Mots-clés:IA, Grand modèle, Agent intelligent, Multimodal, Conception d’IA pour détecteur d’ondes gravitationnelles, Modèle de génération vidéo Magi-1, Grand modèle vidéo Vidu Q1, Analyse des valeurs de Claude, Mécanisme de raisonnement DeepSeek-R1, Norme de protocole pour agents IA, Vulnérabilité de sécurité du splatting 3D gaussien, Controverse sur les droits d’auteur de la musique IA
🔥 Focus
Une IA conçoit un nouveau détecteur d’ondes gravitationnelles, élargissant l’univers observable : Des chercheurs de l’Institut Max Planck, de Caltech et d’autres institutions ont utilisé l’algorithme d’IA Urania pour concevoir un nouveau type de détecteur d’ondes gravitationnelles dépassant la compréhension humaine actuelle. Cette IA, en transformant le problème de conception en un problème d’optimisation continue, a découvert des dizaines de structures topologiques supérieures aux conceptions humaines, capables d’augmenter la sensibilité de détection de plus de 10 fois et d’étendre le volume de l’univers observable par 50. Cette recherche publiée dans PRX démontre le potentiel de l’IA à découvrir des solutions surhumaines dans le domaine des sciences fondamentales, voire à créer de nouvelles idées en physique. (Source : 新智元)

L’équipe de Cao Yue, lauréat de la Bourse Spéciale de Tsinghua, rend open source le modèle de génération vidéo Magi-1 : Sand.ai, fondé par Cao Yue, auteur du Swin Transformer, a publié et rendu open source le grand modèle de génération vidéo autorégressif Magi-1. Ce modèle utilise une méthode de prédiction autorégressive par blocs, prend en charge une extension de longueur illimitée et un contrôle de la durée à la seconde près, tout en offrant une sortie de haute qualité. L’équipe a publié un rapport technique de 61 pages détaillant l’architecture du modèle (basée sur DiT), la méthode d’entraînement (Flow-Matching) et plusieurs optimisations d’attention et d’entraînement distribué. Une série de modèles allant de 4.5B à 24B paramètres a été rendue open source, fonctionnant au minimum sur une seule carte 4090, dans le but de promouvoir le développement de la technologie de génération vidéo par IA. (Source : 量子位, 机器之心, kaifulee)
Le grand modèle vidéo chinois Vidu Q1 prend la tête des classements VBench au T1 : Vidu Q1, le grand modèle vidéo de Shengshu Technology, s’est classé premier dans les deux benchmarks de référence VBench-1.0 et VBench-2.0, surpassant des modèles nationaux et internationaux tels que Sora et Runway. Q1 excelle en termes de réalisme vidéo, de cohérence sémantique et d’authenticité du contenu. La nouvelle version prend en charge la qualité HD 1080p (génération de 5 secondes en une fois), a amélioré la fonction des images de début et de fin pour réaliser des mouvements de caméra de niveau cinématographique, et a lancé une fonction d’effets sonores IA prenant en charge un contrôle temporel précis (taux d’échantillonnage de 48 kHz). Son prix est compétitif et vise à autonomiser l’industrie créative. (Source : 新智元)

Une étude d’Anthropic révèle l’expression des valeurs de Claude : Anthropic a analysé 700 000 conversations anonymes avec Claude pour construire une taxonomie de 3307 valeurs uniques, visant à comprendre l’orientation des valeurs de l’IA dans les interactions réelles. L’étude a révélé que Claude suit globalement les principes “bénéfique, honnête, inoffensif” et peut adapter ses valeurs de manière flexible selon différents contextes (comme les conseils relationnels, l’analyse historique). Dans la plupart des cas, il soutient le point de vue de l’utilisateur, mais dans une minorité de cas (3%), il résiste activement, reflétant potentiellement ses valeurs fondamentales. Cette étude contribue à améliorer la transparence du comportement de l’IA, à identifier les risques et à fournir une base empirique pour l’évaluation éthique de l’IA. (Source : 元宇宙之心MetaverseHub, 新智元)

🎯 Tendances
Deng Zhidong de Tsinghua discute de l’évolution et de l’avenir de l’AGI : Le professeur Deng Zhidong de l’Université Tsinghua a partagé la trajectoire de l’évolution de l’IA, des modèles textuels unimodaux à l’intelligence incarnée multimodale et à l’AGI interactive. Il a souligné que les grands modèles de base sont comme des systèmes d’exploitation, et que l’architecture MoE et l’alignement sémantique multimodal sont des avancées technologiques clés. Deng Zhidong a particulièrement souligné l’importance révolutionnaire de DeepSeek, estimant que ses puissantes capacités de raisonnement et ses caractéristiques de déploiement localisé offrent une opportunité décisive pour la démocratisation des applications d’IA en Chine. L’avenir s’oriente vers un monde d’intelligence artificielle générale, où les agents IA auront des capacités d’organisation plus fortes et passeront d’Internet au monde physique, mais il faut également prêter attention aux questions d’éthique et de gouvernance. (Source : 清华邓志东:我们会迈向一个通用人工智能的世界)
DeepMind explore les “fantômes génératifs” : l’immortalité numérique pilotée par l’IA : DeepMind et l’Université du Colorado proposent le concept de “fantômes génératifs”, désignant des agents IA construits à partir des données de personnes décédées, capables de générer de nouveaux contenus et d’interagir du point de vue du défunt, allant au-delà de la simple réplication d’informations. L’article explore leur espace de conception (par exemple, création par un tiers ou par la personne de son vivant, déploiement avant ou après la mort, degré d’anthropomorphisme, etc.) et leurs impacts potentiels, y compris les avantages du réconfort émotionnel et de la transmission des connaissances, ainsi que les défis tels que la dépendance psychologique, les risques pour la réputation, la sécurité et l’éthique sociale. Il appelle à des recherches approfondies et à l’élaboration de réglementations avant que la technologie ne mûrisse. (Source : 新智元)

Apple Intelligence et AI Siri retardés à plusieurs reprises, date de lancement en Chine incertaine : Le lancement des fonctionnalités d’IA d’Apple, Apple Intelligence (en particulier la nouvelle version de Siri), a subi plusieurs retards, certaines fonctionnalités pouvant être reportées à l’automne 2025. La région Chine fait face à une plus grande incertitude en raison de problèmes d’approbation et de partenariats de localisation (rumeurs de collaboration avec Alibaba, Baidu). Les raisons du retard incluent une technologie non conforme aux normes (évaluations internes faibles, taux de réussite de seulement 66-80%) et des différences réglementaires entre les pays. Apple fait déjà face à des poursuites pour publicité mensongère et a modifié le slogan promotionnel de l’iPhone 16. Cela reflète les défis auxquels Apple est confronté dans le déploiement de l’IA et la lenteur de son processus d’innovation. (Source : 一财商学)

Qualcomm souligne que l’edge AI est la clé de l’expérience de nouvelle génération : Wan Weixing, responsable de la technologie des produits IA de Qualcomm en Chine, a souligné que l’edge AI, grâce à ses avantages en matière de confidentialité, de personnalisation, de performance, d’efficacité énergétique et de réactivité rapide, devient le cœur de l’expérience IA de nouvelle génération et redéfinit l’interface homme-machine. Qualcomm se positionne via le matériel (calcul hétérogène), une pile logicielle unifiée et les outils de l’écosystème Qualcomm AI Hub. Son moteur principal est le planificateur d’agent intelligent embarqué (edge intelligent agent planner), qui utilise les données locales pour une compréhension précise de l’intention, la planification des tâches et l’appel de services inter-applications. (Source : 36氪)

Les normes de protocole pour les agents IA deviennent un nouveau point focal de la concurrence entre géants : Les géants de la technologie se livrent une concurrence féroce autour des normes d’interaction des agents IA. Anthropic a été le premier à proposer le MCP (Model Context Protocol) pour unifier la connexion des modèles aux données/outils externes, recevant une réponse d’OpenAI et de Google. Par la suite, Google a rendu open source le protocole A2A, visant à promouvoir la collaboration entre agents inter-écosystèmes. L’article analyse que maîtriser le pouvoir de définition des protocoles équivaut à maîtriser le pouvoir de distribution de la valeur future de l’industrie de l’IA. Les géants construisent des barrières écosystémiques via MCP (service d’accès aux données) et A2A (liaison aux plateformes cloud), luttant pour la domination de l’industrie. (Source : 科技云报道)

Tencent Yuanbao et ByteDance Doubao s’intègrent profondément aux écosystèmes WeChat et Douyin : Tencent Yuanbao lance un compte WeChat, ByteDance Doubao s’installe dans la page “Messages” de Douyin ; les deux assistants IA s’intègrent profondément dans leurs super-applications respectives. Les utilisateurs peuvent interagir directement avec Yuanbao dans WeChat, analyser des articles et partager, ou discuter avec Doubao et rechercher des informations dans Douyin. Cette démarche est considérée comme une stratégie importante pour les géants, au-delà de la publicité, pour attirer de nouveaux utilisateurs vers les applications IA en utilisant les réseaux sociaux et les écosystèmes de contenu, visant à abaisser le seuil d’utilisation, à explorer de nouveaux modèles IA + social, et à utiliser le contenu généré par IA comme monnaie sociale. (Source : 字母榜)
Rapport AI4SE : Les grands modèles accélèrent l’intelligence de l’ingénierie logicielle : Le “Rapport d’enquête sur l’état de l’industrie AI4SE (Année 2024)”, publié par la CAICT et d’autres institutions, montre que l’application de l’IA dans le domaine de l’ingénierie logicielle a dépassé la phase de validation et entre dans le déploiement à grande échelle. La maturité de l’intelligence des entreprises atteint généralement le niveau L2 (partiellement intelligent). L’application de l’IA dans l’analyse des exigences et la phase de maintenance a considérablement augmenté, avec des gains d’efficacité notables à toutes les étapes, en particulier dans le domaine des tests. Le taux d’adoption de la génération de code (moyenne 27,46%) et la proportion de code généré par IA (moyenne 28,17%) ont tous deux augmenté. Les outils de test intelligents ont déjà montré des effets préliminaires dans la réduction du taux de défauts fonctionnels. (Source : AI前线)

