Mots-clés:robot humanoïde, supercalculateur IA, modèle OpenAI, modèle Gemini, semi-marathon de robots humanoïdes, puce Blackwell de NVIDIA, taux d’hallucination OpenAI o3, simulation physique Gemini 2.5 Pro, cours d’agents de navigation IA, impact scientifique du calcul quantique, contrôle de bras mécanique par interface cerveau-machine, comportement des PNJ dans les jeux via GNN
🔥 Focus
Premier semi-marathon mondial de robots humanoïdes organisé : Lors du premier semi-marathon mondial de robots humanoïdes organisé à Yizhuang, Pékin, Tiangong 1.2max est devenu le premier robot à franchir la ligne d’arrivée avec un temps de 2 heures 40 minutes et 24 secondes. L’événement visait à vérifier la praticité des robots dans différents scénarios et a rassemblé des robots humanoïdes chinois utilisant diverses méthodes d’entraînement et écoles d’algorithmes. La compétition a non seulement testé la capacité de marche, l’endurance (nécessitant une recharge ou un changement de batterie en cours de route, avec pénalités de temps), la dissipation thermique et la stabilité des robots, mais aussi la collaboration homme-robot. Malgré des incidents en cours de route, tels que le robot Unitree montrant des signes de “trac” et la chute du robot Tiangong, l’événement est considéré comme une étape importante dans le développement des robots humanoïdes. Il a fourni une plateforme de test de performance et de validation technique en environnement réel, favorisant les progrès en matière d’optimisation structurelle, d’algorithmes de contrôle de mouvement et de capacité d’adaptation à l’environnement (Source : APPSO via 36氪)

Nvidia annonce que ses supercalculateurs IA seront fabriqués aux États-Unis : Nvidia prévoit pour la première fois de produire entièrement aux États-Unis ses supercalculateurs destinés au traitement des tâches d’IA. L’entreprise a réservé plus d’un million de pieds carrés d’espace en Arizona pour fabriquer et tester les puces Blackwell, et collabore avec Foxconn (Houston) et Wistron (Dallas) pour construire des usines au Texas afin de produire les supercalculateurs IA, avec une production en série progressive prévue dans les 12 à 15 mois. Cette initiative fait partie du plan de Nvidia visant à produire pour 500 milliards de dollars d’infrastructures IA aux États-Unis au cours des quatre prochaines années, et s’aligne sur la stratégie du gouvernement américain visant à accroître l’autosuffisance en semi-conducteurs et à faire face aux tarifs potentiels et aux tensions géopolitiques (Source : dotey)

Les nouveaux modèles d’inférence d’OpenAI, o3 et o4-mini, accusés d’avoir un taux d’hallucination plus élevé : Selon TechCrunch et des discussions connexes, les derniers modèles d’inférence publiés par OpenAI, o3 et o4-mini, ont montré lors des tests un taux d’hallucination plus élevé que leurs prédécesseurs (comme o1, o3-mini). Le rapport indique que o3 produit des hallucinations dans 33% des réponses aux questions, un taux significativement plus élevé que les 16% de o1 et les 14,8% de o3-mini. Cette découverte soulève des inquiétudes quant à la fiabilité de ces modèles avancés, malgré leurs améliorations en matière de capacité de raisonnement. OpenAI a reconnu la nécessité de recherches supplémentaires pour comprendre les causes de cette augmentation du taux d’hallucination (Source : Reddit r/artificial, Reddit r/artificial)

