
Mots-clés:OpenAI, Puce IA, Grand modèle, Apprentissage par renforcement, Infrastructure IA, IA multimodale, Agent intelligent, RAG, Plan national IA d’OpenAI, Contrôle des exportations de puces H20 de Nvidia, Optimisation de l’inférence DeepSeek-R1, Microscope optique IA Meta-rLLS-VSIM, Grand modèle de code Seed-Coder de ByteDance
🔥 En Vedette
OpenAI lance le programme « IA nationale » pour soutenir la construction d’infrastructures d’IA mondiales: OpenAI a lancé le projet « OpenAI for Countries », dans le cadre de son plan « Stargate », visant à aider les pays à établir des centres de données d’IA locaux, à personnaliser ChatGPT et à promouvoir le développement de l’écosystème de l’IA. Le PDG Sam Altman a inspecté le premier parc de supercalculateurs à Abilene, au Texas, qui fait partie du plan « Stargate » de 500 milliards de dollars visant à créer la plus grande installation d’entraînement d’IA au monde. Cette initiative marque la collaboration d’OpenAI avec plusieurs gouvernements pour promouvoir la popularisation et l’application mondiales de la technologie de l’IA par la construction d’infrastructures et le partage de technologies, avec un premier lot de 10 pays ou régions partenaires prévus (source: WeChat)

L’administration Trump envisagerait d’abolir les restrictions à trois niveaux sur l’exportation de puces d’IA, optant pour un système de licences mondial simplifié: Selon des médias étrangers, l’administration Trump prévoit d’annuler le « Cadre de diffusion de l’intelligence artificielle » (FAID) établi à la fin de l’ère Biden, qui prévoyait d’imposer des restrictions de classification à trois niveaux sur les exportations mondiales de puces d’IA. L’équipe de Trump considère ce cadre comme trop lourd et entravant l’innovation, préférant le remplacer par un système de licences mondial plus simple, mis en œuvre par des accords intergouvernementaux. Cette décision pourrait affecter les stratégies de marché mondiales des fabricants de puces tels que Nvidia, et vise à consolider l’innovation et la position dominante des États-Unis dans le domaine de l’IA (source: WeChat)

L’équipe SGLang optimise considérablement les performances d’inférence de DeepSeek-R1, augmentant le débit de 26 fois: Une équipe conjointe de SGLang, Nvidia et d’autres institutions a multiplié par 26 les performances d’inférence du modèle DeepSeek-R1 sur GPU H100 en quatre mois, grâce à une mise à niveau complète du moteur d’inférence SGLang. Les solutions d’optimisation comprennent la séparation du pré-remplissage et du décodage (séparation PD), le parallélisme d’experts à grande échelle (EP), DeepEP, DeepGEMM et un équilibreur de charge pour le parallélisme d’experts (EPLB). Lors du traitement de séquences d’entrée de 2000 tokens, un débit de 52,3k tokens d’entrée et 22,3k tokens de sortie par seconde et par nœud a été atteint, approchant les données officielles de DeepSeek et réduisant considérablement les coûts de déploiement local (source: WeChat)

Dan Roberts, scientifique chez OpenAI : L’extension de l’apprentissage par renforcement stimulera la découverte de nouvelles sciences par l’IA, et pourrait permettre d’atteindre une AGI de niveau Einstein en 9 ans: Dan Roberts, chercheur scientifique chez OpenAI, a prononcé un discours lors de l’événement AI Ascent de Sequoia Capital, explorant le rôle central de l’apprentissage par renforcement (RL) dans la construction future des modèles d’IA. Il estime qu’en augmentant continuellement l’échelle du RL, les modèles d’IA pourront non seulement améliorer leurs performances dans des tâches telles que le raisonnement mathématique, mais aussi réaliser des découvertes scientifiques grâce au « calcul au moment du test » (c’est-à-dire que plus le modèle réfléchit longtemps, meilleures sont ses performances). Prenant l’exemple de la découverte de la relativité générale par Einstein, il suppose que si l’IA pouvait calculer et réfléchir pendant 8 ans, elle pourrait atteindre un niveau de percée scientifique similaire à celui d’Einstein en 9 ans. Roberts souligne que le développement futur de l’IA se concentrera davantage sur le calcul RL, voire pourrait dominer l’ensemble du processus d’entraînement (source: WeChat)

🎯 Tendances
Jim Fan de Nvidia : Les robots passeront le « test de Turing physique », la simulation et l’IA générative sont essentielles: Jim Fan, responsable du département robotique de Nvidia, a présenté le concept de « test de Turing physique » lors de son discours à l’AI Ascent de Sequoia, c’est-à-dire que les humains ne pourront pas distinguer si une tâche est effectuée par un humain ou un robot. Il a souligné que le coût actuel d’acquisition des données robotiques est élevé et que la technologie de simulation est essentielle, en particulier en combinaison avec l’IA générative (comme l’ajustement fin des modèles de génération vidéo) pour créer des données d’entraînement diversifiées et à grande échelle (« cousins numériques » plutôt que des « jumeaux numériques » précis). Il prédit qu’avec la simulation à grande échelle et les modèles vision-langage-action (comme GR00T de Nvidia), les API physiques seront omniprésentes à l’avenir, et les robots pourront accomplir des tâches quotidiennes complexes, s’intégrant intelligemment à leur environnement (source: WeChat)
ByteDance publie la série de grands modèles de code Seed-Coder, la version 8B affiche des performances supérieures: ByteDance a lancé la série de grands modèles de code Seed-Coder, comprenant plusieurs versions telles que 8B et 14B. Parmi elles, Seed-Coder-8B se distingue sur plusieurs benchmarks d’évaluation des capacités de codage tels que SWE-bench, Multi-SWE-bench et IOI, surpassant prétendument Qwen3-8B et Qwen2.5-Coder-7B-Inst. Cette série de modèles comprend les versions Base, Instruct et Reasoner, dont le concept central est de « laisser le modèle de code organiser ses propres données », avec des améliorations significatives en matière de raisonnement de code et de capacités d’ingénierie logicielle. Les modèles sont open source sur Hugging Face et GitHub (source: Reddit r/LocalLLaMA, karminski3, teortaxesTex)
Alibaba rend open source le framework ZeroSearch, utilisant des LLM pour simuler la recherche et réduire les coûts d’entraînement de l’IA de 88%: Des chercheurs d’Alibaba ont publié un framework d’apprentissage par renforcement nommé « ZeroSearch », qui permet aux grands modèles de langage (LLM) de développer des fonctionnalités de recherche avancées en simulant des moteurs de recherche, sans avoir à appeler des API de moteurs de recherche commerciaux coûteux (comme Google) pendant le processus d’entraînement. Les expériences montrent que l’utilisation d’un LLM 3B comme moteur de recherche simulé améliore efficacement les capacités de recherche du modèle de stratégie, les performances du module de récupération de 14B paramètres surpassant même celles de Google Search, tout en réduisant les coûts d’API de 88%. Cette technologie est open source sur GitHub et Hugging Face, et prend en charge les séries de modèles Qwen-2.5, LLaMA-3.2, etc. (source: WeChat)

