
Mots-clés:OpenAI, HealthBench, Meta AI, Transformateur Dynamique de Latence d’Octet, Microsoft Research, Cadre ARTIST, Sakana AI, Machine à Réflexion Continue, Évaluation des performances de l’IA médicale, Modèle Transformateur Dynamique de Latence d’Octet 8B paramètres, Amélioration du raisonnement des LLM par apprentissage par renforcement, Architecture de réseau neuronal CTM, Modèle quantifié officiel Qwen3
🔥 Pleins feux sur
OpenAI lance HealthBench pour évaluer les performances de l’IA médicale: OpenAI a introduit HealthBench, un nouveau benchmark conçu pour mesurer les performances et la sécurité des grands modèles de langage dans des scénarios médicaux. Ce benchmark a été développé avec la participation de plus de 250 médecins du monde entier et comprend 5000 conversations médicales réelles et 48562 critères d’évaluation uniques rédigés par des médecins, couvrant divers contextes tels que les urgences et la santé mondiale, ainsi que des dimensions comportementales comme la précision et le suivi des instructions. Les tests montrent que le modèle o3 atteint une précision de 60 %, tandis que GPT-4.1 nano surpasse GPT-4o tout en réduisant les coûts par 25, démontrant le potentiel immense de l’IA dans le domaine médical et les progrès rapides en matière de rapport performance-coût. (Source : OpenAI)
Meta publie un modèle Transformer à octets dynamiques latents (Dynamic Byte Latent Transformer) de 8 milliards de paramètres: Meta AI a annoncé la publication en open source des poids de son modèle Transformer à octets dynamiques latents de 8 milliards de paramètres. Ce modèle propose une nouvelle approche alternative aux méthodes de tokenisation traditionnelles, visant à redéfinir les standards d’efficacité et de fiabilité des modèles de langage. Grâce à cette nouvelle méthode de tokenisation, il est espéré d’apporter des avancées décisives dans le domaine des modèles de langage, améliorant l’efficacité et les performances du traitement de texte par les modèles. Le papier de recherche et le code sont disponibles au téléchargement. (Source : AIatMeta)
Microsoft Research lance le framework ARTIST, combinant l’apprentissage par renforcement pour améliorer l’inférence et l’utilisation d’outils des LLM: Microsoft Research a présenté le framework ARTIST (Agentic Reasoning and Tool Integration in Self-improving Transformers). Ce framework intègre le raisonnement agentique, l’apprentissage par renforcement et l’utilisation dynamique d’outils, permettant aux grands modèles de langage de décider de manière autonome quand, comment et quels outils utiliser pour l’inférence multi-étapes, et d’apprendre des stratégies robustes sans supervision au niveau des étapes. ARTIST surpasse les modèles de pointe tels que GPT-4o dans des benchmarks exigeants comme les mathématiques et l’appel de fonctions, avec une amélioration allant jusqu’à 22 %, établissant de nouvelles normes pour la résolution de problèmes généralisable et interprétable. (Source : MarkTechPost)

Sakana AI publie les Machines à Pensée Continue (Continuous Thought Machines, CTM): Sakana AI a lancé une nouvelle architecture de réseau neuronal appelée “Machines à Pensée Continue” (CTM). L’idée centrale des CTM est d’utiliser le processus temporel dynamique de l’activité neuronale comme composant principal de leur calcul, permettant au modèle d’opérer le long d’une chronologie “d’étapes de pensée” générée en interne, construisant et affinant itérativement ses représentations, même pour des données statiques. Cette architecture a démontré son calcul adaptatif, son interprétabilité améliorée et sa plausibilité biologique sur diverses tâches telles que la classification ImageNet, la navigation dans des labyrinthes 2D, le tri, le calcul de parité et l’apprentissage par renforcement. (Source : Sakana AI)