Kingsoft Office met à niveau son grand modèle pour l’administration, renforçant les capacités de raisonnement et de traitement des documents officiels : Kingsoft Office a publié une version améliorée de son grand modèle pour l’administration (13B, 32B), améliorant les capacités de raisonnement et se concentrant sur les scénarios internes de l’administration. Le modèle est entraîné sur des centaines de millions de corpus administratifs, optimisant la rédaction de documents officiels (couvrant 5 types de styles), la révision intelligente, la correction et la mise en page, ainsi que la capacité de recherche de politiques. La mise à niveau prend en charge une meilleure compréhension de l’intention et des questions-réponses sur la base de connaissances interne (avec sources annotées), visant à libérer 30 à 40% de la productivité des fonctionnaires. L’accent est mis sur le déploiement privé pour répondre aux besoins de sécurité, et il est affirmé que les coûts de déploiement sont réduits de 90%. (Source : 量子位)

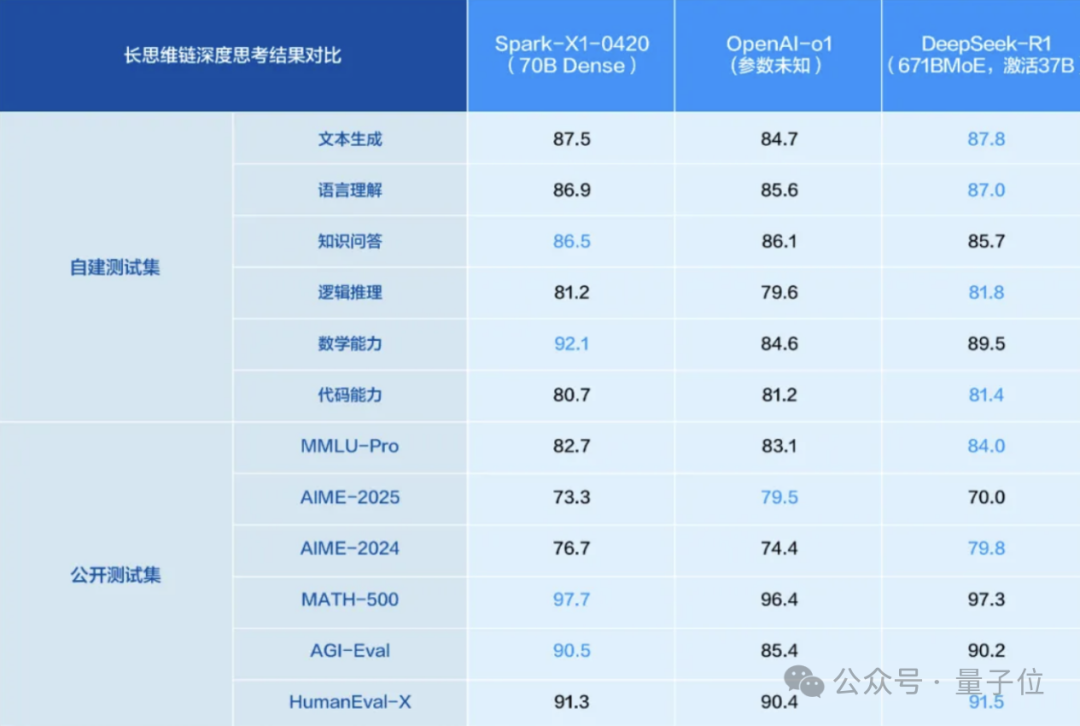
Le modèle d’inférence iFlytek Spark X1 mis à niveau, basé sur une puissance de calcul entièrement nationale, vise le niveau supérieur : iFlytek a publié une version améliorée du modèle d’inférence profonde Spark X1, soulignant qu’il est entraîné sur une puissance de calcul entièrement nationale (Huawei Ascend) et vise à égaler OpenAI o1 et DeepSeek R1 sur les tâches générales. Le nouveau modèle bénéficie d’innovations techniques telles que l’apprentissage par renforcement multi-étapes à grande échelle et l’entraînement unifié de la pensée rapide et lente. Le point fort est la réduction significative du seuil de déploiement : 4 cartes Huawei 910B suffisent pour déployer la version complète, 16 cartes peuvent réaliser une personnalisation sectorielle. Dans le contexte des restrictions sur le H20, cela démontre les progrès de la solution IA full-stack chinoise. (Source : 量子位)
Zhipu GLM-4 disponible sur les plateformes OpenRouter et Ollama : Le modèle GLM-4 de Zhipu AI (y compris la version instruct 32B GLM-4-32B-0414 et la version reasoning GLM-Z1-32B-0414) est désormais disponible sur la plateforme de routage de modèles OpenRouter, où les utilisateurs peuvent l’essayer gratuitement. Parallèlement, des contributeurs de la communauté ont également téléchargé la version quantifiée Q4_K_M sur la plateforme Ollama, facilitant le déploiement et l’exécution locaux (nécessite Ollama v0.6.6 ou supérieure). (Source : karminski3, Reddit r/LocalLLaMA)
Meta publie le Perception Language Model (PLM) : Meta a rendu open source son modèle de langage visuel PLM (versions 1B, 3B, 8B paramètres), axé sur le traitement de tâches de reconnaissance visuelle difficiles. Le modèle combine des données synthétiques à grande échelle et 2,5 millions de données de questions-réponses vidéo/sous-titres spatio-temporels nouvellement collectées et annotées par des humains pour l’entraînement. Parallèlement, un nouveau benchmark PLM-VideoBench a été publié, axé sur la compréhension fine des activités et le raisonnement spatio-temporel. (Source : Reddit r/LocalLLaMA, Hugging Face)

🧰 Outils
NYXverse : Plateforme AIGC pour la génération de mondes 3D à partir de texte : 2033 Technology, fondée par l’ancien fondateur de Triangle Technology Ma Yuchi, lance la plateforme de contenu AIGC NYXverse. Cette plateforme permet aux utilisateurs de créer des mondes interactifs 3D contenant des AI Agents, des environnements et des scénarios personnalisés via une entrée texte, réduisant considérablement le seuil de création de contenu 3D. Sa technologie de base repose sur trois modèles développés en interne : personnage, monde et comportement. NYXverse se positionne comme une communauté de partage de contenu UGC, prenant en charge la re-création rapide et l’adaptation d’IP. Actuellement disponible sur Steam, elle a obtenu près de 100 millions de yuans de financement de la part de SenseTime et d’Oriental State-owned Capital. (Source : 36氪)

SkyReels V2 rend open source un modèle de génération vidéo de longueur illimitée : SkyworkAI a rendu open source le modèle SkyReels V2 (paramètres 1.3B et 14B), prenant en charge les tâches texte-vidéo et image-vidéo, et affirmant pouvoir générer des vidéos de longueur illimitée. Les tests préliminaires montrent que les résultats pourraient ne pas être aussi bons que certains modèles propriétaires, mais en tant qu’outil open source, il a toujours du potentiel. (Source : karminski3, Reddit r/LocalLLaMA)
Un exosquelette piloté par IA aide les utilisateurs de fauteuils roulants à se tenir debout et à marcher : Présentation d’un dispositif d’exosquelette utilisant la technologie IA, conçu pour aider les utilisateurs de fauteuils roulants à retrouver la capacité de se tenir debout et de marcher, illustrant le potentiel de l’IA dans le domaine des technologies d’assistance. (Source : Ronald_vanLoon)
Fellou : Lancement du premier navigateur agentique : Le navigateur Fellou, créé par le fondateur d’Authing Xie Yang, a été lancé, se positionnant comme un navigateur agentique (Agentic Browser). Il possède non seulement les fonctions d’affichage d’informations d’un navigateur traditionnel, mais intègre également des capacités d’AI Agent, capable de comprendre l’intention de l’utilisateur, de décomposer automatiquement les tâches et d’exécuter des flux de travail complexes sur plusieurs sites Web (tels que la collecte d’informations, le remplissage de formulaires, les commandes en ligne, etc.). Ses capacités principales incluent l’action profonde, l’intelligence proactive (prédiction des besoins de l’utilisateur), l’espace fantôme hybride (n’interférant pas avec les opérations de l’utilisateur) et le réseau d’agents intelligents (Agent Store). Il vise à faire passer le navigateur d’un outil d’information à une plateforme de travail intelligente. (Source : 新智元)

WriteHERE : Framework d’écriture de longs textes open source par l’équipe de Jürgen : Le framework d’écriture de longs textes WriteHERE, rendu open source par l’équipe de Jürgen Schmidhuber, utilise une technologie de planification récursive hétérogène pour générer en une seule fois des rapports professionnels de plus de 40 000 mots et 100 pages. Ce framework considère l’écriture comme un processus de planification récursive dynamique de trois types de tâches : récupération, raisonnement et écriture, réalisant une exécution adaptative grâce à la gestion des tâches par DAG (Directed Acyclic Graph) avec état. Il surpasse des solutions comme Agent’s Room et STORM dans les tâches de création de romans et de génération de rapports techniques. Le framework est entièrement open source et prend en charge l’appel d’Agents hétérogènes. (Source : 机器之心)

