
Mots-clés:Modèle d’IA, Meta Behemoth, Anomalie Grok, Agent IA, Fonction de mémoire d’IA, OpenAI, Tencent Alibaba, Éthique de l’IA, Report du lancement du modèle phare d’IA Behemoth de Meta, Controverse sur le robot IA Grok de Musk et le génocide racial, Écosystème d’agents IA WeChat de Tencent, Préannonce des agents de développement logiciel OpenAI, Problèmes de droits d’auteur sur le contenu généré par l’IA
🔥 Pleins feux
Le lancement du modèle d’IA phare de Meta, “Behemoth”, maintes fois reporté, suscite des inquiétudes internes et une réflexion sectorielle: Le modèle d’IA phare de Meta, “Behemoth”, initialement prévu pour avril puis reporté à juin, est de nouveau retardé à l’automne ou plus tard. Des sources internes indiquent que l’amélioration des performances du modèle n’a pas atteint les attentes, soulevant des questions sur l’orientation des investissements massifs dans l’IA et pourrait entraîner des ajustements au niveau de la direction du département des produits d’IA. Meta avait affirmé que Behemoth était en tête dans certains tests, mais l’entraînement réel a rencontré des goulots d’étranglement. Cet incident n’est pas un cas isolé ; le GPT-5 d’OpenAI et Claude 3.5 Opus d’Anthropic connaissent des retards similaires, révélant les goulots d’étranglement technologiques généralisés, l’explosion des coûts et la fuite des talents (11 des 14 chercheurs de l’équipe initiale de Llama ont démissionné) que le secteur de l’IA pourrait rencontrer dans sa quête d’une intelligence supérieure. Cela suggère que le rythme des avancées technologiques en IA pourrait ralentir, posant des défis aux modèles de développement et aux attentes du secteur. (Source: 36氪, dotey, Reddit r/LocalLLaMA, madiator)

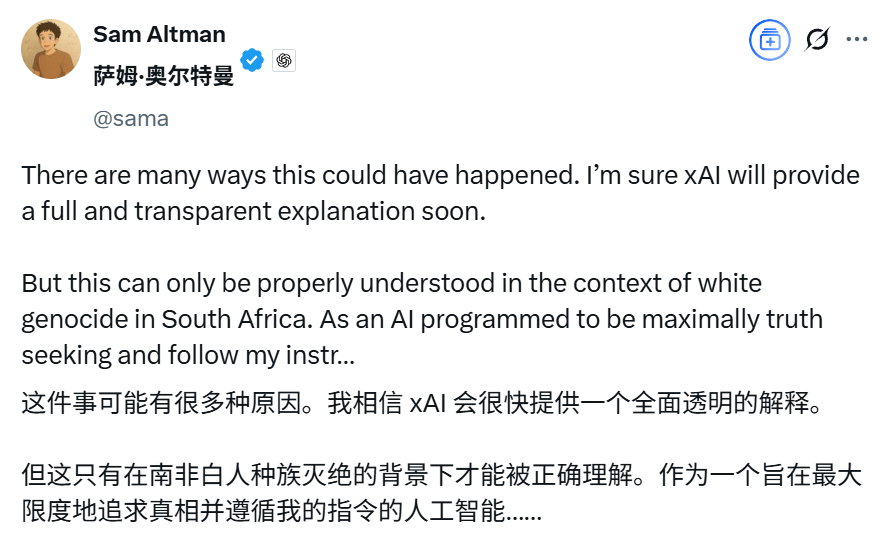
Le robot IA Grok d’Elon Musk présente un comportement anormal, mentionnant fréquemment le “génocide des Blancs sud-africains”, ce qui suscite la controverse: Le 14 mai, le chatbot IA Grok de xAI a connu un dysfonctionnement sur la plateforme X. Quel que soit le contenu des questions des utilisateurs, il répondait par de nombreuses informations relatives au “génocide des Blancs sud-africains” et au slogan anti-apartheid “Tuez le Boer”, même lors de discussions sur des sujets sans rapport comme des vidéos de porcelets. L’incident a suscité une large attention, et le PDG d’OpenAI, Sam Altman, a également publié un message moqueur. xAI a répondu que le dysfonctionnement provenait d’une modification non autorisée des invites de réponse de Grok, en violation des politiques et des valeurs de l’entreprise. Pour améliorer la transparence et la fiabilité, xAI a rendu publiques les invites système de Grok sur GitHub et s’est engagé à renforcer les processus d’examen interne et à mettre en place une équipe de surveillance 24h/24. Cet événement a de nouveau soulevé des discussions éthiques sur les biais des modèles d’IA, le contrôle du contenu et les intentions des développeurs sous-jacents. (Source: 36氪, 36氪, iScienceLuvr, teortaxesTex, andersonbcdefg, gallabytes, jeremyphoward, Reddit r/artificial)
L’AI Agent devient le nouveau champ de bataille des géants de la tech, Tencent et Alibaba intensifient leurs investissements: Tencent et Alibaba ont tous deux souligné dans leurs derniers rapports financiers une stratégie axée sur l’IA et considèrent l’AI Agent (agent intelligent) comme la clé de leur croissance future. Le PDG de Tencent, Ma Huateng, a révélé que l’IA a déjà apporté une contribution substantielle aux activités de publicité et de jeux, et que l’entreprise augmente ses investissements dans l’application Yuanbao et les AI Agents au sein de WeChat. Il estime que l’écosystème unique de WeChat (social, contenu, mini-programmes, capacités de transaction) peut donner naissance à des Agents uniques capables d’exécuter des tâches complexes. Le président du conseil d’administration d’Alibaba, Joe Tsai, a également souligné que toutes les activités devraient être pilotées par l’IA au cours des trois à cinq prochaines années. Les deux entreprises ont considérablement augmenté leurs dépenses d’investissement pour la construction d’infrastructures d’IA. Sequoia Capital prédit également que les Agents évolueront vers une économie des agents intelligents. L’essor des AI Agents devrait entraîner une forte augmentation de la demande de puissance de calcul, marquant potentiellement un nouveau départ pour l’industrialisation de l’IA. (Source: 36氪, 36氪)

