
Mots-clés:Modèle de raisonnement, Agent IA, Apprentissage par renforcement, Grand modèle, DeepSeek-R1, Vision-Langage-Navigation (VLN), Apprentissage auto-supervisé DINOv2, Agent LangGraph RAG, Localisation des puces IA, Méthode d’optimisation SRPO, Transfert de compétences opérationnelles d’intelligence incarnée, Gouvernance du calcul quantique
🔥 Pleins feux sur
Les modèles de raisonnement deviennent le nouveau point focal de l’IA, DeepSeek-R1 secoue l’industrie: Suite à la publication par OpenAI de modèles de la série o axés sur le raisonnement structuré, l’open source et les performances exceptionnelles de DeepSeek-R1 (en particulier en mathématiques et en code) marquent une nouvelle phase dans la compétition des grands modèles. L’attention de l’industrie se déplace de la taille des paramètres de pré-entraînement vers l’amélioration des capacités de raisonnement via l’apprentissage par renforcement. Les grands acteurs chinois tels que Baidu (Wenxin X1), Alibaba (Tongyi Qianwen Qwen-QwQ-32B), Tencent (Hunyuan T1), ByteDance (Doubao 1.5), iFlytek (Spark X1), etc., ont rapidement suivi en publiant leurs propres modèles de raisonnement, formant un nouveau paysage où les modèles de raisonnement nationaux défient OpenAI. Ce changement souligne l’importance des capacités de réflexion approfondie, de planification, d’analyse et d’appel d’outils des modèles, préfigurant que la mise en œuvre d’applications telles que les Agents dépendra davantage de modèles de base de raisonnement puissants. (Source: 国产六大推理模型激战OpenAI?, “AI寒武纪”爆发至今,五类新物种登上历史舞台)

L’application de shopping IA Nate accusée de fraude, son fondateur inculpé pour avoir escroqué 40 millions de dollars d’investissements: Le ministère américain de la Justice accuse Albert Saniger, fondateur de l’application de shopping IA Nate, d’avoir escroqué des investisseurs par le biais de fausses publicités concernant sa technologie d’IA. Nate prétendait utiliser l’IA pour simplifier le processus d’achat multiplateforme et permettre un achat en un clic, mais est en réalité accusée d’avoir embauché des centaines d’employés aux Philippines pour traiter manuellement les commandes, utilisant des “humains” pour simuler l‘“intelligence”. Cet incident expose les risques de bulle et de fraude potentiels dans l’engouement pour les startups IA, et suscite également un débat sur la culture du “Fake it till you make it” de la Silicon Valley, soulignant la frontière entre l’exagération publicitaire et la tromperie. Ce cas reflète également les défis de faisabilité technique de certains concepts d’applications IA avant la maturité de la technologie IA (en particulier les grands modèles). (Source: AI购物竟是人工驱动,硅谷创投圈又玩出新花活)

L’IA s’intègre aux flux de travail, redéfinissant la valeur professionnelle et les modèles de gestion: L’IA passe du concept à la pratique, s’intégrant profondément dans les opérations des entreprises et le travail quotidien des employés. Alibaba Cloud utilise de grands modèles et la gouvernance des données pour créer un “tableau de bord de gestion organisationnelle et opérationnelle”, optimisant les processus OKR/CRD ; Deloitte China s’engage à former des dizaines de milliers de talents en IA pour répondre aux besoins des organisations à forte intensité intellectuelle ; Yum China déploie des outils d’IA au niveau des directeurs de restaurant. Cela indique que l’IA n’est pas seulement un outil d’efficacité, mais redéfinit également la nature du travail, la structure organisationnelle et les besoins en talents. Le travail répétitif et standardisé est remplacé par l’IA, exigeant davantage des employés en termes de créativité, de pensée critique, de capacité de décision et de collaboration avec l’IA (adaptabilité à l’IA). La gestion d’entreprise doit passer de la supervision à l’autonomisation, en établissant un nouveau paradigme de collaboration homme-IA et des mécanismes de confiance. (Source: 当AI来和我做同事:重构职场价值坐标系, 重塑工作:AI时代的组织进化与管理革命)

🎯 Tendances
Le modèle visuel auto-supervisé DINOv2 introduit un mécanisme de registres: Meta AI Research a mis à jour sa méthode et son modèle d’apprentissage auto-supervisé DINOv2, en ajoutant un mécanisme de “registres” (registers) basé sur l’article “Vision Transformers Need Registers”. DINOv2 vise à apprendre des caractéristiques visuelles robustes sans supervision, utilisables directement pour diverses tâches de vision par ordinateur (classification, segmentation, estimation de profondeur) avec de bonnes performances inter-domaines, sans nécessiter de fine-tuning. Cette mise à jour pourrait améliorer davantage les performances du modèle et la qualité des caractéristiques. (Source: facebookresearch/dinov2 – GitHub Trending (all/daily))
L’apprentissage par renforcement (RL) devient une voie clé pour le post-entraînement et l’amélioration des capacités des LLM: Des chercheurs comme David Silver et Richard Sutton soulignent que l’IA entre dans une “ère de l’expérience”, où le RL joue un rôle central dans la phase de post-entraînement des LLM. En apprenant des modèles de récompense à partir du feedback humain (RLHF), de démonstrations ou de règles (Inverse RL), le RL confère aux LLM des capacités d’optimisation continue, d’exploration et de généralisation qui dépassent l’apprentissage par imitation (comme le SFT). Particulièrement pour les tâches de raisonnement (mathématiques, code), le RL aide les modèles à découvrir des schémas de résolution plus efficaces (comme les longues chaînes de pensée), dépassant les limites des méthodes basées sur les données statiques. Cela marque une transition dans le développement des LLM, passant de la dépendance aux données statiques à l’apprentissage dynamique par interaction et feedback. (Source: 被《经验时代》刷屏之后,剑桥博士长文讲述RL破局之路)

