Mots-clés:robot humanoïde, application d’IA, AGI, conduite autonome, marathon de robots humanoïdes, Agent+MCP, prédiction AGI de DeepMind, FSD pure vision de Tesla, clonage vocal GPT-SoVITS, raisonnement chimique ChemAgent, modèle commercial d’Agibot, défi du monopole des GPU NVIDIA
🔥 À la Une
Première apparition de robots humanoïdes au semi-marathon de Pékin : opportunités et défis coexistent : Lors du semi-marathon de Pékin Yizhuang 2025, 21 équipes de robots humanoïdes ont concouru pour la première fois aux côtés de coureurs humains. Tiangong Ultra, Songyan Dynamics N2 et Zhuoyide Walker II ont remporté les trois premières places. La compétition a mis en évidence le potentiel des robots humanoïdes, mais a également révélé de nombreux défis tels que les chutes, l’autonomie de la batterie et le contrôle (principalement par télécommande). Après la course, Unitree a répondu à l’incident de la chute de son robot G1, soulignant que le développement et l’exploitation par les utilisateurs ont un impact considérable sur les performances du robot. Cet événement a non seulement démontré l’échelle initiale de l’industrie chinoise des robots humanoïdes, mais a également suscité de vastes discussions sur la maturité technologique, les coûts (le prix de prévente du Songyan N2 commence à 39 900 yuans), les voies de commercialisation (location, applications industrielles) et le développement futur (grands modèles d’IA, apprentissage autonome). Bien que le secteur attire les capitaux, la rentabilité à court terme est difficile et la mise sur le marché prendra encore du temps (Source : 摔倒的宇树和人形机器人的“求生”博弈, 从进厂到马拉松:人形机器人离“实用”还有多远?)
Nouveau paradigme des applications IA : Agent+MCP devient la formule à succès pour 2025 : La combinaison des capacités de planification et d’action autonomes des Agents avec la capacité du protocole MCP à appeler des outils et des données externes devient une nouvelle tendance dans les applications IA. Des produits tels que Coze Space, Fellou, Dia, GenSpark et Zhipu AutoGLM émergent successivement et suscitent l’attention. Ces produits proviennent souvent d’une transformation de la recherche IA et tentent d’établir des barrières d’expérience utilisateur grâce à différentes conceptions de produits (facilité d’utilisation, capacités de recherche, exécution concrète). Malgré un potentiel énorme, ils sont actuellement confrontés à des défis tels que les limites des capacités des modèles, l’acquisition d’informations multiplateformes et les modèles de commercialisation. Microsoft a également lancé UFO², un système multi-agents pour ordinateurs de bureau, indiquant que l’AM (Agent+MCP) deviendra une direction importante pour les produits IA (Source : 2025年,AI应用的爆款公式只有一个)
Débat houleux sur l’avenir de l’IA : Hassabis prédit la guérison de toutes les maladies en dix ans, un historien de Harvard met en garde contre l’extinction humaine par l’AGI : Le PDG de Google DeepMind, Demis Hassabis, a prédit lors d’une interview que l’IA atteindrait l’AGI d’ici 5 à 10 ans et pourrait guérir toutes les maladies en une décennie, présentant des avancées de l’IA telles que Project Astra. Il estime que l’IA deviendra l’outil ultime pour accélérer la découverte scientifique. Cependant, l’historien de Harvard Niall Ferguson a lancé un avertissement, estimant que l’avènement de l’AGI pourrait entraîner l’obsolescence, voire l’extinction de l’humanité, à l’instar des calèches, devenant ainsi les “extraterrestres” créés par l’homme lui-même. Il souligne que des tendances telles que la rigidité institutionnelle et la baisse mondiale de la fécondité pourraient pousser l’humanité à choisir de “se retirer de la scène historique” face à l’AGI. Cette discussion met en lumière le contraste saisissant entre l’optimisme extrême quant au potentiel de l’AGI et les profondes inquiétudes concernant l’avenir de la civilisation humaine (Source : 诺奖得主Hassabis豪言:AI十年治愈所有疾病,哈佛教授警告AGI终结人类文明, 哈佛历史学家预警:AGI灭绝人类,美国或将解体)
🎯 Tendances
Progrès fréquents dans l’industrie de la robotique, accélération de la commercialisation : La Foire de Canton a créé pour la première fois une zone dédiée aux robots de service, où des fabricants nationaux tels que Pangolin Robot et Hongxu Jin Technology ont remporté de nombreuses commandes à l’étranger, démontrant la compétitivité des robots de service chinois sur le marché mondial. Parallèlement, les robots humanoïdes de sociétés comme Midea sont en cours d’itération et prévoient d’entrer dans les usines pour “travailler”. Au niveau de la chaîne d’approvisionnement, bien que des secteurs tels que les PCB, les capteurs et les nouveaux matériaux (comme le PEEK) soient en cours de développement, la production à grande échelle prendra encore du temps ; la technologie, les coûts et la boucle fermée des scénarios d’application sont essentiels. Plusieurs fabricants prévoient d’atteindre une production de masse de niveau millier d’unités d’ici 2025, ce qui devrait stimuler le développement de la chaîne d’approvisionnement et l’accumulation de données, accélérant ainsi la progression des robots vers une phase plus pratique (Source : 机器人组团“营业”引爆声量场,产业链频刷进展)

Tesla persiste avec le FSD purement visuel, la voie du LiDAR fait face à des défis et des opportunités : Musk réaffirme sa confiance dans la solution purement visuelle pour réaliser le FSD, estimant que les caméras associées à l’IA peuvent simuler la conduite humaine sans nécessiter de LiDAR. Malgré la baisse des coûts (les LiDAR chinois sont descendus à quelques centaines de dollars) et la popularisation sur le marché (déjà présents sur des modèles de voiture à 100 000 yuans), Tesla maintient sa ligne, ce qui impose des exigences extrêmement élevées en termes de puissance de calcul, d’algorithmes et de données. Parallèlement, des fabricants de LiDAR tels que Hesai et RoboSense dominent le marché grâce à leurs avantages en termes de coûts et à l’itération technologique, tout en explorant activement les marchés étrangers et les activités non automobiles comme la robotique. L’approche de la conduite autonome de niveau L3 pourrait offrir de nouvelles opportunités au LiDAR, car sa capacité de redondance de sécurité et de perception dans des scénarios spécifiques est considérée comme indispensable (Source : 马斯克最新的AI驾驶方案,会终结激光雷达吗?)

Google Imagen 3/4 seraient en test interne : Des rumeurs indiquent que Google teste en interne ses prochains modèles de génération d’images, Imagen 3 et Imagen 4, suggérant que Google pourrait préparer de nouvelles avancées majeures dans le domaine de la génération d’images, visant à rattraper ou dépasser ses concurrents (Source : Google 又憋图像大招?传 Imagen 3/4 内测中。)
THUDM publie la série de modèles de codage SWE-Dev : Le groupe de recherche en ingénierie des connaissances et exploration de données de l’Université Tsinghua (THUDM) a publié la série de grands modèles de codage SWE-Dev basée sur Qwen-2.5 et GLM-4, incluant les versions 7B, 9B et 32B, visant à améliorer les capacités de l’IA pour les tâches de développement logiciel et de codage (Source : Reddit r/LocalLLaMA)

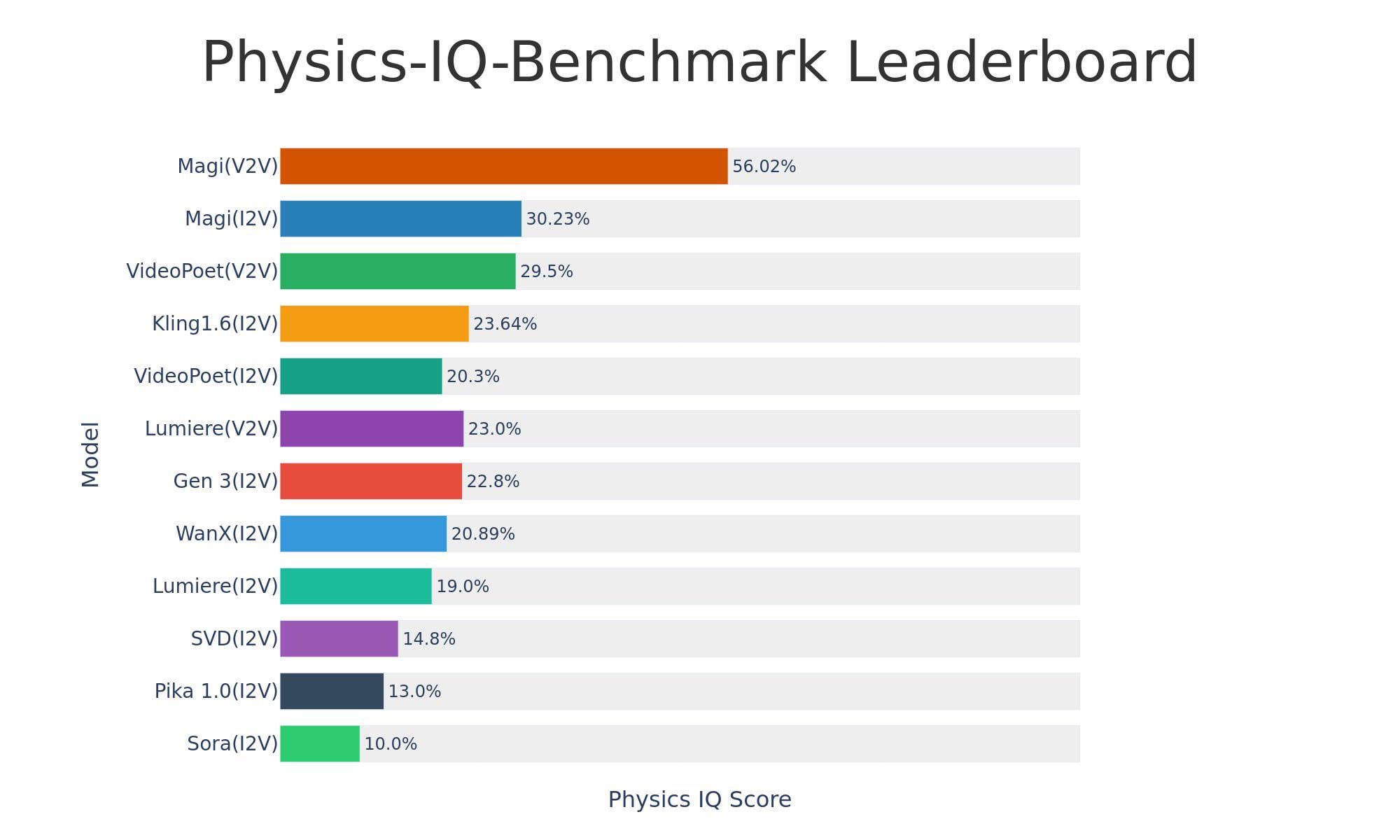
Sand-AI publie le modèle open-source de génération vidéo Magi-1 : Sand-AI a publié Magi-1, un modèle open-source de génération vidéo par diffusion autorégressive, prétendant pouvoir générer des vidéos de durée illimitée et prenant en charge la génération texte-vidéo, image-vidéo et vidéo-vidéo. Le modèle obtient d’excellents résultats aux benchmarks de compréhension physique, mais nécessite une VRAM extrêmement élevée pour fonctionner (environ 640 Go de VRAM). Le code et le modèle sont disponibles sur GitHub et Hugging Face (Source : Reddit r/LocalLLaMA)
Grok ajoute des capacités visuelles, audio multilingues et de recherche en temps réel : xAI annonce que le modèle Grok dispose désormais de capacités de compréhension visuelle et prend en charge l’entrée audio multilingue ainsi que la recherche en temps réel en mode vocal, améliorant ainsi ses capacités d’interaction multimodale et d’acquisition d’informations (Source : grok, xai)
Le modèle Grok 3 arrive sur You.com : Le modèle phare de xAI, Grok 3, est désormais disponible sur le moteur de recherche You.com, permettant aux utilisateurs d’expérimenter les capacités de Grok 3 sur cette plateforme (Source : xai)

