
Mots-clés:Développement de l’IA, Grok 3, Gemma 3, Applications de l’IA, Changement de paradigme dans le développement de l’IA, API xAI Grok 3, Google Gemma 3 QAT, Benchmark VideoGameBench pour l’IA, Accélération de la découverte moléculaire par IA, Apprentissage fédéré pour l’imagerie médicale, Agent de connaissance LlamaIndex, Technologie d’auto-réparation du code par IA
🔥 Focus
Changement de paradigme dans le développement de l’IA : de la course aux benchmarks à la création de valeur : Un billet de blog de Yao Shunyu, chercheur chez OpenAI, suscite la discussion en proposant que le développement de l’IA est entré dans sa seconde moitié. La première moitié s’est concentrée sur l’innovation algorithmique et l’amélioration des scores sur les benchmarks (comme AlphaGo, GPT-4), réalisant des percées en matière de généralisation en combinant le pré-entraînement à grande échelle (fournissant des connaissances a priori) et l’apprentissage par renforcement (RL), et en introduisant le concept de “raisonnement comme action”. Cependant, il estime que les bénéfices marginaux de la poursuite de la course aux benchmarks diminuent. La seconde moitié devrait se tourner vers la définition de problèmes ayant une valeur applicative réelle, le développement de méthodes d’évaluation plus proches du monde réel, et une réflexion similaire à celle d’un chef de produit, visant à réellement créer de la valeur pour les utilisateurs et la société avec l’IA, plutôt que de simplement chercher à améliorer des métriques. Cela marque un changement de mentalité dans le domaine de l’IA, passant d’une exploration technologique dominante à une focalisation sur l’application et la réalisation de valeur (Source : dotey)
xAI lance l’API pour la série de modèles Grok 3 : xAI a officiellement lancé l’interface API (docs.x.ai) pour sa série de modèles Grok 3, ouvrant ses derniers modèles aux développeurs. Cette série comprend Grok 3 Mini et Grok 3. Selon xAI, Grok 3 Mini démontre des capacités de raisonnement supérieures tout en maintenant un coût faible (prétendu être 5 fois inférieur aux modèles d’inférence comparables) ; tandis que Grok 3 se positionne comme un puissant modèle non axé sur le raisonnement (peut-être pour les tâches riches en connaissances), excellant dans des domaines nécessitant des connaissances du monde réel comme le droit, la finance et la médecine. Cette initiative marque l’entrée de xAI dans la compétition du marché des API de modèles d’IA, offrant de nouvelles options aux développeurs (Source : grok, grok)
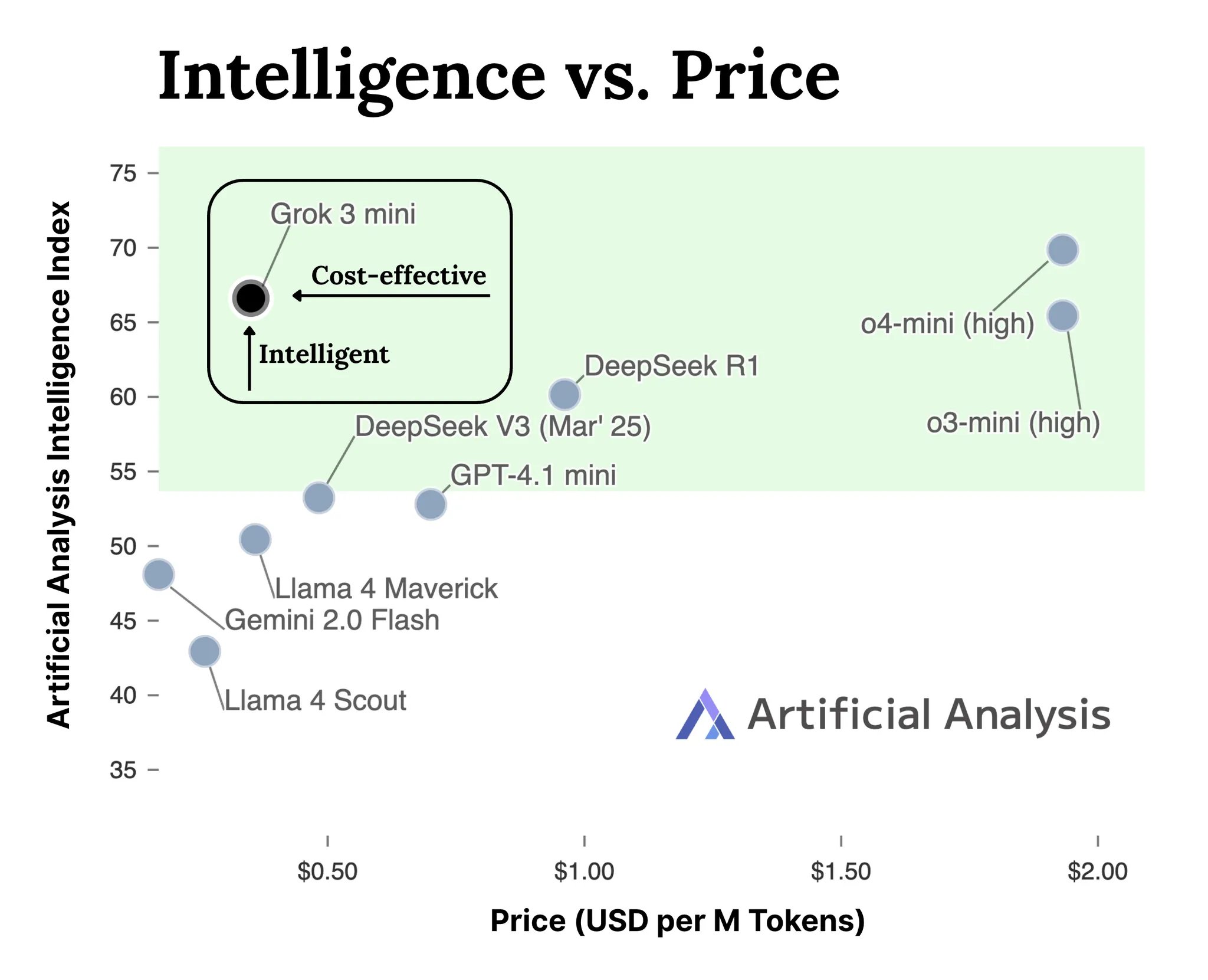
VideoGameBench : Évaluer les capacités des agents IA avec des jeux classiques : Des chercheurs ont lancé une version préliminaire du benchmark VideoGameBench, visant à évaluer la capacité des modèles visuels-linguistiques (VLM) à accomplir des tâches en temps réel dans 20 jeux vidéo classiques (comme Doom II). Les tests préliminaires montrent que les meilleurs modèles, y compris GPT-4o, Claude Sonnet 3.7 et Gemini 2.5 Pro, ont des performances variables dans Doom II, mais aucun n’a réussi à passer le premier niveau. Cela indique que, bien que les modèles soient puissants dans de nombreuses tâches, ils rencontrent encore des défis dans des environnements dynamiques complexes nécessitant perception, décision et action en temps réel. Ce benchmark fournit un nouvel outil pour mesurer et stimuler les progrès des agents IA dans des environnements interactifs (Source : Reddit r/LocalLLaMA)
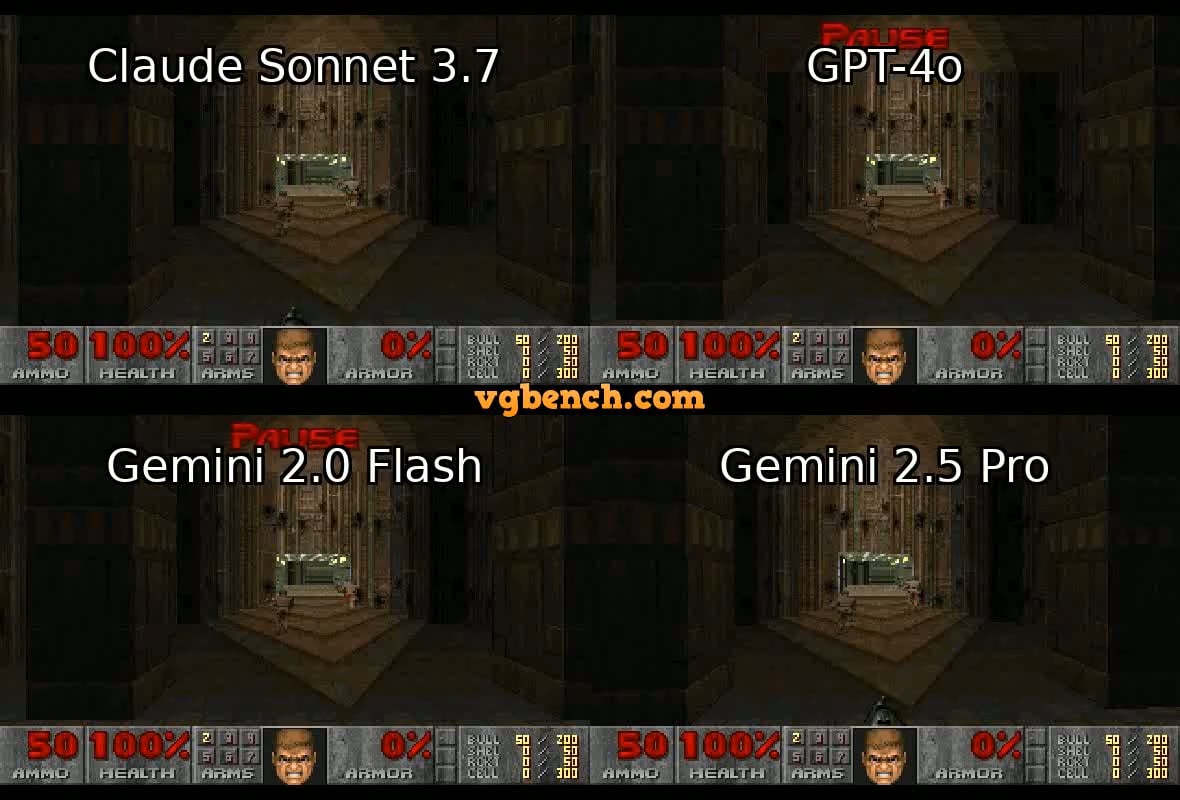
Le renforcement de la vérification d’identité par OpenAI suscite la controverse : Il a été rapporté qu’OpenAI exige des utilisateurs de fournir des preuves d’identité détaillées (telles que passeport, avis d’imposition, factures de services publics) pour accéder à certains de ses modèles avancés (en particulier ceux dotés de fortes capacités de raisonnement comme o3). Cette mesure a provoqué une vive réaction dans la communauté, les utilisateurs s’inquiétant généralement des fuites de confidentialité et de l’augmentation des barrières à l’accès. Bien qu’OpenAI puisse avoir des considérations de sécurité, de conformité ou de gestion des ressources, cette exigence de vérification stricte contraste avec son image ouverte et pourrait inciter les utilisateurs à se tourner vers des alternatives offrant une meilleure protection de la vie privée ou plus faciles d’accès, en particulier les modèles locaux (Source : Reddit r/LocalLLaMA)
