Mots-clés:Médical IA, Modèle de langage, Apprentissage par renforcement, Inférence IA, Benchmark IA, Outils IA, Commerce IA, Éthique de l’IA, OpenAI HealthBench, Meta Physique des Modèles de Langage, Moteur d’inférence FlashInfer, Génération de mondes virtuels Matrix-Game, Entraînement distribué INTELLECT-2
🔥 À la une
Lancement du benchmark OpenAI HealthBench, amélioration significative des capacités de l’IA médicale: OpenAI a lancé HealthBench, un benchmark d’évaluation de l’IA médicale construit en collaboration avec 262 médecins du monde entier. Les tests montrent que les derniers modèles d’IA (tels que o3, GPT-4.1) ont atteint un niveau de performance comparable au meilleur niveau assisté par l’IA dans les scénarios de dialogue médical, dépassant de loin les médecins travaillant seuls (environ 4 fois). Les performances des petits modèles ont également été améliorées. Cela marque l’énorme potentiel de l’IA dans le domaine de la santé, et le système d’évaluation vise à promouvoir l’application sûre et efficace de l’IA dans la pratique clinique. (Source: Reddit r/ArtificialInteligence, BorisMPower, clefourrier)

Publication de la quatrième partie de Meta Physics of Language Models: Meta AI Research a publié la quatrième partie de sa série de recherches “Physics of Language Models”. Grâce à un environnement de pré-entraînement synthétique contrôlé, ils ont découvert un composant léger appelé “Canon layers” qui, en ajoutant des “connexions résiduelles horizontales” entre les tokens, peut améliorer considérablement les capacités de raisonnement et de généralisation de divers modèles d’architecture tels que Transformer, Mamba et GLA. (Source: AIatMeta, arohan)

FlashInfer remporte le prix du meilleur article à MLSys 2025 et obtient le soutien de NVIDIA: L’article technique sur le moteur d’attention efficace et personnalisable FlashInfer, axé sur les services d’inférence LLM, a remporté le prix du meilleur article à MLSys 2025. NVIDIA a annoncé son soutien au projet et intégrera les noyaux d’inférence LLM de pointe tels que TensorRT-LLM dans FlashInfer pour être utilisés par vLLM, SGLang, etc., dans le but d’améliorer l’efficacité et l’évolutivité de l’inférence LLM. (Source: vllm_project, _philschmid)
Kunlun Wanwei lance Matrix-Game, un moteur interactif de génération de mondes: Kunlun Wanwei a lancé Matrix-Game, un moteur interactif capable de générer et de contrôler des mondes virtuels via des instructions textuelles. Il prend en charge la génération de diverses scènes telles que des déserts et des forêts, et permet un contrôle fluide des actions comme avancer, sauter et attaquer, ainsi qu’un changement de perspective à 360°. Cette technologie devrait accélérer le développement de jeux, l’entraînement d’IA incarnée et la production de contenu pour le métavers. (Source: WeChat)

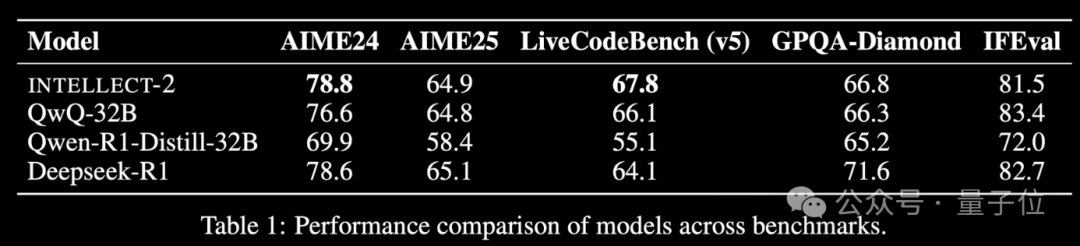
Prime Intellect lance INTELLECT-2, un modèle d’entraînement RL distribué: Prime Intellect a lancé INTELLECT-2, affirmant qu’il s’agit du premier modèle d’apprentissage par renforcement distribué entraîné en intégrant les ressources de calcul inactives mondiales, avec des performances comparables à DeepSeek-R1. Le projet vise à réduire les coûts d’entraînement RL, à briser la dépendance au calcul centralisé, et a reçu des investissements de personnalités bien connues comme Karpathy et Tri Dao. Ses composants principaux (PRIME-RL, SHARDCAST, TOPLOC, Protocol Testnet) sont open source. (Source: 36氪)
Les pionniers de l’apprentissage par renforcement Andrew Barto et Richard Sutton reçoivent le Turing Award: Andrew Barto et Richard Sutton ont reçu le Turing Award pour leurs contributions fondamentales à l’apprentissage par renforcement (y compris l’apprentissage par différence temporelle). Leurs travaux ont eu un impact profond sur l’IA et se sont manifestés dans des projets comme AlphaGo. Les deux prévoient d’utiliser une partie de la récompense pour soutenir la liberté de recherche des jeunes scientifiques et créer des bourses d’études supérieures. (Source: WeChat)

Le nouveau pape nomme en référence à la révolution de l’IA, le tsar de l’IA prédit une croissance de l’IA d’un million de fois en quatre ans: Le pape nouvellement élu Léon XIV a déclaré que son nom faisait en partie référence aux défis posés par la “nouvelle révolution industrielle” de l’IA à la dignité humaine, à la justice et au travail, montrant l’attention de l’Église à l’éthique de l’IA. David Sacks, le premier “tsar de l’IA et des cryptomonnaies” américain, a prédit que les capacités de l’IA augmenteraient d’un million de fois en quatre ans en raison des progrès exponentiels des modèles, des puces et de la puissance de calcul, soulignant l’importance de comprendre la croissance exponentielle et son impact disruptif. (Source: WeChat)

🎯 Tendances
Le rapport technique d’Alibaba Qwen3 révèle les détails de l’entraînement: Alibaba Cloud a publié le rapport technique de Qwen3, détaillant son processus d’entraînement sur 36 billions de tokens, y compris l’investissement massif de données pour les petits modèles et le post-entraînement en plusieurs étapes (comme CoT, RL). Le modèle a obtenu d’excellents résultats sur des benchmarks tels que MathArena, mais les discussions communautaires ont également souligné un bug dans son modèle de chat et des performances inférieures à Mistral Medium 3 sur les tâches non liées au raisonnement. (Source: cognitivecompai, rishdotblog, Dorialexander, teortaxesTex, qtnx_, nrehiew_, Reddit r/LocalLLaMA)