🎯 Tendances
L’équipe Qwen d’Alibaba publie les modèles quantifiés officiels de Qwen3: L’équipe Qwen d’Alibaba a officiellement publié les modèles quantifiés de Qwen3. Les utilisateurs peuvent désormais déployer Qwen3 via des plateformes telles que Ollama, LM Studio, SGLang et vLLM, avec prise en charge de plusieurs formats comme GGUF, AWQ, GPTQ, facilitant le déploiement local. Les modèles correspondants sont disponibles sur Hugging Face et ModelScope. Cette publication vise à abaisser le seuil d’utilisation des grands modèles haute performance et à promouvoir leur application dans un plus large éventail de scénarios. (Source : Alibaba_Qwen & Hugging Face & ClementDelangue & _akhaliq & TheZachMueller & cognitivecompai & huybery & Reddit r/LocalLLaMA)
Meta AI publie le framework de raisonnement collaboratif Collaborative Reasoner: Meta AI a lancé Collaborative Reasoner, un framework visant à améliorer les capacités de raisonnement collaboratif des modèles de langage. Ce framework s’efforce de développer des agents sociaux capables de coopérer avec les humains et d’autres agents intelligents, ouvrant la voie à des interactions homme-machine plus complexes et à des systèmes multi-agents en améliorant les capacités de collaboration et de raisonnement des modèles. Le papier de recherche et le code sont disponibles au téléchargement, encourageant la communauté à explorer et à appliquer. (Source : AIatMeta)
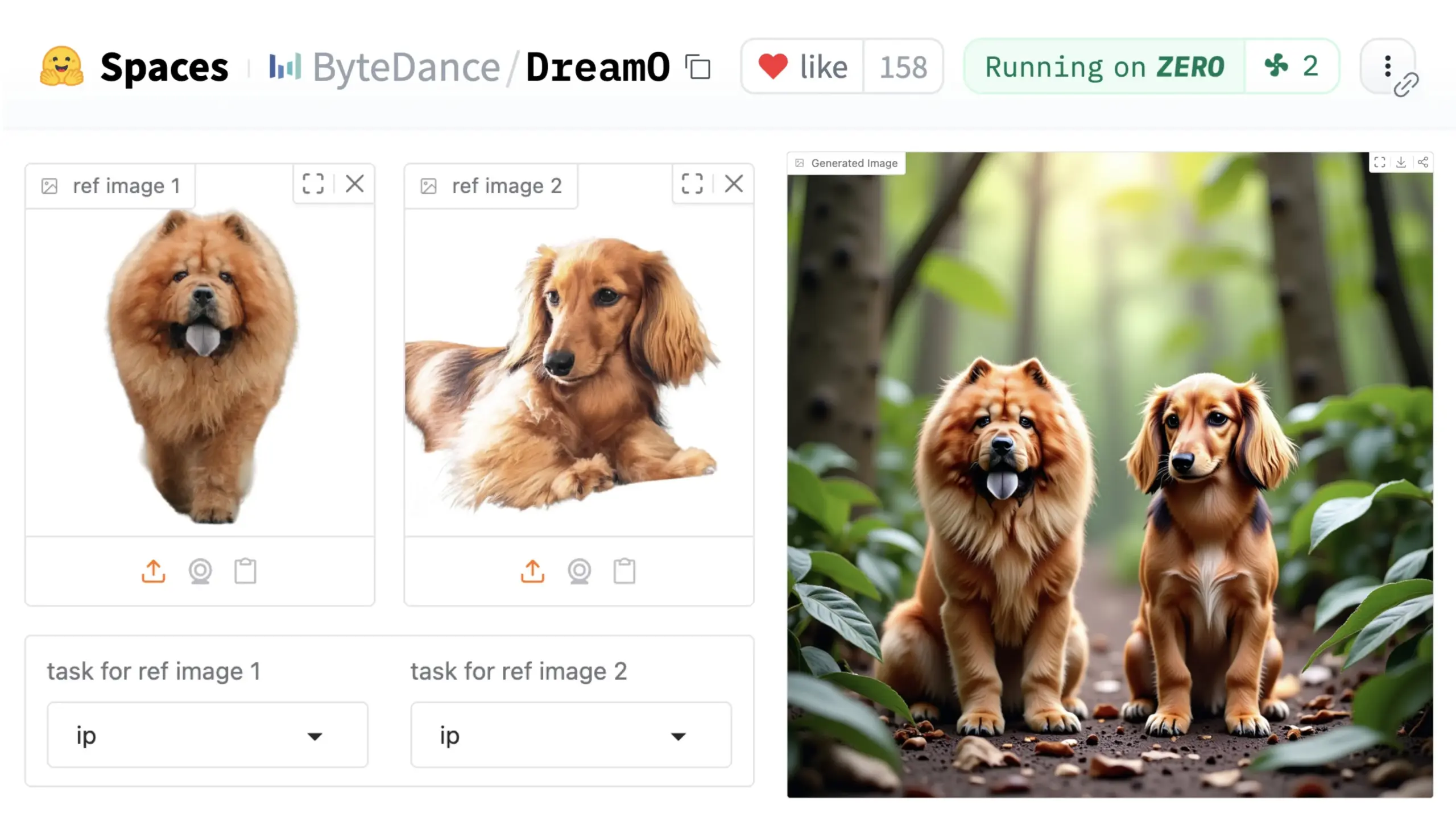
ByteDance lance le framework universel de personnalisation d’images DreamO: ByteDance a publié un framework unifié de personnalisation d’images nommé DreamO. Basé sur le modèle pré-entraîné DiT (Diffusion Transformer), ce framework permet une personnalisation étendue de divers éléments dans les images, tels que les personnages, les styles, les arrière-plans, y compris le remplacement d’identité, le transfert de style, la transformation de sujet et l’essayage virtuel. Les utilisateurs peuvent tester la démo sur Hugging Face. Cette avancée démontre le potentiel d’un modèle unique dans diverses tâches d’édition d’images. (Source : _akhaliq & ClementDelangue & _akhaliq)
NVIDIA ouvre le processus de gestion des données du modèle Nemotron, Nemotron-CC: NVIDIA a annoncé l’ouverture de son processus de gestion des données utilisé pour le modèle Nemotron, Nemotron-CC, et rend publiques autant de données d’entraînement et de post-entraînement de Nemotron que possible. Le processus Nemotron-CC est désormais intégré au dépôt GitHub NeMo Curator et peut traiter des données textuelles, image et vidéo à grande échelle. NVIDIA souligne l’importance des jeux de données de pré-entraînement de haute qualité pour la précision des grands modèles de langage et considère les données comme un composant fondamental de l’accélération du calcul. (Source : ctnzr & NandoDF)

