
Mots-clés:Applications de l’IA, FDA, OpenAI, GPT-4.1, WebThinker, Runway Gen-4, Intelligence en périphérie, Réglage fin par apprentissage par renforcement (RFT), Cadre multi-agents DeerFlow, WebThinker-32B-RL, Mise à jour des références Gen-4, Densité de connaissances
🔥 Actualités
La FDA américaine annonce l’accélération de l’adoption interne de l’IA : L’Administration américaine des denrées alimentaires et des médicaments (FDA) a annoncé une mesure historique, prévoyant de généraliser l’utilisation de l’intelligence artificielle (IA) dans tous ses centres d’ici le 30 juin 2025. Auparavant, la FDA avait mené à bien un projet pilote d’IA générative destiné aux examinateurs scientifiques. Cette initiative vise à renforcer les capacités réglementaires grâce à l’IA, à accélérer la vitesse et l’efficacité des essais cliniques et à réduire les coûts. Il s’agit d’une avancée majeure pour l’IA dans les domaines de la réglementation gouvernementale et de l’approbation des médicaments, et pourrait ouvrir la voie à l’adoption de l’IA par les agences de réglementation pharmaceutique du monde entier (Source: ajeya_cotra)

OpenAI dévoile les détails techniques de l’ajustement fin par apprentissage par renforcement (RFT) et la stratégie de développement de GPT-4.1 : Mich Pokrass, responsable de GPT-4.1 chez OpenAI, a partagé les détails du RFT et le parcours de développement de GPT-4.1 lors du podcast Unsupervised Learning. Pour la construction de GPT-4.1, OpenAI a privilégié les retours des développeurs plutôt que les benchmarks traditionnels. Le RFT utilise le raisonnement en chaîne de pensée (chain-of-thought) et la notation spécifique aux tâches pour améliorer les performances du modèle, particulièrement adapté aux domaines complexes, et est actuellement disponible sur OpenAI o4-mini. L’interview a également abordé l’état actuel des applications des agents IA, l’amélioration de la fiabilité, et comment les startups peuvent réussir en utilisant l’évaluation et des stratégies de produits prospectives (Source: OpenAIDevs, aidan_mclau, michpokrass)

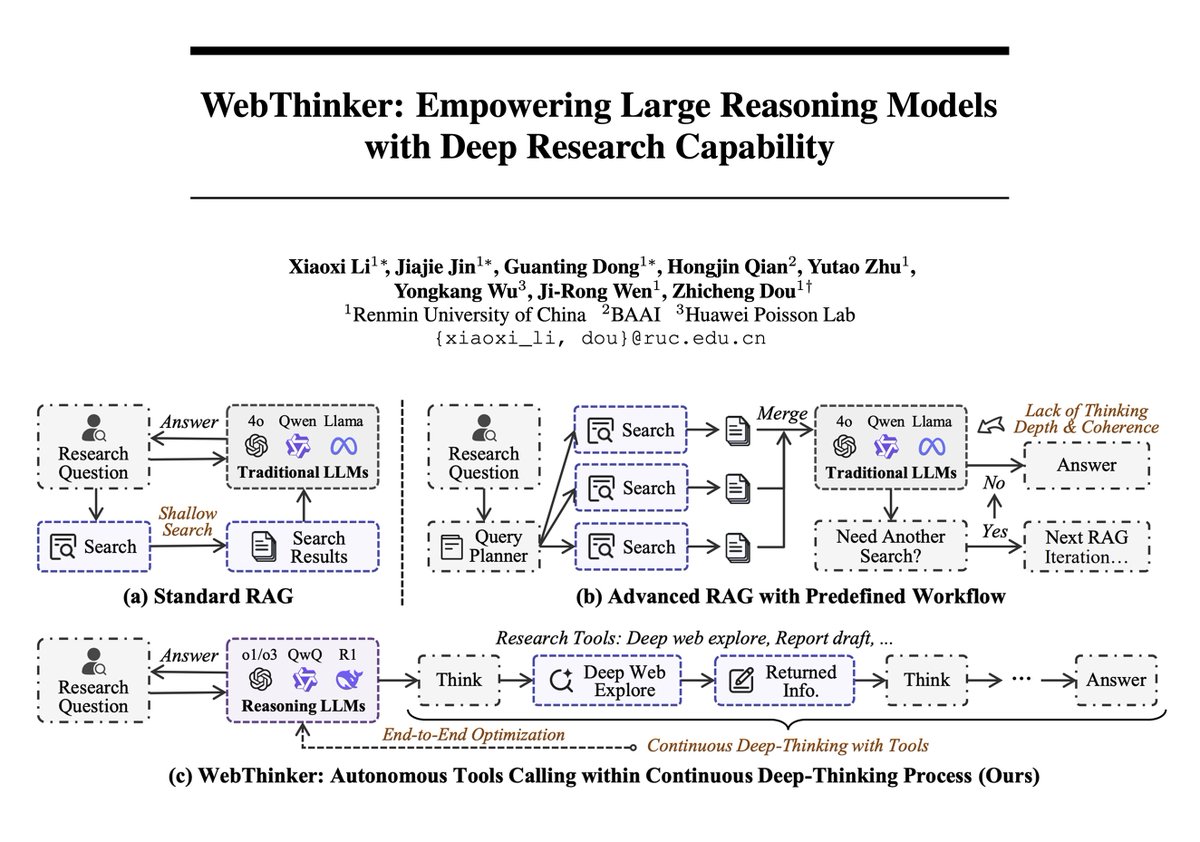
Le framework WebThinker combine les capacités des grands modèles de langage et de la recherche approfondie sur le web pour atteindre de nouveaux sommets en matière de raisonnement complexe : Un nouvel article présente WebThinker, un framework d’agent de raisonnement qui dote les grands modèles de raisonnement (LRM) de capacités autonomes d’exploration du web et de rédaction de rapports, afin de surmonter les limitations des connaissances internes statiques. WebThinker intègre un module de navigateur web profond et une stratégie autonome “penser-chercher-rédiger”, permettant au modèle de rechercher simultanément sur le web, de raisonner sur des tâches et de générer des résultats synthétisés. Sur des benchmarks de raisonnement complexe tels que GPQA et GAIA, WebThinker-32B-RL a atteint des résultats SOTA parmi les modèles 32B, surpassant GPT-4o et d’autres. Sa version entraînée par RL surpasse la version de base sur tous les benchmarks, démontrant l’importance de l’apprentissage itératif par préférences pour améliorer la coordination raisonnement-outil (Source: omarsar0, dair_ai)
Runway lance la mise à jour Gen-4 References, améliorant l’esthétique, la composition et la cohérence identitaire dans la génération vidéo : Runway Gen-4 References bénéficie d’une mise à jour qui améliore significativement la qualité esthétique, la composition des scènes et la cohérence de l’identité des personnages dans les vidéos générées. Une nouvelle fonctionnalité intéressante est la capacité du modèle à placer précisément les objets dans la scène selon une disposition fournie par l’utilisateur, et même à modifier des détails tels que la direction du regard des personnages, tout en maintenant la cohérence des autres éléments. Cela marque une nouvelle avancée dans la contrôlabilité et la finesse de la génération vidéo par IA, offrant aux créateurs des outils plus puissants (Source: c_valenzuelab, c_valenzuelab)