Le modèle TTS open-source Dia est publié et attire l’attention : Un modèle open-source de synthèse vocale (TTS) nommé Dia a été publié, prétendant rivaliser avec les modèles commerciaux tels que ElevenLabs et OpenAI. Il prend en charge le clonage vocal zero-shot et la synthèse en temps réel, et peut fonctionner sur un MacBook. Le modèle a rapidement gagné en popularité sur Hugging Face et a été couvert par des médias tels que VentureBeat (Source : huggingface, huggingface, huggingface)
Présentation de la technologie de conduite autonome de Tesla : Présentation de vidéos ou d’informations relatives à la technologie de conduite autonome Autopilot de Tesla, continuant de susciter l’intérêt pour les progrès de la technologie de conduite autonome (Source : Ronald_vanLoon)
Présentation de technologies robotiques : Plusieurs sources présentent différentes applications robotiques, notamment un bras robotique pour l’assemblage de petits gadgets, l’évaluation du robot TITA, le robot amphibie Copperstone HELIX Neptune et la manière dont les robots perçoivent le monde, montrant le développement continu de la technologie robotique dans divers domaines (Source : Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
🧰 Outils
GPT-SoVITS : Puissant outil de clonage vocal few-shot et de synthèse vocale : Développé par RVC-Boss, GPT-SoVITS est un projet open-source (plus de 44k étoiles sur GitHub) qui permet d’entraîner un modèle TTS de haute qualité avec seulement 1 minute de données vocales pour réaliser un clonage vocal few-shot. Il prend en charge le TTS zero-shot (conversion instantanée avec 5 secondes d’entrée), l’inférence interlingue (supporte l’anglais, le japonais, le coréen, le cantonais, le chinois) et intègre une boîte à outils WebUI comprenant la séparation voix/accompagnement, la segmentation automatique des ensembles d’entraînement, l’ASR chinois et l’annotation de texte, facilitant la création de jeux de données et de modèles par les utilisateurs. Le projet a été mis à jour vers la version V4, optimisant continuellement la similarité du timbre, la stabilité et la qualité de sortie (Source : RVC-Boss/GPT-SoVITS – GitHub Trending (all/daily))

L’équipe de Tsinghua lance SurveyGO (Juan Ji) : Outil de synthèse bibliographique et de génération de longs rapports piloté par l’IA : Basé sur la technologie LLMxMapReduce-V2 développée par les équipes de Tsinghua NLP, OpenBMB et ModelBest, SurveyGO peut traiter efficacement une grande quantité de littérature (via recherche en ligne ou téléchargement de fichiers) pour générer de longs rapports de synthèse de dizaines de milliers de mots, structurés, logiques et avec des citations précises. L’outil optimise le plan grâce à un mécanisme de convolution piloté par l’entropie de l’information et génère le contenu par niveaux, résolvant le problème de l’assemblage de contenu et du manque de profondeur des longs textes générés par l’IA traditionnelle. Les utilisateurs peuvent l’utiliser via une version web en entrant un sujet ou en téléchargeant des fichiers, visant à améliorer considérablement l’efficacité de la recherche documentaire et de la rédaction pour les chercheurs et les créateurs de contenu (Source : INTJ式学术暴力!清华团队造出“论文卷姬”:3分钟速通200小时文献综述, 如何 AI「拼好文」:生成万字报告,不限模型)

text-generation-webui lance une version portable, axée sur llama.cpp : Pour simplifier le déploiement, text-generation-webui a publié une version portable et autonome (environ 700 Mo) spécifiquement pour llama.cpp. Les utilisateurs peuvent la télécharger, la décompresser et l’exécuter sans installer Python, PyTorch ou d’autres dépendances. La nouvelle version prend en charge Windows, Linux, macOS (avec versions CPU et CUDA), et optimise la vitesse de démarrage et l’expérience utilisateur (par exemple, ouverture automatique du navigateur, démarrage de l’API par défaut). Cela offre une grande commodité aux utilisateurs souhaitant uniquement utiliser llama.cpp pour l’inférence locale (Source : Reddit r/LocalLLaMA)
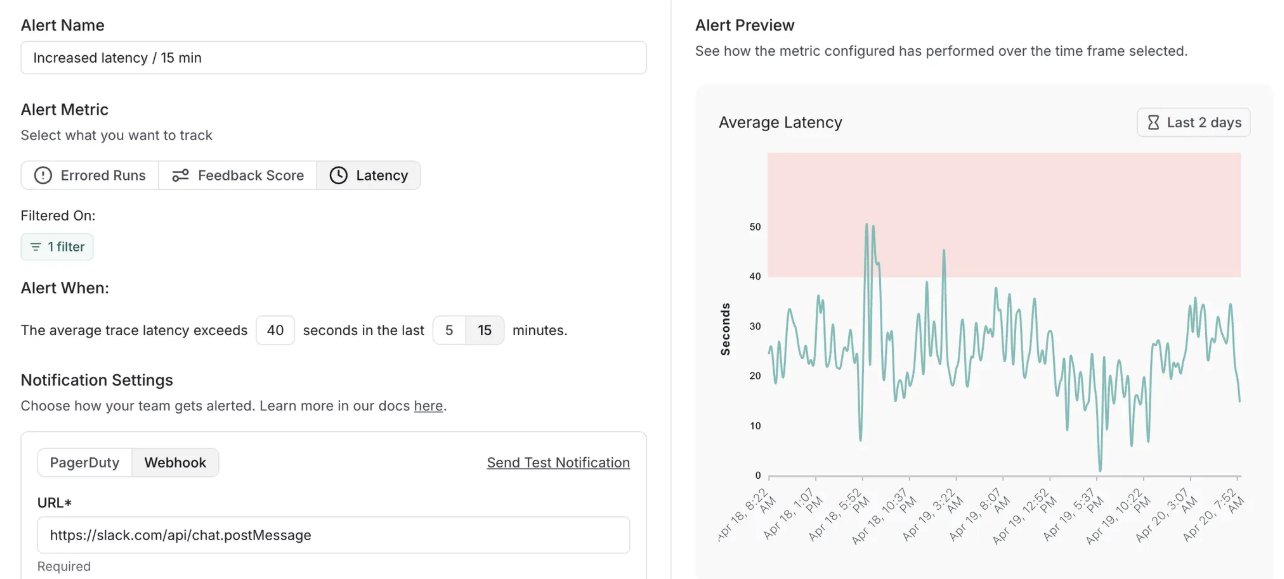
LangSmith ajoute une fonction d’alerte et met à jour sa version auto-hébergée : La plateforme MLOps de LangChain, LangSmith, a ajouté une fonction d’alerte en temps réel. Les utilisateurs peuvent définir des notifications pour les taux d’erreur, la latence d’exécution et les scores de feedback afin de détecter les problèmes avant qu’ils n’affectent les clients. Parallèlement, sa version auto-hébergée a été mise à jour vers la v0.10, incluant la fonction d’alerte, une nouvelle interface utilisateur pour la création et la visualisation des évaluations, la prise en charge des données de suivi des clients OpenTelemetry et des optimisations de performances (Source : LangChainAI, LangChainAI)
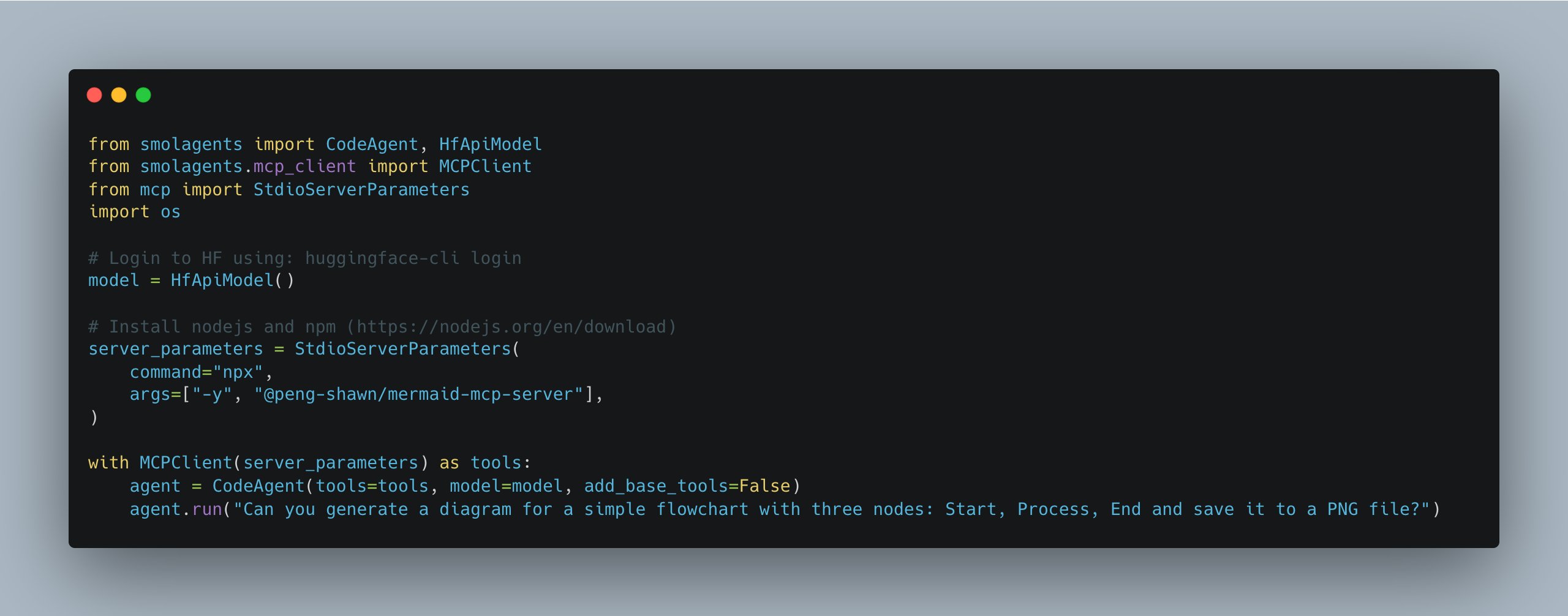
Mise à jour de smolagents, simplifiant la gestion de plusieurs serveurs MCP : La bibliothèque smolagents de Hugging Face a publié une nouvelle version introduisant la classe MCPClient, qui facilite grandement la gestion des connexions à plusieurs serveurs MCP (Model Communication Protocol), permettant aux développeurs de construire et de coordonner des systèmes d’Agents plus complexes (Source : huggingface)
Suna : Plateforme d’Agent open-source concurrente de Manus : Kortix AI a publié la plateforme d’Agent open-source Suna, visant à concurrencer Manus. Suna intègre l’automatisation du navigateur, la gestion de fichiers, le web crawling, la recherche étendue, l’exécution de lignes de commande, le déploiement de sites web et l’intégration d’API, permettant à l’IA d’opérer ces outils de manière coordonnée pour résoudre des problèmes complexes et automatiser les flux de travail via le dialogue (Source : karminski3)
Exa MCP prend désormais en charge la recherche sur Twitter sans API : Le serveur MCP (Model Communication Protocol) d’Exa a été mis à jour et prend désormais en charge la recherche de contenu sur Twitter sans nécessiter d’API Twitter. Cela facilite la tâche des Agents IA nécessitant des informations de Twitter, bien que la prise en charge de l’exploration de données en langue chinoise semble actuellement limitée (Source : karminski3)
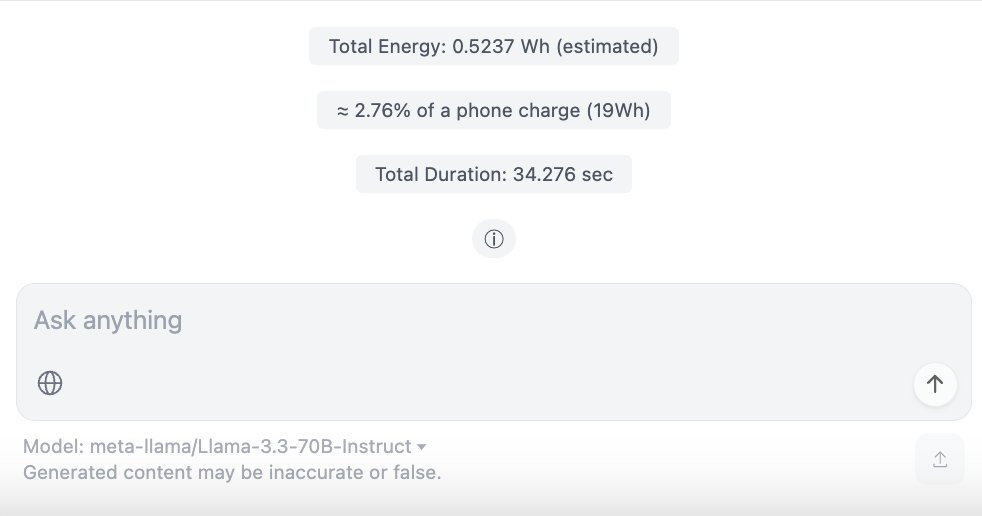
ChatUI-energy : Interface affichant en temps réel la consommation d’énergie des conversations IA : Des membres de la communauté Hugging Face ont publié ChatUI-energy, une variante de Chat UI capable d’afficher en temps réel l’énergie consommée lors des conversations des utilisateurs avec des modèles IA (tels que Llama, Mistral, Qwen, Gemma, etc.). Cette initiative vise à accroître la transparence énergétique de l’utilisation de l’IA (Source : huggingface, huggingface)
Utilisation de l’IA pour le développement, le déploiement et l’optimisation d’applications Web : L’article partage une expérience pratique d’utilisation de l’IA (comme Lovable, Cursor, BrowserTools MCP) pour le développement (un outil d’assemblage d’images), le débogage, l’audit SEO et l’optimisation des performances d’une application Web. Il détaille comment utiliser Vercel et GitHub pour réaliser un déploiement automatisé CI/CD, ainsi que la configuration de la résolution de noms de domaine et de sous-domaines. Il montre le rôle d’assistance de l’IA dans le codage et la maintenance de sites Web (Source : AI 编码 + Vercel 部署 + 域名解析:一文搞定Web 应用开发上线全流程,氛围编码+MCP 审计优化。)

