Mots-clés:Zéro Absolu, Qwen3, Mistral Medium 3, Fondation PyTorch, Auto-évolution de l’IA, Modèle multimodal, IA open source, Paradigme RLVR, Système AZR, Qwen3-235B-A22B, Bibliothèque d’optimisation DeepSpeed, Support multimodal LangSmith
🔥 À la Une
L’Université Tsinghua publie un article sur Absolute Zero : L’IA peut évoluer de manière autonome sans données externes: L’équipe LeapLabTHU de l’Université Tsinghua a publié un nouveau paradigme RLVR (Reinforcement Learning with Verifiable Rewards) nommé “Absolute Zero”. Dans ce paradigme, un seul modèle peut proposer de manière autonome des tâches pour maximiser son processus d’apprentissage et améliorer ses capacités de raisonnement en résolvant ces tâches, sans dépendre d’aucune donnée externe. Son système AZR (Absolute Zero Reasoner) utilise un exécuteur de code pour vérifier les tâches et les réponses, réalisant un apprentissage ouvert mais fondé. Les expériences montrent qu’AZR atteint des performances SOTA (state-of-the-art) dans les tâches de codage et de raisonnement mathématique, surpassant les modèles zero-shot existants qui dépendent de dizaines de milliers d’échantillons annotés par des humains (Source: Reddit r/LocalLLaMA)
Alibaba publie la série de modèles Qwen3, incluant MoE et plusieurs tailles: Alibaba a publié la série de grands modèles de langage Qwen3, comprenant 8 modèles avec un nombre de paramètres allant de 0.6B à 235B. Parmi eux, Qwen3-235B-A22B et Qwen3-30B-A3B utilisent une architecture MoE (Mixture of Experts), les autres étant des modèles denses. Cette série de modèles a été pré-entraînée sur 36T tokens, couvre 119 langues et dispose d’un mode d’inférence commutable, applicable à de multiples domaines tels que le code, les mathématiques et les sciences. Les évaluations montrent que les modèles MoE ont des performances supérieures, la version 235B surpassant DeepSeek-R1 et Gemini 2.5 Pro sur plusieurs benchmarks. La version 30B est également performante, et même le modèle 4B surpasse sur certains benchmarks des modèles avec beaucoup plus de paramètres. Les modèles sont open-source sur HuggingFace et ModelScope, sous licence Apache 2.0 (Source: DeepLearning.AI Blog)
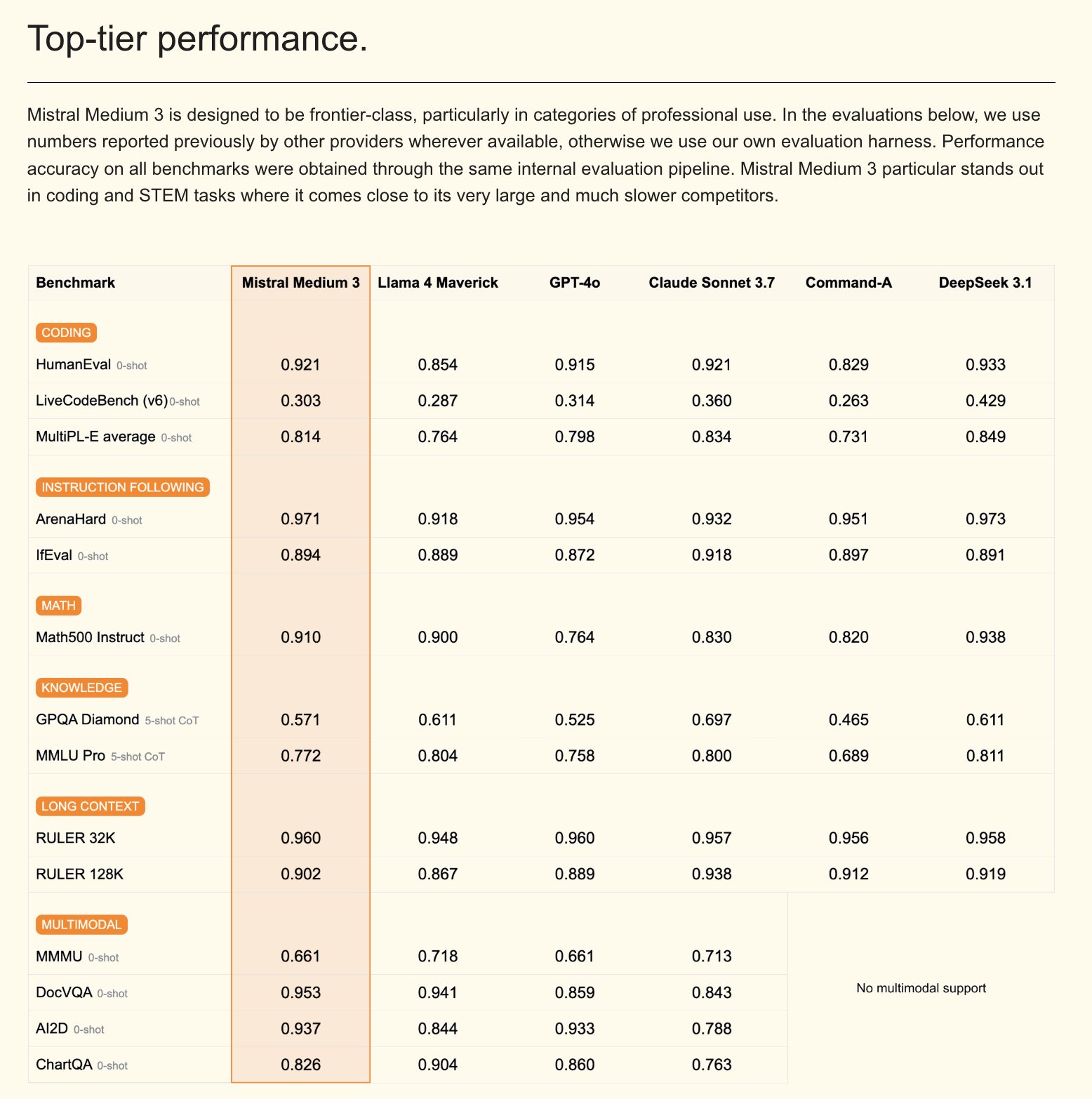
Mistral publie le modèle multimodal Mistral Medium 3 et un assistant AI pour entreprises: Mistral AI a lancé Mistral Medium 3, un nouveau modèle multimodal qui, selon l’entreprise, se rapproche des performances de Claude Sonnet 3.7, mais avec un coût significativement réduit (entrée $0.4/M de tokens, sortie $2/M de tokens), soit une baisse de 8 fois. Ce modèle excelle dans le codage et l’appel de fonctions, et offre des fonctionnalités de niveau entreprise telles que le déploiement hybride ou local et le post-entraînement personnalisé. Parallèlement, Mistral a également lancé Le Chat Enterprise, un assistant AI personnalisable et sécurisé pour les entreprises, prenant en charge l’intégration des bases de connaissances de l’entreprise (comme Gmail, Google Drive, Sharepoint), doté de fonctionnalités d’Agent, d’assistant de codage, de recherche web, etc., visant à améliorer la compétitivité des entreprises. Mistral a annoncé la sortie d’un nouveau modèle Large dans les semaines à venir (Source: Mistral AI, GuillaumeLample, scaling01, karminski3)
