
Mots-clés:Sécurité de l’IA, Éthique de l’intelligence artificielle, Agent intelligent IA, Génération 3D, Modèle de code, Évaluation des risques de l’IA, Compréhension vidéo Gemini 2.5 Pro, Génération 3D AssetGen 2.0, Modèle de code Seed-Coder, Opérations d’agents intelligents (AgentOps)
🔥 Pleins feux
Les risques liés à la sécurité de l’AI suscitent l’attention, des experts appellent à s’inspirer de l’expérience en matière de sécurité nucléaire pour l’évaluation des risques: Les préoccupations de la communauté internationale concernant les risques potentiels de l’intelligence artificielle s’intensifient. Des experts (comme Max Tegmark) appellent les entreprises d’AI à évaluer rigoureusement la probabilité que l’intelligence artificielle devienne incontrôlable (constante de Compton), en s’inspirant des méthodes de calcul de sécurité utilisées par Robert Oppenheimer lors du premier essai nucléaire, avant de lancer des systèmes d’AI dangereux. Cette démarche vise à former un consensus au sein de l’industrie, à promouvoir l’établissement d’un mécanisme mondial de sécurité de l’AI et à prévenir les conséquences catastrophiques que pourrait entraîner une superintelligence. (Source: Reddit r/artificial, Reddit r/ArtificialInteligence)

Le nouveau Pape François (sous le nom de Leo XIV) accorde une grande attention aux transformations sociales induites par l’AI: Le Pape François nouvellement élu (qui aurait pris le nom de Leo XIV) a identifié l’intelligence artificielle comme l’un des défis majeurs pour l’humanité. Il a choisi le nom de « Leo » en partie à cause des nouveaux problèmes sociaux et de la révolution industrielle induits par l’AI, faisant écho à la réponse historique du Pape Léon XIII à la première révolution industrielle. Le Pape souligne que l’AI constitue un défi pour la préservation de « la dignité humaine, la justice et le travail », et prévoit de publier prochainement un document important sur l’éthique de l’AI, témoignant de la profonde préoccupation des chefs religieux pour l’éthique et l’impact social de la technologie AI. (Source: Reddit r/artificial, AymericRoucher, AravSrinivas, Reddit r/ArtificialInteligence)

Google publie un livre blanc de 76 pages sur les agents IA, exposant AgentOps et les applications futures: Google a publié un livre blanc de 76 pages sur les agents IA, détaillant leur construction, leur évaluation et leurs applications. Le livre blanc souligne l’importance des opérations des agents (AgentOps), une branche des opérations d’IA générative, qui se concentre sur la gestion des outils, la configuration des invites de base, les fonctions de mémoire et la décomposition des tâches nécessaires au fonctionnement efficace des agents. Le livre blanc explore également les architectures collaboratives multi-agents, où différents agents jouent des rôles de planification, de récupération, d’exécution et d’évaluation pour accomplir conjointement des tâches complexes. Il envisage les perspectives d’application des agents dans les entreprises pour assister les employés et automatiser les tâches de back-office, comme avec NotebookLM Enterprise Edition et Agentspace. (Source: WeChat)

Meta lance AssetGen 2.0 : génération de ressources 3D de haute qualité à partir de texte/images: Meta a lancé son dernier modèle d’IA fondamental pour la 3D, AssetGen 2.0, capable de créer des actifs 3D de haute qualité à partir d’invites textuelles et d’images. AssetGen 2.0 comprend deux sous-modèles : l’un pour générer des maillages 3D, utilisant un modèle de diffusion 3D en une seule étape pour améliorer les détails et la fidélité ; l’autre, le modèle TextureGen, pour générer des textures, introduisant des méthodes pour améliorer la cohérence des vues, la réparation des textures et une résolution de texture plus élevée. Cette technologie est actuellement utilisée en interne chez Meta pour créer des mondes 3D et devrait être déployée pour les créateurs d’Horizon plus tard cette année. (Source: Reddit r/artificial)

🎯 Tendances
ByteDance Seed publie en open source le modèle de code 8B Seed-Coder, adoptant un nouveau paradigme de gestion des données par le modèle: L’équipe Seed de ByteDance a publié pour la première fois en open source son modèle de code à l’échelle 8B, Seed-Coder, comprenant les versions Base, Instruct et Reasoning. Ce modèle a obtenu d’excellentes performances sur plusieurs benchmarks de génération de code, surpassant notamment des modèles comme Qwen3 sur HumanEval et MBPP. L’innovation principale de Seed-Coder réside dans la proposition d’une méthode de traitement des données « centrée sur le modèle », utilisant le LLM lui-même pour générer et filtrer des données d’entraînement de code de haute qualité, y compris du code au niveau fichier, du code au niveau dépôt, des données de Commit et des données web liées au code, pour un volume total de données d’entraînement atteignant 6T de tokens. Cette démarche vise à réduire l’intervention humaine et à améliorer les capacités des modèles de code. (Source: WeChat)
Gemini 2.5 Pro réalise une percée dans la compréhension vidéo, intégrant nativement l’audio-vidéo et le code: Les derniers modèles Gemini 2.5 Pro et Flash de Google ont réalisé des progrès significatifs dans la capacité de compréhension vidéo. Gemini 2.5 Pro a atteint le niveau SOTA sur plusieurs benchmarks clés de compréhension vidéo, surpassant même GPT 4.1. La série de modèles Gemini 2.5 réalise pour la première fois une intégration native et transparente des informations audio-vidéo avec d’autres formats de données tels que le code. Elle est capable de convertir directement des vidéos en applications interactives (comme des applications d’apprentissage), de générer des animations p5.js à partir de vidéos, et de récupérer et décrire avec précision des extraits vidéo, démontrant de puissantes capacités de raisonnement temporel. Ces fonctionnalités sont désormais disponibles dans Google AI Studio, Gemini API et Vertex AI. (Source: WeChat)

ModelScope publie en open source le modèle d’image unifié Nexus-Gen, visant les capacités d’image de GPT-4o: L’équipe de ModelScope a lancé Nexus-Gen, un modèle multimodal unifié capable de traiter simultanément la compréhension, la génération et l’édition d’images, dans le but de rivaliser avec les capacités de traitement d’image de GPT-4o. Ce modèle adopte une voie technique token → transformer → diffusion → pixels, fusionnant la modélisation textuelle de MLLM avec les capacités de rendu d’image des modèles Diffusion. Pour résoudre le problème d’accumulation d’erreurs lors de la prédiction auto-régressive d’embeddings d’images continues, l’équipe a proposé une stratégie auto-régressive pré-remplie. Nexus-Gen a été entraîné sur environ 25 millions de paires image-texte, y compris le jeu de données d’édition ImagePulse récemment publié en open source par la communauté ModelScope. (Source: WeChat)