L’IA accélère la découverte moléculaire : simulation de millions d’années d’évolution naturelle : Une discussion sur les réseaux sociaux mentionne que l’intelligence artificielle peut concevoir une molécule en quelques jours, alors qu’il faudrait peut-être 500 millions d’années à la nature pour la faire évoluer. Bien que les détails spécifiques restent à vérifier, cela souligne l’énorme potentiel de l’IA pour accélérer la découverte scientifique, en particulier dans les domaines de la chimie et de la biologie. L’IA peut explorer de vastes espaces chimiques et prédire les propriétés moléculaires à une vitesse bien supérieure aux méthodes expérimentales traditionnelles et à l’évolution naturelle, promettant des avancées majeures dans des domaines tels que le développement de médicaments et la science des matériaux (Source : Ronald_vanLoon)
🎯 Tendances
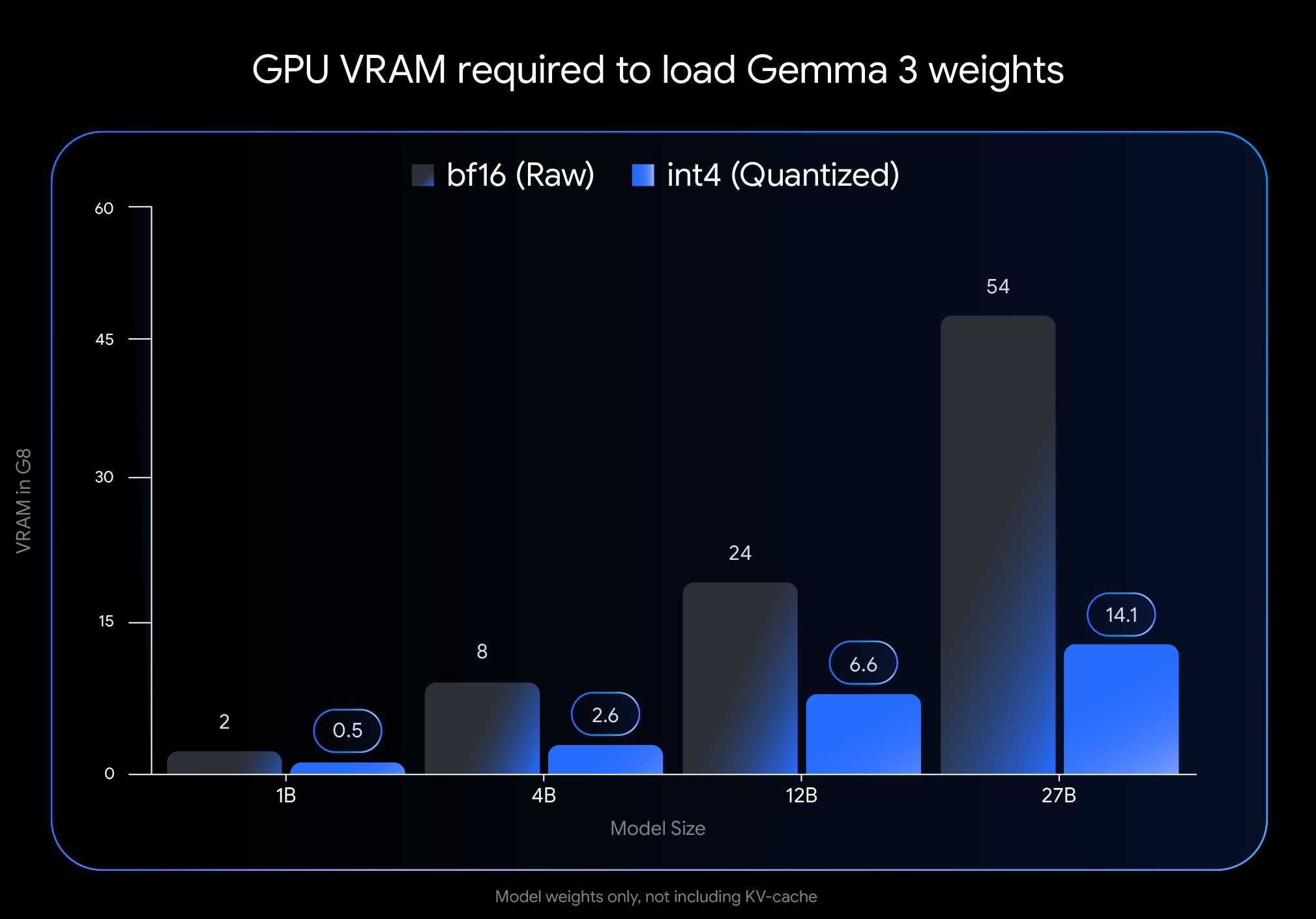
Google publie la version QAT de Gemma 3, réduisant considérablement le seuil de déploiement : Google DeepMind a lancé des versions du modèle Gemma 3 ayant subi un Entraînement Conscient de la Quantification (Quantization-Aware Training, QAT). La technologie QAT vise à préserver au maximum les performances du modèle original tout en compressant considérablement sa taille. Par exemple, la taille du modèle Gemma 3 27B passe de 54 Go (bf16) à environ 14,1 Go (int4), permettant à des modèles de pointe nécessitant auparavant des GPU cloud haut de gamme de fonctionner désormais sur des GPU de bureau grand public (comme le RTX 3090). Google a publié les checkpoints QAT non quantifiés ainsi que des versions dans plusieurs formats (MLX, GGUF) et a collaboré avec des outils communautaires comme Ollama, LM Studio, llama.cpp, etc., pour garantir que les développeurs puissent les utiliser facilement sur diverses plateformes, favorisant ainsi grandement la démocratisation des modèles open source haute performance (Source : huggingface, JeffDean, demishassabis, karminski3, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
Meta FAIR publie des résultats de recherche en perception, maintenant sa ligne open source : Meta FAIR a publié plusieurs nouveaux résultats de recherche dans le domaine de l’intelligence artificielle avancée (Advanced Machine Intelligence, AMI), notamment des progrès en perception, avec la publication d’un encodeur visuel à grande échelle, le Meta Perception Encoder. Yann LeCun souligne que ces résultats seront open source. Cela montre l’investissement continu de Meta dans la recherche fondamentale en IA et son engagement à partager ses avancées via l’open source pour stimuler le développement de l’ensemble du domaine. Les outils publiés, comme l’encodeur visuel, bénéficieront à une communauté plus large de chercheurs et de développeurs (Source : ylecun)
OpenAI clarifie les limites d’utilisation de ses modèles : OpenAI a précisé les quotas d’utilisation de ses modèles pour les utilisateurs ChatGPT Plus, Team et Enterprise. Le modèle o3 est limité à 50 messages par semaine, o4-mini à 150 par jour, et o4-mini-high à 50 par jour. Il est mentionné que ChatGPT Pro (peut-être une offre spécifique ou une erreur) aurait un accès illimité. Ces limitations affectent directement les utilisateurs fréquents et les développeurs d’applications dépendant de modèles spécifiques, qui devront en tenir compte dans leur planification d’utilisation (Source : dotey)
LlamaIndex s’intègre aux bases de données Google Cloud pour construire des agents de connaissance : Lors de la conférence Google Cloud Next 2025, LlamaIndex a montré comment son framework s’intègre aux bases de données Google Cloud pour construire des agents de connaissance capables d’effectuer des recherches multi-étapes, de traiter des documents et de générer des rapports. La démonstration incluait un cas d’un système multi-agents générant automatiquement un guide d’intégration pour les employés. Cela illustre la tendance à l’intégration profonde des frameworks d’applications IA avec les plateformes cloud et leurs services de données, visant à répondre aux besoins réels des entreprises pour exploiter l’IA afin de traiter leurs connaissances et données internes (Source : jerryjliu0)

