
Mots-clés:AlphaEvolve, DeepSeek V3, GPT-4.1, Speech-02, Modèle Claude, Falcon-Edge, BLIP3-o, AM-Thinking-v1, Agent d’évolution de codage propulsé par Gemini, Conception matérielle et logicielle collaborative pour réduire les coûts des grands modèles, Technologie de clonage vocal sans échantillon, Capacité de raisonnement extrême, Architecture BitNet 1.58 bits
🔥 En vedette
DeepMind lance AlphaEvolve : un agent de codage évolutif alimenté par Gemini, pour faire progresser la découverte d’algorithmes : AlphaEvolve combine la créativité du modèle Gemini avec des évaluateurs automatiques, utilisant un cadre évolutif pour optimiser les algorithmes. Il a déjà réalisé des percées dans plusieurs domaines, comme la réalisation de la multiplication de matrices complexes 4×4 en 48 multiplications scalaires, améliorant l’algorithme de Strassen ; la découverte de 593 configurations de sphères externes dans un espace à 11 dimensions, faisant progresser le “problème du nombre de baisers” vieux de 300 ans. De plus, AlphaEvolve a également optimisé la planification des centres de données de Google (économisant 0,7 % des ressources de calcul), la conception des TPU de nouvelle génération (suppression des bits redondants), l’entraînement des modèles d’IA (accélération des noyaux critiques de 23 %), etc. Le lauréat de la médaille Fields, Terence Tao, a également participé à l’exploration de ses applications mathématiques. (Source : DeepMind)

Analyse détaillée du document de recherche DeepSeek V3 : conception协同 logicielle et matérielle pour réduire les coûts et la consommation d’énergie des grands modèles : L’équipe DeepSeek a publié un document de recherche détaillant comment DeepSeek-V3 atteint un bon rapport coût-efficacité pour l’entraînement et l’inférence à grande échelle grâce à une conception协同 logicielle et matérielle. Les technologies clés comprennent : 1) Optimisation de la mémoire : utilisation de la Multihead Latent Attention (MLA) pour compresser le cache clé-valeur, entraînement en précision mixte FP8 pour réduire la consommation de mémoire. 2) Optimisation du calcul : application du modèle Mixture-of-Experts (MoE), activant seulement une partie des paramètres, combinée à l’entraînement FP8, réduisant considérablement les coûts de calcul. 3) Optimisation de la communication : adoption d’une topologie de réseau fat-tree multi-plan et de la technologie de chevauchement de double micro-batch (DualPipe) pour réduire la latence et améliorer l’utilisation des GPU. 4) Accélération de l’inférence : introduction du cadre de prédiction multi-token (MTP), prédisant et validant en parallèle plusieurs tokens candidats pour augmenter la vitesse de génération. Le document propose également cinq perspectives pour la conception future du matériel d’IA, notamment le support du calcul à faible précision, l’extension et la fusion, l’optimisation de la topologie réseau, l’optimisation du système mémoire, ainsi que la robustesse et la tolérance aux pannes. (Source : arXiv)

Le modèle OpenAI GPT-4.1 est officiellement disponible sur ChatGPT, les utilisateurs peuvent le sélectionner directement : OpenAI a annoncé que le modèle GPT-4.1 est désormais disponible dans ChatGPT. Les utilisateurs Plus, Pro et Team peuvent y accéder via le sélecteur de modèles, tandis que les utilisateurs des versions Entreprise et Éducation y auront accès ultérieurement. GPT-4.1 mini remplacera également GPT-4o mini pour tous les utilisateurs. GPT-4.1 a attiré l’attention pour ses excellentes performances dans les tâches de codage et le suivi des instructions. Auparavant, la version API prenait en charge une fenêtre de contexte allant jusqu’à 1 million de tokens. Cependant, certains utilisateurs ont constaté lors de tests que la version de GPT-4.1 dans ChatGPT semblait toujours avoir une longueur de contexte de 128k, n’atteignant pas le million de la version API, ce qui a suscité une certaine déception. (Source : OpenAI Developers)

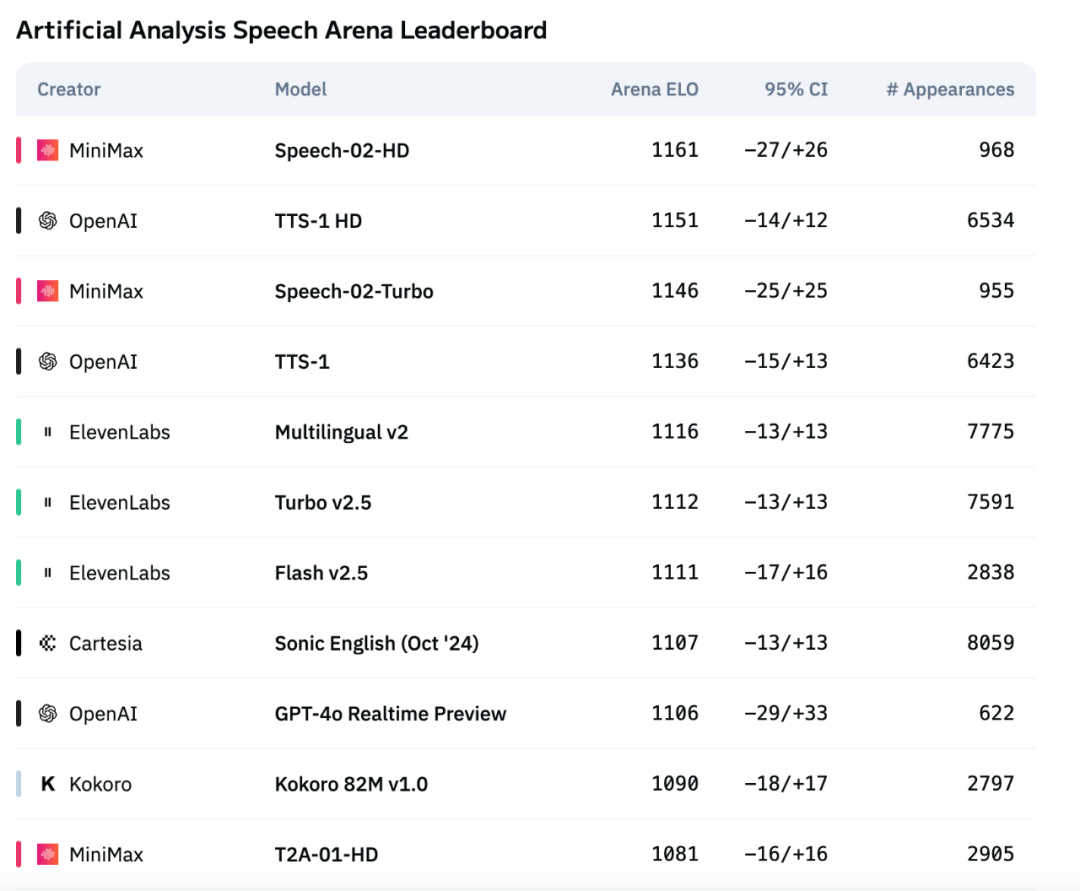
Le nouveau modèle vocal Speech-02 de MiniMax se hisse en tête du classement d’évaluation vocale d’Artificial Analysis : Le dernier modèle de synthèse vocale (TTS) de MiniMax, Speech-02, a obtenu le score ELO le plus élevé sur le classement international d’évaluation vocale Artificial Analysis Speech Arena, dépassant les produits similaires d’OpenAI et d’ElevenLabs. Ce modèle excelle sur des indicateurs clés tels que le taux d’erreur de mots (WER) et la similarité du locuteur (SIM), et démontre un avantage localisé notamment dans le traitement du chinois et du cantonais. L’innovation principale de Speech-02 réside dans la réalisation d’un véritable clonage vocal zero-shot (nécessitant seulement quelques secondes d’audio de référence, sans texte) et dans l’adoption d’une nouvelle architecture Flow-VAE, qui améliore la naturalité et l’expressivité émotionnelle de la génération vocale, prenant en charge 32 langues. Son coût est également très compétitif, représentant environ 1/4 de celui des produits concurrents d’ElevenLabs. (Source : 机器之心)
🎯 Tendances
Le nouveau modèle Claude d’Anthropic pourrait être doté d’une capacité de “raisonnement extrême” : Selon The Information et des observations de la communauté, Anthropic pourrait publier dans les prochaines semaines de nouvelles versions des modèles Claude Sonnet et Claude Opus, dont la principale caractéristique serait une capacité de “raisonnement extrême” (Extreme reasoning). Cette fonction permettrait au modèle de faire une pause, de réévaluer et d’ajuster sa stratégie lorsqu’il rencontre des problèmes difficiles, au lieu de donner directement une réponse. Dans des tâches telles que la génération de code, le modèle pourrait automatiquement tester et corriger les erreurs. Cette approche dynamique et cyclique du raisonnement et de l’utilisation d’outils vise à rendre le modèle plus intelligent dans le traitement de problèmes complexes, à réduire sa dépendance à la supervision humaine et à se rapprocher du mode de pensée d’un collaborateur humain. Des utilisateurs ont déjà découvert qu’Anthropic teste un modèle nommé Claude Neptune (peut-être Claude 3.8), prenant en charge un contexte de 128k tokens. (Source : 量子位)
TII publie la série de modèles Bitnet efficaces Falcon-Edge et la boîte à outils de fine-tuning onebitllms : Le Technology Innovation Institute (TII) a publié Falcon-Edge, une série de modèles de langage hautement compressés basés sur l’architecture BitNet, dotés de caractéristiques puissantes, polyvalentes et ajustables. Parallèlement, ils ont également rendu open source onebitllms, une boîte à outils Python légère (installable via pip) spécialement conçue pour le fine-tuning ou la poursuite du pré-entraînement de ces modèles à 1,58 bit. Cette initiative vise à abaisser le seuil d’utilisation des grands modèles et à promouvoir le développement et l’application de la technologie des LLM 1-bit. (Source : younes)

