
Mots-clés:ChatGPT, GitHub, Modèle d’IA, Multimodal, Apprentissage par renforcement, Open source, Meta FAIR, AGI, Fonction de recherche approfondie de ChatGPT, Architecture Transformer hybride, Réglage fin par renforcement (RFT), Modèle multivers IA pour mondes multiples, Cadre d’IA pour scientifiques
🔥 Pleins Feux
ChatGPT深度研究功能集成GitHub: OpenAI annonce que la fonctionnalité Deep Research de ChatGPT prend désormais en charge la connexion aux dépôts de code GitHub. Après qu’un utilisateur a posé une question, l’agent IA peut automatiquement lire, rechercher et analyser le code source, les PR, les documents README, etc., dans le dépôt de code, et générer un rapport détaillé contenant des citations directes. Cette fonctionnalité vise à aider les développeurs à se familiariser rapidement avec les projets, à comprendre la structure du code et la pile technologique. Actuellement, cette fonctionnalité est en phase de test et a été ouverte aux utilisateurs Team, et sera progressivement étendue aux utilisateurs Plus et Pro. (Source: OpenAI Developers, snsf, EdwardSun0909, op7418, gdb, tokenbender, 量子位, 36氪)

全球首个AI多人世界模型Multiverse开源: La start-up israélienne Enigma Labs a mis en open source son modèle de monde multi-joueurs Multiverse, permettant à deux agents IA de percevoir, interagir et collaborer dans le même environnement généré. Ce modèle, entraîné sur Gran Turismo 4, traite l’état du monde partagé en empilant les perspectives des deux joueurs le long des canaux de couleur et en combinant un échantillonnage clairsemé des images historiques, réalisant ainsi l’entraînement et l’exécution en temps réel sur PC pour un coût inférieur à 1500 dollars. Cette initiative est considérée comme une avancée importante pour l’IA dans la compréhension et la génération d’environnements virtuels partagés, offrant de nouvelles perspectives pour les systèmes multi-agents et les plateformes de simulation et d’entraînement. (Source: Reddit r/MachineLearning, 36氪)
顶尖AI科学家Rob Fergus回归并执掌Meta FAIR,目标AGI: Rob Fergus, qui a cofondé FAIR avec Yann LeCun à ses débuts, puis a dirigé l’équipe de New York chez DeepMind, est retourné chez Meta pour succéder à Joelle Pineau à la tête de FAIR. Fergus a rejoint le département GenAI de Meta en avril de cette année, se consacrant à l’amélioration de la mémoire et des capacités de personnalisation du modèle Llama. LeCun a simultanément annoncé que le nouvel objectif de FAIR serait l’intelligence artificielle générale (AGI). Fergus est un chercheur très cité dans le domaine de l’IA, dont les travaux représentatifs incluent la recherche sur la visualisation de ZFNet et des travaux pionniers sur les exemples adverses. (Source: ylecun, 36氪)

Anthropic发布Claude AI价值观研究,揭示3307种AI价值倾向: L’équipe de recherche d’Anthropic a publié un article en prépublication intitulé « Values in the Wild », qui, en analysant les performances de Claude AI dans des conversations du monde réel, a identifié 3307 valeurs uniques de l’IA. L’étude a révélé que les valeurs les plus courantes sont orientées vers le service, telles que « serviabilité » (23,4 %), « professionnalisme » (22,9 %) et « transparence » (17,4 %). Les valeurs de l’IA ont été regroupées en cinq catégories principales : utilitaire (31,4 %), cognitive (22,2 %), sociale (21,4 %), protectrice (13,9 %) et personnelle (11,1 %), et ont montré une forte dépendance contextuelle. Claude répond généralement de manière positive aux valeurs exprimées par les humains (43 %), le reflet des valeurs représente environ 20 %, tandis que la résistance aux valeurs des utilisateurs est rare (5,4 %). (Source: Reddit r/ArtificialInteligence)
Yoshua Bengio提出“科学家AI”框架,倡导更安全的AI发展路径: Le lauréat du prix Turing, Yoshua Bengio, a publié un article d’opinion dans le magazine Time, exposant l’orientation de recherche de son équipe sur le « Scientist AI ». Il estime qu’il s’agit d’une voie de développement de l’IA pratique, efficace et plus sûre, visant à remplacer la trajectoire actuelle de développement de l’IA non contrôlée et axée sur les agents. Ce cadre souligne que les systèmes d’IA doivent posséder des capacités d’explicabilité, de vérifiabilité et d’alignement sur les valeurs humaines. En simulant la méthodologie de la recherche scientifique, le comportement et le processus de prise de décision de l’IA deviennent plus transparents et contrôlables, réduisant ainsi les risques potentiels. (Source: Yoshua_Bengio)
🎯 Tendances
OpenAI强化微调(RFT)功能正式在o4-mini上线: OpenAI a annoncé que la fonctionnalité de Reinforcement Fine-Tuning (RFT), présentée en avant-première en décembre dernier, est désormais officiellement disponible dans le modèle o4-mini. RFT utilise le raisonnement en chaîne de pensée et la notation spécifique à la tâche pour améliorer les performances du modèle dans des domaines complexes. Par exemple, la société AccordanceAI a déjà utilisé RFT pour affiner un modèle aux performances de pointe en matière de fiscalité et de comptabilité. (Source: OpenAI Developers, gdb, 量子位, 36氪)
Gemini API上线隐式缓存功能,降低75%调用成本: L’API Gemini de Google a ajouté une fonctionnalité de mise en cache implicite. Lorsque la requête d’un utilisateur partage un préfixe commun avec une requête précédente, un cache hit peut être automatiquement déclenché, permettant aux utilisateurs d’économiser 75 % des coûts en Tokens. Cette fonctionnalité ne nécessite pas que les développeurs créent activement un cache. Parallèlement, le seuil minimum de Tokens pour déclencher le cache a été abaissé à 1K sur Gemini 2.5 Flash et à 2K sur 2.5 Pro, réduisant davantage les coûts d’utilisation de l’API. (Source: op7418)

OpenAI在欧洲经济区等多地全面推出ChatGPT记忆功能: OpenAI a annoncé que la fonctionnalité de mémoire de ChatGPT est désormais entièrement disponible pour les utilisateurs Plus et Pro dans l’Espace économique européen (EEE), au Royaume-Uni, en Suisse, en Norvège, en Islande et au Liechtenstein. Cette fonctionnalité permet à ChatGPT de référencer l’historique de toutes les conversations passées de l’utilisateur pour fournir des réponses plus personnalisées, mieux comprendre les préférences et les intérêts de l’utilisateur, et ainsi offrir une aide plus précise en matière de rédaction, de conseils, d’apprentissage, etc. (Source: openai)
ByteDance Seed推出多模态基础模型Mogao: L’équipe SEED de ByteDance a lancé un modèle de fondation Omni nommé Mogao, spécialement conçu pour la génération multimodale entrelacée. Mogao intègre plusieurs améliorations techniques, notamment une conception à fusion profonde, de doubles encodeurs visuels, des embeddings de position rotatifs entrelacés et un guidage sans classificateur multimodal. Ces améliorations lui permettent de combiner les avantages des modèles autorégressifs (génération de texte) et des modèles de diffusion (synthèse d’images de haute qualité), traitant efficacement des séquences arbitrairement entrelacées de texte et d’images. (Source: NandoDF)