Réplique légère de “Her” OS1/Samantha basée sur des modèles locaux : Un développeur a recréé localement dans le navigateur l’assistant IA OS1/Samantha du film “Her” en utilisant transformers.js et des modèles ONNX (incluant Ultravox Llama 3.2 1B, Whisper Base, Kokoro TTS et MiniLM embeddings). Le projet démontre la possibilité de réaliser une IA conversationnelle vocale fonctionnant localement avec des ressources limitées (environ 2 Go de téléchargement de modèles) (Source : Reddit r/LocalLLaMA)
ChatWise combine des serveurs MCP pour réaliser le RAG et la synchronisation de données : Un utilisateur partage une configuration de flux de travail simple dans ChatWise utilisant des instructions système, combinant les serveurs MCP de Pinecone (base de données), Exa (recherche) et Time (temps) pour réaliser une génération augmentée par récupération (RAG) et une synchronisation de données (Source : op7418)

📚 Apprentissage
L’Université de Stanford ouvre son cours sur les Transformers CS25 : Le cours séminaire CS25 de l’Université de Stanford sur les Transformers est ouvert au public et peut être suivi en direct via Zoom. Le cours invite des chercheurs de premier plan tels qu’Andrej Karpathy, Geoffrey Hinton, Jim Fan, Ashish Vaswani et des intervenants d’OpenAI, Google, NVIDIA pour des conférences couvrant l’architecture des LLM, les applications multimodales, la biologie, la robotique et d’autres sujets de pointe. Les enregistrements des cours seront publiés sur YouTube, et une communauté Discord est disponible pour les discussions (Source : karminski3, dotey, Reddit r/deeplearning, Reddit r/LocalLLaMA)
Une étude de Tsinghua et SJTU révèle les limites du RL pour les capacités de raisonnement des LLM : Une étude de l’Université Tsinghua et de l’Université Jiao Tong de Shanghai remet en question l’idée que l’apprentissage par renforcement (RL) améliore les capacités de raisonnement des grands modèles. Les expériences montrent que bien que le RL puisse améliorer la précision du modèle à faible taux d’échantillonnage (efficacité), à taux d’échantillonnage élevé, le modèle de base peut résoudre plus de problèmes difficiles (frontière de capacité). Cela suggère que le RL est meilleur pour optimiser les performances du modèle dans ses capacités existantes plutôt que pour étendre sa capacité de raisonnement fondamentale. L’article souligne que les méthodes RL actuelles (comme GRPO) peuvent tomber dans des optima locaux en raison d’une exploration insuffisante, limitant la résolution de problèmes complexes (Source : RL 是推理神器?清华上交大最新研究指出:RL 让大模型更会 「套公式」,却不会真推理, Reddit r/artificial)

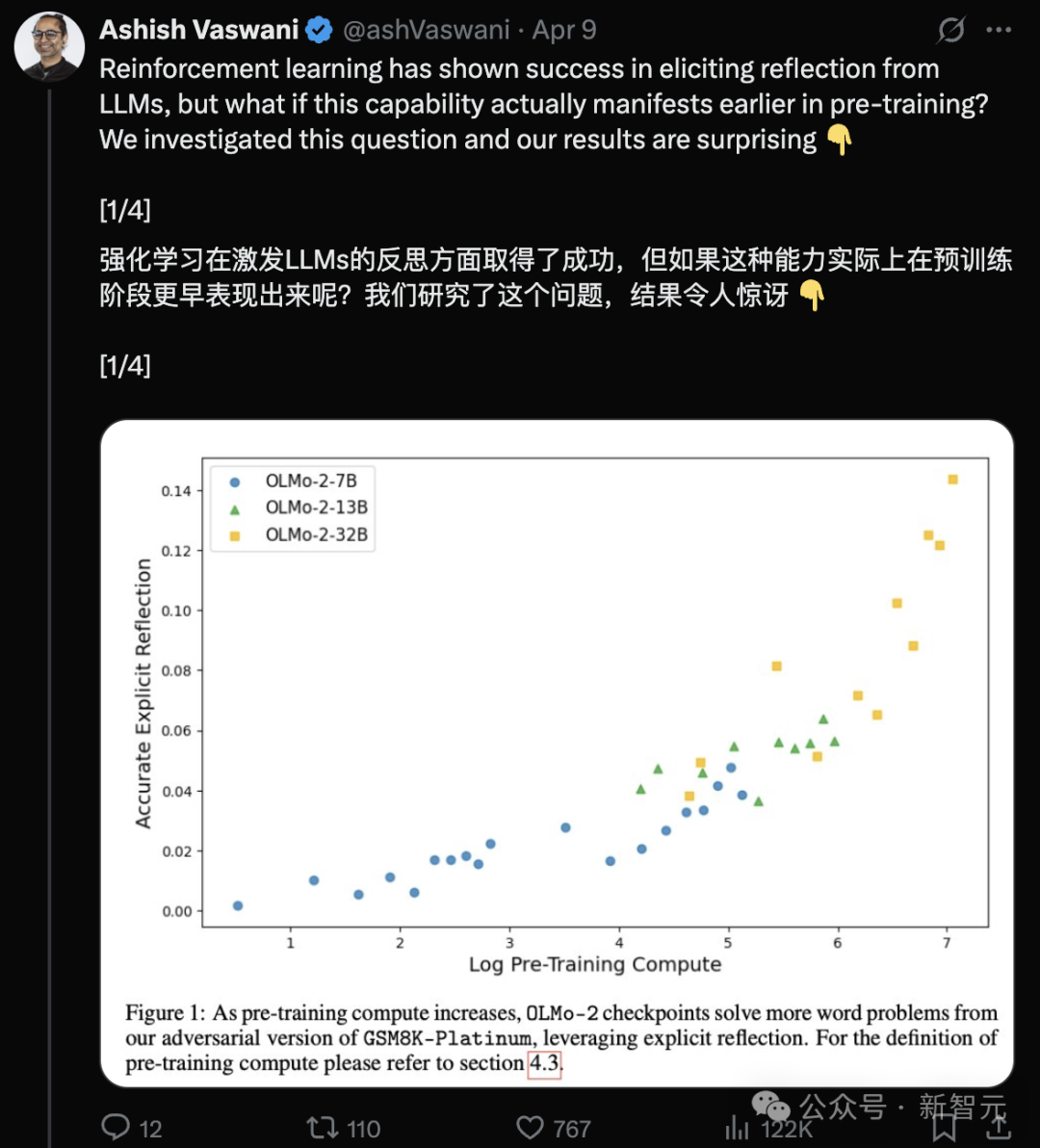
L’équipe des auteurs de Transformer : Les LLM possèdent déjà une capacité de réflexion pendant le pré-entraînement : Une équipe dirigée par Ashish Vaswani, premier auteur de l’article sur les Transformers, publie une étude suggérant que les grands modèles de langage développent des capacités de réflexion et d’autocorrection dès la phase de pré-entraînement, et non entièrement grâce à l’apprentissage par renforcement (RLHF). L’étude, en introduisant des chaînes de pensée adverses, distingue et quantifie les capacités de réflexion contextuelle et d’autoréflexion, constatant que ces capacités augmentent avec la quantité de calcul de pré-entraînement. Une simple invite comme “Wait,” peut efficacement déclencher une réflexion explicite. Cela remet en question les points de vue comme celui de DeepSeek selon lesquels la réflexion provient principalement du RL, et offre une nouvelle perspective pour comprendre et accélérer le développement des capacités de raisonnement lors du pré-entraînement (Source : Transformer原作打脸DeepSeek观点?一句Wait就能引发反思,RL都不用)
ChemAgent : Une base de mémoire auto-actualisable améliore la capacité de raisonnement chimique des LLM : Des chercheurs de Yale, Stanford et d’autres institutions proposent le framework ChemAgent, qui améliore considérablement les performances des LLM dans les tâches de raisonnement chimique en introduisant une base de mémoire dynamique auto-actualisable comprenant la planification, l’exécution et la mémoire des connaissances. Ce framework simule le processus d’apprentissage humain, en résolvant des problèmes chimiques complexes par décomposition des tâches et récupération de mémoire. Les expériences sur l’ensemble de données SciBench montrent que ChemAgent améliore la précision en moyenne de 10 % (par rapport au SOTA) à 37 % (par rapport au raisonnement direct) par rapport aux méthodes de référence, en particulier dans la précision des calculs et des conversions d’unités. L’étude analyse également la relation entre la similarité et la quantité de mémoire et les performances, ainsi que les limites actuelles (Source : 准确率飙升46%!耶鲁-斯坦福「自更新记忆库」新框架,重塑LLM化学推理能力)
L’Université de Technologie de Chine du Sud réalise une série de progrès dans le domaine du calcul évolutif distribué : L’équipe d’intelligence computationnelle de l’Université de Technologie de Chine du Sud a obtenu une série de résultats dans l’optimisation du consensus distribué des systèmes multi-agents (MAS). Les recherches comprennent : la publication d’une revue de ce domaine interdisciplinaire ; la proposition de l’algorithme MASOIE, qui optimise la collaboration grâce à des mécanismes d’apprentissage internes et externes ; la proposition de l’algorithme MACPO, qui utilise l’incitation par objectifs pour piloter la coopération ; la conception du mécanisme d’auto-adaptation du pas CCSA pour améliorer les performances d’optimisation en boîte noire ; la proposition de l’algorithme MASTER pour améliorer la précision de la localisation des réseaux de capteurs. L’équipe a également organisé des compétitions connexes pour promouvoir le développement du domaine (Source : 打破共识优化壁垒!华南理工深耕分布式进化计算,实现多智能体高效协同)
Série de tutoriels vidéo “Construire DeepSeek à partir de zéro” : Vizuara a publié sur YouTube une série de tutoriels vidéo “Construire DeepSeek à partir de zéro”, actuellement mise à jour avec 13 leçons. Le contenu couvre les bases de DeepSeek, le processus de traitement des tokens, les mécanismes d’attention (auto-attention, attention causale, attention multi-têtes, attention multi-requêtes, attention groupée par requêtes, attention latente multi-têtes) et des concepts clés comme le KV Cache, avec explication et implémentation de code. La série vise à analyser en profondeur l’architecture de DeepSeek, avec un total prévu de 35 à 40 vidéos couvrant RoPE, MoE, MTP, SFT, GRPO et plus encore (Source : karminski3, Reddit r/LocalLLaMA)
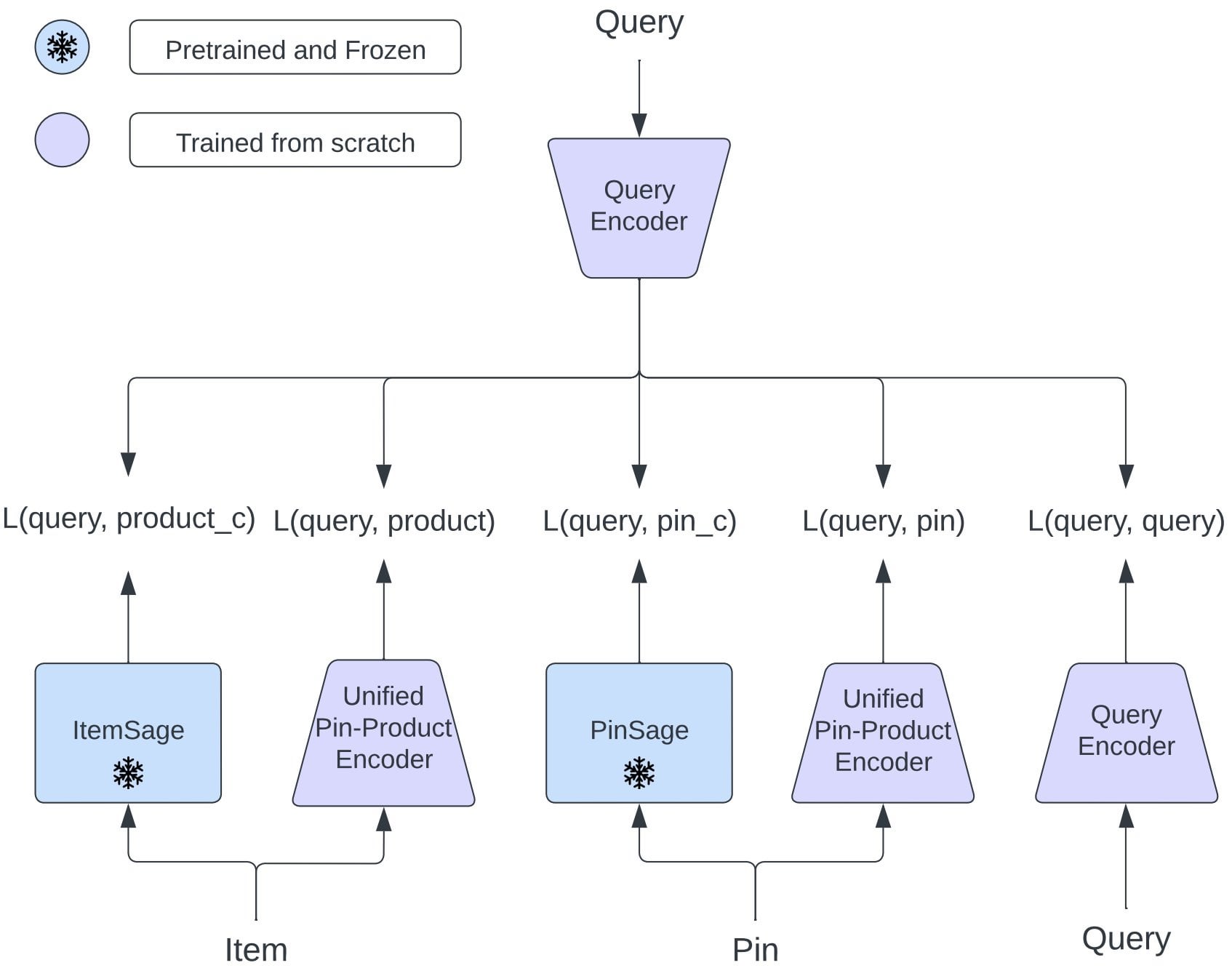
Pinterest propose OmniSearchSage : Un modèle d’embedding unifié améliore la recherche multi-tâches : Les chercheurs de Pinterest proposent OmniSearchSage, un modèle d’embedding de requête unifié, entraîné par apprentissage multi-tâches, capable de récupérer simultanément des pins, des produits et des requêtes associées, défiant l’architecture traditionnelle à deux tours. Ce modèle fusionne les titres générés par GenAI, les signaux des tableaux organisés par les utilisateurs et les données d’engagement comportemental, enrichissant la compréhension des éléments, et peut être directement intégré dans les systèmes existants (comme PinSage). Les résultats montrent que cette méthode a permis des améliorations pratiques significatives en matière de recherche, de publicité et de latence (Source : Reddit r/MachineLearning)
FlowReasoner : Flux de travail multi-agents ajusté dynamiquement en fonction de la requête : Un article propose FlowReasoner, visant à déduire instantanément un flux de travail multi-agents (workflow) dédié pour chaque requête utilisateur. Grâce à l’inférence SFT et à l’apprentissage par renforcement GRPO, le modèle peut ajuster dynamiquement la combinaison et l’ordre des tâches des Agents (comme la génération de code, la revue, le test, la révision) en fonction du feedback d’exécution. Cette méthode est validée dans le scénario Code Interpreter, s’appuyant sur l’exécution Python et les tests unitaires, démontrant le potentiel d’adaptation dynamique du flux de travail aux besoins de la requête, et pourrait être généralisée à l’avenir à des domaines tels que la récupération d’informations, l’analyse de données, etc. (Source : dotey)

