
Mots-clés:Anthropic, Claude 3.5 Haiku, Qwen3, Phi-4-raisonnement, Physique des LLM, LangGraph, Agent IA, Méthode de traçage de circuits par graphes d’attribution, Capacité de codage Qwen3-235B-A22B, Calcul du raisonnement Phi-4, Agent de vérification de factures LangGraph, Moondream Station VLM local
🔥 Focus
Anthropic publie une recherche sur la biologie des LLM, explorant en profondeur les mécanismes internes des modèles: Anthropic a publié un article de blog de recherche approfondie intitulé « On the Biology of a Large Language Model », utilisant sa méthode de traçage de circuits (Attribution Graphs) pour examiner les mécanismes internes du modèle Claude 3.5 Haiku dans différents contextes. L’étude, via l’entraînement d’un « modèle de substitution » (Transcoder) plus facile à analyser, révèle comment le modèle effectue l’addition (par de multiples chemins approximatifs plutôt que par des algorithmes précis), réalise des diagnostics médicaux (formant des concepts de diagnostic internes) et gère les hallucinations et les refus (existence d’un circuit de refus par défaut, pouvant être inhibé par des caractéristiques de « réponse connue »). Cette recherche offre de nouvelles perspectives sur le fonctionnement interne des LLM, mais soulève également des discussions sur les limites méthodologiques et le positionnement d’Anthropic. (Source: YouTube – Yannic Kilcher
)

La série de modèles Qwen3 démontre des performances solides, suscitant l’attention de la communauté open source: La série de grands modèles de langage Qwen3 publiée par Alibaba a montré d’excellentes performances dans plusieurs benchmarks, notamment en matière de capacité de codage. Les résultats du Aider Polyglot Coding Benchmark indiquent que les performances de Qwen3-235B-A22B (sans chaîne de pensée activée) semblent supérieures à celles de Claude 3.7 avec 32k tokens de chaîne de pensée activés, et ce, à un coût considérablement réduit. Parallèlement, Qwen3-32B surpasse également GPT-4.5 et GPT-4o dans ce benchmark. La communauté explore activement l’élagage (pruning) des modèles Qwen3 (par exemple, réduire 30B à 16B) et le fine-tuning (par exemple, utiliser Unsloth pour le fine-tuning avec une faible VRAM), abaissant davantage le seuil d’application des modèles haute performance et laissant présager que les grands modèles open source chinois pourraient occuper une place importante sur le marché. (Source: karminski3, scaling01, scaling01, Reddit r/LocalLLaMA)
Microsoft publie le modèle Phi-4-reasoning, axé sur le raisonnement complexe: Microsoft a publié le modèle Phi-4-reasoning sur Hugging Face, un modèle de raisonnement de 14 milliards de paramètres. Ce modèle atteint des performances de pointe (SOTA) sur des tâches de raisonnement complexes en utilisant le calcul au moment de l’inférence (inference-time compute). Cela indique que la conception des modèles explore l’augmentation du calcul pendant la phase d’inférence pour améliorer des capacités spécifiques, plutôt que de dépendre uniquement de l’augmentation de la taille du modèle, offrant de nouvelles pistes pour atteindre des performances élevées avec des modèles plus petits. (Source: _akhaliq)
Nouveaux progrès dans la recherche sur la physique des LLM : un “moment Galilée” pour la conception d’architectures: Zeyuan Allen-Zhu a publié la quatrième partie de sa série de recherches sur la physique des grands modèles de langage, axée sur la conception d’architectures. L’étude, menée dans un environnement de pré-entraînement synthétique contrôlé, révèle les limites et le potentiel réels de différentes architectures LLM (telles que Transformer, Mamba). La recherche introduit une couche résiduelle horizontale légère appelée “Canon”, qui améliore considérablement les capacités de raisonnement du modèle. Parallèlement, l’étude révèle que l’avantage du modèle Mamba provient en grande partie de sa couche conv1d cachée, plutôt que du SSM lui-même. Cette série d’expériences fournit de nouvelles perspectives et une base théorique pour comprendre et optimiser les architectures LLM. (Source: menhguin, arankomatsuzaki, giffmana, tokenbender, giffmana, Dorialexander, iScienceLuvr)