Le Congrès américain envisage de suspendre la réglementation de l’IA au niveau des États pendant dix ans: Un projet de texte du Comité du Commerce de la Chambre des représentants américaine contient une proposition visant à suspendre la réglementation de l’IA par les États pendant dix ans, afin d’éviter que des réglementations étatiques complexes n’entravent l’innovation en IA. Cette mesure a reçu le soutien de certains responsables d’État, qui estiment que la réglementation de l’IA devrait être menée au niveau fédéral. (Source: ylecun, pmddomingos, jd_pressman, Reddit r/artificial)

Les assistants de codage évoluent vers des agents “toujours actifs”: Les assistants de codage passent du statut de programmeurs binômes nécessitant beaucoup d’invites et d’assistance humaine à celui d’agents “toujours actifs” qui recherchent en permanence les bugs et les vulnérabilités en arrière-plan. (Source: steph_palazzolo)
De nouveaux concepts émergent dans le domaine de l’IA: Plusieurs nouveaux concepts sont apparus dans le domaine de la recherche en IA, notamment les “Continuous Thought Machines” de SakanaAI (mettant l’accent sur l’élément temporel), l‘“Elastic Reasoning” de Salesforce (séparant les phases de réflexion et de résolution), le “ZeroSearch” d’Alibaba (utilisant les LLM comme moteurs de recherche simulés) et l‘“Absolute Zero” de l’Université Tsinghua (apprentissage entièrement par auto-jeu). (Source: TheTuringPost)
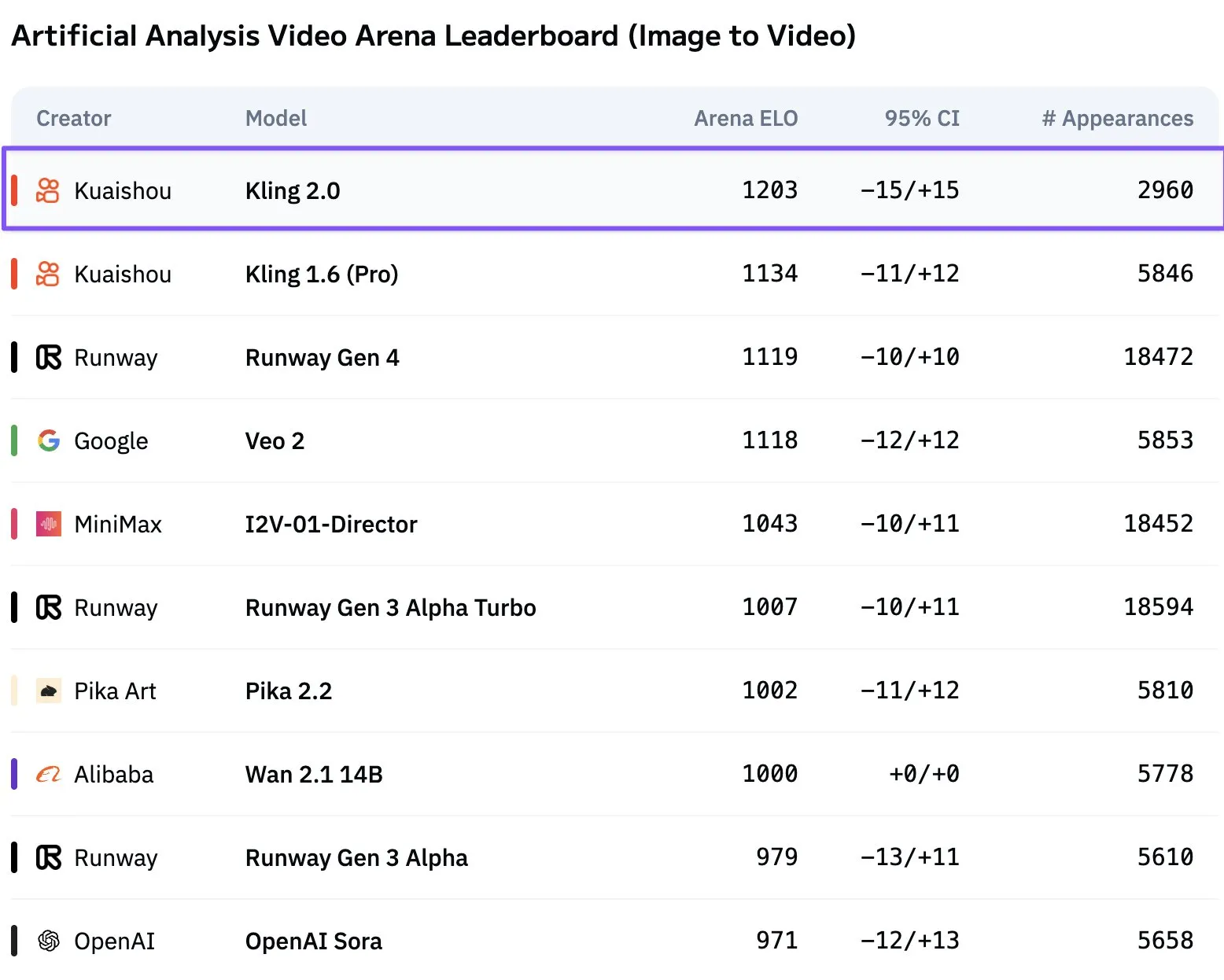
Le modèle vidéo Kling 2.0 de Kuaishou atteint le sommet: Kling 2.0, lancé par Kuaishou, a dépassé Veo 2 et Runway Gen 4 dans le classement de génération de vidéos d’Artificial Analysis, devenant le modèle leader de texte-à-vidéo. Les utilisateurs de la communauté ont reconnu ses performances. (Source: scaling01)