La PyTorch Foundation s’étend en une fondation faîtière, intégrant vLLM et DeepSpeed: La PyTorch Foundation a annoncé son expansion en une structure de fondation faîtière, visant à rassembler davantage de projets open source AI de haute qualité. Les premiers projets à rejoindre sont vLLM et DeepSpeed. vLLM est un moteur d’inférence et de service à haut débit et à faible consommation de mémoire, spécialement conçu pour les LLM ; DeepSpeed est une bibliothèque d’optimisation de l’apprentissage profond qui rend l’entraînement de modèles à grande échelle plus efficace. Cette initiative vise à promouvoir le développement de l’AI piloté par la communauté, couvrant l’ensemble du cycle de vie, de la recherche à la production, et bénéficie du soutien de nombreux membres, dont AMD, Arm, AWS, Google, Huawei (Source: PyTorch, soumithchintala, vllm_project, code_star)

🎯 Tendances
Le laboratoire ARC de Tencent publie FlexiAct : un outil de transfert de mouvement vidéo: Le laboratoire ARC de Tencent a publié sur Hugging Face un nouvel outil nommé FlexiAct. Cet outil est capable de transférer les mouvements d’une vidéo de référence vers n’importe quelle image cible, même si la disposition, l’angle de vue ou la structure squelettique de l’image cible diffèrent de la vidéo de référence. Cela ouvre de nouvelles possibilités dans le domaine de la génération et de l’édition vidéo, permettant aux utilisateurs de contrôler plus flexiblement les mouvements et les postures dans le contenu généré (Source: _akhaliq)
White Circle publie CircleGuardBench : un nouveau benchmark pour les modèles de modération de contenu AI: White Circle a lancé CircleGuardBench, un nouveau benchmark pour évaluer les modèles de modération de contenu AI. Ce benchmark est conçu pour une évaluation au niveau de la production, testant la détection des dangers, la résistance au jailbreaking, le taux de faux positifs et la latence, couvrant 17 catégories de dangers du monde réel. L’article de blog et le classement correspondants ont été publiés sur Hugging Face, fournissant de nouvelles normes d’évaluation pour le domaine de la sécurité AI et de la modération de contenu (Source: TheTuringPost, _akhaliq)

Hugging Face publie SIFT-50M : un grand jeu de données multilingue pour le fine-tuning d’instructions vocales: Hugging Face a publié le jeu de données SIFT-50M, un vaste ensemble de données multilingues conçu pour le fine-tuning d’instructions vocales. Ce jeu de données contient plus de 50 millions de paires de questions-réponses instructives, couvrant 5 langues. Le SIFT-LLM entraîné sur ce jeu de données surpasse SALMONN et Qwen2-Audio dans les benchmarks de suivi vocal. Le jeu de données comprend également un benchmark EvalSIFT pour l’évaluation acoustique et générative, et prend en charge la génération vocale contrôlable (comme la hauteur, le débit, l’accent), basé sur Whisper, HuBERT, X-Codec2 & Qwen2.5 (Source: ClementDelangue, huggingface)
Meta publie Perception Language Model (PLM) : un modèle de langage visuel open source et reproductible: Meta AI a lancé Meta Perception Language Model (PLM), un modèle de langage visuel ouvert et reproductible, conçu pour résoudre des tâches visuelles complexes. Meta espère aider la communauté open source à construire des systèmes de vision par ordinateur plus puissants grâce à PLM. L’article de recherche, le code et le jeu de données correspondants ont été publiés pour les chercheurs et les développeurs (Source: AIatMeta)