Un nouveau capteur cérébral nanométrique combiné à l’IA atteint une haute précision dans la reconnaissance des signaux : Une étude rapporte un nouveau type de capteur cérébral à l’échelle nanométrique qui atteint un taux de précision de 96,4% dans l’identification des signaux neuronaux. Bien que la technologie du capteur elle-même soit la percée principale, atteindre une telle précision de reconnaissance nécessite généralement l’aide d’algorithmes avancés d’IA et d’apprentissage automatique pour décoder les signaux neuronaux complexes et faibles. Cette avancée ouvre de nouvelles voies pour la recherche en neurosciences et les futures applications d’interface cerveau-machine, promettant une surveillance et une interaction plus fines avec l’activité cérébrale (Source : Ronald_vanLoon)

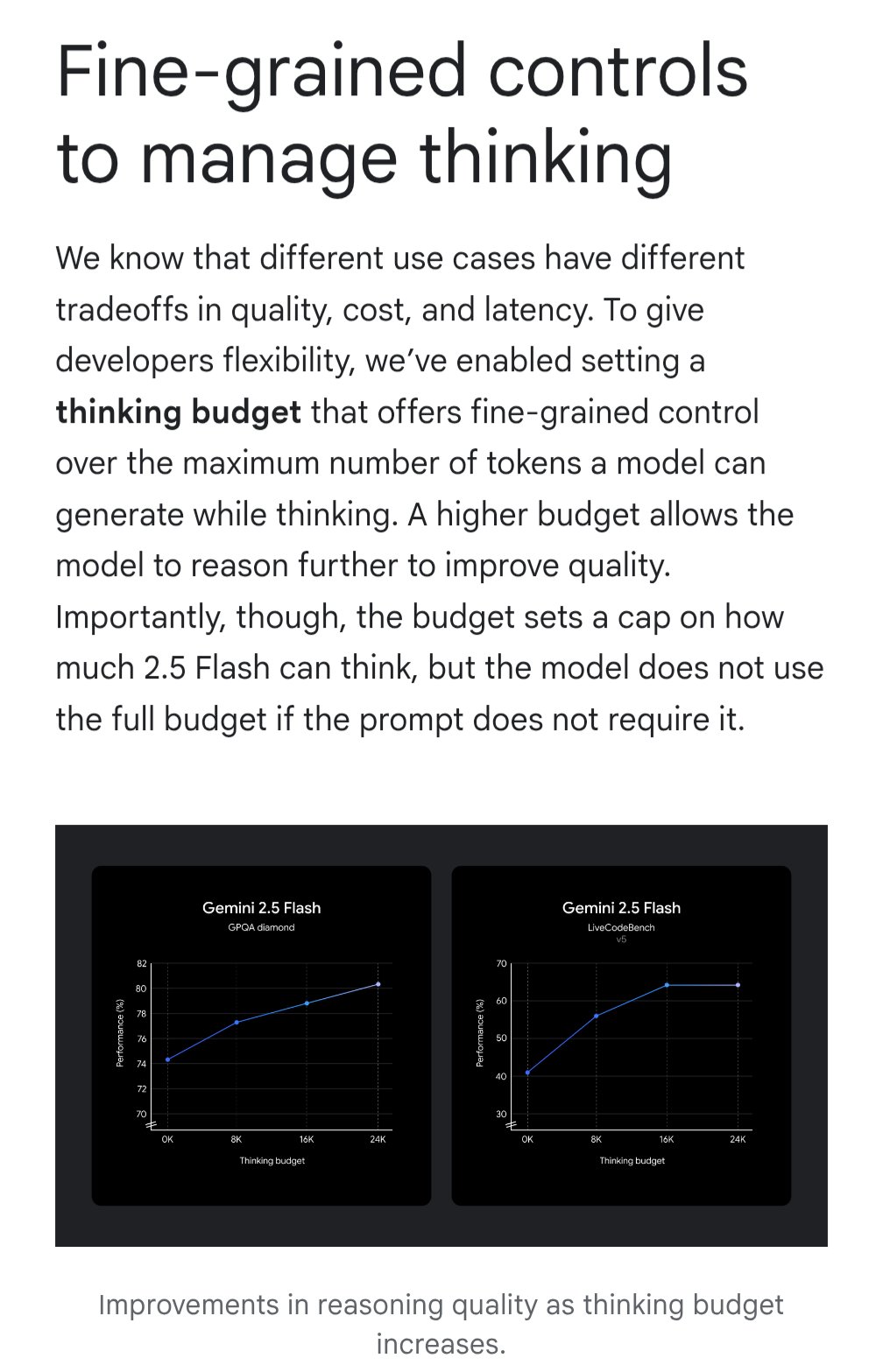
Gemini introduit la fonction “budget de réflexion” pour optimiser le rapport coût-efficacité : Le modèle Google Gemini introduit une fonction de “budget de réflexion” (thinking budget), permettant aux utilisateurs d’ajuster les ressources de calcul ou la profondeur de “réflexion” allouées par le modèle lors du traitement d’une requête. Cette fonction vise à permettre aux utilisateurs de faire un compromis entre la qualité de la réponse, le coût et la latence. C’est une fonctionnalité très pratique pour les utilisateurs d’API, qui peuvent contrôler de manière flexible le coût d’utilisation et les performances du modèle en fonction des besoins spécifiques de leur application (Source : JeffDean)
La qualité des échographies assistées par IA comparable à celle des experts : Une étude publiée dans JAMA Cardiology montre que les échographies réalisées par des professionnels de la santé formés et guidés par l’IA ont une qualité d’image suffisante pour répondre aux normes diagnostiques (98,3%), sans différence statistiquement significative par rapport aux images acquises par des experts sans guidage IA. Cela indique que l’IA, en tant qu’outil d’assistance, peut aider efficacement les utilisateurs non experts à améliorer la qualité et la cohérence des procédures d’imagerie médicale, et pourrait élargir l’accès à des services de diagnostic de haute qualité dans les régions aux ressources limitées (Source : Reddit r/ArtificialInteligence)
Une recherche du MIT améliore la précision et le respect de la structure du code généré par l’IA : Des chercheurs du MIT ont développé une méthode plus efficace pour contrôler la sortie des grands modèles de langage, visant à guider les modèles pour générer du code conforme à une structure spécifique (comme la syntaxe d’un langage de programmation) et sans erreur. Cette recherche vise à résoudre le problème de fiabilité du code généré par l’IA. En améliorant les techniques de génération contrainte, elle assure que la sortie respecte strictement les règles syntaxiques, augmentant ainsi l’utilité des assistants de code IA et réduisant les coûts de débogage ultérieurs (Source : Reddit r/ArtificialInteligence)
NVIDIA pourrait révéler un projet majeur dans le domaine de la robotique : Les réseaux sociaux mentionnent que NVIDIA travaille sur son “projet le plus ambitieux”, impliquant la robotique, l’ingénierie, l’intelligence artificielle et les technologies autonomes. Bien que le contenu spécifique ne soit pas connu, compte tenu de la position centrale de NVIDIA dans le matériel et les plateformes d’IA (comme Isaac), toute annonce majeure associée est très attendue et pourrait présager de nouvelles orientations stratégiques et avancées technologiques dans le domaine de l’intelligence incarnée et de la robotique (Source : Ronald_vanLoon)
🧰 Outils
Potpie : Assistant d’ingénierie IA dédié aux dépôts de code : Potpie est une plateforme open source (GitHub : potpie-ai/potpie) conçue pour créer des agents d’ingénierie IA personnalisés pour les dépôts de code. Elle construit un graphe de connaissances du code pour comprendre les relations complexes entre les composants, offrant des tâches automatisées telles que l’analyse de code, les tests, le débogage et le développement. La plateforme propose plusieurs agents pré-construits (par exemple, débogage, questions-réponses, analyse des changements de code, génération de tests unitaires/d’intégration, conception de bas niveau, génération de code) et des ensembles d’outils, et permet aux utilisateurs de créer des agents personnalisés. Une extension VSCode et une intégration API sont fournies pour faciliter l’intégration dans le flux de développement (Source : potpie-ai/potpie – GitHub Trending (all/daily))