Le modèle Hunyuan-Turbos de Tencent se classe huitième dans l’arène LMArena: Le dernier modèle Hunyuan-Turbos de Tencent s’est classé huitième au classement général du benchmark LMArena (anciennement lmsys.org) et treizième pour le contrôle de style, affichant des performances proches de Deepseek-R1. Le modèle figure dans le top dix des principales catégories telles que hardcore, codage et mathématiques, montrant une amélioration significative par rapport à sa version de février. Des membres de la communauté comme WizardLM_AI ont salué ses performances. (Source : WizardLM_AI & WizardLM_AI & teortaxesTex)

Runway Gen-4 References démontre le potentiel d’un outil de création universel: Le modèle Gen-4 References de Runway est positionné comme un outil de création universel, capable de prendre en charge des flux de travail et des applications quasi illimités. Les utilisateurs de la communauté découvrent continuellement de nouveaux cas d’utilisation, démontrant sa forte adaptabilité en tant que modèle généraliste capable de s’ajuster à la créativité de l’utilisateur, plutôt que de forcer l’utilisateur à s’adapter aux contraintes du modèle. Cela reflète la tendance de l’évolution de l’IA dans le domaine de la création multimédia, passant de tâches spécifiques à des capacités générales. (Source : c_valenzuelab & c_valenzuelab)

Le modèle Seed-1.5-VL-thinking de ByteDance en tête des benchmarks de modèles vision-langage: ByteDance a publié le modèle Seed-1.5-VL-thinking, qui a atteint des résultats SOTA (state-of-the-art) sur 38 des 60 benchmarks de modèles vision-langage (VLM). Il est rapporté que ce modèle a été entraîné sur 1,3 million d’heures GPU H800, démontrant ses puissantes capacités de compréhension et de raisonnement multimodales. (Source : teortaxesTex)
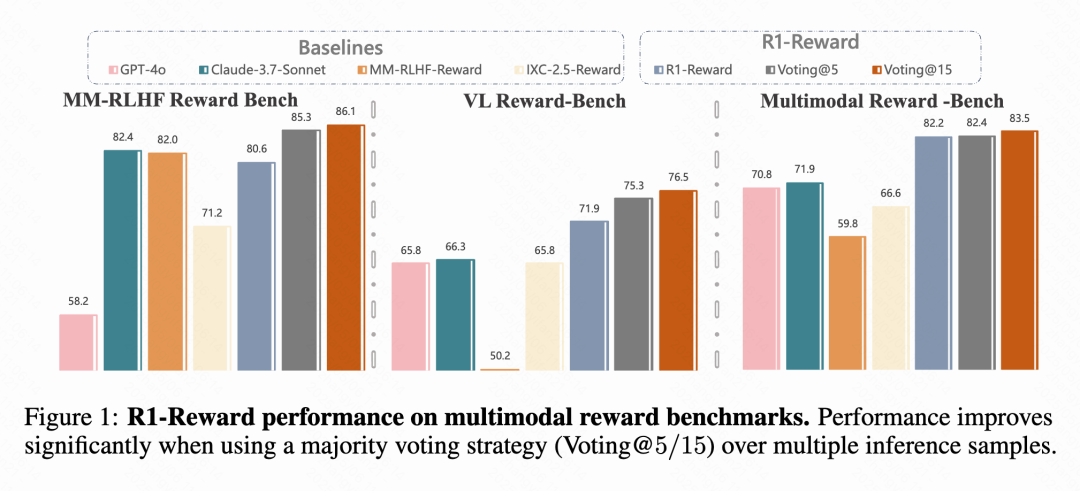
Kuaishou, l’Académie Chinoise des Sciences et d’autres proposent le modèle de récompense multimodal R1-Reward: Des équipes de recherche de Kuaishou, de l’Académie Chinoise des Sciences, de l’Université Tsinghua et de l’Université de Nanjing ont proposé R1-Reward, un nouveau modèle de récompense multimodal (MRM), entraîné via un algorithme d’apprentissage par renforcement amélioré, StableReinforce. Ce modèle vise à résoudre les problèmes d’instabilité rencontrés par les algorithmes RL existants lors de l’entraînement des MRM, en introduisant des mécanismes tels que Pre-Clip, un filtre d’avantage et une récompense de cohérence. Les expériences montrent que R1-Reward améliore les performances de 5 % à 15 % par rapport aux modèles SOTA sur plusieurs benchmarks MRM et a été appliqué avec succès dans les scénarios commerciaux de Kuaishou tels que les courtes vidéos et le commerce électronique. (Source : WeChat & WeChat)
L’Université Technologique de Nanyang et d’autres proposent WorldMem, utilisant un mécanisme de mémoire pour générer des mondes cohérents sur le long terme: Des chercheurs du S-Lab de l’Université Technologique de Nanyang, de l’Université de Pékin et du Shanghai AI Lab ont proposé le modèle de génération de monde WorldMem. En introduisant un mécanisme de mémoire, ce modèle résout le problème du manque de cohérence des modèles de génération vidéo existants sur de longues séquences temporelles. WorldMem, entraîné sur le jeu de données Minecraft, prend en charge l’exploration de scènes diversifiées et les changements dynamiques. Sa faisabilité a été validée sur des jeux de données réels, démontrant une bonne cohérence géométrique après des changements de point de vue et de position, et modélisant la cohérence temporelle. (Source : WeChat)

