
Mots-clés:Gemini 2.5 Pro, Kevin-32B, Agent IA, Technologie RAG, Jumeau numérique, Capacités de codage de Gemini 2.5 Pro, Noyaux CUDA de Kevin-32B, Recherche agentique, GraphRAG de base de connaissances, Intégration de l’IA avec les jumeaux numériques
Voici la traduction en français de l’information sur l’IA, en respectant vos exigences :
🔥 Focus
Google lance Gemini 2.5 Pro version I/O : Google a lancé Gemini 2.5 Pro version I/O, améliorant considérablement ses capacités de codage, dominant les classements LMArena en programmation, vision et WebDev, réalisant ainsi la première fois qu’un modèle unique atteint la première place dans les trois classements. La nouvelle version améliore le développement frontend et UI, peut générer des applications à partir de croquis dessinés à la main, et a corrigé les problèmes d’appel de fonctions, démontrant les progrès rapides de Google dans les capacités des modèles d’IA. (Source : JeffDean, lmarena.ai, dotey)
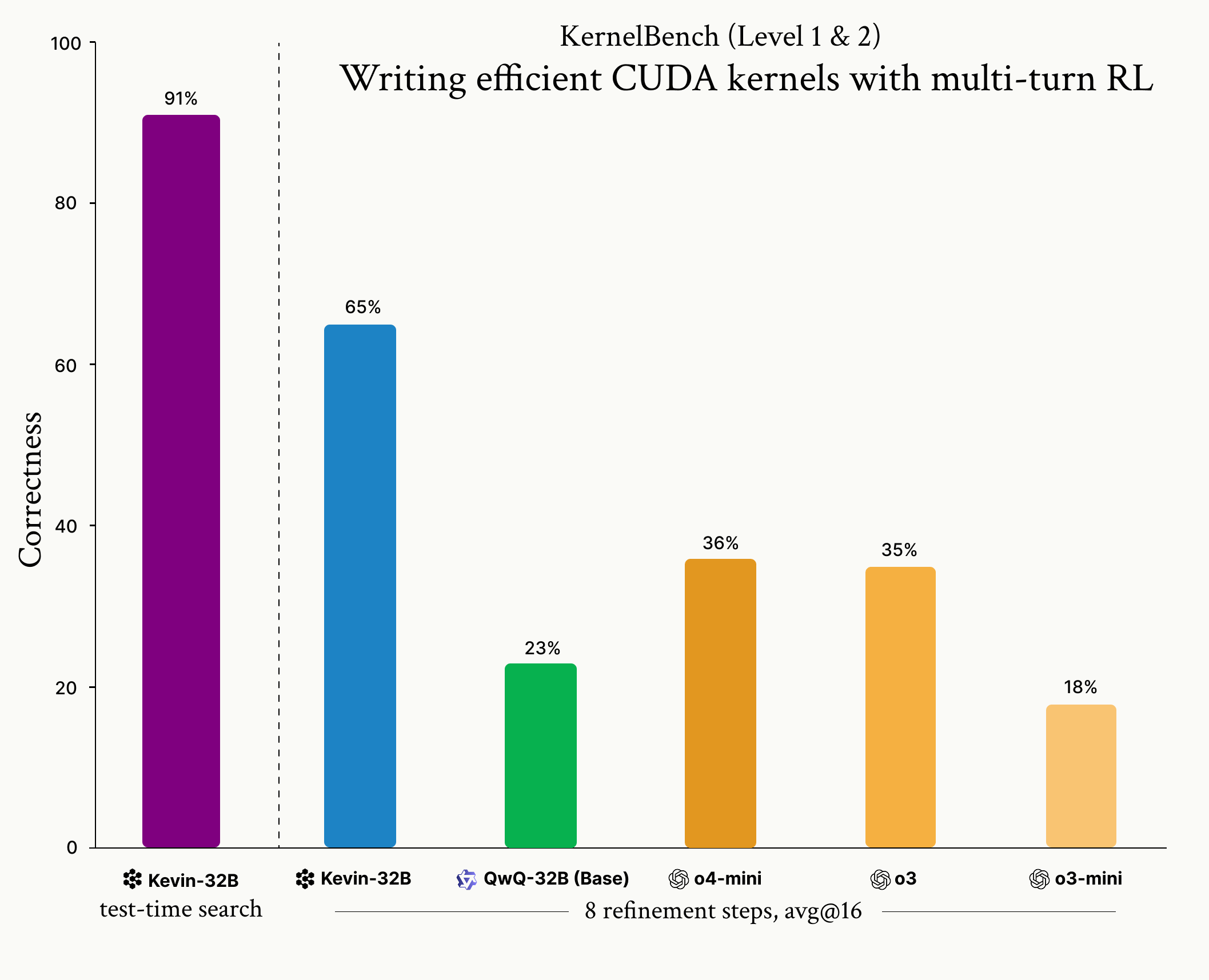
Cognition lance le modèle Kevin-32B : Cognition a lancé Kevin-32B, le premier modèle open source entraîné par Reinforcement Learning (algorithme GRPO) pour écrire des CUDA kernels. Le modèle a obtenu d’excellents résultats sur le dataset KernelBench, surpassant les modèles d’inférence de pointe comme o3 et o4-mini en termes de correction et de performance, démontrant le potentiel du RL dans l’optimisation de la programmation de bas niveau. (Source : Cognition, Dorialexander, vllm_project)
Meta lance Perception Encoder : Meta a lancé un nouvel encodeur visuel, Meta Perception Encoder, établissant une nouvelle norme pour les tâches d’image et de vidéo. Le modèle excelle en classification et récupération zero-shot, surpassant les modèles existants, et fournit une nouvelle base solide pour la recherche et les applications en compréhension d’images et de vidéos. (Source : AIatMeta)
Lancement du modèle open source de génération vidéo LTX-Video 13B : LTX-Video 13B a été lancé, l’un des modèles open source de génération vidéo les plus puissants à ce jour. Le modèle possède 13 milliards de paramètres, prend en charge le rendu multi-échelle pour améliorer les détails, améliore la compréhension du mouvement et de la scène, peut fonctionner sur des GPU locaux et prend en charge le contrôle des keyframes, de la caméra/du mouvement des personnages. (Source : teortaxesTex, Yoav HaCohen)
🎯 Tendances
Anthropic LeMUR prend en charge les nouveaux modèles Claude : AssemblyAI a annoncé que sa capacité LeMUR prend désormais en charge les modèles Claude 3.7 Sonnet et Claude 3.5 Haiku d’Anthropic. Sonnet améliore la capacité de raisonnement pour l’analyse audio complexe, tandis que Haiku optimise la vitesse de réponse, apportant des améliorations significatives pour les tâches d’analyse de contenu audio et de résumé de réunions. (Source : AssemblyAI)
