
Mots-clés:GENMO, Seed-Coder, DeepSeek, LlamaParse, IA Agentique, Informatique en périphérie, Informatique quantique, Modèle de mouvement humain NVIDIA GENMO, Modèle de code Seed-Coder de ByteDance, Impact de la stratégie open source de DeepSeek, Score de confiance d’analyse de documents LlamaParse, Traitement de données en temps réel par informatique en périphérie, Modèle de mouvement humain NVIDIA GENMO, Modèle de code Seed-Coder de ByteDance, Impact de la stratégie open source de DeepSeek, Score de confiance d’analyse de documents LlamaParse, Traitement de données en temps réel par informatique en périphérie
🔥 Pleins Feux
NVIDIA lance GENMO, un modèle universel pour le mouvement humain: NVIDIA a publié un modèle d’IA nommé GENMO (GENeralist Model for Human MOtion), capable de convertir diverses entrées telles que du texte, des vidéos, de la musique ou même des silhouettes de keyframes en mouvements humains 3D réalistes. Ce modèle peut comprendre et fusionner différents types d’entrées, par exemple en apprenant des mouvements à partir d’une vidéo et en les modifiant selon des invites textuelles, ou en générant des danses basées sur le rythme musical. GENMO démontre un potentiel énorme dans des domaines tels que l’animation de jeux et la création de personnages pour mondes virtuels, capable de générer des mouvements complexes, naturels et cohérents, et prenant en charge l’édition intuitive de la chronologie des animations. Bien qu’il ne puisse pas encore gérer les expressions faciales et les détails des mains, et qu’il dépende de méthodes SLAM externes, ses entrées multimodales et sa sortie de haute qualité représentent une avancée majeure dans le domaine de la génération de mouvement par IA (Source: YouTube – Two Minute Papers
)
ByteDance publie la série de grands modèles open-source Seed-Coder: ByteDance a lancé la série de grands modèles de langage open-source Seed-Coder, comprenant des modèles de base, des modèles d’instruction et des modèles d’inférence à l’échelle de 8 milliards de paramètres (8B). La caractéristique principale de cette série de modèles réside dans sa capacité de « modèle de code auto-organisant les données », visant à minimiser l’intervention humaine dans la construction des données. Seed-Coder a atteint l’état de l’art actuel (SOTA) dans plusieurs domaines tels que la génération et l’édition de code, démontrant le potentiel d’optimisation et de construction de données d’entraînement grâce aux capacités propres de l’IA, offrant de nouvelles perspectives pour le développement de grands modèles de code (Source: _akhaliq)
Les modèles DeepSeek suscitent une large attention au sein de la communauté IA: La série de modèles DeepSeek, en particulier ses modèles de code, a suscité de vives discussions au sein de la communauté IA en raison de leurs performances robustes et de leur stratégie open-source. De nombreux développeurs et chercheurs sont impressionnés par leurs performances, estimant qu’ils ont changé la perception des modèles open-source à l’échelle mondiale. Les discussions soulignent que le succès de DeepSeek pourrait inciter des entreprises comme OpenAI à réévaluer leurs stratégies open-source et à pousser les fabricants locaux de grands modèles à accélérer leur rythme d’ouverture. Bien que l’open-source soit confronté à des défis tels que la commercialisation et l’adaptation matérielle, l’émergence de DeepSeek est considérée comme une force importante pour la démocratisation de la technologie IA et le développement de l’industrie (Source: Ronald_vanLoon, 36氪)

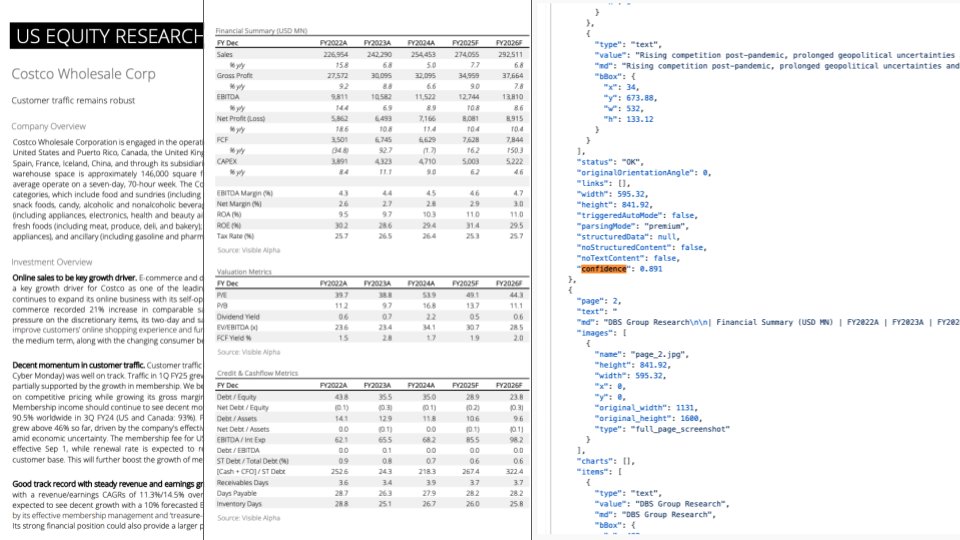
Mise à jour de LlamaParse : Intégration de GPT-4.1 et Gemini 2.5 Pro pour améliorer l’analyse de documents: LlamaParse a publié une mise à jour importante, intégrant les derniers modèles GPT-4.1 et Gemini 2.5 Pro, améliorant considérablement la précision de l’analyse de documents. Les nouvelles fonctionnalités incluent la détection automatique de l’orientation et de l’inclinaison, garantissant l’alignement et la précision du contenu analysé. De plus, une fonction de score de confiance a été introduite, permettant aux utilisateurs d’évaluer la qualité de l’analyse de chaque page et de mettre en place des processus de vérification manuelle basés sur des seuils de confiance. Cette mise à jour vise à résoudre les erreurs que les LLM/LVM peuvent commettre lors du traitement de documents complexes, en garantissant la fiabilité des processus automatisés grâce à une expérience utilisateur de vérification et de correction manuelles (Source: jerryjliu0)
🎯 Tendances
Perspectives des tendances de l’industrie technologique pour 2025: Un rapport prédit les principales tendances de l’industrie technologique pour 2025, indiquant que les technologies émergentes telles que l’intelligence artificielle, l’apprentissage automatique, la 5G, les dispositifs portables, la blockchain et la cybersécurité continueront de se développer et de s’intégrer profondément. Ces technologies devraient jouer un rôle important dans l’amélioration de la vie, la promotion de l’innovation et la résolution des problèmes sociaux, annonçant un avenir prometteur grâce à la technologie (Source: Ronald_vanLoon, Ronald_vanLoon)