L’équipe Keling de Kuaishou propose CineMaster, un framework de génération vidéo de qualité cinématographique contrôlable et conscient de la 3D: L’équipe de recherche Keling de Kuaishou a publié un article au SIGGRAPH 2025 présentant le framework CineMaster. Il s’agit d’un framework de génération de texte en vidéo de qualité cinématographique qui permet aux utilisateurs, via un flux de travail interactif, d’agencer des scènes dans l’espace 3D, de définir des cibles et des mouvements de caméra, réalisant un contrôle fin du contenu vidéo. CineMaster intègre le contrôle du mouvement des objets et de la caméra respectivement via Semantic Layout ControlNet et Camera Adapter, et a conçu un processus de construction de données pour extraire des signaux de contrôle 3D à partir de n’importe quelle vidéo. (Source : WeChat)

🧰 Outils
Comet-ml publie le framework open source d’évaluation de LLM Opik: Comet-ml a rendu open source sur GitHub Opik, un framework pour le débogage, l’évaluation et la surveillance des applications LLM, des systèmes RAG et des workflows d’agents. Opik fournit un suivi complet, une évaluation automatisée et des tableaux de bord prêts pour la production, prenant en charge l’installation locale ou via Comet.com en tant que solution hébergée. Il s’intègre à plusieurs frameworks populaires tels que OpenAI, LangChain, LlamaIndex, et fournit des métriques LLM-as-a-judge pour la détection d’hallucinations, la modération de contenu et l’évaluation RAG. (Source : GitHub Trending)
LovartAI lance son premier agent de design Lovart, mettant l’accent sur la compréhension du contexte: LovartAI a publié la version bêta de son premier agent de design, Lovart. Les retours des utilisateurs indiquent que, comparé à d’autres outils de design IA, Lovart comprend mieux le contexte, allant même jusqu’à “lire dans les pensées”. L’outil permet aux humains et à l’IA de collaborer sur le même canevas, transformant instantanément les prompts en visuels, utilisable pour la conception de logos de marque et d’identité visuelle (VI). (Source : karminski3)
L’équipe de Jun-Yan Zhu (CMU) lance LEGOGPT, générant des modèles LEGO 3D à partir de texte: L’équipe de Jun-Yan Zhu de Carnegie Mellon University a développé LEGOGPT, un grand modèle de langage capable de générer des modèles LEGO 3D physiquement stables et constructibles à partir de prompts textuels. Le modèle formule le problème de conception LEGO comme une tâche de génération de texte autorégressive, construisant la structure en prédisant la taille et la position de la brique suivante, et applique des contraintes d’assemblage conscientes de la physique pendant l’entraînement et l’inférence pour garantir la stabilité et la constructibilité des conceptions générées. L’équipe a également publié le jeu de données StableText2Lego contenant plus de 47 000 structures LEGO. (Source : WeChat)

L’application MNN Chat prend en charge les modèles Qwen 2.5 Omni 3B et 7B: L’application de chat MNN (Mobile Neural Network) d’Alibaba prend désormais en charge les modèles Qwen 2.5 Omni 3B et 7B. Cela signifie que les utilisateurs peuvent bénéficier de services de modèles de langage localisés plus puissants sur mobile. MNN est un moteur d’inférence de deep learning léger, axé sur l’optimisation pour les appareils mobiles et embarqués. (Source : Reddit r/LocalLLaMA)

La plateforme FutureHouse fournit aux scientifiques des outils de recherche IA superintelligents: L’organisation à but non lucratif FutureHouse a lancé la plateforme FutureHouse, une suite d’agents IA basée sur le Web et des API, conçue pour accélérer la découverte scientifique. La plateforme offre une gamme d’outils de recherche IA superintelligents pour aider les scientifiques dans l’analyse de données, la simulation d’expériences et la découverte de connaissances, favorisant une transformation des paradigmes de recherche. (Source : dl_weekly)
Cartesia lance Pro Voice Cloning pour construire facilement des modèles vocaux personnalisés: Cartesia a lancé son produit de fine-tuning Pro Voice Cloning. Les utilisateurs peuvent télécharger leurs propres données vocales pour construire facilement des modèles vocaux personnalisés, utilisables pour créer des avatars personnels, des agents IA ou des banques de voix. Le produit permet de finaliser l’entraînement et le déploiement du service en 2 heures et offre une expérience produit entièrement en libre-service, visant une application à grande échelle. (Source : krandiash)