Tutoriel LangChain : Construire un flux de travail de génération de rapports de conformité avec LlamaIndex : LlamaIndex publie un tutoriel vidéo montrant comment construire un Agentic Workflow pour générer des rapports de conformité. Ce flux de travail utilise un LLM pour traiter de grands volumes de textes réglementaires, les comparer au langage contractuel et générer des résumés concis. Le tutoriel montre comment configurer un index LlamaCloud, définir des schémas pour l’extraction de clauses et la vérification de conformité, et utiliser la recherche sémantique pour trouver le langage réglementaire pertinent (Source : jerryjliu0)

Tutoriel LangChain : Agent de génération de code auto-réparateur : LangChain publie un tutoriel expliquant comment construire un Agent de génération de code IA doté de capacités d’auto-réparation. Ce tutoriel utilise le framework OpenEvals et l’environnement sandbox E2B pour évaluer et améliorer le code généré par l’IA, en ajoutant une étape de réflexion pour valider le code avant de renvoyer la réponse (Source : LangChainAI)

Une analyse d’Anthropic révèle que Claude possède un code moral intrinsèque : Après avoir analysé 700 000 conversations Claude, Anthropic a découvert que son modèle IA fait preuve d’un code moral intrinsèque. Cette découverte pourrait avoir des implications importantes pour la recherche sur la sécurité et l’éthique de l’IA (Source : Reddit r/ClaudeAI, Reddit r/artificial)

Google propose “l’ère de l’expérience” pour faire face à la pénurie de données d’entraînement IA : Des chercheurs de Google (dont David Silver) publient un article intitulé “The Era of Experience”, proposant de résoudre le problème de la pénurie de données, actuellement dépendant des données humaines pour l’entraînement, en laissant les Agents IA générer leurs propres données d’entraînement. Cela pourrait annoncer une nouvelle direction pour le paradigme d’entraînement de l’IA et potentiellement remettre en question les méthodes d’entraînement dépendant des jeux de données existants (Source : Reddit r/artificial)

Liste de ressources de certificats et cours gratuits : Le dépôt GitHub cloudcommunity/Free-Certifications rassemble un grand nombre de ressources offrant des cours et certifications gratuits, couvrant divers domaines tels que la technologie générale, la sécurité, les bases de données, la gestion de projet, le marketing, etc. Il comprend certaines ressources gratuites liées à l’IA, au machine learning et à la science des données, comme le cours de machine learning de freeCodeCamp, les bases de GenAI de Databricks, les cours d’IA d’IBM Cognitive Class, etc. (Source : cloudcommunity/Free-Certifications – GitHub Trending (all/daily))
Test de fiabilité des LLM pour l’édition de code : Un utilisateur partage une vidéo testant la fiabilité de plusieurs grands modèles de langage (LLM) dans l’écriture et la modification de code de deep learning, explorant l’efficacité réelle et les limites actuelles des LLM dans les tâches d’assistance à la programmation (Source : Reddit r/deeplearning)

💼 Affaires
La guerre tarifaire américaine impacte les startups chinoises de matériel IA : L’imposition par les États-Unis de droits de douane élevés sur les produits chinois (certains taux atteignant 125 %) affecte gravement les startups chinoises de matériel IA (comme les jouets IA, les lunettes intelligentes, etc.) ciblant le marché américain. Le marché américain étant un terrain clé pour la validation du marché et l’acquisition des premiers utilisateurs pour de nombreux produits matériels IA (par exemple via Kickstarter), les droits de douane élevés entraînent une réduction drastique des bénéfices, voire des pertes, obligeant certaines entreprises à suspendre leurs livraisons vers les États-Unis. Bien que des catégories comme les lunettes intelligentes bénéficient d’exemptions temporaires, les perspectives sont incertaines. Les risques liés au modèle de “dédouanement gris” sur lequel s’appuie l’industrie augmentent également. Cela contraint les entreprises à réévaluer leurs stratégies de marché, à accélérer leur déploiement mondial et à diversifier les risques (Source : 襁褓中的AI硬件,迎接最激烈的关税战)

Analyse approfondie de Zhiyuan Robot : Produits, technologie et modèle économique : Fondée par Peng Zhihui (“Zhihui Jun”) et d’autres, Zhiyuan Robot possède la série “Yuanzheng” (A1, A2, A2-W à roues, A2-Max charges lourdes) destinée aux scénarios industriels et commerciaux, et la série “Lingxi” (X1 open-source, X1-W collecte de données, X2 bipède interactif) axée sur la légèreté et l’open-source, ainsi que les robots nettoyeurs Jingling G1 et Juechen C5. Technologiquement, l’entreprise met l’accent sur la synergie matériel-logiciel et la boucle de données fermée, développe en interne le module articulaire PowerFlow, la main dextre, et a développé le grand modèle Qiyuan (GO-1), la plateforme de données AIDEA, le framework de communication AimRT, etc. Le modèle économique comprend la vente de matériel, les services d’abonnement et le partage des revenus de l’écosystème (composants open-source, coopération avec la chaîne d’approvisionnement). L’entreprise a réalisé 8 levées de fonds, est valorisée à 15 milliards de yuans, avec des investisseurs tels que Hillhouse, BYD, Tencent, etc., et collabore avec plusieurs entreprises de la chaîne d’approvisionnement et gouvernements locaux, visant à créer un robot incarné universel de classe mondiale (Source : 智元机器人深度拆解:人形机器人独角兽进化论)

