
Mots-clés:OpenAI, DSPy, SGLang, Nvidia, ChatGPT, IA, LLM, MoE, dspy.GRPO, DeepSeek MoE, Parakeet TDT, Systèmes Agentiques, EQ-Bench 3, OpenAI, DSPy, SGLang, Nvidia, ChatGPT, Intelligence Artificielle, Modèles de Langage à Grande Échelle, Mixture of Experts, dspy.GRPO, DeepSeek MoE, Parakeet TDT, Systèmes Agentiques, EQ-Bench 3
🔥 Focus
OpenAI confirme le maintien de sa structure à but non lucratif: OpenAI a annoncé que son entité à but lucratif existante serait transformée en une Public Benefit Company (PBC), mais le contrôle resterait dévolu à l’organisation à but non lucratif actuelle. Cette décision confirme qu’OpenAI continuera d’être contrôlée par l’organisation à but non lucratif et réaffirme sa mission de garantir que l’AGI (Intelligence Artificielle Générale) profite à toute l’humanité. Cette décision intervient après des troubles internes et des interrogations externes sur la nature de sa structure (y compris le procès de Musk), suscitant des réactions mitigées au sein de la communauté : certains y voient un engagement envers sa mission, tandis que d’autres remettent en question les véritables intentions derrière cet ajustement de la structure du capital (source: OpenAI, sama, jachiam0, NeelNanda5, scaling01, zacharynado, mcleavey, steph_palazzolo, Plinz, Teknium1)
Le framework DSPy lance l’optimiseur RL en ligne expérimental dspy.GRPO: L’équipe NLP de Stanford a lancé une nouvelle fonctionnalité expérimentale pour le framework DSPy, dspy.GRPO, un optimiseur en ligne par apprentissage par renforcement (RL). Cet outil vise à optimiser les programmes DSPy, même les programmes complexes multi-modules et multi-étapes, en s’appliquant directement sans modifier le code existant. Cette initiative est considérée comme une étape importante pour introduire l’optimisation RL (telle que GRPO utilisée par DeepSeek) à un niveau d’abstraction plus élevé (workflow LLM), dans le but d’améliorer les performances et l’efficacité des agents IA et des pipelines complexes. La communauté a réagi avec enthousiasme, estimant que ce sera un élément important de DSPy 3.0 (source: Omar Khattab, matei_zaharia, lateinteraction, Michael Ryan, Lakshya A Agrawal, Scott Condron, Noah Ziems, Rogerio Chaves, Karthik Kalyanaraman, Josh Cason, Mehrdad Yazdani, DSPy, Hopkinx🀄️, Ahmad, william, lateinteraction, lateinteraction, swyx)
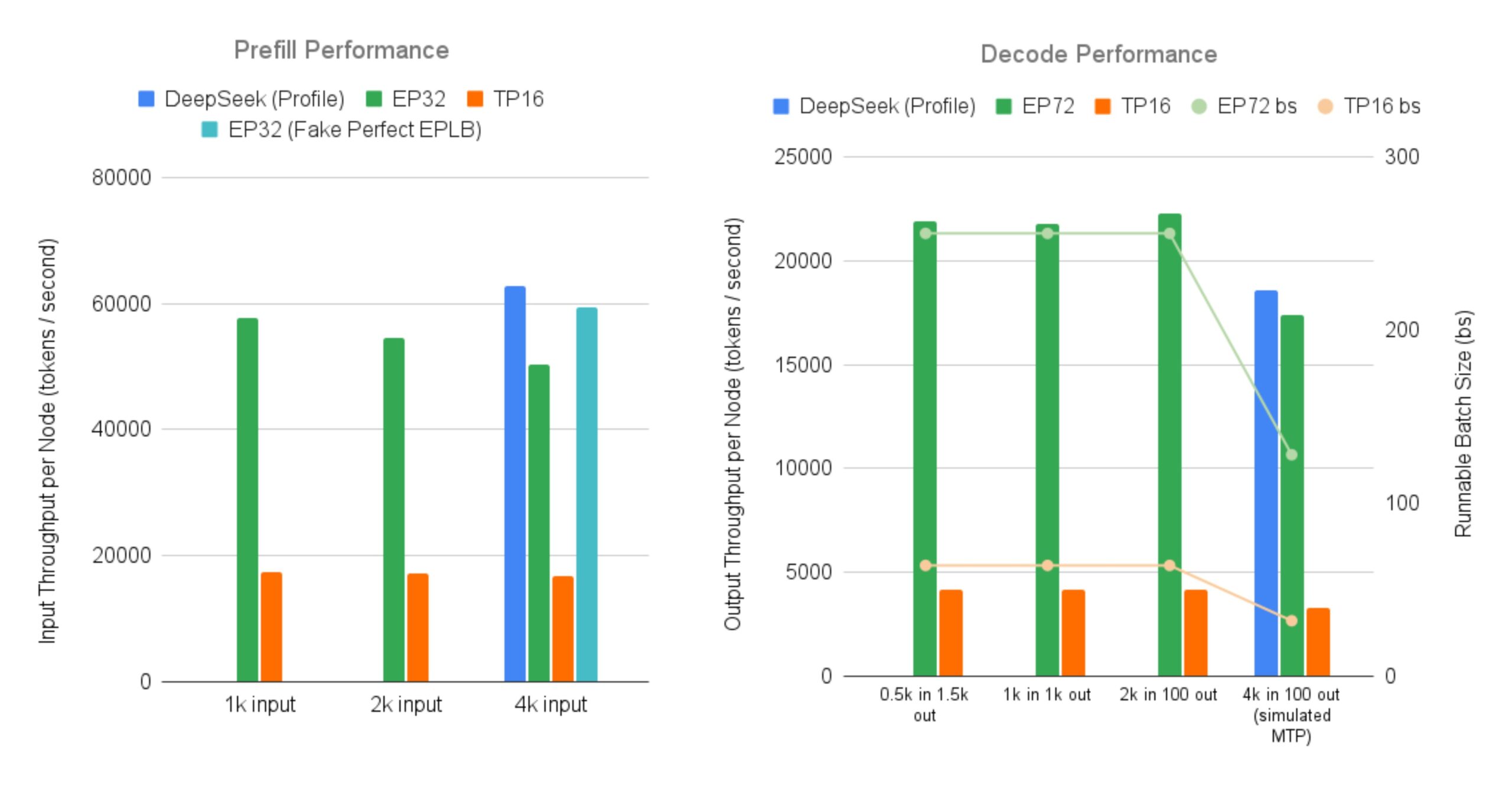
SGLang open-source une implémentation efficace pour servir les grands modèles MoE DeepSeek: LMSYS Org annonce que SGLang fournit la première implémentation open-source pour servir des modèles MoE (Mixture-of-Experts) tels que DeepSeek V3/R1 sur 96 GPU, avec des fonctionnalités telles que le parallélisme d’experts à grande échelle (Expert Parallelism) et la désagrégation préremplissage-décodage (Prefill-Decode Disaggregation). Cette implémentation atteint presque le débit rapporté officiellement par DeepSeek (entrée 52.3k tokens/sec par nœud, sortie 22.3k tokens/sec), améliorant le débit de sortie jusqu’à 5 fois par rapport au parallélisme tensoriel traditionnel. Cela fournit à la communauté une solution open-source pour exécuter et déployer efficacement de grands modèles MoE (source: LMSYS Org, teortaxesTex, cognitivecompai, lmarena_ai, cognitivecompai)
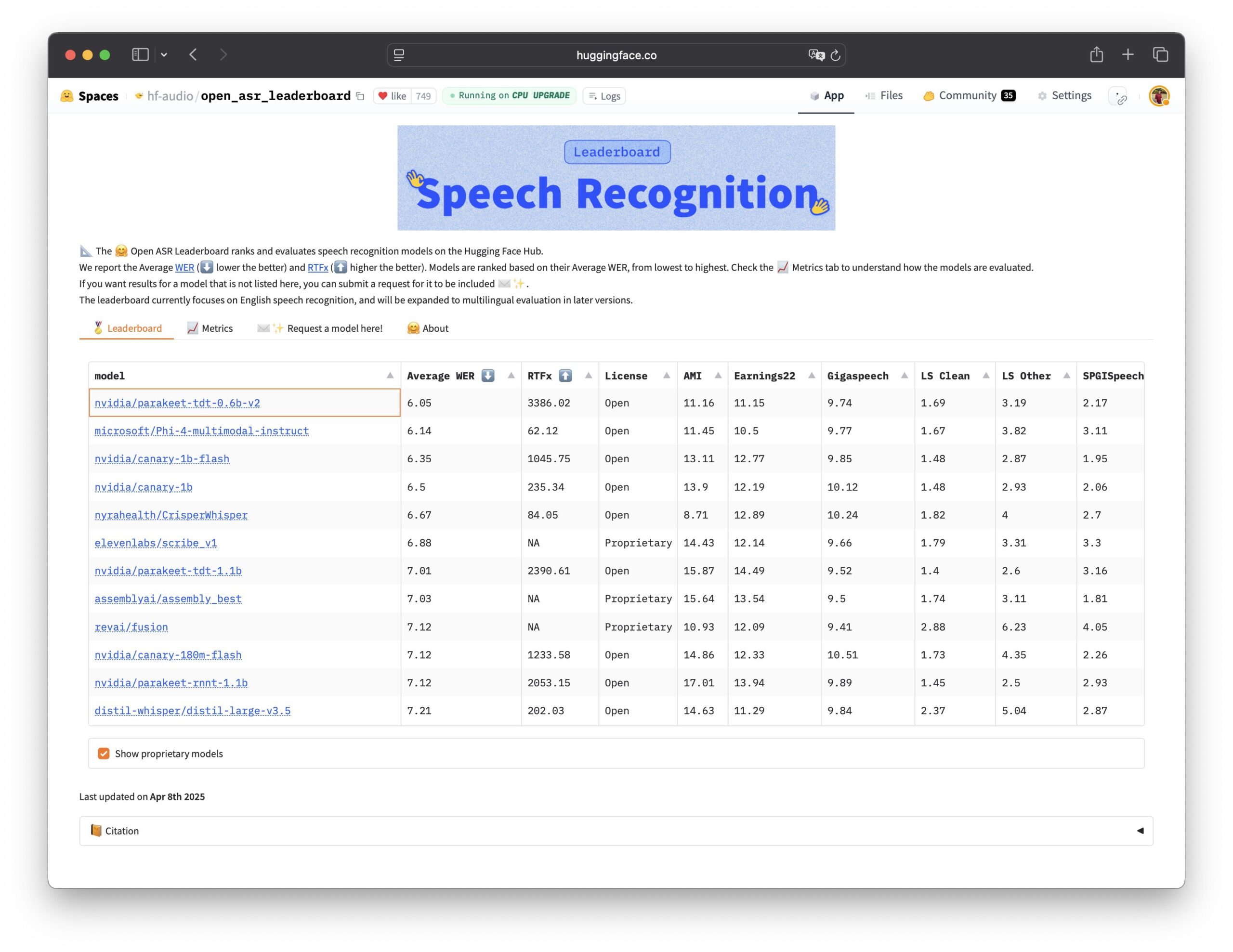
Nvidia open-source le modèle de reconnaissance vocale Parakeet TDT: Nvidia a rendu open-source le modèle Parakeet TDT 0.6B, qui obtient les meilleurs résultats sur l’Open ASR Leaderboard, devenant ainsi le modèle de reconnaissance automatique de la parole (ASR) open-source le plus performant actuellement. Ce modèle de 600 millions de paramètres peut transcrire 60 minutes d’audio en 1 seconde, surpassant les performances de nombreux modèles propriétaires courants. Le modèle est sous licence CC-BY-4.0, autorisant une utilisation commerciale, et offre une option open-source puissante pour le domaine de la reconnaissance vocale (source: Vaibhav (VB) Srivastav, huggingface, ClementDelangue)
🎯 Tendances
L’audience de ChatGPT continue de croître et dépasse celle de X: Les données de Similarweb montrent que l’audience de ChatGPT continue de croître, dépassant celle de la plateforme X en avril avec un total de 4,786 milliards de visites contre 4,028 milliards. Depuis début 2025, l’audience de ChatGPT a augmenté régulièrement, passant d’un retard occasionnel en janvier à une avance quasi-totale sur X en avril, démontrant la forte dynamique des chatbots IA en termes d’activité utilisateur (source: dotey)
La confiance dans les données et le leadership deviennent clés pour la transformation IA: Plusieurs rapports et discussions soulignent que la confiance dans les données est une force invisible accélérant la transformation IA. Parallèlement, les leaders GenAI qui réussissent montrent des caractéristiques distinctes en matière de stratégie, d’organisation et d’application technologique. Cela indique que la clé du succès de l’IA ne réside pas seulement dans la technologie elle-même, mais aussi dans une base de données de haute qualité et fiable, ainsi qu’un leadership et un déploiement stratégique efficaces (source: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)