🎯 Tendances
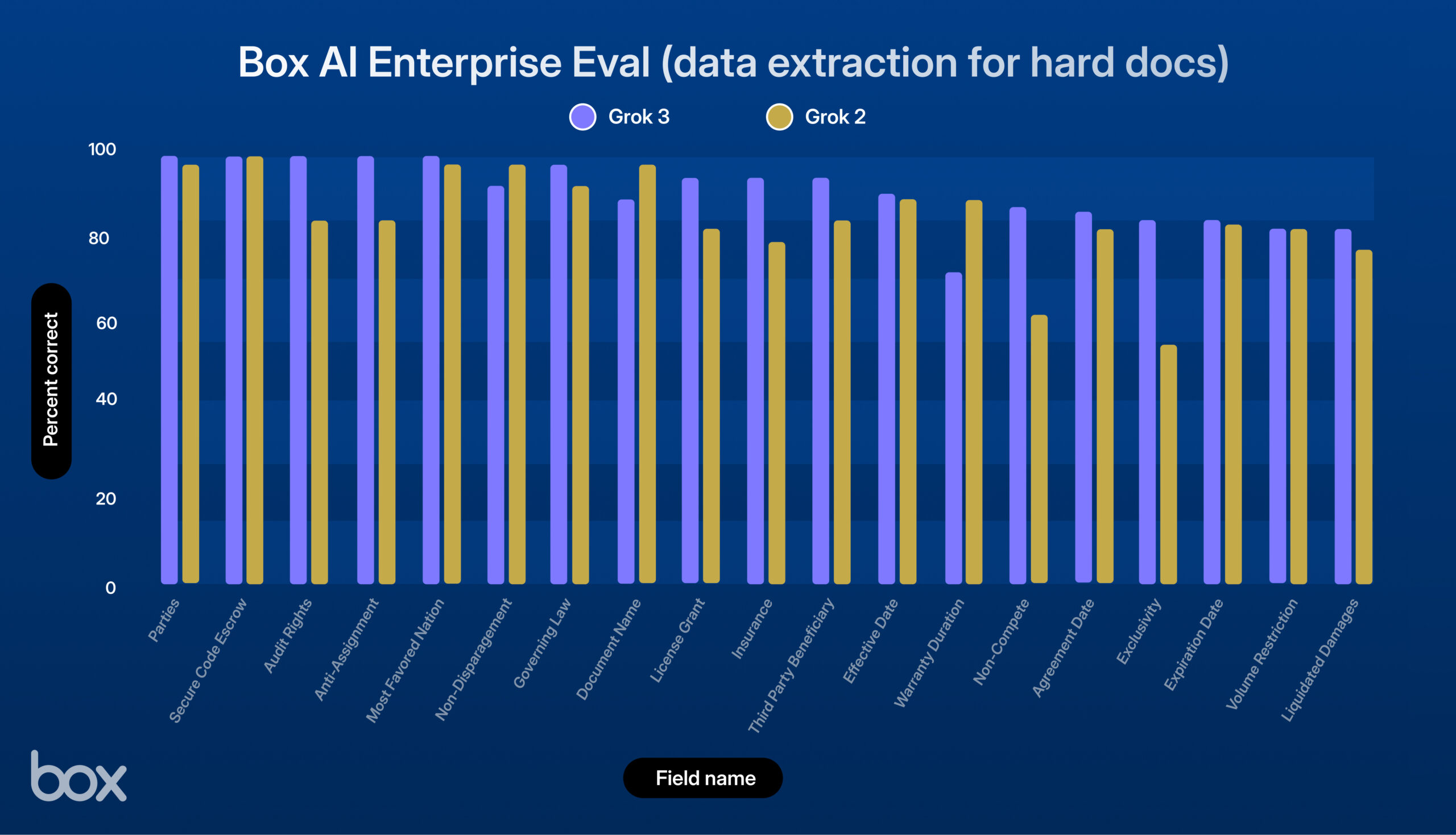
xAI lance Grok 3, excellentes performances lors des tests de Box : xAI a lancé son nouveau modèle Grok 3. La plateforme tierce Box l’a testé dans ses flux de travail de gestion de contenu et a constaté que Grok 3 excellait dans les questions-réponses sur un ou plusieurs documents et dans l’extraction de données (amélioration de 9% par rapport à Grok 2). Le modèle s’est montré performant dans des tâches complexes telles que le traitement de contrats juridiques complexes, le raisonnement en plusieurs étapes, la récupération précise d’informations et l’analyse quantitative, réussissant à traiter des cas d’utilisation complexes comme l’extraction de données économiques à partir de tableaux, l’analyse de cadres RH et l’évaluation de documents SEC. Box estime que Grok 3 a un potentiel énorme, mais qu’il y a encore une marge d’amélioration en termes de précision linguistique et de traitement de la logique très complexe (Source : xai)
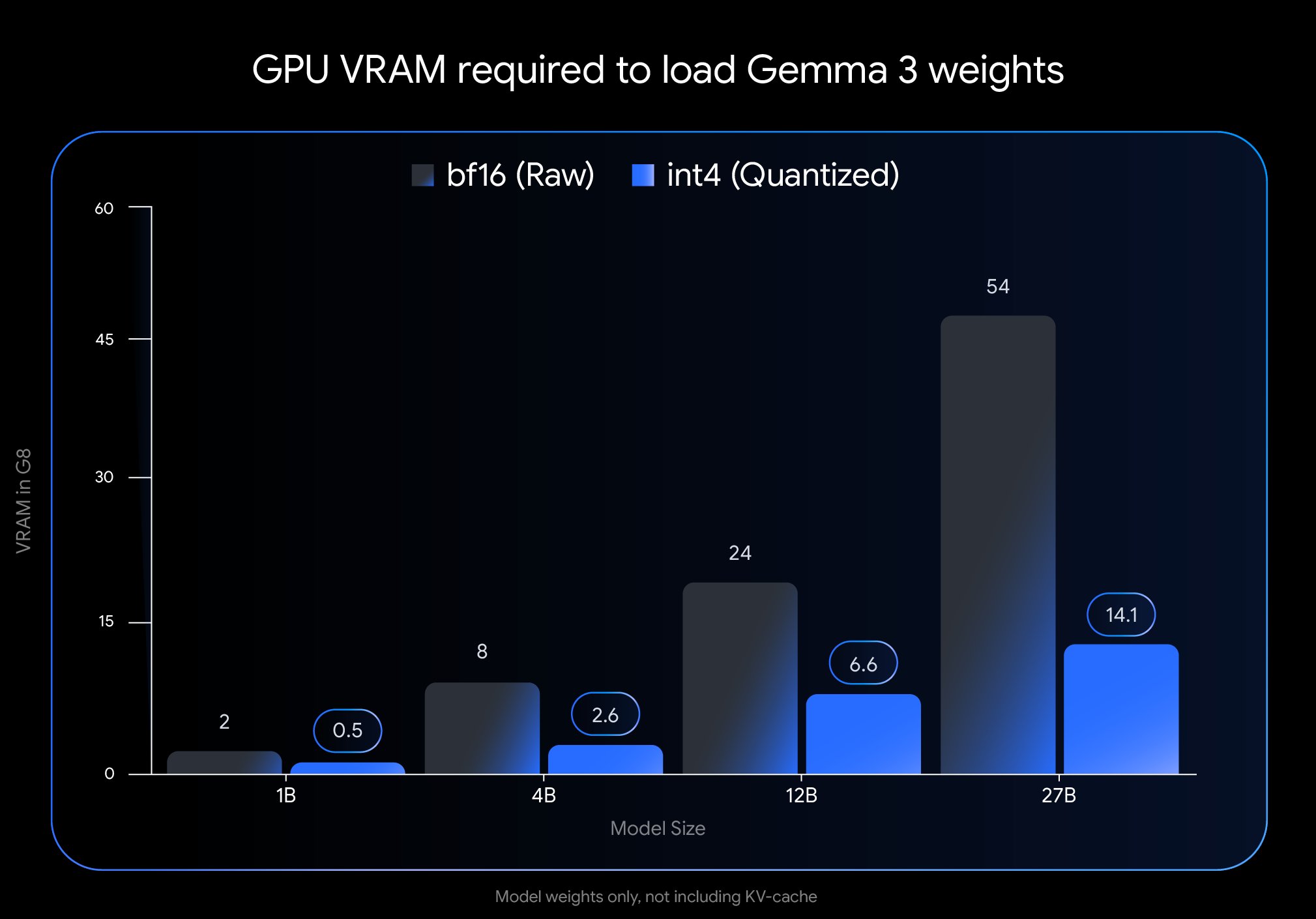
Google publie une nouvelle version quantifiée du modèle Gemma 3 : Google a lancé une nouvelle version du modèle Gemma 3 en utilisant la technologie Quantization-Aware Training (QAT). Cette technique réduit considérablement l’empreinte mémoire du modèle, permettant à un modèle qui nécessitait auparavant un GPU H100 de fonctionner efficacement sur un seul GPU de bureau, tout en maintenant une qualité de sortie élevée. Cette optimisation réduit considérablement les exigences matérielles pour la puissante série de modèles Gemma 3, la rendant plus facile à déployer et à utiliser par un large éventail de chercheurs et de développeurs sur du matériel standard (Source : JeffDean)
Google Cloud ajoute une fonctionnalité de génération de musique par IA pour les entreprises : Google a ajouté un mode de génération de musique piloté par l’IA à sa plateforme cloud pour entreprises. Cette nouvelle fonctionnalité permet aux clients professionnels d’utiliser la technologie d’IA générative pour créer de la musique, étendant les services d’IA de Google Cloud du texte et de l’image au domaine audio. Cela pourrait fournir de nouveaux outils pour des scénarios commerciaux tels que le marketing, la création de contenu, la construction de marque, etc., mais les scénarios d’application spécifiques et les détails du modèle utilisé ne sont pas détaillés dans le résumé (Source : Ronald_vanLoon)

NVIDIA présente une technologie de génération de scènes 3D à partir d’une seule invite : Nvidia a présenté une nouvelle technologie capable de générer automatiquement des scènes 3D complètes à partir d’une seule invite textuelle fournie par l’utilisateur. Cette avancée de l’IA générative vise à simplifier le processus de création de contenu 3D, l’utilisateur n’ayant qu’à décrire la scène souhaitée pour que l’IA construise l’environnement 3D correspondant. Cette technologie devrait avoir un impact important sur des domaines tels que le développement de jeux, la réalité virtuelle, la conception architecturale et la visualisation de produits, en abaissant le seuil d’entrée pour la production 3D (Source : Ronald_vanLoon)
Le modèle Gemma 3 27B QAT fonctionne bien avec la quantification Q2_K : Des tests utilisateurs montrent que le modèle Google Gemma 3 27B IT, entraîné avec Quantization-Aware Training (QAT), affiche toujours des performances étonnamment bonnes dans les tâches en japonais après avoir été quantifié au niveau Q2_K (environ 10,5 Go). Malgré le faible niveau de quantification, le modèle reste stable dans le suivi des instructions, le maintien de formats spécifiques et le jeu de rôle, sans problème de grammaire ou de confusion linguistique. Bien que la capacité de rappel d’informations factuelles comme les dates diminue, les capacités linguistiques de base sont bien préservées, montrant que les modèles QAT peuvent maintenir de bonnes performances à faible débit binaire, ouvrant la voie à l’exécution de grands modèles sur du matériel grand public (Source : Reddit r/LocalLLaMA)

