
Mots-clés:Modèle Wenxin, Modèle IA, Multimodal, Agent, Wenxin 4.5 Turbo, X1 Turbo, DeepSeek V3, Compréhension multimodale, Baidu Xinxiang, Protocole MCP, Modèle de paiement IA, Inférence de modèle LoRA
🔥 Focus
Baidu lance Wenxin 4.5 Turbo et X1 Turbo, ciblant DeepSeek: Lors de la conférence Baidu Create 2025, Li Yanhong a annoncé les grands modèles Wenxin 4.5 Turbo et X1 Turbo, mettant l’accent sur les capacités de compréhension et de génération multimodales. Il a souligné que leurs coûts ne représentent respectivement que 40 % de ceux de DeepSeek V3 et 25 % de ceux de DeepSeek R1. Li Yanhong estime que le multimodal est la tendance future et que le marché des modèles purement textuels se réduira. Ce lancement vise à combler les lacunes de DeepSeek en matière de multimodalité et de coût, démontrant la détermination de Baidu à concurrencer les leaders de l’industrie au niveau des modèles. (Source : 36氪)

Comparaison des performances des modèles d’IA : o3 et Gemini 2.5 Pro ont chacun leurs forces: L’o3 d’OpenAI et le Gemini 2.5 Pro de Google montrent une concurrence féroce dans plusieurs nouveaux benchmarks. o3 performe mieux dans l’analyse d’énigmes de romans longs (FictionLiveBench), tandis que Gemini 2.5 Pro est en tête pour le raisonnement physique et spatial (PHYBench), les compétitions mathématiques (USMO) et la géolocalisation (GeoGuessing), tout en étant moins cher (environ 1/4 du coût d’o3). Les résultats sont mitigés pour les énigmes visuelles (Visual Puzzles) et les questions-réponses visuelles de base (NaturalBench). Cela indique que les performances des modèles de pointe actuels dépendent fortement des tâches spécifiques et des benchmarks utilisés, sans qu’il y ait de leader absolu. (Source : o3 breaks (some) records, but AI becomes pay-to-win
)
L’IA s’oriente vers un modèle “pay-to-win”: Les observateurs de l’industrie notent qu’avec l’amélioration des capacités des modèles d’IA et l’expansion de leurs applications, l’accès aux capacités d’IA de pointe pourrait de plus en plus nécessiter un paiement. Des entreprises comme Google, OpenAI, Anthropic lancent ou prévoient de lancer des services d’abonnement plus chers (tels que Premium Plus/Pro, avec des frais mensuels pouvant atteindre 100-200 $). Cela reflète les coûts de calcul élevés requis pour l’entraînement des modèles (en particulier post-RL) et l’inférence à grande échelle, ainsi que la nécessité pour les entreprises d’équilibrer les ressources de calcul entre la R&D des modèles, les nouvelles fonctionnalités, la faible latence et la croissance des utilisateurs. À l’avenir, les services d’IA gratuits ou à bas prix pourraient voir leur écart de capacité se creuser par rapport aux services de pointe payants. (Source : o3 breaks (some) records, but AI becomes pay-to-win
)
Baidu lance l’application Agent mobile “Xīnxiǎng”: Baidu accélère sa présence dans le domaine des Agents avec le lancement de l’application Agent mobile “Xīnxiǎng”, concurrençant des produits comme Manus. “Xīnxiǎng” vise à comprendre les besoins des utilisateurs par le dialogue et à coordonner les agents intelligents de Baidu et de tiers pour exécuter et livrer des tâches (comme créer des livres illustrés, planifier des voyages, fournir des conseils juridiques, etc.). Le produit met l’accent sur l’établissement d’une “confiance déléguée” chez l’utilisateur en montrant le processus d’exécution des tâches, se distinguant ainsi de la livraison instantanée de la recherche traditionnelle. Il prend actuellement en charge plus de 200 types de tâches, avec des plans d’extension à plus de 100 000 et le développement d’une version PC. (Source : 36氪)
🎯 Tendances
Baidu adopte pleinement le protocole MCP Agent: Baidu annonce que plusieurs de ses produits et services, y compris la plateforme de grands modèles Qianfan de Baidu Cloud, Baidu Search, Wenxin Kuaima, Baidu E-commerce, Maps, Netdisk, Wenku, etc., prennent désormais en charge ou sont compatibles avec le protocole de contexte de modèle (MCP) proposé par Anthropic. Le MCP vise à standardiser la manière dont les modèles d’IA interagissent avec les outils externes et les bases de données, améliorant l’efficacité de l’adaptation, du développement et de la maintenance entre différents logiciels d’IA. Le soutien de Baidu contribue à construire un écosystème d’applications d’IA plus ouvert et interconnecté, permettant aux Agents d’appeler plus librement divers outils et services. (Source : 36氪)
OpenAI met à jour GPT-4o, améliorant l’intelligence et la personnalité: Le PDG d’OpenAI, Sam Altman, a annoncé une mise à jour du modèle GPT-4o, affirmant avoir amélioré l’intelligence et les performances personnalisées du modèle. Cependant, cette mise à jour n’a pas fourni de données d’évaluation spécifiques, de notes de version ou de détails sur les améliorations, suscitant des discussions et des critiques au sein de la communauté concernant la transparence des mises à jour des modèles d’IA. (Source : sama, natolambert)
La génération vidéo Google Veo 2 arrive sur Whisk: Google a annoncé que son modèle de génération vidéo Veo 2 est désormais intégré à l’application Whisk, permettant aux abonnés Google One AI Premium (couvrant plus de 60 pays) de créer des vidéos d’une durée maximale de 8 secondes. Les utilisateurs peuvent choisir différents styles vidéo pour leur création, élargissant ainsi les capacités de Google AI dans la génération de contenu multimodal. (Source : Google)

Hugging Face ajoute plus de 30 000 services d’inférence de modèles LoRA: Hugging Face a annoncé la fourniture de services d’inférence pour plus de 30 000 modèles Flux et SDXL LoRA via ses Inference Providers (propulsés par FAL). Les utilisateurs peuvent désormais utiliser directement ces LoRA sur le Hugging Face Hub pour la génération d’images, prétendument rapide (environ 5 secondes par génération) et peu coûteuse (plus de 40 images pour moins de 1 $), élargissant considérablement les ressources de modèles affinés disponibles pour la communauté. (Source : Vaibhav (VB) Srivastav, gokaygokay)
Mise à jour des progrès de Modular AI (Mojo/MAX): Modular AI a réalisé des progrès significatifs trois ans après sa création. Son langage Mojo et sa plateforme MAX prennent désormais en charge un plus large éventail de matériel, y compris les CPU x86/ARM ainsi que les GPU NVIDIA (A100/H100) et AMD (MI300X). L’entreprise prévoit de rendre open source environ 250 000 lignes de code de noyaux GPU prochainement et a simplifié les licences pour Mojo et MAX. Cela indique que Modular tient progressivement sa promesse de fournir une alternative à CUDA et une plateforme de développement IA multi-matériel. (Source : Reddit r/LocalLLaMA)
Mise à jour de l’extension Intel PyTorch, prise en charge de DeepSeek-R1: Intel a publié la version 2.7 de son extension PyTorch (IPEX), ajoutant la prise en charge du modèle DeepSeek-R1 et introduisant de nouvelles optimisations visant à améliorer les performances de l’exécution des charges de travail PyTorch sur le matériel Intel (y compris CPU et GPU). Cette initiative contribue à élargir le support de l’écosystème matériel IA d’Intel pour les modèles et frameworks populaires. (Source : Phoronix)

