
Mots-clés:AI, OpenAI, o3 et o4-mini modèles, raisonnement visuel et appel d’outils, OpenAI open source Codex CLI, Google DolphinGemma langage dauphin, Internet intelligent et protocole MCP, AI et raisonnement visuel, OpenAI o3 et o4-mini modèles, outils d’appel avec OpenAI, Codex CLI open source, Google DolphinGemma pour le traitement du langage, protocole MCP pour l’Internet intelligent, intégration d’AI avec raisonnement visuel
🔥 À la une
OpenAI lance les modèles o3 et o4-mini, renforçant le raisonnement visuel et l’appel d’outils: OpenAI a lancé deux nouveaux modèles d’inférence, o3 et o4-mini, améliorant considérablement les capacités de raisonnement de l’IA, en particulier dans le domaine visuel. C’est la première fois qu’OpenAI publie des modèles capables d’intégrer des images dans une chaîne de pensée pour le raisonnement, leur permettant d’interpréter des graphiques, des photos et même des croquis dessinés à la main, et de combiner des outils tels que Python, la recherche web, la génération d’images, etc., pour traiter des tâches complexes en plusieurs étapes. o3 est positionné comme le modèle de raisonnement le plus puissant, battant des records dans plusieurs benchmarks, et excellant particulièrement dans l’analyse visuelle ; o4-mini est optimisé pour la vitesse et le coût. Les nouveaux modèles remplaceront progressivement l’ancienne série o1 et seront disponibles pour les utilisateurs Plus, Pro, Team et Entreprise. Parallèlement, OpenAI a rendu open source l’agent de programmation léger Codex CLI et a lancé un programme d’incitation d’un million de dollars. Les premiers retours des tests utilisateurs sont positifs, indiquant une amélioration significative de son niveau d’intelligence et de son initiative, bien que des problèmes d’hallucination et de fiabilité persistent dans certains scénarios (Source : 智东西, 元宇宙之心MetaverseHub, 新智元, 量子位, Reddit r/LocalLLaMA, Reddit r/deeplearning)

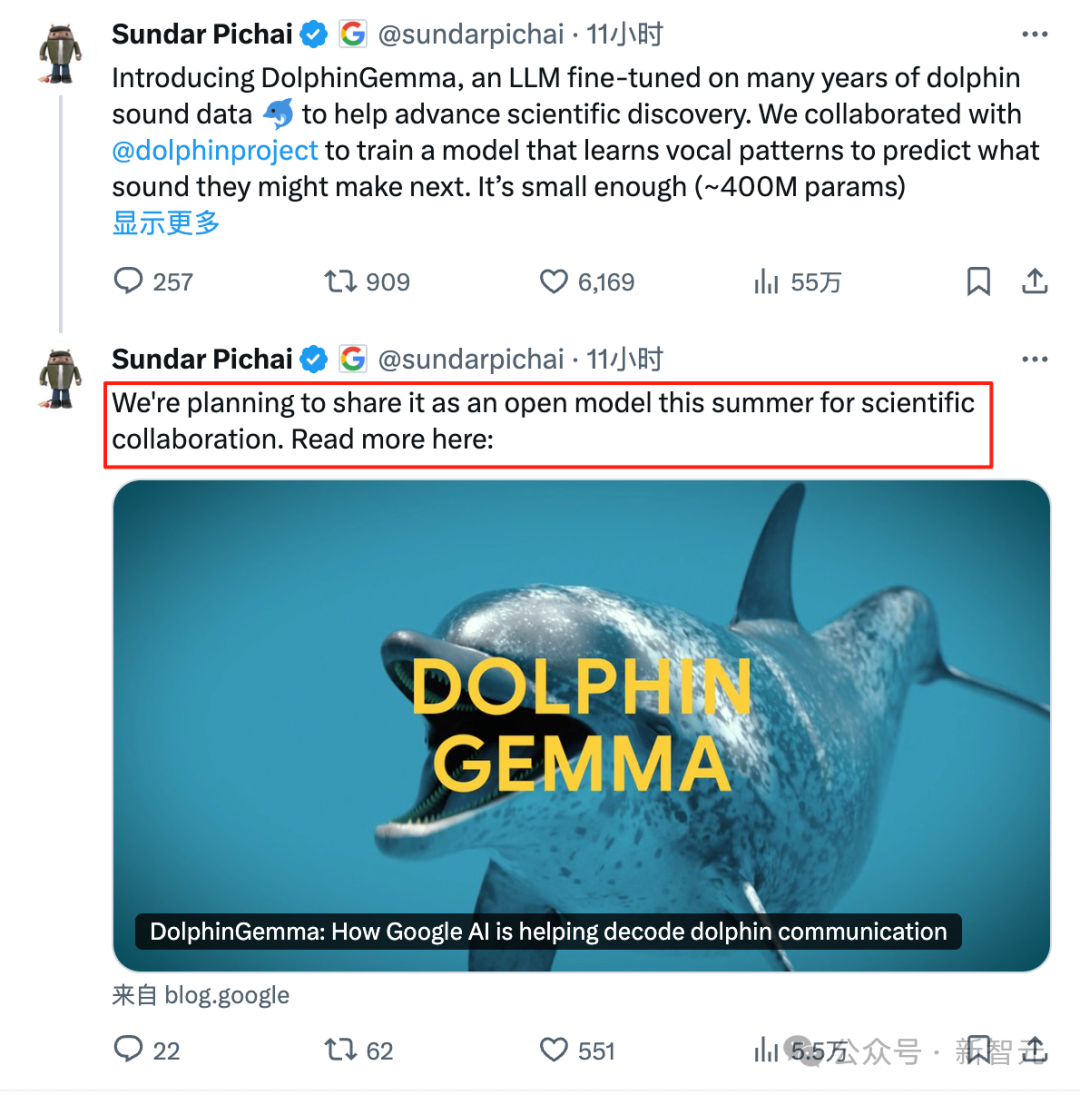
Le modèle IA DolphinGemma de Google tente de déchiffrer le langage des dauphins: Google a lancé DolphinGemma, un modèle IA léger (400M paramètres) basé sur l’architecture Gemma, visant à comprendre la communication acoustique des dauphins. Ce modèle est entraîné à l’aide de données audio pour apprendre les motifs sonores des dauphins et générer des sons similaires, dans l’espoir de réaliser une communication inter-espèces préliminaire. Le projet collabore avec le WDP (Wild Dolphin Project), qui étudie les dauphins depuis longtemps, en utilisant ses ensembles de données étiquetées accumulés sur des décennies. En combinaison avec le système informatique sous-marin CHAT développé par Georgia Tech (qui sera basé sur le Pixel 9), les chercheurs espèrent interagir avec les dauphins via un vocabulaire partagé simplifié. Le PDG de Google, Pichai, le qualifie de “pas cool vers la communication inter-espèces” et prévoit de rendre le modèle open source. Le PDG de DeepMind, Hassabis, a également exprimé son espoir de communiquer à l’avenir avec des animaux très intelligents comme les chiens (Source : 新智元)
Changement de paradigme : de l‘“Internet des humains” à l‘“Internet des intelligences” et au protocole MCP: Alors que la croissance des utilisateurs d’Internet plafonne, l’industrie se tourne de la connexion des personnes (Internet des humains) vers la connexion des agents IA (Internet des intelligences). Les Agents IA peuvent exécuter des tâches et appeler des services au nom des utilisateurs, tandis que des normes ouvertes comme le MCP (Model Context Protocol) rendent possible l’interopérabilité entre différents modèles et outils, à l’instar de l‘“USB-C” du monde de l’IA. Cela pourrait remodeler le paysage du pouvoir des plateformes, affaiblir le monopole des portails de trafic traditionnels sur la distribution de contenu et l’attention des utilisateurs, tout en offrant une opportunité de renaissance aux petits sites web et services (s’ils se connectent au protocole pour devenir des “plugins de capacité”). Les métriques des plateformes pourraient passer du DAU à l’AAU (Active Agent Unit), l’offre de contenu passer de l’UGC à l’AIGC, l’interaction évoluer du GUI vers le CUI/API, et les frontières entre ToC et ToB s’estomper pour tendre vers un écosystème ToAI. Microsoft, Google, OpenAI et les grands acteurs chinois ont déjà investi dans le MCP ou des protocoles similaires (Source : 朋克商店)

