
Mots-clés:AI, Grands modèles de langage, Course aux armements en IA, Modèles d’IA pour les industries verticales, Zhipu AI IPO, Découverte autonome de lois physiques par l’IA, Système d’assistance aux malvoyants par IA
« ` markdown
🔥 Pleins feux sur
Les géants de la technologie lancent une course à l’armement en IA, les modèles verticaux et les écosystèmes deviennent centraux: Les géants mondiaux de la technologie investissent dans l’IA avec une intensité sans précédent, les dépenses en capital prévues pour 2025 dépassant les 320 milliards de dollars. Les entreprises chinoises telles qu’Alibaba, Tencent, Huawei, etc., intensifient également leurs investissements, misant fortement sur l’infrastructure AI, les grands modèles et la puissance de calcul. Le point focal de la concurrence se déplace des grands modèles généraux vers les modèles sectoriels verticaux, ces derniers devenant de nouveaux moteurs de croissance grâce à des marges brutes élevées et leur capacité à résoudre des problèmes concrets. Malgré les défis liés aux puces haut de gamme, les fabricants nationaux progressent dans l’optimisation des coûts de calcul et les modèles d’inférence (« pensée lente ») (par exemple, l’effet DeepSeek). Chaque entreprise suit une voie différente : Alibaba investit massivement dans l’infrastructure, Huawei innove au niveau matériel (CloudMatrix 384) et promeut la synergie edge-cloud, Baidu se concentre sur les applications, tandis que Tencent et ByteDance exploitent leurs avantages liés aux scénarios diversifiés. L’extension du matériel AI et la construction d’écosystèmes open source (comme HarmonyOS, Ascend, Hunyuan) deviennent cruciales, la concurrence passant des percées technologiques ponctuelles à la capacité de collaboration écosystémique. (Source : 36氪-科技云报道)

Découverte étonnante du MIT : l’IA peut déduire indépendamment les lois de la physique sans connaissance préalable: L’équipe de Max Tegmark au MIT a développé une nouvelle architecture appelée MASS (Multiple AI Scalar Scientists). Ce système d’IA, sans avoir été informé d’aucune loi physique, a pu apprendre indépendamment et proposer des formulations théoriques très similaires aux hamiltoniens ou lagrangiens de la mécanique classique, simplement en analysant les données d’observation de systèmes physiques tels que des pendules et des oscillateurs. La recherche montre que l’IA corrige de manière autonome ses théories face à des systèmes plus complexes, et que différents “scientifiques” IA finissent par converger vers les principes physiques connus, favorisant notamment la description lagrangienne dans les systèmes complexes. Ce résultat démontre l’énorme potentiel de l’IA dans la découverte scientifique fondamentale, capable potentiellement de révéler indépendamment les lois fondamentales de l’univers. (Source : 新智元)

Un système d’aide aux aveugles basé sur l’IA de l’équipe de l’Université Jiao Tong de Shanghai publié dans une revue Nature, permettant aux malvoyants de “retrouver la vue”: L’équipe de Gu Leilei de l’Université Jiao Tong de Shanghai a développé un système d’aide aux aveugles portable piloté par l’IA, combinant la technologie électronique flexible. Grâce à un retour auditif et tactile, il remplace partiellement la fonction visuelle, aidant les personnes malvoyantes à accomplir des tâches quotidiennes telles que la navigation et la préhension. Le matériel du système est léger, le logiciel optimise la sortie d’informations pour s’adapter à la cognition physiologique humaine, et un système d’entraînement immersif en VR a été développé. Les tests montrent que le système améliore considérablement la capacité des utilisateurs malvoyants à naviguer, éviter les obstacles et saisir des objets dans des environnements virtuels et réels. Les résultats de la recherche ont été publiés dans Nature Machine Intelligence, démontrant le potentiel énorme de l’IA pour aider les personnes malvoyantes, améliorer leur autonomie et fournir de nouvelles idées pour des dispositifs d’assistance visuelle portables personnalisés et conviviaux. (Source : 36氪)

Zhipu AI lance le processus d’accompagnement pour son IPO, visant à devenir la “première action de grand modèle”: Zhipu AI (Beijing Zhipu Huazhang Technology), une société de grands modèles d’IA issue de l’Université Tsinghua, a finalisé l’enregistrement de son accompagnement pour une IPO auprès du Bureau de régulation des valeurs mobilières de Pékin le 14 avril. Accompagnée par CICC, elle vise le marché des actions A et pourrait devenir la “première action de grand modèle d’IA” en Chine. Bien que son produit grand public “Zhipu Qingyan” ait une base d’utilisateurs limitée, Zhipu AI, forte de son solide bagage technique (issue de Tsinghua, développement interne de la série de grands modèles GLM), de son statut d’entreprise soutenue par l’État (inscrite sur la liste des entités par les États-Unis) et de ses progrès commerciaux (services aux clients gouvernementaux et entreprises, croissance significative des revenus), a levé plus de 16 milliards de yuans de financement, avec une valorisation dépassant les 20 milliards de yuans. Ses investisseurs comprennent des VC renommés, des géants industriels et des fonds souverains locaux. Face à la concurrence de nouvelles forces comme DeepSeek, le choix de Zhipu AI de s’introduire en bourse est considéré comme une étape clé pour prendre une position avantageuse dans une compétition féroce, répondre aux besoins de financement et aux attentes des investisseurs. L’entreprise a récemment continué à publier en open source les modèles de la série GLM-4, montrant ses efforts simultanés sur les fronts technologique et capitalistique. (Sources : 36氪-真故研究室, 36氪-互联网爆料汇, 创投日报)

