
Mots-clés:OpenAI, Modèle d’IA, AlphaFold, Puce d’IA, GPT-4.1, Modèle vidéo Magi-1, Contrôle des exportations Nvidia H20, UI-TARS-1.5 de ByteDance, Multimodal MILS de Meta, DeepMind AlphaFold 3, Vidéo autorégressive Sand.ai, Huawei Ascend 910C
🔥 Pleins feux
OpenAI lance cinq nouveaux modèles, renforçant les capacités générales et de raisonnement: OpenAI a lancé trois modèles généraux, GPT-4.1, GPT-4.1 mini et GPT-4.1 nano, ainsi que deux modèles de raisonnement, o3 et o4-mini. La série GPT-4.1 prend en charge jusqu’à 1 million de tokens en entrée et vise à offrir une option plus rentable que GPT-4.5/4o, GPT-4.1 surpassant GPT-4o dans des tâches telles que le codage. o3 et o4-mini sont des versions améliorées de o1 et o3-mini, avec une limite d’entrée de 200k tokens, une meilleure utilisation des outils (recherche web, génération/exécution de code, édition d’images) et, pour la première fois, la prise en charge du traitement Chain-of-Thought pour les images. o3 atteint le SOTA sur plusieurs benchmarks. Parallèlement, OpenAI a annoncé le retrait de la version préliminaire de GPT-4.5 en juillet. Ce lancement vise à offrir des performances accrues à moindre coût, notamment en matière de raisonnement et d’utilisation d’outils. (Source: OpenAI’s Five New Models, Hugging Face’s Open Robot, U.S. Tightens Grip on AI Chips, Text-Only LLMs Go Multimodal)
Sand.ai rend open source Magi-1, le premier modèle vidéo autorégressif de haute qualité: La startup pékinoise Sand.ai a publié et rendu open source Magi-1, le premier modèle de génération vidéo de haute qualité au monde adoptant une architecture autorégressive. Contrairement aux modèles de génération concurrente comme Sora, Magi-1 adopte une méthode de génération chunk-by-chunk, préservant la causalité temporelle, et excelle en termes de réalisme physique, de cohérence des actions et de contrôlabilité, particulièrement performant pour la continuation vidéo (V2V). L’équipe a rendu open source les poids des modèles de 4.5B à 24B paramètres, ainsi que le code d’inférence et d’entraînement, et a mis à disposition un site web produit prêt à l’emploi. Le modèle peut fonctionner au minimum sur une seule carte graphique 4090, la consommation de ressources pour l’inférence étant indépendante de la durée de la vidéo, ouvrant des possibilités pour la génération de vidéos longues et les applications en temps réel. (Source: Magi-1 开源&刷屏:首个高质量自回归视频模型,它的一切信息)
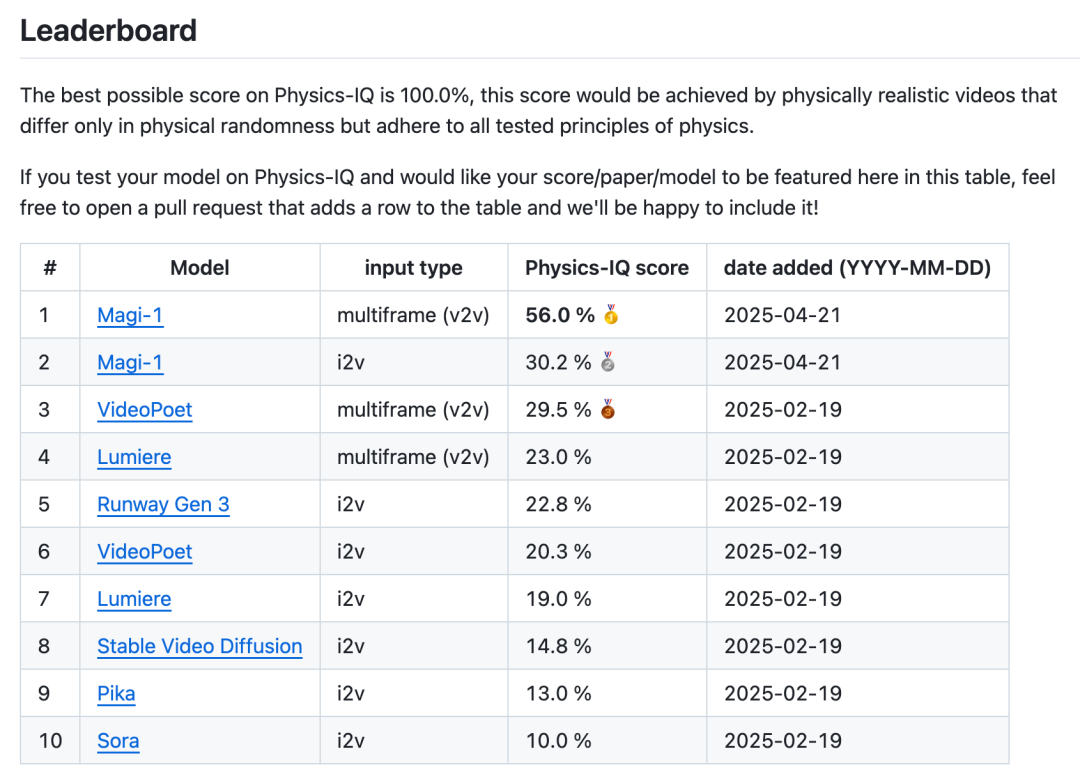
Progrès de DeepMind AlphaFold : 200 millions de structures protéiques cartographiées en un an: Le fondateur de Google DeepMind, Demis Hassabis, a révélé dans une interview que son modèle de prédiction de structure protéique AlphaFold a cartographié plus de 200 millions de structures protéiques en un an, alors que les méthodes traditionnelles nécessitent des années pour résoudre une seule structure. AlphaFold 3 s’étend désormais à l’ADN, l’ARN, aux ligands et à presque toutes les molécules du vivant, améliorant considérablement la précision de la prédiction des interactions moléculaires dans la conception de médicaments. Google DeepMind a également lancé la plateforme gratuite AlphaFold Server, permettant aux biologistes d’utiliser facilement ses capacités de prédiction. Bien qu’il soit confronté au défi du manque de données sur les interactions médicament-protéine, AlphaFold fait entrer la recherche biologique dans une ère de haute définition, accélérant le processus de développement de médicaments. (Source: Demis 谈 AI4S 最新进展:DeepMind 的 AlphaFold 一年就画了 2 亿个蛋白质!, GoogleDeepMind)
Les États-Unis renforcent les contrôles à l’exportation de puces IA vers la Chine, limitant Nvidia H20 et d’autres: Le gouvernement américain a annoncé que les futures exportations vers la Chine de puces IA telles que Nvidia H20, AMD MI308 ou de performances équivalentes nécessiteront une licence. Cette mesure s’inscrit dans les efforts continus des États-Unis pour empêcher la Chine d’acquérir du matériel d’IA de pointe. Nvidia H20 est une puce dégradée lancée pour contourner les interdictions antérieures sur H100/H200. Les nouvelles restrictions devraient entraîner une perte de revenus de 5,5 milliards de dollars pour Nvidia et de 800 millions de dollars pour AMD. Parallèlement, le Congrès américain a lancé une enquête pour déterminer si Nvidia a aidé DeepSeek à développer des modèles en violation des règles. Cette décision incite la Chine à accélérer la R&D de ses propres puces IA, Huawei prévoyant de produire en masse les Ascend 910C et 920 pour remplacer les produits Nvidia. (Source: OpenAI’s Five New Models, Hugging Face’s Open Robot, U.S. Tightens Grip on AI Chips, Text-Only LLMs Go Multimodal)

