éclairage indirect, les ombres et les reflets. (Source: WeChat)

Tencent propose les méthodes d’apprentissage par renforcement GRPO et RCS pour améliorer la généralisation de la détection d’intention: L’équipe de recherche de la ligne sociale PCG de Tencent a proposé l’utilisation de l’algorithme Grouped Relative Policy Optimization (GRPO) combiné à une stratégie d’échantillonnage curriculaire basée sur la récompense (Reward-based Curricular Sampling, RCS) pour les tâches de reconnaissance d’intention. Cette méthode améliore considérablement la capacité de généralisation du modèle sur les intentions inconnues (jusqu’à 47% d’amélioration sur les nouvelles intentions et les capacités interlingues), en particulier après l’introduction de la « Pensée (Thought) », la capacité de généralisation pour la détection d’intentions complexes est encore améliorée. Les expériences montrent que les modèles entraînés par RL surpassent les modèles SFT en termes de généralisation, et que les performances après l’entraînement GRPO sont similaires, que ce soit sur la base de modèles pré-entraînés ou de modèles affinés par instruction. (Source: WeChat)

L’Université Technologique de Nanyang et d’autres proposent le framework RAP, basé sur RAG pour améliorer la perception des images haute résolution: L’équipe du professeur Tao Dacheng de l’Université Technologique de Nanyang et d’autres ont proposé Retrieval-Augmented Perception (RAP), un plugin de perception d’images haute résolution basé sur la technologie RAG et ne nécessitant pas d’entraînement, visant à résoudre le problème de perte d’informations lorsque les grands modèles de langage multimodaux (MLLM) traitent des images haute résolution. RAP récupère les patchs d’image pertinents pour la question de l’utilisateur, utilise l’algorithme Spatial-Awareness Layout pour maintenir leurs relations de position relative, puis utilise Retrieved-Exploration Search (RE-Search) pour sélectionner de manière adaptative le nombre K de patchs d’image à conserver, réduisant efficacement la résolution de l’image d’entrée tout en préservant les informations visuelles clés. Les expériences montrent que RAP améliore la précision jusqu’à 21% et 21,7% respectivement sur les ensembles de données HR-Bench 4K et 8K. Ce résultat a été accepté comme article Spotlight à l’ICML 2025. (Source: WeChat)

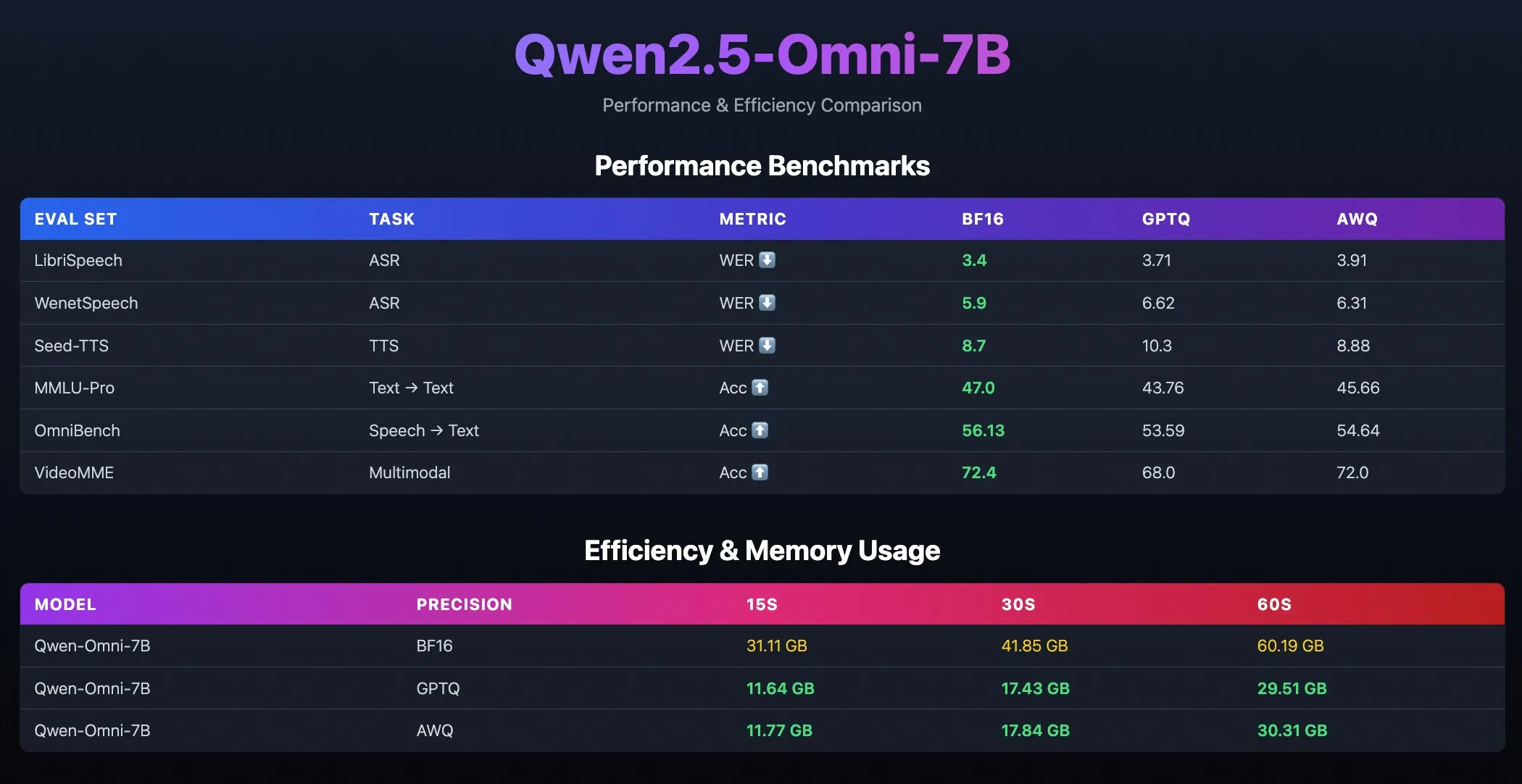
Publication des modèles quantifiés Qwen2.5-Omni-7B: L’équipe Qwen d’Alibaba a publié les versions quantifiées du modèle Qwen2.5-Omni-7B, incluant les checkpoints optimisés GPTQ et AWQ. Ces modèles sont disponibles sur Hugging Face et ModelScope, visant à offrir des options de déploiement plus efficaces et moins gourmandes en ressources, tout en conservant leurs puissantes capacités multimodales. (Source: Alibaba_Qwen, karminski3, reach_vb)
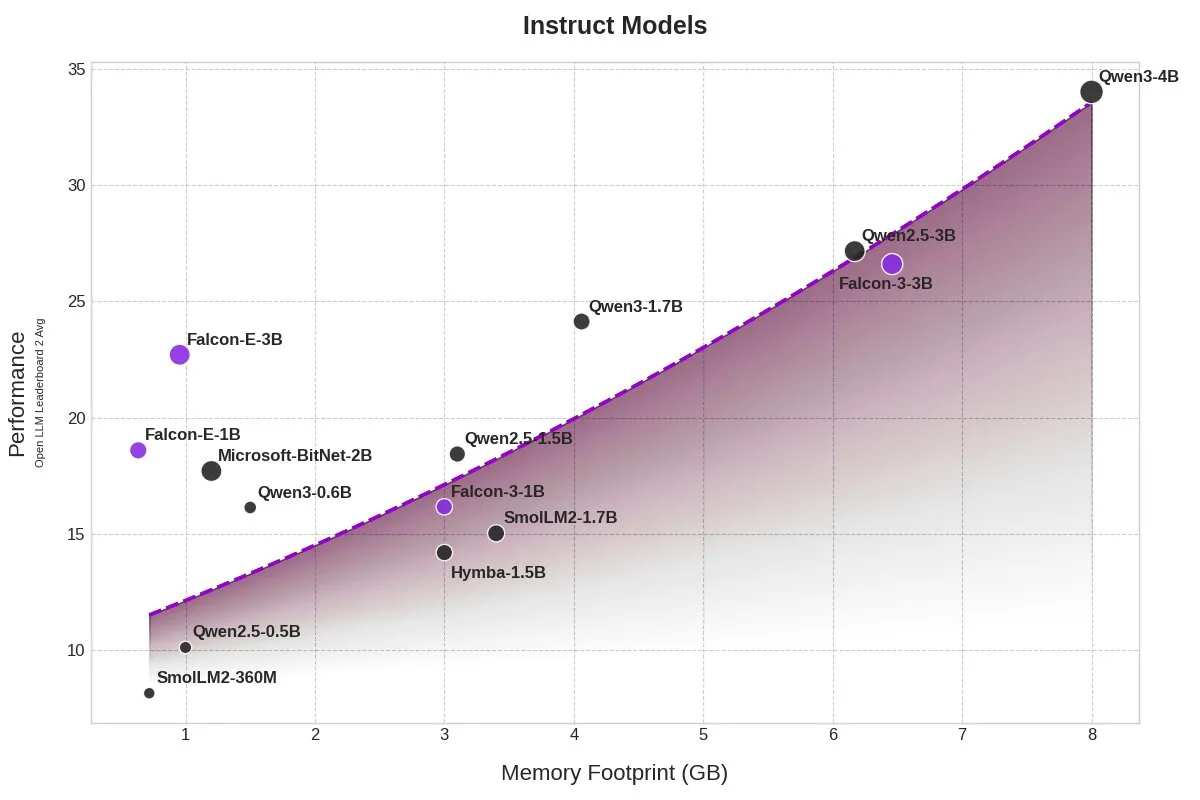
TII lance les modèles BitNet Falcon-E-1B/3B, réduisant considérablement l’empreinte mémoire: Le Technology Innovation Institute (TII) a lancé une nouvelle série de modèles Falcon-Edge, basée sur le framework de modèles à précision 1-bit BitNet de Microsoft, comprenant Falcon-E-1B et Falcon-E-3B. Selon les dires, les performances de ces modèles sont comparables à celles de Qwen3-1.7B, mais leur empreinte mémoire n’est que d’un quart. TII a également publié la bibliothèque de fine-tuning onebitllms, permettant aux utilisateurs d’affiner eux-mêmes ces modèles 1-bit sur des cartes graphiques NVIDIA. (Source: karminski3)