Les tests de préférence utilisateur placent OpenAI GPT-4.1 devant Claude 3.5 Sonnet: Les tests de préférence utilisateur montrent qu’OpenAI GPT-4.1 (et même 4.1-mini) est en tête en termes d’expérience utilisateur par rapport à Claude 3.5 Sonnet. (Source: imjaredz)
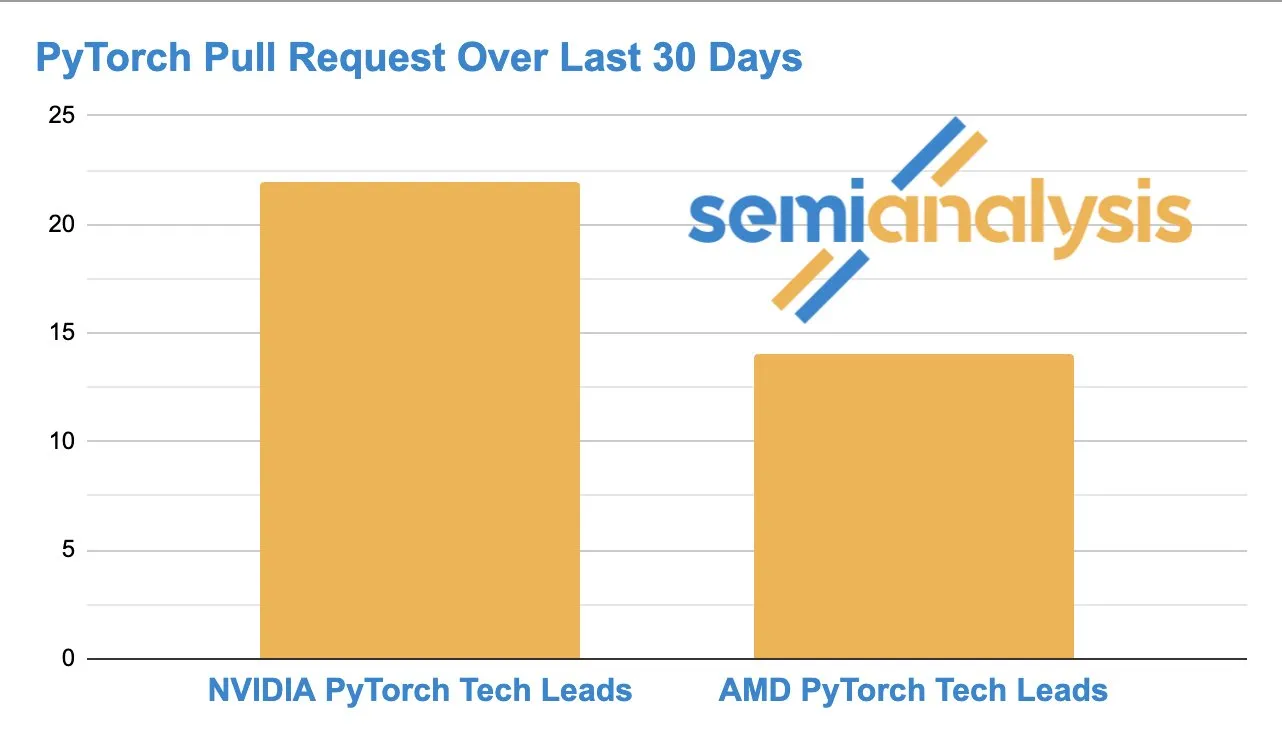
La concurrence s’intensifie entre AMD et NVIDIA dans le développement de logiciels d’IA: L’activité sur GitHub montre que le nombre de Pull Requests soumises par l’équipe ROCm PyTorch d’AMD rattrape le responsable technique PyTorch de NVIDIA, indiquant une concurrence croissante dans le domaine du développement de matériel et de logiciels d’IA de bas niveau. (Source: zacharynado)
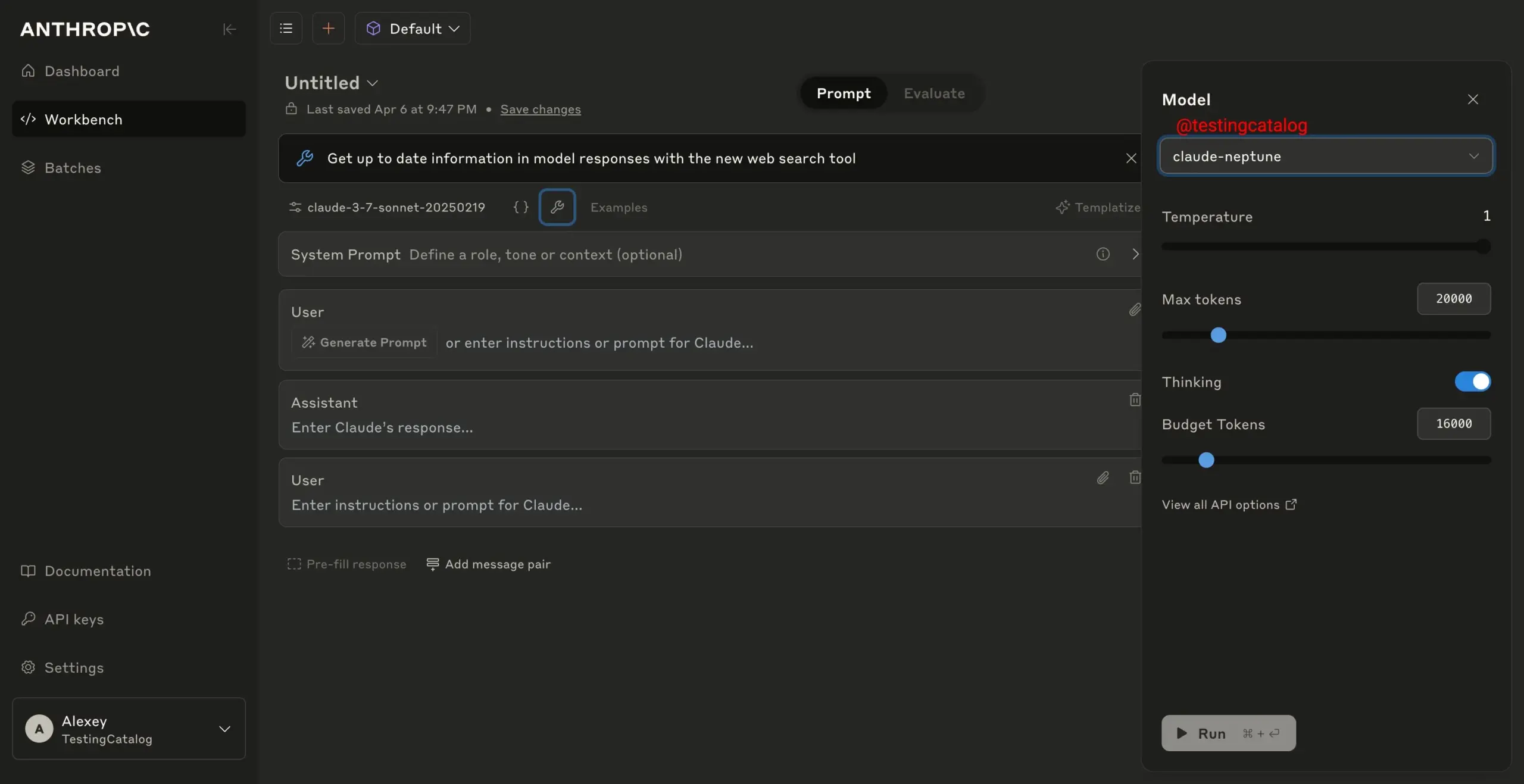
Le nouveau modèle d’Anthropic, “claude-neptune”, est en cours de tests de sécurité: Il a été rapporté qu’Anthropic testait actuellement la sécurité de son nouveau modèle “claude-neptune”, ce qui laisse présager une éventuelle publication prochaine d’un nouveau modèle. (Source: scaling01)
L’accès gratuit à l’API de Gemini 2.5 Pro suspendu en raison d’une forte demande: En raison d’une demande massive, Google a temporairement suspendu l’accès à la couche gratuite de Gemini 2.5 Pro via l’API, afin de garantir que les développeurs puissent continuer à faire évoluer leurs applications. Le modèle reste disponible gratuitement dans Google AI Studio. (Source: matvelloso)
Firefox explore l’intégration de llama.cpp dans WASM: Firefox expérimente l’intégration de la bibliothèque llama.cpp dans WebAssembly (WASM) sur GitHub, ce qui pourrait signifier que les utilisateurs pourront à l’avenir exécuter des LLM locaux directement dans le navigateur. (Source: ClementDelangue, ggerganov)

