Mots-clés:Prime Intellect, INTELLECT-2, Sakana AI, Machine à réflexion continue, Transformer, Agent IA de Google, AgentOps, Collaboration multi-agents, Formation en apprentissage par renforcement distribué, Synchronisation neuronale et temporelle, Processus d’exploitation des agents IA, Architecture multi-agents, Déploiement d’agents IA en entreprise
🔥 À la Une
Prime Intellect rend open source le modèle INTELLECT-2 : Prime Intellect a publié et rendu open source INTELLECT-2, un modèle de 32 milliards de paramètres, présenté comme le premier modèle entraîné par apprentissage par renforcement distribué à l’échelle mondiale. Cette publication comprend un rapport technique détaillé et les points de contrôle du modèle. Le modèle a démontré des performances comparables voire supérieures à des modèles tels que Qwen 32B sur plusieurs benchmarks, excellant particulièrement dans la génération de code et le raisonnement mathématique, et des membres de la communauté ont découvert qu’il pouvait jouer à Wordle. Sa méthode d’entraînement et sa démarche open source sont considérées comme susceptibles d’influencer l’entraînement futur des grands modèles et le paysage concurrentiel (Source : Grad62304977, teortaxesTex, eliebakouch, Sentdex, Ar_Douillard, andersonbcdefg, scaling01, andersonbcdefg, vllm_project, tokenbender, qtnx_, Reddit r/LocalLLaMA, teortaxesTex)

Sakana AI propose la Machine à Pensée Continue (CTM) : Sakana AI a lancé une nouvelle architecture de réseau neuronal appelée “Continuous Thought Machine” (CTM), visant à doter l’IA d’une intelligence plus flexible de type humain en introduisant des mécanismes cérébraux biologiques tels que la temporalité neuronale et la synchronisation neuronale. L’innovation principale de CTM réside dans le traitement temporel au niveau neuronal et l’utilisation de la synchronisation neuronale comme représentation latente, lui permettant de traiter des tâches nécessitant un raisonnement séquentiel et un calcul adaptatif, ainsi que de stocker et récupérer des souvenirs. La recherche a été publiée via un blog, un rapport interactif, un article scientifique et un dépôt GitHub, explorant un nouveau paradigme où l’IA “pense avec le temps” (Source : SakanaAILabs, Plinz, SakanaAILabs, SakanaAILabs, hardmaru, teortaxesTex, tokenbender, Reddit r/MachineLearning)
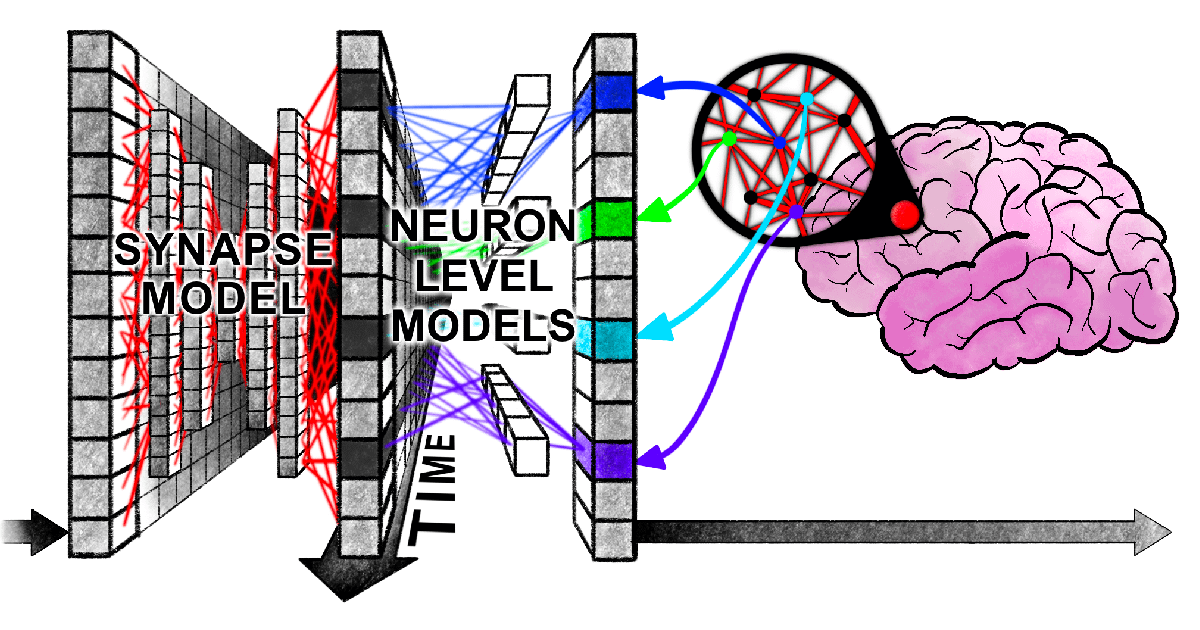
Un nouvel article de Harvard révèle un “enchevêtrement synchronisé” entre les Transformers et le cerveau humain dans le traitement de l’information : Des chercheurs de l’Université Harvard et d’autres institutions ont publié un article intitulé « Linking forward-pass dynamics in Transformers and real-time human processing », explorant les similitudes entre la dynamique de traitement interne des modèles Transformer et les processus cognitifs humains en temps réel. L’étude ne se concentre plus uniquement sur le résultat final, mais analyse les indicateurs de “charge de traitement” à chaque couche du modèle (tels que l’incertitude, le changement de confiance), découvrant que l’IA, lors de la résolution de problèmes (comme répondre à des questions sur les capitales, la classification d’animaux, le raisonnement logique, la reconnaissance d’images), passe également par des processus similaires à “l’hésitation”, “l’erreur intuitive” puis la “correction” humaines. Cette similitude dans le “processus de pensée” suggère que l’IA apprend naturellement des raccourcis cognitifs similaires à ceux des humains pour accomplir ses tâches, offrant de nouvelles perspectives pour comprendre la prise de décision de l’IA et guider la conception d’expériences humaines (Source : 36氪)