Le projet d’impression 3D incubé en interne par Dreame, “AtomFab”, lève des dizaines de millions de yuans : AtomFab Technology (AtomFab), incubé en interne par Dreame Technology (Dreame), a finalisé un tour de financement providentiel de plusieurs dizaines de millions de yuans, investi par ZhuiChuang Ventures. Fondée en janvier 2025, l’entreprise se concentre sur le marché de l’impression 3D grand public, utilisant la technologie IA pour résoudre les problèmes de facilité d’utilisation, de stabilité et d’efficacité. L’entreprise réutilisera les technologies de moteur, de capteur, d’interaction IA de Dreame ainsi que ses ressources de chaîne d’approvisionnement matures pour réduire les coûts et accélérer la mise sur le marché. Les produits seront d’abord lancés sur les marchés européen et américain, en utilisant le réseau après-vente international de Dreame pour le support. Le premier produit devrait être lancé au second semestre 2025 (Source : 追觅内部孵化3D打印项目获数千万融资,优先布局欧美等海外市场|硬氪首发)
La position dominante des GPU Nvidia pourrait être menacée : Bien que les livraisons de GPU Nvidia continuent de croître, sa domination à long terme est confrontée à des défis. Principales raisons : 1) La forte demande des géants du cloud (Google, Microsoft, Amazon, Meta) s’accompagne d’investissements massifs dans leurs propres puces (TPU, Maia, Trainium, MTIA) pour réduire les coûts et la dépendance ; 2) L’industrie s’oriente vers une optimisation distribuée, intégrée verticalement et au niveau du système (puces, réseau, refroidissement, logiciel), où Nvidia est relativement moins bien positionné ; 3) La demande de personnalisation augmente, les ASIC montrant des avantages pour des charges de travail spécifiques (comme l’inférence, la recommandation) ; 4) La technologie réseau de Nvidia (Infiniband) et sa pile logicielle (comme BaseCommand) pourraient être moins performantes que les solutions internes des géants du cloud en termes d’hyper-échelle et de tolérance aux pannes. Bien que Nvidia s’efforce de s’adapter (par exemple avec Blackwell, Spectrum-X), les défis structurels persistent (Source : 计算的未来:英伟达王冠正摇摇欲坠)

Rumeur : OpenAI intéressé par l’acquisition du navigateur Chrome : Selon Bloomberg, si Google était contraint par un tribunal fédéral américain de scinder ses activités de recherche en raison d’une affaire antitrust, OpenAI pourrait être intéressé par l’acquisition de son activité de navigateur Chrome. Cela reflète l’intérêt potentiel des entreprises d’IA à maîtriser les points d’entrée des utilisateurs et les sources de données, mais il ne s’agit pour l’instant que d’une rumeur, dépendant de l’issue de l’affaire antitrust de Google (Source : karminski3)
Stratégies pour obtenir des résultats commerciaux avec la GenAI : Un article de Forbes explore comment les entreprises peuvent dépasser la phase expérimentale et obtenir des résultats commerciaux concrets grâce à l’IA générative (GenAI), proposant 9 stratégies pour aider les entreprises à intégrer la GenAI dans leurs processus métier afin d’améliorer l’efficacité et l’innovation (Source : Ronald_vanLoon)

La nouvelle puce de Huawei pourrait concurrencer Nvidia : Des discussions sur les réseaux sociaux mentionnent le lancement d’une nouvelle puce par Huawei, qui pourrait concurrencer Nvidia dans le domaine de l’IA, ce qui pourrait influencer l’équilibre des négociations sino-américaines sur les puces et les tarifs douaniers (Source : Reddit r/ArtificialInteligence)
🌟 Communauté
La ruée vers l’or déclenchée par DeepSeek et réflexions : La popularité de DeepSeek a engendré de nombreuses tentatives commerciales, notamment la création de contenu (production en masse de scripts de courtes vidéos, de textes publicitaires), la vente de connaissances (vente de tutoriels d’utilisation, de cours de monétisation) et les services d’agence. Cependant, de nombreux expérimentateurs découvrent que le contenu produit en masse par l’IA est très homogène, facilement limité ou banni par les plateformes, et difficile à convertir en revenus réels. L’article souligne que les véritables bénéficiaires sont souvent les “intermédiaires” qui vendent des cours ou des services en exploitant l’asymétrie d’information, plutôt que les utilisateurs directs. Parallèlement, DeepSeek lui-même révèle des problèmes tels que des serveurs occupés et des réponses stéréotypées, suscitant des discussions sur sa valeur applicative et ses limites (Source : DeepSeek走红三个月,第一批想靠它赚钱的怎么样了?)

Le financement d’un développeur d’outils de triche IA suscite une controverse éthique : Chungin Lee, étudiant de 21 ans à Columbia, a été suspendu pour avoir développé Interview Coder, un outil IA de triche pour les entretiens techniques. Moins d’un mois plus tard, il a fondé la société Cluely avec un camarade, étendant l’outil à divers scénarios (examens, ventes, réunions) et levant 5,3 millions de dollars en financement de démarrage. Ils affirment qu’il ne s’agit pas de triche, mais d’une amélioration de l’efficacité grâce à la technologie, prédisant que tout le monde utilisera l’IA comme assistance à l’avenir. L’affaire a suscité une vive controverse : les partisans y voient une innovation audacieuse, tandis que les critiques s’inquiètent de l’atteinte à l’équité, du brouillage des limites de compétence, comparant même la situation à un épisode de “Black Mirror”. L’événement a déclenché un débat intense sur l’éthique de l’IA, l’équité dans l’éducation et la définition des compétences (Source : 21岁学生开发AI作弊工具被哥大停学,转身拿下530万美元融资,网友:《黑镜》成真, 靠开发AI作弊神器成名,21岁小伙遭学校开除不足一月后,转身拿下530万美元融资)

Le durcissement de la politique américaine des visas pourrait entraîner une fuite des talents en IA : Récemment, le gouvernement américain a révoqué massivement les enregistrements SEVIS et les visas d’étudiants internationaux (y compris des doctorants en IA), pour des motifs allant d’infractions mineures à des erreurs système (pouvant impliquer un filtrage par IA), avec un processus manquant de transparence et de possibilités d’appel. Des professeurs comme Yisong Yue de Caltech craignent que cette mesure ne nuise à l’attractivité des États-Unis pour les meilleurs talents en IA, de nombreux chercheurs d’institutions comme OpenAI et Google envisageant déjà de partir. Cela pourrait entraîner un recul des projets d’IA américains et affaiblir leur avantage dans ce domaine. Des étudiants ont déjà intenté une action collective contre le gouvernement et obtenu une ordonnance restrictive temporaire (Source : 加州AI博士一夜失身份,谷歌OpenAI学者掀「离美潮」,38万岗位消失AI优势崩塌)

Discussion sur l’état actuel du développement des modèles open-source : La communauté discute des dernières nouvelles concernant les grands modèles open-source, mentionnant l’attente de Qwen 3, l’adoption lente de Llama 4, un possible plafond pour les modèles d’inférence, la sous-estimation des modèles multimodaux et la domination continue de la Chine dans le domaine de l’open-source. Les participants soulignent que la compréhension de la “saturation de l’inférence” doit distinguer l’open-source du fermé, et que cela concerne davantage la diversité des modèles et les défis de l’extension du RL (Source : natolambert)
Les capacités de recherche du modèle OpenAI o3 sont saluées : Un utilisateur loue les puissantes capacités de recherche du modèle OpenAI o3, capable de trouver des informations très spécifiques sans nécessiter beaucoup de contexte supplémentaire, offrant une expérience interactive similaire à celle d’une conversation avec un collègue (Source : gdb)
Signification et impact du TTS open-source : En discutant du modèle Dia TTS, les membres de la communauté soulignent que ses performances de haute qualité prouvent que l’entraînement de modèles TTS SOTA ne nécessite plus des investissements de plusieurs milliards de dollars. L’effet cumulatif de l’industrie de l’IA facilite de plus en plus l’entraînement, et la force de l’open-source accélère la démocratisation de la technologie (Source : huggingface, huggingface)
Meta organise LlamaCon 2025 pour célébrer la communauté open-source : Meta annonce l’organisation de l’événement LlamaCon 2025, visant à célébrer la communauté open-source Llama et ses réalisations, et partagera les dernières avancées et les projets futurs pour les modèles et outils Llama (Source : AIatMeta)

L’IA est-elle vraiment “intelligente” ? Le débat est lancé : L’article “Nous devons cesser de prétendre que l’IA est intelligente” suscite une discussion sur les limites des capacités technologiques actuelles de l’IA et la complexité de la définition de l‘“intelligence” (Source : Ronald_vanLoon)

Expérience utilisateur de ChatGPT : Perte de connexion et test d’honnêteté : Un utilisateur signale des problèmes fréquents de “perte de connexion réseau” avec ChatGPT, supposant que cela pourrait être lié à la charge d’utilisation. Parallèlement, un autre utilisateur partage une invite intéressante demandant à ChatGPT d’utiliser sa fonction de mémoire pour donner son “avis réel” sur ses utilisateurs, suscitant une discussion sur l’interaction personnalisée de l’IA et la “conscience” (Source : natolambert, dotey)
Optimisme quant au développement dans le domaine de la robotique : Le co-fondateur de Hugging Face, Thomas Wolf, commente que les laboratoires de robotique de 2025 sont passionnants grâce au matériel open-source, aux bons progrès de l’apprentissage par renforcement et à la concentration des talents, reflétant l’enthousiasme de l’industrie pour le développement rapide de la technologie robotique (Source : huggingface)
L’utilité de Gemini Deep Research est confirmée : Un utilisateur partage un cas d’utilisation de la fonction Gemini Deep Research pour vérifier la fiabilité des informations d’un tweet, montrant sa valeur pratique pour la vérification des faits et la recherche approfondie (Source : dotey)

Critiques et défense des bibliothèques IA open-source : Des membres de la communauté observent de nombreuses critiques négatives récentes envers diverses bibliothèques IA open-source, estimant que ces critiques pourraient être basées sur des informations obsolètes ou des indicateurs partiels, et appellent les critiques à participer à la construction de meilleures versions (Source : natolambert)
Spéculations sur l’expérience de jeu IA : Un utilisateur exprime sa curiosité quant à l’expérience de jeu future pilotée par l’IA, spéculant qu’elle pourrait ressembler au mode d’interaction de VRChat, mais exprime des doutes sur le fait de tout contrôler par la voix (Source : karminski3)
Discussion sur la fonction d’agrandissement d’image de ChatGPT : Un utilisateur tente de faire agrandir la résolution d’une image par ChatGPT, découvrant qu’il ne s’agit pas d’un véritable agrandissement des pixels, mais de la recréation d’une image similaire mais avec des détails différents en haute résolution. Les commentaires confirment généralement ce point et discutent de la véritable technologie d’agrandissement d’image par IA (Source : Reddit r/ChatGPT)
ChatGPT génère une image de son monde imaginaire : Un utilisateur demande à ChatGPT de générer l’apparence du monde tel qu’il l’imagine, obtenant une image de scène de parc idyllique. Les commentateurs soulignent les incohérences logiques de l’image (comme la distance Terre-Lune, la position des bancs) et les biais potentiels (race des personnages), reflétant les limites actuelles des modèles de génération d’images (Source : Reddit r/ChatGPT)

Exploration des raisons de la popularité de l’ancien modèle LLM MythoMax13B : Un utilisateur Reddit demande pourquoi le modèle MythoMax13B basé sur Llama2 reste populaire dans les scénarios RPG sur des plateformes comme OpenRouter. Les commentaires suggèrent que les raisons incluent : le faible coût (souvent proposé comme option gratuite), sa relative stabilité et sa capacité à suivre les instructions, la familiarité des utilisateurs avec ses invites et paramètres, et l’effet de consolidation des tutoriels initiaux (Source : Reddit r/LocalLLaMA)
Recherche d’un outil de filtrage de confidentialité local : Un utilisateur Reddit recherche un outil ou un petit modèle de langage (SLM) pouvant s’exécuter sur un appareil local pour détecter et anonymiser automatiquement (par exemple, remplacer par des placeholders) les informations sensibles dans les invites avant de les envoyer à un LLM, et restaurer les informations originales après réception de la réponse du LLM, afin de protéger la vie privée (Source : Reddit r/OpenWebUI)
Discussion sur l’avertissement d’Anthropic concernant les “employés entièrement IA” : Anthropic avertit que des employés virtuels entièrement constitués d’IA pourraient apparaître d’ici un an, ce qui suscite des discussions au sein de la communauté. Les commentateurs expriment leur scepticisme, soulignant les problèmes de stabilité des propres services d’Anthropic, et considèrent cela davantage comme une forme de publicité ou d’alarmisme (Source : Reddit r/ArtificialInteligence, Reddit r/artificial, Reddit r/ClaudeAI)