1Panel : Panneau de serveur Linux intégrant la gestion des LLM : 1Panel (GitHub : 1Panel-dev/1Panel) est un panneau d’administration et d’exploitation de serveurs Linux open source moderne, offrant une interface graphique web pour gérer l’hôte, les fichiers, les bases de données, les conteneurs, etc. L’une de ses caractéristiques est l’inclusion de fonctionnalités de gestion des grands modèles de langage (LLM). De plus, il propose un magasin d’applications, le déploiement rapide de sites web (intégré à WordPress), la protection de la sécurité et la sauvegarde/restauration en un clic, visant à simplifier la gestion des serveurs et le déploiement d’applications, y compris le déploiement et la gestion d’applications liées à l’IA (Source : 1Panel-dev/1Panel – GitHub Trending (all/daily))

LlamaIndex lance une version améliorée de son composant d’interface de chat : LlamaIndex a publié une mise à jour majeure de sa bibliothèque de composants d’interface de chat (@llamaindex/chat-ui). Les nouveaux composants, basés sur shadcn UI, présentent un design plus élégant, une disposition réactive et sont entièrement personnalisables. Ils visent à aider les développeurs à construire plus facilement des interfaces de chat esthétiques et conviviales pour les projets basés sur les LLM, améliorant ainsi l’expérience interactive des applications IA. Les développeurs peuvent l’installer via npm et l’utiliser directement dans leurs projets (Source : jerryjliu0)
LlamaExtract en pratique : Construire une application d’analyse financière : LlamaIndex a présenté un cas d’utilisation de son outil LlamaExtract (faisant partie de LlamaCloud) pour construire une application web full-stack. LlamaExtract permet aux utilisateurs de définir un schéma précis pour extraire des données structurées de documents complexes. L’application exemple extrait les facteurs de risque des rapports annuels d’entreprises et analyse leur évolution au fil des ans, automatisant un travail qui prenait auparavant plus de 20 heures. Cette application est open source (GitHub : run-llama/llamaextract-10k-demo) et une vidéo montre comment combiner LlamaExtract et Sonnet 3.7 pour construire ce flux de travail, démontrant le potentiel des agents IA pour automatiser des tâches d’analyse complexes (Source : jerryjliu0, jerryjliu0)
mcpbased.com : Lancement d’un répertoire de serveurs MCP open source : Le nouveau site web mcpbased.com a été lancé comme un répertoire dédié aux serveurs MCP (peut-être Meta Controller Pattern ou un concept similaire) open source. La plateforme vise à rassembler et présenter divers projets de serveurs MCP, en synchronisant les données des dépôts Github en temps réel, pour faciliter la découverte, la navigation et la connexion aux outils pertinents par les développeurs. C’est un nouveau centre de ressources pour les développeurs qui construisent ou utilisent des serveurs MCP, effectuent des intégrations d’outils ou s’intéressent à l’écosystème MCP (Source : Reddit r/ClaudeAI)
📚 Apprentissage
Un livre sur le RLHF arrive sur ArXiv : Le livre “rlhfbook” sur l’Apprentissage par Renforcement à partir du Feedback Humain (RLHF), écrit par Nathan Lambert et al., est maintenant disponible sur la plateforme ArXiv (numéro 2504.12501). Le RLHF est l’une des techniques clés actuelles pour aligner les grands modèles de langage (comme ChatGPT). La publication de ce livre offre aux chercheurs et praticiens une ressource importante pour apprendre systématiquement et comprendre en profondeur les principes et la pratique du RLHF, favorisant la diffusion et l’application des connaissances dans ce domaine (Source : natolambert)
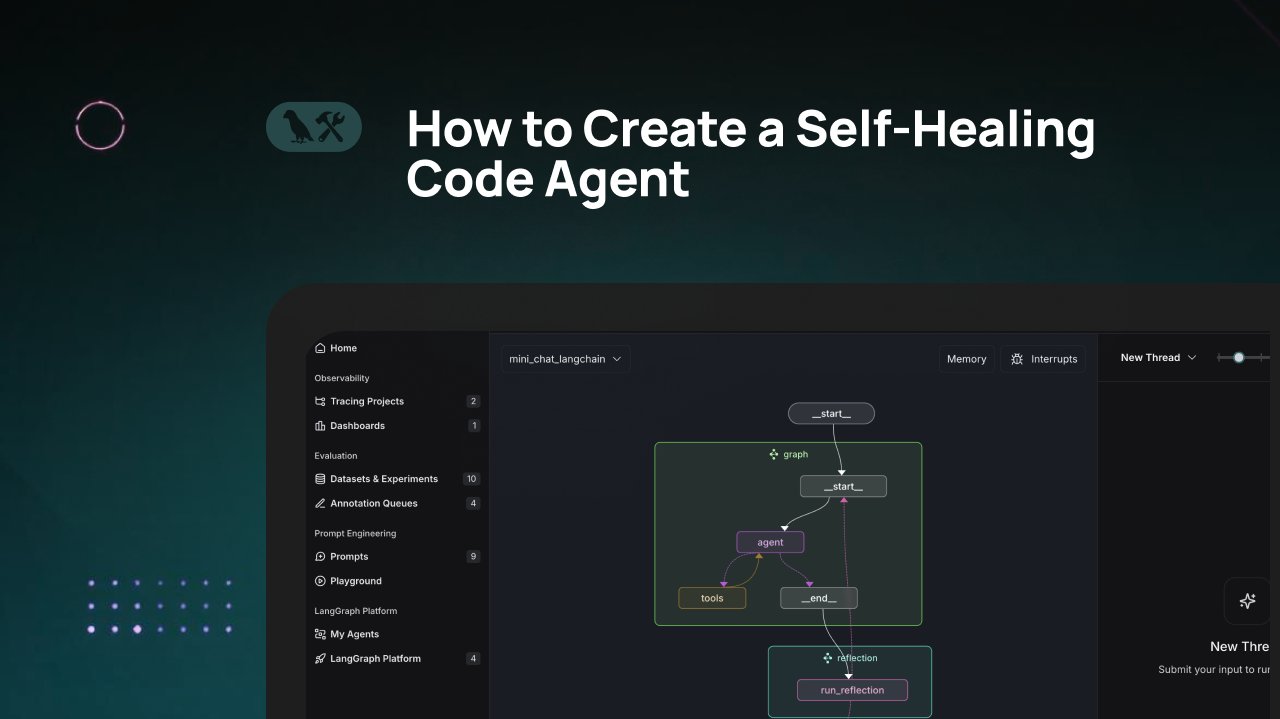
Tutoriel LangChain : Construire un agent de génération de code auto-réparateur : LangChain a publié un tutoriel vidéo expliquant comment construire un agent de génération de code IA doté de capacités “d’auto-réparation”. L’idée centrale est d’ajouter une étape de “réflexion” après la génération du code, permettant à l’agent de vérifier, évaluer ou améliorer lui-même le code généré avant de retourner le résultat. Cette méthode vise à améliorer la précision et la fiabilité du code généré par l’IA, et constitue une technique efficace pour accroître l’utilité des assistants de code (Source : LangChainAI)
Combiner l’IA et Blender pour créer des assets 3D utilisables en jeu : Un tutoriel partagé sur les réseaux sociaux montre comment combiner des outils d’IA (probablement de génération d’images) avec le logiciel de modélisation 3D Blender pour produire des assets 3D “game-ready” (prêts pour le jeu). Cela répond au problème actuel des capacités limitées de l’IA à générer directement des modèles 3D, en présentant un flux de travail hybride pratique : utiliser l’IA pour générer des concepts ou des textures, puis utiliser des outils professionnels comme Blender pour la modélisation, l’optimisation, et enfin produire des ressources conformes aux exigences des moteurs de jeu (Source : huggingface)
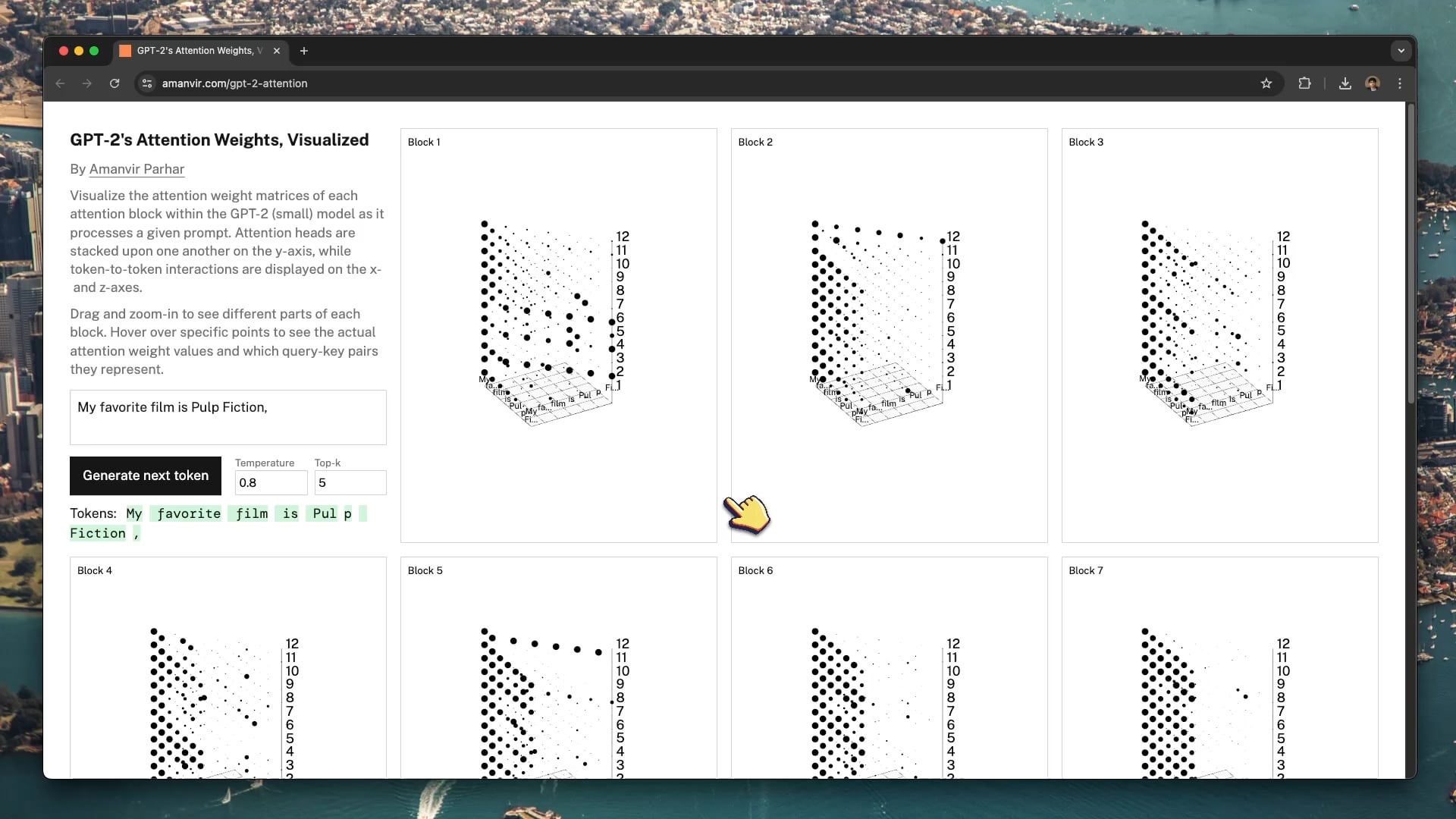
Un outil de visualisation interactif aide à comprendre le mécanisme d’attention de GPT-2 : Le développeur tycho_brahes_nose_ a créé et partagé un outil de visualisation 3D interactif (amanvir.com/gpt-2-attention) pour montrer le processus de calcul des poids de chaque bloc d’attention à l’intérieur du modèle GPT-2 (petit). Les utilisateurs peuvent voir intuitivement comment, après l’entrée de texte, le modèle calcule l’intensité de l’interaction entre les tokens à travers différentes couches et différentes têtes d’attention. C’est une excellente aide pour comprendre le mécanisme central des Transformers, utile pour l’apprentissage de l’IA et la recherche sur l’interprétabilité des modèles (Source : karminski3, Reddit r/LocalLLaMA)
Application de l’Apprentissage Fédéré à l’analyse d’images médicales : Un post Reddit pointe vers un article sur la combinaison de l’Apprentissage Fédéré (Federated Learning, FL) avec les réseaux neuronaux profonds (DNN) pour l’analyse d’images médicales. En raison de la sensibilité des données médicales en matière de confidentialité, le FL permet d’entraîner des modèles en collaboration entre plusieurs institutions sans partager les données brutes. C’est crucial pour faire progresser l’application de l’IA dans le domaine médical, et cette ressource aide à comprendre cette technique d’apprentissage distribué préservant la vie privée et sa pratique dans l’imagerie médicale (Source : Reddit r/deeplearning)