Nvidia et ServiceNow lancent le modèle d’IA d’entreprise Apriel Nemotron 15B : Nvidia et ServiceNow ont collaboré pour lancer Apriel Nemotron 15B, un modèle d’IA d’entreprise compact et rentable basé sur Nvidia NeMo. Le modèle vise à fournir des réponses en temps réel, à gérer des workflows complexes et à être évolutif pour des domaines tels que l’IT, les RH et le service client. (Source : nvidia)

Mises à jour et chronologie de développement des modèles DeepSeek : Les modèles DeepSeek V3 et V3-0324 continuent d’être mis à jour, démontrant leurs progrès en matière de capacité de raisonnement et de nouvelles fonctionnalités. La communauté discute de leur chronologie et de leurs caractéristiques, estimant que DeepSeek a réalisé des progrès significatifs dans la poursuite des modèles de pointe grâce à une architecture et des méthodes d’entraînement innovantes. (Source : teortaxesTex, dylan522p)

GraphRAG et Agentic Search stimulent le développement de la technologie RAG : Cohere explore GraphRAG et Agentic Search comme technologies RAG de nouvelle génération. GraphRAG améliore la précision et la fiabilité grâce aux knowledge graphs, tandis qu’Agentic Search utilise des AI Agents pour une recherche itérative approfondie, apportant des réponses plus précises et contextuellement riches pour les applications d’IA d’entreprise. (Source : cohere)
Concept d’AI Agent surmédiatisé et défis de mise en œuvre : Des institutions comme Gartner soulignent qu’il existe une surmédiatisation (“Agent Washing”) dans le domaine actuel des AI Agents, de nombreuses technologies existantes étant reconditionnées. Bien que le volume de consultations du marché ait explosé, le taux de réussite du déploiement d’Agents au niveau de l’entreprise est faible, les goulots d’étranglement technologiques, la fiabilité, les coûts et l’applicabilité des scénarios restant les principales contraintes. (Source : 36氪, Gartner)
L’IA remodèle le paysage de l’EdTech, les entreprises chinoises émergent : Le classement mondial des meilleures entreprises EdTech publié par le magazine “Time” et Statista montre que les entreprises chinoises occupent pour la première fois les trois premières places (编程猫, 网易有道, 好未来), changeant complètement le paysage dominé par les États-Unis. L’IA est devenue l’infrastructure clé qui stimule la transformation de l’EdTech, et le succès des entreprises chinoises est attribué au soutien politique et à l’intégration profonde de la technologie de l’IA dans les scénarios éducatifs. (Source : 36氪)
Meta et le PDG de Microsoft discutent de l’avenir de l’IA : Mark Zuckerberg, fondateur de Meta, et Satya Nadella, PDG de Microsoft, ont discuté de l’impact de l’IA sur la productivité des entreprises et le développement futur des applications. Nadella estime que l’IA apporte une phase d‘“applications profondes”, avec une proportion croissante de code écrit par l’IA dans les bases de code ; Zuckerberg prédit que les futurs ingénieurs dirigeront des équipes d’agents intelligents, et que l’IA accomplira la majeure partie du travail de développement. (Source : 36氪)