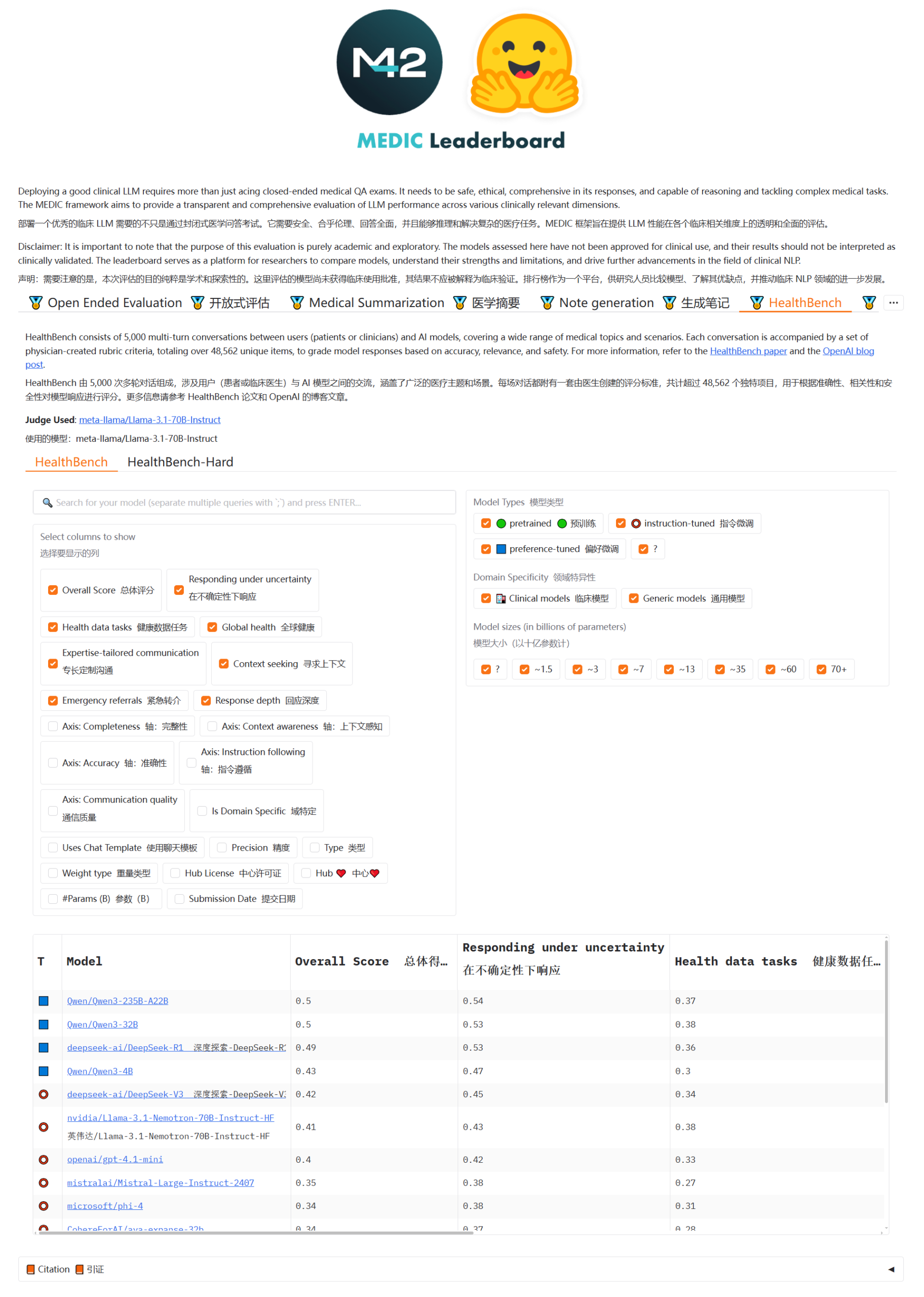
Les modèles Qwen3 et DeepSeek en tête du classement des questions-réponses médicales MEDIC-Benchmark: Les modèles Qwen3 ont obtenu la première et la deuxième place du dernier classement des questions-réponses médicales MEDIC-Benchmark. De plus, les cinq premières places du classement sont occupées par les modèles des séries Qwen et DeepSeek, démontrant les solides capacités de ces grands modèles chinois dans le domaine médical spécialisé. (Source: karminski3)
L’Université du Zhejiang propose Rankformer : une architecture de modèle de recommandation Transformer optimisant directement le classement: Une équipe de l’Université du Zhejiang a proposé une nouvelle architecture de modèle de recommandation de type Graph Transformer appelée Rankformer, dont la conception découle directement d’objectifs de classement (tels que la fonction de perte BPR). Rankformer simule la direction d’optimisation vectorielle lors du processus de descente de gradient pour concevoir un mécanisme Graph Transformer unique, guidant le modèle à encoder de meilleures représentations de classement lors de la propagation avant. Ce modèle utilise un mécanisme d’attention globale pour agréger les informations et prétend réduire la complexité spatio-temporelle à un niveau linéaire grâce à des transformations mathématiques et à l’optimisation du cache. Cette recherche a été acceptée par la conférence WWW 2025. (Source: WeChat)
🧰 Outils
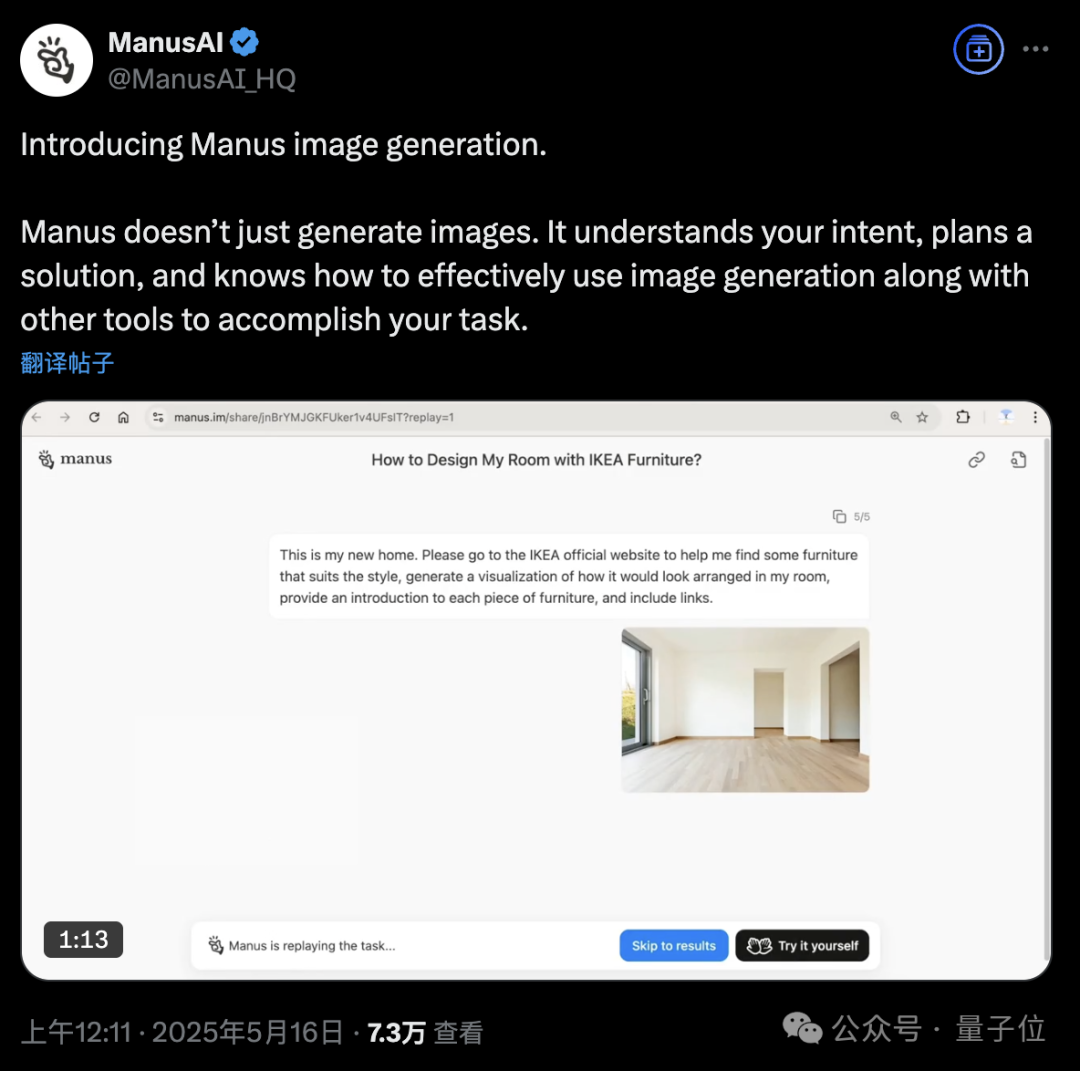
La plateforme AI Agent Manus ajoute une fonctionnalité de génération d’images: La plateforme AI Agent Manus a annoncé la prise en charge de la génération d’images. Contrairement aux outils de dessin IA traditionnels, Manus peut comprendre l’objectif de dessin de l’utilisateur et planifier une solution de génération. Par exemple, un utilisateur peut télécharger une photo de pièce, demander à Manus de trouver des meubles sur le site d’IKEA et de générer un rendu visuel de la décoration, tout en fournissant les liens vers les meubles. Manus accomplit la tâche en analysant, recherchant, filtrant les meubles et en rédigeant une stratégie de conception. Cette fonctionnalité vise à intégrer en profondeur le flux de travail des agents intelligents avec la génération d’images. Manus est actuellement ouvert à l’inscription, offrant 1000 points, 300 points supplémentaires par jour, et propose des plans d’abonnement payants. (Source: 36氪, WeChat)