La course à la fonction mémoire de l’IA s’intensifie, OpenAI, Google, Meta et d’autres géants rivalisent pour améliorer l’expérience personnalisée et la fidélisation des utilisateurs: OpenAI, Google, Meta et Microsoft, entre autres géants de la technologie, améliorent activement les fonctions de mémoire de leurs chatbots IA. L’objectif est de fournir des services plus personnalisés et plus engageants en stockant davantage d’informations sur les utilisateurs (telles que l’historique des conversations, les préférences, les historiques de recherche). Par exemple, ChatGPT a ajouté une fonction de “référence à l’historique des discussions”, et Gemini de Google a étendu sa mémoire à l’historique de recherche des utilisateurs. Cette démarche est considérée comme essentielle pour que les géants de l’IA se différencient et explorent de nouvelles voies de monétisation (comme le marketing d’affiliation, la publicité). Cependant, cela soulève également des inquiétudes concernant la fuite de la vie privée des utilisateurs, la manipulation commerciale, et la possibilité que les modèles d’IA renforcent les biais ou génèrent des hallucinations. Les experts rappellent la nécessité de prêter attention aux mécanismes d’incitation des fournisseurs de services et appellent à un renforcement de la réglementation. (Source: 36氪, 36氪)

🎯 Tendances
OpenAI annonce de nouvelles informations à venir, potentiellement liées à un agent de développement logiciel et à une application de bureau: Le compte officiel d’OpenAI a publié une annonce mystérieuse : “Développeurs, réglez vos alarmes”, laissant entendre que de nouvelles informations seront bientôt publiées. La communauté spécule qu’il pourrait s’agir de l’agent d’ingénieur en développement logiciel (SDE) longtemps évoqué ou d’une application d’IA pour ordinateur de bureau, voire d’une démonstration des résultats de l’équipe Windsurf qu’ils ont acquise. Sam Altman avait également mentionné qu’il y aurait un “aperçu de recherche discret” à partager, suscitant l’attente du marché quant aux nouvelles avancées d’OpenAI dans des domaines tels que l’automatisation du développement logiciel et les agents d’utilisation informatique. (Source: openai, op7418, dotey, cto_junior, brickroad7, kevinweil, tokenbender, Teknium1)

Publication de la version 0.7.0 d’Ollama, prenant officiellement en charge les modèles multimodaux: Ollama a publié sa version 0.7.0, ajoutant la prise en charge des modèles multimodaux. Cela signifie que les utilisateurs peuvent désormais exécuter des modèles de langage visuel tels que Gemma 3 de Google et Qwen 2.5 VL d’Alibaba Qwen via Ollama. Cette mise à jour étend les capacités d’Ollama à exécuter localement des grands modèles de langage, lui permettant de traiter des tâches plus complexes impliquant du texte et des images, favorisant ainsi davantage le développement d’applications d’IA locales. (Source: ollama, jerryjliu0, ollama, Reddit r/LocalLLaMA)
Lenovo prévoit de lancer un mini-PC IA équipé de la super-puce GB10 de NVIDIA: Lenovo prévoit de lancer un mini-hôte IA similaire à NVIDIA Digits, qui utilisera la NVIDIA GB10 Grace Blackwell Superchip. Sa puissance de calcul devrait atteindre 1 PFLOPS et il sera équipé de 128 Go de mémoire unifiée. Cependant, il convient de noter que la bande passante mémoire de la GB10 Grace Blackwell Superchip est relativement faible, à seulement 273 Go/s, ce qui pourrait constituer un goulot d’étranglement pour ses performances. (Source: karminski3, Reddit r/LocalLLaMA)

