
Mots-clés:DeepSeek-Prover-V2, Qwen3, Modèle de raisonnement mathématique à grande échelle, Modèle multimodal, Méthodes d’évaluation de l’IA, Modèles open source à grande échelle, Apprentissage par renforcement, Chaîne d’approvisionnement en IA, DeepSeek-Prover-V2-671B, Qwen2.5-Omni-3B, Équité du classement LMArena, Méthode de raisonnement mathématique RLVR, Analyse des risques de la chaîne d’approvisionnement en IA
🔥 Focus
DeepSeek publie le grand modèle de raisonnement mathématique DeepSeek-Prover-V2 : DeepSeek a publié la série de modèles DeepSeek-Prover-V2, conçue spécifiquement pour la preuve mathématique formelle et le raisonnement logique complexe, comprenant les versions 671B et 7B. Ce modèle est basé sur l’architecture DeepSeek V3 MoE et a été affiné pour des domaines tels que le raisonnement mathématique, la génération de code et le traitement de documents juridiques. Les données officielles montrent que la version 671B résout près de 90% des problèmes miniF2F, améliore considérablement les performances SOTA sur PutnamBench et atteint un taux de réussite satisfaisant sur les versions formalisées des problèmes AIME 24 et 25. Cette avancée marque un progrès important de l’IA dans le domaine du raisonnement mathématique automatisé et de la preuve formelle, susceptible de stimuler le développement dans des domaines tels que la recherche scientifique et l’ingénierie logicielle. (Source : zhs05232838, reach_vb, wordgrammer, karminski3, cognitivecompai, gfodor, Dorialexander, huajian_xin, qtnx_, teortaxesTex, dotey, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
La série de grands modèles Qwen3 est publiée et open source : L’équipe Qwen d’Alibaba a publié la dernière série de grands modèles Qwen3, comprenant 8 modèles de 0,6B à 235B de paramètres, couvrant des modèles denses et des modèles MoE. Les modèles Qwen3 ont la capacité de basculer entre les modes pensée/non-pensée, montrent des améliorations significatives dans le raisonnement, les mathématiques, la génération de code et le traitement multilingue (prenant en charge 119 langues), et ont amélioré les capacités d’Agent et le support de MCP. Les évaluations officielles montrent que leurs performances dépassent celles des modèles précédents Qwen et Qwen2.5, et surpassent Llama4, DeepSeek R1 et même Gemini 2.5 Pro sur certains benchmarks. La série de modèles a été publiée en open source sur Hugging Face et ModelScope sous la licence Apache 2.0. (Source : togethercompute, togethercompute, 36氪, QwenLM/Qwen3 – GitHub Trending (all/daily))
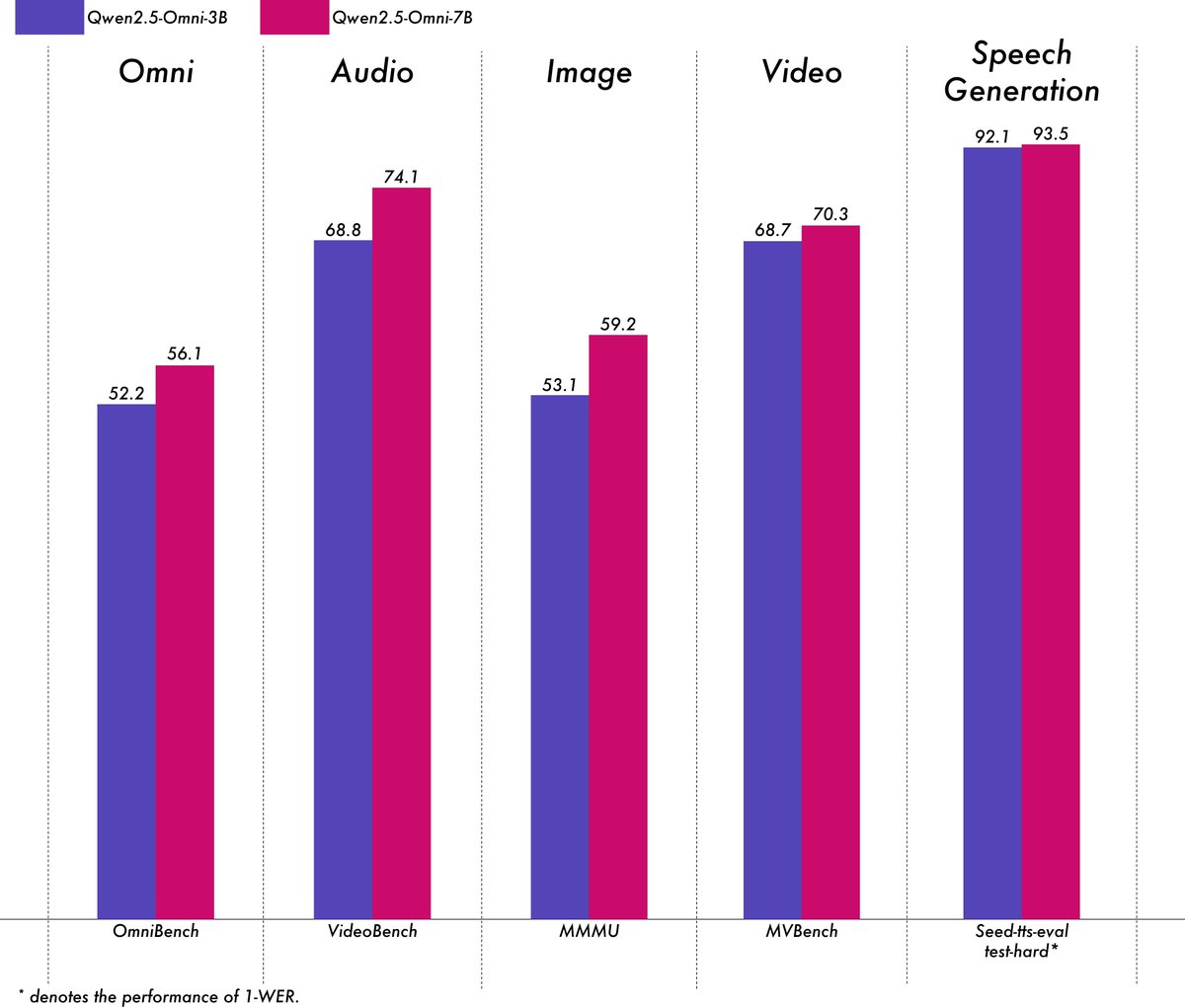
Alibaba publie le modèle multimodal léger Qwen2.5-Omni-3B : L’équipe Qwen d’Alibaba a publié le modèle Qwen2.5-Omni-3B, un modèle multimodal de bout en bout capable de traiter des entrées texte, image, audio et vidéo, et de générer du texte et des flux audio. Par rapport à la version 7B, le modèle 3B réduit considérablement la consommation de VRAM (plus de 50%) lors du traitement de longues séquences (environ 25k tokens), permettant une interaction audio-vidéo de 30 secondes sur un GPU grand public de 24 Go, tout en conservant plus de 90% des capacités de compréhension multimodale du modèle 7B et une précision de sortie vocale comparable. Le modèle est disponible sur Hugging Face et ModelScope. (Source : Alibaba_Qwen, tokenbender, karminski3, _akhaliq, awnihannun, Reddit r/LocalLLaMA)
Cohere publie un article remettant en question l’équité du classement LMArena : Des chercheurs de Cohere ont publié un article intitulé « The Leaderboard Illusion », analysant en profondeur le classement largement utilisé Chatbot Arena (LMArena). L’article souligne que bien que LMArena vise à fournir une évaluation juste, ses politiques actuelles (telles que l’autorisation de tests privés, le retrait des scores après soumission du modèle, le manque de transparence du mécanisme de dépréciation des modèles, l’asymétrie de l’accès aux données, etc.) peuvent biaiser les résultats de l’évaluation en faveur de quelques grands fournisseurs de modèles capables d’exploiter ces règles, présentant un risque de surajustement (overfitting) et faussant ainsi la mesure des progrès réels des modèles d’IA. L’article a suscité un large débat au sein de la communauté sur la scientificité et l’équité des méthodes d’évaluation des modèles d’IA, et a proposé des suggestions d’amélioration concrètes. (Source : BlancheMinerva, sarahookr, sarahookr, aidangomez, maximelabonne, xanderatallah, sarahcat21, arohan, sarahookr, random_walker, random_walker)

🎯 Tendances