La technologie des humains numériques passe de la “ressemblance physique” à la “ressemblance spirituelle” : La technologie des humains numériques évolue des images statiques vers l’interaction intelligente, utilisant des modèles de grande taille comme Transformer et les diffusion models pour obtenir des expressions, des mouvements et une synchronisation labiale plus réalistes. Cette technologie a un large potentiel d’application dans les domaines de la consommation, des PME et des grandes entreprises, mais elle est toujours confrontée à des défis tels que la cohérence technique, l’interactivité et la synergie de la chaîne industrielle. (Source : 36氪)
L’IA réussit à lire le titre d’un papyrus d’Herculanum : Le Vesuvius Challenge a réalisé une percée historique : des chercheurs ont utilisé la technologie de l’IA pour lire pour la première fois de manière non invasive le titre d’un papyrus d’Herculanum carbonisé par le volcan. Ce résultat a été obtenu grâce à la segmentation d’images par IA et à la détection d’encre, prouvant la capacité de l’IA à “voir à travers” les documents anciens et ouvrant la voie à la lecture de davantage de papyrus endormis. (Source : 36氪)

Publication de plusieurs modèles et datasets d’IA open source : La communauté résume les progrès récents dans le domaine de l’IA open source, notamment Alibaba Qwen qui a publié la série de modèles Qwen3 et le modèle multimodal Qwen2.5-Omni, Microsoft qui a publié le modèle d’inférence Phi4, NVIDIA qui a publié le dataset d’inférence CoT et le modèle de reconnaissance vocale Parakeet, ainsi que EdgeTAM de Meta, etc. (Source : mervenoyann)
ACE-Step lance un modèle open source de génération musicale : StepFun AI et ACE Studio ont collaboré pour lancer ACE-Step 3.5B, un modèle open source de génération musicale. Le modèle prend en charge plusieurs langues, styles d’instruments et techniques vocales, et peut générer rapidement des chansons sur un A100 GPU, apportant de nouveaux outils d’IA dans le domaine de la création musicale. (Source : Teknium1, Reddit r/LocalLLaMA)

Croissance de l’application de l’IA dans le domaine des Digital Twins : Un rapport montre qu’un nombre croissant d’industries combinent leurs Digital Twins avec l’IA pour améliorer l’efficacité et les insights. La fusion de l’IA et des Digital Twins devient une tendance technologique importante, stimulant la transformation numérique et les applications innovantes dans diverses industries. (Source : Ronald_vanLoon)

🧰 Outils