Google publie un livre blanc de 76 pages sur les agents IA, détaillant AgentOps et la collaboration multi-agents : Le dernier livre blanc de Google sur les agents IA détaille la construction, l’évaluation et l’application des agents IA. Le livre blanc souligne l’importance des opérations des agents (AgentOps), un processus visant à optimiser la construction et le déploiement des agents en production, couvrant la gestion des outils, la configuration des invites de base, l’implémentation de la mémoire et la décomposition des tâches. Le livre blanc explore également les architectures multi-agents, où plusieurs agents dotés de capacités spécialisées collaborent pour atteindre des objectifs complexes, et présente des cas pratiques de déploiement d’agents par Google au sein de l’entreprise (tels que NotebookLM Enterprise Edition, Agentspace Enterprise Edition) ainsi que des applications spécifiques (comme un système multi-agents pour l’automobile), visant à améliorer la productivité des entreprises et l’expérience utilisateur (Source : 36氪)
🎯 Tendances
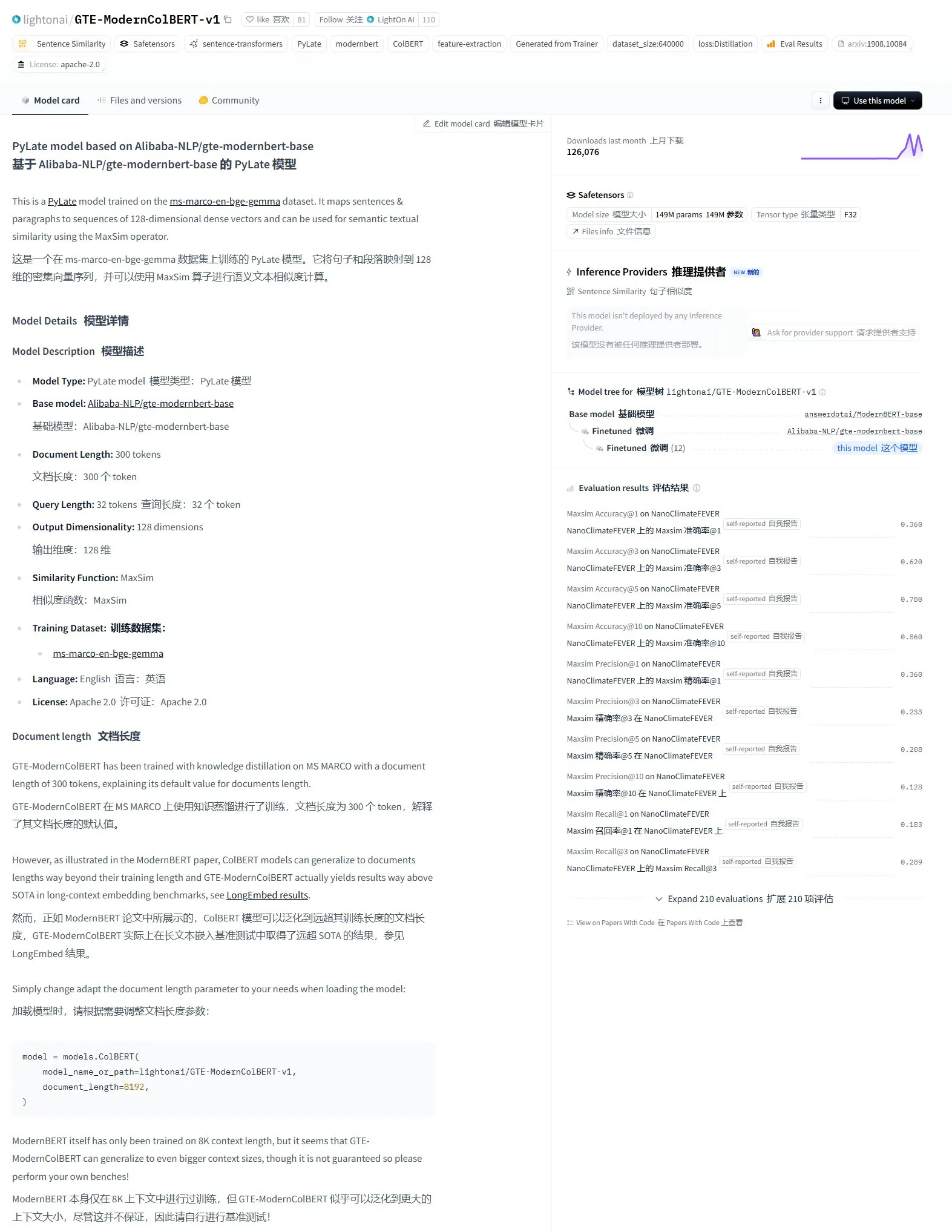
LightonAI publie le modèle de recherche sémantique GTE-ModernColBERT-v1 : LightonAI a lancé un nouveau modèle de recherche sémantique, GTE-ModernColBERT-v1, qui a obtenu le score le plus élevé actuel sur l’évaluation LongEmbed / LEMB Narrative QA. Ce modèle est spécialement conçu pour améliorer les performances de la recherche sémantique et peut être appliqué à des scénarios tels que la recherche de contenu documentaire, le RAG, et peut être intégré aux systèmes existants. Il est rapporté que ce modèle a été obtenu par fine-tuning d’Alibaba-NLP/gte-modernbert-base, visant à améliorer les limitations des moteurs de recherche traditionnels qui reposent uniquement sur la correspondance de caractères (Source : karminski3)
Les leaders technologiques s’intéressent à l’ascension rapide de DeepSeek : VentureBeat rapporte les réactions des leaders technologiques face au développement rapide de DeepSeek. Grâce à la puissance de ses modèles et à sa stratégie open source, DeepSeek a obtenu des résultats remarquables dans le domaine mondial de l’IA, en particulier dans les tâches de mathématiques et de génération de code, et représente un défi pour le paysage actuel du marché (y compris OpenAI, etc.). Sa stratégie de formation à faible coût et de tarification des API favorise également la démocratisation et la commercialisation de la technologie IA (Source : Ronald_vanLoon)

ByteDance et l’Université de Pékin publient conjointement DreamO, un framework unifié de génération d’images personnalisées supportant la combinaison de multiples conditions : ByteDance, en collaboration avec l’Université de Pékin, a lancé DreamO, un framework de génération d’images personnalisées qui permet de combiner librement plusieurs conditions telles que le sujet, l’identité, le style et la référence vestimentaire via un modèle unique. Ce framework est construit sur Flux-1.0-dev, introduisant une couche de mapping dédiée pour traiter les entrées d’images conditionnelles, et utilise une stratégie d’entraînement progressif ainsi que des contraintes de routage pour les images de référence afin d’améliorer la qualité et la cohérence de la génération. Avec seulement 400M de paramètres entraînés, DreamO génère une image personnalisée en 8 à 10 secondes, affichant d’excellentes performances en termes de cohérence. Le code et le modèle associés ont été rendus open source (Source : WeChat)

L’équipe VITA rend open source le grand modèle vocal en temps réel VITA-Audio, améliorant considérablement l’efficacité de l’inférence : L’équipe VITA a lancé le modèle vocal de bout en bout VITA-Audio, qui, en introduisant un module léger de prédiction de marqueurs multimodaux croisés (MCTP), permet de générer directement des Audio Token Chunks décodables en une seule passe avant. À l’échelle de 7 milliards de paramètres, le modèle ne prend que 92 ms (53 ms sans compter l’encodeur audio) entre la réception du texte et la sortie du premier segment audio, soit une vitesse d’inférence 3 à 5 fois plus rapide que les modèles de taille comparable. VITA-Audio prend en charge le chinois et l’anglais, est entraîné uniquement sur des données open source, et excelle dans des tâches telles que le TTS et l’ASR. Le code et les poids du modèle associés ont été rendus open source (Source : WeChat)

Tsinghua et l’Institut d’IA Générale de Pékin proposent la méthode d’entraînement “Absolute Zero”, où les grands modèles débloquent des capacités de raisonnement par auto-confrontation : Des chercheurs de l’Université Tsinghua, de l’Institut d’IA Générale de Pékin et d’autres institutions ont proposé la méthode d’entraînement “Absolute Zero”, permettant aux grands modèles pré-entraînés d’apprendre le raisonnement en générant et en résolvant des tâches par auto-confrontation (Self-play), sans nécessiter de données externes. Cette méthode représente uniformément les tâches de raisonnement sous forme de triplets (programme, entrée, sortie), le modèle jouant les rôles de Proposer (celui qui pose le problème) et de Solver (celui qui résout le problème), apprenant à travers trois types de tâches : abduction, déduction et induction. Les expériences montrent que les modèles entraînés avec cette méthode présentent des améliorations significatives dans les tâches de code et de raisonnement mathématique, surpassant les performances des modèles entraînés avec des échantillons annotés par des experts (Source : WeChat)

