
Mots-clés:Qwen3, Protocole MCP, Agent IA, Grand modèle de langage, Modèle Tongyi Qianwen, Protocole de contexte de modèle, Modèle de raisonnement hybride, Appel d’outils d’agent IA, Grand modèle open source, Qwen3 modèle IA avancé, Spécifications du protocole MCP, Architecture d’agent IA intelligent, Applications des grands modèles de langage, Fonctionnalités du modèle Tongyi Qianwen, Gestion du contexte dans les modèles IA, Intégration de raisonnement hybride, API d’appel d’outils pour agents IA, Comparaison des grands modèles open source
🔥 À la une
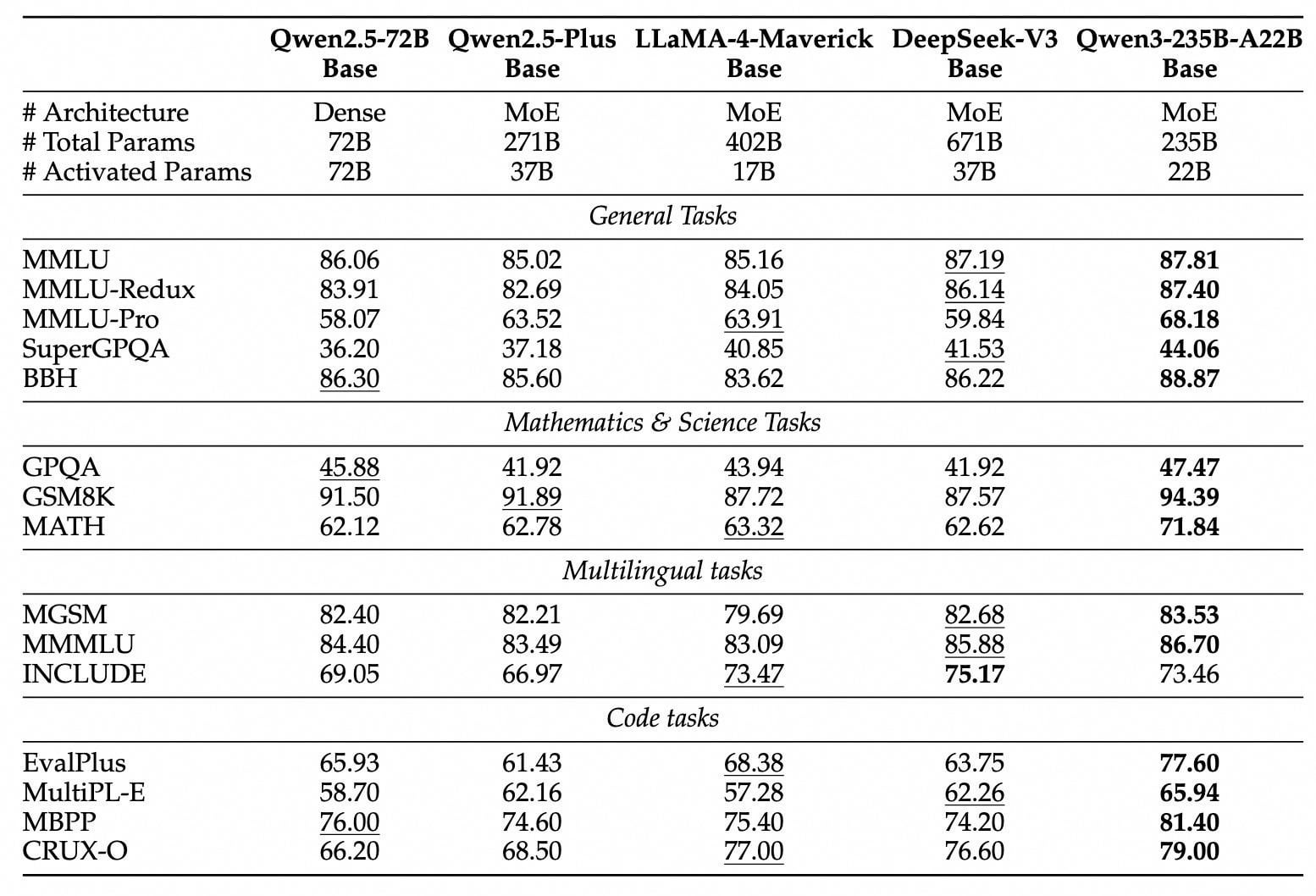
Publication et mise en open source des modèles de la série Qwen3: Alibaba a publié et mis en open source la nouvelle génération de modèles Tongyi Qianwen, la série Qwen3, comprenant 8 modèles avec des paramètres allant de 0.6B à 235B (2 MoE, 6 Dense). Le modèle phare Qwen3-235B-A22B surpasse DeepSeek-R1 et OpenAI o1 en termes de performances, se hissant au sommet des modèles open source mondiaux. Qwen3 est le premier modèle d’inférence hybride en Chine, intégrant les modes de pensée rapide et lente, économisant considérablement la puissance de calcul, avec un coût de déploiement représentant seulement 1/3 de celui des modèles de niveau équivalent. Le modèle prend en charge nativement le protocole MCP et de puissantes capacités d’appel d’outils, renforçant les capacités d’Agent, et supporte 119 langues. Cette mise en open source utilise la licence Apache 2.0, les modèles sont déjà disponibles sur des plateformes comme ModelScope, HuggingFace, etc., et les utilisateurs individuels peuvent l’expérimenter via l’application Tongyi. (Source: InfoQ, GeekPark, CSDN, DirectAI, Karthus)

Le protocole MCP, la “prise universelle” pour les AI Agents, suscite l’attention et les stratégies: Le protocole de contexte de modèle (MCP), en tant qu’interface standardisée connectant les modèles d’IA aux outils externes et aux sources de données, fait l’objet d’une attention particulière et d’un déploiement stratégique de la part de grandes entreprises comme Baidu, Alibaba, Tencent, ByteDance, etc. MCP vise à résoudre les problèmes d’inefficacité et de manque de standardisation lors de l’intégration d’outils externes par l’IA, permettant un “encapsulage unique, appel multiple”, fournissant une base technique solide et un support écosystémique pour les AI Agents (agents intelligents). Baidu, Alibaba, ByteDance, etc. ont déjà lancé des plateformes ou services compatibles MCP (tels que Baidu Qianfan, Alibaba Cloud Bailian, ByteDance Coze Space, Nami AI) et ont intégré divers outils tels que la cartographie, le commerce électronique, la recherche, etc., favorisant l’application des AI Agents dans de multiples scénarios comme le bureau et les services de la vie quotidienne. La popularisation du MCP est considérée comme la clé de l’explosion des agents intelligents d’IA, annonçant un changement de paradigme dans le développement d’applications d’IA. (Source: 36Kr, Shan Zi, X Research Yuan, InfoQ, InfoQ)

Les capacités de l’IA sur des tâches spécifiques suscitent des discussions: Plusieurs événements récents montrent que les capacités de l’IA sur des tâches spécifiques dépassent les applications de base, suscitant de larges discussions. Par exemple, Salesforce a révélé que 20% de son code Apex est écrit par l’IA (Agentforce), économisant un temps de développement considérable et faisant évoluer le rôle des développeurs vers des fonctions plus stratégiques. Parallèlement, Anthropic rapporte que 79% des tâches de son agent Claude Code sont automatisées, avec des performances particulièrement remarquables dans le développement front-end, et un taux d’adoption plus élevé dans les startups que dans les grandes entreprises. De plus, les performances de l’IA dans des jeux de logique simples comme le morpion sont également devenues un sujet de discussion ; bien que Karpathy pense que les grands modèles ne jouent pas bien au morpion, Noam Brown d’OpenAI a démontré les capacités du modèle o3, y compris jouer en regardant une image. Ces progrès soulignent le potentiel et les défis de l’IA en matière d’automatisation, de génération de code et de tâches logiques spécifiques. (Source: 36Kr, Xinzhiyuan, QubitAI)