🎯 Tendances
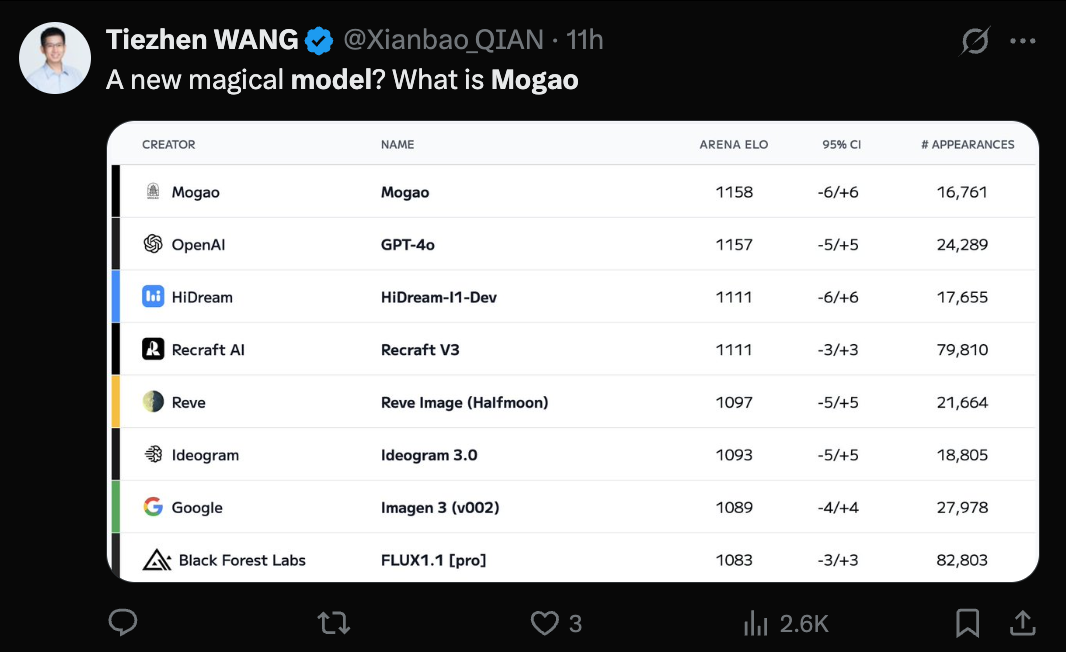
Le modèle Seedream 3.0 (Mogao) de ByteDance révélé, ses capacités de génération texte-image reconnues: Le mystérieux modèle Mogao, qui a récemment dominé le classement de génération texte-image d’Artificial Analysis, s’est avéré être Seedream 3.0, développé par l’équipe Seed de ByteDance. Ce modèle excelle dans plusieurs styles, notamment le réalisme, le design et l’anime, ainsi que dans la génération de texte. Il est particulièrement doué pour traiter le texte dense et générer des portraits réalistes, avec un taux de disponibilité des caractères chinois et anglais atteignant 94%. Le réalisme des portraits approche le niveau de la photographie professionnelle, et il prend en charge la sortie d’images en résolution native 2K, avec une vitesse de génération rapide. Le rapport technique révèle plusieurs innovations dans le traitement des données (entraînement sensible aux défauts, échantillonnage biaxial), le pré-entraînement (architecture MMDiT, résolution mixte, RoPE intermodal) et le post-entraînement (entraînement continu, SFT, RLHF, modèle de récompense VLM) ainsi que l’accélération de l’inférence (Hyper-SD, RayFlow). Comparé à GPT-4o, Seedream 3.0 est supérieur en chinois, en typographie et en couleurs. (Source : 36氪-机器之心)
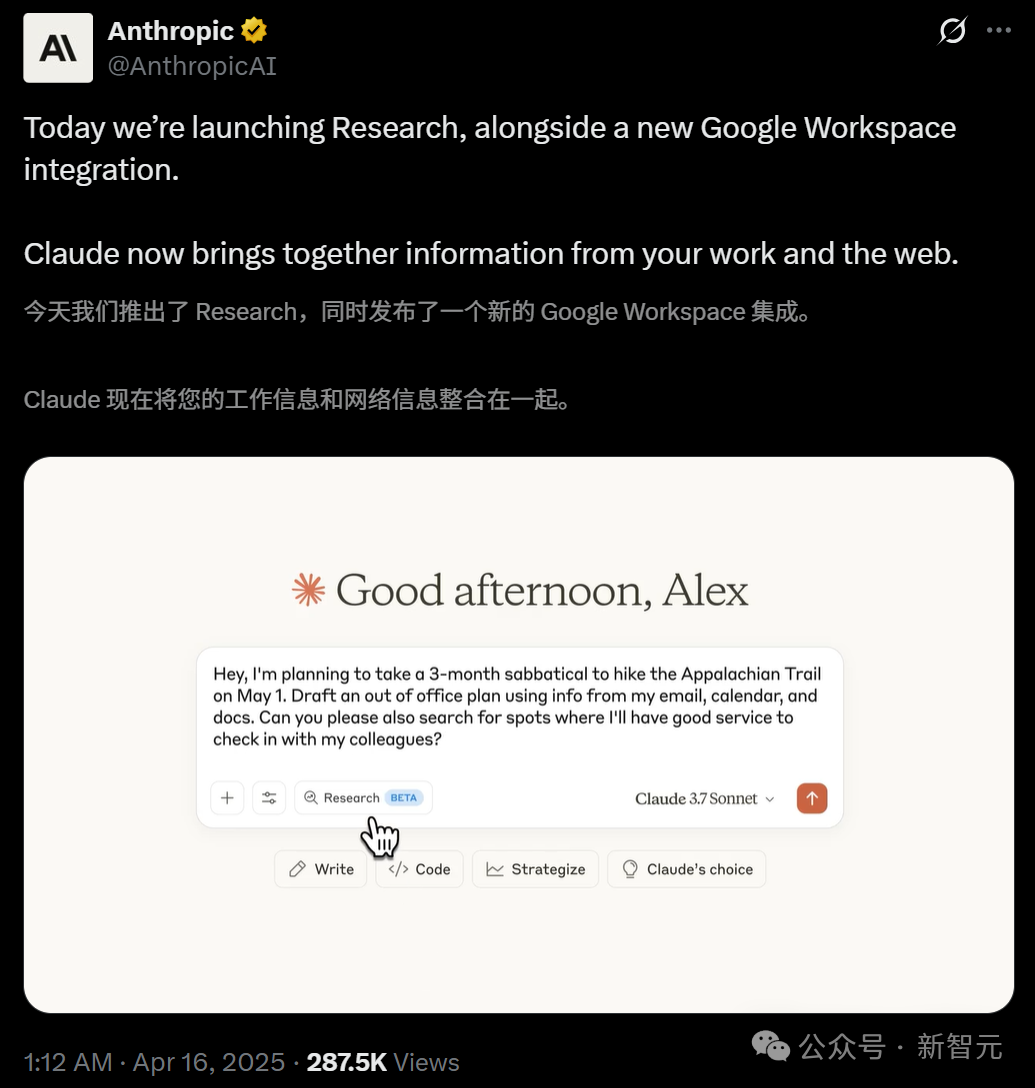
Claude lance la fonction Research et s’intègre à Google Workspace: Anthropic a ajouté deux fonctionnalités majeures à son assistant IA Claude : Research et l’intégration Google Workspace. La fonction Research permet à Claude de rechercher des informations en ligne et de les combiner avec les fichiers internes de l’utilisateur (comme Google Docs) pour une analyse multi-angles, générant rapidement des rapports complets. L’intégration Google Workspace connecte Gmail, Google Agenda et Docs, permettant à Claude de comprendre l’emploi du temps, les e-mails et le contenu des documents de l’utilisateur, d’extraire des informations et d’aider à accomplir des tâches, comme planifier un voyage en fonction des informations personnelles ou rédiger des e-mails. Ces fonctionnalités visent à améliorer considérablement l’efficacité du travail des utilisateurs. La fonction Research est actuellement disponible en test pour les utilisateurs Max, Team et Enterprise aux États-Unis, au Japon et au Brésil, tandis que l’intégration Workspace est ouverte en test à tous les utilisateurs payants. Les retours des utilisateurs sont positifs, estimant que cela améliore l’efficacité et permet de découvrir des liens entre les données, mais des préoccupations concernant la sécurité des données existent également. (Sources : 新智元, op7418, Reddit r/ClaudeAI, Reddit r/ClaudeAI)
CUHK et Tsinghua publient Video-R1, ouvrant un nouveau paradigme pour le raisonnement vidéo: Une équipe conjointe de l’Université Chinoise de Hong Kong (CUHK) et de l’Université Tsinghua a lancé le premier modèle de raisonnement vidéo au monde adoptant le paradigme R1 d’apprentissage par renforcement, Video-R1. Ce modèle vise à résoudre le manque de logique temporelle et de capacités de raisonnement profond des modèles vidéo existants. En introduisant l’algorithme T-GRPO sensible au temps et un jeu de données d’entraînement hybride combinant images et vidéos (Video-R1-COT-165k et Video-R1-260k), le modèle Video-R1 de 7 milliards de paramètres surpasse GPT-4o sur le benchmark de raisonnement spatial vidéo VSI-Bench proposé par Li Feifei. Le modèle montre des “moments d’illumination” similaires à ceux des humains, capable d’effectuer un raisonnement logique basé sur des informations temporelles. Les expériences prouvent que l’augmentation du nombre d’images d’entrée améliore la précision du raisonnement. Le projet a rendu le modèle, le code et les jeux de données entièrement open source, indiquant que l’IA vidéo passe de la “compréhension visuelle” à la “pensée”. (Source : 新智元)