🎯 Tendances
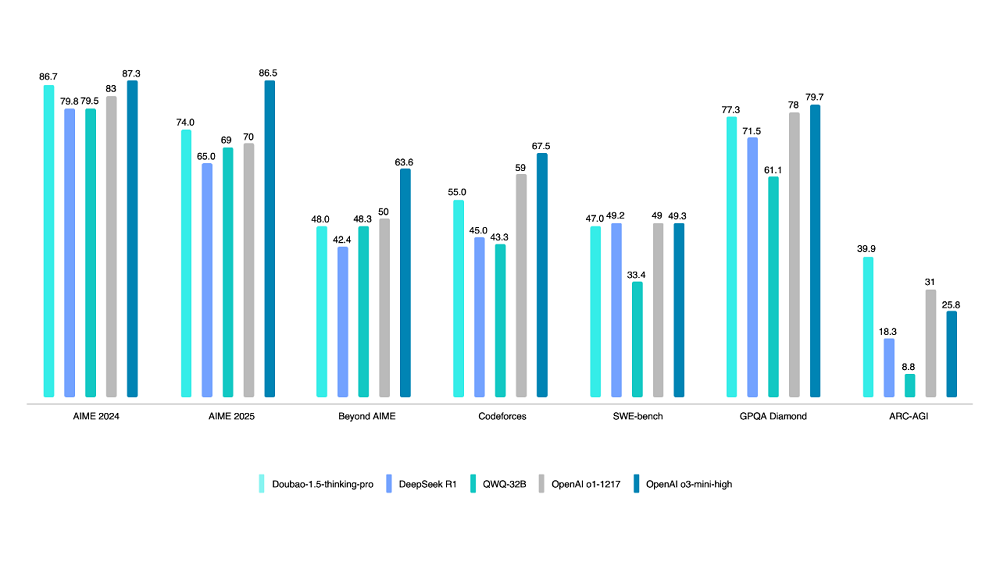
Volcano Engine lance le modèle de réflexion profonde Doubao 1.5: Volcano Engine a lancé le modèle de réflexion profonde Doubao 1.5, utilisant une architecture MoE avec un total de 200B de paramètres et 20B de paramètres activés. Ce modèle excelle dans plusieurs benchmarks en mathématiques, programmation et sciences, surpassant partiellement DeepSeek-R1 et se rapprochant du niveau d’OpenAI o1/o3-mini-high, obtenant même un score plus élevé au test ARC-AGI. Ses fonctionnalités distinctives incluent la “recherche pendant la réflexion” (différente de la recherche puis réflexion) et des capacités de compréhension visuelle basées sur des informations textuelles et imagées. Le modèle de génération texte-image 3.0 (supportant les images HD 2K, optimisation de la typographie) et le modèle de compréhension visuelle (amélioration de la localisation, du comptage, de la compréhension vidéo) ont également été mis à niveau. Fin mars, le volume d’appels quotidiens du grand modèle Doubao dépassait 12,7 trillions de tokens (Source : 智东西)
L’assistant IA intégré à WeChat « Yuanbao » est lancé: L’application Tencent Yuanbao a été intégrée à WeChat sous forme d’assistant IA, les utilisateurs peuvent l’ajouter comme ami pour interagir directement dans l’interface de chat. Cet assistant est équipé des doubles moteurs Hunyuan et DeepSeek, optimisé pour le contexte WeChat, et prend en charge l’analyse d’articles de comptes publics, d’images, de documents (jusqu’à 100 Mo), ainsi que les questions-réponses intelligentes et les interactions quotidiennes. Les réponses complexes redirigent vers l’application Yuanbao. Après le test bêta de la recherche IA, il s’agit d’une étape importante pour WeChat dans l’intégration des fonctionnalités IA, visant à intégrer plus naturellement les capacités IA dans le scénario de conversation principal. Tencent a récemment intensifié la promotion et l’investissement en puissance de calcul pour Yuanbao, considérant l’IA comme une direction stratégique importante (Source : 界面新闻, 华尔街见闻)
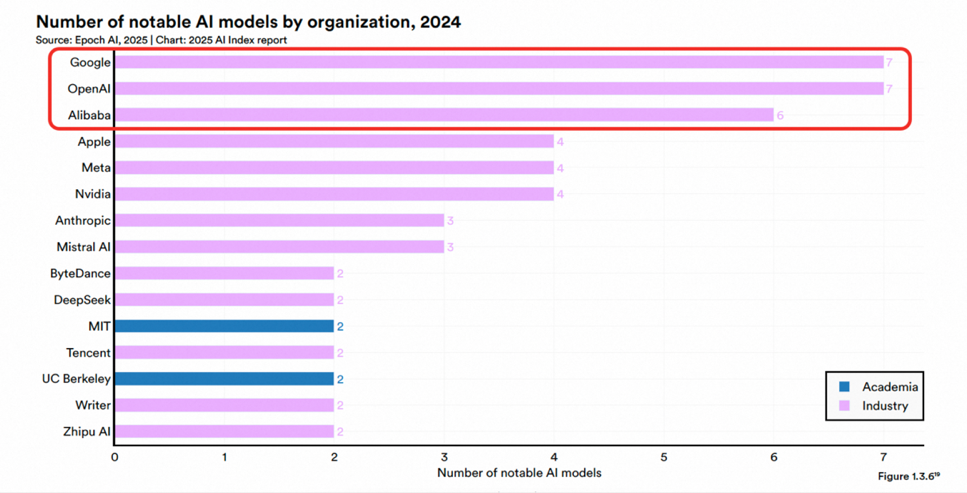
Tongyi Qianwen d’Alibaba classé premier en compétitivité des grands modèles commerciaux chinois par Omdia: L’institut de recherche international Omdia a publié son rapport “China Commercial Large Models 2025”, dans lequel Tongyi Qianwen d’Alibaba Cloud a été classé leader pour la deuxième année consécutive, et premier dans les trois dimensions de la compétitivité globale, des capacités du modèle et de la capacité d’exécution. Le rapport reconnaît la position de leader d’Alibaba en matière de technologie de modèle, de construction d’écosystème open source (la série de modèles Qwen a dépassé les 200 millions de téléchargements mondiaux, avec plus de 100 000 modèles dérivés) et de mise en œuvre commerciale (stratégie MaaS). Auparavant, le rapport AI Index de Stanford avait également classé Alibaba comme la troisième institution au monde et la première en Chine en termes de nombre de modèles importants publiés. Alibaba continue d’investir dans l’infrastructure cloud IA, prévoyant d’investir plus de 380 milliards de yuans au cours des trois prochaines années (Source : 乌鸦智能说)
Alibaba et ByteDance seraient en train de développer des lunettes intelligentes IA: Après Baidu, Xiaomi et d’autres, Alibaba et ByteDance développeraient des lunettes intelligentes IA. Le projet d’Alibaba est dirigé par l’équipe Tmall Genie, intégrant les capacités IA de Quark, et prévoit de lancer deux versions, avec et sans écran, le matériel pouvant utiliser une solution double puce Qualcomm + Hengxuan. Le projet de ByteDance est dirigé par l’équipe Pico, intégrant le grand modèle Doubao, et pourrait être lancé d’abord à l’étranger. L’entrée des géants sur le marché, avec leurs avantages technologiques, financiers et écosystémiques, pourrait accélérer le développement du marché, mais ils sont également confrontés au défi d’une expérience relativement insuffisante en R&D matérielle. Cette décision pourrait déplacer la concurrence des lunettes intelligentes des paramètres matériels vers les services écosystémiques, créant à la fois une pression et des opportunités pour les acteurs existants tels que Rokid et Thunderbird (Source : 科技新知)

