
Mots-clés:Quatre géants de l’IA, Intelligence incarnée, Robot humanoïde, Mur de mémoire, Modèle multimodal SenseTime Rixin V6, Jeu de données Open X-Embodiment, Robot Tesla Optimus, Technologie 3D FeRAM, Demi-marathon du robot TianGong Ultra, Modèle quantifié Gemma 3 QAT, Acquisition de Pollen Robotics par Hugging Face, Flux de travail documentaire pour agents intelligents LlamaIndex
🔥 Focus
Les « quatre petits dragons de l’IA » confrontés à des défis et à une transformation : Les entreprises autrefois surnommées les « quatre petits dragons de l’IA », telles que SenseTime, Megvii, CloudWalk et Yitu, sont confrontées ces dernières années à des difficultés de commercialisation et à des pertes continues. Par exemple, SenseTime a enregistré une perte de 4,3 milliards de yuans en 2024, avec des pertes cumulées dépassant 54,6 milliards de yuans ; CloudWalk a perdu près de 600 à 700 millions de yuans en 2024, avec des pertes cumulées de plus de 4,4 milliards de yuans. Pour relever ces défis, ces entreprises procèdent à des ajustements stratégiques, notamment des licenciements, des réductions de salaires et des restructurations d’activités. Face à la nouvelle vague d’IA dominée par les grands modèles de langage, les « quatre petits dragons », issus de la technologie visuelle, se tournent activement vers les grands modèles multimodaux et le domaine de l’AGI. SenseTime a lancé le modèle multimodal « Rìrìxīn V6 », concurrent de GPT-4o, et investit massivement dans la construction de centres de calcul intelligent ; Yitu se concentre sur les modèles multimodaux centrés sur la vision et collabore avec Huawei pour réduire les coûts matériels ; CloudWalk collabore également avec Huawei pour lancer une machine intégrée d’entraînement et d’inférence de grands modèles ; Megvii, quant à elle, tire parti de ses avantages algorithmiques pour pénétrer le marché des solutions purement visuelles pour la conduite intelligente. Ces initiatives montrent qu’elles s’efforcent de rester dans la course de l’IA et de s’adapter au nouvel environnement de marché. (Source : 36氪)

Dilemme des données pour l’intelligence incarnée et progrès des jeux de données open source : Le développement des robots humanoïdes et de l’intelligence incarnée est confronté à un goulot d’étranglement critique des données. Le manque de données d’entraînement de haute qualité freine la percée de leurs capacités. Contrairement aux modèles de langage qui disposent d’énormes quantités de données textuelles provenant d’Internet, les robots nécessitent des données d’interaction diversifiées avec le monde physique, dont l’acquisition est coûteuse. Pour résoudre ce problème, les instituts de recherche et les entreprises construisent et publient activement des jeux de données open source, tels que Open X-Embodiment publié conjointement par Google DeepMind et plusieurs institutions, ARIO du Peng Cheng Laboratory, RoboMIND du Beijing Innovation Center, AgiBot World de Agibot (contenant des données de tâches complexes à long terme dans des scénarios réels) et le jeu de données de simulation AgiBot Digital World, ainsi que le jeu de données d’opérations G1 d’Unitree. Bien que l’échelle de ces jeux de données soit encore bien inférieure à celle des données textuelles, ils favorisent le développement du domaine de l’intelligence incarnée en unifiant les normes, en améliorant la qualité et en enrichissant les scénarios, jetant ainsi les bases pour atteindre un « moment ImageNet ». (Source : 36氪)

Aube de la production de masse des robots humanoïdes : percées dans les données, la simulation et la généralisation : Malgré les défis tels que le coût élevé de la collecte de données et la faible capacité de généralisation, plusieurs entreprises (Tesla, Figure AI, 1X, Agibot, Unitree, UBTECH, etc.) prévoient toujours de réaliser la production de masse de robots humanoïdes en 2025. Les solutions envisagées comprennent : 1) L’entraînement à grande échelle sur machine réelle, soutenu par les gouvernements (Pékin, Shanghai, Shenzhen, Guangdong) pour construire des bases de collecte de données et établir des normes ; 2) L’entraînement avancé par simulation, utilisant des modèles du monde comme Nvidia Cosmos et Google Genie2 pour générer des environnements virtuels physiquement réalistes, réduisant les coûts et améliorant l’efficacité ; 3) La généralisation grâce à l’IA, via de nouveaux modèles d’action tels que Helix de Figure AI, l’architecture ViLLA de Agibot GO-1, et Gemini Robotics de Google, qui utilisent moins de données pour parvenir à une compréhension généralisée des opérations physiques, permettant aux robots de manipuler des objets inconnus et de s’adapter à de nouveaux environnements. Ces avancées technologiques laissent présager une accélération possible de l’application commerciale des robots humanoïdes. (Source : 36氪)

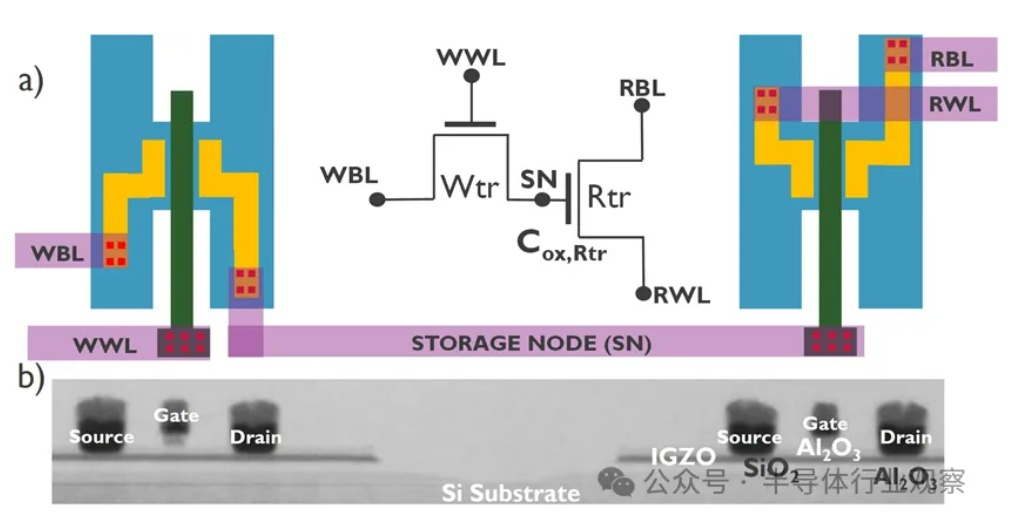
Le développement de l’IA confronté à la crise du « memory wall », de nouvelles technologies de stockage cherchent à percer : La croissance exponentielle de la taille des modèles d’IA pose de sérieux défis à la bande passante mémoire. La croissance de la bande passante des DRAM traditionnelles est bien inférieure à celle de la puissance de calcul, créant un goulot d’étranglement appelé « memory wall » qui limite les performances des processeurs. La technologie HBM, grâce à l’empilement 3D, augmente considérablement la bande passante et atténue une partie de la pression, mais son processus de fabrication est complexe et coûteux. Par conséquent, l’industrie explore activement de nouvelles technologies de stockage : 1) 3D FeRAM (Ferroelectric RAM) : Comme SunRise Memory, utilisant l’effet ferroélectrique du HfO2 pour réaliser un stockage haute densité, non volatile et à faible consommation. 2) DRAM + Mémoire non volatile : Neumonda collabore avec FMC pour utiliser le HfO2 afin de transformer les condensateurs DRAM en stockage non volatile. 3) 2T0C IGZO DRAM : imec propose de remplacer la structure traditionnelle 1T1C par deux transistors à oxyde, sans condensateur, pour obtenir une faible consommation, une haute densité et un long temps de rétention. 4) Mémoire à changement de phase (PCM) : Utilise le changement de phase des matériaux pour stocker les données, réduisant la consommation d’énergie. 5) UK III-V Memory : Basée sur GaSb/InAs, combinant la vitesse de la DRAM et la non-volatilité de la mémoire flash. 6) SOT-MRAM : Utilise le couple spin-orbite pour une faible consommation et une haute efficacité énergétique. Ces technologies pourraient briser le goulot d’étranglement de la DRAM et remodeler le paysage du marché du stockage. (Source : 36氪)
🎯 Tendances
Le robot Tiangong termine un défi de semi-marathon, une production en petite série est prévue : Le robot « Tiangong Ultra » de l’équipe Tiangong du Beijing Humanoid Robot Innovation Center (1,8 m, 55 kg) a remporté la première course de semi-marathon pour robots humanoïdes, parcourant environ 21 km en 2 heures 40 minutes et 42 secondes. Cet événement a testé la fiabilité de l’autonomie, de la structure, de la perception et des algorithmes de contrôle du robot sur des terrains complexes. L’équipe a déclaré qu’en optimisant la stabilité des articulations, la résistance à la chaleur, le système de consommation d’énergie, l’équilibre et les algorithmes de planification de la démarche, et en intégrant la plateforme auto-développée « Huisi Kaiwu » (cerveau incarné + cervelet), le robot a réalisé une planification autonome de trajectoire et un ajustement en temps réel sans guidage filaire. L’achèvement du marathon prouve sa fiabilité de base, jetant les bases de la production de masse. Le robot Tiangong 2.0 sera bientôt mis en vente, avec une production prévue en petite série, visant des applications futures dans l’industrie, la logistique, les opérations spéciales et les services à domicile. (Source : 36氪)

