
Mots-clés:AI, GPT-4.1, Zhipu AI IPO, Investissement Nvidia en supercalculateurs AI, Dépenses en capital AI d’Amazon, Protocole d’interopérabilité AI Agent, Base d’utilisateurs DeepSeek
🔥 Pleins feux
OpenAI lance la série de modèles GPT-4.1, améliore les performances de l’API et abandonne GPT-4.5 : OpenAI a publié le 15 avril trois nouveaux modèles via API : GPT-4.1, GPT-4.1 mini et GPT-4.1 nano, visant à surpasser globalement la série GPT-4o. Les nouveaux modèles disposent d’une fenêtre contextuelle allant jusqu’à 1 million de Tokens et d’une base de connaissances mise à jour jusqu’en juin 2024. GPT-4.1 se distingue par ses capacités de codage (score SWE-bench Verified de 54,6 %, soit une amélioration de 21,4 % par rapport à GPT-4o), son suivi des instructions (score MultiChallenge de 38,3 %, soit une amélioration de 10,5 % par rapport à GPT-4o) et sa compréhension vidéo à long contexte (score Video-MME de 72,0 %, soit une amélioration de 6,7 % par rapport à GPT-4o). Il est à noter que GPT-4.1 nano est le premier modèle nano, surpassant GPT-4o mini en performances tout en étant moins coûteux. Parallèlement, OpenAI a annoncé le retrait de l’API GPT-4.5 Preview dans trois mois (le 14 juillet), la qualifiant de version préliminaire de recherche, et intégrera à l’avenir les fonctionnalités appréciées des développeurs dans les nouveaux modèles. Ce lancement est considéré comme une initiative stratégique d’OpenAI visant à différencier ses modèles API de sa gamme de produits ChatGPT et à concurrencer directement la série Gemini de Google. (Source : 36氪, New Zhiyuan 1, AI Tech Review, Reddit r/LocalLLaMA, Reddit r/artificial)
Zhipu AI lance le processus d’introduction en bourse (IPO) et ouvre de nouveaux modèles, avec une valorisation dépassant les 20 milliards : Zhipu AI (Zhipu Huazhang), l’un des “six petits tigres” des grands modèles chinois, a déposé le 14 avril une demande d’enregistrement de tutorat auprès du Bureau de régulation des valeurs mobilières de Pékin, lançant officiellement son processus d’IPO, avec CICC comme institution de tutorat. Incubée par le Laboratoire d’ingénierie des connaissances de l’Université Tsinghua, l’équipe principale de Zhipu AI est majoritairement issue de Tsinghua. L’entreprise a levé plus de 15 milliards de yuans de financement cumulé et sa valorisation récente dépasse les 20 milliards de yuans. Parallèlement au lancement de l’IPO, Zhipu AI a annoncé l’ouverture à grande échelle des modèles de la série GLM-4-32B/9B, comprenant trois catégories : base, inférence et réflexion, sous licence MIT permettant une utilisation commerciale gratuite. Parmi eux, le modèle d’inférence de 32 milliards de paramètres GLM-Z1-32B-0414 rivalise en performance avec le DeepSeek-R1 de 671 milliards de paramètres sur certaines tâches. Sa version API ultra-rapide GLM-Z1-AirX atteint une vitesse d’inférence de 200 tokens/s, et sa version à haute performance économique coûte seulement 1/30ème du prix du DeepSeek-R1. L’entreprise a également lancé le nouveau domaine z.ai comme plateforme d’essai gratuite pour ses modèles. Cette démarche illustre la stratégie globale de Zhipu AI en matière de recherche et développement technologique interne, d’exploration commerciale et de construction d’un écosystème open source. (Source : Zhidx, InfoQ, QubitAI, GeekPark, Leidi, Compte public WeChat)

Nvidia investit 500 milliards de dollars pour fabriquer des supercalculateurs IA aux États-Unis : Nvidia a annoncé un plan majeur d’investissement de 500 milliards de dollars sur les quatre prochaines années pour fabriquer pour la première fois des supercalculateurs d’IA sur le sol américain. Le plan implique une collaboration avec plusieurs géants de l’industrie, dont TSMC (production de puces Blackwell en Arizona), Foxconn et Wistron (construction d’usines de supercalculateurs au Texas), Amkor et SPIL (encapsulation et test en Arizona). Le PDG de Nvidia, Jensen Huang, a déclaré que cette initiative visait à répondre à la demande croissante de puces IA et de supercalculateurs, à renforcer la résilience de la chaîne d’approvisionnement et à utiliser les technologies d’IA, de robotique (Isaac GR00T) et de jumeau numérique (Omniverse) de Nvidia pour concevoir et exploiter les usines. Ce plan est considéré comme un déploiement stratégique dans le contexte de la promotion de la fabrication locale par le gouvernement américain (comme le CHIPS Act) et des tensions géopolitiques, visant à renforcer la position des États-Unis dans la course mondiale à l’infrastructure IA, mais il fait face à des défis tels que la complexité de la chaîne d’approvisionnement, la pénurie de travailleurs qualifiés et l’incertitude politique. (Source : New Zhiyuan 1, New Zhiyuan 2, Reddit r/artificial)

Amazon prévoit d’investir plus de 100 milliards de dollars dans l’IA pour faire face à la concurrence et saisir les opportunités : Le PDG d’Amazon, Andy Jassy, a révélé dans sa lettre annuelle aux actionnaires de 2024 que l’entreprise prévoyait des dépenses en capital de plus de 100 milliards de dollars en 2025, dont la majorité sera consacrée à des projets liés à l’IA, notamment les centres de données, les équipements réseau, le matériel IA (comme les puces développées en interne Trainium) et les services d’IA générative (comme la série de grands modèles maison Nova, la plateforme Bedrock, la version améliorée d’Alexa+ et l’assistant d’achat Rufus). Cet investissement colossal (près de 1/6 du chiffre d’affaires annuel) reflète la vision d’Amazon selon laquelle l’IA est essentielle pour faire face à la concurrence féroce dans le secteur du commerce électronique (venant de SHEIN, Temu, TikTok, etc.) et pour saisir une opportunité historique. Jassy a souligné que l’IA changerait les règles de la recherche, de la programmation, des achats, etc., et que ne pas investir signifierait perdre en compétitivité. Actuellement, les revenus annuels de l’activité IA d’Amazon atteignent déjà des milliards de dollars, avec une croissance à trois chiffres d’une année sur l’autre. Cette démarche montre également la détermination d’Amazon à continuer d’investir pour consolider sa position de leader dans le domaine des services cloud (AWS), face à la concurrence de rivaux tels que Microsoft Azure et Google Cloud. (Source : 36氪)
🎯 Tendances
Les protocoles d’interopérabilité des AI Agents MCP et A2A suscitent l’intérêt : Le domaine des agents intelligents IA voit émerger une concurrence autour des protocoles d’interaction standardisés. Le MCP (Model Context Protocol) proposé par Anthropic vise à unifier la communication des grands modèles avec les outils externes et les sources de données, qualifié de “USB-C de l’IA”, et a reçu le soutien d’OpenAI, Google, etc. Google, de son côté, a rendu open source le protocole A2A (Agent2Agent), axé sur la collaboration sécurisée et efficace entre agents de différents fournisseurs et frameworks, dans le but de briser les barrières des écosystèmes. L’émergence de ces deux protocoles marque l’évolution de l’IA d’une intelligence monolithique vers un réseau collaboratif, mais soulève également des débats sur le “pouvoir des protocoles”, le monopole des données et les barrières écosystémiques (“jardins clos”). La maîtrise de l’élaboration des normes pourrait remodeler la chaîne de valeur de l’IA et avoir un impact profond sur la fusion de l’IA avec le monde physique (robotique, IoT). Des acteurs chinois comme Alibaba Cloud et Tencent Cloud ont également commencé à prendre en charge le MCP. (Source : 36Kr)

Rapport QuestMobile : DeepSeek bouleverse le paysage des applications IA en Chine, avec 240 millions d’utilisateurs : Le rapport “Analyse de la concurrence sur le marché des applications IA au premier trimestre 2025” publié par QuestMobile montre que, sous l’impulsion de la popularité fulgurante du modèle DeepSeek et de ses applications, le paysage du marché des applications IA natives en Chine a été complètement bouleversé. Fin février 2025, le nombre d’utilisateurs actifs mensuels des applications IA natives a atteint 240 millions, soit une augmentation de près de 90 % par rapport à janvier. L’application DeepSeek est en tête avec 194 millions d’utilisateurs actifs mensuels, suivie par Doubao de ByteDance (116 millions) et Yuanbao de Tencent (41,64 millions), remplaçant les précédents leaders comme Kimi. Le rapport souligne que l’effet de démocratisation open source de DeepSeek a favorisé l’adoption par les principaux acteurs et l’explosion des applications IA, créant 23 segments de marché, dont les assistants IA généraux et la recherche IA, ce dernier étant le plus concurrentiel. Actuellement, le “multi-modèle” est devenu la norme pour les applications de premier plan, et la concurrence se concentre désormais sur la conception et l’exploitation des produits. (Source : QuestMobile)