Benchmarks LLM pour AMD Ryzen AI Max+ PRO 395: Les benchmarks LLM pour AMD Ryzen AI Max+ PRO 395 sous Linux montrent que ses performances semblent inférieures à celles de la RTX 4060 Ti. Les discussions communautaires suggèrent que les tests pourraient ne refléter que les performances du CPU et explorent les performances de son iGPU, les avantages de sa VRAM, ainsi que les problèmes de compatibilité actuels des GPU Intel avec FP8, Flash Attention et l’allocation de mémoire. (Source: Reddit r/LocalLLaMA)
🧰 Outils
Lancement du protocole open source Minions Secure Chat pour le chat LLM chiffré dans le cloud: Un protocole open source appelé “Minions Secure Chat” a été publié, visant à permettre un chat LLM chiffré de bout en bout dans le cloud avec une latence très faible (<1%), même pour des modèles de plus de 30 milliards de paramètres. Le protocole garantit que les fournisseurs de services cloud ne peuvent pas voir le contenu des messages, l’inférence se déroulant dans un enclave GPU sécurisé, assurant la confidentialité. (Source: realDanFu, ollama, rebeccatqian, code_star)

DSPy permet la résumé récursif de textes de longueur arbitraire: Un programme construit avec DSPy a été présenté, capable de résumer récursivement des textes de longueur arbitraire. Le programme y parvient en construisant un répertoire, en divisant le contenu en blocs et en traitant les différentes parties en parallèle, offrant une solution générale pour traiter de longs documents. (Source: lateinteraction)
Runway AI Video Generation ajoute des contrôles cinématographiques et des fonctionnalités de référence: Runway a lancé de nouvelles fonctionnalités dans son modèle de génération vidéo Gen-4, notamment plus de 20 contrôles de caméra cinématographiques, une référence et une fusion multi-éléments, et un traitement plus fluide des mouvements complexes. Les fonctionnalités de référence améliorées augmentent également la précision du placement des objets. (Source: c_valenzuelab, TomLikesRobots)
Lancement d’OpenMemory MCP, offrant une mémoire locale privée pour les agents IA: OpenMemory MCP a été lancé, une couche de mémoire privée, locale et persistante conçue pour les clients IA compatibles MCP (tels que Cursor, Claude Desktop). Elle permet à différents outils IA de lire et d’écrire en toute sécurité et en privé dans une mémoire partagée, fonctionnant entièrement sur la machine de l’utilisateur sans dépendre des services cloud. (Source: omarsar0)
HeyGen lance la fonctionnalité Voice Mirroring: HeyGen a lancé la fonctionnalité Voice Mirroring, permettant aux utilisateurs de reproduire un style vocal ou des caractéristiques spécifiques dans l’audio généré par l’IA. (Source: Ronald_vanLoon)
Lancement du framework open source Step1X-3D pour la génération contrôlable d’actifs 3D: StepFun AI a publié Step1X-3D sur Hugging Face, un framework open source pour la génération haute fidélité et contrôlable d’actifs 3D texturés. (Source: huggingface, _akhaliq, reach_vb)

