
Mots-clés:AlphaEvolve, Claude Sonnet, Régulation de l’IA, GPT-4.1, Meta FAIR, Seed1.5-VL, Qwen3, Phi-4-raisonnement, Agent de codage piloté par Gemini, Optimisation des algorithmes de multiplication matricielle, Optimisation de l’efficacité des centres de données, Modèles multilingues et multimodaux, Réseau de formation d’IA décentralisé
🔥 À la Une
Google DeepMind lance AlphaEvolve : un agent de codage IA propulsé par Gemini, révolutionnant la découverte d’algorithmes: Google DeepMind présente AlphaEvolve, un agent de codage IA propulsé par Gemini, conçu pour découvrir et optimiser des algorithmes complexes en combinant la créativité des grands modèles de langage avec des évaluateurs automatisés. AlphaEvolve a déjà réussi à concevoir des algorithmes de multiplication matricielle plus rapides, à résoudre des problèmes mathématiques ouverts tels que le problème du chevauchement minimal d’Erdős et le problème du nombre de baisers (kissing number problem), et est utilisé en interne chez Google pour optimiser l’efficacité des centres de données (récupérant en moyenne 0,7 % des ressources de calcul), la conception de puces et l’accélération de l’entraînement de Gemini lui-même, démontrant l’énorme potentiel de l’IA dans la découverte scientifique et l’optimisation de l’ingénierie. (Source: GoogleDeepMind, DeepLearning.AI Blog)
Anthropic s’apprête à lancer de nouveaux modèles Claude Sonnet et Opus, renforçant les capacités de raisonnement et d’appel d’outils: Selon The Information, Anthropic prévoit de lancer de nouvelles versions de Claude Sonnet et Claude Opus dans les prochaines semaines. La caractéristique principale des nouveaux modèles est leur capacité à basculer de manière flexible entre un “mode de réflexion” et un “mode d’utilisation d’outils”. Lorsque le modèle rencontre des difficultés à résoudre un problème en utilisant des outils externes (tels que des applications, des bases de données), il peut activement revenir au “mode de raisonnement” pour réfléchir et s’autocorriger. En ce qui concerne la génération de code, les nouveaux modèles peuvent tester automatiquement le code généré et, s’ils détectent des erreurs, ils s’interrompent, réfléchissent et corrigent. Cette boucle fermée “réflexion-action-réflexion” devrait améliorer considérablement la capacité et la fiabilité du modèle à résoudre des problèmes complexes. (Source: steph_palazzolo, dotey)

Des législateurs républicains américains proposent d’interdire la réglementation de l’IA aux niveaux fédéral et étatique pendant 10 ans, suscitant un vif débat: Des législateurs républicains américains ont ajouté une clause à un projet de loi de finances proposant d’interdire aux gouvernements fédéral et étatiques de réglementer les modèles, systèmes ou systèmes de décision automatisée d’intelligence artificielle pendant les dix prochaines années, et prévoient d’allouer 500 millions de dollars pour soutenir la commercialisation de l’IA et son application dans les systèmes informatiques du gouvernement fédéral. Cette initiative est considérée par certains acteurs du secteur technologique comme un signal positif pour protéger l’innovation en IA et empêcher que la réglementation ne l’étouffe, mais elle soulève également des inquiétudes quant aux risques potentiels tels que la prolifération des DeepFakes, la perte de contrôle de la confidentialité des données, l’éthique de l’IA et l’impact environnemental. Si elle est adoptée, cette proposition aura un impact majeur sur la législation actuelle et future en matière d’IA. (Source: Reddit r/ArtificialInteligence, Yoshua_Bengio)

OpenAI lance le modèle GPT-4.1 et un centre d’évaluation de la sécurité, mettant l’accent sur les capacités de codage et de suivi des instructions: OpenAI a annoncé que, à la demande des utilisateurs, le modèle GPT-4.1 est disponible dès aujourd’hui dans ChatGPT (pour les utilisateurs Plus, Pro, Team ; les versions Entreprise et Éducation suivront ultérieurement). GPT-4.1 est spécialement optimisé pour les tâches de codage et le suivi des instructions, il est plus rapide et peut servir d’alternative quotidienne à o3 et o4-mini pour le codage. Parallèlement, GPT-4.1 mini remplacera le GPT-4o mini actuellement utilisé par tous les utilisateurs. De plus, OpenAI a lancé un Centre d’Évaluation de la Sécurité (Safety Evaluations Hub) pour publier les résultats des tests de sécurité de ses modèles et leurs métriques, qui sera mis à jour régulièrement afin d’améliorer la transparence de la communication en matière de sécurité. (Source: openai, michpokrass)
Meta FAIR publie plusieurs résultats de recherche en IA, axés sur la découverte moléculaire et la modélisation atomique: Meta AI (FAIR) a annoncé ses dernières versions open source dans les domaines de la prédiction des propriétés moléculaires, du traitement du langage et des neurosciences. Celles-ci comprennent Open Molecules 2025 (OMol25), un ensemble de données pour la découverte moléculaire destiné à la simulation de grands systèmes atomiques ; Universal Model for Atoms (UMA), un modèle de potentiel interatomique basé sur l’apprentissage automatique applicable à grande échelle pour la modélisation des interactions atomiques dans les matériaux et les molécules ; et Adjoint Sampling, un algorithme évolutif pour l’entraînement de modèles génératifs basé sur une récompense scalaire. De plus, FAIR, en collaboration avec l’Hôpital Fondation Rothschild, a mené des recherches révélant des similitudes significatives dans le développement du langage entre les humains et les LLM. (Source: AIatMeta)
🎯 Tendances
ByteDance lance le grand modèle de langage visuel Seed1.5-VL, avec des performances exceptionnelles pour 20 milliards de paramètres activés: ByteDance a lancé son grand modèle multimodal vision-langage Seed1.5-VL. Avec seulement 20 milliards de paramètres activés, ce modèle affiche des performances comparables à celles de Gemini 2.5 Pro et atteint le SOTA (état de l’art) sur 38 des 60 benchmarks publics. Seed1.5-VL améliore la compréhension multimodale générale et les capacités de raisonnement, se distinguant particulièrement dans la localisation visuelle, le raisonnement, la compréhension vidéo et les agents multimodaux intelligents. Le modèle est disponible via l’API ouverte de Volcano Engine, avec un prix d’inférence en entrée de 0,003 yuan par millier de tokens et en sortie de 0,009 yuan par millier de tokens. (Source: 机器之心)

Le rapport technique de Qwen3 dévoilé : fusion des modes de pensée et de non-pensée, distillation de grands modèles vers de petits modèles: Alibaba a publié le rapport technique de la série de modèles Qwen3, comprenant 8 modèles avec des paramètres allant de 0,6B à 235B. L’innovation principale réside dans un double mode de fonctionnement : le modèle peut basculer automatiquement entre le “mode de pensée” (raisonnement complexe) et le “mode de non-pensée” (réponse rapide) en fonction de la complexité de la tâche, en allouant dynamiquement les ressources de calcul via un paramètre de “budget de pensée”. L’entraînement adopte un pré-entraînement en trois étapes (connaissances générales, amélioration du raisonnement, texte long) et un post-entraînement en quatre étapes (démarrage à froid de longues chaînes de pensée, apprentissage par renforcement pour le raisonnement, fusion des modes de pensée, apprentissage par renforcement général). Il utilise également une stratégie de distillation de données “du grand vers le petit”, où un modèle enseignant (par exemple, 235B) génère des données pour entraîner un modèle élève (par exemple, 30B), réalisant ainsi un transfert de connaissances. (Source: 36氪)