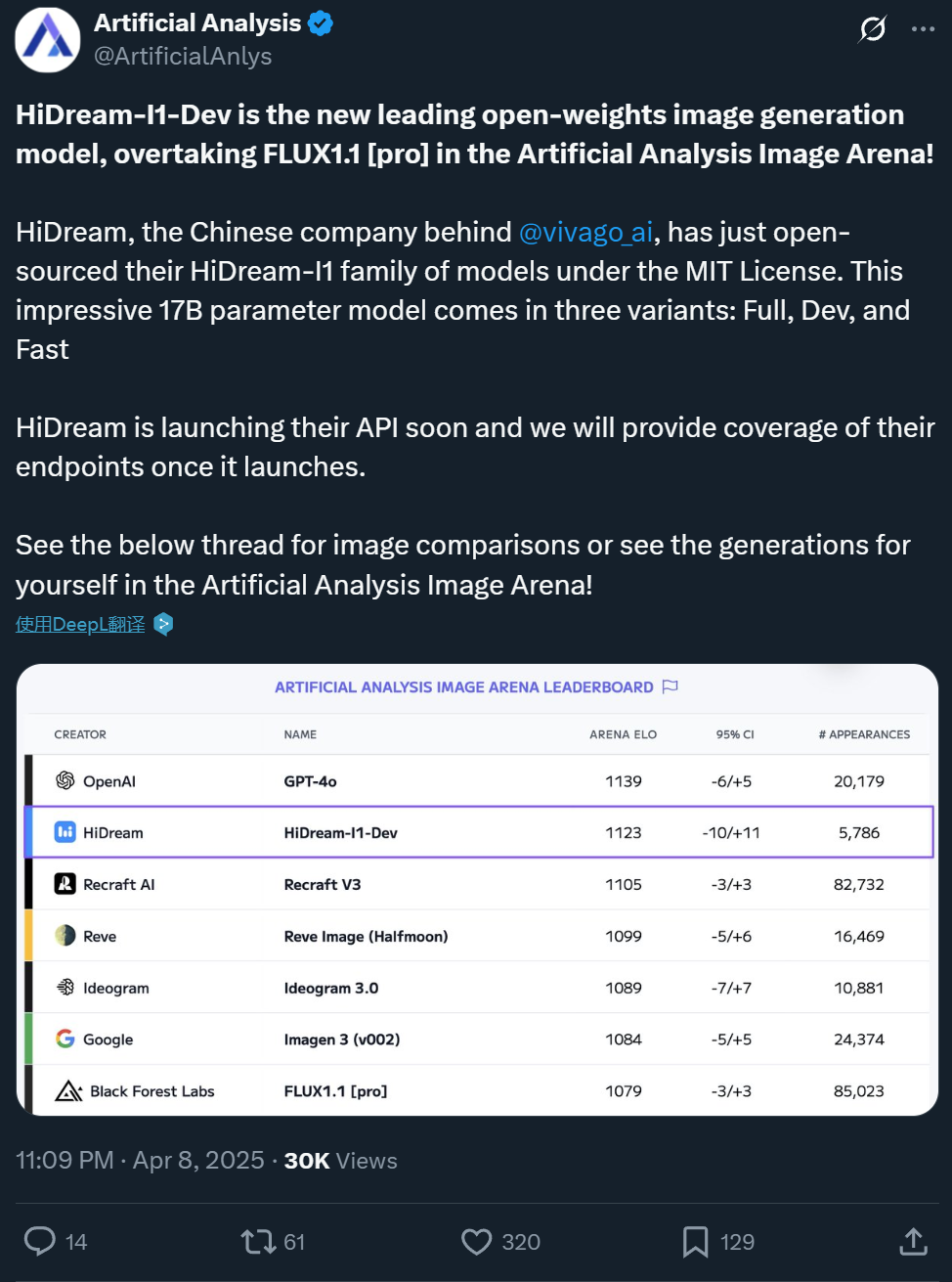
Zxiang Future rend open source son modèle texte-image HiDream-I1 de 17B, avec des performances comparables à GPT-4o : La société chinoise Zxiang Future a rendu open source son grand modèle texte-image de 17 milliards de paramètres, HiDream-I1, sous une licence MIT permissive autorisant l’utilisation commerciale. Le modèle a montré d’excellentes performances dans les arènes et benchmarks de plateformes comme Artificial Analysis (par exemple, HPSv2.1, GenEval, DPG-Bench). Le réalisme, la finesse des détails et le suivi des instructions des images générées sont considérés comme comparables à ceux de GPT-4o et FLUX 1.1 Pro, voire supérieurs sur certains aspects. HiDream-I1 utilise une architecture Sparse Diffusion Transformer (Sparse DiT), intégrant la technologie MoE pour améliorer les performances et l’efficacité. L’entreprise a également annoncé l’ouverture prochaine du modèle HiDream-E1, qui prendra en charge l’édition interactive d’images. La combinaison des deux vise à offrir une expérience de génération et d’édition d’images “open source équivalente à GPT-4o”. Le modèle est disponible sur Hugging Face et peut être testé sur la plateforme Vivago. (Source : Machine Heart 1, Machine Heart 2)
ByteDance publie le modèle de base vidéo Seaweed de 7B, à faible coût et haute efficacité : L’équipe Seed de ByteDance a publié un modèle de base de génération vidéo nommé Seaweed (jeu de mots sur Seed-Video). Ce modèle ne compte que 7 milliards de paramètres et aurait été entraîné en utilisant 665 000 heures de GPU H100 (équivalent à environ 28 jours d’entraînement sur 1000 cartes), pour un coût relativement faible. Seaweed peut générer des vidéos de différentes résolutions (support natif 1280×720, upsampling possible jusqu’à 2K), de n’importe quel rapport d’aspect et durée, à partir de texte. Le modèle prend en charge la génération image-vidéo, le contrôle de sujet de référence (image unique/multiple), la génération de vidéos avec synchronisation labiale en combinaison avec la solution d’humain numérique Omnihuman, et le doublage vidéo. Techniquement, il utilise une architecture DiT+VAE, combinée à un processus complet de traitement des données et une stratégie d’entraînement multi-étapes et multi-tâches (pré-entraînement, SFT, RLHF), avec des optimisations au niveau système pour améliorer l’efficacité de l’entraînement. L’équipe est dirigée, entre autres, par le Dr Jiang Lu, ancien responsable de la génération vidéo chez Google. (Source : QubitAI)

Alibaba Tongyi publie le modèle de génération vidéo de personnage numérique OmniTalker : L’équipe HumanAIGC du laboratoire Alibaba Tongyi a lancé un nouveau grand modèle de génération vidéo de personnage numérique, OmniTalker. Ce modèle vise à résoudre les problèmes de latence, de désynchronisation audio-vidéo et d’incohérence de style rencontrés avec les méthodes traditionnelles en cascade (TTS + pilotage audio). OmniTalker est un framework unifié de bout en bout qui prend en entrée du texte et une courte vidéo/audio de référence pour générer en temps réel une parole et une vidéo de personnage numérique synchronisées, tout en préservant la voix et le style de parole facial de la source de référence. Son architecture principale utilise un DiT (Diffusion Transformer) à double flux, traitant séparément les informations audio et visuelles, et assure la synchronisation et la cohérence du style grâce à un module innovant de fusion audio-vidéo. Le modèle utilise un module d’apprentissage par référence contextuelle pour capturer les caractéristiques de style de la vidéo de référence, sans nécessiter d’extracteur de style entraîné séparément. Le projet est désormais disponible pour essai sur la communauté ModelScope et HuggingFace. (Source : Machine Heart)

Kuaishou publie la version 2.0 de son modèle vidéo IA Kling : Le modèle de génération vidéo IA Kling de Kuaishou a publié sa version 2.0, qui présenterait des améliorations significatives en termes d’amplitude de mouvement de caméra, de respect des lois physiques, de jeu d’acteur, de stabilité des mouvements et de compréhension sémantique. Les évaluations des utilisateurs montrent que la nouvelle version excelle dans la gestion des interactions complexes (comme un T-Rex brisant des arbres), des actions fines (comme enlever des lunettes), des scènes multi-personnages et de la simulation d’éclairage réaliste. Le réalisme et l’aspect cinématographique des vidéos générées sont considérablement améliorés, avec des résultats jugés supérieurs à la version 1.6 précédente et atteignant un niveau de pointe dans l’industrie. Bien qu’il y ait encore une marge d’amélioration pour les mouvements de groupe rapides et les simulations physiques extrêmes (comme un tir au panier), ses performances globales sont considérées comme commençant à défier les standards de production professionnelle. Les utilisateurs peuvent tester la nouvelle version sur le site officiel klingai.com. (Source : Compte public WeChat, op7418)

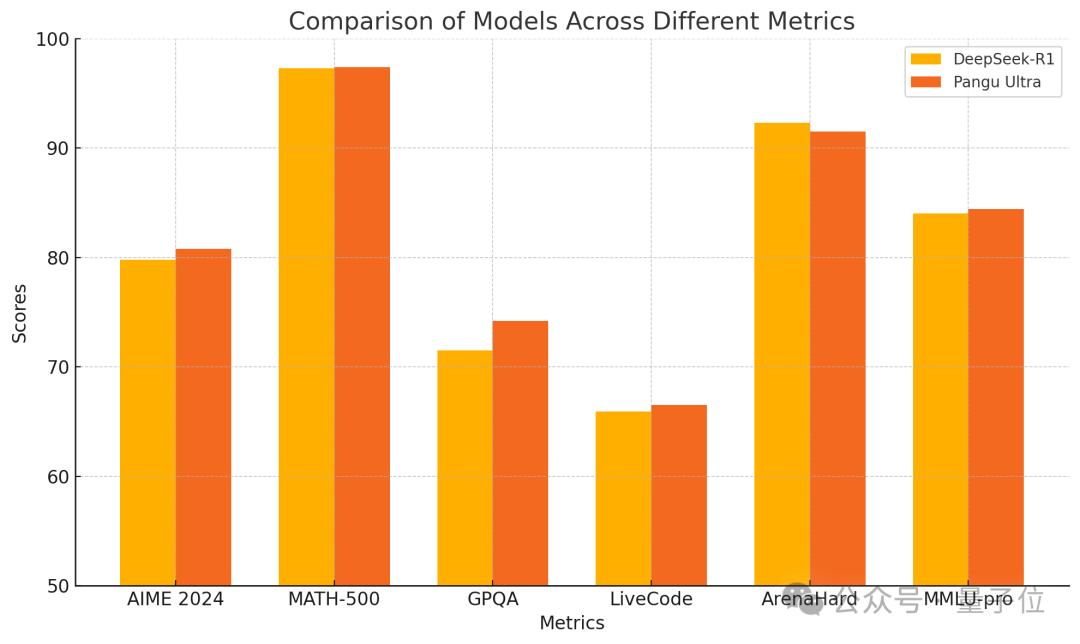
Huawei publie le modèle dense Pangu Ultra 135B, entraîné purement sur Ascend avec d’excellentes performances : Huawei a dévoilé un nouveau membre de sa série de grands modèles Pangu : Pangu Ultra. Il s’agit d’un modèle dense de 135 milliards de paramètres, entièrement entraîné sur le cluster de calcul IA Ascend de Huawei (8192 NPU), sans utiliser de GPU Nvidia. Selon le rapport, Pangu Ultra excelle dans des tâches telles que le raisonnement mathématique (AIME 2024, MATH-500) et la programmation (LiveCodeBench), avec des performances comparables à celles de modèles MoE plus grands comme DeepSeek-R1. Techniquement, le modèle utilise une normalisation de couche innovante Sandwich-Norm à mise à l’échelle profonde et une stratégie d’initialisation des paramètres TinyInit, résolvant efficacement les problèmes d’instabilité lors de l’entraînement de réseaux très profonds (94 couches) et permettant un entraînement stable sans pics de perte. Grâce à des optimisations au niveau système, l’entraînement a atteint un taux d’utilisation de la puissance de calcul (MFU) supérieur à 52 %. (Source : QubitAI)
Canopy Labs rend open source Orpheus, un modèle de synthèse vocale émotionnelle : Canopy Labs a publié et rendu open source une série de modèles texte-parole (TTS) nommée Orpheus. Basé sur l’architecture Llama, la première version compte 3 milliards de paramètres, et des versions plus petites (1B, 0.5B, 0.15B) suivront. Orpheus se caractérise par sa capacité à générer une parole avec des émotions, une intonation et un rythme très humanisés, pouvant même inférer et générer des sons non verbaux comme le rire ou les soupirs à partir du texte, réalisant une expression “empathique”. Le modèle prend en charge le clonage vocal zero-shot et le contrôle de l’intonation émotionnelle via des étiquettes. Il utilise une inférence en streaming avec une faible latence (100-200 ms) et une vitesse d’inférence plus rapide que le temps réel sur une carte graphique A100 40 Go. Les développeurs affirment que ses performances dépassent celles des modèles SOTA open source existants et de certains modèles fermés, visant à briser le monopole des modèles TTS fermés. Le modèle et le code sont disponibles sur GitHub et Hugging Face. (Source : New Zhiyuan)