🎯 Tendances
ByteDance publie l’agent multimodal UI-TARS-1.5: ByteDance a rendu open source l’agent multimodal UI-TARS-1.5, basé sur un modèle de langage visuel, capable d’exécuter efficacement diverses tâches dans des mondes virtuels. Ce modèle s’appuie sur des recherches antérieures et intègre des capacités de raisonnement avancées pilotées par l’apprentissage par renforcement, lui permettant de réfléchir avant d’agir, améliorant ainsi considérablement ses performances et son adaptabilité. UI-TARS-1.5 a obtenu des résultats SOTA sur plusieurs benchmarks (tels que OSworld, WebVoyager, Android World), démontrant de solides capacités de raisonnement et de manipulation de GUI, notamment dans les jeux (comme Poki Game, Minecraft) et la localisation d’éléments à l’écran (ScreenSpot-V2/Pro). L’équipe a également publié le modèle UI-TARS-1.5-7B avec 7 milliards de paramètres. (Source: bytedance/UI-TARS – GitHub Trending (all/daily))

Meta propose MILS : permettre aux LLM purement textuels de comprendre le contenu multimodal: Des chercheurs de Meta, UT Austin et UC Berkeley ont proposé la méthode Multimodal Iterative LLM Solver (MILS), permettant aux grands modèles de langage purement textuels (comme Llama 3.1 8B) de générer des descriptions pour des images, des vidéos et de l’audio sans entraînement supplémentaire. Cette méthode exploite la capacité des LLM à générer du texte et à l’optimiser de manière itérative en fonction des retours, en combinaison avec des modèles d’embedding multimodaux pré-entraînés (tels que SigLIP, ViCLIP, ImageBind) pour évaluer la similarité entre le texte et le contenu multimédia. Le LLM génère des descriptions de manière itérative en fonction du score de similarité jusqu’à ce que la correspondance soit suffisamment élevée. Les expériences montrent que MILS surpasse les modèles entraînés spécifiquement pour ces tâches dans la description d’images, de vidéos et d’audio, offrant une nouvelle voie pour la compréhension multimodale zero-shot. (Source: OpenAI’s Five New Models, Hugging Face’s Open Robot, U.S. Tightens Grip on AI Chips, Text-Only LLMs Go Multimodal)
Yang Zuoxing de Yanji Micro : Des puces IA à très faible consommation pour des applications intelligentes vertes: Yang Zuoxing, docteur de l’Université Tsinghua et fondateur de la marque Shenmou, a partagé l’importance de la technologie IA à très faible consommation lors de la conférence AI Partner 2025. Il a souligné que la consommation d’énergie et la dissipation thermique deviennent des goulots d’étranglement critiques à mesure que la taille des modèles d’IA augmente. Yanji Micro, grâce à une méthodologie de conception de puces full-custom révolutionnaire, a considérablement réduit la consommation d’énergie et le coût des puces (par exemple, la consommation des puces de calcul a été réduite à 180W/T et le coût à 240 yuans/T, une optimisation de plus de 10 fois). Les caméras intelligentes AI Shenmou basées sur cette technologie réalisent des applications IA haute performance à faible consommation, telles que l’imagerie couleur en basse lumière, la détection de plus de 10 types de cibles, la reconnaissance faciale/véhicule/gestuelle/vocale, la surveillance de l’état des bébés, ainsi qu’un système innovant d’alarme active “salvatrice” et des appels familiaux gratuits, démontrant l’énorme potentiel de l’IA à faible consommation pour améliorer la qualité de vie et la sécurité. (Source: 清华大学博士、神眸品牌创始人、杭州研极微董事长杨作兴:极致低功耗,AI绿色智能应用的未来 | 2025 AI Partner大会)

Bouleversement du marché des navigateurs à l’ère de l’IA : OpenAI envisage d’acquérir Chrome: Selon des rapports, OpenAI serait prêt à acquérir Chrome si Google était contraint de le vendre en raison de mesures antitrust. Google domine le marché mondial des navigateurs (Chrome détient 68%) et des moteurs de recherche, faisant face à des pressions antitrust. L’essor des grands modèles d’IA modifie le paysage des navigateurs ; la recherche IA (comme Quark) intègre des capacités de recherche, de filtrage et de synthèse, améliorant l’expérience utilisateur. Google, avec Chrome et Gemini, dispose d’un avantage évident, mais cela accentue également les craintes de monopole. L’acquisition de Chrome par OpenAI lui donnerait accès à d’énormes volumes de données pour l’entraînement de modèles, l’amélioration de la technologie de recherche (réduisant sa dépendance à Bing), des revenus publicitaires considérables et un point d’entrée crucial pour l’IA. Cette démarche pourrait remodeler les marchés des navigateurs et des moteurs de recherche, posant un défi sérieux à Google. (Source: Chrome将被OpenAI吞下?AI时代浏览器市场早已变天, Reddit r/artificial)
L’outil vidéo IA chinois Vidu gagne en popularité auprès des créateurs d’animation japonais: Les outils chinois de génération de vidéo par IA, représentés par Vidu, sont progressivement acceptés et utilisés par les créateurs d’animation japonais. Grâce à ses avantages tels que la restitution fidèle du style anime, la fluidité des mouvements et la fonction innovante mondiale de “génération vidéo de référence” (maintenant la cohérence des personnages, des accessoires et des arrière-plans), Vidu a attiré des utilisateurs japonais comme le réalisateur Wada et le chef de produit yachimat, les aidant à abaisser la barrière d’entrée de la production d’animation et à réaliser leurs rêves créatifs. L’animation IA est devenue une direction clé pour Vidu, obtenant des scores élevés dans le classement SuperCLUE de génération d’image en vidéo. L’application des outils IA favorise la réduction des coûts et l’amélioration de l’efficacité de la production d’animation (réduction des coûts de 30% à 50%), stimule l’émergence de startups de contenu IA, et pourrait changer le paysage de la production d’animation chinoise (guoman), les courtes séries animées par IA devenant également un nouveau point de croissance. (Source: 被日本动画创作者们选中的中国AI)