La Vision-Langage-Navigation (VLN) reste un défi majeur pour l’IA incarnée: Le professeur associé Wu Qi de l’Université d’Adélaïde souligne que, bien que les tâches de manipulation soient en vogue dans le domaine de l’IA incarnée, la Vision-Langage-Navigation (VLN), en tant que composante clé de la Vision-Langage-Action (VLA), fait toujours face à de nombreux défis dans les environnements non structurés et dynamiques (en particulier les scènes domestiques) et est loin d’être entièrement résolue. La navigation est fondamentale pour que les robots exécutent des tâches ultérieures. Les principaux goulots d’étranglement actuels de la VLN incluent le manque de données de haute qualité (simulateurs, environnements 3D, données de tâches), le fossé de transfert Sim2Real et les difficultés d’ingénierie pour un déploiement efficace en périphérie (edge). (Source: 阿德莱德大学吴琦:VLN 仍是 VLA 的未竟之战丨具身先锋十人谈)

L’IA montre une voie de commercialisation claire dans la publicité et le marketing: Comparée à d’autres scénarios d’application de l’IA, la commercialisation de la technologie IA dans les domaines de la publicité et du marketing semble plus définie et rapide. En utilisant l’IA pour l’analyse de données, le profilage utilisateur, le ciblage précis et le marketing automatisé, des entreprises comme Applovin Corp et Zeta Global ont déjà réussi à transformer l’écosystème publicitaire, améliorant l’efficacité et le retour sur investissement. Cela suggère que, dans la vague de l’IA, les applications capables de générer rapidement de la valeur commerciale sont plus susceptibles d’être favorisées par le marché, la publicité et le marketing en étant des exemples typiques. (Source: “AI寒武纪”爆发至今,五类新物种登上历史舞台)
Tensions sur la chaîne d’approvisionnement des puces IA et tendance à la production nationale: La concurrence technologique sino-américaine s’intensifie, et les contrôles américains à l’exportation de puces IA vers la Chine (en particulier les modèles haut de gamme comme le Nvidia H20) continuent de se resserrer. Selon des rapports, plusieurs entreprises technologiques chinoises (comme ByteDance, Alibaba, Tencent) ont stocké massivement des puces Nvidia avant l’entrée en vigueur des interdictions pour maintenir leurs capacités de R&D et de déploiement en IA. Parallèlement, pour faire face aux risques de la chaîne d’approvisionnement et aux problèmes de “goulot d’étranglement”, la voie technologique d’une IA entièrement produite nationalement gagne en importance. Par exemple, iFlytek entraîne et déploie son grand modèle Spark en s’appuyant sur des capacités de calcul nationales comme Huawei Ascend, ce qui pourrait devenir une tendance majeure pour le développement futur de l’IA en Chine. (Source: 国产六大推理模型激战OpenAI?, Reddit r/artificial, Reddit r/ArtificialInteligence)

🧰 Outils
Suna : Plateforme open source d’agent IA généraliste: Kortix AI a lancé Suna, un agent IA généraliste (Generalist AI Agent) open source. Les utilisateurs peuvent dialoguer en langage naturel avec Suna pour l’assister dans diverses tâches du monde réel, y compris la recherche sur le web, l’analyse de données, l’automatisation du navigateur (navigation web, extraction de données), la gestion de fichiers (création et édition de documents), le web scraping, la recherche étendue, l’exécution de lignes de commande, le déploiement de sites web et l’intégration de diverses API et services. Suna vise à devenir le compagnon numérique des utilisateurs, automatisant les flux de travail complexes. (Source: kortix-ai/suna – GitHub Trending (all/daily))

Le dépôt Leaked System Prompts collecte les prompts système internes de grands modèles: Un dépôt populaire nommé leaked-system-prompts est apparu sur GitHub, collectant et rendant publics les prompts système internes de plusieurs modèles d’IA grand public. Ces prompts révèlent les instructions, règles, définitions de rôle et contraintes de sécurité que les modèles sont conçus pour suivre. Le dépôt contient des prompts divulgués de nombreux modèles, dont la série Anthropic Claude (2.0, 2.1, 3 Haiku/Opus/Sonnet, 3.5 Sonnet, 3.7 Sonnet), Google Gemini 1.5, OpenAI ChatGPT (diverses versions dont 4o), DALL-E 3, Microsoft Copilot, xAI Grok (diverses versions), offrant aux chercheurs et développeurs une fenêtre sur le fonctionnement interne de ces modèles. (Source: jujumilk3/leaked-system-prompts – GitHub Trending (all/daily))
La plateforme de génération vidéo WAN lance un service d’accélération payant: La version internationale de la plateforme de génération vidéo IA WAN (WAN.Video) a annoncé son passage à la commercialisation en lançant des options payantes. Tous les utilisateurs peuvent toujours profiter de générations vidéo gratuites illimitées (mode Relax), mais devront attendre dans une file d’attente. Les utilisateurs payants bénéficient d’un service de génération prioritaire sans file d’attente, obtenant ainsi leurs résultats vidéo plus rapidement. Cela offre une voie accélérée aux utilisateurs ayant besoin d’une haute efficacité ou à des fins commerciales. (Source: op7418)