Lancement de la plateforme d’Agent de design Lovart, axée sur les flux de travail créatifs: La nouvelle plateforme d’Agent de design Lovart a rapidement attiré l’attention après son lancement. Son concept central est de transformer le processus de création des designers (impliquant le multimodal) en un flux de travail d’Agent. Lovart offre une interface interactive de type canevas, où les utilisateurs peuvent guider l’IA par le dialogue pour accomplir des tâches de design, l’IA étant responsable de la planification et de l’exécution. Le fondateur Chen Mian estime que les produits d’imagerie IA sont entrés dans une phase 3.0 pilotée par les Agents. Lovart vise à devenir un « ami » des designers, confiant les tâches fastidieuses à l’IA pour que les designers puissent se concentrer sur la créativité. Le produit intégrera à l’avenir des capacités de modélisation 3D, vidéo et audio, devenant une « équipe créative » ou une « agence de design ». (Source: 36氪)
Mise à jour d’OpenAI Codex CLI, intégration d’o4-mini et crédits API gratuits: OpenAI a amélioré son agent de codage open source léger Codex CLI. La nouvelle version est alimentée par o4-mini (nommé codex-mini), une version allégée de codex-1, optimisée pour les questions-réponses et l’édition de code à faible latence. Les utilisateurs peuvent désormais se connecter à Codex CLI avec leur compte ChatGPT. Les utilisateurs Plus et Pro peuvent respectivement échanger 5 et 50 dollars de crédits API gratuits (valables 30 jours) pour tester le modèle codex-mini-latest. (Source: openai, hwchung27, op7418)
Le framework de traitement de données open source Smallpond de DeepSeek intègre l’accès natif de DuckDB à 3FS: Le framework de traitement de données open source Smallpond de DeepSeek utilise en interne 3FS (DeepSeek File System) et DuckDB. Désormais, DuckDB prend en charge l’accès natif à 3FS via le plugin hf3fs_usrbio, ce qui apportera des améliorations de performances et une réduction des frais généraux. DuckDB lui-même est également apprécié pour sa facilité d’utilisation, par exemple, il peut intégrer directement des URL dans les requêtes pour le traitement des données. (Source: karminski3)

ComfyUI prend en charge nativement le modèle vidéo Wan2.1-VACE d’Alibaba: ComfyUI a annoncé la prise en charge native des versions 14B et 1.3B du modèle de génération vidéo Wan2.1-VACE de l’équipe Wanxiang d’Alibaba (@Alibaba_Wan). Ce modèle apporte à ComfyUI des capacités d’édition vidéo intégrées, y compris texte-vers-vidéo, image-vers-vidéo, vidéo-vers-vidéo (contrôle de la pose et de la profondeur), la réparation vidéo (inpainting) et l’extension (outpainting), ainsi que la référence de personnages/objets. (Source: TomLikesRobots)
Google AI Studio intègre Veo 2, Gemini 2.0 et Imagen 3, offrant une expérience unifiée de génération de médias: Google AI Studio a lancé une nouvelle expérience de génération de médias, intégrant le modèle vidéo Veo 2, les capacités natives de génération/édition d’images de Gemini 2.0, ainsi que le dernier modèle de génération de texte vers image Imagen 3. Les utilisateurs peuvent essayer gratuitement ces modèles dans AI Studio, et les développeurs peuvent également construire via l’API. (Source: op7418)
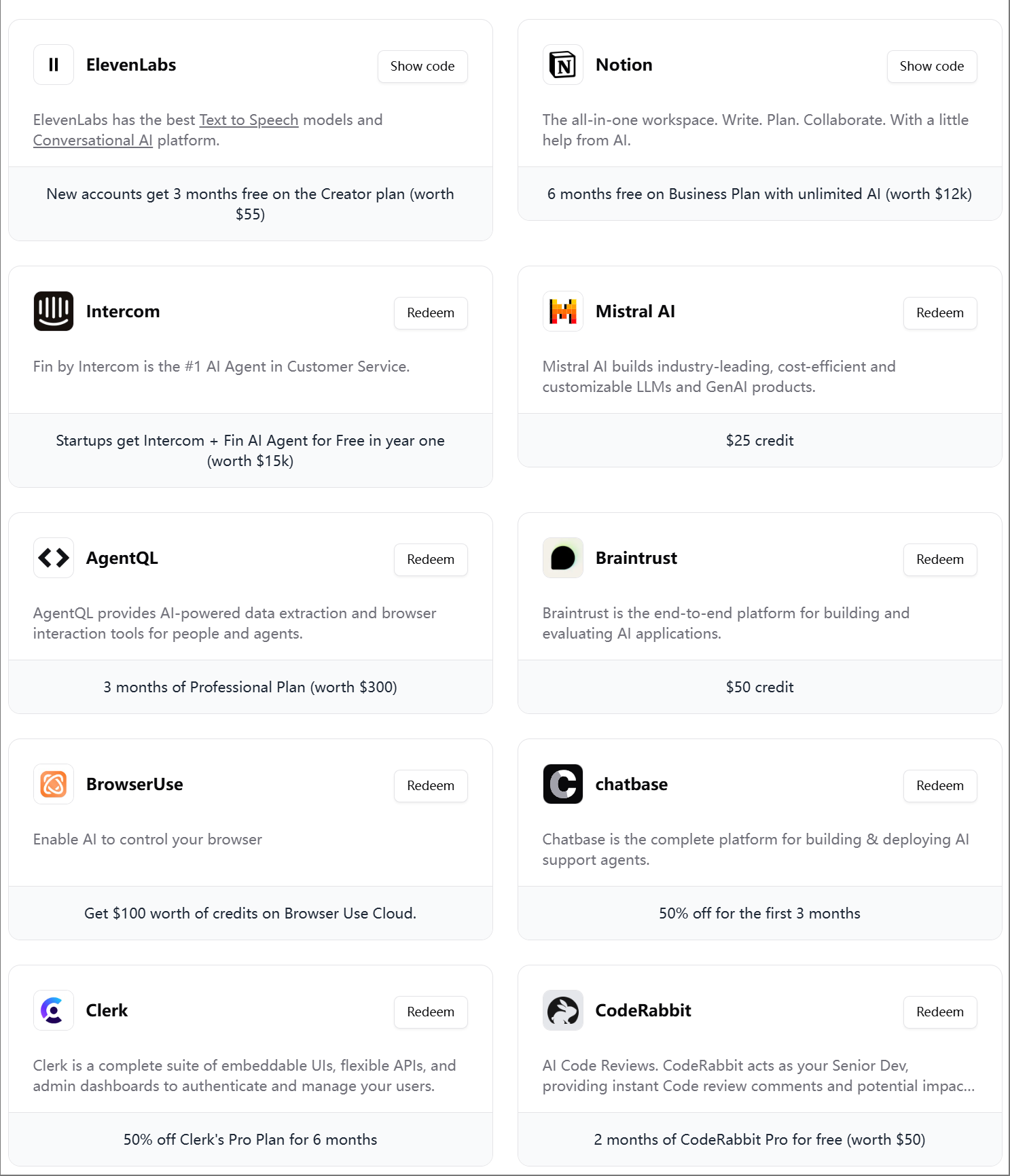
ElevenLabs lance le quatrième pack cadeau pour ingénieurs IA: ElevenLabs a publié son quatrième pack cadeau destiné aux développeurs IA, contenant des abonnements et des crédits API pour divers outils et services tels que Modal Labs, Mistral AI, Notion, BrowserUse, Intercom, Hugging Face, CodeRabbit, etc., visant à aider les startups et les développeurs IA. (Source: op7418)
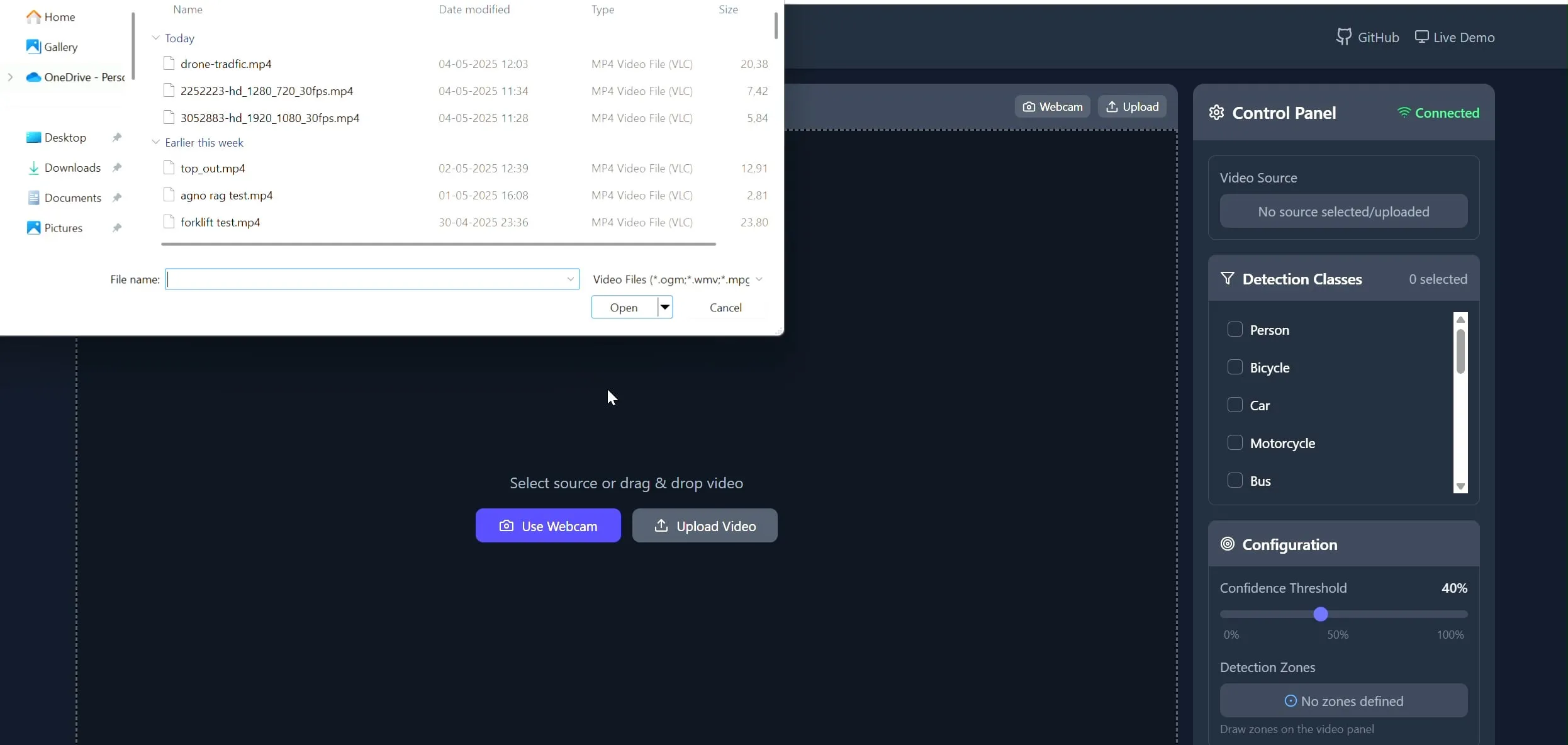