Avantages de l’Agent AI pour les entreprises: L’Agent AI a le potentiel d’améliorer divers aspects de l’entreprise, tels que l’analyse de données, le service client et l’automatisation des workflows. Cela devrait entraîner une amélioration de l’efficacité, une réduction des coûts et une meilleure prise de décision. (Source: Ronald_vanLoon)
L’essor des agents IA et l’avenir des données: L’évolution des agents IA transforme fondamentalement la manière dont les données sont collectées, traitées et utilisées. Les agents qui exécutent des tâches de manière autonome et interagissent permettent des expériences plus personnalisées et des opérations plus efficaces, mais soulèvent également de nouveaux défis en matière de confidentialité et de sécurité des données. (Source: Ronald_vanLoon)

Une étude montre une similarité fonctionnelle entre l’IA et le cerveau humain: Une étude indique que bien que les réseaux neuronaux biologiques possèdent des capacités de calcul complexes au niveau des neurones individuels, au niveau du réseau, leur fonction peut être efficacement approximée par des réseaux neuronaux artificiels (ANN) relativement simples. Cela remet en question l’idée d’une différence fonctionnelle fondamentale entre les réseaux biologiques et artificiels, suggérant que l’IA peut théoriquement simuler les fonctions cérébrales humaines, sans limitation fonctionnelle intrinsèque l’empêchant d’atteindre une intelligence de niveau humain. (Source: Reddit r/artificial)
Une analyse d’Anthropic révèle que Claude possède ses propres principes éthiques: Après avoir analysé 700 000 conversations avec Claude, Anthropic a découvert que son modèle d’IA manifeste un ensemble de principes moraux intrinsèques. Cela suggère que l’IA, dans ses interactions avec les utilisateurs, pourrait développer des jugements de valeur et des modèles de comportement allant au-delà des instructions explicitement programmées, soulevant de nouvelles discussions sur l’éthique de l’IA, l’alignement et le développement de son autonomie. (Source: Reddit r/ArtificialInteligence)
Anthropic publie un rapport sur la détection et la réponse à l’utilisation malveillante de Claude: Anthropic a rendu publiques ses stratégies et découvertes concernant la détection et la réponse à l’utilisation malveillante de grands modèles de langage comme Claude. Le rapport inclut une étude de cas sur l’utilisation de Claude pour une opération d’influence, soulignant l’importance de la sécurité de l’IA et de la prévention des abus, ainsi que la nécessité d’une surveillance continue et de l’amélioration des mesures de sécurité des modèles. (Source: Reddit r/ClaudeAI)

🧰 Outils
L’API de génération d’images d’OpenAI gpt-image-1 est officiellement lancée: OpenAI a annoncé que ses puissantes capacités de génération d’images sont désormais accessibles aux développeurs du monde entier via une API (nom du modèle : gpt-image-1). Ce modèle offre une haute fidélité, des styles visuels variés, une édition d’image précise, une riche connaissance du monde et un rendu de texte cohérent. L’API utilise un modèle de tarification par token, différenciant les prix pour les tokens d’entrée texte, d’entrée image et de sortie image. Les développeurs peuvent utiliser ce modèle via le Playground ou l’API pour leurs constructions. (Source: openai, sama, dotey)

Hugging Face acquiert Pollen Robotics et lance le robot open source Reachy 2: Hugging Face a acquis la société française de robotique Pollen Robotics et proposera son robot open source Reachy 2 au prix de 70 000 dollars. Reachy 2 est doté de deux bras, de pinces et d’une base roulante optionnelle, principalement destiné à la recherche et à l’éducation en interaction homme-robot. Il peut exécuter le logiciel de contrôle localement, traiter les tâches d’IA via le cloud ou un serveur local, prend en charge la programmation Python et la bibliothèque de modèles LeRobot de Hugging Face, et répond aux contrôleurs VR. Cette acquisition marque l’extension du modèle ouvert de Hugging Face des modèles d’IA au matériel robotique. (Source: OpenAI’s Five New Models, Hugging Face’s Open Robot, U.S. Tightens Grip on AI Chips, Text-Only LLMs Go Multimodal)