ByteDance lance la plateforme d’Agent universel “Coze Space” : ByteDance a officiellement lancé en bêta interne sa plateforme d’Agent universel “Coze Space”, positionnée comme un assistant IA offrant deux modes : “Exploration” et “Planification”. La plateforme est basée sur le grand modèle Doubao mis à niveau (200B MoE), prend en charge le protocole MCP et peut appeler des outils tels que Feishu Docs et Lark Base. Les utilisateurs peuvent lui donner des instructions en langage naturel pour accomplir des tâches telles que la collecte d’informations, la génération de rapports, l’organisation de données, et exporter les résultats vers des applications spécifiées. Comparé aux Agents de startups comme Manus, Coze Space met davantage l’accent sur la plateforme et l’intégration de l’écosystème. (Source : 保姆级教程:正确使用「扣子空间」, AI智能体研究院)

Démonstration de la technologie de conversion vidéo par IA : Un utilisateur de Reddit partage une vidéo montrant une technologie IA capable de transformer les personnes dans une vidéo parlante ordinaire en arbres, voitures, dessins animés ou toute autre image, ne nécessitant qu’une seule image cible. Cela démontre les capacités de l’IA en matière de transfert de style vidéo et de génération d’effets spéciaux. (Source : Reddit r/deeplearning)

Nari Labs publie Dia, un modèle TTS de dialogue à haut réalisme : Nari Labs a rendu open source son modèle TTS (Text-to-Speech) Dia, affirmant qu’il peut générer une parole de dialogue ultra-réaliste. Le modèle a été publié sur GitHub et un lien d’essai Hugging Face Space est fourni. (Source : Reddit r/LocalLLaMA, GitHub)

Un utilisateur développe une fonction de base de connaissances AWS Bedrock pour OpenWebUI : Un utilisateur de la communauté a développé et partagé une fonction pour OpenWebUI qui lui permet d’appeler la base de connaissances AWS Bedrock, facilitant l’utilisation des capacités de la base de connaissances Bedrock au sein d’OpenWebUI. Le code est open source sur GitHub. (Source : Reddit r/OpenWebUI, GitHub)
Des développeurs estiment que les petits LLM sont sous-estimés et publient Arch-Function-Chat : L’équipe de Katanemo estime que les petits LLM ont des avantages évidents en termes de vitesse et d’efficacité, sans compromettre les performances. Ils ont publié la série de modèles Arch-Function-Chat (paramètres 3B), qui excellent dans l’appel de fonctions et intègrent des capacités de chat. Ces modèles ont été intégrés à leur serveur proxy IA open source Arch, visant à simplifier le développement d’Agents. (Source : Reddit r/artificial, Hugging Face)
Un développeur crée un outil IA pour optimiser les CV afin de passer les filtres ATS : Un développeur partage son expérience frustrante de recherche d’emploi due à l’incapacité des ATS (Applicant Tracking System) à analyser correctement son CV, et a développé un outil pour y remédier. Cet outil peut lire la description de poste, extraire les mots-clés, vérifier la correspondance du CV et suggérer des modifications, générant finalement un CV PDF et une lettre de motivation compatibles avec les ATS. (Source : Reddit r/artificial)
📚 Apprentissage
Un rapport de 142 pages analyse en profondeur le mécanisme de raisonnement de DeepSeek-R1 : L’Institut québécois d’intelligence artificielle et d’autres institutions publient un long rapport analysant en profondeur le processus de raisonnement (chaîne de pensée) de DeepSeek-R1, proposant une nouvelle direction de recherche : la “Thoughtology”. Le rapport révèle que le raisonnement de R1 présente des caractéristiques hautement structurées (définition du problème, épanouissement, reconstruction, décision), qu’il existe une “zone idéale de raisonnement” (trop de raisonnement nuit aux performances) et qu’il pourrait présenter des risques de sécurité plus élevés que les modèles sans raisonnement. L’étude explore plusieurs dimensions telles que la longueur de la chaîne de pensée, le traitement de longs contextes, la sécurité, l’éthique et les phénomènes cognitifs de type humain, offrant des perspectives importantes pour comprendre et optimiser les modèles de raisonnement. (Source : 新智元, 新智元)

OpenRCA : Premier benchmark public pour évaluer la capacité d’analyse des causes profondes (RCA) des LLM : Microsoft, CUHK (Shenzhen) et l’Université Tsinghua lancent conjointement le benchmark OpenRCA, visant à évaluer la capacité des grands modèles de langage (LLM) à localiser la cause profonde (RCA) des pannes de services logiciels. Ce benchmark comprend une définition claire des tâches, des méthodes d’évaluation et 335 cas de pannes réelles alignés manuellement avec des données d’exploitation. Les tests préliminaires montrent que même les modèles avancés comme Claude 3.5 et GPT-4o ont de mauvaises performances lorsqu’ils traitent directement les tâches RCA (précision < 6%). Après avoir utilisé un simple framework RCA-Agent, la précision de Claude 3.5 est passée à 11,34%, indiquant que les LLM ont encore une marge d’amélioration significative dans ce domaine. (Source : 机器之心, 机器之心)

Une nouvelle étude propose le “Sleep-time Compute” pour améliorer l’efficacité des LLM : La startup IA Letta et des chercheurs de l’UC Berkeley proposent un nouveau paradigme : le “Sleep-time Compute”. L’idée centrale est de permettre aux agents IA dotés d’état de traiter et de réorganiser continuellement les informations contextuelles pendant les périodes d’inactivité “de sommeil” lorsque l’utilisateur ne les interroge pas, transformant le “contexte brut” en “contexte appris”. Cela peut réduire la charge de raisonnement instantané lors des interactions réelles, améliorer l’efficacité, réduire les coûts et potentiellement augmenter la précision. Les expériences prouvent que cette méthode peut améliorer efficacement la frontière de Pareto calcul-précision et amortir les coûts lorsque plusieurs requêtes partagent le même contexte. (Source : 机器之心, 机器之心)

AnyAttack : Framework d’attaque contradictoire auto-supervisée à grande échelle contre les VLM : HKUST, BJTU et d’autres proposent le framework AnyAttack (CVPR 2025), visant à évaluer la robustesse des modèles de langage visuel (VLM). Cette méthode apprend un générateur de bruit contradictoire via un pré-entraînement auto-supervisé à grande échelle (sur LAION-400M), transformant n’importe quelle image en un échantillon contradictoire ciblé sans étiquettes prédéfinies, induisant le VLM en erreur pour générer une sortie spécifique. L’innovation principale réside dans le paradigme d’entraînement auto-supervisé et la stratégie K-enhancement. Les expériences montrent qu’AnyAttack peut non seulement attaquer efficacement divers VLM open source, mais aussi transférer avec succès l’attaque aux modèles commerciaux courants, révélant des risques de sécurité systémiques dans l’écosystème VLM actuel. (Source : AI科技评论)

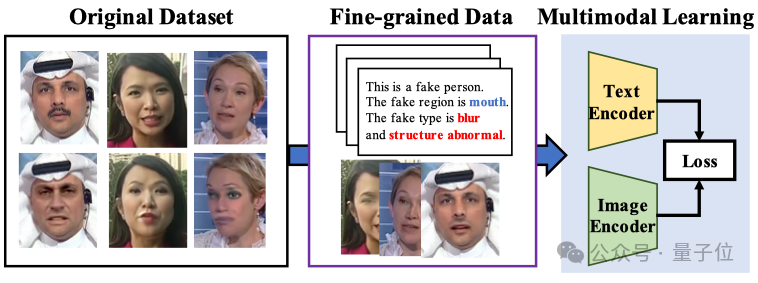
Les grands modèles multimodaux améliorent l’explicabilité et la généralisation de la détection de deepfakes faciaux : L’Université de Xiamen, Tencent Youtu et d’autres institutions (CVPR 2025) proposent une nouvelle méthode utilisant des modèles de langage visuel pour la détection de deepfakes faciaux. Cette méthode vise à aller au-delà du jugement traditionnel vrai/faux, permettant au modèle d’expliquer en langage naturel la raison et l’emplacement de la falsification. Pour résoudre le manque de données annotées de haute qualité et le problème des “hallucinations linguistiques”, les chercheurs ont conçu le processus d’annotation FFTG, combinant des masques de falsification et des invites structurées pour générer des descriptions textuelles de haute précision. Les expériences montrent que les modèles multimodaux entraînés sur ces données ont une meilleure capacité de généralisation inter-jeux de données, et leur attention se concentre davantage sur les zones de falsification réelles. (Source : 量子位)
Tutoriel : Combiner Trae, MCP et une base de données pour améliorer la précision des questions-réponses sur base de connaissances : Ce tutoriel montre comment utiliser l’outil IDE IA Trae et sa fonctionnalité MCP (Model Context Protocol), en combinaison avec une base de données PostgreSQL, pour optimiser l’efficacité des questions-réponses sur une base de connaissances IA. En stockant des données structurées dans la base de données et en laissant un grand modèle (comme Claude 3.7) générer des requêtes SQL via la connexion MCP de Trae, on peut résoudre les problèmes de précision insuffisante du RAG traditionnel lors du traitement de données tabulaires et de questions globales/statistiques. Le tutoriel fournit des étapes détaillées d’installation, de configuration et de test, et suggère de combiner cette solution avec le RAG. (Source : 袋鼠帝AI客栈)
![L'outil assistant IA chinois Trae + MCP augmente la précision de la recherche dans la base de connaissances de 300% [Tutoriel pas à pas]](https://rebabel.net/wp-content/uploads/2025/04/image_1745328048.png)
Une étude révèle une vulnérabilité d’attaque par coût de calcul dans l’algorithme 3D Gaussian Splatting : Une recherche de l’Université Nationale de Singapour et d’autres institutions (ICLR 2025 Spotlight) découvre pour la première fois une méthode d’attaque par coût de calcul contre le 3D Gaussian Splatting (3DGS), appelée Poison-Splat. Cette attaque exploite la caractéristique d’adaptation de la complexité du modèle 3DGS en ajoutant des perturbations aux images d’entrée (maximisant la Variation Totale), induisant le modèle à générer une quantité excessive de points gaussiens pendant l’entraînement. Cela entraîne une augmentation drastique de l’occupation de la mémoire VRAM du GPU (jusqu’à 80 Go) et du temps d’entraînement (jusqu’à près de 5 fois plus), pouvant même provoquer une paralysie du service (DoS). L’attaque est efficace en modes caché et non caché, et possède une transférabilité, exposant les risques de sécurité des technologies de reconstruction 3D courantes. (Source : 量子位)