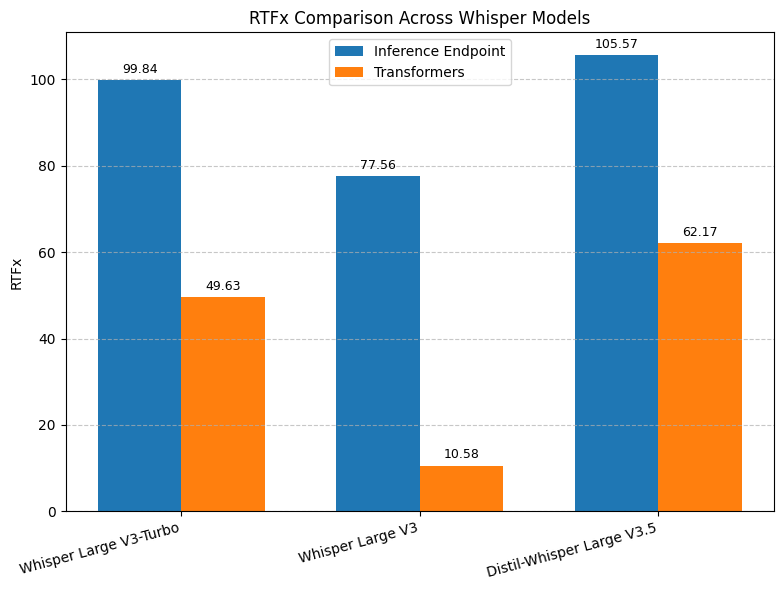
Amélioration de la vitesse de transcription de Hugging Face Whisper: Hugging Face a lancé un endpoint de transcription Whisper basé sur vLLM et optimisé pour les GPU NVIDIA, offrant une vitesse jusqu’à 8 fois plus rapide et de meilleures performances à moindre coût. (Source: ClementDelangue, huggingface, vllm_project)
Mise à jour de l’API mémoire de LlamaIndex, prenant en charge la fusion de la mémoire à court et long terme: LlamaIndex a mis à jour son API mémoire pour la rendre plus flexible, fusionnant l’historique de chat à court terme et la mémoire à long terme via des modules enfichables (statique, extraction de faits, mémoire vectorielle). (Source: jerryjliu0)

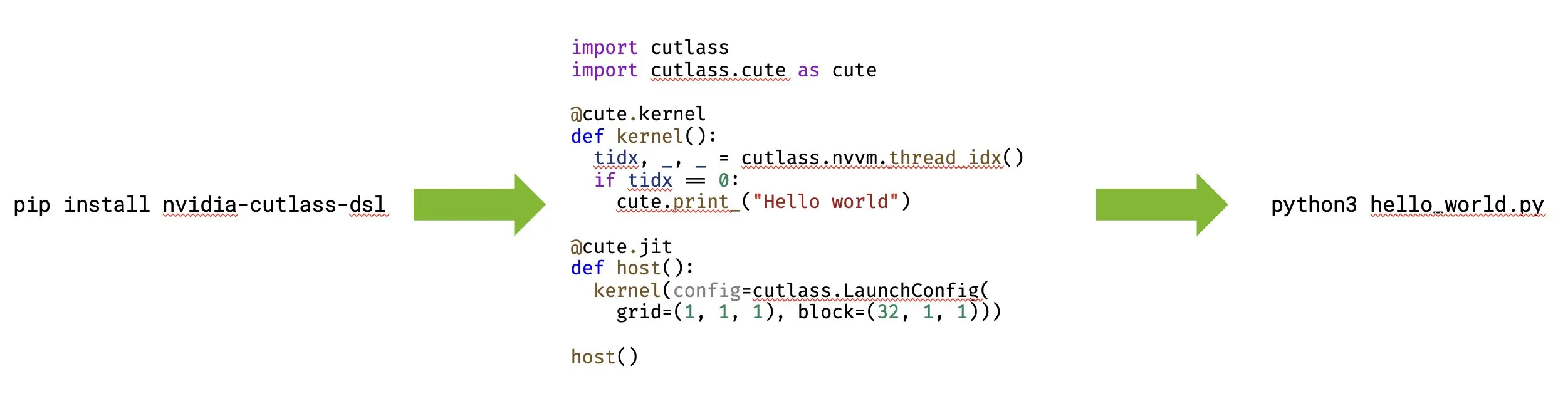
NVIDIA lance CUTLASS 4.0, prenant en charge la programmation GPU native en Python: NVIDIA a lancé CUTLASS 4.0, une bibliothèque prenant en charge la programmation GPU native en Python. Cette mise à jour vise à accélérer le développement de noyaux et l’exploration de nouvelles idées dans les domaines du ML et de la programmation GPU. (Source: marksaroufim, tri_dao)
Projet open source WeClone, créant des jumeaux numériques à partir d’historiques de chat: Un projet open source populaire sur GitHub, WeClone, propose une solution pour créer des jumeaux numériques à partir d’historiques de chat WeChat. Il permet d’affiner de grands modèles linguistiques pour capturer le style de conversation personnel et de les lier à des chatbots WeChat, QQ, Telegram, etc., tout en incluant des fonctionnalités de filtrage de confidentialité. (Source: GitHub Trending)

Outil open source Google Maps Scraper, pour l’extraction de données cartographiques: Un outil open source populaire sur GitHub, utilisé pour extraire des données de listes Google Maps. Il offre des interfaces en ligne de commande, Web UI et REST API, et peut extraire des informations telles que le nom de l’entreprise, l’adresse, les coordonnées, les évaluations, les avis, et prend en charge l’extraction d’e-mails et un “mode rapide”. (Source: GitHub Trending)
Les utilisateurs d’OpenWebUI signalent plusieurs problèmes techniques: Les utilisateurs d’OpenWebUI ont signalé plusieurs problèmes techniques, notamment l’ignorance des paramètres Modelfile (comme num_ctx) entraînant des plantages, l’impossibilité d’accéder à l’UI sur le réseau local après une mise à jour, l’impossibilité d’utiliser la recherche web intégrée d’OpenAI avec certains modèles, et des problèmes de timeout avec les anciennes sessions de chat. (Source: Reddit r/OpenWebUI)
Robot d’inspection de surface ferroviaire: Un robot multifonctionnel appelé RailScan a été mentionné, utilisé pour les travaux d’inspection de surface ferroviaire, un exemple d’application de l’IA et de la robotique dans l’industrie. (Source: Ronald_vanLoon)

Robot de construction par impression 3D: La technologie d’impression 3D est combinée à la robotique pour l’application dans le domaine de la construction, par exemple pour l’impression 3D de structures, représentant les progrès de la robotique et de l’IA dans la construction automatisée. (Source: Ronald_vanLoon)
Robots d’IA incarnée: Mention de robots autonomes et pilotés par l’IA capables de naviguer sans heurts dans des environnements complexes et d’exécuter des tâches avec précision, démontrant le potentiel de l’IA incarnée et de la robotique dans les applications du monde réel. (Source: Ronald_vanLoon)
Robot bio-inspiré: Une étude sur des champignons dotés d’un corps robotique qui ont appris à ramper a été mentionnée, montrant comment l’inspiration biologique peut faire progresser la robotique. (Source: Ronald_vanLoon)