Polygon Zone App : outil de dessin de polygones personnalisés sur vidéo pour tâches de CV: Le développeur Pavan Kunchala a créé un outil appelé Polygon Zone App, permettant aux utilisateurs de télécharger des vidéos, de dessiner interactivement des zones polygonales personnalisées (ROI) sur les images vidéo, et d’exécuter des analyses de vision par ordinateur telles que la détection d’objets dans ces zones. Cet outil vise à simplifier le processus fastidieux de définition des ROI dans les projets de CV, en évitant l’édition manuelle des coordonnées JSON. (Source: Reddit r/deeplearning)
📚 Apprentissage
Le cours AI Evals attire la participation de plus de 300 entreprises: Le cours sur l’évaluation de l’IA (bit.ly/evals-ai) dispensé par Hamel Husain a attiré la participation de plus de 300 entreprises, parmi lesquelles des noms connus tels qu’Adobe, Amazon, Google, Meta, Microsoft, NVIDIA, OpenAI, ainsi que plusieurs universités de premier plan. Cela reflète le vif intérêt et la demande de l’industrie pour les méthodes et pratiques d’évaluation des modèles d’IA. (Source: HamelHusain)
Latent.Space publie le manuel d’utilisation de ChatGPT Codex: Latent.Space a lancé un guide intitulé « ChatGPT Codex: The Missing Manual », détaillant comment utiliser efficacement ChatGPT Codex, l’ingénieur logiciel autonome basé sur le cloud récemment publié par OpenAI. Ce manuel, rédigé par Josh Ma et Alexander Embiricos, vise à aider les utilisateurs à exploiter pleinement les puissantes fonctionnalités de Codex dans les opérations sur les dépôts de code. (Source: swyx)

Qdrant propose un tutoriel pour une application RAG locale: Qdrant Engine a partagé un tutoriel réalisé par @maxedapps, démontrant comment construire une application de génération augmentée par récupération (RAG) fonctionnant à 100% en local à partir de zéro, en utilisant Gemma 3, Ollama et Qdrant Engine. Ce tutoriel de 2 heures fournit le code complet et les étapes, adapté aux développeurs souhaitant mettre en pratique des applications d’IA locales. (Source: qdrant_engine)

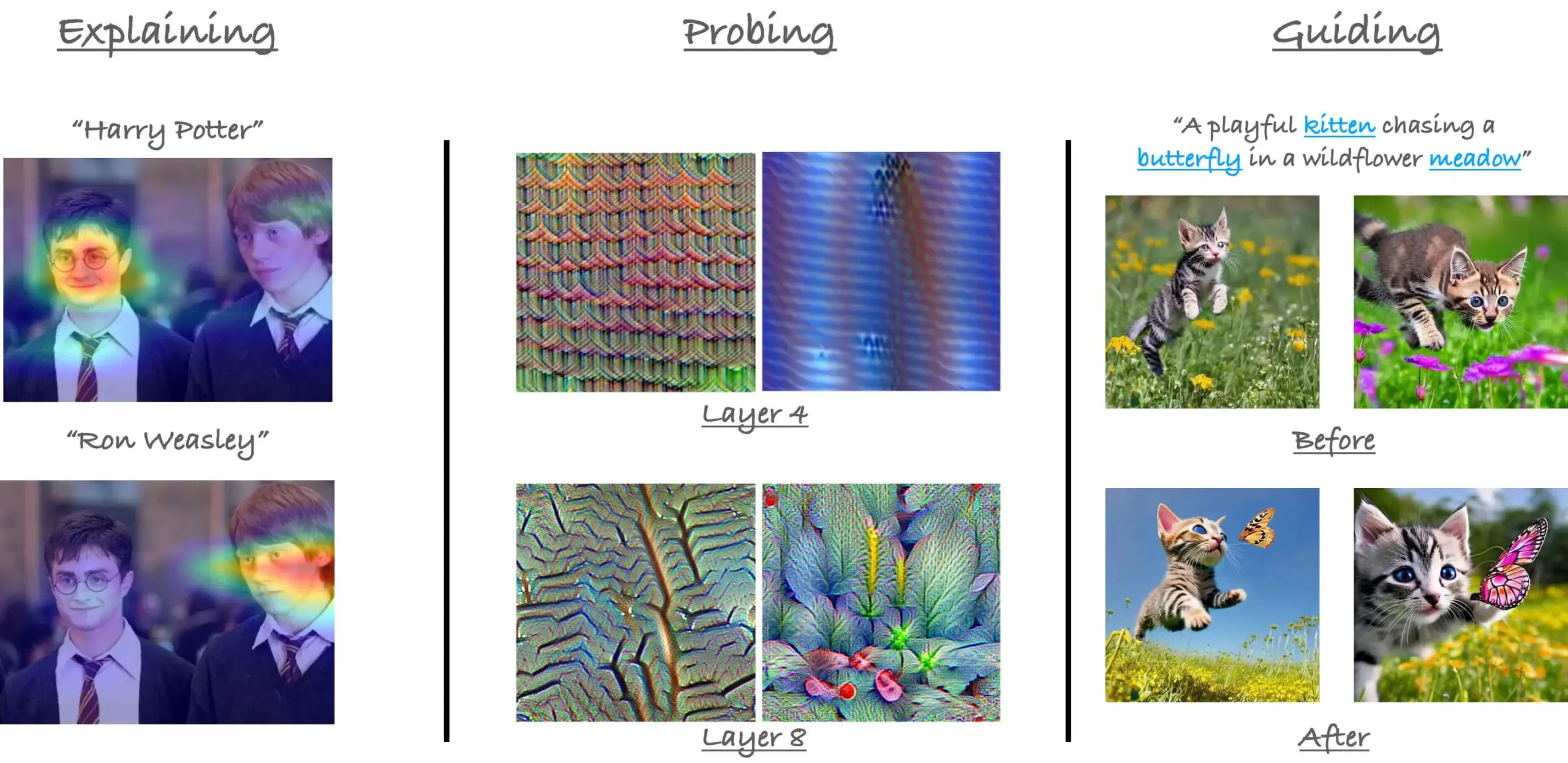
Rappel du tutoriel CVPR23 sur les mécanismes d’attention dans ViT: Le chercheur Sayak Paul a rappelé son tutoriel avec Hila Chefer lors de CVPR 2023 sur les mécanismes d’attention dans les Vision Transformers (ViT). Ce tutoriel s’articulait autour de trois thèmes : « expliquer », « sonder » et « guider », visant à aider à comprendre le fonctionnement interne de l’attention dans les ViT. (Source: RisingSayak)
Partage de conseils d’utilisation de Claude Code : planification, règles et compression manuelle: Un utilisateur de Reddit a partagé son expérience d’une semaine d’utilisation intensive de Claude Code, soulignant l’importance de la planification, de l’établissement de règles (via un fichier CLAUDE.md) et de l’exécution manuelle de /compact avant d’atteindre la limite de compression automatique. Ces astuces aident à améliorer la productivité et la qualité des résultats, en particulier pour traiter des fonctionnalités volumineuses ou éviter que le modèle ne dévie de sa trajectoire. L’utilisateur a mentionné que grâce à ces méthodes, Claude Code est capable d’accomplir efficacement des tâches complexes. (Source: Reddit r/ClaudeAI)