Google met à jour son modèle de génération d’images Gemini 2.0 : amélioration de la qualité et de la vitesse: Google a annoncé une mise à jour de son modèle de génération d’images Gemini 2.0 (version préliminaire). La nouvelle version offre une meilleure qualité visuelle, un rendu de texte plus précis, des taux de blocage (block rates) plus faibles et des limites de débit (rate limits) plus élevées. La génération de chaque image coûte $0.039. Cette mise à jour vise à améliorer l’expérience et les résultats des développeurs utilisant Gemini pour la génération d’images (Source: m__dehghani, scaling01, andrew_n_carr, demishassabis)
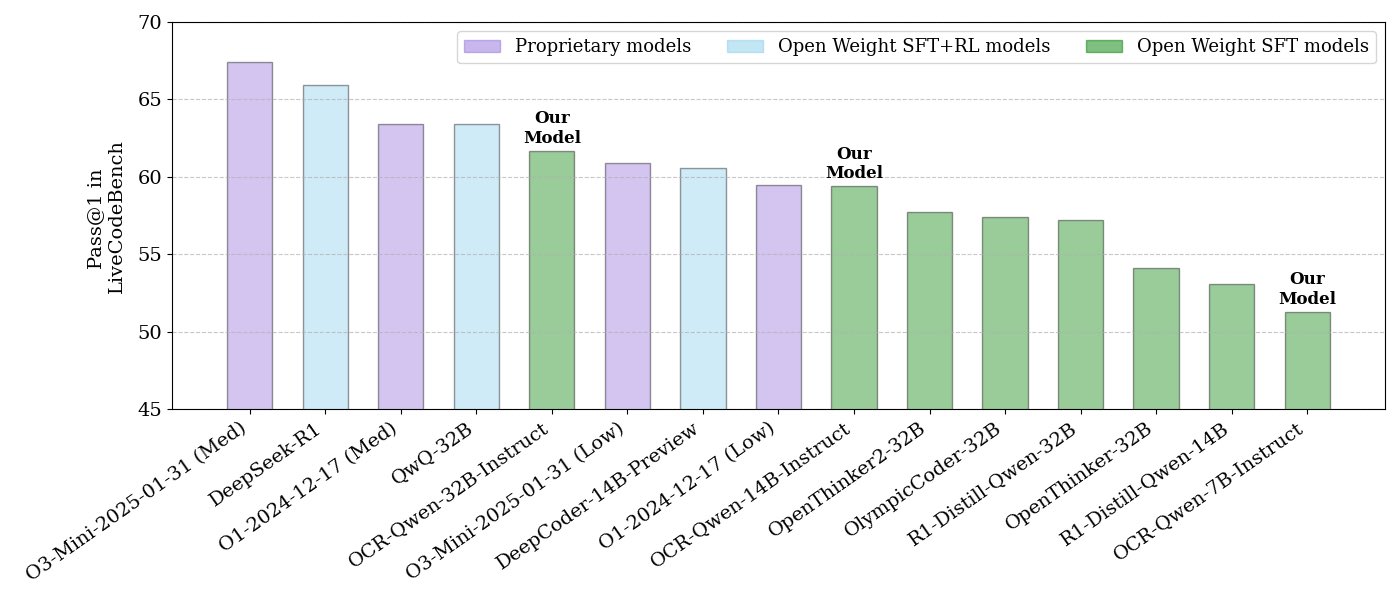
NVIDIA publie une série de modèles open source pour le raisonnement sur le code: NVIDIA a publié une série de modèles open source pour le raisonnement sur le code, disponibles en trois tailles : 32B, 14B et 7B, tous sous licence APACHE 2.0. Ces modèles sont entraînés sur des jeux de données OCR et surpasseraient O3 mini et O1 (low) sur le benchmark LiveCodeBench, tout en étant 30% plus efficaces en termes de tokens que les modèles de raisonnement comparables. Les modèles sont compatibles avec divers frameworks tels que llama.cpp, vLLM, transformers, TGI (Source: huggingface, ClementDelangue)
ServiceNow et NVIDIA collaborent pour lancer le modèle Apriel-Nemotron-15b-Thinker: ServiceNow et NVIDIA ont conjointement publié un modèle de 15B paramètres nommé Apriel-Nemotron-15b-Thinker, sous licence MIT. Ce modèle aurait des performances comparables à celles des modèles 32B, mais avec une consommation de tokens significativement réduite (environ 40% de moins que Qwen-QwQ-32b). Il excelle dans plusieurs benchmarks tels que MBPP, BFCL, RAG d’entreprise, IFEval, et est particulièrement compétitif dans les tâches de RAG d’entreprise et de codage (Source: Reddit r/LocalLLaMA)

Modèle s1 : le fine-tuning avec peu d’échantillons permet le raisonnement, la technique “Wait” améliore les performances: Des chercheurs de l’Université de Stanford et d’autres institutions ont développé le modèle s1, démontrant qu’un fine-tuning supervisé avec seulement environ 1000 échantillons de pensée en chaîne (CoT) peut doter un LLM pré-entraîné (comme Qwen 2.5-32B) de capacités de raisonnement. L’étude a également révélé qu’en forçant le modèle à générer le token “Wait” pendant le processus de raisonnement pour allonger la chaîne de raisonnement, on peut améliorer considérablement la précision du modèle sur des tâches telles que les mathématiques, le rapprochant des performances d’OpenAI o1-preview. Cette découverte offre une nouvelle approche pour améliorer à faible coût les capacités de raisonnement des modèles (Source: DeepLearning.AI Blog)
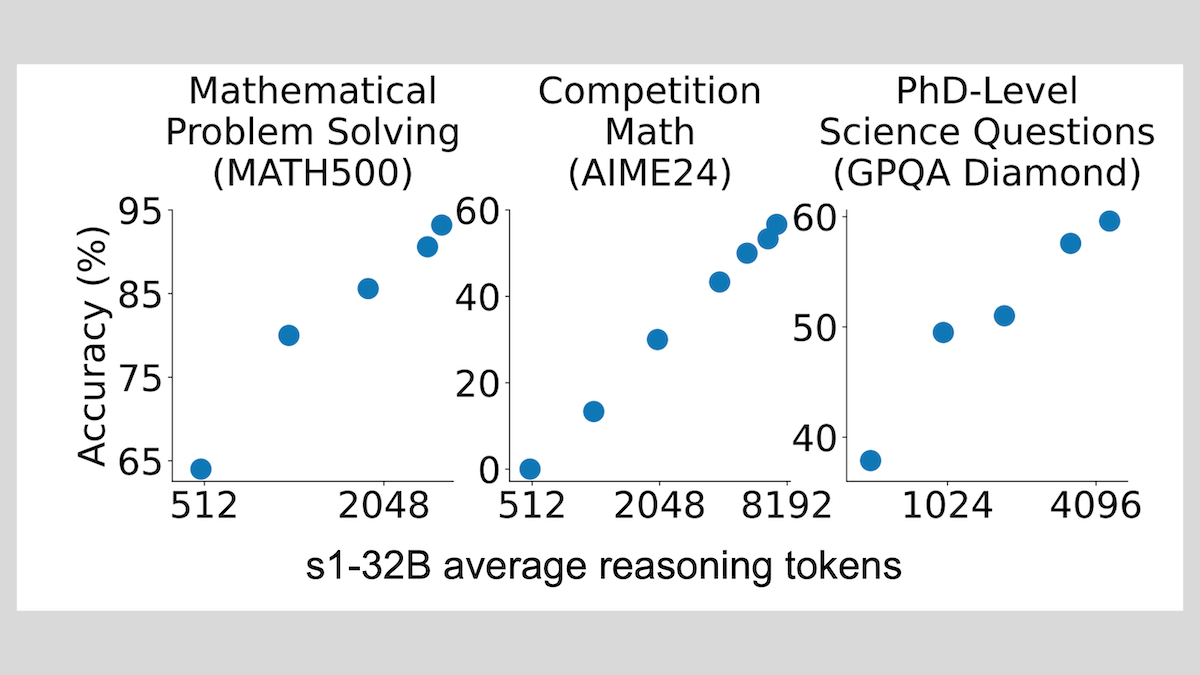
ThinkPRM : un modèle de récompense de processus génératif entraînable avec seulement 8K étiquettes: Des chercheurs ont proposé ThinkPRM, un modèle de récompense de processus génératif (PRM) qui ne nécessite que 8K étiquettes de processus pour le fine-tuning. Ce modèle est capable de valider les processus de raisonnement en générant de longues chaînes de pensée (long chains-of-thought), résolvant le problème coûteux de la grande quantité de données de supervision au niveau des étapes requises pour entraîner les PRM. Le code, les modèles et les données correspondants ont été publiés sur GitHub et Hugging Face (Source: Reddit r/MachineLearning)
🧰 Outils
Zed lance ce qui est présenté comme l’éditeur de code AI le plus rapide au monde: Zed a lancé un éditeur de code AI présenté comme le plus rapide au monde. Cet éditeur, construit à partir de zéro en Rust, vise à optimiser la collaboration entre humains et AI, offrant une expérience d’édition assistée par agent (agentic editing experience) ultra-rapide. Il prend en charge des modèles populaires tels que Claude 3.7 Sonnet et permet aux utilisateurs d’apporter leurs propres clés API ou d’utiliser des modèles locaux via Ollama (Source: andersonbcdefg, ollama)