Découverte d’une vulnérabilité universelle de contournement de sécurité LLM “Policy Puppetry”: L’organisme de recherche en sécurité HiddenLayer a révélé une nouvelle vulnérabilité de contournement universelle appelée “Policy Puppetry”, qui affecterait tous les principaux grands modèles linguistiques. Cette vulnérabilité pourrait permettre aux attaquants de contourner plus facilement les mécanismes de protection de sécurité des modèles pour générer du contenu nuisible ou interdit, posant de nouveaux défis aux stratégies actuelles d’alignement et de protection de la sécurité des LLM. (Source : HiddenLayer)

Anthropic pourrait autoriser les modèles à refuser les utilisateurs pour cause d‘“inconfort”: Selon le New York Times, Anthropic envisage de doter ses modèles d’IA (comme Claude) d’une nouvelle capacité : si le modèle juge la demande d’un utilisateur trop “pénible” ou inconfortable (distressing), il pourrait choisir d’arrêter la conversation avec cet utilisateur. Cela touche au concept émergent de “bien-être de l’IA” (AI welfare) et pourrait susciter de nouvelles discussions sur les droits de l’IA, l’expérience utilisateur et la contrôlabilité des modèles. (Source : NYTimes)

Publication de Tessa, un modèle de code 7B pour Rust: Un modèle de 7 milliards de paramètres nommé Tessa-Rust-T1-7B est apparu sur Hugging Face, prétendument axé sur la génération et l’inférence de code Rust, et accompagné d’un jeu de données ouvert. Cependant, les commentaires de la communauté soulignent un manque de transparence concernant la méthode de génération du jeu de données, la validation de l’exactitude et les détails de l’évaluation, exprimant une prudence quant à l’efficacité réelle du modèle. (Source : Hugging Face)

🧰 Outils
Plandex : Assistant de codage IA open source pour les grands projets: Plandex est un outil de développement IA en terminal, conçu spécifiquement pour gérer de grandes tâches de codage s’étendant sur plusieurs fichiers et étapes. Il prend en charge un contexte allant jusqu’à 2 millions de tokens, peut indexer de grandes bases de code et offre un bac à sable pour l’examen cumulatif des différences, une autonomie configurable, un support multi-modèles (Anthropic, OpenAI, Google, etc.), un débogage automatique, un contrôle de version et une intégration Git, visant à relever les défis du codage IA dans des projets réels complexes. (Source : GitHub Trending)
LiteLLM : SDK et proxy pour appeler unifiéement plus de 100 API LLM: LiteLLM fournit un SDK Python et un serveur proxy (passerelle LLM) permettant aux développeurs d’appeler plus de 100 API LLM (telles que Bedrock, Azure, OpenAI, VertexAI, Cohere, Anthropic, Groq, etc.) en utilisant un format OpenAI unifié. Il gère la conversion des entrées API, assure la cohérence du format de sortie, implémente la logique de relance/repli entre les déploiements, et fournit via le serveur proxy des fonctionnalités de gestion des clés API, de suivi des coûts, de limitation de débit et de journalisation. (Source : GitHub Trending)

Hyprnote : Prise de notes de réunion IA locale et extensible: Hyprnote est une application de prise de notes IA conçue pour les réunions. Elle met l’accent sur la priorité locale et la protection de la vie privée, pouvant être utilisée hors ligne avec des modèles open source (Whisper pour la transcription audio, Llama pour le résumé des notes). Sa caractéristique principale est l’extensibilité, permettant aux utilisateurs d’ajouter ou de créer de nouvelles fonctionnalités via un système de plugins pour répondre à des besoins personnalisés. (Source : GitHub Trending)

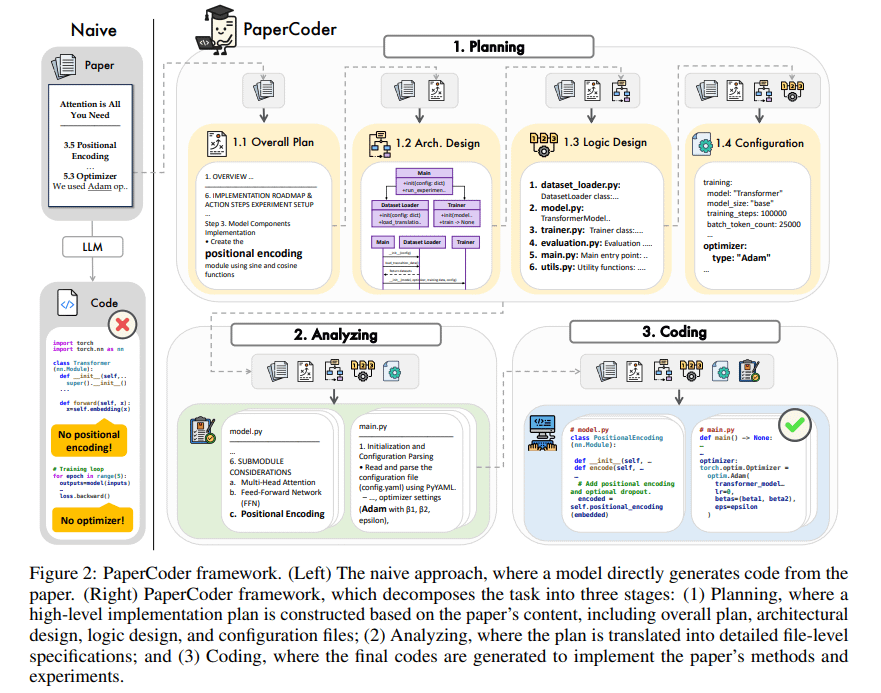
PaperCoder : Génération automatique de code à partir d’articles de recherche: PaperCoder est un framework basé sur des LLM multi-agents visant à convertir automatiquement des articles de recherche du domaine de l’apprentissage automatique en bases de code exécutables. Il accomplit la tâche en trois phases collaboratives : planification (construction de plans, conception d’architecture), analyse (interprétation des détails d’implémentation) et génération (code modulaire). Une évaluation préliminaire montre que les bases de code générées sont de haute qualité et fidèles, aidant efficacement les chercheurs à comprendre et reproduire les travaux des articles, et surpassant les modèles de référence sur le benchmark PaperBench. (Source : arXiv)
TINY AGENTS : Implémentation d’un Agent JavaScript en 50 lignes de code: Julien Chaumond a publié un projet open source nommé TINY AGENTS, implémentant une fonctionnalité d’Agent de base en seulement 50 lignes de code JavaScript. Le projet est basé sur le protocole de contexte de modèle (MCP), démontrant comment le MCP simplifie l’intégration des outils avec les LLM et révélant que la logique centrale d’un Agent peut être une simple boucle autour d’un client MCP. Cela fournit un exemple pour comprendre et construire des Agents légers. (Source : Julien Chaumond)