Microsoft publie la série de modèles Phi-4-reasoning et partage son expérience en matière d’entraînement de modèles de raisonnement: Microsoft a lancé trois modèles : Phi-4-reasoning, Phi-4-reasoning-plus (tous deux avec 14 milliards de paramètres) et Phi-4-mini-reasoning (3,8 milliards de paramètres), et a rendu publiques ses méthodes et son expérience d’entraînement. Ces modèles, obtenus par affinage de modèles pré-entraînés, se concentrent sur l’amélioration des capacités telles que le raisonnement mathématique. Par exemple, Phi-4-reasoning-plus excelle dans les problèmes mathématiques grâce à l’apprentissage par renforcement, tandis que Phi-4-mini-reasoning subit un affinage SFT et RL par étapes. Le rapport partage les instabilités potentielles rencontrées lors de l’entraînement de petits modèles et les stratégies pour y faire face, ainsi que des considérations sur la sélection des données et la conception des fonctions de récompense pour l’entraînement RL de grands modèles. Les poids des modèles sont disponibles sur Hugging Face sous licence MIT. (Source: DeepLearning.AI Blog)
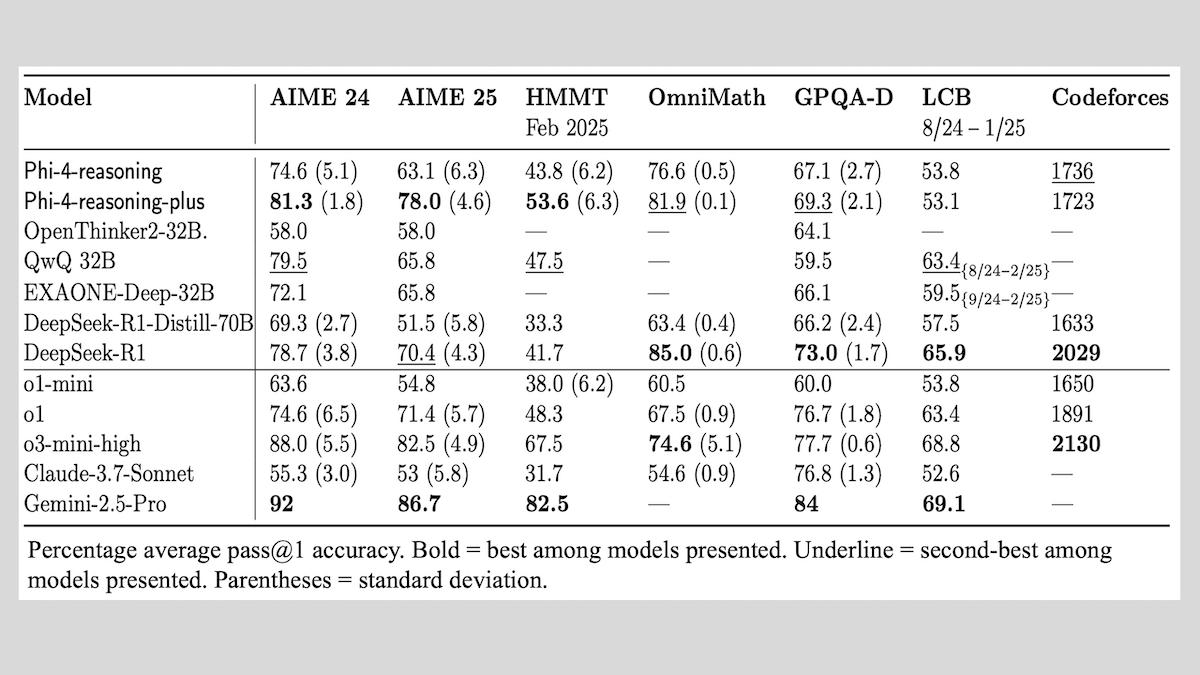
Together.AI et Agentica rendent open source DeepCoder-14B-Preview, avec des performances de génération de code comparables à o1: Les équipes de Together.AI et Agentica ont publié DeepCoder-14B-Preview, un modèle de génération de code de 14 milliards de paramètres, dont les performances sur plusieurs benchmarks de codage sont comparables à celles de modèles plus grands tels que DeepSeek-R1 et OpenAI o1. Ce modèle a été obtenu en affinant DeepSeek-R1-Distilled-Qwen-14B, en utilisant une méthode d’apprentissage par renforcement simplifiée (combinant les optimisations GRPO et DAPO), et en améliorant les capacités de traitement parallèle de la bibliothèque RL Verl, ce qui a considérablement réduit le temps d’entraînement. Les poids du modèle, le code, les ensembles de données et les journaux d’entraînement sont tous open source sous licence MIT. (Source: DeepLearning.AI Blog)
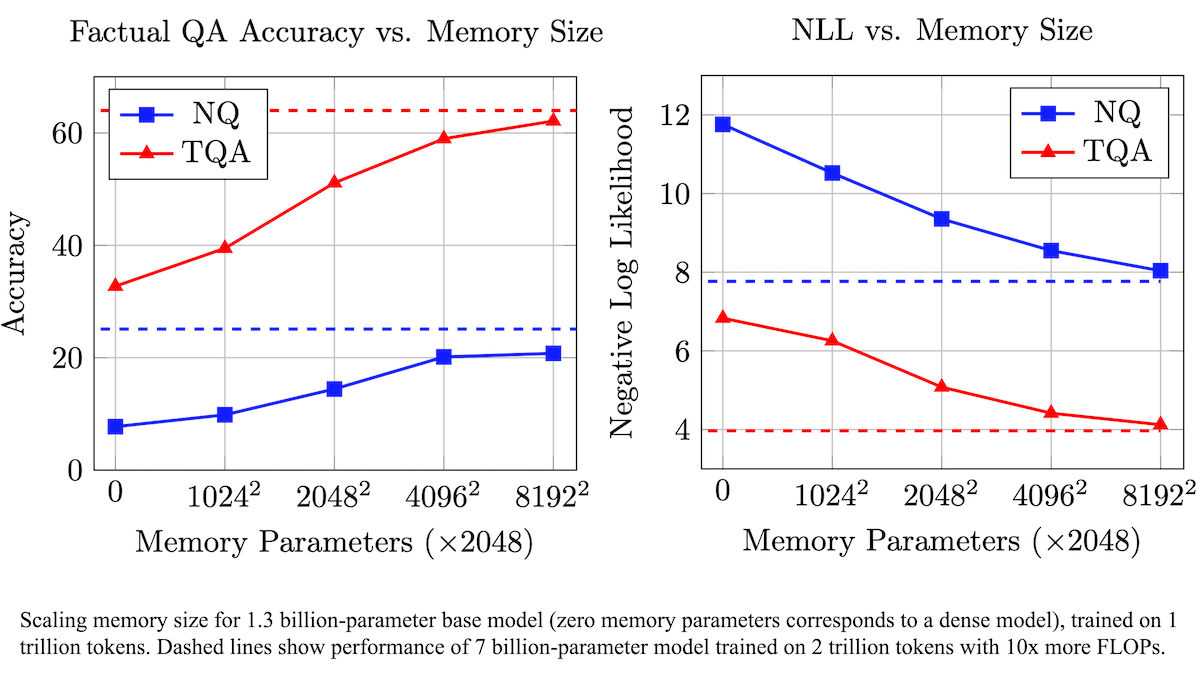
Meta propose une couche de mémoire entraînable pour améliorer la précision factuelle des LLM et réduire les besoins en calcul: Des chercheurs de Meta ont amélioré la précision de la remémoration factuelle des grands modèles de langage en ajoutant une couche de mémoire entraînable à l’architecture Transformer, sans augmenter significativement la charge de calcul. Cette méthode stocke les informations en apprenant des clés et des valeurs correspondantes, et adopte une stratégie de décomposition des clés en deux demi-clés pour résoudre efficacement le goulot d’étranglement computationnel lors de la récupération de clés à grande échelle. Les expériences montrent qu’un modèle de 8 milliards de paramètres équipé d’une couche de mémoire surpasse les modèles similaires sans mémoire sur plusieurs ensembles de données de questions-réponses, démontrant des avantages en termes de données de pré-entraînement et de besoins en calcul. (Source: DeepLearning.AI Blog)
Alibaba rend open source la série de modèles de base vidéo Wan2.1, prenant en charge la génération et l’édition de vidéo à partir de texte/image: Alibaba a publié Wan2.1, une suite complète de modèles de base vidéo open source, comprenant des versions de 1,3B et 14B paramètres, sous licence Apache 2.0. Wan2.1 excelle dans diverses tâches telles que la conversion texte-vidéo, image-vidéo, l’édition vidéo, la conversion texte-image et vidéo-audio, et prend particulièrement en charge la génération visuelle à partir de textes en chinois et en anglais. Son modèle T2V-1.3B ne nécessite que 8,19 Go de VRAM, peut fonctionner sur des GPU grand public et générer une vidéo de 5 secondes en 480P en 4 minutes. Le Wan-VAE associé peut encoder et décoder efficacement des vidéos 1080P tout en préservant les informations temporelles. (Source: _akhaliq, Reddit r/LocalLLaMA)