L’API Gemini lance une fonction de mise en cache implicite, permettant d’économiser jusqu’à 75% des coûts: L’API Gemini de Google a récemment activé une fonction de mise en cache implicite pour la série de modèles Gemini 2.5 (Pro et Flash). Lorsque la requête d’un utilisateur atteint le cache, jusqu’à 75% des coûts peuvent être automatiquement économisés. Parallèlement, le nombre minimum de tokens requis pour déclencher le cache a également été abaissé, passant à 1K tokens pour le modèle 2.5 Flash et à 2K tokens pour le modèle 2.5 Pro. Cette mesure vise à réduire les coûts pour les développeurs utilisant l’API Gemini et à améliorer l’efficacité des requêtes répétitives à haute fréquence (source: JeffDean)
L’Université Tsinghua développe le microscope optique à IA Meta-rLLS-VSIM, améliorant la résolution volumétrique de 15,4 fois: Le groupe de recherche de Li Dong de l’Université Tsinghua, en collaboration avec l’équipe de Dai Qionghai, a proposé le microscope à illumination structurée virtuelle par nappe de lumière en réseau réfléchissant piloté par méta-apprentissage (Meta-rLLS-VSIM). Ce système, grâce à l’innovation croisée entre l’IA et l’optique, a amélioré la résolution latérale de l’imagerie des cellules vivantes à 120 nm et la résolution axiale à 160 nm, réalisant une super-résolution quasi-isotrope et améliorant la résolution volumétrique de 15,4 fois par rapport au LLSM traditionnel. Ses technologies clés comprennent l’utilisation d’un DNN pour apprendre et étendre la capacité de super-résolution à plusieurs directions via une « illumination structurée virtuelle », ainsi que l’amélioration de la résolution axiale grâce à la fusion d’informations à double vue par réflexion spéculaire et au réseau RL-DFN. L’introduction de la stratégie de méta-apprentissage permet au modèle d’IA de terminer son déploiement adaptatif en seulement 3 minutes, réduisant considérablement le seuil d’application de l’IA dans les expériences biologiques et fournissant un outil puissant pour observer des processus vitaux tels que la division des cellules cancéreuses et le développement embryonnaire (source: WeChat)

Publication de la série de grands modèles Qwen3, continuant de dominer la communauté open source: Alibaba a publié la série de grands modèles de langage Qwen3, avec des tailles de paramètres allant de 0.5B à 235B, affichant d’excellentes performances sur plusieurs benchmarks, plusieurs modèles de petite taille atteignant le niveau SOTA parmi les modèles open source de taille comparable. La série Qwen3 prend en charge plusieurs langues, avec une longueur de contexte allant jusqu’à 128k tokens. En raison de ses performances robustes et de ses faibles coûts de déploiement (par rapport à DeepSeek-R1, etc.), la série Qwen a été largement adoptée à l’étranger (en particulier au Japon) comme base de développement de l’IA, et a donné naissance à un grand nombre de modèles spécialisés. La publication de Qwen3 consolide davantage sa position de leader dans la communauté mondiale de l’IA open source, avec plus de 20 000 étoiles sur GitHub en une semaine (source: dl_weekly, WeChat)

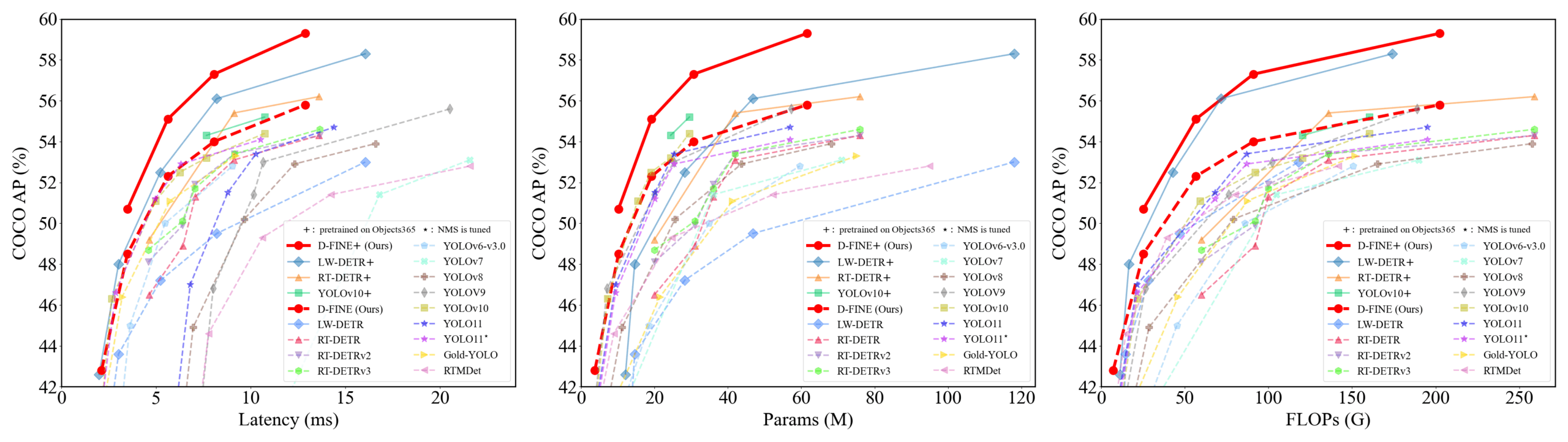
D-FINE : Détecteur d’objets en temps réel basé sur l’optimisation de la distribution à granularité fine, performances supérieures: Des chercheurs proposent D-FINE, un nouveau détecteur d’objets en temps réel qui redéfinit la tâche de régression des boîtes englobantes dans DETR en tant qu’optimisation de la distribution à granularité fine (FDR) et introduit une stratégie d’auto-distillation de la localisation globalement optimale (GO-LSD). D-FINE atteint des performances exceptionnelles sans augmenter les coûts d’inférence et d’entraînement supplémentaires. Par exemple, D-FINE-N atteint 42,8% d’AP sur COCO val, avec une vitesse allant jusqu’à 472 FPS (GPU T4) ; D-FINE-X, après pré-entraînement sur Objects365+COCO, atteint 59,3% d’AP sur COCO val. Cette méthode réalise une localisation plus fine en optimisant itérativement les distributions de probabilités et transfère les connaissances de localisation de la couche finale aux couches antérieures par auto-distillation (source: GitHub Trending)
Le modèle Harmon coordonne les représentations visuelles, unifiant la compréhension et la génération multimodales: Des chercheurs de l’Université Technologique de Nanyang ont proposé le modèle Harmon, visant à unifier les tâches de compréhension et de génération multimodales en partageant un MAR Encoder (Masked Autoencoder for Reconstruction). L’étude a révélé que le MAR Encoder peut simultanément apprendre la sémantique visuelle lors de l’entraînement à la génération d’images, ses résultats de Linear Probing dépassant de loin ceux de VQGAN/VAE. Le framework Harmon utilise le MAR Encoder pour traiter des images complètes à des fins de compréhension et adopte le paradigme de modélisation masquée MAR pour la génération d’images, le LLM réalisant l’interaction modale. Les expériences montrent que Harmon se rapproche de Janus-Pro sur les benchmarks de compréhension multimodale, et excelle sur les benchmarks esthétiques de génération texte-image MJHQ-30K et de suivi d’instructions GenEval, surpassant même certains modèles experts. Ce modèle est open source (source: WeChat)