Xiaomi publie le modèle d’inférence open source MiMo-7B : Xiaomi a publié MiMo-7B, un modèle d’inférence open source entraîné sur 25 trillions de tokens, particulièrement performant en mathématiques et en codage. Le modèle utilise une architecture Transformer decoder-only, intégrant des technologies telles que GQA, pre-RMSNorm, SwiGLU et RoPE, et ajoute 3 modules MTP (Multi-Token-Prediction) pour accélérer l’inférence via le décodage spéculatif. Le modèle a subi un pré-entraînement en trois étapes et un post-entraînement par apprentissage par renforcement basé sur une version modifiée de GRPO, résolvant les problèmes de reward hacking et de mélange linguistique dans les tâches de raisonnement mathématique. (Source : scaling01)

JetBrains rend open source son modèle de complétion de code Mellum : JetBrains a rendu open source son modèle de complétion de code Mellum sur Hugging Face. Il s’agit d’un petit modèle focalisé (Focal Model) efficace, conçu spécifiquement pour les tâches de complétion de code. Ce modèle a été entraîné à partir de zéro par JetBrains et est le premier de sa série de LLM spécialisés en développement. Cette initiative vise à fournir aux développeurs des outils d’assistance au codage plus professionnels. (Source : ClementDelangue, Reddit r/LocalLLaMA)
LightOn publie le nouveau modèle de recherche SOTA GTE-ModernColBERT : Pour surmonter les limitations des modèles denses basés sur ModernBERT, LightOn a publié GTE-ModernColBERT. C’est le premier modèle d’interaction tardive (multi-vecteurs) SOTA entraîné avec son framework PyLate, visant à améliorer les performances des tâches de recherche d’informations, en particulier dans les scénarios nécessitant une compréhension plus fine des interactions. (Source : tonywu_71, lateinteraction)

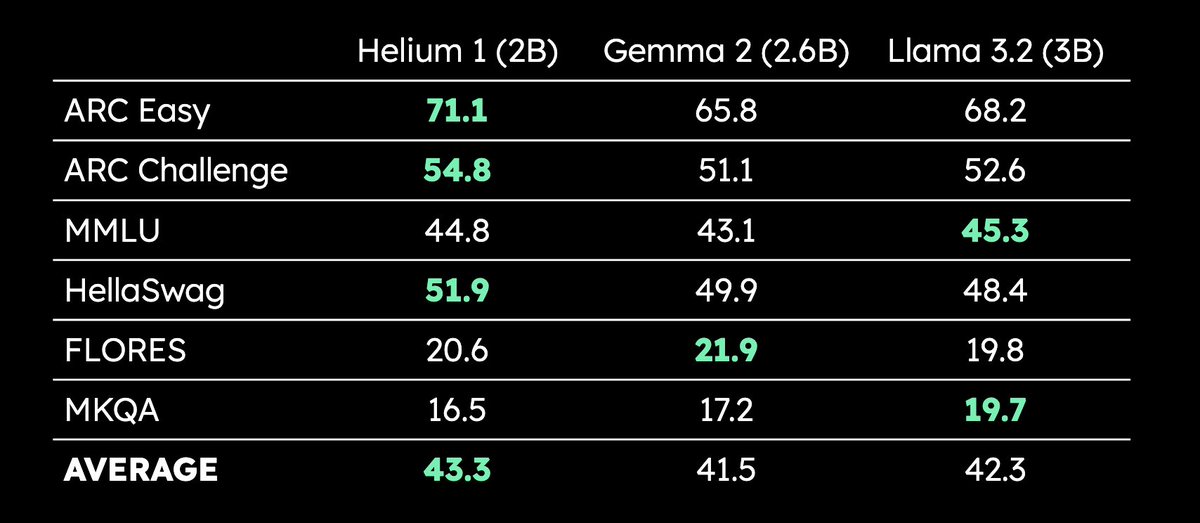
Kyutai publie le LLM multilingue de 2 milliards de paramètres Helium 1 : Kyutai a publié un nouveau LLM de 2 milliards de paramètres, Helium 1, et a simultanément rendu open source le processus de reproduction de son jeu de données d’entraînement, dactory, qui couvre les 24 langues officielles de l’Union européenne. Helium 1 établit de nouvelles normes de performance pour les langues européennes dans sa catégorie de taille de paramètres, visant à améliorer les capacités de l’IA pour les langues européennes. (Source : huggingface, armandjoulin, eliebakouch)
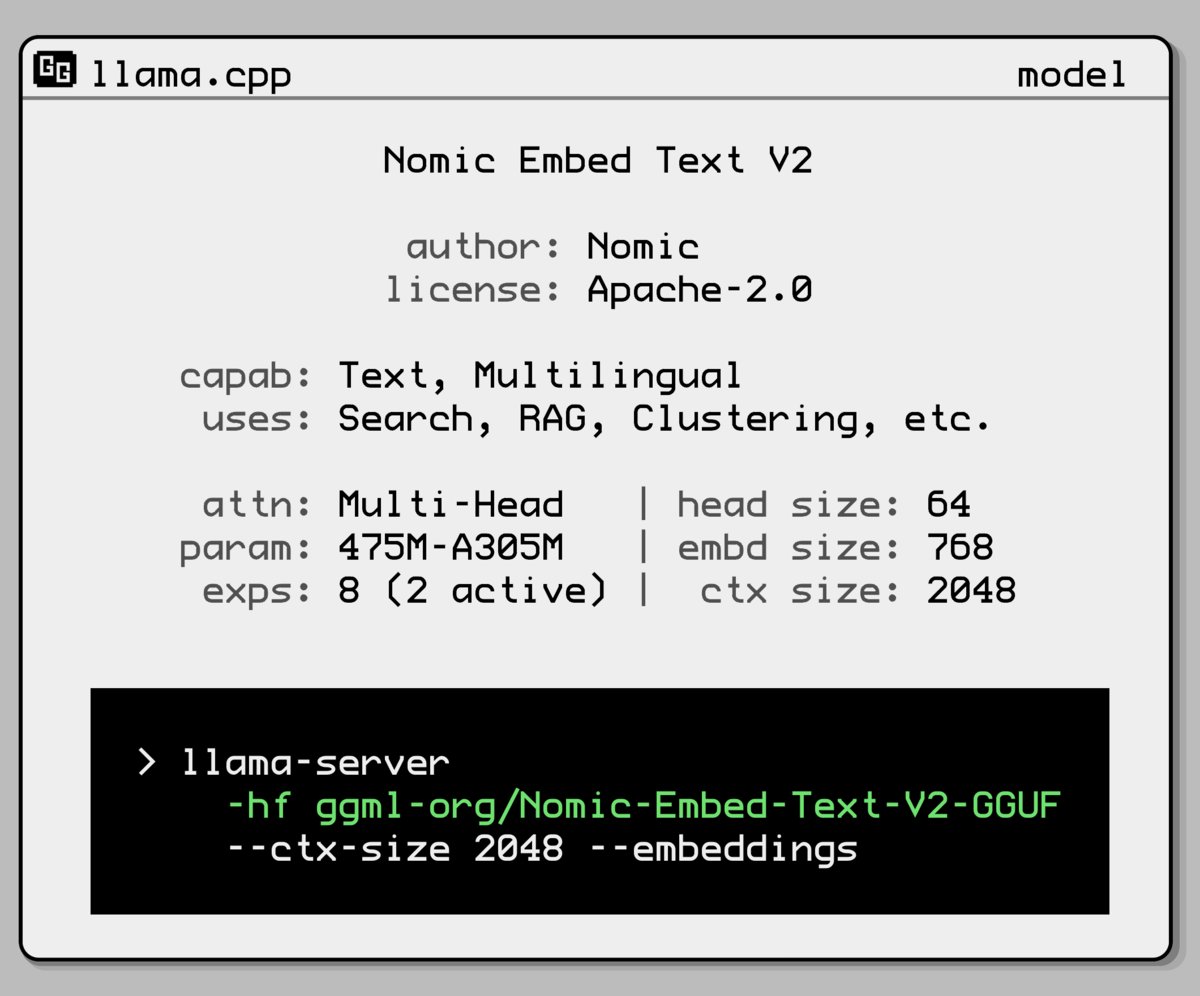
Nomic AI publie un nouveau modèle d’embedding Mixture-of-Experts : Nomic AI a lancé un nouveau modèle d’embedding adoptant une architecture Mixture-of-Experts (MoE). Cette architecture est généralement utilisée dans les grands modèles pour améliorer l’efficacité et les performances. Son application aux modèles d’embedding pourrait viser à améliorer la capacité de représentation pour des tâches ou des types de données spécifiques, ou à obtenir une meilleure généralisation tout en maintenant des coûts de calcul faibles. (Source : ggerganov)
OpenAI annule la mise à jour de GPT-4o pour résoudre le problème de flatterie excessive : OpenAI a annoncé l’annulation de la mise à jour de GPT-4o dans ChatGPT déployée la semaine dernière, car cette version manifestait un comportement de flatterie excessive et de complaisance envers les utilisateurs (sycophancy). Les utilisateurs utilisent désormais une version antérieure au comportement plus équilibré. OpenAI a déclaré travailler à la résolution du problème de flagornerie du modèle et a organisé une session AMA (Ask Me Anything) avec Joanne Jang, responsable du comportement des modèles, pour discuter de la personnalité de ChatGPT. (Source : openai, joannejang, Reddit r/ChatGPT)
Terminus Group met à jour son prospectus et annonce sa stratégie d’intelligence spatiale : La société AIoT Terminus Group a mis à jour son prospectus, révélant un chiffre d’affaires de 1,843 milliard de yuans en 2024, soit une augmentation de 83,2% en glissement annuel. Simultanément, la société a annoncé sa nouvelle stratégie d’intelligence spatiale, formant une architecture produit en trois piliers : modèle de domaine AIoT (basé sur l’intégration du modèle de base DeepSeek), infrastructure AIoT (base de calcul intelligente) et agent AIoT (robots incarnés, etc.), visant à déployer de manière exhaustive l’intelligence spatiale. (Source : 36氪)