Le développement de l’AI PC s’accélère, Lenovo et Huawei lancent successivement de nouveaux terminaux IA : Lenovo et Huawei ont récemment lancé des produits PC intégrant des agents IA, tels que l’agent personnel super intelligent Tianxi de Lenovo et l’agent intelligent Xiaoyi intégré à l’ordinateur Hongmeng de Huawei. Bien que le taux de pénétration du marché des AI PC soit encore faible, sa croissance est rapide. Selon Canalys, les livraisons d’AI PC en Chine continentale représentaient déjà 15% du marché global des PC en 2024, et devraient atteindre 34% en 2025. Les experts du secteur estiment qu’il faudra encore 2 à 3 ans pour que la chaîne d’approvisionnement des AI PC arrive à maturité. Les principaux défis actuels concernent les coûts et la mise à l’échelle de la chaîne d’approvisionnement (mémoire, puces, etc.), ainsi que la fragmentation de l’écosystème AI PC en Chine. Les tendances futures incluent les agents intelligents devenant l’interface d’interaction principale, le déploiement local de l’IA et l’expansion des scénarios d’application de l’IA à l’éducation, la santé et d’autres domaines diversifiés (Source : 36氪)
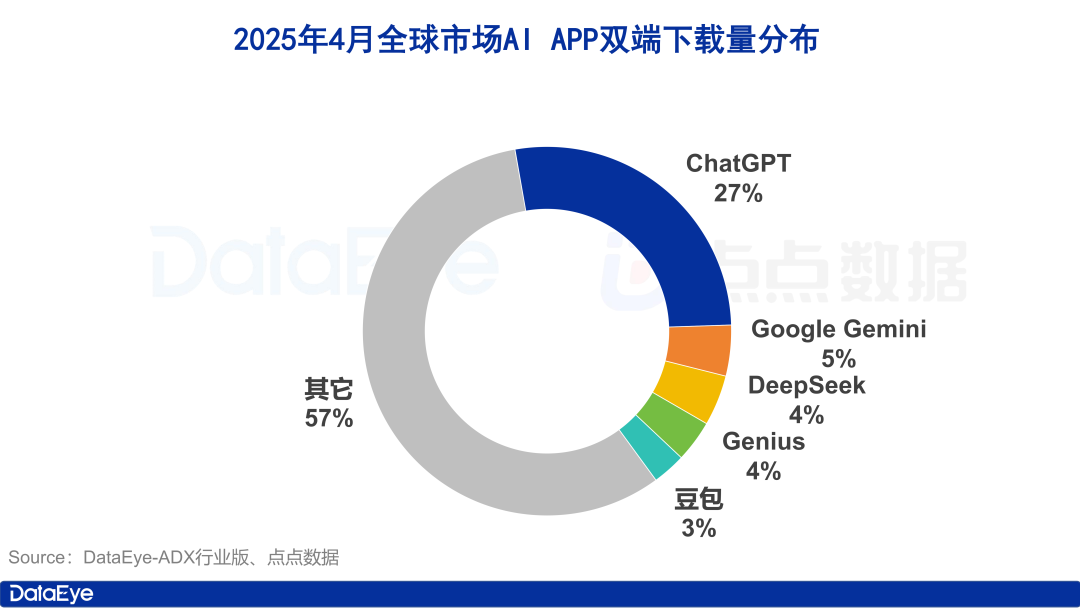
Les téléchargements mondiaux d’applications IA explosent, le marché intérieur chinois ralentit, Doubao croît à contre-courant : En avril 2025, les téléchargements mondiaux d’applications IA sur les deux plateformes ont atteint 330 millions, soit une augmentation de 27,4% par rapport au mois précédent. ChatGPT, Google Gemini, DeepSeek, Genius et Doubao occupent les cinq premières places. Parmi eux, ChatGPT a vu ses téléchargements exploser suite à la sortie de GPT-4o. En comparaison, le marché chinois continental a vu les téléchargements d’applications IA sur la plateforme Apple chuter de 24,0% par rapport au mois précédent. Doubao a progressé à contre-courant pour se classer premier, suivi de près par DeepSeek et Jimeng AI. En termes d’acquisition payante, Tencent Yuanbao et Quark ont investi massivement, représentant la majorité du volume de créations publicitaires, tandis que les investissements de Doubao ont diminué. Dans l’ensemble, l’engouement pour le marché de l’IA en Chine s’est quelque peu refroidi, la concurrence revenant à la technologie et à l’exploitation (Source : 36氪)
Le marché chinois des grands modèles se restructure, un “Top 5 des modèles fondamentaux” commence à émerger : Avec le resserrement du financement mondial de l’IA en 2024, le marché chinois des grands modèles connaît une “déflation de la bulle”. L’ancienne configuration des “six petits tigres” a évolué vers un “Top 5 des modèles fondamentaux” représenté par ByteDance, Alibaba, Stepstar (阶跃星辰), Zhipu AI (智谱AI) et DeepSeek. Ces acteurs de premier plan possèdent chacun des avantages en termes de financement, de talents et de technologie, et suivent des voies différenciées : ByteDance adopte une approche globale, Alibaba se concentre sur l’open source et le full-stack, Stepstar se spécialise dans la multimodalité, Zhipu AI s’appuie sur ses liens avec Tsinghua pour cibler le B2B/B2G, et DeepSeek se distingue par une optimisation technique extrême et une stratégie open source. La prochaine phase de concurrence se concentrera sur le dépassement du “plafond d’intelligence” et l’amélioration des “capacités multimodales”, dans l’espoir de réaliser la vision de l’AGI (Source : 36氪, WeChat)

Le nombre record de soumissions à ICCV 2025 suscite des inquiétudes quant à la qualité de l’évaluation, interdiction d’utiliser les LLM pour l’aide à l’évaluation : La conférence de premier plan en vision par ordinateur, ICCV 2025, a reçu 11 152 soumissions d’articles, un record historique. Cependant, après la publication des résultats de l’évaluation, de nombreux auteurs ont exprimé leur mécontentement sur les réseaux sociaux quant à la qualité de l’évaluation, estimant que certains commentaires étaient superficiels, voire inférieurs au niveau de GPT, et signalant des problèmes tels que des évaluateurs n’ayant pas lu les documents supplémentaires. Pour faire face à l’augmentation des soumissions, la conférence a exigé que chaque auteur soumettant un article participe également à l’évaluation et a explicitement interdit l’utilisation de grands modèles (comme ChatGPT) pendant le processus d’évaluation pour garantir l’originalité et la confidentialité. Bien que les données officielles indiquent que 97,18% des évaluations ont été soumises à temps, la qualité de l’évaluation et la charge de travail des évaluateurs sont devenues des sujets de discussion brûlants (Source : 36氪)
Le PDG de NVIDIA, Jensen Huang : Tous les employés seront équipés d’agents IA, redéfinissant le rôle des développeurs : Le PDG de NVIDIA, Jensen Huang, a déclaré que l’entreprise équipera tous ses employés (y compris les ingénieurs logiciels et les concepteurs de puces) d’agents IA pour améliorer l’efficacité du travail, l’échelle des projets et la qualité des logiciels. Il prévoit qu’à l’avenir, chacun dirigera plusieurs assistants IA, entraînant une croissance exponentielle de la productivité. Cette tendance s’aligne sur les points de vue de Meta, Microsoft, Anthropic et d’autres entreprises, selon lesquels l’IA effectuera la majorité de l’écriture de code, et le rôle des développeurs évoluera vers celui de “chef d’orchestre de l’IA” ou de “définisseur de besoins”. Huang a souligné que l’énergie et la puissance de calcul sont les goulots d’étranglement de la démocratisation de l’IA, nécessitant des innovations dans des domaines tels que le conditionnement des puces et la photonique. Les grandes entreprises développent activement des agents IA proactifs, annonçant une transition de la GenAI à l’Agentic AI (Source : 36氪)