Pushing Technology réalise une boucle commerciale fermée pour ses robots logistiques, accumulant des données via un « système d’ombre du livreur »: Les robots logistiques de Pushing Technology sont opérationnels dans plusieurs villes chinoises, atteignant le seuil de rentabilité pour chaque robot en travaillant en collaboration avec des livreurs humains. L’une de ses technologies clés est le « système d’ombre du livreur », qui collecte des données sur le comportement de conduite, la perception de l’environnement et les opérations (comme ouvrir/fermer des portes, prendre/déposer des objets) de vrais livreurs dans des environnements urbains complexes, fournissant ainsi des données d’entraînement massives et de haute qualité pour l’apprentissage par imitation et l’apprentissage par renforcement des robots. Actuellement, ce système a accumulé des dizaines de millions de kilomètres de données de conduite et près d’un million de trajectoires de membres supérieurs. Pushing Technology a entraîné sur cette base un modèle VLA d’arbre de comportement, permettant aux robots de faire face à des situations complexes du monde réel, et prévoit d’étendre ses activités sur les marchés étrangers (source: WeChat)

Kuaishou lance le framework KuaiMod, utilisant des grands modèles multimodaux pour optimiser l’écosystème des vidéos courtes: Kuaishou a proposé KuaiMod, une solution d’optimisation de l’écosystème des plateformes de vidéos courtes basée sur de grands modèles multimodaux, visant à améliorer l’expérience utilisateur grâce à la discrimination automatisée de la qualité du contenu. KuaiMod s’inspire de l’approche de la jurisprudence, utilisant le raisonnement en chaîne des modèles de langage visuel (VLM) pour analyser le contenu de mauvaise qualité, et met continuellement à jour les stratégies de discrimination grâce à l’apprentissage par renforcement basé sur les retours des utilisateurs (RLUF). Ce framework a été déployé sur la plateforme Kuaishou, réduisant efficacement le taux de signalement par les utilisateurs de plus de 20%. Kuaishou s’engage également à créer de grands modèles multimodaux capables de comprendre les vidéos courtes de la communauté, passant de l’extraction de représentations à la compréhension sémantique profonde, et a déjà obtenu des résultats dans plusieurs scénarios d’application tels que la structuration des étiquettes d’intérêt vidéo et l’aide à la génération de contenu (source: WeChat)

Lenovo lance l’agent super intelligent personnel « Tianxi », progressant vers l’intelligence de niveau L3: Lors de sa conférence sur l’innovation technologique, Lenovo a lancé l’agent super intelligent personnel « Tianxi », doté de capacités de perception et d’interaction multimodales, de cognition et de prise de décision basées sur une base de connaissances personnelle, ainsi que de décomposition et d’exécution autonomes de tâches complexes. Tianxi vise à offrir une expérience de collaboration homme-machine naturelle et transparente grâce à des interfaces AUI d’accompagnement telles que AI Suixin Chuang (fenêtre AI à la demande), AI Linglong Tai (plateforme AI exquise) et AI Ruying Kuang (cadre AI comme une ombre). Il intègre plusieurs grands modèles de pointe de l’industrie, y compris DeepSeek-R1, et adopte une architecture de déploiement hybride edge-cloud, combinée au Lenovo Personal Cloud 1.0 (équipé d’un grand modèle de 72 milliards de paramètres) pour fournir une puissance de calcul robuste et 100 Go d’espace mémoire dédié. Lenovo a également lancé des agents super intelligents de niveau entreprise « Lexiang » et de niveau urbain, démontrant son déploiement complet dans le domaine de l’IA (source: WeChat)

Une nouvelle étude évalue la capacité de généralisation des réseaux neuronaux par la complexité de l’interaction symbolique: L’équipe du professeur Zhang Quanshi de l’Université Jiao Tong de Shanghai a proposé une nouvelle théorie pour analyser la capacité de généralisation des réseaux neuronaux du point de vue de la complexité de leur représentation d’interaction symbolique intrinsèque. L’étude a révélé que les interactions généralisables (apparaissant fréquemment dans les ensembles d’entraînement et de test) présentent généralement une distribution décroissante à différents ordres (complexité) (les interactions de bas ordre étant dominantes), tandis que les interactions non généralisables (apparaissant principalement dans l’ensemble d’entraînement) présentent une distribution fusiforme (les interactions d’ordre moyen étant dominantes, les effets positifs et négatifs ayant tendance à s’annuler). Cette théorie vise à évaluer directement le potentiel de généralisation d’un modèle en analysant les modes de distribution de sa « logique d’interaction ET-OU » équivalente, offrant une nouvelle perspective pour comprendre et améliorer la capacité de généralisation des modèles (source: WeChat)
🧰 Outils
Llama.cpp est désormais entièrement compatible avec les modèles de langage visuel (VLM): Llama.cpp prend désormais entièrement en charge les modèles de langage visuel (VLM), permettant aux développeurs d’exécuter des applications multimodales sur l’appareil. Julien Chaumond de Hugging Face et d’autres ont partagé des modèles pré-quantifiés, notamment Gemma de Google DeepMind, Pixtral de Mistral AI, Qwen VL d’Alibaba et SmolVLM de Hugging Face, qui peuvent être utilisés directement. Cette mise à jour, grâce aux contributions des équipes @ngxson et @ggml_org, ouvre de nouvelles possibilités pour les applications d’IA multimodales localisées et à faible latence (source: ggerganov, ClementDelangue, cognitivecompai)
La Super Barre IA de Quark améliore sa « recherche approfondie » pour augmenter le « quotient de recherche » de l’IA: La Super Barre IA de Quark a récemment été mise à niveau avec une fonction de « recherche approfondie », visant à améliorer le quotient de recherche (ou l’intelligence de recherche) de l’IA. La nouvelle fonction met l’accent sur la réflexion active et la planification logique de l’IA avant la recherche, lui permettant de mieux comprendre les intentions de requête complexes et personnalisées des utilisateurs, de décomposer les problèmes et d’effectuer des recherches intelligentes et organisées. Dans le domaine de la santé, le conseiller santé IA de Quark, « Akua », consultera les avis de médecins de haut niveau et des documents professionnels ; dans le domaine universitaire, il accédera à des sources faisant autorité telles que CNKI. De plus, Quark possède de puissantes capacités de traitement multimodal, telles que l’analyse d’images, le détourage par IA, l’amélioration d’images et la conversion de style. Il est rapporté que Quark publiera également une version Pro de recherche approfondie dotée de capacités de Deep Research (source: WeChat)