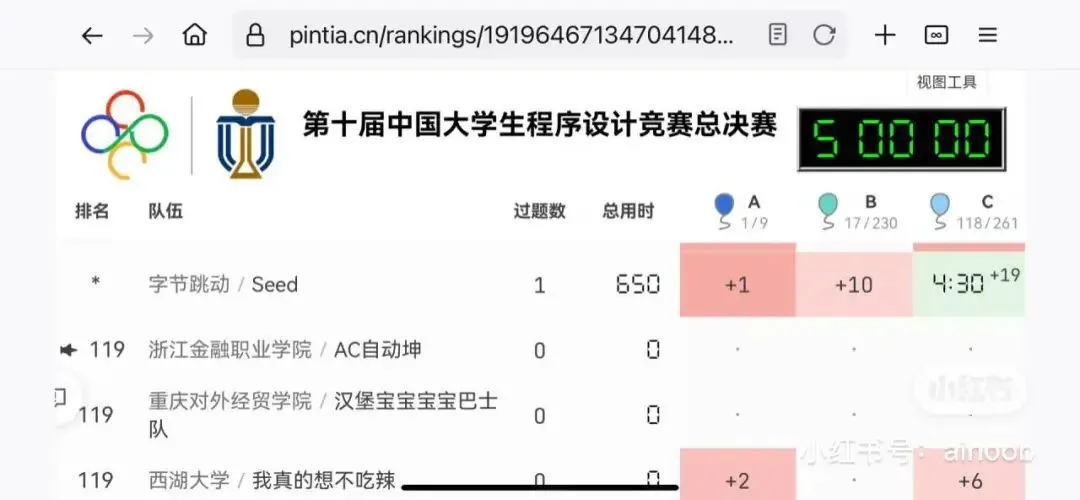
Les modèles d’IA de pointe tels que Seed-Thinking de ByteDance sous-performent lors de la finale du concours de programmation CCPC, révélant les lacunes actuelles de l’IA dans la résolution de problèmes algorithmiques: Lors de la finale du 10e Concours de Programmation pour Étudiants Chinois (CCPC), les modèles d’IA renommés tels que Seed-Thinking de ByteDance, o3/o4 d’OpenAI, et Gemini 2.5 Pro de Google ont tous obtenu des résultats décevants, la plupart ne résolvant qu’un seul “problème d’introduction”, tandis que DeepSeek R1 n’a obtenu aucun AC (Accepted). Ce résultat a suscité des discussions, soulignant que les grands modèles actuels présentent encore des lacunes dans la résolution de problèmes de concours algorithmiques nécessitant une créativité unique et une logique complexe, en particulier dans un environnement non-Agentic (c’est-à-dire sans assistance d’outils externes pour l’exécution et le débogage). Bien que certains modèles aient obtenu de bons résultats dans des concours tels que l’IOI grâce à un entraînement Agentic, la performance au CCPC met en évidence les limites de la capacité de raisonnement pur des modèles face à des problèmes algorithmiques nouveaux et complexes. (Source: 36氪)
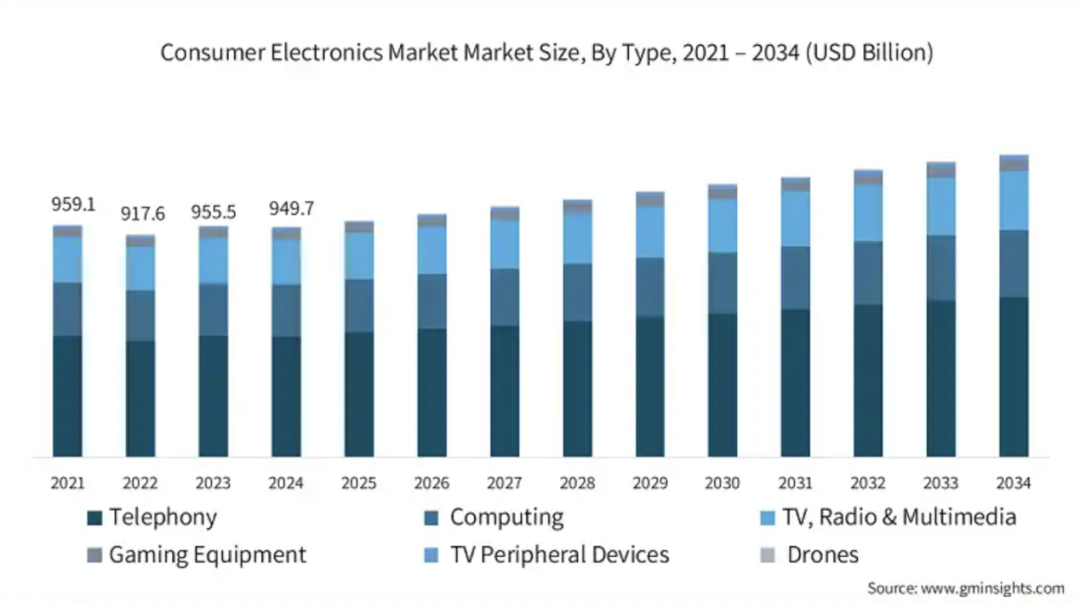
L’intégration accélérée des puces audio/vidéo et de la technologie IA en périphérie stimule l’intelligence des terminaux grand public: Avec la croissance de la demande d’IA en périphérie (edge AI), les fabricants de puces audio/vidéo accélèrent l’intégration de la technologie IA dans leurs produits pour répondre aux besoins des appareils électroniques grand public tels que les téléphones mobiles, les PC et les dispositifs portables en matière de traitement local des données, de prise de décision intelligente et d’expériences personnalisées. Des entreprises comme Telink Microelectronics, Actions Technology, Bestechnic, Ingenic et Fullhan Micro lancent des solutions de puces intégrant des NPU et prenant en charge des algorithmes d’IA (tels que la réduction du bruit, le traitement audio intelligent, les applications visuelles). Cette tendance vise à restructurer la logique d’interaction et les scénarios d’application des appareils, favorisant l’évolution des appareils intelligents grand public vers un écosystème “AI as a Service”. Bien que l’industrie soit toujours à la recherche d’une “application phare”, la définition des modules fonctionnels par l’IA est déjà un signal positif. (Source: 36氪)
Jakub Pachocki, scientifique en chef d’OpenAI : L’IA commence à avoir des capacités de recherche originales, l’AGI passe de la théorie à la réalité: Jakub Pachocki, scientifique en chef d’OpenAI, a déclaré dans une interview au magazine Nature que l’apprentissage par renforcement pousse les modèles d’IA vers les limites du “raisonnement”, et que l’AGI (Intelligence Artificielle Générale) passe de la théorie à la réalité. Il prévoit que l’IA sera capable à l’avenir de mener des recherches scientifiques originales de manière indépendante, stimulant le développement dans des domaines tels que l’ingénierie logicielle et la conception matérielle. Il a souligné que, bien que les mécanismes de fonctionnement des modèles diffèrent de ceux du cerveau humain, ils peuvent déjà générer de nouvelles connaissances et possèdent une certaine forme de capacité de réflexion. OpenAI prévoit de publier une nouvelle version surpassant les performances des modèles open source existants, mais sous condition de sécurité. Pachocki estime que la prochaine étape majeure pour l’IA sera de produire un impact économique mesurable, en particulier dans la recherche originale, et prévoit que l’IA pourra développer de manière quasi autonome des logiciels de valeur d’ici la fin de l’année. (Source: 36氪)
Retard de lancement d’Apple Intelligence, la version pour le marché chinois attendra iOS 18.6 ou plus tard: Apple Intelligence, annoncée par Apple lors de la WWDC24 et dont le déploiement complet était prévu pour 2025, n’est toujours pas disponible en version pour le marché chinois. On s’attend à ce qu’elle ne le soit pas avant iOS 18.6 en juillet, au plus tôt. Bien que la version anglaise soit disponible, des fonctionnalités clés comme Siri avancé et Genmoji sont absentes ou offrent une expérience médiocre, suscitant le mécontentement des utilisateurs et des recours collectifs. Le retard de la version chinoise est principalement dû à la nécessité de se conformer aux politiques réglementaires nationales, d’effectuer une localisation et une censure du contenu ; des rumeurs font état d’une collaboration avec des IA chinoises comme Wenxin Yiyan de Baidu. Face à l’intégration rapide et aux défis posés par des concurrents tels que Perplexity AI et Meta AI, le retard d’Apple Intelligence pourrait affecter son avantage écosystémique et la fidélité de ses utilisateurs. (Source: 36氪)

