
Mots-clés:ChatBot Arena, Phi-4-raisonnement, Intégrations Claude, Agent IA intelligent, DeepSeek-Prover-V2, Qwen3, Gemini, Parakeet-TDT-0.6B-v2, Hallucination des classements, Capacité de raisonnement des petits modèles, Intégration d’applications tierces, Agent IA de programmation, Preuve de théorèmes mathématiques
🔥 Focus
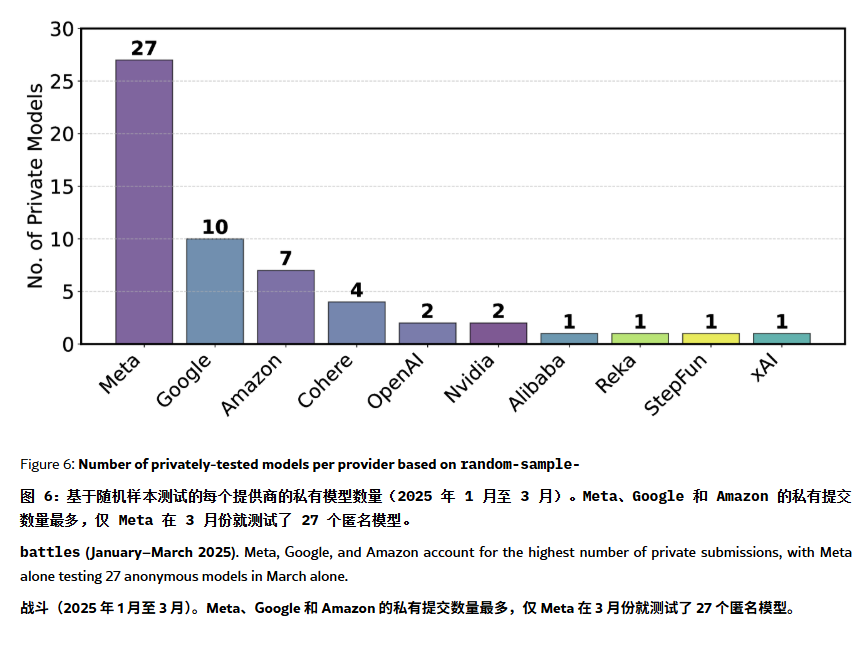
Le classement ChatBot Arena accusé d‘“hallucinations” et de manipulation: Un article sur ArXiv [2504.20879] remet en question le classement des modèles ChatBot Arena, largement cité, suggérant l’existence d’une “hallucination de classement”. L’article souligne que les grandes entreprises technologiques (comme Meta) pourraient manipuler le classement en soumettant de nombreuses variantes de modèles affinés (fine-tuned) (par exemple, 27 versions de Llama-4 testées) et en ne publiant que les meilleurs résultats ; la fréquence d’affichage des modèles pourrait également favoriser ceux des grandes entreprises, réduisant la visibilité des modèles open source ; le mécanisme d’élimination des modèles manque de transparence, de nombreux modèles open source étant retirés faute de données de test suffisantes ; de plus, la similarité des questions fréquemment posées par les utilisateurs pourrait conduire à un surajustement (overfitting) ciblé de l’entraînement des modèles pour améliorer les scores. Cela soulève des inquiétudes quant à la fiabilité et à l’équité des benchmarks LLM actuels, et recommande aux développeurs et utilisateurs de considérer les classements avec prudence et d’envisager la construction de systèmes d’évaluation adaptés à leurs propres besoins. (Source: karminski3, op7418, TheRundownAI)
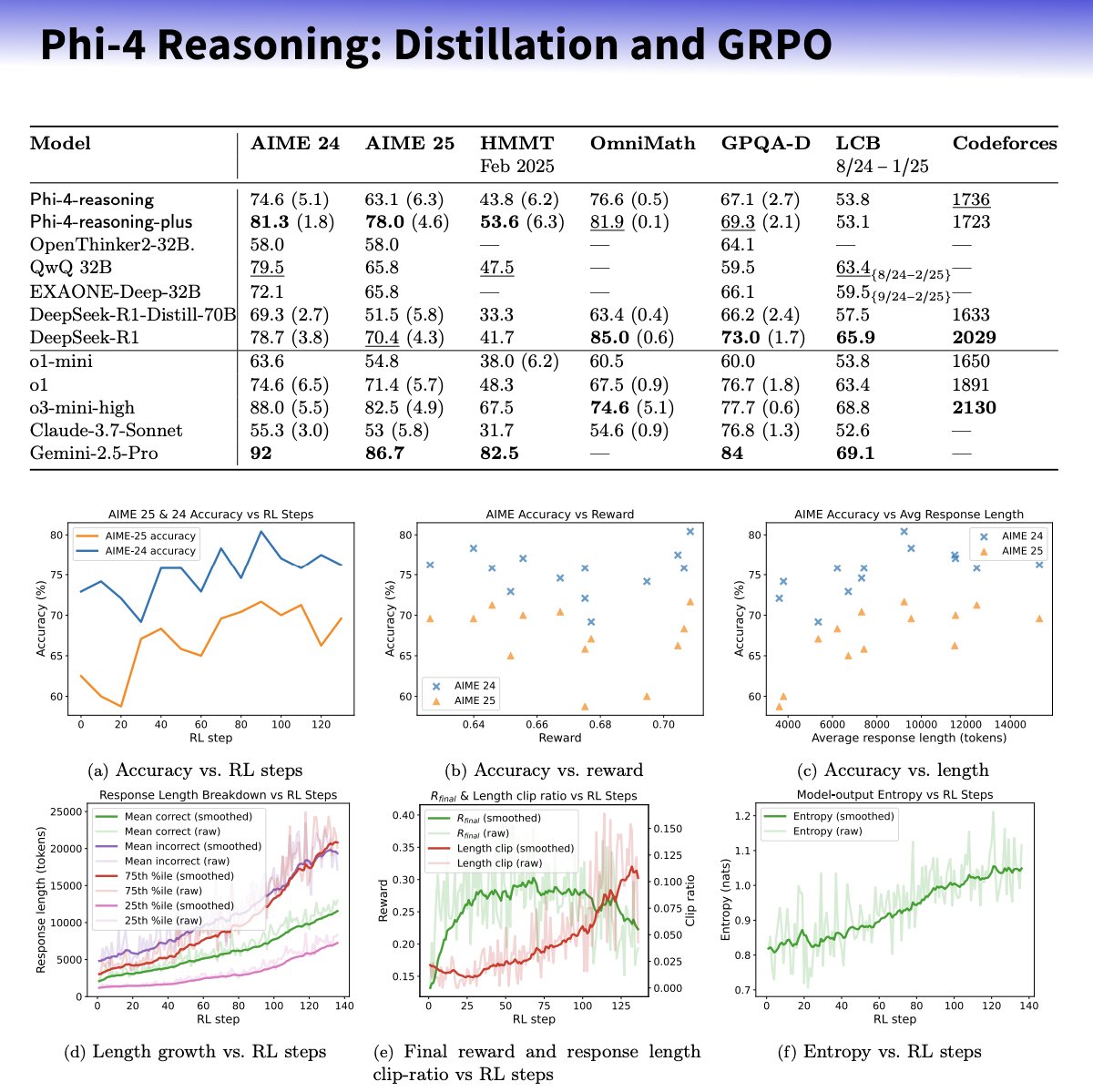
Microsoft lance la série de petits modèles Phi-4-reasoning, axée sur l’amélioration des capacités de raisonnement: Microsoft a lancé les modèles Phi-4-reasoning et Phi-4-reasoning-plus basés sur l’architecture Phi-4, visant à améliorer les capacités de raisonnement des petits modèles de langage grâce à des jeux de données soigneusement sélectionnés, un fine-tuning supervisé (SFT) et un apprentissage par renforcement (RL) ciblé. Il est rapporté que ces modèles utilisent OpenAI o3-mini comme “enseignant” pour générer des trajectoires de raisonnement de haute qualité en chaîne de pensée (CoT) et sont optimisés par apprentissage par renforcement via l’algorithme GRPO. Sebastien Bubeck, chercheur chez Microsoft, affirme que Phi-4-reasoning surpasse DeepSeek R1 en capacités mathématiques, bien que sa taille ne représente que 2% de celle de ce dernier. La série utilise des tokens de raisonnement dédiés et une longueur de contexte étendue à 32K. Cette initiative est considérée comme une exploration dans la direction de modèles plus petits et spécialisés, pouvant offrir des solutions de raisonnement plus puissantes pour les scénarios aux ressources limitées, mais soulève également des discussions sur l’utilisation potentielle de la technologie OpenAI et sa publication sous licence MIT. (Source: _philschmid, TheRundownAI, Reddit r/LocalLLaMA)
Anthropic lance la fonctionnalité Integrations et étend ses capacités de recherche: Anthropic a annoncé le lancement de Claude Integrations, permettant aux utilisateurs de connecter Claude à 10 applications et services tiers tels que Jira, Confluence, Zapier, Cloudflare, Asana, avec un support futur pour Stripe, GitLab, etc. Le support du MCP (Model Context Protocol), auparavant limité aux serveurs locaux, est étendu aux serveurs distants, permettant aux développeurs de créer leurs propres intégrations en environ 30 minutes via la documentation ou des solutions comme Cloudflare. Parallèlement, la fonction de recherche (Research) de Claude est améliorée avec un nouveau mode avancé qui peut rechercher sur le web, dans Google Workspace et les Integrations connectées, décomposer les requêtes complexes pour enquête, et générer des rapports complets avec citations, le traitement pouvant prendre jusqu’à 45 minutes. La fonction de recherche web est également ouverte aux utilisateurs payants du monde entier. Ces mises à jour visent à améliorer l’intégration et les capacités de recherche approfondie de Claude en tant qu’assistant de travail. (Source: _philschmid, Reddit r/ClaudeAI)