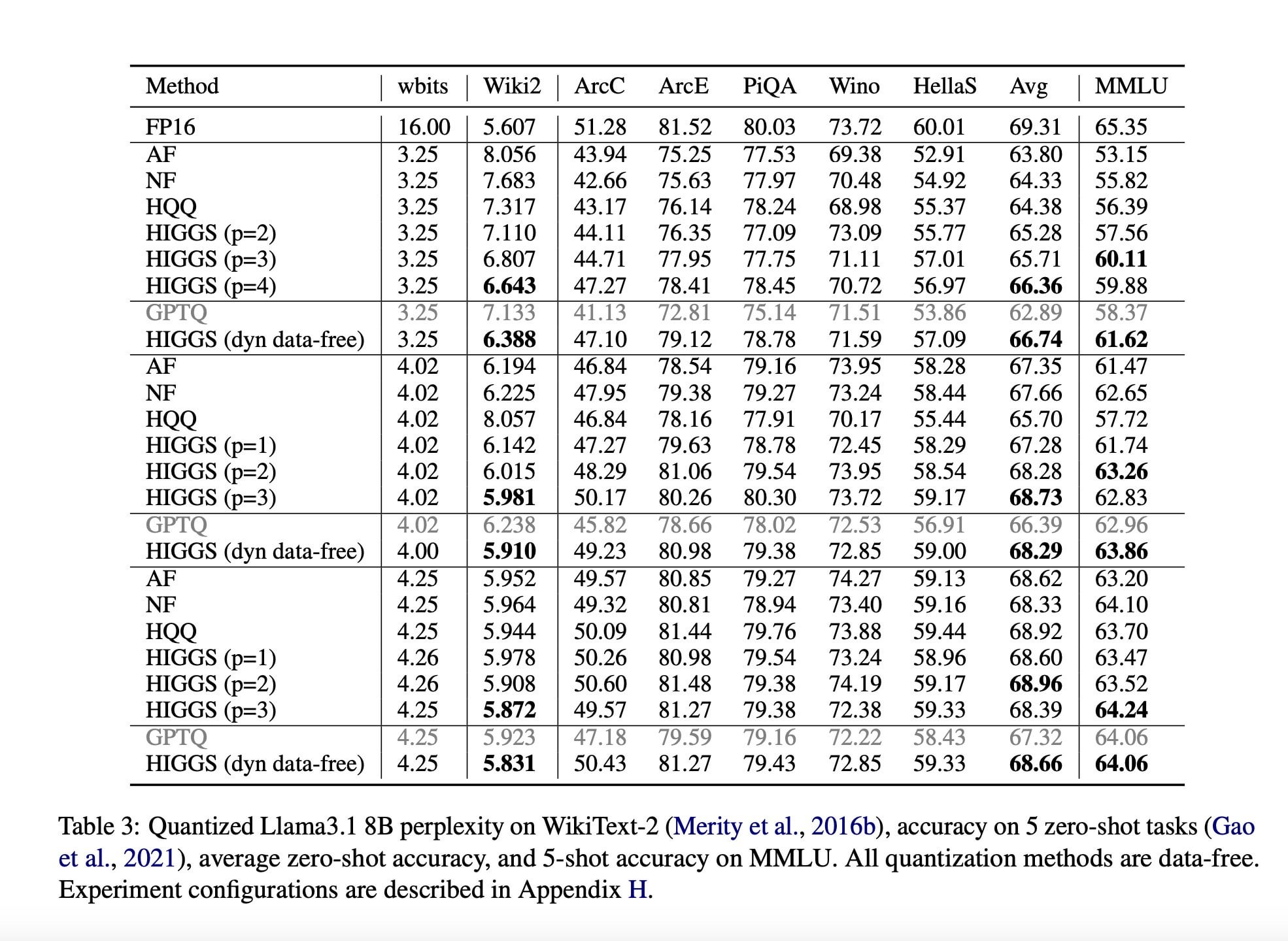
Une étude propose une nouvelle technique de compression LLM pour réduire les besoins matériels : Un article de recherche publié en novembre 2024 (arXiv:2411.17525), fruit d’une collaboration entre des chercheurs du MIT, de KAUST, de l’ISTA et de Yandex, propose une nouvelle méthode d’IA visant à compresser rapidement les grands modèles de langage (LLM) sans perte significative de qualité. L’objectif de cette technique (potentiellement liée à des méthodes comme la quantification Higgs) est de permettre aux LLM de fonctionner sur du matériel moins performant. Bien que l’article vante son potentiel, les commentaires de la communauté soulignent que l’article a été publié il y a longtemps et n’a pas été adopté à grande échelle, exprimant des doutes sur son actualité et son impact réel (Source : Reddit r/LocalLLaMA)
Résumé des actualités IA (18 avril) : Johnson & Johnson rapporte que 15% de ses cas d’utilisation de l’IA génèrent 80% de la valeur, montrant une forte concentration de la valeur des applications IA. Un journal italien a mené une expérience d’écriture par IA, laissant l’IA s’exprimer librement et louant sa capacité à faire preuve d’ironie. De plus, le nombre de faux candidats utilisant des outils d’IA pour falsifier leur identité et leur CV a explosé, posant de nouveaux défis au marché du recrutement (Source : Reddit r/artificial)

🧰 Outils
Microsoft lance le service de conversion de documents MarkItDown MCP : Microsoft a lancé un nouveau service appelé MarkItDown MCP qui utilise le Model Context Protocol (MCP) pour convertir divers formats de documents Office (y compris PDF, PPT, Word, Excel), ainsi que les archives ZIP et les livres électroniques ePub, au format Markdown. Cet outil vise à simplifier le flux de travail des créateurs de contenu et des développeurs pour migrer des documents complexes vers le format texte brut Markdown, améliorant ainsi l’efficacité (Source : op7418)

Perplexity lance un widget d’information sur les tournois IPL : Perplexity a intégré un nouveau widget IPL (Indian Premier League) dans sa plateforme de recherche IA. Cette fonctionnalité vise à fournir aux utilisateurs un accès rapide aux scores en direct, aux calendriers ou à d’autres informations pertinentes concernant les tournois IPL. Cette initiative montre que Perplexity s’efforce d’intégrer des services d’information en temps réel et spécifiques à des événements pour améliorer son utilité en tant qu’outil de découverte d’informations, et sollicite les commentaires des utilisateurs sur cette fonctionnalité (Source : AravSrinivas)
La communauté développe une application de bureau simple pour OpenWebUI : Étant donné la lenteur des mises à jour de l’application de bureau officielle OpenWebUI, des membres de la communauté ont développé et partagé une application d’encapsulation de bureau non officielle appelée “OpenWebUISimpleDesktop”. Compatible avec Mac, Linux et Windows, cette application offre aux utilisateurs une solution temporaire et autonome pour utiliser OpenWebUI sur leur bureau en attendant les mises à jour officielles (Source : Reddit r/OpenWebUI)
PayPal lance un service MCP pour le traitement des factures : Selon les rapports, PayPal a lancé un service Model Context Protocol (MCP) pour le traitement des factures. Cela indique que PayPal intègre des capacités d’IA (potentiellement via MCP utilisant des LLM) pour automatiser ou améliorer les processus de création, de gestion, d’analyse, etc. des factures sur sa plateforme. Cette initiative vise à offrir aux utilisateurs des fonctionnalités de facturation plus intelligentes et à simplifier les opérations financières associées (Source : Reddit r/ClaudeAI)