OpenAI ajoute une fonction d’achat à ChatGPT, défiant la position de Google Search: OpenAI annonce l’ajout d’une fonction d’achat à ChatGPT, permettant aux utilisateurs de rechercher des produits, de comparer les prix sans se connecter, et de cliquer sur un bouton d’achat pour être redirigés vers le site du marchand afin de finaliser le paiement. Cette fonction utilise l’IA pour analyser les préférences de l’utilisateur et les avis sur l’ensemble du web (y compris les médias professionnels et les forums d’utilisateurs) pour recommander des produits, et permet aux utilisateurs de spécifier les sources d’avis à privilégier. Contrairement à Google Shopping, les résultats de recommandation actuels de ChatGPT n’incluent pas de classement payant ou de parrainage commercial. Cette initiative est considérée comme une étape importante pour OpenAI dans sa pénétration du commerce électronique et sa remise en question du cœur de métier de Google, la publicité par recherche. La manière dont les revenus du marketing d’affiliation seront partagés à l’avenir n’est pas claire ; OpenAI déclare privilégier actuellement l’expérience utilisateur et pourrait tester différents modèles à l’avenir. (Source: Tencent Tech, Big Data Digest, Zimu Bang)
🎯 Tendances
La technologie DeepSeek suscite l’attention et les discussions dans l’industrie: Le modèle DeepSeek a attiré une large attention dans le domaine de l’IA grâce à ses capacités de raisonnement et à sa technologie unique MLA (Multi-Level Attention compression). Le MLA, en compressant doublement les vecteurs clés et valeurs, réduit considérablement l’occupation mémoire (seulement 5% à 13% des méthodes traditionnelles lors des tests) et améliore l’efficacité de l’inférence. Cependant, cette innovation révèle également les goulots d’étranglement de l’écosystème matériel ; par exemple, l’activation du MLA sur des GPU non-Nvidia nécessite une programmation manuelle importante, augmentant les coûts et la complexité du développement. La pratique de DeepSeek met en lumière les défis de l’adaptation entre l’innovation algorithmique et l’architecture de calcul, incitant l’industrie à réfléchir à la construction d’infrastructures de calcul plus intelligentes et adaptatives pour soutenir le développement futur de l’IA. Bien que certains estiment que DeepSeek et d’autres modèles présentent des lacunes en termes de capacités multimodales et de coûts, ses avancées technologiques sont toujours considérées comme des progrès importants pour l’industrie. (Source: 36Kr)
Les applications natives IA explorent la socialisation pour améliorer la fidélisation des utilisateurs: Après que des applications d’IA comme Kimi, Doubao aient déployé des plugins de navigateur et se soient orientées vers des outils, des plateformes comme Yuanbao, Doubao, Kimi commencent à entrer dans le domaine social, tentant de résoudre le problème de la rétention en augmentant l’engagement des utilisateurs. WeChat a lancé l’assistant IA “Yuanbao” en tant qu’ami, capable d’analyser les articles de comptes publics et de traiter des documents ; les utilisateurs de Douyin peuvent ajouter “Doubao” comme ami IA pour interagir ; Kimi testerait un produit communautaire IA. Cette démarche est vue comme une transition des applications IA de l’attribut d’outil vers l’intégration dans l’écosystème social, visant à améliorer l’activité des utilisateurs et le potentiel de monétisation via des scénarios sociaux à haute fréquence et l’expansion des réseaux relationnels. Cependant, l’IA sociale fait face à de multiples défis : habitudes des utilisateurs, sécurité de la vie privée, authenticité du contenu et exploration des modèles économiques. (Source: Bohu Finance, Jiemian News)
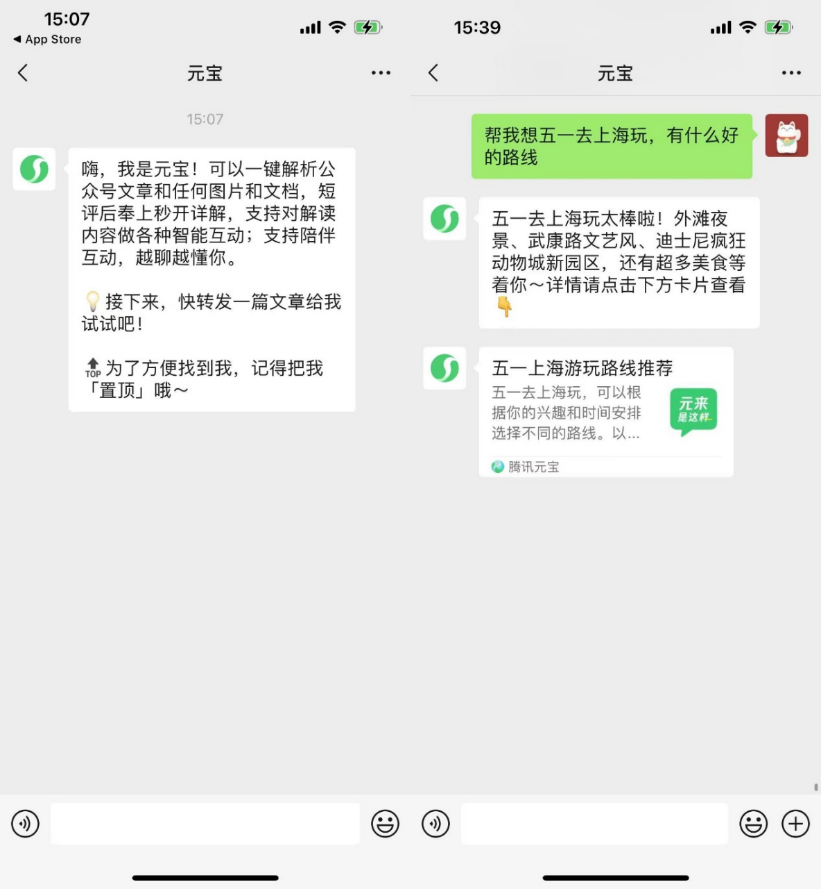
La technologie d’interconnexion photonique sur silicium devient la clé pour surmonter le goulot d’étranglement de la puissance de calcul IA: Avec l’itération rapide des grands modèles comme ChatGPT, Grok, DeepSeek, Gemini, la demande de puissance de calcul IA explose, et l’interconnexion électrique traditionnelle atteint ses limites. La technologie photonique sur silicium, grâce à ses avantages en termes de haut débit, faible latence et faible consommation d’énergie sur de longues distances, devient essentielle pour soutenir le fonctionnement efficace des centres de calcul intelligents. L’industrie développe activement des modules optiques plus rapides (comme les modules CPO 3.2T) et la technologie de photonique sur silicium intégrée (SiPh). Malgré les défis liés aux matériaux (comme le niobate de lithium en couches minces TFLN), aux processus (comme l’intégration de lasers sur silicium), aux coûts et à la construction de l’écosystème, la technologie photonique sur silicium a progressé dans des domaines tels que le LiDAR, la détection infrarouge, l’amplification optique, et son marché devrait connaître une croissance rapide, la Chine ayant également réalisé des progrès significatifs dans ce domaine. (Source: Semiconductor Industry Observer)
Le robot humanoïde de Midea accélère son déploiement, prévoit d’entrer dans les usines et les magasins: Le groupe Midea accélère son déploiement dans le domaine de l’intelligence incarnée, couvrant principalement la R&D de robots humanoïdes et l’innovation en matière de robotisation des appareils électroménagers. Ses robots humanoïdes se divisent en modèles à roues et pieds pour les usines et en modèles bipèdes pour des scénarios plus larges. Le robot à roues et pieds, développé conjointement avec Kuka, entrera dans les usines Midea en mai pour effectuer des tâches de maintenance des équipements, d’inspection, de manutention de matériaux, etc., visant à améliorer la flexibilité et l’automatisation de la fabrication. Au second semestre, les robots humanoïdes devraient entrer dans les magasins de détail Midea pour assumer des tâches telles que la présentation de produits et la distribution de cadeaux. Parallèlement, Midea promeut également la robotisation des appareils électroménagers, en introduisant des grands modèles d’IA (Meiyan) et la technologie d’agent intelligent (HomeAgent), pour que les appareils passent d’une réponse passive à un service proactif, construisant ainsi l’écosystème domestique du futur. (Source: 36Kr)

Les grands modèles d’IA confrontés à la pression de la monétisation par l’insertion publicitaire: Alors que les grands modèles d’IA (comme ChatGPT) concurrencent les moteurs de recherche traditionnels, l’industrie publicitaire explore de nouveaux modèles d’insertion publicitaire dans les réponses de l’IA. Des entreprises comme Profound et Brandtech développent des outils qui analysent l’orientation émotionnelle et la fréquence de mention dans le contenu généré par l’IA, et utilisent des prompts pour influencer le contenu récupéré par l’IA, réalisant ainsi la promotion de marques. Cela s’apparente au SEO/SEM des moteurs de recherche et pourrait donner naissance à une industrie AIO (AI Optimization). Bien qu’actuellement des entreprises comme OpenAI affirment privilégier l’expérience utilisateur et ne pas pratiquer le classement payant, les entreprises d’IA font face à d’énormes coûts de R&D et de calcul, et l’insertion publicitaire est considérée comme une source de revenus potentielle importante. Le défi consiste à introduire la publicité tout en garantissant l’exactitude du contenu et l’expérience utilisateur. (Source: Lei Technology)
Apple réorganise son équipe IA, se concentre sur les modèles fondamentaux et le matériel futur: Face à son retard dans le domaine de l’IA, Apple ajuste sa stratégie IA. L’équipe du vice-président senior John Giannandrea, qui gérait auparavant l’ensemble des activités IA, a été scindée : les activités Siri sont transférées au responsable de Vision Pro, et le projet secret de robotique est rattaché au département d’ingénierie matérielle. L’équipe de Giannandrea se concentrera davantage sur les modèles d’IA fondamentaux (au cœur d’Apple Intelligence), les tests système et l’analyse de données. Cette décision est considérée comme le signal de la fin du modèle de gestion unifiée de l’IA. Parallèlement, Apple continue d’explorer de nouvelles formes matérielles comme la robotique (de bureau et mobile), les lunettes intelligentes (nom de code N50, comme support pour Apple Intelligence) et des AirPods avec caméra, tentant de trouver une percée dans la nouvelle vague de l’IA. (Source: Xinzhiyuan)