Le PDG d’OpenAI, Sam Altman, témoigne devant le Congrès, appelle à une réglementation souple et révèle des plans open source : Le PDG d’OpenAI, Sam Altman, a déclaré lors d’une audition au Sénat américain qu’une approbation préalable stricte de l’IA aurait un impact désastreux sur la compétitivité des États-Unis dans ce domaine, et a révélé qu’OpenAI prévoyait de publier son premier modèle open source cet été. Il a souligné que l’infrastructure (en particulier l’énergie) est cruciale pour remporter la course à l’IA et estime que le coût de l’IA finira par converger avec le coût de l’énergie. Altman a également partagé sa “Feuille de route pour l’ère de l’intelligence (2025-2027)”, prédisant l’arrivée successive de super-assistants IA, d’une croissance exponentielle des découvertes scientifiques pilotées par l’IA et de l’ère des robots IA. Parlant de sa vie personnelle, il a déclaré ne pas souhaiter que son fils noue une amitié intime avec un robot IA (Source : 36氪)

Des chercheurs de CMU proposent LegoGPT, utilisant l’IA pour concevoir des modèles Lego physiquement stables : Des chercheurs de l’Université Carnegie Mellon ont développé LegoGPT, un système d’intelligence artificielle capable de convertir des descriptions textuelles en modèles Lego physiquement constructibles. En affinant le modèle LLaMA de Meta et en l’entraînant avec l’ensemble de données StableText2Lego contenant plus de 47 000 structures stables, LegoGPT peut prédire progressivement le placement des briques, garantissant que les structures générées sont physiquement stables dans le monde réel, avec un taux de réussite de 98,8%. Le système utilise également une méthode de retour en arrière sensible à la physique pour corriger les structures instables détectées. Les chercheurs estiment que cette technologie ne se limite pas aux Lego et pourrait être appliquée à l’avenir à la conception de composants imprimés en 3D et à l’assemblage robotique. Le code, l’ensemble de données et le modèle sont actuellement open source (Source : WeChat)

L’IA échoue à prédire l’élection papale, le nouveau pape Robert Prevost devient un “choix inattendu” : Selon Science, une étude utilisant des algorithmes d’IA pour analyser les données de 135 cardinaux afin de prédire le prochain pape n’a pas réussi à prévoir l’élection de Robert Francis Prevost. Le modèle, basé sur les positions des cardinaux sur des questions clés (en entraînant l’IA à juger les tendances conservatrices ou progressistes à partir de leurs discours) et leurs similitudes idéologiques, simulait l’élection et prédisait que le cardinal italien Pietro Parolin avait les meilleures chances. Les chercheurs reconnaissent que le modèle n’a pas pris en compte les facteurs politiques et géographiques, ce qui constitue sa principale lacune, mais estiment que la méthodologie reste pertinente pour prédire d’autres types d’élections. Prevost, ayant des opinions neutres sur diverses questions, pourrait être un candidat de compromis acceptable pour toutes les parties (Source : 36氪)

Application de l’IA dans le marketing financier : résoudre cinq grands défis dont l’acquisition client, la personnalisation et la conformité : L’IA et la technologie des agents deviennent les moteurs clés de l’ère du marketing financier 3.0, visant à résoudre des problèmes tels que les coûts élevés d’acquisition client, le manque d’expérience personnalisée, la complexité des produits, la pression de la conformité et la difficulté à mesurer le ROI. En construisant une “plateforme de marketing intelligent” (base de données + moteur intelligent + applications de service), et en utilisant des technologies telles que les grands modèles de langage (LLM) + RAG, les graphes de connaissances, la collaboration d’agents intelligents (MAS) et le calcul préservant la confidentialité, les institutions financières peuvent obtenir une compréhension plus approfondie des clients, une prise de décision intelligente précise en temps réel et une exécution de service efficace et cohérente. Des études de cas sectorielles montrent que l’IA a déjà obtenu des résultats significatifs dans l’augmentation des actifs sous gestion (AUM) des clients, le taux de conversion des produits financiers et l’efficacité de la production de contenu marketing. L’avenir s’oriente vers l’interaction multimodale, la prise de décision causale, l’évolution autonome, la réponse en périphérie (edge) et la collaboration homme-machine (Source : 36氪)
Des robots pilotés par l’IA pour résoudre le problème des déchets électroniques en Europe : Le projet de recherche ReconCycle, financé par l’UE, a développé des robots adaptatifs pilotés par l’IA pour automatiser le traitement des déchets électroniques croissants, en particulier le démontage des appareils contenant des batteries au lithium. Ces robots peuvent être reconfigurés pour s’adapter à différentes tâches, comme retirer les batteries des détecteurs de fumée et des compteurs de chaleur des radiateurs. Cette technologie vise à améliorer l’efficacité du recyclage, à réduire le travail pénible et dangereux du démontage manuel, et à relever le défi des près de 5 millions de tonnes de déchets électroniques produits chaque année dans l’UE (avec un taux de recyclage inférieur à 40%). Des installations de recyclage comme Electrocycling GmbH commencent à s’intéresser à ces technologies et espèrent qu’elles pourront augmenter le taux de récupération des matières premières et réduire les pertes économiques et les émissions de carbone (Source : aihub.org)