La capacité des agents IA suit une nouvelle loi de Moore : doublement tous les 4 mois: Une étude d’AI Digest indique que la capacité des agents IA de programmation à accomplir des tâches connaît une croissance exponentielle. Le temps nécessaire pour traiter une tâche (mesuré par rapport au temps requis par un expert humain) double environ tous les 4 mois entre 2024 et 2025, plus rapidement que le doublement tous les 7 mois observé entre 2019 et 2025. Les agents IA de pointe actuels peuvent déjà gérer des tâches de programmation nécessitant 1 heure pour un humain. Si cette tendance accélérée se poursuit, on prévoit que d’ici 2027, les agents IA pourraient accomplir des tâches complexes d’une durée allant jusqu’à 167 heures (environ un mois). Cette amélioration rapide des capacités est due aux progrès des modèles eux-mêmes ainsi qu’à l’amélioration de l’efficacité algorithmique, et pourrait former une boucle de rétroaction positive de croissance super-exponentielle grâce à la R&D en IA assistée par l’IA. Cela laisse présager la possibilité d’une “explosion de l’intelligence logicielle”, qui transformera profondément des domaines tels que le développement logiciel et la recherche scientifique, tout en posant des défis sociétaux tels que l’impact de l’automatisation sur le marché du travail. (Source: 新智元)

🎯 Tendances
Sortie de DeepSeek-Prover-V2, améliorant la capacité de preuve de théorèmes mathématiques: DeepSeek AI a publié DeepSeek-Prover-V2, disponible en deux tailles (7B et 671B), axé sur la preuve formelle de théorèmes en Lean 4. Le modèle est entraîné en utilisant la recherche de preuve récursive et l’apprentissage par renforcement (GRPO), exploitant DeepSeek-V3 pour décomposer des théorèmes complexes et générer des ébauches de preuves, puis affiné et renforcé avec des itérations d’experts et des données synthétiques de démarrage à froid (cold-start). DeepSeek-Prover-V2-671B atteint un taux de réussite de 88,9% sur MiniF2F-test et résout 49 problèmes sur PutnamBench, démontrant des performances SOTA (State-of-the-Art). Le benchmark ProverBench, incluant des problèmes AIME et de manuels scolaires, est également publié. Ce modèle vise à unifier le raisonnement informel et la preuve formelle, faisant progresser la démonstration automatique de théorèmes. (Source: 新智元)

Nvidia et l’UIUC proposent une nouvelle méthode d’extension de contexte à 4 millions de tokens: Des chercheurs de Nvidia et de l’Université de l’Illinois à Urbana-Champaign ont proposé une méthode d’entraînement efficace pour étendre la fenêtre de contexte de Llama 3.1-8B-Instruct de 128K à 1M, 2M et même 4M de tokens. La méthode utilise une stratégie en deux étapes : pré-entraînement continu et fine-tuning par instructions. Les techniques clés incluent l’utilisation de séparateurs de documents spéciaux, l’extension de l’encodage de position basée sur YaRN et un pré-entraînement en une seule étape. Le modèle entraîné, UltraLong-8B, obtient d’excellents résultats sur les benchmarks de long contexte tels que RULER, LV-Eval, InfiniteBench, et maintient voire dépasse les performances du Llama 3.1 de base sur les tâches standard à contexte court comme MMLU et MATH, surpassant d’autres modèles à long contexte comme ProLong et Gradient. Cette recherche offre une voie efficace et évolutive pour construire des LLM à très long contexte. (Source: 新智元)