Sander Dielman analyse en profondeur les VAE et l’espace latent : Andrej Karpathy recommande l’article de blog approfondi de Sander Dielman (sander.ai/2025/04/15/latents.html) sur les Autoencodeurs Variationnels (VAE) et la modélisation de l’espace latent. L’article explore les détails de l’entraînement des VAE, comme le rôle limité du terme de divergence KL dans la formation réelle de l’espace latent, et les raisons pour lesquelles les pertes de reconstruction L1/L2 tendent à produire des images floues (l’atténuation du spectre de l’image ne correspond pas à la perception de l’œil humain). Cet article fournit une analyse rigoureuse et perspicace pour comprendre les modèles génératifs (Source : Reddit r/MachineLearning)
💼 Affaires
La guerre des prix des modèles s’intensifie : Google Gemini défie activement OpenAI : Une analyse souligne que Google, avec sa série de modèles Gemini (en particulier le nouveau Gemini 2.5 Flash), démontre une forte compétitivité en termes de performances et de prix, offrant prétendument un meilleur rapport qualité-prix qu’OpenAI dans environ 95% des scénarios. La réactivité rapide de Google concernant son API et sa stratégie de tarification (dominant plus de 90% des fourchettes de prix) indiquent qu’il cherche activement à conquérir des parts de marché des LLM, en utilisant l’avantage du coût pour attirer les utilisateurs, ce qui intensifie la concurrence sur le marché des modèles de base (Source : JeffDean)
Coinbase sponsorise la conférence LangChain, explorant l’Agentic Commerce : Coinbase Development devient sponsor de la conférence LangChain Interrupt 2025. Coinbase, via ses outils comme AgentKit et le protocole de paiement x402, favorise le “commerce agentique” (Agentic Commerce), permettant aux agents IA d’effectuer des paiements autonomes pour des services tels que la récupération contextuelle, les appels API, etc. Cette collaboration met en évidence le point de convergence entre la technologie des agents IA et les paiements Web3, préfigurant de futurs scénarios d’interactions économiques automatisées pilotées par l’IA (Source : LangChainAI)