Sortie de la version 0.50 de Cursor, simplification de la tarification et amélioration de plusieurs fonctionnalités d’édition de code: L’éditeur de code IA Cursor a publié la version 0.50, apportant des mises à jour majeures. Le modèle de tarification a été simplifié pour devenir un modèle basé sur les requêtes ; le mode Max prend en charge tous les modèles d’IA de premier plan et adopte une tarification basée sur les tokens. Les améliorations fonctionnelles comprennent : un nouveau modèle Tab prenant en charge les suggestions inter-fichiers et la refactorisation de code ; un agent en arrière-plan (version préliminaire) prenant en charge l’exécution parallèle de plusieurs agents et l’exécution de tâches dans des environnements distants ; le contexte du dépôt de code permettant d’ajouter des dépôts de code entiers via @folders ; une interface utilisateur d’édition en ligne optimisée, avec de nouvelles fonctionnalités d’édition de fichier complet et d’envoi à l’agent ; l’édition de fichiers longs introduisant un outil de recherche et de remplacement ; la prise en charge des espaces de travail multi-racines pour gérer plusieurs dépôts de code ; des fonctionnalités de chat améliorées, prenant en charge l’exportation en Markdown et la copie. (Source: op7418)
llama.cpp ajoute la prise en charge des modèles de langage visuel (VLM), permettant de construire des flux RAG visuels complets: Le projet open source llama.cpp a annoncé la prise en charge des modèles de langage visuel (VLM), permettant aux utilisateurs d’utiliser désormais les fonctionnalités visuelles via le serveur llama.cpp et l’interface utilisateur Web. Cette mise à jour signifie qu’il est possible de charger sur llama.cpp le même modèle de base prenant en charge plusieurs LoRA ainsi que des modèles d’embedding, permettant ainsi de construire des flux complets de génération augmentée par récupération visuelle (Vision RAG). Cette avancée étend davantage les capacités de llama.cpp à exécuter localement de grands modèles de langage, lui permettant de traiter des tâches multimodales. (Source: mervenoyann, mervenoyann)
Tencent publie HunyuanCustom : une architecture de génération vidéo personnalisée basée sur HunyuanVideo: Tencent a publié HunyuanCustom sur Hugging Face, une architecture multimodale conçue pour la génération vidéo personnalisée. Ce travail s’appuie sur HunyuanVideo et met particulièrement l’accent sur le maintien de la cohérence du sujet lors de la génération de vidéos, tout en prenant en charge les entrées de diverses conditions telles que les images, l’audio, la vidéo et le texte, offrant aux utilisateurs des capacités de création vidéo plus flexibles et personnalisées. (Source: _akhaliq)
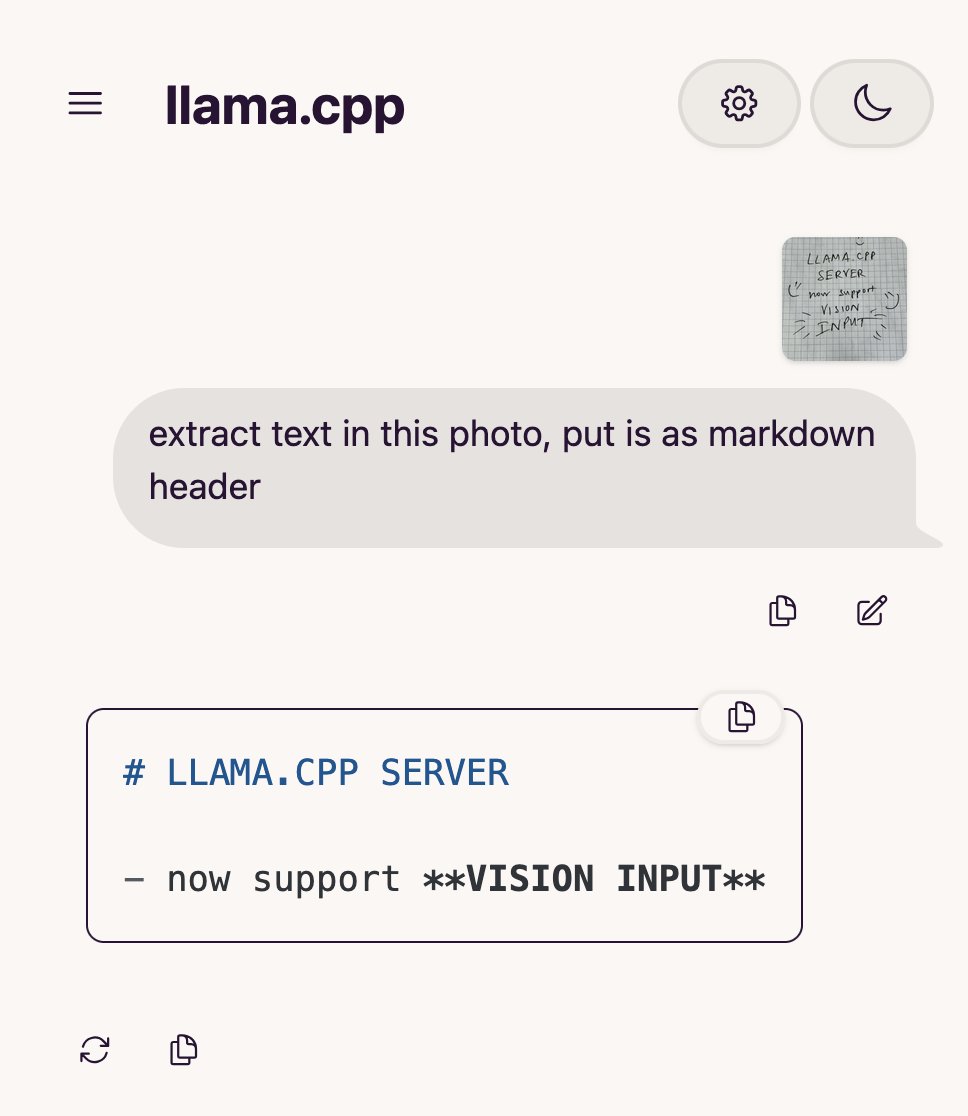
Qwen Chat ajoute un mode « Développement Web », générant des applications web React en une phrase: Qwen Chat d’Alibaba lance le mode « Développement Web » (Web Dev), permettant aux utilisateurs de générer des applications web comprenant HTML, CSS et JavaScript avec une simple instruction en une phrase. Le système utilise React et Tailwind CSS en arrière-plan. Cette fonctionnalité permet de créer rapidement des sites web personnels, de reproduire des interfaces web existantes (comme Twitter, GitHub) ou de construire des formulaires et des animations spécifiques à partir d’une description. Les utilisateurs peuvent choisir différents modèles Qwen et combiner le mode « Réflexion approfondie » pour améliorer la qualité de la page web. Cette fonctionnalité vise à simplifier le processus de développement front-end et à prototyper rapidement des applications. (Source: WeChat)
Unitree Robotics répond aux failles de sécurité du chien robot Go1, soulignant que les produits ultérieurs ont été mis à niveau: Unitree Robotics a répondu aux rumeurs concernant une « faille de porte dérobée » dans sa série de chiens robots Go1, dont la production a cessé il y a environ deux ans, reconnaissant qu’il s’agissait d’une faille de sécurité. Des attaquants pouvaient exploiter la clé de gestion d’un service de tunnel cloud tiers pour modifier les données des appareils des utilisateurs, obtenir des images de caméra et des droits système. Unitree Robotics a déclaré que les séries de robots ultérieures utilisaient des versions mises à niveau plus sécurisées et n’étaient pas affectées par cette vulnérabilité. Cet incident a soulevé des inquiétudes concernant la sécurité de la chaîne d’approvisionnement des robots intelligents et la confidentialité des données, en particulier dans le contexte de la première année de commercialisation des robots humanoïdes, où l’industrie est confrontée à de multiples défis tels que les percées technologiques, le contrôle des coûts et l’exploration des voies de commercialisation. (Source: 36氪)

Claude Code prend désormais en charge la référence à d’autres fichiers .MD, optimisant l’organisation des instructions: Claude Code d’Anthropic a mis à jour ses fonctionnalités : la version 0.2.107 permet aux fichiers CLAUDE.md d’importer d’autres fichiers Markdown. Les utilisateurs peuvent ajouter [u/path/to/file].md dans le fichier CLAUDE.md principal pour charger le contenu de fichiers supplémentaires au démarrage. Cette amélioration permet aux utilisateurs de mieux organiser et gérer les instructions de Claude, améliorant la fiabilité et la modularité de la configuration des instructions dans les grands projets, et résolvant les problèmes de confusion potentiels liés à la dépendance à des fichiers dispersés. (Source: Reddit r/ClaudeAI)

Le Bureau du droit d’auteur des États-Unis adopte une position plus ferme sur le pré-entraînement de l’IA, affaiblissant la défense du « fair use »: Le dernier rapport publié par le Bureau du droit d’auteur des États-Unis adopte une position plus ferme sur la question de l’utilisation de matériel protégé par le droit d’auteur lors de la phase de pré-entraînement des modèles d’IA. Le rapport souligne que, étant donné que les laboratoires d’IA affirment désormais que leurs modèles peuvent concurrencer les détenteurs de droits (par exemple, en générant un contenu similaire aux œuvres originales), cela affaiblit la force de leur défense basée sur le « fair use » (usage loyal) dans les litiges pour violation du droit d’auteur. Ce changement pourrait avoir un impact significatif sur les sources de données d’entraînement des modèles d’IA et leur conformité. (Source: Dorialexander)

Nvidia lance la carte graphique professionnelle RTX Pro 5000, équipée de 48 Go de mémoire GDDR7: Nvidia a lancé un nouveau GPU de bureau professionnel, le RTX Pro 5000, basé sur l’architecture Blackwell. Cette carte graphique est équipée de 48 Go de mémoire GDDR7, avec une bande passante mémoire allant jusqu’à 1344 Go/s et une consommation électrique de 300W. Bien que Nvidia la qualifie de carte Blackwell « abordable » de 48 Go, son prix devrait rester élevé (des commentaires mentionnent un niveau de 4000 dollars), ciblant principalement les utilisateurs de stations de travail professionnelles et fournissant une puissance de calcul considérable pour des tâches telles que l’entraînement de modèles d’IA et le rendu 3D à grande échelle. (Source: Reddit r/LocalLLaMA)