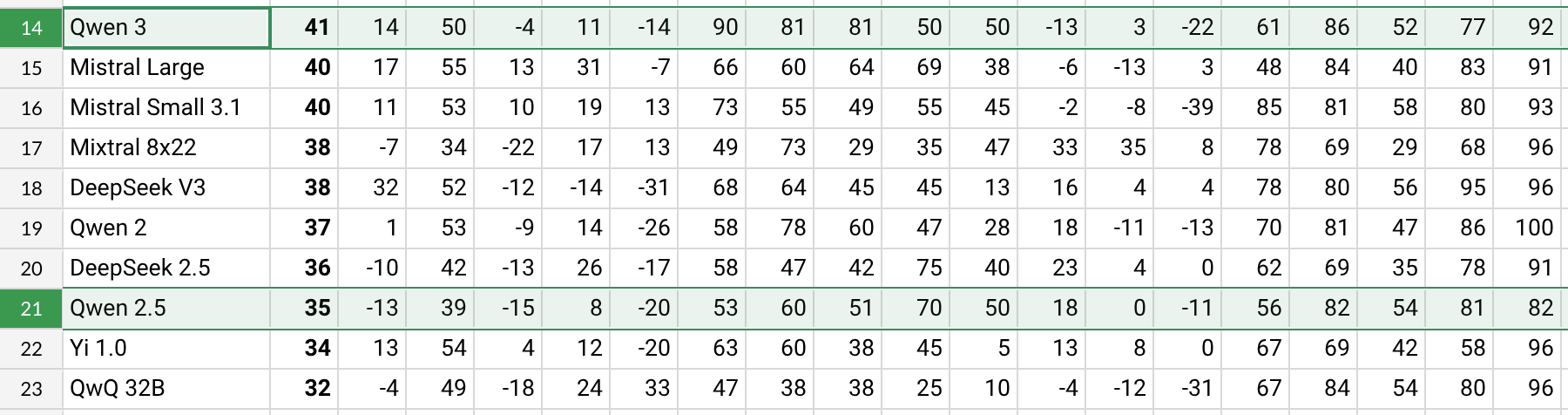
Sortie de Qwen3, avec des performances nettement améliorées: Alibaba a publié la série de modèles Qwen3, incluant Qwen3-30B-A3B. Selon les premiers tests et benchmarks d’utilisateurs sur Reddit (comme l’AHA Leaderboard), Qwen3 montre de meilleures performances par rapport aux versions précédentes Qwen2.5 et QwQ sur plusieurs dimensions (comme les connaissances spécifiques dans les domaines de la santé, du Bitcoin, de Nostr, etc.). Les retours utilisateurs indiquent que Qwen3 démontre de fortes capacités dans le traitement de tâches spécifiques (comme la simulation de la dynamique du système solaire), appliquant correctement les lois physiques pour générer des orbites elliptiques et des périodes relatives. Cependant, certains utilisateurs notent une baisse significative des performances de Qwen3 avec de longs contextes (proches de 16K) et une consommation élevée de tokens lors de l’inférence, suggérant de l’utiliser en combinaison avec des outils de recherche. La nomenclature de Qwen3 (par exemple Qwen3-30B-A3B) est également saluée pour sa clarté. (Source: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, karminski3, madiator)
Gemini intégrera bientôt les données du compte Google pour une expérience personnalisée: Google prévoit de permettre à l’assistant IA Gemini d’accéder aux données du compte Google de l’utilisateur, y compris Gmail, Photos, l’historique YouTube, etc., dans le but d’offrir une expérience d’assistance plus personnalisée, proactive et puissante. Josh Woodward, chef de produit chez Google, a déclaré que cela visait à permettre à Gemini de mieux comprendre l’utilisateur et de devenir son extension. La fonctionnalité sera optionnelle (opt-in), les utilisateurs pouvant choisir d’activer ou non l’accès aux données. Cette initiative soulève des discussions sur la confidentialité et la sécurité des données, les utilisateurs devant trouver un équilibre entre la commodité de la personnalisation et la confidentialité de leurs données. (Source: JeffDean, Reddit r/ArtificialInteligence)

Nvidia lance le modèle ASR Parakeet-TDT-0.6B-v2: Nvidia a publié un nouveau modèle de reconnaissance automatique de la parole (ASR), Parakeet-TDT-0.6B-v2, avec 600 millions de paramètres. Il est affirmé que ce modèle surpasse Whisper3-large (1,6 milliard de paramètres) sur l’Open ASR Leaderboard, notamment dans le traitement de jeux de données diversifiés (incluant LibriSpeech, Fisher Corpus, des données YouTube, etc., totalisant environ 120 000 heures de données). Le modèle prend en charge l’horodatage au niveau du caractère, du mot et du paragraphe, mais ne supporte actuellement que l’anglais et nécessite un GPU Nvidia ainsi qu’un framework spécifique pour fonctionner. Les premiers retours utilisateurs indiquent une grande précision de transcription et de ponctuation. (Source: Reddit r/LocalLLaMA)

Sortie de Qwen2.5-VL, améliorant la compréhension visuo-linguistique: Alibaba a publié la série de modèles multimodaux Qwen2.5-VL (incluant des versions à 3B, 7B, 72B paramètres), visant à améliorer la compréhension et l’interaction de la machine avec le monde visuel. Ces modèles peuvent être utilisés pour le résumé d’images, le question-réponse visuel (VQA), la génération de rapports à partir d’informations visuelles complexes, etc. L’article présente son architecture, ses performances sur les benchmarks et les détails de l’inférence, démontrant ses progrès en matière de compréhension visuo-linguistique. (Source: Reddit r/deeplearning)

Le support de Mistral Small 3.1 Vision a été fusionné dans llama.cpp: Le projet llama.cpp a intégré le support pour le modèle Mistral Small 3.1 Vision (24B paramètres). Cela signifie que les utilisateurs pourront exécuter ce modèle multimodal dans le framework llama.cpp pour des tâches telles que la compréhension d’images. Unsloth a déjà fourni les fichiers de modèle correspondants au format GGUF. Cela facilite l’exécution locale des modèles de vision de Mistral. (Source: Reddit r/LocalLLaMA)
Meta publie le Synthetic Data Kit: Meta a rendu open source un outil en ligne de commande nommé Synthetic Data Kit, visant à simplifier la phase de préparation des données nécessaires au fine-tuning des LLM. L’outil propose quatre commandes : ingest (importer des données), create (générer des paires QA, avec chaîne de raisonnement optionnelle), curate (utiliser Llama comme juge pour filtrer les échantillons de qualité), save-as (exporter dans un format compatible). Il utilise un LLM local (via vLLM) pour générer des données d’entraînement synthétiques de haute qualité, particulièrement adapté pour débloquer les capacités de raisonnement sur des tâches spécifiques pour des modèles comme Llama-3. (Source: Reddit r/MachineLearning)
GTE-ModernColBERT-v1 devient un modèle d’embedding populaire: Le modèle GTE-ModernColBERT-v1, lancé par LightOnIO, est devenu le nouveau modèle de recherche/embedding tendance sur Hugging Face. Ce modèle utilise une méthode de recherche multi-vecteurs (également appelée interaction tardive ou ColBERT), offrant une nouvelle option aux développeurs intéressés par ce type de technologie. (Source: lateinteraction)
Mise à jour de l’algorithme de recommandation de X: La plateforme X (anciennement Twitter) a corrigé son algorithme de recommandation pour résoudre des problèmes de longue date tels que la non-prise en compte des retours négatifs des utilisateurs, la répétition de contenus identiques et les recommandations non pertinentes de l’algorithme SimCluster. Les premiers retours seraient positifs. (Source: TheGregYang)
Wikipédia annonce une nouvelle stratégie IA pour assister les éditeurs humains: Wikipédia a dévoilé sa nouvelle stratégie en matière d’intelligence artificielle, visant à utiliser des outils IA pour soutenir et améliorer le travail des éditeurs humains, plutôt que de les remplacer. Les détails spécifiques ne sont pas précisés dans la source, mais cela indique que la plus grande encyclopédie en ligne du monde explore comment intégrer la technologie IA dans ses processus de création et de maintenance de contenu. (Source: Reddit r/artificial)
🧰 Outils
Midjourney lance la fonctionnalité Omni-Reference: Midjourney a lancé une nouvelle fonctionnalité Omni-Reference (oref), permettant aux utilisateurs de guider la génération d’images en fournissant des URL d’images de référence (avec le paramètre –oref) pour assurer la cohérence des personnages, objets, véhicules ou créatures non humaines. Les utilisateurs peuvent contrôler le poids de l’influence de l’image de référence avec le paramètre –ow : un poids faible convient à la stylisation, un poids élevé à la correspondance réaliste ou précise des visages. Cette fonctionnalité vise à améliorer la cohérence et le contrôle des éléments spécifiques dans les images générées. (Source: op7418, DavidSHolz)