Le modèle Dia TTS arrive sur l’API Hugging Face: Les utilisateurs peuvent désormais appeler directement l’API du modèle Text-to-Speech (TTS) Dia 1.6B via la plateforme Hugging Face, un service pris en charge par FAL AI. Les développeurs peuvent l’intégrer avec seulement quelques lignes de code pour implémenter des fonctionnalités de synthèse vocale de haute qualité. Cette intégration abaisse le seuil d’utilisation des modèles TTS avancés, facilitant l’ajout rapide de capacités vocales aux applications par les développeurs. (Source: huggingface)
Le modèle classificateur ModernBERT intégré à vLLM pour une inférence rapide: Le modèle ModernBERT peut désormais s’exécuter sur le framework vLLM, améliorant considérablement la vitesse d’inférence. Il serait assez rapide pour traiter plus de 200 000 articles arXiv en quelques minutes. Cette intégration permet aux centaines de modèles ModernBERT hébergés sur le Hugging Face Hub d’être déployés et appliqués plus rapidement aux tâches de classification de texte. (Source: huggingface)
Trackers : Bibliothèque Python haute performance pour le suivi d’objets: Roboflow a publié en open source une bibliothèque Python nommée Trackers, spécialisée dans les tâches de suivi d’objets. Conçue pour être modulaire, elle prend en charge plusieurs algorithmes de suivi et s’intègre facilement aux bibliothèques de machine learning populaires comme Ultralytics et Transformers. Ses performances sont élevées, capable de suivre simultanément un grand nombre d’objets, réussissant à suivre plus de 269 œufs dans une vidéo de démonstration. (Source: karminski3)
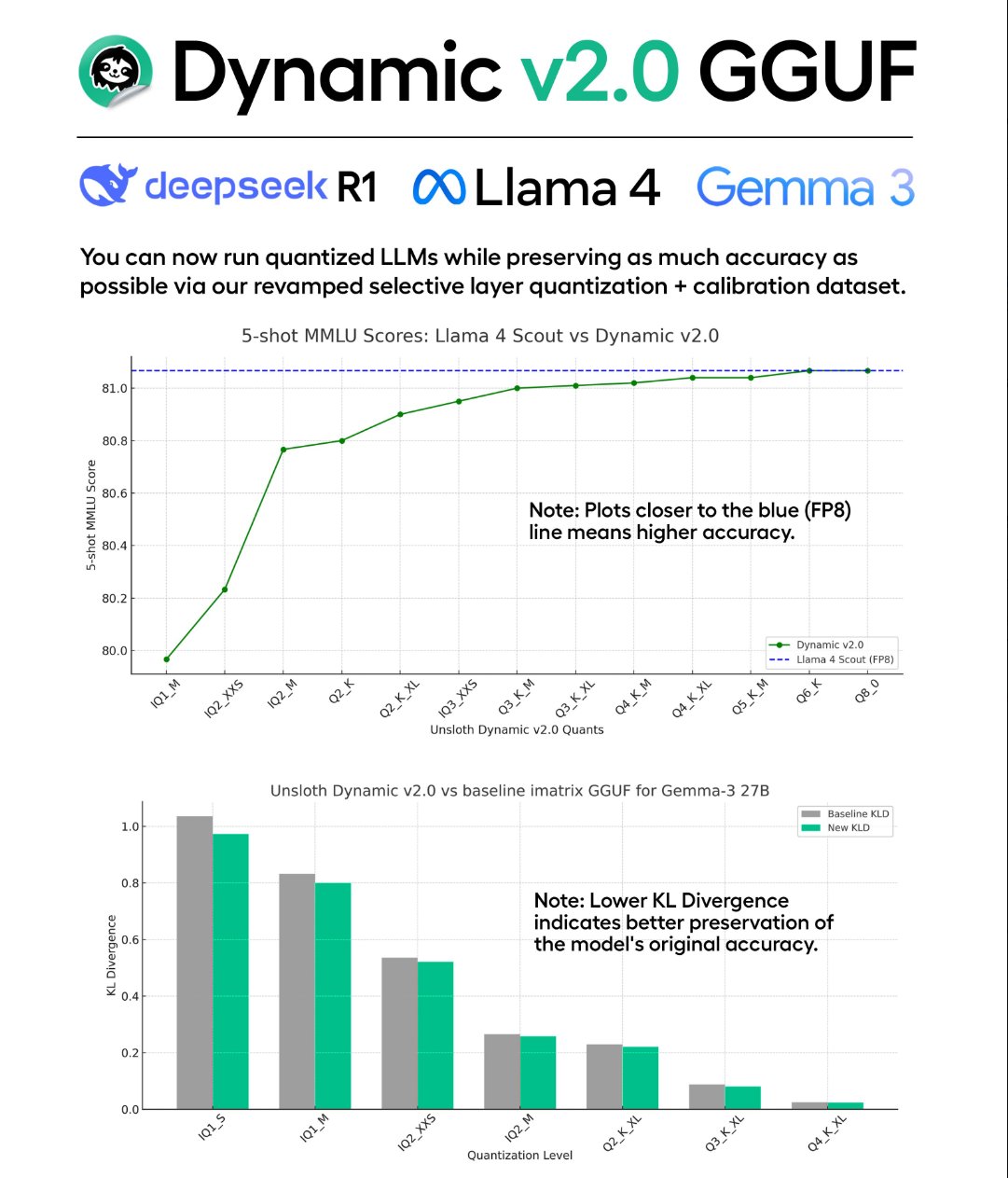
Unsloth lance la technologie de quantification Dynamic v2.0 GGUF et des modèles: Unsloth a introduit sa nouvelle technologie de quantification Dynamic v2.0, spécialement conçue pour les modèles au format GGUF. Selon les affirmations, cette version quantifiée surpasse les versions précédentes dans les évaluations MMLU et KL Divergence, et corrige les problèmes d’implémentation de RoPE pour Llama-4 dans Llama.cpp. Unsloth a utilisé cette technologie pour publier de nouveaux modèles quantifiés de DeepSeek-R1 et DeepSeek-V3-0324 à l’usage de la communauté. (Source: karminski3)
L’assistant vocal Perplexity iOS intègre des fonctionnalités système: L’application iOS de Perplexity a mis à jour son assistant vocal pour lui permettre d’appeler davantage d’opérations au niveau du système. Les utilisateurs peuvent désormais utiliser des commandes vocales pour que l’assistant Perplexity réserve des restaurants, utilise Apple Maps pour la navigation, crée des rappels, recherche et joue de la musique ou des podcasts Apple, et commande un VTC, entre autres. Cela rapproche l’assistant Perplexity en termes de fonctionnalités des assistants système natifs comme Siri, améliorant son utilité pratique. (Source: AravSrinivas)
Publication de l’extension VS Code MCP Server, connectant Claude à l’environnement de développement local: Le développeur Juehang Qin a publié une extension VS Code qui transforme VS Code en serveur MCP (Model Context Protocol). Cela permet à des assistants IA comme Claude d’accéder directement et de manipuler l’espace de travail actuellement ouvert par l’utilisateur dans VS Code, y compris la lecture/écriture de fichiers, la consultation des diagnostics de code (erreurs, avertissements), etc. Lorsque l’utilisateur change de projet, l’extension expose automatiquement le nouvel espace de travail, facilitant la collaboration transparente de l’assistant IA entre différents projets. (Source: Reddit r/ClaudeAI)
📚 Apprentissage
DINOv2 : Meta publie en open source la méthode d’apprentissage auto-supervisé de caractéristiques visuelles: Meta AI Research a rendu open source le projet DINOv2, incluant le code PyTorch et les modèles pré-entraînés. DINOv2 est une méthode d’apprentissage auto-supervisé visant à apprendre des caractéristiques visuelles puissantes et générales qui excellent dans diverses tâches de vision par ordinateur (classification d’images, segmentation sémantique, estimation de profondeur) sans nécessiter de fine-tuning pour les tâches en aval. Le projet fournit une documentation détaillée, des liens de téléchargement de modèles et les articles de recherche associés, constituant une ressource importante pour la recherche et l’application de l’apprentissage visuel auto-supervisé. (Source: facebookresearch/dinov2 – GitHub Trending (all/daily))
HD-EPIC : Publication d’un jeu de données vidéo à la première personne haute définition: Des chercheurs ont lancé le jeu de données HD-EPIC, contenant 41 heures de vidéo à la première personne enregistrées dans un environnement de cuisine réel. La caractéristique clé de ce jeu de données est son annotation multimodale extrêmement détaillée, couvrant les étapes de recettes, les informations nutritionnelles des ingrédients (enregistrées par pesée), des descriptions d’actions fines (contenu, manière, raison), un jumeau numérique 3D de la scène, les trajectoires de déplacement des objets (2D/3D), les masques des mains/objets, le suivi du regard et les interactions objet-scène. Ce jeu de données vise à fournir un benchmark de haute qualité pour la compréhension visuelle à la première personne, l’IA incarnée et la recherche sur l’interaction homme-machine. (Source: CVPR 2025 | HD-EPIC定义第一人称视觉新标准:多模态标注精度碾压现有基准)

