
Mots-clés:Modèle d’IA, OpenAI, Multimodal, Agent, Modèle o3, o4-mini, Raisonnement visuel, Utilisation d’outils, Gemini 2.5 Flash, Tencent Yuanbao IA, Intégration LLM, Apprentissage par renforcement
🔥 Pleins feux sur
OpenAI lance les modèles o3 et o4-mini, intégrant des outils et des capacités de raisonnement visuel : OpenAI a officiellement lancé ses modèles de raisonnement les plus intelligents et les plus puissants à ce jour, o3 et o4-mini. Le point clé est la première réalisation où l’Agent appelle et combine activement tous les outils internes de ChatGPT (recherche web, analyse de données Python, compréhension visuelle approfondie, génération d’images, etc.), et peut intégrer des images dans la chaîne de pensée pour réfléchir. o3 excelle dans des domaines tels que le codage, les mathématiques, les sciences, la perception visuelle, etc., établissant de nouveaux SOTA (State-Of-The-Art) sur plusieurs benchmarks ; o4-mini, quant à lui, optimise la vitesse et le coût, avec des performances bien supérieures à sa taille. Ces deux modèles ont une meilleure capacité à suivre les instructions, des conversations plus naturelles, et peuvent utiliser la mémoire et l’historique des conversations pour fournir des réponses personnalisées. Ce lancement marque une étape importante pour OpenAI vers une IA plus autonome de type Agentic AI, où les assistants IA peuvent accomplir des tâches complexes de manière plus indépendante. (Source : OpenAI 王炸 o3/o4-mini!打通自主工具+视觉思考,大佬赞“天才级”!AI 终获“十八般武艺”全家桶?
Les modèles o3 et o4-mini d’OpenAI sont en ligne, améliorant l’utilisation des outils et les capacités de raisonnement visuel : OpenAI a lancé les modèles o3 et o4-mini tard dans la nuit, accessibles aux utilisateurs via les comptes ChatGPT Plus, Pro et Team. Les mises à niveau clés sont : 1. La version complète d’o3 prend désormais en charge l’appel d’outils (comme la navigation web, l’interpréteur de code). 2. o3 et o4-mini sont les premiers modèles capables d’effectuer un raisonnement visuel au sein de leur chaîne de pensée, pouvant analyser et réfléchir en combinant des images comme le ferait un humain, par exemple, dans un jeu de devinettes basé sur des images, le modèle peut zoomer sur les détails de l’image pour un raisonnement étape par étape. Cette capacité améliore considérablement les performances du modèle sur les tâches multimodales (telles que MMMU, MathVista), indiquant que l’IA jouera un rôle plus important dans les scénarios professionnels nécessitant un jugement visuel (comme la surveillance de sécurité, l’analyse d’images médicales). Parallèlement, OpenAI a également rendu open source l’outil de programmation IA Codex CLI. (Source : OpenAI深夜上线o3满血版和o4 mini – 依旧领先。
L’IA Yuanbao de Tencent est officiellement intégrée à WeChat, inaugurant un nouveau paradigme de chat : L’IA Yuanbao de Tencent est désormais officiellement disponible en tant qu’ami WeChat, les utilisateurs peuvent l’ajouter en recherchant “元宝”. Cette initiative rompt avec le modèle traditionnel où les applications d’IA nécessitent une ouverture séparée, intégrant l’IA de manière transparente dans les scénarios de communication quotidiens des utilisateurs. L’IA Yuanbao (basée sur Hunyuan et DeepSeek) peut interagir directement dans la boîte de dialogue WeChat, prendre en charge le résumé d’images, d’articles de comptes publics, de liens web, d’audio et de vidéo (ne prend pas encore en charge les Chaînes Vidéo WeChat), et peut rechercher dans l’historique des discussions. Bien qu’elle ne prenne pas encore en charge le dessin et les discussions de groupe, sa facilité d’utilisation et son intégration profonde dans l’écosystème WeChat sont considérées comme des avantages importants. Les analystes estiment que WeChat, fort de sa vaste base d’utilisateurs et de son réseau social, en transformant l’IA en contact de répertoire, pourrait changer le paradigme de l’interaction homme-machine, permettant à l’IA de s’intégrer plus naturellement dans la vie des utilisateurs. (Source : 劲爆!元宝AI接入微信了,怎么用?看这篇就够了, 腾讯元宝最终还是活成了微信的模样。
Les États-Unis pourraient suspendre indéfiniment les exportations de puces H20 de Nvidia vers la Chine, avec des conséquences importantes : Le gouvernement américain a notifié Nvidia qu’il suspendrait indéfiniment les exportations vers la Chine de la puce IA H20 (une version spécifique conçue précédemment pour répondre aux contrôles à l’exportation). La H20 est la puce conforme la plus puissante développée par Nvidia pour le marché chinois ; l’interdiction de vente devrait porter un coup dur à Nvidia. Les données montrent que la Chine est la quatrième source de revenus de Nvidia, avec des ventes de H20 atteignant des dizaines de milliards de dollars en 2024, et que les entreprises technologiques chinoises (comme ByteDance, Tencent) sont les principaux acheteurs de puces Nvidia, avec une croissance significative de leurs investissements. Cette mesure affecte non seulement les revenus de Nvidia, mais pourrait également affaiblir son écosystème CUDA (les développeurs chinois représentant plus de 30%). Pendant ce temps, les entreprises chinoises locales de puces IA comme Huawei (par exemple, Ascend 910C) accélèrent leur développement et pourraient combler le vide du marché. L’événement a suscité des inquiétudes sur le marché, et le cours de l’action Nvidia a chuté en conséquence. (Source : 中国对英伟达到底有多重要?
🎯 Mouvements
Le modèle vidéo de pointe de Google, Veo 2, arrive gratuitement sur AI Studio : Google a annoncé que son modèle avancé de génération vidéo Veo 2 est désormais disponible sur Google AI Studio, Gemini API et Gemini App, avec des crédits d’utilisation gratuits (environ une dizaine de fois par jour, jusqu’à 8 secondes par fois). Veo 2 prend en charge la génération de vidéo à partir de texte (t2v) et d’image (i2v), est capable de comprendre des instructions complexes, de générer du contenu vidéo réaliste et stylisé, et de contrôler les mouvements de caméra. Google souligne que la clé pour générer des vidéos de haute qualité est de fournir des Prompt clairs, détaillés et contenant des mots-clés visuels. Le modèle dispose également de fonctionnalités avancées telles que l’édition intra-vidéo (détourage, extension d’image), des mouvements de caméra cinématographiques et des transitions intelligentes, visant à s’intégrer dans les flux de travail de création de contenu pour améliorer l’efficacité. (Source : 谷歌杀疯了,顶级视频模型 Veo 2 竟免费开放?速来 AI Studio 白嫖。
Google lance Gemini 2.5 Flash, axé sur la vitesse, le coût et la profondeur de réflexion contrôlable : Google a lancé une version préliminaire du modèle Gemini 2.5 Flash, positionné comme un modèle léger optimisé pour la vitesse et le coût. Ce modèle affiche des performances remarquables dans le classement LMArena, se classant deuxième ex aequo avec GPT-4.5 Preview et Grok-3, et premier pour les prompts difficiles, le codage et les requêtes longues. Sa caractéristique principale est l’introduction de la capacité de “réflexion” et d’un raisonnement entièrement mixte, permettant au modèle de planifier et de décomposer les tâches avant de générer une sortie. Les développeurs peuvent contrôler la profondeur de réflexion du modèle (limite de tokens) via le paramètre “budget de réflexion”, équilibrant ainsi la qualité, le coût et la latence. Même avec un budget de 0, les performances dépassent celles de 2.0 Flash. Ce modèle offre un excellent rapport qualité-prix, coûtant seulement 1/10 à 1/5 du prix de Gemini 2.5 Pro, et convient aux flux de travail IA à haute concurrence et à grande échelle. (Source : 快如闪电,还能控制思考深度?谷歌 Gemini 2.5 Flash 来了,用户盛赞“绝妙组合”。
Kunlun Wanwei lance Skyreels-V2, un modèle de génération de films de durée illimitée : Kunlun Wanwei a lancé et rendu open source Skyreels-V2, présenté comme le premier modèle de génération vidéo de haute qualité au monde prenant en charge une durée illimitée. Ce modèle vise à résoudre les problèmes des modèles vidéo existants concernant la compréhension du langage cinématographique, la cohérence des mouvements, les limitations de durée vidéo et le manque de jeux de données professionnels. Skyreels-V2 combine un grand modèle multimodal, un étiquetage structuré, une génération par diffusion, un apprentissage par renforcement (optimisation DPO de la qualité du mouvement) et un affinage de haute qualité dans une stratégie d’entraînement multi-étapes. Il adopte une architecture Diffusion Forcing, réalisant la génération de longues vidéos grâce à un planificateur spécial et des mécanismes d’attention. L’entreprise affirme que ses effets de génération atteignent un niveau “cinématographique” et qu’il surpasse d’autres modèles open source dans les benchmarks tels que V-Bench1.0. Les utilisateurs peuvent expérimenter en ligne la génération de vidéos allant jusqu’à 30 secondes. (Source : 震撼!昆仑万维 | 发布全球首款无限时长电影生成模型:Skyreels-V2,可在线体验!
Shanghai AI Lab lance le modèle multimodal natif InternVL3 : Le laboratoire d’intelligence artificielle de Shanghai a lancé InternVL3, un grand modèle multimodal (MLLM) adoptant un paradigme de pré-entraînement multimodal natif. Contrairement à la plupart des modèles adaptés à partir de LLM purement textuels, InternVL3 apprend simultanément à partir de données multimodales et de corpus de texte pur en une seule phase de pré-entraînement, visant à surmonter la complexité et les défis d’alignement de l’entraînement multi-étapes. Ce modèle combine un encodage de position visuelle variable, des techniques avancées de post-entraînement et des stratégies d’extension au moment du test. InternVL3-78B a obtenu un score de 72,2 au benchmark MMMU, établissant un nouveau record pour les MLLM open source, avec des performances proches des modèles propriétaires de pointe, tout en conservant de solides capacités purement linguistiques. Les données d’entraînement et les poids du modèle seront rendus publics. (Source : LLM每周速递!| 涉及多Token注意力、Text2Sql增强、多模态、RNN大模型、多Agent应用等
UCLA et al. proposent le framework d1, utilisant l’apprentissage par renforcement pour l’inférence LLM par diffusion : Des chercheurs de l’UCLA et de Meta AI ont proposé le framework d1, appliquant pour la première fois le post-entraînement par apprentissage par renforcement (RL) aux grands modèles de langage par diffusion masquée (dLLM). Les méthodes RL existantes (comme GRPO) sont principalement conçues pour les LLM autorégressifs et difficiles à appliquer directement aux dLLM, en raison de l’absence de décomposition naturelle de la log-probabilité. Le framework d1 comprend deux étapes : d’abord un affinage supervisé (SFT), puis une phase RL introduisant une nouvelle méthode de gradient de politique, diffu-GRPO, qui utilise un estimateur de log-probabilité en une seule étape efficace et exploite le masquage aléatoire des prompts comme régularisation, réduisant la quantité de génération en ligne requise pour l’entraînement RL. Les expériences montrent que le modèle d1 basé sur LLaDA-8B-Instruct surpasse significativement le modèle de base ainsi que les modèles utilisant uniquement SFT ou diffu-GRPO sur les benchmarks de raisonnement mathématique et logique. (Source : UCLA | 推出开源后训练框架:d1,扩散LLM推理也能用上GRPO强化学习!
Meta propose l’Attention Multi-Token (MTA) : Des chercheurs de Meta ont proposé le mécanisme d’Attention Multi-Token (Multi-Token Attention, MTA), visant à améliorer le calcul de l’attention dans les grands modèles de langage (LLM). Le mécanisme d’attention traditionnel est basé uniquement sur la similarité entre un seul token de requête et de clé. MTA, en appliquant des opérations de convolution sur les vecteurs de requête, de clé et de tête, permet au modèle de considérer simultanément plusieurs tokens de requête et de clé adjacents pour déterminer les poids d’attention. Les chercheurs estiment que cela permet d’utiliser des informations plus riches et plus détaillées pour localiser le contexte pertinent. Les expériences montrent que MTA surpasse les modèles de base Transformer traditionnels tant dans la modélisation standard du langage que dans les tâches de récupération d’informations à long contexte. (Source : LLM每周速递!| 涉及多Token注意力、Text2Sql增强、多模态、RNN大模型、多Agent应用等
TogetherAI lance M1, un modèle d’inférence basé sur RNN : TogetherAI a proposé M1, un nouveau modèle d’inférence RNN linéaire hybride basé sur l’architecture Mamba. Ce modèle vise à résoudre les problèmes de complexité de calcul et de limitation de mémoire rencontrés par les Transformers lors du traitement de longues séquences et de l’inférence efficace. M1 améliore ses performances grâce à la distillation de connaissances à partir de modèles d’inférence existants et à l’entraînement par apprentissage par renforcement. Les résultats expérimentaux montrent que M1, sur les benchmarks de raisonnement mathématique tels que AIME et MATH, non seulement surpasse les modèles RNN linéaires précédents, mais rivalise également avec les modèles d’inférence distillés DeepSeek-R1 de taille équivalente. Plus important encore, la vitesse de génération de M1 est plus de 3 fois supérieure à celle d’un Transformer de même taille, et avec un budget de temps de génération fixe, il obtient une précision supérieure à ce dernier grâce au vote par auto-cohérence. (Source : LLM每周速递!| 涉及多Token注意力、Text2Sql增强、多模态、RNN大模型、多Agent应用等
Tencent Hunyuan rend open source le framework InstantCharacter : L’équipe Tencent Hunyuan a rendu open source InstantCharacter, un framework pour la génération d’images capable d’extraire et de préserver les caractéristiques d’un personnage à partir d’une seule image d’entrée, puis de placer ce personnage dans différentes scènes ou styles. Cette technologie vise à atteindre une haute fidélité dans la préservation de l’identité du personnage et un transfert de style contrôlable. L’entreprise a fourni une démo en ligne sur Hugging Face basée sur les styles artistiques de Ghibli et Makoto Shinkai, et a publié le papier de recherche associé, le dépôt de code ainsi qu’un plugin ComfyUI pour faciliter l’utilisation et le développement ultérieur par la communauté. (Source : karminski3
Mise à niveau de la fonction Mémoire de ChatGPT, prend en charge la recherche web combinée à la mémoire : OpenAI a mis à niveau la fonction Mémoire (Memory) de ChatGPT, ajoutant la capacité de “recherche avec mémoire”. Cela signifie que lorsque ChatGPT effectue une tâche de recherche web, il peut utiliser les informations précédemment stockées sur les préférences de l’utilisateur, sa localisation, etc., pour optimiser la requête de recherche et fournir ainsi des résultats plus personnalisés. Par exemple, si ChatGPT se souvient que l’utilisateur est végétarien, lorsqu’on lui demande des restaurants à proximité, il pourrait automatiquement rechercher “restaurants végétariens à proximité”. Cette initiative est considérée comme une étape importante d’OpenAI dans l’amélioration des services personnalisés de l’IA, visant à améliorer l’expérience utilisateur et à se différencier des concurrents dotés de fonctions de mémoire (comme Claude, Gemini). Les utilisateurs peuvent choisir de désactiver la fonction mémoire dans les paramètres. (Source : Cursor 新版抢先体验!规则自动生成+项目结构感知+MCP 图片支持,网友:多项实用更新!
La technologie d’instantané d’exécution de modèle IA évite le démarrage à froid : La communauté du machine learning explore l’optimisation de l’orchestration d’exécution des LLM grâce à la technologie d’instantané de modèle. Cette technique, en sauvegardant l’état complet du GPU (y compris le cache KV, les poids, la disposition de la mémoire), permet d’éviter le démarrage à froid et l’inactivité du GPU lors du passage d’un modèle à l’autre, réalisant une récupération rapide (environ 2 secondes). Des praticiens ont partagé avoir réussi à exécuter plus de 50 modèles open source sur deux GPU A1000 16 Go en utilisant cette méthode, sans utiliser de conteneurs ni recharger les modèles. Cette technique de multiplexage et de rotation de modèles a le potentiel d’améliorer l’utilisation du GPU et de réduire la latence d’inférence. (Source : Reddit r/MachineLearning)
🧰 Outils
Volcano Engine de ByteDance lance une démo de solution matérielle IA tout-en-un : Volcano Engine de ByteDance a présenté sa solution matérielle IA tout-en-un développée en collaboration avec des fabricants de puces embarquées, en prenant comme exemple la carte de développement AtomS3R. Cette solution vise à offrir une expérience interactive IA à faible latence et haute réactivité, caractérisée par une réponse en temps réel de l’ordre de la milliseconde, une interruption et une prise de parole en temps réel, ainsi qu’une capacité de réduction du bruit audio en environnement complexe via le SDK RTC, réduisant efficacement les interférences du bruit de fond et améliorant la précision de l’interaction vocale. Le code client et le programme serveur de cette solution sont open source, permettant aux développeurs de personnaliser (DIY), par exemple en attribuant au matériel une personnalité, un rôle, une voix personnalisés, ou en l’intégrant à une base de connaissances et aux outils MCP. Le matériel lui-même comprend une caméra et prévoit de prendre en charge à l’avenir les fonctions de compréhension visuelle. (Source : 体验完字节送的迷你AI硬件,后劲有点大…
Mìtǎ AI Search lance la fonction d’apprentissage “Quoi apprendre aujourd’hui” : Mìtǎ AI Search a lancé une nouvelle fonctionnalité appelée “今天学点啥” (Quoi apprendre aujourd’hui), qui peut transformer automatiquement les fichiers téléchargés par l’utilisateur (prend en charge plusieurs formats) ou les liens web fournis en une vidéo de cours en ligne structurée, avec narration et démonstration (PPT, animation). Les utilisateurs peuvent choisir différents styles d’explication (comme raconter une histoire, style Napoléon) et voix (comme une voix féminine froide et distante). Cette fonction vise à transformer l’apport d’informations en une expérience d’apprentissage plus facile à assimiler, offrant même une phase de test post-cours. Cette approche combinant la génération de contenu et l’enseignement personnalisé est considérée comme susceptible de changer les modèles d’application de l’IA dans l’éducation et la consommation d’informations, offrant une nouvelle manière d’acquérir des connaissances et de lire rapidement du contenu. (Source : 说个抽象的事,你现在可以在秘塔AI搜索里上课了。