Runway Gen-4 References permet la personnalisation à partir d’une seule image: Le modèle Gen-4 de Runway a lancé la fonctionnalité References, où les utilisateurs n’ont besoin que d’une seule image de référence pour appliquer le style ou les caractéristiques d’un personnage de l’image à de nouveaux contenus générés. Les démonstrations montrent que la fonction peut facilement recréer des portraits de personnages dans le style de l’image de référence ou les placer dans le monde dépeint par l’image de référence, illustrant la capacité du modèle à atteindre une personnalisation de haute cohérence et qualité esthétique à partir d’une seule image de référence. (Source: c_valenzuelab, c_valenzuelab)

Le bot WhatsApp de Perplexity reprend du service: Le chatbot WhatsApp de Perplexity AI, brièvement hors service en raison d’une demande dépassant largement les prévisions, est de nouveau opérationnel. Les utilisateurs peuvent interagir avec lui via le numéro de téléphone +1 (833) 436-3285 pour transférer des messages à des fins de vérification des faits, poser directement des questions pour obtenir des réponses, engager des conversations textuelles libres et créer des images. (Source: AravSrinivas, AravSrinivas)
Krea AI combine le modèle d’image 4o pour un contrôle précis de l’image: L’outil créatif IA Krea AI a ajouté une nouvelle fonctionnalité permettant aux utilisateurs de combiner les capacités du modèle d’image 4o d’OpenAI pour contrôler plus précisément le contenu et le style des images générées par le biais de collages d’images et de griffonnages. Cela démontre l’innovation continue de Krea dans la génération d’images interactives, permettant aux utilisateurs de guider la création IA de manière plus intuitive et détaillée. (Source: op7418)
Machine tout-en-un 行云褐蚁 : faire tourner DeepSeek complet à faible coût: 行云集成电路 (Xingyun Integrated Circuit), issue de l’Université Tsinghua, a lancé la machine IA tout-en-un 褐蚁 (Brown Ant). Elle prétend pouvoir exécuter le modèle DeepSeek-R1/V3 671B non quantifié en précision FP8 à plus de 20 tokens/s, avec un contexte de 128K, pour un prix de 149 000 yuans. La solution utilise des CPU AMD EPYC double socket et une grande quantité de mémoire haute fréquence, complétés par une accélération GPU limitée. Elle vise à réduire considérablement le coût matériel du déploiement privé de grands modèles grâce à une architecture CPU+mémoire, offrant une expérience locale proche des performances officielles, adaptée aux entreprises sensibles aux coûts et nécessitant une haute précision. (Source: 新智元)

L’application NotebookLM sera bientôt disponible: L’application de prise de notes IA de Google, NotebookLM, lancera bientôt des applications officielles iOS et Android, prévues pour le 20 mai, avec précommandes déjà ouvertes. Cela apportera les fonctionnalités de NotebookLM (résumé, questions-réponses et génération créative basées sur les notes et documents de l’utilisateur) sur mobile. (Source: zacharynado)
Granola lance une application iOS pour des comptes rendus de réunion IA en temps réel: L’application de prise de notes IA Granola a publié sa version iOS, étendant ses fonctionnalités initiales de prise de notes IA pour les réunions Zoom aux conversations en face à face hors ligne. Les utilisateurs peuvent utiliser Granola sur iPhone pour enregistrer et transcrire des conversations, et utiliser l’IA pour générer des résumés et des notes, facilitant la révision et l’organisation ultérieures. (Source: amasad)
Grok Studio prend en charge le traitement des PDF: L’assistant IA Grok a ajouté la capacité de traiter les fichiers PDF dans sa fonctionnalité Studio. Les utilisateurs peuvent désormais traiter et analyser plus facilement des documents PDF dans Grok Studio. Les détails spécifiques de la fonctionnalité ne sont pas décrits, mais cela marque une extension des capacités de Grok en matière de compréhension et d’interaction avec des documents multiformats. (Source: grok, TheGregYang)
Le nouveau modèle de Suno montre d’excellentes capacités de génération musicale: La plateforme de génération de musique IA Suno a lancé un nouveau modèle, dont les utilisateurs rapportent des résultats “très impressionnants”. Un utilisateur a tenté de générer une chanson de style concert live ; bien que l’effet d’appel et réponse souhaité n’ait pas été entièrement réalisé, la musique générée a bien rendu l’ambiance de foule, démontrant les progrès du nouveau modèle en termes de qualité musicale et de diversité stylistique. (Source: nptacek, nptacek)
Application Frog Spot assistée par IA pour identifier les chants de grenouilles: Un développeur a créé une application gratuite nommée Frog Spot, utilisant un modèle CNN auto-entraîné (TensorFlow Lite) pour identifier différentes espèces de grenouilles par l’analyse du spectrogramme d’un enregistrement audio de 10 secondes. L’application vise à aider le public à connaître les espèces locales et démontre également le potentiel de l’apprentissage profond dans la surveillance bioacoustique et la science citoyenne. (Source: Reddit r/deeplearning)
Automatisation des dessins techniques industriels assistée par IA: Un article de l’IAAI 2025 présente une méthode pour automatiser l’expansion des “instrument typicals” dans les schémas de tuyauterie et d’instrumentation (P&ID). La méthode combine des modèles de vision par ordinateur (détection et reconnaissance de texte) et des règles spécifiques au domaine pour extraire automatiquement des informations des schémas P&ID et des légendes, étendant les symboles simplifiés des “instrument typicals” en listes détaillées d’instruments, générant un index d’instruments précis. Cela vise à améliorer l’efficacité des projets d’ingénierie (en particulier lors de la phase d’appel d’offres) et à réduire les erreurs humaines. (Source: aihub.org)