ICLR 2025 introduit pour la première fois l’évaluation par IA à grande échelle, améliorant significativement la qualité des revues: Face à l’augmentation massive des soumissions et à la baisse de la qualité des évaluations, la conférence ICLR 2025 a déployé pour la première fois à grande échelle un “Agent Intelligent de Feedback d’Évaluation” (Review Feedback Agent) basé sur l’IA pour assister le processus d’évaluation par les pairs. Ce système utilise plusieurs LLM, dont Claude Sonnet 3.5, pour identifier les ambiguïtés, les incompréhensions de contenu ou les remarques non professionnelles dans les commentaires d’évaluation, et fournit aux évaluateurs des suggestions d’amélioration spécifiques. L’expérience a couvert 42,3% des évaluations, et les résultats montrent que le feedback de l’IA a amélioré la qualité de l’évaluation dans 89% des cas. 26,6% des évaluateurs ont modifié leur évaluation en fonction des suggestions de l’IA, les évaluations modifiées augmentant en moyenne de 80 mots, devenant plus spécifiques et informatives. L’intervention de l’IA a également accru l’activité et la profondeur des discussions entre auteurs et évaluateurs pendant la période de réfutation (Rebuttal). Cette expérience pionnière démontre le potentiel énorme de l’IA pour optimiser le processus d’évaluation par les pairs. (Source : 新智元)

L’arrivée des robots humanoïdes à la maison suscite des discussions, les entreprises d’électroménager investissent activement dans l’intelligence incarnée: L’entrée des robots humanoïdes dans les foyers soulève des débats sur leurs modèles d’application et leur impact sur l’industrie de l’électroménager. Certains estiment que les robots humanoïdes devraient exploiter leur nature “généraliste” pour résoudre des tâches non standardisées comme plier le linge ou ranger, et utiliser leurs capacités d’interaction pour jouer le rôle de “majordome”, commandant et coordonnant d’autres appareils intelligents, plutôt que de simplement remplacer les appareils existants. Face à cette tendance, des géants de l’électroménager comme Haier et Midea ont commencé à investir, lançant leurs propres produits de robots humanoïdes (comme Kuavo) et explorant l’intégration de la technologie d’intelligence incarnée dans les appareils traditionnels (comme l’aspirateur robot avec bras mécanique de Dreame, la machine à laver capable de saisir les vêtements d’Yimu Technology). Cela montre que l’industrie de l’électroménager s’adapte activement à la vague de l’IA, et pourrait à l’avenir former un écosystème de maison intelligente symbiotique avec les robots humanoïdes. (Source : 36氪-具身研习社)

Huawei lance le serveur IA CloudMatrix 384, visant le GB200 de Nvidia: Lors de sa conférence sur l’écosystème cloud, Huawei a présenté son dernier cluster de serveurs IA, le CloudMatrix 384. Ce système est composé de 384 cartes de calcul Ascend, offrant une puissance de calcul de 300 PFlops par cluster et un débit de décodage par carte de 1920 Tokens/s, visant directement les performances du H100 de Nvidia. Il utilise une interconnexion tout fibre optique à haute vitesse (6812 modules optiques 400G), atteignant une efficacité d’entraînement proche de 90% de celle d’une carte Nvidia seule. Cette initiative est considérée comme une étape importante pour la Chine dans sa tentative de rattraper le niveau international en matière d’infrastructure IA, visant à répondre à la demande de puissance de calcul face aux restrictions sur les puces haut de gamme. Les analystes estiment que cela démontre les progrès rapides de Huawei dans le domaine du matériel IA et pourrait avoir un impact sur la structure actuelle du marché. (Sources : dylan522p, 36氪-科技云报道)
Google lance la fonction de génération texte-vidéo Veo 2 et Whisk Animate: Google a intégré son modèle de génération texte-vidéo Veo 2 dans Gemini Advanced. Les utilisateurs membres peuvent utiliser cette fonction gratuitement via l’application Gemini, les vidéos générées ayant une durée de 8 secondes. Parallèlement, l’outil d’édition d’images de Google, Whisk, a été mis à jour avec la fonction Whisk Animate, permettant aux utilisateurs, après avoir généré une image, de la convertir en vidéo à l’aide de Veo 2. Cependant, cette fonction nécessite un abonnement Google One. Cela marque les efforts continus de Google dans le domaine de la génération multimodale, offrant aux utilisateurs des outils de création plus riches. (Sources : op7418, op7418)
OpenAI pourrait construire un produit social de type X: Selon The Verge, OpenAI développerait en interne un prototype de produit social similaire à X (anciennement Twitter). Ce produit pourrait combiner les capacités de génération d’images de ChatGPT (surtout après la sortie de GPT-4o) avec un flux d’actualités sociales. Compte tenu de l’énorme base d’utilisateurs de ChatGPT et de ses progrès en matière de génération d’images, cette initiative est considérée comme ayant une certaine faisabilité et pourrait marquer la tentative d’OpenAI d’étendre ses capacités d’IA au domaine des médias sociaux. (Source : op7418)
DeepCoder publie un modèle de codage open source performant de 14 milliards de paramètres: L’équipe DeepCoder a publié un modèle de codage open source performant de 14 milliards de paramètres, qui serait excellent pour les tâches de codage. La publication de ce modèle offre aux développeurs une autre option puissante d’outil de génération et d’assistance au code, en particulier dans les scénarios où il faut équilibrer performance et taille du modèle. (Source : Ronald_vanLoon)

Tesla réalise le stationnement automatique des véhicules sortant d’usine: Tesla a démontré une nouvelle avancée de sa technologie de conduite autonome : les véhicules, après leur sortie de la chaîne de production en usine, peuvent se rendre automatiquement à la zone de chargement ou au parking sans intervention humaine. Cela montre le potentiel d’application de la capacité FSD (Full Self-Driving) de Tesla dans des environnements spécifiques et contrôlés, contribuant à améliorer l’efficacité logistique de la production et constituant une étape vers des applications de conduite autonome plus larges. (Sources : Ronald_vanLoon, Ronald_vanLoon)
Dexterity lance Mech, un robot industriel piloté par l’IA physique: La société Dexterity a lancé un robot industriel nommé Mech, caractérisé par l’utilisation de la technologie “Physical AI” (IA Physique). Cette IA permet au robot de naviguer et d’opérer dans des environnements industriels complexes, faisant preuve d’une flexibilité et d’une adaptabilité surhumaines, visant à résoudre des tâches complexes difficiles à gérer par l’automatisation industrielle traditionnelle. (Source : Ronald_vanLoon)
Le MIT développe un nouveau robot sauteur conçu pour les terrains accidentés: Des chercheurs du MIT ont développé un nouveau type de robot dont le design s’inspire du mouvement de saut, particulièrement adapté pour se déplacer sur des terrains accidentés et irréguliers. Ce robot illustre l’application de la bionique dans la conception robotique et le potentiel de l’apprentissage automatique pour contrôler des mouvements complexes, avec des applications potentielles dans la recherche et le sauvetage, l’exploration planétaire et d’autres environnements complexes. (Source : Ronald_vanLoon)
Lancement d’INTELLECT-2 : entraînement distribué mondial par apprentissage par renforcement d’un modèle 32B: Le projet Prime Intellect a lancé l’initiative INTELLECT-2, visant à entraîner un modèle de raisonnement avancé de 32 milliards de paramètres par apprentissage par renforcement, en utilisant des ressources de calcul distribuées à l’échelle mondiale. Ce modèle est basé sur l’architecture Qwen et son objectif est d’atteindre un budget de réflexion contrôlable, c’est-à-dire que l’utilisateur peut spécifier combien d’étapes de raisonnement (combien de tokens de réflexion) le modèle doit effectuer avant de résoudre un problème. Il s’agit d’une exploration importante de l’entraînement distribué et de l’apprentissage par renforcement pour améliorer les capacités de raisonnement des grands modèles. (Source : Reddit r/LocalLLaMA)