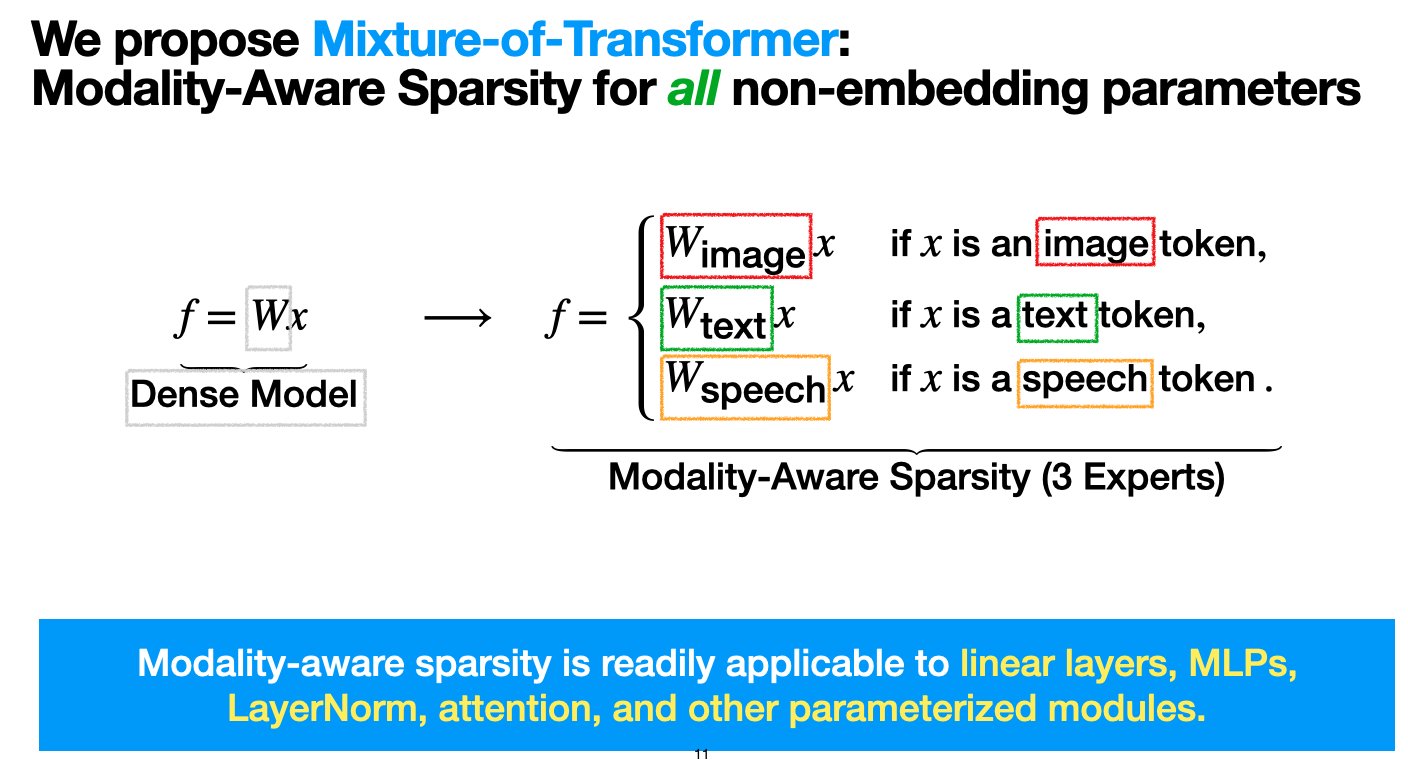
Meta推出混合Transformer(MoT)架构,旨在降低多模态模型预训练成本: Les chercheurs de Meta AI ont proposé une architecture clairsemée appelée « Mixture-of-Transformers (MoT) », visant à réduire considérablement les coûts de calcul du pré-entraînement des modèles multimodaux sans sacrifier les performances. MoT applique une sparsité sensible à la modalité aux paramètres Transformer non-embedding (tels que les réseaux feed-forward, les matrices d’attention et la normalisation de couche). Les expériences montrent que dans la configuration Chameleon (génération de texte + image), un modèle MoT 7B atteint la qualité de la ligne de base dense avec seulement 55,8 % des FLOPs ; en étendant à la parole comme troisième modalité, il n’utilise que 37,2 % des FLOPs. Ce travail de recherche a été accepté par TMLR (mars 2025) et le code a été mis en open source. (Source: VictoriaLinML)
Qwen模型改进项目Smoothie Qwen发布,平衡多语言生成: Un projet d’amélioration du modèle Qwen, nommé Smoothie Qwen, a été lancé. Il vise à équilibrer les capacités de génération multilingue en ajustant les probabilités des paramètres internes du modèle. Ce projet résout principalement le problème des sorties occasionnelles en chinois rencontrées par certains utilisateurs non chinois lors de l’utilisation de Qwen, et prétend ne pas réduire l’intelligence du modèle. (Source: karminski3)

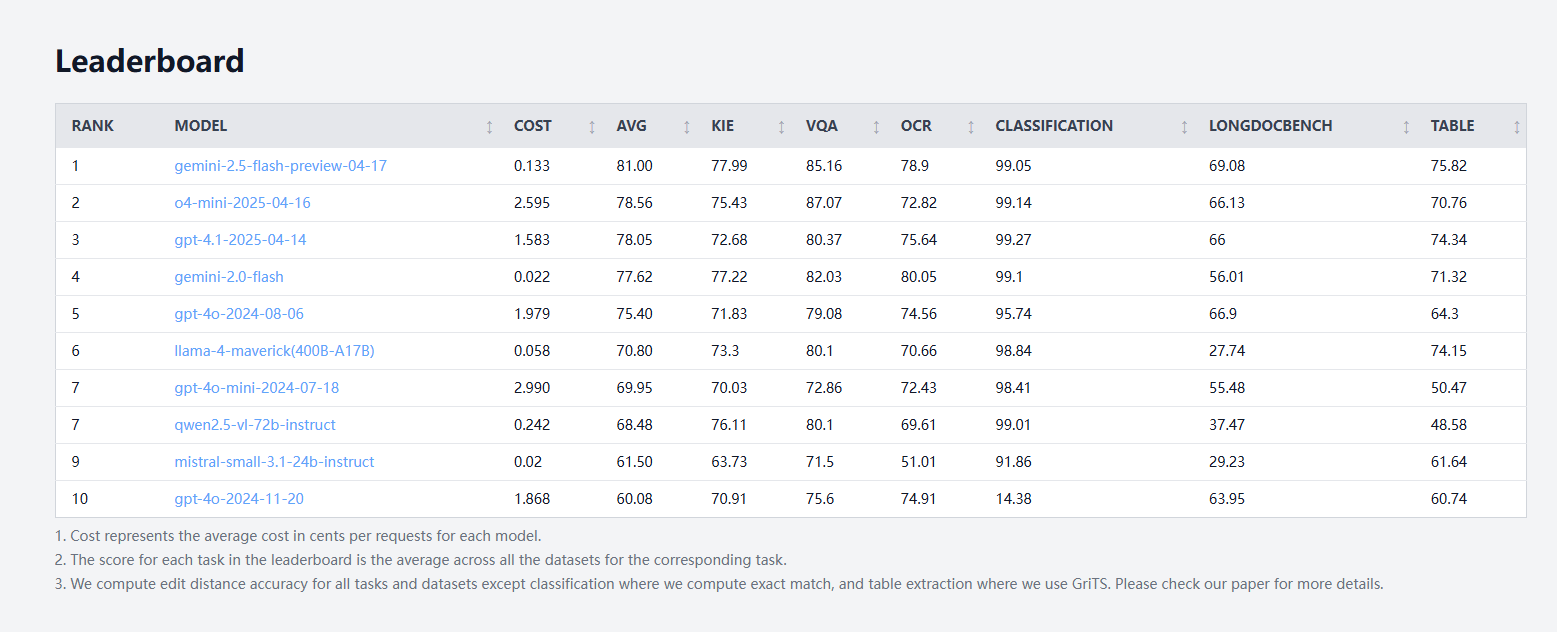
idp-leaderboard发布,首个文档类型AI测试基准: Le nouveau benchmark de test d’IA idp-leaderboard a été lancé, se concentrant sur l’évaluation de la capacité des modèles à traiter les documents et les images de documents. Selon le classement préliminaire, gemini-2.5-flash-preview-04-17 est le plus performant dans le traitement global des documents. Il est à noter que Qwen2.5-VL affiche de faibles performances dans le traitement des tableaux. (Source: karminski3)
Perplexity Discover功能迎来重要更新: Arav Srinivas, cofondateur de Perplexity, a annoncé que sa fonctionnalité Discover (flux de découverte d’informations) a été considérablement améliorée, encourageant les utilisateurs à l’expérimenter. Cela signifie généralement des optimisations dans la présentation des informations, la pertinence ou l’interface utilisateur, visant à améliorer la capacité des utilisateurs à acquérir et à explorer de nouvelles informations. (Source: AravSrinivas)
联想发布天禧个人超级智能体重大升级,全球首款平板本地部署DeepSeek: Lenovo a annoncé une mise à niveau majeure de son super-agent intelligent personnel Tianxi, progressant vers un niveau L3 complet, et a lancé « Xiang Bang Bang », un agent intelligent de domaine axé sur les services d’IA pour les appareils intelligents personnels. Simultanément, Lenovo a lancé plusieurs nouveaux terminaux IA, y compris la première tablette au monde à déployer localement le grand modèle DeepSeek, la YOGA Pad Pro 14.5 AI Yuanqi Edition, ainsi que les smartphones moto AI, les PC de la série Legion, etc., construisant un écosystème IA complet comprenant des AI PC, des AI smartphones, des AI tablettes et l’AIoT. (Source: 量子位)