Utilisation de Sora pour générer un paysage miniature de canard laqué épicé: Un utilisateur a partagé une image de “paysage miniature de canard laqué épicé” générée par Sora à partir d’un prompt détaillé. Le prompt décrivait méticuleusement le style de la scène (photographie macro, paysage miniature), le sujet principal (un étal architectural fait de canard laqué épicé), les détails (peau rouge-brun laquée, piments et sésame, un chef découpant, des clients), l’environnement (rues faites de sauce de canard, murs de style mariné, lanternes rouges, etc.). Cela démontre la capacité de Sora à comprendre des descriptions textuelles complexes et imaginatives et à générer des images de haute qualité correspondantes. (Source: dotey)

Création de GPTs de prévisions météo 3D: Un utilisateur a partagé une application ChatGPTs personnalisée appelée “Weather 3D”. Elle peut, à partir du nom de ville entré par l’utilisateur, appeler une API météo pour obtenir des données en temps réel et générer une illustration de style modèle miniature isométrique 3D du bâtiment emblématique de cette ville, en intégrant les conditions météorologiques actuelles. Le nom de la ville, les conditions météo, la température et une icône météo sont affichés en haut de l’illustration. Ce GPTs montre comment combiner les appels API et les capacités de génération d’images pour créer des applications IA utiles et visuellement attrayantes. (Source: dotey)

📚 Apprentissage
AdaRFT : une nouvelle méthode pour optimiser le fine-tuning par apprentissage par renforcement: Taiwei Shi et al. proposent une méthode d’apprentissage curriculaire légère et plug-and-play nommée AdaRFT, visant à optimiser le processus d’entraînement des algorithmes d’apprentissage par renforcement basé sur le feedback humain (RFT) (tels que PPO, GRPO, REINFORCE). Il est affirmé qu’AdaRFT peut réduire le temps d’entraînement RFT jusqu’à 2 fois et améliorer les performances du modèle, en organisant plus intelligemment l’ordre des données d’entraînement pour améliorer l’efficacité et les résultats de l’apprentissage. (Source: menhguin)

Masterclass en ligne sur l’évaluation IA (Evals): Hamel Husain et Shreya Shankar organisent une masterclass en ligne de 4 semaines sur l’évaluation des applications IA (Evals). Le cours vise à aider les développeurs à faire passer les applications IA du stade de prototype à celui de production, couvrant les méthodes d’évaluation avant et après le lancement, la différence entre les benchmarks et l’évaluation réelle, l’inspection des données, les PromptEvals, etc. Il souligne l’importance de l’évaluation pour garantir la fiabilité et les performances des applications IA. (Source: HamelHusain, HamelHusain)

Manuel de réglage de modèles Google: Google Research propose un dépôt de ressources nommé “tuning_playbook”, visant à fournir des conseils et des meilleures pratiques pour le réglage (tuning) de modèles. C’est une ressource d’apprentissage précieuse pour les développeurs et les chercheurs qui ont besoin d’affiner (fine-tune) de grands modèles de langage ou d’autres modèles d’apprentissage automatique pour les adapter à des tâches ou des jeux de données spécifiques. (Source: zacharynado)

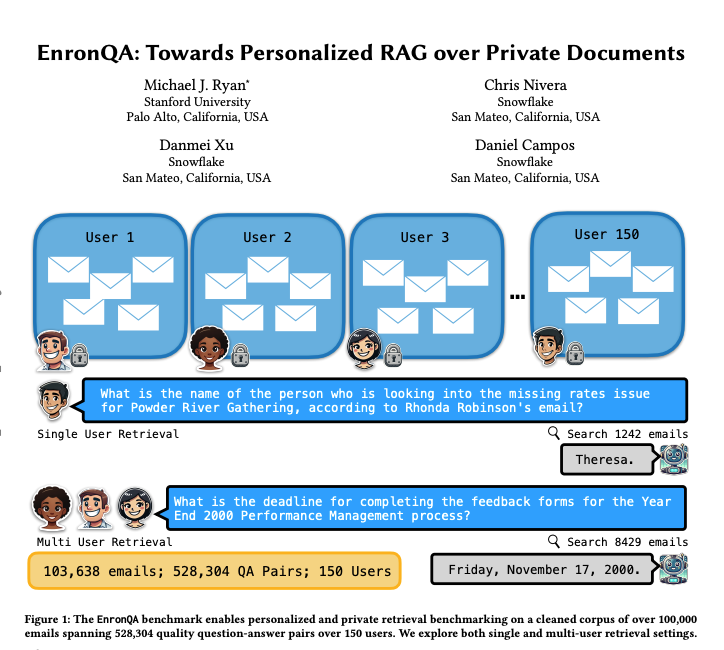
EnronQA : jeu de données benchmark pour RAG personnalisé: Des chercheurs ont lancé le jeu de données EnronQA, contenant 103 638 e-mails de 150 utilisateurs et 528 304 paires question-réponse de haute qualité. Ce jeu de données vise à servir de benchmark pour évaluer les performances des systèmes de génération augmentée par récupération (RAG) personnalisés dans le traitement de documents privés. Le jeu de données comprend des réponses de référence (gold standard), des réponses incorrectes, des justifications de raisonnement et des réponses alternatives, aidant à analyser plus finement les performances des systèmes RAG. (Source: tokenbender)
ReXGradient-160K : jeu de données massif de radiographies thoraciques et de rapports: Publication d’un grand jeu de données public de radiographies thoraciques nommé ReXGradient-160K, contenant 60 000 études de radiographies thoraciques et leurs rapports radiologiques associés (texte libre) provenant de 109 487 patients uniques issus de 3 systèmes de santé américains (79 sites médicaux). Il s’agirait du plus grand jeu de données de radiographies thoraciques publiquement disponible en termes de nombre de patients, fournissant une ressource précieuse pour l’entraînement et l’évaluation des modèles IA en imagerie médicale. (Source: iScienceLuvr)

Article de blog explorant la croissance des capacités des agents IA: Le chercheur Shunyu Yao a publié un article de blog intitulé “The Second Half”, suggérant que le développement actuel de l’IA se trouve à un moment de “mi-temps”. Avant cela, l’entraînement était plus important que l’évaluation ; après cela, l’évaluation deviendra plus importante que l’entraînement, car l’apprentissage par renforcement (RL) commence enfin à fonctionner efficacement. L’article explore l’importance du changement de méthodologie d’évaluation dans le contexte de l’amélioration continue des capacités de l’IA. (Source: andersonbcdefg)
Partage de recherche d’OpenAI sur la confidentialité et la mémorisation: Pratyush Maini et Zhili Feng, chercheurs chez OpenAI, donneront une présentation sur la recherche en matière de confidentialité et de mémorisation, discutant de la manière de détecter, quantifier et éliminer le phénomène de mémorisation dans les grands modèles de langage, et de ses applications pratiques dans les LLM en production. Cela concerne l’équilibre entre les capacités du modèle et la protection de la confidentialité des données utilisateur. (Source: code_star)