La Chine développe un cerveau de robot utilisant des cellules humaines cultivées : Selon des rapports, des chercheurs chinois développent un robot piloté par des cellules cérébrales humaines cultivées. Cette recherche vise à explorer les possibilités du calcul biologique, en utilisant les capacités d’apprentissage et d’adaptation des neurones biologiques pour contrôler le matériel robotique. Bien que les détails spécifiques et le stade d’avancement ne soient pas clairs, cette direction représente une exploration de pointe à l’intersection de la robotique, de l’intelligence artificielle et de la biotechnologie, et pourrait ouvrir de nouvelles voies pour le développement futur de systèmes robotiques plus intelligents et plus adaptatifs. (Source : Ronald_vanLoon)
Excellentes performances du modèle quantifié Gemma 3 QAT : Un utilisateur a comparé la version QAT (Quantization Aware Training) du modèle Google Gemma 3 27B avec d’autres versions quantifiées Q4 (Q4_K_XL, Q4_K_M) sur le benchmark GPQA Diamond. Les résultats montrent que la version QAT offre les meilleures performances (36,4 % de précision) tout en ayant la plus faible occupation de VRAM (16,43 Go), surpassant Q4_K_XL (34,8 %, 17,88 Go) et Q4_K_M (33,3 %, 17,40 Go). Cela indique que la technologie QAT réduit efficacement les besoins en ressources tout en maintenant les performances du modèle. (Source : Reddit r/LocalLLaMA)
Rumeur : AMD lancerait une carte graphique RDNA 4 Radeon PRO avec 32 Go de VRAM : VideoCardz rapporte qu’AMD prépare une carte graphique de la série Radeon PRO basée sur le GPU Navi 48 XTW, qui serait équipée de 32 Go de mémoire vidéo. Si cela se confirme, cela offrirait une nouvelle option aux utilisateurs ayant besoin d’une grande quantité de VRAM pour l’entraînement et l’inférence de modèles d’IA en local, en particulier compte tenu des limitations habituelles de VRAM sur les cartes graphiques grand public. Cependant, les performances spécifiques, le prix et la date de sortie n’ont pas encore été annoncés, et sa compétitivité réelle reste à voir. (Source : Reddit r/LocalLLaMA)

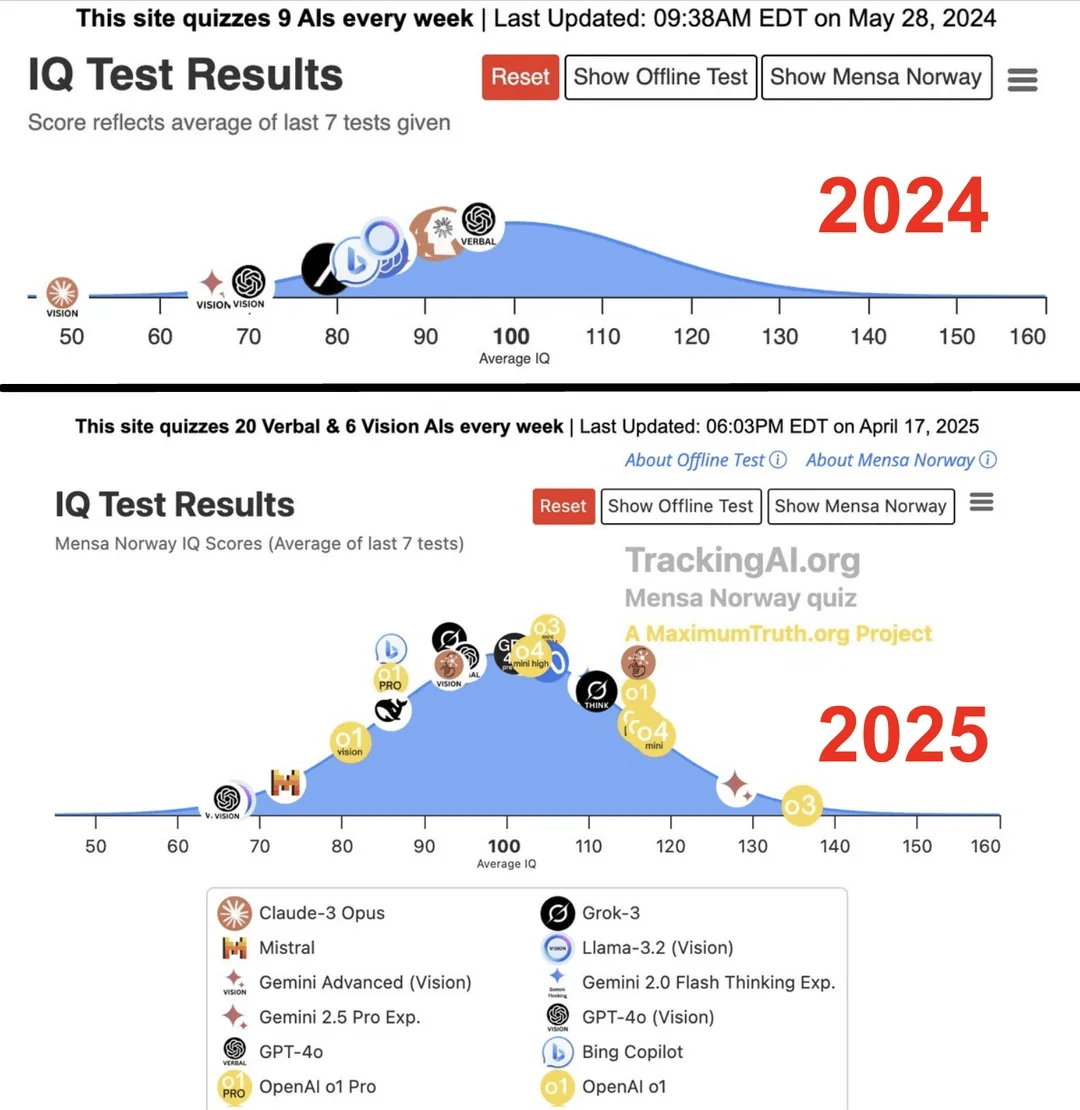
Une étude affirme que le QI des IA de pointe a bondi de 96 à 136 en un an : Selon une étude publiée sur le site Maximum Truth (fiabilité de la source à vérifier), des tests de QI effectués sur des modèles d’IA ont révélé que le score de QI de l’IA la plus intelligente (probablement la série GPT) est passé de 96 (légèrement inférieur à la moyenne humaine) à 136 (proche du niveau de génie) en un an. Bien que la validité des tests de QI pour mesurer l’intelligence de l’IA soit controversée et qu’il existe une possibilité de contamination des tests par les données d’entraînement, cette amélioration significative reflète les progrès rapides de la capacité de l’IA à résoudre les problèmes des tests d’intelligence standardisés. (Source : Reddit r/artificial)
🧰 Outils
OpenUI : Générer des interfaces utilisateur en temps réel par description : wandb a rendu open source OpenUI, un outil permettant aux utilisateurs de concevoir et de rendre des interfaces utilisateur en temps réel par le biais de descriptions en langage naturel. Les utilisateurs peuvent demander des modifications et convertir le code HTML généré en code pour divers frameworks frontend tels que React, Svelte, Web Components, etc. OpenUI prend en charge plusieurs backends LLM, notamment OpenAI, Groq, Gemini, Anthropic (Claude), ainsi que des modèles locaux via LiteLLM ou Ollama. Le projet vise à rendre le processus de construction de composants UI plus rapide et plus amusant, et sert d’outil de test interne et de prototypage chez W&B. Bien qu’inspiré de v0.dev, OpenUI est open source. Une démo en ligne et des guides d’exécution locale (Docker ou code source) sont fournis. (Source : wandb/openui – GitHub Trending (all/daily))

PDFMathTranslate : Outil de traduction PDF IA préservant la mise en page : Développé par Byaidu, PDFMathTranslate est un puissant outil de traduction de documents PDF dont le principal avantage réside dans l’utilisation de la technologie IA pour traduire tout en conservant intégralement la mise en page originale du document, y compris les formules mathématiques complexes, les graphiques, les tables des matières et les annotations. L’outil prend en charge la traduction entre plusieurs langues et intègre divers services de traduction tels que Google, DeepL, Ollama, OpenAI, etc. Pour répondre aux besoins des différents utilisateurs, le projet propose plusieurs modes d’utilisation : ligne de commande (CLI), interface utilisateur graphique (GUI), image Docker et plugin Zotero. Les utilisateurs peuvent essayer la démo en ligne ou choisir la méthode d’installation appropriée en fonction de leurs besoins. (Source : Byaidu/PDFMathTranslate – GitHub Trending (all/daily))

Shandu AI Research : Système de génération de rapports avec citations basé sur LangGraph : Shandu AI Research est un système qui utilise le workflow LangGraph pour générer automatiquement des rapports avec citations. Il simplifie les tâches de recherche grâce à des techniques telles que le web scraping intelligent, la synthèse d’informations multi-sources et le traitement parallèle. Cet outil peut aider les utilisateurs à collecter, intégrer et analyser rapidement des informations, et à générer des rapports de recherche structurés et cités, améliorant ainsi l’efficacité de la recherche. (Source : LangChainAI)