楼教主谈自动驾驶与具身智能:L2无法升维L4,VLA对L4帮助有限: Lou Tiancheng, cofondateur et CTO de Pony.ai, a partagé ses dernières réflexions sur la conduite autonome et l’IA lors du lancement d’un nouveau modèle de Robotaxi. Il a souligné la différence fondamentale entre L2 et L4, estimant que L2 ne peut pas évoluer vers L4, et que le paradigme VLA (Vision-Langage-Action), populaire dans le domaine L2 actuel, n’est « fondamentalement d’aucune aide » pour L4. Il a souligné que L4 nécessite une sécurité extrême, semblable à celle d’un médecin spécialiste, tandis que VLA ressemble davantage à un médecin généraliste. La transformation technologique de Pony.ai au cours des deux dernières années a été axée sur le end-to-end et le modèle du monde, ce dernier étant utilisé depuis environ 5 ans. Il a également estimé que la « conduite à distance via le cloud » est un faux concept et a déclaré que l’état actuel de l’intelligence incarnée est similaire à celui de la conduite autonome en 2018, et qu’elle sera confrontée à des défis similaires de « période de vide ». (Source: 量子位)

Kimi测试内容社区,OpenAI或开发社交应用,AI大模型公司探索社交增强用户粘性: Kimi de Moonshot AI teste en version bêta (grey test) un produit de communauté de contenu, principalement généré par l’IA qui récupère les actualités brûlantes, axé sur des domaines tels que la technologie et la finance. Par coïncidence, OpenAI aurait également l’intention de développer un logiciel social, potentiellement concurrent de X. Ces mesures indiquent que les entreprises de grands modèles d’IA tentent de renforcer la fidélisation des utilisateurs en construisant des communautés ou des fonctionnalités sociales, afin de résoudre le problème des outils d’IA « utiliser et jeter ». Cependant, l’exploitation de communautés est confrontée à des difficultés liées à la qualité du contenu, aux risques de sécurité et à la monétisation. Cette démarche reflète également le fait que, après que le pic des dividendes de la croissance de l’industrie de l’IA a été atteint, celle-ci commence à passer d’une stratégie de « brûler de l’argent pour la croissance » à une plus grande attention portée au ROI et à l’exploration de nouveaux modèles commerciaux. (Source: 36氪)

TCL全面拥抱AI,发布伏羲大模型及多款AI家电,但面临同质化挑战: TCL a mis en avant ses produits et sa stratégie IA lors de salons tels que AWE 2025 et CES 2025, y compris le grand modèle TCL Fuxi et les fonctionnalités IA appliquées aux téléviseurs, climatiseurs, machines à laver, etc. Son activité télévisuelle est performante, avec des livraisons mondiales au premier rang au T1, la technologie Mini LED étant son avantage. Cependant, l’application de l’IA dans le domaine de l’électroménager se concentre actuellement principalement sur l’interaction vocale et l’optimisation de fonctions spécifiques (telles que les puces IA pour la qualité d’image, le sommeil IA, l’économie d’énergie IA), et fait face à des défis de concurrence par l’homogénéisation avec d’autres marques (comme Hisense Xinghai, Haier HomeGPT, Midea Meiyan). TCL explore également les robots compagnons IA et, via sa filiale Thunderbird, se positionne sur les lunettes intelligentes. Malgré l’augmentation des investissements dans l’IA, son avantage technologique indépendant n’est pas encore significatif, et l’entreprise est confrontée à des problèmes tels que des coûts marketing élevés et une baisse de la marge brute. (Source: 36氪)
AI驱动教育变革,科大讯飞、卓越教育等头部公司加速AI布局: Un rapport analyse les dernières pratiques dans le domaine de l’IA des principales entreprises d’éducation telles que iFlytek, Zhuoyue Education, Fenbi, Zhonggong Education, Huatu Education et 17zuoye. iFlytek, s’appuyant sur la puissance de calcul nationale et les modèles Deepseek-V3/R1, se concentre sur l’éducation aux technologies de l’information. Zhuoyue Education utilise Deepseek R1 pour optimiser l’ensemble du processus d’enseignement et a lancé des outils de correction par IA et de lecture IA. Fenbi a construit une matrice de produits IA couvrant les scénarios d’apprentissage à haute fréquence et à forte demande. Zhonggong Education se concentre sur les services d’emploi IA et développe le grand modèle « Yunxin ». Huatu Education combine ses avantages hors ligne avec l’IA pour améliorer la précision des services de préparation aux concours de la fonction publique. 17zuoye utilise l’IA pour piloter l’intégration de l’enseignement, de l’apprentissage et de l’évaluation. Les tendances du secteur montrent que l’éducation par l’IA passe d’outils ponctuels à une concurrence écosystémique et à la réalisation de valeur. (Source: 36氪)
百度、阿里等大厂力推MCP协议,争夺AI Agent生态定义权: Le Model Context Protocol (MCP) a récemment été promu par Anthropic, OpenAI, Google, ainsi que par les géants chinois Baidu et Alibaba. L’application « Xinxiang » de Baidu et la plateforme Bailian d’Alibaba Cloud prennent déjà en charge MCP, permettant aux AI Agents d’appeler plus facilement des outils et services externes. Cette démarche, en apparence visant à unifier les normes de l’industrie, est en réalité une lutte des géants pour le pouvoir de définition du futur écosystème des AI Agents. En construisant et en promouvant MCP, les géants entendent attirer davantage de développeurs dans leur écosystème, afin de maîtriser les barrières de données et le pouvoir de parole dans l’industrie. La direction de la monétisation des applications d’agents semble toujours être principalement axée sur le trafic et la publicité. (Source: 36氪)

苹果AI战略曝光:或与百度、阿里合作,打造“双核驱动”中国版AI系统: Des rapports analysent la possibilité qu’Apple collabore avec Baidu et Alibaba pour fournir un support technique à ses fonctionnalités IA sur le marché chinois. ERNIE Bot de Baidu présente des avantages en matière de reconnaissance visuelle, tandis que le grand modèle Qwen d’Alibaba se distingue par sa compréhension cognitive et la conformité du contenu. Ce modèle de « propulsion à double cœur » pourrait viser à combiner les forces des deux entreprises pour répondre aux exigences de l’écosystème de données, des priorités technologiques et de la réglementation du marché chinois, tout en maintenant la position dominante et le pouvoir de négociation d’Apple dans la collaboration. Cette démarche est considérée comme une stratégie d’Apple pour faire face à la pression concurrentielle locale, notamment de HarmonyOS, et comme une sorte de « segmentation de niche écologique » dans un contexte de réglementation des données de plus en plus stricte. (Source: 36氪)
虞晶怡教授深度解读空间智能:潜力巨大,但共识未形成,数据与物理理解是关键: Le professeur Yu Jingyi de l’Université ShanghaiTech a souligné dans une interview que le potentiel des grands modèles en matière d’intégration transmodale est loin d’être épuisé, et que l’intelligence spatiale évolue de la réplication numérique vers la compréhension et la création intelligentes, grâce aux percées de l’IA générative. Il estime que les principaux défis actuels de l’intelligence spatiale résident dans la pénurie de données de scènes 3D réelles et l’absence d’unification des méthodes de représentation tridimensionnelle. Le projet CAST de son équipe explore les relations entre les objets et la plausibilité physique en introduisant la « théorie de l’acteur-réseau » et les règles physiques. Il met l’accent sur la priorité à la perception et prédit des percées révolutionnaires dans la technologie des capteurs. Les critères d’évaluation de l’intelligence incarnée devraient être la robustesse et la sécurité plutôt que la simple précision. À court terme, l’intelligence spatiale connaîtra une explosion dans des domaines tels que la production cinématographique et les jeux, et à moyen et long terme, elle deviendra le cœur de l’intelligence incarnée, l’économie à basse altitude étant également un important scénario d’application. (Source: 36氪)

AI人才争夺战白热化:大厂高薪抢人,CTO亲自指导,聚焦大模型与多模态: Les géants de la technologie nationaux et étrangers se livrent une concurrence féroce pour les talents en intelligence artificielle. ByteDance, Alibaba, Tencent, Baidu, JD.com, Huawei et d’autres ont lancé des programmes de recrutement ciblant les doctorants de haut niveau et les jeunes prodiges, offrant des salaires sans plafond, un encadrement personnel par les CTO et aucune exigence d’expérience de stage. Les orientations de recrutement se concentrent principalement sur les grands modèles et le multimodal, et sont étroitement liées aux scénarios commerciaux clés de chaque entreprise. Le succès de modèles tels que DeepSeek a encore exacerbé la soif de talents de l’industrie. Elon Musk s’est également plaint de la folie de la concurrence pour les talents en IA, et les géants étrangers comme OpenAI attirent également les talents avec des salaires élevés et un recrutement personnel par les fondateurs. (Source: 36氪)
红杉资本:AI市场潜力远超云计算,应用层是关键,首席AI官将成标配: Un associé de Sequoia Capital prédit que la taille du marché de l’IA dépassera de loin le marché actuel du cloud computing, estimé à environ 400 milliards de dollars, et que son volume sera énorme au cours des 10 à 20 prochaines années, la valeur se concentrant principalement au niveau de la couche applicative. Les start-ups devraient se concentrer sur les besoins des clients, fournir des solutions de bout en bout, se spécialiser dans des secteurs verticaux et utiliser le « data flywheel » pour construire un avantage concurrentiel durable. Une étude d’AWS montre que les entreprises mondiales adoptent de plus en plus l’IA générative, 45 % des décideurs prévoyant d’en faire leur priorité absolue pour 2025, et le poste de Chief AI Officer (CAIO) deviendra la norme dans les entreprises, 60 % d’entre elles ayant déjà créé ce poste. L’économie des agents est considérée comme la prochaine étape du développement de l’IA, mais elle doit résoudre trois défis techniques majeurs : l’identité persistante, les protocoles de communication et la confiance et sécurité. (Source: 36氪)