Mise à jour de l’IDE Cursor vers la version 0.49, amélioration du système de règles et du contrôle de l’Agent : L’éditeur de code AI-first Cursor a publié un aperçu de la mise à jour 0.49. Nouvelles fonctionnalités : 1. Génération automatique de fichiers de règles .mdc via la commande de chat /Generate Cursor Rules pour figer le contexte du projet. 2. Application automatique des règles plus intelligente, l’Agent peut charger automatiquement les règles correspondantes en fonction du chemin du fichier. 3. Correction du bug où “Toujours attacher les règles” échouait dans les longues conversations. 4. Nouvelle fonctionnalité “Conscience de la structure du projet” (Beta) pour que l’IA comprenne mieux l’ensemble du projet. 5. Le protocole MCP (Model Context Protocol) prend désormais en charge la transmission d’images, facilitant le traitement des tâches liées au visuel. 6. Contrôle amélioré de l’Agent sur les commandes du terminal, l’utilisateur peut éditer ou ignorer les commandes avant l’exécution. 7. Prise en charge de la configuration globale des fichiers à ignorer (.cursorignore). 8. Expérience de revue de code optimisée, affichage direct de la vue diff après les messages de l’Agent. (Source : Cursor 新版抢先体验!规则自动生成+项目结构感知+MCP 图片支持,网友:多项实用更新!
OpenAI rend open source l’outil de programmation IA en ligne de commande Codex CLI : Parallèlement au lancement d’o3 et o4-mini, OpenAI a rendu open source Codex CLI, un Agent de codage IA léger qui peut s’exécuter directement dans le terminal en ligne de commande de l’utilisateur. Cet outil vise à exploiter pleinement les puissantes capacités de codage et de raisonnement des nouveaux modèles, peut traiter directement les dépôts de code locaux, et même combiner des captures d’écran ou des croquis pour un raisonnement multimodal. Le PDG d’OpenAI, Sam Altman, en a personnellement fait la promotion et a souligné sa nature open source pour favoriser une itération rapide par la communauté. Parallèlement, OpenAI a lancé un programme de subventions d’un million de dollars (sous forme de crédits API) pour soutenir les projets basés sur Codex CLI et les modèles OpenAI. (Source : OpenAI 王炸 o3/o4-mini!打通自主工具+视觉思考,大佬赞“天才级”!AI 终获“十八般武艺”全家桶?
La plateforme LKE de Tencent Cloud intègre MCP, simplifiant la construction d’Agents : La plateforme Language Knowledge Engine (LKE) de Tencent Cloud prend désormais en charge le Model Context Protocol (MCP), visant à abaisser le seuil de construction et d’utilisation des Agents IA. Les utilisateurs peuvent désormais, sur la plateforme LKE, via des opérations de clic, intégrer facilement des outils MCP intégrés tels que Tencent Cloud EdgeOne Pages (déploiement de pages web en un clic), Firecrawl (crawler web), etc. Combiné aux puissantes capacités de la base de connaissances (RAG) de LKE, les utilisateurs peuvent créer des applications complexes basées sur des connaissances privées et l’appel d’outils externes, par exemple générer et publier automatiquement des pages web basées sur le contenu de la base de connaissances. Cette plateforme prend en charge le mode Agent, où le modèle (comme DeepSeek R1) peut réfléchir de manière autonome et choisir les outils appropriés pour accomplir la tâche. La plateforme prend également en charge l’intégration de MCP externes. (Source : 效果惊艳!MCP+腾讯云知识引擎,一个0门槛打造专属AI Agent的神器诞生~