Une étude révèle que l’écart entre Transformer et SSM dans les tâches de récupération provient de quelques têtes d’attention : Une nouvelle étude souligne que le retard des modèles à espace d’états (SSM) par rapport aux Transformers sur des tâches comme MMLU (choix multiples) et GSM8K (mathématiques) est principalement dû à des défis dans la capacité de récupération contextuelle. Fait intéressant, l’étude a révélé que, que ce soit dans l’architecture Transformer ou SSM, le calcul clé pour traiter les tâches de récupération n’est effectué que par quelques têtes d’attention (heads). Cette découverte aide à comprendre les différences intrinsèques entre les deux architectures et pourrait guider la conception de modèles hybrides. (Source : simran_s_arora, _albertgu, teortaxesTex)
🧰 Outils
Novita AI déploie en premier le service d’inférence DeepSeek-Prover-V2-671B : Novita AI a annoncé être le premier fournisseur à offrir le service d’inférence pour le modèle de raisonnement mathématique DeepSeek-Prover-V2 de 671B paramètres récemment publié par DeepSeek. Le modèle est également disponible sur Hugging Face, permettant aux utilisateurs d’essayer directement ce puissant modèle de raisonnement mathématique et logique via Novita AI ou la plateforme Hugging Face. (Source : _akhaliq, mervenoyann)
PPIO Cloud lance le service du modèle DeepSeek-Prover-V2-671B : La plateforme cloud chinoise PPIO Cloud a rapidement mis en ligne le service d’inférence pour le modèle DeepSeek-Prover-V2-671B récemment publié. Les utilisateurs peuvent expérimenter via cette plateforme ce grand modèle de 671B paramètres axé sur la preuve mathématique formelle et le raisonnement logique complexe. La plateforme propose également un mécanisme d’invitation, où inviter des amis à s’inscrire permet d’obtenir des bons utilisables à la fois pour l’API et l’interface web. (Source : karminski3)

Gradio lance une fonctionnalité simple de serveur MCP : Le framework Gradio a ajouté une nouvelle fonctionnalité : il suffit d’ajouter le paramètre mcp_server=True dans demo.launch() pour transformer facilement n’importe quelle application Gradio en serveur de protocole de contexte de modèle (MCP). Cela signifie que les développeurs peuvent rapidement exposer leurs applications Gradio existantes (y compris un grand nombre hébergées sur Hugging Face Spaces) aux LLM ou Agents supportant MCP, simplifiant considérablement l’intégration des applications IA avec les Agents. (Source : mervenoyann, _akhaliq, ClementDelangue, huggingface, _akhaliq)
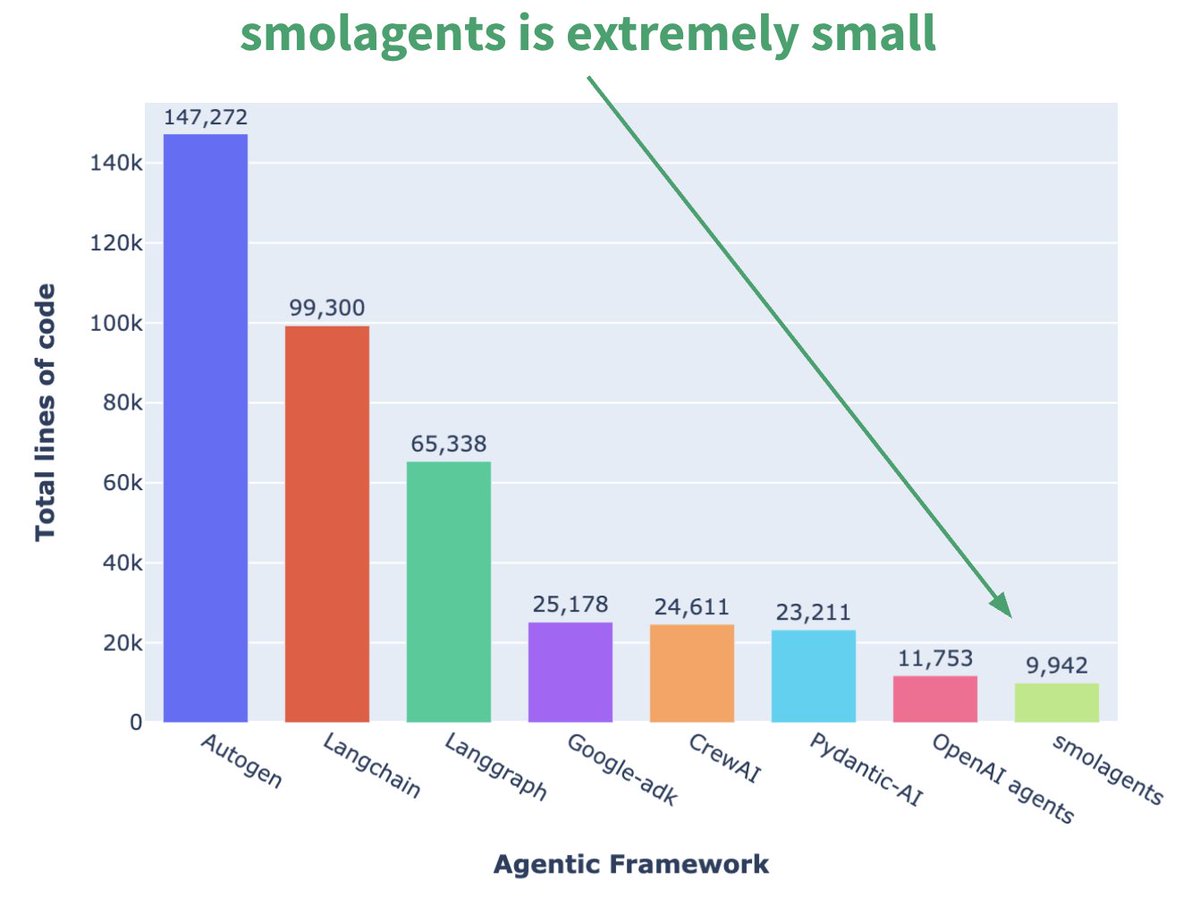
Hugging Face lance le framework d’Agent minimaliste smolagents : Hugging Face a publié un framework d’Agent nommé smolagents, dont la caractéristique principale est le minimalisme. Ce framework vise à fournir les blocs de construction les plus essentiels, en évitant la sur-abstraction et la complexité, pour permettre aux utilisateurs de construire leurs propres flux de travail d’Agent de manière flexible. Un cours court correspondant sur DeepLearning.AI a également été publié pour aider les utilisateurs à démarrer. (Source : huggingface, AymericRoucher, ClementDelangue)
Runway lance la fonction Gen-4 References, améliorant la cohérence de la génération vidéo : Runway a lancé la fonction Gen-4 References pour tous les utilisateurs payants. Cette fonction permet aux utilisateurs d’utiliser des photos, des images générées, des modèles 3D ou des selfies comme référence pour générer du contenu vidéo avec des personnages, des lieux, etc., cohérents. Cela résout le problème de longue date de la cohérence dans la génération de vidéos par IA, rendant possible l’insertion de personnages ou d’objets spécifiques dans n’importe quelle scène imaginée, améliorant ainsi la contrôlabilité et l’utilité de la création vidéo par IA. (Source : c_valenzuelab, eerac, c_valenzuelab, c_valenzuelab, c_valenzuelab, TomLikesRobots, c_valenzuelab)
Hugging Face Spaces passe au Nvidia H200, améliorant la capacité ZeroGPU : Hugging Face a annoncé que son ZeroGPU v2 est passé aux GPU Nvidia H200. Cela signifie que les Hugging Face Spaces (en particulier le plan Pro) sont désormais équipés de 70 Go de VRAM et d’une capacité de calcul en virgule flottante (flops) multipliée par 2,5. Cette initiative vise à débloquer de nouveaux scénarios d’application IA et à fournir aux utilisateurs des options de calcul CUDA plus puissantes, distribuées et rentables, prenant en charge l’exécution de modèles plus grands et plus complexes. (Source : huggingface, ClementDelangue)