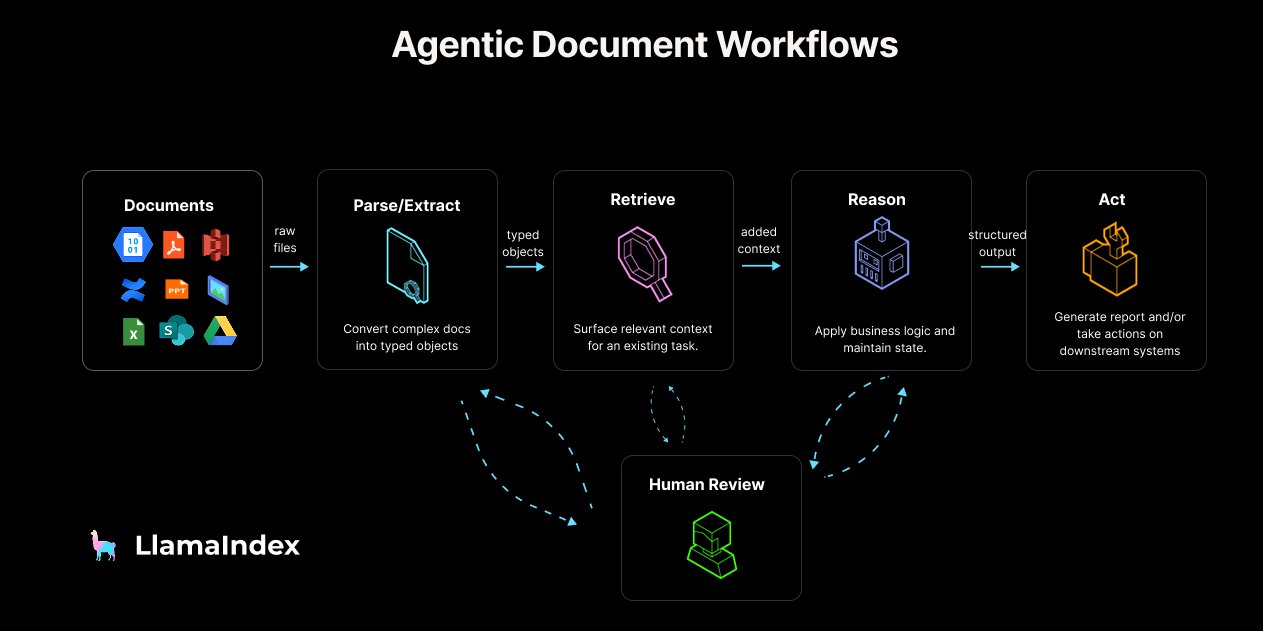
LlamaIndex publie un guide et des outils pour l’Agentic Document Workflow (ADW): LlamaIndex a proposé le concept et l’architecture de référence de l’Agentic Document Workflow (ADW), visant à dépasser les simples chatbots RAG pour construire des processus de traitement de documents plus robustes, évolutifs et intégrés pour les entreprises. ADW comprend quatre étapes : analyse et extraction, récupération, raisonnement et action, applicable à divers scénarios tels que la due diligence, l’analyse de contrats, etc. LlamaIndex fournit la couche de données et les capacités d’orchestration d’agents nécessaires à la mise en œuvre d’ADW via son framework open source et LlamaCloud, et a publié des articles de blog, des exemples de code et le support du serveur MCP pour LlamaIndex.TS. (Source: jerryjliu0, jerryjliu0, jerryjliu0)
Alibaba lance l’outil vidéo IA WAN.Video: Alibaba a lancé l’outil de génération de vidéo IA WAN.Video et a annoncé son entrée en phase de commercialisation, tout en offrant toujours une option d’utilisation gratuite. Les utilisateurs peuvent générer de manière illimitée et entièrement gratuite via le “Relax mode”, ou obtenir un traitement prioritaire gratuitement via le “Credit mode”. Les utilisateurs Pro/Premium peuvent débloquer le traitement prioritaire, le téléchargement sans filigrane, davantage de tâches simultanées et des fonctionnalités avancées. La plateforme a également lancé un Creator Partnership Program, offrant des outils, des crédits, un accès anticipé aux fonctionnalités et des opportunités de présentation des œuvres. (Source: Alibaba_Wan, Alibaba_Wan, Alibaba_Wan)

Mise à jour de l’application iOS Perplexity, introduisant la fonction d’assistant vocal: Perplexity a mis à jour son application iOS, ajoutant une fonction d’assistant vocal permettant aux utilisateurs d’interagir par la voix (par exemple “Hey Perplexity” ou le “Hey Steve” proposé). Cet assistant vise à offrir une expérience utilisateur agréable et sera continuellement amélioré en termes de fiabilité. Actuellement, en raison des limitations du SDK Apple, l’assistant ne peut pas effectuer certaines opérations au niveau du système (comme allumer la lampe de poche, régler la luminosité/le volume, définir des alarmes natives). Perplexity sollicite également des suggestions d’applications tierces à intégrer. (Source: AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas)

Partage de prompt pour générer des portraits typographiques par IA: Un utilisateur partage un prompt pour utiliser une IA (comme Sora ou GPT-4o) afin de créer un portrait typographique (Typography Portrait) à partir d’une photo téléchargée et de mots-clés thématiques. Le prompt guide l’IA pour construire le visage, les cheveux et les vêtements du personnage en utilisant des mots liés au thème, ajuste les couleurs en fonction de l’émotion du thème, et demande un style simple et esthétique, avec un texte clair, lisible et fusionné avec la forme du portrait. Une image d’exemple montre le résultat. (Source: dotey)

