
Mots-clés:Modèle Gemini, Mistral AI, NVIDIA NeMo, LTX-Video, Navigateur Safari, RTX 5060, Agent IA, Réglage fin par apprentissage par renforcement, Génération d’images natives Gemini, Performances de programmation Mistral Medium 3, Modularité du cadre NeMo 2.0, Génération vidéo en temps réel DiT, Transformation de la recherche pilotée par l’IA
🔥 En Vedette
Mise à niveau de la fonction native de génération d’images de Gemini de Google, améliorant la qualité visuelle et la précision du rendu de texte: Google a annoncé une mise à jour importante de la fonction native de génération d’images de son modèle Gemini. La nouvelle version, « gemini-2.0-flash-preview-image-generation », est disponible sur Google AI Studio et Vertex AI. Cette mise à niveau améliore significativement la qualité visuelle des images et la précision du rendu de texte, tout en réduisant la latence. Les nouvelles fonctionnalités incluent la fusion d’éléments d’image, l’édition en temps réel (comme l’ajout d’objets ou la modification de contenu localisé) et la combinaison avec Gemini 2.0 Flash pour permettre à l’IA de concevoir et de générer des images de manière autonome. Les utilisateurs peuvent l’essayer gratuitement sur Google AI Studio, et le coût d’appel API est de 0,039 dollar par image. Malgré des progrès notables, certains utilisateurs estiment que ses performances globales restent légèrement inférieures à celles de GPT-4o. (Source: 量子位)

Mistral AI lance Mistral Medium 3, axé sur la programmation et le multimodal, avec une réduction significative des coûts: La start-up française d’IA, Mistral AI, a lancé son dernier modèle multimodal, Mistral Medium 3. Ce modèle excelle dans les tâches de programmation et STEM, atteignant ou dépassant prétendument 90 % des performances de Claude Sonnet 3.7 dans divers benchmarks, pour seulement 1/8 de son coût (0,4 dollar/million de tokens en entrée, 2 dollars/million de tokens en sortie). Mistral Medium 3 offre des capacités de niveau entreprise telles que le déploiement hybride, le post-entraînement personnalisé et l’intégration avec les outils d’entreprise. Il est déjà disponible sur Mistral La Plateforme et Amazon Sagemaker, et sera déployé sur d’autres plateformes cloud à l’avenir. Parallèlement, Mistral AI a également lancé Le Chat Enterprise, un service de chatbot destiné aux entreprises. (Source: 量子位)

Lancement de NVIDIA NeMo Framework 2.0, modularité et facilité d’utilisation améliorées, prise en charge des modèles Hugging Face et des GPU Blackwell: Le framework NVIDIA NeMo a été mis à jour vers la version 2.0. Les améliorations principales incluent l’adoption de configurations Python en remplacement de YAML pour une flexibilité accrue, la simplification de l’expérimentation et de la personnalisation grâce à l’abstraction modulaire de PyTorch Lightning, et l’utilisation de l’outil NeMo-Run pour une extension transparente des expériences à grande échelle. La nouvelle version ajoute la prise en charge du pré-entraînement et du fine-tuning des modèles Hugging Face AutoModelForCausalLM, et offre un support initial pour les GPU NVIDIA Blackwell B200. De plus, le framework NeMo intègre le support de la plateforme de modèles de base du monde NVIDIA Cosmos, destinée à accélérer le développement de modèles du monde pour les systèmes d’IA physique, y compris la bibliothèque de traitement vidéo NeMo Curator et le tokenizer Cosmos. (Source: GitHub Trending)

Lightricks lance LTX-Video : un modèle de génération vidéo DiT en temps réel: La société Lightricks a rendu open source LTX-Video, présenté comme le premier modèle de génération vidéo en temps réel basé sur Diffusion Transformer (DiT). Ce modèle est capable de générer des vidéos de haute qualité en résolution 1216×704 à 30 FPS, et prend en charge de multiples fonctionnalités telles que la conversion texte-image, image-vidéo, l’animation par images clés, l’extension vidéo et la conversion vidéo-vidéo. La dernière version 13B v0.9.7 améliore le respect des prompts et la compréhension physique, et introduit un pipeline vidéo multi-échelle pour un rendu rapide et de haute qualité. Le modèle est disponible sur Hugging Face et dispose d’intégrations ComfyUI et Diffusers. (Source: GitHub Trending)

Apple envisage une refonte majeure du navigateur Safari, pourrait se tourner vers la recherche alimentée par l’IA, relations avec Google sous surveillance: Eddy Cue, vice-président senior d’Apple, a révélé lors de son témoignage dans le procès antitrust du ministère américain de la Justice contre Google qu’Apple envisage activement de remanier le navigateur Safari, en mettant l’accent sur un moteur de recherche alimenté par l’IA. Il a souligné que le volume de recherche de Safari a diminué pour la première fois, en partie parce que les utilisateurs se tournent vers des outils d’IA tels qu’OpenAI et Perplexity AI. Apple a eu des discussions avec Perplexity AI et pourrait introduire davantage d’options de recherche IA dans Safari. Cette décision pourrait affecter l’accord annuel d’environ 20 milliards de dollars entre Apple et Google concernant le moteur de recherche par défaut, et avoir un impact sur le cours des actions des deux sociétés. Apple a déjà intégré ChatGPT dans Siri et prévoit d’ajouter Gemini de Google. (Source: 36氪)

🎯 Mouvements
La carte graphique de bureau NVIDIA RTX 5060 sera commercialisée le 20 mai, au prix de 2499 yuans en Chine: NVIDIA a annoncé que la carte graphique de bureau RTX 5060 sera mise en vente le 20 mai, heure de Pékin, au prix de 2499 yuans en Chine. Cette carte utilise l’architecture Blackwell RTX, dispose de 3840 cœurs CUDA, de 8 Go de mémoire GDDR7 et d’une puissance totale de 145 W. Selon les déclarations officielles, dans les jeux prenant en charge la technologie de génération multi-images DLSS 4, ses performances sont deux fois supérieures à celles de la RTX 4060, l’objectif étant de permettre aux utilisateurs de jouer à plus de 100 FPS. La levée de l’embargo sur les tests et la mise en vente auront lieu le même jour. (Source: 量子位)