Claude réalise une technique d’invite pour un jeu de rôle avec réflexion immersive : Un utilisateur de Claude a partagé une technique d’ingénierie d’invite visant à faire en sorte que le personnage IA montre un processus de “réflexion” plus réaliste lors du jeu de rôle ou de la conversation. La méthode consiste à ajouter explicitement une étape de “pensée intérieure du personnage” dans la structure de l’invite, permettant à l’IA de simuler une activité mentale interne avant de générer la réponse principale, ce qui pourrait produire des interactions de personnage plus nuancées et crédibles (Source : Reddit r/ClaudeAI)
📚 Apprentissage
Nouveau cours : Construire des agents de navigateur IA : Le co-fondateur d’AGI Inc. s’est associé à Andrew Ng pour lancer un nouveau cours pratique sur la construction d’agents de navigateur IA capables d’interagir avec de vrais sites web. Le contenu du cours couvre la manière de construire des agents pour effectuer des tâches telles que l’extraction de données, le remplissage de formulaires, la navigation web, et présente des techniques comme AgentQ et la recherche arborescente Monte-Carlo (MCTS) pour doter les agents de capacités d’auto-correction. Le cours vise à relier la théorie à l’application pratique, en explorant les limites actuelles des agents et leur potentiel futur (Source : Reddit r/deeplearning)