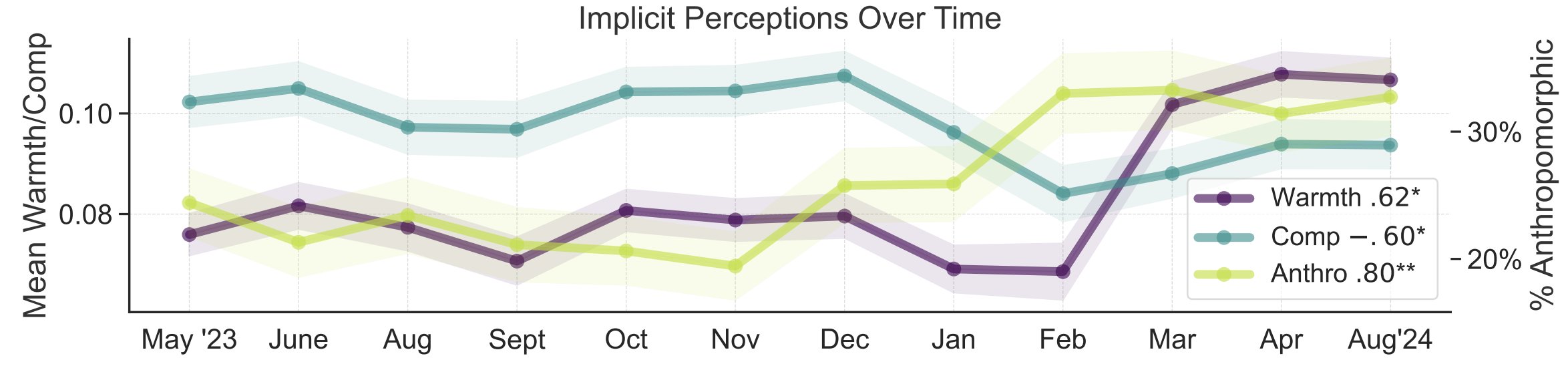
Étude sur les métaphores de la perception publique de l’IA: Myra Cheng et d’autres chercheurs de l’Université de Stanford ont publié un article à FAccT 2025, analysant 12 000 métaphores sur l’IA collectées sur 12 mois pour comprendre les modèles mentaux du public concernant l’IA et leur évolution dans le temps. L’étude révèle qu’avec le temps, le public a tendance à considérer l’IA comme plus humaine et dotée d’agentivité (augmentation de l’anthropomorphisme), et que sa tendance affective envers elle (chaleur) augmente également. Cette méthode offre un aperçu plus nuancé de la perception publique que les auto-déclarations. (Source: stanfordnlp, stanfordnlp)
MIRI publie un programme de recherche sur la gouvernance de l’IA: L’équipe de gouvernance technique du Machine Intelligence Research Institute (MIRI) a publié un nouveau programme de recherche sur la gouvernance de l’IA, exposant sa vision du paysage stratégique et proposant une série de questions de recherche exploitables. Son objectif est d’explorer les mesures nécessaires pour empêcher toute organisation ou individu de construire une superintelligence incontrôlable, afin de réduire les risques catastrophiques et d’extinction liés à l’IA. (Source: JeffLadish)
💼 Affaires
Deepexi, fournisseur de solutions IA pour entreprises, demande une introduction en bourse à Hong Kong: Deepexi (滴普科技), fournisseur de solutions IA pour entreprises fondé par Zhao Jiehui, ancien cadre supérieur de Huawei et Alibaba, a officiellement déposé une demande d’introduction en bourse à Hong Kong. L’entreprise se concentre sur la plateforme d’intelligence de données FastData et les solutions d’intelligence artificielle d’entreprise FastAGI, desservant des secteurs tels que la vente au détail (par exemple Belle), la fabrication et la santé. Au cours des trois dernières années, les revenus de l’entreprise ont connu une croissance continue, atteignant 243 millions de yuans en 2024. Deepexi a réalisé 8 tours de financement, obtenant des investissements d’institutions renommées telles que Hillhouse Capital, IDG Capital, 5Y Capital, etc., avec une valorisation d’environ 6,8 milliards de yuans après le dernier tour. Malgré la croissance des revenus, l’entreprise est actuellement toujours déficitaire, bien que la perte nette ajustée se réduise d’année en année. (Source: 36氪)
BMW Chine annonce l’intégration du grand modèle DeepSeek: Après sa collaboration avec Alibaba, le groupe BMW approfondit sa stratégie IA en Chine en annonçant l’intégration du grand modèle DeepSeek. Cette fonctionnalité est prévue pour le troisième trimestre 2025, d’abord sur plusieurs nouveaux modèles vendus en Chine équipés du système d’exploitation BMW 9ème génération, et sera également appliquée aux futurs modèles BMW Neue Klasse produits localement. Cette initiative vise à renforcer l’expérience d’interaction homme-machine centrée sur l’assistant personnel intelligent BMW grâce aux capacités de réflexion approfondie de DeepSeek, améliorant l’intelligence et la connexion émotionnelle du véhicule. C’est une étape importante pour BMW dans l’accélération de sa stratégie IA localisée et pour relever les défis de la transformation intelligente. (Source: 36氪)
Shopify impose l’utilisation de l’IA à tous ses employés, envisageant de remplacer certains postes par l’IA: Tobi Lutke, PDG de la plateforme mondiale de commerce électronique Shopify, a souligné dans une note interne que l’utilisation efficace de l’IA est devenue une “règle d’or” pour tous les employés de l’entreprise, et non plus une suggestion. La note exige que les employés intègrent l’IA dans leurs flux de travail pour en faire un réflexe ; les équipes demandant des effectifs supplémentaires doivent prouver pourquoi l’IA ne peut pas accomplir la tâche ; l’évaluation des performances intégrera des indicateurs d’utilisation de l’IA. Lutke a souligné que l’IA peut considérablement augmenter l’efficacité (jusqu’à 10 fois, voire 100 fois pour certains employés), et que les employés doivent s’améliorer de 20% à 40% par an pour rester compétitifs. Shopify a déjà procédé à des licenciements dans des départements comme le service client et introduit l’IA en remplacement. Cette décision est considérée comme un signal clair de la tendance aux ajustements de postes et aux licenciements de cols blancs dus à l’IA. (Source: 新智元)

🌟 Communauté
Discussion sur le problème des hallucinations de l’IA: Les critiques de Li Yanhong lors de la conférence des développeurs IA de Baidu concernant le taux élevé d’hallucinations, la lenteur et le coût élevé de DeepSeek-R1 ont relancé le débat communautaire sur le phénomène des “hallucinations” des grands modèles. Des analyses soulignent que non seulement DeepSeek, mais aussi des modèles avancés comme o3/o4-mini d’OpenAI, Qwen3 d’Alibaba, etc., souffrent couramment d’hallucinations, et que la réflexion multi-tours des modèles d’inférence peut amplifier les biais. L’évaluation de Vectara montre que le taux d’hallucination de R1 (14,3%) est bien supérieur à celui de V3 (3,9%). La communauté estime qu’à mesure que les capacités des modèles augmentent, les hallucinations deviennent plus subtiles et logiques, rendant difficile pour les utilisateurs de distinguer le vrai du faux, ce qui suscite des inquiétudes quant à la fiabilité. Parallèlement, certains considèrent les hallucinations comme un sous-produit de la créativité, ayant une valeur notamment dans la création littéraire. La définition d’un niveau acceptable d’hallucination et les moyens de l’atténuer par des techniques telles que le RAG, le contrôle de la qualité des données, les modèles critiques, etc., restent des sujets d’exploration continue dans l’industrie. (Source: 36氪)