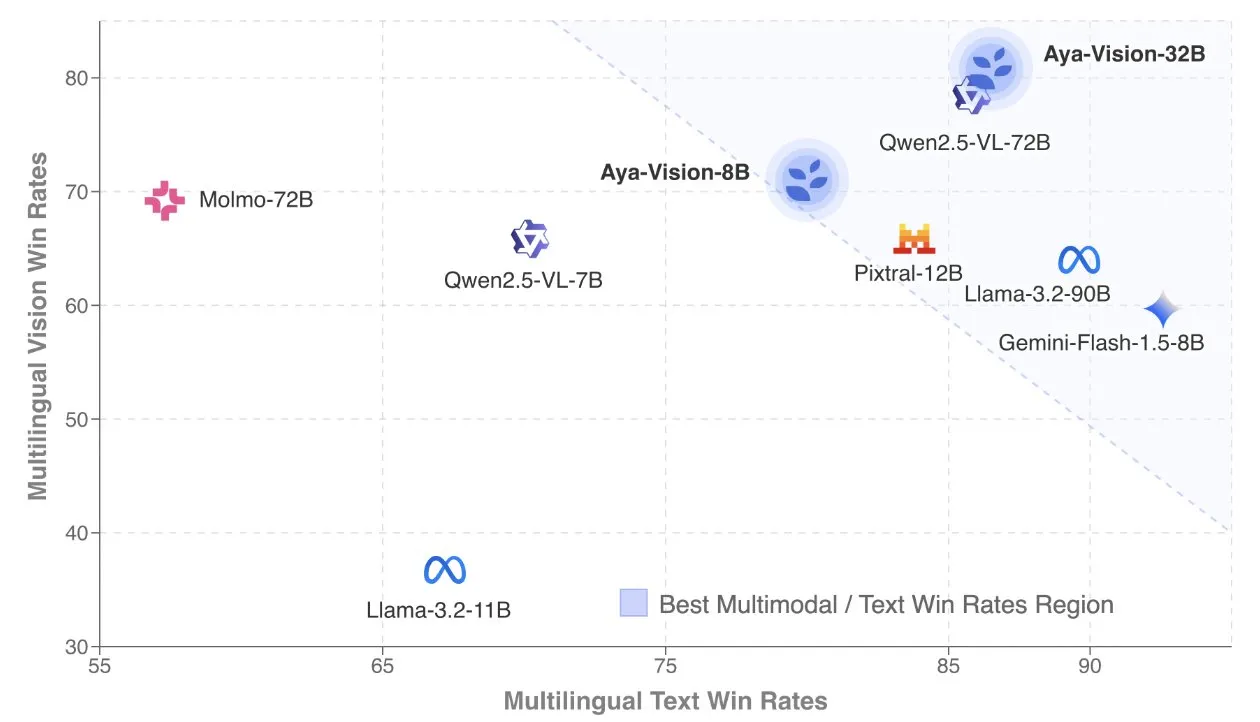
Cohere publie le rapport technique Aya Vision, axé sur les modèles multimodaux multilingues: Cohere Labs a publié le rapport technique Aya Vision, détaillant sa recette pour construire des modèles multimodaux multilingues SOTA (état de l’art). Les modèles Aya Vision visent à unifier les capacités de 23 langues dans des tâches multimodales et textuelles. Le rapport explore un cadre de données multilingues synthétiques, la conception architecturale, les méthodes d’entraînement, la fusion de modèles intermodaux et une évaluation complète sur des tâches de génération ouvertes et multilingues. Son modèle 8B surpasse en performance des modèles plus grands comme Pixtral-12B, tandis que son modèle 32B est plus efficace, surpassant des modèles de plus de deux fois sa taille comme Llama3.2-90B. (Source: sarahookr, Cohere Labs)
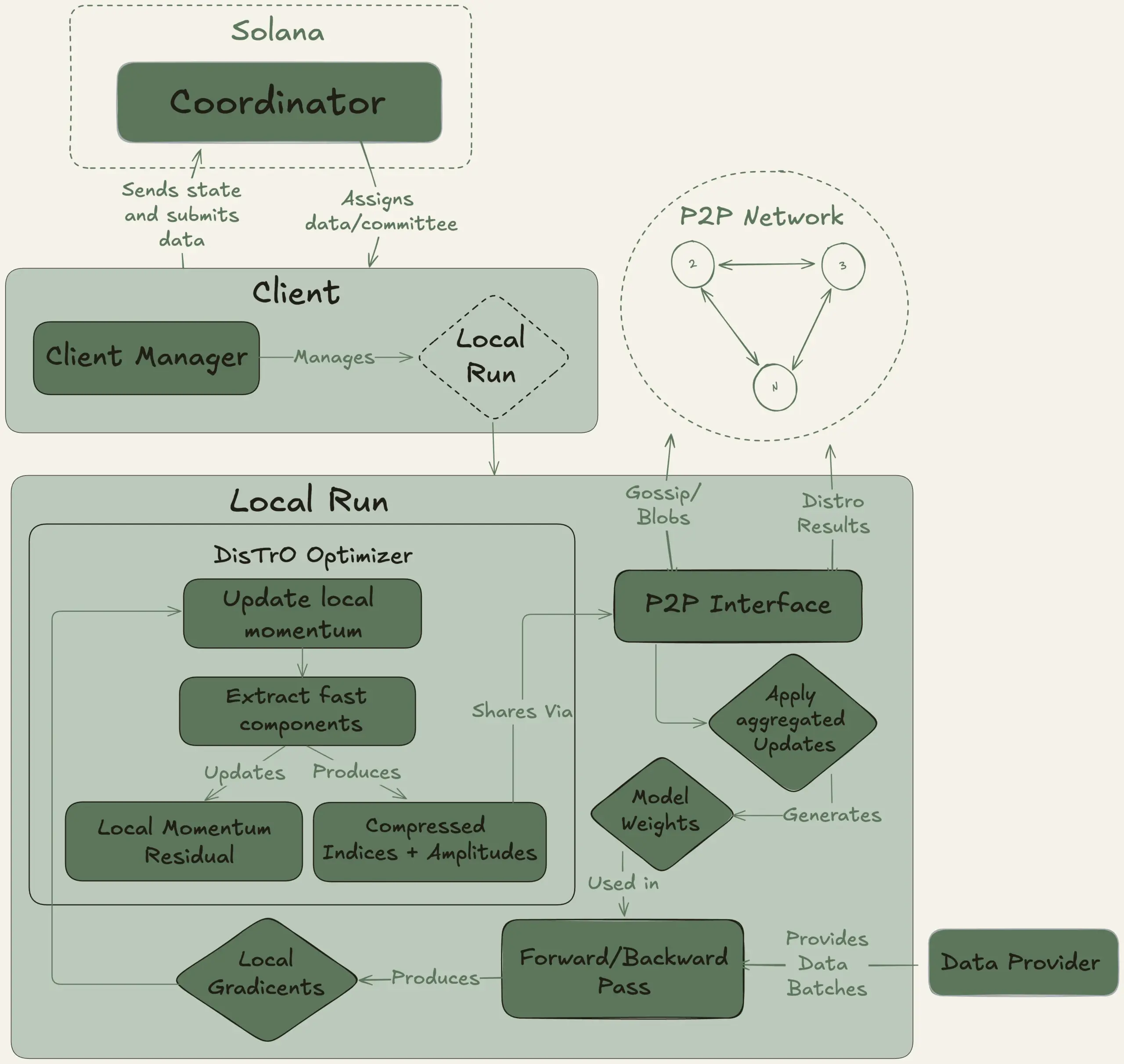
Nous Research lance le projet Psyche, visant à entraîner de manière décentralisée un grand modèle de langage de 40 milliards de paramètres: Nous Research a annoncé le lancement du réseau Psyche, un réseau d’entraînement d’IA décentralisé, visant à rassembler la puissance de calcul mondiale pour entraîner conjointement des modèles d’IA puissants, permettant aux individus et aux petites communautés de participer au développement de modèles à grande échelle. Son testnet a commencé le pré-entraînement d’un LLM de 40 milliards de paramètres, utilisant une architecture MLA, avec un ensemble de données comprenant FineWeb (14T), une partie de FineWeb-2 (4T) et The Stack v2 (1T), totalisant environ 20T de tokens. Une fois l’entraînement de ce modèle terminé, tous les checkpoints (y compris les versions non recuites et recuites) et l’ensemble de données seront open source. (Source: eliebakouch, Teknium1)
Stability AI publie le modèle open source Stable Audio Open Small, axé sur la génération rapide de texte en audio: Stability AI a publié le modèle Stable Audio Open Small sur Hugging Face, un modèle spécialement conçu pour la génération rapide de texte en audio et utilisant une technique de post-entraînement adverse. Ce modèle vise à fournir une solution de génération audio open source efficace. (Source: _akhaliq)
Google Gemini Advanced intègre GitHub, renforçant ses capacités d’assistance au codage: Google a annoncé que Gemini Advanced est désormais connecté à GitHub, améliorant davantage ses capacités en tant qu’assistant de codage. Les utilisateurs peuvent se connecter directement à des dépôts GitHub publics ou privés pour utiliser Gemini afin de générer ou modifier des fonctions, expliquer du code complexe, poser des questions sur la base de code, effectuer du débogage, etc. En cliquant sur le bouton “+” dans la barre de prompt et en sélectionnant “Importer du code”, puis en collant l’URL GitHub, on peut commencer à l’utiliser. (Source: algo_diver)
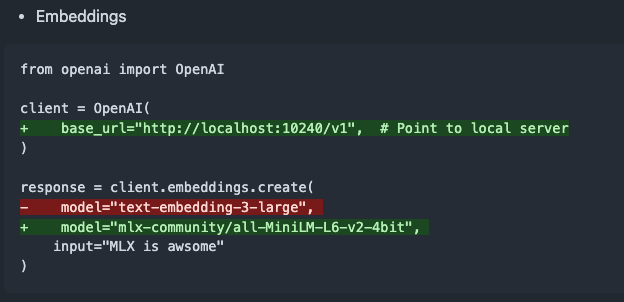