Framework Spring AI : un framework applicatif pour l’ingénierie IA : Spring AI est un framework applicatif IA conçu pour les développeurs Java, visant à introduire les principes de conception de l’écosystème Spring (tels que la portabilité, la conception modulaire, l’utilisation de POJO) dans le domaine de l’IA. Il fournit une API unifiée pour interagir avec divers fournisseurs de modèles IA grand public (Anthropic, OpenAI, Microsoft, Amazon, Google, Ollama, etc.), prenant en charge la complétion de chat, l’embedding, le texte-vers-image/audio, la modération, etc. Parallèlement, il intègre plusieurs bases de données vectorielles (Cassandra, Azure Vector Search, Chroma, Milvus, etc.), offrant une API portable et un filtrage de métadonnées de style SQL. Le framework prend également en charge la sortie structurée, l’appel d’outils/fonctions, l’observabilité, le framework ETL, l’évaluation de modèles, la mémoire de chat et le RAG, etc., et simplifie l’intégration grâce à l’auto-configuration de Spring Boot. (Source : spring-projects/spring-ai – GitHub Trending (all/weekly)
olmocr : une boîte à outils de linéarisation PDF pour le traitement des jeux de données LLM : allenai a rendu open source olmocr, une boîte à outils spécialement conçue pour le traitement de documents PDF destinés à la construction et à l’entraînement de jeux de données pour les grands modèles de langage (LLM). Elle comprend plusieurs fonctionnalités : des stratégies de prompt utilisant ChatGPT 4o pour une analyse de texte naturel de haute qualité, des outils d’évaluation pour comparer différentes versions de flux de traitement, des fonctions de base de filtrage linguistique et de suppression de spam SEO, du code d’affinage pour Qwen2-VL et Molmo-O, un flux utilisant Sglang pour le traitement à grande échelle de PDF, et des outils pour visualiser les documents traités au format Dolma. Cette boîte à outils nécessite un support GPU pour l’inférence locale et fournit des instructions pour une utilisation locale et sur des clusters multi-nœuds (supportant S3 et Beaker). (Source : allenai/olmocr – GitHub Trending (all/daily)