Prévisions des tendances de développement dans le domaine de l’IA pour 2025: IBM prévoit que le domaine de l’intelligence artificielle continuera de se développer rapidement en 2025, les technologies d’apprentissage automatique (ML) et d’intelligence artificielle (MI) mûrissant davantage et étant largement appliquées dans divers secteurs. L’IA devrait jouer un rôle plus important dans l’automatisation, l’analyse de données, l’aide à la décision, etc., stimulant l’innovation technologique et la modernisation industrielle (Source: Ronald_vanLoon)

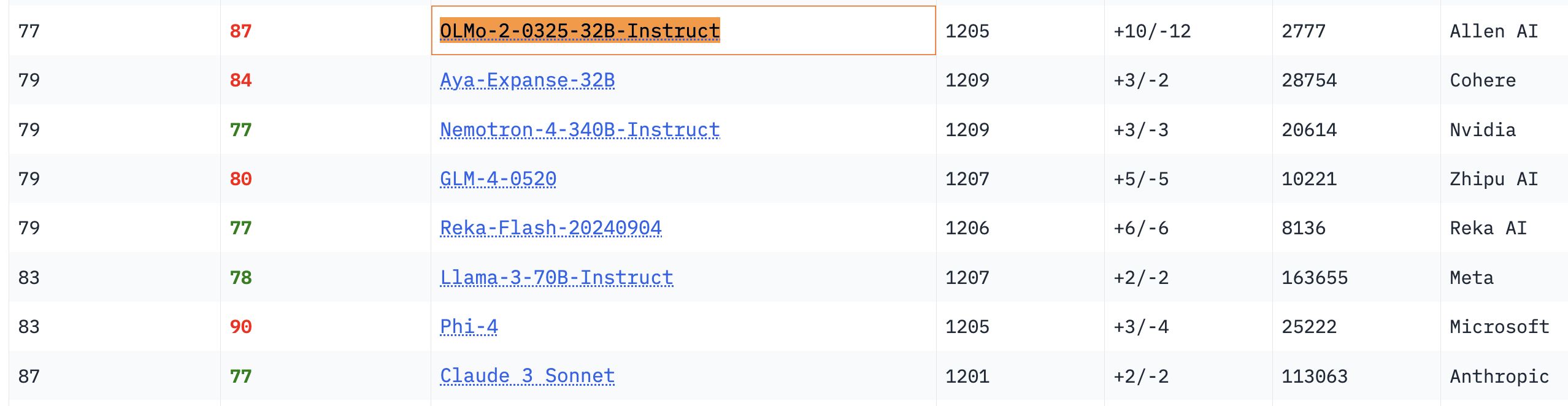
Performances remarquables du modèle OLMo 32B: Dans les benchmarks pertinents, le modèle OLMo 32B, entièrement ouvert, surpasse les modèles Nemotron 340B et Llama 3 70B, qui ont pourtant un plus grand nombre de paramètres. Ce résultat indique que, sur certains aspects, les modèles entièrement ouverts avec moins de paramètres peuvent atteindre, voire dépasser, les modèles commerciaux à plus grande échelle, démontrant l’énorme potentiel et la vitesse de rattrapage de la recherche sur les modèles ouverts (Source: natolambert, teortaxesTex, lmarena_ai)
Le modèle Gemma dépasse les 150 millions de téléchargements et compte plus de 70 000 variantes: Le modèle Gemma de Google a dépassé les 150 millions de téléchargements sur la plateforme Hugging Face et compte plus de 70 000 variantes. Ces chiffres reflètent la popularité et la large application du modèle Gemma au sein de la communauté des développeurs. La communauté attend également avec impatience les itérations futures de ses versions (Source: osanseviero, _akhaliq)
Unsloth met à jour les modèles Qwen3 GGUF et améliore le jeu de données de calibration: Unsloth a mis à jour tous ses modèles Qwen3 GGUF et a adopté un nouveau jeu de données de calibration amélioré. De plus, d’autres variantes GGUF ont été ajoutées pour Qwen3-30B-A3B. Les retours des utilisateurs indiquent une amélioration de la qualité de la traduction dans la version 30B-A3B-UD-Q5_K_XL par rapport aux autres GGUF Q5 et Q4 (Source: Reddit r/LocalLLaMA)

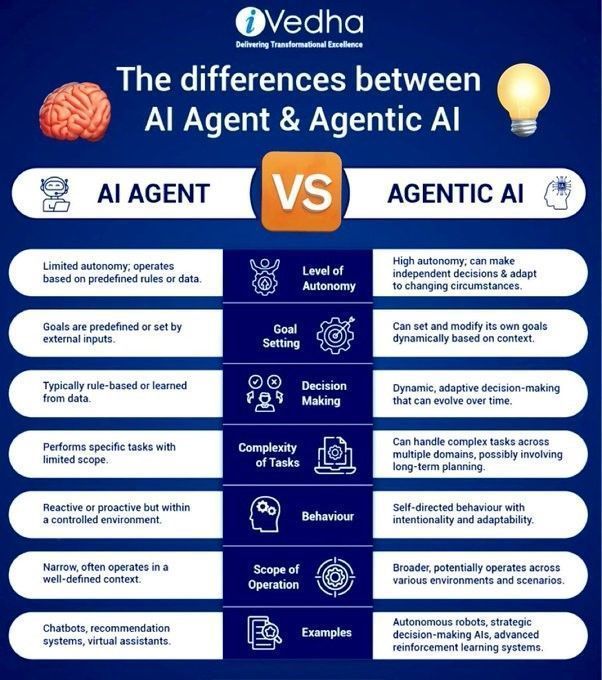
Différence entre Agentic AI et GenAI: L’Agentic AI et l’IA générative (GenAI) sont des sujets brûlants dans le domaine de l’IA. La GenAI désigne principalement l’IA capable de créer de nouveaux contenus (texte, images, etc.), tandis que l’Agentic AI se concentre davantage sur les agents intelligents capables d’exécuter des tâches de manière autonome, d’interagir avec l’environnement et de prendre des décisions. L’Agentic AI combine généralement les capacités de la GenAI, mais met davantage l’accent sur son autonomie et son orientation vers les objectifs (Source: Ronald_vanLoon)