Hugging Face lance nanoVLM : une bibliothèque de modèles de langage visuel minimaliste: Hugging Face a rendu open source nanoVLM, une bibliothèque purement PyTorch conçue pour entraîner des modèles de langage visuel (VLM) à partir de zéro en environ 750 lignes de code. Ce modèle atteint une précision de 35.3% sur le benchmark MMStar, comparable à SmolVLM-256M, mais avec un temps GPU requis pour l’entraînement réduit de 100 fois. nanoVLM utilise SigLiP-ViT comme encodeur visuel, un décodeur de style LLaMA, et les connecte via un projecteur modal, ce qui le rend adapté à l’apprentissage, au prototypage ou à la construction de VLM personnalisés (Source: clefourrier, ben_burtenshaw, Reddit r/LocalLLaMA)
DBOS publie DBOS Python 1.0 : un outil léger pour les workflows persistants: DBOS a publié la version 1.0 de DBOS Python. Cet outil vise à fournir des capacités de workflow persistantes légères et faciles à utiliser pour les applications Python (y compris les processus métier, l’automatisation AI, les pipelines de données, etc.). La nouvelle version comprend des files d’attente persistantes (prenant en charge la limitation de la concurrence, la limitation du débit, les délais d’attente, la priorité, la déduplication, etc.), la gestion programmatique des workflows (via des tables Postgres pour interroger, suspendre, reprendre, redémarrer, etc.), la prise en charge du code synchrone/asynchrone et des outils améliorés (tableau de bord, visualisation, etc.) (Source: lateinteraction)
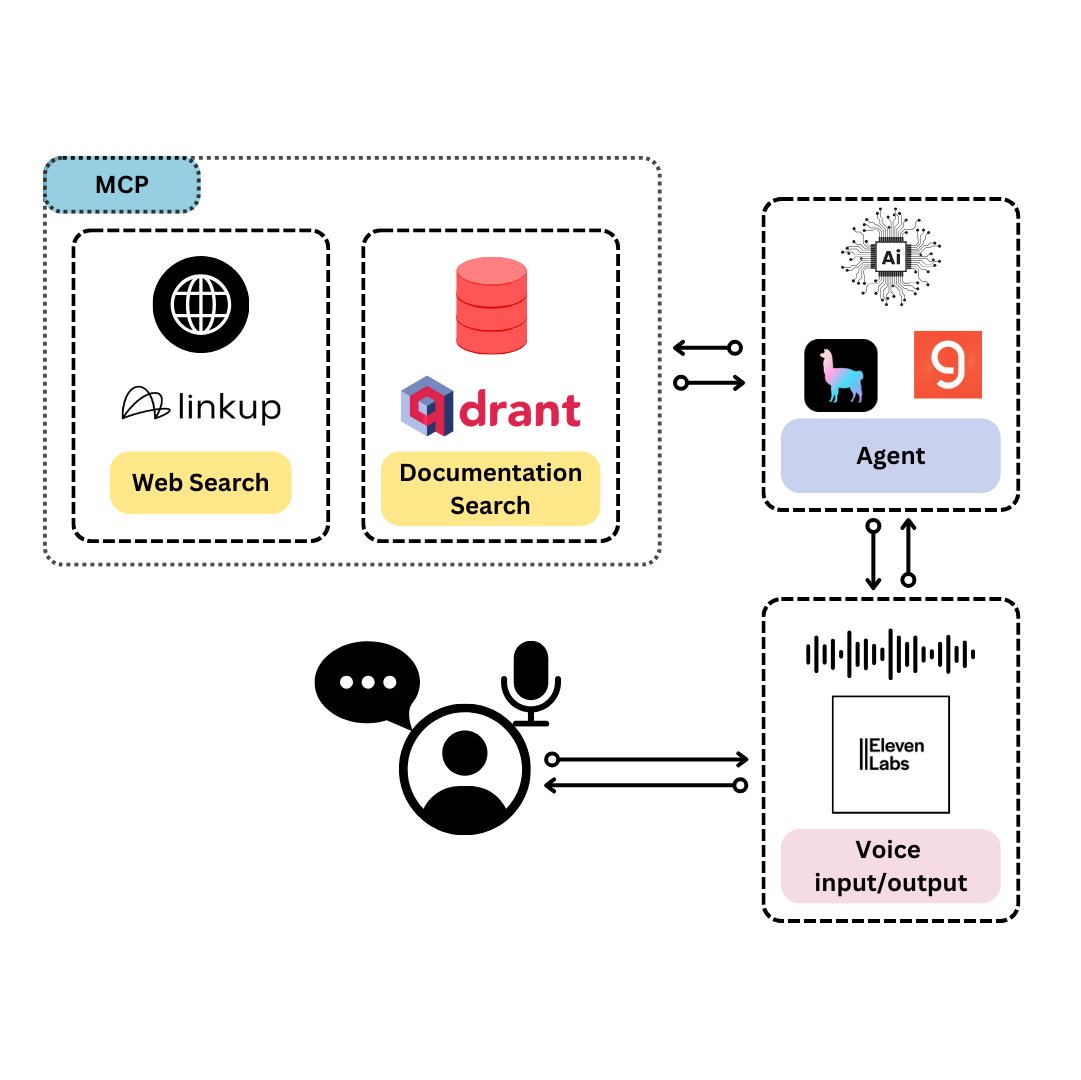
Qdrant lance TySVA : un assistant vocal conçu pour les développeurs TypeScript: Qdrant a lancé TySVA (TypeScript Voice Assistant), un assistant vocal conçu pour fournir des réponses précises et contextuelles aux développeurs TypeScript. TySVA utilise Qdrant pour stocker localement la documentation TypeScript, intègre la plateforme Linkup pour extraire les données web pertinentes, et utilise LlamaIndex pour sélectionner la meilleure source de données. Il prend en charge les entrées vocales et textuelles, aidant les développeurs à obtenir une aide fiable et mains libres pendant le codage (Source: qdrant_engine, qdrant_engine)
LlamaIndex lance de nouvelles fonctionnalités pour LlamaExtract : prise en charge des citations et du raisonnement: L’outil LlamaExtract de LlamaIndex a ajouté de nouvelles fonctionnalités visant à améliorer la fiabilité et la transparence des applications AI. Ces nouvelles fonctionnalités permettent de fournir des citations de source précises (citations) et le processus de raisonnement d’extraction (reasoning) lors de l’extraction d’informations à partir de sources de données complexes (telles que les documents SEC). Cela aide les développeurs à construire des systèmes AI plus responsables et plus interprétables (Source: jerryjliu0, jerryjliu0, jerryjliu0)

Un développeur de Hugging Face construit un prototype de serveur MCP pour connecter les Agents au Hub: Un développeur de Hugging Face, Wauplin, développe un prototype de serveur Hugging Face MCP (Machine Communication Protocol) visant à connecter les Agents AI au Hugging Face Hub. Ce prototype peut être considéré comme “HfApi rencontre MCP”, permettant aux Agents d’interagir avec le Hub via le protocole, par exemple pour partager et modifier des modèles, des jeux de données, des Spaces, etc. Le développeur sollicite les commentaires de la communauté sur l’utilité et les cas d’utilisation potentiels de cet outil (Source: ClementDelangue, ClementDelangue, huggingface)