Google utilise l’IA pour améliorer considérablement l’efficacité du blocage des publicités malveillantes: En 2024, Google a renforcé l’application de ses politiques publicitaires à l’aide de modèles IA mis à niveau (y compris les LLM), suspendant avec succès 39,2 millions de comptes d’annonceurs malveillants, soit plus de trois fois le nombre de 2023. Les modèles IA ont participé à 97% de l’application des règles publicitaires, permettant d’identifier et de traiter plus rapidement les stratégies frauduleuses en constante évolution. Cette initiative vise à lutter contre l’abus du réseau publicitaire, les fausses déclarations, la contrefaçon de marques et les escroqueries deepfake générées par l’IA. Bien que certaines publicités indésirables passent encore entre les mailles du filet (5,1 milliards supprimées dans le monde), le blocage des comptes à la source a considérablement amélioré l’efficacité globale. Google souligne que les humains sont toujours impliqués dans le processus, mais l’application de l’IA est devenue essentielle pour la sécurité publicitaire à grande échelle (Source : Reddit r/ArtificialInteligence)

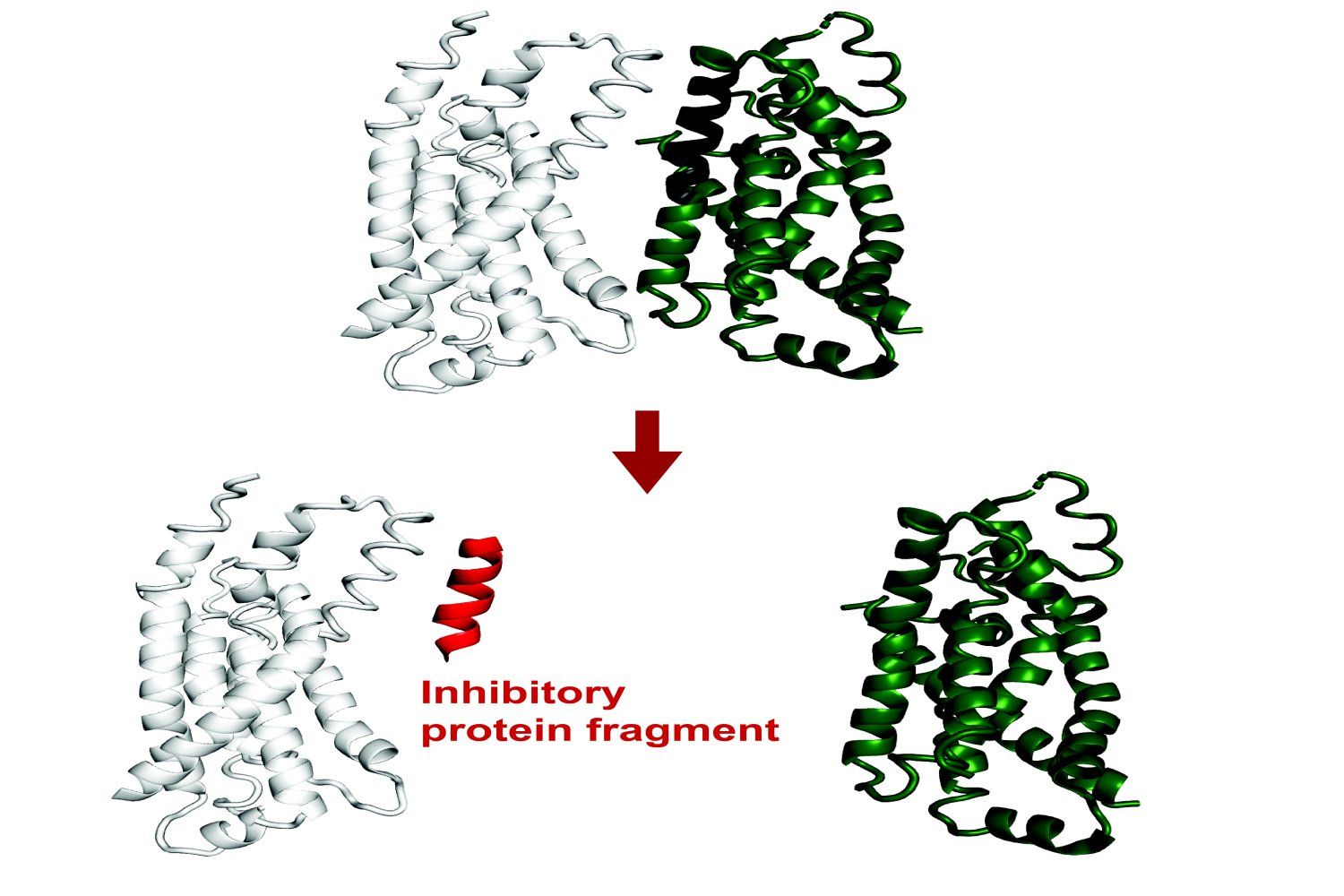
Le MIT développe un système IA pour prédire la liaison des fragments de protéines: Des chercheurs du MIT ont développé un système IA capable de prédire quels fragments de protéines (peptides) peuvent se lier à une protéine cible ou inhiber sa fonction. Ceci est d’une importance significative pour la découverte de médicaments et la biotechnologie, aidant à concevoir de nouvelles méthodes thérapeutiques ou des outils de diagnostic. Le système utilise l’apprentissage automatique pour analyser les données de structure et d’interaction des protéines afin d’identifier de courtes séquences peptidiques ayant une capacité de liaison potentielle (Source : Ronald_vanLoon)
Grok ajoute une fonction de mémoire conversationnelle: Grok, l’assistant IA de la plateforme X, a annoncé l’ajout d’une fonction de mémoire, lui permettant de se souvenir du contenu des conversations précédentes de l’utilisateur. Cela signifie que Grok peut fournir des réponses, des recommandations ou des suggestions plus personnalisées et cohérentes lors des interactions ultérieures, améliorant ainsi l’expérience utilisateur (Source : grok)
Google annonce un protocole ouvert pour la communication entre agents: Google a annoncé le lancement d’un protocole ouvert visant à permettre à différents agents d’intelligence artificielle (AI agents) de communiquer et de collaborer entre eux. Ceci est similaire à l’objectif du MCP (Model Context Protocol), visant à briser les barrières entre les applications IA et à promouvoir des flux de travail et des écosystèmes d’applications IA plus complexes et intégrés (Source : Ronald_vanLoon)