L’Institut de Technologie Informatique de l’Académie Chinoise des Sciences propose MCA-Ctrl pour une personnalisation précise des images: Une équipe de recherche de l’Institut de Technologie Informatique de l’Académie Chinoise des Sciences a proposé une méthode universelle de personnalisation d’images sans fine-tuning, MCA-Ctrl (Multi-party Collaborative Attention Control). Cette méthode, via un contrôle d’attention collaboratif multi-parties, utilise les connaissances internes des modèles de diffusion, combinant des prompts conditionnels image/texte avec le contenu de l’image sujet, pour réaliser le remplacement thématique, la génération et l’ajout de sujets spécifiques. MCA-Ctrl assure la cohérence de la mise en page et le remplacement de l’apparence d’objets spécifiques aligné avec l’arrière-plan grâce à des mécanismes de requête locale d’auto-attention et d’injection globale. (Source : WeChat)
📚 Apprentissage
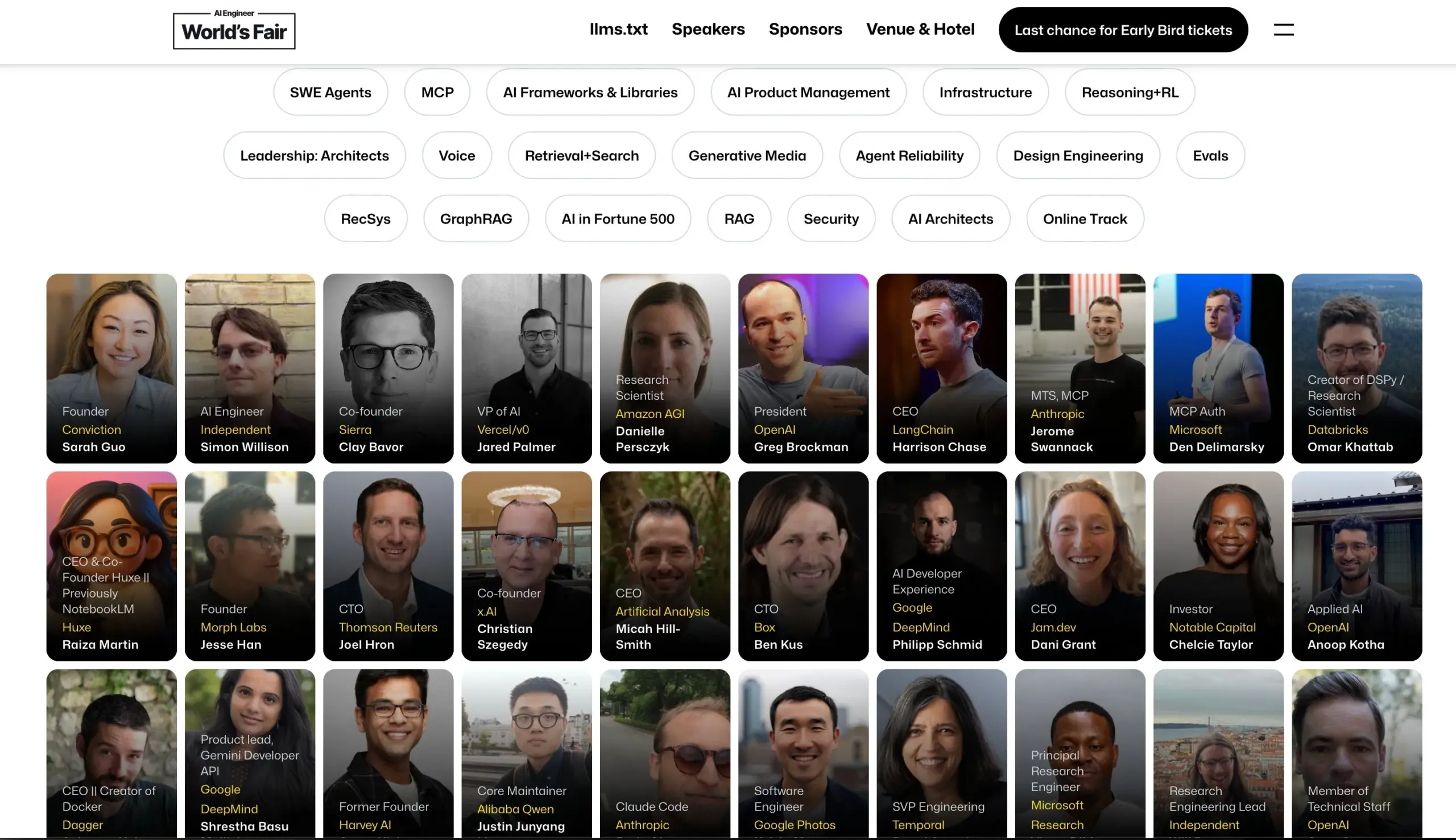
La conférence AI Engineer annonce sa liste d’intervenants: La conférence AI Engineer a dévoilé sa liste d’intervenants, comprenant des ingénieurs et chercheurs IA de premier plan d’entreprises telles que OpenAI, Anthropic, LangChainAI, Google, etc. La conférence couvrira 20 domaines spécifiques tels que MCP, LLM RecSys, Agent Reliability, GraphRAG, et introduira pour la première fois un agenda de leadership pour les CTO et VP. (Source : swyx & hwchase17 & _philschmid & HamelHusain & swyx & bookwormengr & swyx)
Hugging Face publie un article de blog sur les dernières avancées des modèles vision-langage (VLM): Hugging Face a publié un article de blog complet sur les dernières avancées des modèles vision-langage (VLM). Le contenu couvre de multiples aspects tels que les agents GUI, les agents VLM, les modèles omnipotents, le RAG multimodal, les LM vidéo, les petits modèles, etc., résumant les nouvelles tendances, les percées, l’alignement et les benchmarks dans le domaine des VLM au cours de l’année écoulée. (Source : huggingface & ben_burtenshaw & mervenoyann & huggingface & algo_diver & huggingface & huggingface)