🧰 Outils
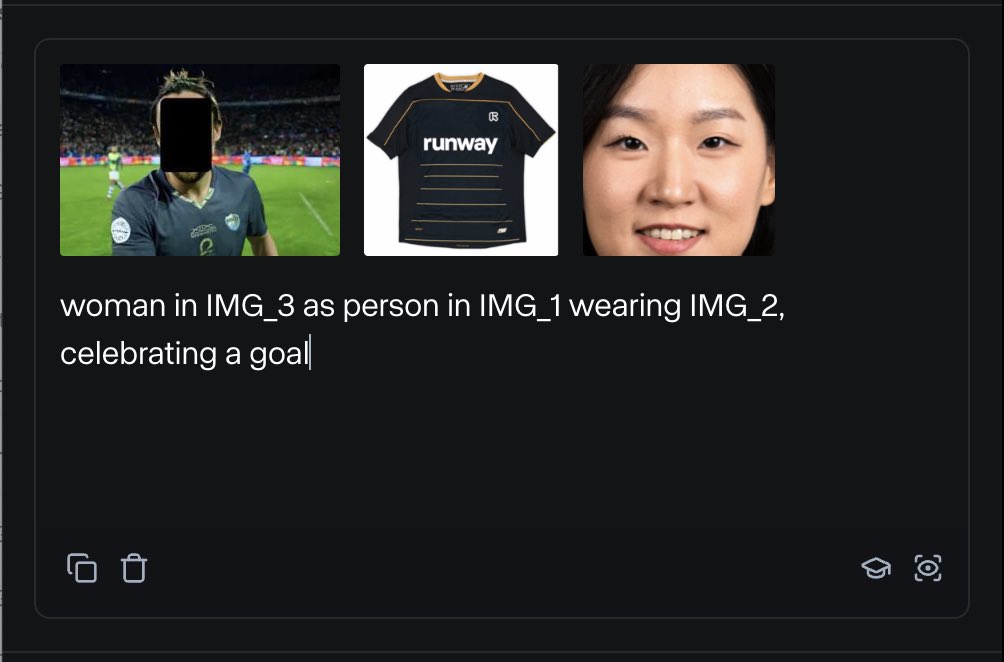
RunwayML lance la fonctionnalité References, permettant de mélanger divers matériaux de référence pour générer du contenu: La nouvelle fonctionnalité “References” de RunwayML permet aux utilisateurs de mélanger différents matériaux de référence (tels que des images, des styles) comme des “ingrédients” et de générer de nouveaux contenus visuels basés sur n’importe quelle combinaison de ces “ingrédients”. Cette fonctionnalité est considérée comme une machine de création quasi temps réel, capable d’aider les utilisateurs à réaliser rapidement diverses idées créatives, élargissant considérablement la flexibilité et les possibilités de l’IA dans la création de contenu visuel. (Source: c_valenzuelab)
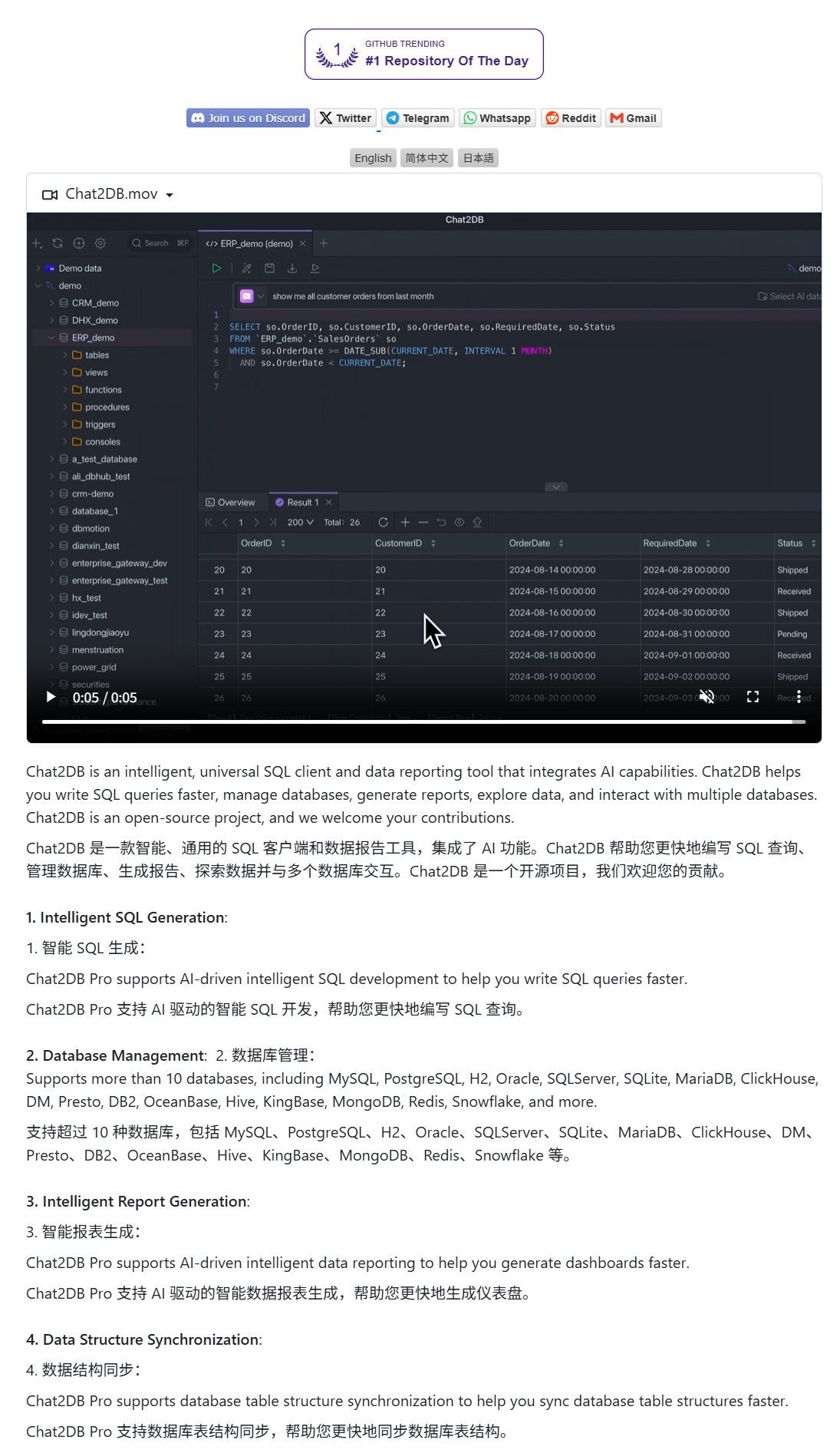
Chat2DB : un client IA pour interagir avec les bases de données en langage naturel: Chat2DB est un outil client de base de données piloté par l’IA qui permet aux utilisateurs d’interagir avec les bases de données en langage naturel. Par exemple, un utilisateur peut demander « Quel client a dépensé le plus ce mois-ci ? », et Chat2DB peut comprendre la question grâce à l’IA, générer automatiquement la requête SQL correspondante en fonction de la structure de la table de la base de données, exécuter la requête et renvoyer les résultats. Cela réduit considérablement la barrière technique pour les opérations de base de données, permettant même aux non-techniciens d’interroger et d’analyser facilement les données. Le projet est open source sur GitHub. (Source: karminski3)
Le modèle Qwen 3 8B démontre d’excellentes capacités de codage, capable de générer un clavier HTML: Le modèle Qwen 3 8B (version quantifiée Q6_K), malgré son faible nombre de paramètres, excelle dans la génération de code. Un utilisateur a réussi, avec deux courtes invites, à faire générer par ce modèle un code de clavier HTML jouable. Cela montre le potentiel des modèles réduits à atteindre une grande utilité pratique pour des tâches spécifiques, ce qui est particulièrement intéressant pour les scénarios de déploiement local aux ressources limitées. (Source: Reddit r/LocalLLaMA)
Ollama Chat : un outil de chat LLM local avec une interface de type Claude: Ollama Chat est une interface de chat web conçue pour les grands modèles de langage locaux, dont le style d’interface utilisateur et l’expérience utilisateur s’inspirent de Claude d’Anthropic. L’outil prend en charge le téléchargement de fichiers texte, l’historique des conversations et la configuration des invites système, visant à fournir une solution d’interaction LLM locale facile à utiliser et esthétique. Le projet est open source sur GitHub, permettant aux utilisateurs de le déployer et de l’utiliser eux-mêmes. (Source: Reddit r/LocalLLaMA)
Astuces de prompts pour la génération par IA de cartes personnalisées (anniversaire/fête des mères): Un utilisateur partage des astuces de prompts pour utiliser l’IA afin de générer des cartes personnalisées (comme des cartes d’anniversaire, des cartes de fête des mères). L’essentiel est de spécifier clairement le thème de la carte (par exemple, fête des mères, anniversaire), le style (par exemple, style féminin, style enfantin), le destinataire (par exemple, maman, Sandy, Jimmy), l’âge (par exemple, 30 ans, 6 ans) ainsi que le contenu spécifique du message de vœux ou un ton chaleureux et doux. En combinant ces éléments, on peut guider l’IA pour générer un design de carte répondant aux besoins. (Source: dotey)