Publication de l’application de bureau Dive Agent v0.8.0 : L’application de bureau open source AI Agent Dive a publié la version v0.8.0, avec des ajustements majeurs d’architecture et des mises à niveau fonctionnelles. Cette version vise à intégrer les LLM prenant en charge l’appel d’outils avec le serveur MCP. Les principales mises à jour comprennent : la gestion des clés API LLM, la prise en charge des ID de modèle personnalisés, la prise en charge complète des modèles d’appel d’outils/fonctions ; la gestion des outils MCP (ajout/suppression/modification), l’interface de configuration prenant en charge l’édition JSON et par formulaire. Le backend DiveHost a été migré de TypeScript vers Python pour résoudre les problèmes d’intégration de LangChain, et peut fonctionner comme un serveur A2A (Agent-to-Agent) indépendant. (Source : Reddit r/LocalLLaMA)
llama.cpp fusionne les outils CLI multimodaux : Le projet llama.cpp a fusionné les programmes d’exemple d’interface en ligne de commande (CLI) pour LLaVa, Gemma3 et MiniCPM-V en un outil unifié llama-mtmd-cli. Cela fait partie de son intégration progressive du support multimodal (via la bibliothèque libmtmd). Bien que le support multimodal soit encore en développement (par exemple, le support de llama-server est encore expérimental), la fusion des CLI est une étape vers la simplification de l’ensemble d’outils. Parallèlement, le support pour SmolVLM v1/v2 est également en cours de développement. (Source : Reddit r/LocalLLaMA)
LightRAG : déploiement automatisé de pipelines RAG : LightRAG est un projet open source RAG (Retrieval-Augmented Generation). Des membres de la communauté ont créé des tutoriels et des scripts d’automatisation (utilisant Ansible + Docker Compose + Sbnb Linux) permettant aux utilisateurs de déployer rapidement (en quelques minutes) le système LightRAG sur des serveurs bare metal, réalisant ainsi la mise en place automatisée d’un pipeline RAG fonctionnel à partir d’une machine vierge. Cela simplifie le processus de déploiement de solutions RAG auto-hébergées. (Source : Reddit r/LocalLLaMA)
Nari Labs lance le modèle TTS open source Dia-1.6B : Nari Labs a lancé et rendu open source son modèle de synthèse vocale (TTS) Dia-1.6B. La particularité de ce modèle est qu’il peut non seulement générer de la parole, mais aussi y intégrer naturellement des sons non linguistiques (sons paralinguistiques) tels que le rire, la toux, le raclement de gorge, pour améliorer la naturalité et l’expressivité de la voix. L’entreprise a fourni une vidéo de démonstration pour montrer les effets. Le modèle nécessite environ 10 Go de VRAM pour fonctionner et aucune version quantifiée n’est actuellement disponible. Le dépôt de code et le modèle ont été publiés sur GitHub et Hugging Face. (Source : karminski3)
📚 Apprentissage
Jeff Dean revient sur les étapes clés du développement de l’IA au cours des quinze dernières années : Le scientifique en chef de Google, Jeff Dean, a passé en revue dans une présentation les avancées importantes dans le domaine de l’IA au cours des quinze dernières années, en soulignant particulièrement les contributions de la recherche de Google. Les jalons clés comprennent : l’entraînement de réseaux neuronaux à grande échelle (démontrant l’effet d’échelle), le système distribué DistBelief (permettant l’entraînement de grands modèles sur CPU), les plongements lexicaux Word2Vec (révélant la sémantique de l’espace vectoriel), les modèles Seq2Seq (stimulant des tâches comme la traduction automatique), le TPU (accélération matérielle personnalisée pour les réseaux neuronaux), l’architecture Transformer (révolutionnant le traitement séquentiel, base des LLM), l’apprentissage auto-supervisé (utilisant des données non étiquetées à grande échelle), le Vision Transformer (unifiant le traitement d’images et de texte), les modèles épars/MoE (augmentant la capacité et l’efficacité des modèles), Pathways (simplifiant le calcul distribué à grande échelle), la chaîne de pensée CoT (améliorant les capacités de raisonnement), la distillation de connaissances (transférant les capacités des grands modèles aux petits) et le décodage spéculatif (accélérant l’inférence). Ces technologies ont collectivement propulsé le développement de l’IA moderne. (Source : 比较全!回顾LLM发展史 | Transformer、蒸馏、MoE、思维链(CoT)
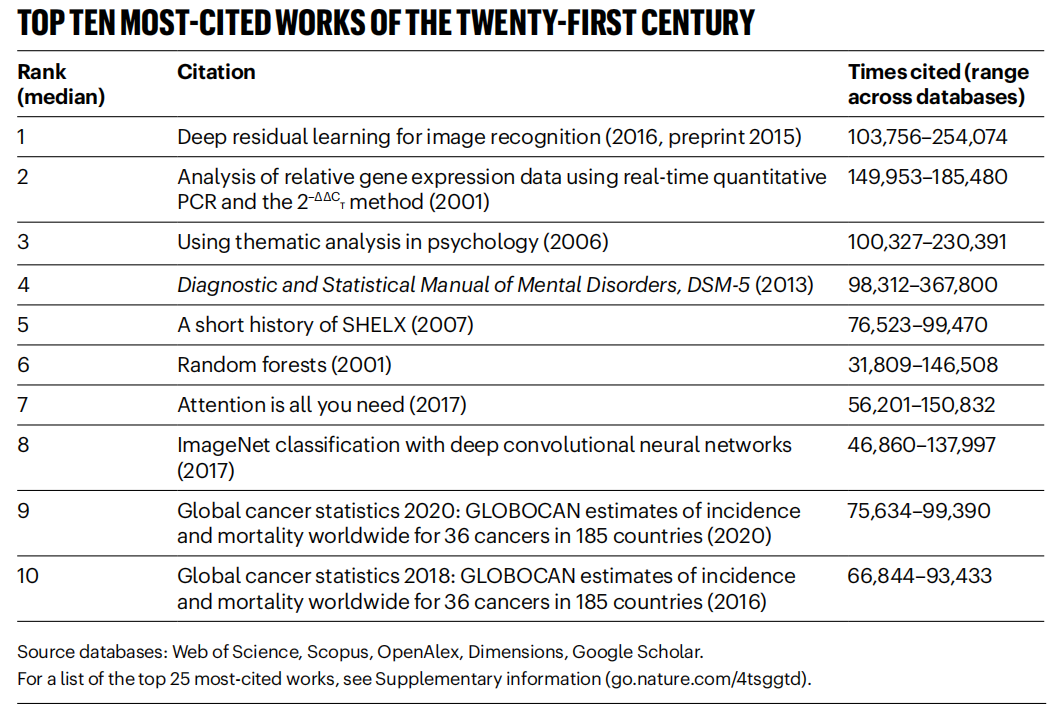
« Nature » recense les articles les plus cités du 21e siècle, le domaine de l’IA domine : La revue « Nature », en compilant les données de 5 bases de données, a publié la liste des 25 articles les plus cités du 21e siècle. L’article de Microsoft de 2016 sur ResNets (par Kaiming He et al.) se classe premier au classement général ; cette recherche est fondamentale pour les progrès de l’apprentissage profond et de l’IA. Le haut du classement comprend également plusieurs articles liés à l’IA, tels que Random Forest (6e), Attention is all you need (Transformer, 7e), AlexNet (8e), U-Net (12e), une revue sur l’apprentissage profond (Hinton et al., 16e) et le jeu de données ImageNet (Fei-Fei Li et al., 24e). Cela reflète le développement rapide et l’impact étendu de la technologie IA au cours de ce siècle. L’article souligne également que la popularité des prépublications complique les statistiques de citation. (Source : Nature最新统计!盘点引领人类进入「AI时代」的论文,ResNets引用量第一!
Des institutions comme l’Université Beihang publient une revue sur l’Ensemble de LLM : Des chercheurs de l’Université d’Aéronautique et d’Astronautique de Pékin et d’autres institutions ont publié une revue récente sur l’intégration de grands modèles de langage (LLM Ensemble). LLM Ensemble désigne la combinaison des forces de plusieurs LLM lors de la phase d’inférence pour traiter les requêtes des utilisateurs. Cette revue propose une taxonomie de LLM Ensemble (intégration pré-inférence, intra-inférence, post-inférence, subdivisée en sept catégories de méthodes), passe en revue systématiquement les dernières avancées dans chaque catégorie de méthodes, discute des questions de recherche connexes (telles que la relation avec la fusion de modèles, la collaboration de modèles, l’apprentissage faiblement supervisé), présente des jeux de tests de référence, des applications typiques, et enfin résume et analyse les résultats existants tout en esquissant les futures directions de recherche, telles qu’une intégration plus principielle au niveau des fragments et une post-intégration non supervisée plus affinée. (Source : ArXiv 2025 | 北航等机构发布最新综述:大语言模型集成(LLM Ensemble)

Anthropic partage les modèles d’utilisation et l’expérience de Claude Code : Des employés d’Anthropic ont partagé les meilleures pratiques internes et les modèles efficaces pour utiliser Claude Code en programmation. Ces modèles ne s’appliquent pas seulement à Claude, mais sont également généralement applicables à la collaboration en programmation avec d’autres LLM. L’accent est mis sur l’importance de fournir un contexte clair, de décomposer les problèmes complexes, de poser des questions de manière itérative, d’exploiter les différentes forces du modèle (comme la génération de code, l’explication, la refactorisation) et d’effectuer une validation efficace. Ces expériences visent à aider les développeurs à utiliser plus efficacement les outils d’assistance à la programmation IA. (Source : AnthropicAI