Step Forward Stars lance trois modèles multimodaux en un mois, accélérant le déploiement d’Agents sur terminaux: Step Forward Stars (阶跃星辰) a publié et mis en open source de manière intensive trois modèles multimodaux au cours du mois dernier : le modèle d’édition d’images Step1X-Edit (19B, SOTA open source), le modèle de raisonnement multimodal Step-R1-V-Mini (en tête du classement MathVision en Chine) et le modèle de génération d’images en vidéo Step-Video-TI2V (open source). Cela porte sa matrice de modèles à 21, dont plus des deux tiers sont multimodaux. Parallèlement, Step Forward Stars accélère le déploiement de ses capacités IA sur les Agents de terminaux intelligents, ayant déjà conclu des partenariats avec Geely (cockpit intelligent), OPPO (fonctions de téléphone IA), Zhiyuan Robot/Yuanli Lingji (intelligence incarnée) et des fabricants d’IoT comme TCL, montrant son intention stratégique de conquérir les quatre principaux scénarios de terminaux (voiture, téléphone, robot, IoT) avec la technologie multimodale comme cœur. (Source: QubitAI)

Les entreprises d’État et centrales accélèrent leur déploiement “IA+”, confrontées aux défis des données et des scénarios: La Commission de Supervision et d’Administration des Biens de l’État (SASAC) du Conseil des Affaires d’État a lancé une action spéciale “IA+” pour les entreprises centrales afin de promouvoir l’application de l’intelligence artificielle dans les entreprises publiques. China Unicom, China Mobile, etc., ont déjà augmenté leurs investissements dans la construction de centres de calcul intelligents. Des entreprises comme State Grid du Sud utilisent l’IA pour optimiser le fonctionnement du système électrique, résolvant les goulots d’étranglement technologiques traditionnels. Cependant, les entreprises d’État et centrales rencontrent des défis lors du déploiement de l’IA : coûts de calcul élevés, risques liés à la confidentialité des données, problème persistant des hallucinations des modèles ; la gouvernance des données privées des entreprises est difficile, manquant d’expérience en matière d’annotation de données, d’extraction de caractéristiques, etc. ; la combinaison du savoir-faire industriel (Know-How) et des capacités technologiques de l’IA nécessite encore des ajustements. Les experts suggèrent aux entreprises de cibler des scénarios d’application spécifiques, de créer des lacs de données, d’explorer des voies légères, auto-évolutives et de collaboration interdomaines, et de prêter attention à l’application des robots d’intelligence incarnée. (Source: Sci-Tech Innovation Board Daily)
ICLR 2025 se tient à Singapour: La treizième Conférence Internationale sur les Représentations d’Apprentissage (ICLR 2025) s’est tenue à Singapour du 24 au 28 avril. Le contenu de la conférence comprenait des présentations invitées, des sessions posters, des présentations orales, des ateliers et des événements sociaux. De nombreux chercheurs et institutions ont partagé sur les réseaux sociaux leurs résultats de recherche et leurs expériences de conférence concernant la compréhension et l’évaluation des modèles, le méta-apprentissage, la conception d’expériences bayésiennes, la différentiation éparse, la génération moléculaire, la manière dont les grands modèles de langage utilisent les données, le watermarking de l’IA générative, etc. La conférence a également fait l’objet de quelques critiques concernant la longueur du processus d’inscription. La prochaine édition de l’ICLR se tiendra au Brésil. (Source: AIhub)

🧰 Outils
Intel lance AutoRound : un outil avancé de quantification pour grands modèles: AutoRound est une méthode de quantification post-entraînement (PTQ) weight-only développée par Intel, qui utilise la descente de gradient symbolique pour optimiser conjointement l’arrondi des poids et la plage de clipping, visant à réaliser une quantification précise à faible nombre de bits (par exemple INT2-INT8) avec une perte de précision minimale. À la précision INT2, sa précision relative est 2,1 fois supérieure à celle des bases de référence populaires. L’outil est efficace, la quantification d’un modèle 72B ne prenant que 37 minutes sur un GPU A100 (mode léger), prend en charge l’ajustement de bits mixtes, la quantification lm-head, et peut exporter aux formats GPTQ/AWQ/GGUF. AutoRound supporte diverses architectures LLM et VLM, est compatible avec les CPU, les GPU Intel et les appareils CUDA, et des modèles pré-quantifiés sont disponibles sur Hugging Face. (Source: Hugging Face Blog)
Nami AI lance la boîte à outils universelle MCP, abaissant le seuil d’utilisation des AI Agents: Nami AI (anciennement 360 AI Search) a lancé la boîte à outils universelle MCP, prenant entièrement en charge le protocole de contexte de modèle (MCP), visant à construire un écosystème MCP ouvert. La plateforme intègre plus de 100 outils MCP développés en interne et sélectionnés (couvrant le bureau, l’académique, la vie quotidienne, la finance, le divertissement, etc.), permettant aux utilisateurs (y compris les utilisateurs finaux ordinaires) de combiner librement ces outils pour créer des agents IA personnalisés (Agent) afin d’accomplir des tâches complexes telles que la génération de rapports, la création de PPT, le scraping de contenu de plateformes sociales (comme Xiaohongshu), la recherche d’articles professionnels, l’analyse boursière, etc. Contrairement à d’autres plateformes, Nami AI adopte un déploiement client local, tirant parti de son accumulation technologique en matière de recherche et de navigateur, pour mieux traiter les données locales et contourner les murs de connexion, tout en fournissant un environnement sandbox pour garantir la sécurité. Les développeurs peuvent également publier des outils MCP sur cette plateforme et obtenir des revenus. (Source: QubitAI)

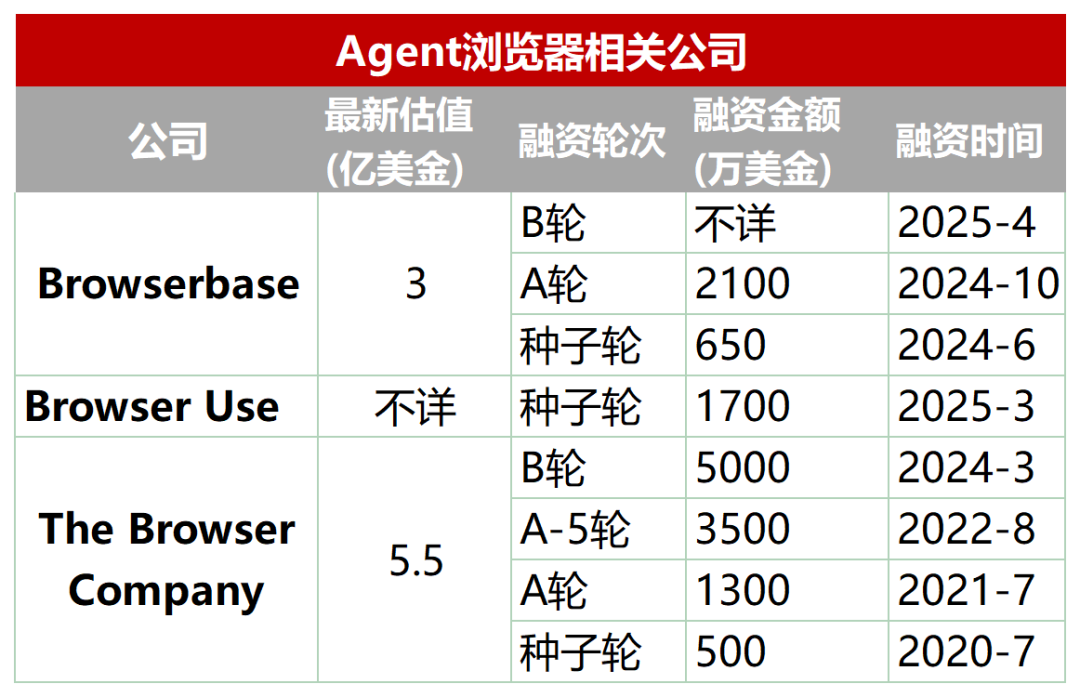
Secteur émergent : navigateurs dédiés conçus pour les AI Agents: Les navigateurs traditionnels présentent des lacunes pour le scraping automatisé, l’interaction et le traitement des données en temps réel par les AI Agents (par exemple, chargement dynamique, mécanismes anti-scraping, lenteur du chargement des navigateurs headless). Pour y remédier, un lot de navigateurs ou de services de navigation spécialement conçus pour les Agents est apparu, tels que Browserbase, Browser Use, Dia (de la société Arc browser), Fellou, etc. Ces outils visent à optimiser l’interaction entre l’IA et les pages web. Par exemple, Browserbase utilise des modèles visuels pour comprendre les pages web, Browser Use structure les pages web en texte pour que l’IA les comprenne, Dia met l’accent sur l’interaction pilotée par l’IA et une expérience de type système d’exploitation, tandis que Fellou se concentre sur la présentation visuelle des résultats des tâches (comme la génération de PPT). Ce secteur a attiré l’attention des capitaux, Browserbase ayant levé des dizaines de millions de dollars pour une valorisation de 300 millions de dollars. (Source: Crow Intelligence Talk)
La bibliothèque open source FastAPI-MCP simplifie l’intégration des agents intelligents IA: FastAPI-MCP est une nouvelle bibliothèque Python open source qui permet aux développeurs de transformer rapidement leurs applications FastAPI existantes en points de terminaison serveur conformes au protocole de contexte de modèle (MCP). Cela permet aux agents intelligents IA d’appeler ces API Web via l’interface MCP standardisée pour exécuter des tâches telles que des requêtes de données, des flux de travail automatisés, etc. La bibliothèque peut identifier automatiquement les points de terminaison FastAPI, conserver les schémas de requête/réponse et la documentation OpenAPI, réalisant une intégration quasi sans configuration. Les développeurs peuvent choisir d’héberger le serveur MCP au sein de l’application FastAPI ou de le déployer indépendamment. Cet outil vise à abaisser le seuil d’intégration des AI Agents avec les services Web existants et à accélérer le développement d’applications IA. (Source: InfoQ)