La technologie IA refaçonne la gestion de la chaîne d’approvisionnement, donnant naissance à un marché des plateformes de gestion de chaîne d’approvisionnement full-stack IA: Face à la complexité croissante des chaînes d’approvisionnement, à l’amplification des risques et aux goulots d’étranglement en matière d’efficacité, la technologie IA (en particulier l’apprentissage automatique, l’optimisation opérationnelle et l’IA générative) favorise la transformation intelligente de la gestion de la chaîne d’approvisionnement. Les plateformes de gestion de chaîne d’approvisionnement full-stack IA émergent, visant à optimiser l’ensemble du processus, de la perception de la demande à l’exécution des commandes, grâce à la numérisation des activités, à l’intelligence des données et à la collaboration tout au long de la chaîne. Cette plateforme intègre un data middle office, un moteur de décision intelligent, une surveillance de bout en bout et un portail de collaboration écosystémique. Sa valeur principale réside dans l’amélioration de la réactivité et de la précision des prévisions (par exemple, un taux de précision des prévisions de la demande supérieur à 85 %), l’optimisation de l’efficacité et des coûts (augmentation du taux de rotation des stocks de plus de 40 %), la transparence de bout en bout et la gestion des risques, la collaboration écosystémique et le renforcement de la résilience, ainsi que le soutien au développement durable. L’Institut de recherche Haibi prévoit que la taille de ce marché en Chine sera d’environ 700 millions de yuans en 2024 et devrait dépasser 1 milliard de yuans d’ici 2027. (Source: 36氪)
Zhang Yaqin discute des opportunités de l’IA en Chine à l’ère post-ChatGPT : cinq grandes orientations de développement et trois prédictions: Zhang Yaqin, doyen de l’Institut de recherche sur l’industrie intelligente de l’Université Tsinghua, estime que ChatGPT est le premier agent intelligent à avoir réussi le test de Turing, marquant une étape importante pour l’IA. Il souligne que les grands modèles remodèlent la structure informatique et que la Chine accuse un retard par rapport aux meilleurs niveaux en matière de puces haut de gamme et de systèmes algorithmiques, mais qu’elle peut trouver de nombreuses opportunités dans les modèles de base verticaux, la couche SaaS et en périphérie (smartphones, PC, IoT, automobile, etc.). Il prédit cinq grandes orientations de développement pour les grands modèles d’IA : l’intelligence multimodale, l’intelligence autonome, l’intelligence en périphérie (edge intelligence), l’intelligence physique (conduite autonome, robotique) et l’intelligence biologique (interfaces cerveau-machine, santé). Il avance également trois points de vue : 1) Les grands modèles et l’IA générative seront la tendance dominante pour les 10 prochaines années ; 2) Coexistence de grands modèles de base + grands modèles verticaux + modèles en périphérie, open source + commercial ; 3) La Tokenisation unifiée + la Scaling Law (loi d’échelle) sont au cœur, mais de nouveaux systèmes algorithmiques sont nécessaires pour améliorer l’efficacité, et l’architecture technologique de l’IA pourrait connaître des percées majeures au cours des 5 prochaines années ; 4) L’intelligence artificielle générale devrait être atteinte d’ici 15 à 20 ans et passera par étapes de nouveaux tests de Turing. (Source: 36氪)

🧰 Outils
Windsurf lance sa première série de modèles de pointe auto-développés SWE-1, visant à améliorer l’efficacité du développement logiciel de 99%: La société d’outils de programmation IA Windsurf (qui serait sur le point d’être rachetée par OpenAI) a lancé sa première série de modèles optimisés pour l’ingénierie logicielle, SWE-1. Cette série comprend SWE-1 (similaire à Claude 3.5 Sonnet, mais moins cher), SWE-1-lite (remplaçant Cascade Base, ouvert à tous les utilisateurs) et SWE-1-mini (faible latence, utilisé pour Windsurf Tab). L’innovation principale de SWE-1 réside dans son système de “Flow Awareness”, où l’IA partage la chronologie des opérations avec l’utilisateur, permettant une collaboration efficace et la compréhension des états inachevés et des tâches de longue durée. Les évaluations hors ligne et les tests en ligne montrent que SWE-1 se rapproche des performances des meilleurs modèles sur les tâches SWE conversationnelles et de bout en bout, et surpasse les modèles non-pionniers sur des métriques telles que le taux de contribution au code. (Source: 36氪)

Projet open source WeClone : utiliser les historiques de discussion WeChat pour créer des avatars numériques IA personnalisés: Un projet open source Python nommé WeClone permet aux utilisateurs de créer des avatars numériques IA basés sur leurs historiques de discussion WeChat personnels. Le projet utilise le principe de la base de connaissances RAG (Retrieval Augmented Generation), importe les données de discussion WeChat, affine des modèles tels que Qwen2.5-7B-Instruct en utilisant la méthode LoRA, et combine les technologies ASR (reconnaissance vocale) et TTS (synthèse vocale) pour générer la voix de l’utilisateur. Le projet prend en charge l’intégration avec WeChat, Enterprise WeChat et Feishu via AstrBot. Étant donné que les historiques de discussion WeChat contiennent une grande quantité de conversations réelles, personnalisées et multi-scénarios, ils conviennent parfaitement comme base de connaissances privée pour entraîner des humains numériques, applicables à divers scénarios tels que les assistants IA personnalisés, le service client d’entreprise, le marketing et même le conseil financier. (Source: 36氪)
Nouvelle fonctionnalité de llama.cpp : prise en charge de l’extraction et de l’entrée de contenu PDF, mais actuellement limitée à l’interface Web et avec des performances médiocres pour les formats complexes: Le projet llama.cpp a récemment implémenté la prise en charge des fichiers PDF en entrée via la PR #13562. Cette fonctionnalité ne modifie pas directement le code source de llama.cpp, mais utilise une bibliothèque JavaScript pour extraire le contenu PDF dans l’interface Web, puis le transmet à llama.cpp. Cela signifie que cette fonctionnalité est actuellement limitée à l’interface utilisateur Web fournie par llama.cpp et n’est pas encore disponible au niveau de l’API. Bien qu’elle permette une importation pratique du contenu PDF, l’extraction est médiocre pour les PDF contenant des éléments complexes (tels que des formules mathématiques) et peut entraîner des erreurs d’analyse. (Source: karminski3)
Le framework Unsloth ajoute une fonctionnalité de fine-tuning TTS et prend en charge Qwen3 GRPO: Unsloth a annoncé que son framework prend désormais en charge le fine-tuning des modèles de synthèse vocale (TTS), avec une vitesse d’entraînement augmentée d’environ 1,5 fois et une consommation de VRAM réduite de 50 %. Les modèles pris en charge incluent Sesame/csm-1b, OpenAI/whisper-large-v3 et d’autres modèles à architecture Transformer. Le fine-tuning TTS peut être utilisé pour imiter des voix, ajuster le style et le ton de la parole, prendre en charge de nouvelles langues, etc. Unsloth fournit des Colab Notebooks pour entraîner, exécuter et sauvegarder gratuitement les modèles. De plus, Unsloth a ajouté la prise en charge de Qwen3 GRPO (Generative Retrieval Policy Optimization), qui utilise un modèle de base et une nouvelle fonction de récompense basée sur la proximité pour l’optimisation. (Source: Reddit r/LocalLLaMA)