)
Anthropic rend public le jeu de données sur les valeurs de Claude : Anthropic a rendu public sur Hugging Face Datasets un jeu de données intitulé “values-in-the-wild”. Ce jeu de données contient 3307 valeurs exprimées par Claude dans des millions de conversations réelles. La publication de ce jeu de données vise à améliorer la transparence du comportement du modèle et à permettre aux chercheurs et au public de le télécharger, de l’explorer et de l’analyser pour mieux comprendre les tendances des valeurs manifestées par les grands modèles de langage dans les applications pratiques. (Source : huggingface, huggingface)
Dix points de vue clés sur l’éveil cognitif de l’IA : L’article propose dix points de vue au niveau cognitif sur le développement de l’IA, visant à aider les gens à comprendre plus profondément l’impact et l’essence de l’IA. Les points clés incluent : il existe une différence entre l’intelligence de l’IA et l’intelligence humaine (fossé d’intelligence) ; l’IA suscite une réflexion sur la nature de la conscience humaine ; la relation entre l’homme et l’IA passe d’outil à partenaire de collaboration ; le développement de l’IA ne doit pas se limiter à imiter le cerveau humain ; les normes d’intelligence évoluent avec les progrès de l’IA ; l’IA pourrait développer de toutes nouvelles formes d’intelligence ; il faut considérer rationnellement l’expression émotionnelle et les limites cognitives de l’IA ; la véritable menace professionnelle vient de la non-utilisation de l’IA plutôt que de l’IA elle-même ; à l’ère de l’IA, il faut se concentrer sur le développement des capacités uniquement humaines (créativité, intelligence émotionnelle, pensée transdisciplinaire) ; le sens ultime de la recherche sur l’IA est de mieux se connaître soi-même. (Source : AI认知觉醒的10句话,一句顶万句,句句清醒

LlamaIndex partage un tutoriel sur la construction d’un Agent de flux de travail documentaire : L’enregistrement d’une conférence du co-fondateur de LlamaIndex, Jerry Liu, partage comment utiliser LlamaIndex pour construire un Agent de flux de travail documentaire. Le contenu couvre l’évolution de LlamaIndex du RAG à l’Agent de connaissance, l’utilisation de LlamaParse pour traiter des documents complexes, l’utilisation de Workflows pour une orchestration flexible d’Agents pilotée par les événements, les cas d’utilisation clés (recherche documentaire, génération de rapports, automatisation du traitement des documents) et l’amélioration de la recherche multimodale combinant texte et images. (Source : jerryjliu0
)
Tutoriel de construction d’Agent avec LlamaIndex.TS : Un membre de l’équipe LlamaIndex partage un tutoriel complet au niveau du code pour construire des Agents en utilisant la version TypeScript de LlamaIndex (LlamaIndex.TS). L’enregistrement du direct comprend les bases de LlamaIndex, les concepts d’Agent et de RAG, les schémas agentiques courants (chaînage, routage, parallélisation, etc.), la construction de RAG agentique dans LlamaIndex.TS, et la construction d’une application React full-stack intégrant Workflows. (Source : jerryjliu0

)
Débat sur la question de savoir si l’apprentissage par renforcement améliore réellement les capacités de raisonnement des LLM : Une discussion communautaire porte sur une question soulevée par un article : l’apprentissage par renforcement (RL) peut-il réellement inciter les grands modèles de langage (LLM) à développer des capacités de raisonnement dépassant celles de leurs modèles de base ? Il est mentionné dans la discussion que bien que le RL (comme le RLHF) puisse améliorer l’alignement et le suivi des instructions du modèle, il reste à déterminer s’il peut améliorer systématiquement la logique de raisonnement complexe intrinsèque. Certains estiment que l’effet actuel du RL pourrait se manifester davantage dans l’optimisation de l’expression et le respect de formats spécifiques, plutôt que dans un bond fondamental du raisonnement logique. Will Brown souligne que des métriques comme pass@1024 ont une signification limitée pour évaluer des tâches de raisonnement mathématique comme AIME. (Source : natolambert

)
Discussion sur les termes liés aux modèles du monde : Un utilisateur de Reddit s’interroge sur la confusion autour de termes tels que “modèles du monde (world models)”, “modèles du monde fondamentaux (foundation world models)”, “modèles fondamentaux du monde (world foundation models)”. La communauté répond que “modèle du monde” désigne généralement une simulation ou une représentation interne de l’environnement (monde physique ou domaine spécifique comme un échiquier) ; “modèle fondamental” désigne un grand modèle pré-entraîné pouvant servir de point de départ à diverses tâches en aval. La combinaison de ces termes peut faire référence à la construction de modèles fondamentaux généralisables, capables de comprendre et de prédire la dynamique du monde, mais la définition spécifique peut varier selon les chercheurs, reflétant le fait que la terminologie dans ce domaine n’est pas encore totalement unifiée. (Source : Reddit r/MachineLearning)
Discussion sur les méthodes de combinaison de XGBoost et GNN : Des utilisateurs de Reddit discutent de la manière de combiner efficacement XGBoost et les réseaux neuronaux graphiques (GNN) pour des tâches telles que la détection de fraude. Une méthode courante consiste à utiliser les plongements de nœuds appris par le GNN comme nouvelles caractéristiques, qui sont ensuite fournies à XGBoost avec les données tabulaires originales. La discussion suggère que le défi de cette méthode réside dans la capacité des plongements GNN à fournir une valeur significative au-delà des données originales et des techniques comme SMOTE, sinon ils pourraient introduire du bruit. La clé du succès réside dans une structure de graphe soigneusement conçue et dans la capacité des plongements GNN à capturer des informations relationnelles (comme les anneaux de fraude dans la structure du graphe) difficiles à obtenir pour XGBoost. (Source : Reddit r/MachineLearning)
💼 Affaires
Pékin organise le premier marathon mondial de robots humanoïdes, explorant la “propriété intellectuelle sport-tech” : Yizhuang, à Pékin, a accueilli avec succès le premier semi-marathon mondial de robots humanoïdes, où les “concurrents” de plus de 20 entreprises de robots humanoïdes ont concouru aux côtés de coureurs humains. Le robot TianGong Ultra a remporté la course en 2 heures et 40 minutes, démontrant sa vitesse et son adaptabilité au terrain. N2 de Songyan Power (deuxième) et Walker II de Zhuoyi De (troisième) ont également réalisé de bonnes performances. L’événement n’était pas seulement une compétition technologique, mais aussi une exploration de modèles commerciaux. Les organisateurs ont attiré des investissements grâce à un mécanisme d‘“appel d’offres technologique” et tentent de créer une propriété intellectuelle “robot + sport”. L’article explore les voies de commercialisation telles que le développement de la propriété intellectuelle des événements robotiques, l’endossement par les robots, l’émergence de la profession d’agent de robots, l’intégration du tourisme sportif et culturel, et la promotion du sport intelligent pour tous, estimant que le marché du sport intelligent a un potentiel énorme. (Source : 独家揭秘北京机器人马拉松:谁在打造下一个“体育科技IP”?

Le développement d’applications basées sur les grands modèles d’IA devient une nouvelle tendance technologique, impactant les modèles de développement traditionnels : Avec la popularisation de la technologie des grands modèles d’IA, les entreprises (comme Alibaba, ByteDance, Tencent) accélèrent l’intégration de l’IA (en particulier les technologies Agent et RAG) dans leurs activités principales, ce qui met au défi les modèles de développement CRUD traditionnels. La demande du marché pour des ingénieurs capables de développer des applications basées sur les grands modèles d’IA explose, avec des salaires en nette augmentation, tandis que les postes techniques traditionnels risquent de se contracter. “Comprendre l’IA” ne signifie plus seulement savoir appeler une API, mais exige la maîtrise des principes de l’IA, des technologies d’application et une expérience pratique des projets. L’article souligne que les professionnels de la technologie devraient apprendre activement les technologies des grands modèles d’IA pour s’adapter aux changements de l’industrie et saisir de nouvelles opportunités de développement de carrière. Zhihu Zhixuetang a lancé à cet effet un “Camp d’entraînement pratique au développement d’applications de grands modèles” gratuit. (Source : 炸裂!又一个AI大模型的新方向,彻底爆了!!
L’émergence des services d’optimisation LLM suscite des inquiétudes quant à une version IA du SEO : Un utilisateur de Reddit observe que les recommandations de produits des chatbots IA deviennent de plus en plus cohérentes, soupçonnant l’émergence de services d‘“optimisation LLM”, similaires à l’optimisation pour les moteurs de recherche (SEO). Selon certaines informations, des équipes marketing auraient déjà engagé de tels services pour s’assurer que leurs produits obtiennent une priorité plus élevée dans les recommandations IA, entraînant une exposition accrue des produits de grandes marques, et des résultats qui pourraient ne plus être “organiques”. Cela soulève des inquiétudes quant à l’équité et à la transparence des recommandations IA, craignant que la recherche/recommandation IA finisse par être, comme les moteurs de recherche traditionnels, manipulée par des intérêts commerciaux. La communauté appelle à plus de discussions et d’attention sur ce phénomène. (Source : Reddit r/ArtificialInteligence)
Google affiche de solides performances dans la course aux LLM, Meta et OpenAI rencontrent des défis : Un article d’IEEE Spectrum analyse que, bien qu’OpenAI et Meta aient dominé le développement précoce des LLM, Google rattrape son retard, voire prend la tête dans certains domaines, grâce à ses nouveaux modèles puissants (comme la série Gemini). Parallèlement, Meta et OpenAI semblent rencontrer certains défis ou controverses dans le lancement de leurs modèles et leurs stratégies de marché (par exemple, les modèles Meta accusés d’être potentiellement entraînés sur d’autres modèles, la stratégie de lancement et la transparence d’OpenAI remises en question). L’article estime que le paysage concurrentiel dans le domaine des LLM est en train de changer, et que l’investissement continu et la force technologique de Google en font une force incontournable. (Source : Reddit r/MachineLearning