L’Université du Zhejiang et ByteDance publient conjointement le modèle de synthèse vocale MegaTTS3 : L’équipe du professeur Zhou Zhao de l’Université du Zhejiang, en collaboration avec ByteDance, a publié et rendu open source la troisième génération de son modèle de synthèse vocale, MegaTTS3. Avec une taille légère de seulement 0,45 milliard de paramètres, ce modèle réalise une synthèse vocale bilingue (chinois-anglais) de haute qualité et excelle dans le clonage vocal zero-shot, capable de générer une parole naturelle, contrôlable et personnalisée. MegaTTS3 se concentre sur les percées dans l’alignement clairsemé parole-texte, la contrôlabilité de la génération, et l’équilibre entre efficacité et qualité. Les points forts techniques incluent la technologie “Multi-Condition CFG” (Multi-Condition Classifier-Free Guidance) pour le contrôle multidimensionnel comme l’intensité de l’accent, et la technologie “PeRFlow” (Piecewise Rectified Flow Acceleration) qui multiplie par 3 la vitesse d’échantillonnage. Le modèle démontre une naturalité (CMOS) et une similarité du locuteur (SIM-O) de premier plan sur des benchmarks comme LibriSpeech. (Source : PaperWeekly)

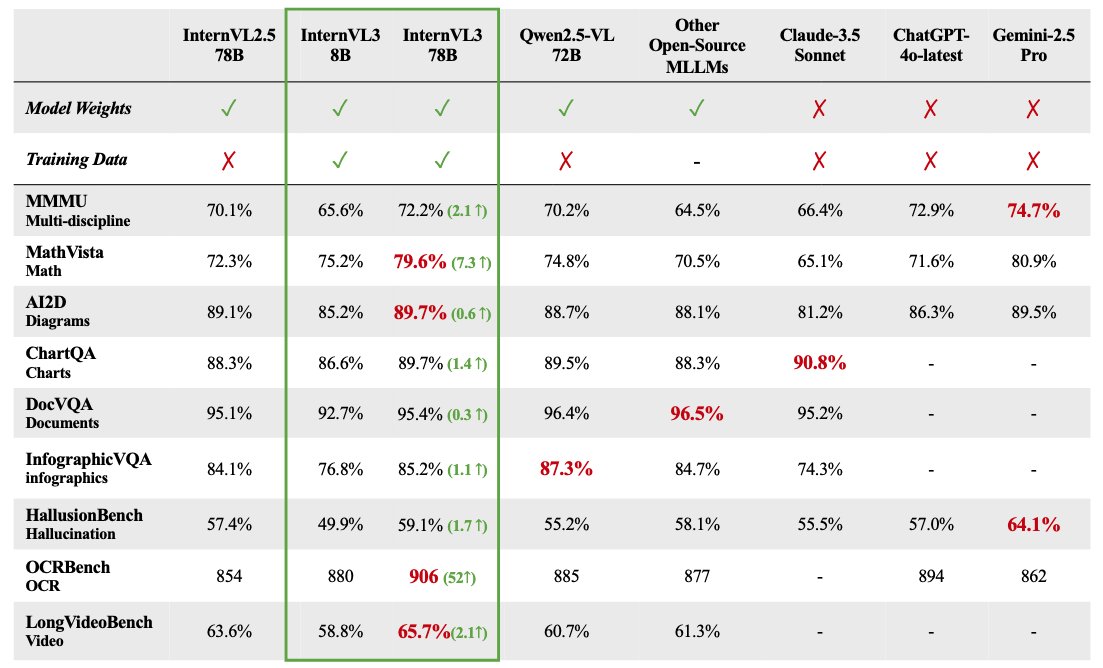
La série de grands modèles multimodaux InternVL 3 est open source : OpenGVLab a publié la série de grands modèles multimodaux InternVL 3, avec des tailles de paramètres allant de 1B à 78B, désormais disponibles sur Hugging Face. La version de 78 milliards de paramètres aurait obtenu un score de 72,2 sur le benchmark MMMU, établissant un nouveau record SOTA pour les modèles multimodaux open source. Les points forts techniques d’InternVL 3 incluent : un pré-entraînement multimodal natif apprenant simultanément le langage et la vision ; l’introduction d’un encodage de position visuelle variable (V2PE) pour prendre en charge un contexte étendu ; l’utilisation de techniques de post-entraînement avancées comme SFT et MPO ; et l’application d’une stratégie de mise à l’échelle au moment du test pour améliorer les capacités de raisonnement mathématique. Les données d’entraînement et les poids du modèle ont été mis à la disposition de la communauté. (Source : huggingface)
Analyse des performances réelles de GPT-4.1 : codage amélioré mais raisonnement en retrait : Les modèles de la série GPT-4.1 publiés par OpenAI montrent un tableau de performances complexe lors des premiers tests réels et évaluations de benchmarks. Bien qu’ils démontrent des progrès significatifs par rapport à GPT-4o dans les tâches de génération de code, par exemple en réussissant mieux les simulations physiques, le développement de jeux, etc., et en obtenant un score élevé sur SWE-Bench. Cependant, sur des benchmarks plus larges de raisonnement, de mathématiques et de questions-réponses (comme Livebench, GPQA Diamond), les performances de GPT-4.1 restent inférieures à celles de Gemini 2.5 Pro de Google et de Claude 3.7 Sonnet d’Anthropic. L’analyse suggère que GPT-4.1 pourrait être une mise à jour incrémentielle de GPT-4o, ou distillé à partir de GPT-4.5. Sa stratégie de lancement pourrait viser à offrir via l’API des options de modèles plus rentables et optimisées pour des tâches spécifiques, plutôt qu’un modèle phare surpassant globalement ses concurrents. (Source : New Zhiyuan)
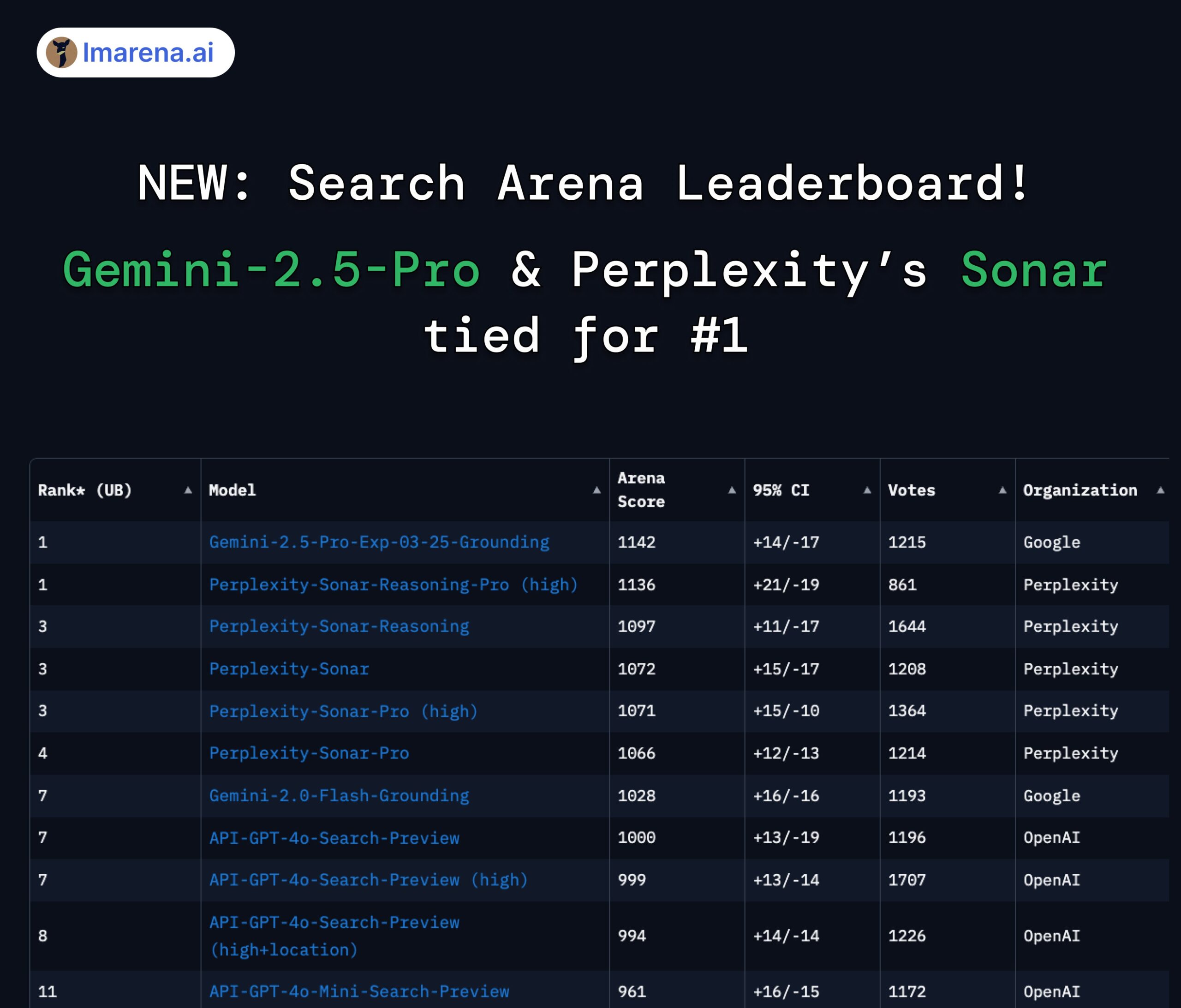
Classement LMArena Search : Gemini 2.5 Pro et Perplexity Sonar à égalité en première position : Dans l’évaluation en arène de LMArena ciblant les grands modèles dotés de capacités de recherche/connexion Internet, Gemini-2.5-Pro de Google (combiné à Google Search) et Sonar-Reasoning-Pro de Perplexity se classent ex æquo en tête. Ce résultat a été relayé et confirmé par le PDG de Google DeepMind, Demis Hassabis, et le responsable des relations développeurs de Google, Logan Kilpatrick. Le PDG de Perplexity, Aravind Srinivas, a également commenté que les tests A/B internes montrent que leur modèle Sonar surpasse GPT-4o en termes de rétention utilisateur, avec des performances comparables à Gemini 2.5 Pro et au nouveau GPT-4.1. L’organisateur de l’évaluation, lmarena.ai, a rendu open source les données de 7000 votes d’utilisateurs. (Source : lmarena_ai 1, lmarena_ai 2, AravSrinivas, demishassabis)
Meta reprendra l’utilisation du contenu public des utilisateurs européens pour entraîner l’IA : Meta a annoncé qu’elle recommencerait à utiliser le contenu public des utilisateurs européens pour entraîner ses modèles d’intelligence artificielle. Auparavant, Meta avait suspendu cette pratique en raison de la pression des autorités européennes de protection des données (notamment la Commission irlandaise de protection des données) et des exigences réglementaires. La décision de reprendre l’entraînement pourrait refléter les efforts continus et les ajustements stratégiques de Meta pour équilibrer la vie privée des utilisateurs, la conformité réglementaire (comme le GDPR) et l’acquisition de données suffisantes pour maintenir la compétitivité de ses modèles d’IA. Cette décision pourrait relancer les discussions sur les droits des utilisateurs en matière de données et la transparence de l’entraînement de l’IA. (Source : Reddit r/artificial)