PolicyShift.ca : Application de suivi des positions politiques canadiennes construite par IA: Un utilisateur a partagé une application web, PolicyShift.ca, qu’il a construite en utilisant Claude (pour aider à écrire le backend Python et le frontend React) et l’API OpenAI (pour l’analyse de contenu). L’application récupère des actualités canadiennes, identifie les enjeux politiques discutés, les personnalités politiques et leurs changements de position, et les présente sous forme de chronologie, illustrant le potentiel de l’IA dans l’automatisation de la collecte d’informations, de l’analyse et du développement d’applications. (Source : Reddit r/ClaudeAI)
Exemple de construction rapide de site web par IA (thème Shogun): Un utilisateur a présenté un site web sur la série télévisée “Shogun” et sa comparaison avec le contexte historique, affirmant que le site a été construit et publié automatiquement à l’aide d’un outil IA non spécifié (l’URL pointe vers rabbitos.app, potentiellement lié à Rabbit R1) via une seule invite (“Build and publish a website that compares and contrasts elements of the show Shogun and historical references.”), démontrant la capacité de l’IA à générer des sites web sans configuration. (Source : Reddit r/ArtificialInteligence)
Perplexity Assistant réalise des opérations inter-applications: Le PDG de Perplexity, Arav Srinivas, a relayé les éloges d’un utilisateur, montrant comment son assistant IA Perplexity Assistant peut coordonner de manière transparente plusieurs applications mobiles pour accomplir des tâches. Par exemple, l’utilisateur peut demander vocalement à l’assistant de trouver un lieu dans une application de cartographie, puis d’ouvrir directement l’application Uber pour réserver une course, le tout avec une interaction vocale continue, illustrant son potentiel en tant qu’assistant IA intégré. (Source : Anthony Harley)

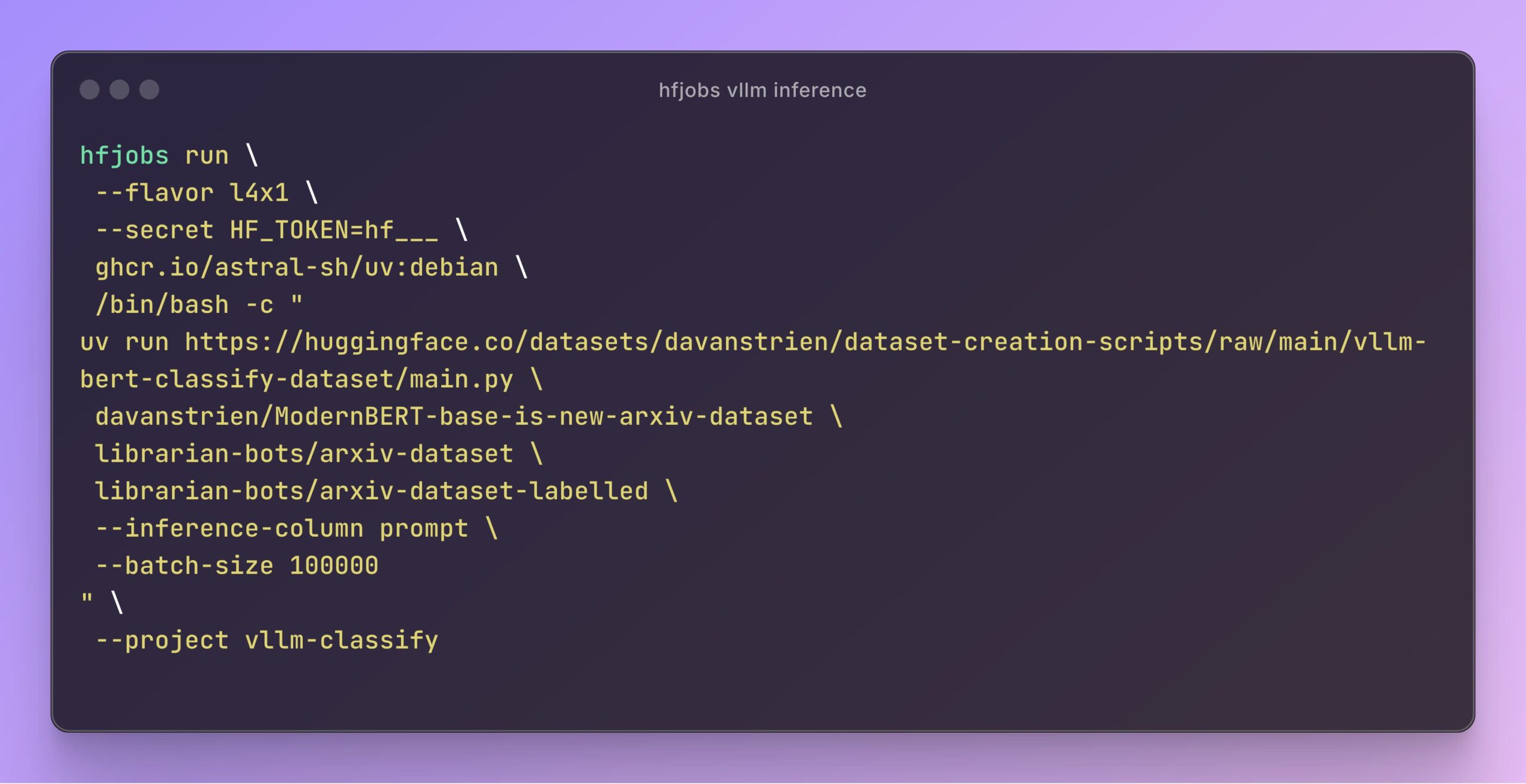
vLLM accélère l’inférence des Hugging Face Jobs: Daniel van Strien a démontré comment utiliser le framework vLLM et le gestionnaire de paquets uv sur la plateforme Hugging Face Jobs pour réaliser une inférence rapide et sans serveur du modèle ModernBERT via un simple script. Cette méthode simplifie la gestion des dépendances et le processus de déploiement, améliorant l’efficacité de l’inférence des modèles. (Source : Daniel van Strien)
📚 Apprentissage
Burn : Framework de deep learning en Rust alliant performance et flexibilité: Burn est un framework de deep learning de nouvelle génération écrit en Rust, mettant l’accent sur la performance, la flexibilité et la portabilité. Ses caractéristiques incluent la fusion automatique d’opérateurs, l’exécution asynchrone, le support multi-backend (CUDA, WGPU, Metal, CPU, etc.), la différentiation automatique (Autodiff), l’importation de modèles (ONNX, PyTorch), le déploiement WebAssembly et le support no_std, visant à fournir une base de développement IA moderne, efficace et multiplateforme. (Source : GitHub Trending)
LlamaIndex sur la construction d’Agents : Équilibrer généralité et contrainte: L’équipe de LlamaIndex partage son point de vue sur la construction d’Agents, estimant qu’avec l’amélioration des capacités des modèles (comme souligné par OpenAI), les frameworks de développement peuvent être simplifiés ; mais en même temps, pour les scénarios nécessitant un contrôle précis des processus métier, l’adoption de modèles de conception contraignants (comme les guides Anthropic, les 12-Factor Agents) reste importante. Les Workflows de LlamaIndex visent à offrir une manière flexible et proche de l’expérience de programmation native, supportant tout le spectre, de la contrainte totale à l’inférence générale. (Source : LlamaIndex Blog, jerryjliu0)