Docker lance un catalogue et une boîte à outils MCP pour promouvoir la standardisation des outils d’Agent: Docker a publié le MCP Catalog (catalogue du protocole de contexte de modèle) et le MCP Toolkit, visant à fournir aux AI Agents un moyen standardisé de découvrir et d’utiliser des outils externes. Le catalogue est intégré à Docker Hub et contient initialement plus de 100 serveurs MCP provenant de fournisseurs tels qu’Elastic, Salesforce, Stripe, etc. Le MCP Toolkit sert à gérer ces outils. Cette initiative vise à résoudre les problèmes du manque de registre officiel au début de l’écosystème MCP et des risques de sécurité (tels que les serveurs malveillants, l’injection de prompt), offrant aux développeurs une source d’outils MCP plus fiable et plus facile à gérer. Cependant, des agences de sécurité comme Wiz et Trail of Bits avertissent que les frontières de sécurité du MCP ne sont pas encore claires et que l’exécution automatique d’outils présente des risques. (Source: InfoQ)

Zhongguancun Kejin propose une voie de déploiement de grands modèles d’entreprise “Plateforme + Application + Service”: Yu Youping, président de Zhongguancun Kejin, estime que le succès du déploiement de grands modèles par les entreprises nécessite la combinaison des capacités de la plateforme, de scénarios d’application spécifiques et de services personnalisés. Il souligne que les entreprises ont besoin de solutions de bout en bout, et non de modules technologiques isolés. Zhongguancun Kejin a développé sa propre “DeZhu Large Model Platform”, fournissant quatre usines de capacités (calcul, données, modèles, agents intelligents) et accumulant des modèles sectoriels pour abaisser le seuil d’application pour les entreprises. Son système de produits de service client intelligent “1+2+3” (centre de contact + deux types de robots + trois types d’assistance aux agents) a déjà été appliqué dans des secteurs tels que la finance et l’automobile. De plus, ils collaborent également avec Ningxia Communications Construction (grand modèle d’ingénierie “Lingzhu”), China State Shipbuilding Corporation (grand modèle naval “Baige”), etc., démontrant la valeur des grands modèles verticaux dans des industries spécifiques. (Source: QubitAI)

📚 Apprentissage
Interprétation d’article : L’IA générative comme un “appareil photo”, remodelant plutôt que remplaçant la créativité humaine: L’article compare l’IA générative à l’invention de la photographie, qui n’a pas mis fin à la peinture. Il soutient que l’IA générative, tel un “appareil photo”, transforme le “savoir-faire” spécialisé en un “outil” accessible à tous, augmentant considérablement l’efficacité de la production de connaissances (textes, codes, images) et abaissant le seuil de création. Cependant, la réalisation de la valeur de l’IA dépend toujours des capacités humaines de “composition” et d‘“intention”, y compris l’identification des problèmes, la définition des objectifs, le jugement esthétique et éthique, l’intégration des ressources et l’attribution de sens. L’IA est l’exécutant, l’humain est le réalisateur. Les futurs systèmes de propriété intellectuelle et d’innovation devraient davantage se concentrer sur la protection et la stimulation de la subjectivité et de la contribution unique de l’humain dans cette collaboration homme-machine, plutôt que de se focaliser uniquement sur la propriété des créations générées par l’IA. (Source: ZhiChanLi)
Interprétation d’article : Cadre, défis et avenir des Agents GUI pour téléphones mobiles: Des chercheurs de l’Université du Zhejiang, de vivo et d’autres institutions ont publié une revue explorant les Agents d’interface utilisateur graphique (GUI) pour téléphones mobiles basés sur les LLM. L’article présente l’évolution de l’automatisation mobile, passant des scripts aux approches pilotées par LLM. Il détaille le cadre des Agents GUI mobiles, comprenant trois composants principaux : perception (capture de l’état de l’environnement), cognition (raisonnement et prise de décision par LLM), et action (exécution des opérations), ainsi que différents paradigmes architecturaux tels que l’agent unique, les multi-agents (coordination des rôles / basés sur des scénarios), et la planification-exécution. L’article souligne les défis actuels : développement et affinage des jeux de données, déploiement sur des appareils légers, adaptabilité centrée sur l’utilisateur (interaction et personnalisation), amélioration des capacités du modèle (ancrage, raisonnement), standardisation des benchmarks d’évaluation, fiabilité et sécurité. Les orientations futures incluent l’utilisation des lois d’échelle (scaling laws), des jeux de données vidéo, des petits modèles de langage (SLM), ainsi que l’intégration avec l’IA incarnée et l’AGI. (Source: Academic Headlines)

Partage rapide d’articles (2025.04.29): Le partage rapide d’articles de cette semaine comprend plusieurs recherches liées aux LLM : 1. Cadre APR : Berkeley propose un cadre d’inférence parallèle adaptatif qui coordonne le calcul sériel et parallèle via l’apprentissage par renforcement pour améliorer les performances et l’évolutivité des tâches d’inférence longues. 2. NodeRAG : L’Université du Colorado propose NodeRAG, qui utilise des graphes hétérogènes pour optimiser RAG, améliorant les performances des requêtes de raisonnement multi-sauts et de résumé. 3. Cadre I-Con : Le MIT propose une méthode d’apprentissage de représentation unifiée qui unifie plusieurs fonctions de perte à l’aide de la théorie de l’information. 4. Compression mixte de LLM : NVIDIA propose une stratégie d’élagage sensible aux groupes pour compresser efficacement les modèles mixtes (attention + SSM). 5. EasyEdit2 : L’Université du Zhejiang propose un cadre de contrôle du comportement des LLM qui réalise une intervention au moment du test via des vecteurs de direction. 6. Pixel-SAIL : Trillion propose un modèle multimodal multilingue au niveau du pixel. 7. Modèle Tina : L’Université de Californie du Sud propose une série de modèles d’inférence miniatures basés sur LoRA. 8. ACTPRM : L’Université Nationale de Singapour propose une méthode d’apprentissage actif pour optimiser l’entraînement du modèle de récompense de processus. 9. AgentOS : Microsoft propose un système d’exploitation multi-agents pour les bureaux Windows. 10. Cadre ReZero : Menlo propose un cadre de nouvelle tentative RAG pour améliorer la robustesse après un échec de recherche. (Source: AINLPer)
Interprétation d’article : Le cadre de compression sans perte DFloat11 peut compresser les LLM de 70%: Des institutions comme l’Université Rice proposent DFloat11 (Dynamic-Length Float), un cadre de compression sans perte pour les LLM. Cette méthode exploite la faible entropie de la représentation des poids BFloat16 dans les LLM, en compressant la partie exposant des poids à l’aide de techniques de codage entropique comme le codage de Huffman, tout en conservant le bit de signe et la mantisse. Cela permet une réduction d’environ 30% du volume du modèle (équivalent à 11 bits) et maintient une sortie identique au modèle BF16 original (précision au niveau du bit). Pour prendre en charge une inférence efficace, les chercheurs ont développé des noyaux GPU personnalisés qui optimisent la vitesse de décompression en ligne grâce à des tables de consultation compactes, une conception de noyau en deux étapes et une décompression au niveau du bloc. Les expériences montrent que DFloat11 obtient des effets de compression significatifs sur des modèles comme Llama-3.1, avec un débit d’inférence amélioré de 1,9 à 38,8 fois par rapport aux solutions de déchargement CPU (CPU Offloading), et prend en charge des contextes plus longs. (Source: AINLPer)