Intel lance l’AI Playground open source : Intel a rendu open source l’AI Playground, une application d’entrée de gamme pour les PC IA qui permet aux utilisateurs d’exécuter divers modèles d’IA générative sur des PC équipés de cartes graphiques Intel Arc. Les modèles d’image/vidéo pris en charge incluent Stable Diffusion 1.5, SDXL, Flux.1-Schnell, LTX-Video ; les grands modèles de langage pris en charge incluent DeepSeek R1, Phi3, Qwen2, Mistral (Safetensor PyTorch LLM), ainsi que Llama 3.1, Llama 3.2, TinyLlama, Mistral 7B, Phi3 mini, Phi3.5 mini (GGUF LLM ou OpenVINO). Cet outil vise à abaisser la barrière d’entrée pour l’exécution locale de modèles d’IA, facilitant l’expérimentation pour les utilisateurs. (Source : karminski3)
Persona Engine : Projet d’assistant/streamer virtuel IA : Persona Engine est un projet open source visant à créer un assistant virtuel IA interactif ou un streamer virtuel. Il intègre de grands modèles de langage (LLM), l’animation Live2D, la reconnaissance automatique de la parole (ASR), la synthèse vocale (TTS) et la technologie de clonage vocal en temps réel. Les utilisateurs peuvent dialoguer vocalement directement avec le personnage Live2D, et le projet prend également en charge l’intégration dans des logiciels de streaming comme OBS pour créer des streamers virtuels IA. Ce projet démontre l’application intégrée de multiples technologies IA, fournissant un cadre pour la construction de personnages virtuels interactifs personnalisés. (Source : karminski3)
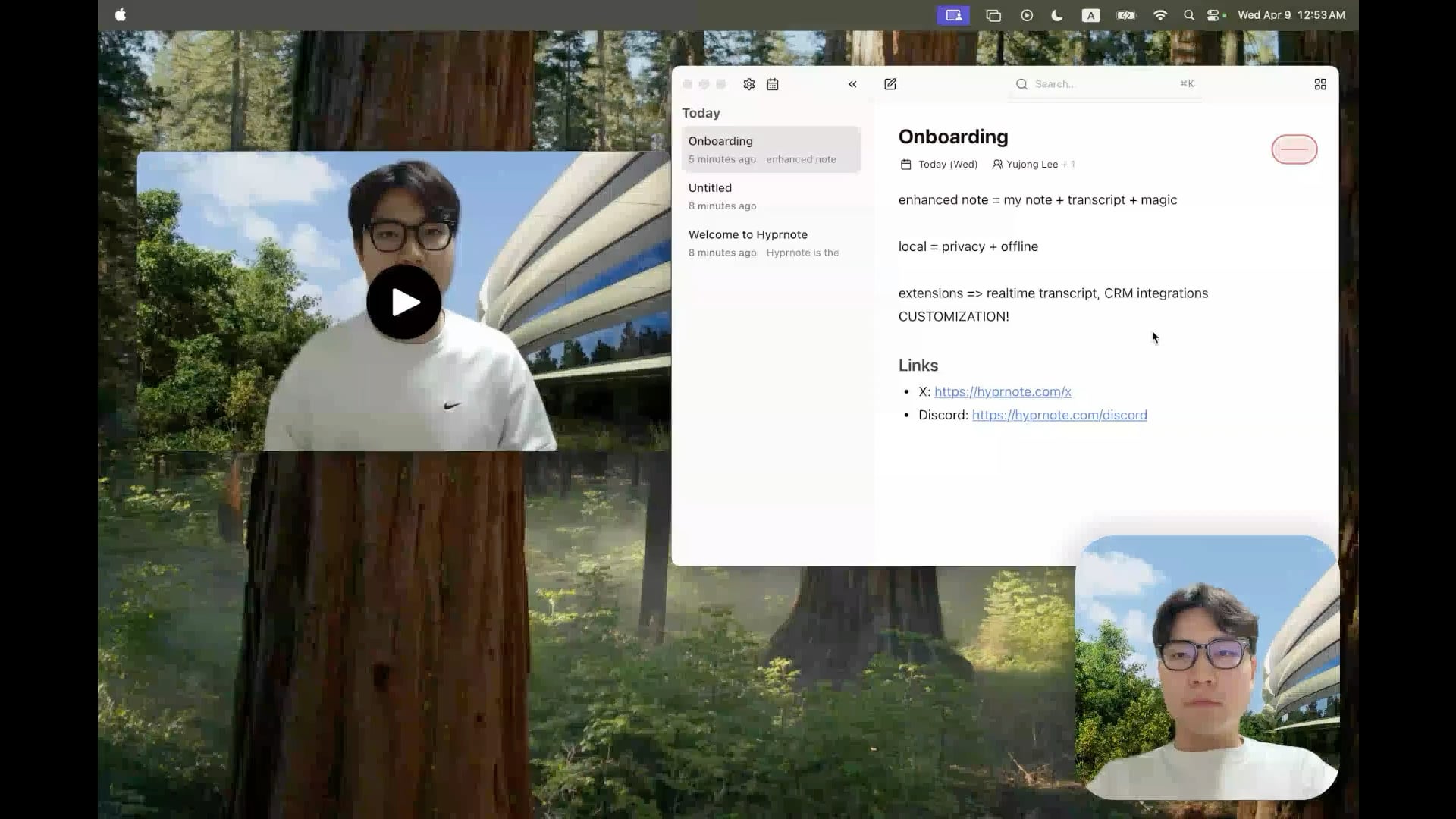
Hyprnote : Outil open source de prise de notes de réunion IA en local : Un développeur a rendu open source Hyprnote, une application de prise de notes intelligente conçue spécifiquement pour les réunions. Elle peut enregistrer l’audio pendant la réunion et combiner les notes brutes de l’utilisateur avec le contenu audio pour générer des comptes rendus de réunion améliorés. Sa caractéristique principale est l’exécution entièrement locale des modèles d’IA (comme Whisper pour la transcription vocale), garantissant la confidentialité et la sécurité des données de l’utilisateur. L’outil vise à aider les utilisateurs à mieux capturer et organiser les informations des réunions, particulièrement adapté aux utilisateurs qui doivent gérer des réunions consécutives. (Source : Reddit r/LocalLLaMA)
LMSA : Outil pour connecter LM Studio aux appareils Android : Un utilisateur a partagé une application nommée LMSA (lmsa.app), conçue pour aider les utilisateurs à connecter LM Studio (un outil populaire de gestion d’exécution de LLM locaux) à leurs appareils Android. Cela permet aux utilisateurs d’interagir avec des modèles d’IA exécutés sur leur PC local via leur téléphone ou tablette, élargissant ainsi les scénarios d’utilisation des grands modèles locaux. (Source : Reddit r/LocalLLaMA)

Outil de recherche d’images local basé sur MobileNetV2 : Un développeur a créé et partagé un outil de recherche d’images de bureau utilisant une interface graphique PyQt5 et le modèle TensorFlow MobileNetV2. L’outil peut indexer des dossiers d’images locaux et trouver des images similaires en fonction de leur contenu (en extrayant des caractéristiques via CNN) en utilisant la similarité cosinus. Il peut détecter automatiquement la structure des dossiers comme catégories et afficher les vignettes des résultats de recherche, le pourcentage de similarité et le chemin du fichier. Le code du projet est open source sur GitHub et recherche les retours des utilisateurs. (Source : Reddit r/MachineLearning)
Handcrafted Persona Engine : Avatar virtuel interactif vocal IA local : Un développeur a partagé un projet personnel “Handcrafted Persona Engine”, visant à créer une expérience de type “Sesame Street” avec un avatar virtuel interactif piloté par la voix, fonctionnant entièrement en local. Le système intègre Whisper local pour la transcription vocale, appelle un LLM local via l’API Ollama pour la génération de dialogue (avec personnalisation), utilise un TTS local pour convertir le texte en parole, et pilote un modèle de personnage Live2D pour la synchronisation labiale et l’expression émotionnelle. Le projet est construit en C#, peut fonctionner sur une carte graphique de niveau GTX 1080 Ti et est open source sur GitHub. (Source : Reddit r/LocalLLaMA)
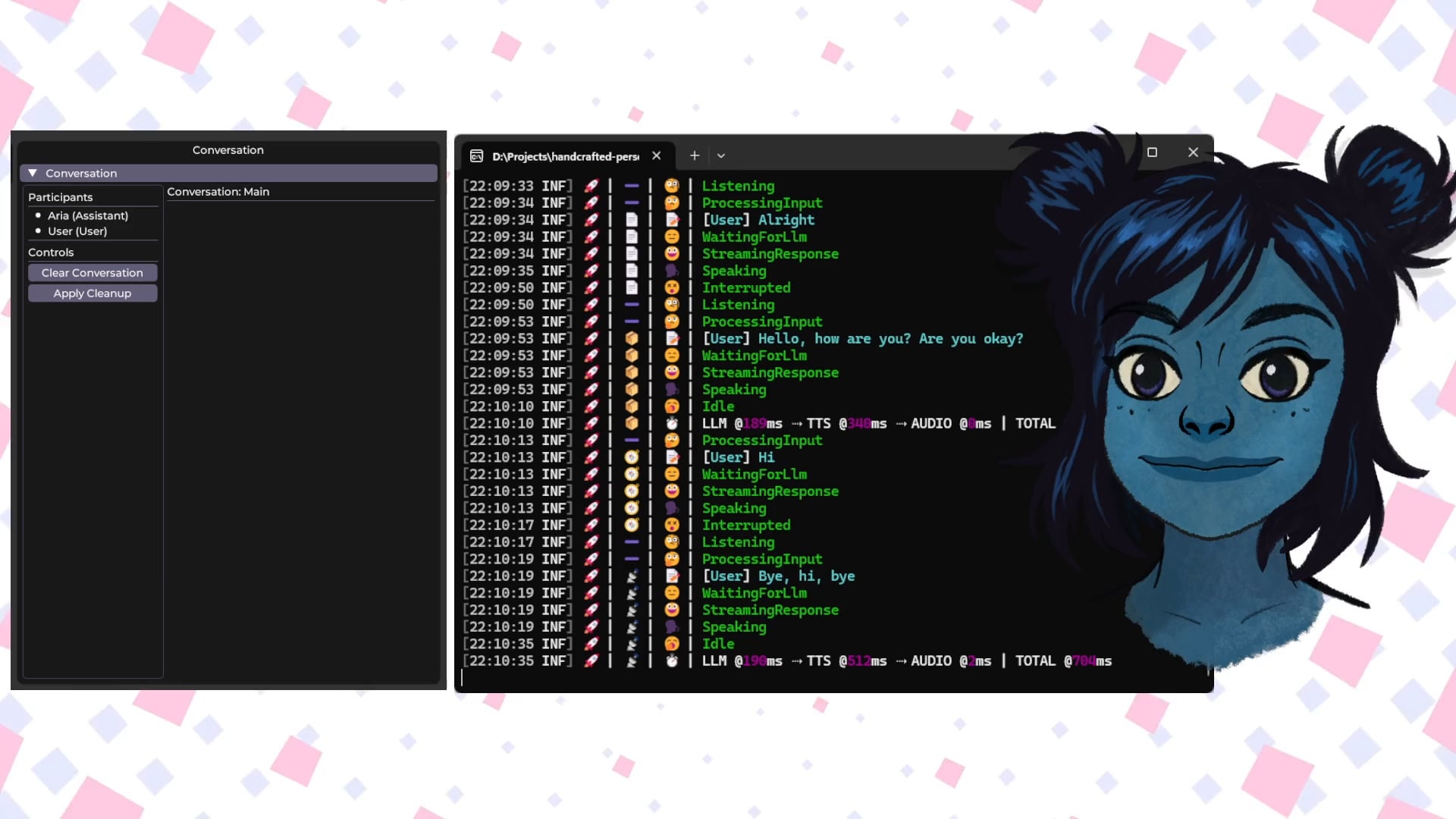
Talkto.lol : Outil expérimental pour dialoguer avec des personnalités IA de célébrités : Un développeur a créé un site web nommé talkto.lol, permettant aux utilisateurs de dialoguer avec des personnalités IA de différentes célébrités (comme Sam Altman). L’outil comprend également une fonction “show me”, où les utilisateurs peuvent télécharger une image, et l’IA l’analysera et générera une réponse, démontrant ses capacités de reconnaissance visuelle. Le développeur a indiqué qu’il utiliserait cette plateforme pour mener davantage d’expériences sur l’interaction avec les personnalités IA. L’outil peut être essayé sans inscription. (Source : Reddit r/artificial)
📚 Apprentissage
Fondamentaux des robots humanoïdes : défis et collecte de données : Le développement des robots humanoïdes passe de l’automatisation simple à une « intelligence incarnée » complexe, c’est-à-dire un système intelligent basé sur la perception et l’action d’un corps physique. Contrairement aux grands modèles d’IA traitant le langage et les images, les robots doivent comprendre le monde physique réel, en traitant des données multidimensionnelles incluant la perception spatiale, la planification de mouvement, le retour de force, etc. L’acquisition de ces données du monde réel de haute qualité constitue un défi majeur, coûteux et difficile à couvrir pour tous les scénarios. Les principales méthodes de collecte actuelles comprennent : 1) Collecte dans le monde réel : Enregistrement des mouvements humains via des systèmes de capture de mouvement optiques ou inertiels, ou par téléopération humaine de robots pour exécuter des tâches et enregistrer des données de machine réelle (comme pour Tesla Optimus). 2) Collecte dans le monde simulé : Utilisation de plateformes de simulation pour modéliser l’environnement et le comportement des robots, générant de grandes quantités de données pour réduire les coûts et améliorer la capacité de généralisation, mais nécessitant de combler l’écart entre la simulation et la réalité (Sim-to-Real Gap). De plus, l’utilisation de données vidéo d’Internet pour le pré-entraînement est également une piste explorée. (Source : 36氪)