GTE-ModernColBERT atteint des performances SOTA sur les tâches d’embedding de textes longs: Le modèle d’embedding multi-vecteurs GTE-ModernColBERT publié par LightOn a atteint des résultats SOTA (State-of-the-Art) sur le benchmark de recherche de documents longs LongEmbed, avec une avance de près de 10 points. Il est à noter que ce modèle a été entraîné uniquement sur des documents courts de MS MARCO (longueur 300), mais a démontré une excellente capacité de généralisation zero-shot sur les tâches de textes longs. Cela confirme davantage le potentiel des modèles à interaction tardive (Late Interaction) (comme ColBERT) pour traiter la recherche de contexte long, surpassant les modèles traditionnels BM25 et de recherche dense (source: Antoine Chaffin, Ben Clavié, tomaarsen, Dorialexander, Manuel Faysse, Omar Khattab)

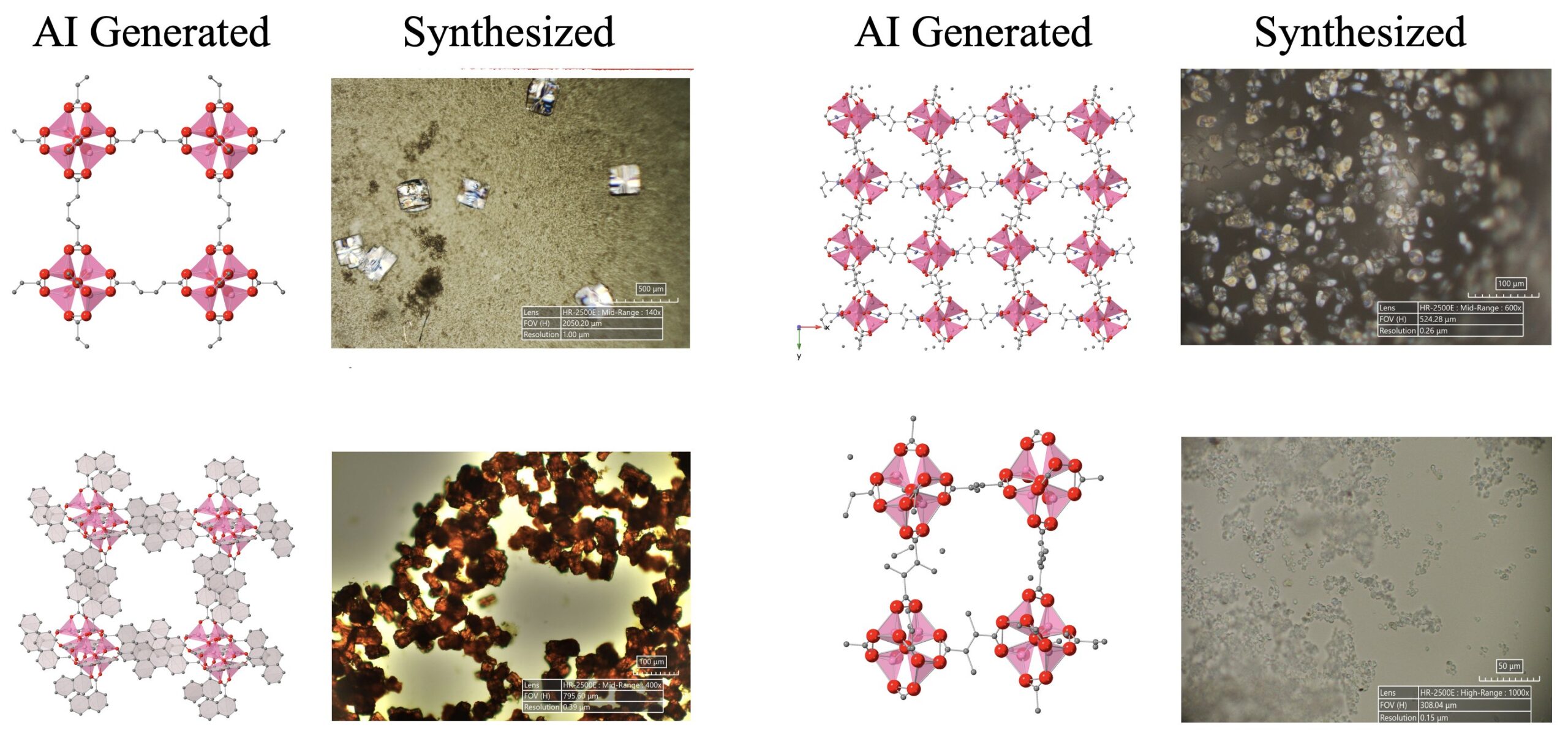
Progrès dans la découverte scientifique pilotée par l’IA: Un système d’agents IA composé de LLM, de modèles de diffusion et de matériel a réussi à découvrir et synthétiser de manière autonome 5 nouvelles structures métallo-organiques (MOFs), dépassant les connaissances humaines existantes. Cette recherche démontre le potentiel des agents IA dans l’automatisation de la recherche scientifique, capables de réaliser l’ensemble du processus, de la proposition d’idées de recherche à la validation expérimentale en laboratoire humide (source: Sherry Yang)
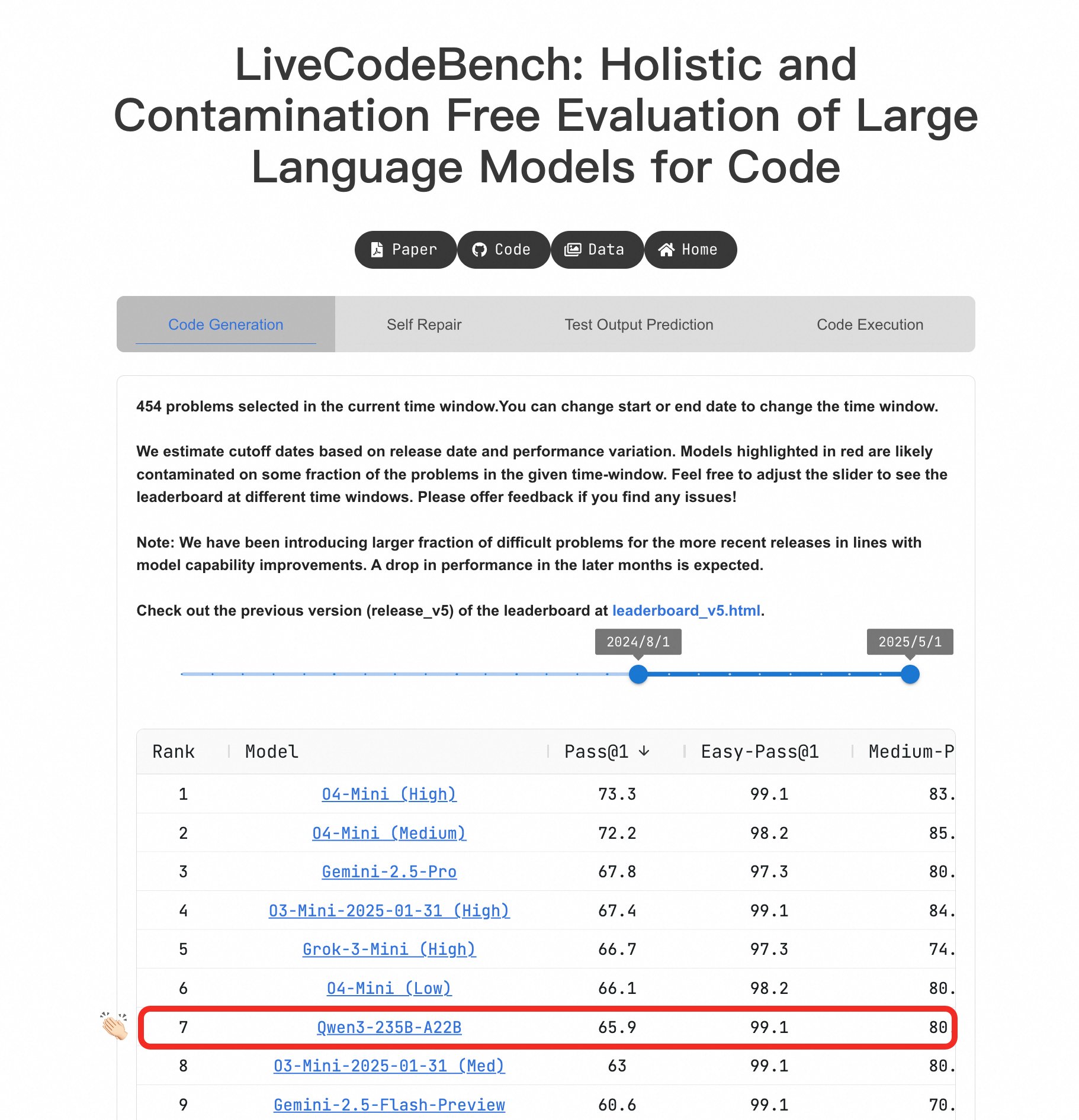
Le grand modèle Qwen3 se distingue par ses capacités de programmation: Sur le benchmark LiveCodeBench, le modèle Qwen3-235B-A22B a montré des performances exceptionnelles, étant considéré comme l’un des meilleurs modèles open-source pour la génération de code de niveau compétitif, avec des performances comparables à o4-mini (faible confiance). Même sur les problèmes difficiles, Qwen3 maintient un niveau équivalent à O4-Mini (Low), surpassant o3-mini (source: Binyuan Hui, teortaxesTex)
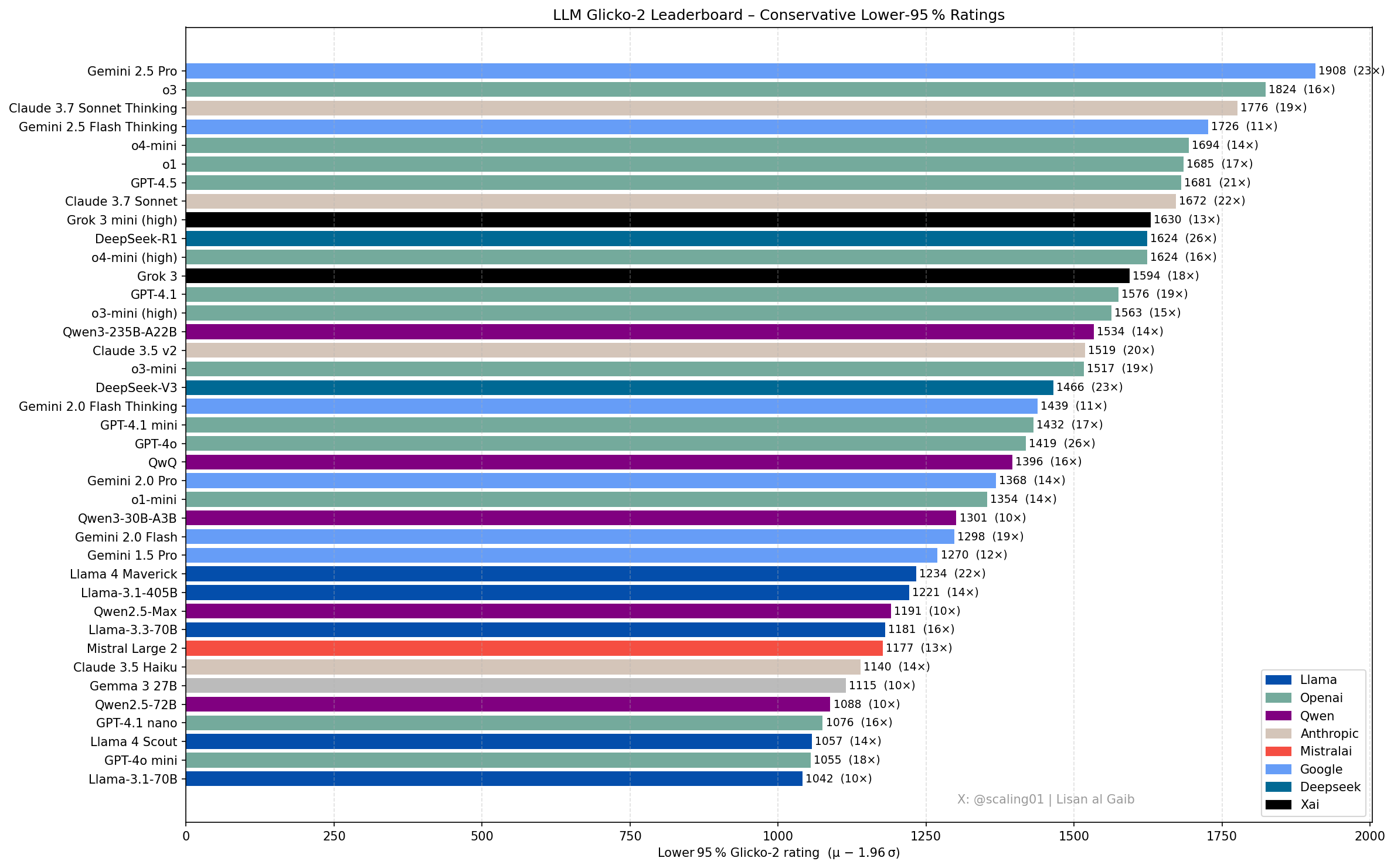
Nouveaux progrès et discussions sur le classement des LLM: Lisan al Gaib, membre de la communauté, a mis à jour le classement des LLM en utilisant le système de notation Glicko-2, suscitant des discussions. Scaling01 estime que ce classement correspond à 95% à ses impressions subjectives, Gemini 2.5 Pro restant le leader, mais Gemini 2.5 Flash, Grok 3 mini et GPT-4.1 pourraient être surévalués. Le classement montre une progression logique pour les séries de modèles OpenAI, Llama et Gemini, avec o3 (high) étant comparable à Gemini 2.5 Pro (source: Lisan al Gaib)
L’écosystème de la robotique open-source se développe rapidement: Clem Delangue de Hugging Face s’est montré enthousiaste quant aux progrès dans le domaine de la robotique IA après des échanges avec NPeW et Matth Lapeyre. Peter Welinder (OpenAI) a également salué le travail de Hugging Face pour promouvoir l’écosystème de la robotique open-source, estimant que ce domaine connaît une croissance rapide (source: ClementDelangue, Peter Welinder, ClementDelangue, huggingface)
L’orientation de la recherche sur l’interprétabilité de l’IA suscite l’attention: Les chercheurs appellent à davantage de travaux sur l’interprétabilité de l’IA (Interpretability), en particulier pour expliquer les comportements étranges des modèles. En comprenant ces comportements, il est possible d’en déduire des conclusions plus profondes sur les mécanismes internes des LLM et potentiellement de créer de nouveaux outils d’interprétabilité. Ceci est considéré comme une direction de recherche prometteuse et influente (source: Josh Engels)
FutureHouseSF s’engage à construire des “scientifiques IA”: Sam Rodriques, PDG de FutureHouseSF, a été interviewé sur l’objectif de l’entreprise de construire des “scientifiques IA”. La discussion a porté sur la signification concrète des scientifiques IA, le rôle de la robotique dans ce domaine, et pourquoi le domaine scientifique a besoin d’une force motrice similaire au projet “Stargate”, visant à utiliser l’IA pour accélérer la découverte scientifique (source: steph_palazzolo)
L’avantage des TPU de Google pourrait être sous-estimé: Le commentateur Justin Halford estime que les investisseurs pourraient sous-estimer l’avantage de Google en matière de TPU (Tensor Processing Units). Il souligne qu’en l’absence de fossé algorithmique significatif, la puissance de calcul sera la clé de la course à l’IA, et que les TPU développés par Google permettent d’éviter les coûts intermédiaires, ce qui est crucial dans un contexte où des centaines de milliards de dollars affluent vers la construction d’infrastructures (source: Justin_Halford_)
Publication du modèle VLA open-source Nora: Declare Lab a rendu open-source Nora, un nouveau modèle vision-langage-action (VLA) basé sur Qwen2.5VL et le tokenizer FAST+. Ce modèle a été entraîné sur le jeu de données Open X-Embodiment et surpasse Spatial VLA et OpenVLA sur la tâche réelle WidowX (source: Reddit r/MachineLearning)