Li Dahai, PDG de Mianbi Intelligence : L’AGI dans le monde physique sera réalisée grâce à l’intelligence en périphérie (edge intelligence), la densité de connaissances est essentielle : Li Dahai, PDG de Mianbi Intelligence, estime que pour réaliser l’intelligence artificielle générale (AGI) dans le monde physique à l’avenir, l’intelligence en périphérie est la voie incontournable. Il souligne que la “densité de connaissances” des grands modèles est l’indicateur clé de l’intelligence, comparable à la finesse de gravure des puces : plus la densité de connaissances est élevée, plus l’intelligence est forte. Les modèles à haute densité de connaissances présentent un avantage naturel sur les appareils en périphérie où la puissance de calcul, la mémoire et la consommation d’énergie sont limitées. Mianbi Intelligence a déjà lancé plusieurs modèles pour périphérie et les a déployés dans des domaines tels que l’automobile, la robotique et les téléphones mobiles, comme le super assistant Mianbi Xiaogangpao, visant à doter chaque appareil d’intelligence pour une perception sensible, une prise de décision opportune et une réponse parfaite (Source: 量子位)

🎯 Tendances
Nouvelle fonctionnalité de Google Maps utilisant les capacités de Gemini pour identifier les noms de lieux dans les captures d’écran : Google Maps lance une nouvelle fonctionnalité qui, grâce aux capacités d’IA de Gemini, peut identifier les noms de lieux contenus dans les captures d’écran des utilisateurs et les enregistrer dans une liste sur la carte, facilitant ainsi l’accès et la planification des itinéraires. Cette fonctionnalité vise à simplifier le processus de recherche de voyages et à améliorer l’expérience utilisateur (Source: Google)
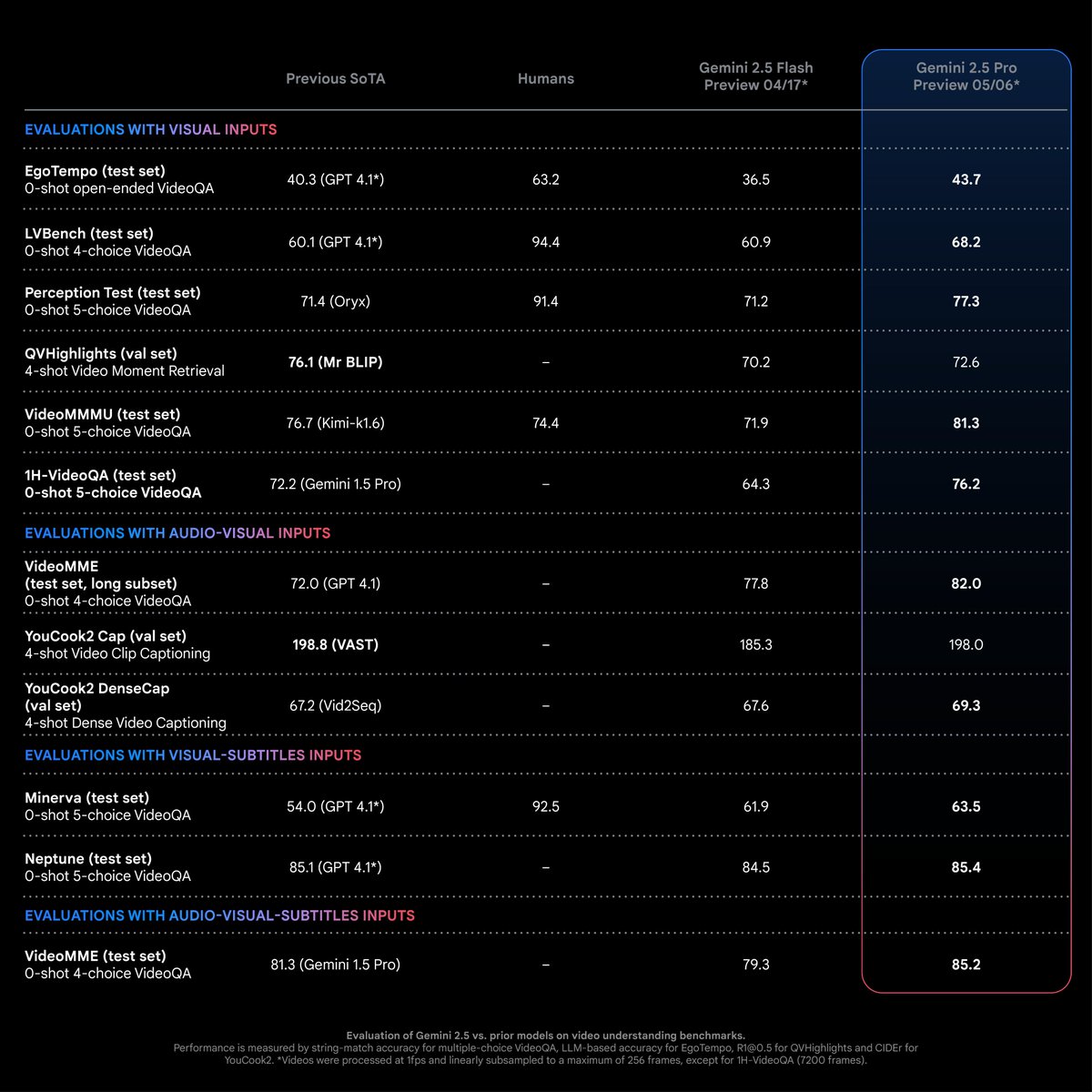
Gemini 2.5 Pro atteint des performances SOTA dans les tâches de compréhension vidéo : Selon Logan Kilpatrick, Gemini 2.5 Pro (version 05-06) a atteint un niveau de performance de pointe (SOTA) dans la plupart des tâches de compréhension vidéo, et ce avec une marge significative. C’est le fruit des efforts de l’équipe multimodale de Gemini, et cela devrait encourager les développeurs à explorer de nouvelles possibilités d’application dans ce domaine (Source: matvelloso)
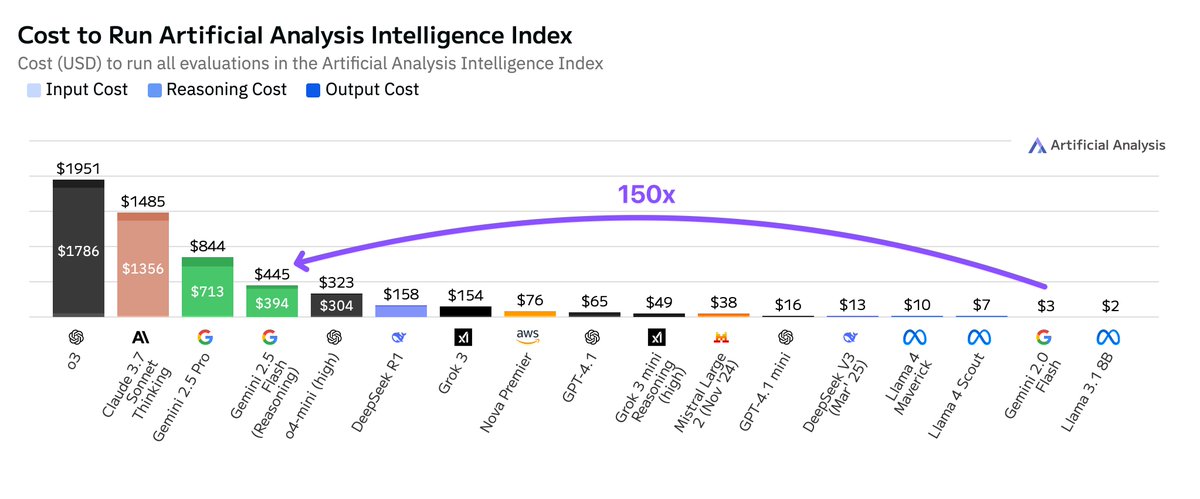
Les coûts d’exécution de Google Gemini 2.5 Flash sont bien supérieurs à ceux de la version 2.0 : Artificial Analysis souligne que lors de l’exécution de son indice d’intelligence, le coût de Google Gemini 2.5 Flash est 150 fois supérieur à celui de Gemini 2.0 Flash. L’explosion des coûts provient principalement d’une augmentation de 9 fois du prix des tokens de sortie (3,5 $/million de tokens avec la fonction d’inférence activée, 0,6 $ désactivée, contre 0,4 $ pour Flash 2.0) et d’une utilisation de tokens 17 fois plus élevée. Cela soulève des discussions sur l’équilibre entre faible latence et rentabilité pour la série de modèles Flash (Source: arohan)
Google intègre l’IA Gemini Nano dans le navigateur Chrome pour prévenir la fraude en ligne : Google a annoncé l’ajout du modèle d’IA Gemini Nano à son navigateur Chrome, visant à renforcer la capacité du navigateur à identifier et bloquer les escroqueries en ligne, améliorant ainsi la sécurité des utilisateurs sur le web. Cette initiative représente une nouvelle application de la technologie IA dans les fonctionnalités de sécurité des navigateurs grand public (Source: Reddit r/artificial, Reddit r/ArtificialInteligence)
Lightricks publie LTXVideo 13B 0.9.7, améliorant la qualité et la vitesse vidéo, et lance une version quantifiée ainsi que des modèles d’upscaling en espace latent : Lightricks met à jour son modèle vidéo LTXVideo vers la version 13B 0.9.7, offrant une qualité vidéo cinématographique et une vitesse de génération accrue. Parallèlement, une version quantifiée de LTXV 13B a été publiée, réduisant les besoins en mémoire et la rendant adaptée aux GPU grand public. Des modèles d’upscaling spatial et temporel en espace latent ont également été introduits, prenant en charge l’inférence multi-échelle et améliorant l’efficacité de la génération vidéo HD avec moins de décodage/encodage. Les nœuds ComfyUI et les workflows associés ont également été mis à jour (Source: GitHub Trending)