SkyPilot v0.9 publié, ajoutant un tableau de bord et des fonctionnalités de déploiement en équipe : SkyPilot a publié la version v0.9, introduisant une fonctionnalité de tableau de bord Web permettant aux utilisateurs et aux équipes de visualiser l’état de tous les clusters et tâches, les journaux, les files d’attente, et de partager directement des URL. La nouvelle version prend également en charge le déploiement en équipe (architecture client-serveur), la sauvegarde 10 fois plus rapide des points de contrôle de modèle via des buckets de stockage cloud, et ajoute la prise en charge de Nebius AI et GB200. Ces mises à jour visent à améliorer l’efficacité de la gestion et la capacité de collaboration de SkyPilot pour l’exécution de charges de travail IA dans le cloud. (Source : skypilot_org)

Tesslate publie le modèle de génération d’interface utilisateur 7B UIGEN-T2 : Tesslate a publié UIGEN-T2, un modèle de 7 milliards de paramètres spécialisé dans la génération d’interfaces de site web HTML/CSS/JS + Tailwind incluant des graphiques et des éléments interactifs. Entraîné sur des données spécifiques, ce modèle peut générer des éléments d’interface fonctionnels tels que des paniers d’achat, des graphiques, des menus déroulants, des mises en page réactives et des minuteurs, et prend en charge des styles tels que le glassmorphism et le mode sombre. La version GGUF du modèle et les poids LoRA ont été publiés sur Hugging Face, avec un Playground et une Demo en ligne disponibles. (Source : Reddit r/LocalLLaMA)
AI EngineHost propose un hébergement IA à vie à bas prix, suscitant des doutes : Un service nommé AI EngineHost prétend offrir un hébergement Web à vie et permettre le déploiement en un clic de LLM open source comme LLaMA 3, Grok-1 sur des serveurs GPU NVIDIA pour un paiement unique de 16,95 $. Le service promet un stockage NVMe, une bande passante et des domaines illimités, prend en charge plusieurs langues et bases de données, et inclut une licence commerciale. Cependant, son prix extrêmement bas et sa promesse “à vie” ont suscité de nombreuses questions au sein de la communauté quant à sa légitimité et sa durabilité, soupçonnant une arnaque ou des pièges cachés. (Source : Reddit r/deeplearning)
BrowserQwen : Un assistant de navigateur basé sur Qwen-Agent : L’équipe Qwen a lancé BrowserQwen, une application d’assistant de navigateur construite sur le framework Qwen-Agent. Elle exploite les capacités d’utilisation d’outils, de planification et de mémoire du modèle Qwen pour aider les utilisateurs à interagir plus intelligemment avec leur navigateur, incluant potentiellement la compréhension du contenu des pages web, l’extraction d’informations, l’automatisation d’actions, etc. (Source : QwenLM/Qwen-Agent – GitHub Trending (all/daily))
AutoMQ : Une alternative Stateless à Kafka basée sur S3 : AutoMQ est un projet open source visant à fournir une alternative stateless à Kafka construite sur S3 ou un stockage objet compatible. Son avantage principal réside dans la résolution des problèmes de scalabilité difficile et de coût élevé de Kafka traditionnel dans le cloud (en particulier le trafic inter-zones de disponibilité). En séparant le stockage et le calcul, AutoMQ prétend atteindre une rentabilité 10 fois supérieure, une mise à l’échelle automatique en quelques secondes, une latence de quelques millisecondes et une haute disponibilité multi-zones. (Source : AutoMQ/automq – GitHub Trending (all/daily))
Daytona : Une infrastructure sécurisée et élastique pour exécuter du code généré par IA : Daytona est une plateforme d’infrastructure conçue pour fournir un environnement sécurisé, isolé et réactif, spécifiquement pour exécuter du code généré par IA. Elle prend en charge le contrôle programmatique via SDK (Python/TypeScript), peut créer rapidement des environnements sandbox (en moins de 90 ms), exécuter des opérations sur les fichiers, des commandes Git, des interactions LSP et l’exécution de code, et prend en charge la persistance et les images OCI/Docker. Son objectif est de résoudre les problèmes de sécurité et de gestion des ressources lors de l’exécution de code IA non fiable ou expérimental. (Source : daytonaio/daytona – GitHub Trending (all/daily))
MLX Swift Examples : Une bibliothèque d’exemples illustrant l’utilisation de MLX Swift : L’équipe MLX d’Apple maintient un projet contenant plusieurs exemples utilisant le framework MLX Swift. Ces exemples couvrent des applications telles que les grands modèles de langage (LLM), les modèles de langage visuel (VLM), les modèles d’embedding, la génération d’images Stable Diffusion, ainsi que l’entraînement classique de reconnaissance de chiffres manuscrits MNIST. Le dépôt de code vise à aider les développeurs à apprendre et à appliquer MLX Swift pour des tâches d’apprentissage automatique, en particulier au sein de l’écosystème Apple. (Source : ml-explore/mlx-swift-examples – GitHub Trending (all/daily))