L’API Gemini de Google lance une fonctionnalité de mise en cache implicite, permettant d’économiser 75 % des coûts: Google a annoncé le lancement d’une fonctionnalité de mise en cache implicite pour son API Gemini. Lorsque la requête d’un utilisateur atteint le cache, le coût d’utilisation du modèle Gemini 2.5 peut être automatiquement réduit de 75 %. Parallèlement, le nombre minimum de tokens requis pour déclencher le cache a également été abaissé : à 1K tokens pour Gemini 2.5 Flash et à 2K tokens pour Gemini 2.5 Pro. Cette fonctionnalité vise à réduire les coûts pour les développeurs utilisant l’API Gemini, sans nécessiter la création explicite d’un cache. (Source: matvelloso, demishassabis, algo_diver, jeremyphoward)
Meta FAIR nomme Rob Fergus à sa tête, avec un focus sur l’intelligence artificielle générale (AGI): Meta a annoncé que Rob Fergus prendra la direction de son équipe de recherche fondamentale en IA (FAIR). Yann LeCun a indiqué que FAIR se recentrera sur l’intelligence artificielle avancée, communément appelée IA de niveau humain ou AGI. Cette nouvelle a été largement saluée et félicitée par la communauté de la recherche en IA. (Source: ylecun, Ar_Douillard, soumithchintala, aaron_defazio, sainingxie)
OpenAI lance la fonctionnalité de fine-tuning par apprentissage par renforcement (RFT) pour le modèle o4-mini: OpenAI a annoncé que son modèle o4-mini prend désormais en charge le fine-tuning par apprentissage par renforcement (RFT). Cette technique, en développement depuis décembre dernier, utilise le raisonnement en chaîne de pensée (Chain-of-Thought) et une notation spécifique à la tâche pour améliorer les performances du modèle, particulièrement dans les domaines complexes. La société Ambience, en utilisant un modèle ajusté par RFT, a obtenu une précision de codage ICD-10 supérieure de 27 % à celle des cliniciens experts. La société Harvey a également entraîné des modèles avec RFT pour améliorer la précision des citations dans les tâches juridiques. Parallèlement, le modèle le plus rapide et le plus petit d’OpenAI, 4.1-nano, est également ouvert au fine-tuning. (Source: stevenheidel, aidan_mclau, andrwpng, teortaxesTex, OpenAIDevs, OpenAIDevs)
L’Université Tsinghua présente Absolute Zero Reasoner : l’IA auto-génère des données d’entraînement pour un raisonnement exceptionnel: Une équipe de l’Université Tsinghua a développé un modèle d’IA nommé Absolute Zero Reasoner, capable de générer entièrement des tâches d’entraînement par auto-apprentissage (self-play) et d’apprendre à partir de celles-ci, sans aucune donnée externe. Dans des domaines tels que les mathématiques et le codage, ses performances ont dépassé celles des modèles entraînés sur des données organisées par des experts humains. Cette avancée pourrait signifier une atténuation du goulot d’étranglement des données dans le développement de l’IA, ouvrant de nouvelles voies vers l’AGI. (Source: corbtt)

Meta et NVIDIA collaborent pour améliorer les performances de recherche vectorielle GPU de Faiss avec cuVS: Meta et NVIDIA ont annoncé une collaboration pour intégrer cuVS (CUDA Vector Search) de NVIDIA dans la bibliothèque open source de recherche de similarité de Meta, Faiss v1.10, afin d’améliorer considérablement les performances de recherche vectorielle sur GPU. Cette intégration permet d’accélérer jusqu’à 4,7 fois le temps de construction des index IVF et de réduire la latence de recherche jusqu’à 8,1 fois. Concernant les index de graphes, le temps de construction de CUDA ANN Graph (CAGRA) est 12,3 fois plus rapide que HNSW sur CPU, et la latence de recherche est réduite de 4,7 fois. (Source: AIatMeta)
Google AI Studio et Firebase Studio intègrent Gemini 2.5 Pro: Google a annoncé l’intégration du modèle Gemini 2.5 Pro dans Gemini Code Assist (version personnelle) et Firebase Studio. Cela offrira aux développeurs plus de commodité et des fonctionnalités puissantes lors de l’utilisation de modèles de codage de premier plan sur ces plateformes, visant à améliorer l’efficacité et l’expérience de codage. (Source: algo_diver)
Microsoft Copilot lance la fonctionnalité Pages, prenant en charge l’édition en ligne et le surlignage de texte: Microsoft Copilot a ajouté une nouvelle fonctionnalité « Pages », permettant aux utilisateurs d’éditer directement les réponses générées par l’IA dans l’interface de Copilot. Ils peuvent surligner du texte et proposer des modifications spécifiques. Cette fonctionnalité vise à aider les utilisateurs à transformer plus rapidement et intelligemment leurs questions et résultats de recherche en documents utilisables, améliorant ainsi l’efficacité du travail. (Source: yusuf_i_mehdi)
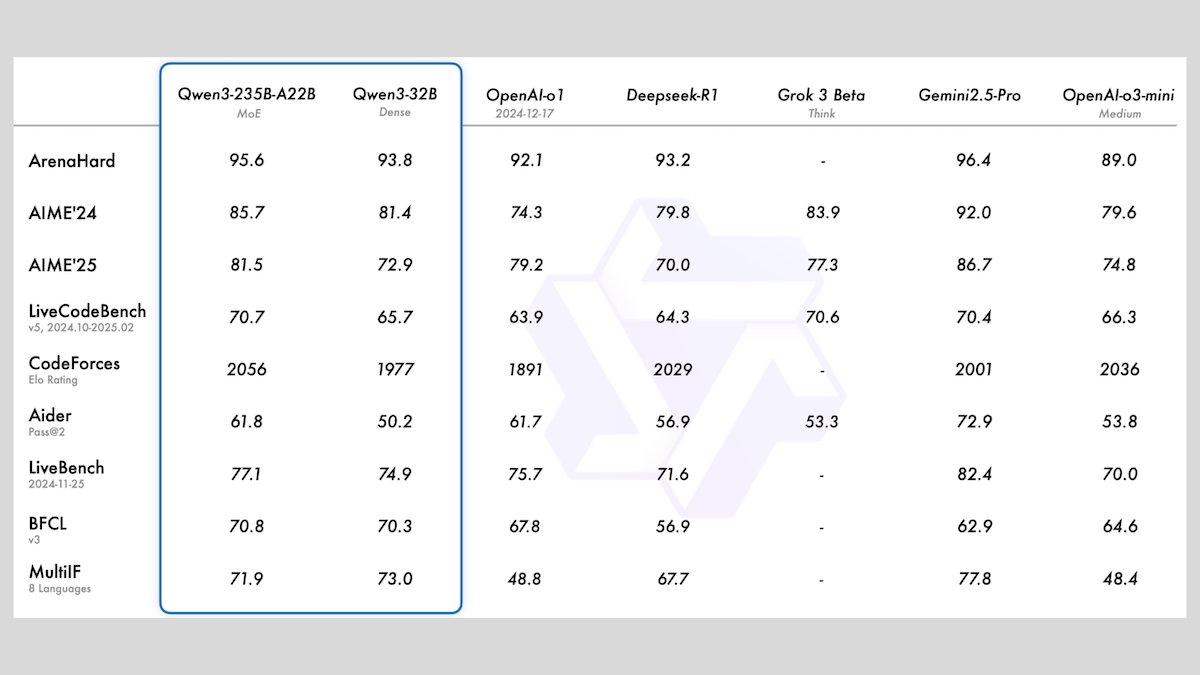
Alibaba lance la série de modèles Qwen3, comprenant 8 grands modèles de langage open source: Alibaba a publié la série Qwen3, qui comprend 8 grands modèles de langage open source, dont 2 modèles Mixture of Experts (MoE) et 6 modèles denses avec des paramètres allant de 0.6B à 32B. Tous les modèles prennent en charge des modes d’inférence optionnels et des capacités multilingues dans 119 langues. Qwen3-235B-A22B et Qwen3-30B-A3B excellent dans les tâches d’inférence, de codage et d’appel de fonction, rivalisant avec les modèles de pointe tels que ceux d’OpenAI. Qwen3-30B-A3B, en particulier, suscite l’attention pour ses performances robustes et sa capacité d’exécution locale. (Source: DeepLearningAI)
Meta lance le modèle Meta Locate 3D pour la localisation précise d’objets dans des environnements 3D: Meta AI a publié Meta Locate 3D, un modèle conçu spécifiquement pour la localisation précise d’objets dans des environnements 3D. Ce modèle vise à aider les robots à comprendre plus précisément leur environnement et à interagir plus naturellement avec les humains. Meta a mis à disposition le modèle, l’ensemble de données, le document de recherche ainsi qu’une démonstration pour l’usage et l’expérimentation par le public. (Source: AIatMeta)
Google publie un nouveau rapport expliquant comment utiliser l’IA pour lutter contre les escroqueries en ligne: Google a publié un nouveau rapport sur la manière dont il utilise la technologie de l’intelligence artificielle pour lutter contre les escroqueries en ligne dans son moteur de recherche, son navigateur Chrome et son système d’exploitation Android. Le rapport détaille les efforts de Google depuis plus d’une décennie et les dernières avancées dans l’utilisation de l’IA pour protéger les utilisateurs contre la fraude en ligne, soulignant le rôle crucial de l’IA dans l’identification et le blocage des activités frauduleuses. (Source: Google)
Cohere lance le modèle d’embedding Embed 4, renforçant les capacités de recherche et de récupération d’informations par l’IA: Cohere a lancé son dernier modèle d’embedding, Embed 4, conçu pour révolutionner la manière dont les entreprises accèdent et utilisent leurs données. Embed 4, le modèle d’embedding le plus puissant de Cohere à ce jour, se concentre sur l’amélioration de la précision et de l’efficacité de la recherche et de la récupération d’informations par l’IA, aidant les organisations à débloquer la valeur cachée de leurs données. (Source: cohere)