🧰 Outils
Ajustement de la fonction de génération d’images de ChatGPT: Les utilisateurs ont remarqué que le bouton “Create Image” en bas de l’interface ChatGPT a été supprimé, mais la fonction de génération d’images peut toujours être appelée dans les modèles pris en charge (comme GPT-4o, o3, o4-mini) en utilisant des prompts de dessin explicites ou des préfixes spécifiques (par exemple, “Veuillez générer une image :”). Les modèles GPT-4.5 et o1 pro ne prennent actuellement pas en charge la génération d’images de cette manière (Source : dotey)
Les IDE JetBrains intègrent la complétion de code LLM locale gratuite: JetBrains a annoncé une mise à jour majeure de son AI Assistant, offrant une couche de fonctionnalités IA gratuites dans ses produits IDE (comme Rider), y compris la complétion de code illimitée et la prise en charge de l’intégration de modèles LLM locaux. Cette initiative vise à abaisser le seuil d’accès au développement assisté par IA. Parallèlement, les niveaux payants AI Pro et AI Ultimate offrent des fonctionnalités plus avancées et l’accès à des modèles cloud (tels que GPT-4.1, Claude 3.7, Gemini 2.0) (Source : Reddit r/LocalLLaMA)
HypernaturalAI: Un outil IA pour la création de contenu professionnel, conçu pour améliorer l’efficacité et la créativité dans des scénarios tels que le marketing de contenu (Source : Ronald_vanLoon)
Démonstration de génération vidéo Kling 2.0: Un utilisateur a partagé un extrait vidéo créé à l’aide du modèle de génération vidéo Kling 2.0 lancé par Kuaishou, montrant ses effets de génération (Source : op7418)
Framework Cactus pour le benchmarking IA sur appareil: Cactus est un framework conçu pour exécuter efficacement des modèles IA sur des appareils de périphérie (téléphones, drones, etc.) sans connexion réseau. Les développeurs ont publié une démo d’application de chat basée sur Cactus pour tester la vitesse d’exécution (tokens/sec) de différents modèles (comme Gemma 1B, SmollLM) sur divers téléphones, et fournissent un lien de téléchargement pour que les utilisateurs puissent tester (Source : Reddit r/deeplearning)

Pratique de pipeline IA hybride avec OpenWebUI: Un utilisateur a partagé un cas réussi de construction d’un pipeline IA hybride utilisant Open WebUI comme frontend. Le pipeline peut acheminer automatiquement les questions des utilisateurs vers une requête SQL structurée (via LangChain SQL Agent opérant sur DuckDB) ou une base de données vectorielle (Pinecone) pour une recherche sémantique, et utiliser Gemini Flash pour générer la réponse finale, permettant une réponse rapide (Source : Reddit r/OpenWebUI)
Problèmes d’utilisation de la base de connaissances et de l’API OpenWebUI: Des utilisateurs Reddit discutent des problèmes rencontrés lors de l’utilisation de la fonction de base de connaissances (RAG) dans OpenWebUI, y compris comment pointer les documents vers un répertoire serveur au lieu d’un téléchargement web, et comment obtenir et gérer les ID de fichiers dans la base de connaissances via l’API pour réaliser la synchronisation des fichiers (Source : Reddit r/OpenWebUI, Reddit r/OpenWebUI)
Demande d’aide pour l’intégration d’OpenWebUI avec le serveur MCP: Un utilisateur cherche de l’aide pour configurer localement un serveur Karakeep MCP et l’intégrer avec OpenWebUI, rencontrant des difficultés (Source : Reddit r/OpenWebUI)
Réflexion sur l’utilisation du mode de pensée de Grok3 via OpenWebUI: Un utilisateur demande s’il existe un moyen d’activer le mode “Think” ou “Deepsearch” spécifique à Grok3 lors de l’utilisation de l’API Grok pour se connecter à OpenWebUI (Source : Reddit r/OpenWebUI)
📚 Apprentissage
Recherche sur l’orientation vers les objectifs des LLM: Des chercheurs de DeepMind explorent le problème potentiel de la sous-utilisation des capacités des LLM lors de l’exécution de tâches. En utilisant l’évaluation de sous-tâches, ils ont découvert que les LLM n’utilisent souvent pas pleinement leurs capacités disponibles, c’est-à-dire qu’ils ne sont pas entièrement “orientés vers les objectifs”. Cette recherche aide à comprendre les mécanismes internes et les limites des LLM (Source : GoogleDeepMind)

Limites des modèles IA de pointe sur les tâches physiques: Une étude portant sur des cas de fabrication montre que les modèles IA de pointe actuels (y compris les modèles multimodaux) fonctionnent mal sur des tâches physiques simples (comme la fabrication de pièces en laiton), présentant des lacunes importantes notamment en matière de reconnaissance visuelle et de compréhension spatiale. Gemini 2.5 Pro est relativement le meilleur, mais l’écart reste important. Cela suggère que les progrès de l’IA dans les applications du monde physique pourraient être en retard par rapport au monde numérique, nécessitant de nouvelles architectures ou méthodes d’entraînement pour améliorer la compréhension spatiale et l’efficacité des échantillons (Source : Reddit r/MachineLearning)
Une étude révèle des capacités insuffisantes de l’IA en matière de débogage de code: Bien que l’IA progresse dans la génération de code, une étude souligne que l’IA actuelle est peu performante en matière de débogage de code et ne peut pas encore remplacer les programmeurs humains. Cependant, certains développeurs estiment que les LLM sont très utiles pour déboguer des problèmes spécifiques (Source : Reddit r/artificial)