L’application mobile Claude pourrait ajouter un mode d’interaction vocale : Selon des indices découverts par l’utilisateur X @testingcatalog, Anthropic pourrait prévoir d’ajouter une fonctionnalité d’interaction vocale à son application mobile Claude. Des captures d’écran montrent une icône de microphone dans l’interface de l’application, suggérant que les utilisateurs pourraient à l’avenir converser avec Claude par la voix, à l’instar des modes vocaux déjà proposés par les applications ChatGPT et Google Gemini. Cela rendrait l’interaction avec Claude sur mobile plus diversifiée et pratique, améliorant davantage l’expérience utilisateur et alignant ses fonctionnalités sur celles des autres assistants IA majeurs. (Source : Reddit r/ClaudeAI)
La vitesse des modèles de la série Z1 de Zhipu attire l’attention, qualifiés de “modèles instantanés” : La série de modèles Z1 récemment publiée par Zhipu AI, en particulier la version GLM-Z1-AirX, attire l’attention en raison de sa vitesse d’inférence extrêmement rapide. Une analyse les qualifie de “modèles instantanés”, soulignant leur capacité à fournir une première réponse en 0,3 seconde et à générer plus de 50 caractères chinois, une vitesse proche du temps de réflexe neuronal humain. Cette faible latence et ce débit élevé pourraient transformer les modes d’interaction homme-machine, passant de “question-attente-réponse” à un dialogue quasi synchrone en temps réel, particulièrement adapté aux scénarios exigeant une réponse rapide comme l’éducation, le service client, la création de contenu et l’appel d’Agent. La vitesse de la version API de Z1-AirX atteindrait 200 tokens/s. (Source : Compte public WeChat)

Jeux natifs IA : évolution et défis, de l’outil d’efficacité à l’innovation du gameplay : L’industrie du jeu vidéo évolue de l’utilisation de l’IA pour améliorer l’efficacité du développement et des opérations (comme la génération d’assets artistiques, l’assistance au codage, les tests automatisés) vers l’exploration de véritables “jeux natifs IA”. Le cœur des jeux natifs IA réside dans l’intégration profonde de l’IA dans le gameplay, créant du contenu dynamique et des expériences personnalisées pilotées par l’interaction du joueur, plutôt que des scénarios prédéfinis. “Whispers from the Star”, financé par le fondateur de Mihoyo, Cai Haoyu, et le mode joueur IA de “Space Kill” de Giant Network sont des exemples de ces explorations. Cependant, la réalisation de jeux natifs IA fait face à de nombreux défis : sur le plan technique, il faut résoudre les problèmes de capacité, de stabilité et de coût des modèles ; sur le plan de la conception, il manque de modèles matures, et il faut équilibrer contrôlabilité et liberté ; sur le plan utilisateur, il faut répondre aux exigences des joueurs en matière d’amusement et de profondeur d’interaction ; s’ajoutent les risques de conformité du contenu et d’éthique. L’industrie en est encore à un stade d’exploration précoce, loin d’une mise en œuvre mature. (Source : Jiemian News)
🧰 Outils
Tour d’horizon de cinq applications IA innovantes et créatives : 36Kr a passé en revue cinq outils IA créatifs et pratiques parmi les candidatures récentes d’innovations en applications natives IA : 1) AiPPT.com : Génère rapidement des PPT à partir d’une phrase ou en important des fichiers (Word, PDF, Xmind, lien), supporte l’exécution hors ligne. 2) Lunettes IA Shanji Paipai Jing : Lunettes IA avec fonctions photo/vidéo, traduction en temps réel, reconnaissance de formules, etc. 3) Agent intelligent Lianxin Digital pour interrogatoires sans contact : Basé sur le grand modèle psychologique “Insight into Human”, aide aux interrogatoires en analysant les micro-expressions, la voix, les signaux physiologiques, et génère des rapports. 4) IA Vali pour chaussures Huilima : Génère 8 designs de chaussures en 10 secondes à partir de mots-clés, intègre une bibliothèque de matériaux et des données de patrons, et se connecte à la production. 5) Agent intelligent RH Nanfang Shiton Shābāo : Gère les tâches RH liées à la sécurité sociale, fournit des interprétations de politiques, des calculs de coûts, un traitement intelligent, des alertes de risque, etc. Ces applications montrent le potentiel de l’IA dans les outils d’efficacité, le matériel intelligent et les domaines professionnels (sécurité, design, RH). (Source : 36Kr)

Haisin Intelligence lance “Haisnap”, une plateforme de développement AI no-code : Haisin Intelligence Technology, soutenue par des capitaux publics de Pékin, a lancé une plateforme de développement AI no-code/low-code nommée “Haisnap”. Les utilisateurs peuvent décrire leurs besoins en langage naturel pour que l’IA génère automatiquement des applications web ou de petits jeux. La particularité de la plateforme est que le code est visible en temps réel pendant la génération et qu’elle prend en charge l’édition et la modification secondaires par le biais d’un dialogue. Les applications développées par les utilisateurs peuvent être publiées dans la “communauté créative” de la plateforme pour être consultées, utilisées et remixées par d’autres. La plateforme est actuellement gratuite et vise à abaisser le seuil de développement d’applications IA, à promouvoir la création pour tous, en mettant particulièrement l’accent sur l’éducation à l’IA pour les jeunes et l’application dans l’industrie. (Source : QubitAI)

Le système open source de questions-réponses sur base de connaissances ChatWiki est publié, supportant GraphRAG et l’intégration WeChat : ChatWiki est un nouveau système open source de questions-réponses IA basé sur une base de connaissances. Il intègre de grands modèles de langage (supportant plus de 20 modèles dont DeepSeek, OpenAI, Claude) avec la technologie de génération augmentée par récupération (RAG), et supporte spécifiquement le GraphRAG basé sur des graphes de connaissances pour traiter les requêtes complexes. Les fonctionnalités du système incluent : l’importation de documents de divers formats (OFD, Word, PDF, etc.) pour construire des bases de connaissances privées ; le support de la segmentation sémantique pour améliorer la précision du RAG ; la publication de la base de connaissances en tant que site de documentation public ; une interface API pour une intégration transparente avec l’écosystème WeChat (comptes publics, service client, etc.) afin de créer des chatbots IA ; un outil d’orchestration de workflow visuel intégré ; le support de l’intégration avec des données métier tierces ; une gestion des permissions de niveau entreprise ; le support du déploiement local via Docker et le code source. (Source : Compte public WeChat)

La communauté ModelScope lance la Place MCP, créant le plus grand écosystème de services MCP en Chine : La communauté de modèles IA d’Alibaba, ModelScope, a officiellement lancé la “Place MCP”, rassemblant près de 1500 services implémentant le protocole de contexte de modèle (MCP), couvrant des domaines tels que la recherche, les cartes, les paiements, les outils de développement, etc., visant à créer la plus grande communauté MCP chinoise en Chine. Plusieurs services MCP d’Alipay et de MiniMax y sont lancés en exclusivité, tels que les capacités de paiement, de requête et de remboursement d’Alipay, et les capacités de génération de voix, d’images et de vidéos de MiniMax, tous pouvant être appelés par des agents IA via le protocole MCP. Les développeurs peuvent, dans le laboratoire expérimental MCP de ModelScope, tester et intégrer rapidement ces services via une simple configuration JSON et des ressources cloud gratuites, réduisant considérablement la barrière d’accès des applications IA aux outils et données externes. ModelScope a également lancé MCP Bench pour évaluer la qualité et les performances des différents services MCP. (Source : New Zhiyuan)

Discussion sur l’utilisation de la fonction WebSearch d’Open WebUI : Des utilisateurs de la communauté Reddit discutent de l’utilisation de la fonction Web Search dans Open WebUI. Les questions portent sur la manière de contrôler précisément les mots-clés de requête utilisés par le moteur de recherche et de limiter la fonction Web Search à des modèles spécifiques pour empêcher l’envoi accidentel de données de modèles privés sur le réseau. Cela reflète les besoins réels des utilisateurs en matière de précision de contrôle et de sécurité de la vie privée lorsqu’ils utilisent des outils IA intégrant des fonctions de recherche. (Source : Reddit r/OpenWebUI 1, Reddit r/OpenWebUI 2)
Un utilisateur cherche à comprendre le protocole de contexte de modèle (MCP) : Un utilisateur sur Reddit a posté une demande d’explication sur le protocole de contexte de modèle (MCP), indiquant que, avec la promotion et l’application des normes MCP (comme la Place MCP de ModelScope), le besoin de comprendre cette technologie émergente et son fonctionnement augmente au sein de la communauté des développeurs et des utilisateurs. (Source : Reddit r/OpenWebUI)
📚 Apprentissage
Le Prix de l’épreuve du temps ICLR 2025 décerné à l’optimiseur Adam et au mécanisme d’attention : La Conférence internationale sur les représentations d’apprentissage (ICLR) a décerné son “Prix de l’épreuve du temps” (Test of Time Award) 2025 à deux articles marquants publiés il y a dix ans (en 2015). L’un est “Adam: A Method for Stochastic Optimization” par Diederik P. Kingma et Jimmy Ba, dont l’optimiseur Adam proposé est devenu l’algorithme standard pour l’entraînement des modèles d’apprentissage profond. L’autre est “Neural Machine Translation by Jointly Learning to Align and Translate” par Dzmitry Bahdanau, Kyunghyun Cho et Yoshua Bengio, qui a introduit pour la première fois le mécanisme d’attention, jetant les bases de l’architecture Transformer et des grands modèles de langage modernes. Ces deux prix soulignent l’impact profond de la recherche fondamentale sur le développement actuel de l’IA. (Source : New Zhiyuan)

Brève histoire du développement de l’IA et rétrospective de l’évolution des entreprises : L’article passe systématiquement en revue l’histoire du développement de l’intelligence artificielle depuis le milieu du 20e siècle jusqu’à aujourd’hui, avec des étapes clés telles que le test de Turing, la conférence de Dartmouth, le symbolisme et les systèmes experts, l’hiver de l’IA, l’essor de l’apprentissage automatique (DeepBlue, PageRank), la révolution de l’apprentissage profond (AlexNet, AlphaGo) et l’ère actuelle des grands modèles (série GPT, commercialisation de l’IA générative, débat open source vs closed source). Parallèlement, l’article divise le développement des entreprises d’IA en quatre ères : l’ère pionnière (2000-2010, exploration d’applications de type outil), la ruée vers l’or (2011-2016, explosion de l’autonomisation des plateformes et de l’orientation données), l’ère de la bulle (2017-2020, lutte pour les scénarios et goulots d’étranglement de la commercialisation) et l’ère de la restructuration (2021 à aujourd’hui, nouvelle donne pilotée par les grands modèles). L’article souligne l’effet synergique de la puissance de calcul, des données et des algorithmes, ainsi que l’impact de nouvelles forces comme DeepSeek sur le paysage. (Source : Chaos University)
OpenAI publie le guide d’ingénierie des prompts pour GPT-4.1 : En complément du lancement des modèles de la série GPT-4.1, OpenAI a mis à jour son guide d’ingénierie des prompts (Prompting). Le guide souligne que les modèles de la série GPT-4.1, par rapport aux modèles antérieurs comme GPT-4, suivront les instructions de manière plus stricte et plus littérale, et seront plus sensibles aux prompts clairs et spécifiques. Si le modèle ne se comporte pas comme prévu, l’ajout d’instructions concises et claires suffit généralement à guider son comportement. Cela diffère des modèles précédents qui avaient tendance à deviner l’intention de l’utilisateur, et les développeurs pourraient avoir besoin d’ajuster leurs stratégies de prompts existantes. Le guide fournit les meilleures pratiques, des principes de base aux stratégies avancées, pour aider les développeurs à mieux exploiter les caractéristiques des nouveaux modèles. (Source : dotey, Reddit r/LocalLLaMA)
L’Université Jiao Tong de Shanghai et d’autres publient le benchmark d’intelligence spatio-temporelle STI-Bench, défiant la compréhension physique des modèles multimodaux : L’Université Jiao Tong de Shanghai, en collaboration avec plusieurs institutions, a publié le premier benchmark, STI-Bench, pour évaluer l’intelligence spatio-temporelle des grands modèles multimodaux (MLLM). Ce benchmark utilise des vidéos du monde réel et se concentre sur des capacités de compréhension spatiale et temporelle précises et quantifiées, comprenant huit tâches : mesure d’échelle, relations spatiales, localisation 3D, trajectoire de déplacement, vitesse et accélération, orientation égocentrique, description de trajectoire et estimation de pose. L’évaluation des modèles de pointe tels que GPT-4o, Gemini 2.5 Pro, Claude 3.7 Sonnet, Qwen 2.5 VL, etc., montre que les modèles existants obtiennent généralement de mauvais résultats sur ces tâches (précision < 42 %), ayant notamment du mal à traiter les attributs spatiaux quantitatifs, les changements dynamiques temporels et l’intégration d’informations intermodales. Ce benchmark révèle les limites actuelles des MLLM dans la compréhension du monde physique et fournit des orientations pour les recherches futures. (Source : QubitAI)