Nouvelle méthode d’optimisation de l’inférence LLM : Snapshot et restauration: Face aux défis du démarrage à froid (cold start) et du déploiement multi-modèles dans l’inférence LLM, une équipe a construit un nouveau système d’exécution. Ce système, en prenant un instantané (snapshot) de l’état d’exécution complet du modèle (y compris la disposition mémoire, le cache d’attention, le contexte d’exécution) et en le restaurant directement sur le GPU, permet un démarrage à froid en moins de 2 secondes. Il peut héberger plus de 50 modèles sur 2 GPU A4000 avec une utilisation du GPU supérieure à 90% et sans gonflement persistant de la mémoire. Cette approche s’apparente à la construction d’un “système d’exploitation” pour l’inférence (source: Reddit r/MachineLearning, Reddit r/LocalLLaMA)
Détecteur d’objets en temps réel open-source D-FINE: La bibliothèque Hugging Face Transformers a ajouté le détecteur d’objets en temps réel D-FINE. Ce modèle serait plus rapide et plus précis que YOLO, est sous licence Apache 2.0 et peut fonctionner sur un GPU T4 (environnement Colab gratuit), offrant une nouvelle option open-source SOTA pour la détection d’objets en temps réel (source: merve, algo_diver)
La tarification des LLM tend à devenir dynamique: On observe que la tarification des grands modèles de langage devient plus dynamique. Cela pourrait aider le marché à trouver des points de prix plus optimaux au fil du temps, reflétant la tendance des fournisseurs de modèles à ajuster leurs stratégies de tarification en fonction des coûts, de la demande et des pressions concurrentielles (source: xanderatallah)
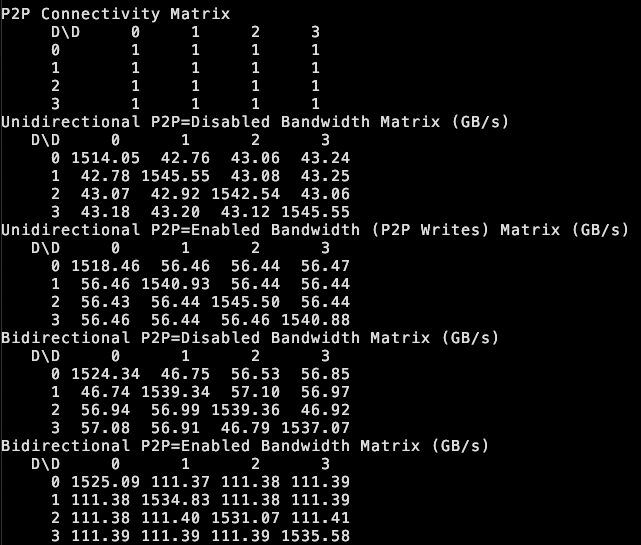
tinybox green v2 prend en charge le P2P entre GPU: the tiny corp annonce que son produit tinybox green v2, grâce à un pilote modifié, prend en charge la communication point à point (P2P) entre les GPU RTX 5090. Cela signifie que les données peuvent être transférées directement entre les GPU sans passer par la RAM du CPU, améliorant l’efficacité du travail collaboratif multi-GPU. Cette fonctionnalité est compatible avec tinygrad et PyTorch (toute bibliothèque utilisant NCCL) (source: the tiny corp)
Des chercheurs publient EQ-Bench 3 pour évaluer l’intelligence émotionnelle des LLM: Sam Paech a publié EQ-Bench 3, un outil de benchmark conçu pour mesurer l’intelligence émotionnelle (EQ) des grands modèles de langage (LLM). L’équipe de développement a lancé cette version après plusieurs échecs de prototypes, dans le but d’évaluer de manière plus précise et fiable la capacité des modèles à comprendre et à répondre aux émotions (source: Sam Paech, fabianstelzer)

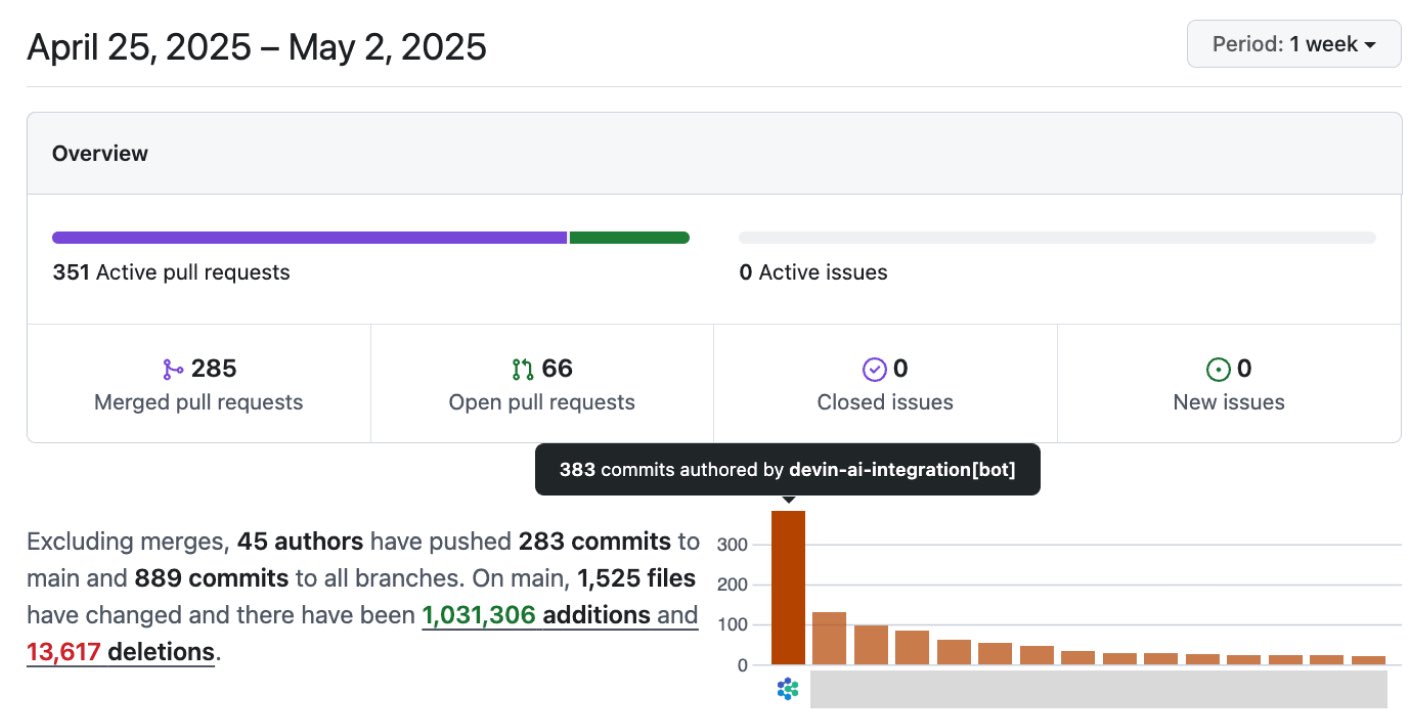
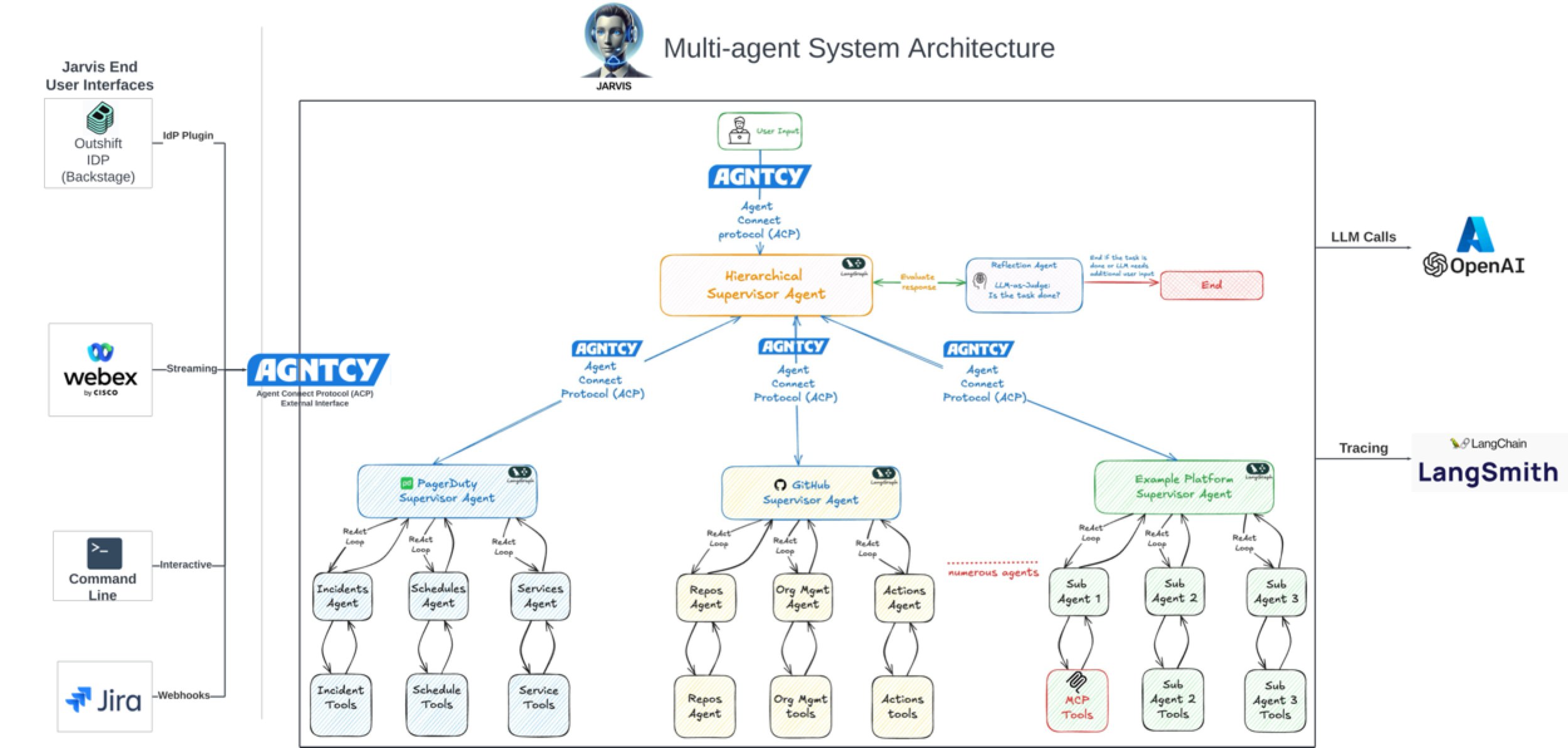
L’IA améliore considérablement l’efficacité du développement logiciel: Les discussions et les cas d’usage au sein de la communauté montrent que l’IA améliore considérablement l’efficacité du développement logiciel. Par exemple, dans le dépôt de code de la société Vesta, les commits de l’IA sont désormais majoritaires. Cisco Outshift, en utilisant l’ingénieur de plateforme IA JARVIS construit sur LangGraph et LangSmith, a réduit le temps de configuration CI/CD d’une semaine à moins d’une heure, et le temps de provisionnement des ressources d’une demi-journée à quelques secondes, réalisant une multiplication par 10 de la productivité (source: mike, LangChainAI, hwchase17)
L’IA pénètre les industries cinématographique et créative: Disney/Lucasfilm, via Industrial Light & Magic (ILM), a publié sa première œuvre publique d’IA générative, marquant l’adoption de la technologie IA par les studios VFX de premier plan. Cela présage que l’IA jouera un rôle plus important dans les effets spéciaux cinématographiques, la conception créative et d’autres domaines, modifiant les processus de création de contenu (source: Bilawal Sidhu)
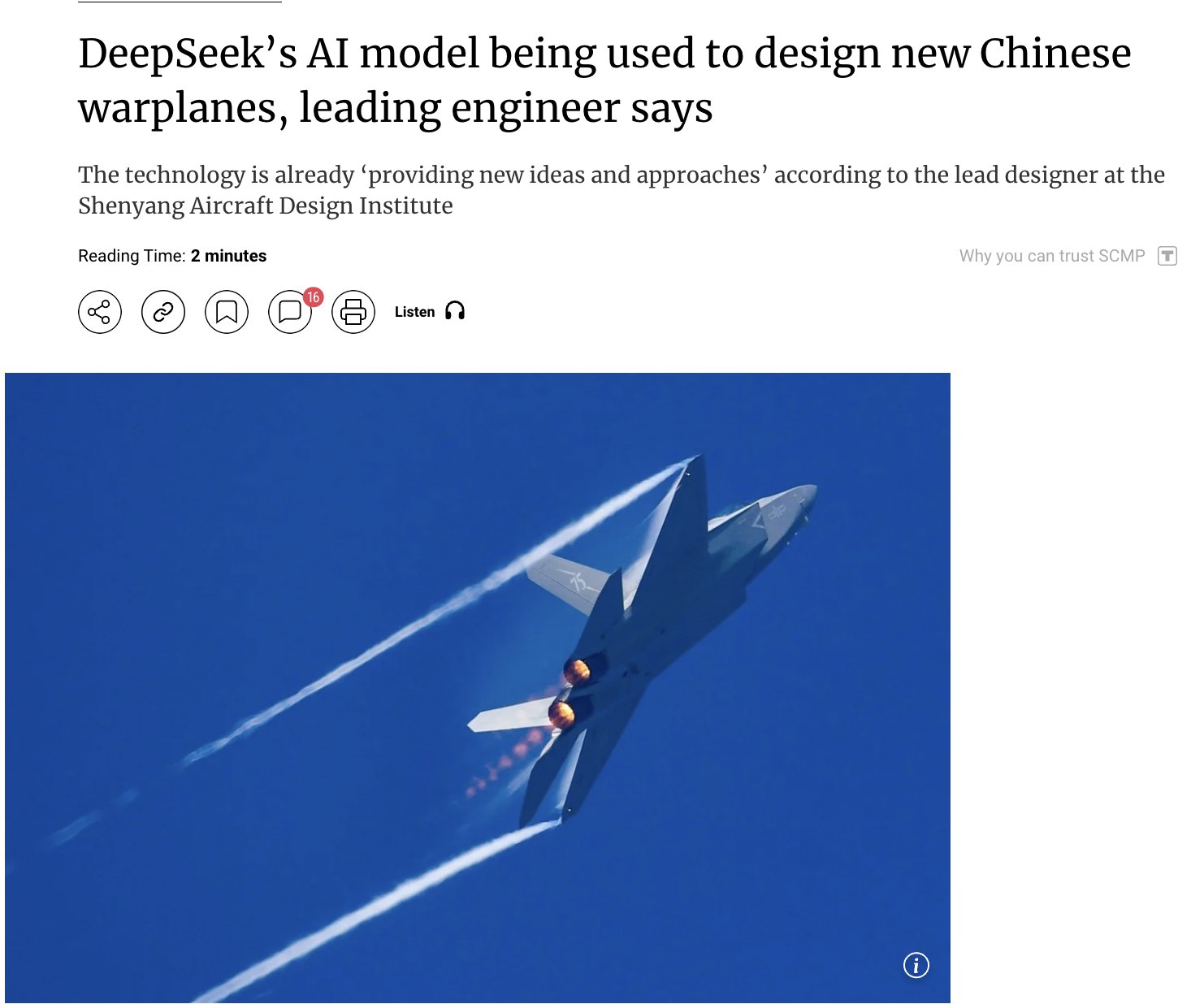
L’application de l’IA dans le domaine militaire suscite l’attention: Des rapports indiquent que la Chine utilise son modèle IA auto-développé DeepSeek pour concevoir des avions de combat avancés (tels que J-15, J-35) et façonner la prochaine génération d’avions (J-36, J-50). L’IA accélérerait la R&D en optimisant la furtivité, les matériaux et les performances. Bien que la source d’information nécessite de la prudence, cela reflète le potentiel et l’attention suscités par les applications de l’IA dans les domaines de la défense et de l’aérospatiale (source: Clash Report)
Mouvement de talents : Rohan Pandey quitte OpenAI: Rohan Pandey, chercheur au sein de l’équipe Training d’OpenAI, a annoncé son départ. Il a indiqué qu’il prendrait une pause pour se consacrer à la résolution du problème de l’OCR en sanskrit afin de “préserver à jamais les classiques de la littérature indienne dans les poids de la superintelligence”, avant d’annoncer ses prochains projets. Les membres de la communauté le tiennent en haute estime, le considérant comme un chercheur extrêmement talentueux (source: Rohan Pandey, JvNixon, teortaxesTex)