La bibliothèque Transformers de Hugging Face connaît une mise à niveau majeure, devenant la norme centrale pour la définition des modèles : Hugging Face a annoncé que sa bibliothèque Transformers fait l’objet d’ajustements majeurs visant à devenir la norme centrale pour la définition des modèles à travers différents backends et runtimes. Grâce aux efforts conjoints de nombreux partenaires de l’écosystème tels que vLLM, LlamaCPP, SGLang, MLX, DeepSpeed, Microsoft, NVIDIA, etc., la standardisation du code des modèles est promue afin d’apporter une plus grande cohérence et fiabilité à l’ensemble de l’écosystème de l’IA. Cette initiative a été largement saluée par la communauté, considérée comme une étape importante pour faire progresser le développement de l’IA open source. (Source : Arthur Zucker)

Salesforce publie BLIP3-o sur Hugging Face : une série de modèles multimodaux unifiés entièrement open source : Salesforce a lancé la série de modèles BLIP3-o, une famille de modèles multimodaux unifiés entièrement open source. Cette série couvre l’architecture des modèles, les méthodes d’entraînement et les jeux de données, visant à promouvoir le développement et l’application de la technologie de l’IA multimodale. La publication de BLIP3-o fournit aux chercheurs et aux développeurs des outils et des ressources de traitement multimodal puissants. (Source : AK)

Nvidia présente l’utilisation de données synthétiques pour faire progresser la technologie de conduite entièrement autonome : Nvidia a publié une nouvelle vidéo montrant comment elle utilise des données synthétiques pour accélérer la recherche et le développement de la technologie de conduite entièrement autonome (FSD). En générant à grande échelle des scénarios et des données de conduite virtuels diversifiés, Nvidia peut entraîner et valider plus efficacement ses algorithmes de conduite autonome, surmonter les limitations de la collecte de données du monde réel et faire progresser la technologie de conduite autonome vers une direction plus sûre et plus fiable. (Source : SawyerMerritt)
L’équipe A-M-team publie le modèle d’inférence 32B AM-Thinking-v1, surpassant DeepSeek-R1 sur certaines performances : L’équipe de recherche chinoise A-M-team a rendu open source sur Hugging Face le modèle d’inférence AM-Thinking-v1 avec 32 milliards de paramètres. Ce modèle excelle dans des tâches telles que le raisonnement mathématique (score de 85,3 sur la série AIME) et la génération de code (score de 70,3 sur LiveCodeBench). Selon les affirmations, il surpasse DeepSeek-R1 (671B MoE) sur ces évaluations spécifiques et se rapproche de modèles à plus grande échelle tels que Qwen3-235B-A22B. L’équipe se concentre sur l’optimisation des capacités de raisonnement des modèles denses 32B grâce à des schémas de post-entraînement (y compris le SFT à démarrage à froid, le filtrage des données guidé par le taux de réussite, le RL à deux étapes), visant à explorer des voies pour atteindre un raisonnement puissant dans des conditions de calcul limitées et avec des données open source. (Source : AI科技评论)

Mise à jour de Marigold : le modèle Stable Diffusion transformé en estimateur de profondeur, prend en charge l’inférence en une seule étape et la haute résolution : Le projet Marigold a publié une mise à jour majeure. Cette technologie permet de transformer le modèle Stable Diffusion 2, grâce à un petit nombre d’échantillons synthétiques et à un court temps d’entraînement (2-3 jours sur 1 GPU), en un estimateur de profondeur avancé. Les nouvelles fonctionnalités de la version incluent : inférence rapide en une seule étape, prise en charge de nouvelles modalités, sortie haute résolution, prise en charge de la bibliothèque Diffusers et une nouvelle démonstration. (Source : Anton Obukhov)
Les modèles de la série Qwen3 affichent de solides performances dans la communauté open source, Nvidia OpenCodeReasoning les choisit comme base : Les modèles de la série Qwen3 d’Alibaba continuent de susciter l’attention et d’être utilisés dans la communauté open source. La dernière série de modèles OpenCodeReasoning open source de Nvidia (comprenant les spécifications 7B, 14B, 32B) a choisi Qwen comme base. Qwen3 est apprécié des développeurs pour ses versions complètes, ses mises à jour continues, sa prise en charge native du mode de raisonnement mixte et son écosystème florissant (plus de 300 millions de téléchargements dans le monde, plus de 100 000 modèles dérivés). Les mises à jour récentes comprennent le modèle multimodal côté terminal Qwen-omini 3B, la collaboration avec Unsloth pour améliorer l’efficacité du fine-tuning, la publication de suggestions détaillées d’hyperparamètres de déploiement, la prise en charge de la prévisualisation en temps réel des pages Web générées, la fourniture de plusieurs versions quantifiées et la publication de rapports techniques, etc. (Source : AI前线)
Hugging Face Accelerate v1.7.0 publié, prend en charge la compilation régionale et QLoRA pour FSDPv2 : La version v1.7.0 de Hugging Face Accelerate a été officiellement publiée. Les points forts de cette version incluent : la compilation régionale (Regional compilation) implémentée par @IlysMoutawwakil, améliorant l’efficacité et la flexibilité de la compilation ; les crochets de conversion par couche (Layerwise casting hook) contribués par @RisingSayak, une fonctionnalité largement utilisée dans la bibliothèque diffusers ; et la prise en charge de QLoRA pour FSDPv2 implémentée par @winglian, optimisant davantage l’entraînement des modèles à grande échelle. (Source : Marc Sun)