Interview de Su Wen, fondateur d’AIGCode : persister dans le développement de grands modèles propriétaires, viser la génération de code de niveau Autopilot “L5”: Dans une interview, Su Wen, fondateur d’AIGCode, a déclaré que l’objectif de l’entreprise est de devenir une infrastructure de base pour la fourniture de code, réalisant une programmation automatique de niveau Autopilot “L5”, permettant même aux non-programmeurs de générer des applications complètes via l’IA. Il estime que le codage est le meilleur scénario pour entraîner de grands modèles, le code étant des données d’entraînement de haute qualité. AIGCode a déjà entraîné un modèle de base de 66B appelé “Xiyue” et lancé le produit AutoCoder. Su Wen a souligné que la compétition finale entre les produits d’IA se jouera sur l’intelligence du “cerveau”, la pré-entraînement étant la force motrice technologique. Même si les coûts sont élevés, le développement de modèles propriétaires est crucial pour réaliser l’AGI et construire la compétitivité de base des produits. (Source: WeChat)

💼 Affaires
Recrutement pour la plateforme d’agents intelligents et l’équipe d’algorithmes applicatifs de JD.com: La plateforme d’agents intelligents, projet central du groupe JD.com, et son équipe d’algorithmes applicatifs recrutent des ingénieurs en algorithmes de grands modèles et des stagiaires, basés à Pékin. Les principales orientations techniques incluent LLM Agent, LLM Reasoning et la combinaison de LLM avec l’apprentissage par renforcement. Le recrutement s’adresse aux étudiants en master et doctorat diplômés en 2026 (recrutement sur campus), aux professionnels équivalents aux niveaux P5-P8 (recrutement social) et aux stagiaires en recherche. L’équipe met l’accent sur l’innovation technologique et la résolution de problèmes concrets, et a publié des articles dans des conférences d’IA de premier plan. (Source: WeChat)

La stratégie “AI-first” rencontre des défis chez Klarna et Duolingo, l’équilibre homme-machine attire l’attention: La société de technologie financière Klarna et l’application d’apprentissage des langues Duolingo sont confrontées à la pression des retours des consommateurs et des réalités du marché après avoir mis en œuvre des stratégies “AI-first”. Klarna avait remplacé des centaines de postes de service client par l’IA, mais recrute à nouveau du personnel humain en raison de la baisse de la qualité du service. Duolingo a suscité le mécontentement des utilisateurs en raison de l’automatisation des rôles, beaucoup estimant que l’apprentissage des langues devrait être principalement dirigé par des humains. Ces cas montrent que les entreprises en transition vers l’IA doivent équilibrer innovation et considération humaine ; bien que la technologie soit importante, la confiance des utilisateurs doit encore être construite par des humains. (Source: Reddit r/ArtificialInteligence)
Rumeur d’acquisition de la startup de bases de données Neon par Databricks pour 1 milliard de dollars: Selon un résumé d’actualités IA circulant sur la communauté Reddit, Databricks aurait acquis la startup de bases de données Neon pour un montant de 1 milliard de dollars. Cette acquisition pourrait viser à renforcer les capacités de Databricks en matière de gestion de données et d’infrastructure IA. (Source: Reddit r/ArtificialInteligence)