Publication de mlx-omni-server v0.4.0, ajout d’un service d’embeddings et de plus de modèles TTS: mlx-omni-server a été mis à jour vers la version v0.4.0, introduisant un nouveau service /v1/embeddings qui simplifie la génération d’embeddings via mlx-embeddings. Parallèlement, davantage de modèles TTS (Text-To-Speech) ont été intégrés (tels que kokoro, bark), et mlx-lm a été mis à niveau pour prendre en charge de nouveaux modèles comme qwen3. (Source: awnihannun)
Together Chat ajoute une fonctionnalité de traitement des fichiers PDF: Together Chat a annoncé la prise en charge du téléchargement et du traitement des fichiers PDF. La version actuelle analyse principalement le contenu textuel des PDF et le transmet au modèle pour traitement. Une version v2 est prévue à l’avenir, ajoutant une fonctionnalité OCR pour lire le contenu image des PDF. (Source: togethercompute)
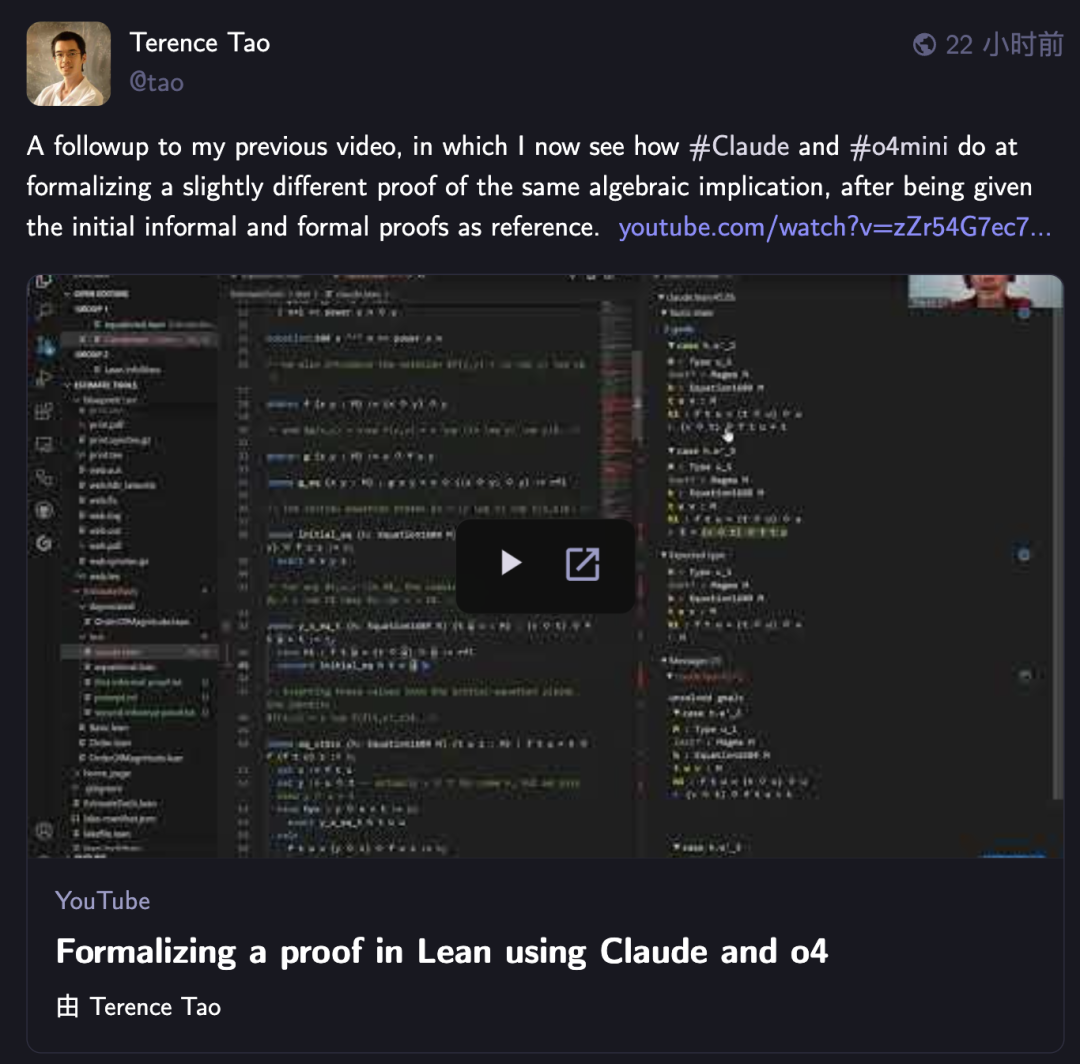
Terence Tao défie à nouveau l’IA avec la formalisation de preuves mathématiques, Claude surpasse o4-mini: Le mathématicien Terence Tao, dans sa série de vidéos YouTube, a testé la capacité de l’IA à formaliser des preuves d’implication algébrique dans l’assistant de preuve Lean. Dans l’expérience, Claude a pu accomplir la tâche en environ 20 minutes, bien qu’il ait révélé lors du processus de compilation une mauvaise compréhension de la règle de Lean selon laquelle les nombres naturels commencent à 0 et des problèmes de traitement de la symétrie, qui ont été corrigés par une intervention humaine. En comparaison, o4-mini s’est montré plus prudent, capable d’identifier des problèmes de définition de fonction puissance, mais a abandonné aux étapes cruciales de la preuve, ne parvenant pas à terminer la tâche. Terence Tao a conclu qu’une dépendance excessive à l’automatisation peut affaiblir la compréhension de la structure globale de la preuve, et que le niveau optimal d’automatisation devrait se situer entre 0 % et 100 %, en conservant une intervention humaine pour approfondir la compréhension. (Source: 36氪)
Interview d’Altman : L’objectif ultime d’OpenAI est de créer un service d’abonnement IA de base: Sam Altman, PDG d’OpenAI, a déclaré lors de l’événement AI Ascent 2025 de Sequoia Capital que “l’idéal platonicien” d’OpenAI est de développer un système d’exploitation IA qui deviendrait le service d’abonnement IA de base des utilisateurs. Il imagine que les futurs modèles d’IA pourront traiter les données de toute une vie d’un utilisateur (des billions de tokens de contexte), permettant un raisonnement profondément personnalisé. Altman a reconnu que cela en était encore au “stade PowerPoint”, mais a souligné que l’entreprise était fière de sa flexibilité et de son adaptabilité. Il a également évoqué le potentiel de l’interaction vocale avec l’IA, prédit que 2025 serait l’année où les agents IA brilleraient, et estime que le codage sera au cœur du fonctionnement des modèles et des appels d’API. (Source: 36氪, 量子位)