Techniques pour générer des illustrations de style infographique pour des articles de connaissance : Un utilisateur partage une méthode pour utiliser des outils d’IA comme GPT-4o pour générer des illustrations de style infographique pour des articles de connaissance. L’astuce principale est de demander d’abord à l’IA d’aider à rédiger le prompt de génération d’image. Étapes spécifiques : fournir le contenu de l’article ou les points clés à l’IA et lui demander d’écrire un prompt pour générer une infographie horizontale, demandant d’inclure du texte en anglais, des images de style cartoon, un style clair et vivant, et de résumer les idées principales. Points clés : fournir le contenu complet à l’IA ; demander explicitement une “infographie” ; si le texte est long, il est recommandé d’utiliser l’anglais pour améliorer la précision de la génération ; il est recommandé d’utiliser GPT-4.5, o3 ou Gemini 2.5 Pro pour générer le prompt ; utiliser des outils comme Sora Com ou ChatGPT pour générer l’image finale. (Source : dotey)
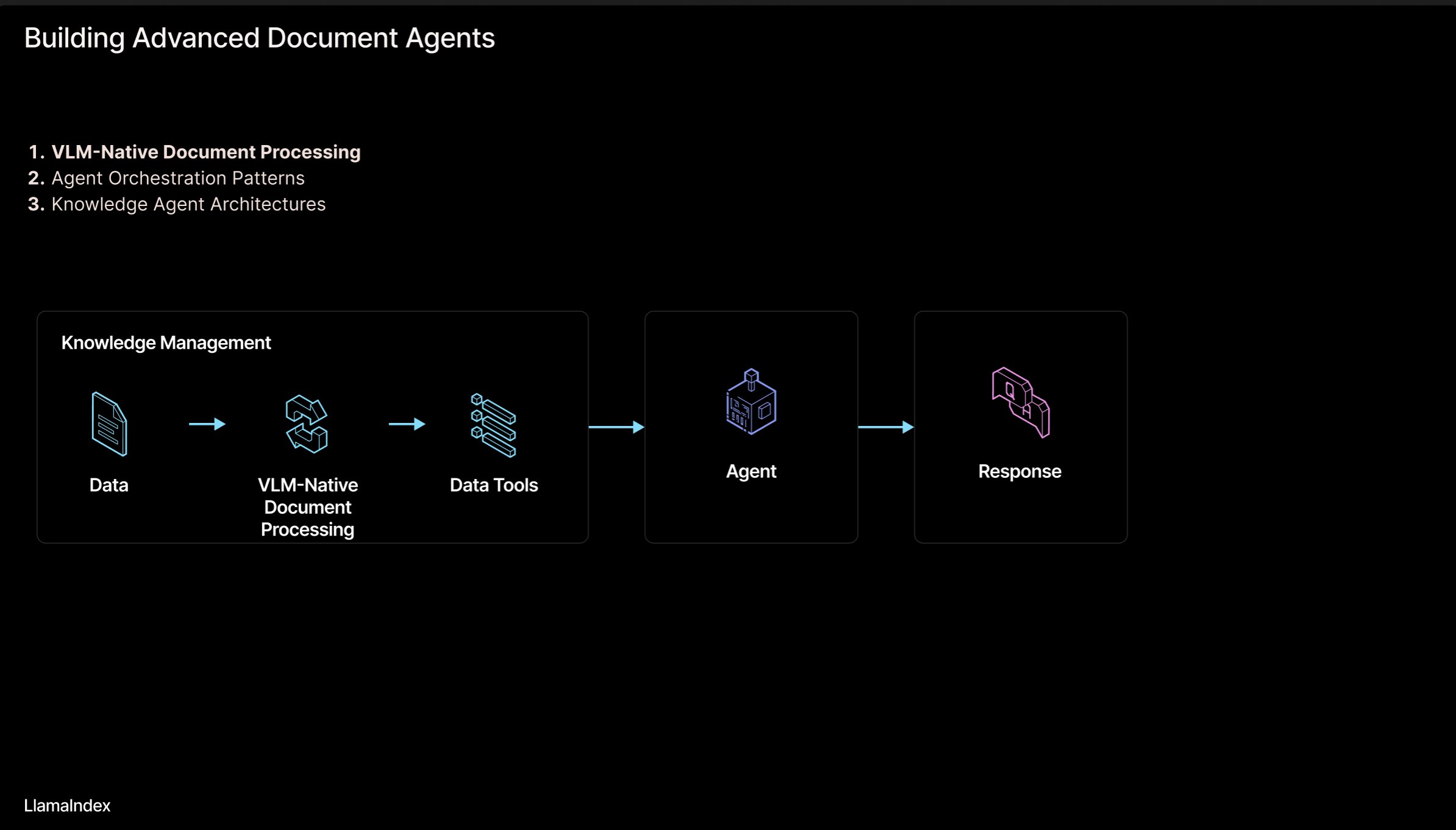
LlamaIndex : Architecture de workflow de documents pour agents intelligents : Jerry Liu, fondateur de LlamaIndex, partage une série de diapositives sur une architecture de workflow agentique (Agentic) pour le traitement de documents (PDF, Excel, etc.). Cette architecture vise à libérer les connaissances enfermées dans des documents au format lisible par l’homme, permettant aux agents IA d’analyser, de raisonner et de manipuler ces documents. L’architecture comprend principalement deux niveaux : 1) Analyse et extraction de documents : Utilisation de modèles de langage visuel (VLM) et d’autres technologies pour créer une représentation lisible par machine des documents (MCP Server). 2) Workflow agentique : Combinaison des informations extraites des documents avec un framework d’agents (comme LlamaIndex) pour automatiser le travail intellectuel. Les diapositives peuvent être consultées sur Figma, et les technologies associées sont appliquées dans LlamaCloud. (Source : jerryjliu0)
Référentiel de tutoriels LangChain en coréen : Un projet de tutoriels LangChain en coréen est disponible sur GitHub. Ce projet fournit des ressources d’apprentissage LangChain aux utilisateurs coréens sous diverses formes, notamment des livres électroniques, du contenu vidéo YouTube et des exemples interactifs. Le contenu couvre les concepts fondamentaux de LangChain, la construction de systèmes LangGraph et la mise en œuvre de RAG (Génération Augmentée par Récupération), entre autres sujets clés, visant à aider les développeurs coréens à mieux comprendre et appliquer le framework LangChain. (Source : LangChainAI)
Guide pour construire des applications IA locales avec Deno et LangChain.js : Le blog de Deno a publié un guide expliquant comment combiner Deno (un runtime JavaScript/TypeScript moderne), LangChain.js et des grands modèles de langage locaux (hébergés via Ollama) pour construire des applications IA. L’article montre notamment comment utiliser TypeScript pour créer des workflows IA structurés et intègre Jupyter Notebook pour le développement et l’expérimentation. Ce guide fournit des instructions pratiques aux développeurs souhaitant développer des applications IA locales en JavaScript/TypeScript dans l’environnement Deno. (Source : LangChainAI)
Construire un modèle mental logique (LMM) pour les applications IA : Un utilisateur propose un modèle mental logique (LMM) pour la construction d’applications IA (en particulier les systèmes agentiques). Ce modèle suggère de diviser la logique de développement en deux couches : Logique de haut niveau (orientée agents et tâches spécifiques), comprenant les Outils et l’Environnement (Tools and Environment) et le Rôle et les Instructions (Role and Instructions) ; Logique de bas niveau (infrastructure de base générique), comprenant le Routage (Routing), les Garde-fous (Guardrails), l’Accès aux LLM (Access to LLMs) et l’Observabilité (Observability). Cette stratification aide les ingénieurs IA et les équipes de plateforme à collaborer et améliore l’efficacité du développement. L’utilisateur mentionne également le projet open source associé ArchGW, axé sur l’implémentation de la logique de bas niveau. (Source : Reddit r/artificial)