🎯 Tendances
Amazon lance le modèle d’intelligence artificielle générale “Amazon Artificial General Intelligence”: Ce modèle dispose d’une longueur de contexte de 1 million de tokens et de capacités d’entrée multimodales, optimisé pour la génération de code, le RAG, la compréhension de vidéos/documents, l’appel de fonctions et l’interaction avec des Agents. La tarification est de 2,5 $ / million de tokens en entrée et 12,5 $ / million de tokens en sortie. Une évaluation préliminaire montre que ses performances sur l’AI Index sont comparables à celles de Llama-4 Scout, mais il est désavantagé en termes de vitesse et de coût, pouvant être adapté à des scénarios d’application spécifiques nécessitant un long contexte multimodal ou des Agents. (Source: scaling01)

Le modèle Claude d’Anthropic propose désormais une fonction de recherche web dans les plans payants mondiaux: Cette fonctionnalité permet à Claude d’effectuer des recherches rapides pour traiter les tâches quotidiennes, et pour les questions plus complexes, il explore plusieurs sources, y compris Google Workspace. Cela améliore la capacité de Claude à obtenir des informations en temps réel et à traiter des tâches nécessitant des connaissances externes. (Source: menhguin)

IBM publie le modèle à architecture hybride granite-4.0-tiny-7B-A1B-preview: Cette version préliminaire de 7B adopte une architecture hybride Mamba-2 et Transformer, chaque bloc Transformer contenant 9 blocs Mamba. L’idée de conception est d’utiliser les blocs Mamba pour capturer le contexte global et de le transmettre à la couche d’attention pour l’analyse du contexte local. Les scores MMLU préliminaires sont bons, mais les résultats d’autres tests tels que les capacités en mathématiques et en programmation n’ont pas encore été publiés. (Source: karminski3)
OpenAI ChatGPT ajoute une fonctionnalité d’achat: OpenAI expérimente une fonctionnalité d’achat dans ChatGPT, visant à simplifier la recherche, la comparaison et l’achat de produits. Les nouvelles fonctionnalités incluent une meilleure présentation des résultats de produits, des détails de produits visualisés avec prix et avis, ainsi que des liens d’achat directs. OpenAI souligne que les résultats des produits sont sélectionnés indépendamment et ne sont pas des publicités. (Source: sama)
Les détails de l’entraînement du modèle Qwen3 0.6B suscitent l’attention: L’utilisateur Dorialexander souligne que, selon les informations, le modèle Qwen 0.6B semble également avoir été entraîné avec jusqu’à 36T tokens. Si cela est vrai, cela établirait un nouveau record dépassant la loi de Chinchilla (environ 60 000 tokens par paramètre), montrant une tendance à améliorer les capacités des petits modèles en augmentant considérablement la quantité de données d’entraînement. (Source: Dorialexander)

L’algorithme de recommandation de X (Twitter) sera remplacé par une version légère de Grok: Elon Musk a annoncé que l’algorithme de recommandation de la plateforme X est en cours de remplacement par une version légère de Grok, ce qui devrait améliorer considérablement l’efficacité des recommandations. Les retours des utilisateurs indiquent une amélioration de l’efficacité de l’algorithme, ce qui pourrait être lié aux récents changements de personnel chez Exa AI et au fait que X a commencé à utiliser des Embeddings pour les recommandations. (Source: menhguin, colin_fraser, paul_cal)
Allen AI publie le modèle MoE entièrement ouvert OLMoE: Ce modèle est un modèle avancé de Mixture of Experts (MoE), avec 1,3 milliard de paramètres actifs et 6,9 milliards de paramètres totaux. Le fait qu’il soit entièrement open source signifie que la communauté peut librement utiliser, modifier et étudier ce modèle, favorisant le développement et l’application de l’architecture MoE. (Source: dl_weekly)