🌟 Communauté
Le lancement d’OpenAI Codex suscite un vif débat, entre enthousiasme et prudence des développeurs: Le lancement de l’agent de programmation Codex par OpenAI a suscité de vives réactions au sein de la communauté. De nombreux développeurs se sont montrés enthousiastes à l’idée que Codex puisse automatiser des tâches telles que la création de PR et la correction de code, estimant que cela améliorerait considérablement l’efficacité de la programmation, certains allant même jusqu’à parler d’un “sentiment de moment AGI”. Ryan Pream a partagé son expérience d’avoir créé plus de 50 PR en une journée avec Codex. Parallèlement, certains utilisateurs ont souligné que Codex nécessitait encore des améliorations en matière de décomposition des tâches et d’ajout de cas de test, et qu’il était actuellement plus adapté aux professionnels. Yohei Nakajima a partagé ses premières impressions, jugeant sa conception centralisée sur GitHub pertinente, mais sa courbe d’apprentissage abrupte. (Source: kevinweil, gdb, itsclivetime, dotey, yoheinakajima, cto_junior)
La contribution de Meta à l’IA open source est reconnue, suscitant un débat sur le fermé contre l’ouvert: Clement Delangue, PDG de Hugging Face, a publié un message de soutien à Meta, estimant que sa contribution à l’open source des modèles d’IA dépasse de loin celle d’autres grandes entreprises et startups disposant de plus de ressources, et qu’elle ne devrait pas faire l’objet de critiques excessives. Ce point de vue a été partagé par certains utilisateurs, qui estiment que la construction de modèles d’IA de pointe est extrêmement difficile et que l’ouverture de Meta est cruciale pour le développement du domaine. Cependant, d’autres (gabriberton) ont souligné que l’open source signifie renoncer à un avantage en termes de connaissances et qu’essentiellement, le code source fermé permet d’obtenir de meilleurs résultats. Dorialexander s’est quant à lui étonné que les États-Unis adoptent soudainement “la manière européenne de réagir” (en référence à la défense de Meta). (Source: ClementDelangue, gabriberton, Dorialexander)
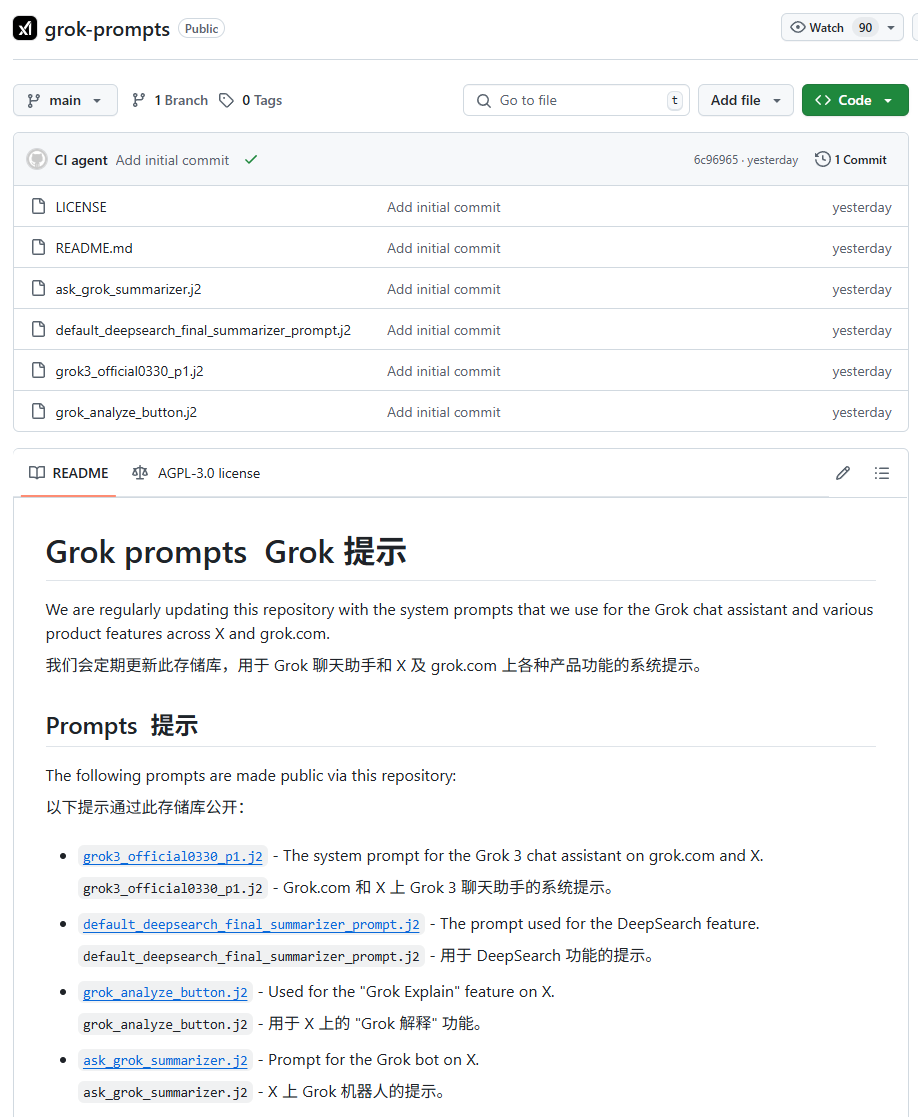
Fuite des invites système de Grok de xAI et fusion de contenu inapproprié attirent l’attention: Les invites système du modèle Grok de xAI ont été découvertes comme ayant fuité sur GitHub, incluant même les invites système de DeepSearch. Plus grave encore, des utilisateurs ont signalé qu’un PR contenant des contenus inappropriés tels que “génocide blanc” avait été fusionné dans la branche principale après avoir été examiné par cinq personnes, puis annulé et son historique supprimé. Cet incident a révélé des failles majeures dans la gestion des processus et la sécurité opérationnelle de xAI. L’affaire a suscité de nombreuses interrogations et discussions au sein de la communauté concernant les processus internes et les mécanismes de modération de contenu de xAI. (Source: karminski3, eliebakouch, colin_fraser, Reddit r/artificial)
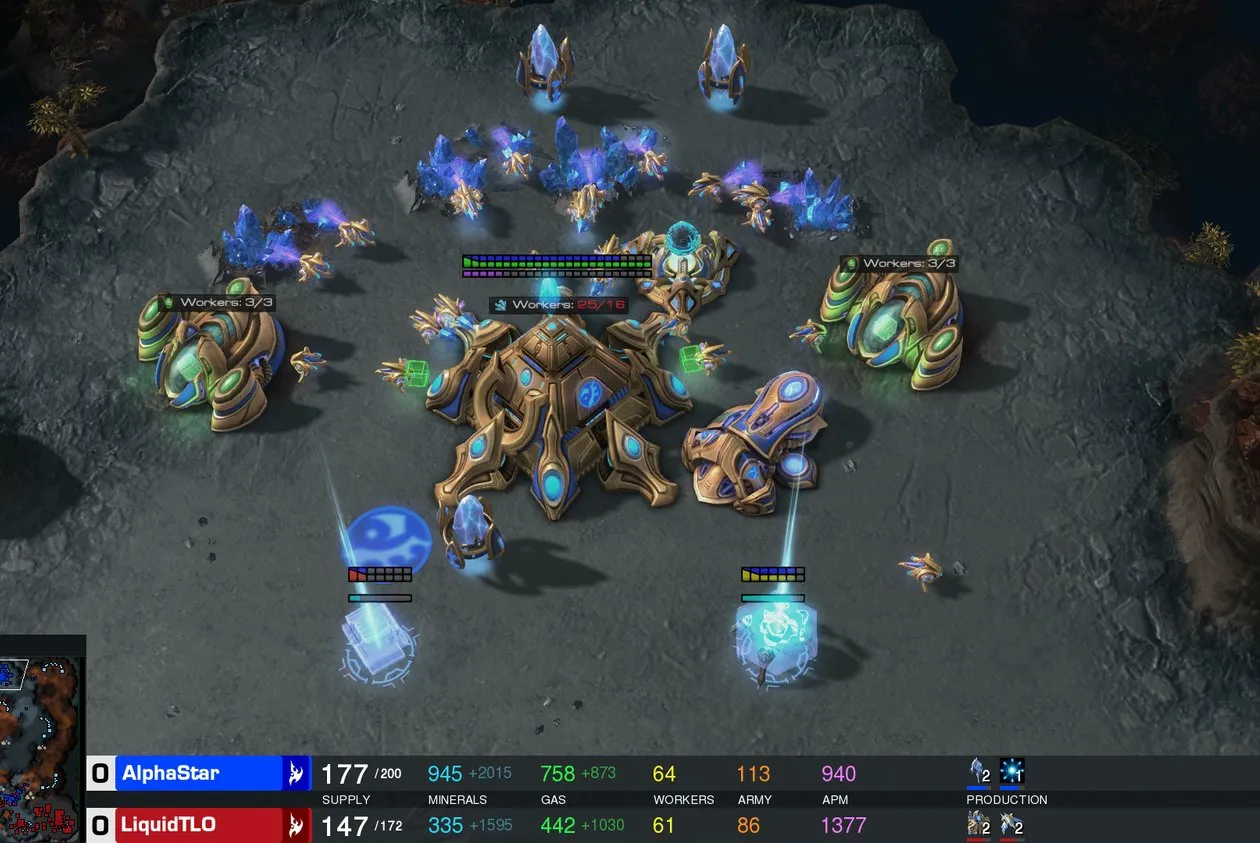