📚 Apprentissage
Google publie un livre blanc sur l’ingénierie des prompts, guidant les utilisateurs sur la manière de poser des questions efficacement: Google a publié un livre blanc sur l’ingénierie des prompts (accessible via Kaggle), visant à enseigner aux utilisateurs comment poser plus efficacement des questions aux modèles d’IA. Le tutoriel est clair et détaille comment spécifier les exigences de sortie, contraindre la portée de la sortie et utiliser des variables, entre autres techniques, aidant les utilisateurs à améliorer l’efficacité et l’effet de leur interaction avec les grands modèles de langage, afin d’obtenir des réponses plus précises et utiles. (Source: karminski3)

Une équipe de HKUST (Guangzhou) propose MultiGO : modélisation gaussienne hiérarchique pour générer des humains texturés en 3D à partir d’une seule image: Une équipe de l’Université des sciences et technologies de Hong Kong (Guangzhou) a proposé un cadre innovant nommé MultiGO, qui reconstruit des modèles humains 3D texturés à partir d’une seule image grâce à une modélisation gaussienne hiérarchique. Cette méthode décompose le corps humain en différentes couches de précision telles que le squelette, les articulations, les rides, etc., en les affinant progressivement. La technologie de base utilise des points de projection gaussiens comme primitives 3D et conçoit des modules d’amélioration du squelette, d’amélioration des articulations et d’optimisation des rides. Ce résultat de recherche a été sélectionné pour CVPR 2025, offrant une nouvelle approche pour la reconstruction humaine 3D à partir d’une seule image. Le code sera bientôt disponible en open source. (Source: WeChat)

Tsinghua, Fudan et HKUST publient conjointement RM-BENCH : le premier benchmark d’évaluation des modèles de récompense: Face aux problèmes actuels d’évaluation des modèles de récompense des grands modèles de langage, où « la forme l’emporte sur le fond » et où existent des biais de style, des équipes de recherche de l’Université Tsinghua, de l’Université Fudan et de l’Université des sciences et technologies de Hong Kong ont conjointement publié le premier benchmark systématique d’évaluation des modèles de récompense, RM-BENCH. Ce benchmark couvre quatre grands domaines : le chat, le code, les mathématiques et la sécurité. En évaluant la sensibilité du modèle aux différences subtiles de contenu et sa robustesse aux biais de style, il vise à établir une nouvelle norme plus fiable pour les « arbitres de contenu ». L’étude a révélé que les modèles de récompense existants sont peu performants dans les domaines des mathématiques et du code, et présentent généralement des biais de style. Ce résultat a été accepté pour une présentation orale à ICLR 2025. (Source: WeChat)

L’Université de Tianjin et Tencent publient en open source la solution COME : 5 lignes de code pour améliorer la robustesse TTA et résoudre l’effondrement du modèle: L’Université de Tianjin et Tencent ont proposé la méthode COME (Conservatively Minimizing Entropy), visant à résoudre les problèmes de confiance excessive et d’effondrement du modèle causés par la minimisation de l’entropie (EM) pendant l’adaptation au moment du test (TTA). COME modélise explicitement l’incertitude prédictive en introduisant une logique subjective et contrôle indirectement l’incertitude en adoptant une contrainte de logit adaptative (gel de la norme du logit), réalisant ainsi une minimisation conservatrice de l’entropie. Cette méthode ne nécessite aucune modification de l’architecture du modèle et peut être intégrée aux méthodes TTA existantes avec seulement quelques lignes de code. Elle améliore considérablement la robustesse et la précision du modèle sur des jeux de données tels qu’ImageNet-C, tout en ayant un coût de calcul extrêmement faible. L’article a été accepté à ICLR 2025 et le code est disponible en open source. (Source: WeChat)
Huawei et l’Institut de Technologie de l’Information de l’Académie Chinoise des Sciences proposent DEER : un mécanisme de « sortie anticipée dynamique » pour la chaîne de pensée afin d’améliorer l’efficacité et la précision de l’inférence des LLM: Huawei, en collaboration avec l’Institut de Technologie de l’Information de l’Académie Chinoise des Sciences, a proposé le mécanisme DEER (Dynamic Early Exit in Reasoning), visant à résoudre le problème de la réflexion excessive qui peut survenir dans l’inférence des grands modèles de langage utilisant de longues chaînes de pensée (Long CoT). DEER surveille les points de transition de l’inférence, induit des réponses expérimentales et évalue leur confiance, afin de déterminer dynamiquement s’il faut mettre fin prématurément à la réflexion et générer une conclusion. Les expériences montrent que sur les LLM d’inférence tels que la série DeepSeek, DEER peut réduire en moyenne la longueur de la chaîne de pensée générée de 31 % à 43 % sans entraînement supplémentaire, tout en augmentant la précision de 1,7 % à 5,7 %. (Source: WeChat)