Google annonce que la conférence Google I/O aura lieu le 20 mai: Google a officiellement annoncé que sa conférence annuelle des développeurs, Google I/O, se tiendra le 20 mai et que les inscriptions sont ouvertes. Des présentations liminaires, des lancements de nouveaux produits et des annonces technologiques y auront lieu, l’IA devant être l’un des thèmes centraux. (Source: Google)
Le modèle Parakeet de NVIDIA établit un nouveau record de transcription audio : 60 minutes d’audio transcrites en 1 seconde: Le modèle Parakeet de NVIDIA a réalisé une percée dans la transcription audio, capable de transcrire jusqu’à 60 minutes d’audio en 1 seconde, et se classe parmi les meilleurs sur les classements pertinents de Hugging Face. Cette réussite démontre la position de leader de NVIDIA dans la technologie de reconnaissance vocale et fournit aux développeurs des outils de traitement audio efficaces. (Source: huggingface)

🧰 Outils
LlamaParse ajoute le support de GPT 4.1 et Gemini 2.5 Pro, renforçant ses capacités d’analyse de documents: LlamaParse a récemment bénéficié d’une série de mises à jour fonctionnelles, incluant l’introduction de nouveaux modèles d’analyse GPT 4.1 et Gemini 2.5 Pro pour améliorer la précision. De plus, la nouvelle version ajoute des fonctionnalités de détection automatique de l’orientation et de l’inclinaison, assurant une analyse parfaitement alignée ; fournit des scores de confiance pour évaluer la qualité de l’analyse ; et permet aux utilisateurs de personnaliser la tolérance aux erreurs et la manière de traiter les pages échouées. LlamaParse offre un quota gratuit de 10 000 pages par mois. (Source: jerryjliu0)