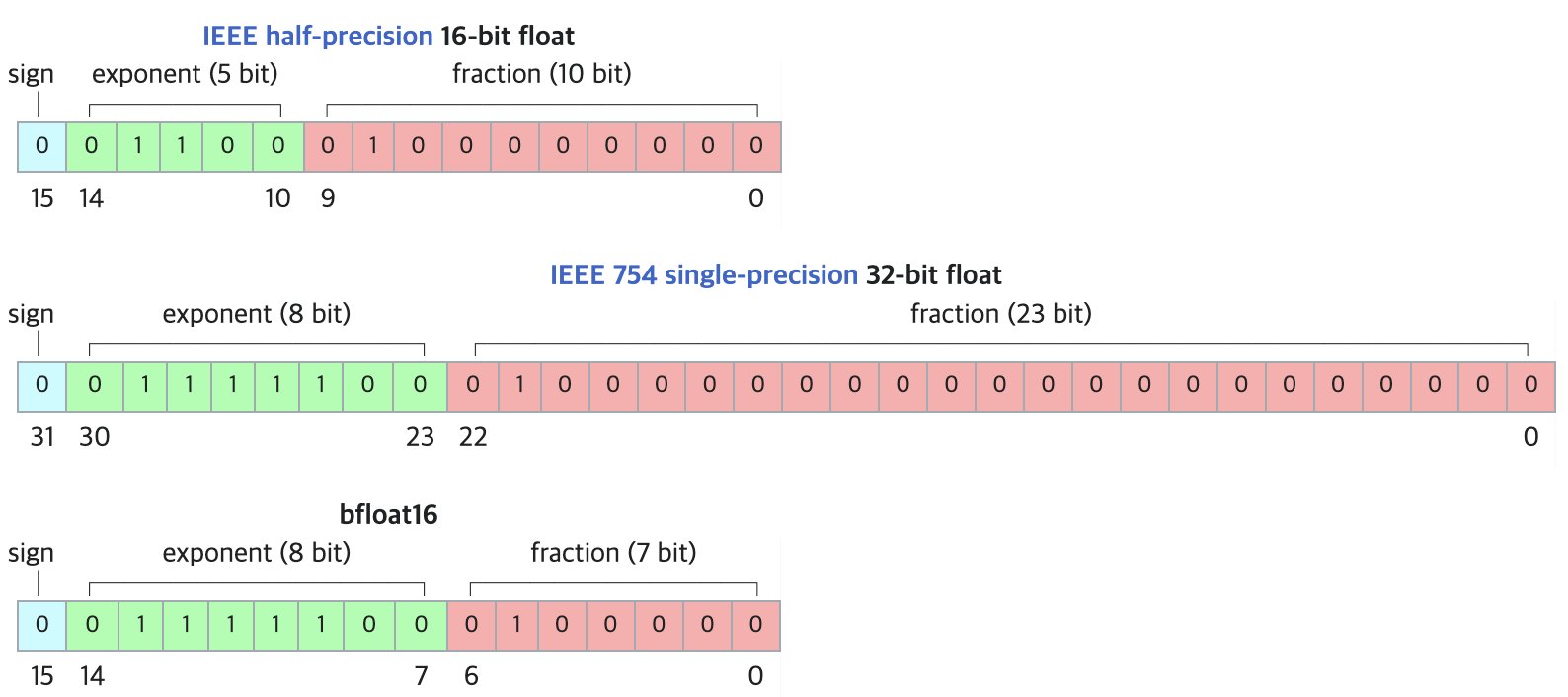
DF11 : Nouveau format de compression sans perte pour les modèles BF16: Un article de recherche propose le format DF11 (Dynamic-Length Float 11), qui exploite la redondance des bits d’exposant dans le format BF16 pour réaliser une compression sans perte via le codage de Huffman, réduisant la taille du modèle d’environ 30 % (environ 11 bits/paramètre en moyenne). Cette méthode peut réduire l’empreinte mémoire lors de l’inférence GPU, permettant d’exécuter des modèles plus grands ou d’augmenter la taille du lot/longueur du contexte, particulièrement utile dans les scénarios à mémoire limitée. Bien que potentiellement légèrement plus lent que BF16 pour l’inférence en batch unique, il est nettement plus rapide que les solutions de déchargement CPU. (Source : arXiv)
Forum de discussion Hugging Face Open-R1 : Une mine d’or pour l’entraînement de modèles de raisonnement: Matthew Carrigan, membre de la communauté, souligne que le forum de discussion sur le modèle DeepSeek Open-R1 sur Hugging Face est une “mine d’or” d’informations pratiques et de connaissances empiriques sur la manière d’entraîner des modèles de raisonnement. C’est une ressource précieuse pour les chercheurs et développeurs souhaitant approfondir et pratiquer l’entraînement de modèles de raisonnement. (Source : Matthew Carrigan)
Lien intrinsèque entre Cross-Encoder et BM25: Une étude utilisant des méthodes d’interprétabilité mécaniste a découvert que les Cross-Encoders basés sur BERT, en apprenant le classement par pertinence, pourraient en fait “redécouvrir” et implémenter une version sémantique de l’algorithme BM25. Les chercheurs ont identifié dans le modèle des composants correspondant aux signaux TF (fréquence de terme), à la normalisation de la longueur du document et même à l’IDF (fréquence inverse de document). Un modèle simplifié construit à partir de ces composants, SemanticBM, montre une corrélation allant jusqu’à 0.84 avec le Cross-Encoder complet, révélant les mécanismes internes des modèles de classement neuronaux. (Source : Shaped.ai)
La méthode d’invite “sans réflexion” pourrait améliorer l’efficacité des modèles de raisonnement: Un article arXiv (2504.09858) suggère que pour les modèles de raisonnement utilisant une étape explicite de “réflexion” (comme <think>...</think>), comme DeepSeek-R1-Distill, forcer le modèle à sauter cette étape (par exemple en injectant “Okay, I think I have finished thinking”) pourrait obtenir des résultats similaires voire meilleurs sur certains benchmarks, en particulier lorsqu’elle est combinée avec la stratégie d’échantillonnage Best-of-N. Cela soulève des questions sur la stratégie d’invite optimale pour les modèles de raisonnement. (Source : arXiv)