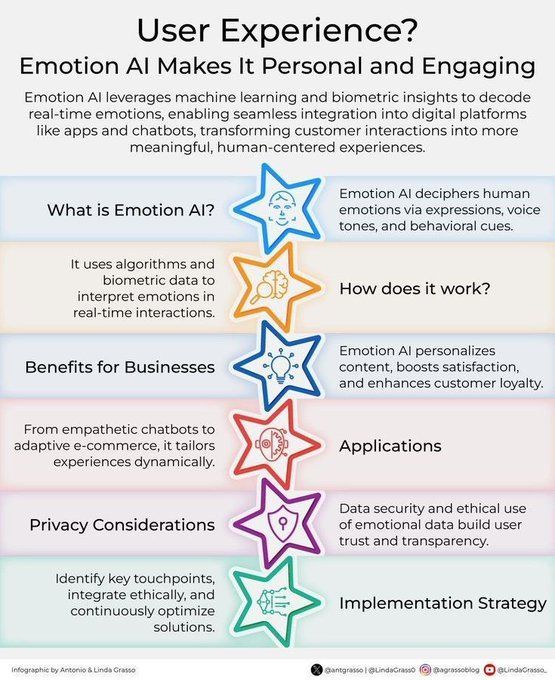
L’IA émotionnelle améliore l’expérience client: La technologie de l’IA émotionnelle, en analysant et en comprenant les émotions humaines, est appliquée pour améliorer l’expérience client (CX). Elle peut aider les entreprises à mieux comprendre les besoins et les émotions des clients, afin de fournir des services plus personnalisés et empathiques, stimulant l’innovation dans la gestion de la relation client à l’ère de la transformation numérique (Source: Ronald_vanLoon)
Concept d’outil de personnalisation piloté par l’IA “Jigging” (Dispositif d’assistance mécanique intelligent): Karina Nguyen propose le concept de “Jigging”, comparant les modèles d’IA à des artisans d’outils auto-améliorants et individualisés. À chaque interaction avec l’utilisateur, l’IA crée de nouveaux outils spécialisés adaptés aux caractéristiques de l’utilisateur et à la tâche, améliorant ainsi ses capacités. Par exemple, l’IA construit un cadre de diagnostic personnalisé pour un médecin, ou un cadre narratif unique pour un écrivain. Cette amélioration récursive fera de l’IA une extension de l’architecture cognitive de l’utilisateur, entraînant une transformation fondamentale de la collaboration homme-machine (Source: karinanguyen_)
Différence entre les agents IA et l’Agentic AI: Khulood Almani explique plus en détail la différence entre les agents IA (AI Agents) et l’Agentic AI. Les agents IA désignent généralement des programmes logiciels exécutant des tâches spécifiques, tandis que l’Agentic AI met davantage l’accent sur l’autonomie, la capacité d’apprentissage et l’adaptabilité du système, capable d’interagir plus activement avec l’environnement et d’atteindre des objectifs complexes. Comprendre cette distinction aide à saisir la direction et le potentiel du développement de l’IA (Source: Ronald_vanLoon)
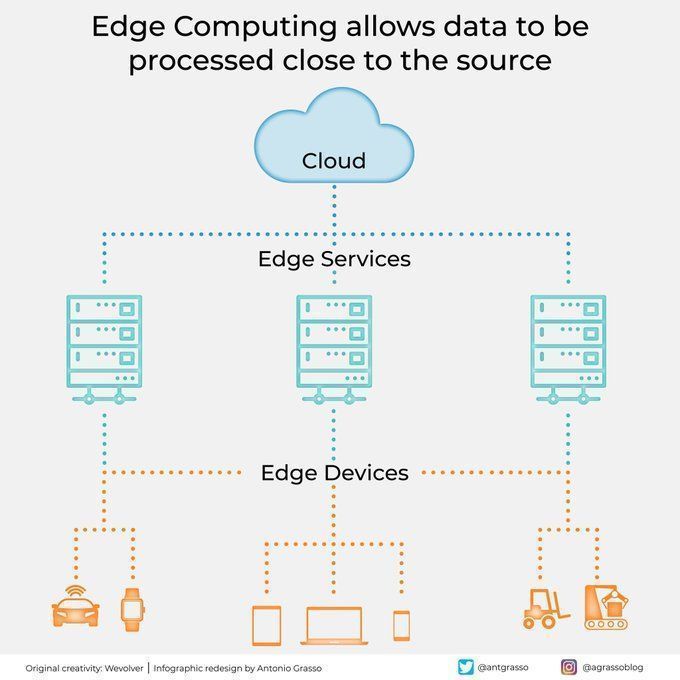
L’edge computing traite les données près de leur source: La technologie de l’edge computing, en traitant les données à proximité de leur source, réduit la latence, diminue les besoins en bande passante et renforce la protection de la vie privée. Ceci est crucial pour les applications IA nécessitant une réponse en temps réel et le traitement de grandes quantités de données (comme la conduite autonome, l’Internet des objets industriel), et constitue un élément important du cloud computing et de la transformation numérique (Source: Ronald_vanLoon)
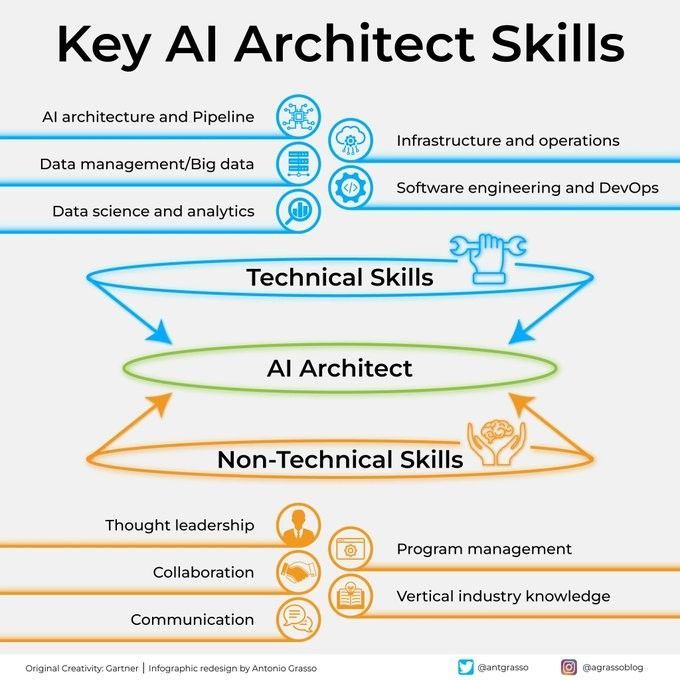
Compétences clés d’un architecte IA: Devenir un architecte IA performant nécessite un large éventail de compétences, y compris une solide base technique (algorithmes d’apprentissage automatique et d’apprentissage profond), des capacités de conception de systèmes, des connaissances en gestion de données, ainsi qu’une compréhension des besoins métier. De plus, des compétences en communication et en collaboration, ainsi qu’un enthousiasme pour l’apprentissage continu des nouvelles technologies, sont également essentiels (Source: Ronald_vanLoon)
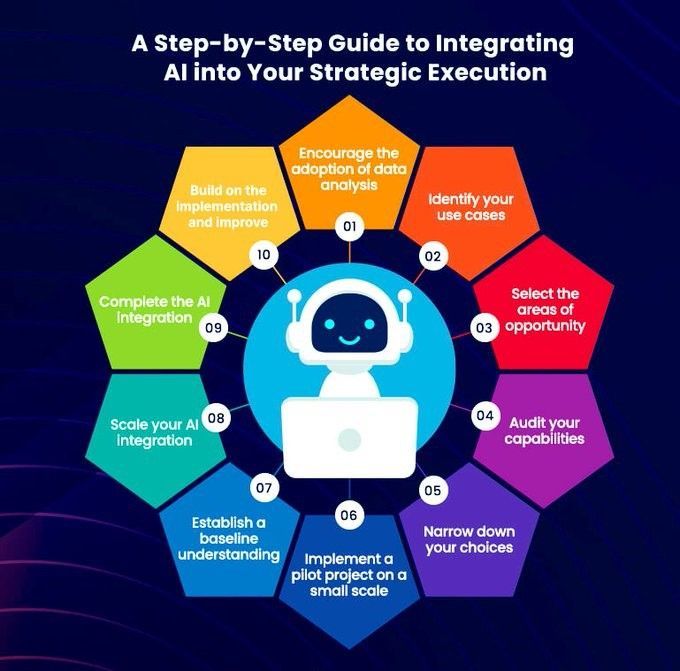
Guide étape par étape pour intégrer l’IA dans l’exécution stratégique: Khulood Almani propose un guide étape par étape pour aider les entreprises à intégrer l’intelligence artificielle dans leurs processus d’exécution stratégique. Cela comprend la définition claire des objectifs de l’IA, l’évaluation des capacités existantes, la sélection des technologies IA appropriées, l’élaboration d’une feuille de route pour la mise en œuvre, ainsi que la mise en place de mécanismes de suivi et d’évaluation pour garantir que les projets d’IA sont alignés sur la stratégie commerciale globale et génèrent la valeur attendue (Source: Ronald_vanLoon)
Comment l’informatique quantique transforme la cybersécurité: L’avènement de l’informatique quantique a un double impact sur la cybersécurité. D’une part, sa puissante capacité de calcul pourrait briser les algorithmes de chiffrement existants, posant une menace pour la sécurité ; d’autre part, la technologie quantique a également donné naissance à de nouveaux moyens de protection, tels que la cryptographie quantique. Khulood Almani explore le rôle transformateur de l’informatique quantique dans le domaine de la cybersécurité, soulignant l’importance de se préparer à l’ère post-quantique (Source: Ronald_vanLoon)
Outils qui domineront le domaine de l’IA en 2025: Perplexity prédit les outils clés qui domineront le domaine de l’intelligence artificielle en 2025, pouvant inclure des grands modèles de langage (LLM) plus avancés, des plateformes d’IA générative, des outils de science des données, ainsi que des solutions d’IA spécialisées pour des applications sectorielles spécifiques. Ces outils favoriseront davantage la popularisation et l’approfondissement des applications de l’IA dans divers secteurs (Source: Ronald_vanLoon)