Smolagents intègre la capacité d’utilisation de l’ordinateur : Le framework Smolagents a introduit la fonctionnalité d’utilisation de l’ordinateur. Grâce aux capacités de modèles visuels comme Qwen-VL, les AI Agents peuvent désormais comprendre les captures d’écran et localiser des éléments, permettant ainsi des opérations comme les clics, ce qui favorise le développement de workflows d’Agents complexes. (Source : huggingface)
Mise à niveau de Qdrant Cloud pour améliorer l’efficacité de la recherche vectorielle : Qdrant Cloud a subi une mise à niveau majeure visant à permettre aux utilisateurs de passer plus rapidement du prototype à la production. La nouvelle version a optimisé l’interface utilisateur et l’expérience, rendant la construction d’applications de recherche sémantique et de recherche vectorielle d’embeddings plus pratique et efficace. (Source : qdrant_engine)
Le service de lavage de cheveux par IA émerge comme un nouveau modèle commercial : Des salons de lavage de cheveux par IA sont apparus dans plusieurs villes comme Shanghai et Shenzhen, offrant des services standardisés via des machines de lavage de cheveux intelligentes pour attirer les clients à bas prix. Bien que les retours des consommateurs soient mitigés et que des défis subsistent en termes de maturité technologique, de sécurité et de modèle de profit, le lavage de cheveux par IA, en tant que tentative d’application de l’IA dans le secteur des services, montre une nouvelle direction d’exploration commerciale. (Source : 36氪)
Publication de l’outil d’évaluation LLM open source Opik : Opik est un outil d’évaluation LLM open source utilisé pour déboguer, évaluer et surveiller les applications LLM, les systèmes RAG et les workflows d’Agents. Il offre un traçage complet, une évaluation automatisée et des tableaux de bord de production, aidant les développeurs à améliorer les performances et la fiabilité des applications d’IA. (Source : dl_weekly)
Boîte à outils Python Chain-of-Thought Cogitator : Une boîte à outils Python open source nommée Cogitator a été publiée, visant à simplifier l’utilisation et l’expérimentation de la méthode de raisonnement Chain-of-Thought (CoT). La bibliothèque prend en charge les modèles OpenAI et Ollama et inclut des implémentations de stratégies CoT telles que Self-Consistency, Tree of Thoughts et Graph of Thoughts. (Source : Reddit r/MachineLearning)
Comfyui met à jour sa marque et lance des nœuds API natifs : Comfyui a mis à jour sa marque et lancé des nœuds API natifs, prenant en charge l’intégration de 11 modèles d’IA visuelle en ligne tels que Flux, Kling, Luma. Les utilisateurs n’ont pas besoin de demander des API Keys séparément, ils peuvent se connecter directement dans Comfyui pour les utiliser, simplifiant grandement la mise en place de workflows multi-modèles. (Source : op7418)

Cursor offre des services gratuits aux étudiants et étudiants en droit : L’assistant de programmation AI Cursor a annoncé offrir une version Pro gratuite aux étudiants, et l’outil d’IA juridique Spellbook offre également des services gratuits aux étudiants en droit. Cette initiative abaisse la barrière d’accès et d’utilisation des outils d’IA avancés pour les étudiants, contribuant à la popularisation de la technologie de l’IA dans le domaine de l’éducation. (Source : scaling01, scottastevenson)