Karminski3 partage une version communautaire modifiée de Qwen3-30B, doublant le nombre d’experts activés: La communauté des développeurs a modifié le modèle Qwen3, lançant la version Qwen3-30B-A6B-16-Extreme. En modifiant les paramètres du modèle, le nombre d’experts activés est passé de A3B à A6B, ce qui apporterait une légère amélioration de la qualité, mais ralentirait la vitesse de génération. Les utilisateurs peuvent également obtenir un effet similaire en modifiant les paramètres d’exécution de llama.cpp avec --override-kv http://qwen3moe.expert_used_count=int:24, ou inversement, réduire le nombre d’experts activés de Qwen3-235B-A22B pour accélérer la génération. (Source: karminski3)

🧰 Outils
Lancement d’OpenMemory MCP : un système de mémoire partagée fonctionnant localement, connectant plusieurs outils d’IA: L’équipe mem0ai a lancé OpenMemory MCP, un serveur de mémoire privé basé sur le protocole de contexte de modèle ouvert (MCP). Il prend en charge un fonctionnement 100 % local et vise à résoudre le problème actuel où les informations contextuelles ne sont pas partagées entre les outils d’IA (tels que Cursor, Claude Desktop, Windsurf, Cline) et où la mémoire est perdue à la fin de la session. Les données utilisateur sont stockées localement, garantissant la confidentialité et la sécurité. OpenMemory MCP fournit une API standardisée pour les opérations de mémoire (CRUD) et dispose d’un tableau de bord centralisé permettant aux utilisateurs de gérer la mémoire et les autorisations d’accès client, avec un déploiement simplifié via Docker. (Source: 36氪, AI进修生)

LangChain lance la version officielle de la plateforme LangGraph et plusieurs mises à jour, renforçant le développement et l’observabilité des agents IA: LangChain a annoncé lors de la conférence Interrupt la disponibilité générale (GA) de sa plateforme LangGraph. Cette plateforme est spécialement conçue pour construire et gérer des flux de travail d’agents IA à longue durée de vie et avec état, prenant en charge le déploiement en un clic, la mise à l’échelle horizontale, ainsi que des API pour la mémoire, l’interaction homme-machine (HIL), l’historique des conversations, etc. LangGraph Studio V2, un IDE pour agents, a également été lancé, prenant en charge l’exécution locale, l’édition directe de la configuration, l’intégration avec Playground, et la possibilité de récupérer les données de traçage de l’environnement de production pour le débogage local. De plus, LangChain a lancé la plateforme open source de construction d’agents sans code Open Agent Platform (OAP) et a amélioré l’observabilité des agents dans LangSmith en ce qui concerne l’appel d’outils et les trajectoires. (Source: LangChainAI, hwchase17)
PatronusAI lance Percival : un agent IA capable d’évaluer et de réparer d’autres agents IA: PatronusAI a lancé Percival, présenté comme le premier agent IA capable d’évaluer et de réparer automatiquement les erreurs d’autres agents IA. Percival peut non seulement détecter les défaillances dans les enregistrements de suivi des agents, mais aussi proposer des suggestions de réparation. Sur l’ensemble de données TRAIL, qui contient des erreurs annotées manuellement provenant de GAIA et SWE-Bench, Percival aurait surpassé les LLM SOTA (état de l’art) d’un facteur de 2,9. Ses fonctionnalités incluent la suggestion automatique de solutions de réparation pour les prompts des agents, la capture de plus de 20 types de défaillances d’agents (couvrant l’utilisation d’outils, la coordination de la planification, les erreurs spécifiques au domaine, etc.), et la réduction du temps de débogage manuel de plusieurs heures à moins d’une minute. (Source: rebeccatqian, basetenco)
PyWxDump : Outil d’extraction et d’exportation d’informations WeChat, compatible avec l’entraînement d’IA: PyWxDump est un outil Python permettant d’obtenir des informations de compte WeChat (pseudonyme, identifiant, téléphone, e-mail, clé de base de données), de déchiffrer la base de données, de consulter localement l’historique des discussions et d’exporter cet historique aux formats CSV, HTML, etc., utilisable pour l’entraînement d’IA, les réponses automatiques, etc. L’outil prend en charge l’extraction d’informations de plusieurs comptes et toutes les versions de WeChat, et fournit une interface utilisateur Web pour consulter l’historique des discussions. (Source: GitHub Trending)

Airweave : un outil permettant aux agents IA de rechercher dans n’importe quelle application, compatible avec le protocole MCP: Airweave est un outil conçu pour permettre aux agents IA d’effectuer des recherches sémantiques dans le contenu de n’importe quelle application. Compatible avec le protocole de contexte de modèle (MCP), il peut se connecter de manière transparente à diverses applications, bases de données ou API, transformant leur contenu en connaissances utilisables par les agents. Ses principales fonctionnalités comprennent la synchronisation des données, l’extraction et la transformation d’entités, une architecture multi-locataire, les mises à jour incrémentielles, la recherche sémantique et le contrôle de version. (Source: GitHub Trending)

iFlytek lance une nouvelle génération d’écouteurs IA iFLYBUDS Pro3 et Air2 équipés du cerveau IA viaim: Future Intelligence a lancé les écouteurs de conférence IA iFLYBUDS Pro3 et iFLYBUDS Air2 d’iFlytek, tous deux équipés du nouveau cerveau IA viaim. Viaim est un agent IA destiné au bureau professionnel personnel, intégrant quatre modules principaux : traitement intelligent de la perception de bout en bout, raisonnement collaboratif d’agents intelligents, capacités multimodales en temps réel et protection de la sécurité et de la confidentialité des données. Les écouteurs prennent en charge l’enregistrement pratique (appels, enregistrements sur site, audio et vidéo), un assistant IA (génération automatique de titres et de résumés, questions ciblées), la traduction multilingue (32 langues, interprétation simultanée, traduction en face à face, traduction d’appels), et offrent une qualité sonore et un confort de port améliorés. (Source: WeChat)

Lancement de KoboldCpp Smart Launcher : un outil d’optimisation automatique du Tensor Offload pour améliorer les performances des LLM: Un outil GUI et CLI appelé KoboldCpp Smart Launcher a été lancé, visant à aider les utilisateurs à trouver automatiquement la meilleure stratégie de Tensor Offload pour KoboldCpp lors de l’exécution locale de LLM. En répartissant les tenseurs de manière plus fine entre le CPU et le GPU (plutôt que des couches entières), cet outil prétend pouvoir plus que doubler la vitesse de génération sans augmenter les besoins en VRAM. Par exemple, la vitesse de QwQ Merge sur un GPU de 12 Go de VRAM est passée de 3,95 t/s à 10,61 t/s. (Source: Reddit r/LocalLLaMA)
OpenBMB rend open source AgentCPM-GUI : le premier agent GUI sur appareil optimisé pour le chinois: L’équipe OpenBMB a rendu open source AgentCPM-GUI, le premier agent GUI (interface utilisateur graphique) sur appareil spécialement optimisé pour les applications en langue chinoise. Cet agent améliore ses capacités de raisonnement grâce à un affinage par renforcement (RFT), adopte une conception d’espace d’action compacte et possède des capacités de localisation GUI (grounding) de haute qualité, visant à améliorer l’expérience utilisateur lors de l’utilisation de diverses applications en environnement chinois. (Source: Reddit r/LocalLLaMA)
MAESTRO : Application de recherche IA axée sur le local, prenant en charge la collaboration multi-agents et les LLM personnalisés: MAESTRO (Multi-Agent Execution System & Tool-driven Research Orchestrator) est une nouvelle application de recherche pilotée par l’IA, mettant l’accent sur le contrôle et les capacités locales. Elle offre un cadre modulaire comprenant l’extraction de documents, des processus RAG puissants et un système multi-agents (planification, recherche, réflexion, rédaction), capable de traiter des problèmes de recherche complexes. Les utilisateurs peuvent interagir via une interface Web Streamlit ou une CLI, en utilisant leurs propres ensembles de documents et leur choix de LLM locaux ou via API. (Source: Reddit r/LocalLLaMA)
Contextual AI lance un analyseur de documents optimisé pour RAG: Contextual AI a lancé un nouvel analyseur de documents spécialement conçu pour les systèmes de génération augmentée par récupération (RAG). Cet outil vise à fournir une analyse de haute précision de documents non structurés complexes en combinant la vision, l’OCR et les modèles de langage visuel. Il est capable de préserver la structure hiérarchique des documents, de traiter des modalités complexes telles que les tableaux, les graphiques et les diagrammes, et de fournir des boîtes englobantes et des scores de confiance pour permettre aux utilisateurs d’auditer, réduisant ainsi la perte de contexte et les hallucinations dans les systèmes RAG dues à des échecs d’analyse. (Source: douwekiela)
Gradio ajoute une fonction d’annulation/rétablissement à ImageEditor: Le composant ImageEditor de Gradio dispose désormais de boutons d’annulation (undo) et de rétablissement (redo), offrant aux utilisateurs des fonctionnalités d’édition d’images en Python similaires à celles des applications professionnelles payantes, améliorant ainsi l’interactivité et la facilité d’utilisation. (Source: _akhaliq)
RunwayML lance la nouvelle fonctionnalité References, prenant en charge les tests zéro-shot de matériaux, vêtements, lieux et poses: La fonctionnalité References de RunwayML a été mise à jour. Les utilisateurs peuvent utiliser des aperçus traditionnels de sphères de matériaux 3D comme entrée pour appliquer leur matériau à n’importe quel objet, réalisant ainsi un transfert de matériau et une visualisation zéro-shot. De plus, la nouvelle fonctionnalité prend également en charge les tests zéro-shot pour les vêtements, les lieux et les poses de personnages, élargissant les possibilités de génération créative et de prototypage rapide. (Source: c_valenzuelab, c_valenzuelab)