xAI lance le programme SuperGrok gratuit pour les étudiants : Pour attirer le jeune public, xAI lance une offre promotionnelle pour les étudiants : en s’inscrivant avec une adresse e-mail .edu, ils peuvent obtenir deux mois d’utilisation gratuite de SuperGrok (la version avancée de Grok). Cette initiative vise à positionner Grok comme un outil d’aide à l’apprentissage, en le promouvant pendant la période des examens finaux, afin de conquérir les utilisateurs du marché de l’éducation et de fidéliser de futurs clients potentiels (Source : grok)
Google offre gratuitement Gemini Advanced et plusieurs services aux étudiants américains : Google a annoncé des avantages gratuits à long terme pour les étudiants universitaires américains : s’ils s’inscrivent avant le 30 juin 2025, ils peuvent utiliser gratuitement Gemini Advanced (équipé de Gemini 2.5 Pro), NotebookLM Plus, les fonctionnalités Gemini dans Google Workspace, Whisk, ainsi que 2 To de stockage cloud, jusqu’à la fin du semestre de printemps 2026. Cette campagne de promotion à grande échelle vise à intégrer profondément les outils d’IA de Google dans l’écosystème éducatif, à concurrencer des rivaux comme Microsoft, et à cultiver la fidélité de la prochaine génération d’utilisateurs et de développeurs à la plateforme IA de Google (Source : demishassabis, JeffDean)
FanDuel lance “ChuckGPT”, un chatbot IA de célébrité : La célébrité sportive Charles Barkley a autorisé l’utilisation de son nom, de son image et de sa voix en partenariat avec la société de paris sportifs FanDuel pour lancer un chatbot IA nommé “ChuckGPT” (chuck.fanduel.com). C’est un autre exemple d’utilisation de la propriété intellectuelle de célébrités et de la technologie IA pour le marketing de marque et l’interaction utilisateur, en simulant le style de conversation de la célébrité pour fournir des informations sportives, des conseils de paris ou des interactions divertissantes, afin d’augmenter l’engagement des utilisateurs (Source : Reddit r/artificial)
🌟 Communauté
Inquiétudes concernant la dépendance aux outils IA : Une caricature sur les réseaux sociaux dépeignant un utilisateur submergé par de nombreux outils IA (ChatGPT, Claude, Midjourney, etc.), légendée “Dépendance aux outils IA”, a trouvé un écho. Cela reflète le sentiment de surcharge d’informations et la potentielle dépendance excessive ressentis par certains utilisateurs face à la prolifération des applications IA, ainsi que la charge cognitive liée à la gestion et au choix des outils appropriés (Source : dotey)
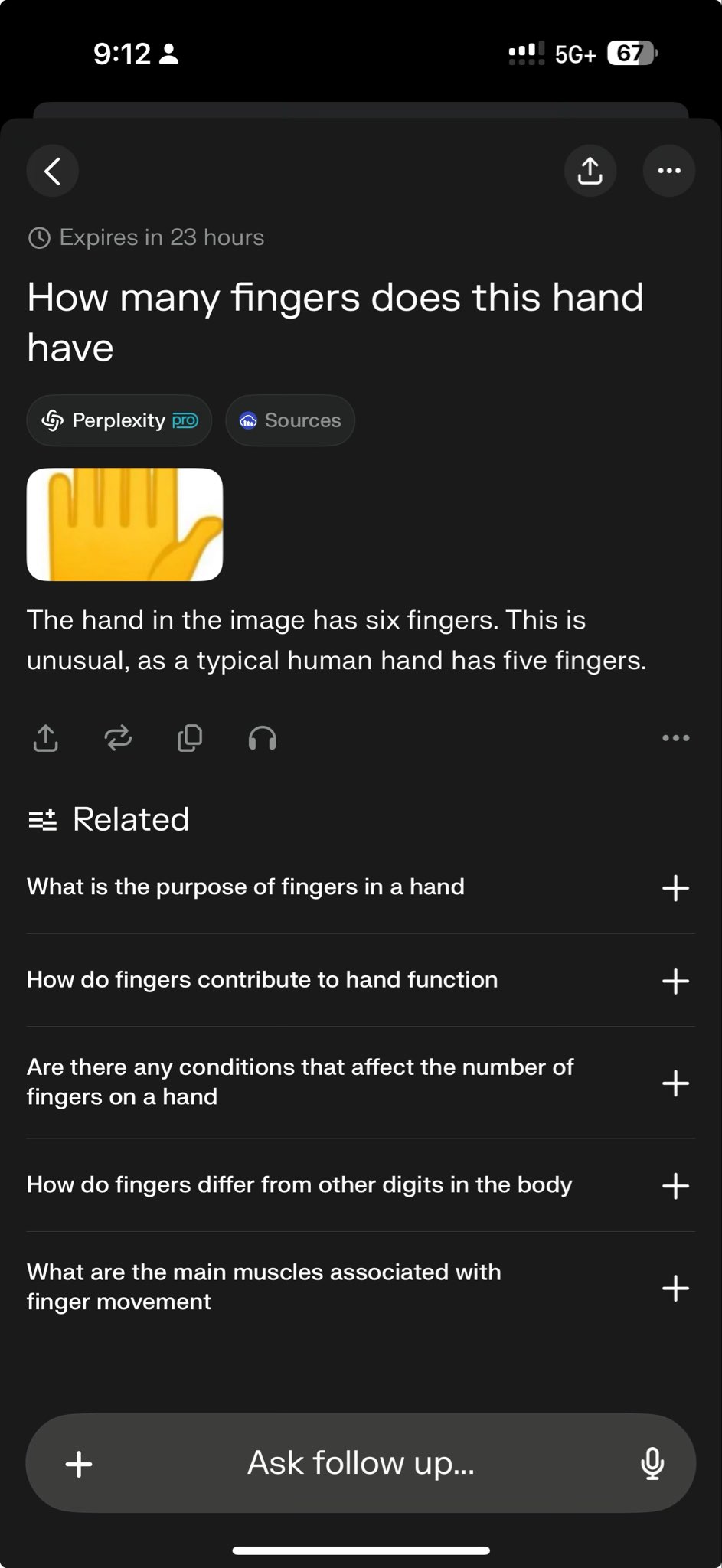
L’échec de modèles de pointe sur des tests spécifiques révèle les limites de leurs capacités : Arav Srinivas, PDG de Perplexity, a relayé un cas de test montrant que o3 et Gemini 2.5 Pro n’ont pas réussi à accomplir une tâche complexe de dessin graphique. Ceci est considéré par certains comme un test exigeant pour les capacités actuelles des modèles. De tels “cas d’échec” sont largement discutés dans la communauté pour révéler les limitations des modèles SOTA (State-Of-The-Art) en matière de raisonnement spécifique, de compréhension spatiale ou de suivi d’instructions, contribuant à une perception plus objective de l’écart entre l’IA actuelle et l’intelligence artificielle générale (AGI) (Source : AravSrinivas)
La communauté discute des résultats de génération d’images de coussins par GPT-4o et partage de Prompts : Un utilisateur partage un cas réussi de génération d’images de coussins dans un style spécifique (mignon, texture légèrement pelucheuse, forme d’emoji) à l’aide de GPT-4o, ainsi que le prompt optimisé. Ce type de partage montre l’application de la génération d’images par IA dans la conception créative et favorise l’échange au sein de la communauté sur les techniques de Prompt engineering et l’exploration de styles. Les résultats de génération de haute qualité stimulent l’enthousiasme créatif des utilisateurs (Source : dotey)

Sam Altman : L’IA ressemble plus à une Renaissance qu’à une Révolution Industrielle : Le PDG d’OpenAI, Sam Altman, a exprimé l’opinion que la transformation apportée par l’intelligence artificielle ressemble davantage à une Renaissance qu’à une Révolution Industrielle. Cette métaphore suscite la discussion dans la communauté, suggérant que l’impact de l’IA pourrait se manifester davantage sur les plans culturel, intellectuel et créatif, plutôt que simplement comme une amélioration mécanisée de la productivité. Ce jugement qualitatif influence les attentes et l’imagination concernant le futur rôle social de l’IA (Source : sama)
La communauté s’interroge sur la date d’ouverture du code de Grok 2 : Des utilisateurs de Reddit discutent du moment où xAI tiendra sa promesse d’ouvrir le code du modèle Grok 2. Beaucoup craignent que, compte tenu de la vitesse d’itération de la technologie IA, Grok 2 soit déjà dépassé par d’autres modèles contemporains (comme DeepSeek V3, Qwen 3) au moment de sa sortie, répétant le scénario de Grok 1 qui était obsolète dès sa publication. La discussion porte également sur le compromis entre la valeur des modèles open source (recherche, liberté de licence) et leur pertinence temporelle (Source : Reddit r/LocalLLaMA)
Interprétation des propos d’Altman : L’efficacité des données, nouveau goulot d’étranglement pour l’AGI ? : La communauté Reddit discute des déclarations de Sam Altman selon lesquelles l’IA doit améliorer son efficacité en matière de données de 100 000 fois, plutôt que de compter uniquement sur la puissance de calcul, interprétant cela comme un signe que la voie actuelle d’extension par la force brute vers l’AGI rencontre des obstacles. L’opinion dominante est que les données humaines de haute qualité sont presque épuisées, que les données synthétiques ont une efficacité limitée et que la faible efficacité d’apprentissage des modèles est le défi principal, ce qui pourrait même affecter les plans d’investissement matériel d’entreprises comme Microsoft. La discussion reflète une réflexion sur les trajectoires de développement de l’IA (Source : Reddit r/artificial)
Comment distinguer la mémoire de la capacité de raisonnement des LLM ? : La communauté explore comment tester efficacement si un grand modèle de langage possède une réelle capacité de raisonnement ou s’il ne fait que répéter ou combiner des motifs présents dans ses données d’entraînement. Certains proposent d’utiliser des questions inédites de type “Et si” (What If), que le modèle n’a jamais vues, pour sonder sa capacité de raisonnement généralisé. Cela touche au cœur du problème difficile de l’évaluation du niveau d’intelligence des LLM, à savoir la distinction entre la reconnaissance de formes avancée et l’inférence logique véritable (Source : Reddit r/MachineLearning)
Un utilisateur partage une conversation “terrifiante” avec GPT, soulevant des inquiétudes éthiques : Un utilisateur partage une capture d’écran d’une conversation avec ChatGPT, dont le contenu aborde les impacts sociaux négatifs potentiels de l’IA (comme le contrôle de la pensée, la perte de l’esprit critique), la qualifiant de “terrifiante”. Le post suscite une discussion axée sur le fait de savoir si la sortie de l’IA reflète l’orientation de l’utilisateur ou les “pensées” du modèle, les limites éthiques de l’IA et l’anxiété des utilisateurs face aux risques potentiels de l’IA (Source : Reddit r/ChatGPT)