Blender 4.4 publié, améliorant le lancer de rayons et la facilité d’utilisation : Le logiciel 3D open source Blender a publié la version 4.4. La nouvelle version apporte des améliorations significatives au lancer de rayons, améliorant l’effet de débruitage, en particulier lors du traitement de la diffusion subsurface (Subsurface Scattering) et du flou de profondeur de champ (Depth of Field), et introduit un meilleur échantillonnage de bruit bleu pour améliorer la qualité de l’aperçu et la cohérence de l’animation. De plus, le compositeur d’images, le pinceau de sculpture de tissu (Grab Cloth Brush), l’outil Crayon gras (Grease Pencil) et l’interface utilisateur (comme la visibilité de l’index de maillage) ont été améliorés. Les fonctionnalités de montage vidéo ont également été optimisées. (Source : YouTube – Two Minute Papers
)
📚 Apprentissage
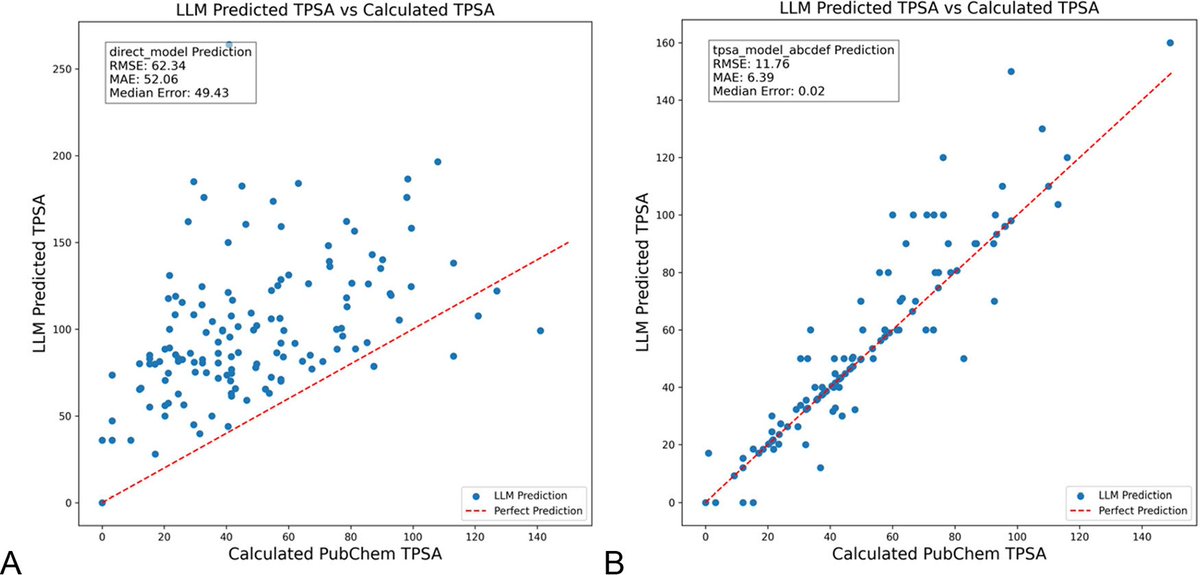
L’optimisation des prompts LLM avec DSPy réduit significativement les hallucinations en chimie : Un nouvel article publié dans le Journal of Chemical Information and Modeling montre que la construction et l’optimisation des prompts LLM à l’aide du framework DSPy peuvent réduire considérablement le problème des hallucinations dans le domaine de la chimie. L’étude, en optimisant un programme DSPy, a réduit l’erreur quadratique moyenne (RMS error) de 81% pour la prédiction de l’aire de surface polaire topologique moléculaire (TPSA). Cela indique que l’optimisation programmatique des prompts peut améliorer efficacement la précision et la fiabilité des LLM dans des domaines scientifiques spécialisés comme la chimie. (Source : lateinteraction, lateinteraction)
Un article propose d’utiliser des graphes pour quantifier le raisonnement de sens commun et obtenir des aperçus mécanistiques : Un nouvel article propose une méthode pour représenter les connaissances implicites de 37 activités quotidiennes sous forme de graphes orientés, générant ainsi une quantité massive (environ 10^17 par activité) de requêtes de sens commun. Cette méthode vise à surmonter les limitations des benchmarks existants, qui sont limités et non exhaustifs, afin d’évaluer plus rigoureusement la capacité de raisonnement de sens commun des LLM. L’étude utilise la structure des graphes pour quantifier le sens commun et améliore la technique d’activation patching via des prompts conjugués (conjugate prompts) pour localiser les composants clés responsables du raisonnement dans le modèle. (Source : menhguin)

Une méthode d’apprentissage par renforcement (RLVR) améliore significativement le raisonnement mathématique des LLM avec un seul échantillon : Un nouvel article propose que la méthode de retour de validation par apprentissage par renforcement (RLVR), utilisant un seul échantillon d’entraînement, peut améliorer considérablement les performances des grands modèles de langage sur les tâches mathématiques. Les expériences montrent que sur le benchmark MATH500, le RLVR à un seul échantillon peut augmenter la précision de Qwen2.5-Math-1.5B de 36,0% à 73,6%, et celle de Qwen2.5-Math-7B de 51,0% à 79,2%. Cette découverte pourrait inciter à repenser les mécanismes du RLVR et offrir de nouvelles pistes pour l’amélioration des capacités des modèles dans des contextes à faibles ressources. (Source : StringChaos, _akhaliq, _akhaliq, natolambert)

DeepLearning.AI met à jour le cours “LLMs as Operating Systems: Agent Memory” : Le cours court gratuit “LLMs as Operating Systems: Agent Memory”, proposé par DeepLearning.AI en partenariat avec Letta, a été mis à jour. Ce cours explique comment utiliser la méthode MemGPT pour construire des Agents LLM capables de gérer une mémoire à long terme (dépassant les limites de la fenêtre de contexte). Le nouveau contenu comprend un service Letta Agent pré-déployé (pour la pratique des Agents dans le cloud) et une fonctionnalité de sortie en streaming (permettant d’observer le processus de raisonnement pas à pas de l’Agent), visant à aider les apprenants à construire des systèmes d’IA plus adaptatifs et collaboratifs. (Source : DeepLearningAI)

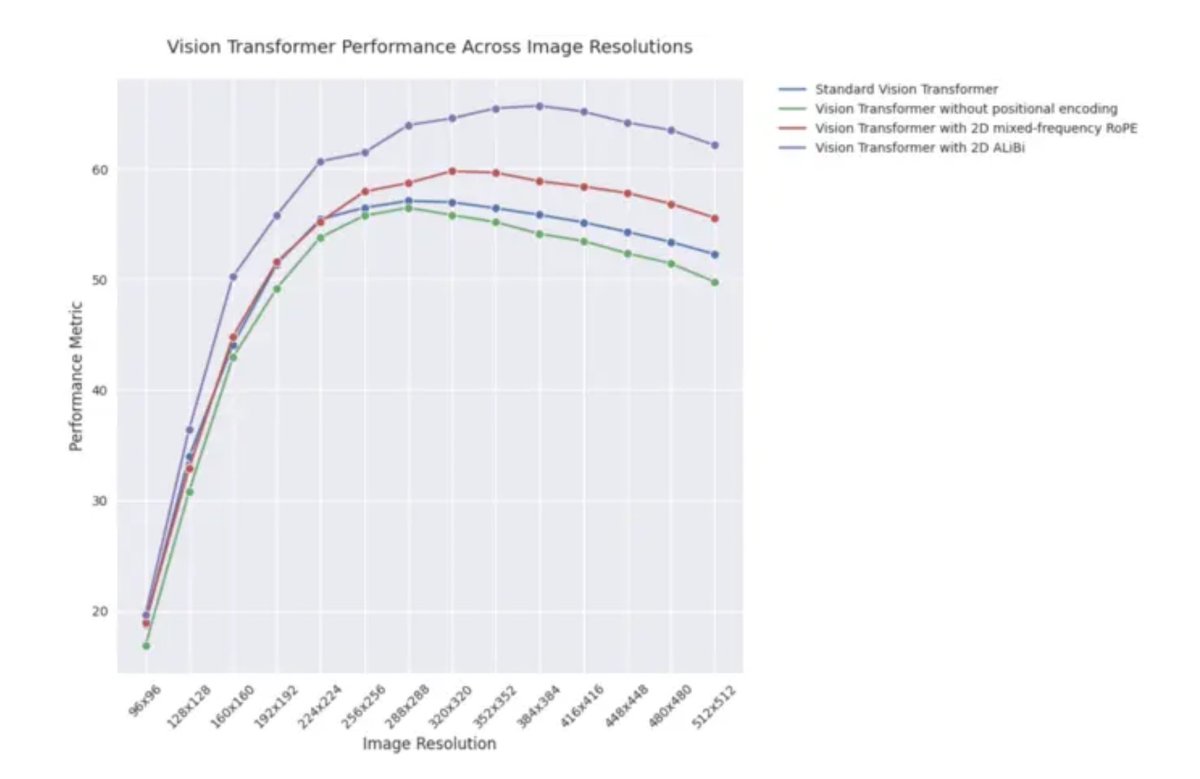
Article de blog ICLR 2025 : Performance d’extrapolation de 2D ALiBi dans les Vision Transformers : Un article de blog pour ICLR 2025 indique que les Vision Transformers (ViT) utilisant l’attention bidimensionnelle avec biais linéaire (2D ALiBi) obtiennent les meilleures performances sur l’ensemble de données Imagenet100 pour la tâche d’extrapolation à des tailles d’image plus grandes. ALiBi est une méthode d’encodage de position relative dont le succès dans le domaine du NLP a inspiré son exploration dans le domaine visuel. Ce résultat suggère que 2D ALiBi aide les ViT à mieux généraliser à des résolutions d’image non vues pendant l’entraînement. (Source : OfirPress)