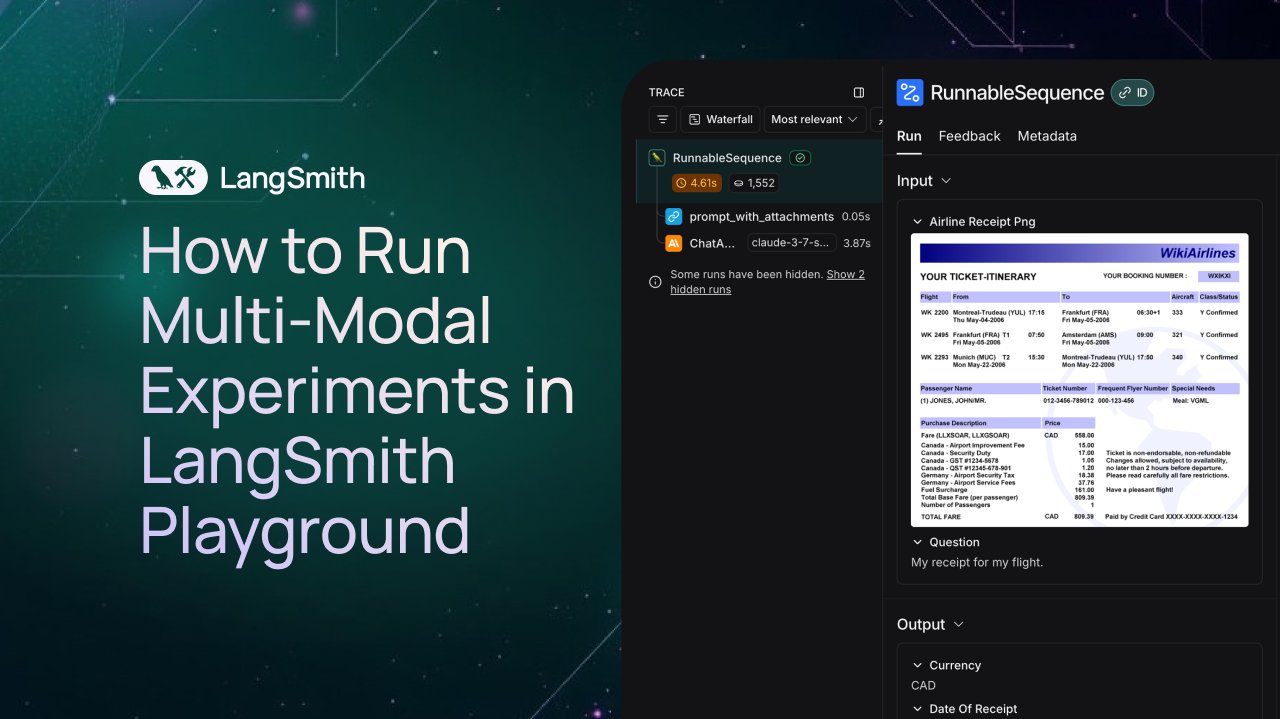
LangSmith ajoute la prise en charge de l’observation et de l’évaluation des Agents multimodaux: La plateforme LangSmith prend désormais en charge le traitement des fichiers image, PDF et audio dans Playground, les files d’attente d’annotation et les jeux de données. Cette mise à jour facilite la création et l’évaluation d’applications multimodales (telles que les Agents d’extraction de tickets). Une vidéo de démonstration et de la documentation officielles ont été publiées pour aider les utilisateurs à démarrer avec les nouvelles fonctionnalités (Source: LangChainAI, Hacubu, hwchase17)
DFloat11 publie une version compressée sans perte du modèle FLUX.1, exécutable sur 20 Go de VRAM: Le projet DFloat11 a publié des versions compressées sans perte des modèles FLUX.1-dev et FLUX.1-schnell (12B paramètres). Grâce à la méthode de compression DFloat11 (application d’un codage entropique aux poids BFloat16), la taille du modèle est réduite de 24 Go à environ 16,3 Go (environ 30%), tout en maintenant une sortie inchangée. Cela permet à ces modèles de fonctionner sur un seul GPU avec 20 Go de VRAM ou plus, avec seulement quelques secondes de surcoût par image. Les modèles et le code correspondants ont été publiés sur Hugging Face et GitHub (Source: Reddit r/LocalLLaMA)

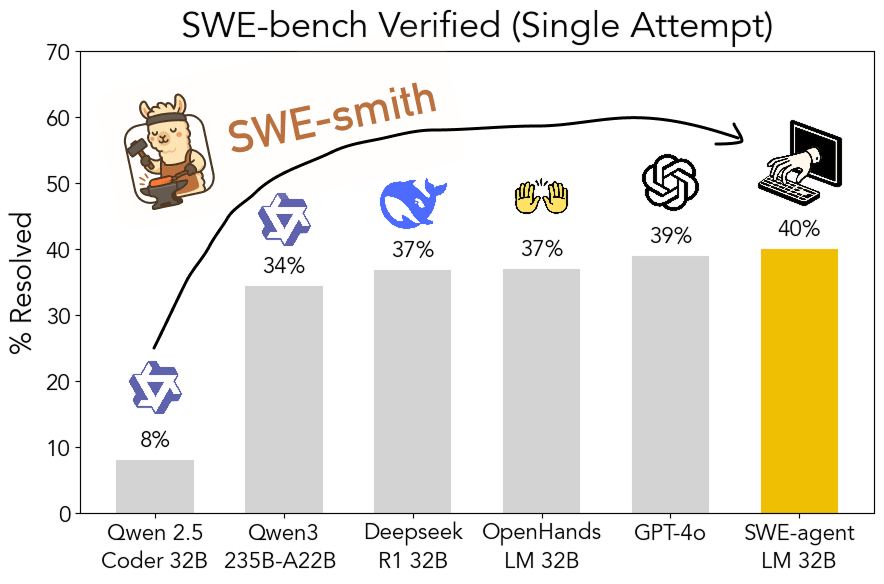
La boîte à outils SWE-smith open source : pour générer des données d’entraînement en ingénierie logicielle à grande échelle: Des chercheurs de l’Université de Stanford ont rendu open source SWE-smith, un pipeline évolutif pour générer des données d’entraînement en ingénierie logicielle à partir de n’importe quel dépôt Python. Plus de 50 000 instances ont été générées à l’aide de cette boîte à outils, sur la base desquelles le modèle SWE-agent-LM-32B a été entraîné. Ce modèle a atteint un Pass@1 de 40,2% sur le benchmark SWE-bench Verified, devenant ainsi le modèle open source le plus performant sur ce benchmark. Le code, les données et les modèles sont tous ouverts (Source: OfirPress, stanfordnlp, stanfordnlp, huybery, Reddit r/LocalLLaMA)
📚 Apprentissage
Weaviate publie un cours gratuit : Évaluation et sélection des modèles d’embedding: L’académie Weaviate a lancé un cours gratuit sur “l’Évaluation et la sélection des modèles d’embedding”. Le cours souligne l’importance d’aller au-delà des benchmarks génériques (comme MTEB), guidant les apprenants sur la manière de constituer un “ensemble d’évaluation de référence” (golden evaluation set) pour des cas d’utilisation spécifiques, et de mettre en place des benchmarks personnalisés pour choisir le modèle d’embedding le plus approprié, ainsi que pour évaluer si les modèles nouvellement publiés sont adaptés. Ceci est crucial pour construire des systèmes de recherche et de RAG efficaces (Source: bobvanluijt)
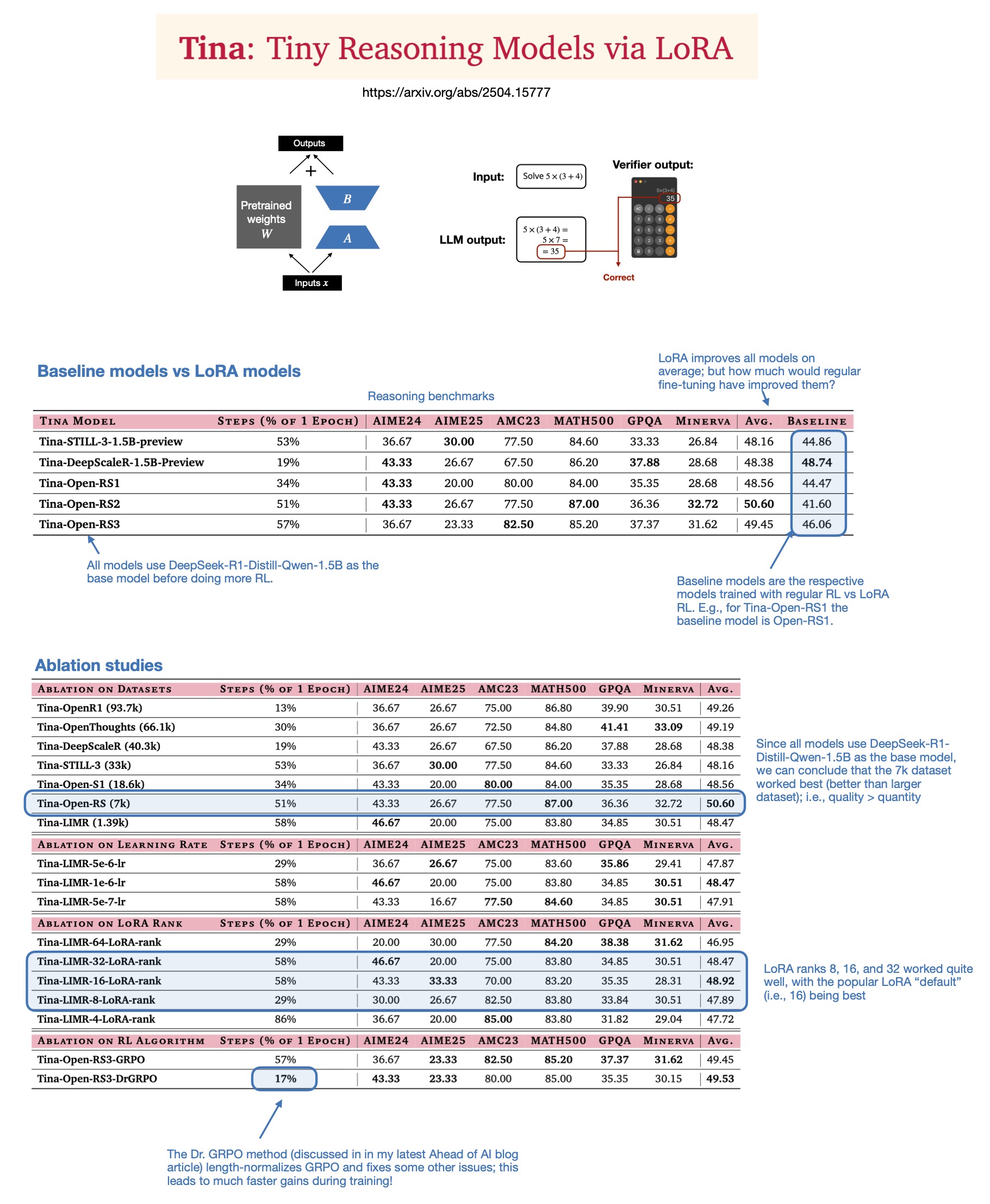