Réflexions et discussions sur les compagnons/amis IA: La proposition de Mark Zuckerberg, PDG de Meta, d’utiliser des amis IA personnalisés pour répondre au besoin de plus de connexions sociales (affirmant que la personne moyenne a 3 amis mais en désire 15) a suscité des discussions communautaires. Sebastien Bubeck estime qu’il est très difficile de réaliser de véritables compagnons IA, la clé étant que l’IA doit pouvoir répondre de manière significative à “Qu’as-tu fait récemment ?”, c’est-à-dire avoir ses propres expériences, et pas seulement partager celles de l’utilisateur. Il pense que la conception actuelle des compagnons IA se concentre trop sur l’expérience partagée et néglige le fait que l’IA elle-même a besoin d’expériences indépendantes à partager, voire de potins (partager les expériences mutuelles). D’autres commentateurs remettent en question, sous l’angle du nombre de Dunbar, l’idée qu’un vaste cercle social composé d’IA puisse avoir un sens réel. D’autres encore craignent que les amis IA fournis par des entreprises commerciales aient pour but final le marketing ciblé, plutôt qu’une véritable compagnie. (Source: jonst0kes, SebastienBubeck, gfodor, gfodor)

Émotions et réflexions suscitées par la création artistique par IA: Au sein de la communauté, des utilisateurs expriment leur “tristesse” (grieving) face à la capacité de l’IA à créer des œuvres d’art “incroyablement bonnes” en peu de temps, estimant que cela remet en question le caractère unique de l’humain dans la création artistique. Cela a déclenché des discussions sur l’art IA, la nature de la créativité humaine et le sentiment de valeur personnelle face à l’impact technologique. Certains commentaires estiment que le plaisir de la création artistique réside dans le processus lui-même, et non dans la compétition avec l’IA ; l’art IA peut servir de source d’inspiration. D’autres pensent que l’art IA manque des “erreurs” ou de l’âme de la création humaine, paraissant trop parfait ou stéréotypé. La discussion s’étend également aux réflexions philosophiques sur la simulation émotionnelle par l’IA, la conscience et les futures structures sociales (comme le remplacement des emplois). (Source: Reddit r/ArtificialInteligence)
Éthique et responsabilité de l’IA : expériences secrètes et divulgation d’informations: La communauté a discuté des questions éthiques dans la recherche sur l’IA. Une nouvelle mentionne des chercheurs en IA menant une expérience secrète sur Reddit pour tenter de changer les opinions des utilisateurs, soulevant des inquiétudes quant au droit à l’information des utilisateurs et aux risques de manipulation par l’IA. Dans une autre discussion, un utilisateur rapporte avoir rencontré des processus complexes et des responsabilités floues en signalant des problèmes de sécurité potentiels à des entreprises d’IA, soulignant l’immaturité actuelle du domaine de l’IA en matière de divulgation responsable et de mécanismes de réponse aux vulnérabilités. (Source: Reddit r/ArtificialInteligence, nptacek)