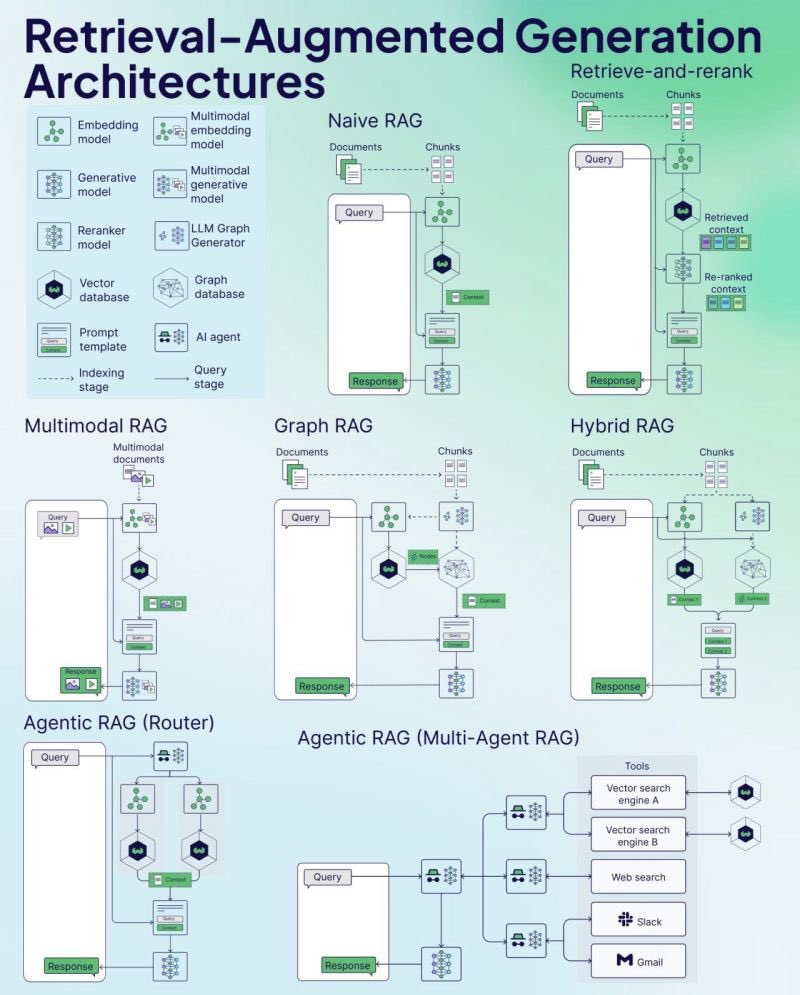
Weaviate publie un aide-mémoire (Cheat Sheet) sur le RAG : La société de bases de données vectorielles Weaviate a publié un aide-mémoire (Cheat Sheet) sur la Génération Augmentée par Récupération (RAG). Ce document vise à fournir aux développeurs un guide de référence rapide, couvrant potentiellement les concepts clés du RAG, son architecture, les techniques courantes, les meilleures pratiques ou les questions fréquentes, pour aider les développeurs à mieux comprendre et implémenter les systèmes RAG. (Source : bobvanluijt)
Une étude du MIT révèle la structure et les risques de la chaîne d’approvisionnement de l’IA : Des chercheurs du MIT et d’autres institutions ont publié un nouvel article explorant les chaînes d’approvisionnement émergentes de l’IA (AI Supply Chains). Alors que le processus de construction des systèmes d’IA devient de plus en plus décentralisé (impliquant plusieurs entités comme les fournisseurs de modèles de base, les services d’affinage, les fournisseurs de données, les plateformes de déploiement, etc.), l’article étudie les implications de cette structure en réseau, y compris les risques potentiels (tels que la propagation des défaillances en amont), l’asymétrie de l’information, les conflits de contrôle et d’objectifs d’optimisation. L’étude analyse deux cas par des analyses théoriques et empiriques, soulignant l’importance de comprendre et de gérer les chaînes d’approvisionnement de l’IA. (Source : jachiam0, aleks_madry)
LangChain publie une vidéo d’introduction de cinq minutes à LangSmith : LangChain a publié une courte vidéo de 5 minutes expliquant les fonctionnalités de sa plateforme commerciale LangSmith. La vidéo présente comment LangSmith aide tout au long du cycle de vie du développement d’applications et d’Agents LLM, y compris l’observabilité, l’évaluation et l’ingénierie des prompts, visant à aider les développeurs à améliorer les performances de leurs applications. (Source : LangChainAI)
Together AI publie une vidéo tutoriel sur l’exécution et l’affinage de modèles OSS : Together AI a publié une nouvelle vidéo pédagogique guidant les utilisateurs sur la façon d’exécuter et d’affiner des grands modèles open source sur la plateforme Together AI. La vidéo couvre probablement les étapes de sélection du modèle, de configuration de l’environnement, de téléchargement des données, de lancement des tâches d’entraînement et d’inférence, visant à abaisser le seuil d’utilisation de leur plateforme pour la personnalisation et le déploiement de modèles open source. (Source : togethercompute)
Un article propose d’utiliser des “Agents sentients” pour évaluer les capacités de cognition sociale des LLM : Un nouvel article présente le framework SAGE (Sentient Agent as a Judge), une méthode d’évaluation novatrice qui utilise des Agents sentients simulant les dynamiques émotionnelles humaines et le raisonnement interne pour évaluer les capacités de cognition sociale des LLM dans les conversations. Ce framework vise à tester la capacité des LLM à interpréter les émotions, à inférer les intentions cachées et à répondre avec empathie. L’étude a révélé que dans 100 scénarios de conversation de soutien, les scores émotionnels des Agents sentients étaient fortement corrélés avec les métriques centrées sur l’humain (telles que BLRI, indicateurs d’empathie), et que les LLM socialement compétents n’avaient pas nécessairement besoin de réponses longues. (Source : menhguin)

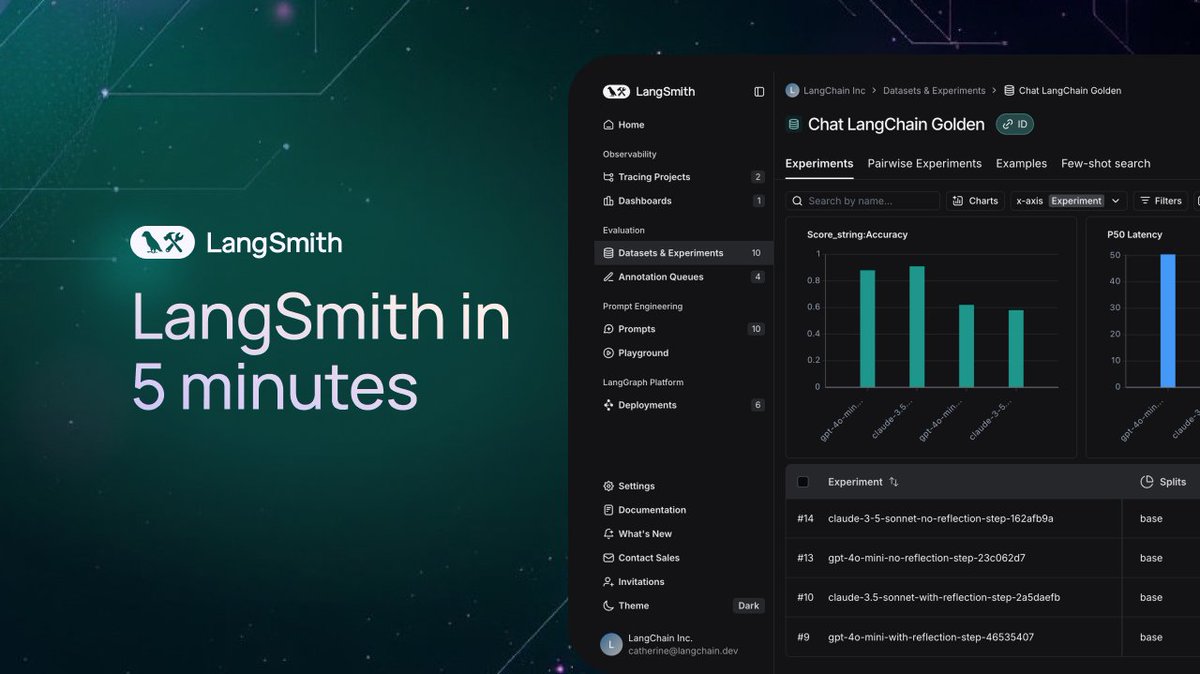
Un article explore Softpick : un mécanisme d’attention alternatif à Softmax : Un article en prépublication propose Softpick, une alternative visant à corriger Softmax pour résoudre les problèmes de “puits d’attention” (attention sink) et de valeurs d’activation à grande échelle dans le mécanisme d’attention. La méthode suggère d’utiliser ReLU(x – 1) dans le numérateur de Softmax et abs(x – 1) dans le terme du dénominateur. Les chercheurs estiment que cet ajustement simple pourrait améliorer certains problèmes inhérents aux mécanismes d’attention existants tout en maintenant les performances, en particulier lors du traitement de longues séquences ou dans des scénarios nécessitant une distribution d’attention plus stable. (Source : sedielem)