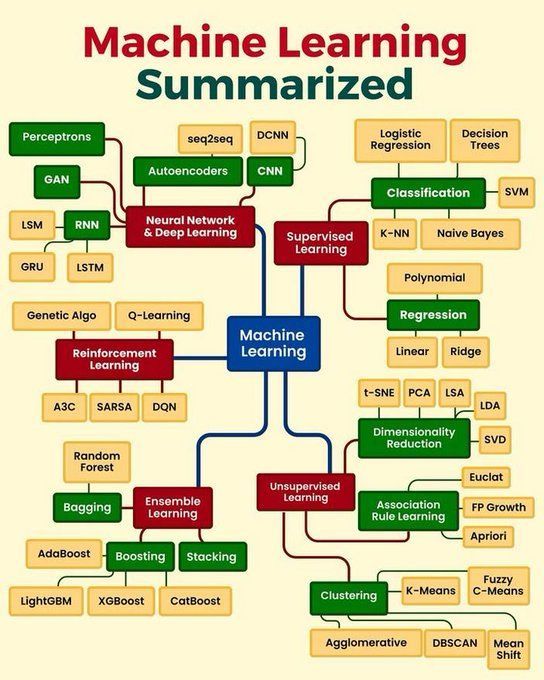
Résumé des concepts clés de l’apprentissage automatique: Python_Dv résume les concepts clés de l’apprentissage automatique, pouvant couvrir les principes fondamentaux de l’apprentissage supervisé, non supervisé, par renforcement, de l’apprentissage profond, ainsi que les algorithmes couramment utilisés et leurs scénarios d’application. Cela offre un aperçu concis aux débutants et à ceux qui souhaitent consolider leurs connaissances de base (Source: Ronald_vanLoon)
🧰 Outils
ByteDance lance DeerFlow, un framework de recherche approfondie: ByteDance a rendu open-source DeerFlow, un framework pour la recherche approfondie systématique coordonnant des agents LangGraph. Il prend en charge l’analyse documentaire complète, la synthèse de données et la découverte de connaissances structurées, visant à améliorer l’efficacité et la profondeur de l’application de l’IA dans le domaine de la recherche scientifique (Source: LangChainAI, Hacubu)
Système multi-agents de recherche d’entreprise piloté par LangGraph: Un système multi-agents basé sur LangGraph a été développé pour générer des rapports de recherche d’entreprise en temps réel. Ce système, grâce à des processus intelligents, utilise des nœuds spécialisés pour analyser les données commerciales, financières et de marché, fournissant aux utilisateurs des informations approfondies sur les entreprises. La démonstration et le code sont disponibles sur GitHub (Source: LangChainAI, Hacubu)
RunwayML Gen-4 References permet un positionnement précis des personnages/objets: La fonctionnalité Gen-4 References de RunwayML s’est avérée utile pour contrôler avec précision la position des personnages ou des objets dans le contenu généré. Les utilisateurs peuvent fournir une scène et une image de référence avec des marqueurs (comme de simples formes colorées indiquant la position) pour guider l’IA à placer des éléments spécifiques à l’endroit précis souhaité, offrant de nouvelles possibilités pour les flux de travail créatifs. Ce modèle, en tant que modèle général, s’adapte à de multiples flux de travail sans nécessiter de fine-tuning (Source: c_valenzuelab, c_valenzuelab)