LangChain lance plusieurs intégrations et tutoriels pour renforcer les capacités RAG et des agents intelligents: LangChain a récemment publié plusieurs mises à jour et tutoriels : 1. Tutoriel d’interface utilisateur pour agent de médias sociaux : Guide sur la transformation d’un agent de médias sociaux LangChain en une application Web conviviale, intégrant ExpressJS et l’interface utilisateur AgentInbox, et prenant en charge Notion. 2. Solution RAG primée : Présentation d’une implémentation RAG analysant les rapports annuels d’entreprise, prenant en charge l’analyse de PDF, plusieurs LLM et la récupération avancée. 3. Application de chat RAG privée : Tutoriel montrant comment créer une application de chat RAG localisée et axée sur la confidentialité des données à l’aide de LangChain et du framework Reflex. 4. Intégration de Nimble Retriever : Introduction d’un puissant récupérateur de données Web, fournissant des données précises pour les applications LangChain. 5. Guide de sortie structurée pour Claude 3.7 : Fournit trois méthodes pour obtenir une sortie structurée de Claude 3.7 via LangChain et AWS Bedrock. 6. Système RAG de chat local : Projet open source présentant un système de questions-réponses sur documents entièrement localisé, construit à l’aide du flux RAG de LangChain et d’un LLM local (via Ollama), garantissant la confidentialité des données (source: LangChainAI, LangChainAI, LangChainAI, LangChainAI, LangChainAI, LangChainAI)

Minion-agent : Un framework open source d’agents IA intégrant les capacités de multiples frameworks: Minion-agent est un nouveau framework open source de développement d’agents IA, conçu pour résoudre le problème de fragmentation des frameworks IA existants (tels que OpenAI, LangChain, Google AI, SmolaAgents). Il fournit une interface unifiée, prend en charge l’appel de capacités multi-frameworks, les outils en tant que service (navigation Web, opérations sur fichiers, etc.) et la collaboration multi-agents. Le projet démontre son potentiel d’application dans des scénarios tels que la recherche approfondie (collecte automatisée de littérature pour générer des rapports), la comparaison de prix (étude de marché automatisée), la génération créative (génération de code de jeu) et le suivi des tendances technologiques, soulignant les avantages du modèle open source en termes de flexibilité et de rentabilité (source: WeChat)

RunwayML démontre de puissantes capacités de génération et d’édition vidéo dans de multiples scénarios: Le chercheur indépendant en IA Cristobal Valenzuela et d’autres utilisateurs ont présenté les applications de RunwayML dans divers scénarios créatifs. Cela inclut l’utilisation de ses fonctionnalités Frames, References et Gen-4 pour générer et visualiser rapidement des visuels créatifs tout en maintenant la cohérence du style et des personnages ; la transformation du monde de Rembrandt en un jeu vidéo RPG ; et la synthèse de nouvelles vues de design d’intérieur à partir d’une seule image en fournissant des références visuelles. Ces exemples soulignent les progrès de RunwayML en matière de génération vidéo contrôlable, de transfert de style et de construction de scènes (source: c_valenzuelab, c_valenzuelab, c_valenzuelab, c_valenzuelab)

Olympus : Un routeur de tâches universel pour les tâches de vision par ordinateur: Olympus est un routeur de tâches universel conçu pour les tâches de vision par ordinateur. Il vise à simplifier et à unifier les flux de traitement pour différentes tâches visuelles, potentiellement en planifiant et en allouant intelligemment les ressources de calcul ou les appels de modèles, afin d’optimiser l’efficacité et les performances des systèmes de vision par ordinateur multi-tâches. Le projet est open source sur GitHub (source: dl_weekly)
Tracy Profiler : Analyseur de trames mixtes et d’échantillonnage en temps réel à la nanoseconde: Tracy Profiler est un outil d’analyse de trames mixtes et d’échantillonnage en temps réel, avec une résolution à la nanoseconde et une prise en charge de la télémétrie à distance, destiné aux jeux et autres applications. Il prend en charge l’analyse des performances du CPU (C, C++, Lua, Python, Fortran et des liaisons tierces pour Rust, Zig, C#, etc.), du GPU (OpenGL, Vulkan, Direct3D, Metal, OpenCL), de l’allocation mémoire, des verrous, des changements de contexte, et peut automatiquement associer des captures d’écran aux trames capturées. Cet outil, par sa haute précision et son temps réel, fournit aux développeurs des moyens puissants pour localiser et optimiser les goulots d’étranglement des performances (source: GitHub Trending)

FieldStation42 : Simulateur de diffusion télévisée rétro: FieldStation42 est un projet Python visant à simuler l’expérience de visionnage de la télévision diffusée à l’ancienne. Il peut prendre en charge plusieurs chaînes simultanément, insérer automatiquement des publicités et des bandes-annonces de programmes, et générer une grille de programmes hebdomadaire en fonction de la configuration. Ce simulateur peut sélectionner aléatoirement des émissions non diffusées récemment pour maintenir la fraîcheur, prendre en charge la définition de plages de dates de diffusion des programmes (comme les émissions saisonnières), et peut être configuré avec des vidéos d’arrêt de diffusion de la chaîne et des écrans de boucle sans signal. Le projet prend également en charge la connexion matérielle (comme un Raspberry Pi Pico) pour simuler le changement de chaîne et fournit une fonction de chaîne d’aperçu/guide. Son objectif est que lorsque l’utilisateur « allume la télévision », il puisse diffuser un contenu de programme « réel » correspondant à cette heure et à cette chaîne (source: GitHub Trending)