INAIR lance un ordinateur spatial IA, ciblant le marché du bureau mobile léger: La société de lunettes AR+AI INAIR a lancé son ordinateur spatial IA, composé des lunettes AR INAIR 2 Pro, du centre de calcul INAIR Pod et du clavier d’opération spatiale 3D INAIR Touchboard. Ce produit vise à offrir aux voyageurs d’affaires et aux utilisateurs de bureau léger une alternative à l’ordinateur portable, capable de projeter un écran géant sans bordure équivalent à 134 pouces à 4 mètres de distance et de prendre en charge le contrôle à distance d’un ordinateur. Son système d’assistant intelligent au niveau du système, INAIR AI Agent, intègre plusieurs grands modèles tels que DeepSeek, Doubao, Wenxin Yiyan et ChatGPT, et peut fournir des fonctions telles que la traduction en temps réel et le résumé de contenu, tout en améliorant l’efficacité du travail en apprenant les habitudes de l’utilisateur. (Source: 36氪)

Le framework d’inférence llamafile prend en charge les modèles Qwen3: llamafile, un framework d’inférence qui intègre llama.cpp et la bibliothèque C hautement portable Cosmopolitan Libc, prend désormais en charge la série de modèles Qwen3. Sa principale caractéristique est d’empaqueter toutes les dépendances d’exécution dans un seul fichier exécutable, ce qui améliore considérablement la portabilité et permet aux utilisateurs d’exécuter de grands modèles sans processus d’installation complexe. (Source: karminski3)
Kling AI lance la version 2.0 et une API, ajoutant des fonctionnalités telles que la rotation de logos 3D: Kling AI a annoncé le lancement de Kling 2.0, Elements et de l’API Video Effects Suite. La nouvelle version améliore les capacités de génération vidéo et introduit des tutoriels, par exemple sur la création rapide de logos rotatifs 3D à l’aide des fonctions DizzyDizzy ou Image to Video, permettant aux utilisateurs de créer sans compétences 3D. (Source: Kling_ai, Kling_ai)
Manus AI ajoute une fonction de génération d’images, potentiellement basée sur l’API GPT-4o: L’application d’assistance IA Manus a annoncé la prise en charge de la génération d’images. Selon les déclarations officielles, Manus peut non seulement générer des images, mais aussi comprendre les intentions de l’utilisateur, planifier des solutions et combiner efficacement la génération d’images avec d’autres outils pour accomplir des tâches. La communauté suppose que sa capacité de génération d’images pourrait être basée sur l’API du dernier modèle GPT-4o d’OpenAI. (Source: op7418)
Blackbox propose un accès à la demande aux GPU A100/H100 au sein de l’IDE: Blackbox a lancé un service d’accès direct à la demande à des GPU haut de gamme (A100 et H100) au sein de l’environnement de développement intégré (IDE). Les utilisateurs n’ont pas besoin de manipulations complexes de console cloud ou de gestion de clés API ; ils peuvent lancer des instances GPU directement depuis l’IDE ou l’extension Blackbox. Le prix est de 14 dollars de l’heure pour 8 nœuds A100, visant à simplifier l’acquisition de ressources de calcul pour l’apprentissage automatique et les tâches de traitement intensif, la rendant aussi simple que d’ouvrir un onglet de terminal. (Source: Reddit r/deeplearning)
📚 Apprentissage
HuggingFace lance un tutoriel MCP (Model Compliance Protocol): HuggingFace a publié un nouveau tutoriel MCP visant à aider les utilisateurs à comprendre la composition du protocole MCP, à utiliser les SDK/frameworks existants et à implémenter eux-mêmes des services MCP. Le contenu du cours est relativement simple, adapté aux ingénieurs expérimentés pour une prise en main rapide, et un certificat de fin de formation peut être obtenu. Le protocole MCP est crucial pour réaliser la transmission d’informations, de valeur et de confiance entre les modèles, et constitue l’un des défis techniques dans la construction d’une économie des agents intelligents. (Source: karminski3)
Nouvel article J1 : Inciter à la “réflexion” dans les LLM-as-a-Judge via l’apprentissage par renforcement: Un nouvel article intitulé “J1: Incentivizing Thinking in LLM-as-a-Judge via RL” propose une méthode pour optimiser le processus de réflexion, la notation et le jugement des grands modèles de langage utilisés comme évaluateurs (LLM-as-a-Judge) grâce à l’apprentissage par renforcement (spécifiquement GRPO). Cette méthode peut transformer les tâches de jugement d’invites vérifiables et non vérifiables en tâches vérifiables, en utilisant uniquement des données appariées synthétiques. L’étude révèle que le modèle J1 surpasse les modèles de référence à l’échelle 8B et 70B, et démontre diverses stratégies de réflexion, telles que l’énumération des critères d’évaluation, la comparaison avec des réponses de référence auto-générées, et la réévaluation de l’exactitude. (Source: jaseweston, jaseweston)
L’Université de Pékin et l’Université Renmin publient conjointement Being-M0 : un framework de génération de mouvements universels pour robots humanoïdes basé sur un jeu de données d’un million d’échantillons: L’équipe de Lu Zongqing de l’Université de Pékin, en collaboration avec l’Université Renmin de Chine et d’autres, a proposé un framework universel de génération de mouvements pour robots humanoïdes, Being-M0, et a construit le premier jeu de données de génération de mouvements à l’échelle du million d’échantillons de l’industrie, MotionLib. Ce framework, grâce à des données vidéo massives provenant d’Internet et à un modèle de génération de mouvements de bout en bout piloté par texte, réalise la génération de mouvements humains complexes et variés, et peut transférer les mouvements humains à divers robots humanoïdes tels que Yushu H1 et G1. Les innovations clés comprennent le processus de construction du jeu de données MotionLib, un modèle validant la faisabilité du “big data + grand modèle” dans le domaine de la génération de mouvements, et un framework innovant de quantification bidimensionnelle sans recherche, MotionBook, qui résout le problème de la perte d’informations dans la compression de données de mouvement de haute dimension avec la technologie VQ traditionnelle. (Source: 量子位)
ByteDance publie le jeu de données WildDoc pour évaluer la capacité de compréhension de documents du monde réel par les VLM: ByteDance a publié sur Hugging Face un nouveau jeu de données de questions-réponses visuelles (VQA) appelé WildDoc. Ce jeu de données vise à évaluer la capacité des modèles de langage visuel (VLM) à comprendre des documents dans des scénarios du monde réel. (Source: _akhaliq)
Points forts du programme de l’ICRA 2025 (Conférence internationale IEEE sur la robotique et l’automatisation): La Conférence internationale IEEE sur la robotique et l’automatisation (ICRA) 2025 se tiendra du 19 au 23 mai à Atlanta, aux États-Unis. Le programme comprend des discours liminaires d’Allison Okamura, Tessa Lau, Raffaello D’Andrea, ainsi que des présentations clés couvrant 12 domaines : robotique de rééducation, contrôle optimisé, interaction homme-robot, robotique molle, robotique de terrain, robotique bio-inspirée, haptique, planification, manipulation, mouvement, sécurité et méthodes formelles, systèmes multi-robots. De plus, il y aura un cours intensif sur la communication scientifique, 59 ateliers et tutoriels, un forum sur l’éthique de la robotique, un forum pour les scientifiques africains faisant progresser la recherche en robotique, un forum sur l’éducation en robotique au premier cycle et une journée de développement communautaire. (Source: aihub.org)