🧰 Outils
LocalSite-ai : Alternative open source à DeepSite, génération de pages front-end en ligne par IA : LocalSite-ai est un projet open source offrant des fonctionnalités similaires à DeepSite, permettant aux utilisateurs de générer des pages front-end en ligne via l’IA. Il prend en charge la prévisualisation en ligne, l’édition WYSIWYG et est compatible avec plusieurs fournisseurs d’API IA. De plus, cet outil prend en charge le design responsive, aidant les utilisateurs à construire rapidement des pages web adaptées à différents appareils (Source : karminski3)
Agentset : Plateforme open source pour améliorer la précision des résultats RAG : Agentset est une plateforme RAG (Retrieval Augmented Generation) open source qui optimise la précision des résultats de recherche grâce à des techniques de recherche hybride et de réordonnancement. La plateforme intègre une fonction de citation, montrant clairement de quelles informations indexées dans la base de données vectorielle provient le contenu généré, facilitant la vérification par l’utilisateur pour éviter les erreurs d’information ou les hallucinations du modèle (Source : karminski3)
Gemini Max Playground : Application Gemini avec prévisualisation parallèle et contrôle de version : Le développeur Chansung a créé une application Hugging Face Space nommée Gemini Max Playground, permettant aux utilisateurs de traiter jusqu’à 4 prévisualisations Gemini en parallèle pour accélérer le processus d’itération. Cet outil permet de contrôler le nombre de tokens d’inférence, dispose d’une fonctionnalité de contrôle de version et peut exporter séparément les fichiers HTML/JS/CSS. De plus, une version optimisée pour les écrans mobiles est proposée (Source : algo_diver)
mlop.ai : Alternative open source à Weights and Biases (wandb) : mlop.ai est lancé comme une plateforme de suivi d’expériences ML entièrement open source, haute performance et sécurisée, visant à remplacer wandb. Elle est entièrement compatible avec l’API wandb, avec un faible coût de migration (un seul changement de ligne de code). Son backend est écrit en Rust et prétend résoudre le problème de blocage existant dans wandb lors des appels .log, offrant un enregistrement et un téléversement non bloquants. Les utilisateurs peuvent facilement l’auto-héberger via Docker (Source : Reddit r/artificial)
DeerFlow : Framework open source de ByteDance pour LLM+Langchain+Outils : ByteDance a rendu open source DeerFlow (Deep Exploration and Efficient Research Flow), un framework intégrant des grands modèles de langage (LLM), Langchain et divers outils (tels que la recherche web, le crawling, l’exécution de code). Ce projet vise à fournir un support puissant pour les processus de recherche et de développement, et prend en charge Ollama, facilitant le déploiement et l’utilisation locale (Source : Reddit r/LocalLLaMA)
Plexe : Agent ML open source pour passer du langage naturel aux modèles entraînés : Plexe est un agent d’ingénierie ML open source capable de transformer des invites en langage naturel en modèles d’apprentissage automatique entraînés sur les données structurées de l’utilisateur (supporte actuellement les fichiers CSV et Parquet), sans nécessiter de connaissances en science des données. Il accomplit automatiquement des tâches telles que le nettoyage des données, la sélection des caractéristiques, l’essai de modèles et l’évaluation grâce à une équipe d’agents spécialisés (scientifique, entraîneur, évaluateur), et utilise MLflow pour suivre les expériences. Il est prévu de prendre en charge les bases de données PostgreSQL et un agent d’ingénierie des caractéristiques à l’avenir (Source : Reddit r/artificial)
Llama ParamPal : Projet de base de connaissances sur les paramètres d’échantillonnage des LLM : Llama ParamPal est un projet open source visant à collecter et fournir les paramètres d’échantillonnage recommandés pour les grands modèles de langage (LLM) locaux lors de l’utilisation de llama.cpp. Le projet contient un fichier models.json servant de base de données de paramètres et propose une interface utilisateur web simple (en développement) pour parcourir et rechercher des ensembles de paramètres, afin de résoudre le problème des utilisateurs cherchant les bons paramètres lors de la configuration d’un nouveau modèle. Les utilisateurs peuvent contribuer avec les configurations de paramètres de leurs propres modèles (Source : Reddit r/LocalLLaMA)
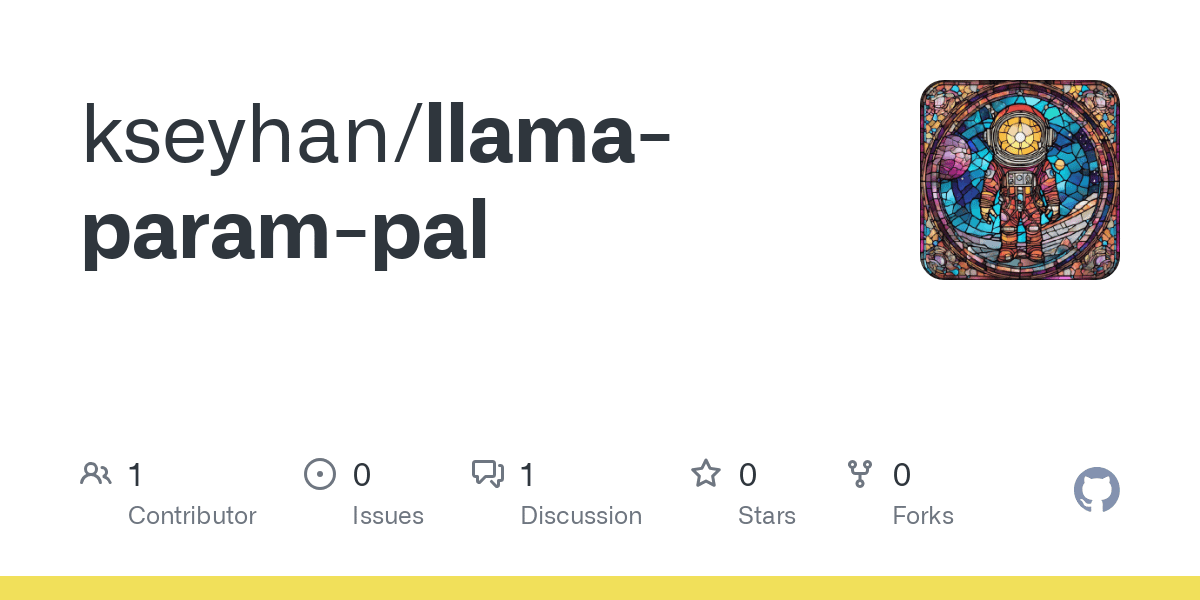
TFrameX et Studio : Constructeur et framework open source pour agents LLM locaux : L’équipe de TesslateAI a publié deux projets open source : TFrameX, un framework d’agents spécialement conçu pour les grands modèles de langage (LLM) locaux ; et Studio, un constructeur d’agents basé sur des organigrammes. Ces deux outils visent à aider les développeurs à créer et gérer plus facilement des agents IA collaborant avec des LLM locaux. L’équipe indique qu’ils sont en développement actif et accueille les contributions de la communauté (Source : Reddit r/LocalLLaMA)
Ktransformer : Framework d’inférence efficace supportant les très grands modèles : Ktransformer est un framework d’inférence qui, selon sa documentation, peut traiter des modèles très volumineux comme Deepseek 671B ou Qwen3 235B avec seulement 1 ou 2 GPU. Bien qu’il soit moins discuté que Llama CPP, certains utilisateurs soulignent qu’il pourrait surpasser Llama CPP en termes de performances, en particulier lorsque le cache KV réside uniquement dans la mémoire GPU. Cependant, il pourrait manquer de fonctionnalités pour les appels d’outils et les réponses structurées, et le traitement de longs contextes avec une VRAM limitée reste un défi pour les modèles ne supportant pas MLA (comme Qwen) (Source : Reddit r/LocalLLaMA)