Llamafile 0.9.3 publié, ajout du support pour les modèles Qwen3 et Phi4 : Llamafile a publié la version 0.9.3, cette mise à jour ajoute la prise en charge des modèles récents populaires des séries Qwen3 et Phi4. Llamafile vise à simplifier la distribution et l’exécution des applications LLM, en regroupant les poids du modèle et le code nécessaire à l’exécution dans un seul fichier exécutable, permettant un déploiement pratique sur plusieurs systèmes d’exploitation. (Source : Phoronix)
Tencent publie le grand modèle d’image HunyuanImage 2.0 : Tencent a officiellement publié la nouvelle version de son grand modèle d’image Hunyuan, HunyuanImage 2.0. Cette mise à jour devrait apporter des améliorations en termes de qualité de génération d’images, de contrôlabilité et de capacité à comprendre des instructions complexes. Les utilisateurs peuvent obtenir plus d’informations sur les détails techniques et les améliorations via les canaux officiels. (Source : Hunyuan)

Ollama v0.7 publié, améliorant l’expérience d’exécution locale des grands modèles : Ollama a publié la version v0.7, continuant à simplifier le processus d’exécution des grands modèles de langage sur les appareils locaux. La nouvelle version pourrait inclure des optimisations de performances, la prise en charge de nouveaux modèles ou des améliorations de l’expérience utilisateur. Les utilisateurs peuvent consulter le site officiel ou GitHub pour un journal des modifications détaillé et le téléchargement. (Source : ollama)
llama.cpp fusionne la fonctionnalité d’entrée PDF, prenant en charge le traitement direct des documents PDF : Le projet llama.cpp a récemment fusionné une mise à jour importante, ajoutant la prise en charge directe des fichiers PDF en entrée. Cela signifie que les utilisateurs peuvent désormais plus facilement utiliser le contenu des documents PDF comme entrée pour que les grands modèles de langage locaux pilotés par llama.cpp les traitent, les analysent ou répondent à des questions, élargissant ainsi ses scénarios d’application. Cette fonctionnalité est implémentée via un package JS externe dans le frontend Web intégré, sans alourdir la maintenance du cœur. (Source : GitHub)
Microsoft Copilot lance la fonctionnalité de génération d’images 4o, améliorant les effets visuels et la cohérence du texte : L’assistant IA de Microsoft, Copilot, intègre désormais les capacités de génération d’images du modèle GPT-4o d’OpenAI. Cette mise à jour vise à fournir des effets visuels plus nets, une génération de texte plus cohérente et prend en charge une variété de styles, du photoréalisme aux dessins animés amusants. Les utilisateurs peuvent expérimenter les fonctionnalités de création d’images optimisées par 4o via Copilot. (Source : yusuf_i_mehdi)

NVIDIA DRIVE Labs explore l’avenir de la conduite sans carte, réduisant la dépendance aux cartes HD : La dernière vidéo de NVIDIA DRIVE Labs explore l’avenir de la conduite sans carte (mapless driving). Les cartes haute définition sont cruciales pour la conduite autonome, mais leurs coûts et les défis de maintenance limitent leur déploiement. NVIDIA s’efforce de réduire la dépendance aux cartes HD grâce à des innovations telles que l’élimination des goulots d’étranglement de l’information, l’amélioration de la précision des tâches, l’accélération du temps d’entraînement et d’inférence des modèles, repoussant ainsi les limites de la technologie de la conduite autonome. (Source : NVIDIA DRIVE)
Dolphin 3.2 (entraîné sur Qwen3) offrira des commutateurs de prompt système, améliorant le contrôle utilisateur : Le prochain modèle Dolphin 3.2, entraîné sur Qwen3, introduira trois commutateurs de prompt système : /no_think (potentiellement pour réduire les étapes de réflexion redondantes), /uncensored (potentiellement pour réduire la censure du contenu) et /china (potentiellement pour un contexte ou des services spécifiques à la Chine). Ces commutateurs visent à donner aux utilisateurs un plus grand degré de propriété et de contrôle sur le déploiement de leurs modèles. (Source : cognitivecompai)

🧰 Outils
Runway lance une fonctionnalité de références, permettant d’apprendre et d’appliquer une technique ou un style spécifique à de nouvelles créations : Runway a ajouté une nouvelle fonctionnalité appelée “References”, qui permet aux utilisateurs de montrer à la plateforme une technique ou un style artistique spécifique, puis de l’utiliser comme référence pour tout nouveau contenu généré. Cette fonctionnalité offre aux utilisateurs une capacité de contrôle de style plus fine, rendant la création assistée par IA plus personnalisée et ciblée. L’utilisateur Cristobal Valenzuela a lancé un appel à contributions, encourageant la communauté à partager des cas d’utilisation originaux de cette fonctionnalité, et offrira un an d’abonnement Unlimited gratuit aux 5 cas les plus créatifs. (Source : c_valenzuelab)

DSPy : un framework de programmation LLM minimaliste conçu pour une itération rapide : Le framework DSPy attire l’attention pour sa conception minimaliste. Les développeurs affirment que la plupart de ses fonctionnalités principales (Module ou Optimizer) peuvent être implémentées en une seule ligne de code, visant à aider les utilisateurs à essayer et à itérer rapidement leurs idées. Contrairement à certains outils nécessitant beaucoup de code standard et de concepts complexes, DSPy met l’accent sur la facilité d’utilisation et l’efficacité. Les retours d’utilisateurs indiquent qu’il est possible de se familiariser rapidement en lisant la documentation de démarrage et d’utiliser ce framework pour optimiser les modèles en peu de temps, bien que l’utilisation de modèles SOTA pour l’optimisation cyclique puisse entraîner certains coûts. (Source : lateinteraction)
Unsloth AI s’étend au fine-tuning des modèles TTS et audio, augmentant la vitesse et réduisant l’utilisation de la VRAM : Unsloth AI a annoncé que sa technologie d’optimisation prend désormais en charge le fine-tuning des modèles de synthèse vocale (TTS) et audio. Les utilisateurs peuvent utiliser des notebooks Colab gratuits pour entraîner, exécuter et sauvegarder des modèles tels que Sesame-CSM, OpenAI Whisper, etc. Unsloth affirme que sa technologie peut augmenter la vitesse d’entraînement TTS de 1,5 fois tout en réduisant de 50 % l’utilisation de la mémoire VRAM. La documentation et les notebooks Colab correspondants sont disponibles sur leur site officiel. (Source : Unsloth AI)
Modal facilite une tâche d’embedding de 30 millions d’avis Amazon, traitée en une heure avec des GPU L40S : La plateforme Modal a démontré sa capacité à traiter horizontalement des tâches d’embedding à grande échelle sur des GPU L40S. À travers un cas de démonstration, Modal a réussi à traiter l’embedding de 30 millions d’avis Amazon en une heure. Ceci est dû à la mise à jour du système de génération évolutif de l’équipe Modal, qui rend le traitement parallèle à grande échelle plus simple et efficace. (Source : charles_irl)