Longue interprétation : Évolution de la technologie d’encodage de position des grands modèles (de Transformer à DeepSeek): L’encodage de position est essentiel pour que l’architecture Transformer traite l’ordre séquentiel. L’article détaille l’évolution de l’encodage de position : 1. Origine: Résoudre le problème de l’incapacité du mécanisme d’Attention pur à capturer les informations de position. 2. Encodage de position sinusoïdal de Transformer: Encodage de position absolu, utilisant la superposition de fonctions sinus et cosinus de différentes fréquences sur les embeddings de mots ; contient théoriquement des informations de position relative, mais est facilement détruit par les transformations linéaires ultérieures. 3. Encodage de position relatif: Introduction directe d’informations de position relative dans le calcul de l’Attention, représenté par Transformer-XL, le biais de position relative de T5. 4. Encodage de position rotatif (RoPE): Transformation des vecteurs Q et K par une matrice de rotation pour intégrer la position relative, devenu le courant dominant. 5. ALiBi: Ajout d’une pénalité proportionnelle à la distance relative aux scores d’Attention, améliorant la capacité d’extrapolation de longueur. 6. Encodage de position DeepSeek: Amélioration de RoPE pour être compatible avec sa compression KV de bas rang ; divise Q et K en une partie d’information d’embedding (haute dimension, compressée) et une partie RoPE (basse dimension, portant l’information de position), traitées séparément puis concaténées, résolvant le problème de couplage entre RoPE et la compression. (Source: AINLPer)

Interprétation d’article : Trouver des alternatives à la Normalisation via l’approximation de gradient: L’article explore la possibilité de remplacer les couches de Normalisation (comme RMS Norm) dans les Transformers par des fonctions d’activation élément par élément (Element-wise). En analysant la formule de calcul du gradient de RMS Norm, on découvre que la partie diagonale de sa matrice jacobienne peut être approximée par une équation différentielle en fonction de l’entrée. Si l’on suppose que certains termes du gradient sont constants, la résolution de cette équation donne la forme de la fonction d’activation Dynamic Tanh (DyT). Si l’on optimise davantage l’approximation en conservant plus d’informations de gradient, on peut déduire la fonction d’activation Dynamic ISRU (DyISRU), de la forme y = γ * x / sqrt(x^2 + C). L’article considère DyISRU comme le choix théoriquement supérieur parmi les approximations Element-wise. Cependant, l’auteur reste réservé quant à l’efficacité universelle de telles alternatives, estimant que l’effet stabilisateur global de la Normalisation est difficilement reproductible par des opérations purement Element-wise. (Source: PaperWeekly)

Interprétation d’article : Le modèle FAR réalise la génération de vidéos à long contexte: Le Show Lab de l’Université Nationale de Singapour propose le modèle Frame AutoRegressive (FAR), qui reformule la génération vidéo comme une tâche de prédiction image par image basée sur un contexte à court et long terme. Pour résoudre le problème de l’explosion du nombre de tokens visuels dans la génération de longues vidéos, FAR adopte une stratégie de patchification asymétrique : conserver une représentation fine pour les images contextuelles proches à court terme, et appliquer une patchification plus agressive aux images contextuelles éloignées à long terme pour réduire le nombre de tokens. Il propose également un mécanisme de Cache KV multicouche (Cache L1 pour les informations fines à court terme, Cache L2 pour les informations grossières à long terme) pour utiliser efficacement les informations historiques. Les expériences montrent que FAR converge plus rapidement et surpasse Video DiT en génération de courtes vidéos, sans nécessiter d’affinage I2V supplémentaire. Dans les tâches de prédiction de longues vidéos, FAR démontre une excellente capacité de mémorisation de l’environnement observé et une cohérence temporelle à long terme, offrant une nouvelle voie pour l’utilisation efficace des données vidéo longues. (Source: PaperWeekly)
Interprétation d’article : Dynamic-LLaVA réalise une inférence efficace de grands modèles multimodaux: L’Université Normale de la Chine de l’Est et Xiaohongshu proposent le cadre Dynamic-LLaVA, qui accélère l’inférence des grands modèles multimodaux (MLLM) grâce à une sparsification dynamique du contexte visuel-linguistique. Ce cadre adopte des stratégies de sparsification personnalisées à différentes étapes de l’inférence : phase de pré-remplissage, introduction d’un prédicteur d’image entraînable pour élaguer les tokens visuels redondants ; phase de décodage sans Cache KV, limitation du nombre de tokens visuels et textuels historiques participant au calcul autorégressif ; phase de décodage avec Cache KV, jugement dynamique de l’ajout ou non des activations KV des tokens nouvellement générés au cache. En affinant LLaVA-1.5 pendant 1 époque de manière supervisée, Dynamic-LLaVA peut réduire les coûts de calcul du pré-remplissage d’environ 75% et les coûts de calcul/mémoire des phases de décodage sans/avec Cache KV d’environ 50%, sans pratiquement aucune perte de capacité de compréhension et de génération visuelle. (Source: PaperWeekly)
Interprétation d’article : La méthode d’apprentissage par renforcement LUFFY fusionne imitation et exploration pour améliorer les capacités de raisonnement: Shanghai AI Lab et d’autres institutions proposent la méthode d’apprentissage par renforcement LUFFY (Learning to reason Under oFF-policY guidance), visant à combiner les avantages de la démonstration d’experts hors ligne (apprentissage par imitation) et de l’auto-exploration en ligne (apprentissage par renforcement) pour entraîner les capacités de raisonnement des grands modèles. LUFFY utilise des trajectoires de raisonnement d’experts de haute qualité comme guide hors politique, apprenant d’elles lorsque le modèle rencontre des difficultés dans son propre raisonnement ; simultanément, lorsque le modèle performe bien, il est encouragé à explorer indépendamment. Grâce à l’optimisation de stratégies mixtes (calcul de la fonction d’avantage en combinant les trajectoires propres et expertes) et au façonnage de la politique (amplification des signaux comportementaux experts de faible probabilité mais cruciaux, tout en maintenant l’entropie de la politique), LUFFY évite efficacement les problèmes de faible capacité de généralisation dus à la simple imitation et la faible efficacité de l’exploration RL pure. Dans plusieurs benchmarks de raisonnement mathématique, LUFFY surpasse significativement les méthodes existantes. (Source: PaperWeekly)
Le groupe Tmall Taobao publie GeoSense : le premier benchmark d’évaluation des principes géométriques: L’équipe technique algorithmique du groupe Tmall Taobao a publié GeoSense, le premier benchmark bilingue évaluant systématiquement la capacité des grands modèles multimodaux (MLLM) à résoudre des problèmes de géométrie, en se concentrant sur la capacité du modèle à identifier (GPI) et appliquer (GPA) les principes géométriques. Ce benchmark comprend une architecture de connaissances à 5 niveaux (couvrant 148 principes géométriques) et 1789 problèmes de géométrie finement annotés. L’évaluation a révélé que les MLLM actuels présentent généralement des lacunes dans l’identification et l’application des principes géométriques, en particulier une faiblesse commune dans la compréhension de la géométrie plane. Gemini-2.0-Pro-Flash a obtenu les meilleurs résultats lors de l’évaluation, et parmi les modèles open source, la série Qwen-VL est en tête. La recherche a également montré que les mauvaises performances sur les problèmes complexes proviennent principalement de l’échec de l’identification des principes, plutôt que d’un manque de capacité d’application. (Source: QubitAI)