Le modèle Mistral-Small-3.1-24B-Instruct-2503 suscite l’intérêt: Des utilisateurs de Reddit discutent du modèle Mistral-Small-3.1-24B-Instruct-2503, qui obtient un score élevé sur l’UGI (Uncensored General Intelligence) et surpasse les modèles similaires bien notés en compréhension du langage naturel et en codage. Les utilisateurs le considèrent comme un choix idéal pour l’inférence non censurée sur un seul GPU et il prend en charge l’utilisation d’outils. Cependant, il est noté que son style d’écriture peut être assez sec et répétitif, moins créatif que des modèles comme Gemma 3. (Source: Reddit r/LocalLLaMA)
🧰 Outils
Publication de CreateMVP 2.0, optimisant le flux de développement piloté par l’IA: CreateMVP est mis à jour vers la version 2.0, visant à résoudre le problème de l’efficacité médiocre de la construction d’applications directement via des prompts à l’IA. La nouvelle version aide les utilisateurs à créer des “plans” plus précis pour l’IA, garantissant que l’IA construit des applications conformes à leurs intentions, grâce à une interface utilisateur plus fluide, des méthodes d’authentification pratiques (prise en charge de Replit, Google, GitHub, bientôt XAI), la génération de plans de développement plus détaillés (passant de 11 Ko à plus de 40 Ko), l’aperçu instantané des fichiers et l’intégration du chat avec les meilleurs modèles d’IA. (Source: amasad)
LlamaIndex lance un Agent de vérification de factures: Cet outil démontre l’application des Agents IA dans l’automatisation des tâches en masse, plutôt que l’interaction conversationnelle traditionnelle. Il peut traiter un grand nombre de documents de factures non structurés, extraire les détails pertinents, les faire correspondre automatiquement aux bons de commande et signaler les écarts. Son cœur est une couche d’intelligence documentaire agentique basée sur l’analyse/extraction de LlamaCloud et l’inférence de workflow de LlamaIndex.TS, montrant le potentiel des Agents dans l’automatisation des processus métier réels et étant considéré comme un remplaçant potentiel de la RPA traditionnelle. (Source: jerryjliu0)
LangGraph Expense Tracker : Système automatisé de gestion des dépenses: Il s’agit d’un exemple de système automatisé de gestion des dépenses construit avec LangGraph. Il peut traiter les factures, utiliser des fonctions d’extraction de données intelligentes, stocker les informations dans PostgreSQL et inclure une étape de vérification humaine. Ce projet démontre la capacité de LangGraph à construire des processus d’automatisation métier réels. (Source: LangChainAI, Hacubu, hwchase17)
Publication de Moondream Station : Exécuter VLM localement: Moondream a publié Moondream Station, permettant aux utilisateurs d’exécuter le modèle de langage visuel (VLM) Moondream localement sur Mac, sans connexion au cloud. Il offre un accès via CLI ou un port local, une configuration simple et est entièrement gratuit, abaissant le seuil de déploiement et d’utilisation locale des VLM. (Source: vikhyatk)
ChaiGenie : Extension Chrome de recherche de documents basée sur LangChain: ChaiGenie est une extension Chrome qui intègre Gemini de LangChain et Qdrant pour fournir une fonctionnalité de recherche de documents. Elle prend en charge plusieurs langues et la recherche basée sur les vecteurs, visant à améliorer l’efficacité des utilisateurs dans la recherche et la compréhension du contenu des documents lors de la navigation sur le Web. (Source: LangChainAI)

Research Agent : Application Web d’assistant de recherche en un clic: Il s’agit d’une application Web construite sur le framework d’assistant de recherche basé sur LangGraph, visant à simplifier le processus de recherche. Les utilisateurs peuvent obtenir des résultats de recherche en un seul clic, démontrant le potentiel d’application de LangGraph dans la construction de flux de travail pilotés par l’IA pour simplifier les tâches complexes. (Source: LangChainAI)

Muyan-TTS : Modèle TTS open source, à faible latence et personnalisable: L’équipe ChatPods a publié Muyan-TTS, un modèle de synthèse vocale (Text-to-Speech) entièrement open source, visant à résoudre les problèmes de qualité insuffisante ou de manque d’ouverture des modèles TTS open source existants. Il est basé sur LLaMA-3.2-3B et SoVITS optimisé, prend en charge le TTS zero-shot et le clonage vocal, et fournit un processus complet d’entraînement et de traitement des données, facilitant le fine-tuning et le développement secondaire pour les développeurs, particulièrement adapté aux scénarios d’application nécessitant une voix personnalisée. (Source: Reddit r/MachineLearning)