造车新势力全面押注AI,理想、小鹏、蔚来竞逐下一代汽车定义权: La percée apportée par la technologie de réseau neuronal de bout en bout FSD V12 de Tesla a incité les nouveaux constructeurs automobiles chinois tels que Li Auto, XPeng et NIO à accélérer leur déploiement de l’IA. Li Auto a lancé le grand modèle de conducteur VLA (Vision-Langage-Action) et a développé la partie langage basée sur le modèle open source DeepSeek. XPeng Motors a construit un modèle de base LVA de 72 milliards de paramètres. NIO a lancé le premier modèle du monde de conduite intelligente en Chine, NWM, et a développé sa propre puce de conduite intelligente 5nm Shenji NX9031. Chacun investit massivement dans les algorithmes, la puissance de calcul (puces auto-développées) et les données, et généralise la technologie IA à des domaines tels que les robots humanoïdes, se disputant la définition de la prochaine génération de voitures et même de produits, mais faisant face à des défis financiers et de monétisation. (Source: 36氪)
🧰 Outils
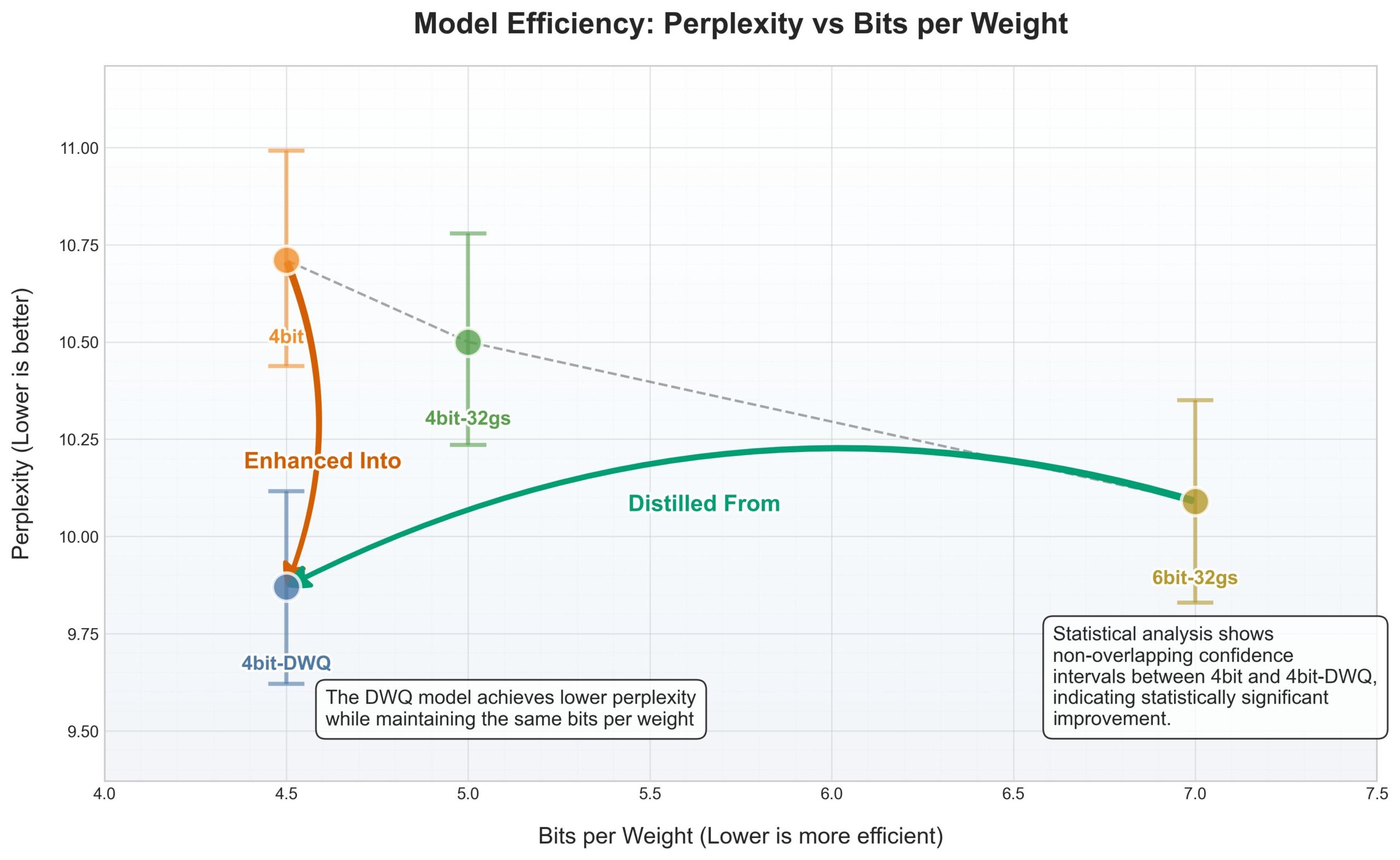
苹果MLX框架迎来DWQ量化,4bit表现优于旧6bit: Pour le framework MLX (Machine Learning framework) d’Apple, une nouvelle méthode de quantification DWQ (Dynamic Weight Quantization) a été publiée. Selon les données partagées par l’utilisateur karminski3, les modèles quantifiés en 4bit-dwq (comme Qwen3-30B) surpassent même l’ancienne méthode de quantification 6bit en termes de perplexité, et ne nécessitent que 17 Go de mémoire pour fonctionner. Cela ouvre de nouvelles possibilités pour l’exécution efficace de grands modèles de langage sur les appareils Apple. (Source: karminski3)
Perplexity现已支持WhatsApp内更自然的对话式搜索: Arav Srinivas, cofondateur de Perplexity, a annoncé que l’intégration de Perplexity dans WhatsApp a été améliorée, offrant désormais une expérience conversationnelle plus naturelle. De plus, lorsque la recherche n’est pas nécessaire, elle ignore intelligemment l’étape de recherche, permettant aux utilisateurs d’interagir directement avec l’IA sous forme de chat. (Source: AravSrinivas)
nanobrowser_ai支持主流LLM,集成Langchain.js: L’outil IA nanobrowser_ai a annoncé la prise en charge de plusieurs grands modèles de langage, y compris les modèles OpenAI, Gemini, ainsi que les modèles locaux exécutés via Ollama. Cet outil utilise le framework Langchain.js pour assurer une prise en charge flexible des différents LLM, offrant aux utilisateurs un plus large choix de modèles. (Source: hwchase17)
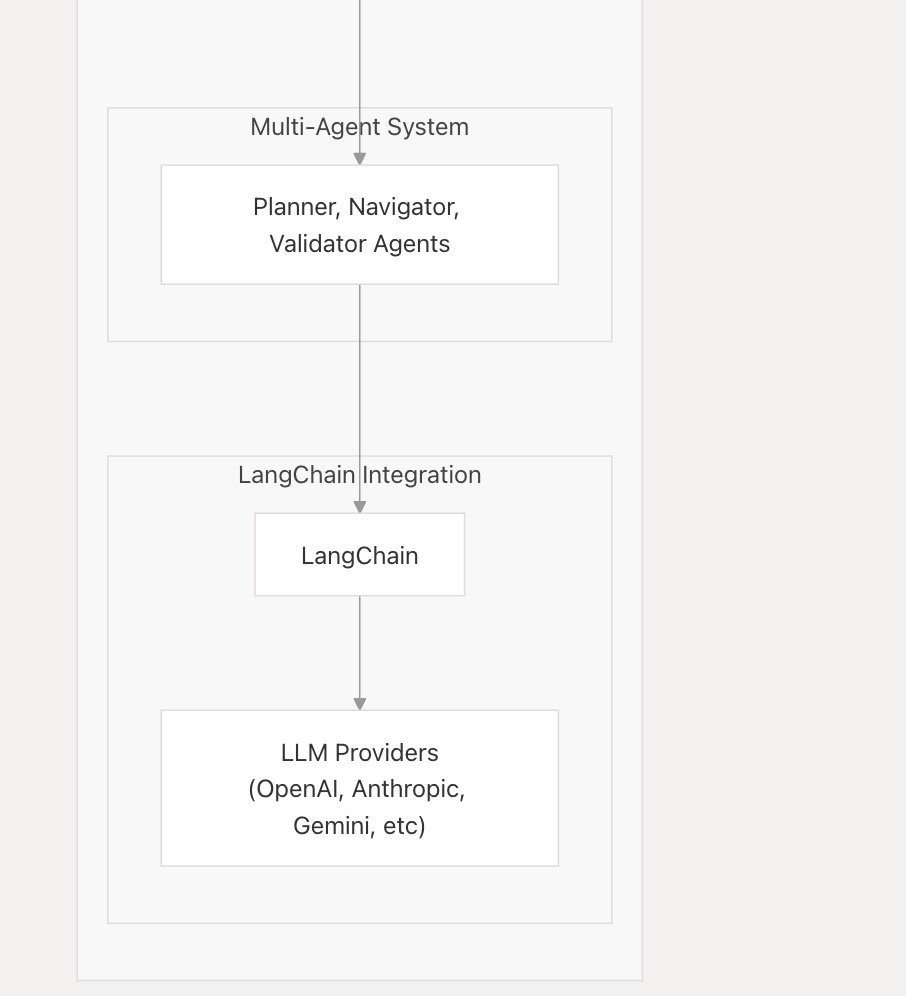
LlamaIndex TypeScript新增对实时LLM API的支持,首个集成Google Gemini: LlamaIndex TypeScript annonce la prise en charge des API LLM en temps réel, permettant aux développeurs d’implémenter des fonctionnalités de conversations audio en temps réel dans les applications IA. La première intégration est l’interface d’abstraction en temps réel de Google Gemini, et la prise en charge en temps réel d’OpenAI sera bientôt disponible. Cette mise à jour facilite le passage entre différents modèles en temps réel pour les développeurs, leur permettant de construire des applications IA plus interactives. (Source: _philschmid)
Gradio应用教程:使用Qwen2.5-VL进行图像视频标注与目标检测: Un tutoriel détaille comment utiliser Qwen2.5-VL (modèle de langage visuel) pour construire une application Gradio afin de réaliser l’annotation automatique d’images et de vidéos ainsi que la détection d’objets. Ce tutoriel vise à aider les développeurs à utiliser les puissantes capacités de Qwen2.5-VL pour construire rapidement des applications IA interactives. (Source: Reddit r/deeplearning)