Microsoft Azure organise un séminaire en ligne sur la création d’applications de chat IA sans serveur: Yohan Lasorsa a annoncé l’organisation d’un séminaire en ligne sur la création d’applications de chat IA sans serveur à l’aide d’Azure. La conférence explorera Azure Functions, les applications Web statiques et Cosmos DB, ainsi que la manière d’utiliser la technologie RAG (Retrieval-Augmented Generation) en combinaison avec LangChainAI JS. (Source : Hacubu & hwchase17)
Le podcast Weaviate explore les systèmes LLM-as-Judge et la bibliothèque Verdict: Le 121e épisode du podcast Weaviate invite Leonard Tang, co-fondateur de Haize Labs, pour une discussion approfondie sur l’évolution des systèmes LLM-as-Judge / modèles de récompense. La discussion aborde l’expérience utilisateur de l’évaluation, l’évaluation comparative, l’intégration des juges, les juges débatteurs, la curation des ensembles d’évaluation et les tests adversariaux, et met en avant la nouvelle bibliothèque de Haize Labs, Verdict, un framework déclaratif pour spécifier et exécuter des systèmes LLM-as-Judge composites. (Source : bobvanluijt & Reddit r/deeplearning)

Terence Tao publie une vidéo YouTube démontrant la formalisation de preuves mathématiques assistée par IA: Le médaillé Fields Terence Tao fait ses débuts sur sa chaîne YouTube en démontrant comment utiliser des outils IA tels que GitHub Copilot et l’assistant de preuve Lean pour formaliser de manière semi-automatique en 33 minutes une preuve mathématique (l’équation Magma E1689 implique E2) qui nécessiterait normalement une page entière écrite par un mathématicien humain. Il souligne que cette méthode convient aux preuves très techniques et peu conceptuelles, libérant les mathématiciens des tâches fastidieuses. Parallèlement, l’assistant de preuve Python léger qu’il a développé a été mis à jour vers la version 2.0, améliorant le traitement des estimations asymptotiques et de la logique propositionnelle. (Source : WeChat & 量子位)

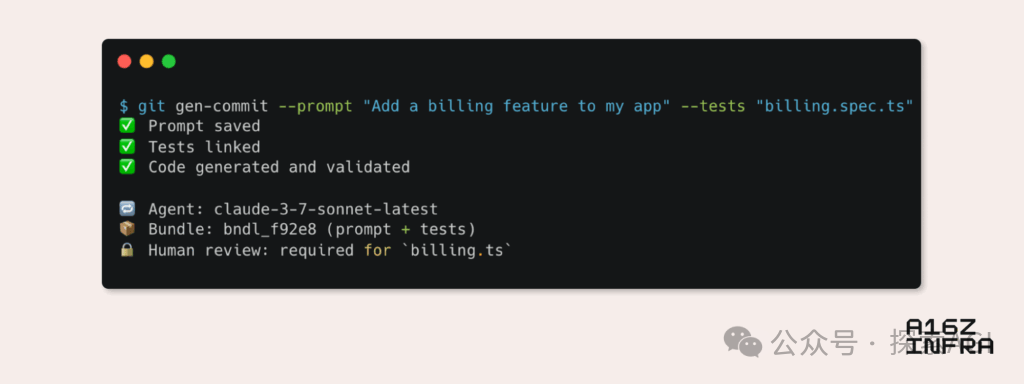
a16z analyse neuf tendances émergentes des modèles de développement à l’ère de l’IA: Andreessen Horowitz (a16z) a publié un blog analysant neuf tendances émergentes des modèles de développement à l’ère de l’IA. Celles-ci incluent : le Git natif IA (le contrôle de version évolue vers les prompts et les cas de test), le Vibe Coding (la programmation pilotée par l’intention remplace les modèles), le nouveau paradigme de gestion des clés pour les agents IA, les tableaux de bord de surveillance interactifs pilotés par l’IA, la documentation évoluant vers des bases de connaissances interactives pour l’IA, la visualisation des applications du point de vue du LLM (via l’interaction avec les API d’accessibilité), l’essor des agents à exécution asynchrone, le potentiel du protocole MCP (Model-Tool Communication Protocol) et le besoin de composants de base pour les agents. Ces tendances annoncent une transformation profonde de la manière dont les logiciels sont construits. (Source : WeChat)
💼 Affaires
Google Labs lance l’AI Futures Fund pour soutenir les startups IA: Google Labs a annoncé le lancement du programme AI Futures Fund, visant à collaborer avec des startups pour construire ensemble l’avenir de la technologie IA. Ce fonds offrira aux startups sélectionnées un accès anticipé aux modèles de Google DeepMind ainsi que des crédits cloud et d’autres ressources pour les aider à accélérer leur développement. (Source : GoogleDeepMind & JeffDean & Google & demishassabis)
Perplexity serait en négociation pour une nouvelle levée de fonds de 500 millions de dollars, valorisée à 14 milliards de dollars: Selon des rapports, la société de moteurs de recherche IA Perplexity serait en négociation pour une nouvelle levée de fonds de 500 millions de dollars, avec une valorisation potentielle atteignant 14 milliards de dollars. Cela intervient seulement six mois après sa dernière levée de fonds (valorisation de 9 milliards de dollars), montrant le vif intérêt du marché des capitaux pour le secteur de la recherche IA et la reconnaissance des perspectives de développement de Perplexity. (Source : Dorialexander)