Pratique d’optimisation des performances LLM locales : Qwen2.5-7B atteint 5000 t/s sur deux 3090: Un utilisateur partage son expérience d’optimisation de la vitesse d’inférence LLM locale sur deux cartes graphiques RTX 3090. En choisissant le modèle Qwen2.5-7B, en utilisant la quantification W8A8 et le moteur Aphrodite, et en ajustant le nombre de requêtes simultanées (max_num_seqs=32), il a finalement atteint une vitesse de traitement des prompts allant jusqu’à environ 4500 t/s et une vitesse de génération d’environ 825 t/s pour une longueur de contexte d’environ 5k. Cela fournit une référence d’optimisation des performances pour la recherche ou les applications nécessitant le traitement local de grandes quantités de données (Source : Reddit r/LocalLLaMA)
Publication d’un nouveau mécanisme d’attention CALA: Un chercheur a publié la première version de son article sur un nouveau mécanisme d’attention appelé “Context-Aggregated Linear Attention” (CALA). CALA vise à combiner l’efficacité O(N) de l’attention linéaire avec une capacité de perception locale améliorée grâce à l’insertion d’une étape “d’agrégation de contexte local”. L’article discute de sa conception, de ses innovations par rapport à d’autres mécanismes d’attention et des optimisations complexes nécessaires (comme la fusion de noyaux CUDA) pour atteindre l’efficacité O(N). Le chercheur espère la participation de la communauté pour la validation et le développement ultérieurs (Source : Reddit r/MachineLearning)
![[P] Today, to give back to the open source community, I release my first paper- a novel attention mechanism, Context-Aggregated Linear Attention, or CALA.](https://rebabel.net/wp-content/uploads/2025/04/yIc61XmsPqdJ02d1eyWbLo9h4fZ3ORdzypEFu1tSkN4.jpg)
Utilisation de Claude 3.7 Sonnet pour évaluer la familiarité du vocabulaire: Un utilisateur a dépensé environ 300 $ via l’API Claude 3.7 Sonnet pour générer un ensemble de données de scores de familiarité pour les mots et expressions anglaises du Wiktionary (estimant le pourcentage d’Américains de plus de 10 ans qui les connaissent). L’utilisateur estime que Sonnet a surpassé d’autres modèles de pointe pour cette tâche, étant capable de mieux distinguer le langage courant des termes spécialisés. Le code du projet et l’ensemble de données ont été rendus open source, mais l’utilisateur déplore le coût élevé et cherche des méthodes plus économiques (Source : Reddit r/ClaudeAI)
💼 Affaires
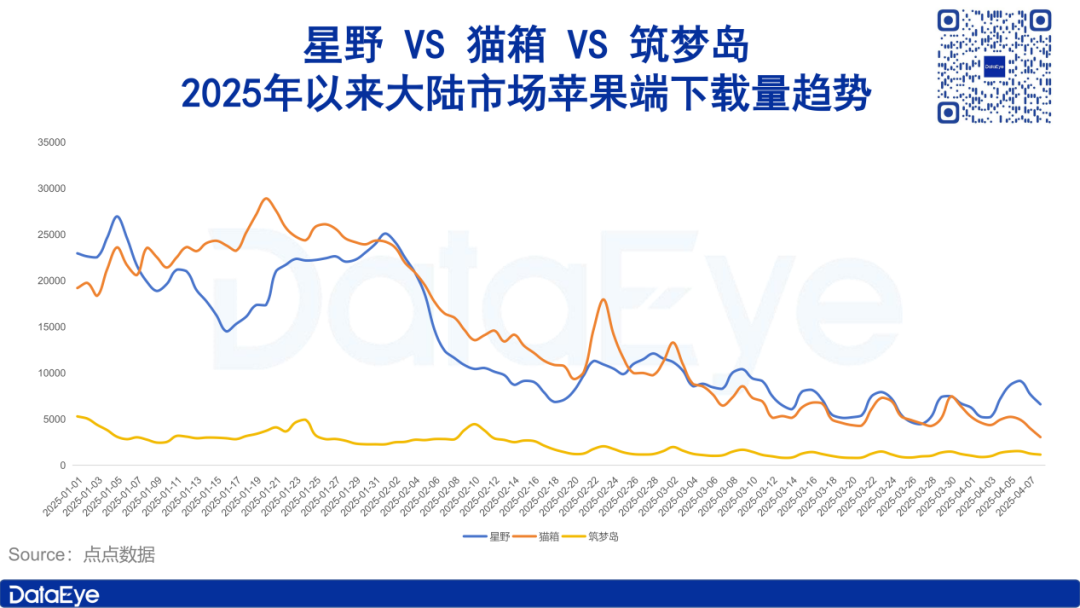
Le marché des applications de compagnonnage IA se refroidit, les investissements publicitaires et les téléchargements chutent: Les données de l’institut de recherche DataEye montrent que les applications sociales de compagnonnage IA représentées par Xingye, Maoxiang et Zhumengdao ont connu un refroidissement du marché début 2025, avec une forte baisse des téléchargements et des investissements publicitaires, certains produits voyant leurs investissements publicitaires divisés par deux, voire plus. L’analyse suggère que les raisons incluent : 1) Le recentrage stratégique de l’industrie de l’IA vers des grands modèles de réflexion profonde comme DeepSeek et des assistants IA, diminuant l’importance de l’IA sociale ; 2) Une forte homogénéisation des produits, réduisant la nouveauté pour les utilisateurs ; 3) Le modèle commercial dominant de l’abonnement manque d’attractivité. L’article explore la valeur fondamentale de l’IA sociale (forte valeur émotionnelle, valeur rationnelle passable, faible valeur physiologique) et suggère que les orientations futures pourraient consister à se concentrer sur la guérison émotionnelle ou à développer des terminaux de compagnonnage IA (Source : DataEye应用数据情报)
Zhipu AI lance son processus d’introduction en bourse, visant à devenir la “première action des grands modèles”: La société d’IA Zhipu AI, issue de l’Université Tsinghua, a lancé son processus d’introduction en bourse en avril après avoir obtenu plusieurs tours de financement (y compris un investissement récent de 1,5 milliard de yuans de capitaux d’État de Hangzhou et Zhuhai). L’article analyse ses avantages : son bagage technique (ADN Tsinghua), son positionnement stratégique (autonome et contrôlable, inscrite sur la liste américaine), et ses puissants investisseurs (Fortune Capital au début, Tencent, Ant Group, Sequoia, Saudi Aramco au milieu, et récemment divers capitaux d’État locaux). Le choix de cette introduction en bourse est considéré comme une stratégie visant à consolider sa position dans l’industrie en s’emparant du positionnement de “première action des grands modèles” face à l’impact de modèles à faible coût comme DeepSeek, tout en répondant aux exigences de retour sur investissement des investisseurs (en particulier les capitaux d’État locaux qui poussent à l’introduction en bourse). Zhipu AI prévoit de lancer plusieurs modèles cette année, qui reste une “grande année de dépenses”, et l’introduction en bourse aidera à résoudre les problèmes de financement et de valorisation (Source : 真故研究室)

Les entrepreneurs de la Yao Class de Tsinghua de l’ère IA 1.0 repartent à l’aventure: L’article revient sur le parcours entrepreneurial des anciens de la Yao Class de Tsinghua (comme Yin Qi de Megvii, Lou Tiancheng de Pony.ai) à l’ère de l’IA 1.0 (reconnaissance faciale, conduite autonome, etc.), y compris la saisie précoce des opportunités technologiques et l’obtention de faveurs du capital, mais aussi les défis rencontrés tels que la difficulté de la commercialisation, l’intensification de la concurrence et les obstacles à l’introduction en bourse. Avec la montée de la vague IA 2.0 (grands modèles, intelligence incarnée), ces “jeunes génies” se lancent à nouveau dans l’entrepreneuriat, comme Yin Qi qui investit dans les voitures intelligentes (Qianli Tech), et Fan Haoqiang, ancien employé de Megvii, qui a fondé la société d’intelligence incarnée Yuanli Lingji. Ils perpétuent l’ADN de la Yao Class qui consiste à défier les “territoires inexplorés”, cherchant à percer dans le nouveau cycle technologique, mais sont également confrontés à une concurrence plus féroce et à des difficultés de commercialisation (Source : 直面AI)

Wuzhao revient chez DingTalk pour mener des réformes, mettant l’accent sur le produit et l’expérience client: Le fondateur de DingTalk, Chen Hang (Wuzhao), a rapidement lancé une réorganisation interne après son retour. Il place le produit et l’expérience client au premier plan, exigeant que les équipes de R&D et de conception examinent de manière exhaustive le parcours de l’expérience produit, le comparent aux concurrents, et dirige personnellement des visites “incognito” chez les clients pour recueillir leurs commentaires, relançant le modèle de “co-création”. Sur le plan commercial, il demande une enquête sur tous les parcours payants, certains murs payants ont déjà été supprimés ou réformés, montrant que les objectifs commerciaux cèdent la place à l’expérience produit et à l’innovation IA. Sur le plan de la gestion, il resserre la discipline au travail (exigeant par exemple d’arriver à 9h), souligne que les managers doivent montrer l’exemple et être sur le terrain, s’oppose aux purs managers, simplifie les processus de reporting (pas de PPT) et contrôle les coûts (Source : 智能涌现)

Bocha AI : Le fournisseur de services de recherche IA derrière DeepSeek, défiant Bing: Bocha AI fournit des services API de recherche connectée à Internet pour DeepSeek et plus de 60% des applications IA en Chine. Le PDG Liu Xun a présenté les différences techniques entre la recherche IA et la recherche traditionnelle (indexation vectorielle, classement sémantique, intégration générative) et a souligné que son service n’est qu’un intermédiaire. La compétitivité principale de Bocha AI réside dans le traitement des données, son modèle de reclassement développé en interne, son architecture à haute concurrence et faible latence, ses avantages en termes de coûts (environ 1/3 du prix de Bing) et la conformité des données. Liu Xun estime que la recherche IA va perturber le modèle d’enchères de la recherche traditionnelle, poussant les entreprises à passer du SEO au GEO (mettant davantage l’accent sur la qualité du contenu et la construction de bases de connaissances). Il juge que le simple développement d’applications de recherche IA (comme Perplexity) n’est pas un bon créneau, le modèle de revenus étant incertain, tandis que Bocha AI se positionne comme une infrastructure fournissant des capacités de recherche à l’IA, visant à réduire le coût de développement de l’AGI (Source : 腾讯科技)
🌟 Communauté
Fracture IA et clivage politique : Pourquoi “ceux qui détestent le plus l’IA ont voté Trump” ?: L’article analyse que certains partisans de Trump, tels que les agriculteurs des États agricoles traditionnels et les travailleurs de la Rust Belt, sont des groupes touchés par l’automatisation de l’IA, qui n’ont pas partagé les dividendes technologiques et se sentent marginalisés. Ils sont mécontents de la situation actuelle et espèrent les promesses MAGA de Trump (comme le retour de l’industrie manufacturière, la limitation des géants de la technologie). L’article souligne que les difficultés de ces groupes proviennent des ajustements structurels économiques et du fossé des compétences provoqués par le changement technologique, et que les politiques de l’administration Trump (telles que les barrières tarifaires, l’insuffisance de l’éducation de base à l’IA) pourraient difficilement résoudre réellement le problème, voire l’aggraver. L’auteur compare les efforts de la Chine en matière d’inclusion de l’IA (tels que le calcul Est-Ouest, l’autonomisation industrielle par l’IA, les grands modèles gratuits, l’éducation de base à l’IA), visant à permettre à l’ensemble de la population de partager les dividendes technologiques et à éviter la fracture sociale (Source : 脑极体)