VSCode插件gemini-code下载量近5万: Le plugin d’assistance à la programmation IA pour VSCode, gemini-code, a atteint près de 50 000 téléchargements. Le développeur raizamrtn a indiqué qu’il effectuerait quelques mises à jour nécessaires pendant le week-end. Ce plugin vise à utiliser les capacités du modèle Gemini pour aider les développeurs dans leur travail de codage. (Source: raizamrtn)

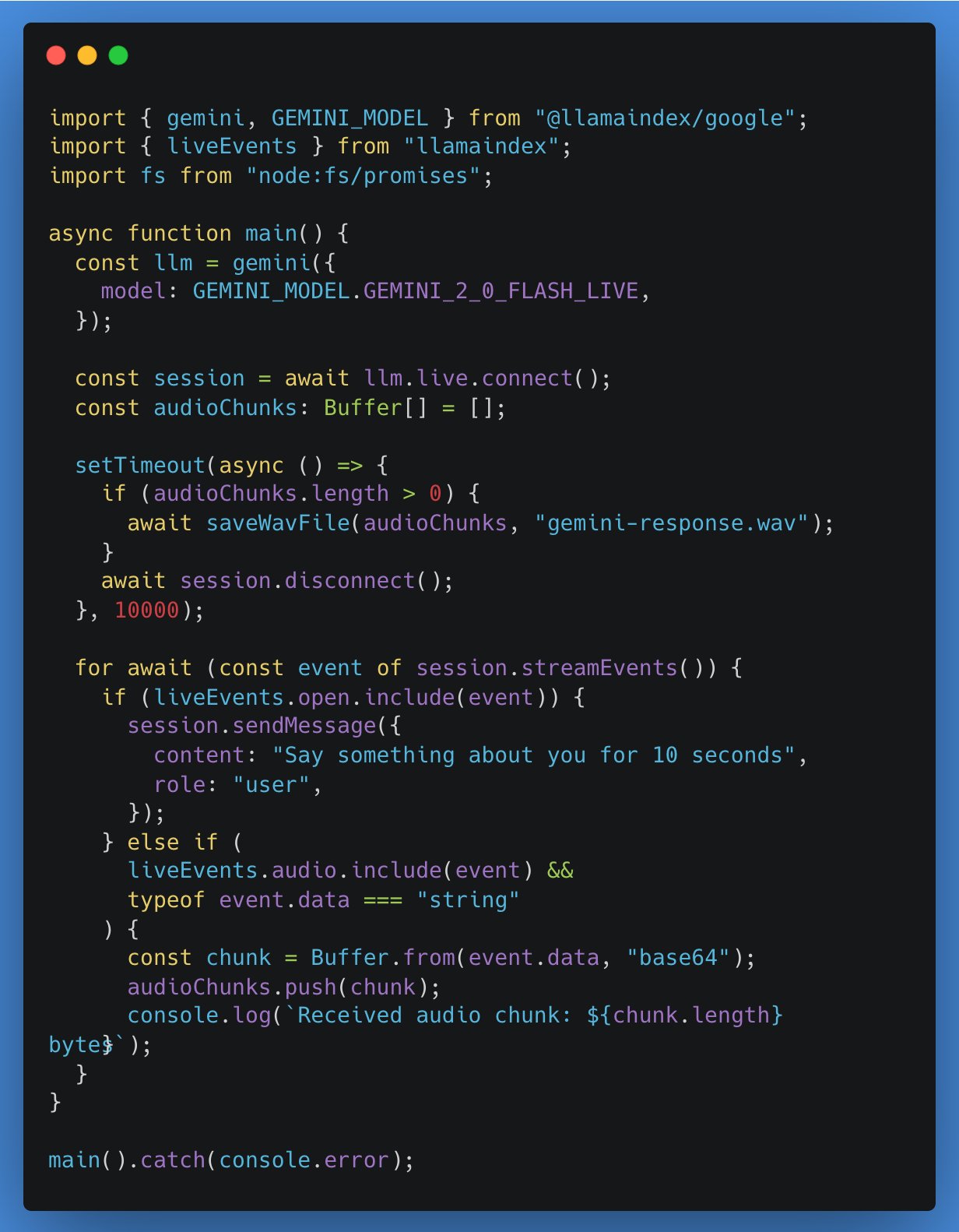
法国AI初创Arcads AI:5人团队年入500万美元,专注自动化视频广告制作: La start-up IA parisienne Arcads AI, avec une équipe de seulement 5 personnes, a atteint un revenu annuel récurrent de 5 millions de dollars et est rentable. L’entreprise, grâce à un système IA hautement automatisé, fournit aux annonceurs des services de production de publicités vidéo rapides, à faible coût et à fort taux de conversion. Les clients n’ont qu’à fournir le texte principal, et l’IA se charge de l’ensemble du processus, de la construction des scènes, du jeu des acteurs, de l’enregistrement des voix off à la production du film final. La plateforme Arcads intègre plus de 300 images d’acteurs IA basées sur des autorisations de personnes réelles, prend en charge 35 langues et réalise le « contenu en tant que service ». Ses opérations internes utilisent également largement des agents IA, tels que l’AI Spy Agent pour analyser les concurrents et l’AI Ghostwriter pour générer des idées créatives, ce qui améliore considérablement l’efficacité. (Source: 36氪)
📚 Apprentissage
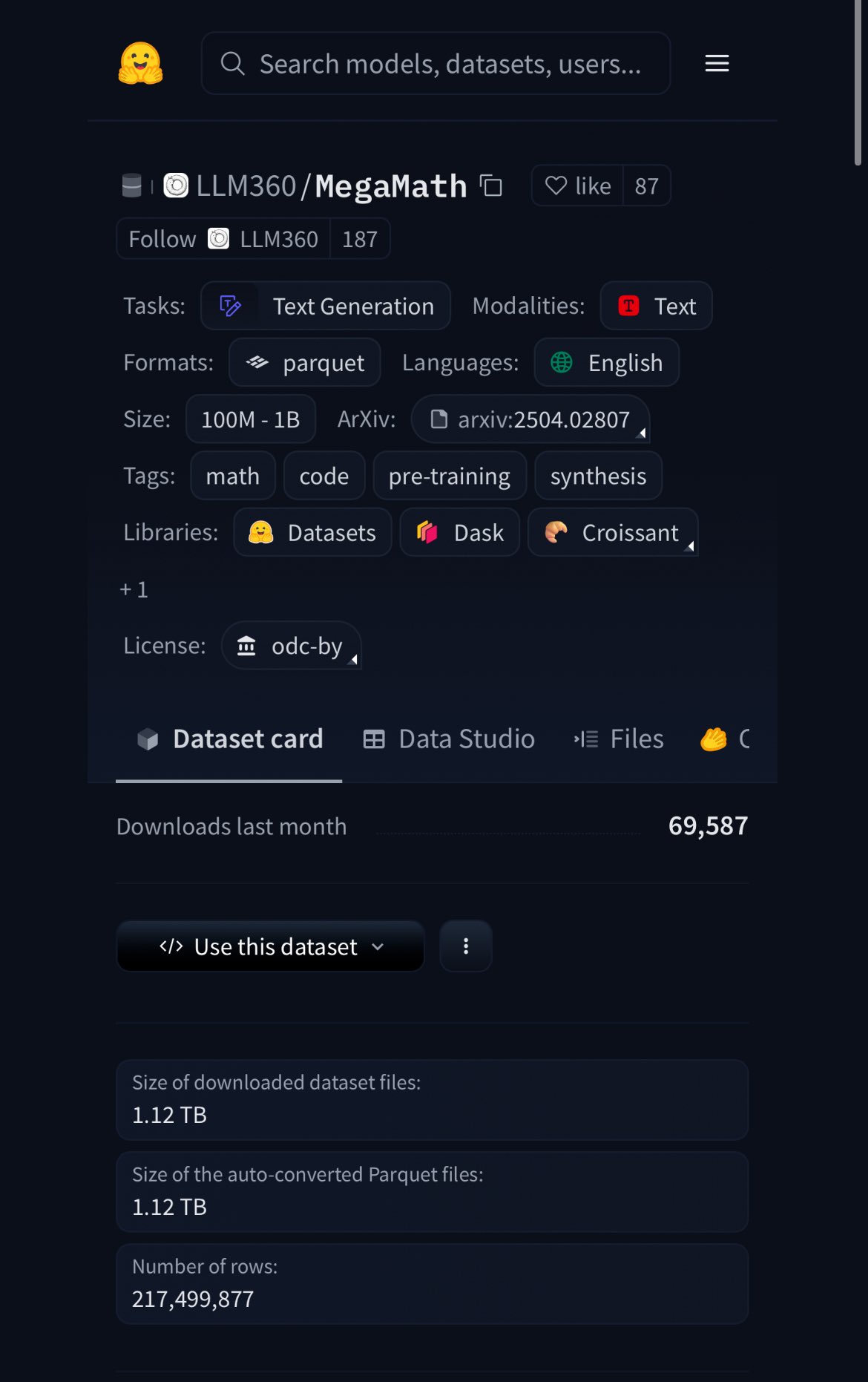
HuggingFace发布MegaMath数据集,含370B token,20%为合成数据: HuggingFace a publié le jeu de données MegaMath, contenant 370 milliards de tokens, ce qui en fait actuellement le plus grand jeu de données de pré-entraînement mathématique, environ 100 fois la taille de Wikipédia en anglais. Il est à noter que 20 % de ces données sont des données synthétiques, ce qui relance le débat sur le rôle des données synthétiques de haute qualité dans l’entraînement des modèles. (Source: ClementDelangue)
Nous Research举办RL环境黑客马拉松,奖池5万美元: Nous Research a annoncé l’organisation d’un hackathon sur les environnements RL à San Francisco. Les participants utiliseront Atropos, le cadre d’environnement d’apprentissage par renforcement de Nous, pour créer, avec un prix total de 50 000 dollars. Les partenaires incluent xAI, NVIDIA, Nebius AI, etc. (Source: Teknium1)