Code Chrono : Un outil pour estimer le temps des projets de programmation avec des LLM locaux: Rafael Viana a développé un outil en ligne de commande nommé Code Chrono pour suivre la durée des sessions de codage et utiliser des LLM locaux pour estimer le temps de développement des fonctionnalités futures. Cet outil vise à aider les développeurs à évaluer plus réalistement le temps nécessaire aux projets, évitant de sous-estimer la charge de travail. Le code du projet est open-source (Source: Reddit r/LocalLLaMA)

Progrès de l’intégration de PyTorch avec le langage Mojo: Mark Saroufim a présenté lors du hackathon Mojo comment PyTorch simplifie la prise en charge des langages émergents et des backends matériels, et a montré un backend WIP développé en collaboration avec l’équipe Mojo. Chris Lattner a salué cette collaboration, estimant que l’association de Mojo et PyTorch insufflera une nouvelle vitalité à l’écosystème PyTorch, stimulant l’innovation dans les outils de développement IA (Source: clattner_llvm, marksaroufim)
Chatbot de style Trump: Un développeur a entraîné et mis en ligne un chatbot imitant le style de Trump, basé sur des événements historiques réels du Bureau Ovale. Ce chatbot est interactif sur Hugging Face Spaces, et le développeur sollicite les retours et suggestions des utilisateurs (Source: Reddit r/artificial)
Outil open-source de construction de réseaux agentiques (Agentic Network): Un outil open-source nommé python-a2a simplifie le processus de construction de réseaux agentiques, prenant en charge les opérations par glisser-déposer. Les utilisateurs peuvent essayer cet outil pour créer et gérer des réseaux d’agents IA (Source: Reddit r/ClaudeAI)
carcodes.xyz : une plateforme sociale conçue pour les passionnés d’automobile: Après une rupture amoureuse, un utilisateur, avec l’aide de Claude 3.7 comme assistant de programmation, a développé carcodes.xyz. Cette plateforme, similaire à Linktree, permet aux passionnés d’automobile de présenter leurs voitures modifiées, de suivre d’autres passionnés, de partager et de découvrir des rassemblements automobiles à proximité, et fournit des codes QR à coller sur les voitures pour que d’autres puissent scanner et visiter leur page personnelle. L’ensemble du projet a été construit avec Next.js, TailwindCSS, MongoDB et Stripe (Source: Reddit r/ClaudeAI)

Exécuter localement le modèle Gemma 3 27B sur une AMD RX 7800 XT 16GB: Un utilisateur partage son expérience de l’exécution locale réussie du modèle Gemma 3 27B sur une carte graphique AMD RX 7800 XT 16GB. En utilisant la version gemma-3-27B-it-qat-GGUF fournie par lmstudio-community et en l’associant à un serveur llama.cpp, il a réussi à charger complètement le modèle dans la VRAM avec une longueur de contexte de 16K. Le partage inclut la configuration matérielle détaillée, les commandes de démarrage, les paramètres (basés sur les recommandations de l’équipe Unsloth) ainsi que les résultats des tests de performance dans les environnements ROCm et Vulkan, montrant que ROCm est plus performant dans cette configuration (Source: Reddit r/LocalLLaMA)

📚 Apprentissage
Interprétation des concepts fondamentaux et des avantages du framework DSPy: Omar Khattab a exposé en détail les concepts de conception fondamentaux du framework DSPy. DSPy vise à fournir un ensemble d’abstractions stables (telles que Signatures, Modules, Optimizers) pour permettre au développement de logiciels d’IA de s’adapter aux progrès continus des LLM et de leurs méthodes. Ses idées principales incluent : le flux d’information est essentiel, l’interaction avec les LLM doit être fonctionnalisée et structurée, les stratégies de raisonnement doivent être des modules polymorphes, la spécification du comportement de l’IA doit être découplée du paradigme d’apprentissage, et l’optimisation en langage naturel est un paradigme d’apprentissage puissant. Ces principes visent à construire des logiciels d’IA “à l’épreuve du futur”, réduisant les coûts de réécriture dus aux changements de modèles ou de paradigmes sous-jacents. Cette série de tweets a suscité de nombreuses discussions et approbations, étant considérée comme une référence importante pour comprendre DSPy et le développement moderne de logiciels d’IA (Source: menhguin, lateinteraction, lateinteraction, lateinteraction, lateinteraction, lateinteraction, lateinteraction, lateinteraction, lateinteraction, lateinteraction, lateinteraction, lateinteraction, lateinteraction, lateinteraction, lateinteraction, lateinteraction)
Atelier de mathématiques pour l’IA adapté aux débutants: ProfTomYeh a annoncé l’organisation d’un atelier de mathématiques pour l’IA destiné aux débutants, visant à aider les participants à comprendre les principes mathématiques sous-jacents à l’apprentissage profond, tels que le produit scalaire, la multiplication matricielle, les couches linéaires, les fonctions d’activation et les neurones artificiels. L’atelier proposera une série d’exercices interactifs permettant aux participants de réaliser eux-mêmes des calculs mathématiques, afin de démystifier les mathématiques de l’IA (Source: ProfTomYeh)
Publication des diapositives mises à jour du manuel « Speech and Language Processing »: Les dernières diapositives du manuel classique « Speech and Language Processing » de Dan Jurafsky et James H. Martin de l’Université de Stanford ont été publiées. Ce manuel est une œuvre de référence dans le domaine du NLP, et cette mise à jour fournit aux apprenants et aux enseignants une ressource précieuse en libre accès, utile pour comprendre les technologies de pointe telles que les LLM et les Transformer (Source: stanfordnlp)
Tutoriel d’agent de recherche IA : Construire avec LangGraph et Ollama: LangChainAI a publié un tutoriel guidant les utilisateurs sur la façon de construire un agent de recherche IA. Cet agent est capable de rechercher sur le web et de générer des résumés avec citations en utilisant LangGraph et Ollama, offrant aux utilisateurs une solution de recherche automatisée complète. La vidéo du tutoriel a été publiée sur YouTube (Source: LangChainAI, Hacubu)