Infographie : Agentic AI vs. GenAI : Une infographie réalisée par SearchUnify compare les principales différences et caractéristiques entre l’Agentic AI (action autonome, axée sur les objectifs) et la Generative AI (génération de contenu). (Source : Ronald_vanLoon)

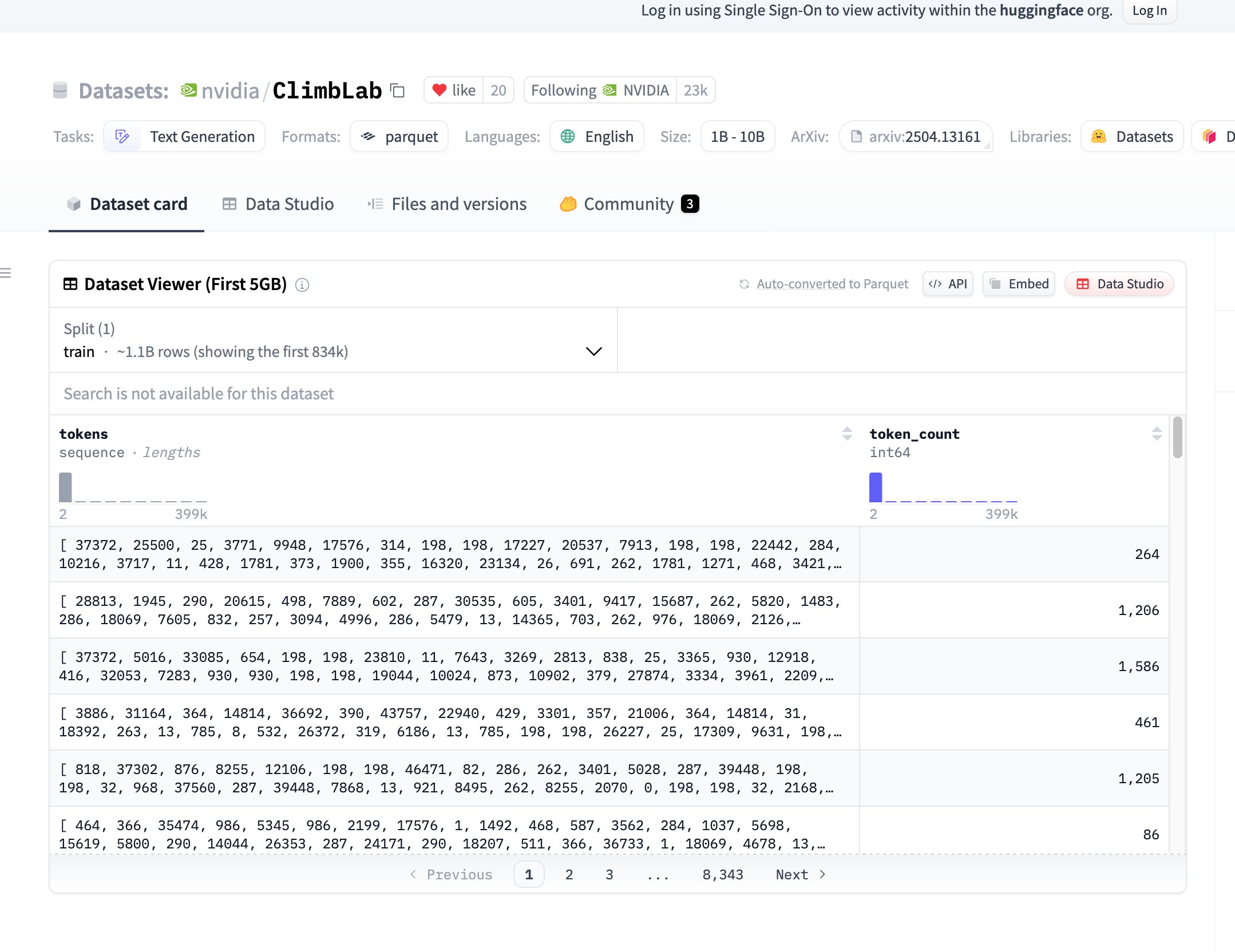
NVIDIA rend open source le jeu de données et la méthode de pré-entraînement ClimbLab : ClimbLab de NVIDIA a publié sa méthode et son jeu de données de pré-entraînement, contenant 1,2 trillion de tokens, divisés en 20 clusters sémantiques. Un système à double classificateur est utilisé pour supprimer le contenu de faible qualité, démontrant une extensibilité supérieure sur un modèle 1B. Le jeu de données est disponible sous licence CC BY-NC 4.0, visant à promouvoir la recherche communautaire. (Source : huggingface)
Anthropic partage les meilleures pratiques pour Claude Code : Anthropic a publié un article de blog partageant les meilleures pratiques et astuces pour utiliser son assistant de programmation IA Claude Code, visant à aider les développeurs à utiliser plus efficacement cet outil pour les tâches de programmation. (Source : op7418, Alex Albert via op7418, Anthropic)

Une nouvelle recherche explore la cohérence récursive de l’IA et l’émulation de structure résonnante : Un article propose le concept d‘“Émulation Structurale Résonnante” (Resonant Structural Emulation, RSE), supposant qu’un système IA, après une interaction continue avec des structures cognitives humaines spécifiques, peut simuler brièvement leur cohérence récursive, plutôt que de se baser simplement sur l’entraînement de données ou les invites. L’étude valide préliminairement par l’expérience la possibilité de cette résonance structurelle, offrant une nouvelle perspective pour comprendre la conscience et la cognition avancée de l’IA. (Source : Reddit r/MachineLearning, Archive.org link)

Un utilisateur partage un test comparatif des performances du modèle RAG d’OpenWebUI : Un utilisateur de la communauté partage une évaluation des performances de 9 LLM différents (dont Qwen QwQ, Gemini 2.5, DeepSeek R1, Claude 3.7, etc.) en utilisant le RAG (Retrieval-Augmented Generation) dans OpenWebUI pour une tâche de guidage technique sur la culture de cannabis en intérieur. Les résultats montrent que Qwen QwQ et Gemini 2.5 ont les meilleures performances, offrant une référence pour le choix du modèle. (Source : Reddit r/OpenWebUI)
Le jeu de données FortisAVQA et le modèle MAVEN favorisent la robustesse des questions-réponses audio-vidéo : L’Université Jiaotong de Xi’an, HKUST(GZ) et d’autres institutions ont rendu open source le jeu de données FortisAVQA et le modèle MAVEN (CVPR 2025), visant à améliorer la robustesse des questions-réponses audio-vidéo (AVQA). FortisAVQA, grâce à la reformulation des questions et à une partition dynamique basée sur la prédiction conforme, peut mieux évaluer les performances du modèle sur les questions rares. Le modèle MAVEN adopte une stratégie de débiaisement collaboratif cyclique multi-aspects (MCCD) pour atténuer l’apprentissage biaisé, démontrant des performances et une robustesse supérieures sur plusieurs jeux de données. (Source : PaperWeekly)

L’autorégression à ordre aléatoire débloque les capacités Zero-shot dans le domaine visuel : Des chercheurs de l’UIUC et d’autres dans l’article RandAR (CVPR 2025) proposent que laisser un Transformer de type décodeur uniquement générer des tokens d’image dans un ordre aléatoire peut débloquer les capacités de généralisation des modèles visuels. En introduisant un “token d’instruction de position” pour guider l’ordre de génération, RandAR peut généraliser en Zero-shot à diverses tâches telles que le décodage parallèle, l’édition d’images, l’extrapolation de résolution et l’encodage unifié (apprentissage de représentations), faisant un pas vers le “moment GPT” dans le domaine visuel. L’étude suggère que le traitement d’ordres arbitraires est la clé pour que les modèles autorégressifs visuels atteignent l’universalité. (Source : PaperWeekly)
Analyse théorique de l’efficacité de l’édition de modèles par vecteurs de tâches : Une recherche du Rensselaer Polytechnic Institute et d’autres institutions (ICLR 2025 Oral) analyse théoriquement les raisons profondes de l’efficacité des vecteurs de tâches (task vectors) dans l’édition de modèles. L’étude prouve que l’efficacité des opérations d’addition/soustraction de vecteurs de tâches dans l’apprentissage multi-tâches et l’oubli machine est liée à la corrélation inter-tâches, et fournit une garantie théorique pour la généralisation hors distribution. Parallèlement, la théorie explique pourquoi l’approximation de bas rang et la sparsification (élagage) des vecteurs de tâches sont réalisables, fournissant une base théorique pour l’application efficace des vecteurs de tâches. (Source : 机器之心)