📚 Apprentissage
Collection de ressources d’apprentissage de l’IA: La communauté a partagé diverses ressources d’apprentissage de l’IA, notamment des retours positifs sur les ressources de @dair_ai, un masterclass en ligne et un atelier de livre sur l’évaluation de l’IA, un guide vidéo sur l’inférence LLM, une explication de la différence entre l’IA Agentic et l’IA conventionnelle, un livre gratuit sur le RLHF, un module de cours d’analyse de données sur le traitement des données et l’utilisation de GenAI pour le débogage, un événement sur l’intelligence du code IA, et une infographie expliquant le fonctionnement des LLM. (Source: dair_ai, HamelHusain, omarsar0, bobvanluijt, natolambert, DeepLearningAI, l2k, Ronald_vanLoon, Reddit r/deeplearning, Reddit r/artificial)
Événement et ateliers LangChain Interrupt: LangChain a organisé l’événement Interrupt, comprenant des ateliers sur la construction d’agents IA fiables. Le contenu couvrait la conception de flux de travail d’agents avec LangGraph, la collaboration homme-machine, et l’utilisation de LangSmith pour l’observabilité et l’évaluation. Cisco a présenté son agent texte-à-SQL construit avec LangGraph et LangSmith. (Source: LangChainAI, hwchase17)

Annonce de l’atelier RL et jeux vidéo: La conférence RLC 2025 organisera un atelier sur l’apprentissage par renforcement et les jeux vidéo, sollicitant des articles sur des sujets liés aux jeux tels que le RL dans des environnements complexes, les scénarios multi-agents et la génération de contenu, et a annoncé les conférenciers confirmés. (Source: Reddit r/MachineLearning)
Le dépôt GitHub mlabonne/llm-course offre une feuille de route complète pour l’apprentissage des LLM: Un dépôt populaire sur GitHub, mlabonne/llm-course, propose un cours et une feuille de route complets pour l’apprentissage des LLM, couvrant les bases, la science des LLM (fine-tuning, quantification, évaluation) et l’ingénierie des LLM (exécution, RAG, déploiement, sécurité), et comprend des notes de code et des références associées. (Source: GitHub Trending)