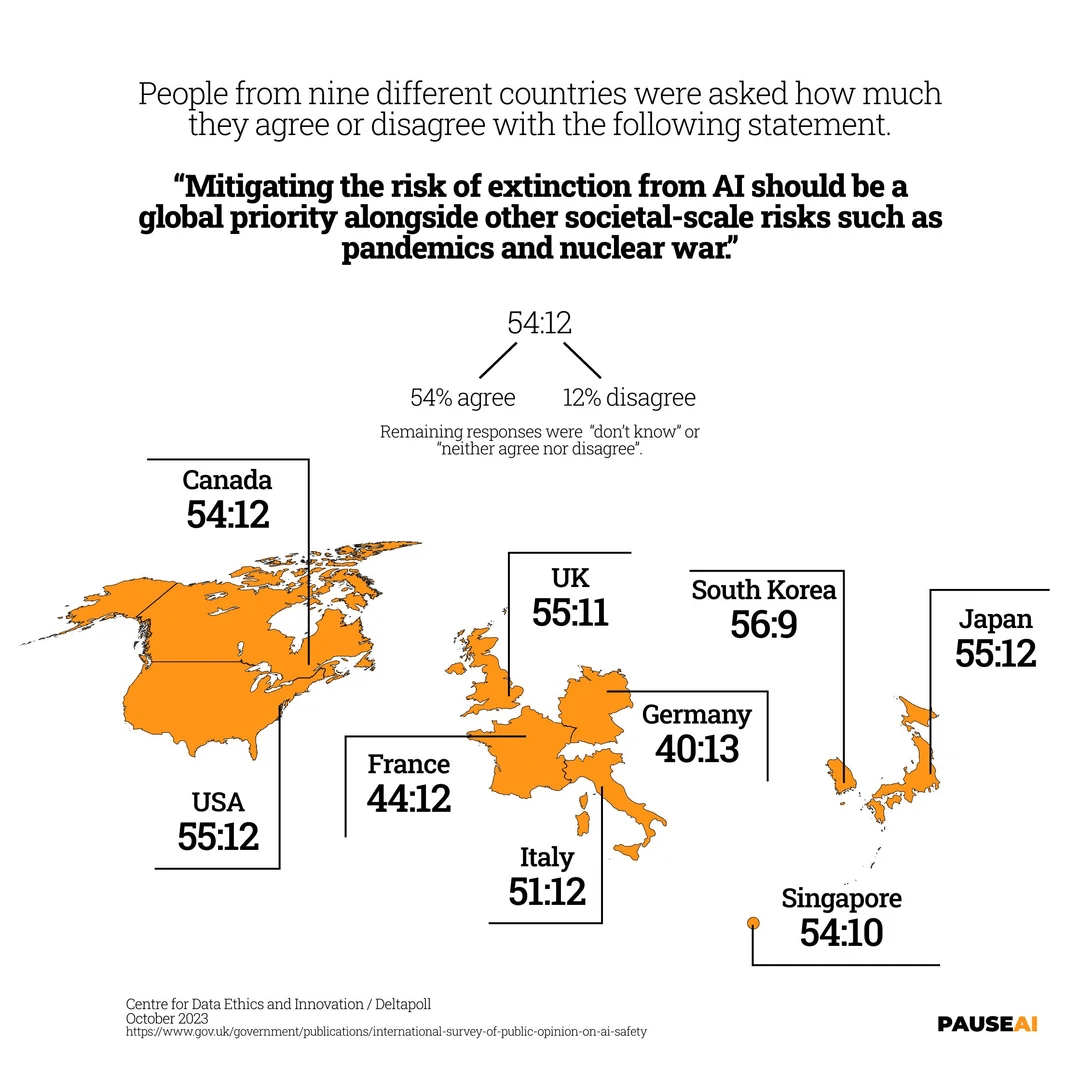
Inquiétude mondiale concernant le risque d’extinction par l’IA : Une image montre les résultats d’une enquête indiquant que la majorité des personnes dans le monde pensent qu’il faut prendre au sérieux le risque que l’IA puisse entraîner l’extinction humaine (Source : Reddit r/artificial)
Le “goût de machine” du texte généré par IA et astuces pour l’humaniser : Des utilisateurs discutent de la manière d’identifier le texte généré par IA (comme les e-mails, les publications), soulignant ses problèmes courants : manque de ton ciblé, trop formel, perfection sans faille. Ils partagent également des astuces pour rendre l’écriture de l’IA plus naturelle : clarifier le scénario, fournir des exemples, ajuster le caractère aléatoire, ajouter des détails concrets, éditer soi-même, conserver de légères imperfections, etc. (Source : Reddit r/artificial)
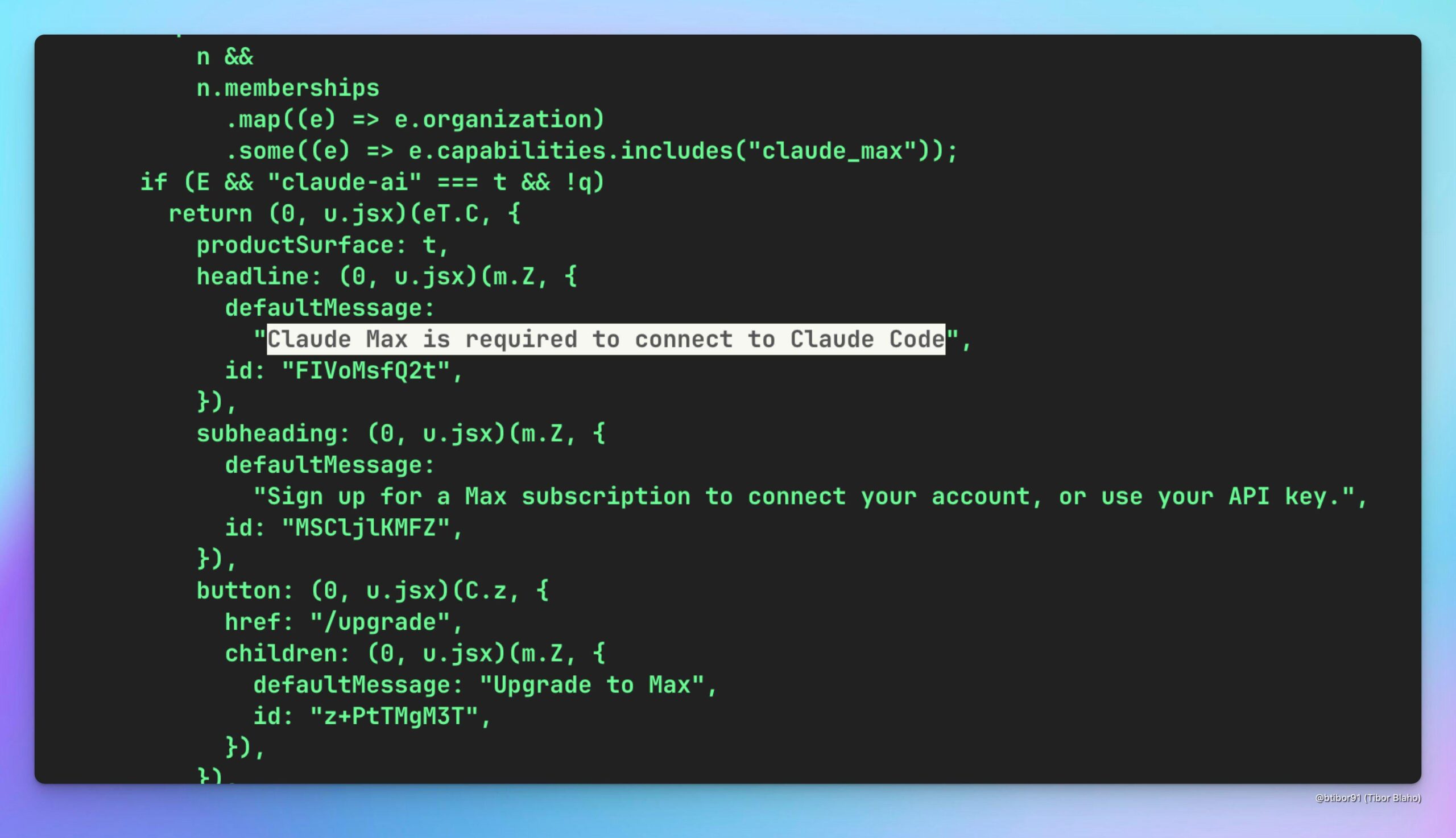
Spéculation sur la possibilité d’utiliser Claude Code via Claude Max : Un utilisateur spécule sur la possibilité d’utiliser indirectement le modèle Claude Code (potentiellement moins cher) en s’abonnant au service Claude Max, et discute de sa valeur potentielle, tout en espérant qu’OpenAI propose une solution similaire (Source : Reddit r/ClaudeAI)
Imitation humoristique du comportement local du modèle o3 : Un utilisateur publie une invite système humoristique visant à faire en sorte qu’un modèle LLM local présente des caractéristiques similaires à celles reprochées au modèle OpenAI o3 par certains utilisateurs (comme des réponses brèves, du code subtilement erroné, un comportement agaçant), afin de se moquer du mécontentement envers le modèle o3 (Source : Reddit r/LocalLLaMA)