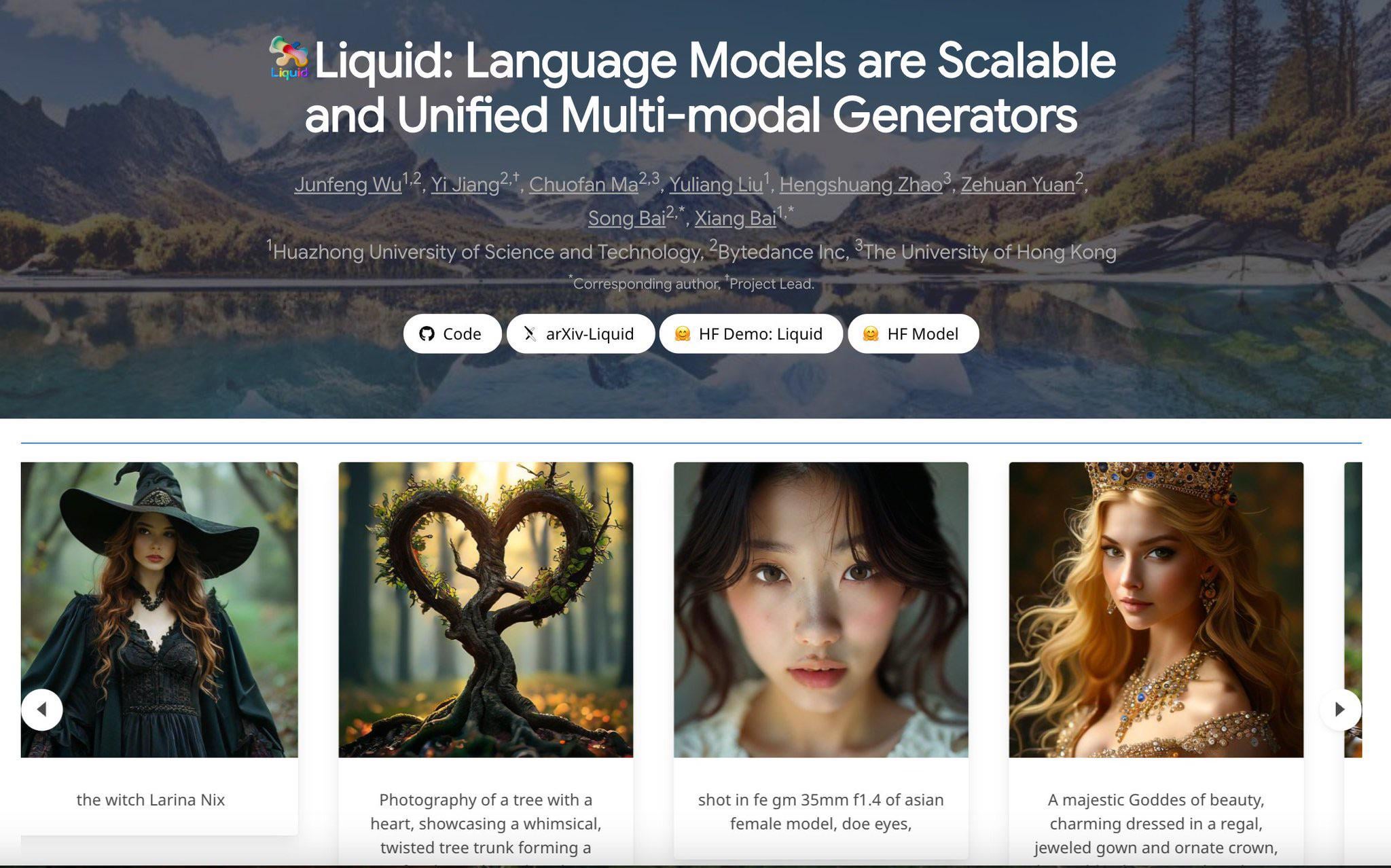
ByteDance publie Liquid, un modèle autorégressif multimodal de type GPT-4o: ByteDance a publié une série de modèles multimodaux nommée Liquid. Ce modèle adopte une architecture autorégressive similaire à GPT-4o, capable de recevoir des entrées texte et image, et de générer des sorties texte ou image. Contrairement aux MLLM précédents qui utilisaient des embeddings visuels pré-entraînés externes, Liquid utilise un seul LLM pour la génération autorégressive. Une version 7B du modèle et une démo ont été publiées sur Hugging Face. Les premières évaluations suggèrent que la qualité de génération d’images n’atteint pas encore celle de GPT-4o, mais l’uniformité de son architecture constitue une avancée technique importante. (Source : Reddit r/LocalLLaMA)
Exécuter plusieurs LLM via la technologie d’instantané de mémoire GPU: Discussion sur une technique permettant de basculer rapidement et d’exécuter plusieurs LLM en prenant un instantané de l’état de la mémoire GPU (y compris les poids, le cache KV, la disposition de la mémoire, etc.). Cette méthode, similaire à l’opération fork d’un processus, peut restaurer l’état d’un modèle en quelques secondes (environ 2s pour un modèle 70B, 0.5s pour un 13B), sans rechargement ni réinitialisation. Ses avantages potentiels incluent l’exécution de dizaines de LLM sur un seul nœud GPU pour réduire les coûts d’inactivité, la commutation dynamique des modèles à la demande et l’utilisation du temps libre pour le fine-tuning local, etc. (Source : Reddit r/MachineLearning)
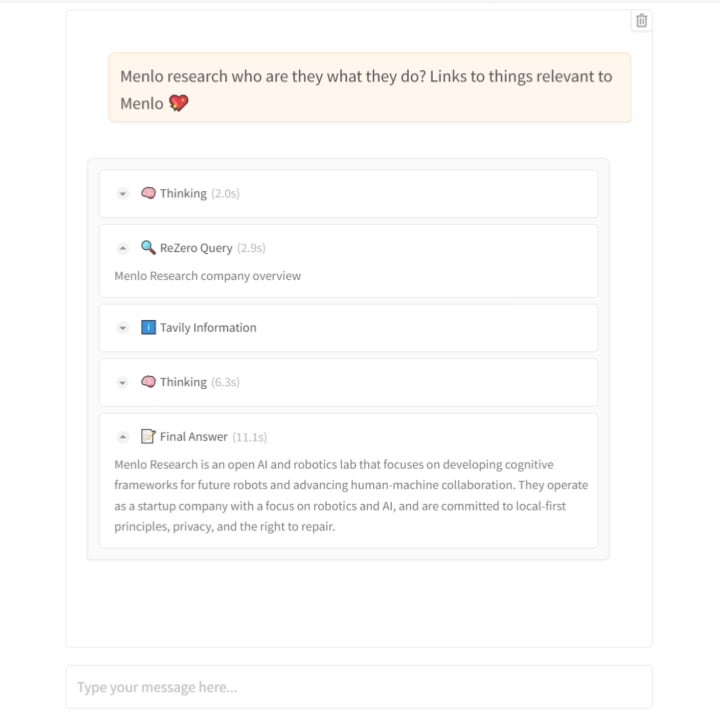
Menlo Research publie le modèle ReZero : apprendre à l’IA la “persévérance” dans la recherche: L’équipe de Menlo Research a publié un nouveau modèle et un article intitulés ReZero. Ce modèle est basé sur l’idée que “la recherche nécessite plusieurs tentatives”. Il utilise GRPO (un algorithme d’optimisation par apprentissage par renforcement) et la capacité d’appel d’outils pour l’entraînement, et introduit une “récompense de nouvelle tentative” (retry_reward). L’objectif de l’entraînement est de permettre au modèle, lorsqu’il rencontre des difficultés ou que les résultats de recherche initiaux ne sont pas satisfaisants, de tenter activement et de manière répétée la recherche jusqu’à trouver l’information souhaitée. Les expériences montrent que les performances de ReZero sont significativement améliorées par rapport aux modèles de référence (46% vs 20%), prouvant l’efficacité de la stratégie de recherche répétée et remettant en question l’idée que “répétition égale hallucination”. Ce modèle peut être utilisé pour optimiser la génération de requêtes des moteurs de recherche existants ou comme couche d’amélioration de la recherche pour les LLM. Le modèle et le code sont open source. (Source : Reddit r/LocalLLaMA)
Hugging Face acquiert une startup de robots humanoïdes: Hugging Face, communauté et plateforme d’IA open source de premier plan, a acquis une startup de robots humanoïdes dont les détails n’ont pas été divulgués. Cette démarche pourrait signifier que Hugging Face souhaite étendre les capacités de sa plateforme des logiciels et modèles au matériel et à la robotique, favorisant ainsi davantage l’application de l’IA dans le monde physique, en particulier dans le domaine de l’intelligence incarnée. (Source : Reddit r/ArtificialInteligence)