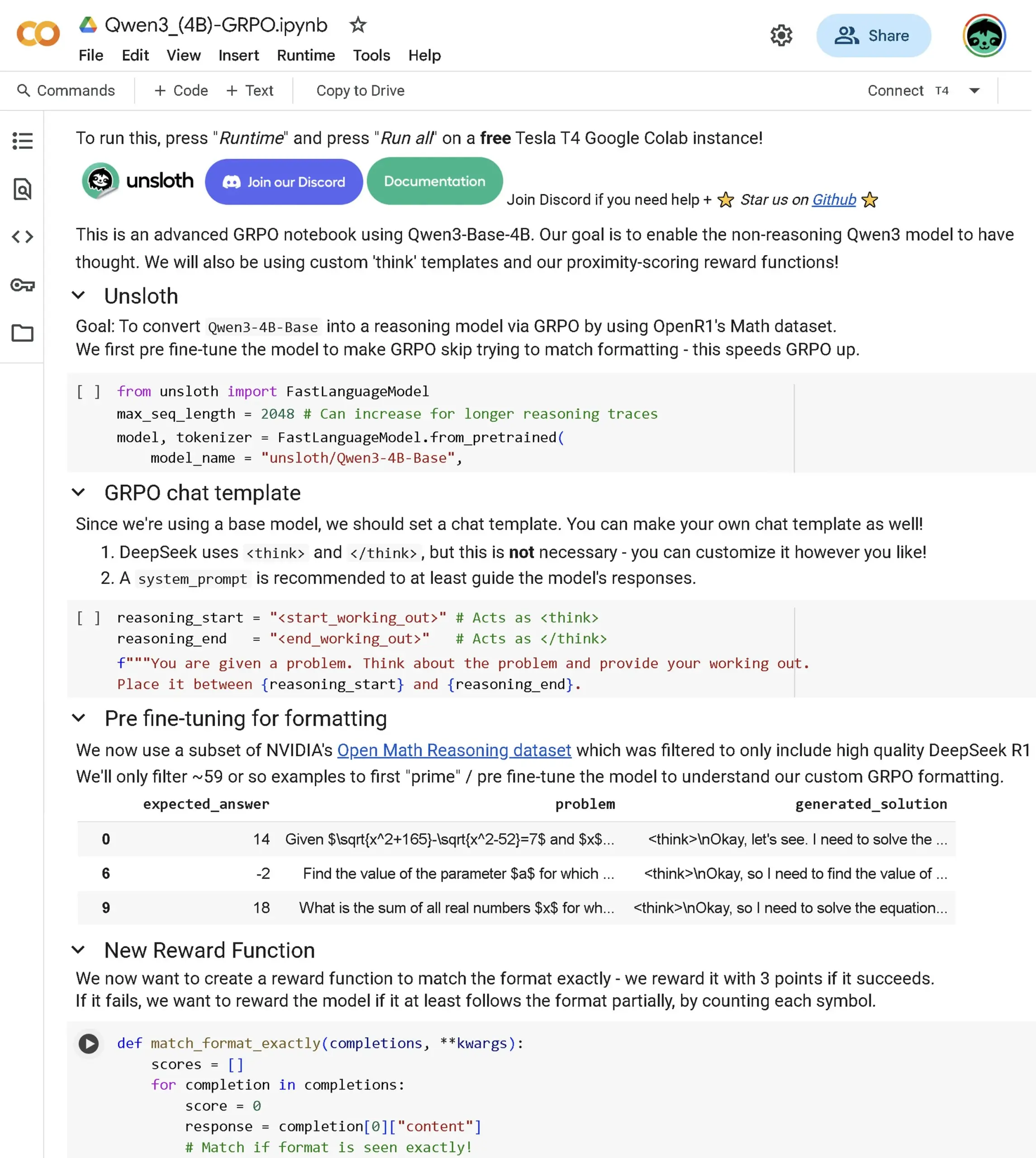
Publication d’un nouveau notebook avancé Qwen3 Base GRPO: Un nouveau notebook avancé GRPO (Generalized Policy Optimization) a été publié, spécialement conçu pour le modèle Qwen3 Base. Le contenu couvre comment affiner le modèle pour améliorer les capacités de raisonnement, le score de proximité, le modèle GRPO, l’ensemble de données OpenR1 et l’optimisation du processus RL via le pré-fine-tuning. (Source: danielhanchen)
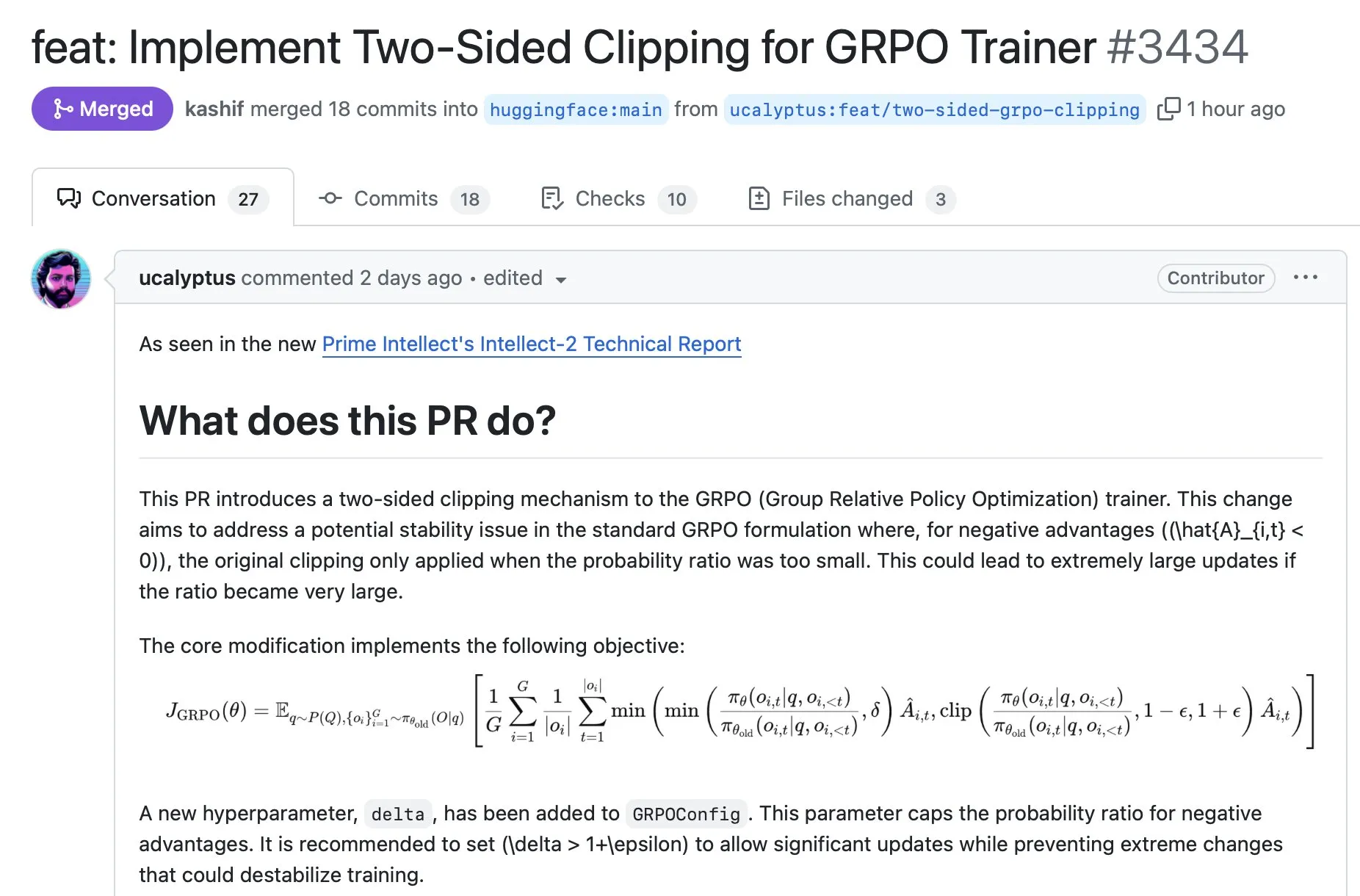
La bibliothèque TRL intègre une technique de stabilisation GRPO: Une nouvelle technique de stabilisation GRPO développée par Prime Intellect a été intégrée dans la populaire bibliothèque Transformer Reinforcement Learning (TRL). Elle peut être utilisée en installant la dernière version et vise à améliorer la stabilité de l’entraînement GRPO. (Source: ClementDelangue)
💼 Affaires
Perplexity AI sur le point de clôturer un financement de 500 millions de dollars, valorisation atteignant 14 milliards de dollars: La startup de recherche IA Perplexity AI serait sur le point de clôturer un tour de financement de 500 millions de dollars mené par Accel, valorisant l’entreprise à 14 milliards de dollars. Cela montre que malgré la concurrence de Google et OpenAI, Perplexity a obtenu un solide soutien en capital. (Source: TheRundownAI, Reddit r/ClaudeAI, 36氪)

NVIDIA s’associe à l’Arabie Saoudite pour construire une “usine d’IA”: NVIDIA a annoncé un partenariat avec HUMAIN, la filiale IA du Fonds d’investissement public d’Arabie Saoudite, pour construire une “usine d’IA” en Arabie Saoudite. NVIDIA fournira l’infrastructure et l’expertise pour aider l’Arabie Saoudite à devenir un leader mondial de l’IA. (Source: nvidia)

L’équipe WizardLM quitte Microsoft pour rejoindre Tencent Hunyuan: L’équipe WizardLM, y compris son responsable Can Xu, a quitté Microsoft pour rejoindre Tencent Hunyuan. Auparavant, le modèle Tencent Hunyuan-Turbos était bien classé (8ème) dans les classements, et ce mouvement de personnel a suscité des discussions sur la concurrence des talents entre les grands laboratoires d’IA. (Source: andrew_n_carr, cognitivecompai, teortaxesTex, Sentdex, WizardLM_AI, madiator)