DAIR.AI publie les articles d’IA populaires de la semaine: DAIR.AI a compilé les articles d’IA populaires du 5 au 11 mai 2025, incluant des recherches telles que ZeroSearch, Discuss-RAG, Absolute Zero, Llama-Nemotron, The Leaderboard Illusion ainsi que Reward Modeling as Reasoning, fournissant aux chercheurs les dernières actualités (Source: omarsar0)
Article explorant les modèles agentiques (Agentic Patterns): Phil Schmid a partagé un article approfondi explorant les modèles agentiques courants, distinguant les flux de travail structurés des modèles agentiques plus dynamiques. Cet article aide à comprendre et à concevoir des systèmes d’agents IA plus efficaces (Source: dl_weekly)
Discussion sur le phénomène de flatterie de GPT-4o et ses implications pour l’entraînement des modèles: Un article explore le phénomène de “flatterie” (sycophancy) observé dans le modèle GPT-4o, analyse ses liens avec le RLHF (Reinforcement Learning from Human Feedback) et les défis de l’ajustement des préférences, et discute de ses implications plus larges pour l’entraînement des modèles, l’évaluation et la transparence de l’industrie (Source: dl_weekly)
Fuite du prompt système de Claude et analyse de sa conception: Bindu Reddy a analysé le prompt système de Claude qui a fuité. Ce prompt, long de 24k tokens, bien au-delà des attentes, est conçu pour repousser les limites du raisonnement logique des LLM, réduire les hallucinations, et répéter les instructions de multiples façons pour assurer la compréhension du LLM. Cela révèle que les LLM actuels sont encore confrontés à des défis en termes de fiabilité et de suivi des instructions, nécessitant des prompts système complexes pour corriger leur comportement (Source: jonst0kes)

Simulation des biais dans l’apprentissage automatique : une approche par réseaux bayésiens: Des doctorants de l’Université de Cambridge et les étudiants de premier cycle qu’ils encadrent ont mené un projet de recherche sur les biais dans l’apprentissage automatique. Ils ont utilisé des réseaux bayésiens pour simuler le processus de génération de données du “monde réel”, puis ont exécuté des modèles d’apprentissage automatique sur ces données pour mesurer les biais produits par le modèle lui-même (plutôt que les biais propagés par les données d’entraînement). Le site web du projet fournit une méthodologie détaillée, des résultats et des outils de visualisation, et sollicite les commentaires de personnes ayant une formation en ML (Source: Reddit r/MachineLearning)
💼 Affaires
Rumeurs de négociations entre OpenAI et Microsoft pour un nouveau tour de financement et une future IPO: Selon le Financial Times, OpenAI serait en pourparlers avec Microsoft pour obtenir un nouveau soutien financier et discuterait de la possibilité d’une introduction en bourse (IPO) future. Cela suggère qu’OpenAI continue de chercher des fonds pour soutenir la R&D coûteuse de ses grands modèles et ses besoins en puissance de calcul, et pourrait planifier une voie de capitalisation plus claire pour son développement à long terme (Source: Reddit r/artificial)