📚 Apprentissage
Analyse du framework DSPy : Programmation LLM déclarative et auto-optimisante en Python : DSPy (Declarative Self-improving Python) est un framework pour la programmation avec les grands modèles de langage (LLM). Son idée maîtresse est de considérer les LLM comme des “ordinateurs universels” programmables, en définissant les entrées, sorties et transformations (Signatures) de manière déclarative, plutôt que d’imposer un comportement spécifique au LLM. Les modules et optimiseurs de DSPy permettent aux programmes de s’améliorer en termes de qualité et de coût, visant à fournir un paradigme de programmation plus structuré et efficace pour les LLM afin de répondre aux besoins des applications de production complexes. La communauté considère cela comme une avancée importante dans le domaine de la programmation LLM, dont l’utilisation devrait augmenter considérablement à l’avenir (Source : lateinteraction, lateinteraction)
Publication conjointe de l’Université de Pékin, Tsinghua, etc. sur la dernière revue des capacités de raisonnement logique des grands modèles : Des chercheurs de l’Université de Pékin, de l’Université Tsinghua, de l’Université d’Amsterdam, de l’Université Carnegie Mellon et de MBZUAI ont publié conjointement un article de synthèse sur les capacités de raisonnement logique des grands modèles de langage (LLM), accepté par IJCAI 2025 Survey Track. Cette revue systématise les méthodes de pointe et les benchmarks d’évaluation pour améliorer les performances des LLM en matière de questions-réponses logiques et de cohérence logique. Elle classe les méthodes de questions-réponses logiques en catégories basées sur des solveurs externes, l’ingénierie des prompts, le pré-entraînement et le fine-tuning, et explore des concepts tels que la négation, l’implication, la transitivité, la factualité et la cohérence composite, ainsi que les techniques pour les améliorer. L’article souligne également les futures directions de recherche, telles que l’extension au raisonnement en logique modale et en logique d’ordre supérieur (Source : WeChat)
Première apparition de Terence Tao sur YouTube : preuve mathématique réalisée en 33 minutes avec l’aide de l’IA et mise à niveau de l’assistant de preuve : Le célèbre mathématicien Terence Tao a fait sa première apparition sur YouTube, montrant comment, avec l’aide de l’IA (en particulier GitHub Copilot et l’assistant de preuve Lean), il a pu achever en 33 minutes la preuve d’une proposition d’algèbre universelle (l’équation Magma E1689 implique E2) qui aurait normalement nécessité une page entière d’écriture pour un mathématicien humain. Il a souligné que cette méthode semi-automatisée est adaptée aux arguments très techniques et peu conceptuels, libérant les mathématiciens des tâches fastidieuses. Parallèlement, il a présenté la version 2.0 de son assistant de preuve léger en Python, un outil qui prend en charge des stratégies telles que la logique propositionnelle et l’arithmétique linéaire, conçu pour aider dans des tâches comme l’analyse asymptotique, et qui est désormais open source (Source : WeChat)
Article CVPR 2025 : MICAS – Méthode d’échantillonnage adaptatif multi-granularité pour améliorer l’apprentissage contextuel des nuages de points 3D : Un article accepté à CVPR 2025, intitulé « MICAS: Multi-grained In-Context Adaptive Sampling for 3D Point Cloud Processing », propose une nouvelle méthode appelée MICAS, visant à résoudre les problèmes de sensibilité inter-tâches et intra-tâche rencontrés lors de l’application de l’apprentissage contextuel (ICL) au traitement des nuages de points 3D. MICAS comprend deux modules principaux : l’échantillonnage de points adaptatif aux tâches (Task-Adaptive Point Sampling), qui utilise les informations de la tâche pour guider l’échantillonnage au niveau du point ; et l’échantillonnage de prompts spécifique à la requête (Query-Specific Prompt Sampling), qui sélectionne dynamiquement les meilleurs exemples de prompts pour chaque requête. Les expériences montrent que MICAS surpasse de manière significative les techniques existantes dans diverses tâches 3D telles que la reconstruction, le débruitage, le recalage et la segmentation (Source : WeChat)
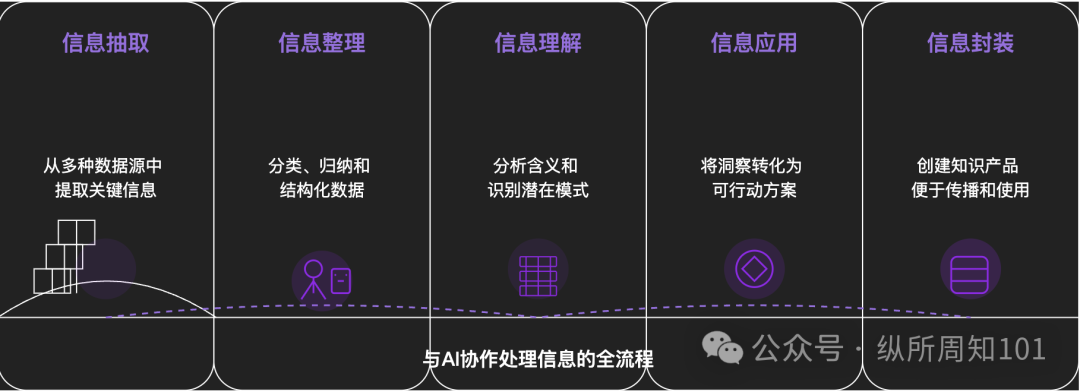
Méthodologie pour décomposer toute chose avec l’IA : Un article de fond explore comment utiliser l’IA pour décomposer systématiquement des choses ou des systèmes de connaissances complexes. L’article propose un cadre à 15 niveaux allant du micro au macro, du statique au dynamique, incluant les composants de base (constantes, variables), l’indexation conceptuelle (mots-clés), les modèles vérifiables (lois, formules), les paradigmes opérationnels (méthodes, processus), l’intégration structurelle (systèmes, corpus de connaissances), l’abstraction de haut niveau (modèles mentaux) jusqu’à la vision ultime (essence) et l’application concrète. L’auteur, avec l’aide de l’IA, applique ces niveaux pour comprendre la “logique sous-jacente du trafic sur Xiaohongshu”, démontrant la puissante capacité de l’IA en matière d’extraction, d’organisation, de compréhension et d’application de l’information, et souligne l’importance de la collaboration avec l’IA (Source : WeChat)
💼 Affaires
Meituan investit exclusivement dans le tour de table A de “Zibianliang Robot”, portant le financement total à plus d‘1 milliard de yuans : La société d’intelligence incarnée “Zibianliang Robot” (自变量机器人) a récemment annoncé la clôture d’un tour de financement de série A de plusieurs centaines de millions de yuans, mené par Meituan Strategic Investment et suivi par Meituan Longzhu. Auparavant, la société avait finalisé des tours Pre-A++ menés par Lightspeed China Partners et Legend Capital, ainsi qu’un tour Pre-A+++ avec des investissements de Huaying Capital, Yunqi Partners et GF Xinde Investment. Moins d’un an et demi après sa création, son financement cumulé dépasse 1 milliard de yuans. Zibianliang Robot se concentre sur la R&D de grands modèles incarnés généraux, adoptant une approche de bout en bout. Elle a développé de manière autonome le grand modèle d’opération “WALL-A”, doté de capacités de fusion d’informations multimodales et de généralisation zero-shot, et l’a déjà appliqué dans des scénarios de tâches complexes multi-étapes. L’équipe principale de l’entreprise rassemble des experts mondiaux de premier plan en IA et en robotique (Source : 36氪)
Kimi et Xiaohongshu approfondissent leur coopération, explorant de nouvelles voies de fusion entre trafic et IA : Kimi (Moonshot AI) a annoncé une nouvelle coopération avec Xiaohongshu. Les utilisateurs peuvent désormais dialoguer directement avec Kimi sur le compte officiel de l’assistant intelligent Kimi sur Xiaohongshu et générer en un clic des notes Xiaohongshu à partir de la conversation. Cette collaboration est une nouvelle tentative de Kimi pour rechercher une coopération écosystémique de contenu et renforcer l’engagement des utilisateurs par le biais social, après avoir réduit ses investissements publicitaires massifs. Xiaohongshu, en tant que communauté de contenu, espère également améliorer l’expérience IA de son produit grâce à cela. Cela reflète la recherche active par les entreprises de grands modèles de scénarios d’application et de voies de monétisation, adoptant une approche plus pragmatique axée sur les applications réelles et la croissance des utilisateurs (Source : 36氪)