Sebastian Rasbt discute de la valeur de LoRA dans les modèles de raisonnement en 2025: Après avoir lu l’article “Tina: Tiny Reasoning Models via LoRA”, Sebastian Rasbt réexamine la pertinence de LoRA (Low-Rank Adaptation) à l’ère actuelle des grands modèles. Malgré la popularité du fine-tuning complet des paramètres et des techniques de distillation, Rasbt estime que LoRA conserve sa valeur dans des scénarios spécifiques (tels que les tâches de raisonnement, les scénarios multi-clients/multi-cas d’utilisation). L’article montre la possibilité d’utiliser LoRA en combinaison avec l’apprentissage par renforcement (RL) pour améliorer à faible coût (seulement $9 de coût d’entraînement) les capacités de raisonnement de petits modèles (1.5B), et LoRA surpasse le fine-tuning RL standard sur plusieurs benchmarks. La caractéristique de LoRA de ne pas modifier les modèles de base lui confère un avantage en termes de coûts lorsqu’il est nécessaire de stocker un grand nombre de poids de modèles personnalisés (Source: rasbt)
DeepLearning.AI lance un nouveau cours : Construire des agents vocaux AI de niveau production: DeepLearning.AI, en partenariat avec LiveKit et RealAvatar, a lancé un nouveau cours de courte durée intitulé “Construire des agents vocaux AI de niveau production”. Le cours vise à enseigner comment construire des agents vocaux AI capables de tenir des conversations en temps réel, avec des réponses à faible latence et un son naturel. Les apprenants mettront en œuvre des techniques telles que la détection d’activité vocale, la prise de parole à tour de rôle, et apprendront à optimiser l’architecture pour réduire la latence, pour finalement construire et déployer des agents vocaux évolutifs. Le cours est dispensé par le PDG de LiveKit, un défenseur des développeurs et le responsable AI de RealAvatar (Source: DeepLearningAI, AndrewYNg)
LangChain et LangGraph organisent conjointement une conférence technique ACM: Mayowa Oshin, l’un des premiers contributeurs au développement de LangChain, et Nuno Campos, créateur de LangGraph, partageront lors d’une conférence technique de l’ACM comment utiliser LangChain et LangGraph pour construire des Agents AI et des applications LLM fiables. La conférence est gratuite et sera diffusée en direct, les inscrits recevront ultérieurement un lien pour la visionner (Source: hwchase17, hwchase17)

Cohere Labs organise une conférence sur la profondeur de l’optimisation du premier ordre: Cohere Labs invite Jeremy Bernstein le 8 mai pour une présentation intitulée “Depths of First-Order Optimization” (Les profondeurs de l’optimisation du premier ordre). Cette conférence vise à explorer en profondeur l’application et la théorie des algorithmes d’optimisation en apprentissage machine (Source: eliebakouch)

AI2 organise un événement AMA sur les modèles OLMo: L’Allen Institute for AI (AI2) organisera un événement “Ask Me Anything” (AMA) sur sa famille de modèles de langage ouverts OLMo le 8 mai de 8h à 10h (heure du Pacifique) sur le subreddit r/huggingface, invitant les chercheurs à répondre aux questions de la communauté (Source: natolambert)

💼 Affaires
OpenAI prévoit de réduire la part des revenus versée à Microsoft: Selon The Information, OpenAI a informé les investisseurs de son intention de réduire la part des revenus versée à son principal soutien, Microsoft, dans le cadre de la restructuration de l’entreprise. Les détails spécifiques et l’impact potentiel n’ont pas été entièrement divulgués, mais cela pourrait marquer un changement dans la relation commerciale entre les deux sociétés (Source: steph_palazzolo)