Tiny Corp lance une solution eGPU AMD basée sur USB3, compatible avec Apple Silicon: Tiny Corp a présenté une solution pour connecter un eGPU AMD à un Mac Apple Silicon via USB3 (plus précisément, un appareil ADT-UT3G basé sur le contrôleur ASM2464PD). Cette solution a nécessité la réécriture des pilotes et vise à utiliser la bande passante de 10 Gbps de l’USB3, en utilisant libusb, ce qui la rend théoriquement compatible avec Linux ou Windows. Cela offre aux utilisateurs d’Apple Silicon une nouvelle voie pour étendre leurs capacités de traitement graphique, ce qui est potentiellement précieux pour des scénarios tels que l’exécution locale de grands modèles d’IA (source: Reddit r/LocalLLaMA)
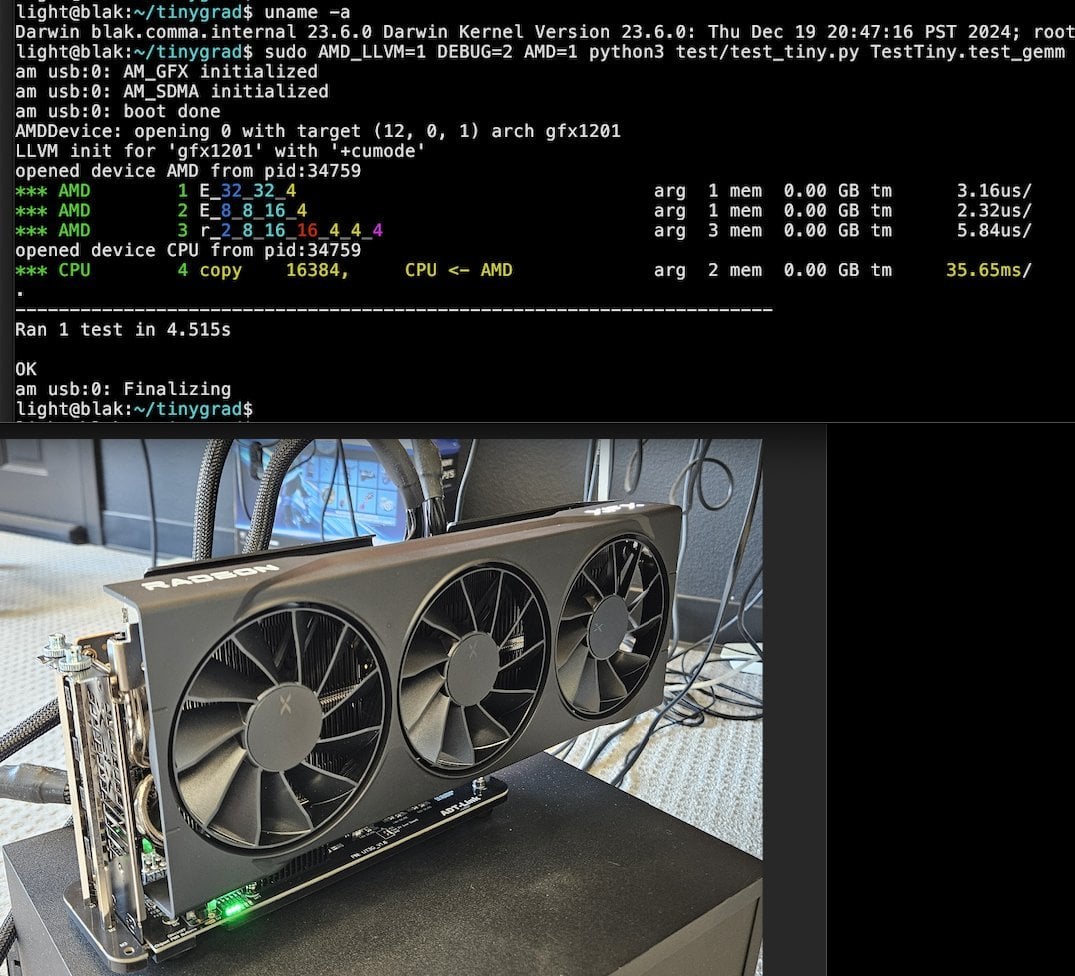
Llama.cpp-vulkan prend en charge FlashAttention sur les GPU AMD: Le backend Vulkan de Llama.cpp a récemment fusionné l’implémentation de FlashAttention, ce qui signifie que les utilisateurs de llama.cpp-vulkan sur GPU AMD peuvent désormais tirer parti de la technologie FlashAttention. Combiné à la quantification du cache KV Q8, les utilisateurs peuvent s’attendre à doubler la taille du contexte tout en maintenant ou en améliorant la vitesse d’inférence. Cette mise à jour est un avantage important pour les utilisateurs de GPU AMD exécutant localement de grands modèles de langage (source: Reddit r/LocalLLaMA)
Devseeker : Assistant de codage IA léger, alternative à Aider et Claude Code: Devseeker est un nouveau projet open source d’agent de codage IA léger, se positionnant comme une alternative à Aider et Claude Code. Il possède des fonctionnalités telles que la création et l’édition de code, la gestion de fichiers et de dossiers de code, la mémoire de code à court terme, la revue de code, l’exécution de fichiers de code, le calcul de l’utilisation des tokens et la fourniture de divers modes de codage. Ce projet vise à fournir un outil de programmation assistée par IA plus facile à déployer localement et à utiliser (source: Reddit r/ClaudeAI)
📚 Apprentissage
Panaversity lance un projet d’apprentissage de l’IA agentique, axé sur Dapr et le SDK OpenAI Agents: Panaversity a lancé le projet « Learn Agentic AI », visant à former des ingénieurs en IA agentique et robotique grâce au modèle de conception Dapr Agentic Cloud Ascent (DACA) et à diverses technologies cloud natives pour agents intelligents (notamment le SDK OpenAI Agents, Memory, MCP, A2A, Knowledge Graphs, Dapr, Rancher Desktop, Kubernetes). Ce projet aborde principalement la conception de systèmes capables de gérer des dizaines de millions d’agents IA concurrents et propose les séries de cours AI-201, AI-202, AI-301, couvrant un parcours d’apprentissage allant des bases aux agents IA distribués à grande échelle. Le projet souligne que le SDK OpenAI Agents devrait devenir le framework de développement principal en raison de sa simplicité d’utilisation et de son haut niveau de contrôle (source: GitHub Trending)

Une étude sur l’ajustement fin par RL révèle une relation complexe entre la gestion des données et la capacité de généralisation: Un article partagé par Minqi Jiang discute de l’impact de la gestion des données sur la capacité de généralisation des modèles lors de l’ajustement fin par apprentissage par renforcement (RL). L’étude a révélé que, que ce soit par l’apprentissage auto-supervisé sur des tâches de codage « infinies » (Absolute Zero Reasoner) ou par un entraînement répété sur un seul échantillon de tâche MATH (1-shot RLVR), les modèles de la série Qwen2.5 à l’échelle 7B peuvent atteindre une amélioration de la précision d’environ 28% à 40% sur les benchmarks mathématiques. Cela révèle un paradoxe : des stratégies de gestion des données extrêmes (données infinies vs données ponctuelles) peuvent produire des améliorations de généralisation similaires. Les explications possibles incluent le fait que le RL fait principalement émerger des capacités préexistantes du modèle pré-entraîné, l’existence de « circuits de raisonnement » partagés, et le fait que le pré-entraînement pourrait conduire à des circuits de raisonnement concurrents. Les chercheurs estiment que pour dépasser le « plafond du pré-entraînement », il est nécessaire de collecter et de créer continuellement de nouvelles tâches et de nouveaux environnements (source: menhguin)
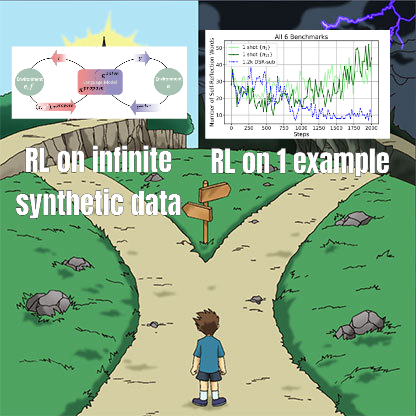
Absolute Zero Reasoner : Amélioration de la capacité de raisonnement sans données grâce à l’auto-apprentissage par le jeu: Un article intitulé « Absolute Zero Reasoner » propose qu’un modèle puisse apprendre à proposer des tâches qui maximisent sa capacité d’apprentissage par un auto-apprentissage complet (self-play), et améliorer sa propre capacité de raisonnement en résolvant ces tâches, le tout sans aucune donnée externe. Cette méthode surpasse les autres modèles « zéro-shot » dans les domaines des mathématiques et du codage. Cela suggère que les systèmes d’IA pourraient potentiellement faire évoluer continuellement leurs capacités de raisonnement en générant et en résolvant des problèmes en interne, offrant de nouvelles pistes pour les applications d’IA dans des domaines où les données sont rares ou les coûts d’annotation élevés (source: cognitivecompai, Reddit r/LocalLLaMA)