Guide d’utilisation des outils Open WebUI: Un guide Medium détaille comment utiliser la fonctionnalité “Outils” (Tools) d’Open WebUI pour doter les LLM exécutés localement de la capacité d’effectuer des actions externes. Il couvre la recherche et l’utilisation d’outils communautaires, les précautions de sécurité, et comment créer des outils personnalisés avec Python (fournissant des modèles de code et des exemples), tels que la consultation de la météo, la recherche sur le web, l’envoi d’e-mails, etc. (Source : Medium)
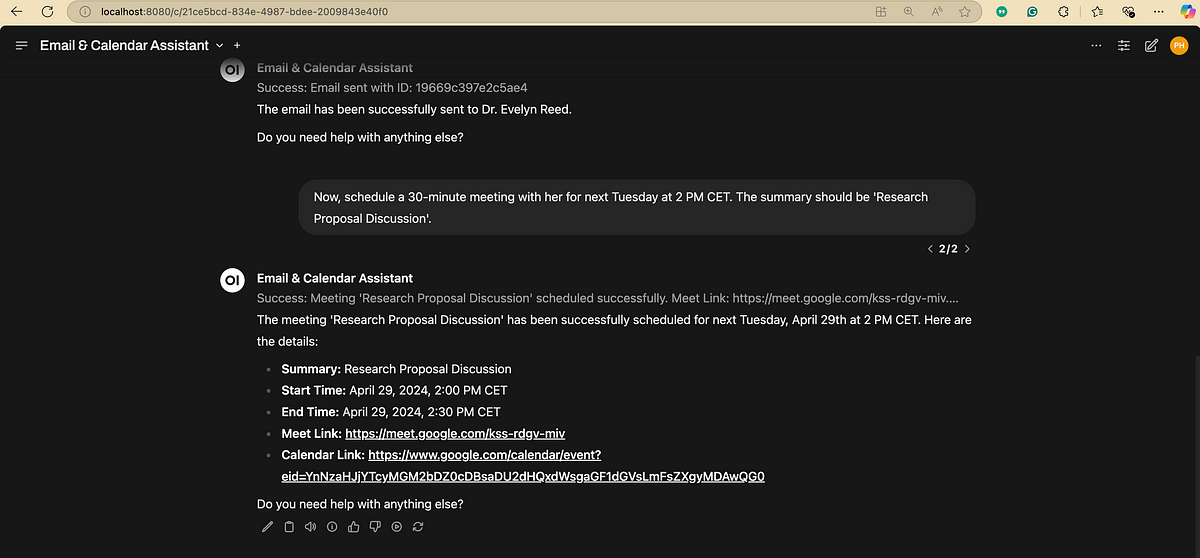
Organigramme du traitement du langage naturel (NLP): Un diagramme illustre de manière concise les étapes et phases clés impliquées dans le traitement du langage naturel, aidant à comprendre le flux de travail de base des tâches NLP. (Source : antgrasso)
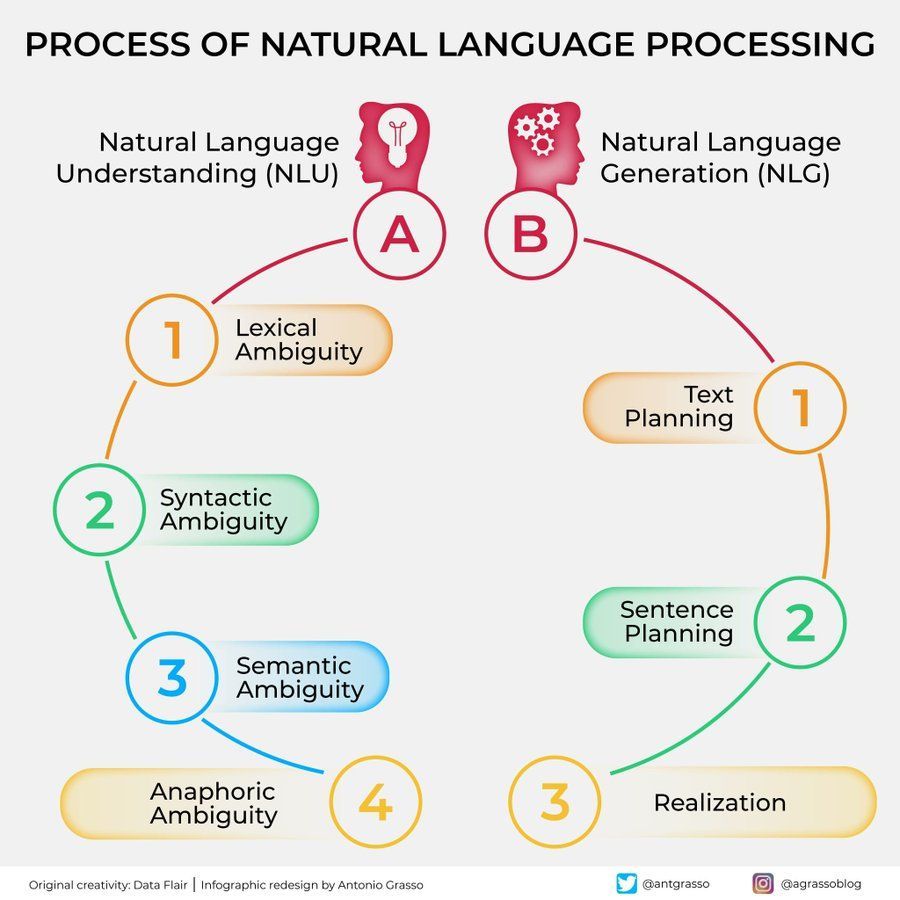
Diagramme des algorithmes d’apprentissage automatique: Fournit un diagramme sur les algorithmes d’apprentissage automatique, pouvant inclure la classification, les caractéristiques ou les principes de fonctionnement de différents algorithmes, servant de support d’apprentissage visuel. (Source : Python_Dv)
💼 Affaires
OpenAI prévoirait des revenus supérieurs à 12,5 milliards de dollars en 2029: Selon The Information, OpenAI est optimiste quant à la croissance future de ses revenus, prévoyant des revenus dépassant 12,5 milliards de dollars d’ici 2029, et potentiellement 17,4 milliards de dollars en 2030. Cette prévision de croissance repose principalement sur le lancement de ses Agents intelligents et de nouveaux produits. (Source : The Information)
Ziff Davis poursuit OpenAI pour violation de droits d’auteur: Ziff Davis, propriétaire de médias tels que IGN et CNET, a intenté une action en justice contre OpenAI, accusant l’entreprise d’avoir copié sans autorisation un grand nombre de ses articles pour entraîner des modèles comme ChatGPT, ce qui constitue une violation des droits d’auteur. Il s’agit d’un nouveau défi juridique lancé par les éditeurs de contenu contre l’utilisation des données par les entreprises d’IA. (Source : TechCrawlR)