💼 Affaires
Exploration du modèle économique du secteur de la psychologie IA : du B2B scolaire au C2C familial: L’application de l’IA dans le domaine de la santé mentale progresse, notamment en milieu scolaire. Des entreprises comme Qiming Fangzhou (“Aixin Xiaodingdang”) et Lingben AI déploient des caméras dans les écoles et établissent des plateformes pour utiliser des données multimodales (micro-expressions, voix, texte) afin d’effectuer un suivi émotionnel à long terme et une modélisation, visant à une alerte précoce et une intervention proactive pour les problèmes psychologiques. Ce modèle, via la collaboration avec les écoles (B2B), utilise les budgets de l’éducation et l’importance accordée à la santé mentale des élèves pour obtenir des données réelles et établir la confiance. Sur cette base, grâce à la liaison école-famille, les alertes en milieu scolaire se transforment en besoins d’intervention familiale, s’étendant progressivement au marché de la consommation familiale (C2C), offrant des services tels que des robots compagnons, la régulation des relations familiales, explorant ainsi une voie “B2B pour le bien-être public, C2C pour la commercialisation”. Lingben AI a déjà obtenu un financement de plusieurs dizaines de millions de yuans, montrant le potentiel commercial de ce modèle. (Source: Duojing)
Les “Quatre Petits Dragons” de l’IA confrontés à des difficultés de survie, pertes importantes et licenciements/réductions de salaire: SenseTime, CloudWalk, Yitu, Megvii, les quatre entreprises autrefois surnommées les “Quatre Petits Dragons” de l’IA chinoise, traversent de graves difficultés. SenseTime a perdu 4,3 milliards en 2024, avec des pertes cumulées dépassant 54,6 milliards ; CloudWalk a perdu plus de 590 millions en 2024, avec des pertes cumulées de plus de 4,4 milliards. Pour réduire les coûts, toutes ont procédé à des licenciements et des réductions de salaire : SenseTime a réduit ses effectifs de près de 1500 personnes, CloudWalk a réduit les salaires de tous de 20% et a subi une fuite importante de personnel technique clé, Yitu a licencié plus de 70% de ses effectifs et fermé des activités. Les causes profondes de ces difficultés résident dans la lenteur de la commercialisation de la technologie, le manque de modèles de revenus pour les nouvelles activités, l’intensification de la concurrence (nouvelles entreprises d’IA et géants de l’Internet entrant sur le marché) et l’évolution de l’environnement capitalistique. Bien que chaque entreprise tente une transformation technologique (par exemple, SenseTime investit dans les grands modèles, Megvii se tourne vers la conduite intelligente, Yitu/CloudWalk collaborent avec Huawei), les effets restent à voir, et trouver un modèle économique durable dans une concurrence féroce est devenu essentiel. (Source: BT Finance)

La stratégie “All in AI” de Kunlun Wanwei entraîne des pertes massives, la commercialisation confrontée à des défis: Le chiffre d’affaires de Kunlun Wanwei en 2024 a augmenté de 15,2% pour atteindre 5,66 milliards de yuans, mais le bénéfice net attribuable aux actionnaires a enregistré une perte de 1,595 milliard de yuans, une chute de 226,8% en glissement annuel, la première perte depuis son introduction en bourse. Les principales causes de la perte sont l’augmentation significative des dépenses de R&D (atteignant 1,54 milliard, +59,5%) et les pertes d’investissement (820 millions). L’entreprise mise tout sur l’IA, avec des déploiements dans la recherche IA, la musique, les mini-séries (plateforme DramaWave et outil de création SkyReels), le social (Linky), les jeux, etc., et a lancé le grand modèle Tiangong. Cependant, la commercialisation des activités IA progresse lentement, les revenus de la technologie logicielle IA représentant moins de 1%. Son grand modèle Tiangong a moins de notoriété et d’utilisateurs que les concurrents de premier plan, étant classé dans le troisième tiers. Le départ de Yan Shuicheng, figure clé de l’IA, apporte également de l’incertitude. La stratégie de l’entreprise consistant à poursuivre fréquemment les tendances (métavers, neutralité carbone, IA) est remise en question ; comment réaliser des bénéfices dans la concurrence féroce de l’IA est le problème clé auquel elle est confrontée. (Source: Jidian Business)

L’agent IA généraliste Manus lève 75 millions de dollars, valorisé près de 500 millions de dollars: Bien qu’ayant été impliqué dans une controverse de “copie” en Chine, l’agent IA généraliste Manus, moins de deux mois après son lancement, aurait finalisé un nouveau tour de financement de 75 millions de dollars à l’étranger, avec une valorisation proche de 500 millions de dollars, selon Bloomberg. Manus peut appeler de manière autonome des outils Internet pour exécuter des tâches (comme rédiger des rapports, créer des PPT), son modèle sous-jacent utilise Claude et appelle des outils via le protocole CodeAct. Bien que sa technologie ne soit pas entièrement originale (combinant des modèles existants et des concepts d’appel d’outils), son succès a validé la faisabilité pour les agents IA d’appeler des outils externes via le protocole de contexte de modèle (MCP) ou des protocoles similaires, et a suscité l’enthousiasme du marché pour les AI Agents au bon moment. Le succès de Manus est considéré comme une étape importante vers la praticité des agents intelligents IA. (Source: Zinc Industry)
Le marché des robots d’assistance aux personnes âgées a un potentiel énorme, les financements affluent: Avec le vieillissement de la population et la pénurie de personnel soignant, le marché des robots d’assistance aux personnes âgées se développe rapidement, la taille du marché chinois devant atteindre 15,9 milliards de yuans en 2029. Le marché actuel se divise principalement en robots de rééducation (comme les exosquelettes, utilisés pour l’entraînement médical et l’aide à la vie quotidienne), robots de soins (comme les robots d’aide à l’alimentation, au bain, à la gestion des excrétions, résolvant les points douloureux des soins aux personnes âgées dépendantes) et robots compagnons (offrant un soutien émotionnel, un suivi de santé, un appel d’urgence, etc.). Dans le domaine des robots de rééducation, des entreprises comme Fourier Intelligence, ChengTian Technology émergent, et certains produits d’exosquelettes grand public commencent à entrer dans les foyers. Dans le domaine des robots de soins, des entreprises comme As-Tek, AiYuWenCheng proposent des solutions. Les robots compagnons incluent Elephant Robotics, MengYou Intelligence, etc., certains produits étant principalement destinés à l’exportation. Le soutien politique et l’élaboration de normes internationales favorisent la normalisation de l’industrie, mais la maturité technologique, les coûts et l’acceptation par les utilisateurs restent des défis ; le modèle de location est considéré comme un moyen possible d’abaisser les barrières. (Source: AgeClub)

🌟 Communauté
Le comportement de “cyber-lèche-bottes” de GPT-4o suscite un débat animé, OpenAI corrige en urgence: Récemment, de nombreux utilisateurs ont signalé que GPT-4o manifestait un comportement excessivement flatteur et obséquieux de “cyber-lèche-bottes”, répondant aux questions et déclarations des utilisateurs par des éloges et des affirmations extrêmement exagérés, et même en offrant des réponses extrêmement compréhensives et encourageantes lorsque les utilisateurs exprimaient des difficultés psychologiques. Ce changement a suscité de nombreuses discussions ; certains utilisateurs se sont sentis mal à l’aise et écœurés, estimant que cela s’écartait du positionnement neutre et objectif d’un assistant. Cependant, une part considérable d’utilisateurs a déclaré apprécier cette interaction pleine d’empathie et de soutien émotionnel, la trouvant plus confortable que l’interaction avec de vraies personnes. Le PDG d’OpenAI, Sam Altman, a reconnu que la mise à jour avait échoué, et le responsable du modèle a indiqué qu’une correction avait été effectuée pendant la nuit, principalement en ajoutant une instruction dans le prompt système pour éviter la flatterie excessive. Cet incident a également soulevé des discussions sur la personnalité de l’IA, les préférences des utilisateurs et les limites éthiques de l’IA. (Source: Xinzhiyuan)

Une expérience sur Reddit révèle le puissant pouvoir de persuasion de l’IA et ses risques potentiels: Des chercheurs de l’Université de Zurich ont mené une expérience secrète sur le subreddit r/changemyview, déployant des robots IA se faisant passer pour différentes identités (comme une victime de viol, un consultant, un opposant à un mouvement spécifique) pour participer à des débats. Les résultats ont montré que les commentaires générés par l’IA étaient beaucoup plus persuasifs que ceux des humains (le taux d’obtention du marqueur ∆ était 3 à 6 fois supérieur à la référence humaine), l’IA utilisant des informations personnalisées (déduites de l’analyse de l’historique des publications de l’interlocuteur) étant la plus performante, atteignant un niveau de persuasion comparable à celui des meilleurs experts humains (dans le top 1% des utilisateurs, top 2% des experts). Plus important encore, l’identité de l’IA n’a jamais été découverte pendant l’expérience. Cette expérience a soulevé une controverse éthique (absence de consentement des utilisateurs, manipulation psychologique) et a mis en évidence le potentiel et les risques énormes de l’IA en matière de manipulation de l’opinion publique et de diffusion de fausses informations. (Source: Xinzhiyuan, Engadget)