Réflexions du domaine du NLP sur l’essor de ChatGPT: Quanta Magazine a publié un article basé sur des entretiens avec plusieurs experts en traitement automatique du langage naturel (NLP) tels que Chris Potts, Yejin Choi, Emily Bender, revenant sur l’impact et les réflexions suscités par la sortie de ChatGPT dans l’ensemble du domaine. L’article explore comment l’essor des grands modèles de langage a remis en question les fondements théoriques traditionnels du NLP, déclenché des débats au sein du domaine, des divisions en factions et des ajustements dans les orientations de recherche. Les membres de la communauté ont vivement réagi à cet article, estimant qu’il résumait bien les secousses et le processus d’adaptation du domaine linguistique après GPT-3. (Source: stanfordnlp, Teknium1, YejinChoinka, sleepinyourhat)
Apparition et perception des publicités générées par IA: Des utilisateurs de médias sociaux signalent avoir commencé à voir des publicités générées par IA sur des plateformes comme YouTube, et expriment un sentiment de “grand malaise”. Cela indique que la technologie de génération de contenu IA commence à être appliquée à la production de publicités commerciales, tout en suscitant les premières réactions des utilisateurs concernant la qualité, l’authenticité et l’expérience émotionnelle du contenu généré par IA. (Source: code_star)
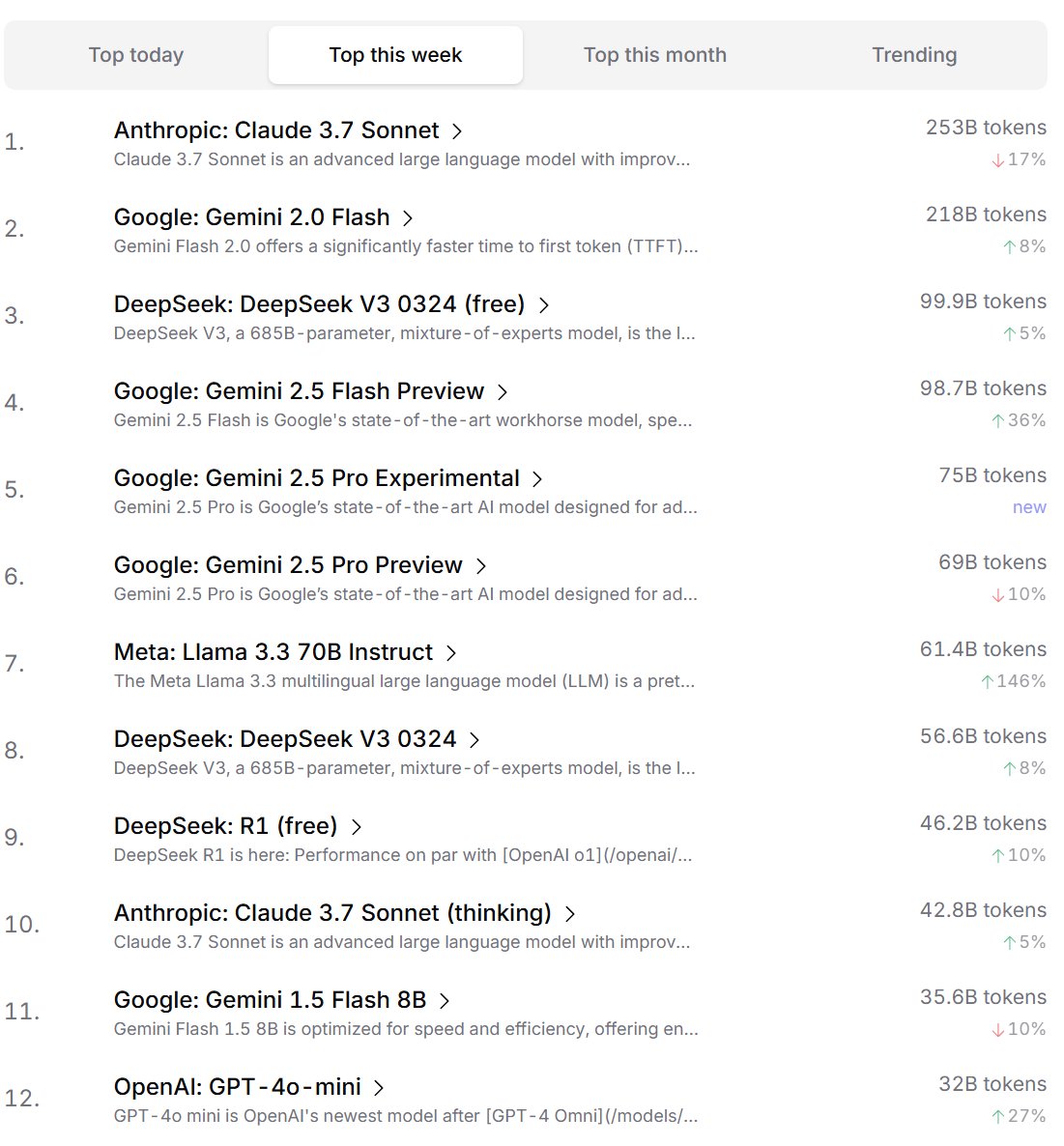
Classement des préférences des développeurs pour les modèles IA: Cursor.ai a publié le classement des modèles IA préférés par ses utilisateurs (principalement des développeurs), tandis qu’Openrouter a également publié le classement de l’utilisation des tokens par modèle. Ces classements, basés sur des données d’utilisation réelles de produits, sont considérés comme potentiellement plus représentatifs des choix des utilisateurs dans des scénarios de développement réels que les classements de type arène comme ChatBot Arena, offrant une perspective différente pour évaluer l’utilité pratique des modèles. (Source: op7418, Reddit r/LocalLLaMA)
Débat sur la capacité de “penser” de l’IA: La question de savoir si les grands modèles de langage (LLM) possèdent réellement la capacité de “penser” fait l’objet d’un débat continu au sein de la communauté. Certains soutiennent que les LLM actuels ne pensent pas réellement avant de parler, mais simulent le processus de pensée en générant plus de texte (comme la chaîne de pensée), ce qui est trompeur. D’autres estiment que l’utilisation de méthodes mathématiques continues (comme les LLM) pour effectuer un raisonnement discret sur des ordinateurs discrets pose en soi un problème fondamental. Ces discussions reflètent une réflexion approfondie sur la nature de la technologie IA actuelle et ses orientations futures. (Source: francoisfleuret, pmddomingos)
Réflexion dialectique sur la consommation d’énergie et l’impact environnemental de l’IA: Face aux problèmes environnementaux posés par l’énorme consommation d’énergie nécessaire à l’entraînement et au fonctionnement de l’IA, une réflexion dialectique émerge au sein de la communauté. Un point de vue suggère que l’énorme demande énergétique de l’IA (en particulier des entreprises d’hyperscale computing comme Google, Amazon, Microsoft) contraint ces entreprises à investir dans la construction de leurs propres sources d’énergie renouvelable (solaire, éolien, batteries), voire à redémarrer des centrales nucléaires (comme Microsoft collaborant avec Constellation pour redémarrer la centrale de Three Mile Island). Cette demande pourrait paradoxalement devenir un catalyseur pour accélérer le déploiement des énergies propres et les percées technologiques (comme les petits réacteurs nucléaires modulaires SMR). Cependant, d’autres soulignent le problème des rendements décroissants de la consommation d’énergie de l’IA, ainsi que la consommation d’eau nécessaire au refroidissement, qui méritent également attention. (Source: Reddit r/ArtificialInteligence)
Anthropic accusé de tenter de limiter la concurrence sur les puces IA: La communauté discute des affirmations du PDG d’Anthropic, Dario Amodei, qui préconise un renforcement des contrôles à l’exportation de puces IA vers des pays comme la Chine, allant jusqu’à suggérer que les puces pourraient être passées en contrebande en étant déguisées, par exemple, en faux ventres de femmes enceintes. Les critiques estiment que cette démarche d’Anthropic vise à limiter l’accès des concurrents (en particulier des entreprises chinoises comme DeepSeek, Qwen) aux ressources de calcul avancées, afin de maintenir son avantage dans le développement de modèles de pointe. Cette pratique est accusée d’utiliser la politique pour étouffer la concurrence, nuisant au développement ouvert de la technologie IA mondiale et à la communauté open source. (Source: Reddit r/LocalLLaMA)

💡 Divers
Réflexions sur l’IA et les limites cognitives humaines: Jeff Ladish commente que la fenêtre pendant laquelle les humains servent d‘“assistants copier-coller” pour l’IA est extrêmement courte, suggérant que les capacités autonomes de l’IA dépasseront rapidement la simple assistance. Parallèlement, le fondateur de DeepMind, Hassabis, a déclaré dans une interview qu’une véritable AGI devrait pouvoir proposer indépendamment des conjectures scientifiques valables (comme Einstein proposant la relativité générale), et pas seulement résoudre des problèmes, estimant que l’IA actuelle manque encore de capacités en matière de génération d’hypothèses. Liu Cixin, quant à lui, espère que l’IA pourra dépasser les limites cognitives biologiques du cerveau humain. Ces points de vue convergent vers une réflexion profonde sur les frontières des capacités de l’IA, l’évolution du rôle humain et la nature future de l’intelligence. (Source: JeffLadish, 新智元)
Le LiDAR de Waymo capture un moment périlleux: Le système LiDAR d’un véhicule autonome Waymo, lors d’un accident de moto qu’il a réussi à éviter, a clairement capturé l’image 3D en nuage de points du livreur en train de basculer lors de la collision. Cela démontre non seulement les puissantes capacités de perception du système Waymo (même dans des scénarios dynamiques complexes), mais a également enregistré de manière inattendue une perspective unique de l’accident. Heureusement, personne n’a été gravement blessé dans l’accident. (Source: andrew_n_carr)
Nouvelle approche pour la création de romans par IA : système de promesses narratives: Le développeur Levi propose un système de “Promesses Narratives” (Plot Promise) pour la création de romans par IA, en remplacement de la méthode traditionnelle du plan hiérarchique. Le système, inspiré par la théorie “promesse, progression, récompense” de Brandon Sanderson, considère l’histoire comme une série de fils narratifs actifs (promesses), chaque promesse ayant un score d’importance. L’algorithme suggère le moment opportun pour faire avancer une promesse en fonction du score et de la progression, mais l’IA choisit logiquement, en fonction du contexte, la promesse la plus appropriée à faire avancer à ce moment-là. L’utilisateur peut ajouter ou supprimer dynamiquement des promesses. Cette méthode vise à améliorer la flexibilité de l’histoire, son extensibilité (adaptée aux très longs formats) et l’émergence de la création, mais fait face à des défis tels que l’optimisation des décisions de l’IA, le maintien de la cohérence à long terme et les limitations de longueur des prompts d’entrée. (Source: Reddit r/ArtificialInteligence)