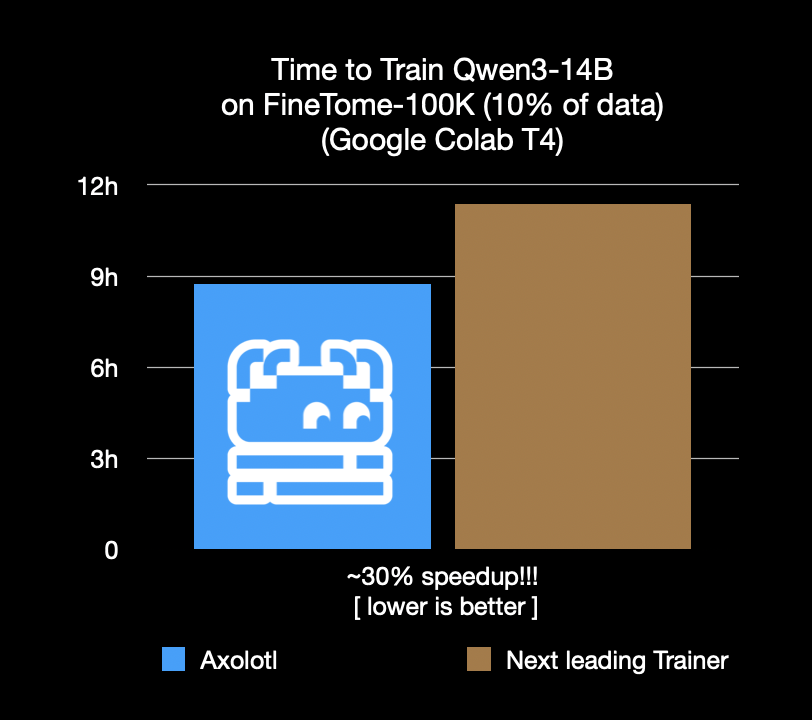
Le framework de fine-tuning Axolotl accélère de 30%, économisant coûts et temps: Le framework de fine-tuning Axolotl annonce une vitesse supérieure de 30% par rapport aux frameworks sous-optimaux sur des charges de travail réelles telles que FineTome-100k. Pour les équipes de machine learning de taille moyenne à grande, cela signifie des économies de plusieurs milliers de dollars par mois. L’optimisation de ce framework vise à aider les utilisateurs à effectuer le fine-tuning de modèles de manière plus efficace et économique. (Source: Teknium1, winglian, maximelabonne)
Runway lance le pilote d’animation « Mars & Siv: No Vacancy », démontrant les capacités du modèle Gen-4: Le studio d’IA de Runway a lancé le pilote d’animation « Mars & Siv: No Vacancy », créé par Jeremy Higgins et Britton Korbel. Cette œuvre illustre l’application du modèle Gen-4 de Runway à toutes les étapes du processus de production d’animation, du concept au produit final, soulignant le potentiel de l’IA dans la génération de contenu créatif. (Source: c_valenzuelab, c_valenzuelab)
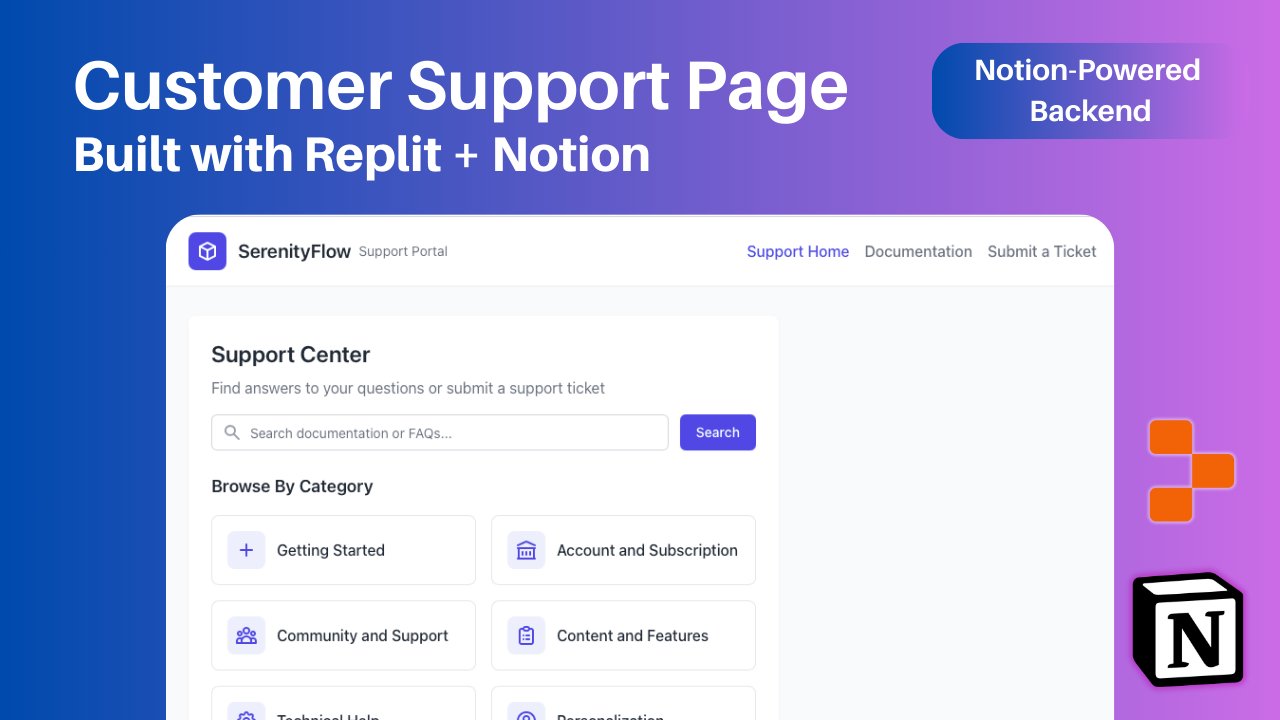
Replit ajoute l’intégration Notion, permettant d’utiliser le contenu Notion comme backend d’application: Replit a annoncé une nouvelle collaboration d’intégration avec Notion, permettant aux développeurs d’utiliser Notion comme backend pour leurs applications. Les utilisateurs peuvent connecter leurs bases de données Notion à des projets Replit pour afficher des FAQ, alimenter des chatbots IA personnalisés basés sur des documents, et enregistrer les tickets de support dans Notion. Cette initiative vise à combiner les capacités d’organisation backend de Notion avec la flexibilité de création frontend de Replit. (Source: amasad, amasad, pirroh)
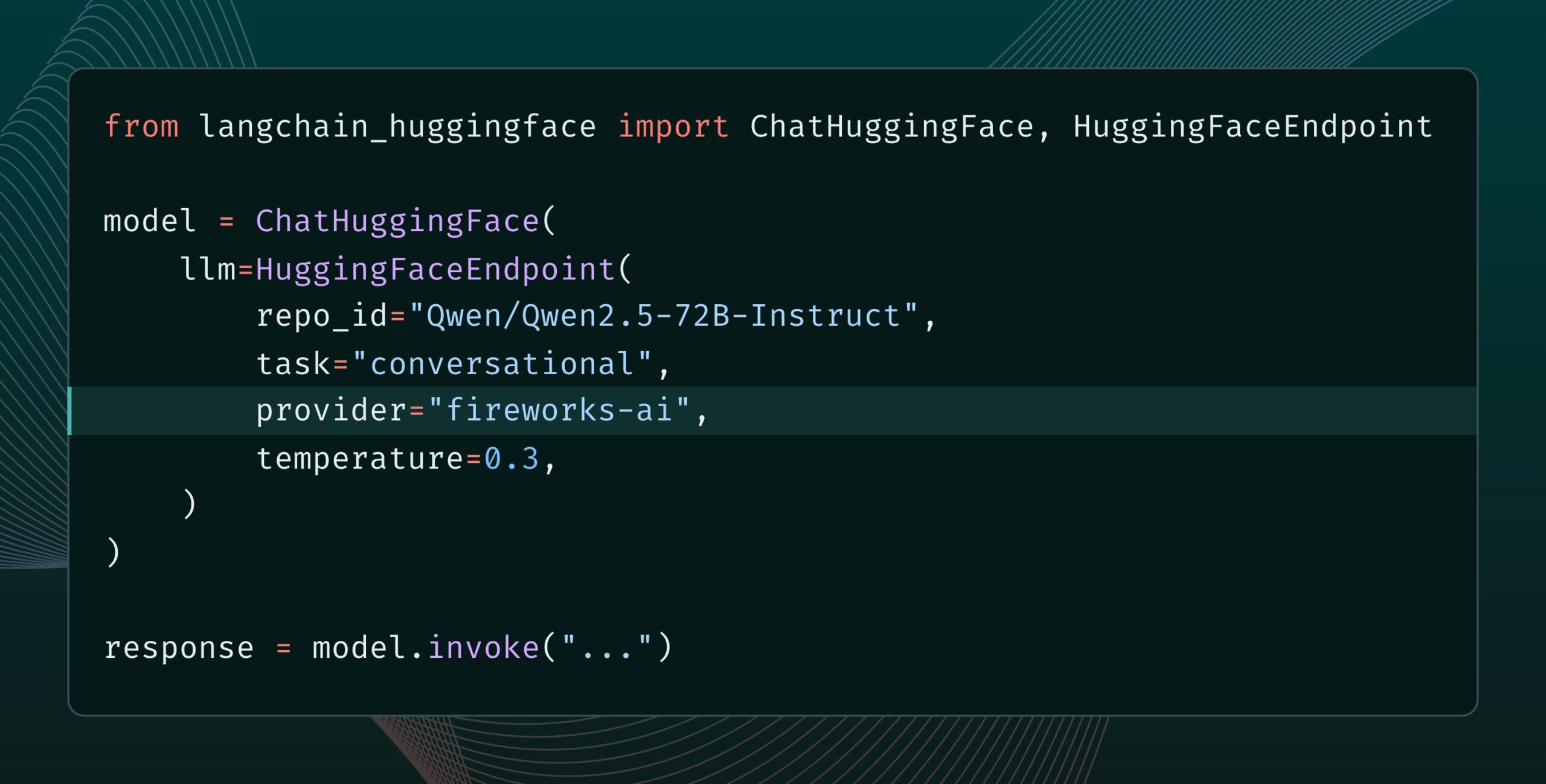
Langchain-huggingface v0.2 publié, prend en charge les HF Inference Providers: Langchain-huggingface a publié la version v0.2, qui ajoute la prise en charge des Hugging Face Inference Providers. Cette mise à jour facilitera l’utilisation des services d’inférence fournis par Hugging Face au sein de l’écosystème LangChain. (Source: LangChainAI, huggingface, ClementDelangue, hwchase17, Hacubu)