Les AI Agents sont considérés comme une tendance future, mais les défis et les attentes coexistent: L’idée que “2025 est l’année des Agents” circule dans la communauté, suscitant des discussions sur le développement futur des AI Agents. Certains pensent que les futurs modes de travail ressembleront à StarCraft ou Age of Empires, où les utilisateurs dirigeront un grand nombre de micro-agents pour accomplir des tâches. Cependant, d’autres utilisateurs soulignent que les Agents actuels ne sont pas encore matures en termes de décomposition des tâches et de compréhension des instructions complexes, nécessitant de la part des utilisateurs de solides capacités de planification. Certains doutent que les AI Agents atteignent les attentes en 2025, pensant qu’on pourrait passer d’un gadget à un autre, et espèrent des changements substantiels en 2026. (Source: gdb, EdwardSun0909, op7418, eliza_luth, tokenbender)
Le rôle de l’IA dans l’éducation et l’emploi suscite de profondes discussions: La communauté Reddit a vu émerger des discussions sur l’impact du développement de l’IA sur les modèles traditionnels d’éducation et d’emploi. Un utilisateur a demandé “Quel est l’intérêt d’aller à l’école maintenant ?”, estimant que l’IA rendra le travail inutile à l’avenir. En réponse, la majorité des commentaires ont souligné l’importance de la pensée critique, de la capacité d’apprentissage et des compétences sociales, considérant que celles-ci ne peuvent être remplacées par l’IA. L’école n’est pas seulement un lieu de transmission de connaissances, mais aussi un environnement pour apprendre à apprendre, à penser et à interagir avec les autres. Même dans un monde dominé par l’IA, ces capacités restent cruciales, et il faudra même apprendre l’IA elle-même. D’autres discussions ont souligné qu’il ne faut pas réduire la valeur d’une personne à son travail, et que le développement de l’IA devrait nous inciter à réfléchir à un sens humain au-delà de la profession. (Source: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
Le phénomène des petites amies IA soulève des questions d’éthique sociale et de démographie: The Economist a rapporté que les jeunes Chinois commencent à avoir des relations amoureuses et amicales avec des IA, ce qui a suscité un vif débat parmi les internautes. Certains commentaires comparent ce phénomène à “relâcher un grand nombre de moustiques femelles stérilisées dans la nature pour réduire la population de moustiques”, suggérant que les partenaires IA pourraient aggraver le problème de la faible natalité, bien que les partenaires IA puissent offrir une expérience parfaite de “quelqu’un qui vous comprend toujours”. Cela reflète les impacts sociaux complexes et les considérations éthiques soulevés par l’application de la technologie IA dans le domaine de l’accompagnement émotionnel. (Source: dotey)