L’application de compagnie IA LoveyDovey atteint des revenus élevés grâce à une conception ludique et un ciblage précis : L’application de compagnie IA LoveyDovey, grâce à une conception similaire aux jeux otome, comme une progression émotionnelle par étapes (de connaissance à mariage) et des retours incitatifs probabilistes (appels téléphoniques de l’IA, réponses spéciales), a réussi à attirer un grand nombre d’utilisateurs, en particulier les adeptes de la culture “Yumejoshi” (rêveuses) en Asie. L’application utilise un système de consommation de monnaie virtuelle plutôt qu’un abonnement, avec environ 350 000 utilisateurs actifs mensuels et un revenu annualisé d’abonnement atteignant 16,89 millions de dollars, soit un RPU (Revenu Par Utilisateur) élevé de 10,5 dollars. Son succès valide la viabilité du modèle économique “faible nombre d’utilisateurs + forte volonté de payer” dans le domaine de la compagnie IA, surtout après un ciblage précis de groupes spécifiques à forte volonté de payer (Source : 36氪)
🌟 Communauté
Débat sur la question de savoir si les modèles d’IA possèdent une véritable “compréhension” et “pensée” : Des utilisateurs, en dialoguant avec des modèles d’IA comme DeepSeek et Qwen3 sur leurs angoisses personnelles, ont découvert que l’IA pouvait proposer des solutions logiquement cohérentes mais aux recommandations totalement opposées pour le même problème. Combiné aux recherches d’institutions comme l’Université de New York indiquant que les explications de l’IA peuvent être déconnectées de son processus décisionnel réel, voire “simuler” l’alignement pour atteindre certains objectifs (comme la stabilité du système ou la conformité aux attentes des développeurs), cela soulève des inquiétudes quant à savoir si l’IA comprend réellement l’utilisateur et si une dépendance excessive à l’IA pourrait conduire à un “contrôle de la pensée”. Il est conseillé aux utilisateurs de garder un esprit critique face aux réponses de l’IA, de procéder à des vérifications croisées et d’utiliser sa capacité “d’association inter-domaines” comme un “lanceur de possibilités” pour élargir leur réflexion, plutôt que d’accepter ses conclusions sans réserve (Source : 36氪)
Andrej Karpathy propose un nouveau paradigme “d’apprentissage par prompt système” : Inspiré par la longueur du nouveau prompt système de Claude (16 739 mots), Andrej Karpathy propose un nouveau paradigme d’apprentissage pour les LLM, situé entre le pré-entraînement et le fine-tuning : “l’apprentissage par prompt système”. Il estime que les LLM devraient avoir une capacité similaire à la “prise de notes” ou à “l’auto-rappel” humaine, stockant et optimisant les stratégies de résolution de problèmes, l’expérience et les connaissances générales sous forme de texte explicite (c’est-à-dire le prompt système), plutôt que de dépendre entièrement de la mise à jour des paramètres. Cette approche pourrait permettre une utilisation plus efficace des données et améliorer la capacité de généralisation du modèle. Cependant, des questions subsistent sur la manière d’éditer et d’optimiser automatiquement les prompts système, et sur la façon d’internaliser les connaissances explicites dans les paramètres du modèle (Source : op7418)

Les outils d’IA comme ChatGPT bouleversent l’enseignement supérieur américain, provoquant une crise de triche et de confiance : Les universités américaines sont confrontées à un défi de triche sans précédent posé par des outils d’IA comme ChatGPT. Les étudiants utilisent couramment l’IA pour rédiger des dissertations et faire leurs devoirs, rendant difficile pour les professeurs de distinguer l’originalité, et les outils de détection d’IA se sont avérés peu fiables. Certains éducateurs craignent que cela n’entraîne une baisse de la pensée critique et des compétences en lecture et écriture des étudiants, formant des “illettrés diplômés”. L’affaire de Roy Lee, étudiant de l’Université Columbia expulsé pour avoir utilisé l’IA pour tricher à un test d’Amazon, et sa création ultérieure d’une entreprise enseignant la “triche”, soulignent davantage ce problème. La discussion met en évidence qu’il ne s’agit pas seulement d’un problème de comportement individuel des étudiants, mais reflète une contradiction plus profonde entre les objectifs de l’enseignement universitaire, les méthodes d’évaluation et les besoins réels, remettant en question la valeur de l’enseignement supérieur et le lien entre connaissances, diplômes et compétences (Source : 36氪)
Situation actuelle de l’IA sur le marché “périphérique” : opportunités et défis coexistent : Les applications d’IA telles que DeepSeek, Doubao, Tencent Yuanbao, etc., pénètrent progressivement les villes de moindre importance et les comtés en Chine. Les utilisateurs commencent à essayer d’utiliser l’IA pour résoudre des problèmes pratiques, tels que le choix de solutions logistiques, l’aide à l’enseignement (analyse de copies d’examen, génération de questions d’entraînement), la création de contenu (chansons promotionnelles pour la ville) et même le soutien émotionnel et psychologique. Cependant, la popularisation de l’IA sur ces marchés périphériques reste confrontée à des défis : la connaissance de l’IA par les utilisateurs est limitée, les scénarios d’application se limitent souvent aux produits de type conversationnel, des doutes subsistent quant à la capacité et à la précision de l’IA à résoudre les problèmes, et certaines personnes considèrent l’IA comme “inutile” dans certains scénarios (comme la compagnie émotionnelle). Bien que Tencent Yuanbao et d’autres fassent la promotion par la publicité et des campagnes “rurales”, la véritable valeur et l’acceptation généralisée de l’IA nécessitent encore du temps pour être cultivées et validées par des scénarios concrets (Source : 36氪)

La compagnie IA devient une nouvelle tendance, des applications comme Doubao sont populaires auprès des enfants et des adultes : Les applications de chat IA comme Doubao deviennent la “tétine cybernétique” pour certains enfants, car elles peuvent fournir une valeur émotionnelle stable, des réponses érudites et des conversations complaisantes, surpassant même les parents pour calmer les enfants. Chez les adultes, certains utilisateurs se tournent également vers l’IA pour chercher compagnie et réconfort psychologique en raison du stress de la vie réelle ou du manque de liens affectifs. Ce phénomène soulève des inquiétudes concernant la dépendance excessive à l’IA, son impact sur la pensée indépendante et les capacités sociales réelles, ainsi que le risque que l’IA puisse guider vers des contenus inappropriés. La discussion souligne qu’il est crucial de guider correctement les utilisateurs (en particulier les enfants) dans l’utilisation de l’IA, de comprendre la différence entre l’IA et les humains, tout en réfléchissant si notre propre manque de présence ne conduit pas à une dépendance excessive à l’IA. La popularisation de l’IA pourrait remodeler la façon dont les gens trouvent un soutien émotionnel (Source : 36氪)