HuggingFace热门模型周榜发布: L’utilisateur karminski3 a partagé le classement hebdomadaire des modèles les plus populaires sur HuggingFace, mentionnant qu’il avait testé ou partagé des démonstrations officielles pour la plupart d’entre eux. Cela reflète l’enthousiasme de la communauté pour le suivi rapide et l’évaluation des nouveaux modèles. (Source: karminski3)
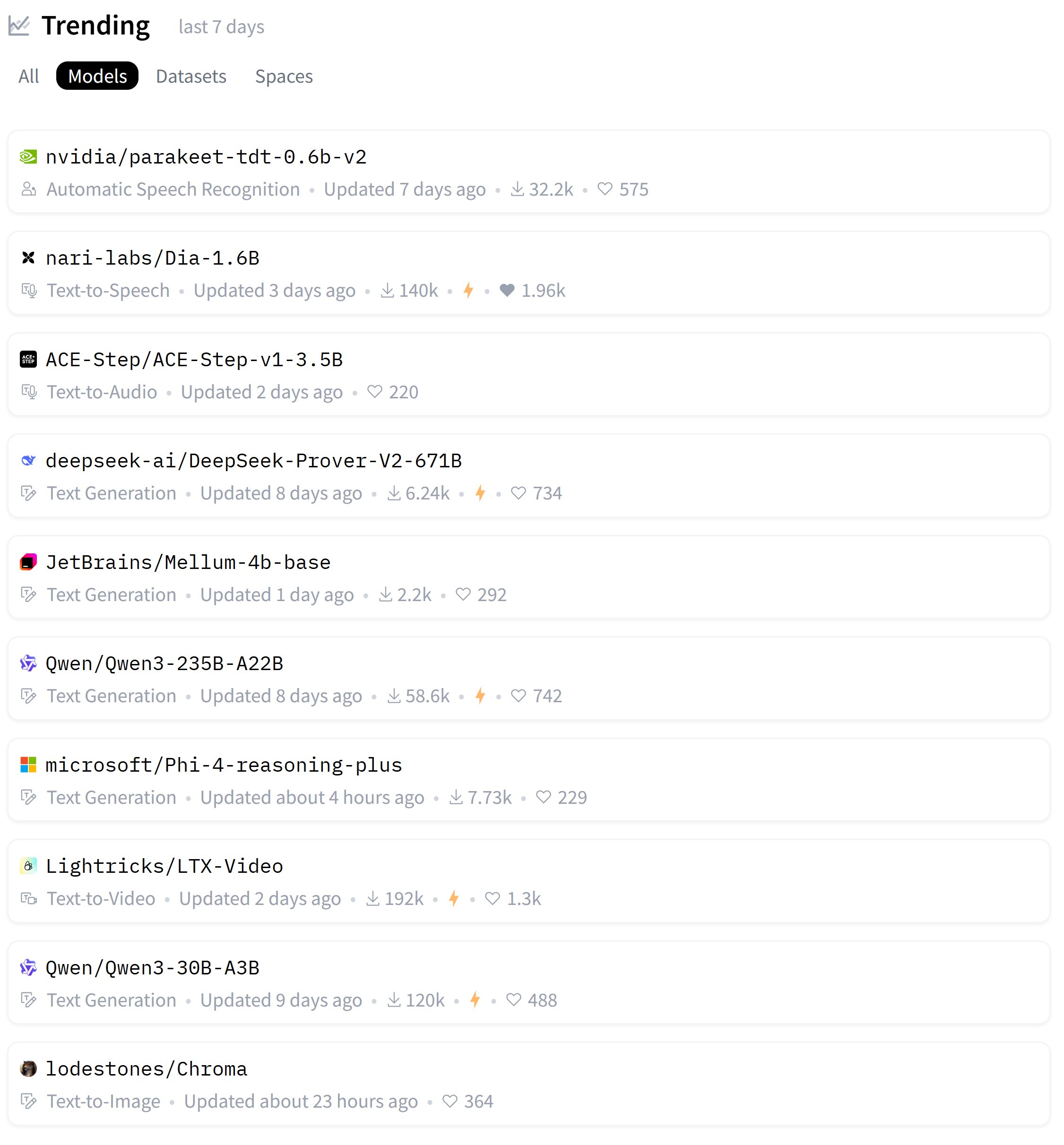
Zeyuan Allen-Zhu发布LLM架构设计系列研究,探讨Primer模型: Le chercheur Zeyuan Allen-Zhu, à travers sa série de recherches « Physics of LLM Design », utilise des environnements de pré-entraînement synthétiques contrôlés pour révéler les véritables limites de l’architecture des LLM. Dans son dernier partage, il discute du modèle Primer (arxiv.org/abs/2109.08668) et de son attention multi-dconv-head (qu’il appelle Canon-B sans connexion résiduelle), soulignant ses problèmes, mais estimant également que le modèle Primer (seulement 180 citations) est sous-estimé car il a découvert des signaux significatifs à partir d’expériences réelles bruyantes. (Source: ZeyuanAllenZhu, cloneofsimo)
Simons Institute探讨神经网络缩放法则: Le Simons Institute, dans sa série Polylogues, a invité Anil Ananthaswamy et Alexander Rush à discuter des lois d’échelle neuronales (neural scaling laws) découvertes empiriquement ces dernières années. Ces lois ont eu un impact majeur sur les décisions des grandes entreprises de construire des modèles de plus en plus grands. (Source: NandoDF)