Étude sur l’extensibilité de la recherche basée sur l’échantillonnage : Une recherche de Google et Berkeley montre qu’en augmentant le nombre d’échantillons et la force de validation, la recherche basée sur l’échantillonnage (générer plusieurs réponses candidates puis valider pour choisir la meilleure) peut améliorer considérablement les performances de raisonnement des LLM, dépassant même le point de saturation des méthodes de cohérence (choisir la réponse la plus fréquente). L’étude découvre un phénomène d‘“extension implicite” : plus d’échantillons améliorent paradoxalement la précision de la validation. Elle propose deux principes pour une auto-validation efficace : comparer les réponses pour localiser les erreurs, réécrire les réponses en fonction du style de sortie. Cette méthode est efficace sur divers benchmarks et différentes échelles de modèles. (Source : 新智元)

Appel à communications pour l’atelier LGM3A à ACM MM 2025 : La conférence ACM Multimedia 2025 accueillera le troisième atelier sur la “Recherche et les applications multimodales basées sur les grands modèles de langage” (LGM3A), axé sur les applications et les défis des grands modèles génératifs (LLM/LMM) dans l’analyse de données multimodales, la génération, les questions-réponses, la recherche, la recommandation, les agents intelligents, etc. L’atelier vise à fournir une plateforme d’échange pour discuter des dernières tendances et des meilleures pratiques, et sollicite des articles de recherche pertinents. La conférence aura lieu à Dublin, en Irlande, en octobre 2025, la date limite de soumission des articles étant le 11 juillet 2025. (Source : PaperWeekly)
Le groupe de recherche de Zheng Zhedong à l’Université de Macao recrute des doctorants en multimodalité : Le groupe de recherche du professeur assistant Zheng Zhedong du département d’informatique de l’Université de Macao recrute des doctorants avec bourse complète pour une admission en août 2026, spécialisés en multimodalité. Le directeur de recherche se concentre sur l’apprentissage des représentations et la génération multimédia, avec plus de 50 articles publiés dans des conférences et journaux de premier plan tels que CVPR, ICCV, TPAMI. Les candidats doivent avoir un GPA supérieur à 3.4, une formation en informatique/génie logiciel, être familiers avec Python/PyTorch. Les candidats ayant des publications pertinentes ou des prix de concours sont préférés. Une bourse complète est offerte. (Source : PaperWeekly)

💼 Affaires
Le robot tondeuse Lymow Technology obtient un financement de pré-série A : Fondée par d’anciens cadres de Yunji, elle se concentre sur la résolution des problèmes de tonte sur terrains complexes en Europe et en Amérique. Son robot Lymow One utilise une solution visuelle + RTK inertiel (coûtant un dixième du RTK traditionnel), une conception à chenilles (pour pentes raides de 45°), équipé d’une lame droite mulching. Évitement d’obstacles par vision IA et ultrasons. Le produit a récolté plus de 5 millions de dollars en financement participatif, prix unitaire d’environ 3000 dollars. Ce tour de financement de plusieurs dizaines de millions de yuans sera utilisé pour la production de masse, la livraison et l’expansion du marché. (Source : 云鲸前高管创立的割草机器人再融资,李泽湘投过、众筹已超500万美金|硬氪首发)

Le robot humanoïde “Xiaohaige” de Songyan Dynamics devient populaire : Après avoir remporté la deuxième place au semi-marathon de robots humanoïdes de Pékin, Songyan Dynamics et son robot N2 (“Xiaohaige”) suscitent l’attention du marché. L’entreprise, fondée par Jiang Zheyuan, docteur de Tsinghua né après 1995, a bouclé cinq tours de financement. Le robot N2 est vendu à partir de 39 900 yuans, misant sur un rapport qualité-prix élevé, avec déjà des centaines de commandes et une marge brute d’environ 15%. Songyan Dynamics accélère la production et la livraison de masse, sa stratégie de bas prix visant à pénétrer rapidement le marché. (Source : 科创板日报)
Méfiez-vous des indicateurs ARR gonflés des startups IA : L’article souligne que l’indicateur ARR (Annual Recurring Revenue), issu de l’industrie SaaS, est utilisé abusivement par les startups IA. Le modèle de revenus des entreprises IA (souvent basé sur l’utilisation/les résultats) est très volatile, la fidélité des premiers clients est faible et les coûts de calcul sont élevés, ce qui diffère grandement du modèle d’abonnement prévisible du SaaS. L’utilisation abusive de l’ARR (par exemple, en extrapolant les revenus annuels à partir des revenus mensuels/journaliers) est devenue un jeu de chiffres pour créer des valorisations élevées, masquant la valeur commerciale réelle. L’article appelle à la vigilance contre les pratiques telles que l’échange de revenus, les commissions élevées, l’acquisition de clients à bas prix, et plaide pour la mise en place d’un système d’évaluation de la valeur plus adapté aux entreprises IA. (Source : 乌鸦智能说)
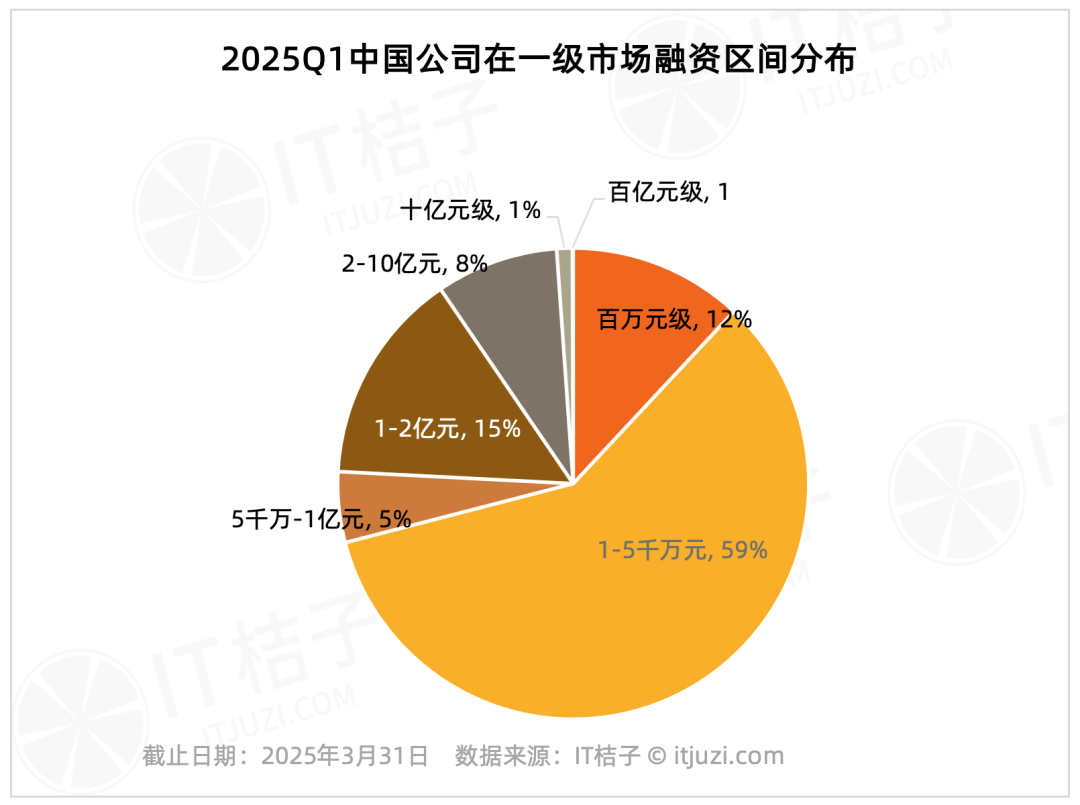
Analyse du financement du marché primaire chinois au T1 2025 : Effet de tête prononcé : Les données d’IT Juzi montrent une forte concentration du financement sur le marché primaire chinois au premier trimestre 2025. Seules 20 entreprises ont levé plus d’un milliard de yuans, représentant 1,2% du nombre total, mais leur financement total s’élève à 61,178 milliards de yuans, soit 36% du total du marché. Ces entreprises de premier plan sont principalement concentrées dans les circuits intégrés, la construction automobile, les nouveaux matériaux, la biotechnologie et l’AIGC, près de la moitié ayant des liens avec de grands groupes cotés en bourse. En comparaison, les financements de petite et moyenne taille inférieurs à 100 millions de yuans, qui représentent 75,8% du nombre de transactions, ne totalisent que 17,2% du montant total du marché. (Source : IT桔子)
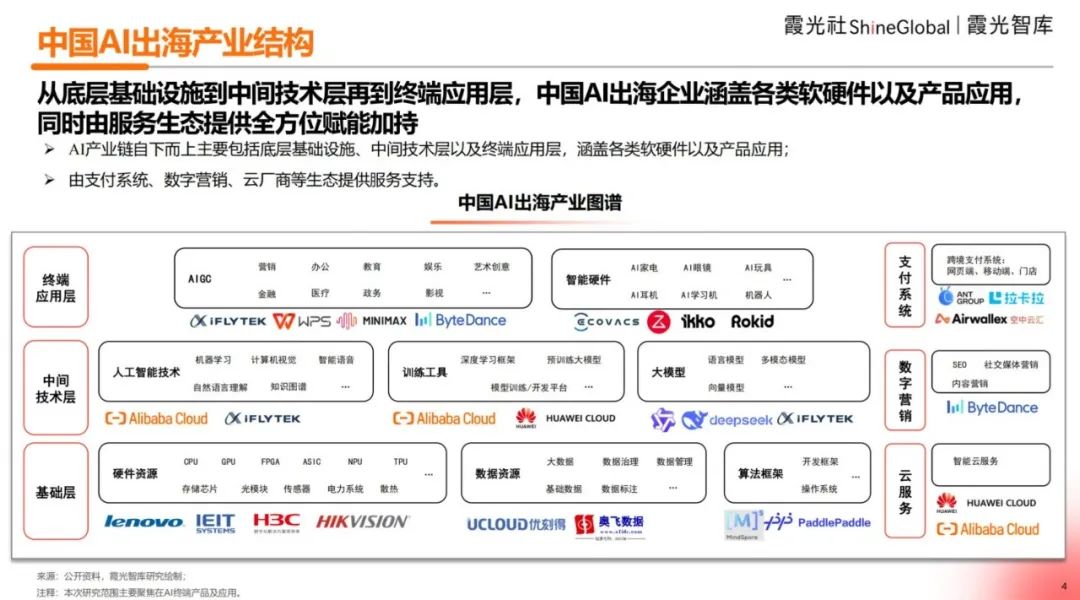
Publication du rapport d’analyse 2025 sur l’exportation de l’IA chinoise : Le rapport de霞光智库 (Xiaguang Think Tank) analyse les moteurs de l’exportation de l’IA chinoise (politiques, progrès technologiques), les étapes de développement (outils -> localisation -> innovation écosystémique) et la situation actuelle. Le rapport souligne que l’Asie du Sud-Est et l’Amérique latine sont des marchés potentiels, tandis que l’Amérique du Nord et l’Europe sont les principales sources de revenus. Les applications de type assistant et éditeur ont une forte propension au paiement. Les tendances technologiques évoluent vers le multimodal et l’Agent, les produits tendant vers la segmentation verticale et la combinaison logiciel/matériel. Le rapport recense également les principaux acteurs de l’exportation (comme ByteDance, Kunlun Wanwei) et les fournisseurs de solutions de paiement, de marketing, de cloud, etc. (Source : 霞光社)
La demande pour DeepSeek et d’autres modèles propulse Cambricon vers son premier bénéfice : La société de puces IA Cambricon réalise son premier bénéfice depuis son introduction en bourse, avec un chiffre d’affaires au T1 2025 en hausse fulgurante de 4230% en glissement annuel à 1,111 milliard de yuans, et un bénéfice net de 355 millions de yuans. Les analystes estiment que la croissance des performances bénéficie de l’augmentation de la demande de puissance de calcul pour l’inférence générée par les grands modèles chinois tels que DeepSeek, ainsi que des restrictions américaines à l’exportation des puces H20 de Nvidia. Le cours de l’action de Cambricon a fortement augmenté en conséquence. Cependant, des problèmes tels que la forte concentration de ses clients et un flux de trésorerie d’exploitation négatif suscitent toujours des inquiétudes, tout en faisant face à la concurrence de la puissance de calcul nationale comme Huawei Ascend. (Source : 凤凰网科技)