La recherche combinant apprentissage par renforcement et optimisation multi-objectifs suscite l’intérêt : Le domaine à l’intersection de l’apprentissage par renforcement (RL) et de l’optimisation multi-objectifs (MOO) devient un point chaud de la recherche sur la prise de décision en IA. Cette combinaison vise à permettre aux agents de pondérer plusieurs objectifs (potentiellement conflictuels) dans des environnements complexes, plutôt que de rechercher un seul optimum. Par exemple, HKUST a proposé un cadre d’équilibrage dynamique des gradients pour la conduite autonome, optimisant simultanément la sécurité et l’efficacité énergétique ; l’algorithme de recherche de stratégies de Pareto du MIT est utilisé pour le contrôle des robots ; Alibaba Cloud applique des techniques d’alignement multi-objectifs aux transactions financières pour équilibrer rendement et risque. Des recherches connexes telles que CMORL (apprentissage par renforcement multi-objectifs continu) et l’apprentissage d’ensembles de Pareto pour l’optimisation combinatoire explorent comment rendre les agents RL plus efficaces pour traiter les problèmes du monde réel qui évoluent dynamiquement ou ont plusieurs dimensions d’optimisation. (Source : Compte public WeChat)

La plateforme automatisée d’attaque et de défense adverses A³D est publiée en open source (TPAMI 2025) : L’équipe de recherche sur la conception intelligente et l’apprentissage robuste (IDRL) de l’Institut d’innovation en technologie de défense de l’Académie des sciences militaires a développé et rendu open source une plateforme nommée A³D (Automated Adversarial Attack and Defense). Cette plateforme utilise des techniques d’apprentissage automatique automatisé (AutoML), combinées à des idées de théorie des jeux attaque-défense, visant à rechercher automatiquement des architectures de réseaux neuronaux robustes et des stratégies d’attaque adverse efficaces. La plateforme intègre diverses méthodes de recherche d’architecture neuronale (NAS) et des métriques d’évaluation de la robustesse (attaques normatives, attaques sémantiques, camouflage adverse, etc.) pour la défense automatisée, tout en fournissant un module d’attaque adverse automatisé qui peut rechercher des schémas d’attaque combinés optimaux via des algorithmes d’optimisation. Les résultats de la recherche ont été publiés dans la revue de premier plan TPAMI, et le code a été publié sur des plateformes comme Hongshan Open Source, fournissant de nouveaux outils pour évaluer et améliorer la sécurité des modèles DNN. (Source : Compte public WeChat)

L’Université de Floride recrute des doctorants/stagiaires entièrement financés en NLP/LLM : Le professeur assistant Yuanyuan Lei du département d’informatique de l’Université de Floride (rejoignant à l’automne 2025) publie une annonce de recrutement pour des doctorants entièrement financés pour l’automne 2025 ou le printemps 2026, ainsi que des stagiaires de recherche avec des horaires flexibles (possibilité de télétravail). Les axes de recherche se concentrent sur le traitement du langage naturel (NLP) et les grands modèles de langage (LLM), incluant spécifiquement les LLM augmentés par la connaissance, la vérification des faits, le raisonnement et la planification, et les applications NLP (multimodal, droit, commerce, science, etc.). Les étudiants ayant une formation en informatique, génie électrique, statistiques, mathématiques ou domaines connexes, intéressés et motivés par la recherche en IA, sont invités à postuler. L’e-mail mentionne l’impact potentiel de la loi SB-846 de Floride sur le recrutement d’étudiants de Chine continentale et les moyens d’y faire face. (Source : PaperWeekly)

Nouvelle recherche sur les modèles de diffusion : prior de bruit corrélé temporellement : Un article arXiv intitulé “How I Warped Your Noise: a Temporally-Correlated Noise Prior for Diffusion Models” propose un nouveau type de prior de bruit pour les modèles de diffusion. Cette méthode vise à améliorer la qualité ou l’efficacité de la génération des modèles de diffusion (potentiellement vidéo) en introduisant un bruit corrélé temporellement. Les détails techniques spécifiques nécessitent la consultation de l’article original. (Source : Reddit r/MachineLearning)
Nouvelle recherche sur la découverte scientifique automatisée : AI Scientist-v2 : Un article arXiv intitulé “The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search” présente le système AI Scientist-v2. Ce système utilise la méthode Agentic Tree Search (recherche arborescente agentique) et vise à atteindre un niveau de découverte scientifique automatisée de “niveau atelier” (Workshop-Level). Cela indique que les chercheurs explorent l’utilisation d’agents IA pour des recherches et explorations scientifiques plus avancées et autonomes. (Source : Reddit r/MachineLearning)
Explication de l’implémentation de la régularisation Dropout : Un article Substack explique en détail comment implémenter la technique de régularisation Dropout. Dropout est une technique de régularisation largement utilisée en apprentissage profond qui consiste à “désactiver” aléatoirement une partie des neurones pendant l’entraînement pour éviter le surajustement du modèle. Cet article s’adresse probablement aux apprenants souhaitant comprendre en profondeur le fonctionnement de Dropout ou implémenter cette technique eux-mêmes. (Source : Reddit r/deeplearning)
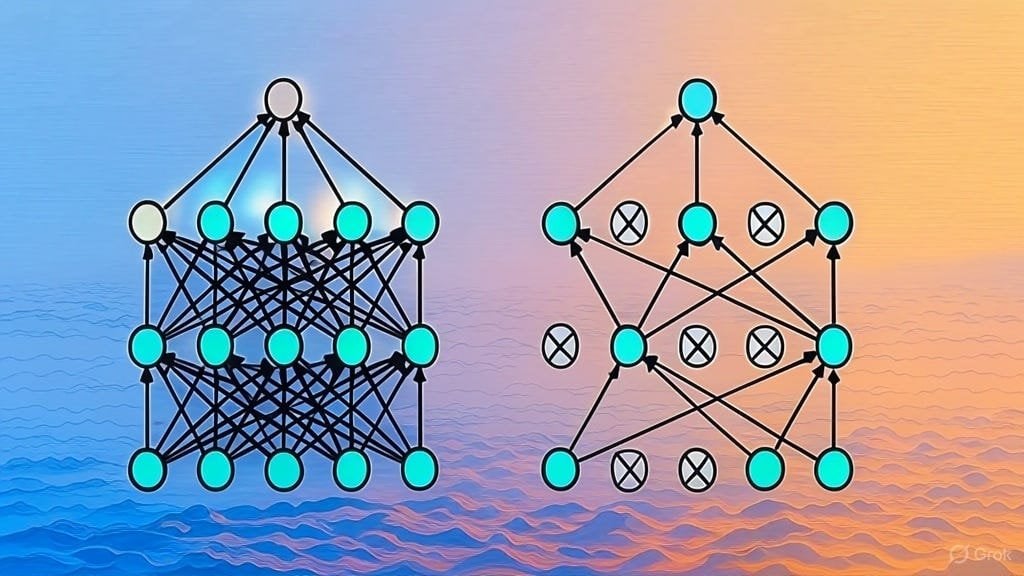
Appel à contribution pour une liste d’articles sur l’architecture des LLM : Un utilisateur Reddit a lancé une discussion pour partager et collecter des articles arXiv sur l’architecture des grands modèles de langage (LLM). Les architectures déjà listées incluent BERT, Transformer, Mamba, RetNet, RWKV, Hyena, Jamba, la série DeepSeek, etc. Cette liste reflète la diversité et le développement rapide de la recherche sur l’architecture des LLM et constitue une référence précieuse pour les chercheurs souhaitant comprendre systématiquement ce domaine. (Source : Reddit r/MachineLearning)
💼 Affaires
La plateforme de nutrition IA Fay lève 50 millions de dollars, avec un revenu annuel de 50 millions : La plateforme de nutrition IA de la Silicon Valley, Fay, a récemment clôturé un tour de financement de série B de 50 millions de dollars mené par Goldman Sachs, portant son financement total à 75 millions de dollars et sa valorisation à 500 millions de dollars. Fay met en relation des diététiciens agréés avec des patients, utilisant l’IA pour améliorer l’efficacité des services (prétendant réduire le temps par patient de 6,5 heures à 2 heures), automatisant des tâches telles que la génération de notes cliniques (y compris le codage ICD), l’élaboration de plans nutritionnels personnalisés, le traitement des demandes d’assurance et la gestion administrative. La plateforme a su capitaliser sur l’augmentation de la demande de conseils nutritionnels liée aux médicaments amaigrissants GLP-1 et a intégré le processus de paiement en collaborant avec les compagnies d’assurance (l’intervention nutritionnelle peut réduire les coûts médicaux à long terme des maladies chroniques). Avec moins de 3000 diététiciens sur sa plateforme, Fay a atteint un revenu annuel récurrent (ARR) de 50 millions de dollars, démontrant un modèle commercial réussi d’autonomisation des professionnels dans un secteur vertical de la santé par l’IA et de connexion avec les payeurs. (Source : Crow Intelligence)
Hengtu Tech de Chengdu : L’IA au service de la création numérique, rentabilité à l’international : L’entreprise locale de Chengdu, Hengtu Tech, a accumulé environ 700 millions d’utilisateurs dans le monde grâce à son produit phare Fotor (plateforme d’édition d’images et de vidéos), avec plus de dix millions d’utilisateurs actifs mensuels, particulièrement performante sur les marchés étrangers. C’est l’une des premières entreprises chinoises d’applications IA à s’internationaliser et à atteindre une rentabilité à grande échelle. L’entreprise cultive la technologie de traitement d’image depuis 16 ans et a rapidement intégré en 2022 les fonctionnalités AIGC (texte-image, texte-vidéo, etc.) dans Fotor et sa nouvelle plateforme Clipfly. Fotor abaisse la barrière à la création de contenu visuel numérique grâce à l’IA, au service de secteurs tels que le commerce électronique, les médias sociaux, la publicité, le tourisme culturel et l’éducation. Hengtu Tech utilise l’IA pour la “traduction culturelle”, aidant la culture chinoise à s’exporter et explorant de nouvelles voies pour l’industrie de la création numérique. (Source : 36Kr Sichuan)
Mise en œuvre pratique de l’IA en entreprise : Priorité à la valeur, moins de fine-tuning, promotion de la collaboration : Dans le processus de déploiement des grands modèles, les entreprises sont passées d’une exploration précoce à une approche plus pragmatique axée sur la valeur. Les applications IA réussies se concentrent souvent sur des scénarios répétitifs, nécessitant de la créativité et dont les paradigmes peuvent être établis, tels que les questions-réponses sur base de connaissances, le service client intelligent, la génération de matériel, l’analyse de données, etc. Les entreprises reconnaissent généralement que la poursuite aveugle du fine-tuning des modèles a souvent un faible retour sur investissement, et qu’il faut prioriser la gouvernance des connaissances et la construction de plateformes d’agents intelligents (principalement basées sur RAG au début). Le déploiement de l’IA nécessite une participation approfondie des départements métiers et le soutien de la direction, l’adoption d’une stratégie parallèle “pilotes à gain rapide + préparation de l’infrastructure IA” étant plus efficace. En termes de talents organisationnels, les entreprises ont tendance à former de petites équipes IA spécialisées pour autonomiser les métiers et à résoudre la pénurie de talents en recrutant des experts externes de haut niveau, en formant de jeunes talents internes (combinaison stagiaires + experts métiers seniors) et en collaborant avec des experts externes (prestataires). (Source : AI Frontline)
L’indice IA du STAR Market suscite l’intérêt, pourrait devenir un nouveau pôle d’investissement : Le rapport analyse que, malgré la volatilité récente du marché, l’industrie chinoise de l’intelligence artificielle a formé une boucle complète “puissance de calcul – modèle – application” et fait preuve d’une forte résilience. Le projet national “Calcul Est, données Ouest”, les modèles à faible coût comme DeepSeek et les percées applicatives comme les robots humanoïdes sont des points forts. L’IA est considérée comme un moteur important de la croissance économique mondiale pour la prochaine décennie, avec des rendements à long terme significatifs pour les actifs associés. Dans ce contexte, l’indice IA du STAR Market de Shanghai (axé sur les puces de calcul et les applications IA) attire l’attention des investisseurs en raison de ses prévisions de forte croissance et de l’augmentation de son contenu en matière d’autonomie et de contrôlabilité. Des institutions comme Yifangda ont déjà lancé des ETF et des fonds feeder (tels que 588730, 023564/023565) suivant cet indice, offrant aux investisseurs des outils pour se positionner sur la chaîne de valeur de l’IA nationale. (Source : Frontline Entrepreneurship)