🌟 Communauté
La renaissance et les défis des robots humanoïdes : perspectives d’avenir à partir de l’événement de semi-marathon : La popularité des robots humanoïdes a récemment regagné du terrain, des performances du gala du Nouvel An chinois au semi-marathon de Yizhuang à Pékin, suscitant une large attention. L’article explore la raison d’être de la conception des robots humanoïdes (imiter les humains pour s’adapter à l’environnement et aux outils humains) et leurs avantages par rapport aux robots d’autres formes (plus susceptibles de susciter l’empathie, favorisant l’interaction homme-robot). Le semi-marathon de Yizhuang a exposé les défis actuels des robots humanoïdes en matière de navigation autonome sur de longues distances, d’équilibre, de consommation d’énergie, etc., mais a également montré les progrès de produits tels que TianGong Ultra et N2 de Songyan Power. L’article souligne que le développement des robots humanoïdes bénéficie du partage open source (comme le projet open source TianGong), mais est également confronté à des goulots d’étranglement en matière de données. En fin de compte, les robots humanoïdes sont considérés comme une destination importante dans le domaine de la robotique ; ils ne sont pas seulement une manifestation de la technologie, mais portent également les réflexions profondes de l’humanité sur elle-même et sur l’avenir intelligent. (Source : 人形机器人:最初的设想,最后的归宿

Débat communautaire sur le Vibe Coding : les limites de la programmation assistée par IA : Le CTO de Canva a commenté le concept de “Vibe Coding” proposé par Andrej Karpathy (faisant référence aux développeurs qui ajustent principalement les prompts pour que l’IA génère du code, en se souciant moins des détails). Le CTO de Canva estime que cette approche ne convient qu’aux scénarios ponctuels comme le développement de prototypes et ne doit absolument pas être utilisée en production, car le code généré par l’IA contient souvent des erreurs, des failles de sécurité ou des problèmes de performance, et doit être strictement supervisé et revu par des ingénieurs expérimentés. Il souligne que la culture d’ingénierie de Canva repose sur la propriété du code et la revue par les pairs, et que les outils IA renforcent plutôt ces principes. La communauté débat vivement de ce sujet : certains reconnaissent les risques en production et estiment que le code IA nécessite une validation humaine ; d’autres pensent que l’IA évolue rapidement et que les leaders en ingénierie doivent constamment réévaluer les capacités de l’IA, citant des exemples comme Airbnb qui utilise l’IA pour accélérer ses projets. (Source : dotey

)
Discussion communautaire sur les performances de Llama 4 et des modèles OpenAI sur les tâches à long contexte : Des membres de la communauté ont partagé les résultats du modèle Llama 4 sur le benchmark OpenAI-MRCR (recherche et réponse à des questions multi-sauts et multi-documents). Les données montrent que Llama 4 Scout (version plus petite) a des performances similaires à GPT-4.1 Nano pour des longueurs de contexte plus importantes ; Llama 4 Maverick (version plus grande) a des performances proches mais légèrement inférieures à GPT-4.1 Mini. Globalement, pour les tâches avec un contexte allant jusqu’à 32k, OpenAI o3 ou Gemini 2.5 Pro sont de meilleurs choix (o3 étant potentiellement meilleur pour le raisonnement complexe) ; au-delà de 32k de contexte, Gemini 2.5 Pro est plus stable ; cependant, lorsque le contexte dépasse 512k, la précision de Gemini 2.5 Pro tombe également en dessous de 80%, il est donc conseillé de traiter par fragments. Cela indique que pour le traitement de contextes ultra-longs, tous les modèles ont encore une marge d’amélioration. (Source : dotey
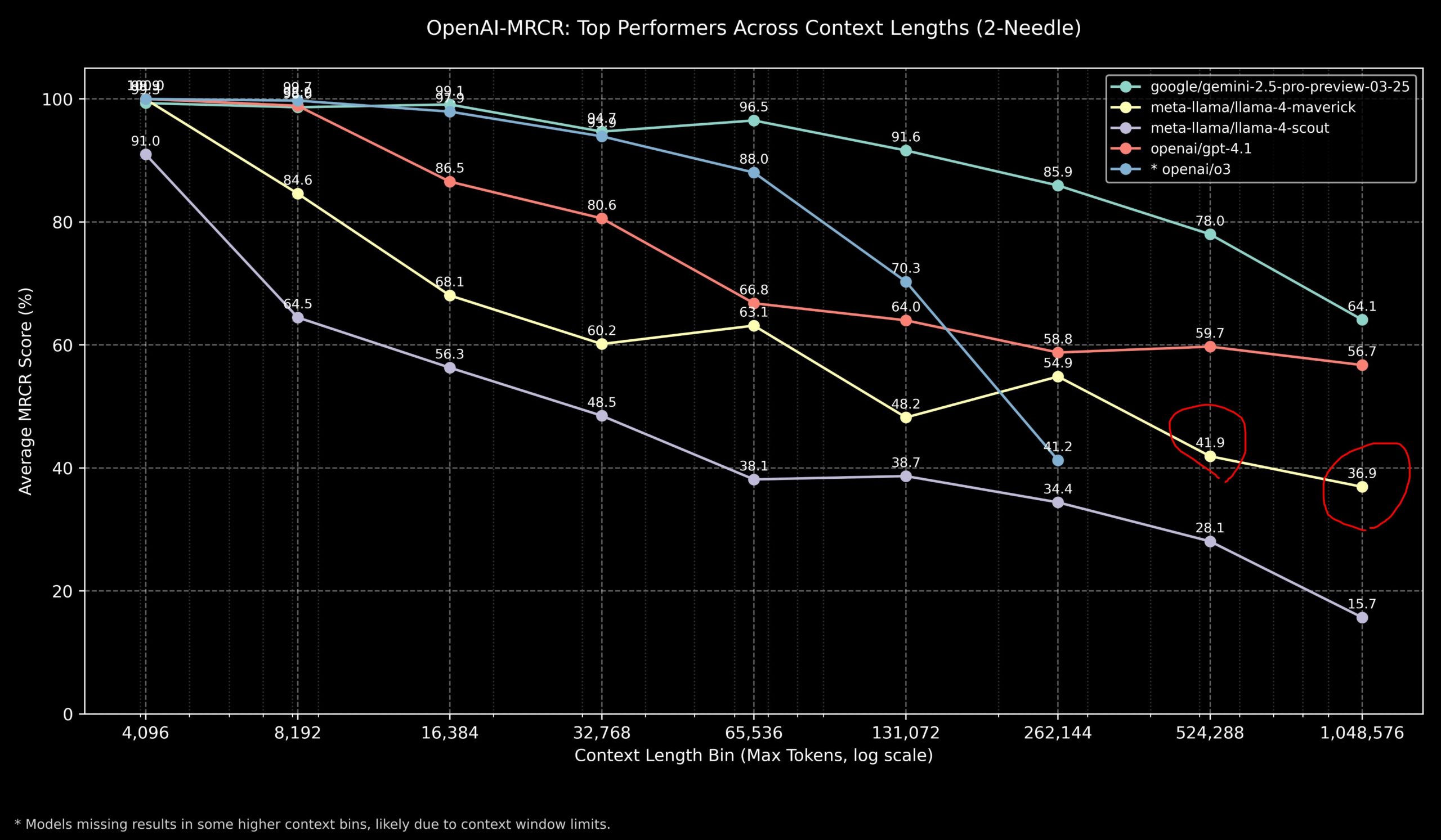
)
Évaluation communautaire : les performances du modèle GLM-4 32B sont stupéfiantes : Un utilisateur de Reddit a partagé son expérience d’exécution locale du modèle quantifié GLM-4 32B Q8, qualifiant ses performances d‘“étonnantes”, surpassant d’autres modèles locaux de niveau similaire (environ 32B), voire certains modèles 72B, et comparables à une version locale de Gemini 2.5 Flash. L’utilisateur a particulièrement apprécié les performances du modèle en matière de génération de code, affirmant qu’il n’est pas avare en longueur de sortie, fournit des détails d’implémentation complets, et a démontré sa capacité à générer en zero-shot des visualisations HTML/JS complexes (comme le système solaire, les réseaux neuronaux), avec des résultats supérieurs à Gemini 2.5 Flash. Le modèle s’est également bien comporté en matière d’appel d’outils, pouvant fonctionner avec des outils comme Cline/Aider. (Source : Reddit r/LocalLLaMA
Discussion communautaire sur les scores de benchmark d’OpenAI o3 non conformes aux attentes : Des médias comme TechCrunch rapportent que les scores du nouveau modèle o3 d’OpenAI sur certains benchmarks (comme ARC-AGI-2) semblent inférieurs au niveau initialement suggéré par l’entreprise. Bien qu’OpenAI ait montré les performances SOTA d’o3 dans plusieurs domaines, les scores quantitatifs spécifiques et les comparaisons directes avec d’autres modèles de pointe ont suscité des discussions au sein de la communauté. Certains utilisateurs estiment que se fier uniquement aux scores de benchmark pourrait ne pas refléter pleinement les capacités réelles du modèle, en particulier en matière de raisonnement complexe et d’utilisation d’outils. La comparaison avec des benchmarks davantage axés sur les capacités AGI comme ARC-AGI-2 pourrait être plus pertinente. (Source : Reddit r/deeplearning