Demande d’aide pour la connexion d’OpenWebUI au serveur proxy MCP : Un utilisateur K8s rencontre un problème lors de l’utilisation d’OpenWebUI, ne parvenant pas à accéder depuis l’interface Web au serveur proxy MCP (application FastAPI) déployé dans le même pod, bien qu’il soit accessible via localhost à l’intérieur du pod. L’utilisateur demande l’aide de la communauté pour résoudre le problème de connexion réseau ou de configuration (Source : Reddit r/OpenWebUI)
Discussion sur les pratiques de sécurité pour les serveurs MCP locaux : Un utilisateur lance une discussion pour savoir comment exécuter en toute sécurité un serveur MCP local afin de faire face aux risques potentiels de vulnérabilités. Les commentaires suggèrent d’utiliser le mode stdio, ou de limiter le mode SSE à localhost/127.0.0.1, ou d’utiliser l’authentification par token, et soulignent que les préoccupations concernant l’injection d’invites/le vol d’identifiants s’appliquent à toutes les installations logicielles (Source : Reddit r/ClaudeAI)
Exploration du mécanisme de paiement du protocole Agent-to-Agent (A2A) : La communauté discute du manque de mécanisme de paiement intégré entre Agents dans le protocole A2A de Google. Les utilisateurs estiment que cela pourrait freiner le développement de l’économie des Agents et explorent des solutions potentielles, telles que l’utilisation de jetons d’authentification liés à la facturation, des processus d’entiercement intégrés ou l’ajout d’informations de tarification dans AgentSkill, etc. (Source : Reddit r/artificial)
Mise en garde contre la dépendance excessive à l’IA : Un utilisateur partage son expérience où l’IA de recherche Google a donné des réponses opposées à la même question, soulignant qu’il ne faut pas se fier entièrement à l’IA pour prendre des décisions finales. Les commentaires expliquent que la nature probabiliste des LLM, les biais des données d’entraînement, la simplification des modèles, etc., entraînent des incohérences, et recommandent d’utiliser l’IA comme un outil de recherche auxiliaire plutôt qu’une source d’information faisant autorité (Source : Reddit r/ArtificialInteligence)
Questions sur l’utilisation de Qdrant pour le RAG dans OpenWebUI : Un utilisateur demande comment intégrer la base de données vectorielle Qdrant dans l’environnement OpenWebUI pour réaliser le RAG (Retrieval-Augmented Generation), en particulier comment faire en sorte qu’OpenWebUI utilise les données de Qdrant et si un script retriever est nécessaire (Source : Reddit r/OpenWebUI)
Discussion sur la comparaison des performances de recherche entre Google et ChatGPT : Un utilisateur publie un graphique comparatif (non affiché), affirmant que les performances de recherche de ChatGPT sont supérieures à celles de Google, ce qui suscite une discussion au sein de la communauté. Certains réfutent, estimant que Google Gemini est performant et dispose d’outils comme NotebookLM ; d’autres jugent cette comparaison inutile, la technologie progressant constamment ; d’autres encore soulignent l’importance de l’expérience utilisateur et de l’intégration (Source : Reddit r/ChatGPT)
Perspectives prometteuses pour la recherche sur le Character Training : Un observateur de l’industrie prédit que le Character Training (entraînement de personnages, faisant probablement référence à l’IA simulant des personnages ou des personnalités spécifiques) deviendra un domaine de recherche académique explosif, estimant que c’est le bon moment pour publier des articles pionniers précoces (Source : natolambert)
💡 Autres
Exploration de la pertinence de la forme humanoïde pour les robots : L’article explore les raisons pour lesquelles les robots sont conçus sous forme humanoïde : principalement pour s’adapter au monde conçu et construit pour les humains (outils, environnement, modes d’interaction). La conception humanoïde facilite la navigation et la manipulation des robots dans les infrastructures existantes, réduit les besoins de modification et permet d’utiliser les outils humains. Les caractéristiques anthropomorphes favorisent également l’interaction et la collaboration homme-machine. Malgré les défis liés à l’équilibre, au contrôle, au coût et à la “vallée de l’étrange”, les progrès technologiques surmontent progressivement ces obstacles. L’article passe également en revue une brève histoire du développement des robots, compare le paysage concurrentiel dans le domaine des robots humanoïdes entre des pays comme la Chine et les États-Unis, et envisage les perspectives de popularisation offertes par la baisse des coûts (Source : 外媒深度:机器人为什么要做成人形?)

Défis et stratégies pour l’emploi en Chine à l’ère de l’IA : L’article analyse l’impact de l’intelligence artificielle sur le marché du travail chinois, en particulier les défis posés à la main-d’œuvre peu qualifiée et au développement régional déséquilibré. S’inspirant de l’expérience américaine en matière de réforme de l’éducation, de reconversion, de système de sécurité sociale et de soutien à l’innovation, l’article propose que la Chine renforce la formation professionnelle et l’éducation tout au long de la vie (en particulier les compétences numériques), améliore le système de sécurité sociale pour couvrir les nouvelles formes d’emploi, promeuve l’intégration de l’industrie et de l’IA ainsi que le développement régional coordonné,健全 la réglementation des algorithmes et la protection de la vie privée des données, renforce la coordination multisectorielle et la surveillance et l’alerte précoce de l’emploi, afin de stabiliser et d’améliorer la base de l’emploi (Source : 人工智能时代:中国如何稳住、提升就业基本盘)
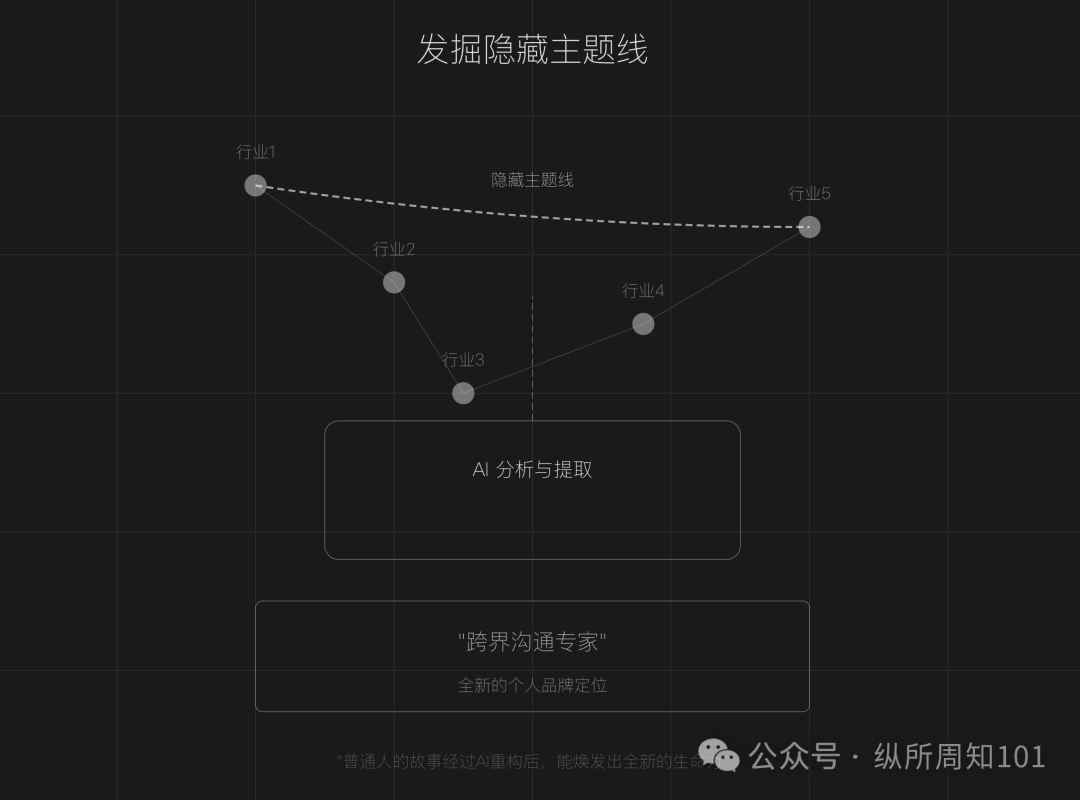
Utiliser l’IA pour remodeler le récit de sa marque personnelle (IP) : L’article propose qu’à l’ère de la saturation de la création de contenu, les individus ordinaires peuvent utiliser des outils IA (comme ChatGPT) pour reconstruire leurs expériences personnelles, découvrir des fils conducteurs cachés, remodeler le récit des tournants clés et façonner un système linguistique différencié, afin de créer une marque personnelle unique. L’article fournit des étapes concrètes (collecte de données, exploration thématique par IA, restructuration de l’histoire, itération pratique) et des techniques (construction inversée, amplification émotionnelle, renforcement par contraste), tout en rappelant d’éviter les pièges de l’embellissement excessif, de l’uniformité et du manque de profondeur émotionnelle, soulignant la combinaison de l’authenticité et de l’assistance de l’IA (Source : 做个人IP的第一步:用AI改写你的人生叙事)
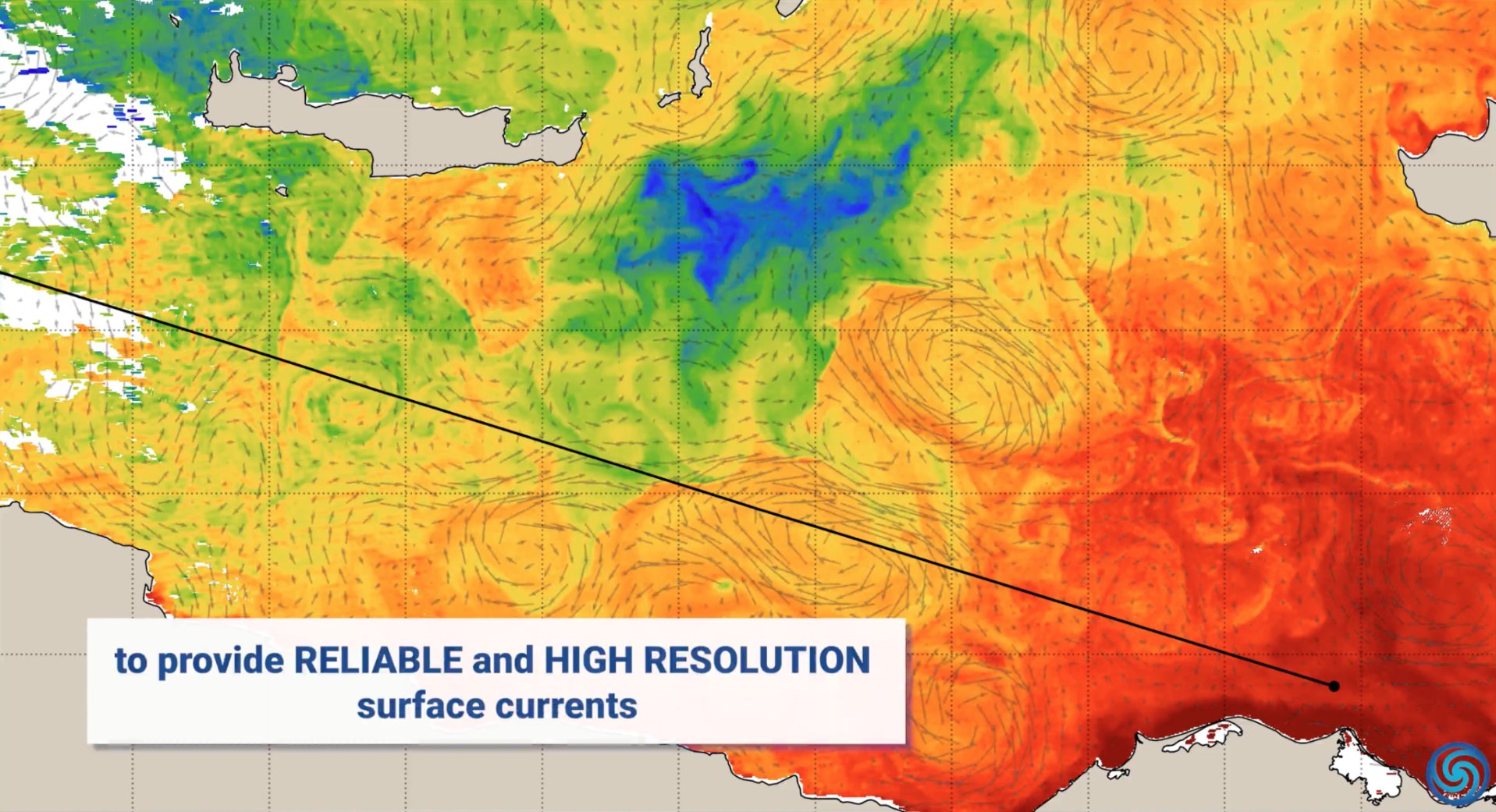
Applications de l’IA dans le domaine de la protection de l’environnement : À l’occasion de la Journée mondiale de la Terre, Nvidia a présenté des exemples d’application de sa technologie IA (telle que Jetson, la plateforme Earth-2) dans la protection de l’environnement, notamment la prévision des courants marins pour réduire la consommation de carburant, la protection en temps réel contre les incendies de forêt et le braconnage, la fourniture de prévisions de tempêtes plus précises et la détection d’astéroïdes, couvrant plusieurs dimensions telles que l’océan, la terre, le ciel et l’espace (Source : nvidia, nvidia, nvidia)
L’IA pour améliorer le service client : Les centres de contact pilotés par l’IA transforment l’expérience du service client, visant à résoudre les points douloureux des appels de service client traditionnels, à améliorer l’efficacité et la satisfaction (Source : Ronald_vanLoon)
Partage d’invites pour générer des selfies réalistes / images amusantes avec l’IA : Un utilisateur partage des invites pour utiliser des outils de génération d’images IA (comme GPT-4o, Sora) afin de générer des selfies “ordinaires” extrêmement réalistes, semblant pris sur le vif, ainsi que des invites pour générer des images amusantes transformant des personnalités spécifiques en brosses de toilette, etc., montrant le potentiel créatif et ludique de l’IA dans la génération d’images (Source : dotey, dotey, dotey)