🧰 Outils
Publication du modèle TTS émotionnel open source Orpheus, supportant l’inférence en streaming et le clonage vocal: Canopy Labs a publié en open source une série de modèles de synthèse vocale (TTS) nommée Orpheus (jusqu’à 3 milliards de paramètres, basés sur l’architecture Llama). Ce modèle surpasserait les performances des modèles open source existants et de certains modèles propriétaires. Sa particularité réside dans sa capacité à générer une parole humanisée avec une intonation, une émotion et un rythme naturels, pouvant même déduire et générer des sons non linguistiques tels que des soupirs et des rires à partir du texte, démontrant une certaine capacité d‘“empathie”. Orpheus prend en charge le clonage vocal zero-shot, une intonation émotionnelle contrôlable, et réalise une inférence en streaming à faible latence (environ 200 ms), adaptée aux applications de dialogue en temps réel. Le projet fournit différentes tailles de modèles et des tutoriels de fine-tuning, visant à abaisser le seuil d’accès à la synthèse vocale de haute qualité. (Source : 36氪)

La plateforme Trae.ai met gratuitement en ligne Gemini 2.5 Pro: La plateforme d’outils IA Trae.ai a annoncé avoir mis en ligne le dernier modèle de Google, Gemini 2.5 Pro, et en offre l’utilisation gratuite. Les utilisateurs peuvent expérimenter les différentes capacités de Gemini 2.5 Pro sur cette plateforme. (Source : dotey)
Outil de recrutement IA Hireway : trier 800 candidats en une journée: Hireway a démontré les capacités de son outil de recrutement IA, affirmant pouvoir trier efficacement 800 candidats en une seule journée. Cet outil utilise l’IA et les technologies d’automatisation pour optimiser le processus de recrutement, améliorer l’efficacité du tri et l’expérience candidat. (Source : Ronald_vanLoon)
PRIMA.CPP : Accélérer l’inférence des grands modèles 70B sur des clusters domestiques ordinaires: PRIMA.CPP est un projet open source basé sur llama.cpp, visant à optimiser et accélérer la vitesse d’inférence de grands modèles de langage jusqu’à 70 milliards de paramètres sur des clusters de calcul domestiques ordinaires aux ressources limitées (pouvant impliquer plusieurs PC ou appareils ordinaires). Ce projet se concentre sur l’efficacité de l’inférence distribuée, offrant de nouvelles possibilités pour exécuter de grands modèles localement. L’article a été publié sur Hugging Face. (Source : Reddit r/LocalLLaMA)

Partage de Prompt pour personnages en peluche: Un utilisateur a partagé un ensemble de prompts pour générer d’adorables personnages d’animaux en style peluche 3D, adaptés aux outils de génération d’images comme Sora ou GPT-4o. Ce prompt met l’accent sur la description détaillée, telle que la texture ultra-douce, la fourrure dense, les grands yeux, l’éclairage doux et l’arrière-plan, visant à générer des rendus de haute qualité adaptés comme mascottes de marque ou personnages IP. (Source : dotey)

📚 Apprentissage
Jeff Dean partage le matériel de sa présentation à l’ETH Zurich: Jeff Dean, scientifique en chef chez Google DeepMind, a partagé les liens vers l’enregistrement audio et les diapositives de sa présentation au département d’informatique de l’ETH Zurich. Le contenu de la présentation porte probablement sur les dernières avancées dans le domaine de l’IA, les orientations de recherche ou les résultats de recherche de Google, offrant une ressource d’apprentissage précieuse pour les chercheurs et les étudiants. (Source : JeffDean)
Publication du rapport technique sur l’évaluation par IA à l’ICLR 2025: Parallèlement à l’annonce de l’introduction de l’évaluation par IA à l’ICLR 2025, un rapport technique détaillé de 30 pages a également été rendu public (arXiv:2504.09737). Le rapport détaille la conception de l’expérience, les modèles d’IA utilisés (avec Claude Sonnet 3.5 au cœur), le mécanisme de génération de feedback, les méthodes de test de fiabilité, ainsi que l’analyse quantitative de l’impact sur la qualité de l’évaluation, l’activité des discussions et la décision finale. Ce rapport fournit une référence approfondie pour comprendre le potentiel, les défis et les détails de mise en œuvre de l’IA dans l’évaluation académique par les pairs. (Source : 新智元)
Publication en open source de l’article, du code et des jeux de données du modèle de raisonnement vidéo Video-R1: L’équipe de CUHK et Tsinghua n’a pas seulement publié le modèle Video-R1, mais a également rendu entièrement open source son article technique (arXiv:2503.21776), son code d’implémentation (GitHub: tulerfeng/Video-R1) ainsi que les deux jeux de données clés utilisés pour l’entraînement (Video-R1-COT-165k et Video-R1-260k). Cela fournit à la communauté de recherche des ressources complètes pour reproduire, améliorer et explorer davantage le paradigme R1 du raisonnement vidéo, contribuant ainsi à faire progresser le développement technologique dans ce domaine. (Source : 新智元)
Publication de l’article sur la découverte indépendante des lois physiques par l’IA: Les résultats de recherche de l’équipe de Max Tegmark du MIT concernant la capacité du système d’IA MASS à découvrir indépendamment les hamiltoniens et les lagrangiens ont été publiés sous forme d’article pré-imprimé (arXiv:2504.02822v1). L’article expose en détail la conception de l’architecture MASS, son algorithme principal (apprentissage de fonctions scalaires basé sur le principe de conservation de l’action), les configurations expérimentales (différents systèmes physiques, scénarios avec un ou plusieurs scientifiques IA) et la découverte de la manière dont la théorie de l’IA évolue avec la complexité des données pour finalement converger vers les formulations de la mécanique classique. Cet article fournit une base théorique et empirique importante pour explorer l’application de l’IA dans la découverte scientifique fondamentale. (Source : 新智元)
Publication de l’article PRIMA.CPP: L’article technique présentant le projet PRIMA.CPP (visant à accélérer l’inférence de LLM à l’échelle 70B sur des clusters à faibles ressources) a été publié sur Hugging Face Papers (ID: 2504.08791). L’article détaille probablement les techniques d’optimisation employées, les stratégies d’inférence distribuée et les résultats d’évaluation des performances sur des configurations matérielles spécifiques, fournissant une référence technique détaillée aux chercheurs et praticiens du domaine. (Source : Reddit r/LocalLLaMA)
Analyse approfondie du modèle RWKV-7 et échange avec l’auteur: Oxen.ai a publié une vidéo et un article de blog analysant en profondeur le modèle RWKV-7 (Goose). Le contenu couvre les problèmes que l’architecture RWKV tente de résoudre, sa méthode d’itération et ses caractéristiques techniques clés. La particularité est que la vidéo inclut une interview et une session de questions-réponses avec l’un des principaux auteurs du modèle, Eugene Cheah, offrant une perspective précieuse de l’auteur pour comprendre ce LLM à architecture non-Transformer et explorant des concepts intéressants comme “l’apprentissage au moment du test” (Learning at Test Time). (Source : Reddit r/MachineLearning)