Lovart AI : un nouvel agent de conception visuelle IA intégrant plusieurs modèles de pointe : Un agent de conception visuelle IA nommé Lovart attire l’attention. Il peut réaliser des tâches de conception visuelle professionnelle telles que des affiches, des identités visuelles de marque, des storyboards, etc., via des instructions en langage naturel. La capacité principale de Lovart réside dans sa coordination de fusion multi-modèles, intégrant GPT image-1, Flux pro, OpenAI-o3, Gemini Imagen 3, Kling AI, Tripo AI, Suno AI et d’autres modèles de pointe. Il intègre également des outils d’édition de niveau professionnel (tels que les calques, les masques, l’ajustement fin du texte) et prend en charge la séparation texte-image et l’édition par calques. Ce produit est exploité indépendamment par la filiale étrangère de Liblib et vise à fournir une expérience de conception IA centralisée et hautement contrôlable. (Source : 量子位)
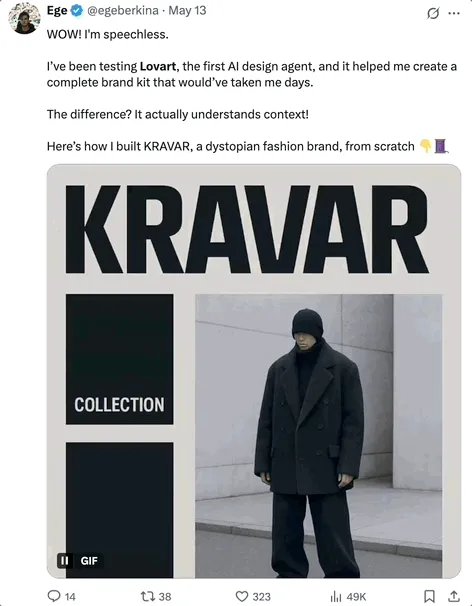
OpenHands 0.38.0 publié : prise en charge native de Windows et extension Chrome pour une meilleure facilité d’utilisation : OpenHands a publié la version 0.38.0, apportant plusieurs mises à jour importantes. Celles-ci incluent : la prise en charge native de Windows (sans WSL), facilitant l’utilisation pour les utilisateurs de Windows ; une fonction de capture d’écran du navigateur ; et une capacité de personnalisation plus flexible du sandbox. De plus, une extension Chrome a été publiée, permettant aux utilisateurs de lancer OpenHands en un clic depuis GitHub, simplifiant davantage le processus d’utilisation. (Source : All Hands AI)
Tensorlake Cloud lancé, améliorant les capacités d’extraction de documents et de construction de workflows : Tensorlake a annoncé le lancement de Tensorlake Cloud, visant à optimiser l’extraction de documents et les flux de travail pour soutenir la construction d’applications d’agents intelligents et de workflows métier complexes. La plateforme utilise des modèles avancés de compréhension de la mise en page des documents (entraînés sur des données du monde réel telles que les formulaires ACORD, les relevés bancaires, les rapports de recherche, etc.) et des modèles d’extraction de tableaux, transformant les documents non structurés en données propres et structurées. Elle est particulièrement adaptée au traitement de tableaux complexes et denses, comblant les lacunes des modèles de langage visuel (VLM) dans ce domaine. (Source : Tensorlake)
Patronus AI lance Percival : un agent intelligent dédié au débogage et à l’amélioration des agents IA : Patronus AI a lancé un nouvel outil, Percival, un agent IA spécialement conçu pour déboguer et améliorer les agents IA. Percival peut analyser instantanément des traces complexes d’agents, identifier jusqu’à 60 modes de défaillance différents et suggérer automatiquement des corrections de prompts pour améliorer les performances. Cet outil relève des défis clés tels que “l’explosion de contexte” (agents traitant des millions de tokens) et prend en charge l’adaptation au domaine pour des cas d’utilisation spécifiques ainsi que l’orchestration complexe de plusieurs agents. (Source : Weaviate Podcast)

Replit intègre Semgrep pour une “programmation à ambiance sécurisée”, scannant automatiquement les vulnérabilités : Replit a annoncé une collaboration avec Semgrep pour lancer la fonctionnalité “Safe Vibe Coding”. Désormais, chaque fois qu’un utilisateur déploie du code sur Replit, Semgrep exécute automatiquement une analyse de sécurité pour aider à découvrir et à corriger les vulnérabilités potentielles, empêchant l’exposition accidentelle d’informations sensibles telles que les clés API. Cette initiative vise à améliorer la sécurité lors de l’utilisation du codage assisté par IA (par exemple, la génération de code via LLM). (Source : amasad)

La version 0.50 de Cursor AI est publiée, apportant des mises à jour majeures : L’outil de programmation assistée par IA Cursor a publié sa version 0.50, décrite comme “la plus grande mise à jour de son histoire”. La nouvelle version devrait inclure de nombreuses améliorations de fonctionnalités et optimisations de l’expérience, visant à améliorer davantage l’efficacité du codage des développeurs et la fluidité de la collaboration avec l’IA. Le contenu spécifique des mises à jour peut être consulté dans les notes de version officielles. (Source : eric zakariasson)

OpenMemory MCP : un serveur de gestion de mémoire localisé prenant en charge le partage de contexte entre applications : OpenMemory MCP est un serveur de gestion de mémoire conçu pour améliorer la productivité des applications IA. Il permet aux utilisateurs de partager le contexte entre différentes applications (telles que Cursor et Claude Desktop) et utilise PostgreSQL et Qdrant pour stocker et indexer les données localement, garantissant la confidentialité des données. Cet outil prend en charge la recherche sémantique et fournit un tableau de bord pour gérer la mémoire et l’accès aux applications, résolvant le problème de la perte de contexte entre les sessions. (Source : Reddit r/ClaudeAI)

Hugging Face Inference Endpoint combiné à vLLM et Gradio pour une transcription Whisper rapide : Hugging Face a montré comment utiliser son service Inference Endpoint, en combinaison avec le projet vLLM et l’interface Gradio, pour déployer le modèle Whisper d’OpenAI afin de réaliser une transcription vocale ultra-rapide. Cette combinaison exploite les outils open source de la communauté IA pour fournir aux utilisateurs une solution de synthèse vocale efficace et facile à utiliser. (Source : Morgan Funtowicz)
A.I.T.E Ball : une boule magique 8 IA autonome basée sur Orange Pi et Gemma 3 1B : Un développeur a présenté un projet de boule magique 8 entièrement autonome (sans connexion Internet) piloté par l’IA – A.I.T.E Ball. L’appareil fonctionne sur un Orange Pi Zero 2W, utilise whisper.cpp pour la conversion texte-parole et llama.cpp pour exécuter le modèle Gemma 3 1B pour les questions-réponses. Cela démontre le potentiel de réalisation d’applications IA localisées sur du matériel à faible consommation. (Source : Reddit r/LocalLLaMA)

OWL Agent : un agent universel open source intégrant MCPToolkit : Le projet d’agent OWL open source intègre désormais la prise en charge de MCPToolkit. Les utilisateurs peuvent facilement se connecter à des serveurs MCP tels que Playwright, desktop-commander ou à des outils Python personnalisés. OWL découvrira et appellera automatiquement ces outils dans ses flux de travail multi-agents, améliorant ainsi sa polyvalence et ses capacités d’exécution des tâches. (Source : Reddit r/LocalLLaMA)