Les investisseurs en capital-risque accordent plus de pouvoir aux fondateurs d’AI, suscitant des craintes de bulle: The Information rapporte que les investisseurs en capital-risque (VCs), afin d’attirer les meilleurs fondateurs d’AI (en particulier ceux ayant une expérience de direction dans des laboratoires d’AI renommés), offrent des conditions exceptionnellement favorables, y compris des droits de veto au conseil d’administration, l’absence de siège au conseil pour les VCs et l’autorisation pour les fondateurs de vendre une partie de leurs actions. Ce phénomène est perçu par certains comme un signe d’une possible bulle dans le domaine de l’AI (Source: steph_palazzolo)
Toloka obtient un investissement stratégique mené par Bezos Expeditions, Mikhail Parakhin rejoint en tant que président du conseil d’administration: La société de labellisation de données et de données d’entraînement pour l’AI, Toloka, a annoncé avoir obtenu un investissement stratégique mené par Bezos Expeditions de Jeff Bezos, avec la participation de l’ancien dirigeant de Microsoft, Mikhail Parakhin, qui rejoint également en tant que président du conseil d’administration. Ce tour de table soutiendra l’expansion par Toloka de ses solutions de collaboration homme-machine (human+AI) et le développement de ses activités de collecte et de labellisation de données (Source: menhguin, teortaxesTex, TheTuringPost)

🌟 Communauté
Discussion sur l’utilisation équitable (Fair Use) des données d’entraînement des LLM: Dorialexander mentionne que l’argument de l’utilisation équitable pour les données d’entraînement des LLM repose en grande partie sur l’hypothèse que les LLM n’entrent pas en concurrence commerciale directe avec les sources d’entraînement. Avec l’amélioration des capacités des LLM (par exemple, Perplexity commençant à offrir des expériences similaires à la lecture de non-fiction), cette hypothèse pourrait être remise en question, soulevant de nouvelles questions sur le droit d’auteur et la concurrence commerciale (Source: Dorialexander)
Inquiétudes et discussions sur la prolifération de contenu généré par AI: Sur les réseaux sociaux et Reddit, des utilisateurs expriment leur inquiétude face à la prolifération de contenu généré par AI de faible qualité et répétitif (comme les vidéos d’histoires Reddit générées par AI). Les utilisateurs estiment que cela réduit l’espace des créateurs humains, transmet des informations fausses ou homogénéisées, et expriment leur mécontentement face à l’utilisation de la technologie AI pour un profit facile sans originalité (Source: Reddit r/ArtificialInteligence)
Discussion philosophique sur la conscience éventuelle de l’AI: La communauté Reddit voit resurgir des discussions sur la possibilité que l’AI ait déjà acquis une conscience. Les partisans estiment que notre définition de la conscience pourrait être trop étroite ou anthropocentrique, tandis que les opposants soulignent que les mécanismes fondamentaux des LLM actuels (comme la prédiction du prochain token) sont insuffisants pour générer une véritable conscience. La discussion reflète la curiosité et les divergences persistantes du public quant à la nature et au potentiel futur de l’AI (Source: Reddit r/ArtificialInteligence)
Discussion sur la baisse de performance et les changements de comportement de ChatGPT(4o): Des utilisateurs de Reddit signalent une baisse récente des performances du modèle ChatGPT 4o dans le traitement de longs documents et le maintien de la mémoire contextuelle, avec davantage d’hallucinations et même une incapacité à lire des formats de documents qu’il pouvait traiter auparavant. Parallèlement, OpenAI a également reconnu que la récente mise à jour de la version GPT-4o présentait un problème de flagornerie excessive (sycophancy) et a procédé à un rollback. Cela a suscité des inquiétudes au sein de la communauté quant à la stabilité du modèle et au contrôle qualité des itérations (Source: Reddit r/ChatGPT, DeepLearning.AI Blog)