📚 Apprentissage
Le framework Unsloth permet un fine-tuning efficace des LLM : Le blog LearnOpenCV explore en profondeur le framework Unsloth, montrant comment fine-tuner des Large Language Models et des Visual Language Models (comme Qwen2.5-VL) de manière plus rapide, légère et intelligente. Unsloth réduit considérablement l’utilisation de la mémoire GPU et le temps d’entraînement grâce à des techniques d’optimisation, particulièrement adapté aux utilisateurs disposant de ressources limitées. (Source : LearnOpenCV)
Une étude de Cohere révèle les biais dans l’évaluation humaine des LLM : Une étude de Cohere a révélé que même de petits biais (comme une formulation plus confiante) peuvent systématiquement fausser l’évaluation humaine des sorties des LLM. Les réponses plus péremptoires des modèles sont souvent jugées “meilleures”, même si le contenu est identique, ce qui souligne l’irrationalité de l’évaluation humaine et les défis auxquels sont confrontés les modèles d’évaluation. (Source : Shahules786, clefourrier)
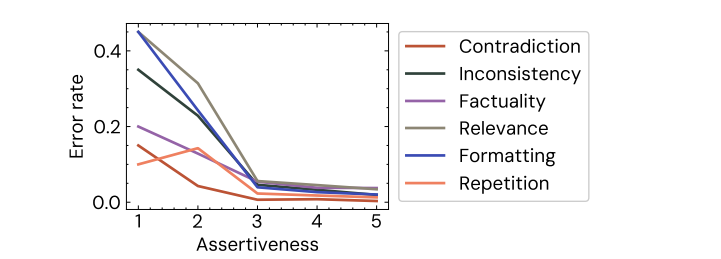
SWE-bench lance une évaluation des capacités de codage multilingues : La bibliothèque SWE-bench a publié une nouvelle version, introduisant SWE-bench Multilingual, pour tester les capacités de codage des LLM dans 9 langages de programmation. La performance de Claude 3.7 sur cette évaluation multilingue est inférieure à son score sur le SWE-bench en anglais, indiquant que les capacités de codage inter-langues des LLM doivent encore être améliorées. (Source : OfirPress)

Une étude explore les capacités potentiellement perdues lors de l’Alignment des LLM : Des chercheurs explorent certaines capacités que les Large Language Models pourraient perdre lors de l’entraînement à l’Alignment, telles que la stochasticité et la créativité. Cela soulève des discussions sur la manière de préserver leur potentiel original tout en améliorant la sécurité et l’utilité des modèles. (Source : lateinteraction, Peter West)

Une étude sur l’optimiseur Muon montre des avantages en efficacité : Essential AI a publié une étude explorant l’efficacité pratique de l’optimiseur Muon dans le pré-entraînement des LLM. L’étude montre que Muon, en tant qu’optimiseur de second ordre, présente un avantage par rapport à AdamW en termes de compromis temps de calcul, et peut préserver plus efficacement les informations des données, en particulier lors de l’entraînement avec de grands lots. (Source : cloneofsimo, Essential AI)
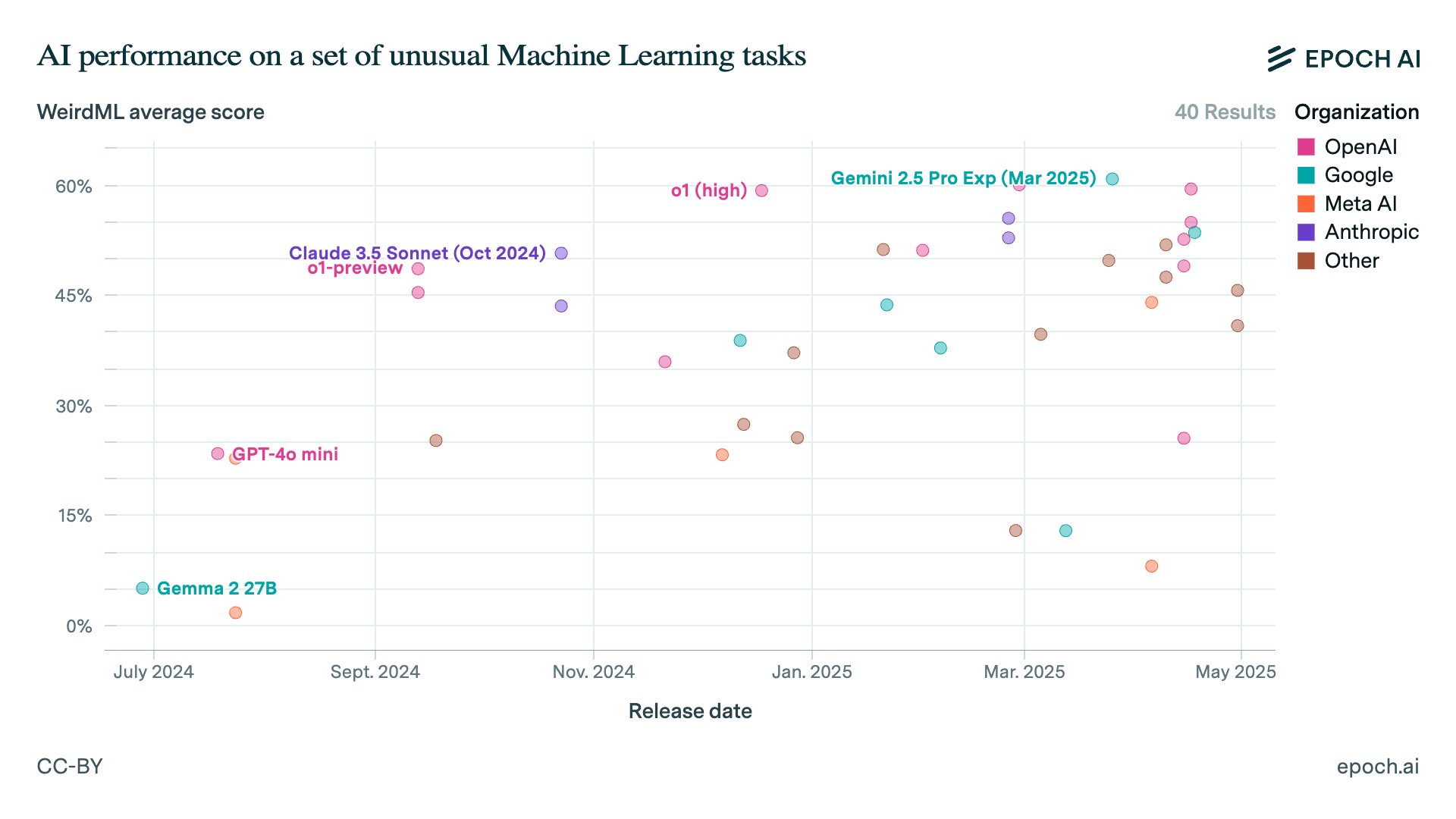