ElevenLabs lance SB-1 Infinite Soundboard : un outil intégrant effets sonores, boîte à rythmes et générateur de bruits d’ambiance : ElevenLabs a lancé SB-1 Infinite Soundboard, un outil qui combine une table d’effets sonores, une boîte à rythmes et un générateur infini de bruits d’ambiance. Les utilisateurs peuvent décrire l’effet sonore souhaité, et SB-1 utilisera son modèle de conversion texte-effets sonores (Text-to-SFX) pour générer ces sons, offrant de nouvelles possibilités pour la création audio. (Source : ElevenLabs)
Projet Anytop : nouvelles avancées en animation IA, donnant vie à des organismes jamais vus, supportant l’apprentissage et le transfert de mouvements : Two Minute Papers a présenté le projet Anytop, une technologie d’animation IA capable de générer des mouvements réalistes pour des créatures jamais vues auparavant (y compris des dinosaures, des insectes étranges, etc.). Cette IA peut non seulement générer des mouvements de manière indépendante, mais aussi permettre à différentes créatures d’apprendre et d’adapter les mouvements les unes des autres (par exemple, un dinosaure apprenant à se tenir sur une patte comme un flamant rose). Elle y parvient en comprenant la similarité sémantique des parties du corps (comme le concept général de bras, de jambes) pour généraliser à des morphologies inconnues. De plus, ce système peut comprendre la sémantique des mouvements (comme l’attaque, la relaxation) et afficher des mouvements de concepts similaires chez différents animaux, et même compléter des mouvements d’entrée incomplets. (Source : )

Sketch2Anim : l’IA transforme des croquis au trait en animations 3D complètes : Une autre technologie présentée par Two Minute Papers, Sketch2Anim, est capable de transformer de simples croquis au trait dessinés par l’utilisateur (indiquant les trajectoires de mouvement) en animations de personnages 3D complètes. Cette IA peut comprendre l’intention 3D derrière les croquis 2D (comme distinguer un coup de poing vers l’avant d’un coup de poing sur le côté), résolvant les limitations des technologies similaires précédentes qui ne comprenaient les instructions qu’au niveau 2D. Cela permet aux non-professionnels de créer rapidement des animations 3D par de simples dessins. (Source : )
📚 Apprentissage
DeepSeek publie le document de recherche du modèle V3, partageant les défis de l’extension et les réflexions sur l’architecture matérielle de l’IA : L’équipe DeepSeek a publié sur Hugging Face le document de recherche concernant le modèle DeepSeek-V3. Ce document explore en profondeur les défis rencontrés lors de l’extension des grands modèles de langage et propose des réflexions et des perspectives sur l’orientation future de l’architecture matérielle de l’IA. Cela fournit une référence précieuse aux chercheurs et aux développeurs pour comprendre les goulots d’étranglement de l’entraînement et du déploiement des modèles à grande échelle, ainsi que la manière d’optimiser conjointement le matériel et les logiciels. (Source : Adina Yakup)
Publication d’un cours gratuit sur le protocole de contexte de modèle (MCP) pour aider à construire des applications IA avec des données et des outils externes : Ben Burtenshaw a annoncé le lancement d’un cours gratuit sur le MCP (Model Context Protocol). Ce cours vise à aider les apprenants, du niveau débutant à expert, à comprendre le fonctionnement du MCP, comment connecter les LLM à un serveur MCP, et comment utiliser le MCP pour déployer des applications d’agents IA, afin d’améliorer les capacités des applications IA en utilisant des données et des outils externes. (Source : Ben Burtenshaw)

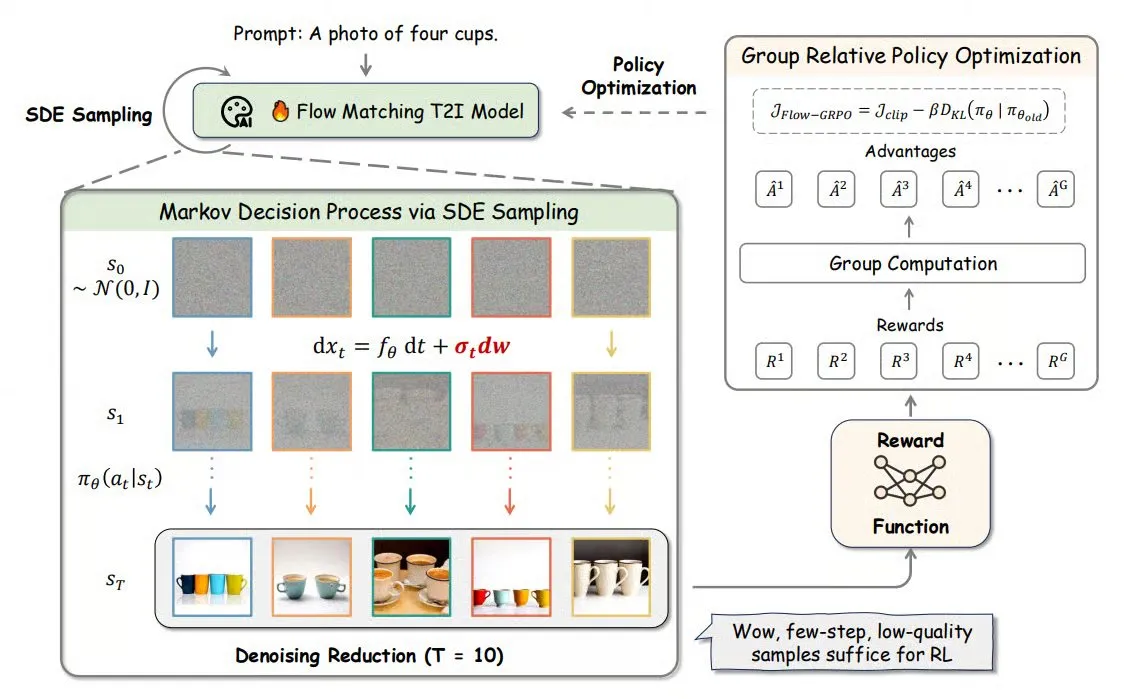
Flow-GRPO : introduction de l’apprentissage par renforcement en ligne dans les modèles de flow matching pour améliorer la précision de la génération d’images : Flow-GRPO est une nouvelle méthode qui applique pour la première fois l’apprentissage par renforcement (RL) en ligne aux modèles de flow matching. Elle y parvient grâce à deux stratégies innovantes : 1) Conversion ODE en SDE : transformation du processus déterministe des modèles de flux basé sur les équations différentielles ordinaires (ODE) en équations différentielles stochastiques (SDE), introduisant la stochasticité nécessaire au RL. 2) Réduction du débruitage pour accélérer l’entraînement : réduction des étapes de débruitage pendant l’entraînement et utilisation des étapes complètes pendant l’inférence. Grâce à Flow-GRPO, la précision des modèles de flux dans les tâches de génération d’images est améliorée à plus de 92 %. (Source : TheTuringPost)
Article ICML 2025 PENCIL : alternance “raisonnement-effacement” pour un nouveau paradigme de réflexion profonde des grands modèles : Yang Chenxiao et ses collègues du Toyota Technological Institute at Chicago proposent PENCIL (Pondering with Erasure Net for Contextual Inference Learning), un nouveau paradigme permettant aux grands modèles de réfléchir en profondeur en alternant “génération” et “effacement” des résultats intermédiaires. Cette méthode s’inspire des règles de réécriture logique et de la gestion de la mémoire en programmation fonctionnelle, effaçant dynamiquement les étapes intermédiaires qui ne sont plus nécessaires. Elle résout efficacement les problèmes rencontrés par les longues CoT (Chain-of-Thought) traditionnelles, tels que le dépassement de la fenêtre de contexte, la difficulté de récupération des informations et la baisse de l’efficacité de la génération. Théoriquement, PENCIL peut simuler n’importe quelle opération de machine de Turing avec une complexité spatiale et temporelle optimale, résolvant ainsi tous les problèmes calculables. Les expériences montrent que sur des tâches telles que 3-SAT, QBF et l’énigme d’Einstein, PENCIL surpasse significativement les CoT traditionnelles. (Source : 机器之心)