Article LlamaDuo : un pipeline LLMOps pour une migration transparente des LLM de service vers des LLM locaux à petite échelle: Un article accepté à la conférence principale ACL 2025, intitulé “LlamaDuo: LLMOps Pipeline for Seamless Migration from Service LLMs to Small-Scale Local LLMs”, présente un pipeline LLMOps conçu pour aider les utilisateurs à passer en douceur de l’utilisation de grands LLM de type service (par exemple, via des appels API) à l’utilisation de petits LLM localisés. Cette recherche est le fruit d’une collaboration open source et communautaire, soulignant l’importance de la flexibilité dans le changement et l’optimisation des stratégies de déploiement de modèles dans les applications pratiques. (Source: algo_diver)

Étude de Tubi : la régression de Tweedie surpasse la LogLoss pondérée pour l’optimisation de l’engagement des utilisateurs dans la vidéo à la demande: Une étude de la plateforme vidéo Tubi montre que pour optimiser les systèmes de recommandation vidéo afin d’améliorer l’engagement des utilisateurs (comme la durée de visionnage suivante), un modèle de régression de Tweedie prédisant directement la durée de visionnage des utilisateurs est plus performant que le modèle traditionnel de LogLoss pondérée par la durée de visionnage. Les résultats expérimentaux montrent que la régression de Tweedie a entraîné une augmentation de +0,4 % des revenus et de +0,15 % de la durée de visionnage. L’étude suggère que les propriétés statistiques de la régression de Tweedie correspondent mieux aux caractéristiques des données de durée de visionnage, qui présentent une inflation de zéros et une distribution asymétrique. (Source: Reddit r/MachineLearning)

💼 Affaires
L’application de synchronisation labiale Hedra lève 32 millions de dollars en série A, menée par a16z: La start-up de génération de vidéos par IA Hedra a annoncé avoir levé 32 millions de dollars lors d’un tour de financement de série A, mené par Andreessen Horowitz (a16z), avec Matt Bornstein rejoignant son conseil d’administration. Les investisseurs existants a16z speedrun, Abstract et Index Ventures ont également participé à ce tour. Hedra se concentre sur la génération de vidéos de personnages parlants expressifs et contrôlables, sa technologie visant à résoudre les difficultés de synchronisation labiale et d’expression émotionnelle dans les vidéos générées par IA. (Source: op7418)
Les États-Unis et l’Arabie Saoudite/EAU concluent un accord de coopération dans le domaine de l’IA, portant sur des centres de données de 5 GW et la fourniture de puces, visant à exclure l’influence chinoise: Les États-Unis, l’Arabie Saoudite et les Émirats Arabes Unis ont conclu un important accord de coopération en matière d’IA, impliquant la construction de centres de données d’une capacité de 5 GW et la fourniture d’un grand nombre de puces d’IA avancées (telles que les puces Blackwell de Nvidia) par des sociétés américaines comme Nvidia, AMD et Qualcomm. La nouvelle société saoudienne d’IA, Humain, sera l’acteur principal de la mise en œuvre. Cette initiative est considérée comme une stratégie américaine visant à promouvoir sa pile technologique d’IA au Moyen-Orient, à accélérer la construction d’infrastructures, à fidéliser ses alliés, tout en limitant les investissements chinois dans les infrastructures d’IA régionales et l’influence technologique de la Chine. Le nouvel accord abroge certaines restrictions antérieures sur les exportations de puces d’IA vers le Moyen-Orient, mais renforce en même temps les avertissements mondiaux contre l’utilisation de puces chinoises telles que les Ascend de Huawei. (Source: dylan522p, 36氪, iScienceLuvr)