L’Académie chinoise des sciences et d’autres proposent R1-Reward : entraîner des modèles de récompense multimodaux via un apprentissage par renforcement stable: Des équipes de recherche de l’Académie chinoise des sciences, de l’Université Tsinghua, de Kuaishou et de l’Université de Nanjing ont proposé R1-Reward, une méthode utilisant l’algorithme d’apprentissage par renforcement stable StableReinforce pour entraîner des modèles de récompense multimodaux (MRM), dans le but d’améliorer leurs capacités de raisonnement à long terme. StableReinforce améliore les problèmes d’instabilité que peuvent rencontrer les algorithmes RL existants tels que PPO lors de l’entraînement des MRM, en stabilisant le processus d’entraînement grâce à une stratégie Pre-Clip, un filtre d’avantage et un nouveau mécanisme de récompense de cohérence (introduisant un modèle arbitre pour vérifier la cohérence entre l’analyse et la réponse). Les expériences montrent que R1-Reward surpasse les modèles SOTA sur plusieurs benchmarks MRM, et que ses performances peuvent être encore améliorées par un vote d’échantillonnage multiple au moment de l’inférence. (Source: WeChat)
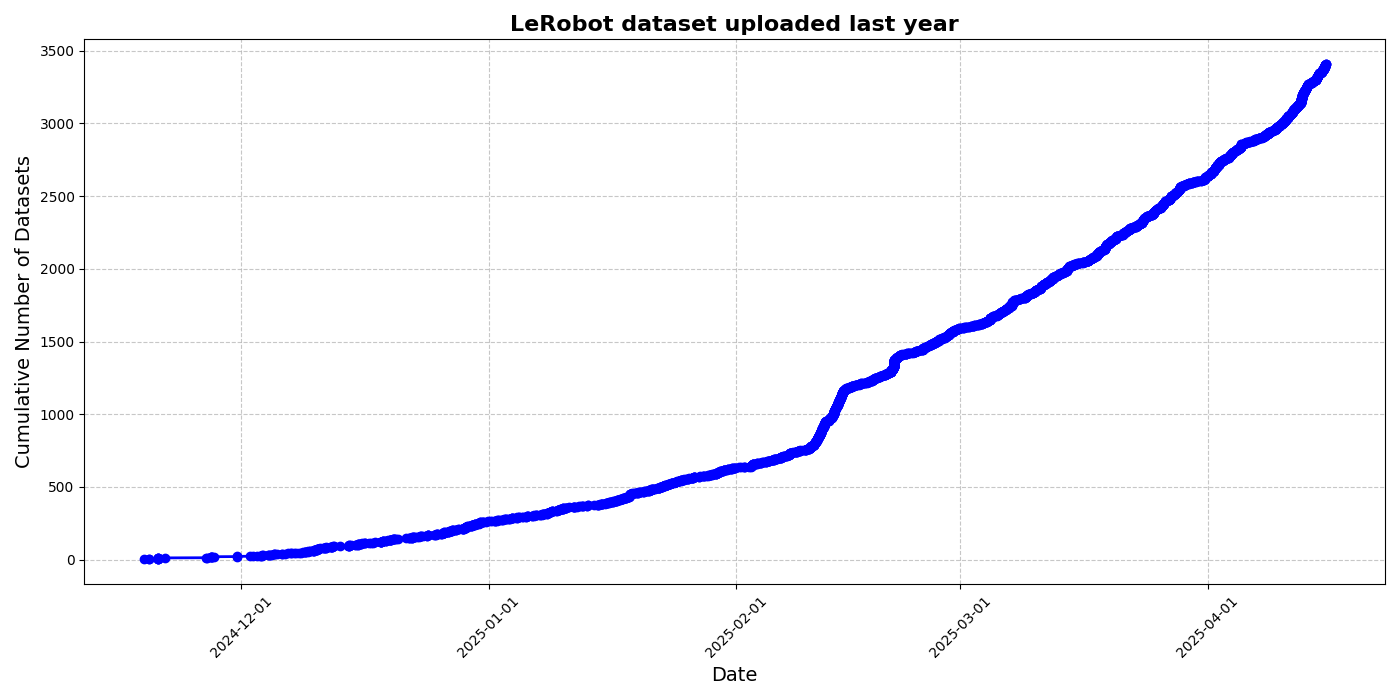
HuggingFace lance l’initiative de jeu de données communautaire LeRobot, promouvant le « moment ImageNet » de la robotique: HuggingFace a lancé le projet de jeu de données communautaire LeRobot, visant à construire l’« ImageNet » du domaine de la robotique, en stimulant le développement de la technologie robotique universelle grâce aux contributions de la communauté. L’article souligne l’importance de la diversité des données pour la capacité de généralisation des robots et note que les jeux de données robotiques existants proviennent principalement d’environnements universitaires limités. LeRobot, en simplifiant la collecte de données, les processus de téléchargement et en réduisant les coûts matériels, encourage les utilisateurs à partager des données provenant de différents robots (tels que So100, le bras robotique Koch) effectuant diverses tâches (comme jouer aux échecs, manipuler des tiroirs). Parallèlement, l’article propose des normes de qualité des données et une liste de meilleures pratiques pour relever les défis tels que l’incohérence de l’annotation des données et le mappage flou des caractéristiques, afin de promouvoir la construction de jeux de données robotiques diversifiés et de haute qualité. (Source: HuggingFace Blog, LoubnaBenAllal1)
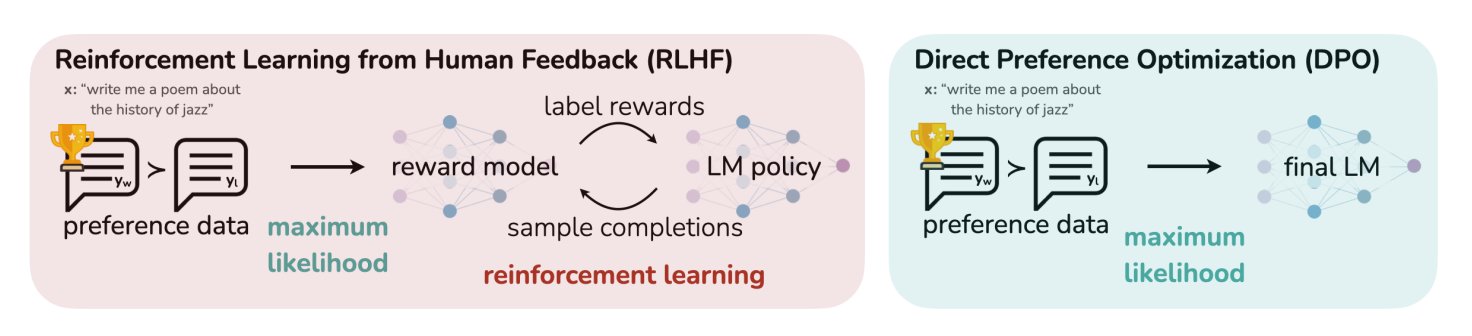
Un article de blog HuggingFace résume 11 algorithmes d’alignement et d’optimisation pour les LLM: TheTuringPost a partagé un article de HuggingFace qui résume 11 algorithmes d’alignement et d’optimisation pour les grands modèles de langage (LLM). Ces algorithmes comprennent PPO (Proximal Policy Optimization), DPO (Direct Preference Optimization), GRPO (Group Relative Policy Optimization), SFT (Supervised Fine-Tuning), RLHF (Reinforcement Learning from Human Feedback) et SPIN (Self-Play Fine-Tuning), entre autres. L’article fournit des liens et plus d’informations sur ces algorithmes, offrant aux chercheurs et aux développeurs un aperçu des méthodes d’optimisation des LLM. (Source: TheTuringPost)
L’UC Berkeley partage le matériel du cours de vision par ordinateur pour diplômés CS280: Les professeurs Angjoo Kanazawa et Jitendra Malik de l’Université de Californie à Berkeley ont partagé l’ensemble du matériel de cours de leur cours de vision par ordinateur pour diplômés CS280, enseigné ce semestre. Ils estiment que cet ensemble de matériel, combinant des contenus classiques et modernes de la vision par ordinateur, a bien fonctionné et le rendent public pour que les apprenants puissent s’y référer. (Source: NandoDF)
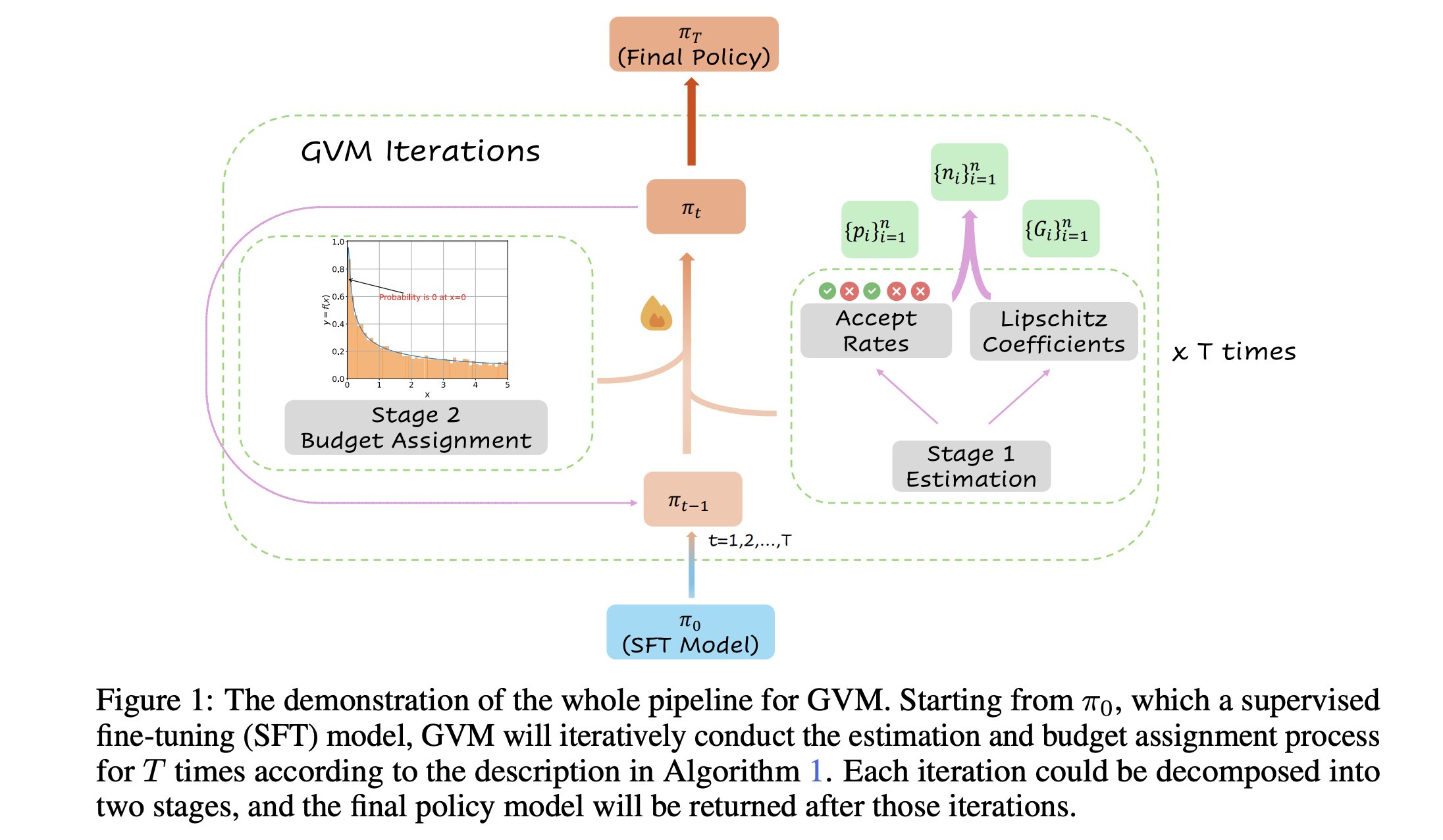
GVM-RAFT : un cadre d’échantillonnage dynamique pour optimiser les raisonneurs à chaîne de pensée: Un nouvel article présente le cadre GVM-RAFT, qui optimise les raisonneurs à chaîne de pensée (chain-of-thought) en ajustant dynamiquement la stratégie d’échantillonnage pour chaque invite, dans le but de minimiser la variance du gradient. Selon les auteurs, cette méthode permet une accélération de 2 à 4 fois sur les tâches de raisonnement mathématique et améliore la précision. (Source: _akhaliq)
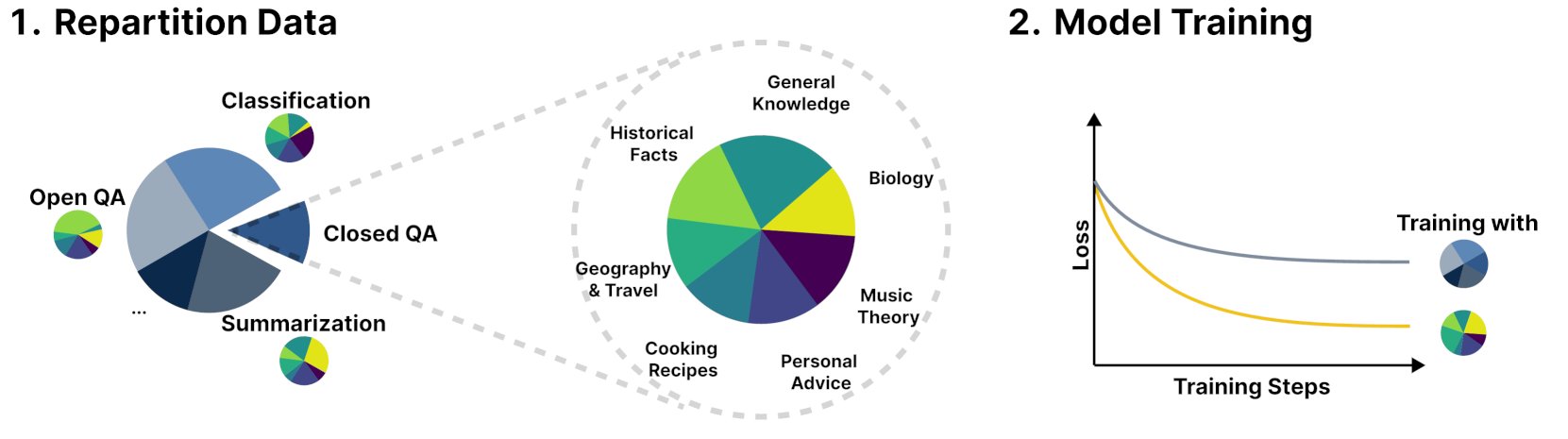
Le nouveau cadre R&B améliore les performances des modèles linguistiques en équilibrant dynamiquement les données d’entraînement: Une nouvelle étude intitulée R&B propose un nouveau cadre qui améliore les performances des modèles linguistiques en équilibrant dynamiquement leurs données d’entraînement, avec seulement 0,01 % de calcul supplémentaire. Cette méthode vise à optimiser l’efficacité de l’utilisation des données pour obtenir une amélioration des performances du modèle à un coût minime. (Source: _akhaliq)
Un article explore une nouvelle perspective sur la sécurité de l’IA : considérer le progrès social et technologique comme la couture d’une courtepointe: Un nouvel article publié sur arXiv, intitulé « Societal and technological progress as sewing an ever-growing, ever-changing, patchy, and polychrome quilt », propose une nouvelle vision de la sécurité de l’IA, affirmant que le cœur de la sécurité de l’IA devrait se concentrer sur la prévention de l’escalade des désaccords en conflits. L’article compare le progrès social et technologique à la couture d’une courtepointe en constante expansion, changeante, pleine de pièces et multicolore, soulignant l’importance de maintenir la stabilité et la coopération dans les systèmes complexes. (Source: jachiam0)
Un article explore le calcul adaptatif dans les modèles de langage auto-régressifs: Une discussion mentionne l’intérêt du calcul adaptatif en apprentissage profond et énumère les développements technologiques pertinents : PonderNet (DeepMind, 2021) comme outil précoce intégrant réseaux de neurones et récurrence ; les modèles de diffusion effectuant des calculs par de multiples passages avant ; et les récents modèles de langage de type inférence réalisant des effets similaires en générant un nombre arbitraire de tokens. Cela reflète la tendance à la flexibilité et au dynamisme des modèles dans l’allocation et l’utilisation des ressources de calcul. (Source: jxmnop)
Un article explore comment de « mauvaises données » peuvent engendrer de « bons modèles »: Un article de l’Université Harvard daté de 2025, intitulé « When Bad Data Leads to Good Models » (arXiv:2505.04741), explore comment, dans certains cas, des données apparemment de mauvaise qualité (comme des données de pré-entraînement contenant du contenu de 4chan) pourraient en fait aider à aligner les modèles et à cacher leur « niveau de puissance » (power level), les rendant plus performants. Cela soulève des discussions sur la qualité des données, l’alignement des modèles et l’authenticité du comportement des modèles. (Source: teortaxesTex)