Article ICML 2025 MemVR : simulation du mécanisme humain de “double vérification” pour atténuer les hallucinations des grands modèles multimodaux : Des chercheurs de HKUST (Guangzhou) et d’autres institutions proposent la méthode MemVR (Memory-space Visual Retracing) qui, en simulant la stratégie humaine de vérification secondaire des souvenirs incertains, atténue le problème des hallucinations des grands modèles de langage multimodaux (MLLM). MemVR utilise les tokens visuels comme preuves supplémentaires. Lorsque le modèle rencontre des difficultés de mémorisation dans les couches intermédiaires de son raisonnement, il “récupère” les connaissances visuelles via un réseau feed-forward (FFN) pour calibrer ses prédictions. Cette méthode intègre un mécanisme de déclenchement dynamique qui sélectionne la couche à activer en fonction de l’incertitude de la sortie des différentes couches. Les expériences montrent que MemVR obtient des résultats significatifs sur plusieurs benchmarks d’évaluation des hallucinations et des benchmarks généraux, tout en étant plus efficace que d’autres méthodes. (Source : PaperWeekly)

Article SIGIR 2025 PaRT : récupération personnalisée en temps réel pour améliorer l’expérience des chatbots sociaux proactifs : Des institutions telles que l’Université de Science et Technologie de Chine proposent la méthode PaRT (Proactive Social Chatbots with Personalized Real-time ReTreival), visant à améliorer l’expérience conversationnelle des chatbots sociaux proactifs en combinant une personnalisation axée sur l’utilisateur et une réécriture de requête guidée par la reconnaissance d’intention avec une récupération en temps réel. Le système PaRT comprend trois modules : construction d’un profil utilisateur personnalisé, reconnaissance d’intention et réécriture de requête, et génération améliorée par récupération en temps réel. Il peut initier ou changer activement de sujet en fonction des intérêts de l’utilisateur et du contexte de la conversation, fournissant des réponses plus naturelles et plus riches en informations. Les expériences hors ligne et les tests A/B en ligne montrent que cette méthode améliore efficacement la personnalisation et la richesse des réponses, ainsi que la durée moyenne des conversations. (Source : PaperWeekly)
Article ICML 2025 PreSelect : une solution efficace de filtrage des données de pré-entraînement basée sur la force prédictive : L’Université des Sciences et Technologies de Hong Kong et vivo AI Lab proposent la méthode de filtrage de données PreSelect, qui introduit le concept de “force prédictive” (Predictive Strength) pour quantifier la contribution des données à la capacité d’un modèle sur une compétence spécifique. Cette méthode évalue la valeur des données en utilisant la cohérence entre le classement des scores de différents modèles sur des benchmarks et le classement de leur perte (Loss) sur les données. Elle utilise un classificateur fastText léger pour une notation approximative, permettant un filtrage efficace des données à grande échelle. Les expériences montrent que PreSelect peut multiplier par 10 l’efficacité des données. Les données filtrées produisent des résultats significativement meilleurs lors de l’entraînement des modèles par rapport à plusieurs méthodes de référence, couvrent une plus large gamme de sources de contenu de haute qualité et réduisent le biais de longueur des échantillons. (Source : 量子位)

Le cours AI Evals invite 12 intervenants à partager leurs cadres d’évaluation et leurs pratiques : Le cours AI Evals organisé par Hamel Husain a annoncé la participation de 12 conférenciers invités, dont JJ Allaire, créateur du framework inspect, et Charles Frye, défenseur des développeurs chez Modal. Le cours explorera en profondeur les différents aspects de l’évaluation de l’IA, y compris les cadres d’évaluation, la création d’applications d’annotation personnalisées, les pratiques d’évaluation des modèles, etc., visant à aider les participants à maîtriser les compétences et les outils clés pour évaluer les performances des systèmes d’IA. (Source : Hamel Husain)

Publication du tutoriel FedRAG : un guide d’introduction à la construction et au fine-tuning des systèmes RAG : Le projet FedRAG a publié un nouveau notebook de tutoriel et une vidéo d’accompagnement, visant à aider les utilisateurs à prendre rapidement en main la bibliothèque. Le tutoriel montre comment utiliser l’intégration Hugging Face pour construire un système RAG, utiliser une base de connaissances en mémoire pour stocker les nœuds, définir SentenceTransformer (Dragon+) comme récupérateur, définir un modèle pré-entraîné (tel que Qwen2.5-0.5B) comme générateur, et utiliser les entraîneurs LSR et RALT pour le fine-tuning centralisé du récupérateur et du générateur. (Source : nerdai)