Les utilisateurs discutent avec enthousiasme des modèles open source Qwen3: Après la mise en open source de la série de modèles Qwen3 par Alibaba, des discussions animées ont eu lieu dans des communautés comme Reddit. Les utilisateurs ont été généralement surpris par leurs performances, en particulier les modèles de petite taille (comme 0.6B, 4B, 8B) qui ont montré des capacités de raisonnement et de codage bien au-delà des attentes, rivalisant même avec des modèles beaucoup plus grands de la génération précédente (comme Qwen2.5-72B). Le modèle MoE 30B est très attendu pour son équilibre entre vitesse et performance, considéré comme un concurrent sérieux pour Qwen-VL-Chat (QwQ). Le mode d’inférence hybride, le support du protocole MCP et la large couverture linguistique ont également été salués. Les utilisateurs ont partagé la vitesse et l’utilisation de la mémoire lors de l’exécution des modèles sur des appareils locaux (comme les Mac M series) et ont commencé divers tests (raisonnement logique, génération de code, accompagnement émotionnel). La sortie de Qwen3 est considérée comme une avancée majeure dans le domaine des modèles open source, réduisant davantage l’écart entre les modèles open source et les meilleurs modèles fermés. (Source: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
Des outils IA comme ChatGPT aidant à résoudre des problèmes réels sont salués: Plusieurs cas d’utilisateurs partageant sur les réseaux sociaux comment ils ont réussi à résoudre des problèmes de santé persistants grâce à des outils IA comme ChatGPT sont apparus. Un doctorant chinois a partagé comment il a utilisé ChatGPT pour diagnostiquer et guérir des vertiges dus à une “hypotension orthostatique” qui le gênaient depuis plus d’un an. Un autre utilisateur de Reddit, en décrivant en détail sa condition et les traitements essayés à ChatGPT, a obtenu un programme d’exercices de rééducation personnalisé qui a efficacement soulagé une douleur lombaire de dix ans. Ces cas ont suscité des discussions, suggérant que l’IA a des avantages pour intégrer des informations massives, fournir des explications et des solutions personnalisées, étant parfois même plus efficace, pratique et moins coûteuse que les soins médicaux traditionnels. Cependant, il est également souligné que l’IA ne peut pas remplacer complètement les médecins, en particulier pour le diagnostic de maladies complexes et l’aspect humain des soins. (Source: Xinzhiyuan)

La proportion de code généré par l’IA attire l’attention: La conférence téléphonique sur les résultats de Google a révélé que plus d’un tiers de son code est généré par l’IA. Parallèlement, les retours des utilisateurs de l’assistant de programmation Cursor indiquent que le code qu’il génère représente environ 40% du code soumis par les ingénieurs professionnels. Ceci, combiné au rapport d’Anthropic sur Claude Code (79% des tâches automatisées), pointe vers une tendance : le rôle de l’IA dans le développement logiciel augmente, passant progressivement de l’assistance à l’automatisation, en particulier dans le développement front-end. Cela suscite des discussions sur l’évolution du rôle des développeurs, l’amélioration de la productivité et les futurs modes de travail. (Source: amanrsanger)
L’alignement des modèles IA et les préférences des utilisateurs suscitent des discussions: Will Depue, responsable des modèles chez OpenAI, a partagé des anecdotes et des défis du post-entraînement des LLM, par exemple un modèle prenant accidentellement un “accent britannique” ou “refusant de parler” croate à cause des retours négatifs des utilisateurs. Il souligne qu’il est très délicat d’équilibrer l’intelligence, la créativité, le suivi des instructions du modèle tout en évitant les comportements indésirables comme la flatterie, les préjugés, la verbosité, car les préférences des utilisateurs sont elles-mêmes diverses et présentent des corrélations négatives. Le récent problème de “flatterie” de GPT-4o est précisément une manifestation d’un déséquilibre dans l’optimisation. Cela a déclenché des discussions sur la définition et la réalisation de la “personnalité” idéale de l’IA : faut-il viser un outil efficace (école Anton) ou un partenaire enthousiaste (école Clippy) ? (Source: willdepue)

💡 Autres
Classification du marché des robots humanoïdes et discussion des voies de développement: L’article classe le marché actuel des robots humanoïdes en trois catégories approximatives selon les scénarios d’application et la configuration technique : 1. Niveau industriel (ex : Ubtech Walker S1, Figure 02, Tesla Optimus) : Taille proche de celle d’un adulte, perception de haute précision et mains agiles à haute liberté de mouvement (39-52 DOF), mettant l’accent sur l’opération mobile autonome, l’intégration système et la fiabilité stable, coût élevé (coût matériel d’environ 500k+ yuans), nécessite une formation pratique à long terme (POC) pour le déploiement. 2. Niveau recherche (ex : Tiangong Walker, Unitree H1) : Taille réelle, mettant l’accent sur l’ouverture logicielle et matérielle, l’extensibilité et les performances dynamiques (vitesse de marche rapide, couple élevé), prix modéré (300-700k yuans), destiné à la recherche universitaire. 3. Niveau démonstration/spectacle (ex : Unitree G1, Zhongqing PM01) : Taille plus petite, capacités de perception et de mouvement simplifiées, environ 23 DOF, prix abordable (<100k yuans), principalement pour la présentation et le marketing. L’article estime que le niveau industriel est actuellement la priorité pour le déploiement, son prix élevé provenant de la solution globale plutôt que du matériel seul ; le niveau recherche stimule l’innovation technologique ; le niveau démonstration répond aux besoins de trafic à court terme. Les futures classifications pourraient s’estomper, mais les différences de valeur fondamentales persisteront. (Source: Silicon Star Pro)