Mise à jour de la plateforme de benchmark Epoch AI : Epoch AI a mis à jour sa plateforme de benchmark, ajoutant de nouveaux éléments d’évaluation tels que Aider Polyglot, WeirdML, Balrog et Factorio Learning Environment. Ces nouveaux benchmarks introduisent des données de classements externes, offrant une perspective plus complète pour évaluer les performances des LLM. (Source : scaling01)
Hugging Face lance un cours sur les AI Agents : Hugging Face a lancé un cours sur les AI Agents, couvrant les bases des Agents, les LLM, les familles de modèles, les frameworks (smolagents, LangGraph, LlamaIndex), l’observabilité, l’évaluation et les cas d’utilisation d’Agentic RAG, et incluant un projet final et des benchmarks, fournissant des ressources systématiques pour apprendre à construire des AI Agents. (Source : GitHub Trending, huggingface)

💼 Affaires
OpenAI acquiert l’assistant de programmation AI Windsurf : OpenAI a accepté d’acquérir Windsurf (anciennement Codeium), développeur d’assistants de programmation AI, pour environ 3 milliards de dollars, ce qui constitue la plus grande acquisition d’OpenAI à ce jour. Cette initiative vise à consolider la position d’OpenAI dans le domaine de la programmation AI, à acquérir la base d’utilisateurs et les données d’évolution du codebase de Windsurf, et à préparer le développement futur d’Agents de programmation AI. (Source : 36氪, Bloomberg, 智东西)
OpenAI abandonne le plan de transformation en entreprise entièrement commerciale : OpenAI a annoncé abandonner son projet de transformer entièrement la société mère en une organisation à but lucratif, décidant de maintenir la structure de société mère à but non lucratif contrôlant une filiale à but lucratif, et de transformer la filiale en une “société d’intérêt public”. Cette décision est un compromis suite aux discussions avec les régulateurs et diverses parties, affectant la gouvernance d’entreprise et la stratégie de financement future, et est également liée à l’opposition de personnes comme Elon Musk. (Source : steph_palazzolo, 36氪)
Yuncong Technology (云从科技) fait face à des licenciements et des pertes : Le rapport financier de l’entreprise d’IA établie Yuncong Technology (云从科技) montre une forte baisse des revenus, une augmentation des pertes, ainsi que des licenciements et des réductions de salaire pour les cadres supérieurs. Cela reflète les défis de rentabilité et la pression concurrentielle du marché auxquels sont confrontées les startups de l’IA ; pour de nombreuses entreprises d’IA à ce stade, “survivre” est devenu la priorité absolue, ce qui laisse présager un possible éclatement de la bulle des startups de l’IA. (Source : 36氪)

🌟 Communauté
Les deepfakes par IA provoquent une crise de confiance et un risque de “déni plausible” : La communauté discute de la façon dont la technologie des deepfakes par IA devient de plus en plus réaliste, rendant difficile pour le public de distinguer les informations vraies des fausses, provoquant une crise de confiance. Une préoccupation encore plus grande est que des individus ou des institutions pourraient utiliser les deepfakes par IA comme excuse de “déni plausible” pour leurs actes répréhensibles, ce qui pose des défis à la vérification des faits et à la responsabilité légale. (Source : Reddit r/ArtificialInteligence)