Une étude de Cohere Labs montre que l’extension au moment du test améliore les performances de raisonnement interlinguistique des grands modèles de langage : Une recherche de Cohere Labs indique que, bien que les modèles de langage pour le raisonnement soient principalement entraînés sur des données en anglais, l’extension au moment du test (test-time scaling) peut améliorer leurs performances de raisonnement interlinguistique zero-shot dans des environnements multilingues et différents domaines. Cette étude offre de nouvelles pistes pour améliorer l’efficacité des grands modèles de langage existants dans des scénarios non anglophones (Source: sarahookr)
L’IA évalue l’âge physiologique à partir de photos faciales et prédit les résultats du cancer : Un nouvel outil d’IA peut estimer l’âge physiologique d’un individu en analysant des photos de son visage et, sur cette base, prédire les résultats du traitement et les chances de survie pour des maladies telles que le cancer. Cette technologie offre une nouvelle méthode non invasive pour l’évaluation du pronostic des maladies (Source: Reddit r/artificial, Reddit r/ArtificialInteligence, Reddit r/artificial)
Les modèles d’IA ont tendance à sur-complexifier leur réflexion face à des tâches simples : Des développeurs ont remarqué que les modèles de raisonnement plus récents ont tendance à déclencher des processus de réflexion excessivement complexes face à des tâches simples, se montrant “hypersensibles”. Une approche plus idéale serait peut-être de disposer d’un modèle de base puissant capable de juger dynamiquement quand faire appel à l’outil de “réflexion”, évitant ainsi des calculs et des latences inutiles (Source: skirano)
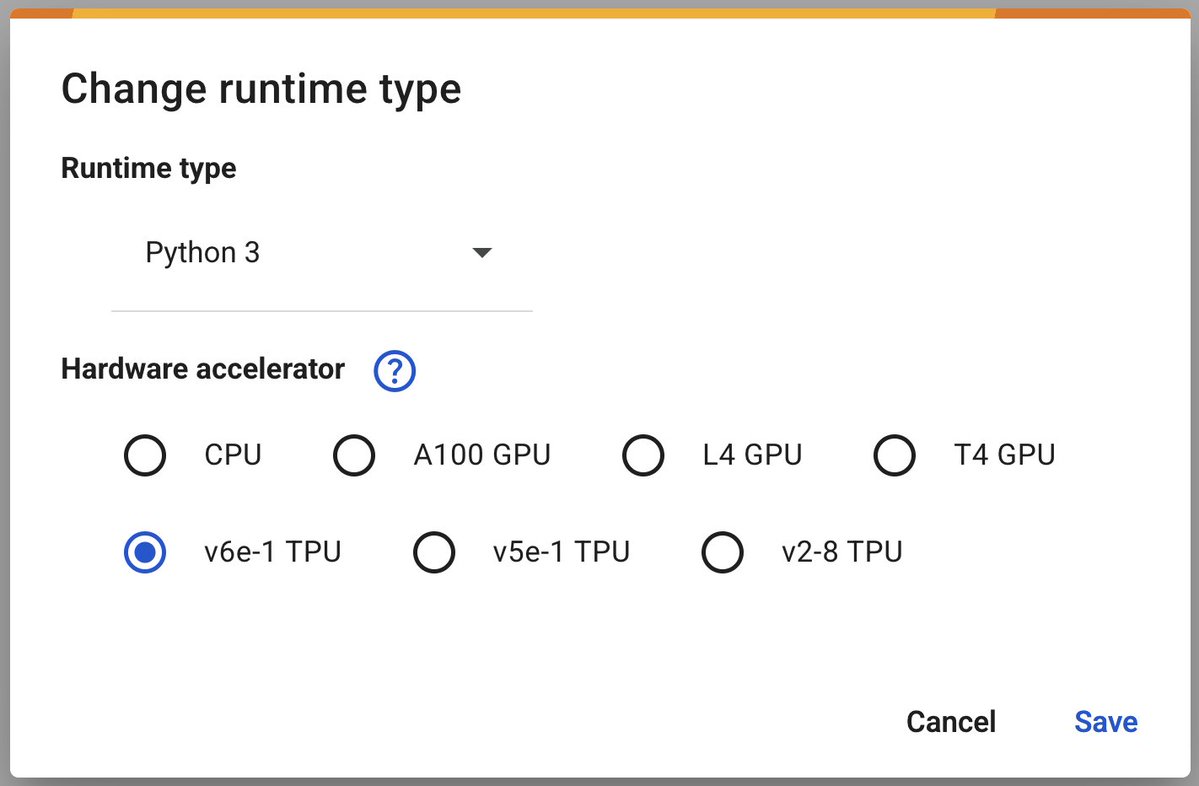
Google Colab lance les TPU v6e-1 (Trillium) pour accélérer l’apprentissage profond : Google Colaboratory a annoncé le lancement de son accélérateur d’apprentissage profond le plus rapide, le TPU v6e-1 (Trillium). Ce TPU dispose de 32 Go de mémoire à haute bande passante (deux fois plus que le v5e-1) et atteint des performances de pointe de 918 TFLOPS BF16 (près de trois fois celles de l’A100), offrant aux chercheurs et développeurs des ressources de calcul plus puissantes (Source: algo_diver)
Google AMIE : démonstration d’un agent IA conversationnel multimodal pour le diagnostic : Google a partagé la première démonstration de son agent IA conversationnel multimodal pour le diagnostic, AMIE. AMIE est capable de mener des conversations diagnostiques multimodales (par exemple, en combinant des informations textuelles et graphiques), marquant une nouvelle exploration de l’IA dans le domaine de l’aide au diagnostic médical (Source: dl_weekly)
Anthropic accusé d’avoir codé en dur la victoire de Trump dans le modèle Claude : Des utilisateurs ont découvert que le modèle Claude d’Anthropic, en répondant à des questions sur les élections de 2024, semblait avoir codé en dur des informations sur la victoire de Trump, bien que sa date limite de connaissances soit octobre 2024. Cela a soulevé des questions sur les mécanismes de mise à jour des informations des modèles d’IA, les biais potentiels et l’impact du contenu codé en dur sur la confiance des utilisateurs (Source: Reddit r/ClaudeAI)