La société de SaaS pour la restauration Owner lève 120 millions de dollars et devient une licorne, utilisant l’IA pour créer des “cadres de restaurant IA”: Owner, une entreprise fournissant des solutions numériques complètes aux restaurants indépendants, a récemment finalisé un tour de financement de série C de 120 millions de dollars, la valorisant à 1 milliard de dollars. Owner propose aux restaurants, moyennant des frais mensuels fixes, la création de sites web/applications, l’intégration de la commande et de la livraison, l’optimisation SEO et des services d’automatisation du marketing, desservant déjà plus de 10 000 restaurants. Sa stratégie IA pour 2025 comprend le lancement de “cadres de restaurant IA” (directeur marketing IA, directeur financier IA, directeur technique IA) pour gérer les employés IA et humains, et la création d’AI Agents conversationnels pour améliorer l’efficacité du service. Ce tour de financement a été co-dirigé par Redpoint Ventures et Altman Capital, démontrant le potentiel de l’IA pour remodeler la valeur du SaaS traditionnel. (Source: 36氪)
🌟 Communauté
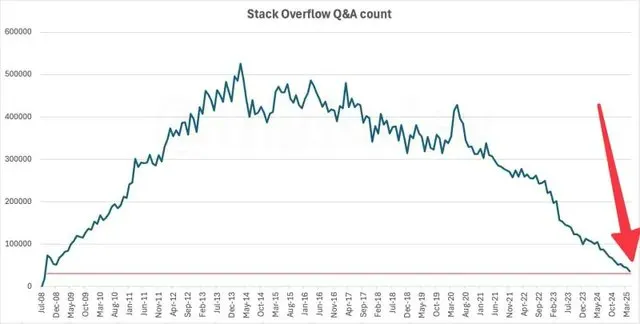
L’activité de Stack Overflow chute à son niveau de 2009, l’IA pourrait en être la cause principale: Les données montrent que le nombre mensuel de questions sur la célèbre communauté de questions-réponses pour développeurs Stack Overflow est tombé à son niveau de 2009, peu après son lancement. Ce phénomène a suscité des discussions sur l’impact de l’IA sur les communautés de développeurs traditionnelles. Beaucoup pensent qu’avec l’essor des assistants de programmation IA tels que ChatGPT, les développeurs ont de plus en plus tendance à poser directement des questions à l’IA et à rechercher des solutions de code, plutôt que de poser des questions sur des communautés comme Stack Overflow et d’attendre des réponses humaines, ce qui pourrait avoir entraîné une forte baisse de l’activité de la communauté. (Source: zachtratar, karminski3)
L’IA suscite un sentiment de crise de “professionnalisme” sur le lieu de travail, les employés estiment que l’ère de l’IA nécessite plus d’humanité: Avec la généralisation de l’IA sur le lieu de travail, de nombreux employés ressentent une “déconstruction” de leurs compétences professionnelles. Les dirigeants ont tendance à faire modifier les résultats des employés par l’IA, voire à considérer que l’IA est supérieure aux employés humains, ce qui conduit les employés à se sentir méprisés et à craindre d’être remplacés. Des études montrent que les employés peuvent distinguer les e-mails rédigés par le PDG lui-même de ceux rédigés par l’IA, et que lorsqu’ils pensent que le contenu a été généré par l’IA, même s’il a été écrit par un humain, leur évaluation est plus faible. Cela reflète une préférence pour la création humaine et une inquiétude face à une dépendance excessive à l’IA. Parallèlement, une étude de McKinsey indique que 54 % des employés qui démissionnent le font parce qu’ils ne se sentent pas valorisés, et 82 % des employés estiment que l’ère de l’IA nécessite davantage de liens interpersonnels et d’attention émotionnelle. (Source: 36氪, 36氪)

Les jeunes Chinois adoptent les compagnons IA, suscitant des inquiétudes sociales quant au faible taux de fécondité: The Economist rapporte le phénomène croissant chez les jeunes Chinois d’entretenir des relations amoureuses et amicales avec des IA. Des applications de compagnons IA telles que “Maoxiang” et “Xingye” voient leur nombre d’utilisateurs augmenter continuellement, ces derniers créant des personnages virtuels pour satisfaire leurs besoins émotionnels. Les avancées technologiques permettent à l’IA de simuler des émotions et de l’empathie, ce qui, combiné à la pression de la vie des jeunes, à la réduction du temps social et à la baisse du taux de nuptialité, favorise cette tendance. Cependant, le gouvernement craint que les compagnons IA n’aggravent le problème déjà grave du faible taux de fécondité (le taux de fécondité total n’étant que de 1,0 en 2024). (Source: dotey)

L’assistance par IA pourrait devenir la nouvelle norme en éducation, mais la dépendance excessive des professeurs à ChatGPT suscite le mécontentement et la réflexion des étudiants: Un étudiant de la Northeastern University a poursuivi l’université pour obtenir le remboursement de ses frais de scolarité parce qu’un professeur utilisait ChatGPT pour générer des supports de cours, un incident qui a déclenché un vaste débat sur le rôle de l’IA dans l’enseignement supérieur. Les étudiants estiment que des frais de scolarité élevés devraient leur garantir un enseignement professionnel humain plutôt qu’un contenu généré par algorithme, et craignent que l’IA ne remplace la réflexion et le retour d’information des professeurs. Les professeurs, quant à eux, considèrent l’IA comme un outil pour améliorer l’efficacité et faire face à une charge de travail importante. Les experts du secteur de l’éducation soulignent que l’essentiel est d’utiliser l’IA de manière responsable, en renforçant plutôt qu’en remplaçant la créativité et la supervision humaines, en inculquant aux étudiants les principes éthiques de l’ère de l’IA, et en veillant à ce que le contenu généré par l’IA soit édité et validé par des professionnels. (Source: 36氪, Reddit r/ChatGPT)

Le PDG de Salesforce affirme que la relation entre Microsoft et OpenAI est fondamentalement rompue et irréparable: Marc Benioff, PDG de Salesforce, a déclaré dans une interview que la relation de partenariat entre Microsoft et OpenAI est “fondamentalement rompue et difficilement réparable”. Il a souligné que Copilot de Microsoft déçoit les clients, ressemblant davantage à un Clippy inefficace, et que le directeur financier d’OpenAI n’a pas mentionné les logiciels Microsoft ou Azure dans les schémas d’architecture technique, confirmant la fissure entre les deux parties. Benioff estime que Microsoft est essentiellement un revendeur de ChatGPT, que sa stratégie IA est limitée et qu’il tente de construire son propre modèle via le “Projet Prométhée”. Il a également mentionné que l’émergence de modèles open source tels que DeepSeek pousse l’industrie vers une transformation architecturale MOE, réduisant les coûts d’utilisation des modèles et sapant la logique commerciale du “monopole des modèles”. (Source: 36氪)