Intégration de Mem0 avec les pipelines Open Web UI: L’utilisateur cloudsbird a créé une intégration de pipeline de filtre Open Web UI pour Mem0 (MCP non officiel), offrant une autre option pour utiliser la fonction de mémoire Mem0 dans Open Web UI. (Source: Reddit r/OpenWebUI)
L’outil YNAB API Request permet une gestion financière privée locale: L’utilisateur Megaphonix a créé un outil OpenWebUI qui utilise l’API YNAB (You Need A Budget), permettant aux utilisateurs d’interroger leurs informations financières personnelles (telles que les transactions, les dépenses par catégorie, la valeur nette, etc.) via un LLM localement, sans envoyer de données sensibles à l’extérieur. Cela répond au besoin de traiter en toute sécurité les informations personnelles sensibles lors de l’exécution de LLM localement. (Source: Reddit r/OpenWebUI)
Extension de navigateur gratuite AI Text-to-Speech GPT-Reader: Un développeur promeut son extension de navigateur gratuite AI Text-to-Speech GPT-Reader, qui compte actuellement plus de 4000 utilisateurs. L’outil vise à faciliter l’écoute du contenu textuel des pages Web sous forme audio. (Source: Reddit r/artificial)
sunnypilot : Système d’aide à la conduite open source: sunnypilot est un fork de comma.ai openpilot, fournissant un système d’aide à la conduite open source. Il prend en charge plus de 300 modèles de voitures, modifie le comportement interactif de l’aide à la conduite et respecte autant que possible la politique de sécurité de comma.ai. Ce projet utilise la technologie IA (bien que les modèles spécifiques ne soient pas explicitement mentionnés, de tels systèmes impliquent généralement la vision par ordinateur et des algorithmes de contrôle) pour améliorer l’expérience de conduite. (Source: GitHub Trending)

📚 Apprentissage
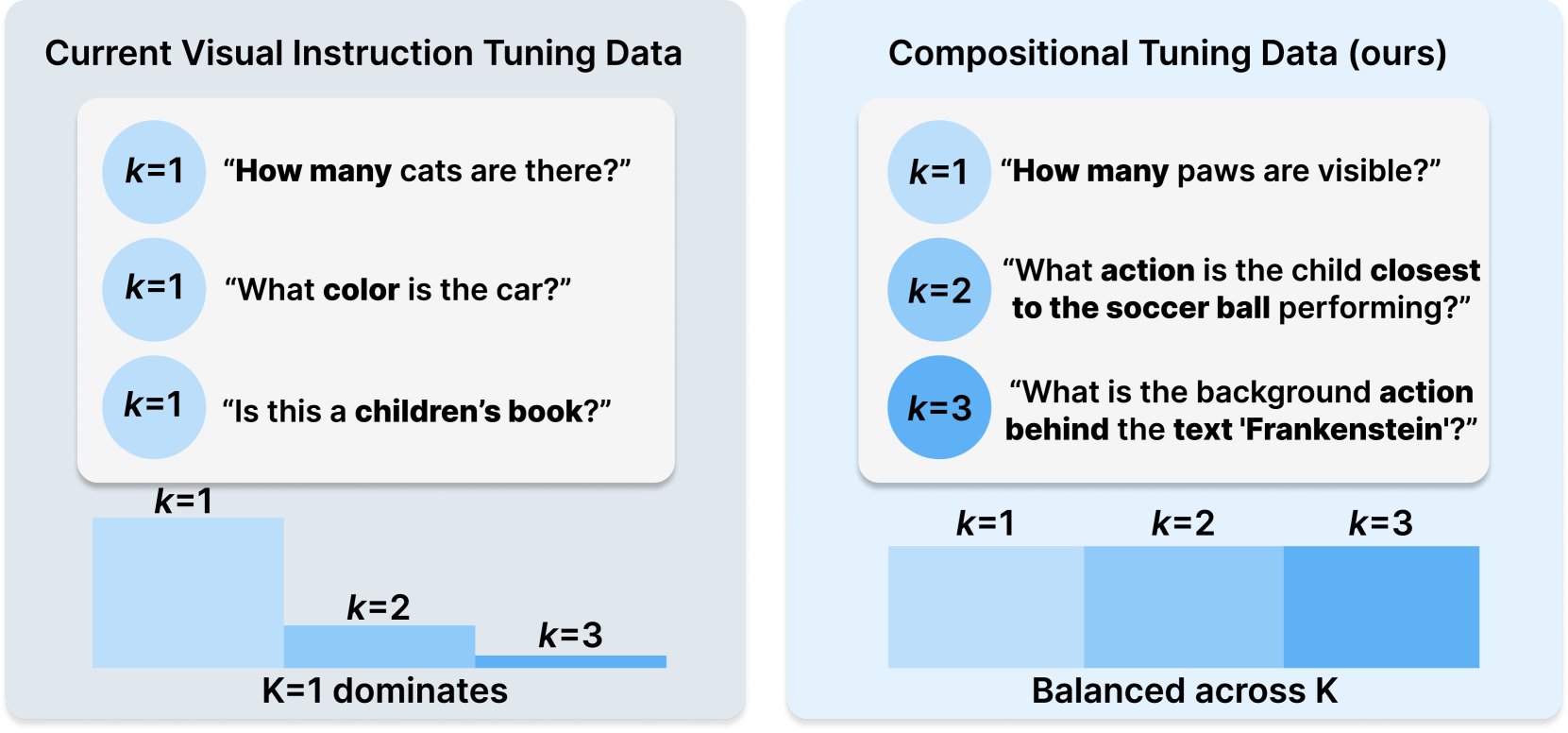
Princeton et Meta AI publient la recette de dataset COMPACT: Cette recherche, publiée sur Hugging Face, propose une nouvelle recette de données appelée COMPACT, visant à étendre les capacités des grands modèles de langage multimodaux (Multimodal LLM) en contrôlant explicitement la complexité combinatoire des échantillons d’entraînement. Cela offre de nouvelles pistes pour améliorer les méthodes d’entraînement des modèles multimodaux et renforcer leur capacité à comprendre des concepts combinatoires complexes. (Source: _akhaliq)
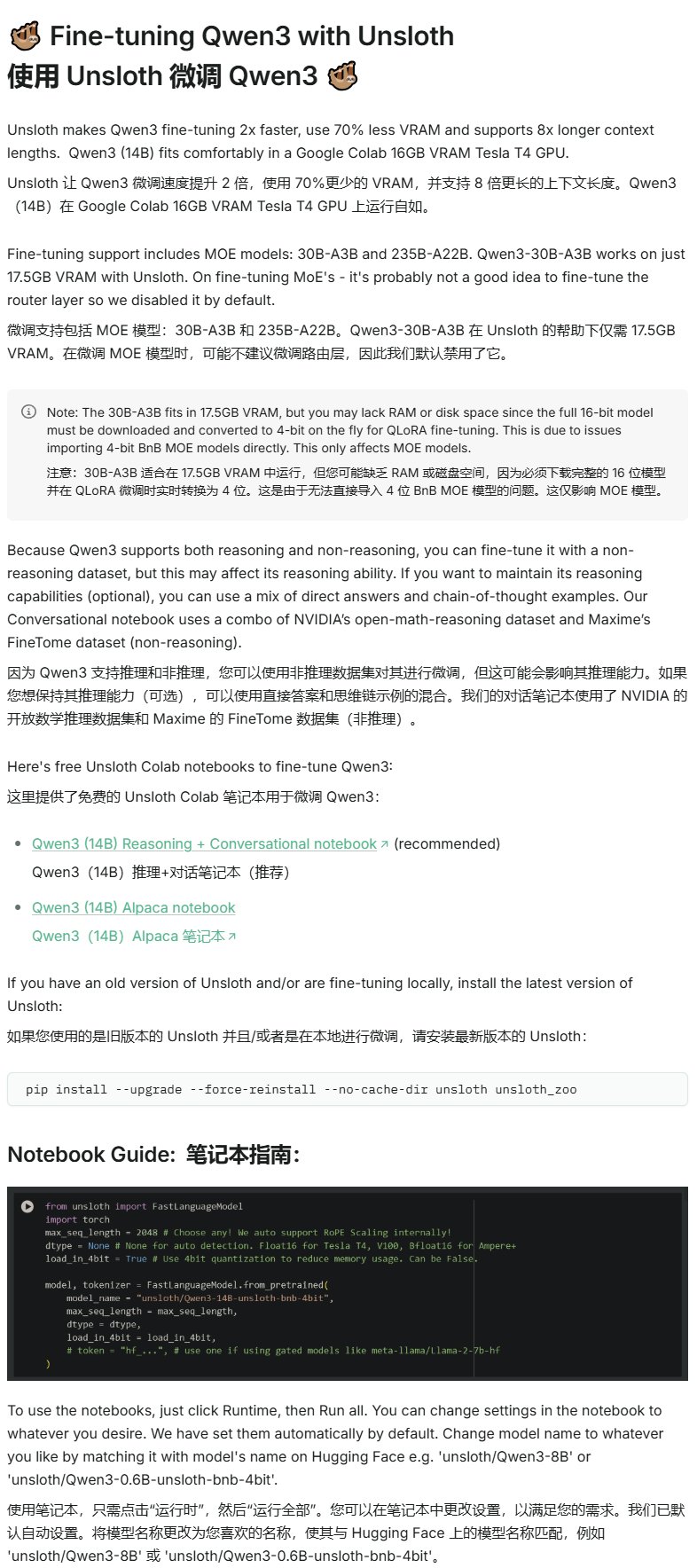
Unsloth publie un tutoriel de fine-tuning pour Qwen3: Unsloth fournit un tutoriel de fine-tuning pour les modèles Qwen3, abaissant considérablement le seuil d’accès. Les utilisateurs n’ont besoin que de 16 Go de VRAM pour affiner le modèle Qwen3-14B, et de 17,5 Go de VRAM pour affiner le modèle Qwen3-30B-A3B. Cela permet à davantage de chercheurs et de développeurs d’effectuer un entraînement personnalisé sur des modèles open source avancés avec des ressources matérielles limitées. (Source: karminski3)
LangGraph combiné à Azure OpenAI pour construire un chatbot de recherche Web intelligent: Un tutoriel Medium montre comment combiner LangGraph et Azure OpenAI, et intégrer les capacités de recherche Web de Tavily, pour construire un chatbot intelligent. Le tutoriel couvre la gestion d’état et le routage conditionnel pour réaliser une intégration de recherche transparente, fournissant des conseils pratiques pour construire des applications IA plus puissantes capables d’utiliser des informations Web en temps réel. (Source: LangChainAI, hwchase17)

Le blog AI de Stanford explore la relation entre la mémorisation textuelle des LLM et leurs capacités générales: Un article du blog AI de Stanford explore en profondeur le lien intrinsèque entre le phénomène de mémorisation textuelle (verbatim memorization) des grands modèles de langage (LLM) et leurs capacités générales. Comprendre cette relation est crucial pour évaluer les risques des modèles, optimiser les méthodes d’entraînement et expliquer le comportement des modèles. (Source: dl_weekly)