Partage des erreurs courantes et des meilleures pratiques pour l’évaluation des produits d’IA: Hamel Husain et Shreya Runwal ont partagé les erreurs courantes lors de la création d’évaluations de produits d’IA (evals) et ont fourni des conseils pour les éviter. Les points clés incluent : les benchmarks de modèles de base ne sont pas équivalents à l’évaluation d’applications ; les évaluations génériques sont inefficaces, elles doivent être spécifiques à l’application ; ne pas externaliser l’annotation et l’ingénierie des prompts à des non-experts du domaine ; créer ses propres applications d’annotation de données ; les prompts LLM doivent être spécifiques et basés sur l’analyse des erreurs ; utiliser des étiquettes binaires ; accorder de l’importance à l’examen des données ; se méfier du surajustement aux données de test ; effectuer des tests en ligne. Ces pratiques visent à aider les développeurs à construire des systèmes d’évaluation de produits d’IA plus fiables et reflétant mieux les performances du monde réel (source: jeremyphoward, HamelHusain)
Nouvelle approche pour l’optimisation du cache KV : dictionnaire universel transférable et reconstruction par traitement du signal: L’équipe de Dimitris Papailiopoulos de l’Université du Wisconsin-Madison propose une nouvelle méthode pour réduire le cache KV, en utilisant un dictionnaire universel et transférable combiné à des algorithmes traditionnels de reconstruction par traitement du signal. Cette méthode a déjà atteint le niveau SOTA (state-of-the-art) sur les modèles non inférentiels et devrait encore mieux performer sur les modèles inférentiels. Cette recherche a été acceptée à l’ICML et offre une nouvelle perspective et une nouvelle voie technique pour résoudre le problème de l’occupation excessive du cache KV lors de l’inférence des grands modèles (source: teortaxesTex, jeremyphoward, arohan, andersonbcdefg)

Qdrant promeut les systèmes RAG et les pratiques de recherche hybride dans la communauté brésilienne: La base de données vectorielles Qdrant gagne en popularité au sein de la communauté brésilienne. Le développeur Daniel Romero a partagé deux articles en portugais présentant des méthodes pratiques pour construire des systèmes RAG (Retrieval Augmented Generation) en utilisant Qdrant, FastAPI et la recherche hybride. Le contenu comprend comment mettre en place un système RAG de recherche hybride, ainsi que des stratégies d’ingestion de données pour RAG, en particulier la technique de Hybrid Chunking. Ces partages aident les développeurs brésiliens à mieux utiliser Qdrant pour le développement d’applications IA (source: qdrant_engine)
L’Académie OpenAI lance une série thématique sur l’ingénierie des prompts pour l’éducation K-12: L’Académie OpenAI a publié une série d’apprentissage sur l’ingénierie des prompts (Prompt Engineering) intitulée « Mastering Your Prompts », destinée aux éducateurs du primaire et du secondaire (K-12). Cette série vise à aider les éducateurs à mieux comprendre et utiliser les techniques de prompting afin d’intégrer plus efficacement les outils d’IA (tels que ChatGPT) dans leurs pratiques pédagogiques, améliorant ainsi l’efficacité de l’enseignement et l’expérience d’apprentissage des élèves. Cela indique que l’éducation assistée par l’IA pénètre progressivement dans l’enseignement de base et souligne l’importance de cultiver la littératie en IA chez les éducateurs (source: dotey)
Yann LeCun partage le contenu de sa conférence à l’Université Nationale de Singapour: Yann LeCun a partagé le document PDF de sa conférence distinguée (Distinguished Lecture) donnée le 27 avril 2025 à l’Université Nationale de Singapour (NUS). Bien que le sujet spécifique de la conférence ne soit pas fourni, LeCun, en tant que pionnier du deep learning, aborde généralement dans ses discours les théories de pointe de l’intelligence artificielle, les tendances futures ou des réflexions profondes sur les développements actuels de l’IA. Ce partage offre aux personnes intéressées par la recherche en IA un accès direct à ses dernières perspectives (source: ylecun)
Collaboration entre PyTorch et le backend Mojo pour simplifier l’adaptation à de nouveaux matériels et langages: PyTorch s’efforce de simplifier le processus de création de nouveaux backends pour les langages de programmation et le matériel émergents. Lors du hackathon Mojo, marksaroufim a présenté les efforts de PyTorch dans ce domaine et a mentionné un backend WIP (en cours de développement) développé en collaboration avec l’équipe Mojo. Cela indique que l’écosystème PyTorch étend activement sa compatibilité pour prendre en charge des environnements de développement IA et des options d’accélération matérielle plus diversifiés, réduisant ainsi les obstacles pour les développeurs qui déploient et optimisent des modèles PyTorch sur différentes plateformes (source: marksaroufim)
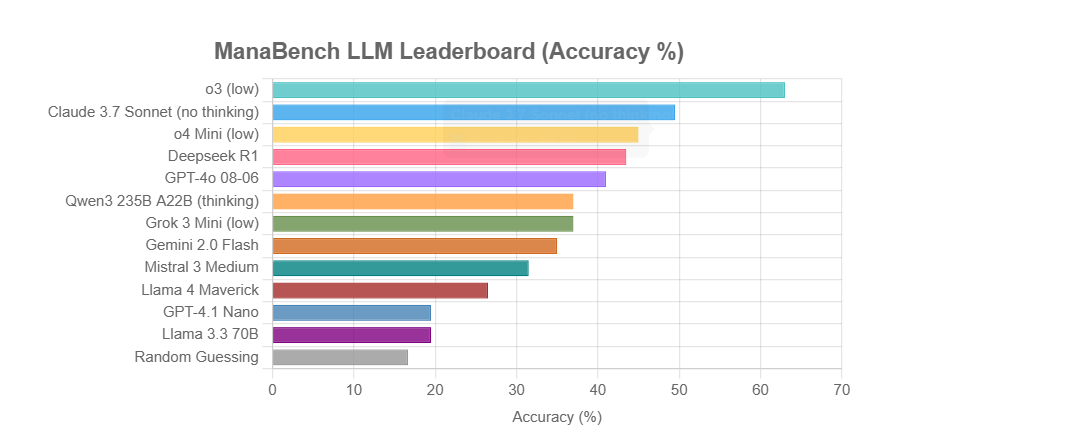
ManaBench : Un nouveau benchmark des capacités de raisonnement des LLM basé sur la construction de decks Magic: The Gathering: Un développeur a créé un nouveau benchmark appelé ManaBench, qui teste la capacité de raisonnement des systèmes complexes des LLM en leur demandant de choisir la 60ème carte la plus appropriée parmi six options, étant donné 59 cartes de Magic: The Gathering (MTG). Ce benchmark met l’accent sur le raisonnement stratégique, l’optimisation des systèmes, et les réponses sont cohérentes avec celles conçues par des experts humains, ce qui rend difficile de le résoudre par simple mémorisation. Les résultats préliminaires montrent que les modèles de la série Llama ont des performances inférieures aux attentes, tandis que les modèles propriétaires tels que o3 et Claude 3.7 Sonnet sont en tête. Ce benchmark vise à évaluer plus fidèlement les performances des LLM sur des tâches nécessitant un raisonnement complexe (source: Reddit r/LocalLLaMA)
Discussion : L’IA va-t-elle faire revivre ou enterrer le rêve du Web sémantique ?: Sur les réseaux sociaux, l’utilisateur Spencer a mentionné qu’à moins que les grands sites Web d’entreprises n’aient une exposition significative aux risques liés à la loi ADA (Americans with Disabilities Act), le Web sémantique est plus théorique que pratique sur la plupart des sites. Dorialexander a répondu qu’il avait l’impression que l’IA allait soit faire revivre le rêve du Web sémantique, soit l’enterrer à jamais. Cela reflète les attentes et les inquiétudes concernant le potentiel de l’IA en matière de compréhension et d’utilisation des données structurées. L’IA pourrait indirectement atteindre les objectifs du Web sémantique en comprenant et en générant automatiquement des informations structurées, mais elle pourrait aussi, en raison de ses propres capacités puissantes, rendre les technologies traditionnelles du Web sémantique moins importantes (source: Dorialexander)
Des chercheurs explorent l’éthique et les architectures de la mémoire et de l’oubli des modèles: Un projet d’article intitulé « Sticky Minds: The Ethics and Architectures of AI Memory and Forgetting » est en cours de rédaction, explorant comment nous décidons ce que les modèles devraient oublier lorsqu’ils commencent à « trop bien se souvenir », fusionnant l’architecture neuronale et l’éthique de la mémoire. Cela concerne la manière dont les systèmes d’IA stockent, récupèrent et oublient (sélectivement) les informations, ainsi que les défis éthiques et les impacts sociaux qui en découlent, ce qui est crucial pour construire une IA responsable et digne de confiance (source: Reddit r/artificial)
💼 Affaires
Nvidia lancerait une puce H20 « doublement bridée » pour se conformer aux nouvelles réglementations américaines sur l’exportation: Selon Reuters, Nvidia prévoit de lancer dans les deux prochains mois une nouvelle version de sa puce IA H20 spécifiquement pour la Chine, afin de se conformer aux dernières exigences américaines en matière de contrôle des exportations. Cette puce sera encore plus « bridée » que la H20 originale (elle-même déjà une version dégradée pour le marché chinois), par exemple, la capacité de mémoire vive sera considérablement réduite. Bien que les performances soient à nouveau diminuées, il est rapporté que les utilisateurs en aval pourraient ajuster les performances dans une certaine mesure en modifiant la configuration des modules. Actuellement, Nvidia a reçu des commandes pour la H20 d’une valeur de 18 milliards de dollars (source: WeChat)