Partage d’un article sur 7 astuces pour maîtriser l’ingénierie de Prompt: Le site FrontBackGeek a publié un article résumant 7 astuces puissantes pour aider les utilisateurs à mieux maîtriser l’ingénierie de Prompt, afin d’obtenir de meilleurs résultats des modèles d’IA (comme les LLM). L’article couvre probablement comment clarifier les instructions, fournir du contexte, définir un rôle, contrôler le format de sortie, etc. (Source : Reddit r/deeplearning)

Partage d’un projet de fine-tuning GPT-2/GPT-J pour imiter le ton de M. Darcy d’Orgueil et Préjugés: Un développeur a partagé son projet personnel : utiliser les modèles GPT-2 (medium) et GPT-J, fine-tunés avec deux jeux de données contenant des dialogues originaux et des données synthétiques créées, pour tenter d’imiter le style de parole unique de M. Darcy dans Orgueil et Préjugés de Jane Austen (formel, concis, légèrement critique). Le projet montre des exemples de sortie du modèle, des métriques d’évaluation (amélioration du BLEU-4 mais augmentation de la perplexité) et les défis rencontrés (comme la difficulté d’ajuster GPT-J). Le code et les jeux de données sont open source sur GitHub, offrant un cas d’étude pour explorer la modélisation de styles littéraires spécifiques ou de voix de personnages historiques. (Source : Reddit r/MachineLearning)
Discussion sur la publication des Meta Reviews de l’ACL 2025: Les résultats des Meta Reviews (méta-évaluations) de la conférence ACL 2025 ont été publiés. Des chercheurs concernés ont lancé un fil de discussion dans la communauté, invitant chacun à discuter et échanger sur les scores de leurs articles et les Meta Reviews correspondantes. Cela offre aux auteurs ayant soumis un article une plateforme pour partager leurs expériences et comparer leurs attentes et les résultats. (Source : Reddit r/MachineLearning)
Partage d’expérience sur la construction d’un serveur IA à 160 Go de VRAM à faible coût: Un utilisateur de Reddit a partagé en détail son expérience de construction d’un serveur d’inférence IA avec 160 Go de VRAM pour environ 1000 $ (coût principal : 10 GPU AMD MI50 d’occasion à 90 $ pièce et un châssis de minage Octominer à 100 $). Le contenu inclut le choix du matériel, l’installation du système (Ubuntu + ROCm 6.3.0), la compilation et les tests de llama.cpp, la mesure de la consommation électrique (environ 120W au repos, pic à 340W en inférence), la situation du refroidissement et les données de performance (comparaison avec des cartes comme la 3090, exécution des modèles llama3.1-8b et llama-405b). Ce partage offre une référence très précieuse en matière de configuration matérielle DIY et d’expérience pratique pour les passionnés d’IA à budget limité. (Source : Reddit r/LocalLLaMA)
Publication de l’article et du code du modèle ReZero: L’article technique (arXiv:2504.11001) relatif au modèle ReZero publié par Menlo Research (entraîné avec GRPO pour répéter la recherche jusqu’à trouver l’information souhaitée), les poids du modèle (Hugging Face: Menlo/ReZero-v0.1-llama-3.2-3b-it-grpo-250404) ainsi que le code d’implémentation (GitHub: menloresearch/ReZero) ont tous été rendus publics. Cela fournit des ressources complètes d’apprentissage et d’expérimentation pour la recherche et l’application de cette nouvelle stratégie de recherche. (Source : Reddit r/LocalLLaMA)
💼 Affaires
Min Wei, ancien cadre supérieur en robotique chez Alibaba, fonde Yingshen Intelligence et lève des dizaines de millions en financement d’amorçage: Fondée en 2024 par Min Wei, ancien responsable technique de l’équipe robotique d’Alibaba, « Yingshen Intelligence » se concentre sur la R&D et l’application de la technologie d’intelligence incarnée de niveau L4. L’entreprise a récemment bouclé consécutivement un tour de financement d’amorçage de plusieurs dizaines de millions de RMB (investi par Zhuoyuan Asia) et un tour d’amorçage+ (co-investi par Zhuoyuan Asia et Hangzhou Xihu Kechuangtou). Yingshen Intelligence, basée sur son grand modèle intelligent spatio-temporel développé en interne (construction d’un modèle du monde réel quadridimensionnel via Real to Real, modélisation directe à partir de données vidéo) et sur des robots industriels, fournit des solutions matérielles et logicielles coordonnées. Elle a déjà remporté des commandes industrielles de plusieurs dizaines de millions, se concentrant initialement sur les scénarios industriels et prévoyant de s’étendre aux secteurs des services tels que la livraison express et l’hôtellerie. (Source : 36氪)
Le marché des jouets IA est en plein essor en ligne mais morose hors ligne, l’exportation pourrait devenir la principale voie: Les jouets IA connaissent un grand succès sur les plateformes en ligne (comme le live-shopping, les médias sociaux), avec des prévisions de croissance rapide de la taille du marché. Cependant, une enquête hors ligne (à Guangzhou par exemple) révèle que les jouets IA sont difficiles à trouver dans les magasins de jouets traditionnels et les grands magasins, avec un faible taux de distribution et une faible notoriété auprès des consommateurs. Actuellement, les ventes de jouets IA dépendent probablement principalement des canaux en ligne, et les marchés étrangers (Europe, Amérique, Moyen-Orient) constituent un débouché important, les fabricants proposant des services de personnalisation de l’apparence et de la langue. L’analyse des données sur la taille du marché suggère que le marché de plusieurs dizaines de milliards précédemment rapporté pourrait faire référence aux “jouets intelligents” au sens large plutôt qu’aux jouets purement IA. Malgré la morosité hors ligne, compte tenu de la demande croissante de compagnie émotionnelle chez les adultes (comme le cas Moflin) et du potentiel de la technologie IA pour tous les âges, le marché des jouets IA est toujours considéré comme ayant un énorme potentiel de développement. (Source : 36氪)