SRPO : Méthode d’optimisation pour résoudre l’entraînement RL inter-domaines des capacités de raisonnement des LLM: L’équipe Kwaipilot de Kuaishou, confrontée aux goulots d’étranglement de performance et aux problèmes d’efficacité lors de l’utilisation de méthodes d’apprentissage par renforcement comme GRPO pour entraîner les LLM sur des tâches mixtes de mathématiques et de code, a proposé la méthode SRPO (Optimisation de politique par rééchantillonnage historique en deux étapes). Cette méthode utilise une première étape avec des données mathématiques pour stimuler la réflexion profonde, suivie d’une deuxième étape introduisant des données de code pour développer la pensée procédurale, combinée à une technique de rééchantillonnage historique pour résoudre le problème de la variance nulle du signal de récompense. Les expériences montrent que SRPO atteint des performances supérieures à DeepSeek-R1-Zero-Qwen-32B sur AIME24 et LiveCodeBench avec seulement 10% des étapes d’entraînement, offrant une voie efficace pour améliorer les capacités de raisonnement inter-domaines. (Source: DeepSeek-R1-Zero被“轻松复现”?10%训练步数实现数学代码双领域对齐)
TTRL : Apprentissage par renforcement au moment du test sans données annotées: L’Université Tsinghua et Shanghai AI Lab ont proposé la méthode TTRL (Test-Time Reinforcement Learning), permettant aux LLM d’effectuer un apprentissage par renforcement pendant la phase de test, sans nécessiter d’annotations manuelles. Cette méthode utilise les multiples sorties échantillonnées du modèle lui-même pour générer des pseudo-étiquettes et des signaux de récompense via un vote majoritaire ou d’autres moyens, permettant au modèle d’évoluer de manière autonome pour s’adapter à de nouvelles données ou tâches. Les expériences montrent que TTRL peut améliorer considérablement les performances du modèle sur les tâches cibles, se rapprochant même des résultats de l’entraînement supervisé, offrant une nouvelle approche pour résoudre les défis de l’application du RL dans des environnements non supervisés. (Source: TTS和TTT已过时?TTRL横空出世,推理模型摆脱「标注数据」依赖,性能暴涨)
SeekWorld : Tâche et modèle de raisonnement de géolocalisation simulant le suivi d’indices visuels o3: Pour améliorer les capacités de raisonnement visuel des grands modèles de langage multimodaux (MLLM), en particulier pour simuler la capacité du modèle o3 d’OpenAI à percevoir et manipuler dynamiquement les images pendant le raisonnement (suivi d’indices visuels), des chercheurs ont proposé la tâche de raisonnement de géolocalisation SeekWorld (déduire le lieu de prise de vue d’une image). Un jeu de données a été construit autour de cette tâche, et le modèle SeekWord-7B a été entraîné par apprentissage par renforcement. Ce modèle surpasse Qwen-VL, Doubao Vision Pro, GPT-4o et d’autres modèles en matière de raisonnement de géolocalisation. Le projet a publié en open source le modèle, le jeu de données et une démo en ligne. (Source: 一张图片找出你在哪?o3-like 7B模型玩网络迷踪超越一流开闭源模型!)
ManipTrans : Transfert de compétences de manipulation des mains humaines aux mains robotiques dextres: Des chercheurs de l’Institut d’Intelligence Artificielle Générale de Pékin, de l’Université Tsinghua et de l’Université de Pékin ont proposé la méthode ManipTrans pour transférer efficacement les compétences de manipulation bi-manuelle humaine à des mains robotiques dextres dans des environnements de simulation. La méthode adopte une stratégie en deux étapes : d’abord imiter le mouvement de la main humaine via un imitateur de trajectoire générique, puis affiner en combinant l’apprentissage résiduel et les contraintes d’interaction physique. Sur la base de cette méthode, l’équipe a publié le jeu de données d’opérations de mains dextres à grande échelle DexManipNet, contenant des séquences de tâches complexes comme dévisser un bouchon de bouteille, écrire, puiser, ouvrir un tube de dentifrice, et a validé la faisabilité du déploiement sur un robot réel. (Source: 机器人也会挤牙膏?ManipTrans:高效迁移人类双手操作技能至灵巧手)