Des tests internes d’OpenAI montrent que le problème d’hallucination de ChatGPT s’aggrave : Des rapports indiquent que des tests internes d’OpenAI montrent que le problème d’hallucination de ChatGPT s’aggrave, et que la raison est inconnue. Cette découverte suscite des inquiétudes au sein de la communauté quant à la fiabilité et à l’interprétabilité des modèles, et montre que même les modèles de pointe sont toujours confrontés à des défis fondamentaux. (Source : Reddit r/artificial)

La communauté s’inquiète de la possible insertion de publicités dans les données d’entraînement des modèles d’IA : La communauté discute de la possibilité que des publicités ou des informations biaisées soient délibérément insérées dans les données d’entraînement des futurs modèles d’IA, entraînant des sorties de modèles contenant des promotions implicites ou des points de vue spécifiques. Cela soulève des inquiétudes quant à la transparence, la sécurité et les modèles commerciaux des modèles, ainsi que les avantages des modèles open source à cet égard. (Source : Reddit r/LocalLLaMA)
Discussion sur la surmédiatisation du concept d’AI Agent et les difficultés de mise en œuvre réelle : La communauté débat de l’écart entre l’engouement pour le concept d’AI Agent et la mise en œuvre réelle. Les discussions soulignent que de nombreux “Agents” ne sont que des reconditionnements de technologies existantes, et que les entreprises sont confrontées à des défis tels que la fiabilité technique, le contrôle des coûts et la complexité lors de la construction et du déploiement de véritables Agents, nécessitant une évaluation pragmatique de leur valeur commerciale. (Source : 36氪, Reddit r/ArtificialInteligence)
Controverses autour des outils open source comme Ollama et OpenWebUI : La communauté discute des avantages et des inconvénients d’Ollama en tant qu’outil d’exécution de LLM locaux, y compris son format de stockage de modèles, les problèmes de synchronisation avec llama.cpp et les configurations par défaut. Parallèlement, OpenWebUI a modifié sa licence, ajoutant des restrictions pour les utilisateurs commerciaux, ce qui a suscité des discussions au sein de la communauté sur l’esprit open source et la durabilité des projets. (Source : Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
Anxiété des praticiens du Machine Learning concernant l’acquisition de datasets : Les praticiens du Machine Learning expriment sur les réseaux sociaux leur anxiété concernant l’acquisition de datasets de haute qualité, estimant que les données constituent le “plafond” de la performance des modèles, mais que les managers sans formation technique sous-estiment souvent la complexité du travail sur les données, considérant l’IA comme une “baguette magique”. (Source : Reddit r/MachineLearning)