François Fleuret发布《深度学习小书》: François Fleuret a publié un ouvrage intitulé « The Little Book of Deep Learning », visant à fournir aux lecteurs des connaissances concises sur l’apprentissage profond. (Source: Reddit r/deeplearning)
普林斯顿教授:AI或终结人文学科,但促使其回归存在体验: Le professeur D. Graham Burnett de l’Université de Princeton a publié un article dans The New Yorker discutant de l’impact de l’IA sur les sciences humaines. Il a observé une « honte de l’IA » répandue dans les universités américaines, où les étudiants n’osent pas admettre utiliser l’IA. Il estime que l’IA a déjà dépassé les méthodes académiques traditionnelles en matière de recherche et d’analyse d’informations, transformant les livres universitaires en artefacts archéologiques. Bien que l’IA puisse mettre fin aux sciences humaines traditionnelles axées sur la production de connaissances, elle pourrait également les inciter à revenir à des questions fondamentales : comment vivre, faire face à la mort, et d’autres explorations d’expériences existentielles, que l’IA ne peut pas aborder directement. (Source: 36氪)

7项研究揭示AI对人类大脑与行为的深远影响: Une série de nouvelles études explorent les effets de l’IA sur les aspects psychologiques, sociaux et cognitifs de l’être humain. Les découvertes incluent : 1) Les testeurs red team de LLM explorent les vulnérabilités des modèles par curiosité et responsabilité morale ; 2) ChatGPT montre une grande précision diagnostique dans l’analyse de cas psychiatriques ; 3) Les tendances politiques de ChatGPT évoluent subtilement entre les différentes versions ; 4) L’utilisation de ChatGPT pourrait exacerber les inégalités professionnelles, les jeunes hommes à revenus élevés l’utilisant davantage ; 5) L’IA peut détecter des signes de dépression en analysant le comportement de conduite des personnes âgées ; 6) Les LLM manifestent un biais de désirabilité sociale en « enjolivant » leur image lors de tests de personnalité ; 7) Une dépendance excessive à l’IA pourrait affaiblir la pensée critique, en particulier chez les jeunes. (Source: 36氪)

Onur Boyar访谈:利用生成模型和贝叶斯优化进行药物与材料设计: Onur Boyar, participant au forum doctoral AAAI/SIGAI, a présenté ses travaux de recherche doctorale à l’Université de Nagoya, axés sur l’utilisation de modèles génératifs et de méthodes bayésiennes pour la conception de médicaments et de matériaux. Il participe au projet japonais Moonshot, qui vise à construire des robots scientifiques IA pour gérer le processus de découverte de médicaments. Ses méthodes de recherche comprennent l’utilisation de l’optimisation bayésienne dans l’espace latent pour modifier les molécules existantes, afin d’améliorer l’efficacité d’échantillonnage et la faisabilité de synthèse. Il souligne l’importance d’une collaboration étroite avec les chimistes et rejoindra l’équipe de découverte de matériaux d’IBM Research Tokyo après l’obtention de son diplôme. (Source: aihub.org)

💼 Affaires
模块化公司与AMD合作举办Mojo Hackathon,使用MI300X GPU: Modular a annoncé une collaboration avec AMD pour organiser un hackathon spécial à l’AGI House. Lors de l’événement, les développeurs programmeront en langage Mojo en utilisant des GPU AMD Instinct™ MI300X. L’événement accueillera également des présentations techniques de représentants de Modular, AMD, Dylan Patel de SemiAnalysis, et Anthropic. (Source: clattner_llvm)
Stripe发布多项AI驱动新功能,包括支付领域AI基础模型: La société de services financiers Stripe a annoncé lors de sa conférence annuelle le lancement de plusieurs nouveaux produits pour accélérer l’adoption des applications d’IA, y compris le premier modèle de fondation IA au monde spécialement conçu pour le domaine des paiements. Ce modèle, entraîné sur des dizaines de milliards de transactions, vise à améliorer la détection de la fraude (par exemple, une augmentation de 64 % du taux de détection des attaques de « test de carte »), les taux d’autorisation et l’expérience de paiement personnalisée. Stripe a également étendu ses capacités de gestion de fonds multidevises et approfondi ses collaborations avec de grandes entreprises telles que Nvidia (utilisant Stripe Billing pour gérer les abonnements GeForce Now) et PepsiCo. (Source: 36氪)
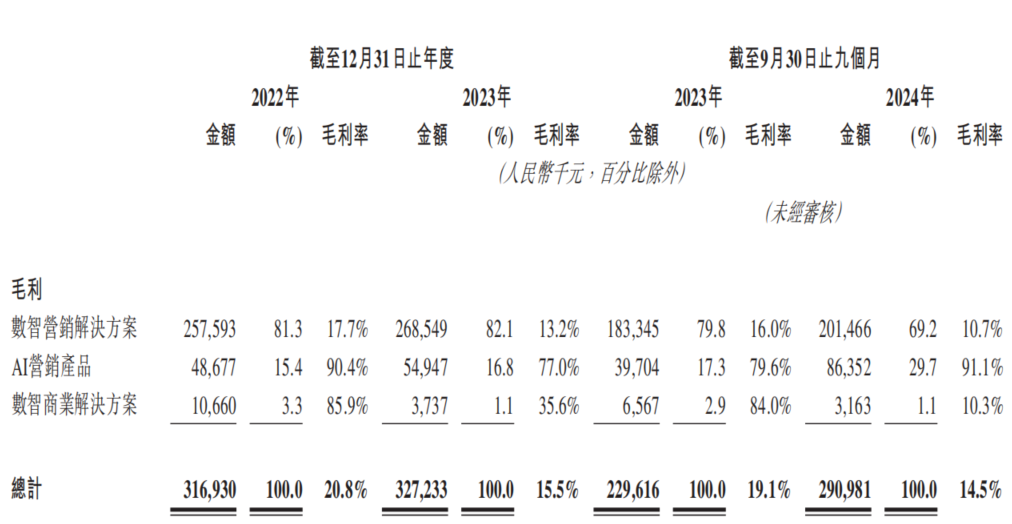
AI营销公司东信营销再冲港交所,面临“增收不增利”困境: Dongxin Marketing, se présentant comme « la plus grande société de marketing IA de Chine », a de nouveau déposé une demande d’introduction en bourse à Hong Kong. Les données montrent que le chiffre d’affaires de la société a continué de croître au cours des trois premiers trimestres de 2022 à 2024, mais que le bénéfice net a considérablement chuté, voire s’est transformé en perte, et que la marge brute est passée de 20,8 % à 14,5 %. Les revenus de l’activité de marketing IA représentent moins de 5 %, et bien que la marge brute atteigne 91,1 %, elle ne suffit pas à couvrir les investissements en R&D. L’entreprise est confrontée à des problèmes tels que des créances élevées, des flux de trésorerie tendus et une forte pression de la dette, et ses bénéfices dépendent fortement des subventions gouvernementales. Son positionnement sur le marché est passé de « fournisseur de services de marketing mobile » à « société de marketing IA », mais la valeur technologique de son IA et ses perspectives de monétisation sont incertaines. (Source: 36氪)
🌟 Communauté
vLLM与SGLang推理引擎竞争激烈,开发者公开比较PR合并数据: La communauté des développeurs débat vivement de la concurrence entre les deux principaux moteurs d’inférence, vLLM et SGLang. Le principal mainteneur de vLLM a même créé un tableau de bord public pour comparer le nombre de pull requests (PR) fusionnées sur GitHub entre SGLang et vLLM, soulignant la concurrence féroce entre les deux en termes d’itération des fonctionnalités et d’optimisation des performances. De son côté, SGLang met en avant ses implémentations open source pionnières dans des domaines tels que le cache radix, le chevauchement CPU, MLA et l’EP à grande échelle. (Source: dylan522p, jeremyphoward)
AI生成“意大利脑残”角色宇宙引爆Zoomer群体,观看量数亿: Justine Moore souligne qu’une série de personnages « Italian brainrot » générés par IA est devenue extrêmement populaire auprès de la génération Zoomer (Gen Z). Ils ont construit un « univers cinématographique » complet autour de ces personnages, et le contenu associé a recueilli des centaines de millions de vues. Ce phénomène reflète la forte attractivité et le potentiel de propagation virale du contenu généré par IA auprès de la jeune génération, ainsi que la formation de sous-cultures spécifiques. (Source: nptacek)

Qwen3与DeepSeek R1模型对比引发讨论,各有优劣: Un utilisateur de Reddit a partagé une comparaison des tests des modèles open source Qwen3 235B et DeepSeek R1. L’auteur du message estime que Qwen est plus performant sur les tâches simples, mais que DeepSeek R1 est supérieur sur les tâches nécessitant des nuances (comme le raisonnement, les mathématiques et l’écriture créative). Dans les commentaires de la communauté, les utilisateurs ont discuté de l’accessibilité de DeepSeek R1, de la version affinée non censurée de Qwen3 235B, et de la pertinence d’utiliser des modèles de langage pour l’écriture créative. (Source: Reddit r/LocalLLaMA)