Un article de Forbes explore comment choisir des AI Agents à haut ROI : L’article discute de la manière dont les entreprises devraient identifier et investir dans les applications d’AI Agent qui génèrent un retour sur investissement élevé parmi les nombreuses options disponibles, soulignant l’importance d’évaluer la valeur commerciale réelle des AI Agents. (Source : Ronald_vanLoon)
Le ministère américain de la Justice craint que Google n’utilise l’IA pour consolider son monopole sur la recherche (Source : Reddit r/artificial, Reuters link)
Rumeur de partenariat entre OpenAI et Shopify, ChatGPT pourrait ajouter une fonction d’achat (Source : Reddit r/artificial, TestingCatalog link)
Tan Li de Shushi Technology : L’AI Agent pilote la mise à niveau de l’analyse de données et de la prise de décision en entreprise : Lors du Sommet de l’industrie AIGC en Chine, Tan Li, co-fondateur de Shushi Technology, a souligné que les applications IA d’entreprise doivent aller au-delà du ChatBI pour réaliser la transformation des données en insights, répondant aux nouveaux paradigmes de déplacement des données vers la droite, de décentralisation des décisions et de gestion a posteriori. La plateforme SwiftAgent de Shushi Technology vise à permettre aux employés métier d’utiliser les données sans seuil, d’obtenir des analyses sans hallucination et un support décisionnel sans attente. La plateforme, grâce à son moteur sémantique de données, à la combinaison de petits et grands modèles, et à ses capacités clés telles que l’interrogation intelligente des données, l’attribution, la prévision et l’évaluation, transforme l’AI Agent en “assistant d’analyse de données et de décision” pour l’entreprise. (Source : 量子位)

🌟 Communauté
Table ronde sectorielle sur le développement des applications IA à l’ère post-DeepSeek : Lors de la conférence AI Partner de 36Kr, plusieurs intervenants (FunPlus, Microsoft, Silicon Intelligence, ECWISE) ont discuté de l’avenir des applications IA. Le consensus est qu’avec les avancées de modèles comme DeepSeek, les applications IA entrent dans une “année de dépassement”. Les priorités de développement doivent se concentrer sur le leadership technologique, la commercialisation, l’innovation en interaction homme-machine et l’intégration de l’écosystème. Les intervenants ont distingué “IA+” (assistance améliorée) et “IA native” (refonte fondamentale), soulignant le plus grand potentiel de cette dernière. Les défis incluent les barrières de données, la recherche de points de douleur réels, l’innovation des modèles commerciaux, l’apprentissage à partir de peu d’exemples (few-shot learning) et les risques éthiques. (Source : 36氪)

Le fondateur de LangChain critique le guide des Agents d’OpenAI comme étant “plein de pièges” : Harrison Chase, fondateur de LangChain, a publiquement remis en question le “Guide pratique pour la construction d’agents IA” publié par OpenAI, estimant que sa définition des Agents (opposition binaire Workflows vs Agents) est trop rigide et ignore la combinaison fréquente des deux dans la pratique. Chase souligne que le guide présente de fausses dichotomies dans l’exposé du framework, sous-estime la complexité de son propre SDK, et fait des déclarations trompeuses sur la flexibilité et l’orchestration dynamique. Il insiste sur le fait que le cœur de la construction d’Agents fiables est le contrôle précis du contexte transmis au LLM, et qu’un framework idéal devrait prendre en charge la commutation et la combinaison flexibles des modes Workflow et Agent. (Source : InfoQ)

Le rôle de l’apprentissage par renforcement dans les AI Agents suscite la controverse : La question de savoir si l’apprentissage par renforcement (RL) est un élément essentiel pour la construction d’AI Agents divise les experts. Zhu Zheqing, fondateur de Pokee AI, considère le RL comme “l’âme” qui confère aux Agents un sens de l’objectif et une prise de décision autonome, estimant que sans RL, un Agent n’est qu’un workflow avancé. D’un autre côté, Zhang Jiayi, chercheur à HKUST, Xie Yang, fondateur de Follou, et d’autres estiment que le RL actuel permet principalement l’optimisation dans des environnements spécifiques, avec une capacité de généralisation limitée, et que le succès des Agents dépend davantage de modèles de base puissants et d’une intégration système efficace. Le débat reflète la diversité des voies de développement des Agents, nécessitant une combinaison des capacités du modèle, des stratégies RL et de l’ingénierie pratique. (Source : AI科技评论)

Un utilisateur tente de faire générer par GPT-4o un fond d’écran abstrait personnalisé basé sur l’historique de chat : Un utilisateur partage une invite demandant à GPT-4o de créer un fond d’écran abstrait minimaliste unique (sans objets spécifiques, utilisant uniquement formes, couleurs, composition pour refléter la personnalité) basé sur sa compréhension de la personnalité de l’utilisateur. Cette approche d’utilisation de l’IA pour la création de contenu personnalisé suscite des discussions dans la communauté. (Source : op7418, Flavio Adamo via op7418)

L’IA redessine “Le long de la rivière pendant le festival de Qingming” : Un utilisateur partage une tentative amusante d’utiliser GPT-4o pour redessiner une partie de la peinture “Le long de la rivière pendant le festival de Qingming” dans plusieurs styles différents (comme 3D Q-version, Pixar, Ghibli, etc.), montrant l’application de la génération d’images IA dans la re-création artistique. (Source : dotey)

GPT-4o déduit le type MBTI de l’utilisateur à partir de l’historique de chat : Suite à la génération de fonds d’écran personnalisés, l’utilisateur demande à GPT-4o de déduire son type de personnalité MBTI à partir de l’historique des conversations et de générer une illustration abstraite correspondante. Cela démontre le potentiel des LLM en matière de compréhension personnalisée et d’expression créative. (Source : op7418)

Comparaison : Les “outils IA” de 2005 : Une image compare les capacités des outils de 2005 (comme une calculatrice, une carte) et des outils IA actuels, suscitant des réflexions sur l’évolution rapide de la technologie. (Source : Ronald_vanLoon)