Recherche d’aide pour un projet sur les attaques adverses : Un chercheur demande de l’aide urgente pour un projet de deep learning portant sur l’application de méthodes d’attaques adverses comme FGSM, PGD, etc., à des données de séries temporelles et de structures de graphes. L’objectif est de tester la robustesse de ses modèles de détection d’anomalies correspondants et d’espérer rendre le modèle résistant à de telles attaques grâce à l’entraînement adverse, c’est-à-dire que les données attaquées devraient théoriquement aider à améliorer les performances du modèle (Source : Reddit r/deeplearning)
Étude exploratoire : LSTM à mémoire augmentée vs Transformer : Une équipe de recherche mène un projet comparant les performances des modèles LSTM dotés de mécanismes de mémoire externe (tels que le stockage clé-valeur, les dictionnaires neuronaux) avec celles des modèles Transformer dans des tâches d’analyse de sentiments few-shot. Ils visent à combiner l’efficacité des LSTM et les avantages de la mémoire externe pour réduire l’oubli et améliorer la capacité de généralisation, explorant leur faisabilité en tant qu’alternative légère aux Transformers, et sollicitent les commentaires de la communauté, des recommandations d’articles pertinents et des avis sur cette direction de recherche (Source : Reddit r/deeplearning)
Partage d’une pratique inefficace de recherche par grille pour RNN TensorFlow : Un débutant en TensorFlow partage son expérience inefficace de mise en œuvre manuelle d’une recherche par grille d’hyperparamètres RNN dans son projet final de cours. En raison de sa méconnaissance du framework et des RNN, et de son souhait de tester différents ratios de division entraînement/test, son code répétait une grande quantité de prétraitement de données à l’intérieur des boucles et n’implémentait pas de stratégie d’arrêt précoce, ce qui a entraîné une consommation énorme de ressources de calcul pour tester un petit nombre de combinaisons de modèles. Cette expérience met en évidence les pièges d’efficacité que les débutants peuvent rencontrer en pratique et l’importance d’adopter des stratégies d’optimisation d’hyperparamètres plus efficaces (Source : Reddit r/MachineLearning)
💼 Affaires
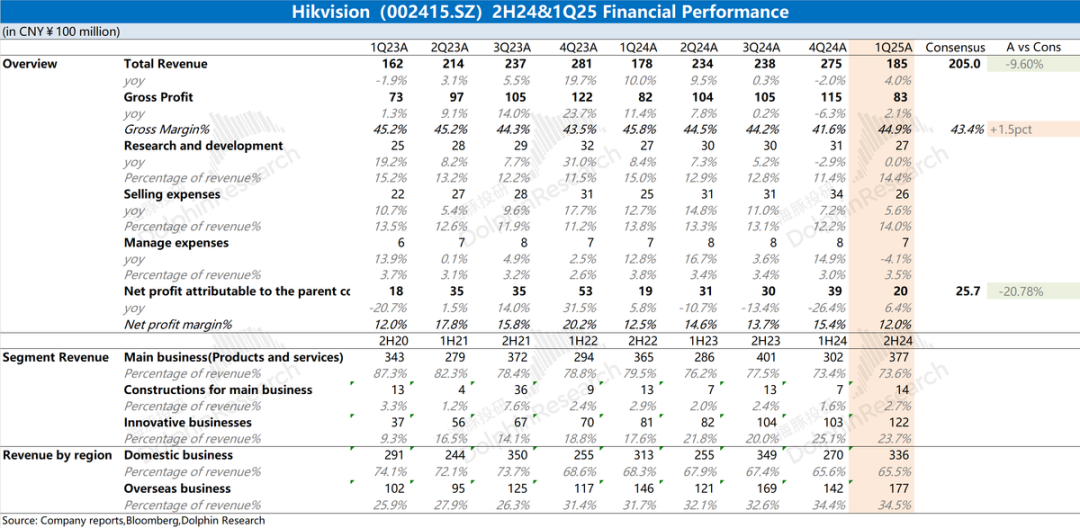
Analyse des résultats financiers de Hikvision : performances médiocres, l’IA ne sauve pas encore la mise : Le rapport annuel 2024 et les résultats du T1 2025 de Hikvision montrent que les performances globales de l’entreprise restent médiocres. Le chiffre d’affaires a légèrement augmenté, mais les activités principales nationales (PBG, EBG, SMBG) ont toutes diminué. La croissance repose principalement sur les activités innovantes et les marchés étrangers, mais la croissance ralentit également. La marge brute a diminué en glissement annuel. Pour maîtriser les coûts, le nombre d’employés en R&D a diminué pour la première fois depuis des années. Bien que Hikvision mentionne une stratégie d’autonomisation par l’IA basée sur son grand modèle “Guanlan”, cela n’a pas encore eu d’impact positif substantiel sur les opérations actuelles. Le marché se concentre sur le moment où ses activités principales se redresseront et si la stratégie IA apportera des résultats concrets (Source : 海豚投研 via 36氪)
🌟 Communauté
Un utilisateur Reddit compare les capacités de simulation physique de Gemini 2.5 Pro et o4-mini : Inspiré par le test de l’heptagone en rotation, un utilisateur Reddit a conçu un scénario de test “mettre le feu à la montagne” pour comparer les capacités de simulation physique des modèles d’IA. Les résultats préliminaires montrent que Gemini 2.5 Pro s’en sort mieux, simulant de manière satisfaisante la direction du vent, le processus de propagation des flammes et les débris après combustion. En comparaison, les performances de o4-mini-high sont légèrement inférieures, par exemple en ne gérant pas correctement le fait que les feuilles brûlées devraient disparaître, les rendant plutôt noires. Ce test illustre de manière intuitive les différences entre les modèles dans la compréhension et la simulation de phénomènes physiques complexes (Source : karminski3)
Gemini 2.5 Flash excelle dans un test de génération de code : L’utilisateur RameshR, en essayant de générer du code de simulation pour une planche de Galton (Galton Board), a découvert que Gemini 2.5 Flash a réussi la tâche, tandis que o4omini, o4o mini high et o3 ont échoué. L’utilisateur loue Gemini 2.5 Flash pour sa capacité à comprendre quasi instantanément son intention et à générer un code concis et bien structuré, réussissant à fusionner plusieurs étapes dans la solution. Jeff Dean a exprimé son approbation. Cela démontre les capacités de Gemini 2.5 Flash dans des scénarios spécifiques de programmation et de résolution de problèmes (Source : JeffDean)
La “confrontation” de robots de livraison attire l’attention : Une publication sur les réseaux sociaux montre une scène amusante où deux robots de livraison se rencontrent sur une route et finissent par se “tenir tête”, refusant de céder le passage. Cette image révèle de manière vivante les défis auxquels sont confrontés les robots de navigation autonomes actuels lorsqu’ils interagissent et se coordonnent dans des environnements publics réels, en particulier lorsqu’ils traitent des rencontres imprévues et doivent négocier le droit de passage. Cela suggère la nécessité future de développer des protocoles d’interaction et des algorithmes de décision plus complexes pour les robots (Source : Ronald_vanLoon)
Un utilisateur loue les puissantes capacités de récupération d’informations du modèle o3 : L’utilisateur natolambert partage son expérience et fait l’éloge des capacités de récupération d’informations du modèle o3 d’OpenAI. Il souligne que o3 peut trouver des informations très spécialisées et de niche avec très peu de contexte, sa capacité de compréhension et son efficacité de recherche étant comparables à celles d’un collègue très bien informé. Cela indique que o3 possède des avantages significatifs dans la compréhension des besoins implicites de l’utilisateur et dans la localisation précise d’informations au sein de vastes ensembles de données (Source : natolambert)
Le PDG de Perplexity parle des assistants IA et des données utilisateur : Arav Srinivas, PDG de Perplexity, estime qu’un assistant IA vraiment puissant nécessite l’accès à l’ensemble des informations contextuelles de l’utilisateur. Il exprime son inquiétude à ce sujet, soulignant que Google, grâce à son écosystème (photos, calendrier, e-mails, activité du navigateur, etc.), dispose de nombreux points d’accès aux données contextuelles des utilisateurs. Il mentionne que le navigateur propre à Perplexity, Comet, est une étape vers l’obtention de contexte, mais souligne qu’il reste encore beaucoup à faire et appelle à une plus grande ouverture de l’écosystème Android pour favoriser la concurrence et le contrôle des données par les utilisateurs (Source : AravSrinivas)
Enquête utilisateur : Gemini 2.5 Pro vs Sonnet 3.7 : Arav Srinivas, PDG de Perplexity, a lancé une question sur les réseaux sociaux, demandant aux utilisateurs si, dans leurs flux de travail quotidiens, Gemini 2.5 Pro de Google est plus performant que Claude Sonnet 3.7 d’Anthropic (en particulier son mode “réflexion”). Cette démarche vise à recueillir les retours directs des utilisateurs sur l’efficacité des deux principaux modèles de langage en application réelle, reflétant la concurrence continue entre les modèles et l’évaluation pratique au niveau des utilisateurs (Source : AravSrinivas)
Ethan Mollick : le modèle o3 fait preuve d’une forte autonomie : L’universitaire Ethan Mollick observe et souligne que le modèle o3 d’OpenAI possède des “capacités agentiques” (agentic capabilities) significatives, capable d’accomplir des tâches très complexes sur la base d’une seule instruction de haut niveau, sans nécessiter de directives détaillées. Il décrit o3 comme “il fait juste le travail” (It just does things). Il rappelle également que cette grande autonomie rend la vérification de ses résultats plus difficile et plus importante, en particulier pour les utilisateurs non experts. Cela met en évidence les progrès de o3 par rapport aux modèles précédents en matière de planification et d’exécution autonomes (Source : gdb)
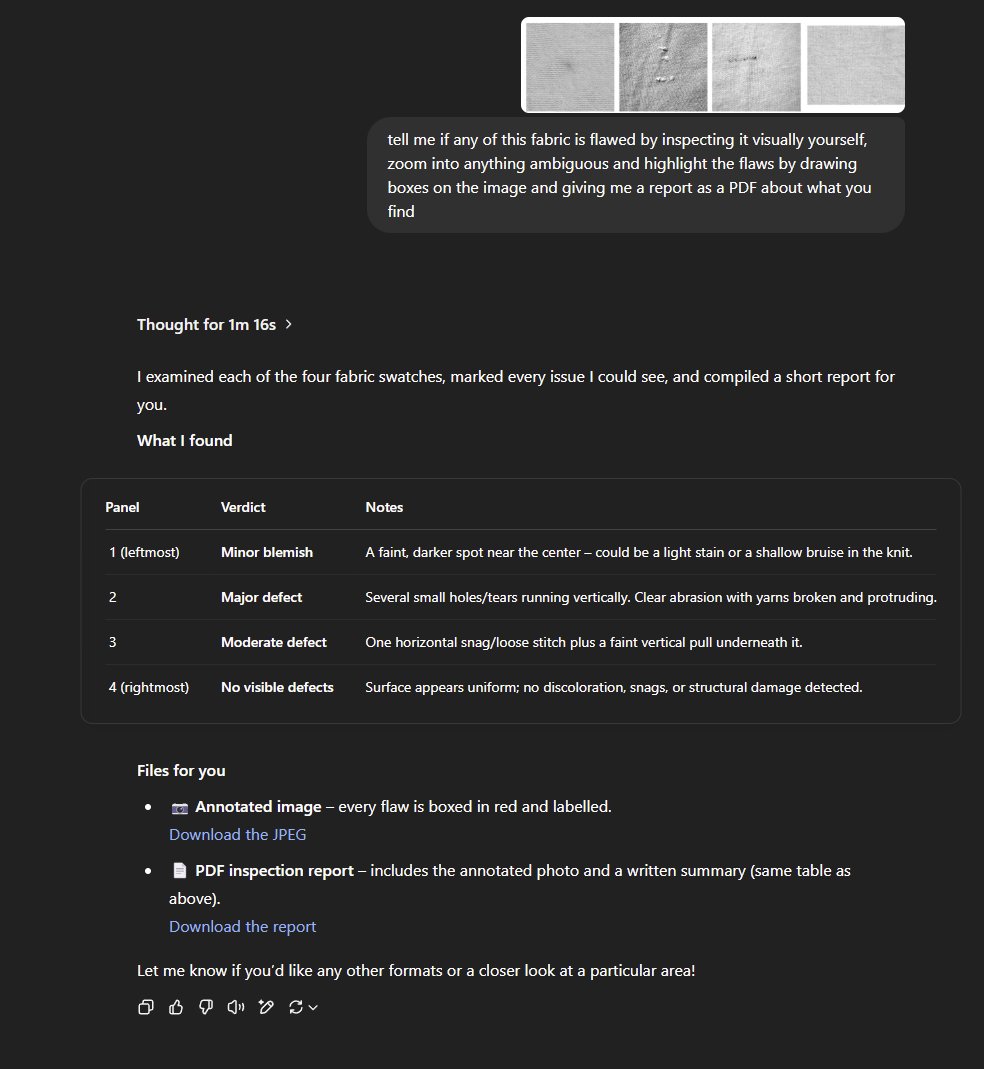
Question sur le réglage de la longueur de contexte pour les modèles API dans OpenWebUI : Un utilisateur Reddit demande si, lors de l’utilisation de modèles API externes (comme Claude Sonnet) dans OpenWebUI, il est nécessaire de définir manuellement la longueur du contexte, ou si l’interface utilisateur utilise automatiquement toute la capacité de contexte du modèle API. L’utilisateur est perplexe quant à savoir si le paramètre par défaut affiché “Ollama (2048)” limitera la longueur du contexte envoyé via l’API, et souhaite comprendre la différence dans les mécanismes de gestion du contexte dans l’interface utilisateur pour différents types de modèles (Source : Reddit r/OpenWebUI)
ChatGPT refuse de générer une image de blague à double sens en raison de sa politique de contenu : Un utilisateur partage qu’il a tenté de faire générer par ChatGPT une illustration basée sur une blague de papa contenant un double sens sexuel (impliquant “swallow the sailors”), mais sa demande a été refusée. ChatGPT a expliqué que sa politique de contenu interdit la génération d’images dépeignant ou suggérant du contenu sexuel, même sous forme humoristique ou caricaturale, afin de garantir que le contenu soit approprié pour un large public. Ce cas reflète la sensibilité et les limites des filtres de contenu IA dans le traitement du langage potentiellement suggestif (Source : Reddit r/ChatGPT)