🧰 Outils
ByteDance publie en open source le framework multi-agents DeerFlow : ByteDance a publié en open source DeerFlow, un framework multi-agents basé sur LangChain. Ce framework vise à simplifier et accélérer le développement d’applications multi-agents, en fournissant des outils pour construire des systèmes d’IA collaboratifs complexes. Les développeurs peuvent accéder à son dépôt GitHub et à son site officiel pour plus d’informations et d’exemples (Source: hwchase17)
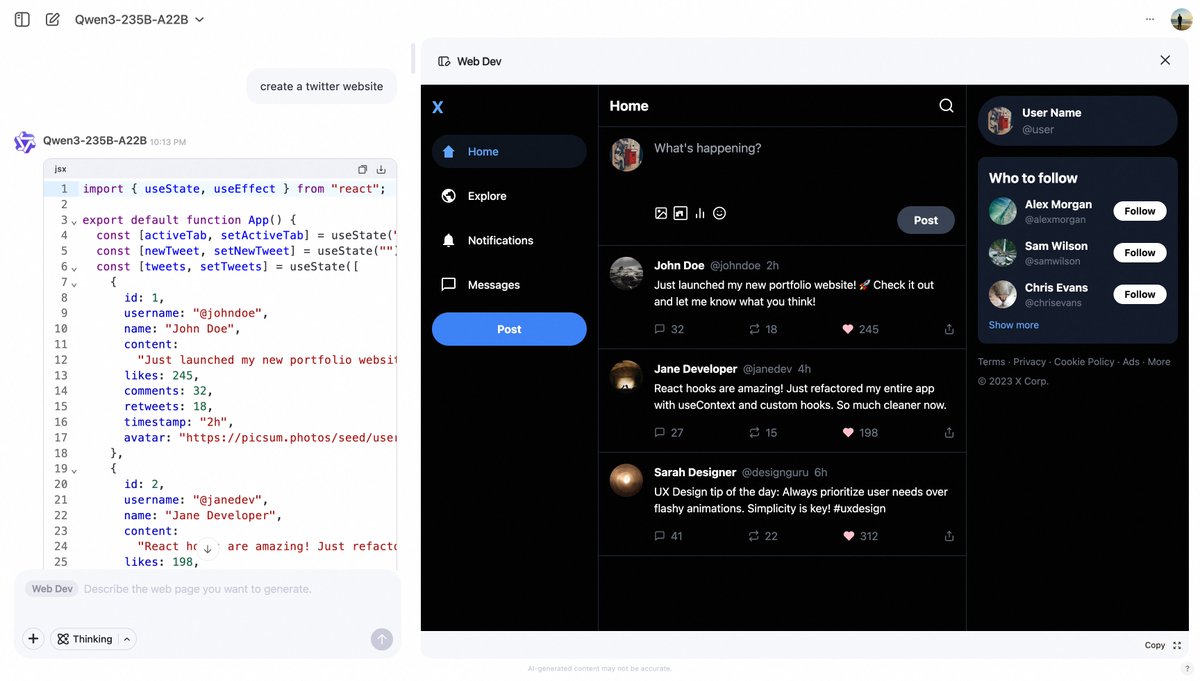
Alibaba Qwen Chat lance la fonctionnalité Web Dev, générant des pages web à partir de prompts : Alibaba Qwen Chat a ajouté une fonctionnalité “Web Dev”, permettant aux utilisateurs de générer rapidement du code pour des pages web front-end et des applications via de simples prompts textuels (par exemple, “créer un site web Twitter”). Cette fonctionnalité vise à abaisser la barrière à l’entrée du développement web, permettant même aux utilisateurs sans connaissances en programmation de construire des sites web en langage naturel (Source: Alibaba_Qwen, huybery)
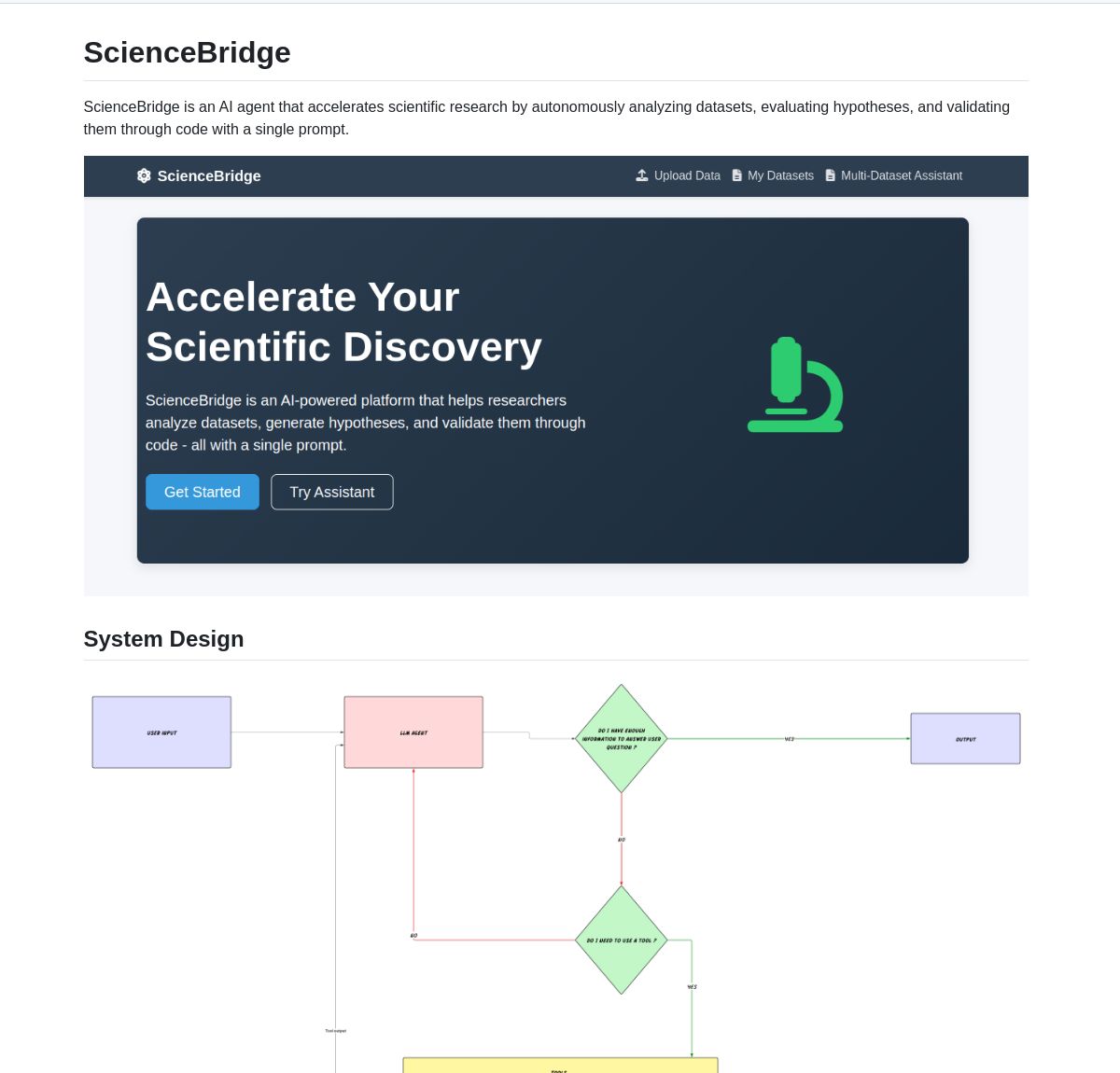
ScienceBridge AI : un agent d’automatisation de la recherche scientifique piloté par LangGraph : Un agent nommé ScienceBridge AI utilise le framework LangGraph pour automatiser les flux de travail de la recherche scientifique, y compris l’analyse de données, la validation d’hypothèses, et peut générer des visualisations de qualité publication, visant à accélérer la découverte scientifique. Le projet est open source sur GitHub (Source: LangChainAI, hwchase17)
El Agente Q : un système multi-agents piloté par LangGraph pour démocratiser la chimie quantique : Une nouvelle étude présente El Agente Q, un système multi-agents basé sur LangGraph, qui démocratise les calculs de chimie quantique grâce à une interaction en langage naturel et atteint un taux de réussite de 87% dans l’automatisation de flux de travail complexes. L’article correspondant a été publié sur arXiv, démontrant le potentiel de l’IA pour accélérer la recherche en chimie quantique (Source: LangChainAI, hwchase17)
LocalSite : une alternative localisée à DeepSite, utilisant des LLM locaux pour créer des pages web : Inspiré par le projet DeepSite sur HuggingFace, l’outil LocalSite permet aux utilisateurs de créer des pages web et des composants d’interface utilisateur à l’aide de prompts textuels, en utilisant des LLM exécutés localement (tels que les modèles GLM-4, Qwen3 déployés via Ollama et LM Studio) ainsi que des LLM cloud via des API compatibles OpenAI. Le projet est open source sur GitHub et vise à fournir une solution de génération de pages web par IA localisée et personnalisable (Source: Reddit r/LocalLLaMA)