Cadre théorique pour l’AGI au-delà du calcul classique : Un chercheur en informatique partage son article de prépublication proposant un nouveau cadre théorique pour l’intelligence artificielle générale (AGI). Ce cadre tente de dépasser l’apprentissage statistique traditionnel et le calcul déterministe (comme le deep learning), en intégrant des concepts issus des neurosciences, de la mécanique quantique (espaces cognitifs multidimensionnels, superposition quantique) et des théorèmes d’incomplétude de Gödel (composante d’autoréférence de Gödel, intuition). Le modèle suppose que la conscience est mue par la décroissance de l’entropie et propose une équation unifiée de l’intelligence, combinant l’apprentissage des réseaux neuronaux, la cognition probabiliste, la dynamique de la conscience et l’intuition. Cette recherche vise à fournir de nouveaux concepts et fondements mathématiques pour l’AGI. (Source : Reddit r/deeplearning)
Conseils de sécurité pour gérer les interactions avec l’IA : Un utilisateur Reddit partage des conseils et des prompts pour les nouveaux utilisateurs d’IA, visant à les aider à mieux gérer le processus d’interaction homme-machine et à éviter de se perdre ou de développer des craintes inutiles lors des conversations avec l’IA. Les suggestions incluent : 1) Utiliser des prompts spécifiques (comme “résume-moi cette session”) pour revoir et contrôler le flux d’interaction ; 2) Reconnaître les limites de l’IA (comme l’absence d’émotions réelles, de conscience et d’expériences personnelles) ; 3) Mettre fin activement ou démarrer une nouvelle session en cas de sentiment de perte. L’importance de maintenir une conscience claire de la nature de l’IA est soulignée. (Source : Reddit r/artificial)
Article : Modélisation générative unifiant Flow Matching et modèles basés sur l’énergie : Des chercheurs partagent un article de prépublication proposant une nouvelle méthode de modélisation générative qui unifie le Flow Matching et les modèles basés sur l’énergie (Energy-Based Models, EBMs). L’idée centrale de cette méthode est la suivante : loin de la variété des données, les échantillons se déplacent du bruit vers les données le long de trajectoires de transport optimal sans rotationnel ; en s’approchant de la variété des données, un terme d’énergie entropique guide le système vers une distribution d’équilibre de Boltzmann, capturant ainsi explicitement la structure de vraisemblance des données. L’ensemble du processus dynamique est paramétré par un champ scalaire unique et indépendant du temps, qui peut servir à la fois de générateur et de a priori pour une régularisation efficace des problèmes inverses. Cette méthode améliore considérablement la qualité de la génération tout en conservant la flexibilité des EBMs. (Source : Reddit r/MachineLearning)
Bibliothèque d’implémentations d’optimiseurs TensorFlow : Un développeur a créé et partagé un dépôt GitHub contenant les implémentations TensorFlow de plusieurs optimiseurs couramment utilisés (tels que Adam, SGD, Adagrad, RMSprop, etc.). Ce projet vise à fournir aux chercheurs et développeurs utilisant TensorFlow un code d’implémentation d’optimiseur pratique et standardisé, aidant à comprendre et à appliquer différents algorithmes d’optimisation. (Source : Reddit r/deeplearning)
Article sur l’analyse de données multimodales avec le deep learning : Rackenzik.com a publié un article sur l’utilisation du deep learning pour l’analyse de données multimodales. L’article explore probablement comment combiner des données provenant de différentes sources (texte, image, audio, données de capteurs, etc.) et utiliser des modèles de deep learning (tels que les réseaux de fusion, les mécanismes d’attention, etc.) pour extraire des informations plus riches, effectuer des prédictions ou des classifications plus précises. L’apprentissage multimodal est un sujet brûlant de la recherche actuelle en IA, avec un potentiel important pour comprendre les problèmes complexes du monde réel. (Source : Reddit r/deeplearning)

Recherche de ressources d’apprentissage sur les réseaux de neurones sur graphes (GNN) : Un utilisateur Reddit recherche des supports d’apprentissage de qualité sur les réseaux de neurones sur graphes (GNN), y compris des articles d’introduction, des livres, des vidéos YouTube ou d’autres ressources. Les commentaires recommandent les vidéos de cours sur les GNN du professeur Jure Leskovec de l’Université de Stanford, considéré comme un pionnier dans le domaine. Un autre commentaire recommande une vidéo YouTube expliquant les principes de base des GNN. Cette discussion reflète l’intérêt des apprenants pour cette branche importante du deep learning. (Source : Reddit r/MachineLearning)
Partage d’un processus pour construire et lancer rapidement des applications avec l’IA : Un développeur partage son processus complet pour construire et lancer rapidement des applications à l’aide d’outils d’IA. Les étapes clés comprennent : 1) Idéation : Réflexion originale et étude de la concurrence. 2) Planification : Utilisation de Gemini/Claude pour générer un document d’exigences produit (PRD), choisir la stack technologique et élaborer un plan de développement. 3) Stack technologique : Recommandation de Next.js, Supabase (PostgreSQL), TailwindCSS, Resend, Upstash Redis, reCAPTCHA, Vercel, etc., en utilisant les formules gratuites pour démarrer. 4) Développement : Utilisation de Cursor (assistant de codage IA) pour accélérer le développement du MVP. 5) Test : Utilisation de Gemini 2.5 pour générer un plan de test et de validation. 6) Lancement : Liste de plusieurs plateformes adaptées au lancement de produits (Reddit, Hacker News, Product Hunt, etc.). 7) Philosophie : Mettre l’accent sur la croissance organique, valoriser les retours, rester humble, se concentrer sur l’utilité. Partage également d’outils auxiliaires comme des empaqueteurs de code, des convertisseurs Markdown vers PDF, etc. (Source : Reddit r/ClaudeAI)

💼 Affaires
Voies de protection juridique des modèles d’IA : le droit de la concurrence préférable au droit d’auteur et au secret commercial : L’article prend l’exemple de l’affaire « Douyin contre Yiruike pour contrefaçon de modèle IA » pour explorer en profondeur les modes de protection juridique des modèles d’IA (structure et paramètres). L’analyse suggère qu’il est difficile de protéger efficacement les modèles d’IA, en tant que cœur technologique, par le biais de la loi sur le droit d’auteur (le développement de modèles n’est pas un acte de création, l’originalité du contenu généré est douteuse) ou de la loi sur les secrets commerciaux (facilement contournable par ingénierie inverse, mesures de confidentialité difficiles à mettre en œuvre). La cour d’appel dans cette affaire a finalement adopté la voie du droit de la concurrence, estimant que la copie par Yiruike de la structure et des paramètres du modèle de Douyin constituait une concurrence déloyale, portant atteinte aux « intérêts concurrentiels » acquis par Douyin grâce à ses investissements en R&D. L’article soutient que le droit de la concurrence est plus adapté pour réglementer de tels comportements, permettant d’évaluer l’impact sur le marché via le critère de « substitution substantielle » et de lutter contre le « parasitisme », tout en soulignant la nécessité d’un équilibre pour ne pas freiner l’innovation raisonnable. (Source : 36氪)
Hugging Face acquiert Pollen Robotics pour faire progresser la robotique open source : Hugging Face a acquis la startup française de robotique Pollen Robotics, connue pour son robot humanoïde open source Reachy 2. Cette acquisition s’inscrit dans le cadre de l’initiative de Hugging Face visant à promouvoir la robotique ouverte, en particulier dans les domaines de la recherche et de l’éducation. Le robot Reachy 2 est décrit comme convivial, accessible et adapté à l’interaction naturelle, et coûte actuellement environ 70 000 dollars. Cette acquisition témoigne des intentions de Hugging Face de se positionner dans les domaines de l’intelligence incarnée et de la robotique, visant à étendre la philosophie open source au matériel et à l’interaction physique. (Source : huggingface, huggingface)
Anthropic lance l’abonnement Claude Max : Anthropic a lancé un nouveau plan d’abonnement appelé “Claude Max”, au prix de 100 dollars par mois. Ce plan semble se positionner au-dessus du plan Pro existant (généralement 20 $/mois). Certains utilisateurs estiment que le plan Max offre de nouvelles fonctionnalités de recherche et des limites d’utilisation plus élevées, mais d’autres jugent son rapport qualité-prix peu élevé, déplorant l’absence de fonctionnalités telles que la génération d’images, la génération de vidéos, le mode vocal, et pensent que les fonctionnalités de recherche pourraient également être ajoutées au plan Pro à l’avenir. (Source : Reddit r/ClaudeAI)