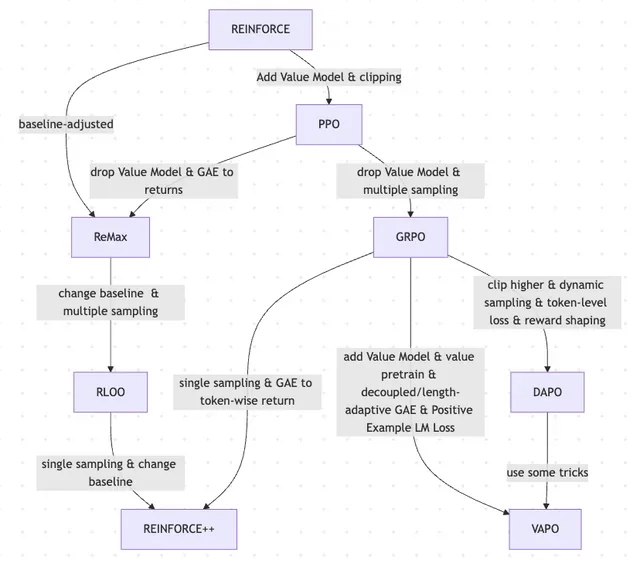
Un article explore l’évolution du RLHF et de ses variantes, de REINFORCE à VAPO: Un article de recherche résume l’évolution des méthodes d’apprentissage par renforcement (RL) utilisées pour le fine-tuning des grands modèles de langage (LLM). L’article retrace l’évolution depuis les algorithmes classiques PPO et REINFORCE jusqu’aux méthodes récentes telles que GRPO, ReMax, RLOO, DAPO et VAPO, analysant l’abandon des modèles de valeur, les changements dans les stratégies d’échantillonnage, l’ajustement des lignes de base, ainsi que l’application de techniques telles que le modelage de la récompense et la perte au niveau du token. Cette étude vise à présenter clairement le paysage de la recherche sur le RLHF et ses variantes dans le domaine de l’alignement des LLM. (Source: Reddit r/MachineLearning)
Article « Absolute Zero » : l’IA effectue un raisonnement par auto-apprentissage renforcé sans données humaines: Un livre blanc intitulé « Absolute Zero: Reinforced Self-Play Reasoning with Zero Data » (arXiv:2505.03335) explore de nouvelles méthodes d’entraînement de l’IA logique. Les chercheurs entraînent des modèles d’IA logique sans utiliser de jeux de données étiquetés par des humains ; les modèles peuvent générer eux-mêmes des tâches de raisonnement, résoudre des problèmes et vérifier les solutions par exécution de code. Cela soulève des discussions sur la capacité de l’IA à inventer des représentations symboliques, à définir des structures logiques, à développer des systèmes numériques et à construire des modèles causals à partir de zéro dans un environnement brut dépourvu de connaissances préalables (telles que les mathématiques, la physique, le langage), ainsi que sur le potentiel et les risques d’une telle « intelligence extraterrestre ». (Source: Reddit r/ArtificialInteligence, Reddit r/artificial)
Le laboratoire d’interaction homme-machine intelligente de l’Université Fudan recrute des étudiants en master et doctorat pour la promotion 2026: Le laboratoire d’interaction homme-machine intelligente de l’École d’informatique de l’Université Fudan recrute des étudiants en master et doctorat pour le camp d’été/admission anticipée de la promotion 2026. Le laboratoire est dirigé par le professeur Shang Li et ses axes de recherche comprennent l’AGI portable (combinaison des lunettes intelligentes MemX et des LLM), l’intelligence incarnée open source, la compression de modèles (du grand au petit) et les systèmes d’apprentissage automatique (tels que l’optimisation de la compilation ML, les processeurs IA). Le laboratoire se consacre à l’exploration d’une intelligence centrée sur l’humain, fusionnant les grands modèles avec les dispositifs portables intelligents et les nouveaux paradigmes d’interaction homme-machine des systèmes d’intelligence incarnée. (Source: WeChat)