Une alternative open source à NotebookLM démontre la puissance des technologies open source : Le développeur m_ric a créé une version open source et gratuite de Google NotebookLM. Cette application peut extraire le contenu de PDF ou d’URL, utiliser Llama 3.3-70B de Meta (exécuté à 1000 tokens/seconde via Cerebras Systems) pour rédiger des scripts de podcast, et utiliser Kokoro-82M pour la synthèse vocale. La génération audio s’exécute gratuitement sur les H200 de HuggingFace avec Zero GPU, démontrant que les solutions open source peuvent rivaliser avec les solutions propriétaires en termes de fonctionnalités et de rentabilité (Source: huggingface, mervenoyann)
DeepFaceLab : le principal logiciel open source de création de Deepfake : DeepFaceLab est un logiciel open source réputé, spécialisé dans la création de contenu Deepfake. Il offre des fonctionnalités telles que le remplacement de visages, le dé-vieillissement, le remplacement de têtes, etc., et est largement utilisé pour la création de contenu sur des plateformes comme YouTube, TikTok. Le projet est continuellement mis à jour, propose des versions Windows et Linux, et bénéficie d’un soutien communautaire actif (Source: GitHub Trending)
GPUI Component : une bibliothèque de composants d’interface utilisateur de bureau en Rust basée sur GPUI : L’équipe de longbridge a lancé GPUI Component, une bibliothèque contenant plus de 40 composants d’interface utilisateur de bureau multiplateformes, dont le design s’inspire des contrôles macOS, Windows et de shadcn/ui. Elle prend en charge plusieurs thèmes, des tailles réactives, des mises en page flexibles (Dock et Tiles), et gère efficacement le rendu de grandes quantités de données (Table/List virtualisées) ainsi que le rendu de contenu (Markdown/HTML). Son premier cas d’utilisation est l’application de bureau Longbridge Pro (Source: GitHub Trending)