smolagents 1.15 publié, ajout de la fonctionnalité de sortie en streaming: Le framework d’agents IA smolagents a publié la version 1.15, introduisant la fonctionnalité de sorties en streaming (streaming outputs). Les utilisateurs peuvent l’activer en initialisant CodeAgent avec stream_outputs=True, ce qui rendra tous les processus d’interaction plus fluides. (Source: huggingface, AymericRoucher, ClementDelangue)
Projet Better-Qwen3 : permettre au modèle Qwen3 de changer automatiquement de mode de pensée: Un projet GitHub nommé Better-Qwen3 attire l’attention. Il vise à permettre au modèle Qwen3 de contrôler automatiquement l’activation du « mode de pensée » en fonction de la complexité de la question de l’utilisateur. Pour les questions simples, le modèle répondra directement ; pour les questions complexes, il entrera automatiquement en mode de pensée pour fournir une réponse plus approfondie. Adresse du projet : http://github.com/AaronFeng753/Better-Qwen3 (Source: karminski3, Reddit r/LocalLLaMA)
MLX-Audio : bibliothèque TTS/STT/STS basée sur le framework Apple MLX: MLX-Audio est une bibliothèque de synthèse vocale (TTS), de reconnaissance vocale (STT) et de conversion voix à voix (STS) spécialement conçue pour les puces Apple Silicon. Basée sur le framework MLX d’Apple, elle vise à fournir des capacités de traitement vocal efficaces. La bibliothèque prend en charge plusieurs langues, la personnalisation de la voix, le contrôle de la vitesse de parole, et offre une interface Web interactive ainsi qu’une API REST. (Source: GitHub Trending)
Le modèle References de Runway prend en charge la fonction d’extension d’image (Outpainting): Le modèle References de Runway prend désormais en charge la fonction d’extension d’image (outpainting). Les utilisateurs n’ont qu’à placer une image dans References, sélectionner le format de sortie souhaité, laisser le prompt vide, puis cliquer sur générer pour étendre l’image originale. Cette fonctionnalité renforce davantage les capacités de Runway en matière d’édition et de création d’images. (Source: c_valenzuelab)