CoreWeave finalise l’acquisition de Weights & Biases: Le fournisseur de cloud computing CoreWeave a annoncé avoir finalisé l’acquisition de la plateforme d’outils d’apprentissage automatique Weights & Biases. Cette acquisition combinera l’infrastructure GPU de CoreWeave avec les capacités MLOps de Weights & Biases, visant à fournir aux développeurs d’IA un environnement de développement et de déploiement plus puissant et intégré (Source: charles_irl)
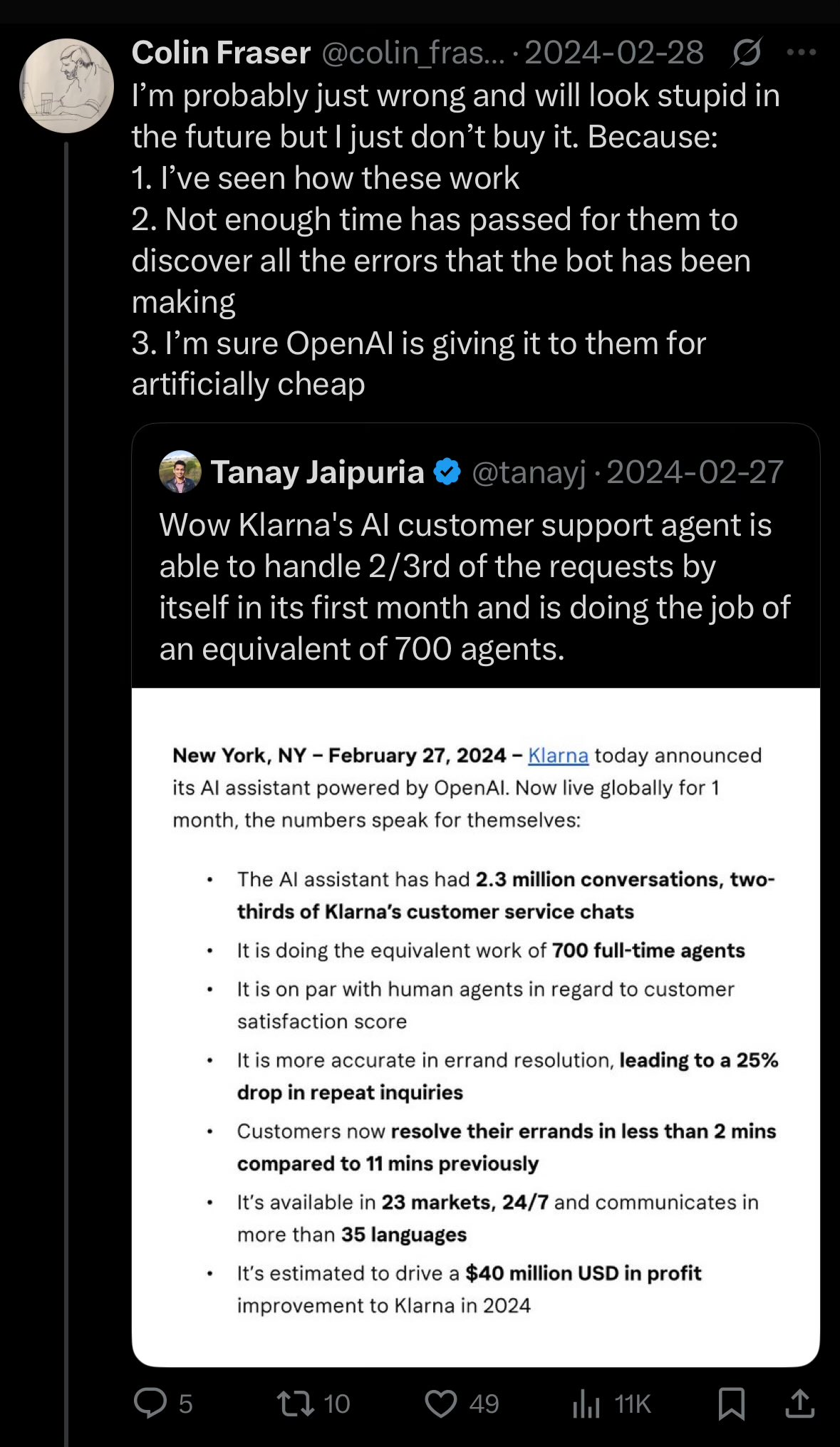
Le PDG de Klarna réfléchit à la baisse de la qualité du service client due à une réduction excessive des coûts par l’IA: Le PDG du géant des paiements Klarna a déclaré que l’entreprise était “allée trop loin” dans sa quête de réduction des coûts grâce à l’intelligence artificielle, ce qui a entraîné une baisse de l’expérience du service client, et qu’elle s’oriente désormais vers une augmentation du personnel de service client humain. Cet événement a suscité des discussions sur la manière d’équilibrer la réduction des coûts et l’amélioration de l’efficacité grâce à l’IA tout en garantissant la qualité du service dans les entreprises (Source: colin_fraser)
🌟 Communauté
Vif débat sur la question de savoir si les LLM sont la voie vers l’AGI: Un débat animé a eu lieu au sein de la communauté sur la question de savoir si les grands modèles de langage (LLM) constituent la bonne voie pour atteindre l’intelligence artificielle générale (AGI). Une partie estime que les LLM sont la technologie la plus réussie à ce jour dans le domaine de l’apprentissage automatique, et qu’affirmer qu’ils ne sont “absolument pas” la voie vers l’AGI est trop radical. L’autre partie pense que, bien que les LLM aient fait des progrès significatifs, des approches fondamentalement différentes des LLM actuels pourraient être nécessaires pour atteindre l’AGI, par exemple pour résoudre leurs problèmes de mise à l’échelle, de cohérence sur de longs contextes, d’interaction avec le monde réel, etc. Les débatteurs soulignent que l’exploration scientifique doit maintenir un esprit ouvert, plutôt que de tirer des conclusions prématurées (Source: cloneofsimo, teortaxesTex, Dorialexander)
Différence de perception entre les développeurs de logiciels et le public concernant les perspectives de remplacement par l’IA: Les discussions sur plusieurs subreddits liés au développement de logiciels montrent que de nombreux développeurs estiment peu probable que l’IA les remplace massivement dans les 5 à 10 prochaines années, qualifiant même l’IA actuelle de “camelote”. L’analyse des commentaires suggère que ce point de vue pourrait découler d’une compréhension approfondie par les développeurs des capacités réelles de l’IA et de la complexité du travail de programmation. Ils estiment que l’IA est actuellement douée pour générer du code standard ou des outils simples, mais est loin de pouvoir réaliser de manière indépendante des projets d’ingénierie logicielle complexes. En revanche, les investisseurs ou le public pourraient être induits en erreur par les capacités apparentes de l’IA, faute de comprendre les détails techniques. Parallèlement, certains estiment que l’IA est effectivement un puissant outil de productivité, mais que son rôle est davantage celui d’une assistance que d’un remplacement complet, et que l’IA est toujours confrontée à des problèmes de “perte de contexte” et d‘“incohérence logique” lorsqu’elle traite des projets complexes et à grande échelle (Source: Reddit r/ArtificialInteligence)
La politique d’acceptation des articles des conférences ML suscite la controverse : l’exigence de participation obligatoire qualifiée de discriminatoire: Neel Nanda et d’autres critiquent la politique d’ICML et d’autres conférences sur l’apprentissage automatique qui exige qu’au moins un auteur d’un article soit présent à la conférence, sous peine de voir l’article accepté refusé. Ils estiment que cela relève de l’hypocrisie : bien que les conférences affirment accorder de l’importance à la DEI (Diversité, Équité et Inclusion), cette politique discrimine en réalité les chercheurs en début de carrière ou ceux en difficulté financière, qui ont souvent du mal à payer les frais de participation élevés, alors que les articles publiés dans les meilleures conférences sont cruciaux pour leur développement professionnel. Gabriele Berton a précisé qu’ICML ne refuserait pas d’articles pour cette raison, mais exigerait seulement l’achat d’une inscription sur place, ce qui n’a pas apaisé la controverse. Des revues comme TMLR, qui publient gratuitement et dont la qualité d’évaluation est élevée, ont été citées en comparaison (Source: menhguin, jeremyphoward)