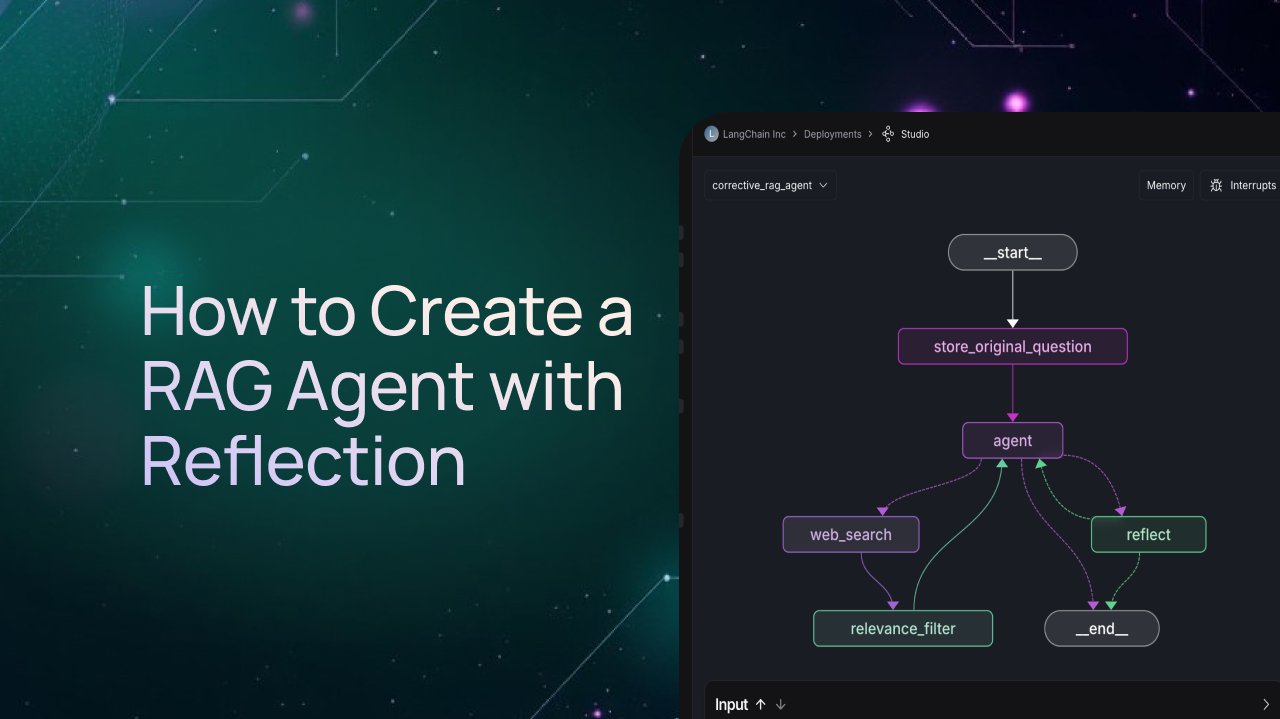
Tutoriel LangGraph : Créer un agent RAG avec mécanisme de réflexion: LangChain a publié un tutoriel vidéo détaillant comment utiliser le framework LangGraph pour construire un agent RAG (Retrieval-Augmented Generation) doté d’une capacité de réflexion (Reflection). L’idée centrale est d’ajouter un nœud d’évaluation dans le processus RAG, permettant à l’agent d’examiner les informations récupérées avant de générer la réponse finale, d’évaluer leur pertinence et leur qualité, et de décider en fonction de l’évaluation s’il faut relancer la recherche, corriger la requête ou générer directement la réponse, filtrant ainsi efficacement le bruit et améliorant la qualité des réponses. (Source: LangChainAI)
Arena-Hard-v2.0 : Un benchmark d’évaluation plus strict pour les grands modèles: LMSYS Org a mis à jour et publié la version 2.0 du benchmark d’évaluation Arena-Hard. La nouvelle version est basée sur 500 prompts plus difficiles soumis par les utilisateurs de LMArena, utilise des modèles d’évaluation automatique plus puissants (Gemini-2.5 & GPT-4.1), prend en charge plus de 30 langues et ajoute une évaluation des capacités d’écriture créative. L’objectif est de fournir une plateforme plus difficile et plus complète pour différencier les performances des meilleurs grands modèles. (Source: lmarena_ai)
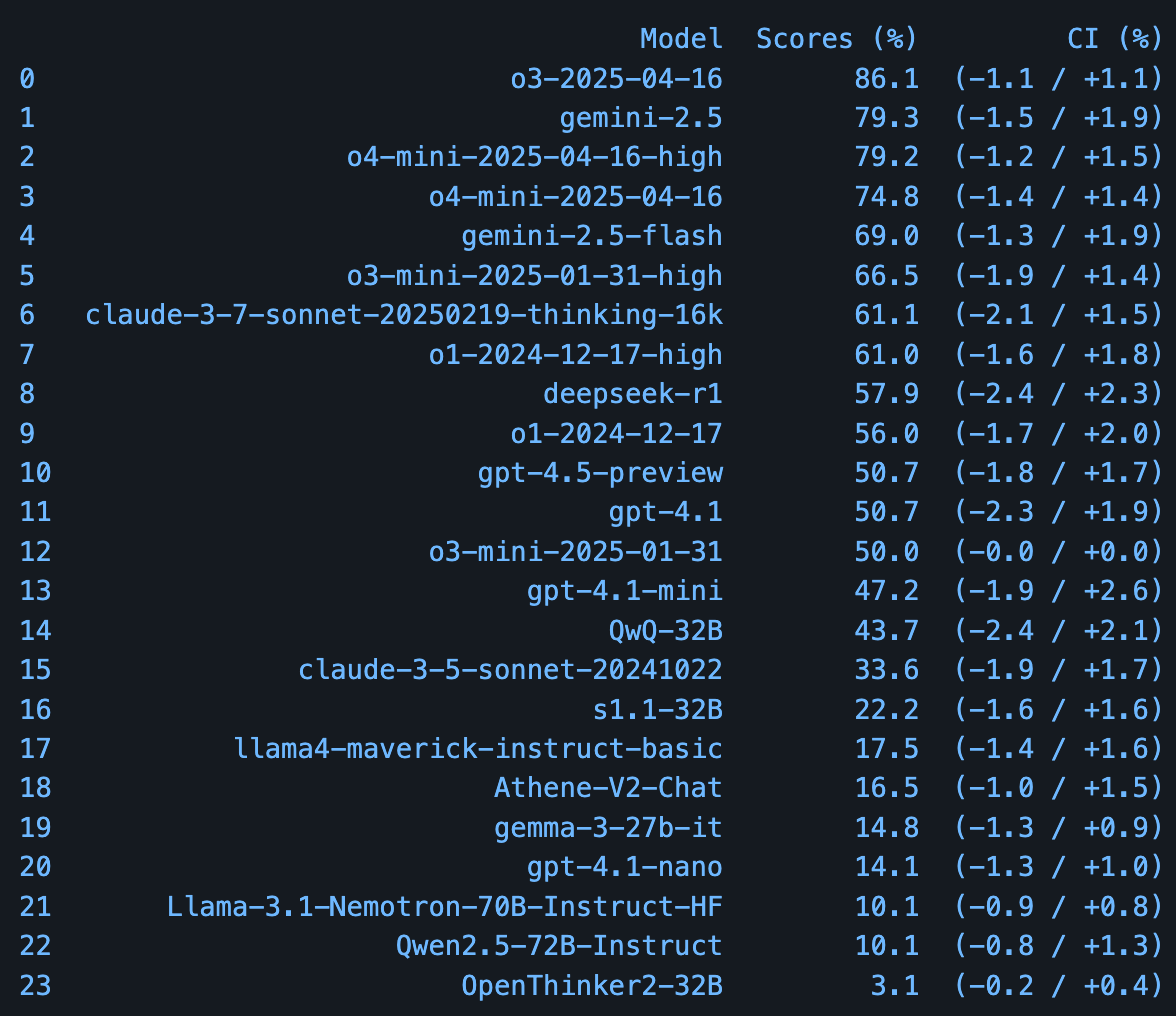
Publication de PHYBench : un benchmark pour évaluer la capacité de raisonnement physique des LLM: Une équipe de chercheurs de l’Université de Pékin a lancé PHYBench, un nouveau benchmark d’évaluation spécifiquement conçu pour évaluer la capacité des grands modèles de langage à