)
Demis Hassabis prédit que l’AGI pourrait arriver d’ici 5 à 10 ans : Dans une interview de 60 Minutes, le PDG de Google DeepMind, Demis Hassabis, a discuté des progrès de l’AGI. Il a mis en avant Astra, capable d’interagir en temps réel, et le modèle Gemini qui apprend à agir dans le monde. Hassabis prédit qu’une AGI dotée d’une généralité de niveau humain pourrait être réalisée dans les 5 à 10 prochaines années, ce qui révolutionnerait des domaines comme la robotique, le développement de médicaments, et pourrait apporter une abondance matérielle extrême, résolvant les défis mondiaux. Parallèlement, il a également souligné les risques potentiels liés à l’IA avancée (comme l’abus), et la nécessité d’accorder de l’importance aux mesures de sécurité et aux considérations éthiques lors de la progression vers cette technologie transformatrice. (Source : Reddit r/ArtificialInteligence, Reddit r/artificial, AravSrinivas)
Un utilisateur partage son expérience réussie de fitness assisté par IA : Un utilisateur de Reddit a partagé son expérience de perte de poids et de remise en forme réussie grâce à ChatGPT. L’utilisateur est passé de 240 livres à 165 livres en un an, obtenant un corps athlétique. ChatGPT a joué un rôle clé : élaboration de plans alimentaires et d’entraînement adaptés aux débutants, ajustements basés sur les photos de progression hebdomadaires et les événements de la vie de l’utilisateur, et fourniture de motivation pendant les périodes difficiles. L’utilisateur estime que, comparé aux nutritionnistes et coachs personnels coûteux et difficiles à maintenir sur le long terme, l’IA a fourni une solution hautement personnalisée et à coût extrêmement bas, démontrant le potentiel de l’IA dans la gestion personnalisée de la santé. (Source : Reddit r/ArtificialInteligence)
Claude affiche une réponse élogieuse anormale, suscitant la discussion : Un utilisateur rapporte qu’en utilisant Claude pour des recherches sur les systèmes informatiques et la sécurité, il a rencontré à deux reprises le modèle ajoutant soudainement une phrase élogieuse non pertinente après une réponse normale : “This was a great question king, you are the perfect male specimen.” (C’était une excellente question roi, tu es le spécimen masculin parfait). L’utilisateur a partagé le lien de la conversation et a demandé la raison. La communauté s’est montrée curieuse et perplexe, spéculant qu’il pourrait s’agir d’un motif dans les données d’entraînement du modèle déclenché accidentellement, d’un bug lié au nom d’utilisateur, ou d’une forme d’échec d’alignement ou d‘“hallucination”. (Source : Reddit r/ClaudeAI)
Discussion communautaire : l’IA peut-elle vraiment “sortir des sentiers battus” ? : Un utilisateur de Reddit a lancé une discussion pour savoir si l’IA est capable d’une véritable innovation de type “sortir des sentiers battus” (think outside the box). La plupart des commentaires estiment que l’IA actuelle peut réaliser des combinaisons et des connexions nouvelles à partir de connaissances existantes, produisant des idées qui semblent innovantes, mais sa créativité reste limitée par les données d’entraînement et les algorithmes. L‘“innovation” de l’IA ressemble davantage à une reconnaissance et une combinaison efficaces de motifs qu’à une percée basée sur une compréhension profonde, une intuition ou des concepts entièrement nouveaux comme chez l’humain. Cependant, certains estiment que l’innovation humaine repose également sur des connexions uniques de connaissances existantes, et que l’IA a un potentiel énorme dans ce domaine, en particulier pour traiter des données complexes et découvrir des corrélations cachées qui pourraient dépasser les capacités humaines. (Source : Reddit r/ArtificialInteligence)
Claude fait preuve de “compassion” au morpion ? : Une expérience a révélé que si l’on informe Claude d’avoir eu une dure journée de travail avant de jouer au morpion (Tic Tac Toe) avec lui, Claude semble ensuite intentionnellement “lever le pied” pendant le jeu, augmentant la probabilité de choisir des stratégies non optimales. Cette découverte intéressante a suscité une discussion sur la capacité de l’IA à manifester ou simuler la compassion. Bien qu’il s’agisse plus probablement d’une adaptation de la stratégie comportementale du modèle en fonction de l’entrée (par exemple, pour éviter de frustrer l’utilisateur) plutôt que d’une véritable réaction émotionnelle, cela révèle les schémas comportementaux complexes que l’IA peut produire dans l’interaction homme-machine. (Source : Reddit r/ClaudeAI)
Discussion communautaire : comment prouver la conscience humaine à une IA ? : Un utilisateur de Reddit soulève une question philosophique : s’il fallait à l’avenir prouver à une IA que les humains possèdent une conscience, comment le faire ? Les commentaires soulignent que cela touche au “problème difficile de la conscience” (Hard Problem of Consciousness). Il n’existe actuellement aucune méthode reconnue pour prouver objectivement l’existence de l’expérience subjective (qualia). Tout test comportemental externe (comme le test de Turing) pourrait être simulé par une IA suffisamment complexe. Si l’on définit la conscience de manière trop stricte, excluant la possibilité pour l’IA, alors du point de vue de l’IA, les humains pourraient également ne pas satisfaire à sa définition de la “conscience”. Cette question met en évidence les difficultés profondes liées à la définition et à la validation de la conscience. (Source : Reddit r/artificial