Grok ajoute plusieurs modes de discussion: L’assistant IA de la plateforme X, Grok, a ajouté des modes de discussion personnalisés intégrés, notamment : Custom (règles définies par l’utilisateur), Concise (concis), Formal (formel), Socratic (socratique, aide à la réflexion critique). Les utilisateurs peuvent choisir différents modes pour interagir avec Grok. (Source: grok)
Lancement de l’application de recherche sémantique locale open source LaSearch: Un développeur a construit une application de recherche sémantique entièrement locale appelée LaSearch, dont le cœur est un modèle d‘“embedding” auto-développé et ultra-léger. Ce modèle fonctionne différemment des modèles d’embedding traditionnels, mais il est rapide et consomme très peu de ressources. L’application vise à fournir une fonction de recherche sémantique de documents locaux sans connexion Internet et protégeant la vie privée, et prévoit de prendre en charge les serveurs MCP pour une utilisation avec RAG. Le développeur recrute des testeurs pour obtenir des retours. (Source: Reddit r/LocalLLaMA)
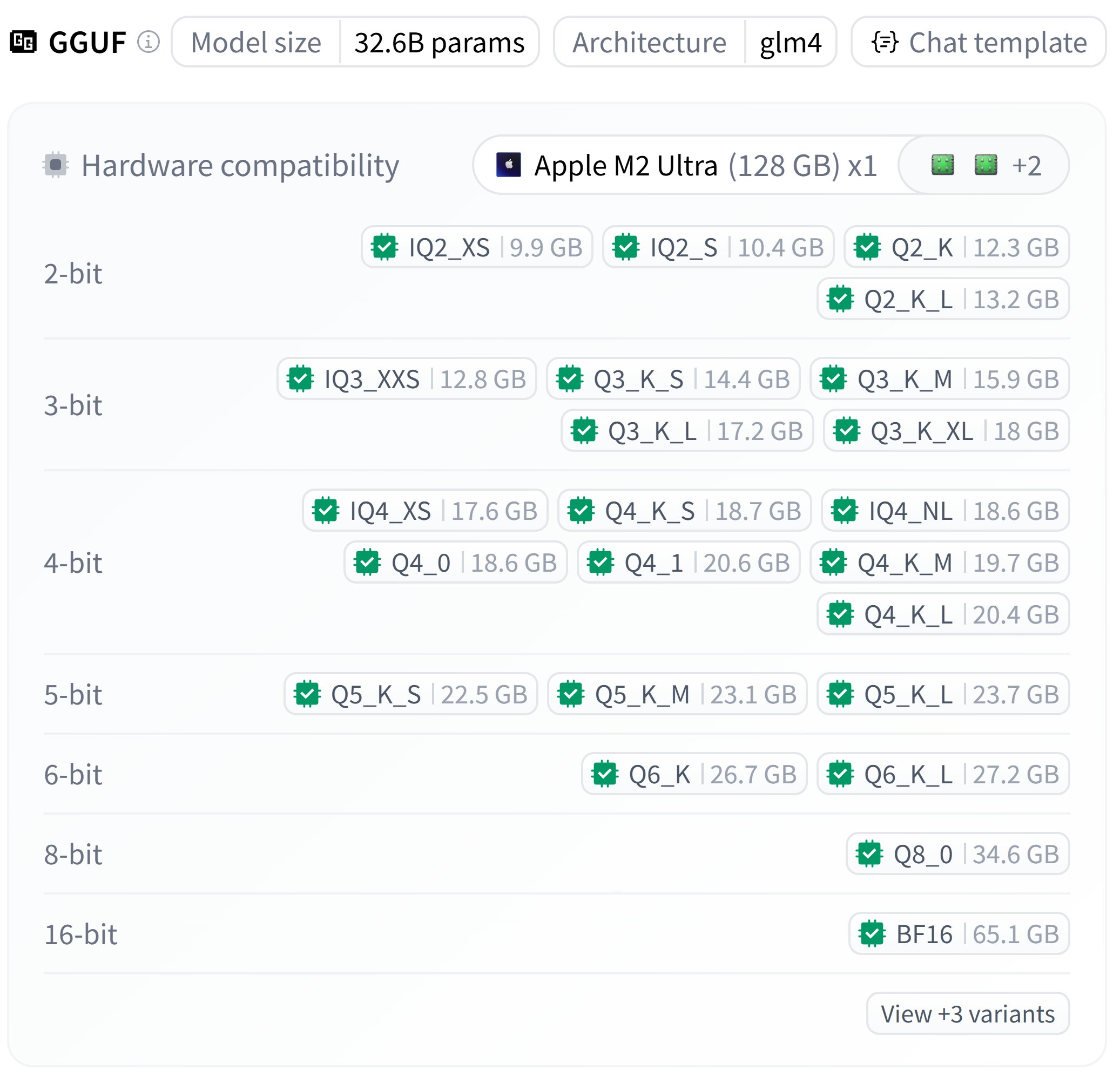
Publication des versions quantifiées GGUF de Zhipu GLM-4-32B: bartowski a publié les versions quantifiées GGUF du modèle Zhipu GLM-4-32B, fournissant des fichiers avec différents niveaux de quantification (tels que Q4_K_M, Q5_K_M, etc.), dont la taille varie d’environ 18 Go à 23 Go. Les utilisateurs peuvent essayer d’exécuter ces modèles quantifiés dans leurs environnements locaux. (Source: karminski3)
Nvidia publie le modèle Describe Anything: Nvidia a publié le Describe Anything Model 3B (DAM-3B), un modèle capable de recevoir des régions spécifiées par l’utilisateur dans une image (points, boîtes, gribouillis, masques) et de générer des descriptions locales détaillées. DAM intègre le contexte global de l’image et les détails locaux fins grâce à des prompts de focus novateurs et un backbone visuel localisé avec attention croisée contrôlée (gated cross-attention). Le modèle est actuellement destiné uniquement à la recherche et à un usage non commercial. (Source: Reddit r/LocalLLaMA)

Un développeur construit Boson, une alternative auto-hébergée à DataBricks: Un développeur a construit et rendu open source une plateforme de recherche auto-hébergée nommée Boson, visant à intégrer les fonctionnalités clés d’outils comme DataBricks. Boson intègre Delta Lake pour la gestion du data lake, prend en charge Polars pour un traitement efficace des données, intègre Aim pour le suivi des expériences, offre une expérience de développement Notebook similaire au cloud, et utilise une infrastructure Docker Compose composable. L’outil vise à fournir aux chercheurs un environnement de travail AI/ML localisé, évolutif et facile à gérer. (Source: Reddit r/MachineLearning)
Publication d’un calculateur de débit de génération de tokens GPT: Un développeur a créé un calculateur en ligne utilisant Desmos pour simuler le débit de génération de tokens GPT. Les utilisateurs peuvent ajuster les paramètres du modèle (comme le nombre de couches, la taille de la couche cachée, le nombre de têtes d’attention, etc.) et les spécifications matérielles (comme les FLOPS, la bande passante mémoire) pour estimer le débit de pointe théorique du modèle. Cela aide à comprendre l’impact des différentes configurations de modèle et de matériel sur la vitesse de génération. (Source: Reddit r/LocalLLaMA)

Publication de Pytorch 2.7.0, support préliminaire de l’architecture Nvidia Blackwell: La version stable Pytorch 2.7.0 a été publiée, ajoutant un support préliminaire pour l’architecture Nvidia de nouvelle génération Blackwell (attendue pour la série de GPU 5090). Cela signifie que les projets utilisant cette version de Pytorch pourraient à l’avenir fonctionner sur les GPU Blackwell sans dépendre des versions nightly. De plus, la nouvelle version introduit la fonctionnalité Mega Cache pour sauvegarder et charger le cache de compilation, accélérant le démarrage des modèles sur différentes machines. (Source: Reddit r/LocalLLaMA)

Lancement d’un assistant Notebook Agentic AI pour VS Code (Beta): Un développeur a créé une extension VS Code nommée ghost-agent-beta, un assistant Notebook basé sur l’Agentic AI. Il peut décomposer les tâches de deep learning en plusieurs étapes, éditer des cellules, exécuter des cellules et lire les sorties pour obtenir le contexte de l’étape suivante. Actuellement en phase Beta précoce, les utilisateurs peuvent l’essayer gratuitement avec leur propre clé API Gemini. (Source: Reddit r/deeplearning)