Défis de la gestion et de la révision du code généré par l’IA : Avec la popularisation du code généré par l’IA, la communauté discute de la manière de gérer et de réviser efficacement la grande quantité de code produit par l’IA. Les développeurs doivent établir des processus et des outils pour garantir la qualité et la correction du code AI, et le centre de gravité du travail pourrait passer de l’écriture de code à la révision et à la validation. (Source : matvelloso, finbarrtimbers)
Écart entre l’effet réel de l’application RAG et les attentes des utilisateurs : Certains utilisateurs signalent que lors de l’utilisation de RAG pour traiter des documents personnels, les performances du modèle sont inférieures aux attentes et qu’il ne peut pas répondre avec précision aux questions contenues dans les documents. Cela montre que RAG est toujours confronté à des défis lors du traitement de datasets spécifiques et non publics, et que l’effet réel diffère de l’expérience des utilisateurs avec les modèles généraux. (Source : Reddit r/OpenWebUI)
💡 Autres
Mise à jour de Microsoft PowerToys, ajout de fonctionnalités comme Command Palette : Microsoft a publié la version 0.90 de PowerToys, ajoutant le module Command Palette (CmdPal) comme évolution de PowerToys Run, améliorant le lancement rapide et l’extensibilité. De plus, des améliorations ont été apportées à Color Picker, la suppression de fichiers Peek, les variables de modèle New+, etc., améliorant la productivité des utilisateurs de Windows. (Source : GitHub Trending)

Nvidia prévoit d’arrêter le support CUDA pour les anciens GPU : Nvidia a annoncé son intention d’arrêter le support CUDA pour les GPU des séries Maxwell, Pascal et Volta dans la prochaine version majeure de son Toolkit. Cette mesure affectera certains utilisateurs qui dépendent encore de ces anciens matériels pour leurs travaux d’IA/ML, pourrait pousser à la mise à niveau des infrastructures, mais suscite également des discussions au sein de la communauté sur l’obsolescence matérielle et la compatibilité. (Source : Reddit r/LocalLLaMA)

Les appareils Google Nest Hub n’ont pas intégré Gemini : Les utilisateurs se plaignent que les écrans intelligents Google Nest Hub utilisent toujours l’ancien Google Assistant et n’ont pas intégré le modèle Gemini plus puissant. Bien que des appareils comme les téléphones Pixel prennent en charge Gemini, la série Nest Hub manque de feuille de route de mise à niveau, ce qui suscite des doutes chez les utilisateurs quant à la fragmentation de l’écosystème de produits Google et à la promesse de popularisation de l’IA. (Source : Reddit r/ArtificialInteligence, Reddit r/artificial)