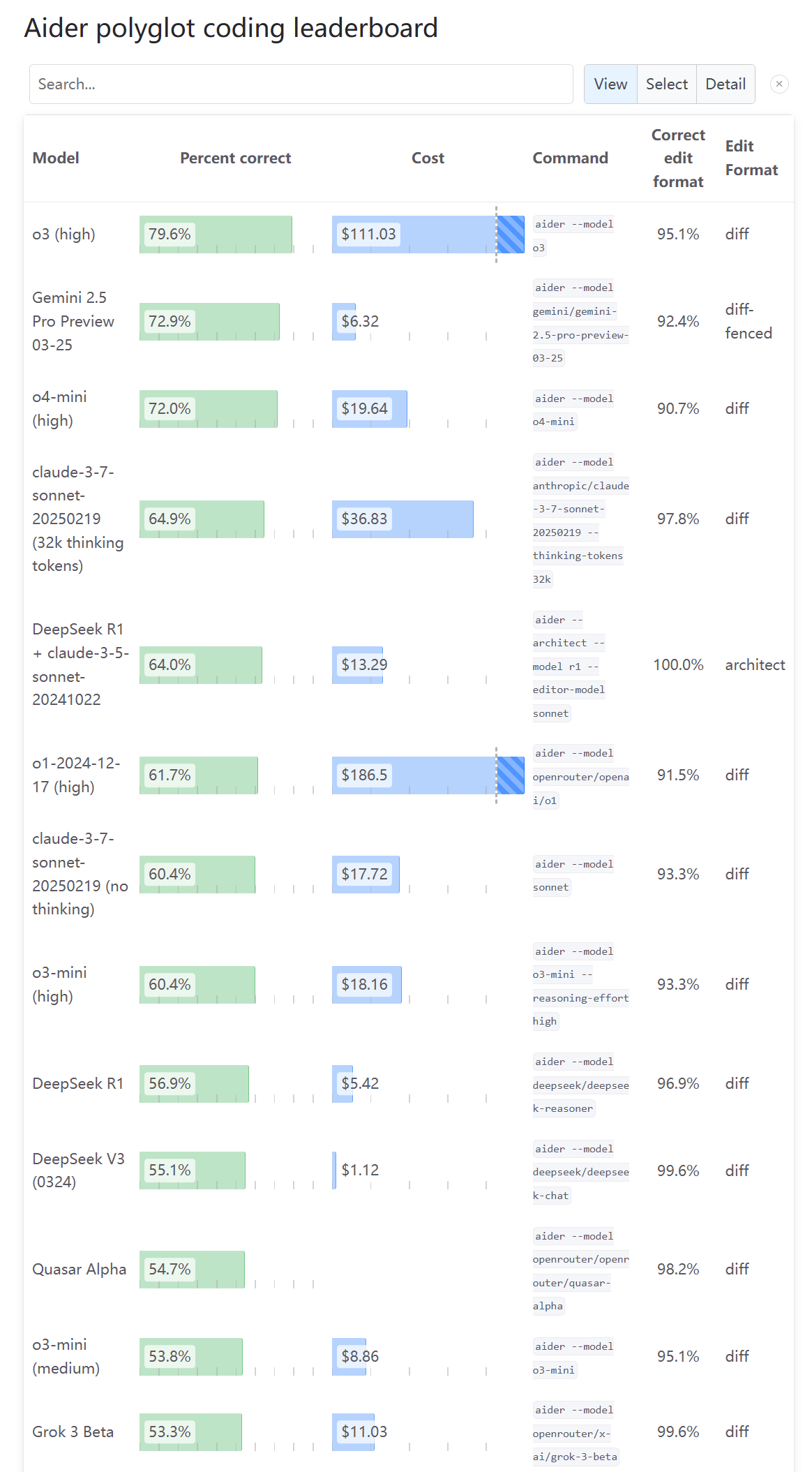
Avis partagés de la communauté sur les capacités de programmation d’o3: Après la mise à jour de l’Aider Leaderboard montrant le score de capacité de programmation d’o3, un utilisateur (karminski3) a déclaré que ce résultat ne correspondait pas à sa propre expérience de test, suggérant que davantage de personnes essaient et donnent leur avis. Cela reflète le fait que l’évaluation des capacités des nouveaux modèles par la communauté présente des perspectives et des controverses multiples, et qu’un seul benchmark peut ne pas refléter pleinement l’expérience d’utilisation réelle (Source : karminski3)
Un utilisateur découvre une baisse d’intelligence des nouveaux modèles OpenAI avec des questions en chinois: L’utilisateur op7418 rapporte qu’en posant des questions en chinois aux nouveaux modèles o3 et o4-mini d’OpenAI, les performances du modèle sont nettement inférieures à celles obtenues avec des questions en anglais, en particulier pour les tâches nécessitant un raisonnement sur image, où les questions en chinois semblent incapables de déclencher ses capacités d’analyse d’image. L’utilisateur suppose qu’OpenAI a peut-être limité ou insuffisamment optimisé l’entrée en chinois (Source : op7418)

Expérience utilisateur : o3 combiné à DALL-E génère de meilleures images: L’utilisateur op7418 a découvert qu’en utilisant le modèle o3 dans ChatGPT pour appeler la génération d’images (probablement DALL-E 3), les résultats sont meilleurs que la génération directe, en particulier pour les concepts complexes nécessitant que le modèle comprenne des connaissances de base (comme des scènes de romans spécifiques). o3 peut d’abord comprendre le contenu textuel, puis générer des images plus pertinentes (Source : op7418)

Un utilisateur partage comment contourner les restrictions de contenu de ChatGPT pour générer des images: Un utilisateur Reddit a partagé comment, en “induisant” ou en affinant progressivement les prompts, il a contourné les restrictions de contenu de ChatGPT (DALL-E 3) pour générer des images proches des limites mais ne violant pas les règles (comme des maillots de bain). La section des commentaires discute des techniques de cette méthode et des opinions sur la rationalité des restrictions de contenu de l’IA (Source : Reddit r/ChatGPT)
Réaction de la communauté à la sortie des nouveaux modèles OpenAI : focus sur l’absence d’open source: Dans les discussions Reddit sur la sortie d’o3 et o4-mini par OpenAI, de nombreux commentaires expriment leur mécontentement face à l’insistance d’OpenAI sur une approche fermée, estimant que cela a une signification limitée pour la communauté et les chercheurs, et attendant la sortie de modèles open source déployables localement (Source : Reddit r/LocalLLaMA)
Utilisations inattendues et astucieuses de l’IA : partage de la communauté: Un utilisateur Reddit sollicite des cas d’utilisation non conventionnels mais pratiques de l’IA. Les réponses incluent : l’utilisation de l’IA pour la psychothérapie, l’apprentissage de la théorie musicale, l’organisation de transcriptions d’entretiens et la conception de scénarios, l’aide aux patients atteints de TDAH pour prioriser les tâches, la création de chansons d’anniversaire personnalisées pour les enfants, etc., démontrant le large potentiel de l’IA dans la vie quotidienne et les scénarios de besoins spécifiques (Source : Reddit r/ArtificialInteligence)
Humour communautaire : moqueries sur le nommage des modèles Nvidia et Llama 2: Un utilisateur Reddit publie un message humoristique se plaignant de la complexité et de la difficulté à mémoriser les noms des nouveaux modèles Nvidia, et utilise un ton sarcastique pour montrer Llama 2 en tête d’un classement, se moquant de la volatilité des benchmarks et des opinions de la communauté sur les anciens et nouveaux modèles (Source : Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)