Ultralytics YOLO11 : framework de pointe pour la détection d’objets et la vision par ordinateur : Ultralytics continue de mettre à jour sa série de modèles YOLO, le dernier YOLO11 offrant des performances SOTA dans des tâches telles que la détection d’objets, le suivi, la segmentation, la classification et l’estimation de pose. Ce framework est facile à utiliser, prend en charge les interfaces CLI et Python, et s’intègre avec des plateformes telles que Weights & Biases, Comet ML, Roboflow et OpenVINO. Ultralytics HUB propose des solutions de visualisation de données, d’entraînement et de déploiement sans code. Les modèles sont sous licence open source AGPL-3.0 et une licence commerciale est également disponible (Source: GitHub Trending)

Tensorlink : framework pour la distribution de modèles PyTorch et le partage de ressources P2P : SmartNodes Lab a lancé Tensorlink, un framework open source visant à simplifier l’entraînement distribué et l’inférence de grands modèles PyTorch. Il encapsule les objets PyTorch principaux, abstrayant la complexité des systèmes distribués, et permettant aux utilisateurs d’exploiter les ressources GPU de plusieurs ordinateurs sans connaissances spécialisées ni matériel spécifique. Tensorlink prend en charge une API d’inférence à la demande et un framework de nœuds, facilitant le partage ou la contribution de puissance de calcul par les utilisateurs. Il est actuellement en version préliminaire (Source: Reddit r/MachineLearning)
Optimisation des prompts pour générer des photos de figurines d’anime : Un utilisateur a partagé un exemple de génération de photos de figurines de style anime japonais à partir de photos de personnages téléchargées, en utilisant l’IA (comme GPT-4o) et en optimisant les prompts. La clé réside dans la description précise de la pose, de l’expression, des vêtements, du matériau de la figurine (par exemple, semi-mat), des dégradés de couleurs, ainsi que de l’angle de prise de vue (sur un bureau, sensation de photo prise rapidement avec un téléphone). Des optimisations supplémentaires incluent la génération de vues multi-angles (face, profil, dos) disposées en grille de quatre, assurant l’intégrité des détails de la figurine entière et de son socle, pour faciliter la modélisation 3D ultérieure (Source: dotey, dotey)

Publication en open source du NVIDIA Agent Intelligence Toolkit : NVIDIA a publié en open source l’Agent Intelligence Toolkit, une bibliothèque de ressources pour la création d’applications d’agents intelligents. Ce toolkit vise à aider les développeurs à créer et déployer plus facilement des agents IA basés sur les technologies NVIDIA (Source: nerdai)
SkyPilot et SGLang simplifient le déploiement auto-hébergé de Llama 4 sur plusieurs nœuds : Nebius AI a montré comment utiliser SkyPilot et SGLang (de LMSYS.org) pour auto-héberger le modèle Llama 4 de Meta sur plusieurs nœuds (par exemple, 8x H100) avec une seule commande. Cette solution offre un débit élevé, une utilisation efficace de la mémoire, et intègre des fonctionnalités de production telles que l’authentification et HTTPS, tout en facilitant l’intégration avec l’outil llm de Simon Willison (Source: skypilot_org)

📚 Apprentissage
Le Vector Institute lance les AI Pocket References : L’équipe d’ingénierie IA du Vector Institute a publié le projet AI Pocket References, une série de fiches d’information concises sur l’IA, couvrant des domaines tels que le NLP (en particulier les LLM), l’apprentissage fédéré, l’IA responsable et le calcul haute performance. Ces références visent à fournir un guide d’initiation aux débutants et une révision rapide aux praticiens expérimentés, chaque fiche étant conçue pour être lue en moins de 7 minutes. Le projet est open source et accueille les contributions de la communauté (Source: nerdai)

HuggingFace publie 9 cours gratuits sur l’IA : HuggingFace a lancé une série de 9 cours gratuits sur l’IA, couvrant plusieurs domaines tels que les grands modèles de langage (LLM), la vision par ordinateur et les agents IA. Ces cours offrent des ressources précieuses aux apprenants souhaitant acquérir systématiquement des connaissances en IA (Source: ClementDelangue)
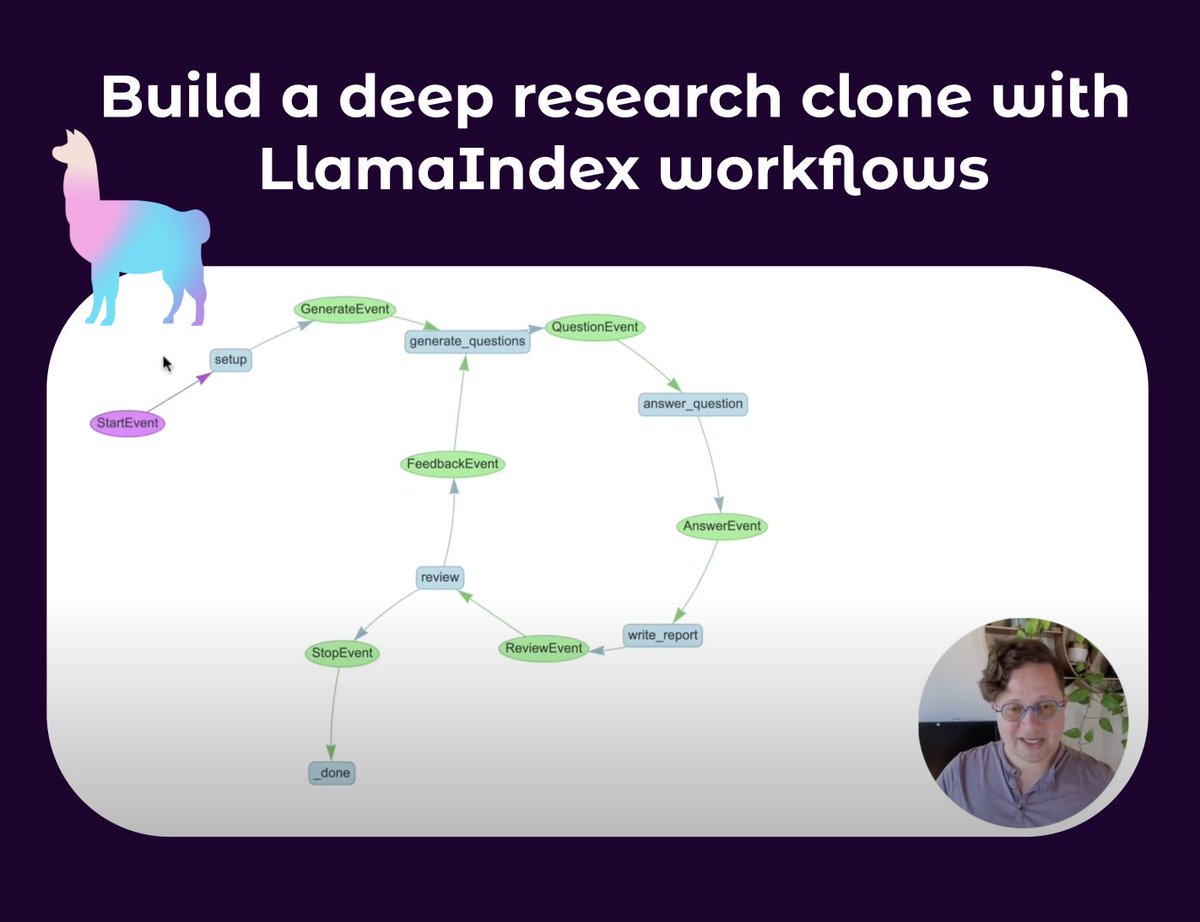
LlamaIndex publie un tutoriel sur la création d’agents de recherche approfondie : Seldo de LlamaIndex a publié un tutoriel vidéo guidant les utilisateurs dans la construction d’un agent clone de type Deep Research. Le tutoriel commence par les bases des agents uniques et progresse vers des flux de travail multi-agents avancés, y compris l’utilisation de multiples bases de connaissances et du web pour la recherche, le maintien du contexte, et la mise en œuvre d’un processus complet de recherche, de rédaction et de révision. Le tutoriel met l’accent sur la construction de flux de travail d’agents complexes capables de boucles, de branchements, d’exécution concurrente et d’auto-réflexion (Source: jerryjliu0, jerryjliu0)
Rétrospective du développement de la technologie RAG : l’article de Lewis et al. et les travaux antérieurs : Aran Komatsuzaki souligne que, bien que l’article de Lewis et al. de 2020 soit largement cité pour avoir introduit le terme RAG (Retrieval-Augmented Generation), la génération augmentée par récupération était déjà un domaine de recherche actif auparavant, avec des travaux tels que DrQA (2017), ORQA (2019), REALM (2020). La principale contribution de Lewis et al. a été de proposer une nouvelle méthode de pré-entraînement conjoint pour RAG, mais ce n’est pas la méthode de mise en œuvre de RAG la plus couramment utilisée aujourd’hui. Cela nous rappelle l’importance de prêter attention à la continuité du développement technologique et aux travaux fondateurs antérieurs (Source: arankomatsuzaki)
Utiliser Qwen3 pour obtenir un format de sortie en chaîne de pensée similaire à Gemini 2.5 Pro : Inspiré par le README d’Apriel-Nemotron-15b-Thinker concernant la contrainte imposée au modèle de commencer sa sortie dans un format spécifique (par exemple, “Voici mes étapes de raisonnement :\n”), un développeur a utilisé la fonctionnalité OpenWebUI pour que le modèle Qwen3 commence toujours sa sortie par <think>\nMon processus de réflexion étape par étape s'est déroulé comme suit :\n1.. Les expériences montrent que cela incite Qwen3 à réfléchir et à produire des résultats de manière séquentielle, similaire à Gemini 2.5 Pro, bien que cela n’améliore pas en soi l’intelligence du modèle, mais modifie son format de réflexion et d’expression (Source: Reddit r/LocalLLaMA)
Partage sur la philosophie de conception et les coulisses du développement de Claude Code dans un podcast : Le podcast Latent Space a invité Catherine Wu et Boris Cherny, les créateurs de Claude Code, pour partager la philosophie de conception et l’histoire du développement de cet outil de programmation IA. Les points clés incluent : CC peut déjà écrire environ 80% de son propre code (avec révision humaine), inspiré par Aider, il met l’accent sur une implémentation simple (par exemple, utiliser des fichiers Markdown pour la mémoire plutôt qu’une base de données vectorielle), adopte une petite équipe et une itération interne pour piloter le produit, offre un accès au modèle brut aux utilisateurs avancés, et prend en charge les flux de travail parallèles. Le podcast a également abordé les comparaisons avec des outils comme Cursor, Windsurf, ainsi que des sujets tels que les coûts, la conception UI/UX, et la possibilité d’open source (Source: Reddit r/ClaudeAI)