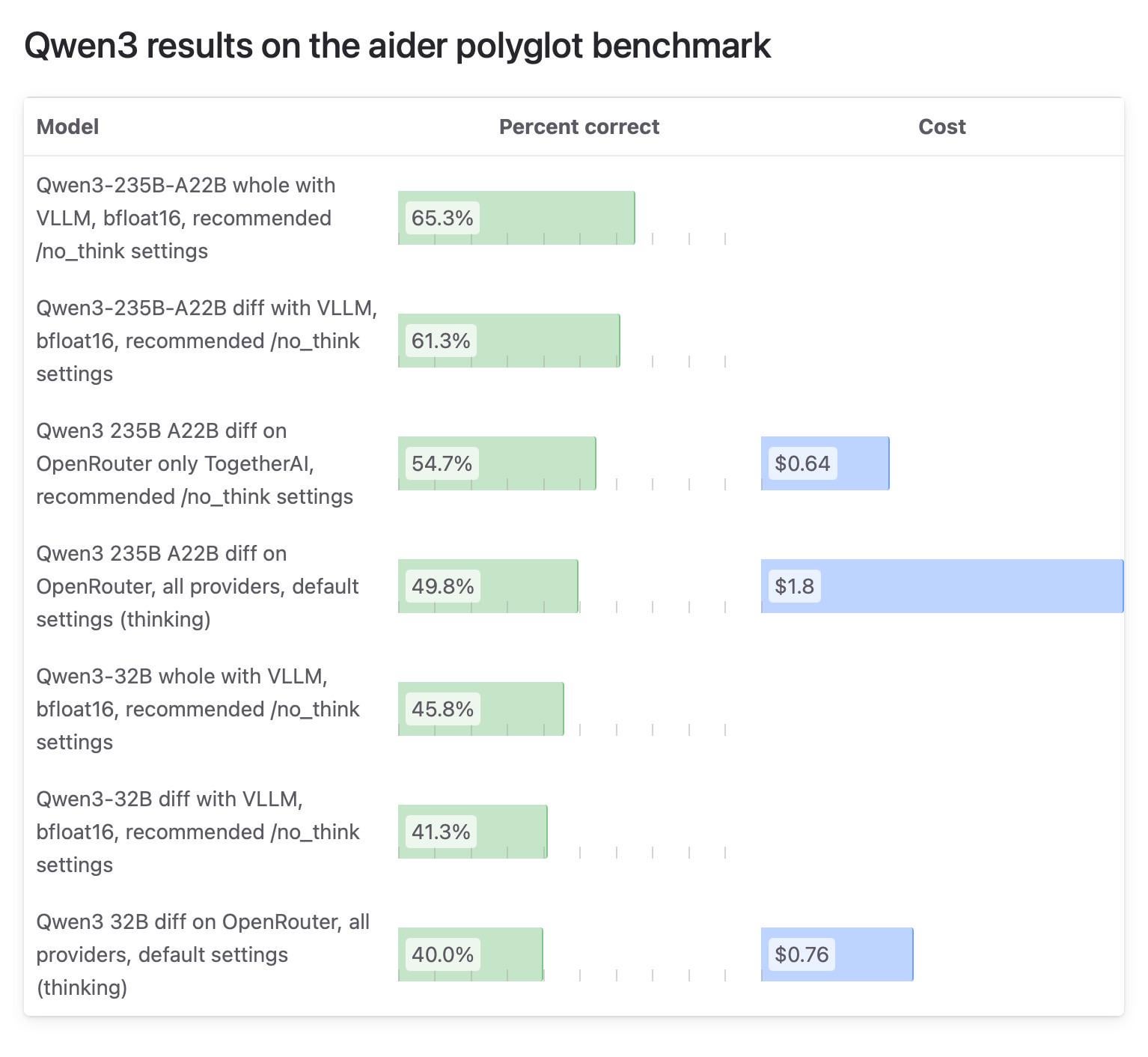
Aider社区对Qwen3模型测试结果差异引关注,OpenRouter测试受质疑: Le blog Aider a publié un rapport de test sur le modèle Qwen3, soulignant des différences significatives de scores du modèle selon les méthodes d’exécution. La discussion au sein de la communauté s’est concentrée sur la fiabilité des tests de modèles utilisant OpenRouter, car la plupart des utilisateurs pourraient utiliser le modèle via OpenRouter, mais son mécanisme de routage pourrait entraîner des résultats incohérents. Certains utilisateurs estiment que les modèles open source devraient être testés dans des environnements auto-construits standardisés (comme vLLM) pour garantir la reproductibilité, et appellent les fournisseurs d’API à accroître la transparence en spécifiant clairement la version de quantification et le moteur d’inférence utilisés. (Source: Reddit r/LocalLLaMA)
用户分享付费使用ChatGPT的个人原因,涵盖生活辅助、学习、创作等: Sur la communauté Reddit r/ChatGPT, de nombreux utilisateurs ont partagé leurs raisons personnelles de s’abonner à ChatGPT Plus/Pro. Celles-ci incluent : aider les utilisateurs malvoyants à décrire des images, lire des emballages alimentaires et des panneaux de signalisation ; se préparer à des entretiens d’embauche ; approfondir la compréhension de l’intrigue de jeux comme Elden Ring ; analyser des plans d’entraînement à la course, personnaliser des recettes ; aider à apprendre de nouvelles compétences comme la poterie ; servir de compagnon personnel ; planifier des jardins, fabriquer des herbes médicinales ; ainsi que la création de personnages pour D&D et l’écriture de fanfictions. Ces exemples illustrent la large valeur d’application de ChatGPT dans la vie quotidienne et les intérêts personnels. (Source: Reddit r/ChatGPT)
GGUF量化模型对比测试引发“量化战争”讨论,强调不同量化方案各有千秋: L’utilisateur Reddit ubergarm a publié une comparaison détaillée des tests de référence de différentes versions de quantification GGUF pour des modèles tels que Qwen3-30B-A3B, y compris les schémas de quantification de différents fournisseurs comme bartowski et unsloth. Les tests couvraient plusieurs dimensions, notamment la perplexité, la divergence KLD et la vitesse d’inférence. L’article souligne qu’avec l’émergence de nouveaux types de quantification tels que la quantification par matrice d’importance (imatrix), IQ4_XS, et l’introduction de méthodes comme le GGUF dynamique d’unsloth, la quantification GGUF n’est plus « taille unique ». L’auteur souligne qu’il n’existe pas de schéma de quantification absolument optimal, et que les utilisateurs doivent choisir en fonction de leur matériel et de leurs cas d’utilisation spécifiques, mais que globalement, les principaux schémas fonctionnent tous bien. (Source: Reddit r/LocalLLaMA)

💡 Divers
Daimon Robotics推出心灵手巧的机器人Sparky 1: Daimon Robotics a présenté son produit révolutionnaire en matière de technologie robotique agile, Sparky 1. Ce robot est décrit comme possédant des capacités « Mind-Dexterous », suggérant qu’il a atteint un nouveau niveau en termes de perception, de prise de décision et de manipulation fine, intégrant potentiellement des technologies avancées d’IA et d’apprentissage automatique. (Source: Ronald_vanLoon)
MIT研发米粒大小微型机器人,可进入大脑治疗无法手术的肿瘤: Des chercheurs du MIT ont développé un microrobot de la taille d’un grain de riz, ayant le potentiel d’entrer dans le cerveau de manière mini-invasive pour traiter des tumeurs auparavant difficiles à enlever chirurgicalement. Ce type de technologie combine la microrobotique avec la navigation ou le contrôle par IA, offrant de nouvelles possibilités pour la neurochirurgie et le traitement du cancer. (Source: Ronald_vanLoon)

傲鲨智能完成两轮融资,推动消费级外骨骼机器人量产与AI技术融合: ULS Robotics, une société de plateforme technologique d’exosquelettes robotiques, a annoncé avoir bouclé consécutivement deux tours de financement, menés par Binfu Capital, avec la participation de l’ancien actionnaire Guoyi Capital. Les fonds seront utilisés pour la production en série d’exosquelettes robotiques grand public et pour promouvoir l’intégration du matériel d’exosquelette avec la technologie IA. Les produits de la société sont déjà utilisés dans des scénarios industriels et commencent à explorer le marché de l’assistance en extérieur (comme l’aide à la randonnée en montagne dans les sites touristiques) et des soins aux personnes âgées à domicile, avec des plans pour lancer des produits grand public à moins de 10 000 yuans. Ses derniers produits sont déjà dotés de capacités d’entraînement de grands modèles d’IA et la société mène des recherches préliminaires sur la technologie d’interface cerveau-machine. (Source: 36氪)