Docker2exe : convertir des images Docker en fichiers exécutables: Docker2exe est un outil qui permet de convertir des images Docker en fichiers exécutables autonomes, facilitant ainsi leur partage et leur exécution par les utilisateurs. Il prend en charge un mode intégré, où le tarball de l’image Docker est directement inclus dans l’exécutable. Lors de l’exécution sur un appareil cible, s’il ne dispose pas localement de l’image Docker correspondante, il chargera automatiquement l’image intégrée ou la récupérera depuis le réseau. (Source: GitHub Trending)
Smoothie Qwen : lisser les probabilités des tokens du modèle Qwen pour équilibrer la génération multilingue: Smoothie Qwen est un outil d’ajustement léger qui, en lissant les probabilités des tokens dans le modèle Qwen, vise à améliorer l’équilibre du modèle lors de la génération multilingue, réduisant les biais involontaires envers des langues spécifiques (comme le chinois), tout en maintenant les performances de base. L’outil utilise des plages Unicode pour identifier les tokens, effectue une analyse N-gram et ajuste les poids des tokens dans lm_head. Les modèles pré-ajustés sont disponibles sur Hugging Face. (Source: Reddit r/LocalLLaMA)

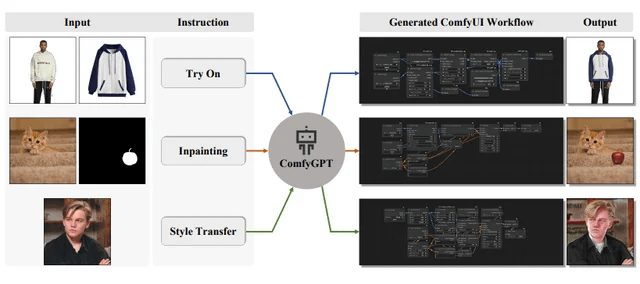
ComfyGPT : système multi-agents auto-optimisant pour la génération complète de workflows ComfyUI: Un article intitulé « ComfyGPT: A Self-Optimizing Multi-Agent System for Comprehensive ComfyUI Workflow Generation » a été soumis à arXiv, présentant un système nommé ComfyGPT. Ce système utilise une approche multi-agents auto-optimisante pour générer de manière exhaustive des workflows ComfyUI, simplifiant la construction de processus complexes de génération d’images. (Source: Reddit r/LocalLLaMA)
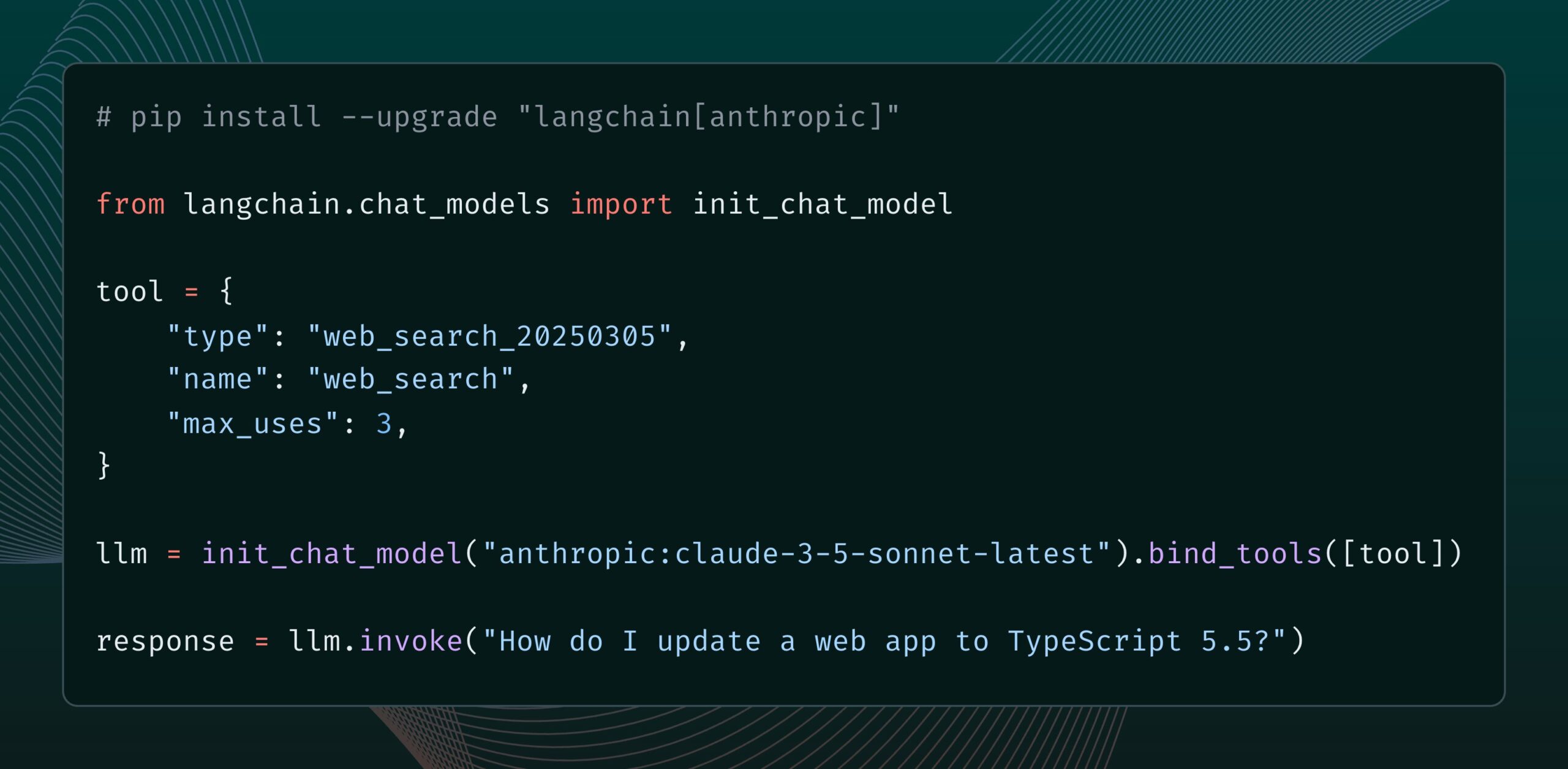
Le modèle Claude d’Anthropic ajoute un outil de recherche web: Anthropic a lancé un nouvel outil de recherche web pour son modèle Claude. Cet outil permet à Claude d’effectuer des recherches sur le web lors de la génération de réponses et d’utiliser les résultats de recherche comme base, fournissant des réponses avec des citations. Cette fonctionnalité a été intégrée à la bibliothèque langchain-anthropic, améliorant la capacité de Claude à obtenir et à utiliser des informations en temps réel. (Source: LangChainAI, hwchase17)
Glass Health lance la fonctionnalité Workspace, utilisant l’IA pour aider au diagnostic clinique et à la planification thérapeutique: Glass Health a lancé sa nouvelle fonctionnalité Workspace, qui permet aux cliniciens d’utiliser l’IA pour accomplir plus efficacement des tâches complexes de raisonnement diagnostique, de planification thérapeutique et de documentation. Cette initiative vise à améliorer l’efficacité et la qualité du travail médical grâce à la technologie de l’IA. (Source: GlassHealthHQ)
OpenWebUI ajoute des notes améliorées par l’IA et des fonctions d’enregistrement de réunions: La dernière version d’OpenWebUI intègre une fonction de prise de notes améliorée par l’IA, permettant aux utilisateurs de créer des notes, d’y joindre des enregistrements audio de réunions ou de mémos vocaux, et de laisser l’IA utiliser la transcription audio pour améliorer, résumer ou optimiser instantanément les notes. De plus, elle prend en charge l’enregistrement et l’importation d’audio de réunion, facilitant la révision et l’extraction d’informations importantes des discussions. (Source: Reddit r/OpenWebUI)
📚 Apprentissage
L’ONU publie un rapport de 200 pages sur l’IA et le développement humain mondial: Le Programme des Nations Unies pour le développement (PNUD) a publié un rapport de 200 pages examinant l’intelligence artificielle sous l’angle du développement humain mondial. Ce rapport explore les impacts de l’IA sur les Objectifs de Développement Durable, les inégalités, la gouvernance et l’avenir du travail, entre autres, et propose des recommandations politiques. Le rapport a attiré l’attention pour ses prises de position tranchées. (Source: random_walker)
The Turing Post publie une analyse approfondie du protocole Agent2Agent (A2A): Face à l’intérêt marqué de la communauté pour les protocoles de communication inter-agents IA, The Turing Post a publié gratuitement sur Hugging Face son analyse approfondie du protocole A2A de Google. L’article explore l’importance du protocole A2A (visant à briser les silos des agents IA et à permettre la collaboration), ses applications potentielles (telles que la collaboration d’équipes d’agents spécialisés, les workflows inter-entreprises, la standardisation de la collaboration homme-machine, un répertoire d’agents consultable) ainsi que son fonctionnement et les méthodes pour démarrer. (Source: TheTuringPost, TheTuringPost, TheTuringPost, dl_weekly)

Un ingénieur en prompts partage : comment créer facilement de bons modèles de prompts: L’ingénieur en prompts dotey a partagé une méthode en trois étapes pour créer des modèles de prompts efficaces : 1. Collecter des prompts de même style mais sur des sujets différents ; 2. Identifier les points communs et les différences (éventuellement avec l’aide de l’IA) ; 3. Tester et optimiser de manière itérative. Il souligne qu’un bon modèle est similaire à une fonction en programmation, permettant de générer des résultats différents avec peu de modifications de variables. Il a également partagé un modèle d’instruction pour générer rapidement de nouveaux prompts avec l’IA, et a souligné que tous les styles ne se prêtent pas à la modélisation, les sujets comportant des détails complexes nécessitant toujours une optimisation personnalisée. (Source: dotey)

L’équipe du chercheur John Jumper de DeepMind recrute pour étendre les découvertes scientifiques basées sur les LLM: John Jumper, chercheur chez Google DeepMind, a annoncé que son équipe recrute pour plusieurs postes afin d’étendre les travaux sur les découvertes scientifiques basées sur les grands modèles de langage (LLM). Les postes à pourvoir incluent des chercheurs scientifiques (RS) et des ingénieurs de recherche (RE), visant à faire progresser l’avenir de l’IA scientifique en langage naturel. (Source: demishassabis, NandoDF)
Le blog Ragas partage deux ans d’expérience dans l’amélioration des applications d’IA: Shahules786 a publié un article sur le blog Ragas, résumant les leçons tirées de deux années de collaboration étroite avec des équipes d’IA, de livraison de cycles d’évaluation et d’amélioration des systèmes LLM. L’article vise à fournir des conseils pratiques et des perspectives aux praticiens qui construisent et optimisent des applications d’IA. (Source: Shahules786)

Kyunghyun Cho discute des méthodes d’enseignement des cours de machine learning pour étudiants diplômés à l’ère des LLM: Kyunghyun Cho, professeur à l’Université de New York, a partagé ses réflexions et expérimentations concernant le contenu pédagogique des cours de machine learning de première année pour étudiants diplômés, à l’ère actuelle des LLM et du calcul à grande échelle. Il propose d’enseigner tous les contenus acceptant la SGD (descente de gradient stochastique) et non liés aux LLM, et d’orienter les étudiants vers la lecture d’articles classiques. (Source: ylecun, sainingxie)