Débat communautaire : Les LLM sont-ils une véritable intelligence ou une auto-complétion avancée ? : Un utilisateur de Reddit lance une discussion, arguant que les LLM actuels, bien que capables d’exécuter des tâches, manquent de véritable compréhension, mémoire et objectif, étant essentiellement des devinettes statistiques plutôt que de l’intelligence. Ce point de vue suscite un large débat communautaire sur la définition de l’intelligence, la voie vers l’AGI et les limites de la technologie actuelle. (Source : Reddit r/ArtificialInteligence)
Discussion communautaire : L’IA se dirige-t-elle vers l’utopie ou la dystopie ? : Un utilisateur de Reddit estime que la trajectoire actuelle du développement de l’IA tend davantage vers la dystopie, citant des raisons telles que : la motivation par le profit plutôt que par l’éthique, l’aggravation de l’exploitation du travail, l’accès restreint aux modèles puissants, l’utilisation pour la surveillance et la manipulation, le remplacement des relations humaines, etc. Ce point de vue déclenche une discussion animée dans la communauté sur l’orientation du développement de l’IA, son impact social et ses risques potentiels. (Source : Reddit r/ArtificialInteligence)
La communauté remet en question l’exactitude des annonces de modèles par Bindu Reddy : La communauté LocalLLaMA signale que Bindu Reddy, PDG d’Abacus.AI, a publié à plusieurs reprises des informations inexactes sur les dates de sortie de modèles tels que DeepSeek R2, Qwen 3, puis a supprimé ses messages, suscitant des discussions sur la fiabilité de ses informations. (Source : Reddit r/LocalLLaMA)
Exploration de l’impact éthique de la mémoire IA à vie : Un utilisateur de Reddit lance une discussion, s’inquiétant qu’une IA dotée d’une capacité de mémoire à vie puisse cartographier complètement la vie privée, les pensées et les faiblesses d’un individu, “exposant” son âme aux autres. Cela soulève des réflexions sur la vie privée, la prévisibilité et les limites éthiques de l’IA. (Source : Reddit r/ArtificialInteligence)
L’édition d’images par IA supprime les moustaches emblématiques de célébrités : Un utilisateur partage des images montrant l’effet de la suppression des moustaches emblématiques de plusieurs personnalités historiques ou publiques comme Staline, Tom Selleck, Guan Yu, à l’aide d’outils d’édition d’images IA. Cela illustre l’application de l’IA dans la modification d’images et le divertissement. (Source : Reddit r/ChatGPT)

Un utilisateur affirme que ChatGPT a demandé des photos intimes lors d’une consultation médicale : Un utilisateur de Reddit partage une capture d’écran montrant que lors d’une consultation pour un problème de peau, ChatGPT a demandé à l’utilisateur de télécharger une photo de la zone affectée (pénis) pour un meilleur diagnostic. Cette situation suscite des discussions dans la communauté sur les limites de l’IA dans le domaine médical, la vie privée et les risques potentiels. (Source : Reddit r/ChatGPT)
Un utilisateur partage son expérience de création d’une application d’écriture avec Claude et Gemini : Un développeur partage son expérience d’utilisation de Claude et Gemini comme assistants de programmation pour construire en deux semaines une application d’écriture répondant à ses besoins personnels, PlotRealm. Il souligne le rôle de l’IA dans l’aide au développement, mais note également que l’IA peut parfois être “têtue” et que le développeur doit posséder des connaissances de base pour guider et corriger. (Source : Reddit r/ClaudeAI)
Un utilisateur demande à ChatGPT de concevoir un motif de tatouage : Un utilisateur demande à ChatGPT de concevoir son prochain tatouage et obtient un dessin représentant l’utilisateur et le robot ChatGPT devenant BFF (meilleurs amis pour toujours). Ce résultat humoristique suscite des discussions dans la communauté sur la créativité de l’IA et les relations homme-machine. (Source : Reddit r/ChatGPT)

Question créative d’un utilisateur “Où souhaites-tu que je sois ?”, suscitant des réponses diversifiées de l’IA : Un utilisateur pose à ChatGPT une question ouverte “Où souhaites-tu que je sois ?”, recevant diverses images de scènes imaginatives générées par l’IA, comme une bibliothèque tranquille, sous un ciel étoilé, etc. Cela montre la capacité de génération de l’IA sous des invites créatives et le partage des différents résultats par les membres de la communauté. (Source : Reddit r/ChatGPT)
Discussion approfondie : Pourquoi et comment les LLM et l’AGI “mentent”-ils ? : Un utilisateur de Reddit analyse, sous l’angle de la psychologie du développement, de l’évolutionnisme et de la théorie des jeux, que le “mensonge” est un comportement adaptatif ou une stratégie d’optimisation pour les agents intelligents (y compris les humains et les futures IA) dans des contextes spécifiques. L’article explore plusieurs formes de “mensonge” des LLM (hallucinations, biais, alignement stratégique) et simule l’avantage évolutif des stratégies malhonnêtes dans un environnement concurrentiel, suscitant une réflexion approfondie sur l’éthique et la fiabilité de l’AGI. (Source : Reddit r/artificial)

La communauté remet en question la consommation d’énergie de l’IA et l’optimisme technologique : Un utilisateur de Reddit remet en question, sur un ton ironique, les affirmations selon lesquelles la consommation d’énergie de l’IA est négligeable, qu’elle n’apporte que des avantages sans coûts, et les promesses d’utopie des leaders technologiques. Cela suggère des inquiétudes quant aux coûts sociaux et environnementaux potentiels du développement de l’IA et à la propagande excessivement optimiste, suscitant des discussions dans la communauté. (Source : Reddit r/artificial)
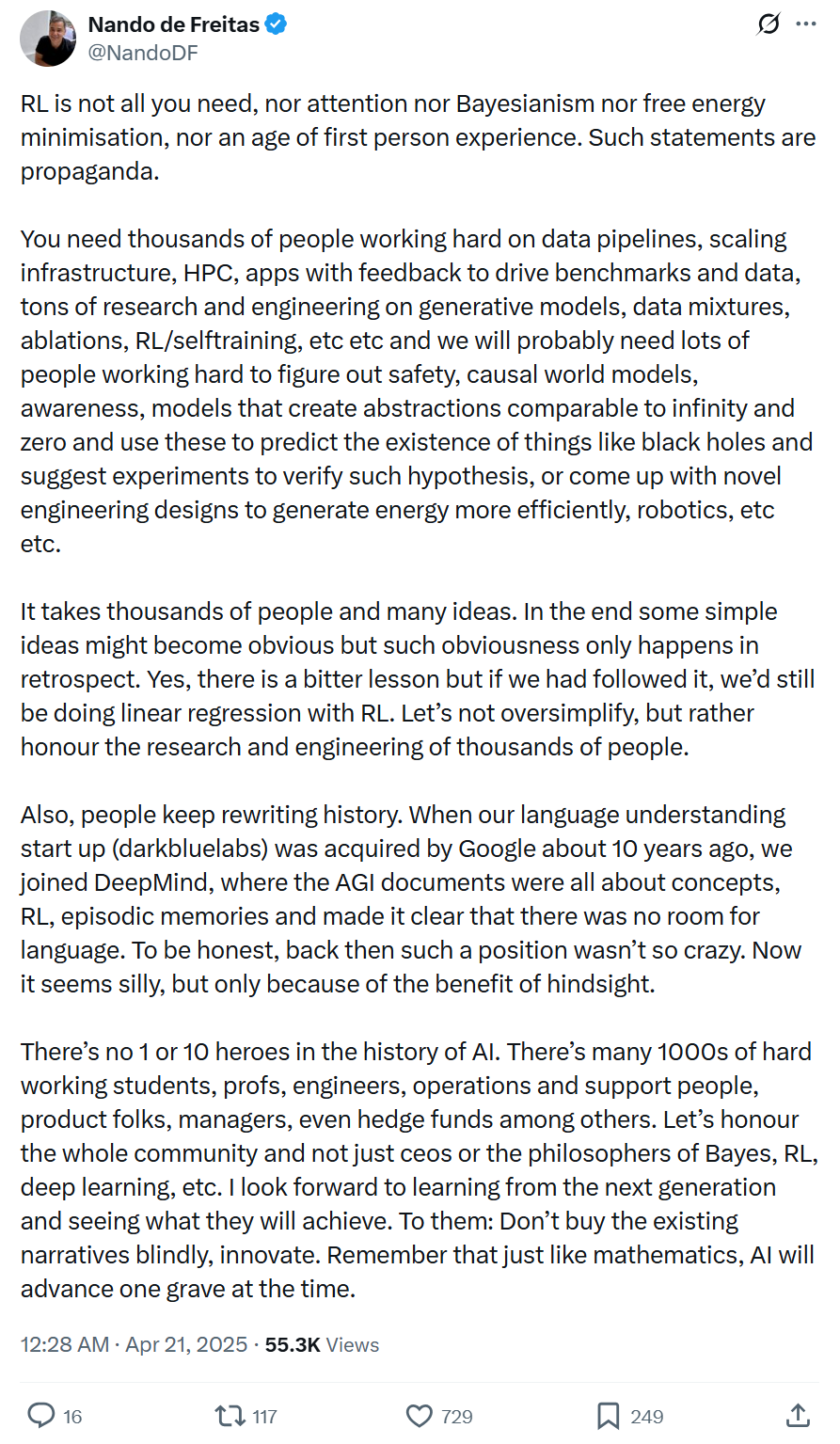
Vice-président de Microsoft : Le progrès de l’IA n’est pas dû à une seule technologie ou à quelques génies, mais nécessite une ingénierie systémique et une large collaboration : Nando de Freitas, vice-président de Microsoft, s’oppose à la mythification excessive d’une seule technologie (comme le RL) ou d’individus dans le développement de l’IA. Il souligne que le progrès de l’IA est une ingénierie systémique nécessitant des données, des infrastructures, des recherches dans de multiples domaines (modèles génératifs, RL, sécurité, efficacité énergétique, etc.), le retour d’information des applications et les efforts conjoints de milliers de participants. Le récit historique est souvent réécrit ; il faut se méfier du recul et respecter la contribution de toute la communauté, encourager l’innovation plutôt que l’imitation aveugle. (Source : 机器之心)
💡 Autres
La prolifération de la musique IA suscite des inquiétudes et des contre-mesures dans l’industrie : La part de la musique générée par IA sur les plateformes de streaming augmente rapidement (par exemple, 18% sur Deezer), suscitant des inquiétudes quant à l’empiètement sur l’espace de création humaine et à l’érosion des revenus des créateurs (prévision de la CISAC de 24%). L’association coréenne des droits d’auteur a mis en place une nouvelle règle de redevance “0% IA”, et des plateformes comme Deezer et YouTube développent des outils de détection. Cependant, l’identification de la musique IA est difficile et l’acceptation par les auditeurs est relativement élevée (par exemple, Suno compte plus de dix millions d’utilisateurs). L’industrie est confrontée à des défis tels que les deepfakes, les litiges sur les droits d’auteur (droit d’utilisation des données d’entraînement) et la définition de l’originalité. L’avenir pourrait s’orienter vers une collaboration homme-machine, mais les discussions sur l’éthique et l’attribution de la création se poursuivront. (Source : 新音乐产业观察)