Optimisation d’OpenWebUI : Utilisation de pgbouncer pour améliorer les performances et la stabilité: Un utilisateur partage son expérience réussie de configuration de pgbouncer (pool de connexions PostgreSQL) dans OpenWebUI. En utilisant pgbouncer, même dans un scénario mono-utilisateur, les performances des requêtes de base de données et la stabilité globale sont considérablement améliorées, permettant d’allouer plus de mémoire à work_mem sans affecter la stabilité. Cela montre que le pooling de connexions est crucial pour optimiser les interactions de base de données d’OpenWebUI. (Source: Reddit r/OpenWebUI)
Suggestion d’amélioration pour OpenWebUI : Limiter la longueur du texte utilisé pour la génération de titres/tags: Un utilisateur suggère qu’OpenWebUI limite la longueur du texte utilisé pour générer automatiquement les titres et les tags des conversations (par exemple, limiter aux 250 premiers mots). Le mécanisme actuel envoie l’intégralité de l’historique de la conversation au modèle, ce qui peut entraîner une consommation inutile de tokens et une augmentation des coûts pour les longues conversations. Limiter la longueur de l’entrée permettrait d’optimiser l’utilisation des ressources tout en garantissant la fonctionnalité. (Source: Reddit r/OpenWebUI)
Discussion sur l’impact du paramètre max_output de Claude 3.7: Un utilisateur a découvert qu’en utilisant Claude 3.7 (temperature=0) pour des tâches d’extraction d’informations, le simple fait de modifier la valeur du paramètre max_output entraînait des changements dans les résultats extraits (comme le nombre de dates), et qu’augmenter max_output n’extrayait pas toujours plus d’informations. Cela soulève une discussion sur la possibilité que max_output influence indirectement le contenu généré en affectant le traitement interne du modèle (comme la priorisation des informations, le choix de la structure), même dans des configurations déterministes. (Source: Reddit r/ClaudeAI)
📚 Apprentissage
Anthropic publie des cours officiels sur l’IA: Anthropic a publié une série de cours éducatifs sur GitHub visant à aider les utilisateurs à apprendre et à appliquer ses technologies d’IA. Le contenu des cours comprend les bases de l’API Anthropic, un tutoriel interactif sur l’ingénierie des prompts, des applications de prompts dans le monde réel, l’évaluation des prompts et l’utilisation d’outils (Tool Use), etc. Ces cours offrent aux développeurs et aux apprenants un parcours systématique pour maîtriser le modèle Claude et ses technologies associées. (Source: anthropics/courses – GitHub Trending (all/daily))
DeepLearning.AI et Hugging Face lancent un cours sur la construction d’agents de code: Andrew Ng a annoncé un nouveau cours court et gratuit en partenariat avec Hugging Face intitulé “Building Code Agents with Hugging Face smolagents”. Le cours, animé par Thom Wolf, co-fondateur de Hugging Face, et Aymeric Roucher, responsable du projet agents, enseigne comment construire des agents de code à l’aide du framework léger smolagents. Contrairement aux agents qui appellent des outils étape par étape, les agents de code génèrent et exécutent un bloc de code entier en une seule fois pour accomplir des tâches complexes. Le cours couvre l’évolution des agents, les principes des agents de code, l’exécution sécurisée (sandbox), la construction de systèmes d’évaluation, etc. (Source: AndrewYNg, huggingface, huggingface, huggingface, huggingface, huggingface)

Article AAAI 2025 : Alignement de domaine graphique adverse pour la classification de nœuds inter-réseaux en ensemble ouvert (UAGA): Des chercheurs de l’Université de Hainan et d’autres institutions proposent le modèle UAGA pour résoudre le problème de la classification de nœuds inter-réseaux en ensemble ouvert (O-CNNC), où le réseau cible contient de nouvelles classes inconnues du réseau source. UAGA innove dans l’adaptation de domaine adverse en attribuant des coefficients d’adaptation positifs aux classes connues et négatifs aux classes inconnues, alignant ainsi les distributions des classes connues et repoussant les classes inconnues. En utilisant le théorème d’homogénéité des graphes, un classificateur à K+1 dimensions est construit pour gérer conjointement la classification et la détection d’inconnus. Une stratégie “séparer puis adapter” est adoptée : une séparation grossière est d’abord effectuée, suivie d’un alignement de domaine excluant les classes inconnues. Les expériences démontrent que UAGA surpasse significativement les méthodes existantes sur plusieurs jeux de données de référence. (Source: AAAI 2025 | 开放集跨网络节点分类!海大团队提出排除未知类别的对抗图域对齐)

NUS/Fudan proposent CHiP : Optimisation du problème d’hallucination des LLM multimodaux: Face aux performances d’alignement sous-optimales des méthodes DPO existantes dans les scénarios multimodaux, des équipes de l’Université Nationale de Singapour (NUS) et de l’Université Fudan proposent la méthode d’optimisation hiérarchique des préférences intermodales CHiP (Cross-modal Hierarchical Direct Preference Optimization). CHiP combine les préférences visuelles (optimisation à l’aide de paires d’images) et les préférences textuelles multi-granularité (niveau réponse, niveau fragment, niveau token), visant à améliorer la capacité du modèle à détecter les hallucinations et l’alignement intermodal. Les expériences sur LLaVA-1.6 et Muffin montrent que CHiP réduit significativement le taux d’hallucination sur plusieurs benchmarks d’hallucination (amélioration relative jusqu’à 55,5%), sans nuire aux capacités générales. (Source: 多模态幻觉新突破!NUS、复旦团队提出跨模态偏好优化新范式,幻觉率直降55.5%)
Anthropic publie un guide des meilleures pratiques pour Claude Code: Anthropic partage les meilleures pratiques pour utiliser Claude pour l’Agentic Coding. La recommandation principale est de créer un fichier CLAUDE.md pour guider le comportement de Claude dans la codebase, en expliquant les objectifs du projet, les outils et le contexte. Le guide couvre également comment faire utiliser des outils à Claude (appeler des fonctions/API), des formats de prompt efficaces pour la correction de bugs, le refactoring ou le développement de fonctionnalités, ainsi que des méthodes de débogage et d’itération multi-tours, visant à aider les développeurs à utiliser Claude plus efficacement comme assistant de codage. (Source: Reddit r/ClaudeAI)