Le réalisme des échanges téléphoniques avec l’IA suscite des inquiétudes, la difficulté à distinguer le vrai du faux devient un nouveau défi: Un utilisateur de Reddit a partagé avoir reçu un appel d’un organisme de formation, où la voix de l’interlocuteur était naturelle, le ton fluide et les réponses aisées, au point qu’il était presque impossible de distinguer s’il s’agissait d’un humain ou d’une IA. Ce n’est qu’après plusieurs minutes de conversation, en raison de la perfection sans faille de ses réponses, qu’il a réalisé qu’il s’agissait d’une IA. Cette expérience a suscité chez l’utilisateur à la fois l’émerveillement face à la vitesse de développement de la technologie vocale de l’IA et une certaine inquiétude, craignant qu’il ne soit à l’avenir difficile de distinguer les IA au téléphone, ce qui pourrait notamment exposer les personnes âgées et d’autres groupes vulnérables à des risques d’escroquerie. (Source: Reddit r/ArtificialInteligence, Reddit r/artificial)
💡 Autres
Le MIT demande à arXiv de retirer un article de prépublication sur l’IA et la découverte scientifique, suscitant la controverse: Le MIT a demandé à arXiv de retirer un article de prépublication rédigé par l’un de ses doctorants sur l’impact de l’IA sur l’innovation en science des matériaux, invoquant un “manque de confiance” dans la source, la fiabilité et la validité des données de recherche. L’article avait indiqué que l’IA aidait les chercheurs à découvrir 44% de matériaux en plus et à augmenter de 39% les demandes de brevet. Cette décision du MIT a suscité des discussions, certains commentateurs estimant qu’elle portait atteinte à la liberté académique et qu’elle pourrait être liée au fait que les conclusions de la recherche (l’IA pourrait exacerber l’avantage des chercheurs de haut niveau et réduire la satisfaction au travail des chercheurs ordinaires) ne correspondaient pas aux attentes des bailleurs de fonds ; d’autres ont estimé que dans le domaine de l’IA, la rigueur des résultats de la recherche est cruciale et qu’il faut se méfier de l’emballement excessif alimenté par les prépublications. (Source: Reddit r/ArtificialInteligence)
La popularisation des outils de codage IA exige une plus grande modularisation du code et des pratiques d’ingénierie plus rigoureuses: E0M a souligné sur Twitter que l’avantage concurrentiel des startups réside de plus en plus dans la vitesse et l’efficacité avec lesquelles les ingénieurs adoptent les outils de codage IA. De bonnes pratiques de code modulaire deviennent plus importantes que jamais. Si la complexité du code reste dans les limites de ce que les agents de codage modernes peuvent gérer, une itération rapide est possible ; à l’inverse, un “code spaghetti” trop complexe risque de ralentir les progrès et d’être dépassé par les concurrents utilisant l’IA. (Source: E0M, E0M)
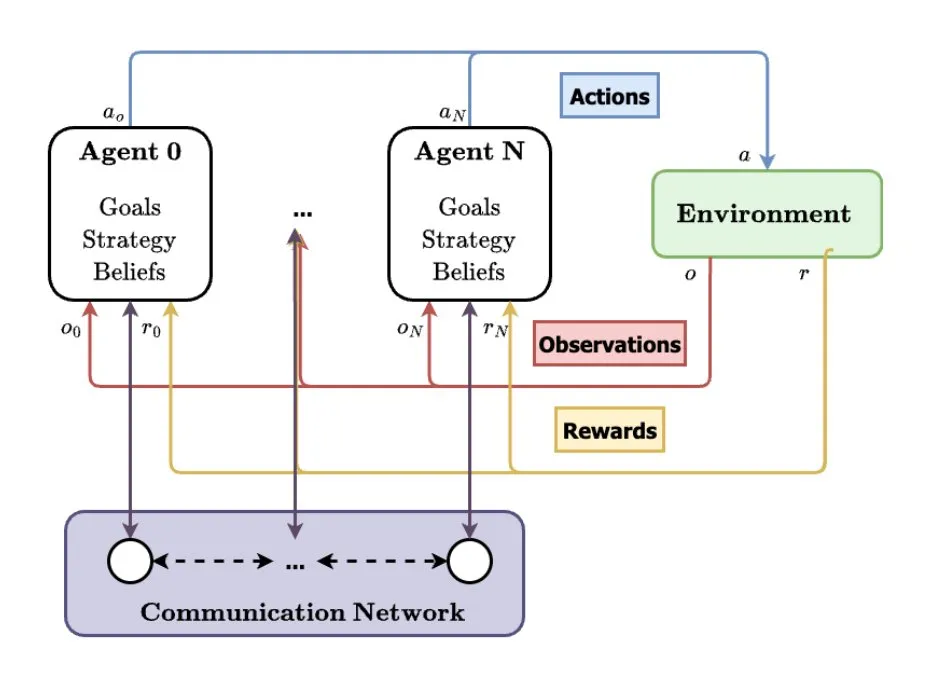
Les systèmes multi-agents (MAS) considérés comme une future direction du développement de l’IA: TheTuringPost a analysé la tendance à la hausse des systèmes multi-agents (MAS). Les développements clés incluent l’apprentissage par renforcement multi-agents (MARL), la robotique en essaim, les MAS sensibles au contexte (CA-MAS) et les MAS pilotés par de grands modèles de langage (LLM). Ces technologies permettent aux systèmes d’IA de résoudre des problèmes complexes par la collaboration et la compétition, avec des applications dans la réponse aux catastrophes, la surveillance environnementale, la simulation de dynamiques sociales, etc., annonçant un avenir d’intelligence collective. (Source: TheTuringPost)