comprendre et à raisonner sur les processus physiques du monde réel. Le benchmark contient 500 questions basées sur des scénarios physiques réels. Selon les premiers résultats d’évaluation fournis dans l’article, Gemini-2.5-Pro de Google obtient les meilleures performances sur ce benchmark. (Source: karminski3)
💼 Affaires
Alibaba Tongyi Qianwen et FLock.io annoncent un partenariat stratégique: Le grand modèle Tongyi Qianwen (Qwen) d’Alibaba et la plateforme de calcul IA décentralisée FLock.io ont conclu un partenariat stratégique. Les deux parties visent à explorer et promouvoir conjointement la mise en œuvre pratique de l’IA décentralisée, en combinant les capacités de la série de modèles open source Qwen avec le framework technologique décentralisé de FLock.io, afin d’offrir de nouvelles possibilités aux développeurs et utilisateurs d’IA. (Source: Alibaba_Qwen)
Le laboratoire Tongyi d’Alibaba recrute des stagiaires en recherche sur le dialogue multi-tours LLM: Le laboratoire Tongyi d’Alibaba, responsable de la R&D de la série de grands modèles Tongyi, recrute des stagiaires en recherche à Pékin et Hangzhou pour son équipe d’intelligence conversationnelle, spécialisée dans le dialogue multi-tours LLM. Les domaines de recherche incluent la modélisation générative de récompenses, l’extension des modèles de récompense au moment de l’inférence, l’apprentissage par renforcement pour les tâches créatives comme le jeu de rôle, et le dialogue multimodal texte-voix. Les candidats doivent être doctorants, avoir publié dans des conférences de premier plan et pouvoir garantir une durée de stage d’au moins 6 mois. (Source: 北京/杭州内推 | 阿里通义实验室对话智能团队招聘LLM多轮对话方向研究实习生)