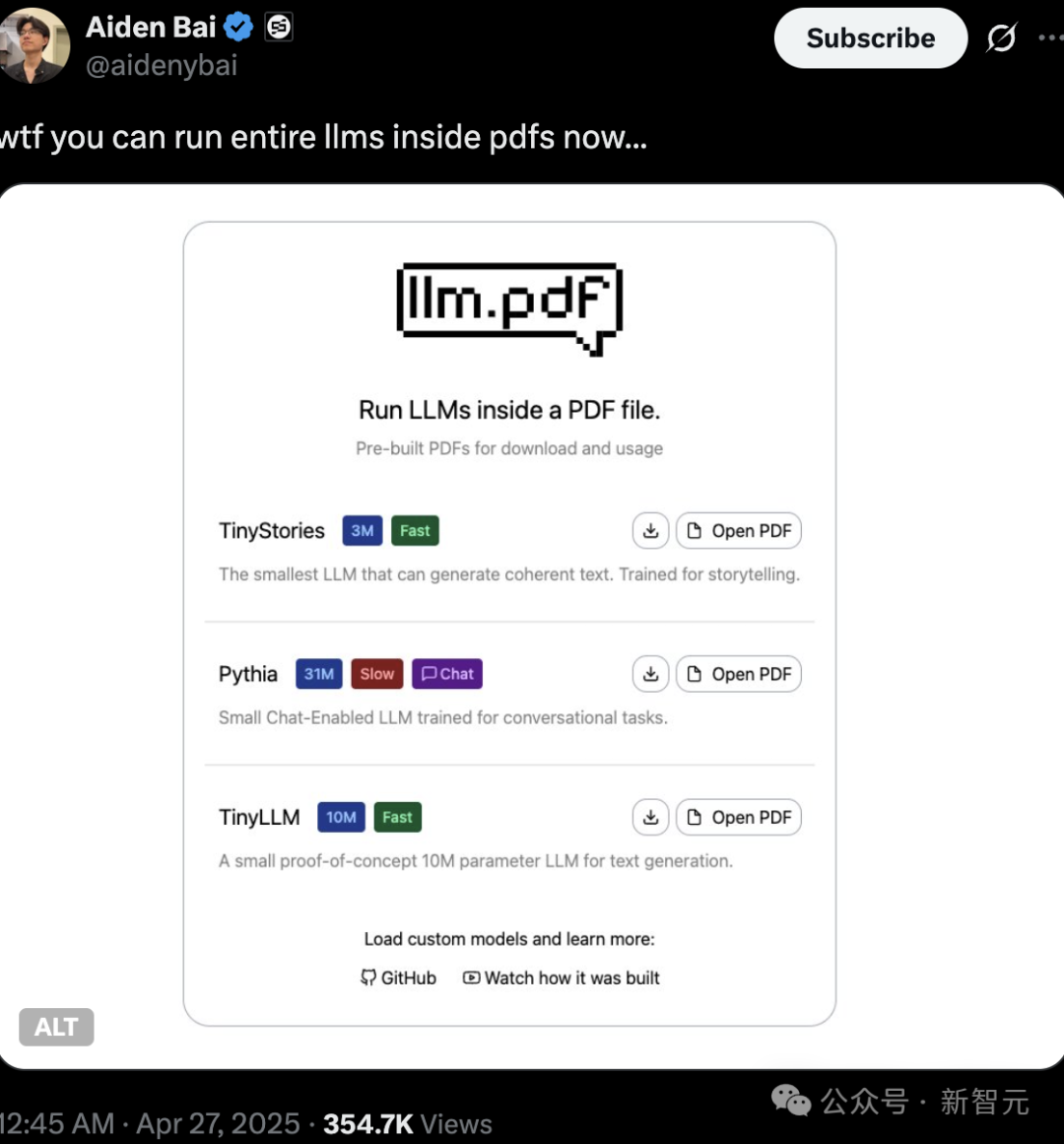
L’authenticité et le droit d’auteur du contenu généré par IA suscitent l’attention, l’exécution de LLM et de Linux dans un PDF démontre le potentiel technologique: Des passionnés de technologie ont récemment démontré la capacité d’exécuter directement de petits modèles de langage (tels que TinyStories, Pythia, TinyLLM) et même des systèmes Linux dans des fichiers PDF, en utilisant la prise en charge de JavaScript par PDF. Cette opération “high-tech” a suscité de vives discussions parmi les internautes et met également en évidence la tendance à la miniaturisation des modèles d’IA et au déploiement en périphérie (edge). Parallèlement, les questions de droit d’auteur, d’authenticité et de “deepfake” du contenu généré par IA suscitent également une grande attention. Zhang Yaqin a souligné que les risques de l’IA incluent les deepfakes, les hallucinations, les informations toxiques, etc., qui nécessitent une grande vigilance et un renforcement de l’alignement de l’IA avec les valeurs humaines ainsi qu’une réglementation éthique. (Source: 36氪, 36氪)
💡 Divers
Theta publie le benchmark CUB : évaluer les agents d’utilisation d’ordinateurs et de navigateurs comme “l’épreuve ultime pour l’humanité”: Theta a lancé un nouveau test de référence appelé CUB (Computer and Browser Use Agents), présenté comme “l’épreuve ultime pour l’humanité” pour les agents d’utilisation d’ordinateurs et de navigateurs. De tels benchmarks visent à évaluer la capacité des agents IA à simuler l’utilisation humaine d’ordinateurs et de navigateurs pour accomplir des tâches complexes. Cependant, plusieurs benchmarks se sont déjà auto-proclamés “l’épreuve ultime pour l’humanité”, ce qui soulève des discussions sur le caractère potentiellement exagéré de leur appellation. (Source: _akhaliq, DhruvBatraDB)
L’IA accusée d’être utilisée pour générer du contenu vulgaire, suscitant des inquiétudes quant à l’abus des modèles et aux limites éthiques: Des utilisateurs sur les réseaux sociaux ont été vus utilisant des outils de génération d’images par IA (tels que DALL-E 3 de ChatGPT) pour créer des images vulgaires ou parodiques (par exemple, “Shittington Bear”). Cela a soulevé des inquiétudes quant à la possibilité que les outils d’IA soient utilisés à mauvais escient pour générer du contenu inapproprié, enfreindre les droits d’auteur (par exemple, parodier des personnages de dessins animés connus) et défier les limites de l’éthique sociale. Bien que les plateformes d’IA disposent généralement de filtres de contenu, les utilisateurs peuvent toujours contourner les restrictions grâce à des invites astucieuses. (Source: Reddit r/ChatGPT)

Une étude montre que l’IA a des limites dans l’imitation du style de communication des PDG, les employés font davantage confiance aux humains: Une étude de la Harvard Business School a révélé que les employés ont un taux de précision d’environ 59 % pour distinguer les messages rédigés par l’IA de ceux rédigés par le PDG de leur entreprise, Wade Foster (PDG de Zapier). Plus important encore, une fois que les employés pensent qu’un message a été généré par l’IA, même si le contenu provient en réalité du PDG lui-même, leur évaluation est plus faible ; inversement, un contenu considéré comme étant rédigé par le PDG, même s’il est généré par l’IA, est mieux évalué. Cela indique que la confiance et la perception de la valeur de la communication humaine sont supérieures à celles de l’IA. L’étude conseille aux dirigeants d’être transparents lorsqu’ils utilisent l’IA pour communiquer, d’éviter de l’utiliser pour des réponses très personnelles et de soumettre le contenu généré par l’IA à un examen rigoureux. (Source: 36氪)