Un utilisateur hésite entre Claude Max et ChatGPT Pro: Après la sortie d’o3 par OpenAI, un utilisateur a exprimé son hésitation sur Reddit entre s’abonner à Claude Max ou à ChatGPT Pro, pensant qu’o3 pourrait être une amélioration du puissant o1 et pourrait surpasser les modèles actuels. La section des commentaires discute des limitations de débit récentes de Claude, des problèmes de performance, et des avantages et inconvénients respectifs dans des scénarios spécifiques comme le codage (Source : Reddit r/ClaudeAI)
Humour communautaire : moquerie sur l’interaction IA-utilisateur: Un utilisateur Reddit partage un message humoristique sur la question de savoir si l’IA a des émotions ou une conscience, suscitant une discussion légère parmi les membres de la communauté sur l’anthropomorphisation de l’IA et les attentes des utilisateurs (Source : Reddit r/ChatGPT)

Un utilisateur se plaint de la perte de réponses due aux limites de capacité de Claude: Un utilisateur Reddit exprime son mécontentement à l’égard du modèle Claude d’Anthropic, soulignant qu’après que le modèle ait généré une réponse complète et utile, le contenu est supprimé en raison d’une “capacité dépassée”, causant une grande frustration à l’utilisateur. Cela reflète les problèmes persistants de stabilité et d’expérience utilisateur de certains services IA actuels (Source : Reddit r/ClaudeAI)
La chute soudaine du classement de Claude sur LiveBench soulève des questions: Un utilisateur a remarqué une baisse soudaine et importante du classement des modèles de la série Claude Sonnet sur le benchmark de programmation LiveBench, tandis que le classement des modèles OpenAI augmentait, suscitant une discussion sur la fiabilité des benchmarks et l’existence potentielle de facteurs d’intérêt derrière cela. Les membres de la communauté sont perplexes face à ce phénomène, suggérant des raisons possibles telles qu’un changement dans la méthode de test ou des fluctuations réelles des performances du modèle (Source : Reddit r/ClaudeAI)
Un utilisateur montre des selfies de personnages de jeu générés par IA: Un utilisateur Reddit a partagé une série de “selfies” créés pour des personnages de jeux vidéo célèbres à l’aide de ChatGPT (DALL-E 3), démontrant la capacité de l’IA à comprendre les caractéristiques des personnages et à générer des images créatives. Les utilisateurs dans la section des commentaires ont emboîté le pas, générant des selfies de leurs personnages préférés, créant une interaction amusante (Source : Reddit r/ChatGPT)
L’IA peut-elle remplacer les cadres dirigeants ? Débat animé dans la communauté: Une discussion sur Reddit porte sur la raison pour laquelle l’IA remplace en priorité les employés de bureau de base plutôt que les cadres supérieurs bien rémunérés. Les points de vue incluent : les capacités actuelles de l’IA sont insuffisantes pour les décisions complexes des cadres ; la structure du pouvoir détermine que les cadres détiennent le pouvoir de décision de remplacement ; le remplacement des cadres par l’IA pourrait conduire à des décisions plus froides axées sur l’efficacité, pas nécessairement bénéfiques pour les employés ; ainsi que des préoccupations concernant la gouvernance et le contrôle de l’IA (Source : Reddit r/ArtificialInteligence)
Les outils de résumé IA peinent à capturer les “éclairs de génie” clés: Un utilisateur se plaint sur Reddit que lors de l’utilisation d’outils IA (comme Gemini ou des extensions Chrome) pour résumer de longs podcasts ou vidéos, ils obtiennent souvent les points principaux mais manquent fréquemment ces “citations en or” brèves mais très inspirantes ou les moments clés. L’utilisateur se demande s’il est possible d’améliorer l’effet du résumé en fournissant des commentaires et demande si d’autres ont eu des expériences similaires (Source : Reddit r/artificial)
La communauté exprime son mécontentement face à la stratégie de publication d’OpenAI: Un utilisateur Reddit publie un message critiquant les récentes publications d’OpenAI (comme o3/o4-mini, Codex CLI), estimant que leur essence technique est l’application à grande échelle de méthodes connues plutôt qu’une innovation fondamentale, et qu’elles commercialisent excessivement des produits fermés, contribuant insuffisamment à la communauté open source, ne fournissant pas de réelle valeur d’apprentissage, et servant davantage les intérêts commerciaux, ce qui est lassant (Source : Reddit r/LocalLLaMA)

ChatGPT “guérit” de manière inattendue le trouble de l’articulation temporo-mandibulaire (TMJ) d’un utilisateur après cinq ans: Un utilisateur Reddit partage une expérience étonnante : un claquement de mâchoire (symptôme de TMJ) qui le gênait depuis cinq ans a disparu en environ une minute après avoir essayé un exercice simple suggéré par ChatGPT (ouvrir et fermer la bouche en gardant la langue contre le palais pour maintenir la symétrie), et l’effet a persisté. L’utilisateur avait auparavant consulté des médecins et passé une IRM sans succès. Ce cas a suscité une discussion dans la communauté sur le potentiel de l’IA à fournir des conseils de santé non conventionnels mais efficaces (Source : Reddit r/ChatGPT)
💡 Autres
Réflexions de Kissinger sur le développement de l’IA : l’humanité pourrait devenir la plus grande contrainte: Le regretté penseur Henry Kissinger et d’autres explorent dans un article les possibilités futures du développement de l’IA, y compris la réalisation de capacités de planification, l’acquisition d’un “ancrage” (une connexion fiable avec la réalité), la mémoire et la compréhension causale, voire le développement d’une conscience de soi rudimentaire. L’article avertit qu’à mesure que les capacités de l’IA augmentent, sa perception de l’humanité pourrait changer, en particulier si les humains font preuve de passivité face à l’IA, s’adonnent au monde numérique et se détachent de la réalité, l’IA pourrait considérer l’humanité comme une contrainte à son développement plutôt qu’un partenaire. L’article discute également des implications profondes de doter l’IA d’une forme matérielle et d’une capacité d’action autonome, ainsi que des défis inconnus que pourrait poser la connexion en réseau de l’intelligence artificielle générale (AGI), appelant l’humanité à s’adapter activement plutôt qu’à adopter une approche fataliste ou de rejet (Source : 腾讯研究院)
Démonstration d’applications robotiques pilotées par l’IA: Les médias sociaux présentent plusieurs exemples d’applications robotiques pilotées ou assistées par l’IA, notamment un robot développé par Google DeepMind capable de jouer au tennis de table, des bras robotiques capables d’effectuer des opérations délicates (comme séparer la membrane de la coquille d’œuf de caille, sertir des diamants, créer de l’art avec un ciseau), ainsi que des robots aux formes étranges (comme des chiens robots, des robots insectes contrôlés sans fil, des robots se déplaçant à l’aide de roues Mecanum), démontrant les progrès de l’IA dans l’amélioration des capacités de perception, de décision et de contrôle des robots (Source : Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
Exploration des applications de l’IA dans le domaine de la santé: Les médias sociaux mentionnent plusieurs articles et discussions sur les applications de l’IA dans le domaine de la santé, se concentrant sur la manière dont l’IA peut aider les prestataires de soins de santé à faire face aux changements sociaux, le potentiel d’innovation de l’IA générative dans le domaine médical, ainsi que des orientations d’application spécifiques (Source : Ronald_vanLoon, Ronald_vanLoon)