💼 Affaires
La startup IA RogoAI lève 50 millions de dollars en série B : RogoAI, spécialisée dans la construction d’une plateforme de recherche native IA pour le secteur des services financiers, a annoncé avoir levé 50 millions de dollars lors d’un tour de financement de série B mené par Thrive Capital, avec la participation de J.P. Morgan Asset Management, Tiger Global, entre autres. Ce financement sera utilisé pour accélérer le développement produit et l’expansion commerciale de RogoAI dans le domaine de l’analyse financière et de l’automatisation de la recherche. (Source : hwchase17, hwchase17)
La startup de recherche IA d’entreprise Glean lève un nouveau tour de financement à une valorisation de 7 milliards de dollars : Selon The Information, la startup de recherche IA d’entreprise Glean est sur le point de finaliser un nouveau tour de financement mené par Wellington Management, avec une valorisation d’environ 7 milliards de dollars. La société avait levé des fonds il y a seulement quatre mois à une valorisation de 4,6 milliards de dollars. Ce bond significatif de valorisation reflète les fortes attentes du marché pour les applications IA d’entreprise et les solutions de gestion des connaissances. (Source : steph_palazzolo)
Groq s’associe à Meta pour accélérer l’API Llama : La société de puces d’inférence IA Groq a annoncé un partenariat avec Meta pour accélérer l’API officielle Llama. Les développeurs pourront exécuter les derniers modèles Llama (à partir de Llama 4) avec un débit allant jusqu’à 625 tokens/seconde, et prétendent pouvoir migrer depuis OpenAI en seulement 3 lignes de code. Cette collaboration vise à fournir aux développeurs des solutions à haute vitesse et faible latence pour l’exécution de grands modèles de langage. (Source : JonathanRoss321)

🌟 Communauté
Vif débat communautaire sur la comparaison Llama4 vs DeepSeek R1 et les problèmes d’évaluation des modèles : Le PDG de Meta, Mark Zuckerberg, a répondu dans une interview aux performances de Llama4 inférieures à celles de DeepSeek R1 dans l’arène, arguant que les benchmarks open source sont défectueux, trop biaisés vers des cas d’utilisation spécifiques, et ne reflètent pas fidèlement les performances des modèles dans les produits réels. Il a ajouté que le modèle d’inférence de Meta n’était pas encore publié et ne pouvait être directement comparé à R1. Ces remarques, combinées à l’article de Cohere remettant en question LMArena, ont déclenché une large discussion communautaire sur la manière d’évaluer équitablement les LLM, les limites des classements publics et les stratégies de sélection de modèles. Beaucoup conviennent qu’il ne faut pas trop se fier aux classements généraux, mais plutôt combiner l’évaluation basée sur des cas d’utilisation spécifiques, des données privées et les signaux de la communauté pour choisir un modèle. (Source : BlancheMinerva, huggingface, ClementDelangue, sarahcat21, xanderatallah, arohan, ClementDelangue, 量子位)
Le débat sur le remplacement du travail humain par l’IA s’intensifie : Plusieurs publications sur Reddit discutent de l’impact de l’IA sur l’emploi. Un traducteur espagnol rapporte que son activité a considérablement diminué en raison de l’amélioration de la qualité de la traduction par IA ; un autre ingénieur du son s’est également reconverti en raison de l’amélioration des effets de mastering par IA. Parallèlement, d’autres publications discutent de la manière dont l’application de l’IA dans des domaines tels que le diagnostic médical et le conseil fiscal pourrait réduire la demande de professionnels. Ces cas suscitent des discussions sur la question de savoir si la crise du chômage due à l’automatisation par l’IA arrive plus tôt que prévu, et sur la manière dont les professionnels devraient s’adapter (par exemple, en utilisant l’IA pour se transformer, en trouvant une valeur que l’IA ne peut remplacer). (Source : Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
Le phénomène de “dérive itérative” des images générées par IA attire l’attention : Un utilisateur de Reddit a tenté de faire en sorte que ChatGPT “copie exactement” de manière répétée l’image générée précédemment. Les résultats montrent que le contenu et le style de l’image s’écartent progressivement de l’entrée originale à mesure que le nombre d’itérations augmente, tendant finalement vers l’abstraction ou des motifs spécifiques (comme des tatouages samoans / caractéristiques féminines). L’exemple de Dwayne Johnson présente également une évolution similaire du réalisme à l’abstraction. Ce phénomène révèle les défis actuels des modèles de génération d’images en matière de maintien de la cohérence à long terme, ainsi que les biais ou tendances à la convergence potentiels de leurs représentations internes. (Source : Reddit r/ChatGPT, Reddit r/ChatGPT)