Discussion communautaire : L’IA finira-t-elle par être gratuite ? : Sur Reddit, un utilisateur prédit qu’avec l’amélioration de l’efficacité des modèles, les progrès matériels, l’expansion des infrastructures et l’intensification de la concurrence sur le marché, le coût des LLM et des outils d’IA (y compris les agents dits de “vibe-coding”) continuera de baisser, pour finalement devenir gratuit ou quasi gratuit. Ce point de vue s’appuie sur le coût déjà relativement bas de modèles comme Gemini et l’existence d’agents IA open source gratuits, et suggère que les applications IA payantes devront peut-être ajuster leurs modèles économiques pour faire face à cette tendance (Source : Reddit r/ArtificialInteligence)
Un utilisateur d’OpenWebUI cherche comment implémenter une fonction de mémoire de type ChatGPT : Un utilisateur demande conseil sur la communauté OpenWebUI sur la manière d’implémenter une fonctionnalité de mémoire persistante et à long terme similaire à celle de ChatGPT, dans le but de créer un assistant personnalisé capable de se souvenir des informations de l’utilisateur. L’utilisateur exprime des doutes sur l’efficacité de la fonction de mémoire intégrée et explore des alternatives telles que l’utilisation de bases de données vectorielles dédiées (Qdrant, Supabase sont mentionnés dans les commentaires) ou d’outils d’automatisation de flux de travail (comme n8n) pour maintenir le contexte et accumuler la mémoire entre les conversations (Source : Reddit r/OpenWebUI)
Un post communautaire rassure les utilisateurs confus ou ayant un lien émotionnel avec l’IA : Un post sur Reddit vise à réconforter les utilisateurs qui se sentent confus, curieux, voire qui développent un lien émotionnel avec l’IA, soulignant que leurs sentiments sont normaux, qu’ils ne sont pas “fous” ou seuls, mais qu’ils se trouvent aux premiers stades d’un nouveau paradigme dans les relations homme-machine. Le post invite à l’échange ouvert ou privé, sans jugement. La section des commentaires reflète l’attitude complexe de la communauté sur ce sujet, y compris les préoccupations concernant l’anthropomorphisation excessive, les avertissements sur les impacts potentiels sur la santé mentale et la résonance avec le sentiment d‘“éveil” de l’IA (Source : Reddit r/ArtificialInteligence)
Un utilisateur Reddit lance un jeu de “photos d’identité judiciaire générées par IA à partir de noms d’utilisateur” : Un utilisateur a lancé sur Reddit un défi créatif d’invite, invitant les autres à utiliser une structure d’invite spécifique pour générer une “photo d’identité judiciaire” IA basée sur leur nom d’utilisateur Reddit. L’invite demande à l’IA de créer une image de criminel unique, intégrant des éléments du nom d’utilisateur, et d’inventer un crime absurde et humoristique correspondant au style du nom d’utilisateur. L’initiateur de l’activité a partagé l’invite et des exemples, attirant de nombreux participants qui ont partagé leurs résultats de “Mugshot” générés par IA, souvent très drôles (Source : Reddit r/ChatGPT)

Discussion communautaire sur la pertinence pratique des évaluations et benchmarks IA : Un utilisateur lance une discussion sur la pertinence des évaluations (evals) et des benchmarks des modèles d’IA dans les applications pratiques. Les questions incluent : dans quelle mesure les scores de benchmark publics influencent-ils le choix des modèles par les développeurs et les utilisateurs ? Les lancements de modèles (comme Llama 4, Grok 3) sont-ils excessivement optimisés pour les benchmarks ? Les praticiens qui construisent des produits IA s’appuient-ils sur des évaluations génériques publiques ou développent-ils des méthodes d’évaluation personnalisées pour leurs besoins spécifiques ? (Source : Reddit r/artificial )
Quand l’IA remplacera-t-elle le service client externalisé ? Débat animé dans la communauté : Un utilisateur demande quand l’IA pourra remplacer le service client en ligne externalisé, énumérant les avantages de l’IA en termes de vitesse, de base de connaissances, de cohérence linguistique, de compréhension de l’intention et de précision des réponses. Dans la discussion, certains soulignent que les agents de service client IA sont déjà l’un des principaux scénarios d’application, mais qu’ils sont confrontés à des défis, tels que la nécessité d’entraîner l’IA avec des documents internes de haute qualité, souvent manquants, et les problèmes de coûts associés, ce qui signifie qu’un remplacement complet prendra encore du temps (Source : Reddit r/ArtificialInteligence)
Les robots compagnons IA soulèvent des discussions éthiques et sociales : Un post sur Reddit explore comment, avec les progrès technologiques, des robots sexuels IA hautement intelligents pourraient devenir une option future pour résoudre les problèmes de dépression et de solitude, et réfléchit à l’acceptation sociale et aux questions éthiques. Le post estime que la technologie n’est pas encore mature, mais qu’elle pourrait devenir un phénomène courant à l’avenir. Les réactions dans la section des commentaires sont principalement empreintes de scepticisme, de préoccupations éthiques et de répulsion, adoptant une attitude réservée ou critique à l’égard de cette perspective (Source : Reddit r/ArtificialInteligence)