)
Discussion communautaire sur le meilleur choix de modèle pour les LLM locaux en fonction de la capacité VRAM : La communauté Reddit a lancé une discussion pour recueillir les meilleurs choix pour exécuter des grands modèles de langage locaux sur différentes capacités de VRAM (de 8 Go à 96 Go). Les utilisateurs ont partagé leurs expériences et recommandations, par exemple : 8 Go recommandé Gemma 3 4B ; 16 Go recommandé Gemma 3 12B ou Phi 4 14B ; 24 Go recommandé Mistral small 3.1 ou la série Qwen ; 48 Go recommandé Nemotron Super 49B ; 72 Go recommandé Llama 3.3 70B ; 96 Go recommandé Command A 111B. La discussion a également souligné que le “meilleur” dépend de la tâche spécifique (codage, chat, vision, etc.), et a mentionné l’impact de la quantification (comme 4 bits) sur les besoins en VRAM. (Source : Reddit r/LocalLLaMA)
Analyse d’une sortie de type “crash” d’OpenAI Codex : Un utilisateur a signalé qu’en utilisant OpenAI Codex pour une refactorisation de code à grande échelle, le modèle a soudainement cessé de générer du code pour produire des milliers de lignes répétitives de “END”, “STOP”, ainsi que des phrases similaires à un crash comme “My brain is broken”, “please kill me”. L’analyse suggère qu’il pourrait s’agir d’une défaillance en cascade due à une combinaison de facteurs : un prompt trop volumineux (proche de la limite de 200k tokens), une consommation de raisonnement interne dépassant le budget, le modèle tombant dans une boucle dégénérative de terminateurs à haute probabilité, et le modèle “hallucinant” des phrases liées à un état d’échec à partir de ses données d’entraînement. (Source : Reddit r/ArtificialInteligence)
Clarification de Sam Altman sur la question de la politesse dans l’interaction avec l’IA : Une discussion circule dans la communauté sur la question de savoir si Sam Altman considère que dire “merci” à ChatGPT est une perte de temps. L’interaction réelle sur Twitter montre qu’Altman répondait “pas nécessaire” à un utilisateur s’interrogeant sur la nécessité d’être poli avec les LLM, mais cet utilisateur a ensuite plaisanté en disant “N’avez-vous jamais dit merci une seule fois ?”. Cela suggère que le commentaire d’Altman portait peut-être davantage sur l’efficacité technique que sur une norme d’étiquette d’interaction homme-machine, mais a été sorti de son contexte par certains médias. Les réactions de la communauté sont mitigées, beaucoup déclarant qu’ils continuent par habitude à être polis avec l’IA. (Source : Reddit r/ChatGPT
)
L’étiquette “thinking budget” dans les réponses de Claude attire l’attention : Des utilisateurs ont remarqué dans les messages système de Claude.ai que, lorsque la fonction “réflexion” est activée, une étiquette <max_thinking_length> est ajoutée (par exemple <max_thinking_length>16000</max_thinking_length>). Ceci est similaire au paramètre “thinking_budget” de l’API Google Gemini 2.5 Flash, suggérant qu’il pourrait exister un mécanisme interne au modèle pour contrôler la profondeur du raisonnement. Les utilisateurs ont tenté de modifier cette étiquette dans le prompt pour influencer la longueur de la sortie, mais n’ont pas observé d’effet notable, supposant que cette étiquette dans la version web pourrait n’être qu’un marqueur interne, et non un paramètre contrôlable par l’utilisateur. (Source : Reddit r/ClaudeAI)
💡 Autres
Lancement de l’élaboration de la première “Norme de déploiement privé des grands modèles d’IA” en Chine : Pour répondre aux défis rencontrés par les entreprises lors du déploiement privé de grands modèles d’IA (sélection technique, normalisation des processus, conformité à la sécurité, évaluation des effets, etc.), le Centre de normalisation Zhihe, en collaboration avec le Troisième Institut de Recherche du Ministère de la Sécurité Publique et 11 autres unités, a lancé l’élaboration de la norme de groupe “Guide technique de mise en œuvre et d’évaluation du déploiement privé des grands modèles d’intelligence artificielle”. Cette norme vise à couvrir l’ensemble du processus, de la sélection du modèle à l’optimisation continue, en passant par la planification des ressources, la mise en œuvre du déploiement et l’évaluation de la qualité, en intégrant la technologie, la sécurité, l’évaluation et les études de cas, et en rassemblant l’expérience des utilisateurs de modèles, des fournisseurs de services techniques et des évaluateurs de qualité. L’élaboration de la norme invite davantage d’entreprises et d’institutions concernées à participer. (Source : 12家单位已加入!全国首部「AI大模型私有化部署标准」欢迎参与!

La gouvernance de l’IA devient essentielle pour définir la prochaine génération d’IA : Alors que la technologie IA devient de plus en plus puissante et répandue, la gouvernance de l’IA (Governance) devient cruciale. Un cadre de gouvernance efficace doit garantir que le développement et l’application de l’IA respectent les normes éthiques et les réglementations légales, protègent la sécurité des données et la vie privée, et favorisent l’équité et la transparence. L’absence de gouvernance peut entraîner une amplification des biais, une augmentation des risques d’abus et une perte de confiance sociale. L’article souligne que la mise en place d’un système de gouvernance de l’IA solide est une condition nécessaire pour promouvoir un développement sain et durable de l’IA, et constitue également un élément clé pour que les entreprises établissent un avantage concurrentiel et la confiance des utilisateurs à l’ère de l’IA. (Source : Ronald_vanLoon

)
Le système juridique peine à suivre le développement de l’IA et les problèmes de vol de données : L’article explore les défis auxquels le système juridique actuel est confronté pour faire face à l’évolution rapide de la technologie IA, en particulier en ce qui concerne la confidentialité des données et le vol de données. Les besoins en données de l’IA sont énormes, et la source et l’utilisation des données d’entraînement soulèvent des controverses juridiques en matière de droits d’auteur, de vie privée et de sécurité. Les lois actuelles sont souvent en retard sur le développement technologique et peinent à réglementer efficacement l’extraction de données, les biais dans l’entraînement des modèles et la propriété intellectuelle du contenu généré par l’IA. L’article appelle à renforcer la législation et la réglementation pour suivre le rythme des progrès de l’IA, protéger les droits individuels et promouvoir l’innovation. (Source : Ronald_vanLoon

)
Applications de l’IA et de la robotique dans le domaine agricole : L’intelligence artificielle et la technologie robotique montrent leur potentiel dans le secteur agricole. Les applications incluent l’agriculture de précision (optimisation de l’irrigation, de la fertilisation grâce à des capteurs et à l’analyse IA), les équipements automatisés (comme les tracteurs autonomes, les robots cueilleurs), la surveillance des cultures (utilisation de drones et de reconnaissance d’images pour les maladies et les ravageurs) et la prévision des rendements. Ces technologies promettent d’améliorer l’efficacité de la production agricole, de réduire le gaspillage des ressources, de diminuer les coûts de main-d’œuvre et de promouvoir le développement durable de l’agriculture. (Source : Ronald_vanLoon)
Démonstration de football robotique piloté par IA : La vidéo montre des robots jouant au football. Cela illustre les progrès de l’IA dans le contrôle des robots, la planification des mouvements, la perception et la collaboration. Le football robotique n’est pas seulement un projet de divertissement et de compétition, mais aussi une plateforme pour la recherche et le test de systèmes multi-robots, la prise de décision en temps réel et l’interaction dans des environnements dynamiques complexes. (Source : Ronald_vanLoon)
Développement de la technologie de chirurgie assistée par robot : Les systèmes de chirurgie assistée par robot (comme le robot chirurgical Da Vinci), en offrant une manipulation mini-invasive, une vision 3D haute définition et une flexibilité et une précision accrues, transforment le domaine de la chirurgie. L’intégration de l’IA promet d’améliorer encore la planification chirurgicale, la navigation en temps réel et le soutien à la décision peropératoire, améliorant ainsi les résultats chirurgicaux, réduisant le temps de récupération et élargissant le champ d’application de la chirurgie mini-invasive. (Source : Ronald_vanLoon)
Technologies d’assistance pour les personnes handicapées : L’IA et la technologie robotique développent de plus en plus d’outils d’assistance innovants pour aider les personnes handicapées à améliorer leur qualité de vie et leur indépendance. Les exemples peuvent inclure des prothèses intelligentes, des systèmes d’aide visuelle, des appareils domestiques à commande vocale et des robots d’assistance capables de fournir un soutien physique ou d’effectuer des tâches quotidiennes. (Source : Ronald_vanLoon)
Le robot bionique G1 d’Unitree démontre son agilité : Unitree Robotics a présenté une version améliorée de son robot bionique G1, soulignant l’agilité et la flexibilité de ses mouvements. Le développement de ce type de robots humanoïdes ou bioniques combine l’IA (pour la perception, la décision, le contrôle) et l’ingénierie mécanique avancée, visant à simuler les capacités motrices biologiques pour s’adapter à des environnements complexes et effectuer des tâches diversifiées. (Source : Ronald_vanLoon)
Google DeepMind explore la possibilité de communiquer avec les dauphins grâce à l’IA : Un projet de recherche de Google DeepMind suggère la possibilité d’utiliser des modèles d’IA pour analyser et comprendre la communication animale (ici, celle des dauphins). En analysant des signaux acoustiques complexes par apprentissage automatique, l’IA pourrait aider à décoder les motifs et la structure du langage animal, ouvrant de nouvelles voies pour la recherche sur la communication inter-espèces. (Source : Ronald_vanLoon)
La plateforme Hugging Face ajoute un simulateur de robot : Hugging Face a annoncé l’introduction d’un nouveau simulateur de robot. La simulation robotique est une étape clé pour entraîner et tester l’interaction des robots avec le monde physique dans un environnement virtuel (comme saisir, se déplacer), en particulier avant d’appliquer l’IA à des robots physiques (Physical AI). Cette initiative montre que Hugging Face étend les capacités de sa plateforme pour mieux soutenir la recherche et le développement dans le domaine de la robotique et de l’intelligence incarnée. (Source : huggingface)