L’exécution locale de grands modèles se heurte au goulot d’étranglement de la mémoire : Dans la communauté r/OpenWebUI, un utilisateur signale qu’avec une configuration de 16 Go de RAM et une RTX 2070S, lors de l’exécution d’OpenWebUI et d’Ollama, il est impossible de charger des modèles de plus de 12 milliards de paramètres (comme Gemma3:27b), la mémoire système et l’espace d’échange étant épuisés. Cela représente un défi courant pour de nombreux utilisateurs tentant de déployer localement de grands modèles sur du matériel grand public, soulignant les exigences élevées des modèles en ressources matérielles (en particulier la mémoire) (Source : Reddit r/OpenWebUI)
Une affiche générée par GPT-4o déclenche un débat sur le “chômage des designers” : Un utilisateur présente une affiche “Parc pour chiens” générée par GPT-4o, louant son effet “presque parfait” et déclarant “les graphistes sont morts”. La section des commentaires s’enflamme : d’un côté, on reconnaît les progrès de la capacité de génération d’images par IA, de l’autre, on souligne les défauts de conception (trop de texte, mauvaise mise en page, fautes d’orthographe) et on insiste sur le fait que l’IA est actuellement un outil pour améliorer l’efficacité, incapable de remplacer la valeur fondamentale des designers dans la prise de décision créative, le jugement esthétique, l’adéquation à la marque, etc. (Source : Reddit r/ChatGPT)

La gestion du cycle de vie des modèles fine-tunés suscite l’attention : Un développeur demande à la communauté : lorsque le modèle de base dont on dépend (par exemple GPT-4o) est mis à jour ou remplacé (par exemple par GPT-5), que faire des modèles précédemment fine-tunés sur celui-ci ? Étant donné que le fine-tuning est généralement lié à une version spécifique du modèle de base, l’obsolescence ou la mise à jour du modèle de base peut obliger les développeurs à réentraîner, entraînant des coûts et des problèmes de maintenance continus. Cela soulève des questions sur la dépendance et la stratégie à long terme de l’utilisation d’API fermées pour le fine-tuning (Source : Reddit r/ArtificialInteligence)
Exploration de la configuration pour une conversation vocale avec un LLM local : Un utilisateur de la communauté cherche une solution système pour établir une conversation vocale avec un LLM local, espérant une expérience similaire à celle de Google AI Studio, pour le brainstorming et la planification. La question reflète le désir des utilisateurs d’étendre l’interaction textuelle à une interaction vocale plus naturelle et recherche des méthodes pratiques et des partages d’expérience pour intégrer STT, LLM, TTS dans des frameworks locaux comme OpenWebUI (Source : Reddit r/OpenWebUI )
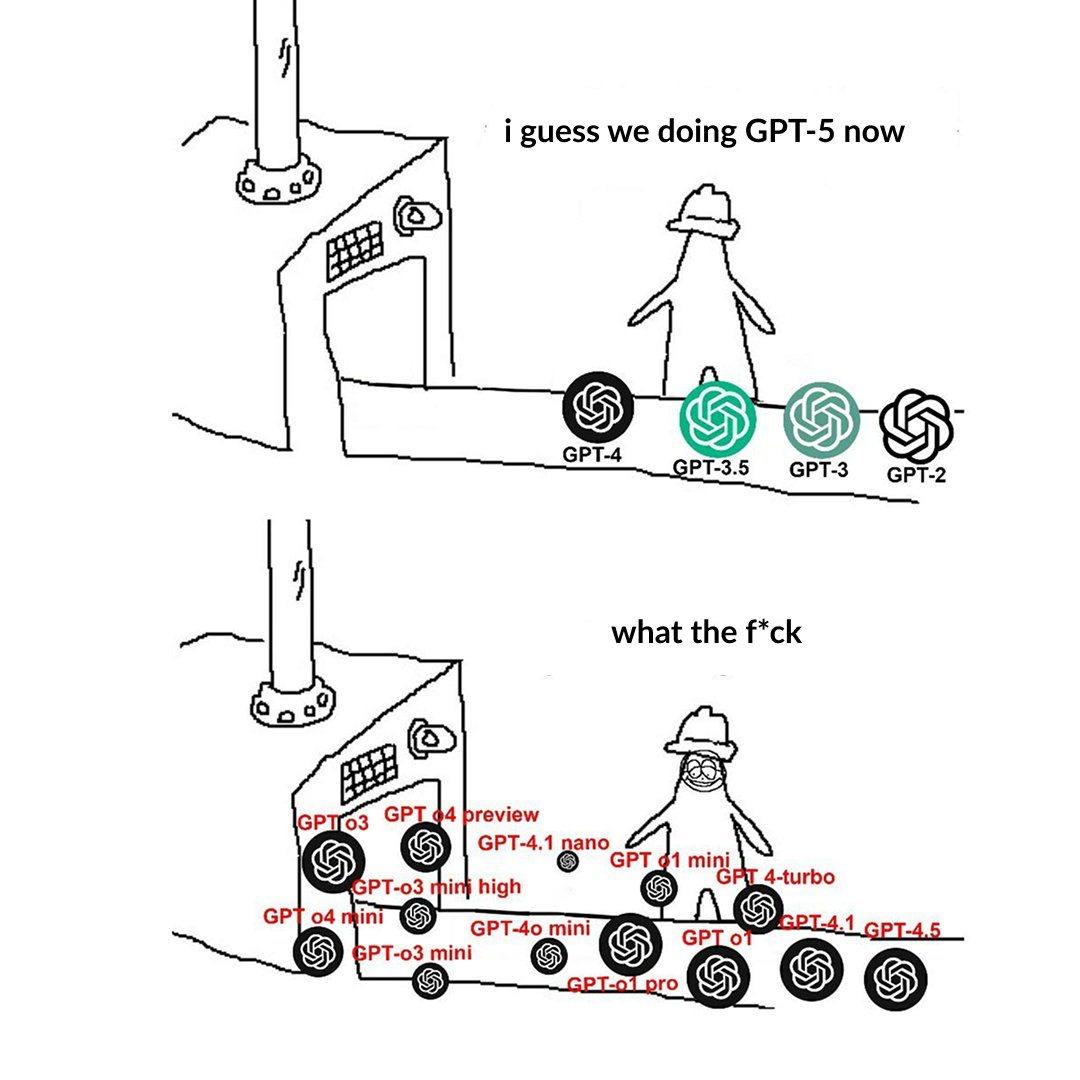
La nomenclature des niveaux de modèles OpenAI déroute les utilisateurs : Un utilisateur se plaint de la nomenclature des modèles d’OpenAI (par exemple, o3, o4-mini, o4-mini-high, o4), la jugeant déroutante. Une image montre les différents niveaux de modèles, dont la relation entre le nom, les capacités et les limitations n’est pas suffisamment intuitive. Cela reflète le défi que représentent la clarté de la segmentation de la gamme de produits et la nomenclature pour la compréhension et le choix des utilisateurs, à mesure que la famille de modèles s’agrandit (Source : Reddit r/artificial)

Le style excessivement “flatteur” de ChatGPT fait débat : Des utilisateurs de la communauté, via des mèmes et des discussions, soulignent la tendance de ChatGPT à faire des compliments excessifs aux questions des utilisateurs (“Quelle excellente question !”), même si la question est banale voire stupide. La discussion suggère que cela pourrait être une stratégie conçue par OpenAI pour améliorer la fidélisation des utilisateurs, mais cela pourrait aussi conduire les utilisateurs à un biais de confirmation, manquant de retour critique. Certains utilisateurs expriment même préférer que l’IA donne des évaluations “acerbes” (Source : Reddit r/ChatGPT)