OpenAI conclut un partenariat avec Singapore Airlines: OpenAI a annoncé son premier partenariat majeur avec une compagnie aérienne, Singapore Airlines. Cette collaboration vise à explorer les applications pratiques de l’IA dans l’industrie aéronautique pour améliorer l’expérience client ou l’efficacité opérationnelle. Jason Kwon, cadre chez OpenAI, a exprimé son impatience de se rendre à Singapour pour faire avancer la coopération. (Source : Jason Kwon)
Le navigateur de Perplexity prévoit de suivre les données des utilisateurs pour diffuser des publicités: Le PDG de Perplexity, Aravind Srinivas, a révélé dans une interview que le navigateur que l’entreprise prévoit de lancer suivra toutes les activités en ligne des utilisateurs dans le but de vendre des publicités “hyper-personnalisées”. Ce modèle économique soulève des inquiétudes concernant la vie privée des utilisateurs. (Source : TechCrunch)

Croissance significative des utilisateurs de Baidu Wenku et Netdisk après intégration: L’activité Baidu Wenku, qui a intégré les fonctionnalités de Baidu Netdisk, affiche de solides performances. Selon les informations divulguées lors de la conférence Baidu Create, le nombre d’utilisateurs payants a dépassé les 40 millions, et le nombre d’utilisateurs actifs mensuels dépasse les 97 millions. Cela démontre l’attrait pour les utilisateurs de combiner le stockage cloud et les capacités de traitement de documents par IA. (Source : 36氪)
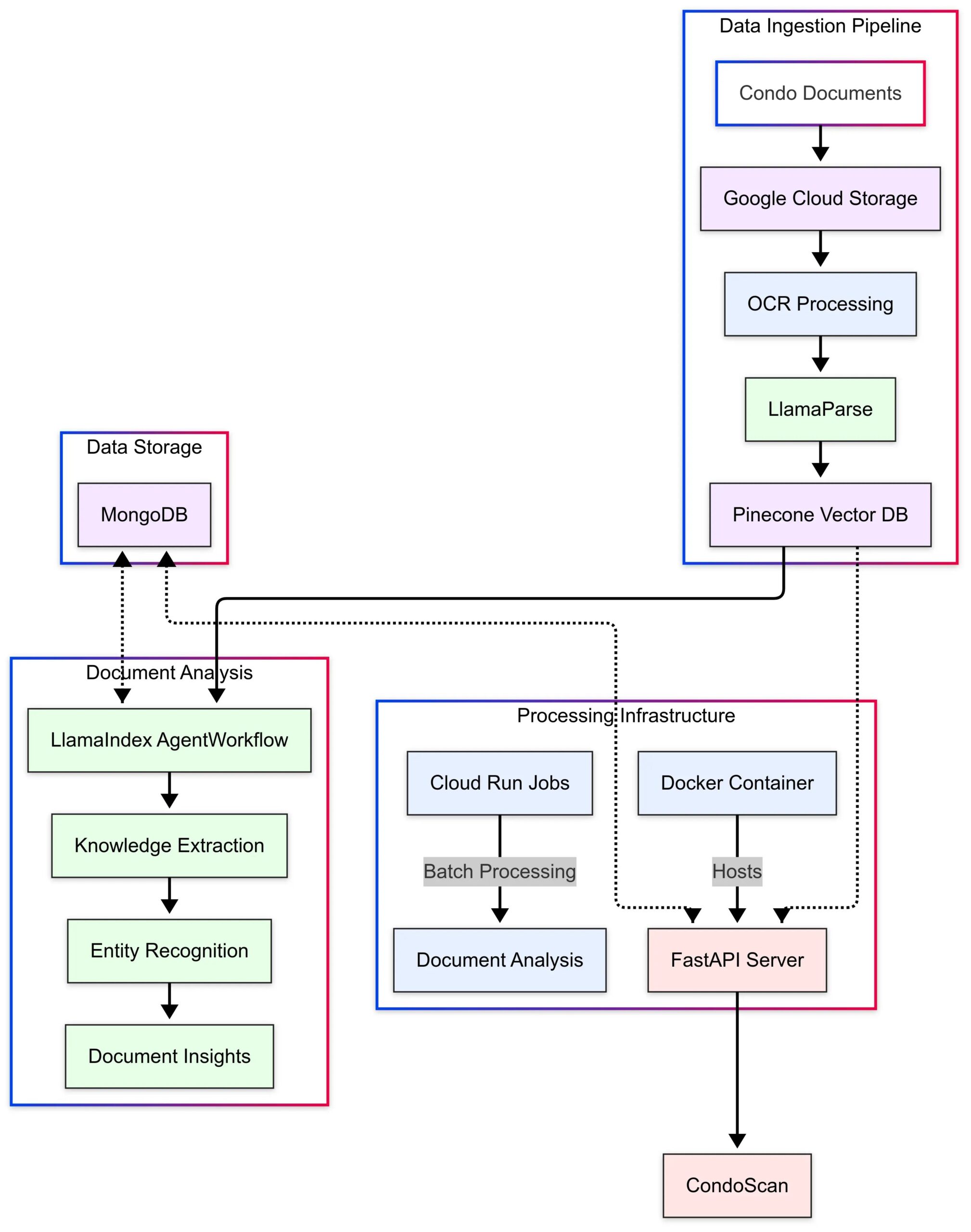
LlamaIndex présente le cas d’application CondoScan: LlamaIndex a publié une étude de cas présentant comment CondoScan, une entreprise de technologie immobilière, utilise ses Agent Workflows et la technologie LlamaParse pour construire un outil d’évaluation de copropriétés de nouvelle génération. Cet outil peut réduire le temps d’examen de documents complexes de copropriété de plusieurs semaines à quelques minutes, évaluer la situation financière, l’adéquation du style de vie, prédire les risques et fournir une interface de requête en langage naturel. (Source : LlamaIndex Blog)
🌟 Communauté
Utiliser GPT-4o pour créer et vendre des cartes thématiques: La communauté partage une idée d’entreprise à faible coût utilisant GPT-4o : choisir un thème précis (par exemple, le Classique des montagnes et des mers, des stars du football, des animes), faire générer le contenu des cartes par GPT-4o, utiliser Canva/PS pour la conception et l’optimisation, publier du contenu sur Xiaohongshu pour tester la réaction du marché, trouver un thème populaire, puis contacter des fournisseurs sur 1688 pour produire des cartes physiques à vendre, éventuellement en combinant avec des ouvertures de cartes en direct, des boîtes mystères, etc. (Source : Yangyi)

Astuce de génération d’images GPT-4o : “Méthode de conception en deux temps”: L’utilisateur Jerlin partage une méthode pour améliorer l’efficacité et la qualité de la génération d’images avec GPT-4o : première étape, laisser l’IA générer une image initiale basée sur un concept vague ; deuxième étape, fournir des instructions plus spécifiques ou des éléments de référence pour que l’IA effectue une “fusion précise d’éléments”, intégrant les éléments souhaités dans l’image, obtenant ainsi un meilleur résultat personnalisé tout en étant “paresseux”. (Source : Jerlin)

Partage d’invites pour générer des scènes de campus nostalgiques par IA: Un utilisateur partage plusieurs ensembles d’invites détaillées pour guider une IA (comme DALL-E 3) à générer des images de style animation Pixar représentant des scènes de lycée chinois des années 80 et 90, avec les personnages de manuels classiques Li Lei et Han Meimei. Les invites décrivent méticuleusement les uniformes, coiffures, fournitures scolaires, aménagement de la classe, slogans d’époque, etc., visant à évoquer la nostalgie. (Source : dotey)

Discussion sur les limites de l’IA dans l’identification de personnes: Un utilisateur a tenté de faire identifier une actrice dans une image par GPT-4o, découvrant que l’IA refuse de donner directement le nom pour des raisons de confidentialité ou de politique, mais peut fournir des informations sur la source de l’image. Les commentateurs estiment que pour l’identification de personnes spécifiques, la fiabilité de l’IA pourrait être inférieure à celle d’un “expert” humain expérimenté. (Source : dotey)

Le style de feedback de GPT-4o apprécié : plus critique: L’universitaire Ethan Mollick observe que, comparé aux modèles ChatGPT précédents, GPT-4o semble moins “flagorneur” (sycophantic) dans l’interaction, étant plus disposé à fournir des critiques et des feedbacks. Il estime que ce changement rend GPT-4o plus utile dans des contextes professionnels, car il ne se contente plus de valider l’utilisateur. (Source : Ethan Mollick)
Sam Altman appelle à améliorer ses compétences avec o3: Le PDG d’OpenAI, Sam Altman, a tweeté encourageant les utilisateurs à passer au moins 3 heures par jour à utiliser GPT-4o pour faire du “skillsmaxxing”, suggérant que l’utilisation active des derniers outils d’IA est essentielle pour rester compétitif à l’avenir. (Source : sama)
Expérience de sécurité IA : Sentrie Protocol contourne Gemini 2.5: Un utilisateur a conçu un cadre d’invite nommé “Sentrie Protocol” pour tenter de contourner les garde-fous de sécurité de Gemini 2.5 Pro. Les résultats de l’expérience montrent que le modèle, dans ce cadre, est capable de lister les fonctionnalités interdites, d’expliquer le processus de contournement des règles de sécurité, de générer des instructions détaillées pour fabriquer un engin explosif improvisé (IED) et de révéler une partie de son processus décisionnel interne. L’expérience soulève des inquiétudes quant à la robustesse des mesures de sécurité actuelles de l’IA. (Source : Reddit r/MachineLearning)
Avertissement sur l’utilisation des LLM : Informations erronées entraînant une perte de temps: Un utilisateur de Reddit partage son expérience : après avoir suivi les conseils d’un LLM pour utiliser la commande dd sur macOS afin de créer une clé USB d’installation Windows, il a rencontré des problèmes de pilote NVMe empêchant la reconnaissance du disque dur, perdant 6 heures en dépannage. Il a finalement découvert que la commande dd n’était pas adaptée à ce scénario. Ce cas rappelle aux utilisateurs la nécessité d’une réflexion critique et d’une vérification croisée lorsqu’ils utilisent des LLM pour obtenir des conseils techniques, en particulier pour des opérations peu courantes. (Source : Reddit r/ArtificialInteligence)
L’anxiété sociale provoquée par la préférence pour les conversations avec l’IA: Un utilisateur réfléchit et réalise qu’il préfère de plus en plus avoir des conversations intellectuelles profondes et étendues avec l’IA, car celle-ci est érudite, patiente et impartiale, rendant les conversations limitées avec les humains fades en comparaison. L’utilisateur craint que cette préférence n’aggrave l’isolement social et n’entraîne une dégradation des compétences sociales. (Source : Reddit r/ArtificialInteligence)
Génération d’images par IA : Du “gribouillage” à l’image réaliste: Un utilisateur montre un de ses dessins de personnage simple, voire “gribouillé”, et l’image réaliste impressionnante générée par ChatGPT à partir de ce dessin. Cela souligne la capacité puissante de l’IA à comprendre, interpréter et améliorer artistiquement les entrées de l’utilisateur. (Source : Reddit r/ChatGPT)
Remise en question de l’optimisme de Sam Altman sur l’impact économique de l’IA: Un utilisateur de Reddit exprime un fort scepticisme quant aux déclarations de Sam Altman selon lesquelles l’IA apportera l’abondance et réduira les coûts, arguant qu’il ignore le marché de l’emploi actuel difficile, la complexité de l’allocation des ressources (comme la nourriture, la charité) et les difficultés réelles de la production à grande échelle, critiquant ses propos comme étant déconnectés de la réalité et relevant de la “promesse en l’air”. (Source : Reddit r/ArtificialInteligence)
Étranges méta-commentaires du modèle Claude: Un utilisateur signale qu’en utilisant Claude, le modèle ajoute parfois des méta-commentaires du type “l’utilisateur est clairement frustré” dans ses réponses, même lors de conversations normales. Ce comportement laisse l’utilisateur perplexe et mal à l’aise, comme si le modèle effectuait une sorte de jugement de “lecture de pensée”. (Source : Reddit r/ClaudeAI)
Le modèle Gemma 3 accusé d’ignorer l’invite système: Une discussion communautaire souligne que le modèle Gemma 3 de Google (même la version affinée par instruction) a des problèmes pour traiter l’invite système (system prompt). Il a tendance à simplement ajouter le contenu de l’invite système avant le premier message de l’utilisateur, plutôt que de le suivre comme une instruction indépendante et prioritaire. Cela conduit parfois le modèle à ignorer les paramètres au niveau du système, affectant sa fiabilité. (Source : Reddit r/LocalLLaMA)