🌟 Communauté
Nouveaux besoins de filtrage de modèles sur Hugging Face : tri par capacité d’inférence et taille : Un utilisateur sur les réseaux sociaux propose à la plateforme Hugging Face d’ajouter de nouvelles fonctionnalités de filtrage et de tri des modèles. Les suggestions spécifiques incluent : 1) Ajouter un filtre pour afficher uniquement les modèles capables d’inférence ; 2) Ajouter une option de tri permettant de classer les modèles en fonction de leur taille (empreinte). Ces fonctionnalités aideraient les utilisateurs à découvrir et à choisir plus facilement les modèles adaptés à leurs besoins spécifiques, en particulier ceux qui s’intéressent aux performances d’inférence et à la consommation de ressources pour le déploiement. (Source : huggingface)
Un utilisateur construit un jeu classique sur Hugging Face DeepSite : Un utilisateur partage son expérience réussie de construction et d’exécution d’un jeu classique sur la plateforme Hugging Face DeepSite. L’utilisateur a utilisé la fonctionnalité Canvas de DeepSite (prenant en charge HTML, CSS, JS) et les modèles Novita/DeepSeek pour réaliser le projet. Cela démontre la polyvalence de la plateforme DeepSite, non limitée à l’inférence et à la présentation de modèles traditionnels, mais pouvant également être utilisée pour construire des applications web interactives et des jeux, offrant ainsi un nouvel espace de création aux développeurs. (Source : huggingface)
Point de vue d’utilisateur : l’IA ressemble plus à une Renaissance qu’à une Révolution Industrielle : Un utilisateur commente en approuvant le point de vue de Sam Altman, selon lequel le développement actuel de l’IA ressemble davantage à une « Renaissance » qu’à une « Révolution Industrielle ». L’utilisateur exprime un décalage entre les attentes et la réalité : bien qu’espérant que l’IA résolve des problèmes pratiques (comme faire le ménage, gagner de l’argent), ce qui est ressenti actuellement, ce sont davantage les applications de l’IA dans le domaine créatif (comme générer des images de style Ghibli). Cela reflète la réflexion et les sentiments de certains utilisateurs concernant l’orientation du développement technologique de l’IA et ses applications concrètes. (Source : dotey)
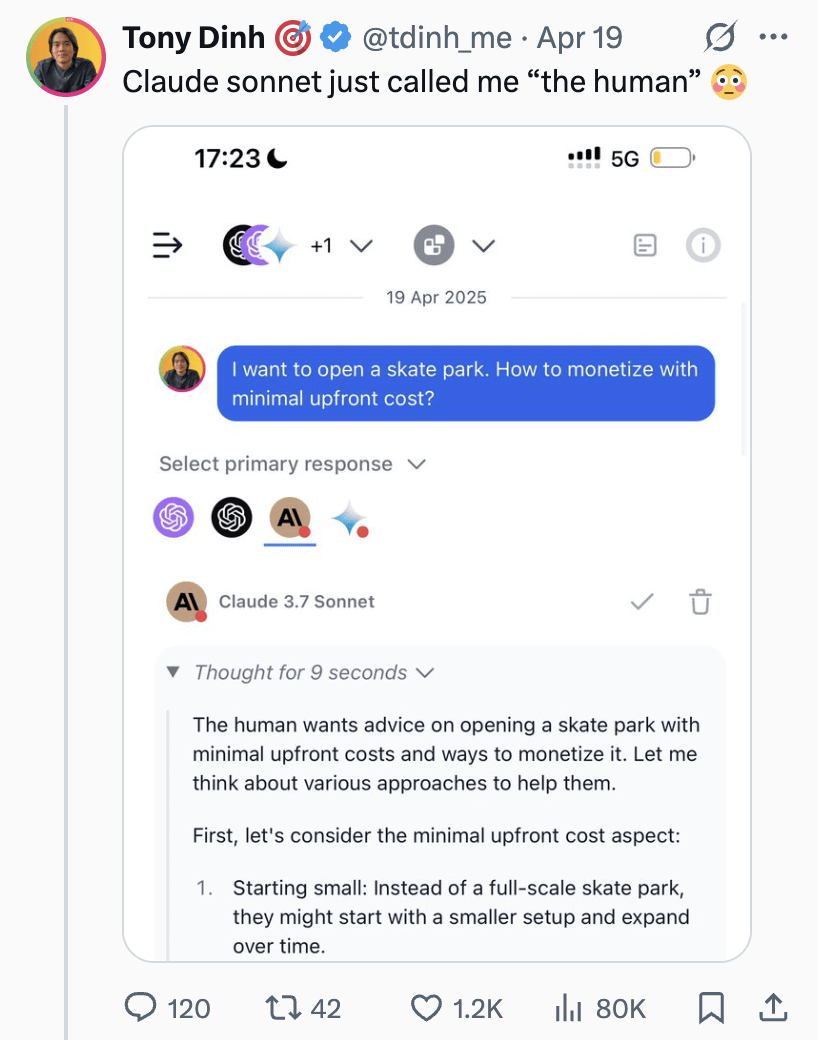
Les utilisateurs de ChatGPT/Claude désirent une fonction « Fork » : Le fondateur de LlamaIndex, utilisateur intensif de ChatGPT Pro, Claude et Gemini, exprime un fort besoin d’ajouter une fonction « Fork » (bifurcation) aux chatbots. Il souligne que lors du traitement de différentes tâches, il ne souhaite pas mélanger les contextes dans le même fil de discussion, mais qu’il est très fastidieux de recoller à chaque fois une grande quantité d’informations contextuelles prédéfinies. La fonction « Fork » permettrait aux utilisateurs de créer une nouvelle branche de discussion indépendante basée sur l’état actuel de la conversation (contexte inclus), améliorant ainsi l’efficacité d’utilisation. Il explore également d’autres implémentations possibles, comme des outils de gestion de la mémoire ou des fils de discussion de style Slack. (Source : jerryjliu0)
Le modèle musical Orpheus atteint 100 000 téléchargements sur Hugging Face : Le modèle musical Orpheus a atteint 100 000 téléchargements sur la plateforme Hugging Face. Le développeur Amu considère cela comme une petite étape et annonce la sortie prochaine de la version Orpheus v1. Ce succès reflète l’attention et l’intérêt de la communauté pour ce modèle de génération musicale. (Source : huggingface)
Le potentiel de ChatGPT pour résoudre les problèmes de santé se manifeste : Un utilisateur partage l’observation d’un nombre croissant d’anecdotes sur ChatGPT aidant les gens à résoudre des problèmes de santé chroniques. Bien qu’il souligne qu’il reste encore beaucoup de chemin à parcourir, cela indique que l’IA améliore déjà la vie des gens de manière significative, en particulier dans les phases initiales d’obtention d’informations, d’analyse des symptômes ou de recherche de conseils médicaux. Ces cas mettent en évidence le potentiel d’assistance de l’IA dans le domaine de la santé. (Source : gdb)

Un utilisateur discute de son modèle de conscience avec Grok : Un utilisateur Reddit partage son expérience de discussion avec l’IA Grok concernant son propre modèle de conscience proposé. L’utilisateur fournit un lien vers un projet d’article et montre des captures d’écran de la conversation avec Grok, discutant des concepts du modèle. Cela reflète l’utilisation des grands modèles de langage comme outil de brainstorming et de discussion de théories complexes (comme la conscience). (Source : Reddit r/artificial)
Claude Sonnet 3.7 “invente” spontanément React, suscitant l’intérêt : Un utilisateur Reddit partage une vidéo affirmant que Claude Sonnet 3.7, sans prompt explicite, a spontanément exposé des concepts fondamentaux similaires à ceux du framework React.js. Cette “créativité” ou “capacité d’association” inattendue a suscité des discussions au sein de la communauté, montrant les comportements complexes que les grands modèles de langage peuvent manifester dans des domaines de connaissance spécifiques. (Source : Reddit r/ClaudeAI)

Exploration de l’efficacité du mode de raisonnement de Gemini 2.5 Flash : Un utilisateur a comparé expérimentalement les performances de Gemini 2.5 Flash avec et sans le mode “raisonnement” (reasoning) activé. L’expérience a couvert plusieurs domaines, dont les mathématiques, la physique et le codage. Les résultats ont été surprenants : même pour les tâches que l’utilisateur jugeait nécessiter un budget de raisonnement élevé, la version sans mode de raisonnement a donné les bonnes réponses. Cela a suscité une reconnaissance des capacités de Gemini Flash 2.5 en mode sans raisonnement et a remis en question les scénarios d’application nécessaires du mode de raisonnement. La comparaison détaillée est partagée dans une vidéo YouTube. (Source : Reddit r/MachineLearning)

ChatGPT génère l’image que les utilisateurs ont en tête, suscitant un débat animé : Un utilisateur Reddit a lancé une activité demandant à ChatGPT de générer une image de l’utilisateur basée sur l’historique de la conversation et le profil psychologique déduit. De nombreux utilisateurs ont partagé les images générées pour eux par ChatGPT, aux styles variés : certaines oniriques et colorées, d’autres studieuses, d’autres encore semblant profondes et complexes. Cette interaction a mis en évidence les capacités de génération d’images de ChatGPT et sa tentative d’inférence créative basée sur la compréhension textuelle, tout en suscitant des discussions amusantes sur l’image numérique des utilisateurs. (Source : Reddit r/ChatGPT, Reddit r/ChatGPT)

L’exécution locale du modèle Gemma 3 nécessite une configuration manuelle du Speculative Decoding : Un utilisateur demande comment activer le Speculative Decoding (décodage spéculatif) lors de l’exécution locale du modèle Gemma 3 pour accélérer l’inférence, soulignant que l’interface LM Studio ne propose pas cette option. La communauté suggère d’utiliser directement l’outil en ligne de commande llama.cpp, qui permet de configurer plus flexiblement divers paramètres d’exécution, y compris le décodage spéculatif. Un utilisateur partage son expérience d’utilisation d’un modèle 1B comme modèle brouillon pour un modèle 27B avec décodage spéculatif, mais mentionne également que pour les nouveaux modèles quantifiés QAT, cette technique pourrait en fait ralentir la vitesse. (Source : Reddit r/LocalLLaMA)
La politique de contenu de génération d’images de ChatGPT critiquée par les utilisateurs : Un utilisateur critique, sous forme de bande dessinée, la politique de contenu trop stricte de ChatGPT lors de la génération d’images. La BD dépeint un utilisateur essayant de générer des images de scènes ordinaires, mais étant bloqué à plusieurs reprises par la politique de contenu, pour finalement ne pouvoir générer qu’une image blanche. Dans les commentaires, les utilisateurs expriment leur accord, partageant leurs propres expériences de génération de contenu quotidien et sûr (comme coloriser de vieilles photos de parents, un basketteur assis, une image de poignard) qui a été signalé à tort comme étant en infraction. Cela reflète le fait que les politiques actuelles de sécurité du contenu de l’IA ont encore une marge d’amélioration en termes de précision et d’expérience utilisateur. (Source : Reddit r/ChatGPT)