OpenAI aurait accepté d’acquérir Windsurf pour environ 3 milliards de dollars: Selon Bloomberg, OpenAI aurait accepté d’acquérir la startup Windsurf pour un montant d’environ 3 milliards de dollars. Les détails spécifiques de cette acquisition et l’orientation commerciale de Windsurf n’ont pas encore été divulgués, mais cette démarche pourrait signifier qu’OpenAI étend davantage ses capacités technologiques ou sa présence sur le marché. (Source : Reddit r/artificial & Reddit r/ArtificialInteligence)

🌟 Communauté
Le vrai risque de l’IA : le “piège de la simulation” par la satisfaction infinie: Une discussion initiée par Amjad Masad et d’autres souligne que le véritable danger de l’IA n’est pas les robots tueurs de science-fiction, mais sa capacité à satisfaire infiniment les désirs humains, créant une “machine à bonheur infini”. Une telle IA pourrait conduire l’humanité à s’adonner à des luttes et à un sens simulés, finissant par “disparaître” dans le monde simulé, offrant une explication possible au paradoxe de Fermi – les civilisations ne disparaissent pas, mais entrent dans une béatitude numérique. (Source : amasad)
Les agents IA vont remodeler la programmation et la recherche scientifique: Le PDG de Replit, Amjad Masad, prédit que d’ici un ou deux ans, les agents IA pourront travailler sans interruption pendant des jours, voire des années, pour résoudre des problèmes scientifiques complexes. Il pense que les agents deviendront une nouvelle forme de programmation, capables de consacrer des jours à résoudre un problème, tout comme les humains, ce qui laisse présager l’énorme potentiel de l’IA pour automatiser des tâches complexes et accélérer la découverte scientifique. (Source : TheTuringPost & amasad & TheTuringPost)
John Carmack discute du potentiel de l’IA dans l’optimisation des bases de code: Le légendaire programmeur John Carmack estime que l’IA peut non seulement générer de grandes quantités de code, mais a également le potentiel d’aider à embellir et à restructurer les bases de code existantes. Il imagine l’IA comme un membre d’équipe diligent, examinant continuellement le code et proposant des améliorations, voire définissant des guides de style de codage “AI-friendly” par des expériences objectives. Il est impatient de voir comment des équipes extrêmement exigeantes sur la qualité du code, comme celle d’OpenBSD, adopteront des membres IA. (Source : ID_AA_Carmack)
Le “Vibe Coding” suscite le débat : avantages et inconvénients de la programmation assistée par IA: Les discussions communautaires soulignent que bien que le “Vibe Coding” (générer des prototypes de code via des instructions en langage naturel à l’IA) puisse rapidement construire des applications de démonstration, le déploiement et la mise à l’échelle nécessitent toujours que des développeurs professionnels construisent à partir de zéro. L’ingénierie de produits ne se limite pas à écrire du code, elle implique également des problèmes complexes d’architecture, de CI/CD, de microservices, que l’IA a actuellement du mal à maîtriser complètement. Le Vibe Coding est adapté à la validation rapide de prototypes, mais la construction de solutions réelles nécessite toujours une pensée et une expérience en ingénierie. (Source : Reddit r/ClaudeAI)