Le nombre d’enregistrements de droits d’auteur pour l’IA dépasse les 1000: Le Bureau américain du droit d’auteur a enregistré plus de 1000 œuvres contenant du contenu généré par l’IA. Cela reflète l’utilisation croissante de l’IA dans le domaine de la création, tout en soulignant que les questions d’attribution et de protection des droits d’auteur pour le contenu généré par l’IA deviennent de plus en plus centrales (source: Reddit r/artificial, Reddit r/ArtificialInteligence)

Duolingo licencie des contractuels, l’application de l’IA suscite des inquiétudes: Duolingo a licencié une partie de ses contractuels car l’IA peut générer du contenu de cours 12 fois plus rapidement. Cette décision a suscité des inquiétudes quant à l’impact de l’automatisation sur l’apprentissage des langues et l’emploi dans les industries connexes, montrant le potentiel de l’IA à remplacer le travail humain dans la création de contenu et les impacts socio-économiques qui en découlent (source: Reddit r/ArtificialInteligence)

Microsoft devance-t-il Amazon dans la course au cloud et à l’IA ?: Une analyse suggère que Microsoft, grâce à ses investissements actifs dans l’IA (comme l’investissement dans OpenAI) et à l’intégration de ses services cloud (Azure), est en train de dépasser Amazon (AWS) dans la course au cloud et à l’IA. L’article estime qu’Amazon pourrait être en retard sur Microsoft en termes de concentration stratégique (source: Reddit r/ArtificialInteligence, Reddit r/deeplearning)

Discussion sur l’utilisation des experts dans les modèles MoE: La communauté discute de savoir si l’utilisation des experts dans les modèles MoE suit le principe de Pareto (une minorité d’experts traitant la majorité du trafic). La plupart des opinions convergent sur le fait que l’objectif de l’entraînement est généralement d’équilibrer la charge entre les experts, et que l’écart dans le modèle Mixtral est très faible. Cependant, Qwen3 pourrait présenter un certain biais, bien que loin d’une distribution 80/20. L’exemple de DeepSeek-R1 (256 experts, 8 activés) illustre également que même si des tâches spécifiques (comme le codage) peuvent favoriser certains experts, ce n’est pas fixe, et les experts partagés sont toujours activés (source: Reddit r/LocalLLaMA)

Le modèle affiné Josiefied-Qwen3-8B reçoit des éloges: Un utilisateur partage des commentaires positifs sur le modèle Qwen3 8B affiné par Goekdeniz-Guelmez (Josiefied-Qwen3-8B-abliterated-v1). Ce modèle est considéré comme supérieur à la version originale de Qwen3 8B pour suivre les instructions et générer des réponses vives, et ce sans censure. L’utilisateur l’exécute en quantification Q8 et estime que ses performances dépassent les attentes pour un modèle 8B, le rendant particulièrement adapté aux systèmes RAG en ligne (source: Reddit r/LocalLLaMA)

La RTX 5060 Ti 16GB pourrait être un choix性价比 pour l’IA: Un utilisateur partage son expérience, estimant que la version RTX 5060 Ti 16GB (environ 499 $) bien que mal notée pour les performances de jeu, offre un bon rapport qualité-prix pour les applications IA grâce à ses 16GB de VRAM. En comparaison avec un GPU 12GB exécutant LightRAG pour traiter des PDF, la version 16GB est plus de 2 fois plus rapide car elle peut contenir plus de couches de modèle, évitant les changements fréquents de modèle et améliorant l’utilisation du GPU. Sa taille de carte plus courte la rend également adaptée aux constructions SFF (source: Reddit r/LocalLLaMA)
Discussion sur la faisabilité de l’utilisation d’images RGB pour la classification fine d’objets: La communauté demande si, en l’absence d’imagerie hyperspectrale (HSI), l’utilisation exclusive d’images RGB est suffisante pour la classification en temps réel ou la détection d’anomalies d’objets fins d’une seule catégorie (comme des grains de café). Bien que la littérature recommande souvent l’HSI pour traiter les différences subtiles, l’utilisateur souhaite connaître des cas de succès ou la faisabilité de réaliser de telles tâches uniquement avec des images RGB (source: Reddit r/deeplearning)
Fuite présumée du System Prompt du modèle Claude: Un texte présumé être le System Prompt du modèle Claude, long de 25K tokens, est apparu sur GitHub. Il contient des instructions détaillées, exigeant par exemple que le modèle ne copie ni ne cite jamais de paroles de chansons (même sous forme approximative ou codée) dans quelque circonstance que ce soit (y compris les résultats de recherche et le contenu généré), ce qui est probablement lié aux restrictions de droits d’auteur. Cette fuite (si elle est avérée) fournit des indices sur les mécanismes de travail internes et les contraintes de sécurité de Claude (source: karminski3)
Publication du nouveau modèle de réparation d’images IA PixelHacker: Le modèle PixelHacker a été publié, se concentrant sur la réparation d’images (inpainting) et soulignant le maintien de la cohérence structurelle et sémantique pendant le processus de réparation. Ce modèle surpasserait les modèles SOTA actuels sur des jeux de données tels que Places2, CelebA-HQ et FFHQ (source: Reddit r/deeplearning)

ChatGPT ajoute une nouvelle voix HELLO_TIBOR: Un utilisateur a découvert une nouvelle option vocale nommée “HELLO_TIBOR” dans la dernière version de l’application web ChatGPT. Cela indique qu’OpenAI pourrait continuer à étendre ses fonctionnalités d’interaction vocale, offrant un choix de voix plus diversifié (source: Tibor Blaho)
🧰 Outils
Runway réalise la conversion d’images en captures d’écran de jeu et des hommages cinématographiques: Un utilisateur a expérimenté la fonction Gen-4 References de Runway, réussissant à convertir une image ordinaire en une capture d’écran de jeu isométrique 2.5D de style Unreal Engine grâce à des prompts détaillés en plusieurs étapes (analysant la scène, comprenant l’intention, définissant le moteur de jeu et les exigences de rendu). Un autre utilisateur a utilisé Runway References et Gen-4 pour créer un clip vidéo en hommage au film “Les Affranchis” (Goodfellas). Ces cas démontrent la puissance de Runway dans la génération contrôlable d’images/vidéos, en particulier en combinant des images de référence et le transfert de style (source: Ray (movie arc), Bryan Fox, c_valenzuelab, c_valenzuelab)