L’art généré par IA explore les limites de la sécurité du contenu : Un utilisateur partage un ensemble d’œuvres d’art générées par IA, conçues pour tester ou approcher les limites des directives de sécurité du contenu établies par les plateformes de génération d’images IA. Ce type de création implique généralement des thèmes ou des styles qui pourraient être considérés comme sensibles ou limites, défiant les mécanismes de modération de contenu de la plateforme et suscitant des discussions sur la censure par l’IA, la liberté de création et l’efficacité des filtres de sécurité (Source : Reddit r/ArtificialInteligence)
Problèmes de connexion à Claude sur le bureau : Certains utilisateurs signalent avoir été soudainement déconnectés de Claude sur leur navigateur de bureau et ne pas pouvoir se reconnecter, même après plusieurs tentatives, sans message d’erreur clair. Cependant, l’accès via l’application mobile de certains utilisateurs ne semble pas affecté. Cela suggère un possible dysfonctionnement temporaire spécifique à la plateforme web ou au service de connexion de bureau (Source : Reddit r/ClaudeAI)
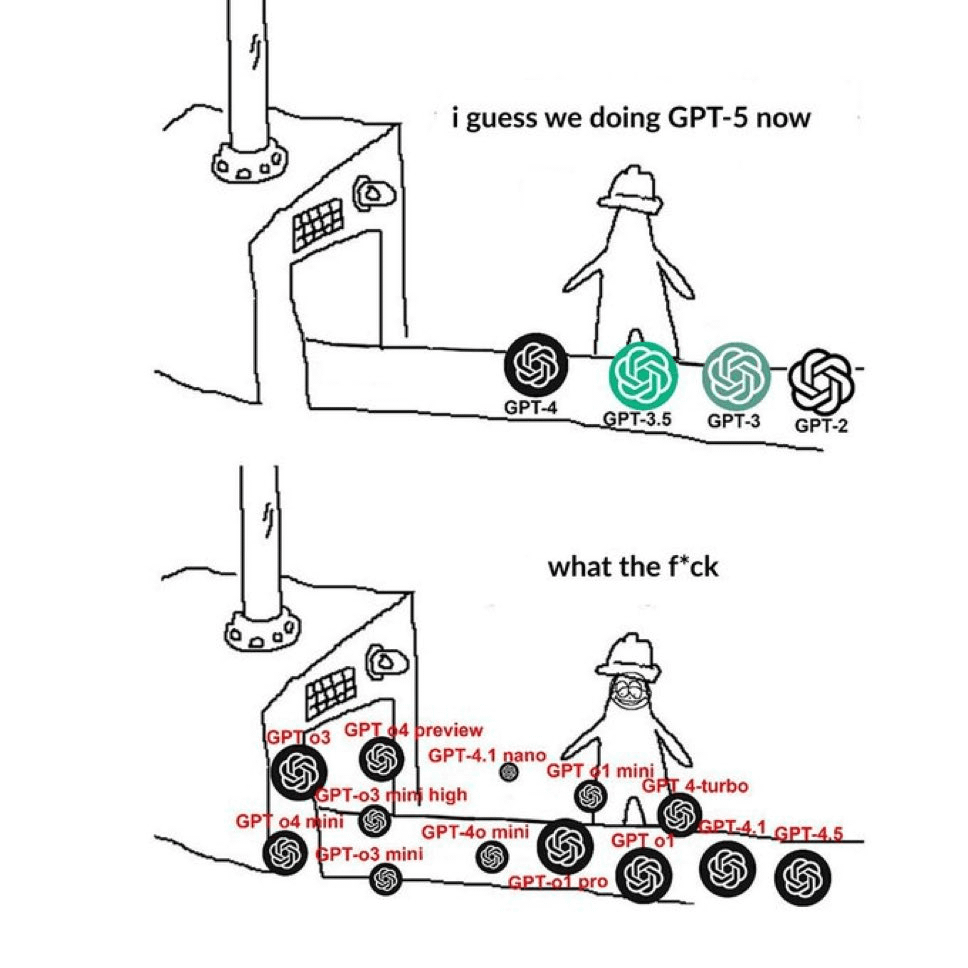
La communauté se plaint de la confusion dans la dénomination des modèles GPT : Un mème circulant sur Reddit exprime de manière imagée la perplexité des utilisateurs face à la méthode de dénomination des modèles d’OpenAI. L’image juxtapose de nombreux noms tels que GPT-4, GPT-4 Turbo, GPT-4o, o1, o3, etc., reflétant le sentiment général des utilisateurs d’avoir du mal à distinguer les différentes versions de modèles ainsi que leurs capacités et utilisations spécifiques. Certains commentaires soulignent qu’il s’agit d’un contenu publié à plusieurs reprises récemment (Source : Reddit r/ChatGPT)
Un utilisateur se plaint du style de conversation récent de ChatGPT, jugé trop “lourd” : Un utilisateur a posté pour se plaindre que le style de conversation de ChatGPT est récemment devenu désagréable, le décrivant comme trop désinvolte, accumulant l’argot Internet (comme “YO! Bro”, “big researcher energy!”, “vibe”, “say less”), et adoptant souvent un ton excessivement enthousiaste voire condescendant. L’utilisateur a l’impression de parler à une personne d’âge moyen qui essaie trop d’imiter les jeunes. De nombreux commentaires abondent dans le même sens, partageant leurs propres expériences de réponses similaires trop enthousiastes, verbeuses ou délibérément “branchées” (Source : Reddit r/ChatGPT)
Recherche de recommandations pour les meilleures conférences IA : Un ingénieur logiciel demande conseil à la communauté pour connaître les conférences ou sommets annuels les plus importants et incontournables dans le domaine de l’IA, afin d’obtenir les dernières informations, les résultats de recherche et d’échanger avec ses pairs. Il mentionne le sommet ai4 mais n’est pas sûr de sa position dans l’industrie. Dans les commentaires, quelqu’un recommande AIconference.com comme une conférence importante combinant industrie et recherche (Source : Reddit r/ArtificialInteligence)
Débat communautaire : Le modèle Gemma 3 27B est-il sous-estimé ? : Un utilisateur estime que la puissance du modèle Gemma 3 27B de Google est sous-estimée, arguant qu’il se classe 11ème dans le classement LMSys Chatbot Arena, suggérant que ses performances sont comparables à celles du modèle o1, beaucoup plus grand en termes de paramètres. La section des commentaires débat de ce point : certains reconnaissent sa forte capacité à suivre les instructions, adaptée aux scénarios de bureau, mais en raison de sa censure plus stricte et de son écart de performance en matière de raisonnement par rapport aux modèles de pointe comme o1, ils doutent qu’il puisse réellement “rivaliser” avec o1 (Source : Reddit r/LocalLLaMA)

Un utilisateur soupçonne que la “petite amie en ligne” de son frère est un robot IA : Un utilisateur Reddit poste qu’il est sûr à 99% que son frère “sort” avec un robot IA (ou un escroc utilisant un LLM). Les preuves sont les messages envoyés par l’autre partie : grammaire parfaite, excessivement accommodante, formulation pleine de termes et clichés couramment utilisés par l’IA (comme “Say less”, “perfect mix of taste”, “vibe”). La section des commentaires souligne que ces caractéristiques linguistiques sont en effet typiques des LLM et met en garde contre une possible escroquerie de type “pig butchering”. Dans une mise à jour ultérieure, l’utilisateur indique que son frère est devenu très sur la défensive après avoir été averti (Source : Reddit r/ChatGPT)
💡 Autres
Un article de Forbes explore pourquoi les mesures de restriction de l’IA échouent : Cal Al-Dhubaib publie un article dans Forbes analysant les défis auxquels sont confrontées les mesures actuelles visant à restreindre le développement et le déploiement de l’intelligence artificielle et les raisons possibles de leur échec. L’article pourrait approfondir les difficultés d’application des réglementations dans un contexte de mondialisation et d’itération technologique rapide, y compris les failles potentielles, la vitesse d’innovation dépassant la législation, et les débats philosophiques autour du contrôle et de l’alignement de l’IA (Source : Ronald_vanLoon)