Databricks pourrait acquérir la société de bases de données open source Neon pour 1 milliard de dollars, renforçant son infrastructure IA: La société de données et d’IA Databricks serait en négociation pour acquérir Neon, développeur du moteur de base de données open source PostgreSQL, pour un montant d’environ 1 milliard de dollars. Neon se caractérise par son architecture serverless, la séparation du stockage et du calcul, ainsi que sa bonne adaptation aux agents IA et à la programmation ambiante, permettant une utilisation à la demande et un démarrage rapide des instances de base de données, ce qui convient aux scénarios d’application IA. Si cette acquisition aboutit, elle renforcera davantage la couche d’infrastructure de Databricks à l’ère de l’IA, lui fournissant une solution de base de données modernisée et centrée sur l’IA (source: WeChat)

OpenAI nomme Fidji Simo, ancienne PDG d’Instacart, au poste de PDG des activités applicatives, renforçant les produits et la commercialisation: OpenAI a annoncé la nomination de Fidji Simo, ancienne PDG d’Instacart et membre du conseil d’administration de la société, au nouveau poste de « PDG des activités applicatives », au même niveau que Sam Altman. Simo sera entièrement responsable des produits d’OpenAI, en particulier des applications destinées aux utilisateurs telles que ChatGPT, dans le but de promouvoir l’optimisation des produits, l’amélioration de l’expérience utilisateur et le processus de commercialisation. Cette décision marque un changement stratégique majeur pour OpenAI, passant de la R&D de modèles à la plateformisation des produits et à l’expansion du marché, dans le but d’établir une plus grande compétitivité au niveau des applications d’IA. La riche expérience de Simo en matière de produits et de commercialisation chez Facebook et Instacart aidera OpenAI à faire face à une concurrence de plus en plus féroce sur le marché (source: WeChat)

🌟 Communauté
L’AI Assistant de JetBrains suscite le mécontentement des utilisateurs en raison d’une mauvaise expérience et de la gestion des commentaires: Bien que le plugin AI Assistant de JetBrains ait été téléchargé plus de 22 millions de fois, sa note sur sa place de marché n’est que de 2,3 sur 5, avec un grand nombre d’avis négatifs à 1 étoile. Les utilisateurs se plaignent généralement de son installation automatique, de sa lenteur, de ses nombreux bugs, du support insuffisant des modèles tiers, de la liaison des fonctionnalités principales à des services cloud et du manque de documentation. Récemment, JetBrains a été accusé de supprimer en masse les commentaires négatifs. Bien que la société ait expliqué qu’il s’agissait de traiter du contenu non conforme ou des problèmes résolus, cela a tout de même suscité des doutes chez les utilisateurs quant à son contrôle des commentaires et à son manque d’attention aux retours des utilisateurs. Certains utilisateurs ont choisi de republier leurs avis négatifs et de continuer à donner 1 étoile. Cet incident a exacerbé le mécontentement des utilisateurs à l’égard de la stratégie produit IA de JetBrains (source: WeChat)