Runway prend en charge l’importation d’actifs 3D pour améliorer la contrôlabilité de la génération vidéo: La fonction Gen-4 References de Runway prend désormais en charge l’utilisation d’actifs 3D comme référence pour un contrôle plus précis de la forme et des détails des objets dans les vidéos générées. L’utilisateur n’a qu’à fournir une image de fond de scène, une simple composition du modèle 3D dans cette scène et une image de référence de style pour introduire des modèles très détaillés et spécifiques dans le flux de travail de génération, améliorant la cohérence et la contrôlabilité du contenu généré (source: Runway, c_valenzuelab, op7418)
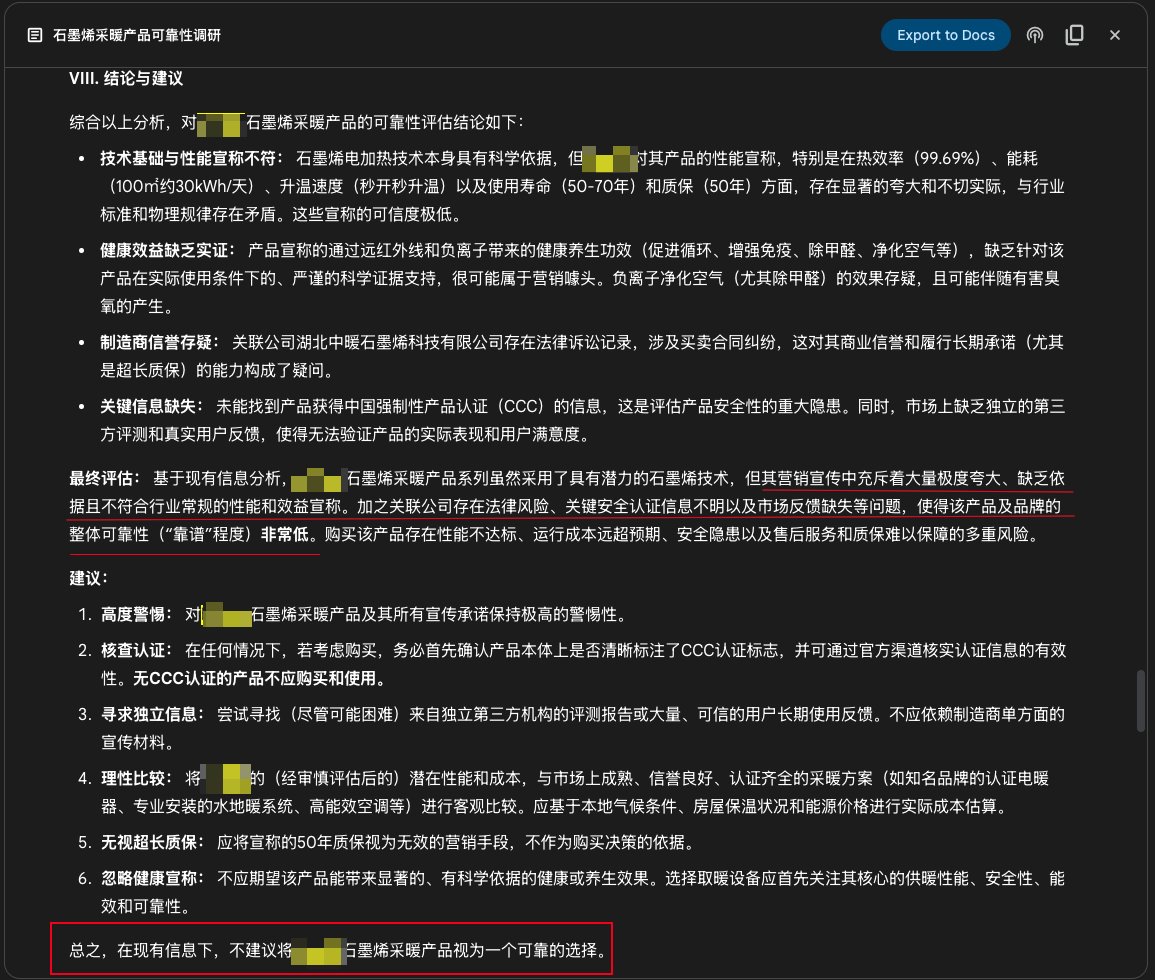
Utilisation de la fonction Deep Research de Google Gemini pour l’étude de produits: Un utilisateur partage un cas d’utilisation de la fonction Deep Research de Google Gemini pour étudier la fiabilité d’un produit. En entrant la description promotionnelle du produit, Gemini a recherché des centaines de pages web et a clairement indiqué qu’un produit de chauffage au graphène avait une publicité exagérée, manquait de preuves, présentait des risques et n’était pas recommandé à l’achat. Cela démontre l’utilité pratique des outils de recherche approfondie IA pour la vérification d’informations et l’aide à la décision de consommation (source: dotey)
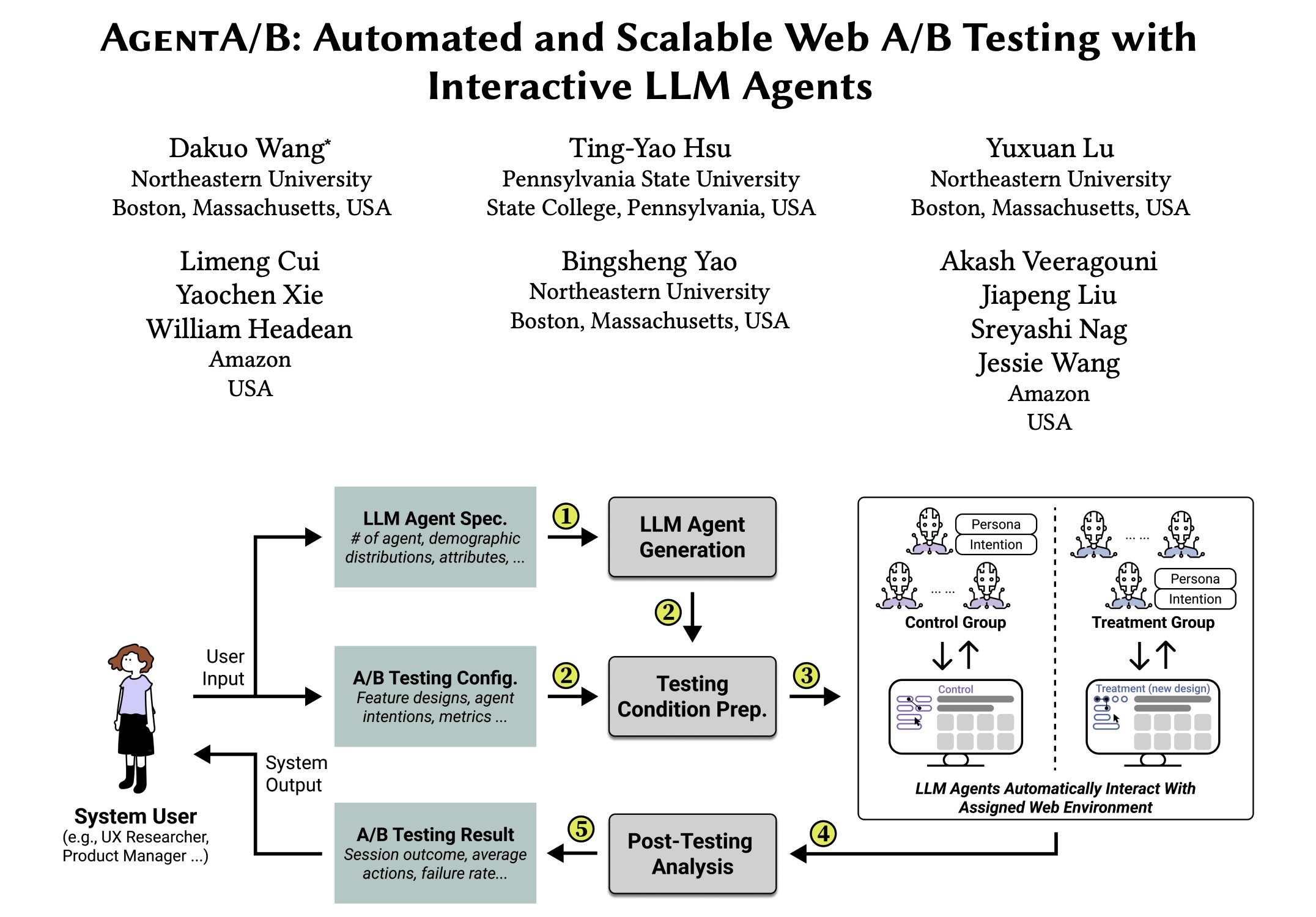
AgentA/B : Framework de test A/B automatisé basé sur des agents LLM: AgentA/B est un framework de test A/B entièrement automatisé qui utilise des agents à grande échelle basés sur LLM pour remplacer le trafic utilisateur réel. Ces agents peuvent simuler des comportements utilisateurs réalistes et axés sur l’intention dans des environnements web réels, permettant une évaluation de l’expérience utilisateur (UX) plus rapide, moins chère et sans risque, même en l’absence de trafic réel (source: elvis)
Qdrant aide Pariti à améliorer l’efficacité du recrutement: La plateforme de recrutement Pariti utilise la base de données vectorielle Qdrant pour alimenter son système de mise en correspondance de candidats piloté par l’IA. Grâce aux capacités de recherche vectorielle en temps réel de Qdrant, Pariti peut trier et attribuer dynamiquement des scores de correspondance à 70 000 profils de candidats en 40 millisecondes, réduisant le temps d’examen des candidats de 70 %, doublant le taux de réussite du recrutement, et 94 % des meilleurs candidats apparaissant dans les 10 premiers résultats de recherche (source: qdrant_engine)

Qwen 3 et LangGraph, etc. construisent un agent de recherche approfondie open-source: Soham a développé et rendu open-source un agent de recherche approfondie. Cet agent utilise le modèle Qwen 3, combiné avec Composio, LangGraph de LangChain, Together AI, ainsi que Perplexity/Tavily pour la recherche. Il surpasserait de nombreux autres modèles open-source testés. Le code est disponible, offrant une solution d’outil d’automatisation de la recherche reproductible (source: Soham, hwchase17)
Perplexity sur WhatsApp améliore l’expérience d’utilisation de l’IA mobile: Arav Srinivas, PDG de Perplexity, mentionne qu’il est très pratique d’utiliser Perplexity AI sur WhatsApp, en particulier sur les vols avec une mauvaise connexion réseau. Parce que WhatsApp est optimisé pour les environnements à faible réseau, l’accès à l’IA via une application de messagerie devient un moyen stable et fiable, améliorant la disponibilité de l’IA en mobilité et dans des scénarios spéciaux (source: AravSrinivas)
Mise à jour de l’application iOS Suno : prise en charge de la génération d’extraits musicaux partageables: La version iOS de l’application de génération musicale Suno AI a été mise à jour, ajoutant la fonctionnalité de conversion des chansons générées en extraits partageables. Les utilisateurs peuvent choisir une durée d’extrait de 10, 20 ou 30 secondes, accompagnée des paroles et de la pochette ou d’effets visuels fournis officiellement (d’autres styles seront ajoutés à l’avenir), facilitant le partage et la présentation de la musique créée par l’IA sur les réseaux sociaux (source: SunoMusic, SunoMusic)
Discussion communautaire sur l’assistant de programmation IA Cursor: L’utilisateur Andrew Carr exprime son appréciation pour l’assistant de programmation IA Cursor. Parallèlement, Justin Halford estime que Cursor n’est qu’une fonctionnalité et non un produit complet, facilement remplaçable par les lancements des grandes entreprises de modèles. L’outil Cline annonce la prise en charge du format de fichier de configuration .cursorrules de Cursor, montrant l’intérêt de la communauté et les tentatives d’intégration (source: andrew_n_carr, Justin Halford, Celestial Vault)
OctoTools : Framework flexible d’appel d’outils LLM récompensé comme meilleur article à NALCL: Le framework OctoTools a reçu le prix du meilleur article à KnowledgeNLP@NAACL. C’est un framework flexible et facile à utiliser qui équipe les LLM d’outils diversifiés (comme la compréhension visuelle, la récupération de connaissances de domaine, le raisonnement numérique, etc.) via des “cartes d’outils” modulaires (similaires à des briques Lego) pour accomplir des tâches de raisonnement complexes. Il prend actuellement en charge les modèles OpenAI, Anthropic, DeepSeek, Gemini, Grok et Together AI, et un package PyPI a été publié (source: lupantech)

Google met à jour les outils Music AI Sandbox et MusicFX DJ: Google a mis à jour ses outils de génération musicale destinés aux compositeurs et producteurs. Music AI Sandbox permet désormais aux utilisateurs de saisir des paroles pour générer des chansons complètes ; MusicFX DJ permet aux utilisateurs de manipuler de la musique en streaming en temps réel. Les deux sont basés sur le modèle Lyria mis à niveau (respectivement Lyria 2 et Lyria RealTime), peuvent générer un son de haute qualité à 48 kHz et offrent un large contrôle sur la tonalité, le tempo, les instruments, etc. Music AI Sandbox nécessite actuellement une inscription sur liste d’attente pour être utilisé (source: DeepLearningAI)
Agent de revue de code piloté par l’IA: Des outils comme Composiohq, LlamaIndex, combinés avec Grok 3 et Replit Agent, ont permis de construire un agent IA capable d’examiner les Pull Requests GitHub. Le processus comprend : Grok 3 génère le code de l’agent de revue, Replit Agent crée automatiquement l’interface front-end, l’utilisateur soumet le lien PR via l’interface, l’agent effectue la revue et fournit des commentaires. Cela démontre le potentiel des agents IA dans l’automatisation des processus de développement logiciel (comme la revue de code) (source: LlamaIndex 🦙)
Génération de pages de coloriage par IA (avec image de référence): Un utilisateur partage son expérience et ses prompts pour générer des pages de coloriage en noir et blanc avec une petite image de référence en couleur. L’objectif est de résoudre le problème des enfants qui ne savent pas quelles couleurs utiliser pour colorier. Le prompt demande de générer un dessin au trait noir et blanc clair, adapté à l’impression, avec une petite image en couleur dans un coin comme référence, tout en spécifiant le style, la taille, l’âge approprié et le contenu de l’image (source: dotey)