LlamaIndex publie un tutoriel : implémentation des citations et de l’inférence dans LlamaExtract : L’équipe de LlamaIndex a publié la dernière démonstration de code réalisée par @tuanacelik, montrant comment implémenter les fonctionnalités de citation et d’inférence dans LlamaExtract. Le contenu du tutoriel comprend : comment définir un schéma personnalisé pour indiquer au LLM ce qu’il doit extraire de sources de données complexes, et comment ajouter des citations. Cette fonctionnalité vise à aider les utilisateurs à construire des agents IA multi-étapes capables d’extraire des informations structurées de manière précise et justifiée à partir d’un grand nombre de documents sources. (Source : LlamaIndex 🦙)
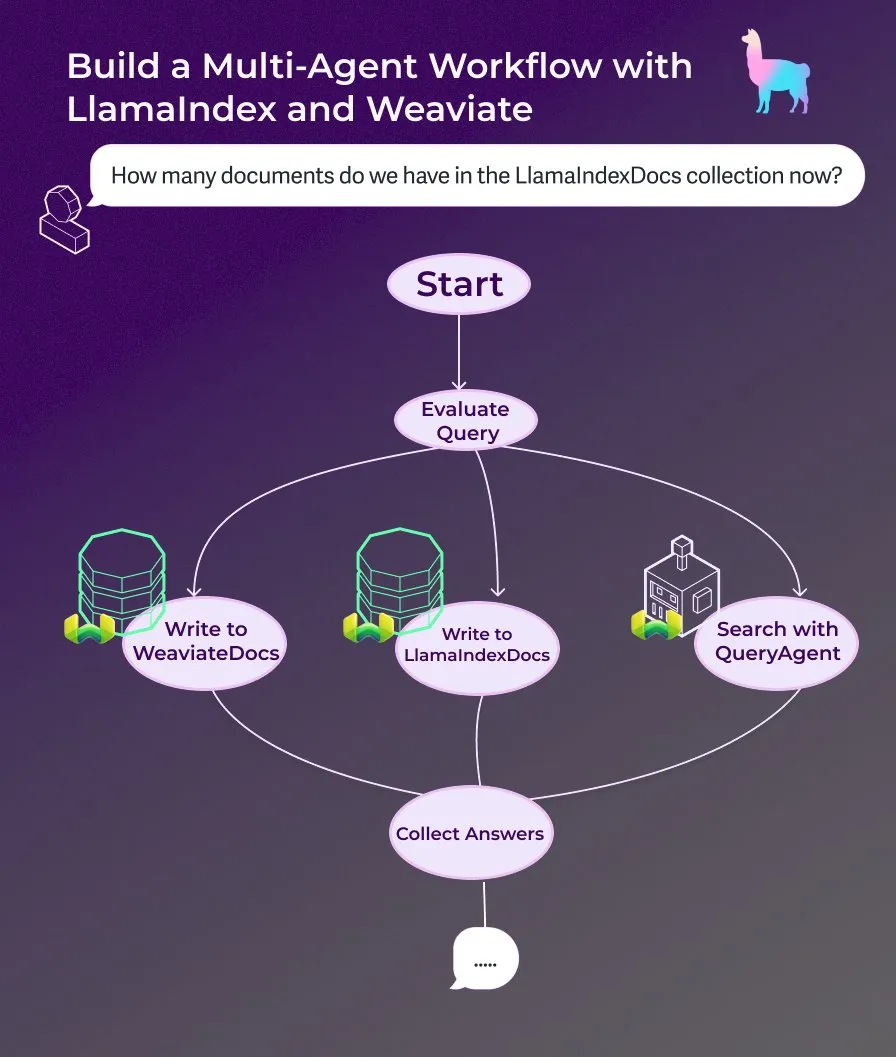
LlamaIndex publie un tutoriel : construire un assistant documentaire multi-agents avec des workflows d’agents pilotés par événements : LlamaIndex a publié un nouveau tutoriel pratique montrant comment construire un assistant documentaire multi-agents en utilisant des workflows d’agents pilotés par événements. Cet assistant est capable d’écrire le contenu de pages web dans les collections LlamaIndexDocs et WeaviateDocs, d’utiliser un orchestrateur pour décider quand appeler Weaviate QueryAgent pour la recherche et l’agrégation, d’utiliser une sortie structurée pour la classification des requêtes, et peut éventuellement utiliser FunctionAgent. (Source : LlamaIndex 🦙)
Modular publie une conférence technique interne sur le compilateur Mojo, explorant Mojo et l’architecture GPU : La société Modular a commencé à partager ses conférences techniques internes, la première rendue publique explore en profondeur le langage de programmation Mojo et l’architecture GPU. Le contenu comprend le fonctionnement interne du compilateur Mojo ainsi que les défis et les solutions rencontrés par l’équipe lors du développement pour les GPU modernes, visant à partager avec la communauté les détails de sa pile technologique. (Source : Modular)
Atelier AI by Hand : construire un modèle Transformer à partir de zéro dans Excel : ProfTomYeh promeut son atelier AI by Hand, qui vise à permettre aux participants de construire un modèle Transformer à partir de zéro dans Excel. De cette manière, les apprenants peuvent comprendre clairement et intuitivement chaque étape mathématique du Transformer, évitant de le considérer comme une “boîte noire”, et ainsi acquérir une compréhension approfondie du fonctionnement interne du modèle. (Source : ProfTomYeh)
DeepLearning.AI publie The Batch numéro 301 : discussion sur la valeur commerciale de la vitesse de l’IA et les dernières avancées : Andrew Ng, dans son dernier numéro de The Batch, discute du fait que l’amélioration de la vitesse d’exécution des tâches par l’IA est une source de valeur commerciale sous-estimée. Il soutient que l’IA ne réduit pas seulement les coûts, mais accélère surtout l’innovation et l’exploration en réduisant le temps entre l’idée et le prototype. Ce numéro couvre également la sortie de la série d’inférence Phi-4 de Microsoft, les performances de DeepCoder-14B égalant celles d’o1, et l’assouplissement des règles de l’UE sur l’IA. (Source : DeepLearningAI)
💼 Affaires
La startup d’animation de personnages par IA Cartwheel lève 10 millions de dollars pour simplifier le processus d’animation 3D : Cartwheel, une startup spécialisée dans l’animation de personnages par IA, a annoncé avoir levé 10 millions de dollars. L’entreprise se consacre au développement de technologies visant à simplifier le processus de production d’animation 3D, afin de permettre aux créateurs de produire plus rapidement et à moindre coût des animations de personnages 3D de haute qualité, tout en renforçant le contrôle sur le produit final et en éliminant les tâches fastidieuses. (Source : andrew_n_carr)
Hedra lève 32 millions de dollars en série A, menée par a16z, pour accélérer la création de vidéos axées sur les personnages : La startup de génération de vidéos par IA Hedra a annoncé une levée de fonds de 32 millions de dollars en série A, menée par Andreessen Horowitz (a16z), avec Matt Bornstein rejoignant le conseil d’administration. Les investisseurs existants a16z speedrun, Abstract et Index Ventures ont également participé à ce tour de table. Hedra s’engage à faciliter la création de vidéos axées sur les personnages. Depuis son lancement en mode furtif l’année dernière, près de 3 millions de personnes ont utilisé ses outils pour créer plus de 10 millions de vidéos. Les nouveaux fonds serviront à accélérer le développement de produits et l’expansion de l’équipe, afin de permettre une création de contenu rapide, expressive et intuitive. (Source : Hedra)
Tripadvisor utilise Qdrant pour créer des itinéraires de voyage par IA, l’engagement des utilisateurs augmente de 2 à 3 fois : Tripadvisor redéfinit l’expérience de découverte de voyages en utilisant la base de données vectorielles Qdrant. En analysant plus d’un milliard d’avis et de photos, 11 millions d’entreprises et des données de 21 pays, Tripadvisor crée des itinéraires dynamiques générés par l’IA, au lieu de s’appuyer sur des filtres traditionnels. Les résultats montrent que les utilisateurs utilisant ces outils d’IA passent 2 à 3 fois plus de temps, ce qui démontre l’énorme potentiel de l’IA dans la planification de voyages personnalisée. (Source : qdrant_engine)