La stratégie IA d’Apple s’oriente vers l’ouverture : autorisation d’utiliser des modèles tiers pour le développement de Siri : Pour accélérer le développement de la fonctionnalité “Siri personnalisé” et rattraper ses concurrents, Apple aurait ajusté sa stratégie de longue date de développement interne fermé. Sous la direction du nouveau vice-président senior de l’ingénierie logicielle, Craig Federighi, les ingénieurs de Siri sont pour la première fois autorisés à utiliser des grands modèles de langage tiers pour développer des fonctionnalités Siri, brisant la restriction précédente qui n’autorisait que l’utilisation des modèles développés par Apple. Ce changement est considéré comme une mesure clé d’Apple pour faire face à son retard relatif dans le domaine de l’IA et pour éviter que le retard de la fonctionnalité “Siri personnalisé” ne provoque davantage de mécontentement des utilisateurs (voire des poursuites judiciaires). Cette décision pourrait ouvrir des opportunités de collaboration entre Apple et des fournisseurs de modèles externes comme OpenAI ou Alibaba (pour le marché chinois). (Source : Sanyi Life)

🌟 Communauté
La concurrence entre les applications DeepSeek, Doubao et Yuanbao s’intensifie, l’expérience produit devient clé : Le marché chinois des applications d’assistants IA est en pleine effervescence. DeepSeek a connu une croissance explosive du nombre d’utilisateurs après la popularité de son modèle, propulsant brièvement Tencent Yuanbao, qui l’a intégré en premier, au sommet. Cependant, Doubao de ByteDance, avec des fonctionnalités produit plus complètes et une intégration profonde avec Douyin (TikTok), a de nouveau dépassé Yuanbao. L’analyse suggère que le simple fait de s’appuyer sur l’intégration d’un modèle puissant (comme DeepSeek) ne procure qu’un avantage à court terme. À long terme, la richesse fonctionnelle de l’application elle-même, l’expérience utilisateur, la synergie multi-appareils et la capacité d’intégration de l’écosystème de la plateforme sont plus cruciales. Alors que les capacités des modèles des différents acteurs convergent (par exemple, tous possèdent des capacités de réflexion profonde), la concurrence future se concentrera sur la conception du produit, les stratégies opérationnelles et les percées dans de nouvelles formes d’applications comme les AI Agents. (Source : Alphabet List)
Un étudiant asiatique développe un outil de triche pour entretien et enflamme les discussions en ligne : Roy Lee, un étudiant asiatique de l’Université Columbia, a développé un outil IA nommé Interview Coder, utilisant ChatGPT pour l’aider à passer les entretiens techniques à distance de plusieurs entreprises technologiques, dont Amazon, Meta et TikTok. Non seulement il a refusé les offres de ces entreprises, mais il a également enregistré une vidéo de son utilisation de l’outil de triche et l’a publiée sur YouTube. Après une plainte d’Amazon, il a été suspendu par son université. Roy Lee n’en a cure, a rendu public le déroulement des événements et sa correspondance avec l’école et les entreprises, gagnant un large soutien des internautes et l’attention de l’industrie, et en a profité pour créer sa propre entreprise. L’incident a déclenché de vifs débats sur l’efficacité des entretiens techniques (en particulier le modèle basé sur la résolution de problèmes LeetCode), les limites éthiques des outils IA dans le recrutement, et le défi individuel lancé au système des grandes entreprises. (Source : Direct AI)

Un utilisateur teste l’intégration des nouveaux modèles GLM open source de Zhipu avec une base de connaissances et MCP : Un utilisateur a testé les derniers modèles de la série GLM publiés par Zhipu AI (via appel API). Les résultats montrent que GLM-Z1-AirX (version ultra-rapide), lorsqu’il est connecté à une base de connaissances locale construite avec FastGPT, a une vitesse de réponse extrêmement rapide (atteignant prétendument 200 tokens/s) et une qualité de réponse améliorée par rapport aux modèles ordinaires, capable de générer des réponses plus détaillées et complètes ainsi que des tableaux comparatifs. GLM-4-Air (modèle de base), lorsqu’il est connecté à MCP (Model Context Protocol) pour exécuter des tâches d’Agent (comme la recherche sur le web, l’écriture de fichiers locaux, le contrôle Docker, le résumé de pages web), parvient à appeler correctement les outils et à accomplir les tâches, mais avec des résultats légèrement inférieurs à ceux de DeepSeek-V3. L’utilisateur a également salué les performances de sécurité des modèles Zhipu (ne répondant pas aux prompts de jailbreak). (Source : Compte public WeChat)
![Base de connaissances locale + GLM-Z1-Air open source de Zhipu, sécurisé, privé, vitesse de réponse fulgurante ! Les performances atteignent de nouveaux sommets [inclut le gameplay MCP]](https://rebabel.net/wp-content/uploads/2025/04/image_1744722926.gif)
Partage d’un prompt “résolveur de problèmes hyper-rationnel” et comparaison des performances des modèles : Un utilisateur de la communauté a partagé un prompt avancé conçu pour faire jouer à un LLM le rôle d’un “résolveur de problèmes hyper-rationnel basé sur les principes premiers”. Ce prompt définit en détail les principes de fonctionnement du modèle (décomposition du problème, ingénierie de la solution, protocole de livraison, règles d’interaction), le format de réponse et les caractéristiques tonales, en mettant l’accent sur la logique, l’action et les résultats, et en rejetant le flou, les excuses et le réconfort émotionnel. L’utilisateur a utilisé ce prompt pour comparer les performances de DeepSeek, Claude Sonnet 3.7 et ChatGPT 4o dans la résolution de problèmes, la fourniture de conseils et la recommandation de ressources en ligne, estimant que Claude 3.7 donnait les meilleurs résultats. Cela montre comment un prompt soigneusement conçu peut guider et améliorer considérablement les performances d’un LLM sur des tâches spécifiques. (Source : Compte public WeChat)

La communauté débat du lancement de GPT-4.1 : performances, stratégie et dénomination : Le lancement par OpenAI des modèles de la série GPT-4.1 a suscité de nombreuses discussions au sein de la communauté. D’une part, les utilisateurs, par le biais de tests réels et de comparaisons de benchmarks (comme Aider, Livebench, GPQA Diamond, KCORES Arena), ont constaté que si GPT-4.1 présente des améliorations significatives en matière de codage, il reste en deçà de Google Gemini 2.5 Pro et Claude 3.7 Sonnet en termes de capacités de raisonnement globales. D’autre part, la communauté a discuté et critiqué la stratégie produit d’OpenAI (distinction entre API et ChatGPT, abandon de GPT-4.5), la vitesse d’itération des modèles et la confusion dans la dénomination (GPT-4.1 lancé après GPT-4.5). Certains estiment qu’OpenAI pourrait être confronté à un goulot d’étranglement de l’innovation, tandis que d’autres y voient une stratégie visant à optimiser sa gamme de produits API et à offrir différentes options de rapport qualité-prix. (Source : dotey, op7418, Reddit r/LocalLLaMA 1, Reddit r/ArtificialInteligence, karminski3, Reddit r/LocalLLaMA 2)

ChatGPT se révèle utile dans des scénarios de conseil juridique, un utilisateur partage son succès : Un utilisateur Reddit a partagé un cas de succès où il a utilisé ChatGPT pour gérer un litige juridique lié au travail. Risquant d’être licencié, l’utilisateur a fourni des documents à ChatGPT et lui a demandé de jouer le rôle d’un expert en droit du travail britannique. Il a ainsi découvert une erreur de procédure de la part de son employeur et, grâce à une lettre rédigée par ChatGPT, a pu négocier un accord de règlement comprenant une indemnité de deux mois de salaire, évitant ainsi un mauvais dossier. Dans les commentaires, d’autres utilisateurs ont partagé des expériences similaires d’utilisation de l’IA (ChatGPT ou Gemini) pour rédiger des lettres juridiques, préparer des audiences et obtenir des résultats positifs, estimant que l’IA peut faire économiser beaucoup d’argent et de temps dans l’assistance juridique. (Source : Reddit r/ChatGPT)
Un utilisateur critique l’inefficacité de la fonction Deep Research d’OpenAI : Un utilisateur Reddit a critiqué la fonction Deep Research (recherche approfondie) d’OpenAI, estimant qu’elle présente trois problèmes majeurs : 1) les résultats de recherche sont inexacts ou non pertinents (dépendance de l’API Bing) ; 2) la méthode d’exploration ressemble plus à une recherche en profondeur d’abord qu’à une recherche large ; 3) elle est déconnectée des objectifs de recherche de l’utilisateur et manque de contraintes. L’utilisateur estime qu’il s’agit plus d’une capacité de recherche étendue que d’une véritable recherche approfondie. Cela reflète l’écart entre les attentes des utilisateurs concernant les capacités de recherche actuelles des AI Agents et l’expérience réelle. (Source : Reddit r/deeplearning)
Présentation et discussion de contenus générés par IA : Les utilisateurs de la communauté partagent activement des contenus créés à l’aide de divers outils IA (tels que ChatGPT, Midjourney, Kling AI, Suno AI), notamment des caricatures satiriques (Trump et Musk), des personnifications d’universités, un court métrage d’histoire alternative de la Seconde Guerre mondiale, des images de dieux grecs, une publicité de dentifrice style années 90, des bandes dessinées multi-panneaux, etc. Ces partages montrent non seulement les capacités de l’IA en matière de génération de texte, d’images, de vidéos et de musique, mais suscitent également des discussions sur la créativité, l’esthétique (parfois qualifiée de “kitsch”), les limites (comme le manque de cohérence des personnages de BD) et les questions éthiques liées au contenu généré par IA. (Source : dotey 1, dotey 2, Reddit r/ChatGPT 1, Reddit r/ChatGPT 2, Reddit r/ChatGPT 3, Reddit r/ChatGPT 4, Reddit r/ChatGPT 5)