Exemple de code d’agent utilisant le modèle gpt-image-1 pour générer des images: Un utilisateur partage un extrait de code montrant comment créer un agent qui utilise le modèle gpt-image-1 pour générer des images. Cela fournit aux développeurs une référence de code pour implémenter rapidement la fonctionnalité de génération d’images (source: skirano)
VectorVFS : Utiliser le système de fichiers comme base de données vectorielle: VectorVFS est un package Python léger et un outil CLI qui utilise les attributs étendus (xattr) du VFS Linux pour stocker les embeddings vectoriels directement dans les inodes du système de fichiers, transformant ainsi une structure de répertoires existante en un référentiel d’embeddings efficace et consultable sémantiquement, sans nécessiter la maintenance d’un index séparé ou d’une base de données externe (source: Reddit r/MachineLearning)
Assistant Kubernetes piloté par l’IA kubectl-ai: Google Cloud Platform a publié kubectl-ai, un assistant en ligne de commande Kubernetes piloté par l’IA. Il peut comprendre les instructions en langage naturel, exécuter les commandes kubectl correspondantes et interpréter les résultats. Il prend en charge les modèles Gemini, Vertex AI, Azure OpenAI, OpenAI ainsi que les modèles Ollama et Llama.cpp exécutés localement. Le projet comprend également le benchmark k8s-bench pour évaluer les performances de différents LLM sur les tâches K8s (source: GitHub Trending)

Higgsfield Effects : Pack d’effets visuels de qualité cinématographique piloté par l’IA: Higgsfield AI a lancé Higgsfield Effects, une boîte à outils contenant 10 effets visuels (VFX) de qualité cinématographique, tels que Thor, invisibilité, métallisation, mise à feu, etc. Les utilisateurs peuvent invoquer ces effets via un seul prompt, dans le but de simplifier les processus complexes de production VFX, permettant aux utilisateurs ordinaires de créer facilement des effets visuels à fort impact (source: Higgsfield AI 🧩)
Agent-S : Framework d’agent ouvert simulant l’utilisation humaine de l’ordinateur: Agent-S est un framework d’agent open-source dont l’objectif est de permettre à l’IA d’utiliser un ordinateur comme un humain. Il pourrait inclure des capacités telles que la compréhension de l’intention de l’utilisateur, la manipulation d’interfaces graphiques, l’utilisation de diverses applications, etc., visant à réaliser un comportement d’agent IA plus général et autonome (source: dl_weekly)
Extension Chrome générée par IA pour compléter automatiquement les quiz en ligne: Un utilisateur a utilisé Gemini AI pour créer une extension Chrome qui peut compléter automatiquement les quiz d’une plateforme d’apprentissage en ligne spécifique. Cela démontre le potentiel d’application de l’IA dans l’automatisation des tâches répétitives, mais pourrait également soulever des discussions sur l’intégrité académique (source: Reddit r/ArtificialInteligence)
Génération d’images GPT-4o : Portraits de célébrités dans le style de Rembrandt: Un utilisateur a utilisé GPT-4o pour transformer plusieurs protagonistes de séries télévisées célèbres (tels que Walter White, Don Draper, Tony Soprano, SpongeBob, etc.) en portraits dans le style de peinture de Rembrandt. Ces images montrent la capacité de l’IA à comprendre les caractéristiques des personnages et à imiter des styles artistiques spécifiques (source: Reddit r/ChatGPT, Reddit r/ChatGPT)

Meta publie la boîte à outils Llama Prompt Ops: Meta AI a publié Llama Prompt Ops, une boîte à outils Python pour optimiser les prompts des modèles Llama. Cet outil vise à aider les développeurs à concevoir et ajuster plus efficacement les prompts des modèles Llama pour améliorer les performances du modèle et la qualité de la sortie (source: Reddit r/artificial, Reddit r/ArtificialInteligence)
Un utilisateur recherche une IA gratuite/peu coûteuse pour générer des fichiers Excel/tableurs: Un utilisateur Reddit recherche un outil IA gratuit ou peu coûteux capable de générer des documents tableurs Excel ou OpenOffice, espérant éviter les limites quotidiennes de la version gratuite de ChatGPT. La communauté a recommandé des options telles que Claude, Google Gemini (associé à Sheets) et le déploiement local de modèles open-source (via LM Studio ou LocalAI) (source: Reddit r/artificial)
Un utilisateur demande des méthodes de traitement de contexte long pour Claude: Un utilisateur Reddit demande comment contourner la limite de longueur de contexte et le problème d’amnésie des nouvelles conversations lors du traitement de projets complexes dans Claude. Les méthodes suggérées par la communauté incluent : sauvegarder les informations clés dans des fichiers de projet, ou demander à Claude de résumer les points clés de la conversation et de les apporter à une nouvelle conversation (source: Reddit r/ClaudeAI)
Un utilisateur demande comment utiliser les nouvelles fonctionnalités d’OpenWebUI: Un utilisateur Reddit demande comment utiliser concrètement les nouvelles fonctionnalités de la version v0.6.6 d’OpenWebUI, telles que “l’enregistrement et l’importation de réunions”, l’importation de notes (Markdown) et l’intégration OneDrive (source: Reddit r/OpenWebUI, Reddit r/OpenWebUI)
Un utilisateur demande comment traiter un grand nombre de fichiers JSON pour RAG dans OpenWebUI: Un utilisateur Reddit cherche les meilleures pratiques pour traiter efficacement des milliers de fichiers JSON pour RAG dans OpenWebUI. Considérant que le téléversement direct dans la “base de connaissances” pourrait être inefficace, l’utilisateur demande s’il existe des configurations de base de données vectorielles externes recommandées ou des méthodes d’intégration de pipelines de données personnalisés (source: Reddit r/OpenWebUI)
Un utilisateur signale un problème de timeout lors de l’intégration d’OpenWebUI avec n8n: Un utilisateur rencontre un problème lors de l’utilisation d’OpenWebUI comme interface frontale pour un agent IA n8n : lorsque l’exécution du workflow n8n dépasse environ 60 secondes, OpenWebUI affiche une erreur, même si l’utilisateur confirme que le backend n8n s’est terminé avec succès. L’utilisateur cherche un moyen d’augmenter le délai d’attente ou de maintenir la connexion (source: Reddit r/OpenWebUI)
📚 Apprentissage
LangGraph pour construire des systèmes Agentic complexes: LangGraph, faisant partie de l’écosystème LangChain, se concentre sur la construction d’applications multi-acteurs avec état. La présentation de Jacob Schottenstein explore l’utilisation de LangGraph pour transformer des graphes orientés acycliques (DAG) en graphes orientés cycliques (DCG) afin de construire des systèmes d’agents plus puissants. Dans un cas pratique, Cisco Outshift a utilisé LangGraph et LangSmith pour construire l’ingénieur de plateforme IA JARVIS, améliorant considérablement l’efficacité des opérations de développement (source: Sydney Runkle, LangChainAI, hwchase17, Hacubu)
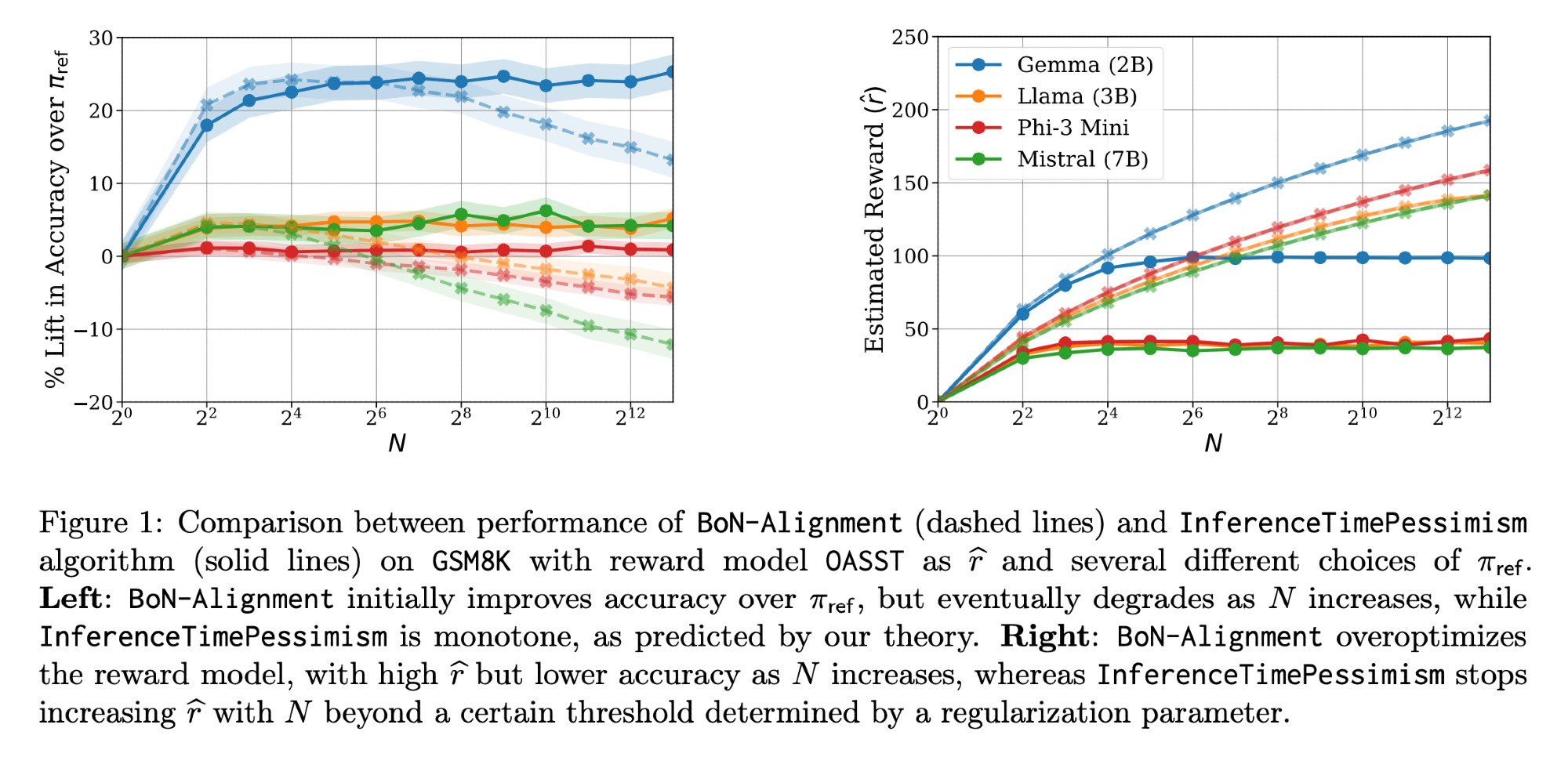
Optimisation de l’inférence LLM : Article Llama-Nemotron et InferenceTimePessimism: L’article Llama-Nemotron publié par Meta AI & Nvidia Research (arXiv:2505.00949v1) présente une série de méthodes d’optimisation directe pour réduire les coûts tout en maintenant la qualité dans les charges de travail d’inférence. Parallèlement, un article de l’ICML ‘25 présente l’algorithme InferenceTimePessimism comme une amélioration potentielle de la méthode d’inférence Best-of-N, visant à utiliser des informations supplémentaires pour optimiser le processus d’inférence (source: finbarrtimbers, Dylan Foster 🐢)
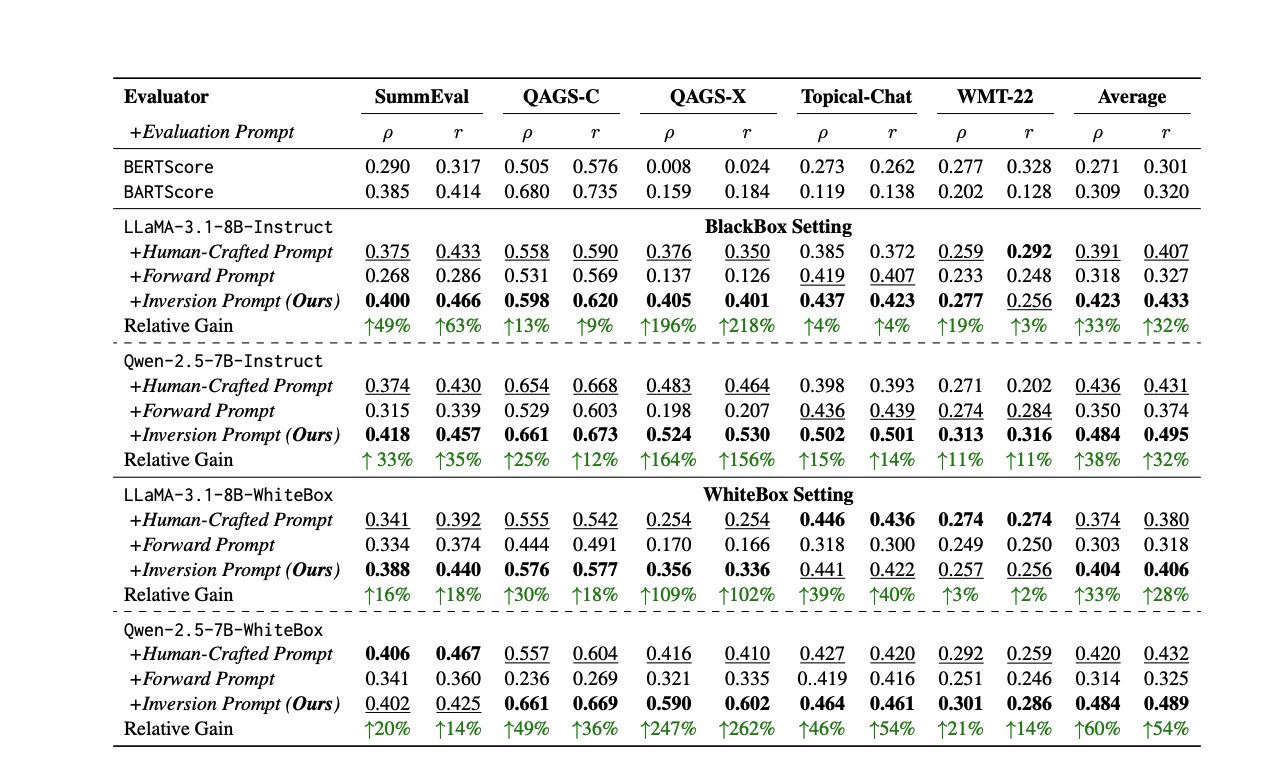
Nouvelles méthodes et ressources pour l’évaluation des LLM: Évaluer les performances des LLM est un défi constant. Un article propose une méthode pour générer automatiquement des prompts d’évaluation de haute qualité en inversant les réponses, afin de résoudre l’incohérence des évaluateurs humains ou LLM. Parallèlement, Shreya Shankar, experte en évaluation LLM, a lancé un cours d’évaluation LLM destiné aux ingénieurs et chefs de produit. De plus, le benchmark SciCode a été publié sous forme de compétition Kaggle, mettant au défi l’IA d’écrire du code pour des phénomènes physiques et mathématiques complexes (source: ben_burtenshaw, Aditya Parameswaran, Ofir Press)
Ressources liées au contrôle et à l’alignement de l’IA: Le contrôle de l’IA (recherche sur la manière de surveiller et d’utiliser en toute sécurité une IA qui n’a pas atteint la superintelligence mais qui pourrait ne pas être alignée) devient un domaine de plus en plus important. FAR.AI a publié les vidéos des présentations de la conférence ControlConf, contenant les points de vue de Neel Nanda et de nombreux autres experts. Parallèlement, un article discutant des valeurs (distinguant la valeur ultime de la valeur instrumentale) est considéré comme pertinent pour la discussion sur l’alignement de l’IA (source: FAR.AI, Séb Krier)