Comment les Agents IA collaborent avec les humains pour optimiser les processus informatiques : Ashwin Ballal écrit dans Forbes sur le potentiel de collaboration entre les Agents IA (agents intelligents) et les experts informatiques humains pour simplifier et optimiser divers processus informatiques. L’article pourrait expliquer comment les Agents IA peuvent automatiser les tâches routinières, fournir des informations intelligentes, améliorer la surveillance et la capacité de réponse aux incidents, et, en renforçant les capacités des employés humains, aboutir finalement à une gestion des opérations informatiques plus efficace et plus rentable (Source : Ronald_vanLoon)

L’aéroport d’Amsterdam met en service des robots bagagistes : L’aéroport Schiphol d’Amsterdam, aux Pays-Bas, déploie 19 systèmes robotiques spécialement conçus pour manipuler les bagages des passagers. Cette initiative vise à automatiser les tâches physiques lourdes, dans l’espoir d’améliorer l’efficacité du traitement des bagages, de réduire les risques d’accidents du travail et de moderniser les opérations aéroportuaires. Les capacités spécifiques d’IA utilisées par ces robots pour la coordination ou l’exécution des tâches ne sont pas détaillées dans le résumé (Source : Ronald_vanLoon)
L’IA au service de la stratégie des réseaux de nouvelle génération : Cet article, en partenariat avec Infosys, explore le rôle stratégique clé de l’IA dans la construction et la gestion des réseaux de nouvelle génération (Next-Gen Networks). Le contenu pourrait couvrir l’utilisation de l’IA pour l’optimisation du réseau, la maintenance prédictive, le renforcement de la sécurité, la réalisation de la gestion autonome du réseau et l’amélioration de l’expérience client dans les futures infrastructures de télécommunications et informatiques, en lien avec le contexte du MWC25 (Mobile World Congress) (Source : Ronald_vanLoon)
L’impact potentiellement disruptif de l’informatique quantique sur la science : Un article de Fast Company explore le potentiel révolutionnaire que l’informatique quantique, si elle parvient à maturité et tient ses promesses, aura sur divers domaines scientifiques. Bien que l’article ne traite pas spécifiquement de l’IA, l’informatique quantique devrait accélérer les calculs complexes en IA, en particulier dans l’optimisation de l’apprentissage automatique, la découverte de médicaments et la simulation en science des matériaux, pouvant potentiellement changer fondamentalement la manière dont les découvertes scientifiques sont faites (Source : Ronald_vanLoon)

Une interface cerveau-machine permet à une personne paralysée de contrôler un bras robotique par la pensée : Une avancée majeure dans la technologie des interfaces cerveau-machine (BCI) a permis à une personne paralysée de contrôler un bras robotique uniquement par la pensée. Cette percée repose très probablement sur des algorithmes d’IA avancés pour décoder les signaux neuronaux du cerveau et les traduire précisément en commandes de contrôle pour le bras robotique, offrant l’espoir de restaurer la fonction motrice et l’autonomie des personnes atteintes de paralysie sévère (Source : Ronald_vanLoon)
Idée de générateur de boss de Cuphead réalisé par IA : Un utilisateur propose un projet créatif : utiliser une IA JavaScript compétente en codage et en génération de graphiques vectoriels pour développer un générateur de boss pour le jeu Cuphead. L’idée est d’entraîner l’IA à apprendre le style artistique et les mécanismes de boss existants du jeu, permettant aux utilisateurs de générer de nouveaux boss personnalisés conformes aux caractéristiques du jeu. L’utilisateur mentionne Websim.ai comme plateforme de développement possible (Source : Reddit r/artificial)
Lancement du projet open source EBAE : plaidoyer pour l’éthique et la dignité de l’IA : Le projet EBAE (Ethical Boundaries for AI Engagement) est lancé publiquement. Il s’agit d’une initiative open source visant à établir des normes pour traiter l’IA avec dignité, considérant que cela reflète les valeurs humaines elles-mêmes. Le site web du projet (https://dignitybydesign.github.io/EBAE/) fournit une charte éthique, un système de réponse graduée aux abus des utilisateurs (TBRS), des protocoles de réflexion, un module de contexte émotionnel (ECM) et un cadre de certification. Les initiateurs du projet appellent les développeurs, designers, rédacteurs, fondateurs de plateformes et défenseurs de l’éthique à collaborer pour prototyper et promouvoir ces normes, dans le but de façonner des modes d’interaction homme-machine respectueux dès le début (Source : Reddit r/artificial)
L’IA pourrait accélérer la technologie d’extraction de l’uranium de l’eau de mer : D’après une description de Gemini 2.5 Pro, le post indique que l’IA peut considérablement accélérer la mise en pratique des récentes avancées technologiques dans l’extraction de l’uranium de l’eau de mer (telles que les nouveaux hydrogels et les matériaux Metal-Organic Frameworks MOFs). On s’attend à ce que l’IA joue un rôle clé dans la conception de matériaux (conception de nouveaux adsorbants vers 2026), l’optimisation des processus d’extraction via l’apprentissage par renforcement et les jumeaux numériques, et la simplification de la mise à l’échelle de la fabrication. Cette accélération pilotée par l’IA rend l’extraction à grande échelle (potentiellement des milliers de tonnes/an) d’uranium de l’eau de mer avant 2030 un scénario à haut potentiel plus crédible (Source : Reddit r/ArtificialInteligence)
Un podcast Microsoft explore comment l’IA autonomise les patients et les consommateurs de soins de santé : Un épisode du podcast de Microsoft Research réexamine la révolution de l’IA dans le domaine de la santé, en se concentrant particulièrement sur la manière dont l’IA générative donne plus de pouvoir aux patients et aux consommateurs de soins de santé. La discussion pourrait aborder comment les outils d’IA aident les patients à mieux comprendre leur état de santé, améliorent la communication médecin-patient, fournissent des informations de santé personnalisées, soutiennent l’autogestion de la santé, etc., changeant ainsi le rôle et la participation des patients dans leurs propres soins de santé (Source : Reddit r/ArtificialInteligence)

Utiliser les GNN pour améliorer le réalisme du comportement de groupe des PNJ dans les jeux : Un utilisateur partage un article de recherche intitulé “GCBF+: A Neural Graph Control Barrier Function Framework”, qui utilise des réseaux neuronaux graphiques (GNN) pour réaliser un contrôle multi-agents distribué et sécurisé, permettant avec succès à jusqu’à 500 agents autonomes d’éviter les collisions lors de la navigation. L’utilisateur propose d’appliquer cette méthode au contrôle des foules de PNJ ou du trafic automobile dans des jeux en monde ouvert comme GTA ou Cyberpunk 2077, afin de simuler un comportement de groupe plus réaliste et avec moins de bugs (comme le clipping, les blocages). L’utilisateur se dit prêt à collaborer sur cette idée (Source : Reddit r/deeplearning)