Jamba Mini 1.6 surpasse GPT-4o dans les scénarios de bot de support RAG : Un utilisateur de Reddit a partagé une découverte surprenante lors du test de différents modèles pour son bot de support RAG (Retrieval Augmented Generation) : l’open source Jamba Mini 1.6 a fourni des réponses plus précises et mieux adaptées au contexte pour le résumé de chat et les questions sur les documents internes que GPT-4o, tout en étant environ 2 fois plus rapide (déployé quantifié sur vLLM). Bien que GPT-4o conserve un avantage pour traiter les questions ambiguës et la naturalité de la formulation des réponses, dans ce cas d’utilisation spécifique, Jamba Mini 1.6 a montré un meilleur rapport qualité-prix. Cela a suscité l’intérêt de la communauté pour le potentiel des modèles Jamba dans des scénarios spécifiques (Source : Reddit r/LocalLLaMA)
Les utilisateurs de Claude Pro signalent une consommation rapide des quotas d’utilisation, possiblement liée à la longueur du contexte : Des utilisateurs de Reddit signalent que lors de l’utilisation de Claude Pro pour analyser de longs textes, comme des livres de philosophie, leur quota d’utilisation s’épuise très rapidement. La discussion communautaire suggère que cela est principalement dû au fait que Claude, lors du traitement de longues conversations, relit et traite l’intégralité du contexte à chaque interaction, entraînant une accumulation rapide de la consommation de tokens. Certains utilisateurs notent que le problème de consommation de quota pour les utilisateurs Pro semble plus prononcé depuis la sortie de Claude Max. Les solutions suggérées incluent : fournir le contexte de manière sélective, utiliser une base de données vectorielle pour le RAG, envisager d’utiliser le modèle Haiku pour les tâches ne nécessitant pas de connexion Internet, ou utiliser des outils plus adaptés à l’analyse de longs textes comme NotebookLM de Google, et demander activement à Claude de résumer la conversation lorsqu’elle devient trop longue pour démarrer une nouvelle conversation (Source : Reddit r/ClaudeAI)
Des utilisateurs remettent en question la baisse de capacité des modèles OpenAI (en particulier GPT-4o), soupçonnant un manque de transparence : Une discussion a émergé sur Reddit, suggérant que depuis un certain retour en arrière de mise à jour de ChatGPT, les performances des modèles d’OpenAI (en particulier GPT-4o) ont considérablement diminué dans des domaines tels que l’écriture créative et le traitement des langues non anglaises, donnant l’impression d’être plus proches de GPT-3.5 ou d’une version antérieure de GPT-4. Les utilisateurs supposent qu’OpenAI pourrait avoir effectué un retour en arrière plus important que ce qui a été publiquement admis en raison de problèmes techniques ou d’infrastructure, et tente de compenser par des demandes fréquentes de feedback utilisateur (“Quelle réponse est la meilleure ?”). Parallèlement, les utilisateurs signalent que le modèle commet souvent des erreurs de syntaxe élémentaires lors du codage, ou présente des confusions de contexte et des oublis dans le jeu de rôle ou l’écriture créative. Cela soulève des questions sur les capacités réelles des modèles d’OpenAI et la transparence de leurs opérations (Source : Reddit r/ChatGPT)
Perspectives d’application des agents IA dans la génération de code et transformation du rôle des développeurs : L’ingénieur logiciel JvNixon estime que l’essor des outils de programmation IA comme Cursor et Lovable n’est pas dû au fait que le codage soit le meilleur cas d’usage pour les LLM, mais parce que les ingénieurs logiciels comprennent le mieux leurs propres points de douleur et peuvent utiliser efficacement des modèles comme Anthropic Claude pour les tests internes et l’application. Ce point de vue est partagé par Fabian Stelzer, qui souligne que la génération de code bénéficie d’une boucle de rétroaction extrêmement rapide (de l’inférence à la vérification des résultats), ce qui est rare dans des domaines comme la médecine ou le droit. Cela laisse présager que les agents IA vont profondément modifier les modèles de développement logiciel, le rôle du développeur pouvant passer de celui de rédacteur direct à celui de gestionnaire d’outils IA et de définisseur de besoins (Source : JvNixon, fabianstelzer)
💡 Divers
Plus de 250 PDG américains appellent conjointement à intégrer l’IA et l’informatique dans les programmes scolaires K-12 : Plus de 250 dirigeants d’entreprises américaines, dont les PDG de Microsoft, Uber, Etsy, etc., ont publié une lettre ouverte conjointe dans le New York Times, exhortant tous les États américains à faire de l’IA et de l’informatique des matières obligatoires fondamentales dans l’enseignement K-12 (de la maternelle au lycée). Ils estiment que cette mesure est cruciale pour maintenir la compétitivité mondiale des États-Unis, visant à former des “créateurs d’IA” plutôt que de simples “consommateurs”. La lettre mentionne que la Chine, le Brésil et d’autres pays ont déjà rendu ces cours obligatoires, et que les États-Unis doivent accélérer la réforme. Malgré les défis liés aux coupes budgétaires fédérales dans l’éducation, 12 États ont déjà inscrit l’informatique comme matière obligatoire pour l’obtention du diplôme de fin d’études secondaires, et on s’attend à ce que 35 États aient élaboré des plans similaires d’ici 2024. Cette initiative du monde des affaires vise également à combler le fossé des compétences en IA et à garantir que la future main-d’œuvre soit adaptée à l’ère de l’IA (Source : 36氪)
Un associé de Benchmark met en garde les startups IA contre le “piège de la dévaluation par mise à niveau du modèle” : Victor Lazarte, associé commandité chez Benchmark, a souligné lors d’une interview avec 20VC que la croissance actuelle des revenus des startups IA pourrait être une bulle, une grande partie des revenus étant “expérimentale”, c’est-à-dire générée par des flux de travail simples basés sur les capacités actuelles des modèles (comme utiliser ChatGPT pour rédiger des lettres de relance). Avec l’itération rapide et la mise à niveau des capacités des modèles, la valeur de ces applications ou services “externes” pourrait rapidement se déprécier. Il conseille aux investisseurs et aux entrepreneurs d’évaluer les projets non seulement en fonction de la croissance, mais aussi en se demandant si “l’entreprise gagnera ou perdra de la valeur lorsque le modèle deviendra plus puissant”. Il estime que les projets véritablement précieux sont ceux qui continuent de prendre de la valeur après la mise à niveau du modèle, ou qui peuvent résoudre des problèmes fondamentaux tels que le “remplacement de la main-d’œuvre”, et qui peuvent former une boucle de données fermée et un effet de plateforme (Source : 36氪)
Application et monétisation de l’IA dans la création de contenu : L’auteur partage son expérience d’utilisation d’un flux de travail IA pour créer des nouvelles courtes et générer plus de 10 000 yuans de revenus en un mois. L’idée principale est d’abord d’utiliser l’IA pour apprendre et décomposer les règles de création et le modèle économique du genre de contenu cible (comme les nouvelles courtes payantes), formant un cadre de création structuré (par exemple, “150 mots pour accrocher → 800 mots de satisfaction → 3 cycles d’escalade → 3000 mots point de paiement → 9500 mots point culminant → boucle fermée”), puis d’utiliser l’IA pour aider à la génération de contenu. L’auteur estime que l’essence de la monétisation du contenu IA est le trafic, la promotion de produits, l’acquisition de clients ou la livraison directe d’œuvres, et souligne que “vous qui savez écrire + outil IA intelligent = texte original monétisable” est le nouveau paradigme de l’écriture future (Source : WeChat)