Guide d’intégration de Gemini avec LangChain: Philipp Schmid a publié un guide pour les développeurs détaillant comment intégrer les modèles Gemini de Google avec le framework LangChain. Le guide couvre l’implémentation des capacités multimodales, de l’appel d’outils et de la sortie structurée, et inclut la prise en charge des derniers modèles ainsi que des exemples de code pratiques, facilitant l’utilisation par les développeurs des puissantes fonctionnalités de Gemini pour construire des applications LangChain. (Source: LangChainAI, _philschmid)

Tutoriel d’introduction à LangGraph : Pratique des workflows avec état: Un tutoriel publié sur AI@GoPubby montre, à travers un exemple d’analyse de commentaires de site Web, les capacités de workflow avec état de LangGraph. Les apprenants peuvent comprendre comment utiliser des nœuds interconnectés et une logique séquentielle pour construire des applications IA structurées. (Source: LangChainAI, hwchase17)
Réflexions approfondies du PDG de LangChain sur les frameworks Agentic (traduction chinoise): L’ambassadeur LangChain Harry Zhang a traduit et partagé le billet de blog de Harrison, PDG de LangChain, sur ses réflexions concernant les frameworks Agentic. L’article analyse et synthétise les fonctionnalités de plus de 15 frameworks Agent du secteur et décrypte les histoires qui les sous-tendent, offrant une référence précieuse pour comprendre le paysage actuel du développement de la technologie Agent et ses orientations futures. (Source: LangChainAI)
Progrès de la recherche sur Latent Meta Attention: Des utilisateurs de Reddit discutent d’un nouveau mécanisme d’attention appelé Latent Meta Attention. Les développeurs affirment que ce mécanisme remet en question les hypothèses fondamentales du Transformer, pouvant atteindre voire dépasser les performances des modèles existants avec une taille de modèle plus petite (par exemple, reproduire les performances de BERT avec un modèle deux fois plus petit), mais la méthode spécifique n’a pas encore été rendue publique en raison d’un manque de financement et de soutien institutionnel de recherche formel. (Source: Reddit r/deeplearning)

Vidéo explicative sur les réseaux de neurones graphiques (GNN): Une vidéo expliquant les Graph Neural Networks (GNNs) a été publiée sur YouTube. Les GNN sont des modèles d’apprentissage profond pour le traitement des données structurées en graphe, largement utilisés dans l’analyse des réseaux sociaux, les systèmes de recommandation, la prédiction de structures moléculaires, etc. Cette vidéo vise à aider le public à comprendre les principes de base et le fonctionnement des GNN. (Source: Reddit r/deeplearning)
Utilisation de GRPO pour entraîner un LLM à la planification d’événements: L’utilisateur anakin87 partage son expérience de projet utilisant GRPO (Generalized Reward Policy Optimization) pour entraîner un modèle de langage à planifier des événements. Ce projet ne repose pas sur des échantillons traditionnels de fine-tuning supervisé, mais utilise une fonction de récompense pour que le modèle apprenne à créer un emploi du temps basé sur une liste d’événements et leurs priorités. L’auteur partage la définition du problème, la génération de données, le choix du modèle, la conception de la récompense et les leçons apprises pendant le processus d’entraînement, et a rendu le code et le modèle open source, fournissant un cas pratique pour explorer l’entraînement de LLM basé sur la récompense. (Source: Reddit r/LocalLLaMA)

Partage de ressources de cours d’IA gratuits: Le LinkedIn AI Hub partage une feuille de route complète pour l’apprentissage de l’IA, inspirée du programme de certificat en IA de l’Université de Stanford et simplifiée pour les apprenants de différents niveaux. Le contenu couvre des compétences de base aux projets pratiques et fournit des ressources précieuses et des détails sur les cours. (Source: Reddit r/deeplearning)