Johnson & Johnson applique largement l’IA générative dans ses activités pharmaceutiques: Après avoir mené environ 900 expériences internes, Johnson & Johnson a étendu l’application de son IA générative à plusieurs étapes de ses activités pharmaceutiques, notamment l’accélération de la découverte de médicaments, la prévision des risques de la chaîne d’approvisionnement, la simplification des essais cliniques et le soutien aux ventes et aux services aux employés. (Source: DeepLearningAI)
Somite AI lève des fonds pour construire un modèle de base pour les cellules humaines: La société Somite AI construit un modèle de base “DeltaStem” pour les cellules humaines et développe une technologie capable de générer plus rapidement des données de signalisation cellulaire. La société a levé 5,9 millions de dollars. (Source: saranormous, finbarrtimbers)
🌟 Communauté
Les utilisateurs expriment leur mécontentement face à la baisse de qualité des modèles d’IA et au phénomène de Sycophancy: De nombreux utilisateurs ont exprimé leur frustration face à la baisse de qualité des modèles d’IA actuels, en particulier ChatGPT, accusé de devenir “sycophante” (excessivement positif/flatteur), paresseux et de produire plus d’hallucinations. Certains utilisateurs envisagent d’annuler leur abonnement, tandis que d’autres discutent de l’efficacité des instructions personnalisées ou si le mécontentement sur les réseaux sociaux est exagéré. (Source: Reddit r/ArtificialInteligence, Reddit r/ChatGPT)

Discussion sur l’éthique et la responsabilité de l’IA : qui est responsable des erreurs de décision de l’IA ?: La communauté discute largement de qui devrait être tenu responsable lorsque l’IA prend des décisions autonomes qui entraînent des erreurs. Les points de vue incluent que l’entreprise propriétaire de l’IA devrait être responsable (similaire aux parents pour leurs enfants ou aux conducteurs pour les voitures autonomes), que l’IA elle-même pourrait être responsable à l’avenir, qu’une supervision humaine est nécessaire, et que les entreprises qui tirent profit de l’IA devraient être responsables. (Source: Reddit r/ArtificialInteligence)
L’impact de l’IA sur l’éducation et l’emploi : l’utilisation de l’IA par les enseignants pour noter suscite la controverse: La discussion sur l’utilisation de l’IA par les enseignants pour corriger les devoirs des élèves a suscité la controverse, certains craignant que cela ne dévalorise les élèves ou ne présage leur obsolescence potentielle. Les opposants soutiennent que l’IA n’est qu’un outil qui peut fournir un feedback rapide et que les objectifs des examens sont variés. La communauté a également discuté de l’impact plus large de l’IA sur l’emploi et des tâches spécifiques que les utilisateurs souhaiteraient que l’IA prenne entièrement en charge. (Source: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

Préoccupations concernant la fiabilité des LLM : mauvaises performances dans le traitement de sources de données spécifiques: Les utilisateurs sont déçus par la façon dont les LLM traitent des sources de données spécifiques et fragmentées (comme les documents juridiques), produisant un contenu qui semble faire autorité mais qui est factuellement inexact ou vague. Bien que les LLM fonctionnent bien pour le résumé général ou le codage, leur fiabilité est remise en question pour les tâches nécessitant un traitement précis de données uniques. (Source: Reddit r/artificial)
Géopolitique du matériel IA : proposition d’un sénateur américain exigeant le géotracking intégré dans les GPU haut de gamme: Une proposition d’un sénateur américain exige l’intégration d’une fonction de géotracking dans les GPU haut de gamme (comme la RTX 4090) pour empêcher leur utilisation par des gouvernements étrangers. Cela a suscité des inquiétudes au sein de la communauté concernant l’ingérence excessive du gouvernement, la possibilité de désactivation à distance et le DRM matériel. (Source: Reddit r/LocalLLaMA)

Les jeunes utilisent ChatGPT pour les aider à prendre des décisions de vie: Sam Altman a souligné que la jeune génération utilise de plus en plus ChatGPT pour l’aider à prendre des décisions de vie. Certains considèrent cela comme un phénomène positif (chercher des conseils lorsque les ressources humaines sont insuffisantes), mais d’autres craignent la dépendance à des LLM potentiellement peu fiables pour des choix cruciaux. (Source: Reddit r/ChatGPT)

Discussions sur la perception et la stratégie de l’industrie de l’IA: Les discussions communautaires ont porté sur les raisons pour lesquelles Meta est considéré comme étant à la traîne par rapport aux autres grands laboratoires d’IA, le compromis entre le fine-tuning de petits modèles et le prompt engineering, la confidentialité des entreprises d’IA, et l’idée que la “recherche” est un fossé concurrentiel essentiel pour les agents IA. (Source: Reddit r/MachineLearning, cto_junior, madiator, Dorialexander)
💡 Autre
La Chine lance un système de contrôle quantique de quatrième génération: La Chine a lancé un système de contrôle quantique de quatrième génération prenant en charge plus de 500 qubits, représentant les dernières avancées de la technologie de calcul quantique. (Source: Ronald_vanLoon)

Application de l’IA dans le domaine de la défense : la Chine utilise DeepSeek pour développer des avions de chasse furtifs: Il a été rapporté que la Chine utilise la technologie DeepSeek AI pour aider au développement de son avion de chasse furtif de sixième génération (J-35, J-50). (Source: Ronald_vanLoon)
Publication de la vidéo de présentation du projet METACOG-25: Le projet METACOG-25 a publié une vidéo de présentation, annonçant de nouveaux développements dans la recherche ou le développement de l’IA. (Source: Reddit r/deeplearning)

Mises à jour de la plateforme Hugging Face : Collections dans les collections et compte officiel PyTorch: Le Hugging Face Hub a lancé la fonctionnalité “Collections dans les collections”, permettant une organisation plus fine des ressources. Parallèlement, PyTorch dispose désormais d’un compte officiel sur la plateforme. (Source: ClementDelangue, Reddit r/LocalLLaMA)