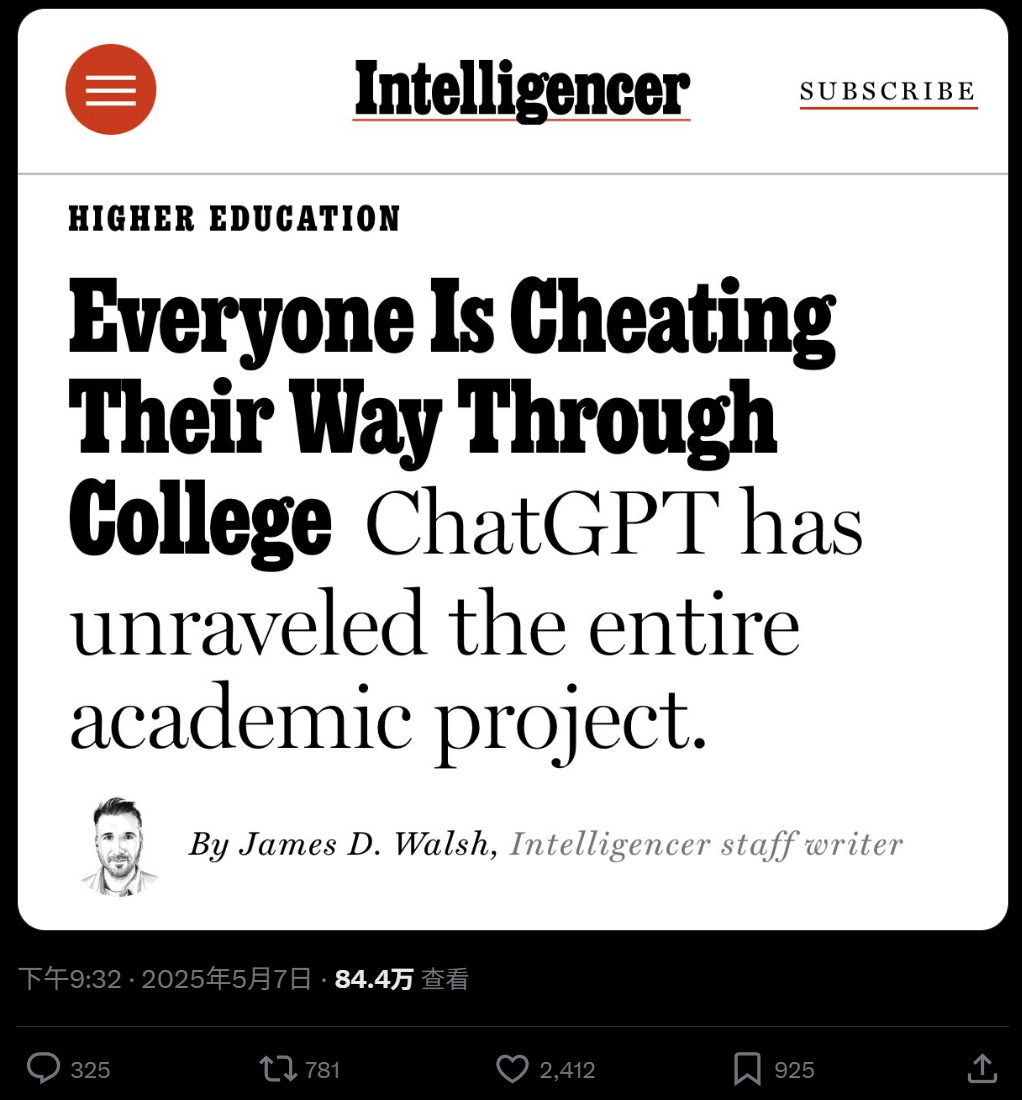
Utilisation généralisée de l’IA dans l’enseignement universitaire et craintes de tricherie: Un reportage du New York Magazine révèle l’utilisation généralisée d’outils IA (comme ChatGPT) dans les universités nord-américaines pour réaliser devoirs et dissertations. Les étudiants utilisent l’IA pour prendre des notes, étudier, faire des recherches et même générer directement le contenu des devoirs, soulevant des inquiétudes quant à l’intégrité académique, la qualité de l’éducation et la baisse des capacités de pensée critique des étudiants. Les éducateurs tentent d’ajuster les méthodes d’enseignement et d’évaluation, mais l’efficacité des outils de détection d’IA est douteuse, rendant la tricherie par IA difficile à éradiquer. (Source : WeChat)
💡 Autres
Cohere explore les défis du passage des applications IA gouvernementales du pilote à la production: Cohere souligne que la plupart des projets IA gouvernementaux en sont encore au stade pilote. Pour passer du pilote à une application de production réelle, les agences gouvernementales ont besoin d’outils fiables, d’une orientation claire vers les résultats, d’une infrastructure efficace et de partenaires appropriés. L’article explore comment les agences gouvernementales peuvent passer de l’expérimentation à l’application réelle grâce à une IA sûre et efficace. (Source : cohere)

Mustafa Suleyman : Plus les grands modèles de langage sont grands, plus ils sont faciles à contrôler: Mustafa Suleyman, co-fondateur d’Inflection AI, estime que, contrairement aux craintes répandues, plus les grands modèles de langage (LLM) sont grands, plus ils sont en réalité faciles à contrôler. Il souligne que les modèles des générations précédentes étaient plus difficiles à guider, styliser et façonner, et que l’augmentation de l’échelle contribue à améliorer la contrôlabilité du modèle, plutôt qu’à la diminuer. (Source : mustafasuleyman)
Débat sur l’éthique de l’IA : Attribution de la responsabilité en cas de préjudice ou de biais causé par l’IA: Un post Reddit a lancé une discussion : lorsqu’un système IA (comme une IA de diagnostic médical) cause un préjudice en raison de biais dans les données d’entraînement (par exemple, entraîné principalement sur des images de peaux claires, entraînant un diagnostic erroné pour les patients à peau foncée), qui devrait être tenu responsable ? Cela soulève la question de la définition de la responsabilité entre les développeurs d’IA, les institutions de déploiement, les régulateurs et d’autres parties prenantes, un enjeu clé que les cadres éthiques et juridiques de l’IA doivent résoudre de toute urgence. (Source : Reddit r/ArtificialInteligence)