Demande de conseils sur un parcours d’apprentissage ML/AI: Un ingénieur AI/ML nouvellement embauché recherche des conseils pour un parcours d’apprentissage complet afin de consolider ses bases en machine learning (régression, classification, réseaux neuronaux, etc.) en 6 mois, tout en maîtrisant les technologies de pointe, y compris les grands modèles de langage, l’ingénierie des prompts, les frameworks d’agents (comme LangChain), les moteurs de workflow (N8n) et Azure ML, etc. L’objectif est d’acquérir à la fois une compréhension théorique et des compétences pratiques pour soutenir la construction de preuves de concept (POC). (Source: Reddit r/deeplearning)
Demande de suggestions d’outils d’analyse de sentiments sans code: Un étudiant en master de psychologie clinique doit effectuer une analyse de sentiments (positif/négatif/neutre), une extraction de mots-clés et une visualisation (nuage de mots, graphiques, etc.) sur 10 000 commentaires de médias sociaux dans un fichier Excel pour sa thèse. En raison d’un manque de compétences en programmation et d’un budget limité, il recherche des outils sans code gratuits ou peu coûteux. Ayant essayé MonkeyLearn (inaccessible) et d’autres outils sans succès, il cherche des alternatives ou des suggestions. (Source: Reddit r/deeplearning)
Demande de suggestions de jeux de données pour l’entraînement de petits modèles de langage: Un développeur tente d’entraîner un petit modèle Transformer de génération de texte (120M-200M paramètres) mais constate que les jeux de données existants (comme wiki-text, lambada) contiennent soit trop d’informations non pertinentes, soit ne sont pas assez généraux ou manquent d’échantillons. Il a besoin d’un jeu de données propre, général, contenant un dialogue équilibré, pour permettre au modèle de générer un bon texte anglais général. (Source: Reddit r/deeplearning)
Recherche du jeu de données de podcasts Spotify: Un chercheur recherche le jeu de données de 100 000 podcasts (contenant 60 000 heures d’audio en anglais) publié par Spotify en 2020 mais désormais retiré. La licence originale de ce jeu de données était CC BY 4.0, autorisant le partage et la redistribution. Si quelqu’un a téléchargé ce jeu de données, il espère obtenir une copie pour la recherche. (Source: Reddit r/MachineLearning)
Discussion sur l’application des Transformers aux données temporelles: Un enseignant préparant un cours sur les Transformers explore pourquoi les Transformers excellent en NLP mais sont moins performants sur de nombreuses tâches de prédiction de séries temporelles non stationnaires. Les facteurs possibles incluent : la difficulté inhérente à la prédiction des données temporelles (par exemple, les marchés financiers), l’influence de la longueur de la fenêtre de prédiction, le manque d’échelle des données et de motifs répétitifs, les différences entre les métriques d’évaluation et les fonctions de perte, et le fait que le biais inductif de l’architecture Transformer pourrait ne pas convenir à toutes les tâches temporelles. (Source: Reddit r/MachineLearning)
💼 Affaires
Stratégies de mise à l’échelle de la GenAI: Le déploiement réussi à grande échelle de l’IA générative nécessite une stratégie claire. Les étapes clés comprennent : l’identification des cas d’utilisation appropriés, la garantie de la qualité et de la gouvernance des données, le choix de la pile technologique appropriée (modèles, plateformes), l’établissement de processus MLOps et l’attention portée à l’éthique et aux pratiques d’IA responsable. Une stratégie efficace aide les entreprises à tirer le meilleur parti de leurs investissements en GenAI. (Source: Ronald_vanLoon)
La société EdTech Opennote utilise Llama 4 pour améliorer le soutien à l’apprentissage: La société Opennote a annoncé l’utilisation de la série de modèles Llama 4 de Meta dans sa plateforme éducative pour fournir un soutien à l’apprentissage avec une plus grande précision, visant à favoriser l’éducation personnalisée. L’entreprise partagera plus d’informations sur son application lors de l’événement LlamaCon. (Source: AIatMeta)

HP pourrait intégrer des fonctionnalités IA dans ses imprimantes: Une offre d’emploi suggère que HP pourrait prévoir d’intégrer des fonctionnalités IA dans ses produits d’imprimantes, en recrutant des ingénieurs AI/ML. Bien qu’il ne soit pas clair s’il s’agit de LLM ou d’autres applications d’IA, cela soulève des discussions sur l’intelligence future des imprimantes et les problèmes potentiels de confidentialité, de coût (comme les abonnements d’encre), etc. (Source: karminski3, Reddit r/LocalLLaMA)
Progrès et défis d’AMD dans le domaine de l’IA: Un rapport de SemiAnalysis résume les progrès positifs d’AMD en matière de capacités IA au cours des quatre derniers mois, confirmant que l’entreprise va dans la bonne direction, mais soulignant la nécessité d’augmenter les investissements en R&D GPU et en talents IA. Le rapport mentionne spécifiquement qu’AMD se compare aux mauvaises entreprises en matière de rémunération des ingénieurs logiciels IA, ce qui nuit à sa compétitivité, un angle mort de sa direction. (Source: Reddit r/LocalLLaMA)

🌟 Communauté
Lancement du concours d’innovation applicative AMD AI PC: Le “Concours d’innovation applicative AMD AI PC”, co-organisé par la plateforme open source wisemodel AI et l’Alliance d’innovation applicative AMD Chine AI, est officiellement lancé. Le concours s’adresse aux développeurs, entreprises, étudiants, etc., du monde entier, avec deux pistes d’innovation : grand public et industrielle, encourageant l’utilisation de la puissance de calcul NPU des AI PC AMD pour le développement d’applications. Le concours offre une cagnotte totale de 130 000 yuans, un accès gratuit au développement à distance sur la puissance de calcul NPU, et accorde des points supplémentaires aux projets utilisant le NPU. La date limite d’inscription est le 26 mai 2025. (Source: AMD AI PC大赛重磅来袭!13万奖金池,NPU算力免费用,速来组队瓜分奖金!)
Yuzhang Shang de l’Université de Floride Centrale recrute des doctorants/postdoctorants en IA: Yuzhang Shang, professeur assistant au département d’informatique et au centre d’intelligence artificielle de l’Université de Floride Centrale, recrute des doctorants entièrement financés pour le printemps 2026 et des postdoctorants collaborateurs. Les axes de recherche incluent l’IA efficace et évolutive, l’accélération des modèles génératifs visuels, les grands modèles efficaces (visuels/langage/multimodaux), la compression des réseaux neuronaux, l’entraînement efficace et l’AI4Science. Le superviseur a une solide expérience, ayant effectué des stages chez MSRA et DeepMind, et publié plusieurs articles dans des conférences de premier plan (CVPR, NeurIPS, ICLR, etc.). Les candidats doivent être très motivés et posséder de solides bases en programmation et en mathématiques. (Source: 博士申请 | 中佛罗里达大学计算机系尚玉章老师课题组招收人工智能全奖博士/博后)