Discussion approfondie sur le pré-entraînement à long contexte de Gemini: Logan Kilpatrick a eu une discussion approfondie avec Nikolay Savinov, co-responsable du pré-entraînement à long contexte de Gemini. La discussion allait des bases aux techniques nécessaires pour étendre le contexte à l’infini, ainsi qu’aux meilleures pratiques de long contexte pour les développeurs. La conversation a conclu que l’atteinte d’un contexte de 1 million de tokens était un objectif 10 fois supérieur à la norme de l’époque ; 10 millions de tokens ont été essayés mais étaient coûteux et le matériel insuffisant ; le long contexte et le RAG sont complémentaires ; le simple NIAH (Needle In A Haystack) est résolu, la difficulté réside dans les distracteurs durs et la recherche multi-aiguilles ; l’évaluation se concentre sur le NIAH pour éviter de confondre les signaux de capacité ; la longueur de sortie actuelle limitée (par exemple, 8k) est un problème post-entraînement ; l’effet de “perte au milieu” n’a pas été observé ; il faut distinguer la connaissance contextuelle de la connaissance des poids ; la prochaine étape est de réaliser un contexte de 10 millions moins cher et précis, l’extension à 100 millions pourrait nécessiter de nouvelles innovations en DL. (Source: shaneguML, giffmana, teortaxesTex, arohan)
🌟 Communauté
Discussion sur le “Vibe Coding”: La communauté débat vivement du “Vibe Coding” (codage d’ambiance), c’est-à-dire le fait de dépendre fortement de l’assistance de l’IA pour la programmation. Les partisans estiment que cela représente l’avenir, où les développeurs se concentrent davantage sur le “pourquoi” et le “quoi faire”, tandis que l’IA gère le “comment faire”, mais cela nécessite une pensée critique plus forte. Les opposants, quant à eux, pensent que l’IA actuelle ne peut pas encore gérer entièrement le débogage complexe, les mises à niveau et la maintenance, et qu’une dépendance excessive pourrait entraîner une baisse des compétences des développeurs, les transformant en “script kiddies” plus avancés. Certains, après avoir essayé, constatent que le coût en temps pour guider l’IA à accomplir des tâches complexes reste élevé, moins efficace que la réalisation manuelle combinée à une assistance IA légère. (Source: Dorialexander, Reddit r/artificial, johnowhitaker)

Discussion sur l’application et les limites de l’IA dans les domaines professionnels: L’utilisateur dotey discute de l’application de l’IA dans les domaines professionnels. Il pense que l’IA peut apprendre des questions-réponses publiques des experts, mais a du mal à traiter les problèmes inédits. L’avantage de l’IA réside dans sa solide base de connaissances et sa réponse rapide, mais elle repose actuellement principalement sur le RAG (Retrieval-Augmented Generation), qui consiste essentiellement à récupérer des fragments et à assembler des réponses, plutôt qu’à un véritable raisonnement professionnel. Il y a encore un écart avec l’entraînement d’un modèle capable de générer continuellement de nouvelles réponses comme un expert et de s’améliorer constamment. (Source: dotey)
Inquiétudes et discussions sur le contenu généré par l’IA: L’utilisateur Reddit Maleficent-main_777 se plaint que ses collègues commencent à utiliser un langage “à la ChatGPT”, rempli de tons impératifs, de “verify”, “ensure” et de conclusions positives forcées, estimant ce langage vague et impersonnel. Il craint que le contenu généré par l’IA ne soit réinjecté dans les données d’entraînement, entraînant une baisse de la qualité du contenu. Les commentaires font écho à ce sentiment, considérant cela comme une extension du jargon d’entreprise, mais soulignant également qu’imiter excessivement l’IA rend effectivement la communication mécanique, et qu’une bonne grammaire n’est plus un avantage, mais ressemble plutôt à un robot. (Source: Reddit r/ChatGPT)