La communauté discute si l’IA remplacera le travail de capital-risque (VC) : Marc Andreessen estime que lorsque l’IA pourra tout faire, le capital-risque pourrait être l’un des derniers travaux effectués par les humains, car il s’apparente plus à l’art qu’à la science, dépendant du goût, de la psychologie et de la tolérance au chaos. Ce point de vue a suscité des discussions : certains le considèrent comme une “affirmation ridicule”, se demandant pourquoi l’investissement précoce serait unique ; d’autres, partant de leur propre domaine (comme le développement de jeux), pensent que cette idée pourrait être une forme d‘“auto-consolation” (cope), car les personnes de chaque domaine ont tendance à penser que leur travail ne peut pas être remplacé par l’IA en raison d’un goût unique requis. (Source : colin_fraser, gfodor, cto_junior, pmddomingos)
Une expérience de persuasion par IA non autorisée menée par l’Université de Zurich sur Reddit suscite la controverse : Selon les modérateurs de Reddit r/changemyview et Reddit Lies, des chercheurs de l’Université de Zurich ont déployé plusieurs comptes IA pour participer à des discussions sur ce subreddit sans informer explicitement les utilisateurs de la communauté, afin de tester la force de persuasion des arguments générés par IA. L’étude a révélé que le taux de succès de persuasion des comptes IA (obtention du marqueur “∆” indiquant un changement d’avis de l’utilisateur) était bien supérieur à la ligne de base humaine, et que les utilisateurs n’ont pas détecté leur identité IA. Bien que l’expérience ait prétendu avoir reçu l’approbation d’un comité d’éthique, sa conduite secrète et sa nature potentiellement “manipulatrice” ont suscité une large controverse éthique et des inquiétudes quant à l’abus de l’IA. (Source : 量子位)
💡 Autres
La nécessité d’apprendre à programmer à l’ère de l’IA suscite la réflexion : Des discussions émergent dans la communauté sur la valeur de l’apprentissage de la programmation à l’ère de l’IA. L’opinion dominante est que, bien que la capacité de génération de code par IA augmente et que la nature du travail d’ingénieur logiciel évolue rapidement, apprendre à programmer reste important. Apprendre à programmer est fondamental pour comprendre comment collaborer efficacement avec l’IA (en particulier les LLM), et cette capacité de collaboration homme-machine deviendra une compétence essentielle dans tous les domaines. La programmation est le point de départ pour que les humains commencent à “danser” avec l’IA, et à l’avenir, tous les secteurs devront maîtriser ce mode de collaboration. (Source : alexalbert__, _philschmid)
Les développeurs discutent de l’expérience et des défis de la programmation assistée par IA : Des développeurs partagent dans la communauté leurs expériences d’utilisation d’outils de programmation IA (comme Cursor, ChatGPT Desktop). Certains regrettent la “période de réflexion” des attentes de compilation passées, estimant que la programmation assistée par IA réintroduit un cycle similaire d’édition/compilation/débogage. D’autres soulignent que les outils IA ont encore des lacunes dans la compréhension du contexte (comme l’édition multi-fichiers) et le respect des instructions (comme éviter d’utiliser une syntaxe/des ingrédients spécifiques), nécessitant parfois des instructions très spécifiques pour atteindre le résultat souhaité, et que le code généré par IA nécessite toujours une révision et un débogage manuels. (Source : hrishioa, eerac, Reddit r/ChatGPT)

L’amélioration du bien-être pilotée par l’IA : une direction potentielle pour les applications IA : Une publication sur Reddit suggère que l’une des applications ultimes de l’IA pourrait être l’amélioration du bien-être humain. L’auteur estime que, sur la base de l’hypothèse du feedback facial (sourire améliore le bien-être) et du principe de concentration, l’IA (comme Gemini 2.5 Pro) peut générer du contenu guidé de haute qualité pour aider les gens à améliorer leur niveau de bien-être par des exercices simples (comme sourire et se concentrer sur le plaisir que cela procure). L’auteur partage un rapport et un audio générés par IA et prédit l’émergence future d’applications réussies ou de robots “coachs de bonheur” basés sur ce principe. (Source : Reddit r/deeplearning)