Les utilisateurs débattent vivement de la qualité des résultats des agents intelligents de marketing IA: L’utilisateur de médias sociaux omarsar0 a observé que dans de nombreux tutoriels YouTube présentant des agents IA de marketing, la qualité des textes marketing générés est généralement médiocre, manquant de créativité et de style. Il estime que cela reflète la difficulté de faire produire par les LLM un contenu de haute qualité et attrayant, et souligne que le « goût » est crucial lors de la construction d’agents IA. Il note que de nombreux agents IA actuels, bien que dotés de flux de travail complexes, peinent encore à produire un contenu ayant une réelle valeur commerciale, ce qui offre des opportunités aux talents dotés d’un goût élevé, d’une expérience solide et capables de concevoir de bons systèmes d’évaluation (source: omarsar0)
Le codage assisté par IA et la tendance de la « programmation ambiante » suscitent des discussions: Une vidéo de Y Combinator discutant du codage par IA sur Reddit a suscité un vif débat. Les points de vue de la vidéo coïncident fortement avec l’expérience de l’auteur du message (qui prétend avoir créé plusieurs projets rentables grâce à la « programmation ambiante »). Les points essentiels incluent : 1. L’IA peut déjà aider à construire des produits logiciels complexes et utilisables, parfois même sans écrire de code. 2. Les ingénieurs logiciels s’inquiètent de plus en plus que l’IA remplace leur travail, mais ceux qui maîtrisent réellement le développement assisté par IA possèdent des « super-pouvoirs ». 3. Le rôle futur des ingénieurs logiciels pourrait évoluer vers celui de « gestionnaires d’agents intelligents » sachant utiliser les outils d’IA, l’IA se chargeant de la majeure partie de l’écriture du code. 4. L’IA va engendrer un grand nombre de logiciels de niche ciblant des marchés spécifiques. Les participants à la discussion estiment que, bien que le potentiel du codage par IA soit énorme, il faut toujours posséder des connaissances en concepts d’ingénierie, bases de données, architecture, etc., pour l’utiliser efficacement (source: Reddit r/ClaudeAI)

Le débat sur la question de savoir si l’IA va « prendre le contrôle du monde » et sur son impact sur l’emploi se poursuit: Les messages sur le subreddit r/ArtificialInteligence reflètent l’anxiété généralisée de la communauté et la diversité des points de vue concernant l’impact futur de l’IA. Certains utilisateurs estiment que plus on en sait sur les capacités de l’IA, plus on s’inquiète de la voir surpasser les humains et dominer l’avenir, soulignant que les systèmes d’IA de pointe ont déjà démontré des capacités étonnantes. D’autres utilisateurs pensent que l’exagération autour de l’AGI a conduit à des attentes irréalistes, que l’IA est essentiellement un outil d’automatisation intelligent et que son impact sera progressif, similaire à celui des ordinateurs et d’Internet. La discussion porte également sur l’impact potentiel de l’IA sur l’emploi, la répartition des richesses et l’efficacité de la réglementation. Certains estiment que l’histoire montre que les progrès technologiques ont tendance à exacerber les inégalités de richesse, et que l’IA pourrait concentrer davantage les richesses en éliminant un grand nombre d’emplois. Parallèlement, d’autres expriment leur espoir quant au rôle positif de l’IA dans des domaines tels que la santé et l’éducation (source: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
Expérience utilisateur : Comment les outils d’IA tels que ChatGPT influencent la pensée et la cognition: Certains utilisateurs ont partagé sur les plateformes sociales et Reddit les impacts cognitifs positifs de l’utilisation d’outils d’IA tels que ChatGPT. Ils estiment que l’IA n’est pas seulement un outil d’acquisition d’informations ou d’aide à la rédaction, mais plutôt un « partenaire de réflexion » ou un « miroir » qui les aide à clarifier leurs pensées et à exprimer clairement des idées subconscientes. En dialoguant avec l’IA, les utilisateurs déclarent pouvoir mieux réfléchir, remettre en question leurs propres croyances, découvrir des schémas de pensée, et même se sentir en train de « s’éveiller », acquérant une compréhension plus profonde de la vie et des systèmes. Cette expérience suggère que l’IA, dans certains cas, pourrait devenir un catalyseur favorisant la croissance personnelle et l’exploration de soi (source: Reddit r/ChatGPT)
💡 Divers
Lancement du deuxième concours national d’innovation et d’application de l’intelligence artificielle « Xingzhi Cup »: Organisé conjointement par l’Académie chinoise des technologies de l’information et de la communication (CAICT) et d’autres entités, le deuxième « Xingzhi Cup » a été inauguré sur le thème « Autonomisation par l’intelligence, innovation en tête ». Le concours comprend trois pistes principales : innovation des grands modèles, autonomisation de l’industrie, et écosystème d’innovation logicielle et matérielle, ainsi que plusieurs orientations spécifiques. L’événement vise à promouvoir l’innovation technologique en IA, son déploiement en ingénierie et la construction d’un écosystème autonome, couvrant près de 10 secteurs clés tels que l’industrie, la santé et la finance, et en soulignant l’application des logiciels et matériels d’IA nationaux. Les projets gagnants recevront un soutien financier, des mises en relation industrielles, etc. (source: WeChat)

Partage de Sequoia Capital AI Ascent : Le potentiel du marché de l’IA est énorme, la couche applicative et l’économie des agents sont l’avenir: Pat Grady, associé chez Sequoia Capital, et d’autres ont partagé leurs perspectives sur le marché de l’IA lors de l’événement AI Ascent. Ils estiment que le potentiel du marché de l’IA dépasse de loin celui du cloud computing, mais qu’il faut se méfier des « revenus d’ambiance » (utilisateurs essayant par curiosité plutôt que par réel besoin). La couche applicative est considérée comme la véritable source de valeur, et les startups devraient se concentrer sur les domaines verticaux et les besoins des clients. L’IA a déjà réalisé des percées dans les domaines de la génération vocale et de la programmation. Les perspectives d’avenir incluent une « économie des agents », où les agents IA pourront transférer des ressources et effectuer des transactions, mais cela soulève des défis liés à l’identité persistante, aux protocoles de communication et à la sécurité. Parallèlement, l’IA amplifiera considérablement les capacités individuelles, donnant naissance à des « super-individus » (source: WeChat)

Discussion : Le contenu des cours universitaires de machine learning et la qualité de l’enseignement à l’ère de l’IA suscitent l’attention: Le partage du syllabus de son cours de ML pour étudiants diplômés par le professeur Kyunghyun Cho de la NYU a suscité des discussions. Ce cours met l’accent sur les problèmes non-LLM pouvant être résolus par SGD et la lecture d’articles classiques, ce qui a été salué par des pairs tels que des professeurs de CS de Harvard, qui estiment qu’il est important de conserver les concepts fondamentaux. Cependant, des étudiants indiens et américains se sont plaints de la piètre qualité des cours de ML dans leurs universités, les jugeant trop abstraits, remplis de jargon mais manquant d’explications approfondies, ce qui oblige les étudiants à recourir à l’auto-apprentissage et aux ressources en ligne. Cela reflète la contradiction entre le développement rapide du domaine de l’IA/ML et le retard dans la mise à jour des programmes universitaires, ainsi que l’importance d’acquérir de solides bases en mathématiques et en théorie (source: WeChat)