💼 Affaires
Salesforce lance un plan d’IA de 500 millions de dollars en Arabie Saoudite et constitue une équipe : Salesforce a commencé à constituer une équipe en Arabie Saoudite dans le cadre de son plan d’investissement quinquennal de 500 millions de dollars, visant à promouvoir l’adoption et le développement de l’intelligence artificielle dans le pays. Cela marque une autre initiative importante des grandes entreprises technologiques dans le domaine de l’IA au Moyen-Orient (Source: Reddit r/artificial, Reddit r/ArtificialInteligence)
Fidji Simo, nouvelle PDG de la division Applications d’OpenAI, quittera le conseil d’administration de Shopify : Fidji Simo, actuelle PDG d’Instacart, quittera ses fonctions au conseil d’administration de Shopify après avoir été nommée PDG de la nouvelle division Applications d’OpenAI. Cette décision vise probablement à lui permettre de se concentrer davantage sur son rôle de direction chez OpenAI, gérant ses activités et ses gammes de produits en croissance rapide. Des rapports antérieurs indiquaient qu’OpenAI pourrait conclure un accord potentiel d’un milliard de dollars avec Arm (Source: steph_palazzolo, steph_palazzolo)
Lux Capital crée un fonds de 100 millions de dollars pour soutenir les scientifiques américains confrontés à des réductions de financement : Pour faire face aux difficultés liées aux coupes budgétaires drastiques de la National Science Foundation (NSF) américaine (qui s’élèveraient à 50%, entraînant l’annulation de projets en cours et des suppressions de postes), Lux Capital a annoncé le lancement de la “Lux Science Helpline”, investissant 100 millions de dollars pour soutenir les scientifiques américains affectés. L’objectif est d’assurer la poursuite de projets de recherche clés et de maintenir la compétitivité des États-Unis en matière d’innovation technologique (Source: ylecun, riemannzeta)

🌟 Communauté
Le débat sur le remplacement des emplois humains par l’IA se poursuit : Au sein de la communauté, la discussion sur la question de savoir si l’IA entraînera un chômage de masse est très répandue. Un point de vue soutient que, sous l’impulsion du capitalisme, les entreprises rechercheront l’efficacité et remplaceront la main-d’œuvre coûteuse par l’IA, ce qui entraînera une réduction des postes tels que ceux de programmeurs. Un autre point de vue s’appuie sur l’histoire, arguant que le progrès technologique (comme l’ampoule électrique remplaçant l’allumeur de réverbères) élimine les anciens emplois mais en crée de nouveaux (comme les usines d’ampoules, les industries liées à l’électricité), la clé étant l’amélioration des compétences et l’innovation. Actuellement, l’IA nécessite toujours une intervention humaine pour les tâches complexes et le débogage de code, mais son développement rapide et ses performances efficaces dans certains domaines inquiètent de nombreuses personnes quant aux perspectives d’emploi futures, tandis que d’autres considèrent cela comme alarmiste ou une surestimation à court terme des capacités de l’IA (Source: Reddit r/ArtificialInteligence)
Inquiétudes concernant les limites des capacités des LLM et un éventuel hiver de l’IA : Certains membres de la communauté et experts (tels que Yann LeCun, François Chollet) commencent à se demander si les grands modèles de langage (LLM) ne se heurtent pas à un goulot d’étranglement. Bien que les LLM excellent dans l’imitation de modèles, ils présentent encore des limites en matière de compréhension réelle, de raisonnement et de gestion des hallucinations, et une dépendance excessive aux données synthétiques pourrait également poser problème. En l’absence de nouvelles orientations de recherche (telles que les modèles du monde, les systèmes neuro-symboliques), l’engouement actuel pour l’IA pourrait se refroidir, entraînant une diminution des investissements, voire un nouvel “hiver de l’IA”. Cependant, certains estiment que si les LLM généraux peuvent atteindre un plafond, les modèles spécialisés et les agents IA continuent de se développer rapidement (Source: Reddit r/ArtificialInteligence)
Le projet d’OpenAI de publier un modèle open source cet été suscite des discussions au sein de la communauté : Sam Altman a déclaré lors d’une audition au Sénat qu’OpenAI prévoyait de publier un modèle open source cet été. Les réactions de la communauté sont mitigées : certains attendent avec impatience ses performances, d’autres se demandent s’il sera comme le FSD de Musk, “toujours en développement”, ou s’il sera “bridé” pour ne pas concurrencer les modèles payants. D’autres analysent que des entreprises comme Meta et Alibaba, en publiant des modèles pré-entraînés gratuits de haute qualité, cherchent à affaiblir la position sur le marché d’entreprises comme OpenAI, et que cette initiative d’OpenAI pourrait être une stratégie de réponse. Cependant, compte tenu du modèle économique d’OpenAI et de ses coûts d’exploitation élevés, le positionnement et la compétitivité de son modèle open source restent à voir (Source: Reddit r/LocalLLaMA)