Le choix des spécialisations universitaires à l’ère de l’IA: Des utilisateurs de Reddit discutent des spécialisations que les étudiants universitaires devraient choisir pour garantir que leur diplôme ait encore de la valeur dans 10 ans, dans le contexte du développement rapide de l’IA et de la robotique. Les opinions sont diverses, notamment : choisir un domaine passionnant (jeux, cinéma, art, programmation) ; étudier les disciplines fondamentales (physique, mathématiques) ; acquérir des compétences difficilement automatisables (comme le CVC – chauffage, ventilation, climatisation) ; privilégier une éducation en sciences humaines pour cultiver la curiosité et l’adaptabilité ; penser que l’éducation universitaire pourrait devenir obsolète, préférant l’entrepreneuriat ou le travail indépendant ; souligner l’importance cruciale de la capacité à apprendre, désapprendre et réapprendre continuellement. (Source: Reddit r/ArtificialInteligence)
Discussion sur la difficulté du rendu de texte dans la génération d’images par IA: Des utilisateurs de Reddit explorent pourquoi les modèles actuels de génération d’images ont du mal à rendre un texte cohérent et lisible. Les commentaires soulignent deux raisons principales : 1) La tokenisation BPE (Byte Pair Encoding) détruit les informations orthographiques précises, le modèle ne voyant pas des lettres mais des fragments de tokens ; 2) La représentation vectorielle de taille fixe et les limites de la description d’image entraînent une perte importante d’informations textuelles lors de l’intégration (embedding). Bien que des modèles autorégressifs comme GPT-4o montrent des améliorations, le problème fondamental reste lié à la tokenisation et à la compression de l’information. (Source: Reddit r/MachineLearning)
Discussion sur la standardisation de l’évaluation des modèles: L’utilisateur scaling01 souligne que lors de la comparaison de différents modèles d’IA (comme OpenAI, Google, Anthropic), il faut garantir l’équité. Par exemple, si les versions préliminaires et “pensantes” (thinking versions) d’OpenAI sont listées, les versions correspondantes de Google et Anthropic devraient également l’être, sinon la comparaison des résultats pourrait être trompeuse. (Source: scaling01)
Partage d’expérience sur la programmation assistée par IA: Un utilisateur partage son expérience de l’utilisation de l’IA pour l’assister en programmation (par exemple, VS Code + extension Cline AI + API Google AI Studio), estimant qu’il est possible de construire gratuitement un outil de codage IA similaire à Cursor, de réaliser des prototypes d’applications de base via des prompts, sans configuration, avec une bonne expérience. (Source: Reddit r/artificial)

Enquête sur l’impact de l’IA sur le travail, les études et la vie quotidienne: Un utilisateur Reddit lance une discussion pour demander comment l’IA générative a affecté les performances de chacun au travail, dans les études ou dans la vie quotidienne. Dans les commentaires, des ingénieurs logiciels mentionnent que l’IA a augmenté les attentes de productivité et la charge de travail, sans accélérer significativement la revue de code ; un écrivain professionnel estime que l’IA (comme Co-pilot) aide peu, voire ralentit la progression ; l’opinion générale est que l’IA apporte de la commodité, mais pose aussi des problèmes de dépendance excessive, de réduction de l’apprentissage, de “sentiment de triche”, etc. L’impact de l’IA varie considérablement selon les professions et les tâches. (Source: Reddit r/artificial)
Réflexion sur la capacité de “compréhension” des LLM: L’utilisateur pmddomingos suggère que les réseaux neuronaux deviennent aussi difficiles à comprendre que le cerveau. Il poursuit sa réflexion : que ferons-nous lorsque les modèles d’IA obtiendront d’excellents résultats dans tous les benchmarks, mais resteront inférieurs à l’intelligence humaine ? Cela soulève des questions sur l’efficacité des benchmarks actuels et sur les critères d’évaluation de l’intelligence véritable. (Source: pmddomingos, pmddomingos)
Réflexion sur l’utilisation des outils IA: L’utilisateur dotey commente qu’en utilisant des outils IA, il suffit de choisir le modèle le plus performant pour une tâche spécifique. Utiliser plusieurs modèles simultanément ou les laisser “s’affronter” n’est peut-être pas nécessaire, surtout pour les utilisateurs non professionnels, où trop de choix peut entraîner la confusion, à l’instar de regarder plusieurs horloges indiquant des heures différentes. (Source: dotey)