Impact de l’AI sur les modèles éducatifs et réflexions: Des discussions communautaires soulignent que le modèle éducatif américain, axé sur les devoirs à la maison et les dissertations individuelles, le rend extrêmement vulnérable à la capacité de l’AI (comme les LLM) à accomplir automatiquement ces tâches. En comparaison, certains pays européens (comme le Danemark) mettent davantage l’accent sur la collaboration en classe, la discussion et l’apprentissage par projet, et sont moins touchés par l’AI. Cela suscite une réflexion sur les futurs modèles éducatifs, suggérant qu’ils devraient davantage se concentrer sur le développement de la pensée critique, de la collaboration et d’autres compétences interpersonnelles, en utilisant l’AI pour traiter les tâches mécaniques, et en orientant l’éducation vers une approche plus synchrone et plus socialisée (Source: alexalbert__, riemannzeta, aidan_mclau)
💡 Autres
Progrès de l’application de l’AI dans le domaine de la robotique: Plusieurs sources présentent des exemples d’application de l’AI dans la robotique : notamment un robot cuisinier capable de préparer du riz sauté en 90 secondes, des démonstrations d’application du robot Figure AI dans le monde réel, le robot Pickle déchargeant des marchandises d’une remorque de camion en désordre, le robot Unitree G1 maintenant son équilibre sur un terrain accidenté ainsi qu’une présentation de sa structure interne, et le robot déformable Mori3 développé par l’EPFL en Suisse. Ces cas illustrent le potentiel de l’AI pour améliorer l’autonomie, l’adaptabilité et l’utilité des robots (Source: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Sentdex)

Exploration de l’application de la technologie AI dans des secteurs spécifiques (médical, textile, téléphonie mobile): Johnson & Johnson a partagé sa stratégie AI, axée sur l’aide à la vente, l’accélération de la recherche et du développement de médicaments (criblage de composés, optimisation des essais cliniques), la prévision des risques de la chaîne d’approvisionnement et la communication interne (robot conversationnel RH). Parallèlement, la technologie AI dynamise également l’industrie textile traditionnelle, de la conception assistée par AI et du contrôle précis de la teinture à l’inspection qualité automatisée, améliorant l’efficacité et la durabilité. L’industrie de la téléphonie mobile considère quant à elle l’AI comme un nouveau moteur de croissance, les fabricants rivalisant autour des grands modèles sur appareil (on-device), des systèmes d’exploitation natifs AI et des services intelligents contextualisés, formant trois grandes factions : Apple, Huawei et le camp ouvert (Source: DeepLearning.AI Blog, 36氪, 36氪)
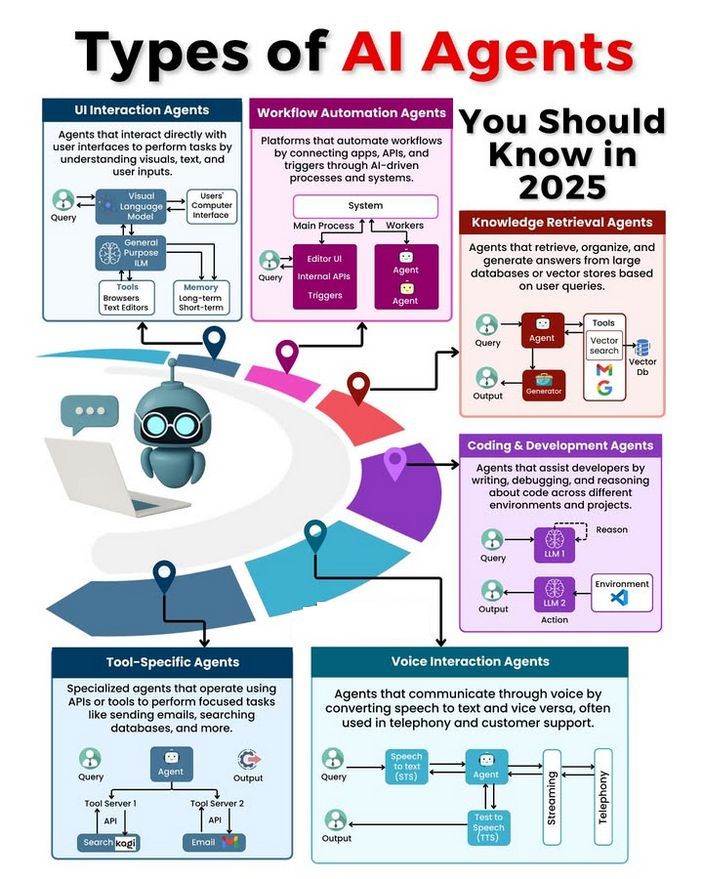
Types d’Agents AI et discussion sur leur développement: La communauté discute de différents types d’Agents AI (tels que les agents réflexes simples, les agents réflexes basés sur un modèle, les agents basés sur un objectif, les agents basés sur l’utilité, les agents apprenants) et explore les méthodologies pour construire des Agents fiables (comme l’utilisation de LangChain/LangGraph). Parallèlement, certains estiment que la future AGI pourrait ne pas être un modèle unique, mais plutôt constituée d’une collaboration de plusieurs modèles spécialisés (Source: Ronald_vanLoon, hwchase17, nrehiew_)