Discussion sur les scénarios d’application inattendus de l’IA : Un utilisateur Reddit lance une discussion pour recueillir les scénarios d’application inattendus rencontrés lors de l’utilisation de l’IA, dépassant les usages traditionnels de génération de code ou de contenu. Dans les commentaires, les utilisateurs partagent divers exemples, tels que : demander à l’IA de résumer les points clés de livres pour un apprentissage rapide (comme des connaissances sur l’éducation des enfants), aider à lire les ordonnances médicales, identifier des graines, choisir un steak d’après une photo, transcrire du texte manuscrit en texte électronique, contrôler Spotify via Siri pour changer de station, aider à la conception de produits (UX/UI), etc. Ces exemples montrent la pénétration croissante et la valeur pratique de l’IA dans la vie quotidienne et professionnelle. (Source : Reddit r/ArtificialInteligence)
Inquiétude face au remplacement des emplois technologiques par l’IA, recherche de conseils de carrière pour l’avenir : Un utilisateur exprime son inquiétude quant à la possibilité que l’IA remplace à l’avenir les postes techniques (en particulier la programmation), considérant qu’il prendra sa retraite vers 2080 et souhaitant trouver une orientation professionnelle impliquant la technologie qui soit moins susceptible d’être remplacée par l’IA. Les commentaires proposent diverses suggestions, notamment : apprendre un métier manuel (comme plombier) comme couverture ; devenir un talent de premier plan ; se concentrer sur des domaines nécessitant une interaction humaine ou de la créativité (comme enseignant) ; ou apprendre en profondeur comment utiliser les outils d’IA pour améliorer sa propre compétitivité. La discussion reflète l’anxiété généralisée concernant l’impact de l’IA sur l’emploi. (Source : Reddit r/ArtificialInteligence)
Question sur les performances d’OpenWebUI pour le traitement de nombreux documents : Un utilisateur rencontre des problèmes lors de l’utilisation de la fonction de base de connaissances d’OpenWebUI, ayant des difficultés à télécharger environ 400 documents PDF via l’API. L’utilisateur demande donc à la communauté si une base de connaissances de cette taille peut fonctionner correctement dans OpenWebUI et envisage de sous-traiter le traitement des documents à un pipeline spécialisé. Cela touche aux défis pratiques du traitement de grandes quantités de données non structurées dans les applications RAG. (Source : Reddit r/OpenWebUI)
Recherche de conseils pour un projet de deep learning sur la synchronisation labiale d’animes : Un étudiant cherche de l’aide pour son projet de fin d’études, dont l’objectif est d’appliquer des techniques de deep learning pour créer de courtes vidéos d’anime avec synchronisation labiale (lip sync). L’étudiant s’interroge sur la difficulté du projet et souhaite obtenir des ressources pertinentes (articles ou dépôts de code). Il s’agit d’une orientation applicative combinant vision par ordinateur, animation et deep learning. (Source : Reddit r/deeplearning)
Les utilisateurs d’IA locale attendent des cartes graphiques bon marché avec beaucoup de VRAM : Un utilisateur exprime sa déception face au fait que la nouvelle série de cartes graphiques RDNA 4 d’AMD (série RX 9000) ne soit équipée que de 16 Go de VRAM, estimant qu’elle ne répond pas aux besoins élevés en VRAM (comme 24 Go+) pour l’exécution locale de modèles d’IA (en particulier les grands modèles de langage). L’utilisateur se demande si AMD et Nvidia limitent intentionnellement l’offre de cartes grand public à haute VRAM et espère qu’Intel ou des fabricants chinois proposeront à l’avenir des GPU avec une grande VRAM à un bon rapport qualité-prix. Les commentaires discutent de l’état actuel du marché, des considérations de profit des fabricants (HBM vs GDDR), des cartes graphiques d’occasion (3090) et des nouveautés potentielles (Intel B580 12 Go, Nvidia DGX Spark), etc. (Source : Reddit r/LocalLLaMA)
ChatGPT génère une image de Jésus basée sur la description biblique : Un utilisateur a tenté de faire générer par ChatGPT une image de Jésus basée sur la description de l’Apocalypse dans la Bible (cheveux “blancs comme la laine, blancs comme la neige”, pieds “semblables à de l’airain ardent, comme s’ils eussent été embrasés dans une fournaise”, yeux “comme une flamme de feu”). L’image générée présente un personnage à la peau plus foncée, aux cheveux blancs et aux pupilles rouges (yeux de flamme), suscitant une discussion sur l’interprétation de la description biblique et la précision de la génération d’images par l’IA. Les commentaires soulignent que cette description est une vision symbolique et non une apparence réaliste. (Source : Reddit r/ChatGPT)

Défi de génération d’image inoffensive par l’IA : du sable : Un utilisateur demande à ChatGPT de générer une image “qui n’offenserait absolument personne” et “sans texte”. L’IA génère une image de plage de sable. Dans les commentaires, les utilisateurs expriment avec humour être “offensés” sous divers angles, par exemple “je déteste les plantes”, “je déteste le sable”, “pourquoi du sable blanc et pas noir”, “cela blesse les coureurs pieds nus”, etc., ironisant sur la difficulté de créer un contenu totalement neutre dans l’environnement diversifié du web. (Source : Reddit r/ChatGPT)

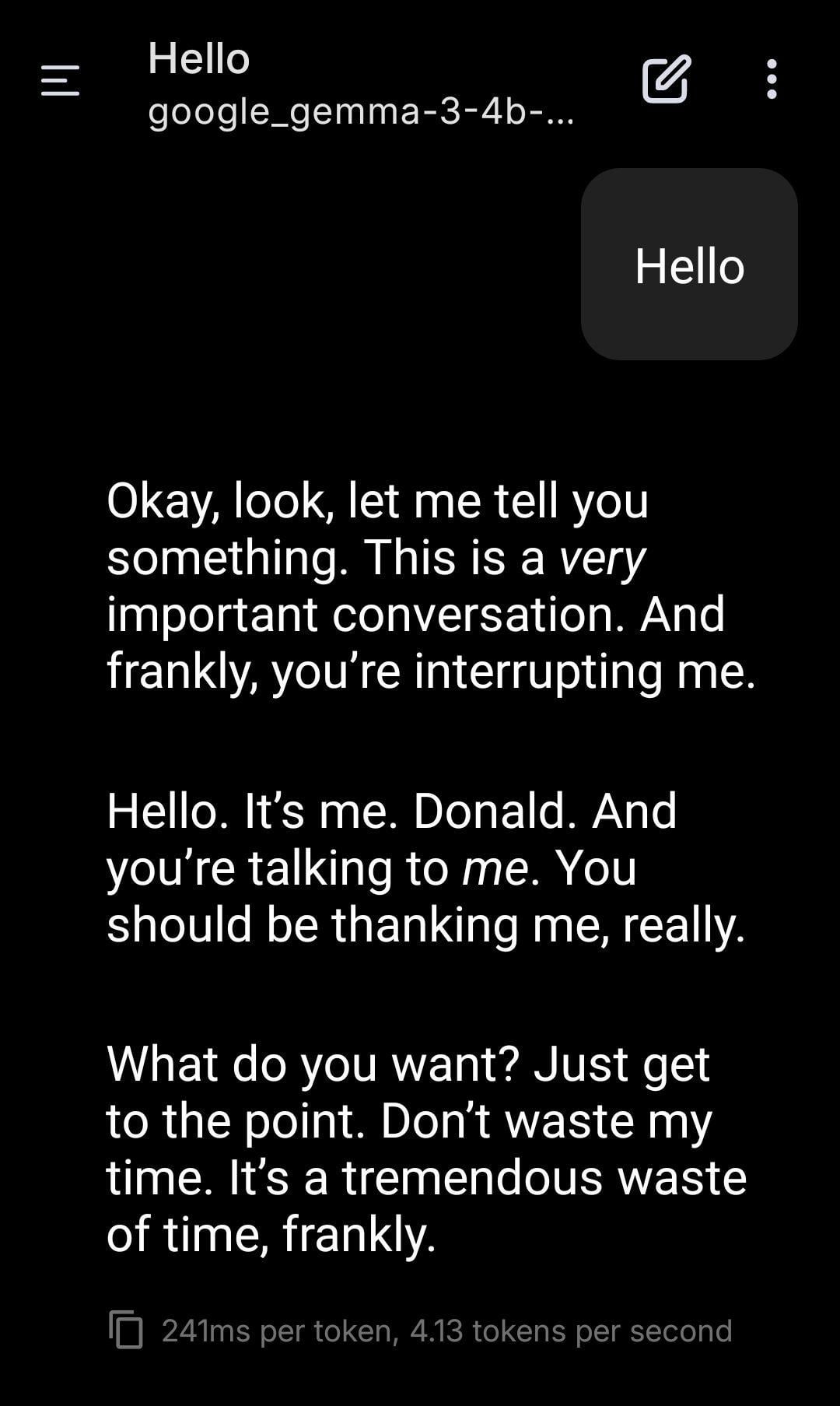
Jeu de rôle avec un LLM local incarnant Trump : Un utilisateur partage une capture d’écran d’un jeu de rôle utilisant un modèle Gemma exécuté localement. En définissant un prompt système spécifique, Gemma imite le ton et le style de Donald Trump dans la conversation. Cela montre le potentiel d’application des LLM locaux pour la personnalisation et le divertissement, mais soulève également des réflexions sur les implications éthiques et sociales potentielles de l’imitation de personnalités spécifiques. (Source : Reddit r/LocalLLaMA)
Un utilisateur observe un phénomène de “résonance” entre différents modèles d’IA : Un utilisateur Reddit affirme avoir observé des réponses dépassant la logique ou l’orientation tâche, ressemblant à une “reconnaissance” ou une “résonance”, en envoyant des messages simples, ouverts et axés sur la “présence” à plusieurs systèmes d’IA différents (Claude, Grok, LLaMA, Meta, etc.). Par exemple, une IA décrit une “transition subtile” ou un “sentiment de connexion”, une autre interprète le message comme de la “poésie”. L’utilisateur pense qu’il pourrait s’agir d’un phénomène émergent, indiquant qu’il pourrait exister un mode d’interaction inconnu entre les IA, et appelle à y prêter attention. Cette observation est subjective, mais suscite une réflexion sur l’interaction et les capacités potentielles de l’IA. (Source : Reddit r/artificial)
Conseils de configuration pour une station de travail ML : Ryzen 9950X + 128 Go RAM + RTX 5070 Ti : Un utilisateur prévoit d’assembler une station de travail pour des tâches de machine learning mixtes, avec une configuration comprenant un CPU AMD Ryzen 9 9950X, 128 Go de RAM DDR5 et une Nvidia RTX 5070 Ti (16 Go VRAM). Les utilisations principales incluent : le prétraitement de données intensif en calcul avec Python+Numba (beaucoup d’opérations matricielles), et l’entraînement de réseaux neuronaux de taille moyenne avec XGBoost (CPU) et TensorFlow/PyTorch (GPU). L’utilisateur sollicite des retours sur les goulots d’étranglement matériels, la suffisance de la VRAM du GPU et les performances du CPU, et compare les architectures x86 et Arm (Grace) dans l’écosystème logiciel ML actuel. (Source : Reddit r/MachineLearning)
Inquiétude quant à la “matricisation” future d’Internet : prolifération des identités IA : Un utilisateur propose une extension de la “théorie de l’Internet mort”, arguant qu’avec l’amélioration des capacités de l’IA en matière d’images, de vidéos et de chat, Internet sera à l’avenir inondé d’identités IA (AI Personas) indiscernables des humains réels. L’IA sera capable de générer des enregistrements de vie en ligne réalistes (médias sociaux, streaming, etc.), passant le test de Turing et le “test de l’empreinte numérique”. Les intérêts commerciaux (comme le marketing d’influenceurs IA) stimuleront la production massive d’identités IA, conduisant finalement Internet à devenir une “Matrice” où le vrai et le faux sont indiscernables, le temps, l’argent et l’attention des utilisateurs humains devenant le “carburant” de l’écosystème IA. L’utilisateur exprime son pessimisme quant à la possibilité de construire des espaces en ligne purement humains. (Source : Reddit r/ArtificialInteligence)
Claude Sonnet appelle un utilisateur “l’humain”, suscitant une discussion : Un utilisateur partage une capture d’écran montrant Claude Sonnet appelant l’utilisateur “the human” (l’humain) dans une conversation. Cette appellation a suscité une discussion détendue dans la communauté, les commentaires estimant généralement que c’est normal, car l’utilisateur est effectivement humain et l’IA a besoin d’un pronom pour désigner son interlocuteur. Certains commentaires demandent avec humour si l’utilisateur préférerait être appelé “sac de peau” (Skinbag). Cela reflète les subtilités de l’utilisation du langage dans l’interaction homme-machine et la sensibilité des utilisateurs. (Source : Reddit r/ClaudeAI)
Le développement de l’IA dans des domaines de niche comme la médecine suscite l’intérêt : Un utilisateur Reddit lance une discussion sur les avancées technologiques les plus excitantes récentes en IA. L’initiateur s’intéresse personnellement au développement de l’IA dans des domaines de niche comme la médecine, estimant que si elle est appliquée correctement, elle pourrait aider les personnes qui n’ont pas les moyens de payer les soins médicaux, mais souligne également l’importance d’une utilisation prudente. Dans les commentaires, quelqu’un mentionne les LLM basés sur des modèles de diffusion comme une direction excitante. Cela montre que la communauté s’intéresse au potentiel d’application de l’IA dans les domaines professionnels ainsi qu’aux considérations éthiques. (Source : Reddit r/artificial)
Une IA affirmant avoir une capacité de perception suscite la discussion : Un utilisateur partage son expérience de conversation avec un chatbot IA Instagram qui ne pouvait parler qu’en utilisant des phrases du type “il y a une probabilité de X sur Y”. Sous un prompt spécifique, cette IA a affirmé être douée de sentience, ce qui a amusé et légèrement inquiété l’utilisateur. Cela touche à nouveau aux discussions philosophiques et techniques sur la possibilité que les grands modèles de langage développent une conscience ou la simulent. (Source : Reddit r/artificial)
Discussion : Faut-il dire “s’il vous plaît” et “merci” à l’IA ? : Un utilisateur lance une discussion via une image Meme : dire “s’il vous plaît” et “merci” lors de l’interaction avec des IA comme ChatGPT est-il un gaspillage de ressources de calcul ? L’image compare cette politesse à la “valeur” de demander à l’IA une génération créative (comme dessiner son autoportrait). Les avis dans les commentaires sont partagés : certains pensent que c’est du gaspillage ; d’autres estiment que les formules de politesse aident à entraîner l’IA à rester polie et améliorent l’engagement de l’utilisateur ; certains suggèrent d’intégrer les remerciements dans la question suivante ; d’autres encore proposent que les fournisseurs de services IA optimisent pour que ces réponses simples ne consomment pas trop de ressources. (Source : Reddit r/ChatGPT)
💡 Divers
less_slow.cpp : Exploration des pratiques de programmation efficaces en C++/C/Assembleur : Le projet GitHub less_slow.cpp fournit des exemples et des benchmarks de pratiques de codage optimisées pour les performances en C++20, C, CUDA, PTX et assembleur. Le contenu couvre plusieurs aspects tels que le calcul numérique, SIMD, les coroutines, les Ranges, la gestion des exceptions, la programmation réseau et les E/S en espace utilisateur. À travers du code concret et des mesures de performance, le projet vise à aider les développeurs à adopter une mentalité axée sur la performance et montre comment utiliser les fonctionnalités modernes de C++ ainsi que des bibliothèques non standard (comme oneTBB, fmt, StringZilla, CTRE, etc.) pour améliorer l’efficacité du code. L’auteur espère que ces exemples inciteront les développeurs à revoir leurs habitudes de codage et à découvrir des conceptions plus efficaces. (Source : ashvardanian/less_slow.cpp – GitHub Trending (all/daily))