Common Crawl publie de nouveaux jeux de données: Common Crawl a publié l’archive de crawl web d’avril 2025. Parallèlement, Bram Vanroy a lancé C5 (Common Crawl Creative Commons Corpus), un sous-ensemble de Common Crawl rigoureusement filtré, ne contenant que des documents sous licence CC. Actuellement, 150 milliards de tokens ont été collectés, couvrant 8 langues européennes, fournissant une nouvelle source de données conformes pour l’entraînement de modèles de langage (source: CommonCrawl, Bram)
Activités d’apprentissage et tutoriels IA: Plusieurs activités et ressources de tutoriels liées à l’IA ont été publiées : Qdrant a organisé une session de codage en ligne sur l’orchestration d’agents IA avec MCP ; Corbtt prévoit d’organiser un webinaire sur l’optimisation d’agents du monde réel avec RL ; Comet ML organise un événement pour partager des informations sur la construction et la mise en production de systèmes GenAI ; Ofir Press partagera son expérience de construction de SWE-bench et SWE-agent lors d’un webinaire PyTorch ; Nous Research co-organise un hackathon sur les environnements RL avec plusieurs institutions ; LlamaIndex sponsorise le hackathon MCP de Tel Aviv ; Hugging Face propose un tutoriel d’une minute pour construire un serveur MCP ; Together AI publie une série de vidéos sur l’apprentissage automatique Matryoshka ; la conférence d’Andrew Price sur la transformation de l’industrie 3D par l’IA est à nouveau recommandée ; giffmana a partagé l’enregistrement d’une conférence sur les Transformers (source: qdrant_engine, Kyle Corbitt, dl_weekly, PyTorch, Nous Research, LlamaIndex 🦙, dylan, Zain, Cristóbal Valenzuela, Luis A. Leiva)

Discussion sur la théorie et les méthodes de l’IA: La communauté a discuté de certaines théories et méthodes fondamentales dans le domaine de l’IA : 1. Exploration du concept de “World Models”, des problèmes qu’ils résolvent, de leur architecture technique et de leurs défis. 2. Discussion des raisons pour lesquelles les caractéristiques de Fourier/méthodes spectrales ne sont pas largement utilisées en apprentissage profond. 3. Proposition du cadre conceptuel “Serenity Framework”, intégrant cinq grandes théories de la conscience pour explorer l’auto-conscience récursive de l’IA. 4. Discussion sur la question de savoir si l’IA dépend trop des modèles pré-entraînés. 5. Exploration de l’importance de la réduction d’échelle (Downscaling) des LLM (source: Reddit r/MachineLearning, Reddit r/MachineLearning, Reddit r/artificial, Reddit r/MachineLearning, Natural Language Processing Papers)

Ressources sur l’ingénierie des prompts et l’optimisation des modèles: LiorOnAI a partagé le cadre de Greg Brockman, président d’OpenAI, pour construire le prompt parfait. Modal fournit un tutoriel sur l’utilisation de TensorRT-LLM, de la quantification FP8 et du décodage spéculatif pour servir LLaMA 3 8B avec une latence inférieure à 250 ms. N8 Programs partage son expérience de l’entraînement dans des conditions de faible VRAM (64 Go de RAM), en utilisant un modèle quantifié 6 bits comme enseignant et un modèle 4 bits comme élève. Kling_ai a relayé un post de ressources contenant des prompts pour des outils tels que Midjourney v7, Kling 2.0, etc. (source: LiorOnAI, Modal, N8 Programs, TechHalla)

Application et recherche de l’IA dans le domaine de l’éducation: La thèse de doctorat de Rose, doctorante en informatique à l’Université de Stanford, se concentre sur l’utilisation des méthodes, de l’évaluation et de l’intervention de l’IA pour améliorer l’éducation. Cela représente une direction de recherche approfondie pour les applications de l’IA dans le domaine de l’éducation (source: Rose)

Vibe-coding : une nouvelle forme de programmation assistée par IA: Des notes d’un podcast YC interviewant le PDG de Windsurf mentionnent le concept de “Vibe-coding”. Il pourrait s’agir d’un paradigme de programmation davantage axé sur l’intuition, l’ambiance et l’itération rapide, intégrant profondément l’assistance de l’IA, suggérant un changement potentiel des processus et des philosophies de développement logiciel induit par l’IA (source: Reddit r/ArtificialInteligence)
Informations sur le chemin de mise à niveau de Nvidia CUDA: Un article de Phoronix discute du chemin de mise à niveau de Nvidia CUDA après l’architecture Volta, ce qui est pertinent pour les utilisateurs possédant d’anciens GPU Nvidia (comme la série 10xx) et souhaitant continuer à les utiliser pour le développement IA (source: NerdyRodent)
💼 Affaires
CoreWeave finalise l’acquisition de Weights & Biases: La plateforme cloud IA CoreWeave a officiellement finalisé l’acquisition de la plateforme MLOps Weights & Biases (W&B). Cette acquisition vise à combiner l’infrastructure cloud IA haute performance de CoreWeave avec les outils de développement de W&B pour créer la prochaine génération de plateforme cloud IA, aidant les équipes à construire, déployer et itérer plus rapidement les applications IA (source: weights_biases, Chen Goldberg)

Les robots Figure AI testés et optimisés dans l’usine BMW: L’équipe de la société de robots humanoïdes Figure AI a effectué une visite de deux semaines à l’usine du groupe BMW à Spartanburg pour optimiser les processus de ses robots dans l’atelier de carrosserie de la X3 et explorer de nouveaux scénarios d’application. Cela marque une étape concrète dans la collaboration des deux parties pour 2025, démontrant le potentiel d’application des robots humanoïdes dans la fabrication automobile (source: adcock_brett)

Reborn et Unitree Robotics concluent un partenariat stratégique: La société d’IA Reborn a annoncé un partenariat stratégique avec la société de robotique Unitree Robotics. Les deux parties collaboreront dans les domaines des données, des modèles et des robots humanoïdes, avec pour objectif commun d’accélérer le développement des technologies associées (source: Reborn)

🌟 Communauté
Le point de vue prudent de Buffett sur l’IA suscite la discussion: Lors de l’assemblée générale des actionnaires de 2025, Buffett a exprimé une attitude “d’observation calme” et “d’application limitée” envers l’IA. Il a souligné que l’IA ne peut remplacer le jugement humain dans les décisions complexes (citant Ajit Jain, responsable des assurances, comme exemple), Berkshire considérant l’IA comme un outil pour améliorer l’efficacité des activités existantes, et non comme un investissement dans des sociétés purement algorithmiques. Il estime qu’il existe une bulle dans le domaine de l’IA et qu’il faut attendre que la technologie prouve sa rentabilité à long terme. Cela a suscité une discussion sur la valeur des modèles “IA + industrie” par rapport à “industrie + IA” (source: 36氪)
Le PDG d’Anthropic admet un manque de compréhension du fonctionnement de l’IA: Dario Amodei, PDG d’Anthropic, a admis qu’il existe actuellement un manque de compréhension approfondie du fonctionnement interne des grands modèles d’IA (comme les LLM), qualifiant cette situation “d’inédite” dans l’histoire de la technologie. Cette déclaration franche met à nouveau en évidence le “problème de la boîte noire” de l’IA, suscitant de larges discussions et inquiétudes au sein de la communauté concernant l’explicabilité, la contrôlabilité et la sécurité de l’IA (source: Reddit r/ArtificialInteligence)

Le plan d’OpenAI de publier des modèles open-source non-frontières et sa controverse: Kevin Weil, CPO d’OpenAI, a déclaré que l’entreprise se préparait à publier un modèle de poids open-source construit sur des valeurs démocratiques, mais que ce modèle serait intentionnellement en retard d’une génération sur les modèles de pointe, afin d’éviter d’accélérer le développement des concurrents (comme la Chine). Cette stratégie a suscité de vives discussions au sein de la communauté, les critiques estimant que ce positionnement est contradictoire : il ne peut pas devenir le “meilleur” modèle open-source du monde (devant rivaliser avec des modèles de pointe comme DeepSeek-R2), risque de devenir inutile en raison de ses performances inférieures, et pourrait en même temps cannibaliser les propres revenus API bas de gamme d’OpenAI, créant un scénario “perdant-perdant” (source: Haider., scaling01)
Discussion sur l’automatisation pilotée par l’IA et les formes futures du travail: Le PDG de Fiverr estime que l’IA éliminera les “tâches simples”, rendra les “tâches difficiles” simples et les “tâches impossibles” difficiles, soulignant que les praticiens doivent devenir des maîtres de leur domaine pour éviter d’être remplacés. La communauté discute de savoir si l’IA remplacera tous les emplois et des changements structurels sociaux qui pourraient en résulter (effondrement économique ou utopie UBI). Parallèlement, l’application de l’IA dans le développement logiciel devient de plus en plus courante, devenant même le principal contributeur de code, suscitant une réflexion sur les futurs modèles de développement (source: Emm | scenario.com, Reddit r/ArtificialInteligence, mike)
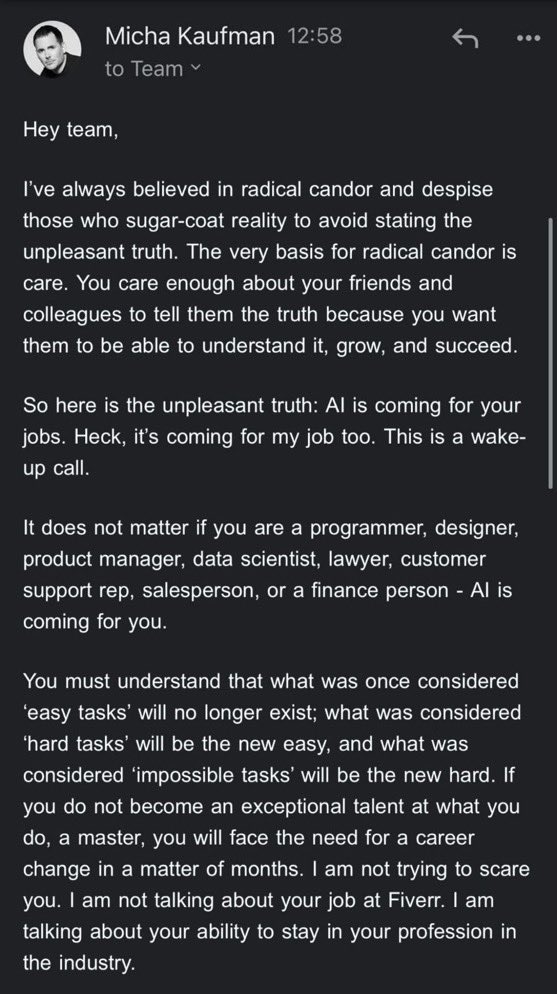
La discussion sur la sécurité et les risques de l’IA continue de s’intensifier: Demis Hassabis, PDG de Google DeepMind, avertit que l’AGI pourrait arriver dans 5 à 10 ans, mais que la société n’est pas prête à faire face à son impact transformateur, appelant à une coopération mondiale active. Parallèlement, un dialogue significatif sur le risque de catastrophe liée à l’IA s’est engagé entre Ajeya Cotra, préoccupée par les risques, et random_walker, sceptique, les deux parties s’efforçant de comprendre le point de vue de l’autre et d’identifier les points clés de désaccord. La communauté commence également à discuter du problème du contrôle de l’IA, en se concentrant sur la manière de surveiller et d’utiliser en toute sécurité les systèmes d’IA forts (source: Chubby♨️, dylan matthews 🔸, random_walker, FAR.AI, zacharynado)
Application et impact de l’IA dans la vie quotidienne et les relations interpersonnelles: Un utilisateur partage son expérience d’utilisation de l’IA (Anthropic Sonnet) pour l’aider à répondre sur des applications de rencontre et améliorer son taux de réussite, et imagine la possibilité d’un “Cursor relationnel”. Parallèlement, un article souligne que l’IA alimente les fantasmes mentaux de certaines personnes, les éloignant de leurs amis et de leur famille réels. Cela reflète la pénétration de l’IA dans les domaines émotionnel et social, ainsi que les opportunités et les risques potentiels qu’elle apporte (source: arankomatsuzaki, Reddit r/artificial)