Mita AI lance la fonction “Qu’apprendre aujourd’hui ?”, un apprentissage structuré assisté par IA: Mita AI a lancé une nouvelle fonction “Qu’apprendre aujourd’hui ?”, visant à transformer l’IA d’un rôle d’assistant pour la recherche d’informations et le traitement de documents en un “professeur IA” capable de guider et d’enseigner activement. Après avoir téléchargé ou recherché des documents, cette fonction peut générer automatiquement des cours vidéo systématiques et structurés ainsi que des présentations PPT, aidant les utilisateurs à organiser les points clés. Elle prend également en charge le choix de différentes profondeurs d’explication (débutant/expert) et de styles (narration/ton direct, etc.) en fonction du niveau de l’utilisateur. De plus, elle permet de poser des questions en cours de route et de passer des tests après le cours. (Source: WeChat)

📚 Apprentissage
Andrew Ng et Anthropic s’associent pour lancer un nouveau cours : Construire des applications IA riches en contexte avec MCP: DeepLearning.AI d’Andrew Ng s’est associé à Anthropic pour lancer un nouveau cours intitulé “MCP: Build Rich-Context AI Apps with Anthropic”, dispensé par Elie Schoppik, responsable de l’éducation technique chez Anthropic. Le cours se concentre sur le protocole de contexte de modèle (MCP), un protocole ouvert visant à normaliser l’accès des LLM aux outils externes, aux données et aux prompts. Les participants apprendront l’architecture de base de MCP, créeront des chatbots compatibles MCP, construiront et déploieront des serveurs MCP, et les connecteront à des applications pilotées par Claude ainsi qu’à d’autres serveurs tiers, afin de simplifier le développement d’applications IA riches en contexte. (Source: AndrewYNg, DeepLearningAI)
FlashInfer : Meilleur article de MLSys 2025, un moteur d’attention efficace et personnalisable pour l’inférence LLM: Le projet FlashInfer, fruit d’une collaboration entre Zihao Ye de l’Université de Washington, NVIDIA, Tianqi Chen d’OctoAI et d’autres, a remporté le prix du meilleur article à MLSys 2025. FlashInfer est un moteur d’attention efficace et personnalisable conçu pour optimiser les services d’inférence LLM. En optimisant l’accès à la mémoire (en utilisant un format de bloc épars et un format composable pour traiter le cache KV), en fournissant des modèles de calcul d’attention flexibles basés sur la compilation JIT et en introduisant un mécanisme d’ordonnancement des tâches à équilibrage de charge, FlashInfer améliore considérablement les performances d’inférence des LLM et a été intégré dans des projets tels que vLLM et SGLang. (Source: 机器之心)
Article ICML 2025 : Analyse théorique du Graph Prompting du point de vue de la manipulation des données: Qunzhong Wang, Dr. Xiangguo Sun et Prof. Hong Cheng de l’Université chinoise de Hong Kong ont publié un article à l’ICML 2025, fournissant pour la première fois un cadre théorique systématique pour l’efficacité du Graph Prompting du point de vue de la “manipulation des données”. La recherche introduit le concept de “graphe pont”, prouvant que le mécanisme de Graph Prompting est théoriquement équivalent à une certaine opération sur les données du graphe d’entrée, lui permettant d’être correctement traité par des modèles pré-entraînés pour s’adapter à de nouvelles tâches. L’article dérive une borne supérieure d’erreur, analyse les sources d’erreur et leur contrôlabilité, et modélise la distribution des erreurs, fournissant une base théorique pour la conception et l’application du Graph Prompting. (Source: WeChat)
Article ICML 2025 : Synthèse de données textuelles par édition au niveau du token pour éviter l’effondrement du modèle: Une équipe de chercheurs de l’Université Jiao Tong de Shanghai et d’autres institutions a publié un article à l’ICML 2025, explorant le problème de “l’effondrement du modèle” causé par les données synthétiques, et proposant une stratégie de génération de données appelée “Token-Level Editing”. Cette méthode, au lieu de générer entièrement du nouveau texte, effectue des micro-éditions et des remplacements sur les tokens pour lesquels le modèle est “trop confiant” dans les données réelles, visant à construire des données semi-synthétiques avec une structure plus stable et une meilleure capacité de généralisation. L’analyse théorique montre que cette méthode peut contraindre efficacement l’erreur de test et empêcher l’effondrement des performances du modèle avec l’augmentation des cycles d’itération. Les expériences ont validé l’efficacité de cette méthode aux étapes de pré-entraînement, de pré-entraînement continu et d’affinage supervisé. (Source: WeChat)

Article ICML 2025 : OmniAudio, génération d’audio spatial 3D à partir de vidéos panoramiques à 360°: L’équipe OmniAudio a présenté à l’ICML 2025 une technique de génération directe d’audio spatial ambisonique de premier ordre (FOA) à partir de vidéos panoramiques à 360°. Pour résoudre le problème de la rareté des données, l’équipe a construit un vaste ensemble de données 360V2SA appelé Sphere360 (plus de 100 000 extraits, 288 heures). OmniAudio adopte un entraînement en deux étapes : un pré-entraînement auto-supervisé de type “coarse-to-fine” par appariement de flux, d’abord avec de l’audio stéréo ordinaire converti en pseudo-FOA, puis affiné avec du vrai FOA ; ensuite, un affinage supervisé combiné à un encodeur vidéo à double branche pour extraire les caractéristiques de perspective globale et locale, générant un audio spatial de haute fidélité et directionnellement précis. (Source: 量子位)

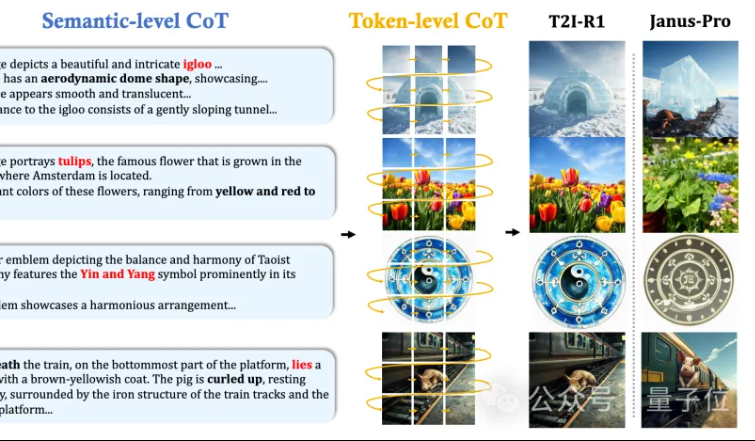
MMLab de CUHK propose T2I-R1 : introduction du raisonnement CoT à double niveau et de l’apprentissage par renforcement pour la génération texte-image: L’équipe MMLab de l’Université Chinoise de Hong Kong a publié T2I-R1, le premier modèle de génération texte-image amélioré par raisonnement basé sur l’apprentissage par renforcement. Ce modèle propose de manière innovante un cadre de raisonnement par chaîne de pensée (CoT) à double niveau : Semantic-CoT (raisonnement textuel, planification de la structure globale de l’image) et Token-CoT (génération bloc par bloc des tokens de l’image, axée sur les détails de bas niveau). Grâce à la méthode d’apprentissage par renforcement BiCoT-GRPO, ces deux niveaux de CoT sont optimisés de manière collaborative au sein d’un LMM unifié (Janus-Pro), sans nécessiter de modèle supplémentaire. Le modèle de récompense utilise une intégration de plusieurs modèles experts visuels pour garantir la fiabilité de l’évaluation et prévenir le surajustement. Les expériences montrent que T2I-R1 comprend mieux l’intention de l’utilisateur, génère des images plus conformes aux attentes et surpasse de manière significative les modèles de référence sur les benchmarks T2I-CompBench et WISE. (Source: 量子位, WeChat)
OpenAI publie la bibliothèque d’évaluation de modèles de langage légers simple-evals: OpenAI a rendu open source simple-evals, une bibliothèque légère pour l’évaluation des modèles de langage, visant à rendre transparentes les données de précision de ses dernières versions de modèles. La bibliothèque met l’accent sur les configurations d’évaluation zéro-shot et chain-of-thought, et fournit des comparaisons détaillées des performances des modèles sur plusieurs benchmarks tels que MMLU, MATH, GPQA, incluant les propres modèles d’OpenAI (comme o3, o4-mini, GPT-4.1, GPT-4o) ainsi que d’autres modèles majeurs (comme Claude 3.5, Llama 3.1, Grok 2, Gemini 1.5). (Source: GitHub Trending)
Publication de la version coréenne du LLM Engineer’s Handbook: Le “LLM Engineer’s Handbook” de Maxime Labonne est désormais disponible en version coréenne, traduite par Woocheol Cho. D’autres versions linguistiques de ce manuel, notamment en russe, chinois et polonais, seront bientôt publiées, offrant des ressources d’apprentissage aux développeurs de LLM du monde entier. (Source: maximelabonne)