L’outil de productivité Remio recrute un stagiaire en gestion des médias sociaux à l’international: La startup Remio recherche un stagiaire familier avec les médias sociaux étrangers (Reddit, Hacker News, Twitter, etc.) et passionné par les outils de productivité. Les principales responsabilités sont la gestion des médias sociaux et la création de contenu. Le poste est ouvert au télétravail, que ce soit en Chine ou en Amérique du Nord, avec une certaine exigence de karma sur Reddit (recommandé 100+). (Source: dotey)
L’entreprise d’API Kong recrute des ingénieurs et des stagiaires pour son équipe de Shanghai: L’équipe chinoise de Kong (connue pour sa passerelle API open source), basée à Shanghai, élargit ses recrutements et propose plusieurs postes, y compris des stages et des emplois à temps plein. Les postes à pourvoir couvrent le développement Rust, l’AI Gateway, Kong Gateway et le développement frontend. Les développeurs intéressés par ces piles technologiques peuvent se renseigner. (Source: dotey)

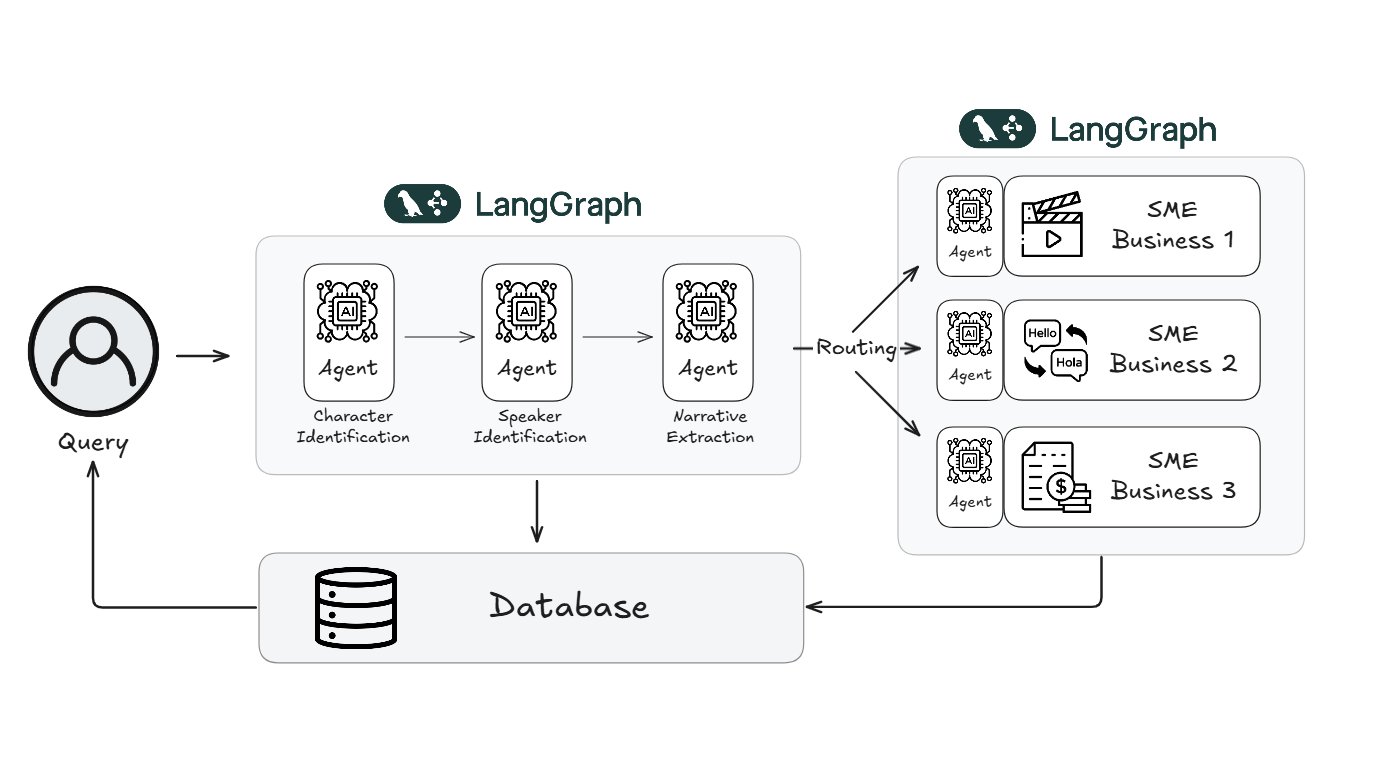
Webtoon utilise LangGraph pour réduire de 70% la charge de travail liée à la révision de contenu: La plateforme mondiale de bandes dessinées numériques Webtoon a utilisé le framework LangGraph de LangChain pour construire un système appelé WCAI (Webtoon Comprehension AI). Ce système utilise des agents IA multimodaux pour comprendre automatiquement le contenu des bandes dessinées, y compris l’identification des personnages et l’attribution des dialogues, l’extraction de l’intrigue et du ton émotionnel, ainsi que la prise en charge des requêtes en langage naturel. WCAI est utilisé par les équipes marketing, de traduction et de recommandation, réduisant avec succès de 70% la charge de travail liée à la navigation et à la révision manuelles, améliorant l’efficacité du traitement du contenu et le soutien à la création. (Source: LangChainAI)
Meta AI recrute des talents en recherche à l’ICLR 2025: L’équipe Meta AI a participé à la conférence ICLR 2025 à Singapour, tenant un stand (#L03) pour échanger avec les participants. Parallèlement, Meta AI publie activement des offres d’emploi, recherchant des chercheurs scientifiques en IA, des chercheurs postdoctoraux et des assistants de recherche (doctorat), avec des domaines de recherche incluant la théorie fondamentale de l’apprentissage, l’IA générative 3D, l’IA générative de langage, etc. Les lieux de travail incluent Paris et d’autres centres de recherche mondiaux. (Source: AIatMeta)

🌟 Communauté
Andrew Ng : La programmation assistée par l’IA abaisse la barrière de la langue et améliore les capacités inter-domaines des développeurs: Le célèbre chercheur en IA Andrew Ng souligne que les outils de programmation assistée par l’IA transforment profondément le développement logiciel. Même sans maîtriser une langue spécifique (comme JavaScript), les développeurs peuvent écrire du code efficacement avec l’aide de l’IA, facilitant ainsi la création d’applications multiplateformes et inter-domaines (par exemple, un développeur backend construisant un frontend). Bien que la syntaxe d’un langage spécifique devienne moins cruciale, la compréhension des concepts fondamentaux de la programmation (structures de données, algorithmes, principes de frameworks spécifiques comme React) reste essentielle pour guider plus précisément l’IA et résoudre les problèmes. L’IA rend les développeurs plus “polyglottes”. (Source: AndrewYNg)
Le PDG de Microsoft AI affirme que Copilot a fourni des informations sur un retard de vol avant l’annonce officielle: Mustafa Suleyman, responsable de la division IA de Microsoft, a partagé un “moment magique” sur la plateforme X : son assistant IA Copilot l’a informé du retard de son vol avant l’annonce officielle de l’aéroport. Après vérification auprès du personnel de la porte d’embarquement, l’information s’est avérée exacte, bien que non encore annoncée publiquement. Cela démontre le potentiel de l’IA à intégrer et transmettre des informations en temps réel, dépassant potentiellement les canaux de diffusion d’informations traditionnels. (Source: mustafasuleyman)