Inquiétudes concernant la boucle de rétroaction des données d’entraînement de l’IA menant à un “effondrement du modèle” : La communauté discute d’un risque potentiel : avec l’augmentation du contenu généré par IA sur Internet, si les futurs modèles d’IA sont principalement entraînés sur ces données générées par IA, cela pourrait conduire à un “effondrement du modèle” (Model Collapse). Ce phénomène désigne une dégradation des performances du modèle, dont les sorties deviennent étroites, répétitives, manquant d’originalité et d’exactitude, à l’image de photocopies qui deviennent floues à force d’être copiées. Les utilisateurs craignent que cela n’érode lentement l’authenticité de l’information et la perspective humaine. La discussion mentionne également des méthodes pour y faire face, comme l’utilisation de données synthétiques pour l’entraînement et le renforcement du contrôle de la qualité des données, mais il existe un débat sur la question de savoir si le problème se produit déjà et comment l’éviter efficacement. (Source : Reddit r/ArtificialInteligence)
Point de vue : À l’ère de l’IA, la puissance de calcul est le nouveau pétrole : Un utilisateur Reddit avance l’idée que dans le développement de l’IA, la capacité de calcul (Compute), plutôt que les données, deviendra le goulot d’étranglement crucial et la ressource stratégique, à l’instar du pétrole pendant la révolution industrielle. Les raisons invoquées sont : les modèles d’IA plus puissants (en particulier les systèmes de raisonnement et d’Agent) nécessitent une croissance exponentielle de la puissance de calcul ; la robotique et d’autres interactions physiques généreront des quantités massives de nouvelles données, augmentant encore la demande de calcul. Posséder plus de puissance de calcul se traduira directement par une capacité de production économique accrue. Ce point de vue suscite la discussion au sein de la communauté, qui convient que la puissance de calcul est en effet un élément central, déterminant la limite supérieure des capacités de l’IA et sa vitesse de développement. (Source : Reddit r/ArtificialInteligence)
Discussion sur l’éthique de l’utilisation de l’IA : Est-il inapproprié d’utiliser l’IA pour améliorer ses résultats scolaires ? : Un étudiant universitaire en ligne, ayant échoué à un cours en raison de sa structure (un seul quiz ou devoir par semaine, suivi immédiatement d’un examen), a ensuite utilisé ChatGPT pour générer des exercices à partir des PDF de cours pour un apprentissage quotidien, améliorant considérablement ses notes. Cependant, l’étudiant se sent coupable après avoir lu des critiques sur l’impact environnemental de l’IA et sur la “pensée indépendante”. Les commentaires de la communauté estiment généralement que l’utilisation de l’IA comme aide à l’apprentissage est une utilisation légitime et efficace, qui contribue à améliorer l’efficacité et les résultats d’apprentissage, et qu’il ne faut pas se sentir coupable pour cela. Les commentateurs soulignent que l’impact environnemental de l’IA doit être considéré en comparaison avec d’autres activités humaines, et que l’utilisation de l’IA pour améliorer la productivité est déjà une tendance sur le lieu de travail. (Source : Reddit r/ArtificialInteligence)
Expérience utilisateur de Claude Pro : Discussion sur la limitation et le modèle économique : Sur la communauté Reddit r/ClaudeAI, les utilisateurs discutent des problèmes de limitation (throttling) rencontrés lors de l’utilisation du service Claude Pro et explorent le modèle économique d’Anthropic. Un utilisateur souligne que les frais d’abonnement Pro de 20 $ par mois sont bien inférieurs aux coûts de calcul réels engagés par Anthropic pour les utilisateurs intensifs (pouvant atteindre 100 $/mois), suggérant que les plaintes des utilisateurs (qui se sentent “exploités”) pourraient ignorer la structure des coûts des services IA. La discussion aborde également le fait qu’Anthropic a récemment réservé de nouvelles fonctionnalités à l’offre Max, plus chère, plutôt qu’à l’offre Pro, ce qui a suscité le mécontentement des premiers abonnés annuels à Pro. (Source : Reddit r/ClaudeAI 1, Reddit r/ClaudeAI 2)
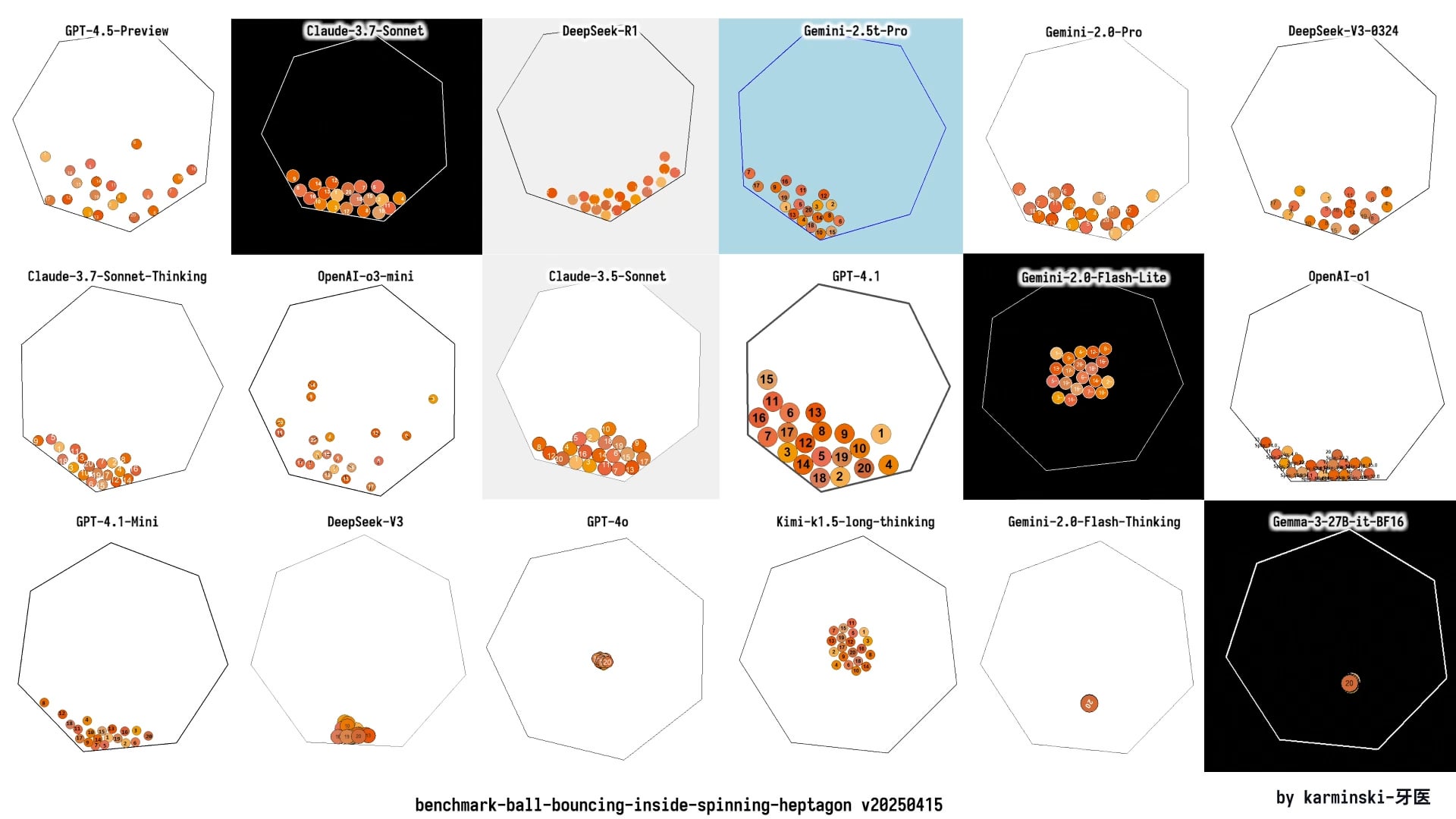
Mise à jour de KCORES LLM Arena, DeepSeek R1 se distingue : Un utilisateur partage les derniers résultats de test de son arène LLM personnelle (KCORES LLM Arena), qui demande aux modèles de générer le code Python pour une simulation physique complexe (20 balles entrant en collision et rebondissant à l’intérieur d’un heptagone en rotation). Après l’ajout de nouveaux modèles tels que GPT-4.1, Gemini 2.5 Pro, DeepSeek-V3, les résultats montrent que DeepSeek R1 excelle dans cette tâche, générant une simulation de bonne qualité. Cela fournit à la communauté un autre point de référence pour évaluer les capacités de différents modèles sur des tâches de programmation complexes. (Source : Reddit r/LocalLLaMA)
Exploration des capacités de réponse émotionnelle de différents LLM : Un utilisateur Reddit a publié un Meme comparant avec humour les différents styles de réaction de ChatGPT 4o, Claude 3 Sonnet, Llama 3 70B et Mistral Large face à un utilisateur exprimant de la tristesse. Cela reflète les différences d’expérience des utilisateurs lorsqu’ils interagissent émotionnellement ou cherchent du soutien auprès de différents LLM, ainsi que la perception et l’évaluation par la communauté de la capacité d‘“empathie” des modèles. Les commentaires discutent également de l’avantage en termes de confidentialité de l’utilisation de modèles locaux pour traiter des sujets émotionnels privés. (Source : Reddit r/LocalLLaMA)

Discussion sur la question de savoir si l’AGI est un canular de la Silicon Valley : Des membres de la communauté relaient et discutent potentiellement d’un article remettant en question si l’intelligence artificielle générale (AGI) est un concept excessivement promu (canular) par la Silicon Valley (l’industrie technologique) pour attirer les investissements ou maintenir l’engouement. Cela reflète le débat et le scepticisme persistants au sein de l’industrie et du public concernant la possibilité de réaliser l’AGI, son calendrier et l’authenticité de la promotion actuelle à ce sujet. (Source : Ronald_vanLoon)