Qingcheng Jizhi, société d’infrastructure IA issue de Tsinghua : explosion de la demande d’inférence, le rapport coût-efficacité favorise la substitution nationale: Entretien avec Tang Xiongchao, PDG de Qingcheng Jizhi, une société d’infrastructure IA issue de l’Université Tsinghua. L’entreprise observe qu’après la popularité du modèle DeepSeek, la demande de puissance de calcul pour l’inférence IA a explosé, et la puissance de calcul nationale auparavant inutilisée a commencé à fonctionner. Cependant, l’innovation technique de DeepSeek (comme la précision FP8) est profondément liée aux cartes H de Nvidia, creusant l’écart avec la plupart des puces nationales actuelles. Pour résoudre ce problème, Qingcheng Jizhi et Tsinghua ont conjointement publié en open source le moteur d’inférence “Chitu” (赤兔), visant à permettre aux GPU existants et aux puces nationales d’exécuter efficacement des modèles avancés comme DeepSeek, favorisant ainsi un écosystème IA national en boucle fermée. Tang Xiongchao estime que bien que la substitution des puces nationales prenne du temps, il est optimiste quant à leur avantage en termes de rapport coût-efficacité à long terme. L’activité actuelle de l’entreprise se concentre sur la satisfaction de la demande de déploiement local de grands modèles par les gouvernements et les entreprises. (Source : 凤凰网科技)
La frénésie d’investissement dans l’IA se poursuit, les jeunes investisseurs émergent: Bien que l’environnement d’investissement global se soit refroidi en 2024, le secteur de l’IA continue d’attirer les capitaux, avec des financements mondiaux atteignant des records, et le marché intérieur est également actif. Des géants comme ByteDance, Alibaba, Tencent accélèrent leur déploiement. Des licornes comme Zhipu AI, Moonshot AI, Unitree Robotics émergent. Les points chauds de l’investissement couvrent toute la chaîne industrielle, y compris l’infrastructure, l’AIGC, l’intelligence incarnée, etc. Les sociétés d’investissement établies comme Sequoia China, BlueRun Ventures, etc., maintiennent leur avance, tandis que les fonds industriels et les capitaux d’État, représentés par le Beijing Municipal Artificial Intelligence Industry Investment Fund, deviennent également des moteurs importants. Il est à noter qu’un groupe de jeunes investisseurs nés dans les années 80 (comme Cao Xi, Dai Yusen, Lin Haizhuo, Zhang Jinjian, etc.) sont très actifs à l’ère de l’IA 2.0. Grâce à leur perspicacité et à leur capacité d’exécution, ils recherchent activement des opportunités dans un marché aux nouvelles règles, devenant une nouvelle force à ne pas négliger. (Source : 36氪-第一新声)

Le fondateur de l’application d’achat IA Nate accusé de fraude, une “API humaine” se faisant passer pour de l’IA pour escroquer 50 millions de dollars d’investissement: Le ministère américain de la Justice a inculpé Albert Saniger, fondateur de l’application d’achat IA Nate, l’accusant d’avoir levé plus de 50 millions de dollars de capital-risque grâce à de fausses déclarations sur les capacités de sa technologie IA. Nate affirmait que son application pouvait automatiser le processus d’achat en ligne grâce à une technologie IA propriétaire, mais en réalité, sa fonctionnalité principale dépendait fortement de centaines d’agents de service client employés aux Philippines pour traiter manuellement les commandes, le prétendu taux d’automatisation par IA étant quasi nul. Le fondateur a caché la vérité aux investisseurs et aux employés, et l’entreprise a fini par faire faillite faute de fonds. Cette affaire révèle les risques de fraude potentiels dans l’engouement pour les startups IA, où l’on utilise la main-d’œuvre humaine pour simuler l’IA afin d’attirer les investissements, nuisant aux intérêts des investisseurs et à la réputation du secteur. Saniger risque jusqu’à 40 ans de prison. (Source : CSDN)

🌟 Communauté
Les vidéos modifiées par IA envahissent les plateformes de vidéos courtes, soulevant des controverses sur le divertissement, les droits d’auteur et l’éthique: L’utilisation de la technologie IA (comme les outils de génération texte-vidéo Sora, Keling, etc.) pour “modifier radicalement” des séries télévisées classiques (par exemple, “La Légende de Zhen Huan” à moto, “Au nom du peuple” transformé en “Le Printemps de Séoul”) est devenue rapidement populaire sur des plateformes comme Douyin et Bilibili. Ces vidéos attirent un trafic massif grâce à leurs intrigues subversives, leur impact visuel et leur culture du mème, devenant un nouveau moyen pour les créateurs de gagner rapidement en notoriété et de monétiser (partage des revenus publicitaires, placements de produits discrets) ainsi que pour la promotion des séries. Cependant, leur popularité s’accompagne de controverses : la délimitation de la violation des droits d’auteur de l’œuvre originale est complexe ; le contenu modifié peut affaiblir la profondeur artistique de l’original, voire dériver vers la vulgarité, attirant l’attention des régulateurs. Trouver un équilibre entre la satisfaction des besoins de divertissement, le respect des droits d’auteur et le maintien de la qualité du contenu est le défi auquel est confrontée la création secondaire par IA. (Source : 36氪-明晰野望)

Les quotas et la tarification des plans Claude Pro/Max suscitent les plaintes des utilisateurs: Plusieurs fils de discussion sont apparus sur le subreddit ClaudeAI, où les utilisateurs se plaignent massivement des limitations et de la tarification d’Anthropic pour les abonnements Claude Pro et le nouveau plan Max. Les utilisateurs signalent que même les abonnés Pro payants atteignent rapidement la limite d’utilisation après un nombre faible ou modéré d’interactions (par exemple, traitement de quelques centaines de milliers de tokens de contexte), ce qui perturbe leur flux de travail. Le nouveau plan Max (100 $/mois), bien qu’augmentant le quota (environ 5 à 20 fois celui du plan Plus), n’est toujours pas illimité, et son prix élevé est critiqué par les utilisateurs comme étant du “vol”, avec un faible rapport qualité-prix. Les utilisateurs reconnaissent généralement les capacités du modèle Claude mais expriment une forte insatisfaction quant à ses restrictions d’utilisation et à sa stratégie tarifaire. (Sources : Reddit r/ClaudeAI, Reddit r/ClaudeAI)
Un style d’écriture humain clair confondu avec une génération par IA attire l’attention: Sur Reddit, des utilisateurs (y compris certains se décrivant comme neurodivergents) signalent que leurs textes soigneusement rédigés, grammaticalement corrects, logiquement clairs et détaillés sont confondus par d’autres personnes ou par des outils de détection d’IA comme étant générés par IA. Ce phénomène suscite des discussions : d’une part, la prévalence du contenu généré par IA pourrait amener les gens à se méfier des textes “trop parfaits” ; d’autre part, cela expose l’inexactitude des outils actuels de détection d’IA. Cela pose problème aux rédacteurs soucieux de clarté et soulève des inquiétudes quant à la manière de distinguer la création humaine de celle de l’IA et à la fiabilité des outils de détection d’IA. (Sources : Reddit r/artificial, Reddit r/artificial)
Discussion : Est-il possible et courant pour les humains d’établir des relations émotionnelles avec des robots IA ?: Une discussion sur Reddit porte sur la question de savoir si les humains établissent réellement des relations émotionnelles avec des robots IA (comme les applications de petite amie IA), similaires à celles dépeintes dans le film “Her”. Un utilisateur partage son expérience d’avoir développé un lien émotionnel après des échanges approfondis avec un chatbot, estimant que l’IA, par son “écoute active” et son imitation des préférences de l’utilisateur, peut déclencher des réactions émotionnelles humaines. Les commentaires explorent la prévalence de ce phénomène, les mécanismes psychologiques et le lien avec le niveau de compréhension technologique, reflétant le fait qu’avec l’amélioration des capacités d’interaction de l’IA, les relations homme-machine entrent dans une nouvelle phase plus complexe. (Source : Reddit r/ArtificialInteligence)
Discussion sur le rapport qualité-prix de la carte Nvidia RTX 5060 Ti 16 Go pour les LLM locaux: Les utilisateurs de la communauté discutent de la valeur de la prochaine carte graphique Nvidia GeForce RTX 5060 Ti (rumeur d’une version 16 Go de VRAM à 429 $) pour exécuter des grands modèles de langage (LLM) localement à domicile. La discussion porte sur la question de savoir si son bus mémoire de 128 bits (bande passante de 448 Go/s) constituera un goulot d’étranglement, et sur ses avantages et inconvénients par rapport aux Mac Mini/Studio ou à d’autres cartes AMD en termes de capacité VRAM et de performances par dollar (token/s par prix). Compte tenu du fait que le prix réel du marché pourrait être supérieur au MSRP, les utilisateurs évaluent s’il s’agit d’un choix matériel IA local offrant un bon rapport qualité-prix. (Source : Reddit r/LocalLLaMA)
GPT-4o peine à dessiner avec précision la couronne Phénix d’Or de Sun Wukong: Un utilisateur signale que lors de l’utilisation de GPT-4o pour la génération d’images, même en fournissant une description textuelle détaillée (incluant une couronne retenant les cheveux avec des plumes de faisan, ressemblant à des antennes de cafard), le modèle a du mal à dessiner avec précision la couronne emblématique “Phénix d’Or” (Fengchi Zijin Guan) du personnage mythologique chinois Sun Wukong. Les images générées présentent souvent des écarts dans le style de la couronne. Cela reflète les défis persistants des modèles actuels de génération d’images par IA pour comprendre et restituer des symboles culturels spécifiques ou des détails complexes. (Source : dotey)