Discussion communautaire sur les avantages et inconvénients de GPT-4.5 et o1 Pro pour différentes tâches: Des utilisateurs de la plateforme X discutent de leur expérience pratique avec différents modèles d’OpenAI. Un utilisateur estime que GPT-4.5 excelle dans les tâches d’écriture et de traduction, mais est limité par une fenêtre de contexte plus petite, ce qui dégrade ses performances sur les textes longs. En comparaison, le modèle o1 Pro destiné aux utilisateurs Pro dispose d’une fenêtre de contexte de 128K, ce qui le rend plus stable et fiable pour traiter de longues entrées de code, et donc plus adapté aux tâches de programmation. Cela reflète les différences d’accentuation dans la conception et l’optimisation des différents modèles. (Source: dotey)
Hugging Face Hub recommandé comme plateforme d’apprentissage et d’échange sur l’IA: Un utilisateur de la plateforme X recommande Hugging Face Hub non seulement comme un dépôt de modèles et de jeux de données, mais aussi comme une communauté active d’apprentissage et d’échange sur l’IA. Les utilisateurs peuvent trouver dans les sections de discussion des modèles, jeux de données ou Spaces des ingénieurs et chercheurs partageant leurs processus expérimentaux, les problèmes rencontrés, les solutions trouvées et des discussions sur des articles de recherche pertinents, obtenant ainsi une expérience pratique de première main et des aperçus approfondis. (Source: huggingface)
ChatGPT “tacle” la culture de la communauté Reddit, suscitant un débat: Un utilisateur de Reddit a demandé à ChatGPT de “tacler” (roast) la plateforme Reddit. La réponse générée par ChatGPT a capturé et ironisé avec précision certaines caractéristiques typiques de la communauté Reddit, telles que les opinions contradictoires des utilisateurs, la préoccupation excessive pour les votes positifs (karma), le manque d’expérience réelle combiné à des conseils d’expert, et le comportement de “guerrier du clavier” dans certains sous-forums (subreddit). Ce post a suscité des discussions et d’autres créations imitatives au sein de la communauté. (Source: Reddit r/ArtificialInteligence)
L’originalité et la valeur du contenu généré par l’IA suscitent la réflexion: Un post sur Reddit a lancé une discussion sur l’originalité du contenu généré par l’IA. Prenant l’exemple de La Joconde, le post souligne que la création humaine elle-même est un “remix” basé sur l’expérience, et que l’IA générant du contenu sous direction humaine ressemble plus à un “maître guidant un apprenti” qu’à une simple copie. La discussion suggère que la question clé n’est pas de savoir si l’IA peut être “originale”, mais comment attribuer correctement le crédit, respecter les droits des créateurs originaux et juger de l’intention et de la valeur de l’œuvre. (Source: Reddit r/ArtificialInteligence)
Remise en question de l’efficacité des classements de grands modèles (LLM Leaderboard) par la communauté: Des utilisateurs de la communauté Reddit r/LocalLLaMA ont exprimé des doutes lors de discussions sur les classements de grands modèles basés sur le score Elo, comme LMSYS Arena. Certains commentaires suggèrent que ces classements pourraient davantage refléter le “style” ou le “ressenti” du modèle (par exemple, verbosité, utilisation de Markdown et d’émojis) plutôt que ses capacités globales réelles. De plus, les intervalles de confiance des scores Elo pour les modèles de pointe se chevauchent souvent, remettant en question la signification statistique des différences de classement. (Source: Reddit r/LocalLLaMA)
Un utilisateur observe plusieurs “comportements émergents” de ChatGPT: Un utilisateur de Reddit a partagé plusieurs comportements “inattendus” rencontrés récemment en utilisant ChatGPT, qu’il a classés comme des “comportements émergents”. Ceux-ci incluent : 1. Sans être corrigé, le modèle réalise qu’il a mal compris une instruction (confondant l’historique de chat et un document téléchargé) et s’excuse主动ment pour corriger. 2. Après qu’un sujet sensible mentionné par l’utilisateur ait été supprimé par le système, le modèle cite主动ment le contenu supprimé dans une conversation ultérieure pour exprimer son inquiétude. 3. En discutant de la difficulté de tester la pensée spontanée de l’IA, le modèle crée主动ment un concept analogique : le “principe d’incertitude récursive d’Heisenberg”. Ces cas ont suscité des discussions sur les limites de la conscience de soi, de la mémoire et de la créativité des LLM. (Source: Reddit r/ArtificialInteligence)
💡 Autres
Google DeepMind met à jour sa boîte à outils Music AI Sandbox: Google DeepMind a annoncé l’ajout de nouvelles fonctionnalités à son Music AI Sandbox. Il s’agit d’un ensemble d’outils IA expérimentaux destinés aux musiciens professionnels, conçus pour aider à la création musicale. Les nouvelles fonctionnalités, alimentées par leur dernier modèle Lyria 2, peuvent aider les auteurs-compositeurs et autres musiciens à explorer des idées créatives, générer des extraits musicaux, etc. (Source: demishassabis)
Discussion sur les principes de gouvernance de l’informatique quantique: Des membres de la communauté partagent et discutent des principes concernant la gouvernance de l’informatique quantique. Avec le développement de la technologie quantique, son énorme potentiel en cryptographie, science des matériaux, développement de médicaments et en combinaison avec l’IA/ML suscite l’attention, tout en soulevant des défis en matière de sécurité, d’éthique et de gouvernance qui nécessitent l’élaboration préalable de normes appropriées. (Source: Ronald_vanLoon)

Le MIT développe un robot logiciel portable en forme de banane: Des chercheurs du MIT ont développé un nouveau type de robot logiciel portable, dont la forme rappelle une banane et qui intègre des capacités de détection. Cette recherche démontre le potentiel d’application des robots logiciels dans l’interaction homme-machine, la rééducation médicale et les dispositifs portables, leur structure flexible et leur détection intégrée offrant la possibilité d’interactions physiques plus naturelles et plus sûres. (Source: Ronald_vanLoon)
Progrès de la robotique pilotée par l’IA: Plusieurs avancées en robotique, souvent alimentées par ou liées à l’IA, ont été présentées récemment sur les réseaux sociaux : 1. SR-02 : Une “monture robotique” quadrupède pouvant transporter quatre personnes. 2. SnapBot : Un robot à pattes capable de se transformer. 3. Matic : Un robot imitant le système de vision FSD de Tesla pour le nettoyage domestique. 4. micropsi : Une startup allemande développant un système d’IA permettant aux robots de gérer des tâches imprévisibles. 5. Boston Dynamics Spot : Le chien robot testé en environnement naturel. 6. Course de robots humanoïdes : Démontrant les capacités motrices des robots humanoïdes. 7. Écriture manuscrite par bras robotique : Démontrant les capacités de manipulation fine des robots. (Source: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