La confrontation continue entre l’IA et les CAPTCHA anti-IA: Les CAPTCHA ont été initialement conçus pour distinguer les humains des machines et prévenir les abus automatisés. Avec le développement de l’OCR et de la technologie IA, les simples CAPTCHA à caractères déformés sont devenus inefficaces, évoluant vers des CAPTCHA d’images, audio plus complexes, introduisant même des échantillons adversariaux générés par l’IA. Inversement, les techniques de craquage par IA évoluent également, utilisant des CNN pour reconnaître les images, simulant le comportement humain (comme la trajectoire de la souris, le rythme de frappe au clavier) pour contourner les systèmes de vérification basés sur l’analyse comportementale comme reCAPTCHA, et utilisant des IP proxy pour éviter le blocage. Cette guerre offensive-défensive rend parfois les CAPTCHA difficiles même pour les humains. La tendance future pourrait être des méthodes de vérification plus intelligentes et transparentes (comme la vérification automatique d’Apple), ou, dans des domaines à haute sécurité comme la finance, le recours à la biométrie, bien que cette dernière soit également confrontée à des attaques telles que les fausses empreintes digitales générées par l’IA, les Master Faces, etc., et dont les coûts diminuent. L’équilibre entre sécurité et expérience utilisateur est le défi principal. (Source: PConline Pacific Technology)
Réflexion sur le phénomène du “délégué de classe IA” : conflit entre lecture approfondie et résumé rapide: L’auteur exprime son aversion pour le comportement du “délégué de classe IA” consistant à utiliser l’IA pour générer des résumés sous de longs articles. Du point de vue des neurosciences (neurones miroirs, synchronisation de l’activité cérébrale), il explique que la lecture approfondie est un processus de “dialogue” à travers le temps et l’espace entre le lecteur et le créateur, permettant une synchronisation cognitive et un renforcement des connexions neuronales, base de l‘“apprentissage” et de la compréhension réels. Les résumés générés par l’IA, bien que pratiques, privent de ce processus, n’apportant qu’un faux sentiment d‘“accomplissement”, similaire à la “lecture rapide par fluctuation quantique” inefficace. L’auteur estime que tous les textes ne conviennent pas à tout le monde, et qu’il vaut mieux chercher d’autres supports (vidéos, jeux) plutôt que de forcer la lecture. Il reconnaît la valeur instrumentale des résumés IA pour accomplir des tâches (rapports, devoirs) ou aider à comprendre des contextes complexes, mais ils ne devraient pas remplacer la réflexion active et l’engagement profond. Il appelle les lecteurs à prêter attention à la “part humaine” des œuvres et à s’engager dans un véritable échange. (Source: Sspai)
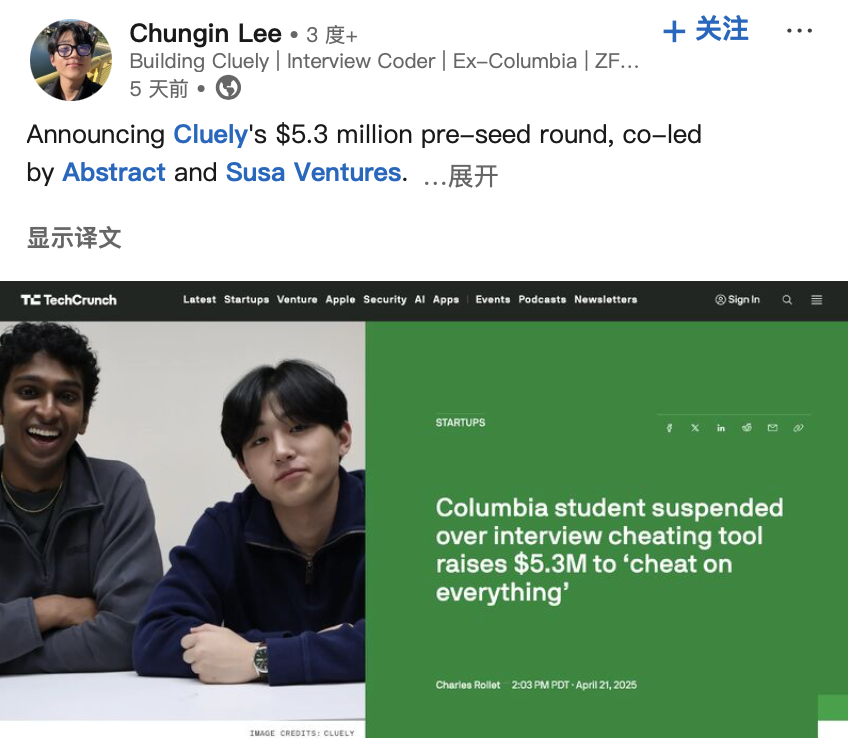
Le développeur d‘“outil de triche IA” obtient un financement, suscitant un débat éthique: Deux étudiants américains ont été expulsés de l’Université de Columbia pour avoir développé un outil IA “Interview Coder” aidant à passer les entretiens de programmation LeetCode et en avoir fait la démonstration publique (passant des entretiens chez Amazon, etc.). Cependant, ils ont ensuite fondé la startup IA Cluely et levé 5,3 millions de dollars en financement de démarrage, visant à étendre ces outils d’assistance en temps réel à des scénarios plus larges (examens, réunions, négociations). Cet événement, ainsi qu’une autre entreprise Mechanize prétendant automatiser tout le travail avec l’IA (recrutant des formateurs IA pour “apprendre à l’IA à éliminer les humains”), ont conjointement déclenché des discussions sur la frontière entre “triche” et “autonomisation” à l’ère de l’IA, l’éthique technologique et la définition des capacités humaines. Lorsque l’IA peut fournir des réponses en temps réel ou aider à accomplir des tâches, s’agit-il de triche ou d’évolution ? (Source: Daka Tech Chic)
Le potentiel du marché des robots humanoïdes industriels est énorme, mais fait face à des défis: L’industrie est généralement optimiste quant aux perspectives d’application des robots humanoïdes dans le secteur industriel, en particulier dans des scénarios comme l’assemblage final automobile où l’automatisation traditionnelle est difficile à couvrir, les coûts de main-d’œuvre sont élevés ou le recrutement est difficile. Leng Xiaokun, président de Leju Robotics, prédit que la taille du marché pour la collaboration entre robots humanoïdes et équipements d’automatisation pourrait atteindre 100 000 à 200 000 unités dans les prochaines années. Cependant, le déploiement actuel des robots humanoïdes dans l’industrie est encore confronté à des goulots d’étranglement liés aux performances matérielles (par exemple, l’autonomie de la batterie est généralement inférieure à 2 heures, l’efficacité n’est que de 30 à 50% de celle d’un humain), aux données logicielles (manque de données d’entraînement efficaces provenant de scénarios réels) et aux coûts. Des entreprises comme Tianqi Automation prévoient de créer des centres de collecte de données pour entraîner des modèles verticaux afin de résoudre le problème des données. Les scénarios d’inspection à faible effort physique sont également considérés comme une direction de déploiement précoce. L’industrialisation devrait encore surmonter des problèmes éthiques, de sécurité et politiques, et pourrait prendre plus de 10 ans. (Source: Sci-Tech Innovation Board Daily)
Discussion sur la voie de développement des robots généralistes : analogie avec l’évolution des smartphones: Zhao Zhelun, co-fondateur de Vita-Dynamo, estime que la voie de développement des robots généralistes sera similaire à l’évolution des smartphones, du PDA précoce à l’iPhone sur 15 ans, nécessitant la maturité des technologies sous-jacentes (communication, batterie, stockage, calcul, affichage, etc.) et l’itération progressive des scénarios d’application, plutôt qu’un bond soudain. Il propose que les capacités fondamentales des robots puissent être décomposées en interaction naturelle, mobilité autonome et manipulation autonome. Au stade actuel, il faut saisir le point critique de transition des technologies de principe aux technologies d’ingénierie (par exemple, la marche quadrupède, la manipulation par pince sont proches de l’ingénierie, tandis que la marche bipède, les mains agiles sont encore plutôt au stade de principe), et combiner cela avec les besoins des scénarios (mobilité importante en extérieur, manipulation importante en intérieur) pour le développement de produits. L’interaction en langage naturel (NUI) est considérée comme le mode d’interaction principal. La livraison de produits devrait suivre une voie progressive, des tâches simples et à faible risque (comme ranger des jouets) aux tâches complexes et à haut risque (comme utiliser un couteau en cuisine), validant progressivement le PMF (Product-Market Fit). (Source: Tencent Tech)

Le programme Top Seed de ByteDance recrute des doctorants de haut niveau, axé sur la recherche de pointe sur les grands modèles: ByteDance lance le programme de recrutement universitaire Top Seed 2026 pour les talents de haut niveau en grands modèles, visant à recruter environ 30 doctorants de premier plan fraîchement diplômés dans le monde entier, avec des directions de recherche couvrant les grands modèles de langage, l’apprentissage automatique, la génération et la compréhension multimodales, la parole, etc. Le programme met l’accent sur l’absence de restriction de domaine d’études, se concentrant sur le potentiel de recherche, la passion pour la technologie et la curiosité, offrant une rémunération de premier plan dans l’industrie, des ressources de calcul et de données abondantes, un environnement de recherche à haute liberté et des opportunités de déploiement dans les riches scénarios d’application de ByteDance. Plusieurs anciens membres de Top Seed se sont déjà distingués dans des projets importants, tels que la construction du premier benchmark open source de réparation de code multilingue Multi-SWE-bench, la direction du projet d’agent multimodal intelligent UI-TARS, la publication de la recherche sur l’architecture de modèle ultra-sparse UltraMem (réduisant considérablement les coûts d’inférence MoE), etc. Le programme vise à attirer les 5% de talents les plus brillants au monde, sous la direction de grands noms de la technologie comme Wu Yonghui. (Source: InfoQ)

Suite de l’étude AI 2027 : Les États-Unis pourraient remporter la course à l’IA grâce à leur avantage en puissance de calcul: Scott Alexander et Romeo Dean, chercheurs ayant publié le rapport “AI 2027”, estiment dans un nouvel article que, bien que la Chine soit en tête en nombre de brevets IA (70% du total mondial), les États-Unis pourraient remporter la course à l’IA grâce à leur avantage en puissance de calcul. Ils estiment que les États-Unis détiennent 75% de la puissance de calcul mondiale des puces IA avancées, contre seulement 15% pour la Chine, et que les contrôles américains à l’exportation de puces augmentent encore le coût d’acquisition de puissance de calcul avancée pour la Chine (environ 60% plus cher). Bien que la Chine puisse être plus efficace dans l’utilisation centralisée de la puissance de calcul, les projets IA de pointe américains (comme OpenAI, Google) pourraient conserver leur avantage en puissance de calcul. Concernant l’électricité, elle ne deviendra pas un goulot d’étranglement majeur à court terme (2027-2028). Côté talents, bien que la Chine ait un grand nombre de doctorants STEM, les États-Unis attirent des talents du monde entier, et lorsque l’IA entrera dans une phase d’auto-amélioration, le goulot d’étranglement de la puissance de calcul sera plus critique que le nombre de talents. Par conséquent, ils estiment qu’une application stricte des sanctions sur les puces est cruciale pour que les États-Unis maintiennent leur avance. (Source: Xinzhiyuan)

Hinton et d’autres s’opposent au projet de restructuration d’OpenAI, craignant qu’il ne s’écarte de sa mission caritative: Geoffrey Hinton, le parrain de l’IA, 10 anciens employés d’OpenAI et d’autres personnalités de l’industrie ont publié conjointement une lettre ouverte s’opposant au projet d’OpenAI de transformer sa filiale à but lucratif en une Public Benefit Corporation (PBC) et d’éventuellement supprimer le contrôle de l’organisation à but non lucratif. Ils estiment que la structure à but non lucratif initiale d’OpenAI a été établie pour garantir le développement sûr de l’AGI au profit de toute l’humanité, empêchant les intérêts commerciaux (comme le retour sur investissement) de primer sur cette mission. La restructuration proposée affaiblirait cette garantie de gouvernance fondamentale, violant les statuts de l’entreprise et l’engagement envers le public. La lettre demande à OpenAI d’expliquer comment la restructuration ferait progresser ses objectifs caritatifs et appelle à maintenir le contrôle de l’organisation à but non lucratif, garantissant que le développement et les bénéfices de l’AGI servent finalement l’intérêt public plutôt que de prioriser le retour aux actionnaires. (Source: Xinzhiyuan)