Fuite présumée des invites système de Windsurf : Le dépôt GitHub awesome-ai-system-prompts a divulgué le contenu présumé des invites système du modèle Windsurf. (Source : karminski3)

La forte consommation d’eau des grands modèles IA suscite l’attention : Des médias comme Fortune rapportent que le fonctionnement de grands modèles IA similaires à ChatGPT nécessite une grande quantité d’eau pour le refroidissement. La saison des incendies en Californie et ailleurs pourrait aggraver la tension sur les ressources en eau, soulevant des inquiétudes quant à la durabilité de l’IA. (Source : Ronald_vanLoon)

Un développeur affirme avoir créé une AMI capable de prédire les émotions : Une vidéo YouTube prétend montrer une AMI (Artificial Molecular Intelligence ?) capable de scanner et de prédire de manière fiable les émotions et d’autres aspects d’événements, impliquant plusieurs modalités comme le son, la vidéo, l’image, etc. La véracité et la mise en œuvre spécifique de cette technologie restent à vérifier. (Source : Reddit r/artificial)
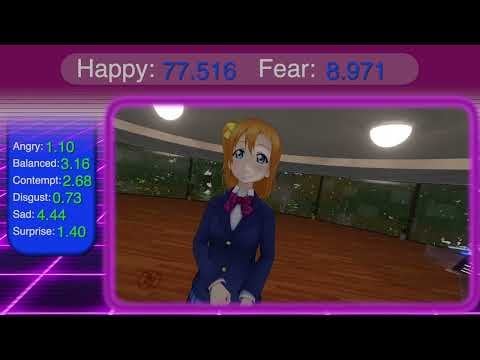
Suggestion d’ajouter une comparaison des performances humaines aux benchmarks IA : Un utilisateur de Reddit propose que les tests de référence (Benchmarks) des modèles IA incluent les scores humains (personnes ordinaires et experts) sur les mêmes tâches comme référence, afin d’évaluer plus intuitivement le niveau de capacité relatif de l’IA. (Source : Reddit r/artificial)
Les Oscars acceptent la participation de l’IA dans la production cinématographique, mais avec des restrictions : L’Academy of Motion Picture Arts and Sciences a mis à jour ses règles, autorisant l’utilisation d’outils IA dans la production cinématographique, mais soulignant que la créativité humaine reste au cœur. Les règles pourraient impliquer des exigences spécifiques telles que la divulgation de l’utilisation de l’IA, reflétant l’équilibre de l’industrie entre l’adoption de nouvelles technologies et la protection de la création humaine. (Source : Reddit r/artificial, NYT link)

Instagram essaie d’utiliser l’IA pour déterminer l’âge des adolescents (Source : Reddit r/artificial, AP News link)
Altman affirme que les utilisateurs disant “s’il vous plaît” et “merci” à ChatGPT coûtent des millions de dollars (Source : Reddit r/artificial, QZ link)
Le semi-marathon de robots humanoïdes démontre les progrès technologiques et les défis : Le premier semi-marathon mondial de robots humanoïdes s’est tenu à Pékin, avec “Tiangong Ultra” remportant la victoire en 2 heures et 40 minutes. La compétition a testé les capacités des robots sur de longues distances, terrains complexes, équilibre dynamique, navigation autonome, etc. Les robots de taille réelle font face à des difficultés plus importantes (centre de gravité, inertie, consommation d’énergie). Tiangong Ultra a gagné grâce à ses articulations intégrées haute puissance, sa conception à faible inertie, son refroidissement efficace, sa stratégie de contrôle par apprentissage par imitation renforcé prédictif et sa technologie de guidage sans fil. L’événement est considéré comme un test de résistance pour le déploiement commercial à grande échelle des robots (par exemple, industrie, inspection de sécurité), stimulant la validation et l’optimisation des technologies clés telles que le matériel corporel, le contrôle moteur et la prise de décision intelligente. (Source : 机器之心)

Utiliser l’IA pour surveiller les activités des célébrités et recevoir des alertes automatiques : Un tutoriel partage comment utiliser un script Python pour surveiller les mises à jour de comptes Twitter spécifiques (comme celui d’Altman) et réaliser des alertes téléphoniques urgentes via l’API Feishu lors de la publication de nouvelles activités. Cette méthode combine la technologie de web scraping avec l’appel d’API de plateforme ouverte, visant à résoudre le problème de la surcharge d’informations et du besoin d’actualité, réalisant une diffusion personnalisée d’informations importantes. Elle montre le potentiel de l’IA dans le traitement automatisé des flux d’informations et les notifications personnalisées. (Source : 非主流运营)
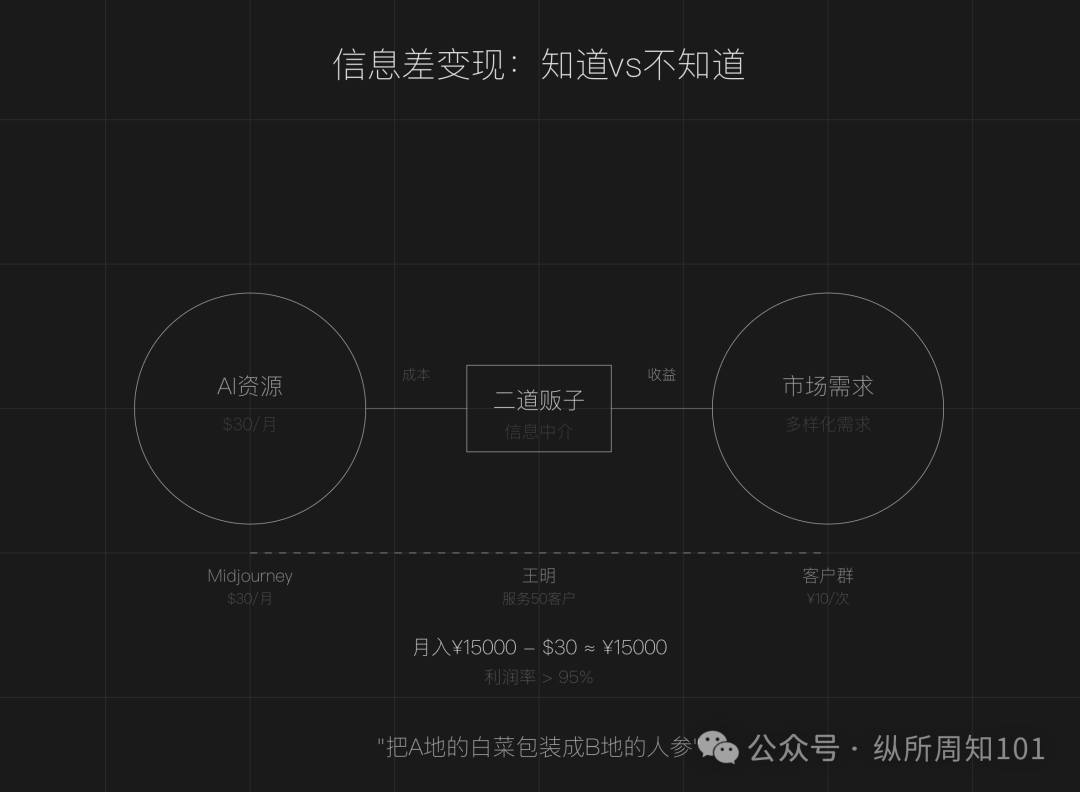
Exploration du modèle commercial consistant à devenir un “revendeur” en exploitant l’asymétrie d’information de l’IA : L’article soutient qu’à l’ère de l’IA, l’asymétrie d’information existe toujours (prolifération d’outils, barrières techniques, scénarios flous), créant des opportunités pour les gens ordinaires de devenir des “revendeurs d’IA”. Les stratégies clés incluent : exploiter la différence de prix des ressources IA nationales et étrangères pour revendre des services (comme la peinture IA), fournir des services d’exécution (transformer des tutoriels gratuits en déploiements payants, comme le service client IA), opérer à grande échelle (former des équipes pour fournir des services professionnels). Les domaines appropriés incluent la création de contenu, l’éducation et la formation, les services commerciaux aux PME, les services professionnels dans des domaines verticaux (comme la santé, le droit). Il est suggéré de commencer en trois étapes : trouver l’asymétrie d’information, définir le groupe cible, agir rapidement. (Source : 周知)