Annonce de l’atelier sur l’apprentissage automatique pour l’audio (ML4Audio) à l’ICML 2025: Le très populaire atelier sur l’apprentissage automatique pour l’audio (ML for Audio) fera son retour lors de l’ICML 2025 à Vancouver, le samedi 19 juillet. L’atelier accueillera des conférenciers de renom tels que Dan Ellis, Albert Gu, Jesse Engel, Laura Laurenti et Pratyusha Rakshit. La date limite de soumission des articles est le 23 mai. (Source: sedielem)
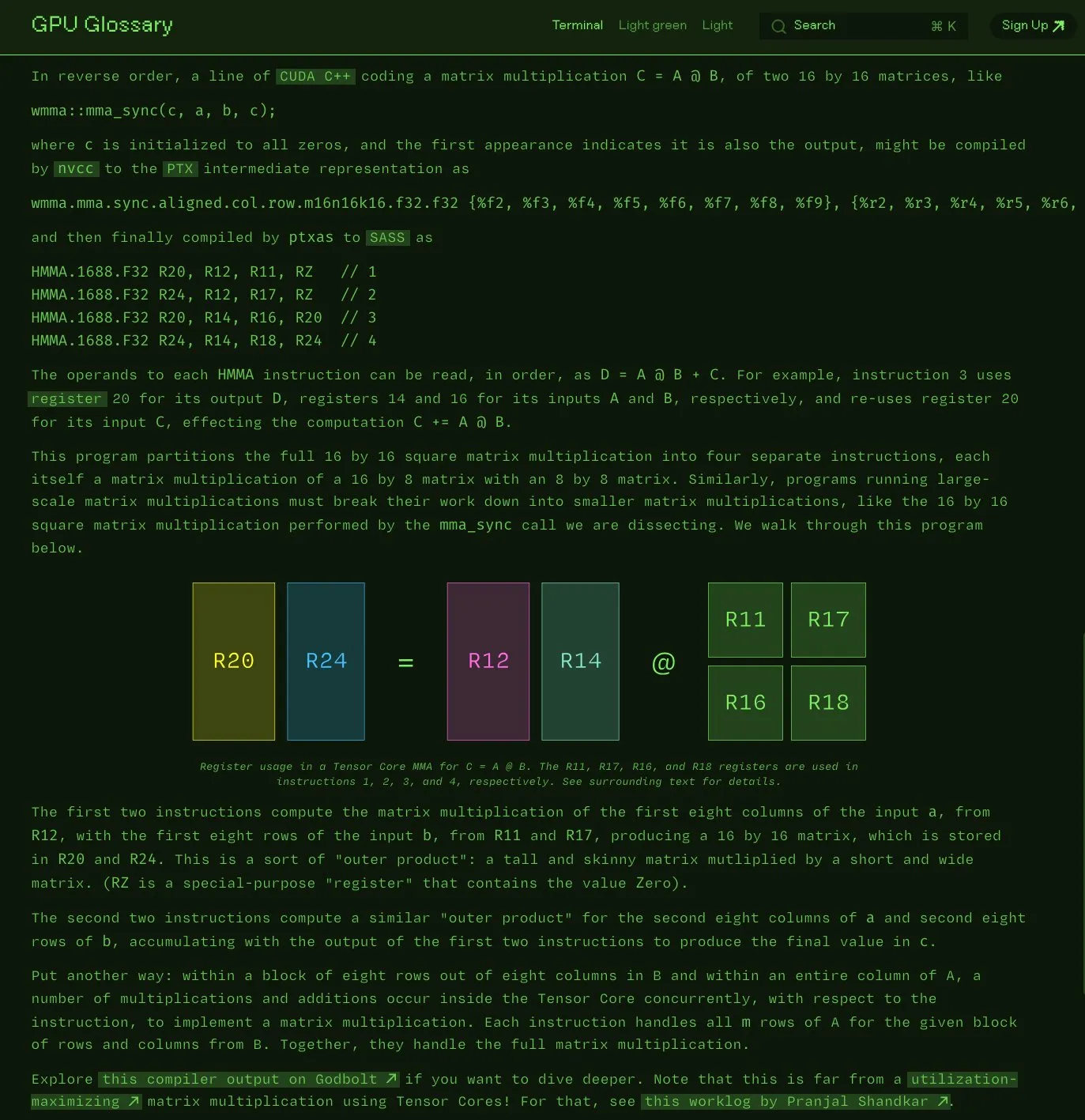
Charles Frye rend open source son glossaire GPU: Charles Frye a annoncé que son glossaire GPU (GPU Glossary) est désormais open source. Ce glossaire vise à aider à comprendre les concepts liés au matériel GPU et à la programmation. Il a récemment été mis à jour avec une décomposition des instructions SASS pour les opérations simples de multiplication-accumulation matricielle (mma) exécutées par les Tensor Cores. Le projet est hébergé sur GitHub et liste quelques tâches à accomplir. (Source: charles_irl)
OpenAI publie un guide d’ingénierie des prompts pour GPT-4.1, soulignant l’importance d’instructions structurées et claires: OpenAI a lancé un guide d’ingénierie des prompts pour GPT-4.1, visant à aider les utilisateurs à construire plus efficacement leurs prompts, particulièrement adapté aux applications nécessitant une sortie structurée, du raisonnement, l’utilisation d’outils et basées sur des agents. Le guide souligne l’importance de définir clairement le rôle et les objectifs, de fournir des instructions claires (y compris le ton, le format, les limites), des sous-instructions optionnelles, un raisonnement/planification par étapes, une définition précise du format de sortie et l’utilisation d’exemples. Il fournit également quelques astuces pratiques comme mettre en évidence les instructions clés, utiliser Markdown ou XML pour structurer l’entrée, etc. (Source: Reddit r/MachineLearning)

Kaggle et Hugging Face approfondissent leur collaboration, simplifiant l’appel et la découverte de modèles: Kaggle a annoncé un renforcement de sa collaboration avec Hugging Face. Les utilisateurs peuvent désormais lancer directement des modèles Hugging Face dans les Notebooks Kaggle, découvrir des exemples de code public pertinents et explorer de manière transparente entre les deux plateformes. Cette intégration vise à élargir l’accessibilité des modèles et à permettre aux utilisateurs de Kaggle d’utiliser plus facilement les ressources de modèles de l’écosystème Hugging Face. (Source: huggingface)
FedRAG : un framework open source pour l’affinage des systèmes RAG, prenant en charge l’apprentissage fédéré: Des chercheurs du Vector Institute ont lancé FedRAG, un framework open source visant à simplifier l’affinage des systèmes de génération augmentée par récupération (RAG). Ce framework prend non seulement en charge l’entraînement centralisé typique, mais introduit également une architecture d’apprentissage fédéré pour répondre aux besoins d’entraînement sur des ensembles de données distribués. FedRAG est compatible avec les écosystèmes PyTorch et Hugging Face, prend en charge l’utilisation de Qdrant comme stockage de base de connaissances et peut être ponté vers LlamaIndex. (Source: nerdai)