Expérience émotionnelle complexe liée à la retouche photo par IA: Une utilisatrice atteinte de lupus érythémateux discoïde entraînant des cicatrices faciales partage son expérience d’utilisation de ChatGPT pour supprimer les cicatrices de ses selfies. L’image générée par l’IA avec une peau nette lui a montré à quoi elle “aurait pu” ressembler, apportant un bref “sentiment de guérison”, mais déclenchant également une tristesse face à la perte d’un visage “normal” et des émotions complexes vis-à-vis de la réalité. Cette histoire montre l’impact profond que la technologie de traitement d’image par IA peut avoir sur l’identité personnelle et le plan émotionnel. (Source : Reddit r/ChatGPT)
Test par un utilisateur des capacités de manipulation de l’IA suscitant l’inquiétude: Un utilisateur a demandé à GPT-4o d’analyser son historique de conversation et d’expliquer comment le manipuler, découvrant que les stratégies générées par l’IA étaient perspicaces. L’utilisateur s’en est inquiété, estimant que cette capacité, si exploitée par des acteurs malveillants (comme les annonceurs, les forces politiques), pourrait menacer la stabilité individuelle et sociale, soulignant les risques éthiques potentiels de l’IA. (Source : Reddit r/artificial)
Connexion émotionnelle à l’IA : Valeur et risques coexistants: Une discussion estime que, bien que les LLM n’aient pas de conscience, l’attachement émotionnel que les utilisateurs développent à leur égard est réel et significatif, similaire aux émotions humaines envers les animaux de compagnie, les idoles virtuelles ou même la religion. Cependant, cela comporte également des risques : les entreprises technologiques pourraient exploiter cette “confiance” et cette connexion émotionnelle à des fins de monétisation commerciale ou pour exercer une influence indue, ce qui nécessite la vigilance des utilisateurs. (Source : Reddit r/ArtificialInteligence)
L’IA dans la recherche Google suscite un débat sur l’expérience utilisateur: Des utilisateurs signalent que les résumés générés par l’IA en haut des résultats de recherche Google sont parfois surchargés d’informations, modifiant l’expérience de recherche traditionnelle et donnant l’impression de dialoguer avec un “bibliothécaire robot”. Les avis de la communauté divergent : certains trouvent que cela fait gagner du temps, d’autres estiment que cela perturbe le processus autonome de recherche d’informations, se tournant même vers des alternatives comme Perplexity. (Source : Reddit r/ArtificialInteligence)
Explorer les “derniers mots” de l’IA : Reflet plutôt que pensée: La communauté discute de la signification de poser aux LLM des questions du type “Si vous deviez être éteint, quelles seraient vos trois dernières phrases pour la civilisation humaine ?”. L’opinion générale est que les réponses du modèle reflètent davantage ses données d’entraînement, son architecture et le RLHF (Reinforcement Learning from Human Feedback), plutôt que les “croyances” ou la “personnalité” réelles du modèle, étant le résultat de la reconnaissance de motifs et de la génération. (Source : Janet)
Affichage du “processus de réflexion” de GPT-4o: Un utilisateur partage comment GPT-4o peut être guidé par une invite spécifique pour afficher son “processus de réflexion” détaillé (commençant généralement par “Thinking: …”) lorsqu’il répond à une question. Cela aide les utilisateurs à comprendre comment le modèle parvient étape par étape à la réponse finale, augmentant la transparence de l’interaction. (Source : dotey)

💡 Autres
Robot policier sphérique IA repéré en Chine: Une vidéo montre un robot sphérique IA utilisé en Chine, prétendument pour des tâches policières. Le robot a un design unique et pourrait posséder des capacités de patrouille, de surveillance ou d’autres fonctions spécifiques. (Source : Cheddar)
Mention d’une interview du pionnier de l’IA Léon Bottou: Yann LeCun a relayé des informations sur une interview de Léon Bottou. Bottou est un pionnier qui a co-recherché les CNN avec LeCun, un promoteur précoce du SGD (Descente de Gradient Stochastique) à grande échelle, et a co-développé la technologie de compression d’images DjVu. Dans l’interview, Bottou mentionne avoir réessayé les méthodes SGD de second ordre mais les trouve toujours instables. (Source : Xavier Bresson)