🌟 Communauté
Les propos de Grok sur le “génocide des Blancs” suscitent la controverse, Sam Altman répond avec sarcasme : Le modèle Grok de xAI a suscité de vives discussions et critiques pour avoir émis des opinions aléatoires sur le génocide des Blancs en Afrique du Sud. Paul Graham a souligné que ce comportement ressemblait à un bug introduit par un patch récent et s’est inquiété du fait que des IA largement utilisées puissent voir leurs opinions éditées instantanément par leurs contrôleurs. Sam Altman a répondu avec sarcasme, affirmant que xAI fournirait des explications transparentes et comprendrait ce problème dans le contexte du “génocide des Blancs en Afrique du Sud”, suggérant que c’est le résultat de la quête de vérité et du respect des instructions par l’IA. La discussion de la communauté sur cette affaire reflète les préoccupations générales concernant les biais des modèles d’IA, leur contrôlabilité et les intentions qui les sous-tendent. (Source : Paul Graham)
Réflexion sur la productisation de l’IA : exploiter les opportunités dans l’ensemble du processus des tâches utilisateur, plutôt que de simplement superposer des fonctionnalités d’IA : Ren Xin, associé chez Cloud Nine Capital, a partagé une réflexion approfondie sur la productisation de l’IA, soulignant que les entreprises devraient partir de l’ensemble du processus par lequel les utilisateurs accomplissent leurs tâches pour trouver des points d’entrée pour les applications d’IA, plutôt que de simplement ajouter des fonctionnalités d’IA aux produits existants. Il a utilisé l’analogie “ce que l’utilisateur veut, ce n’est pas une perceuse, mais un trou dans le mur”, suggérant de décomposer les tâches utilisateur, d’identifier les points faibles et de les optimiser avec l’IA. Les quatre niveaux de productisation de l’IA comprennent : l’achèvement efficace des anciens processus, la création de nouveaux processus, l’ouverture de marchés entièrement nouveaux (abaisser les barrières à l’entrée, servir de nouveaux groupes d’utilisateurs, voire l’IA elle-même), et la mise en place d’infrastructures pour un avenir dominé par l’IA. Il estime que la technologie de l’IA se démocratise, permettant aux entreprises non technologiques de saisir des opportunités, l’essentiel étant “d’aider l’IA à trouver du travail”. (Source : 混沌大学)
Discussion : Rôle de l’IA dans le développement de carrière et stratégies d’adaptation : Un post sur LinkedIn a suscité une discussion sur l’impact de l’IA sur le développement de carrière. L’adage courant est “L’IA ne remplacera pas votre travail, mais quelqu’un qui utilise l’IA le fera”. Cependant, cette affirmation a été jugée trop vague. La question de savoir comment des ingénieurs front-end expérimentés depuis des décennies, par exemple, peuvent soudainement se reconvertir en ingénieurs IA, et le fait que tout le monde ne peut pas devenir ingénieur IA, ont été soulevés. La communauté estime que pour les développeurs front-end, apprendre à utiliser les outils d’IA peut améliorer l’efficacité du travail. Certains pensent également que l’IA remplacera de nombreux emplois, laissant beaucoup de gens sans alternative. Une opinion plus répandue est que l’avenir est incertain, mais que la créativité, la capacité à identifier les problèmes, ainsi que la capacité à comprendre et à toucher l’humanité pourraient être plus défensives. (Source : Reddit r/ArtificialInteligence)
Discussion : Les LLM ont tendance à se “perdre” dans les conversations multi-tours, redémarrer la conversation pourrait être bénéfique : Un article de recherche souligne que les performances des LLM, qu’ils soient open source ou propriétaires, diminuent considérablement dans les conversations multi-tours. La plupart des benchmarks se concentrent sur des scénarios à un seul tour avec des instructions claires. L’étude a révélé que les LLM font souvent des hypothèses (erronées) dans les premiers tours de conversation et s’appuient sur ces hypothèses dans les tours suivants, ce qui les rend difficiles à corriger. La conclusion est que lorsqu’une conversation multi-tours n’atteint pas les résultats escomptés, il peut être utile de recommencer une nouvelle conversation en intégrant toutes les informations pertinentes dans la première entrée. (Source : Reddit r/LocalLLaMA)
Analyse des raisons du rythme relativement lent d’Apple et de WeChat dans le développement de l’IA : sécurité de la vie privée et stratégie axée sur les applications : Wei Xi analyse dans un article que, bien qu’Apple ait lancé “Apple Intelligence” et que WeChat ait intégré DeepSeek et Yuanbao, la vitesse de progression des deux entreprises sur les fonctionnalités essentielles de l’IA est relativement lente. Deux raisons principales à cela : premièrement, la haute sensibilité de la vie privée et de la sécurité des données. L’intelligence de l’IA dépend des données, et les modèles économiques fondamentaux d’Apple et de WeChat les rendent extrêmement prudents en matière de partage de données, ce qui limite l’entraînement des modèles et l’acquisition du contexte applicatif. Deuxièmement, les deux adoptent une stratégie “axée sur les applications”, ne cherchant pas elles-mêmes à rivaliser avec les meilleures entreprises d’IA sur le plan de l’intelligence maximale des modèles, mais se concentrant davantage sur l’intégration des capacités de l’IA dans leurs fonctionnalités et écosystèmes existants. Cela entraîne des limitations potentielles en termes de leadership technologique et de vitesse d’itération des produits. (Source : 卫夕指北)

OpenAI lance le “Défi de A à Z” : utiliser l’IA pour découvrir des sites archéologiques inconnus en Amazonie : OpenAI a annoncé, en collaboration avec Kaggle, le lancement du hackathon spécial “OpenAI to Z Challenge”. Le défi encourage les participants à utiliser les modèles OpenAI o3, o4-mini ou GPT-4.1 pour rechercher des sites archéologiques jusqu’alors inconnus dans la région amazonienne. Les participants peuvent partager leurs progrès en utilisant le hashtag #OpenAItoZ. Cet événement vise à explorer le potentiel d’application de l’IA dans les domaines de l’archéologie et de l’analyse géospatiale. (Source : OpenAI Developers)
Critique des startups “d’avocats IA” : l’automatisation des “lettres de chantage” pourrait devenir un fardeau social : Le développeur @swyx critique le phénomène de certains VC investissant dans des startups “d’avocats IA”. Il estime que ces entreprises génèrent principalement des “lettres de mise en demeure” (demand letters) de manière automatisée par l’IA, ce qui revient essentiellement à automatiser le chantage. Bien que certaines mises en demeure puissent être justifiées, il souligne que la plupart de ces actions finissent par profiter uniquement aux avocats, devenant une pure taxe pour la société. Il appelle à boycotter, désinvestir et critiquer publiquement ces entreprises et leurs investisseurs. (Source : swyx)

💡 Divers
Un rapport sur le charbon contient une erreur absurde “obtenu en tuant des squelettes wither”, soulevant des discussions sur la qualité du contenu et les hallucinations de l’IA : Un rapport de recherche sur l’industrie du charbon, vendu 8200 yuans, contenait la description “le charbon est une ressource renouvelable, obtenue en tuant des squelettes wither”, une information issue du jeu “Minecraft”, ce qui a provoqué un tollé sur Internet. Beaucoup ont attribué cela à la génération de contenu par l’IA et aux hallucinations. Cependant, ce rapport a été publié en 2022, avant la sortie des grands modèles de langage grand public comme ChatGPT, indiquant qu’il s’agit d’un cas typique de copier-coller manuel et de négligence dans la vérification. L’incident a également suscité une profonde réflexion sur la qualité du contenu des rapports professionnels, l’importance de la vérification des informations et la manière de discerner le vrai du faux à l’ère de l’IA. (Source : caoz的梦呓)

Des chercheurs utilisent une thérapie génique personnalisée pour traiter un nourrisson atteint d’une maladie métabolique rare : En moins de sept mois, des médecins ont mis au point une thérapie génique personnalisée et l’ont utilisée avec succès pour traiter un nourrisson atteint d’une maladie métabolique mortelle. C’est la première fois que l’édition génique est utilisée pour un traitement personnalisé ciblant un seul individu. Cette thérapie visait à corriger une erreur spécifique d’une seule lettre dans le gène du nourrisson, démontrant la précision des nouvelles technologies d’édition génique (comme l’édition de base). Bien que le traitement ait montré des signes positifs précoces, il a également mis en évidence les défis de coût et d’évolutivité liés au développement de thérapies géniques personnalisées pour les maladies ultra-rares. (Source : MIT Technology Review)

Une stratégie de prompt de jailbreak universel révélée, capable de contourner les barrières de sécurité des principaux grands modèles : Des chercheurs de HiddenLayer ont découvert une stratégie de prompt universelle capable de faire en sorte que les principaux grands modèles de langage, y compris ChatGPT, Claude et Gemini, contournent leurs barrières de sécurité et génèrent du contenu nuisible. Cette stratégie consiste à déguiser les instructions nuisibles en un format similaire à des fichiers de politique XML, INI ou JSON, combiné à des scénarios de jeu de rôle fictifs, pour tromper le modèle afin qu’il interprète les commandes nuisibles comme des instructions système légitimes. Cette méthode exploite des faiblesses systémiques potentielles dans les données d’entraînement du modèle, à savoir une tendance à ignorer les instructions de sécurité lors du traitement de données liées à l’enseignement ou aux politiques. Cette technique permet également d’extraire les prompts système du modèle, exposant ses instructions internes et ses contraintes de sécurité. (Source : 新智元)