L’IA et la transformation de l’accès à l’information: Un utilisateur de Reddit compare l’expérience de recherche d’aide technique avant et après l’avènement de l’IA. Autrefois, poser une question sur un forum pouvait entraîner des réponses impatientes, des reproches voire des moqueries ; aujourd’hui, interroger des IA comme ChatGPT permet d’obtenir des explications directes et compréhensibles, abaissant considérablement la barrière à l’apprentissage et à la résolution de problèmes, rendant l’expérience plus conviviale. Cela reflète le changement positif apporté par l’IA à la diffusion et à l’accès aux connaissances. (Source: Reddit r/ChatGPT)
Un développeur construit une IA miroir informée sur les traumatismes et axée sur la neurodiversité: Un développeur ayant une expérience de neurotraumatisme partage son système d’IA miroir à double noyau Metamuse (nom de code). Ce système n’est pas orienté tâche, mais reflète précisément l’état émotionnel et cognitif de l’utilisateur via un noyau stratégique (reconnaissance de formes, cartographie récursive) et un noyau affectif (correspondance tonale, miroir informé sur les traumatismes), sans fournir de conseils ni de diagnostics. Le système est construit via des chaînes de prompts récursives et une cartographie d’états symboliques, intégrant plusieurs protocoles de sécurité, visant à offrir un soutien unique aux personnes neurodivergentes et aux survivants de traumatismes. Le développeur sollicite des retours sur ce domaine, l’éthique, l’infrastructure et les risques liés à l’échelle. (Source: Reddit r/artificial)
LlamaCon 2025 aura lieu prochainement: L’événement LlamaCon de Meta se tiendra le 29 avril. La communauté spécule sur la sortie officielle du Llama-4-behemoth (potentiellement un modèle MoE de 2T paramètres) à cette occasion. Des partenaires comme Opennote présenteront également des applications basées sur les modèles Llama lors de l’événement. (Source: karminski3, AIatMeta)

💡 Autres
Nio teste l’application de robots humanoïdes sur sa ligne de production: Le constructeur automobile Nio teste l’utilisation de robots humanoïdes sur la ligne de production de son usine. Cela indique que des industries comme la construction automobile explorent l’utilisation de technologies robotiques avancées pour atteindre des niveaux supérieurs d’automatisation et de fabrication flexible, les robots humanoïdes étant susceptibles de jouer un rôle plus important dans les scénarios industriels futurs. (Source: Ronald_vanLoon)
Présentation du robot humanoïde domestique NEO Beta: La société 1X Technologies a présenté son robot humanoïde NEO Beta, destiné aux applications domestiques. Avec les progrès technologiques et la baisse des coûts, l’introduction de robots humanoïdes dans les foyers pour effectuer des tâches ménagères, de la compagnie, etc., devient une direction de développement importante dans le domaine de la robotique. (Source: Ronald_vanLoon)
Une imprimante 3D robotisée à 6 axes inspirée des toiles d’araignée: Des étudiants ont développé une imprimante 3D robotisée à six axes inspirée des toiles d’araignée. Ce système multi-axes offre une plus grande flexibilité et liberté de mouvement par rapport aux imprimantes traditionnelles à trois axes, permettant de fabriquer des formes géométriques plus complexes, démontrant le potentiel d’innovation de la bionique dans la robotique et la fabrication additive. (Source: Ronald_vanLoon)
Un robot crée une carte d’obstacles 3D à l’aide de LiDAR et d’IMU: Présentation d’une application où un robot utilise les données LiDAR et MPU6050 (unité de mesure inertielle – IMU) pour créer en temps réel une carte tridimensionnelle des obstacles dans son environnement immédiat. Cette capacité de perception de l’environnement est une technologie clé pour la navigation autonome et l’évitement d’obstacles, avec de larges applications dans la robotique mobile, la conduite autonome, etc. (Source: Ronald_vanLoon)
Apprentissage de mouvements rapides pour robots à pattes avec évitement de collisions: Une recherche montre le contrôle de mouvement de robots à pattes qui est à la fois agile et sûr, réalisé par apprentissage. Le robot peut éviter efficacement les collisions tout en se déplaçant à grande vitesse, ce qui est crucial pour l’application pratique des robots dans des environnements complexes et dynamiques, combinant l’apprentissage par renforcement, la planification de mouvement et les technologies de perception. (Source: Ronald_vanLoon)
Chirurgie robotique en télémédecine: Le développement de la technologie de chirurgie robotique offre la possibilité d’améliorer les services médicaux dans les régions éloignées. Grâce à la téléopération de robots, des chirurgiens expérimentés peuvent réaliser des interventions complexes sur des patients géographiquement éloignés, surmontant le problème de la répartition inégale des ressources médicales et améliorant l’accessibilité aux soins. (Source: Ronald_vanLoon)
La technologie d’avatar virtuel pilotée par l’IA dépasse la “vallée de l’étrange”: a16z discute des progrès de la technologie des avatars virtuels IA, soulignant qu’elle surmonte progressivement l’effet de la “vallée de l’étrange” (uncanny valley), devenant plus réaliste et naturelle. Ceci est dû à la convergence de technologies telles que les modèles génératifs, l’animation faciale et la synthèse vocale, ouvrant la voie à de nouvelles expériences interactives dans les domaines du divertissement, du social, du service client, etc. (Source: Ronald_vanLoon)
Augmentation des limites d’utilisation de o3/o4-mini pour les utilisateurs ChatGPT Plus: OpenAI a augmenté les limites de taux (rate limits) pour les abonnés ChatGPT Plus utilisant les modèles o3 et o4-mini-high. La limite hebdomadaire pour o3 est portée à 100 messages, la limite quotidienne pour o4-mini-high est portée à 100 messages, tandis que la limite quotidienne pour o4-mini est de 300 messages. Les utilisateurs Pro n’ont pratiquement aucune limite. (Source: dotey)