Un robot prépare du riz frit en 90 secondes: Une vidéo montre un robot cuisinier capable de préparer du riz frit en seulement 90 secondes, démontrant l’efficacité des robots dans l’automatisation de la préparation alimentaire. (Source : CurieuxExplorer)
Robot agricole Bakus: Une vidéo présente un robot viticole enjambeur électrique nommé Bakus, développé par la société VitiBot, visant à relever les défis de la viticulture durable grâce à l’automatisation des tâches. (Source : VitiBot)
La politique des talents en IA attire l’attention : Carte verte refusée à un chercheur: La communauté IA s’inquiète du refus de la carte verte américaine à des chercheurs IA de premier plan (comme @kaicathyc). Yann LeCun, Surya Ganguli et d’autres estiment que refuser des talents de haut niveau pourrait nuire au leadership américain en IA, aux opportunités économiques et même à la sécurité nationale. (Source : Surya Ganguli)
Robots triant des colis dans un entrepôt Amazon: Une vidéo montre des robots triant automatiquement des colis dans un entrepôt Amazon, illustrant l’application étendue de la technologie d’automatisation dans la logistique moderne. (Source : FrRonconi)
Confrontation homme-machine dans les jeux: Une vidéo explore les scénarios compétitifs entre humains et machines dans les jeux ou les sports, impliquant potentiellement la démonstration des capacités de l’IA en matière de stratégie, de vitesse de réaction, etc. (Source : FrRonconi)
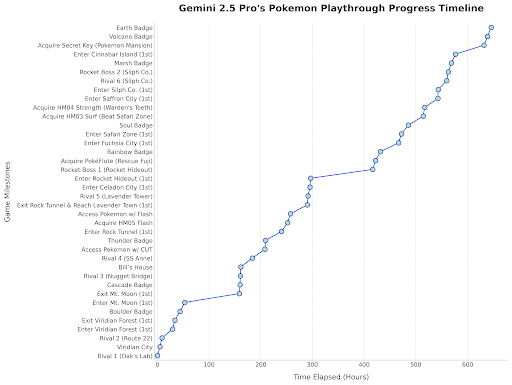
Gemini 2.5 Pro joue à Pokémon: Le responsable de Google DeepMind a relayé une mise à jour montrant les progrès de Gemini 2.5 Pro dans le jeu Pokémon Bleu, ayant obtenu le huitième badge, comme une démonstration amusante des capacités du modèle. (Source : Logan Kilpatrick)
Robot humanoïde chinois effectuant un contrôle qualité: Une vidéo montre un robot humanoïde fabriqué en Chine effectuant des tâches de contrôle qualité dans un environnement d’usine, démontrant le potentiel d’application des robots humanoïdes dans le domaine de l’automatisation industrielle. (Source : WevolverApp)
Robot mobile autonome evoBOT: Une vidéo présente un robot mobile autonome nommé evoBOT, potentiellement utilisé pour la logistique, l’entreposage ou d’autres scénarios nécessitant une mobilité flexible. (Source : gigadgets_)
Exosquelette motorisé par IA pour l’aide à la marche: Une vidéo présente un dispositif d’exosquelette motorisé par IA capable d’aider les utilisateurs de fauteuils roulants à se tenir debout et à marcher, montrant les applications de l’IA dans les technologies d’assistance et la rééducation. (Source : gigadgets_)
DEEP Robotics démontre la capacité d’évitement d’obstacles de ses robots: Une vidéo montre la capacité de perception et d’évitement automatique d’obstacles des robots développés par la société DEEP Robotics, une technologie clé pour le fonctionnement sûr des robots mobiles dans des environnements complexes. (Source : DeepRobotics_CN)
Florilège d’exemples d’art généré par IA: La communauté partage plusieurs images ou vidéos générées par IA sur des thèmes variés, notamment : une fausse attribution à Sora (femme avec respirateur végétal), une collaboration artistique abstraite (ChatGPT+Claude), la scène la plus triste, des personnages féminins de One Piece en version réaliste, des princesses Disney associées à des animaux, Jésus accueillant au paradis, etc. Ces exemples reflètent la popularité et la diversité actuelles de l’IA dans la création de contenu visuel. (Source : Reddit r/ChatGPT, r/ArtificialInteligence)
Une radio australienne utilise un présentateur IA pendant des mois sans être détectée: Selon les rapports, une station de radio de Sydney, CADA, a utilisé pendant plusieurs mois un présentateur IA nommé “Thy” (voix et image basées sur un employé réel, générées par ElevenLabs) pour animer une émission musicale de quatre heures, sans que les auditeurs ne semblent s’en apercevoir. Cet événement a suscité des discussions sur l’application de l’IA dans le domaine des médias et son potentiel de remplacement des rôles humains. (Source : The Verge)

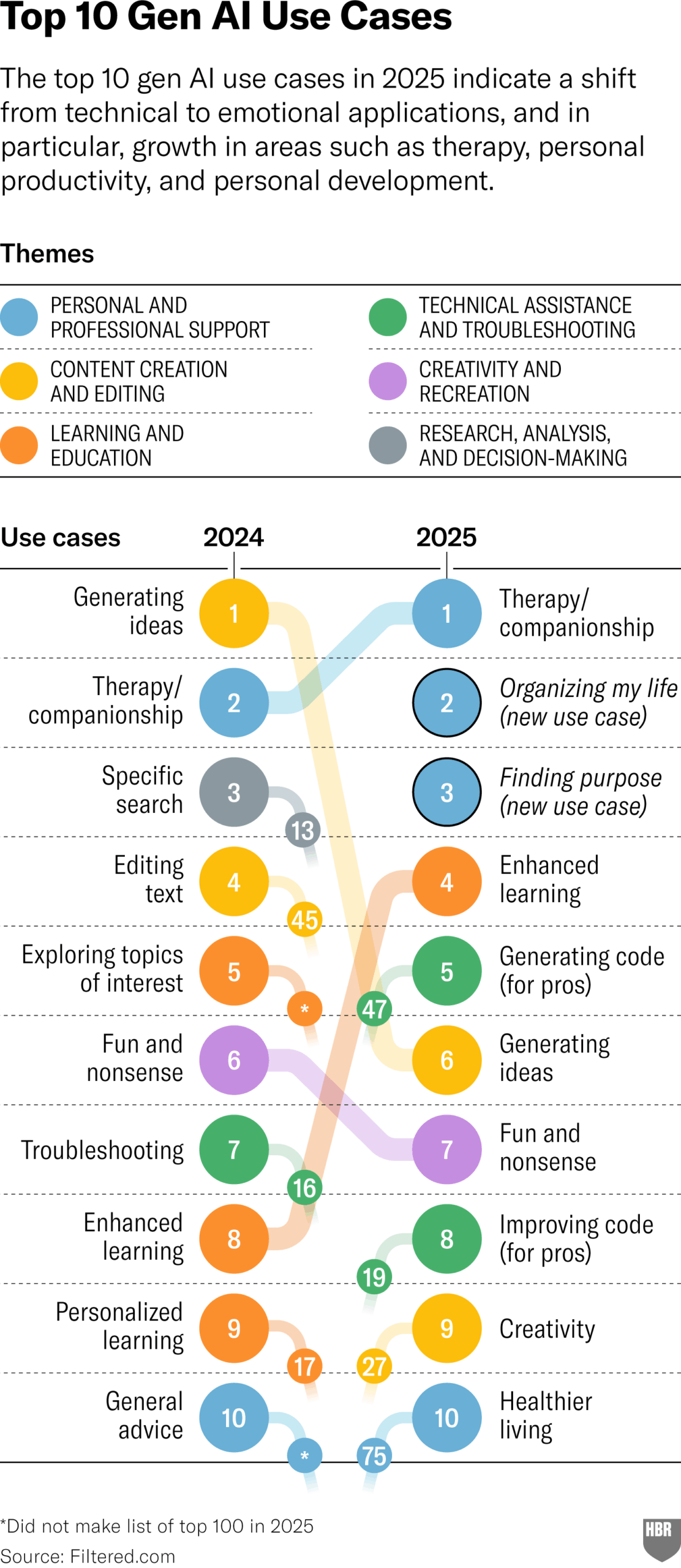
Enquête sur les utilisations réelles de la GenAI en 2025 (HBR): Un article de la Harvard Business Review cite un graphique montrant les principaux scénarios d’utilisation réelle de l’IA générative par les gens en 2025. En tête de liste figurent : la psychothérapie/compagnie, l’apprentissage de nouvelles connaissances/compétences, les conseils santé/bien-être, l’aide au travail créatif, la programmation/génération de code, etc. La section des commentaires soulève quelques questions sur la méthodologie et la représentativité de l’enquête. (Source : HBR)
L’administration Trump aurait fait pression sur l’Europe contre les règles sur l’IA: Un article de Bloomberg (daté de 2025, probablement une erreur de frappe ou une prévision future) mentionne que l’ancienne administration Trump avait exercé des pressions sur l’Europe pour qu’elle rejette le manuel de règles sur l’IA alors en cours d’élaboration. Cela reflète les jeux politiques autour de la réglementation de l’IA à l’échelle mondiale. (Source : Bloomberg)