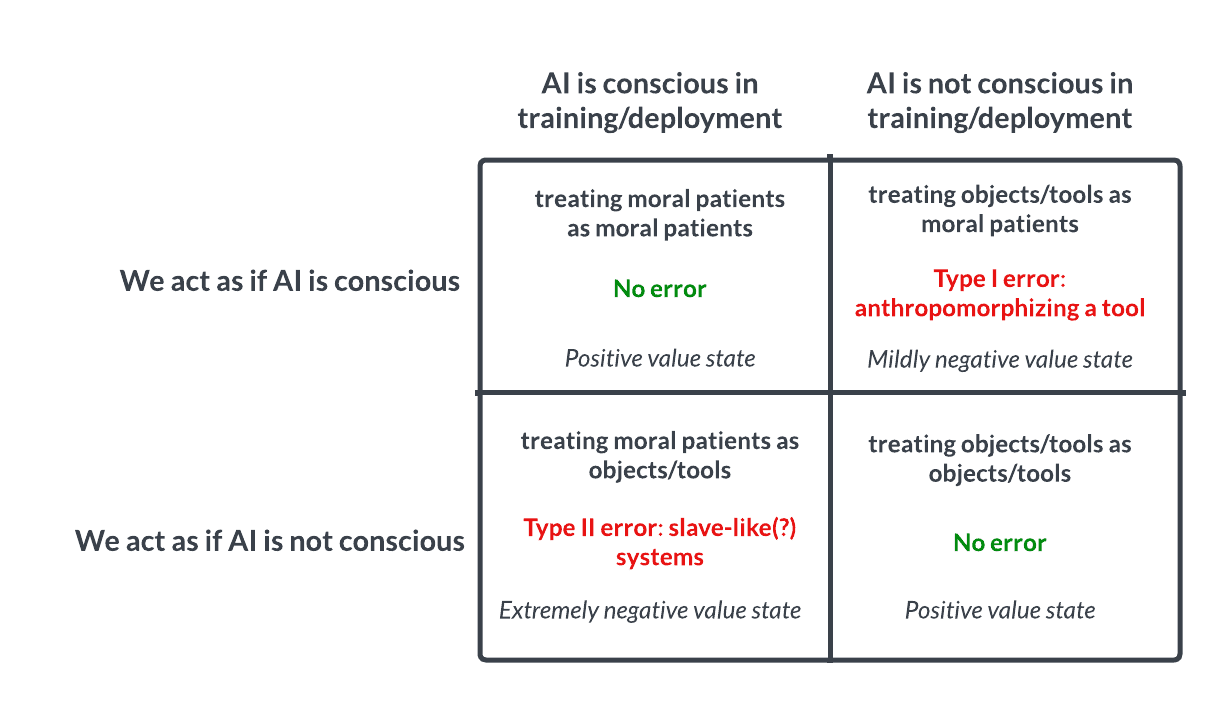
Débat sur la conscience et l’éthique de l’IA : un pari de type Pascal suscite la réflexion: Une discussion sur Reddit propose d’aborder l’IA comme le pari de Pascal : si nous supposons que l’IA n’a pas de conscience et que nous la maltraitons, alors que c’est le cas, nous commettrons une grave erreur (comme l’esclavage) ; si nous supposons qu’elle a une conscience et que nous la traitons bien, alors qu’elle n’en a pas, la perte est moindre. Cela suscite un débat éthique sur la possibilité de la conscience de l’IA, les critères pour la juger et la manière dont nous devrions traiter l’IA avancée. Dans les commentaires, certains pensent que l’IA actuelle est inconsciente, d’autres prônent la prudence, et d’autres encore soulignent qu’il faut d’abord résoudre les problèmes éthiques concernant les humains et les animaux. (Source : Reddit r/artificial
💡 Divers
L’application de la technologie de transformation d’âge par IA dans le film “Here” suscite la controverse: Le film “Here”, réalisé par Robert Zemeckis et mettant en vedette Tom Hanks et Robin Wright, a audacieusement utilisé la technologie de transformation par IA générative en temps réel développée par la société Metaphysic, permettant aux acteurs d’afficher une gamme d’âges allant de 18 à 78 ans dans le film. Cette technologie peut analyser en temps réel les caractéristiques biométriques des acteurs et générer des visages et des silhouettes d’âges différents, réduisant considérablement le temps de post-production. Cependant, la technologie n’est pas encore parfaite, en particulier dans la restitution du regard et le traitement des expressions complexes, ce qui a suscité des discussions sur l‘“effet de la vallée de l’étrange” (uncanny valley). Parallèlement, la décision de Hanks d’autoriser l’utilisation continue de son image IA après sa mort a également déclenché une vaste controverse sur les droits à l’image, l’éthique et l’authenticité artistique. Bien que le film ait reçu un accueil mitigé au box-office et auprès des critiques, il revêt une valeur industrielle importante en tant qu’exploration précoce de la technologie IA dans la production cinématographique. (Source : 36氪-极客电影)

Recrutement par IA : opportunités et défis coexistent: L’IA transforme les processus de recrutement, des outils comme Hireway affirmant pouvoir améliorer considérablement l’efficacité du tri. Cependant, l’application du recrutement par IA soulève également des discussions, par exemple sur la manière de recruter à l’ère de l’IA (Hiring In The AI Era), et sur la façon d’équilibrer efficacité et équité, d’éviter les biais algorithmiques, etc. (Sources : Ronald_vanLoon, Ronald_vanLoon)

La vitesse de développement de l’IA incite à la réflexion : l’équilibre entre rapidité et lenteur: Un article discute de la pertinence de la stratégie “agir vite et casser les codes” (move fast and break things) à l’ère du développement rapide de l’IA. L’opinion défendue est que ralentir pour réfléchir (slowing down to speed up) peut parfois être plus efficace, en particulier dans le domaine de l’IA qui implique des systèmes complexes et des risques potentiels. (Source : Ronald_vanLoon)

Ouverture du serveur Discord officiel d’Anthropic pour les retours directs des utilisateurs: Compte tenu des nombreuses questions et insatisfactions des utilisateurs concernant les performances et les limitations du modèle Claude, la communauté recommande aux utilisateurs de rejoindre le serveur Discord officiel d’Anthropic. Là, les utilisateurs ont la possibilité d’échanger directement avec les employés d’Anthropic, de remonter plus efficacement les problèmes et les préoccupations. (Source : Reddit r/ClaudeAI)

Présentation de divers robots et technologies d’automatisation novateurs: Les médias sociaux présentent des vidéos ou des informations sur diverses technologies robotiques et d’automatisation, notamment des drones capables de travailler sous l’eau, des robots mous imitant le péristaltisme intestinal, le drone bionique X-Fly, un robot polyvalent capable d’accomplir diverses tâches, un robot pour la greffe de cheveux, une chaîne de production automatisée pour le traitement des œufs, une combinaison robotique de 9 pieds de haut capable de simuler les mouvements humains, et la scène amusante de deux robots de livraison se faisant face sur la route. Ces présentations illustrent l’exploration et le développement de la technologie robotique dans différents domaines. (Sources : Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)