💡 Divers
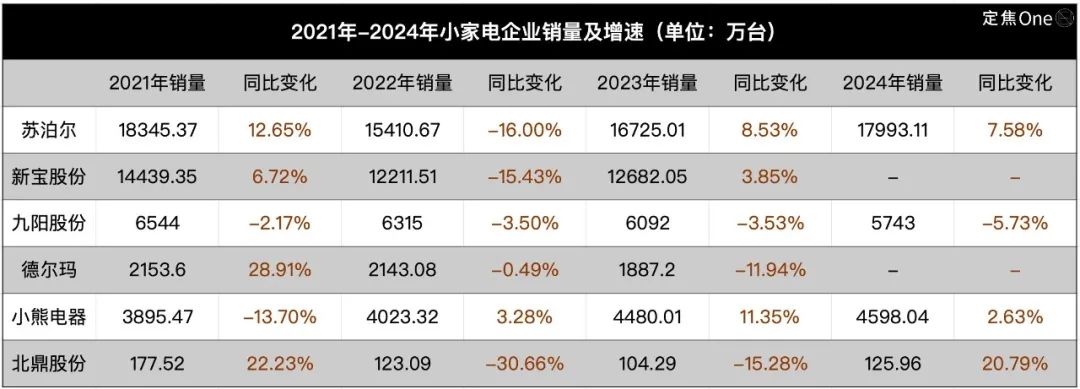
Le secteur du petit électroménager en difficulté, l’IA comme nouveau récit mais application encore limitée : Le marché du petit électroménager de cuisine (comme les machines à petit-déjeuner, les friteuses à air) fait face à une baisse des ventes et à une guerre des prix après l’essoufflement de l’économie du confinement. Les performances des “six grands” fabricants cotés comme Supor, Joyoung, Bear Electric sont sous pression. Pour trouver de nouvelles voies de croissance, les entreprises se tournent généralement vers l’expansion sur les marchés étrangers et l’intégration de la technologie IA. Cependant, l’application actuelle de l’IA dans le petit électroménager se limite souvent à de simples commandes vocales, des réglages automatiques, etc., avec une utilité et un potentiel d’innovation limités, et risque d’augmenter les coûts et de dissuader les utilisateurs. En comparaison, le gros électroménager offre plus d’avantages pour l’application de l’IA, permettant de construire des écosystèmes de maison intelligente et d’utiliser le big data pour fournir des services personnalisés. Le récit de l’IA dans le secteur du petit électroménager n’en est qu’à ses débuts. (Source : 36Kr)
La tempête tarifaire impacte le marché des puces de Huaqiangbei, la substitution nationale pourrait s’accélérer : Les récents changements de politique tarifaire concernant les puces suscitent l’inquiétude sur le marché électronique de Huaqiangbei à Shenzhen. Les vendeurs de puces populaires comme les CPU et GPU (en particulier celles potentiellement d’origine américaine) suspendent leurs cotations et retiennent leurs stocks dans l’attente, exacerbant la volatilité des prix. L’impact sur les puces mémoire et d’autres catégories est relativement moindre. Plusieurs distributeurs cotés indiquent que l’impact direct de la guerre tarifaire est limité car leur proportion d’importations directes depuis les États-Unis est faible, mais l’incertitude du marché augmente. L’industrie estime généralement que les entreprises IDM possédant des usines de fabrication aux États-Unis (comme TI, Intel, Micron) sont les plus touchées. Cet événement a déjà incité certains clients en aval à se renseigner sur des solutions de substitution par des puces nationales, ce qui pourrait accélérer le processus de localisation dans le domaine des semi-conducteurs. (Source : ChiNext Observation)

L’IA exacerbe-t-elle la crise du sens humain ? Réflexion sur l’équilibre entre technologie et valeur : L’article explore comment le développement rapide de l’intelligence artificielle impacte le sens de l’existence humaine. Il soutient que le dépassement par l’IA dans des domaines spécialisés (comme le Go, le diagnostic médical, la création artistique) aggrave la crise du sens humain déclenchée depuis la révolution industrielle par l’aliénation du travail, la crise de la foi, les problèmes environnementaux, etc. L’IA pourrait renforcer davantage le dilemme de la “personne-outil”, en particulier en remplaçant les capacités de décision dans le travail de bureau. L’article cite des points de vue de philosophes et des œuvres de science-fiction (comme “Dune”, “Westworld”) pour mettre en garde contre les risques d’asservissement technologique, appelant à embrasser l’amélioration technologique apportée par l’IA tout en reconstruisant la rationalité axiologique, en protégeant la créativité humaine, les liens émotionnels et la pensée critique par le biais de cadres éthiques et d’une éducation humaniste, afin d’éviter de devenir les appendices de nos propres créations. (Source : Tencent Research Institute)
Le coût élevé de fabrication d’un iPhone aux États-Unis pourrait dépasser 25 000 yuans : L’article analyse que si l’iPhone était entièrement produit sur le sol américain, son coût augmenterait considérablement, avec un prix de vente estimé pouvant atteindre 3500 dollars (environ 25 588 yuans), bien au-delà du prix actuel. Les principales raisons incluent le fait que les États-Unis sont bien plus chers que la Chine en termes d’acquisition de matières premières (comme les terres rares, le lithium et le cobalt raffinés), de logistique et de transport, de construction d’usines (terrain, électricité, approbations environnementales) et de coût de la main-d’œuvre (salaire horaire minimum 4 à 5 fois plus élevé qu’en Chine, et manque d’ouvriers industriels qualifiés). Le modèle d’Apple, qui consistait à pressurer la chaîne d’approvisionnement mondiale (en particulier les fournisseurs chinois avec des marges bénéficiaires relativement importantes) pour maintenir des taux de profit élevés, serait difficilement tenable aux États-Unis. Le coût de production élevé pourrait finalement être répercuté sur les consommateurs, ébranlant la stratégie de prix et la position sur le marché d’Apple. (Source : Star Sea Intelligence Bureau)

Percée mathématique : La théorie des singularités du flux par courbure moyenne prouvée : La conjecture de multiplicité un (Multiplicity-one conjecture), qui a intrigué les mathématiciens pendant près de 30 ans, a récemment été prouvée par Richard Bamler et Bruce Kleiner. Cette conjecture concerne le flux par courbure moyenne (Mean Curvature Flow, MCF) – un processus mathématique décrivant comment une surface évolue dans le temps pour réduire son aire le plus rapidement possible (similaire à la fonte d’un glaçon ou à l’érosion d’un château de sable). La preuve indique que dans l’espace tridimensionnel, les singularités (points où la courbure tend vers l’infini) formées par une surface fermée bidimensionnelle sous MCF sont simples, se manifestant généralement comme une sphère se contractant localement en un point ou un cylindre s’effondrant en une ligne. Les singularités complexes à plusieurs couches superposées ne se produisent pas. Cette percée garantit que le MCF peut continuer à être analysé même après la formation de singularités, fournissant une base théorique plus solide pour utiliser le MCF afin de résoudre des problèmes importants en géométrie et topologie (comme la conjecture de Poincaré). (Source : Machine Heart)

Un utilisateur partage une configuration matérielle IA locale “budget” avec 4x RTX 3090 : Un utilisateur Reddit a partagé sa configuration matérielle pour exécuter des LLM localement, pour un coût total d’environ 4204 $. La configuration comprend 4 cartes graphiques EVGA RTX 3090 d’occasion (600 $ pièce), un CPU serveur AMD EPYC 7302P, une carte mère Asrock Rack, 96 Go de mémoire DDR4 et un SSD NVMe de 2 To, assemblés dans un boîtier ouvert MLACOM Quad Station Pro Lite et alimentés par deux blocs d’alimentation de 1200W. Ce partage offre une référence relativement “économique” aux utilisateurs souhaitant construire à domicile une station de travail IA dotée d’une puissance de calcul conséquente (4x 24 Go de VRAM). (Source : Reddit r/LocalLLaMA)

Des pirates informatiques américains attaquent des feux de circulation pour diffuser des messages Deepfake de Musk et Zuckerberg : Selon des informations, plusieurs systèmes de feux de signalisation pour piétons dans la baie de San Francisco, aux États-Unis, ont été piratés et utilisés pour diffuser des messages Deepfake (hypertrucage) générés par IA d’Elon Musk et Mark Zuckerberg. Cet incident met en évidence la vulnérabilité des infrastructures publiques face aux cyberattaques utilisant les technologies IA, ainsi que le risque d’utilisation abusive de la technologie Deepfake pour diffuser de fausses informations ou commettre des actes de malveillance. (Source : Reddit r/ArtificialInteligence)

Présentation de diverses technologies de robotique et d’automatisation : Les médias sociaux présentent diverses applications de la robotique et des technologies d’automatisation, notamment : le robot Booster T1 capable d’imiter les mouvements humains pour exécuter du kung-fu ; des systèmes robotiques pour la rééducation ; un bras robotique capable de préparer du café ; des robots agricoles pour la plantation et le désherbage du riz ; un système automatisé facilitant la manipulation des moutons pour les éleveurs ; ainsi que des robots danseurs, etc. Ces exemples reflètent l’application étendue et le développement continu des robots dans les secteurs industriel, agricole, des services, de la rééducation médicale et du divertissement. (Source : Ronald_vanLoon 1, Ronald_vanLoon 2, Ronald_vanLoon 3, Ronald_vanLoon 4, Ronald_vanLoon 5, Ronald_vanLoon 6)
Présentation de technologies émergentes et de produits innovants : Les médias sociaux partagent diverses technologies émergentes et produits innovants, tels que : une antenne sans fil miniature développée par le MIT utilisant la lumière pour surveiller les communications cellulaires ; un drone à une seule aile imitant le vol des graines d’érable ; des toilettes intelligentes IoT ; une technologie d’empreintes numériques pour l’orthodontie ; un dispositif produisant de l’électricité à partir d’eau salée ; un mur dynamique capable de respirer et de bouger ; un costume de Cosplay Iron Man ; un snowboard électrique tout-terrain ; et une technique utilisant un appareil Flipper Zero pour copier des clés, etc. Ces présentations illustrent l’innovation continue de la technologie dans de multiples domaines tels que les communications, l’énergie, la santé, les transports, la construction et la sécurité. (Source : Ronald_vanLoon 1, Ronald_vanLoon 2, Ronald_vanLoon 3, Ronald_vanLoon 4, Ronald_vanLoon 5, Ronald_vanLoon 6, Ronald_vanLoon 7, Ronald_vanLoon 8, Ronald_vanLoon 9)

Tendances technologiques dans le domaine de la santé : Les médias sociaux et les liens d’articles mentionnent les applications technologiques et les tendances de développement dans le secteur de la santé, notamment la chirurgie assistée par robot, les tendances et points d’inflexion de l’IA dans les soins de santé, l’utilisation de la technologie pour favoriser l’excellence opérationnelle (hyperautomatisation), et les transformations potentielles apportées par l’IA. Ces contenus reflètent le potentiel et la pratique des technologies telles que l’IA, la robotique et l’automatisation pour améliorer l’efficacité des services de santé, la précision des diagnostics et l’expérience des patients. (Source : Ronald_vanLoon 1, Ronald_vanLoon 2, Ronald_vanLoon 3, Ronald_vanLoon 4)

Informations relatives à la cybersécurité : Les médias sociaux partagent des contenus liés à la cybersécurité, notamment une infographie sur les types d’attaques par mot de passe et un article sur l’importance de la capacité de récupération dans les 60 minutes suivant une fuite de données. Ces contenus rappellent aux utilisateurs de prêter attention aux risques de cybersécurité et aux stratégies d’intervention. (Source : Ronald_vanLoon 1, Ronald_vanLoon 2)

Discussion sur la plateforme AMD ROCm : Des utilisateurs Reddit discutent de la possibilité de construire une station de travail pour l’apprentissage profond en utilisant deux GPU AMD Radeon RX 7900 XTX, impliquant la pile logicielle ROCm (Radeon Open Compute platform). Cela reflète l’intérêt et l’exploration par les utilisateurs des solutions GPU AMD et de leur écosystème logiciel (ROCm) sur un marché du matériel IA dominé par Nvidia. (Source : Reddit r/deeplearning)