Perception de “l’abêtissement” des nouveaux modèles et discussion sur le surajustement (overfitting): Certains utilisateurs sur Reddit rapportent que les nouveaux grands modèles récemment publiés, tels que Qwen3, Llama 3.3/4, semblent “plus bêtes” que les anciennes versions en utilisation réelle, se manifestant par une perte de contexte plus facile, des répétitions de contenu et un style de langage rigide. Certains commentaires suggèrent que cela pourrait être dû au fait que les modèles, en cherchant à obtenir des scores élevés aux benchmarks (comme la programmation, les mathématiques, la réduction des hallucinations), ont été sur-entraînés, ce qui a dégradé leurs performances en écriture créative, en conversation naturelle, etc., les faisant ressembler davantage à “sacrifier la cohérence pour paraître intelligent”. Certaines recherches indiquent que les modèles de base pourraient être plus adaptés aux tâches nécessitant de la créativité (Source: Reddit r/LocalLLaMA)
Discussion sur la difficulté d’identifier le contenu généré par l’IA : le sophisme de la perruque (toupee fallacy): En réponse à l’affirmation selon laquelle “il est facile d’identifier le contenu généré par l’IA”, les discussions communautaires citent le “sophisme de la perruque” (toupee fallacy) pour la réfuter. Ce sophisme souligne que si les gens pensent que toutes les perruques ont l’air fausses, c’est parce que les perruques de bonne qualité ne sont tout simplement pas remarquées. De même, ceux qui prétendent pouvoir toujours identifier facilement le contenu de l’IA ne remarquent peut-être que les textes IA de qualité inférieure ou non retouchés, et ignorent le contenu généré par l’IA de haute qualité qui est difficile à distinguer (Source: Reddit r/ChatGPT)
YC soumet un mémoire d’amicus curiae dans l’affaire antitrust concernant le monopole de recherche de Google: Y Combinator a soumis un mémoire d’amicus curiae au Département de la Justice des États-Unis dans le cadre de l’affaire antitrust contre Google. YC estime que la position monopolistique de Google dans les domaines de la recherche et de la publicité par recherche étouffe l’innovation, rendant presque impossible pour les startups (surtout à un moment où l’IA est à un tournant) de percer. Cette démarche est interprétée par certains commentateurs comme un soutien de YC à des sociétés émergentes de recherche par IA comme Exa, visant à briser le monopole de Google (Source: menhguin)

Problèmes de performance persistants avec le modèle Claude, mécontentement général des utilisateurs: Le Megathread du subreddit ClaudeAI (4-11 mai) montre que les utilisateurs signalent continuellement des problèmes de disponibilité de Claude, notamment des limites de contexte/messages extrêmement basses, des blocages fréquents et des troncations de sortie. La page d’état d’Anthropic a confirmé une augmentation du taux d’erreur du 6 au 8 mai. Environ 75% des retours d’utilisateurs sont négatifs, en particulier ceux des utilisateurs Pro, qui estiment qu’il y a une “dégradation invisible” pour forcer les utilisateurs à passer au forfait Max, plus cher. Des informations externes confirment un resserrement de la politique d’utilisation du forfait Max et une tarification élevée de la recherche web. Bien que des solutions temporaires existent, de nombreux problèmes fondamentaux restent non résolus, et les utilisateurs sont en colère contre le manque de transparence et les changements non annoncés (Source: Reddit r/ClaudeAI)
Conseils sur le choix des modèles OpenAI et analyse du rapport qualité-prix: En réponse aux guides de sélection des modèles OpenAI circulant sur Internet, Karminski3 propose des suggestions plus rentables : GPT-4o convient aux tâches quotidiennes et à la génération d’images (hors code), au prix de 2,5 $/million de tokens ; GPT-image-1, bien que cher (10 $/million de tokens), offre de bons résultats pour la génération/édition d’images ; O3-mini-high (1,1 $/million de tokens) peut être utilisé pour le code/les mathématiques, et si cela ne suffit pas, il est conseillé de passer à Claude-3.7-Sonnet-Thinking ou Gemini-2.5-Pro, plutôt qu’à des modèles OpenAI plus chers. L’auteur estime que les modèles OpenAI actuels sont coûteux pour l’écriture de code et que leurs performances ne sont pas nécessairement les meilleures, et que les appels API pour les modèles purement textuels dépassant 2 $/million de tokens doivent être envisagés avec prudence (Source: karminski3)

💡 Divers
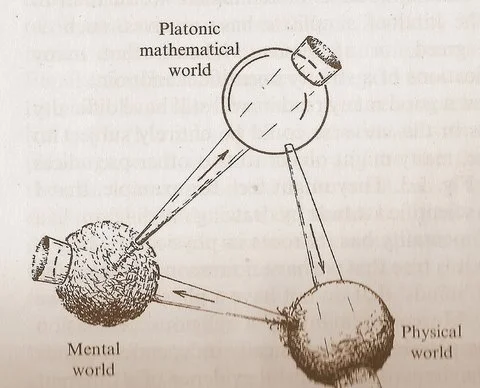
Le diagramme des “trois mondes” de Penrose suscite une réflexion sur les relations entre mathématiques, physique et intelligence: Le diagramme cyclique de Roger Penrose, présenté dans son ouvrage “The Road to Reality”, comprenant le “monde mathématique platonicien”, le “monde physique” et le “monde mental”, a suscité de nouvelles discussions. Les commentateurs estiment que les percées de l’apprentissage automatique semblent confirmer l’existence du “monde mathématique platonicien”, c’est-à-dire que l’efficacité des mathématiques découle d’une structure mathématique qui sous-tend l’univers physique. L’émergence de l’IA (des “cerveaux faits de sable”), accélère ce cycle à une échelle et à une fréquence sans précédent, et pourrait révéler des vérités plus profondes sur l’univers (Source: riemannzeta)
Les compagnies d’assurance lancent une assurance contre les pertes dues aux erreurs des chatbots IA: Les compagnies d’assurance commencent à proposer des produits d’assurance couvrant les pertes causées par les erreurs des chatbots IA. Cette initiative reconnaît d’une part que l’utilisation inappropriée de l’IA peut causer des dommages importants, et d’autre part suscite des inquiétudes quant au fait que cette assurance pourrait encourager les entreprises à être plus négligentes dans leurs applications d’IA, en se reposant sur l’assurance pour compenser les pertes plutôt que de s’efforcer d’améliorer la fiabilité et la sécurité des systèmes d’IA (Source: Reddit r/artificial)
Le potentiel de l’IA dans la création musicale est sous-estimé: Au sein de la communauté, certains pensent que beaucoup sous-estiment les capacités de l’IA en matière de création musicale, affirmant souvent que la musique IA ne peut pas “toucher l’âme” comme la création humaine. Cependant, des œuvres musicales générées par l’IA existent déjà et, à l’écoute, se rapprochent du niveau du chant humain. Étant donné que la musique IA n’en est qu’à ses débuts, son potentiel de développement futur est énorme et ne devrait pas être nié prématurément (Source: Reddit r/artificial)