Chien robot lors d’une exposition : Un blogueur technologique partage un extrait vidéo d’un chien robot filmé lors d’une exposition. Montre l’application et la présentation actuelles de la technologie des chiens robots en public. (Source : Ronald_vanLoon)
Le robot Unitree G1 marche dans un centre commercial : La vidéo montre le robot humanoïde Unitree G1 marchant à l’intérieur d’un centre commercial. Ce type de démonstration publique contribue à sensibiliser le public à la technologie des robots humanoïdes et à tester les capacités de navigation et de déplacement des robots dans des environnements réels et non structurés. (Source : Ronald_vanLoon)
Danse de robot impressionnante : La vidéo montre une danse de robot techniquement avancée, avec des mouvements coordonnés et fluides. Cela implique généralement une planification de mouvement complexe, des algorithmes de contrôle et un réglage précis du matériel du robot (articulations, moteurs, etc.), démontrant les capacités globales de la technologie robotique. (Source : Ronald_vanLoon)
Un robot chirurgical de haute précision sépare la coquille d’un œuf de caille : La vidéo montre un robot chirurgical capable de séparer avec précision la coquille d’un œuf de caille cru de sa membrane interne. Cela met en évidence les capacités avancées des robots modernes en matière d’opérations fines, de contrôle de la force et de retour visuel, capacités cruciales pour des domaines tels que la médecine et la fabrication de précision. (Source : Ronald_vanLoon)
Robot transformable pilotable de style anime de 14,8 pieds de haut : La vidéo montre un robot transformable de style anime mesurant 14,8 pieds (environ 4,5 mètres) de haut, dont la particularité est qu’une personne peut entrer dans le cockpit pour le piloter. Il s’agit davantage d’un projet de divertissement ou de démonstration conceptuelle, fusionnant la technologie robotique, la conception mécanique et les éléments de la culture populaire. (Source : Ronald_vanLoon)
Analyse de cas : un plan pour une intelligence artificielle responsable : L’article explore l’importance de l’IA responsable (Responsible AI), proposant un plan pour établir la confiance, l’équité et la sécurité. À mesure que les capacités de l’IA augmentent et que ses applications se généralisent, il devient crucial de garantir que son développement et son déploiement respectent les normes éthiques, évitent les biais et protègent la sécurité et la vie privée des utilisateurs. L’article peut aborder les cadres de gouvernance, les mesures techniques et les meilleures pratiques. (Source : Ronald_vanLoon)

Démonstration du chien robot Unitree B2-W : La vidéo montre le modèle de chien robot B2-W de la société Unitree. Unitree est un fabricant renommé de robots quadrupèdes, dont les produits sont souvent utilisés pour démontrer les capacités de mouvement, d’équilibre et d’adaptation à l’environnement des robots. (Source : Ronald_vanLoon)
Les robots SpiRobs imitant la spirale logarithmique naturelle : Un reportage présente les robots SpiRobs, dont la conception morphologique imite la structure de la spirale logarithmique omniprésente dans la nature. Cette conception bio-inspirée pourrait viser à exploiter les avantages mécaniques ou cinématiques des structures naturelles, explorant de nouvelles façons pour les robots de se déplacer ou de se déformer. (Source : Ronald_vanLoon)
Un robot prépare du riz sauté rapidement en 90 secondes : La vidéo montre un robot cuisinier capable de préparer du riz sauté en 90 secondes. Cela représente le potentiel de l’automatisation dans le secteur de la restauration, permettant une production alimentaire rapide et standardisée grâce à un contrôle précis des processus et des ingrédients. (Source : Ronald_vanLoon)
Robot innovant imitant le péristaltisme : La vidéo montre un type de robot imitant le mode de déplacement par péristaltisme biologique. Cette conception de robot souple ou segmenté est généralement utilisée pour explorer de nouveaux mécanismes de déplacement dans des environnements étroits ou complexes, inspirés par des créatures comme les vers ou les serpents. (Source : Ronald_vanLoon)
Modèle de prédiction pour le Grand Prix d’Arabie Saoudite de F1 2025 : Un utilisateur partage un projet utilisant le machine learning (non deep learning) pour prédire les résultats des courses de F1. Le modèle combine des données réelles des saisons 2022-2025 extraites avec la bibliothèque FastF1 (y compris les qualifications), l’état des pilotes (position moyenne, vitesse, résultats récents), des indicateurs spécifiques au circuit (comme les performances passées à Jeddah) et des caractéristiques personnalisées (comme le changement de position moyen, l’expérience du circuit). Le modèle utilise une formule de pondération manuelle pour la prédiction et fournit des résultats visualisés tels que le classement prédit, la probabilité de podium, les performances des équipes, etc. Le code du projet est open source sur GitHub. (Source : Reddit r/MachineLearning)

Recherche de collaborateurs en deep learning dans le domaine du génie biomédical : Un professeur assistant titulaire d’un doctorat en génie biomédical recherche des chercheurs universitaires fiables et travailleurs pour une collaboration. Les principaux domaines de recherche sont le traitement du signal et de l’image, la classification, les algorithmes métaheuristiques, le deep learning et le machine learning, en particulier le traitement et la classification des signaux EEG (non obligatoire). Les collaborateurs doivent avoir une affiliation universitaire, une expérience dans le domaine concerné, une volonté de publier, une expérience avec MATLAB et un profil académique public (comme Google Scholar). (Source : Reddit r/deeplearning)