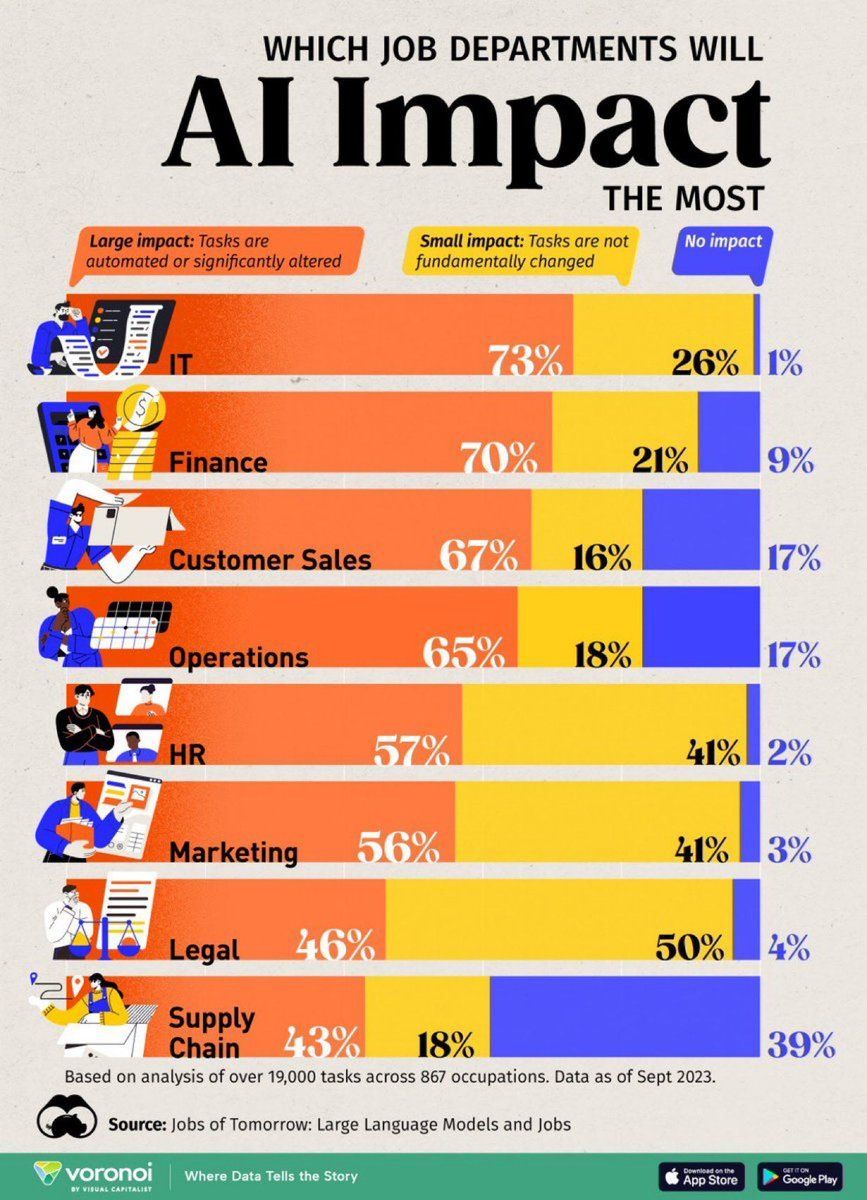
Analyse de l’impact de l’IA sur les emplois : Une infographie réalisée par Visual Capitalist montre les emplois les plus touchés par l’IA, suscitant l’attention sur les changements futurs des formes de travail (Source : Ronald_vanLoon)
L’IA utilisée pour la détection des défauts routiers à Dubaï : Dubaï adoptera une nouvelle technologie IA pour détecter les défauts routiers, démontrant le potentiel d’application de l’IA dans la maintenance des infrastructures urbaines (Source : Ronald_vanLoon)
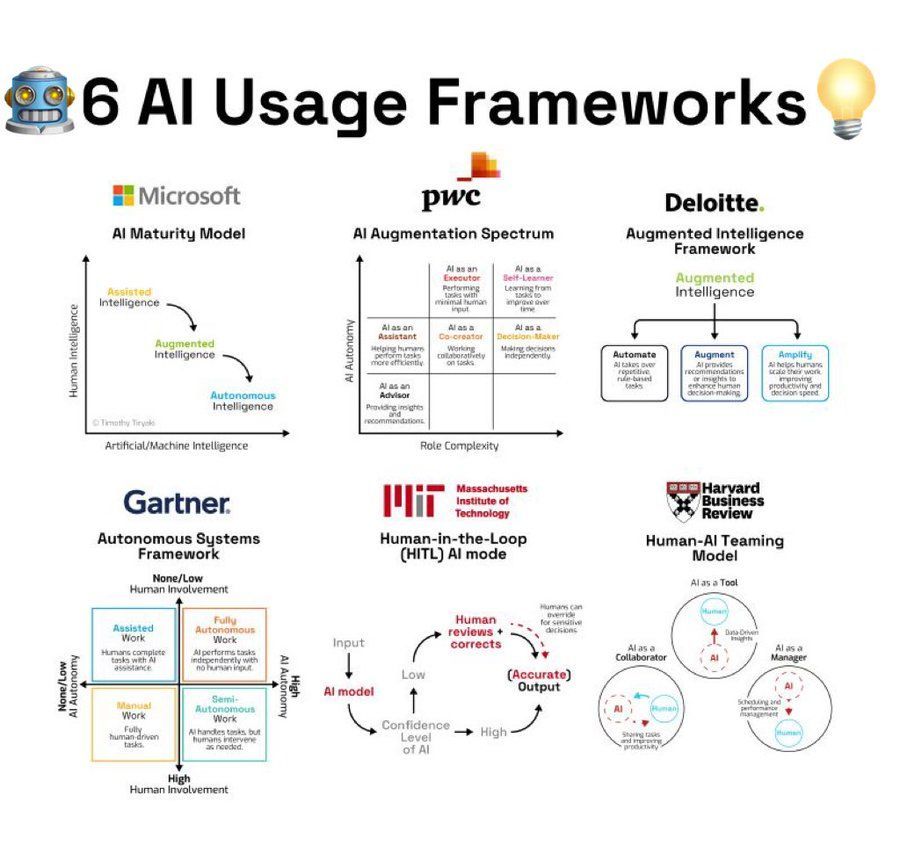
Résumé des cadres d’utilisation de l’IA : Une infographie résume 6 cadres ou méthodologies d’utilisation de l’IA, offrant des pistes de réflexion aux utilisateurs pour appliquer l’IA (Source : Ronald_vanLoon)
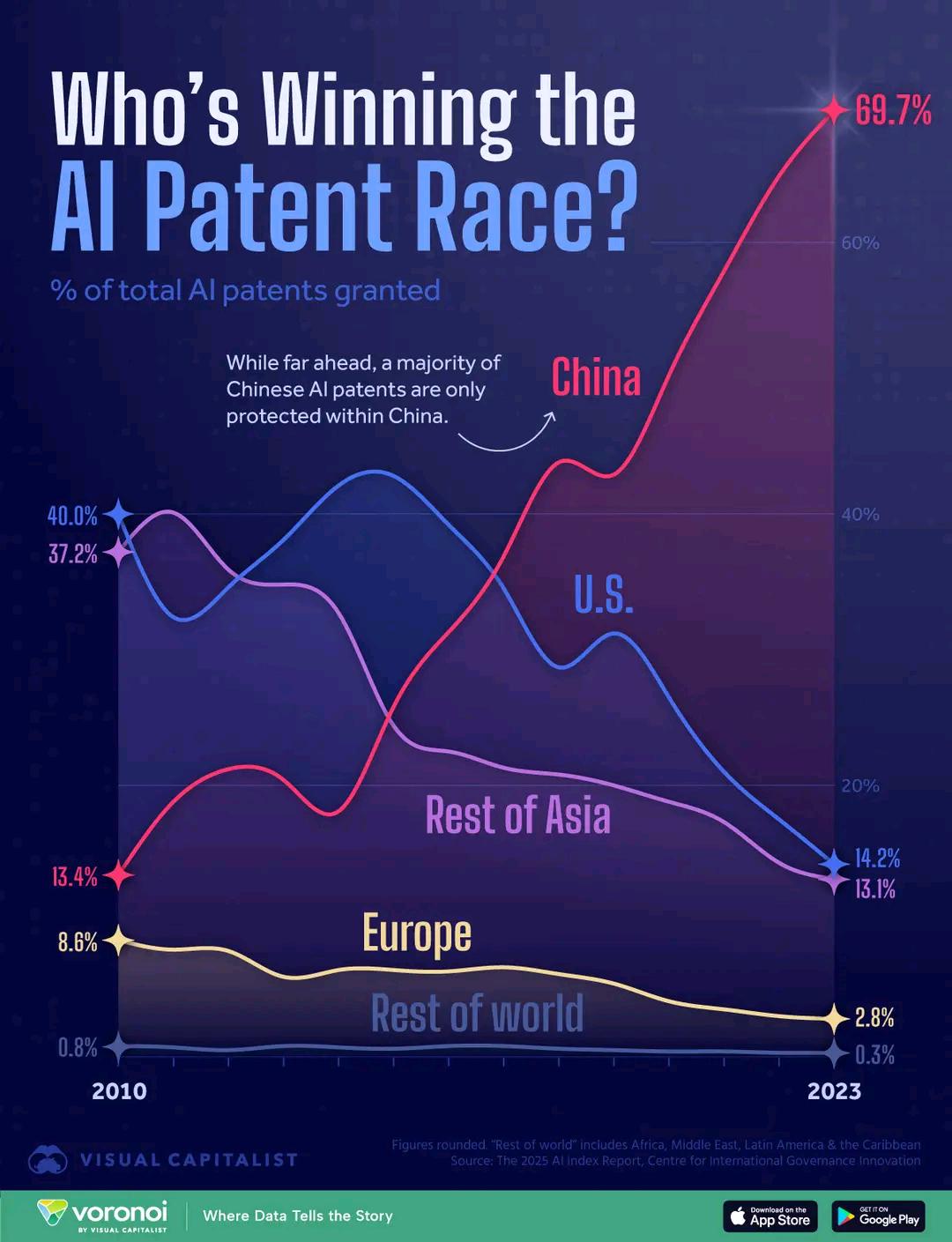
Comparaison du nombre de brevets IA par pays : Un graphique montre la comparaison du nombre de brevets dans le domaine de l’IA par pays, reflétant les différences d’investissement et de production en R&D IA entre les pays. Les commentaires mentionnent que le coût relativement bas des demandes de brevet en Chine pourrait influencer l’interprétation des données (Source : karminski3)
Un bras bionique aide les personnes handicapées : La société Open Bionics installe un bras bionique pour Grace, une jeune fille de 15 ans amputée, démontrant l’application de l’IA et de la technologie robotique dans les domaines de la santé et des technologies d’assistance (Source : Ronald_vanLoon)
L’éligibilité aux Oscars des films assistés par IA suscite l’attention : L’Académie américaine des arts et des sciences du cinéma met à jour ses règles, précisant que les films produits à l’aide d’outils numériques tels que l’IA sont également éligibles aux Oscars, ce qui suscite de vastes discussions à Hollywood et au-delà, concernant l’impact de l’IA sur la création cinématographique et les normes de l’industrie (Source : Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

La Lituanie élabore des règles d’utilisation de l’IA dans les écoles : La Lituanie est en train d’élaborer des règles relatives à l’utilisation de l’intelligence artificielle dans les écoles, ce qui reflète le fait que le secteur de l’éducation commence à normaliser l’application des outils d’IA (Source : Reddit r/ArtificialInteligence)