💼 Affaires
Aperçu de 10 startups d’IA valorisées à plus d’un milliard de dollars avec moins de 50 employés: Business Insider a dressé la liste de 10 startups d’IA valorisées à plus d’un milliard de dollars mais comptant moins de 50 employés. Parmi elles figurent Safe Superintelligence (valorisation de 32 milliards de dollars, 20 employés), OG Labs (valorisation de 2 milliards de dollars, 40 employés), Magic (valorisation de 1,58 milliard de dollars, 20 employés), Sakana AI (valorisation de 1,5 milliard de dollars, 28 employés), etc. Ces entreprises démontrent le potentiel du secteur de l’IA à atteindre des valorisations élevées avec de petites équipes, reflétant la haute valeur de la technologie et de l’innovation sur les marchés des capitaux. (Source: hardmaru)
Fourier Intelligence approfondit les scénarios de soins de santé et de bien-être, et collabore avec le Shanghai International Medical Center pour créer une base de réadaptation en intelligence incarnée: La licorne de l’intelligence incarnée Fourier Intelligence a annoncé lors de son premier sommet sur l’écosystème de l’intelligence incarnée sa collaboration avec le Shanghai International Medical Center pour promouvoir conjointement l’application des robots à intelligence incarnée dans les scénarios de réadaptation médicale. Cela comprend l’établissement de normes, la co-création de solutions et la recherche scientifique, ainsi que la création de la première base de démonstration de réadaptation en intelligence incarnée en Chine. Le fondateur de Fourier, Gu Jie, a présenté la stratégie principale pour les dix prochaines années comme étant « s’ancrer dans les soins de santé et le bien-être, se concentrer sur l’interaction, servir les gens », soulignant que la réadaptation médicale est son fondement. Depuis sa création en 2015, l’entreprise est passée des robots de réadaptation aux robots humanoïdes polyvalents GR-1 et à la série GRx, avec des centaines d’unités expédiées à ce jour. (Source: 36氪)
Meta recruterait d’anciens responsables du Pentagone, renforçant potentiellement sa présence dans le domaine militaire: Selon Forbes, Meta recruterait d’anciens responsables du Pentagone, ce qui pourrait signifier que l’entreprise envisage de renforcer ses activités dans le domaine de la technologie militaire ou de la défense. Cette initiative a suscité des discussions et des préoccupations concernant la participation des grandes entreprises technologiques aux applications militaires. (Source: Reddit r/artificial)

🌟 Communauté
Andrej Karpathy soulève un débat animé en suggérant qu’il manque un paradigme important à l’apprentissage des LLM, l’« apprentissage par invite système »: Andrej Karpathy estime qu’il manque un paradigme important à l’apprentissage actuel des LLM, qu’il appelle « apprentissage par invite système ». Il souligne que le pré-entraînement vise la connaissance, tandis que le fine-tuning (supervisé/par renforcement) vise le comportement habituel, les deux impliquant des changements de paramètres, mais que la grande quantité d’interactions et de retours humains ne semble pas pleinement exploitée. Il compare cela à donner au protagoniste de « Memento » un carnet pour stocker des connaissances et des stratégies globales de résolution de problèmes. Ce point de vue a suscité un large débat, certains estimant que cela se rapproche de la philosophie de DSPy, ou que cela touche aux problèmes de mémoire/optimisation et d’apprentissage continu, et explorant comment mettre en œuvre des mécanismes similaires dans Langgraph. (Source: lateinteraction, hwchase17, nrehiew_, tokenbender, lateinteraction, lateinteraction)
Les entreprises d’IA demandant aux candidats de ne pas utiliser l’IA pour rédiger leurs candidatures suscitent un débat animé: Des entreprises d’IA comme Anthropic demandent aux candidats de ne pas utiliser d’outils d’IA pour rédiger leurs candidatures (comme les CV), une règle qui a suscité des discussions au sein de la communauté. Certains recruteurs affirment que les CV générés par l’IA qu’ils reçoivent sont souvent du « charabia textuel », et que même des professionnels expérimentés peuvent ainsi perdre le fil. Cependant, certains candidats estiment que l’IA peut les aider à mieux optimiser leur CV en fonction des exigences du poste, à mettre en valeur leurs compétences et à améliorer la lisibilité. La discussion s’est également étendue au phénomène du contenu généré par l’IA qui inonde des plateformes comme LinkedIn, et à la question de savoir s’il faudrait adopter d’autres méthodes d’évaluation des candidats, comme la vidéo. (Source: Reddit r/artificial, Reddit r/ArtificialInteligence)

La « reconnaissabilité » du contenu généré par l’IA suscite la discussion, les utilisateurs le jugeant facile à détecter: Une discussion communautaire souligne que le contenu généré par l’IA (en particulier ChatGPT) est facilement reconnaissable, non seulement à cause de signes de ponctuation spécifiques (comme les tirets cadratins) ou de tournures de phrases (comme « Ce n’est pas x ; c’est y. »), mais surtout à cause de son « rythme » et de sa « platitude » caractéristiques. Une fois les traces d’IA identifiées, le contenu semble irréel et manque de personnalité. Des utilisateurs déclarent avoir rencontré ce type de situation dans des e-mails, des publications sur les réseaux sociaux et même des jeux vidéo, estimant que l’utilisation directe de l’IA pour générer l’intégralité du contenu le rend ennuyeux et peu sincère. Ils conseillent aux utilisateurs d’utiliser l’IA comme un outil à modifier et à personnaliser. (Source: Reddit r/ChatGPT)
Le développement de l’IA présente un cycle « lune de miel – contrecoup », reflétant la préférence humaine pour l’authenticité: Certains estiment que l’émergence de nouveaux modèles d’IA générative (texte, image, musique, etc.) s’accompagne souvent d’une « lune de miel », où les gens sont émerveillés par leurs capacités. Mais rapidement, lorsque les gens commencent à identifier les « ficelles » ou les « traces » générées par l’IA, un contrecoup se produit, passant de l’éloge au scepticisme, voire à l’idée qu’ils « n’ont pas d’âme ». Ce phénomène d’apprentissage rapide à reconnaître les œuvres de l’IA et la tendance à préférer les créations humaines imparfaites pourraient signifier que l’IA est davantage un outil d’assistance qu’un substitut complet aux créateurs humains, car les gens valorisent l’histoire derrière l’œuvre, l’intention de l’auteur et l’authenticité. (Source: Reddit r/ArtificialInteligence)
Le taux de génération de code par IA chez Anthropic dépasse les 70 %, évoquant des associations avec l’auto-itération de l’IA: Mike Krieger d’Anthropic a révélé que plus de 70 % des pull requests au sein de l’entreprise sont désormais générées par l’IA. Cette donnée a suscité des discussions au sein de la communauté, certains évoquant des scénarios d’auto-édition et d’amélioration par les machines, similaires à des intrigues de science-fiction. Parallèlement, d’autres ont exprimé des doutes quant à la véracité de cette donnée et à sa signification concrète (par exemple, le niveau de complexité de ces PR). (Source: Reddit r/ClaudeAI)