Lancement d’un classement du traitement intelligent des documents (IDP) pour une évaluation unifiée des capacités de compréhension de documents des VLM: Un nouveau classement du traitement intelligent des documents (IDP) a été mis en ligne, visant à fournir un benchmark unifié pour diverses tâches de compréhension de documents telles que l’OCR, le KIE, le VQA et l’extraction de tableaux. Ce classement couvre 6 tâches IDP principales, 16 ensembles de données et 9229 documents. Les premiers résultats montrent que Gemini 2.5 Flash est globalement en tête, mais tous les modèles affichent de faibles performances sur la compréhension de documents longs, et l’extraction de tableaux reste un goulot d’étranglement. Les performances de la dernière version de GPT-4o ont même diminué. (Source: Reddit r/MachineLearning, Reddit r/LocalLLaMA)
LangGraph lance la fonctionnalité Cron Jobs, permettant le déclenchement programmé d’agents IA: La plateforme LangGraph de LangChain a ajouté une nouvelle fonctionnalité Cron Jobs, permettant aux utilisateurs de configurer des tâches planifiées pour déclencher automatiquement l’exécution d’agents IA. Cette fonctionnalité permet aux agents IA d’exécuter des tâches selon un calendrier prédéfini, ce qui est adapté aux scénarios nécessitant un traitement ou une surveillance périodique. (Source: hwchase17)
💼 Affaires
L’outil de débogage logiciel IA Lightrun lève 70 millions de dollars en série B, menée par Accel et Insight Partners: Lightrun, développeur d’outils d’observabilité et de débogage logiciel IA, a annoncé la clôture d’un financement de série B de 70 millions de dollars, mené par Accel et Insight Partners, avec la participation de Citigroup entre autres, portant son financement total à 110 millions de dollars. Son produit phare, Runtime Autonomous AI Debugger, peut localiser avec précision le code problématique dans l’IDE et fournir des suggestions de correction, visant à réduire le temps de débogage de plusieurs heures à quelques minutes. Le chiffre d’affaires de l’entreprise a été multiplié par 4,5 en 2024, avec des clients tels que Citigroup et Microsoft parmi les entreprises du Fortune 500. (Source: 36氪)

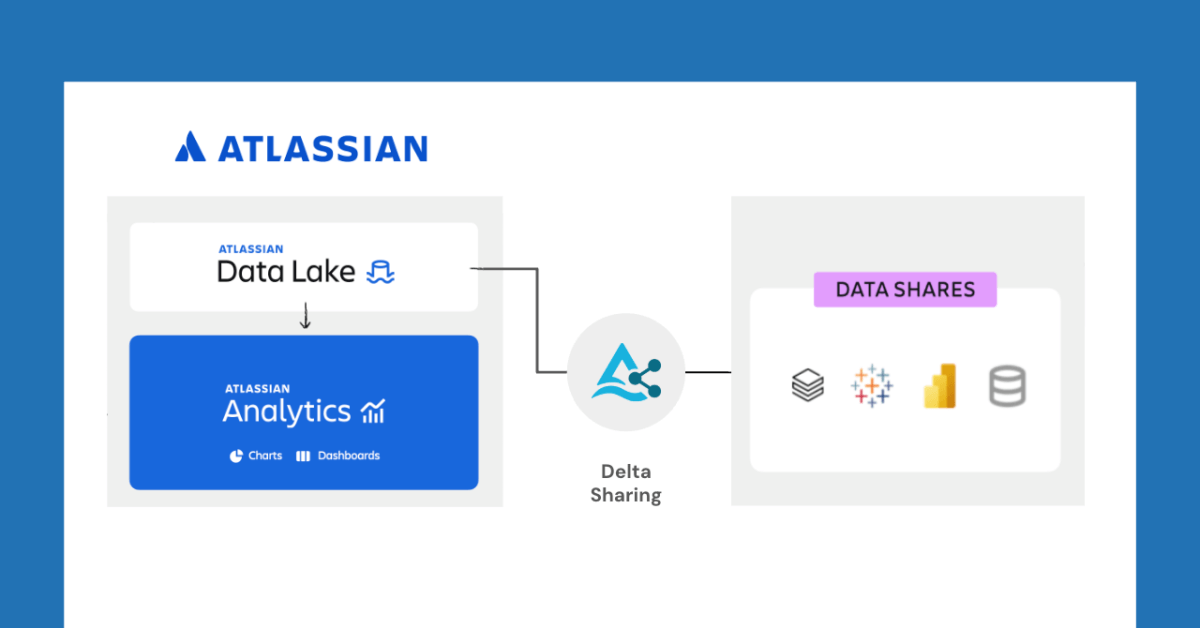
Databricks et Atlassian collaborent pour débloquer de nouvelles fonctionnalités de partage de données via Delta Sharing: Databricks a annoncé une collaboration avec Atlassian pour apporter de nouvelles capacités de partage de données à Atlassian Analytics. Grâce au protocole ouvert de Delta Sharing, les clients d’Atlassian peuvent accéder et analyser en toute sécurité leurs données dans Atlassian Data Lake en utilisant les outils de leur choix. Cette fonctionnalité prend en charge l’intégration BI, les workflows de données personnalisés, la collaboration inter-équipes, etc. (Source: matei_zaharia)
Fastino lève 17,5 millions de dollars pour se concentrer sur les modèles de langage spécifiques à une tâche (TLM): La start-up Fastino a annoncé une levée de fonds de 17,5 millions de dollars (sur un total de 25 millions de dollars en pré-amorçage) menée par Khosla Ventures, pour développer ses modèles de langage spécifiques à une tâche (TLM) innovants. Fastino affirme que son architecture TLM est compacte et optimisée pour des tâches spécifiques, pouvant être entraînée sur des GPU de jeu bas de gamme, ce qui la rend rentable. Les TLM, grâce à une spécialisation au niveau de l’architecture, du pré-entraînement et du post-entraînement, éliminent la redondance des paramètres et l’inefficacité architecturale, visant à améliorer la précision sur des tâches spécifiques et pouvant être intégrés dans des applications sensibles à la latence et aux coûts. (Source: Reddit r/MachineLearning)

🌟 Communauté
Les outils de recherche d’emploi assistés par l’IA suscitent des inquiétudes quant à la triche, les entreprises renforcent les contre-mesures: Récemment, l’utilisation d’outils d’IA pour aider lors d’entretiens en ligne et d’examens écrits s’est accrue. Ces « artefacts d’entretien IA » peuvent personnaliser les réponses en fonction du CV de l’utilisateur, aidant les candidats à obtenir un avantage dans leur recherche d’emploi. L’accès à de tels logiciels est facile, certains proposant même des forfaits payants à plusieurs niveaux et une assistance à distance. Cette tendance remonte à l’apparition d’outils de triche IA plus anciens comme « Interview Coder ». Les entreprises ont commencé à prendre des contre-mesures, telles que la surveillance des comportements anormaux des candidats lors des entretiens, l’envisagement d’introduire la détection d’écran ou le retour aux entretiens en personne. Les avocats soulignent que l’utilisation de l’IA pour tricher constitue une violation du principe d’honnêteté, pouvant entraîner la résiliation du contrat de travail, et comporte des risques de fuite de données personnelles. (Source: 36氪)