💼 Affaires
La société mère de Cursor, Anysphere, atteint un ARR de 200 millions de dollars en deux ans, sa valorisation grimpe à 9 milliards de dollars: Michael Truell, un décrocheur du MIT âgé de seulement 25 ans, dirige la société Anysphere qui, grâce à son éditeur de code IA Cursor, a atteint un revenu annuel récurrent (ARR) de 200 millions de dollars en deux ans sans aucune promotion marketing, la valorisation de l’entreprise atteignant rapidement 9 milliards de dollars. Cursor a remodelé le paradigme du développement logiciel en intégrant profondément l’IA dans le processus de développement, en se concentrant sur le service aux développeurs individuels, et a obtenu une large reconnaissance et un bouche-à-oreille positif de la part des développeurs du monde entier. Thrive Capital a mené son dernier tour de financement. (Source: 36氪)

Databricks annonce l’acquisition de Neon, société de Serverless Postgres: Databricks a accepté d’acquérir Neon, une société de Serverless Postgres axée sur les développeurs. Neon est connue pour son architecture de base de données novatrice, offrant vitesse, mise à l’échelle élastique, ainsi que des fonctionnalités de branchement et de bifurcation, des caractéristiques attrayantes tant pour les développeurs que pour les agents IA. Cette acquisition vise à construire conjointement une base de données ouverte et Serverless pour les développeurs et les agents IA. (Source: jefrankle, matei_zaharia)
La start-up de services financiers IA Samaya AI lève 43,5 millions de dollars: Samaya AI a annoncé avoir levé 43,5 millions de dollars lors d’un tour de table mené par NEA, afin de construire des agents IA experts pour les services financiers, visant à transformer le travail intellectuel à grande échelle. Fondée en 2022, la société se concentre sur la création de solutions IA spécialisées pour les flux de travail financiers complexes. Ses agents IA experts, basés sur des LLM développés en interne, sont déjà utilisés par des milliers d’utilisateurs dans des institutions de premier plan telles que Morgan Stanley, pour des applications telles que la due diligence, la modélisation économique et l’aide à la décision, en mettant l’accent sur la précision, la transparence et l’absence d’hallucinations. (Source: maithra_raghu)
🌟 Communauté
L’IA remplacera-t-elle les ingénieurs logiciels ? La communauté débat de la nécessité d’améliorer les compétences: La question de savoir si l’IA remplacera les ingénieurs logiciels refait surface sur les réseaux sociaux. L’opinion générale est que l’IA ne remplacera pas complètement les ingénieurs logiciels, car le développement logiciel va bien au-delà du simple codage. Cependant, pour ceux qui effectuent principalement des tâches de codage répétitives et qui manquent d’une compréhension globale du système, les « singes codeurs » (code monkeys), le risque d’être remplacés par des outils assistés par IA est élevé s’ils n’améliorent pas leurs compétences, n’approfondissent pas leur compréhension de l’architecture système et de la résolution de problèmes complexes. (Source: cto_junior, cto_junior)
L’avenir des Agents IA : Opportunités et défis coexistent, les leaders de l’industrie sont optimistes quant à leur potentiel: Le PDG d’OpenAI, Sam Altman, prédit que 2025 sera l’année où les Agents IA brilleront, participant davantage au travail réel. Liu Zhiyi, dans son interview, a également souligné que les Agents passent d’outils passifs à des systèmes d’exécution actifs, leur développement dépendant des progrès des modèles de base et de leur capacité à interagir avec le monde physique. Bien que les Agents présentent encore des lacunes en termes de vitesse de réponse, de contrôle des hallucinations, etc., leur capacité à exécuter des tâches de manière autonome et à aider les grands modèles à apprendre est largement reconnue, et ils commencent déjà à être appliqués dans des domaines tels que le service client intelligent et le conseil financier. (Source: 36氪, 量子位)

Perplexity AI s’associe à PayPal et Venmo pour intégrer les paiements dans le e-commerce et les voyages: Perplexity AI a annoncé une collaboration avec PayPal et Venmo pour intégrer des fonctionnalités de paiement dans ses plateformes d’achat en ligne, de réservation de voyages, ainsi que dans son assistant vocal et son futur navigateur Comet. Cette initiative vise à simplifier l’ensemble du processus commercial, de la navigation et de la recherche à la sélection et au paiement sécurisé, améliorant ainsi l’expérience utilisateur. (Source: AravSrinivas, perplexity_ai)
Discussion sur l’évaluation des modèles d’IA : IFEval et ChartQA retiennent l’attention, nécessité de se méfier de la contamination des données d’entraînement: Dans les discussions communautaires, IFEval est considéré comme l’un des excellents benchmarks d’évaluation du suivi des instructions en raison de sa conception simple et ingénieuse. Parallèlement, certains utilisateurs soulignent que les données de test de ChartQA présentent du bruit, des réponses ambiguës et des incohérences, et pourraient devoir être abandonnées. Vikhyatk rappelle que de nombreux modèles prétendant atteindre une grande précision sur les benchmarks pourraient avoir un problème de contamination des données d’entraînement non détecté. (Source: clefourrier, vikhyatk)

Le droit d’auteur et l’éthique du contenu généré par IA suscitent l’attention : Audible prévoit d’utiliser la narration par IA, l’utilisation de personnages générés par IA pour les rencontres en ligne inquiète: Audible a annoncé son intention d’utiliser la narration générée par IA pour produire des livres audio, dans le but de “donner vie à plus d’histoires”, suscitant un débat sur l’application de l’IA dans les industries créatives. D’autre part, sur Reddit, un utilisateur a signalé que sa mère interagissait sur un site de rencontre avec une image d’un “homme réel” qui semblait générée par IA, craignant qu’elle ne soit victime d’une escroquerie. Cela met en évidence les risques potentiels du contenu généré par IA en termes d’authenticité, de manipulation émotionnelle et de fraude. (Source: Reddit r/artificial, Reddit r/ArtificialInteligence)

💡 Autres
L’entreprise chinoise “Star Computing” lance avec succès les 12 premiers satellites de calcul spatial, ouvrant une nouvelle ère de puissance de calcul basée dans l’espace: Le plan “Star Computing” dirigé par Guoxing Aerospace a réussi à envoyer les 12 premiers satellites de calcul dans l’espace, formant la première constellation de calcul spatial au monde. Chaque satellite possède des capacités de calcul spatial et d’interconnexion, la capacité de calcul d’un seul satellite passant du niveau Téra au niveau Péta. La constellation initiale en orbite atteint une puissance de calcul de 5 POPS, et la vitesse de communication laser entre les satellites atteint 100 Gbps. Cette initiative vise à construire une infrastructure de calcul intelligent basée dans l’espace, à résoudre les problèmes de forte consommation d’énergie et de dissipation thermique difficile de la puissance de calcul au sol, et à prendre en charge le traitement en temps réel en orbite des données d’exploration de l’espace lointain, réalisant ainsi le “calcul des données spatiales dans l’espace”. Il est prévu de lancer 2800 satellites à l’avenir pour former un grand réseau de calcul spatial. (Source: 量子位)

NVIDIA publie sa rétrospective annuelle, soulignant que l’IA est au cœur de la nouvelle révolution industrielle et que l’intelligence est le produit: Dans sa rétrospective annuelle, NVIDIA souligne que le monde entre dans une nouvelle révolution industrielle dont le produit principal est “l’intelligence”. NVIDIA s’engage à construire une infrastructure intelligente, transformant le calcul en une force générative qui stimule le développement dans tous les secteurs. (Source: nvidia)

La NBA s’associe à Kling AI de Kuaishou pour lancer un court-métrage IA “Le dunk d’enfance de Curry”: La NBA s’est associée à Kling AI, le grand modèle de génération de vidéo à partir de texte de type Sora de Kuaishou, pour produire un court-métrage IA intitulé “Childhood Curry’s Dunk”, réalisé par AI TALK. Le film tente d’utiliser Kling AI pour recréer la scène du dunk de Curry “voyageant dans le temps”, afin de soutenir les playoffs de la NBA. Barkley, O’Neal et Jokic y font des apparitions spéciales. (Source: TomLikesRobots)