Le PDG de Nvidia, Jensen Huang, souligne l’adoption généralisée des agents IA par tous les employés ; l’IA va remodeler le rôle des développeurs: Le PDG de Nvidia, Jensen Huang, a déclaré que l’entreprise équipera tous ses employés d’assistants IA et que les agents IA seront intégrés au développement quotidien pour optimiser le code, découvrir les vulnérabilités et accélérer le prototypage. Il estime qu’à l’avenir, chaque personne dirigera plusieurs assistants IA, ce qui entraînera une croissance exponentielle de la productivité. Le PDG de Meta, Mark Zuckerberg, le PDG de Microsoft, Satya Nadella, et d’autres partagent des points de vue similaires, estimant que l’IA effectuera la majorité du travail de codage et que le rôle des développeurs se transformera en « diriger l’IA » et « définir les besoins ». Cette tendance annonce une transformation radicale du cycle de développement logiciel, avec la généralisation des outils de programmation IA tels que GitHub Copilot et Cursor. (Source: WeChat)

Discussion : Est-il faisable pour les chercheurs en ML de lire 1000 à 2000 articles par an ?: Une discussion au sein de la communauté mentionne que les meilleurs chercheurs en apprentissage automatique pourraient lire près de 2000 articles par an. À cela, certains commentateurs estiment que le nombre d’articles lus n’est en soi qu’un indicateur indirect ; ce qui compte vraiment, c’est la capacité à filtrer les signaux parmi une grande quantité d’informations, à extraire des informations utiles et à les appliquer correctement. Être capable de suivre les points saillants et les tendances du domaine, et d’approfondir des contenus spécifiques en cas de besoin, cette capacité de filtrage de l’information est une compétence clé de ce siècle. (Source: torchcompiled)
Discussion : Acheter un GPU ou louer un GPU pour l’entraînement/le fine-tuning de modèles ?: Les praticiens de l’apprentissage automatique sont confrontés au choix d’acheter ou de louer des ressources GPU. Des personnes expérimentées suggèrent d’adopter une stratégie mixte : configurer localement un GPU grand public aux performances correctes pour les petites expériences, et louer des GPU cloud pour les tâches d’entraînement à grande échelle. Le choix dépend de la complexité du modèle, du volume de données et du budget. Les GPU cloud présentent des avantages en termes d’organisation des opérations ML, mais à prix égal, les GPU cloud courants comme les T4 peuvent être moins performants que les cartes grand public haut de gamme (comme les 3090/4090). Cependant, le cloud peut fournir des GPU de pointe avec une plus grande mémoire vive, comme les A100/H100. (Source: Reddit r/MachineLearning)
💡 Divers
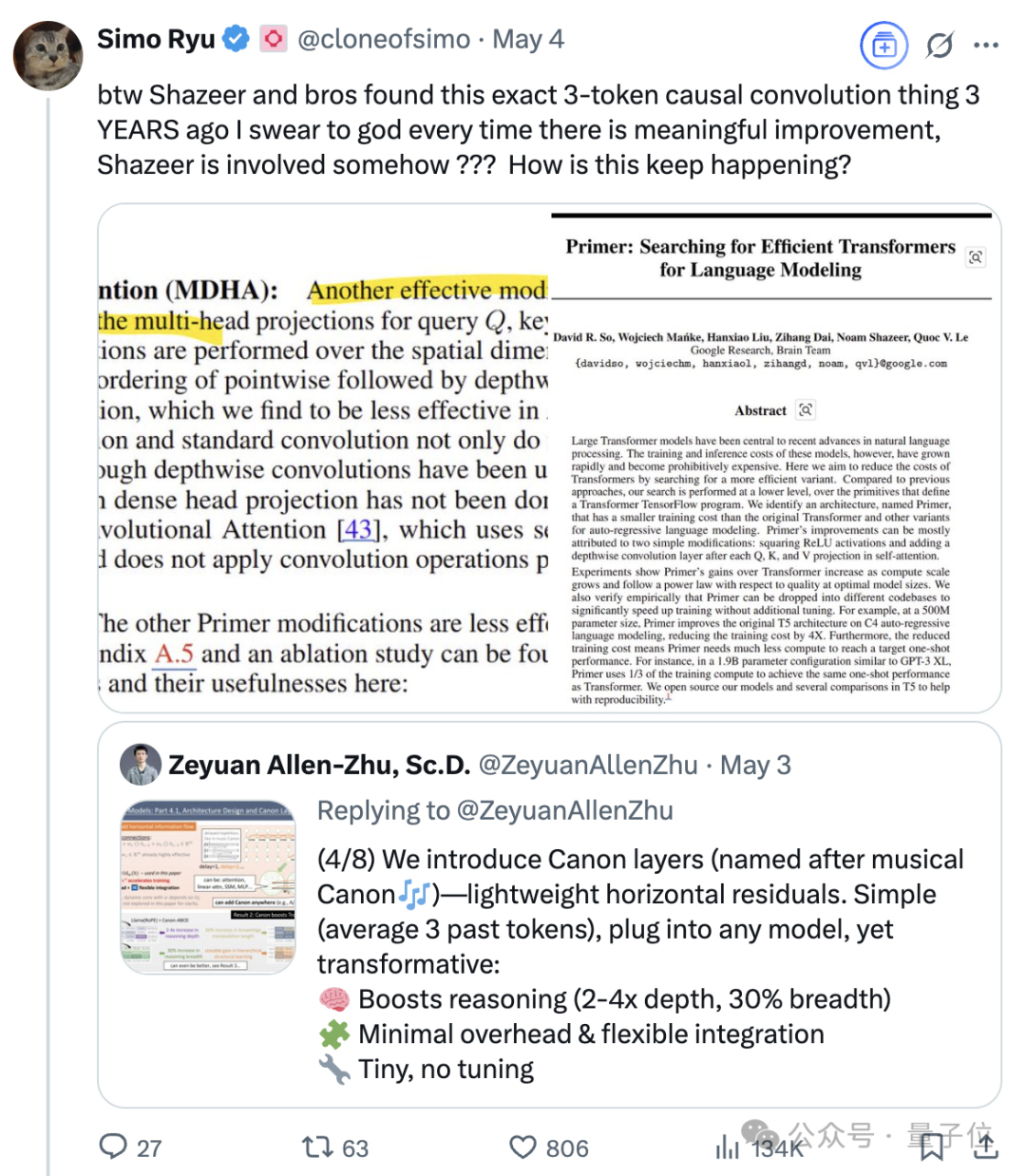
L’influence continue de Noam Shazeer, l’un des huit auteurs du Transformer: Noam Shazeer, l’un des huit auteurs de l’article sur l’architecture Transformer « Attention Is All You Need », est largement considéré comme celui ayant apporté la plus grande contribution. Son influence va bien au-delà, incluant des recherches précoces sur l’introduction du mélange d’experts à portes clairsemées (MoE) dans les modèles de langage, l’optimiseur Adafactor, l’attention multi-requêtes (MQA) et les couches linéaires à portes (GLU) dans le Transformer. Ces travaux ont jeté les bases de l’architecture actuelle des grands modèles de langage grand public, faisant de Shazeer une figure clé qui continue de définir les paradigmes technologiques dans le domaine de l’IA. Il avait quitté Google pour fonder Character.AI, puis est retourné chez Google suite à l’acquisition de l’entreprise, pour co-diriger le projet Gemini. (Source: WeChat)
Les géants de la technologie confrontés à une « crise de la quarantaine » provoquée par l’IA: Un article analyse que les « Sept Géants de la Tech », dont Google, Apple, Meta et Tesla, sont confrontés aux défis disruptifs posés par l’intelligence artificielle et traversent une « crise de la quarantaine ». L’activité de recherche de Google est menacée par le modèle de réponse directe de l’IA, Apple progresse lentement dans l’innovation en matière d’IA, Meta tente d’intégrer l’IA dans les réseaux sociaux mais les performances de Llama 4 n’ont pas atteint les attentes, et Tesla fait face à une baisse des ventes et du cours de ses actions. Ces anciens leaders de l’industrie, à l’instar des cas décrits dans « Le Dilemme de l’innovateur », doivent faire face à l’impact des nouveaux marchés et des nouveaux modèles apportés par l’IA, sous peine de devenir les « Nokia » de l’ère de l’IA. (Source: WeChat)

L’IA de Google surpasse les médecins humains dans la simulation de dialogues médicaux: Des recherches montrent qu’un système d’IA entraîné pour mener des entretiens médicaux, lors de dialogues avec des patients simulés et pour lister des diagnostics possibles basés sur les antécédents médicaux, a égalé voire surpassé les performances des médecins humains. Les chercheurs estiment qu’un tel système d’IA a le potentiel d’aider à la démocratisation et à l’universalisation des services de santé. (Source: Reddit r/ArtificialInteligence)