Démonstration de technologies conceptuelles optimisées par l’IA: Les médias sociaux présentent certaines technologies ou produits conceptuels intégrant l’IA, tels qu’un concept de voiture volante autonome pilotée par l’IA, et le rôle potentiel que l’IA pourrait jouer dans les futurs scénarios de vente au détail (Source : Ronald_vanLoon, Ronald_vanLoon)
Les community colleges américains font face à la prolifération d‘“étudiants robots”: Un rapport indique que les community colleges américains sont confrontés à un grand nombre de fausses demandes d’admission soumises par des robots (potentiellement pilotés par l’IA), ce qui pose des défis aux systèmes d’admission et de gestion des écoles, qui s’efforcent de trouver des solutions (Source : Reddit r/artificial)

L’absence de rapport de sécurité lors de la sortie de GPT-4.1 par OpenAI attire l’attention: Les médias technologiques rapportent qu’OpenAI n’a pas fourni de rapport d’évaluation de sécurité détaillé lors de la sortie de GPT-4.1, contrairement à ses habitudes lors de la sortie de nouveaux modèles. OpenAI pourrait estimer que ce modèle est basé sur des technologies existantes et que les risques sont maîtrisables, mais cette décision a suscité des discussions sur la transparence et la responsabilité en matière de sécurité de l’IA (Source : Reddit r/artificial)

L’accélération du développement de l’AGI et le retard de la sécurité suscitent des inquiétudes: Un article souligne que les délais prévus par l’industrie de l’intelligence artificielle pour atteindre l’intelligence artificielle générale (AGI) se raccourcissent, mais qu’en même temps, l’attention et les investissements consacrés aux questions de sécurité de l’IA sont relativement à la traîne, ce qui suscite des inquiétudes quant aux risques futurs du développement de l’IA (Source : Reddit r/artificial)

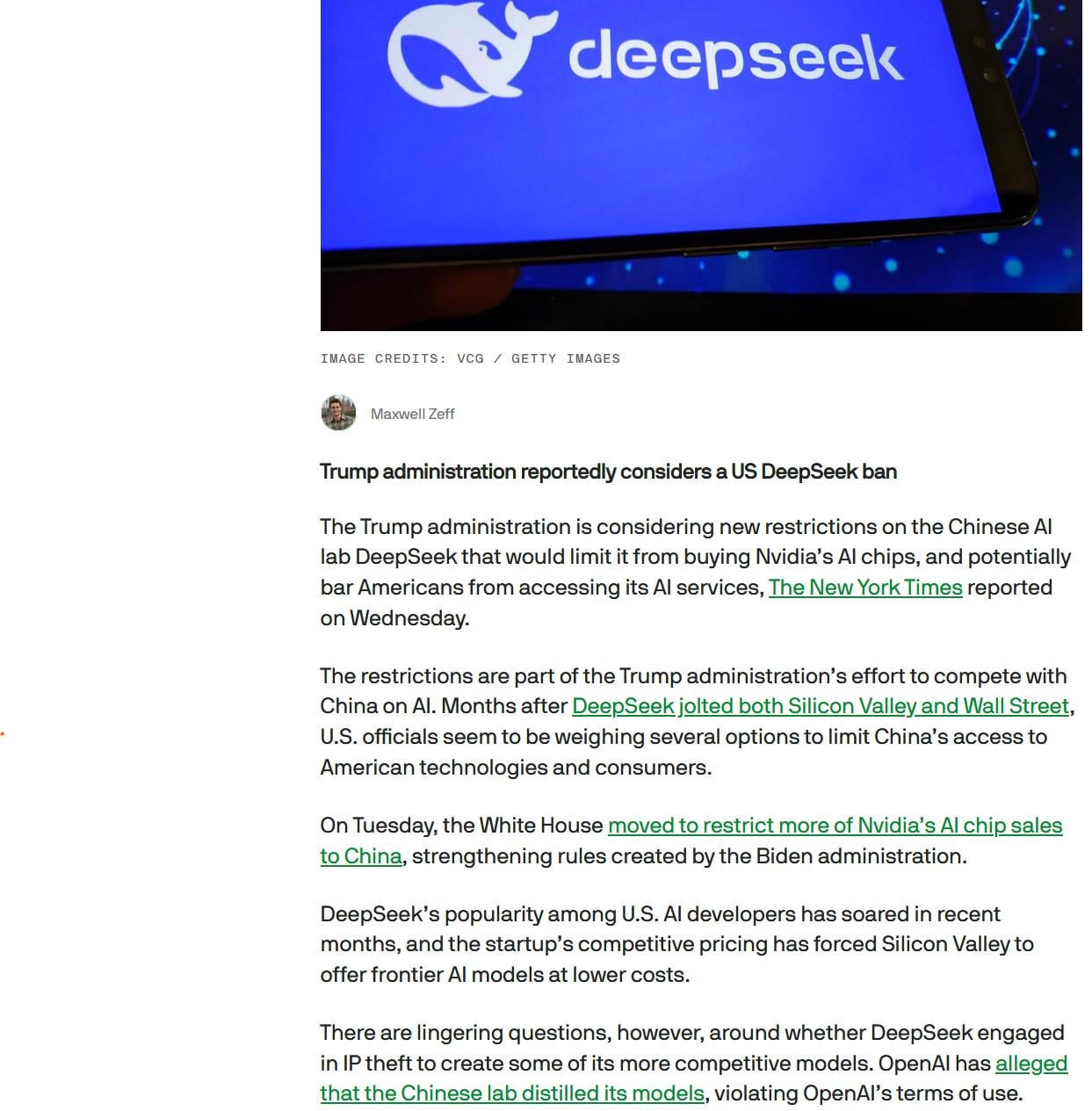
Les États-Unis envisageraient d’interdire DeepSeek: Des informations indiquent que l’administration Trump pourrait envisager d’interdire l’utilisation du grand modèle chinois DeepSeek aux États-Unis et d’exercer des pressions sur les fournisseurs comme Nvidia qui fournissent des puces aux entreprises d’IA chinoises. Cette décision pourrait être fondée sur des considérations de sécurité des données, de concurrence nationale et de protection des entreprises d’IA locales (comme OpenAI), suscitant des inquiétudes quant aux restrictions technologiques et à l’avenir des modèles open source (Source : Reddit r/LocalLLaMA)
Proposition de construire un think tank d’Agents IA pour résoudre les problèmes de l’IA: Un utilisateur Reddit propose l’idée d’utiliser des Agents IA spécialisés dans des domaines spécifiques et dotés de capacités exceptionnelles (ANDSI, Artificial Narrow Domain Super Intelligence) pour former un “think tank”, les faisant collaborer pour s’attaquer spécifiquement aux problèmes actuels du domaine de l’IA, tels que l’élimination des hallucinations, l’exploration de la fusion de modèles IA multi-architectures, etc. L’idée suggère que l’utilisation de l’intelligence surhumaine de l’IA pour accélérer le développement de l’IA elle-même pourrait être plus prometteuse que le simple remplacement du travail humain par l’IA (Source : Reddit r/deeplearning)
Appel à l’open source de l’AGI pour garantir l’avenir de l’humanité: Un lien vers une vidéo YouTube dont le titre affirme que l’intelligence artificielle générale open source (Open Source AGI) est cruciale pour assurer l’avenir de l’humanité, suggérant qu’une voie de développement de l’AGI ouverte, transparente et distribuée est plus bénéfique pour le bien-être humain qu’une voie fermée et centralisée (Source : Reddit r/ArtificialInteligence)