Harrison Chase, PDG de LangChain, propose les concepts d’« agents ambiants » et de « boîte de réception d’agents »: Harrison Chase, PDG de LangChain, a partagé sa vision de l’avenir des agents IA lors de l’événement AI Ascent de Sequoia, proposant les concepts d’« Ambient Agents » (agents ambiants) et d’« Agent Inbox » (boîte de réception d’agents). Les agents ambiants désignent des systèmes d’IA capables de fonctionner en continu en arrière-plan, répondant à des événements plutôt qu’à des instructions humaines directes, tandis que la boîte de réception d’agents est une nouvelle interface homme-machine pour gérer et superviser les activités de ces agents. (Source: hwchase17, hwchase17, hwchase17)

Jim Fan propose le « test de Turing physique » comme nouvelle étoile polaire de l’IA: Jim Fan, scientifique chez NVIDIA, a proposé lors de l’événement AI Ascent de Sequoia le concept de « test de Turing physique », le considérant comme la prochaine « étoile polaire » du domaine de l’IA. Ce test imagine un scénario : après un hackathon du dimanche, la maison est en désordre ; en rentrant le lundi soir, le salon est impeccable et un dîner aux chandelles est prêt, et vous ne pouvez pas distinguer si c’est l’œuvre d’un humain ou d’une machine. Il considère cela comme l’objectif de la robotique générale et a partagé les principes fondamentaux pour résoudre ce problème, y compris les stratégies de données et les lois d’échelle. (Source: DrJimFan, killerstorm)
L’évaluation des modèles d’IA en crise, l’alliance EvalEval appelle à des améliorations: Face aux lacunes actuelles des méthodes d’évaluation des modèles d’IA, telles que la saturation des benchmarks et le manque de rigueur scientifique, l’alliance EvalEval a été mentionnée. Elle vise à unir les personnes préoccupées par l’état actuel de l’évaluation pour travailler ensemble à l’amélioration des rapports d’évaluation, à la résolution du problème de saturation, à l’amélioration de la scientificité de l’évaluation et des infrastructures. Les discussions connexes estiment qu’il faudrait accorder plus d’attention à la validité de l’évaluation. (Source: ClementDelangue)

Discussion animée sur Reddit : observations et expériences dans la construction de workflows LLM: Un développeur a partagé sur Reddit un résumé de son expérience de l’année écoulée dans la construction de workflows LLM complexes. Les points clés incluent : la décomposition des tâches en étapes minimales et l’enchaînement d’appels de prompts sont préférables à un unique prompt complexe ; l’utilisation de balises XML pour structurer les prompts donne de meilleurs résultats ; il faut indiquer clairement au LLM que son rôle se limite à l’analyse et à la transformation sémantiques, sans introduire ses propres connaissances ; l’utilisation de bibliothèques NLP traditionnelles comme NLTK pour valider les sorties du LLM ; les classifieurs de type BERT fine-tunés sur de petites tâches sont souvent supérieurs aux LLM ; les LLM en tant qu’arbitres ou pour l’évaluation de la confiance ne sont pas fiables, surtout en l’absence de critères de notation clairs ; dans les boucles agentiques, la définition des conditions de sortie de boucle pour le LLM est un point difficile ; les performances diminuent généralement lorsque la fenêtre de contexte d’entrée dépasse 4K tokens ; les modèles 32B sont suffisants pour les tâches structurées ; le CoT structuré est supérieur au non structuré ; écrire son propre CoT est préférable à se fier aux modèles de raisonnement ; l’objectif à long terme est de fine-tuner tous les composants, et de veiller à construire des ensembles de données de fine-tuning équilibrés. (Source: Reddit r/LocalLLaMA)
Des utilisateurs de Reddit discutent des paramètres de prompt système pour Claude Sonnet 3.7: Des utilisateurs de la communauté Reddit r/ClaudeAI signalent une instabilité du modèle Claude Sonnet 3.7 en ce qui concerne le respect des instructions, la correction de code et la mémoire contextuelle, et sollicitent des prompts système efficaces. Un utilisateur a partagé un prompt imitant le comportement de Sonnet 3.5, ainsi que des instructions détaillées mettant l’accent sur des solutions efficaces et pratiques, et le respect des principes fondamentaux de l’informatique (tels que DRY, KISS, SRP). D’autres utilisateurs ont suggéré d’améliorer les résultats en laissant Claude réécrire et optimiser lui-même le prompt système, ou en utilisant des instructions concises et claires sur une seule ligne. (Source: Reddit r/ClaudeAI)
Discussion sur le nombre d’époques nécessaires pour le fine-tuning des LLM: Sur Reddit r/MachineLearning, un utilisateur a soulevé une question concernant l’article sur Deepseek R1 qui ne mentionne que 2 époques pour le fine-tuning du modèle Deepseek-V3-Base (environ 800 000 échantillons), explorant les indicateurs, au-delà de la fonction de perte, qui déterminent le nombre d’époques de fine-tuning, tels que les performances sur les données d’évaluation et la qualité des données. (Source: Reddit r/MachineLearning)
💡 Autres
François Chollet : Construire des modèles mentaux solides est une condition préalable à la résolution de problèmes complexes: Le penseur en IA François Chollet souligne que l’établissement de modèles mentaux clairs et cohérents est une condition préalable à la résolution créative de problèmes complexes (plutôt que de dépendre de la chance), ce qui diffère de la capacité à résoudre rapidement des problèmes simples. Il considère que l’élégance est une combinaison d’expressivité et de concision, étroitement liée à la compression. (Source: fchollet, teortaxesTex, fchollet, pmddomingos)

Amjad Masad, PDG de Replit : Les agents IA seront la nouvelle vague de la programmation: Amjad Masad, PDG et co-fondateur de Replit, a déclaré dans une interview pour The Turing Post qu’il a toujours cru que les agents IA mèneraient la prochaine vague de la programmation. Il a partagé l’évolution de sa pensée, passant de l’enseignement de la programmation à la construction d’agents capables de programmer automatiquement. Il a mentionné que les agents logiciels produisent déjà des résultats concrets dans des activités commerciales, par exemple en aidant une entreprise immobilière à optimiser son algorithme d’attribution de prospects, augmentant le taux de conversion de 10 %. Il pense que les futures start-ups valant des milliards de dollars pourraient être créées par des fondateurs indépendants augmentés par l’IA, et a discuté des conditions nécessaires pour réaliser cette vision, de l’état actuel et futur du domaine de la programmation, de l’évolution de la vision de Replit, ainsi que de l’importance de l’AGI et de l’open source. (Source: TheTuringPost, TheTuringPost)
LazyVim : une configuration Neovim pour les « paresseux »: LazyVim est une solution de configuration Neovim basée sur lazy.nvim, conçue pour permettre aux utilisateurs de personnaliser et d’étendre facilement leur environnement Neovim. Elle offre une expérience de type IDE préconfigurée et riche en fonctionnalités, tout en conservant une grande flexibilité, que les utilisateurs peuvent ajuster selon leurs besoins. (Source: GitHub Trending)