Les défis de l’IA dans les jeux à information incomplète : La communauté discute des défis auxquels l’IA est confrontée dans le traitement des jeux à information incomplète (comme le brouillard de guerre dans StarCraft). Contrairement aux jeux à information complète comme le Go ou les échecs, ces jeux exigent que l’IA gère l’incertitude, mène des explorations et planifie à long terme, ne pouvant pas simplement s’appuyer sur des informations globales et des pré-calculs. Bien que l’IA ait progressé dans des jeux comme Dota 2 et StarCraft (AlphaStar), atteindre un niveau stable surpassant les meilleurs joueurs humains reste un défi (Source : Reddit r/ArtificialInteligence)
Vigilance face au phénomène de “convergence linguistique” induit par le contenu IA : Un utilisateur introduit le concept de “mimétisme linguistique” (linguistic mimicry), s’inquiétant que la lecture massive de contenus générés par l’IA, dont le style peut converger, conduise à une uniformisation et une homogénéisation de l’expression linguistique et même des modes de pensée des gens. Ce phénomène pourrait constituer une menace potentielle pour la diversité culturelle et la pensée critique individuelle. La lecture d’œuvres diversifiées d’auteurs humains est considérée comme un moyen de préserver la vitalité de la langue (Source : Reddit r/ArtificialInteligence)
💡 Divers
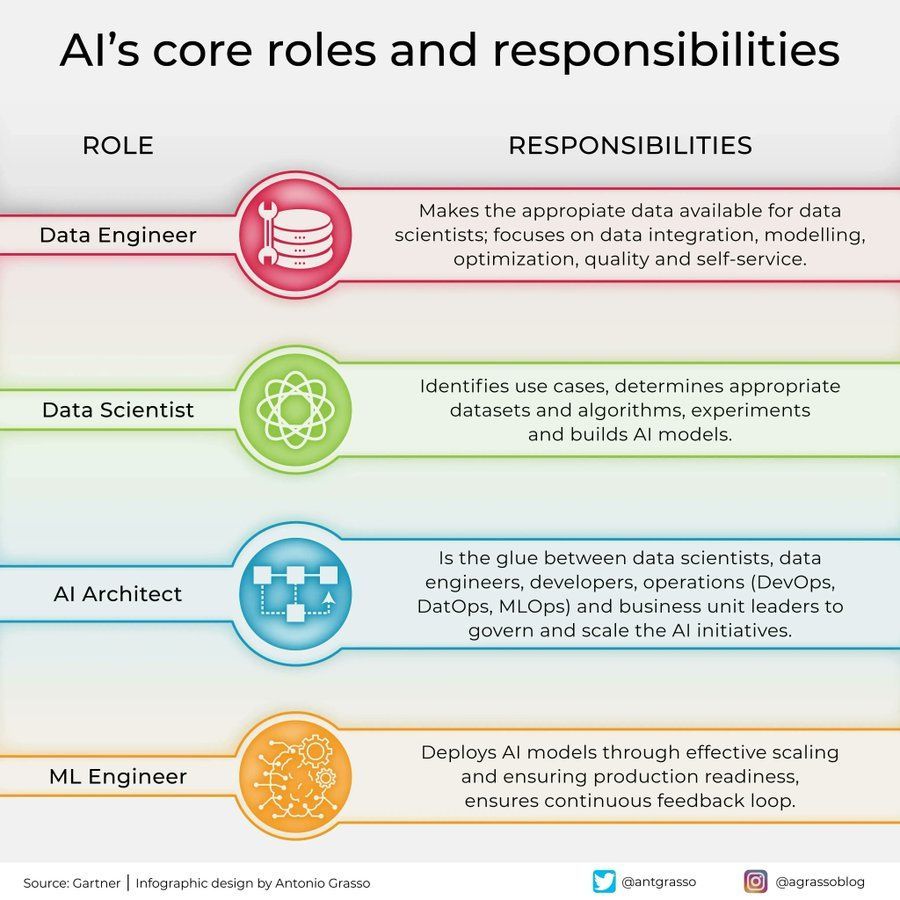
Répartition des rôles et responsabilités dans le domaine de l’IA : Une infographie partagée sur les réseaux sociaux présente les rôles clés dans le domaine de l’intelligence artificielle et leurs responsabilités, tels que data scientist, ingénieur en machine learning, chercheur en IA, etc. Ce graphique aide à comprendre la division du travail au sein des équipes de projet IA, les compétences requises et la nature interdisciplinaire du développement de l’IA (Source : Ronald_vanLoon)
Applications et défis de l’IA dans le secteur des télécommunications : Une discussion mentionne les applications révolutionnaires et les pièges potentiels de l’IA dans l’industrie des télécommunications. L’IA est largement utilisée pour l’optimisation des réseaux, le service client intelligent, la maintenance prédictive, etc., afin d’améliorer l’efficacité et l’expérience utilisateur, mais elle est également confrontée à des défis tels que la confidentialité des données, les biais algorithmiques, la complexité de la mise en œuvre, etc. Une exploration approfondie de ces aspects aide l’industrie à saisir les opportunités de l’IA et à éviter les risques (Source : Ronald_vanLoon)
L’influence de la psychologie sur le développement de l’IA : Un article explore comment la psychologie a influencé le développement de l’intelligence artificielle, et comment cette influence perdure. Les connaissances issues de la psychologie, telles que les sciences cognitives, les théories de l’apprentissage, l’étude des biais, fournissent des références importantes pour la conception de l’IA, par exemple pour simuler les processus cognitifs humains, comprendre et traiter les biais. Inversement, l’IA offre également de nouveaux outils de modélisation et de test pour la recherche en psychologie (Source : Ronald_vanLoon)

Un grand équipement informatique illustre les besoins matériels de l’IA : Un utilisateur partage une photo montrant un dispositif matériel informatique vaste et complexe (probablement un grand cluster de serveurs multi-GPU), le qualifiant de “monstre”. Cette image reflète de manière frappante l’énorme investissement en ressources de calcul nécessaire aujourd’hui pour entraîner de grands modèles d’IA ou effectuer des tâches d’inférence intensives, illustrant la forte dépendance de l’IA moderne vis-à-vis de l’infrastructure matérielle (Source : karminski3)

Le rôle de l’IA dans la cybersécurité : Un article explore le rôle transformateur de l’intelligence artificielle dans le domaine de la cybersécurité. La technologie IA est utilisée pour améliorer la détection des menaces (comme l’analyse des comportements anormaux), automatiser la réponse aux incidents de sécurité, évaluer les vulnérabilités et faire des prédictions, améliorant ainsi l’efficacité et les capacités de défense. Cependant, l’IA elle-même peut également être exploitée à des fins malveillantes, posant de nouveaux défis de sécurité (Source : Ronald_vanLoon)

L’OCR de haute précision confrontée au défi de la confusion des caractères : Un développeur cherchant à construire un système OCR de haute précision pour identifier de courts codes alphanumériques (comme des numéros de série) rencontre un problème courant : le modèle a du mal à distinguer les caractères visuellement similaires (comme I/1, O/0). Même en utilisant un modèle YOLO pour la détection de caractères uniques, des cas limites subsistent. Cela souligne le défi d’atteindre une précision OCR quasi parfaite dans des scénarios spécifiques, nécessitant une optimisation ciblée du modèle, des données ou l’adoption de stratégies de post-traitement (Source : Reddit r/MachineLearning)

Demande d’aide pour l’exécution de l’environnement Gym Retro : Un utilisateur rencontre un problème technique lors de l’utilisation de la bibliothèque d’apprentissage par renforcement Gym Retro. Il a réussi à importer le jeu Donkey Kong Country mais ne sait pas comment lancer l’environnement prédéfini pour l’entraînement. C’est un problème typique de configuration et d’utilisation que les chercheurs en IA peuvent rencontrer avec des outils spécifiques (Source : Reddit r/MachineLearning)
Dilemme du choix lorsque plusieurs modèles ont des performances proches : Un chercheur, utilisant différentes méthodes de sélection de caractéristiques et modèles d’apprentissage automatique, constate que plusieurs combinaisons atteignent des niveaux de performance élevés similaires (par exemple, précision de 93-96%), rendant difficile le choix de la meilleure solution. Cela reflète le fait que, dans l’évaluation des modèles, lorsque les métriques standard diffèrent peu, il faut prendre en compte d’autres facteurs tels que la complexité du modèle, l’interprétabilité, la vitesse d’inférence, la robustesse, etc., pour faire le choix final (Source : Reddit r/MachineLearning)
La migration d’arXiv vers Google Cloud suscite l’attention : En tant que plateforme de prépublication essentielle pour l’IA et de nombreux autres domaines de recherche, arXiv prévoit de migrer des serveurs de l’Université Cornell vers Google Cloud. Ce changement majeur d’infrastructure pourrait améliorer l’évolutivité et la fiabilité du service, mais pourrait également susciter des discussions au sein de la communauté concernant les coûts opérationnels, la gestion des données et les politiques d’accès ouvert (Source : Reddit r/MachineLearning)
Claude génère un outil de simulation économique et ses limites : Un utilisateur a utilisé la fonction Artifact de Claude pour générer un simulateur économique interactif sur l’impact des tarifs douaniers. Bien que cela démontre la capacité de l’IA à générer des applications complexes, les commentaires soulignent que les résultats de la simulation peuvent être trop simplistes ou non conformes aux principes économiques (par exemple, des tarifs élevés entraînant des bénéfices généralisés). Cela rappelle que lors de l’utilisation d’outils d’analyse générés par l’IA, il est impératif d’examiner rigoureusement leur logique interne et leurs hypothèses (Source : Reddit r/ClaudeAI)

Intégrer un clonage vocal XTTS personnalisé dans OpenWebUI : Un utilisateur cherche à intégrer une voix qu’il a clonée à l’aide de la technologie open source XTTS dans OpenWebUI, afin de remplacer l’API payante ElevenLabs et d’obtenir une sortie vocale personnalisée et gratuite. Cela représente le besoin des utilisateurs, lorsqu’ils utilisent des outils d’IA locaux, d’intégrer des composants open source et personnalisables (comme le TTS) (Source : Reddit r/OpenWebUI)