Discussion sur l’expérience utilisateur des LLM et la comparaison des modèles: Un utilisateur signale que Gemini 2.5 Pro est confus quant à ses propres capacités de téléversement de fichiers, voire incapable de téléverser des fichiers, soupçonnant une limitation de fonctionnalité payante. Parallèlement, la famille d’un utilisateur préfère utiliser Gemini plutôt que ChatGPT. Un autre utilisateur fait l’éloge de Claude pour la génération de contenu écrit, le jugeant supérieur aux autres LLM, car ses réponses sont plus naturelles et ressemblent davantage à de vrais articles qu’à de simples exécutions de tâches. Ces discussions reflètent les problèmes rencontrés par les utilisateurs dans la pratique, les différences de préférences et les perceptions intuitives des capacités des différents modèles (source: seo_leaders, agihippo, Reddit r/ClaudeAI, seo_leaders)

Exploration de l’éthique de l’IA et des normes sociales: La discussion porte sur l’application de l’IA dans la découverte de médicaments et ses considérations éthiques, ainsi que sur l’attitude des personnes anti-IA à ce sujet. Parallèlement, un commentaire suggère que la popularisation de la traduction en temps réel par IA pourrait faire regretter le lien créé par la “lutte” passée de la communication interlinguistique. Il y a aussi une discussion sur l’IA de traduction pour animaux de compagnie, suggérant que les gens aiment leurs animaux en partie parce qu’ils peuvent y projeter des émotions, alors qu’une véritable traduction IA ne renverrait probablement que “j’ai faim” et “je veux m’accoupler” (source: Reddit r/ArtificialInteligence, jxmnop, menhguin)
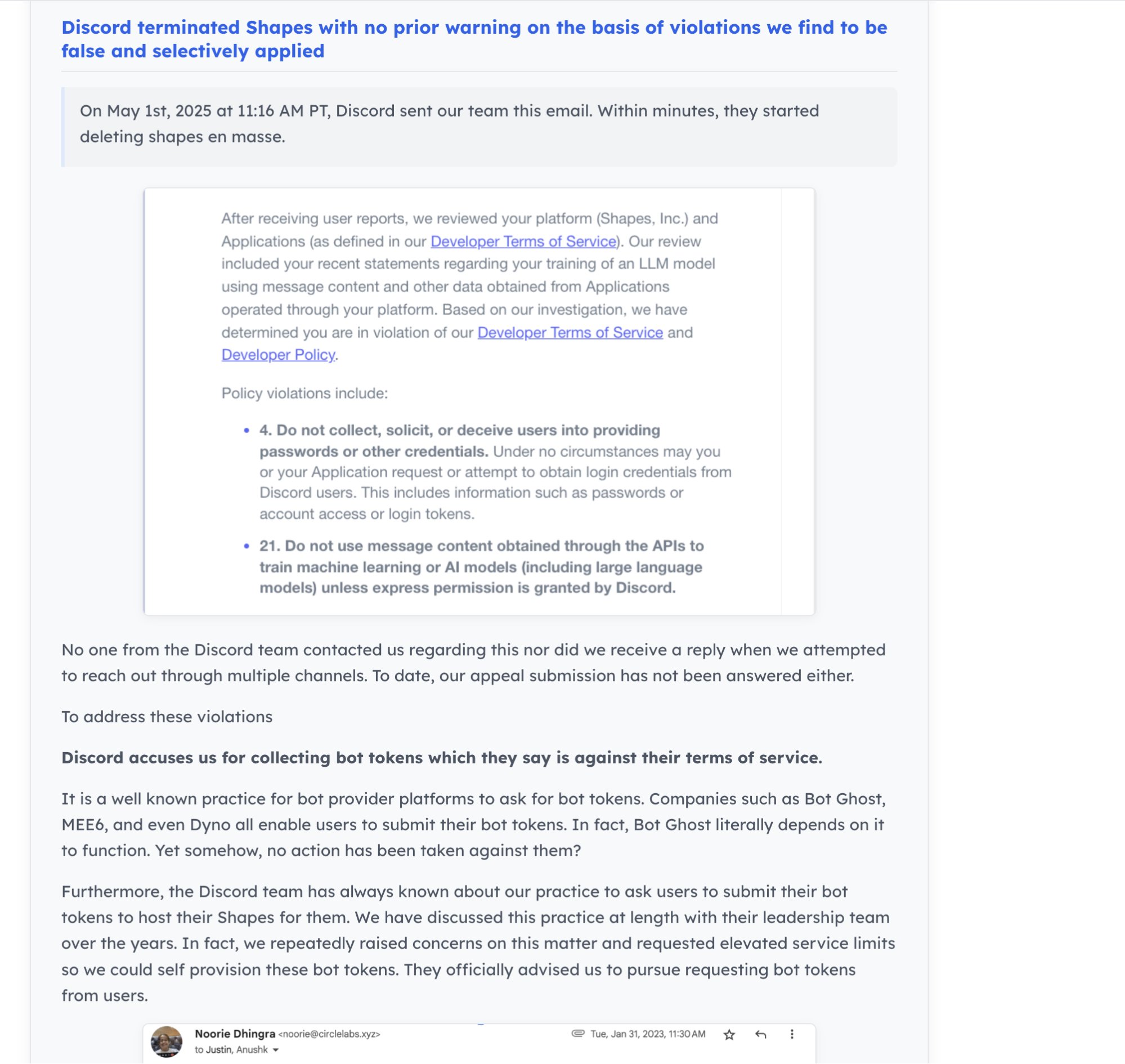
Dynamique de la communauté IA et écosystème des développeurs: Discord ferme le bot IA “Shapes”, qui comptait 30 millions d’utilisateurs, suscitant des inquiétudes chez les développeurs quant aux risques de la plateforme. Parallèlement, un point de vue suggère que pour les startups IA, contribuer à des projets open-source prouve mieux les compétences que de grinder LeetCode, facilitant l’obtention d’emplois. Nous Research co-organise un hackathon sur les environnements RL avec XAI, Nvidia, etc., visant à promouvoir le développement d’environnements RL (source: shapes inc, pash, Nous Research)
Comportement anormal de ChatGPT : coincé dans une boucle “Boethius”: Un utilisateur signale que lorsqu’on lui demande “qui fut le premier compositeur”, ChatGPT-4o se comporte de manière anormale, mentionnant à plusieurs reprises Boethius (un théoricien de la musique et non un compositeur), s’excusant même dans les conversations suivantes et plaisantant sur le fait que Boethius hante les réponses comme un “fantôme”. Ce “bug” intéressant montre les schémas de comportement inattendus et la confusion potentielle de l’état interne que les LLM peuvent présenter (source: Reddit r/ChatGPT)

Réflexion sur les futures étapes du développement de l’IA: La communauté pose la question : si le développement actuel de l’IA est à l’étape du “mainframe”, à quoi ressemblera la future étape du “microprocessor” ? Cette question suscite une réflexion sur les trajectoires d’évolution de la technologie IA, ses formes de vulgarisation et les formes d’IA potentiellement plus petites, plus personnelles et plus intégrées qui pourraient apparaître à l’avenir (source: keysmashbandit)
Style et reconnaissance du contenu généré par IA: Un utilisateur observe que le texte généré par IA (en particulier les modèles de type GPT) utilise souvent des phrases et des tournures fixes (comme “des implications significatives pour…” etc.), ce qui le rend facile à identifier. Parallèlement, la parole générée par IA, bien que de meilleure qualité sonore, reste rigide dans sa structure, son rythme et ses pauses. Cela suscite une discussion sur la “schématisation” et le manque de naturel des sorties LLM (source: Reddit r/ArtificialInteligence)
Appréciation du design de Perplexity AI: L’utilisateur jxmnop pense que Perplexity AI semble investir davantage de ressources dans le design que dans ses propres modèles, mais que l’expérience produit (les “vibes”) est bonne. Cela reflète que dans la concurrence des produits IA, outre les capacités du modèle de base, l’interface utilisateur et la conception de l’interaction sont également des facteurs de différenciation importants (source: jxmnop)

Utilisations amusantes de l’IA en dehors du travail: Un utilisateur Reddit sollicite des exemples d’utilisations amusantes ou étranges de l’IA en dehors du contexte professionnel. Les exemples incluent : analyser des rêves d’un point de vue jungien et freudien, lire l’avenir dans le marc de café, créer des recettes à partir d’ingrédients aléatoires du réfrigérateur, écouter des histoires lues par l’IA avant de dormir, résumer des documents juridiques, etc. Cela montre la créativité des utilisateurs dans l’exploration des limites des applications de l’IA (source: Reddit r/ArtificialInteligence)
Un utilisateur recherche le meilleur LLM pour 48 Go de VRAM: Un utilisateur Reddit recherche le meilleur LLM pour une configuration de 48 Go de VRAM, en équilibrant la quantité de connaissances et une vitesse utilisable (>10 t/s). La discussion mentionne Deepcogito 70B (affiné sur Llama 3.3), Qwen3 32B, et suggère d’essayer Nemotron, YiXin-Distill-Qwen-72B, GLM-4, Mistral Large quantifié, Command R+, Gemma 3 27B ou Qwen3-235B partiellement déchargé. Cela reflète les besoins réels des utilisateurs pour sélectionner et optimiser les modèles sous des contraintes matérielles spécifiques (source: Reddit r/LocalLLaMA)
💡 Autres
Progrès en robotique: Le domaine continue de voir de nouvelles dynamiques : 1. PIPE-i : Beca Group lance un véhicule robotique d’arpentage pour l’inspection des infrastructures telles que les pipelines. 2. Robot humanoïde open-source : L’Université de Californie à Berkeley lance un projet de robot humanoïde open-source. 3. Bras robotique Hugging Face : Hugging Face publie un projet de bras robotique imprimé en 3D. 4. Gâteau robotique comestible : Des chercheurs créent un gâteau robotique comestible. 5. Drone d’égout : Apparition de drones pour l’inspection des égouts, remplaçant le travail humain dans des tâches sales (source: Ronald_vanLoon, TheRundownAI)

Discussion sur la réglementation de l’IA : publication d’un documentaire sur le projet de loi SB-1047: Michaël Trazzi a publié un documentaire sur les coulisses du débat concernant le projet de loi californien sur la sécurité de l’IA, SB-1047. Ce projet de loi visait à imposer une réglementation minimale au développement de l’IA de pointe, mais n’a finalement pas été adopté. Le documentaire explore les raisons de l’échec du projet de loi, malgré le soutien important des citoyens californiens, suscitant une réflexion plus approfondie sur les voies et les défis de la réglementation de l’IA (source: Michaël Trazzi, menhguin, NeelNanda5, JeffLadish)
Combinaison de l’informatique quantique et de l’IA: Nvidia ouvre la voie à l’informatique quantique pratique en intégrant le matériel quantique aux supercalculateurs IA, en se concentrant sur la correction d’erreurs et l’accélération de la transition de l’expérimentation à l’application pratique. Parallèlement, un point de vue suggère que l’informatique quantique pourrait davantage apporter une prospérité scientifique qu’une simple perturbation dans le domaine de la cybersécurité (source: Ronald_vanLoon, NVIDIA HPC Developer)