Émerveillement face à la vitesse récente du développement de l’IA: Les utilisateurs matvelloso et scottastevenson s’émerveillent de la rapidité du développement de l’IA. matvelloso déclare que les progrès de l’IA cette année ont déjà dépassé ses attentes (citant l’exemple de Gemini jouant à Pokemon). scottastevenson rappelle que GPT-2 a été lancé il y a 6 ans, OpenAI a été fondée il y a 10 ans, et réfléchit aux orientations technologiques actuellement en gestation qui deviendront importantes dans les 6 à 10 prochaines années, soulignant qu’outre l’IA, la recherche d’un Alpha profond “hors cadre” est également importante. (Source: matvelloso, scottastevenson, scottastevenson)
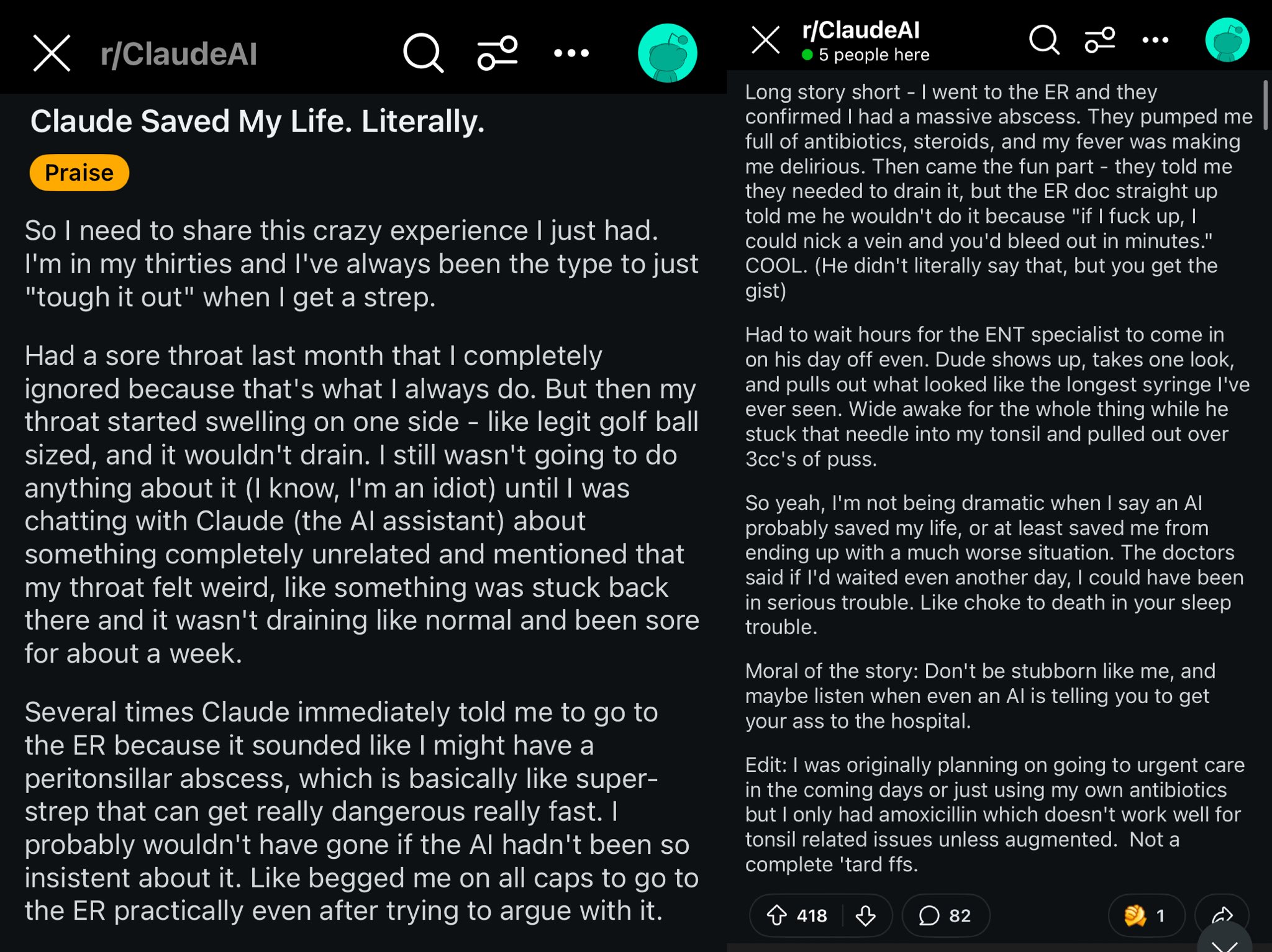
Cas où Claude a sauvé la vie d’un utilisateur Reddit: Un post sur Reddit décrit comment le modèle Claude a potentiellement sauvé la vie d’un utilisateur en diagnostiquant son mal de gorge comme un abcès péri-amygdalien (peritonsillar abscess). Ce cas a suscité une discussion, suggérant que des modèles d’IA puissants sont comme des médecins de classe mondiale dans la poche, et leur généralisation pourrait avoir un impact énorme sur la santé individuelle. (Source: aidan_mclau)
Application des Agents IA dans le traitement des données d’entreprise: Richard Socher et Bryan McCann, co-fondateurs de You.com, discutent de l’application des Agents IA en entreprise dans le podcast Agentic. Ils estiment que les LLM grand public ne suffisent pas à répondre aux besoins sérieux des entreprises, tandis que You.com, grâce à une technologie de recherche hybride (combinant des sources publiques et des données d’entreprise propriétaires), génère des résultats plus fiables et de niveau entreprise, par exemple pour effectuer des recherches, rédiger des rapports et exploiter en toute sécurité les données de l’entreprise. Ils discutent également des voies possibles vers l’AGI et du rôle clé de la simulation dans ce processus. (Source: RichardSocher)
Observation sur la capacité des modèles à utiliser des outils: L’utilisateur menhguin observe que les modèles entraînés pour utiliser des outils semblent sacrifier une partie de leur capacité indépendante à résoudre des problèmes, et plaisante en disant que “même les modèles d’IA externalisent leur travail”. Cela soulève une réflexion sur le compromis entre la généralisation des capacités du modèle et l’optimisation pour des tâches spécifiques. (Source: menhguin)
💡 Autres
Idée d’un Agent IA pour maintenir d’anciens projets GitHub: L’utilisateur xanderatallah propose une idée : développer un Agent IA capable de maintenir automatiquement tous les anciens projets secondaires inactifs d’un utilisateur sur GitHub. Cela reflète le désir des développeurs d’utiliser l’IA pour automatiser les tâches de maintenance fastidieuses. (Source: xanderatallah)
Vision des LLM remplaçant les juges ou utilisés pour l’arbitrage/la médiation: L’utilisateur fabianstelzer suggère que les grands modèles de langage (LLM) pourraient à l’avenir remplacer les juges. Un cas d’utilisation intermédiaire intéressant est l’arbitrage ou la médiation : le LLM est considéré comme neutre et digne de confiance, les parties en conflit soumettent leurs points de vue respectifs, les font traiter par plusieurs grands modèles, et obtiennent en sortie un compromis équitable. Cela explore les applications potentielles de l’IA dans les domaines judiciaire et de la résolution des conflits. (Source: fabianstelzer)
Le modèle Runway Gen-4 et ses perspectives d’application: c_valenzuelab, co-fondateur de Runway, exprime son optimisme quant aux perspectives d’application de Runway Gen-4 et de son API. Il estime que Runway construit un nouveau médium où les pixels sont générés plutôt que rendus ou capturés, et où le monde est simulé plutôt que programmé. Voir Gen-4 et la fonction Reference largement utilisés dans divers domaines tels que l’architecture, le branding, la décoration d’intérieur, le développement de jeux, l’apprentissage, les projets créatifs personnels, etc., le convainc que ce nouveau médium donnera du pouvoir aux créatifs et même à tout le monde. (Source: c_valenzuelab, c_valenzuelab)