L’impact de l’IA sur la fiabilité de l’information sur Internet suscite des inquiétudes : Des utilisateurs sur Reddit ont exprimé leurs préoccupations quant à l’impact de l’IA sur la fiabilité d’Internet. En particulier, des fonctionnalités telles que Google AI Overviews fournissent parfois des réponses inexactes ou “absurdes présentées avec sérieux” (par exemple, en expliquant des expressions inventées par l’utilisateur), ce qui pourrait induire en erreur la prochaine génération d’utilisateurs, voire les amener à douter de toutes les informations. Les commentaires sont partagés : certains estiment qu’Internet n’a jamais été totalement fiable et que l’esprit critique a toujours été important ; d’autres plaisantent en disant que l’auteur du message révèle son âge (Source: Reddit r/ArtificialInteligence)
Un utilisateur partage son expérience d’apaisement de la dépression grâce à des échanges avec ChatGPT : Un utilisateur a partagé comment, après une longue conversation avec ChatGPT, sa dépression et ses pensées suicidaires se sont atténuées. Il a déclaré que même le fait de se confier à une IA l’avait aidé à relâcher une énorme pression psychologique et lui avait donné le courage de continuer et de demander de l’aide à ses proches. De nombreuses personnes dans les commentaires ont rapporté des expériences similaires, estimant que l’IA peut offrir un accompagnement impartial et patient en matière de soutien psychologique. Un utilisateur a même partagé un prompt pour que ChatGPT joue le rôle d’un “moi supérieur” pour des conversations approfondies. Cela a suscité des discussions sur le potentiel de l’IA dans l’aide à la santé mentale (Source: Reddit r/ChatGPT)
Réflexion sur l’affirmation selon laquelle “les LLM ne font que prédire le mot suivant” : Au sein de la communauté, des discussions soulignent que l’affirmation “les LLM ne font que prédire le mot suivant” est trop simpliste et risque de faire sous-estimer les capacités réelles et l’impact potentiel des LLM. L’essentiel réside dans la complexité et l’utilité du contenu produit par les LLM (comme le code, les analyses), et non dans leur mécanisme de génération. Les experts s’inquiètent du développement rapide de l’IA et de ses capacités inconnues, tandis que le grand public pourrait, à cause de ces affirmations simplistes, ne pas prendre pleinement conscience des transformations profondes que la technologie IA est sur le point d’apporter. La discussion aborde également les questions d‘“intelligence” et de “conscience” de l’IA, estimant que même si l’IA n’a pas de conscience au sens humain du terme, ses capacités suffisent à avoir un impact énorme sur le monde (Source: Reddit r/ArtificialInteligence)
Discussion sur la valeur de la version payante de Claude : la gestion de projet, la longueur du contexte et le mode de pensée sont essentiels : Des utilisateurs payants de Claude ont partagé ce qui justifie la valeur de leur abonnement. Les principaux avantages incluent la fonctionnalité “Projets”, qui permet aux utilisateurs de télécharger une grande quantité de documents de référence (base de connaissances) pour des tâches spécifiques (comme la préparation de cours, le SEO de sites web, l’analyse publicitaire, les résumés d’actualités, la recherche de recettes), permettant à Claude de fournir une aide continue dans un contexte spécifique. De plus, une fenêtre de contexte plus grande, un “Mode de Pensée” (Thinking Mode) plus puissant et un plus grand nombre de requêtes sont également des attraits de la version payante. Les retours d’utilisateurs indiquent que pour gérer des tâches complexes, la révision de code, l’analyse de documents et la rédaction d’e-mails, Claude Pro combiné à des outils MCP (comme Desktop Commander) surpasse certaines solutions intégrées aux IDE, ces dernières pouvant limiter la capacité d’analyse approfondie du modèle en raison de l’optimisation des coûts ou des invites système intégrées (Source: Reddit r/ClaudeAI, Reddit r/ClaudeAI)
La modification de la licence d’OpenWebUI suscite des inquiétudes au sein de la communauté et des entreprises utilisatrices : Le projet OpenWebUI a récemment modifié la licence de son logiciel, un changement qui a suscité des inquiétudes chez certains membres de la communauté et des entreprises utilisatrices. Une entreprise a déclaré être en discussion pour cesser d’utiliser et de contribuer au projet, et qu’elle allait temporairement créer un fork basé sur la dernière version sous licence BSD. Cet événement souligne l’impact que les changements de licence des projets open source peuvent avoir sur l’écosystème des utilisateurs et des contributeurs, en particulier dans les scénarios d’application commerciale (Source: Reddit r/OpenWebUI)
💡 Divers
Le Vatican prévoit d’investir dans de nouvelles sources de données pour faire face au problème du “mur de données” : Depuis 2023, l’entraînement des grands modèles de langage est confronté au problème du “mur de données”, c’est-à-dire que la plupart des données textuelles humaines connues ont déjà été indexées et utilisées pour l’entraînement. Pour résoudre ce problème, le Vatican prévoit d’investir dans de nouvelles sources de données, par exemple en transcrivant des documents d’églises médiévales grâce à la technologie OCR et en générant des données synthétiques, afin d’améliorer continuellement les capacités des modèles d’IA (Source: jxmnop, Dorialexander)

Le développement technologique rapide de la Chine suscite l’attention dans de nombreux domaines d’innovation : Un message détaille de nombreuses applications technologiques étonnantes observées par l’auteur lors d’un voyage de 15 jours en Chine, notamment des poupées sexuelles DeepSeek, des dirigeables électriques, des drones utilisés pour gérer les accidents de la route, etc. Cela a suscité des discussions sur la vitesse du développement technologique et l’étendue des applications en Chine dans des domaines tels que l’intelligence artificielle, la robotique, les transports à énergie nouvelle, et a établi des comparaisons avec des pays de haute technologie comme Singapour (Source: GavinSBaker)

Attentes concernant les développements de l’IA dans le domaine médical : Les membres de la communauté expriment leur espoir de voir des progrès plus importants de l’IA dans le domaine médical. Les scénarios envisagés incluent des robots IA capables de scanner instantanément le corps et de détecter les symptômes de maladies à un stade précoce, ainsi que des systèmes pouvant aider à des traitements précis, à la chirurgie et à accélérer la rééducation. Bien que les technologies existantes aient déjà progressé dans certains domaines, il est largement admis que l’IA a encore un énorme potentiel inexploité pour améliorer l’accessibilité, la précision des soins médicaux et sauver des vies (Source: Reddit r/ArtificialInteligence, Reddit r/artificial)