
Mots-clés:GPT-4.1, Hugging Face, Comparaison des performances des modèles de la série GPT-4.1, Hugging Face acquiert Pollen Robotics, Amélioration des capacités de codage du nouveau modèle OpenAI, GPT-4.1 mini coût réduit de 83%, Robot open source Reachy 2
🔥 En vedette
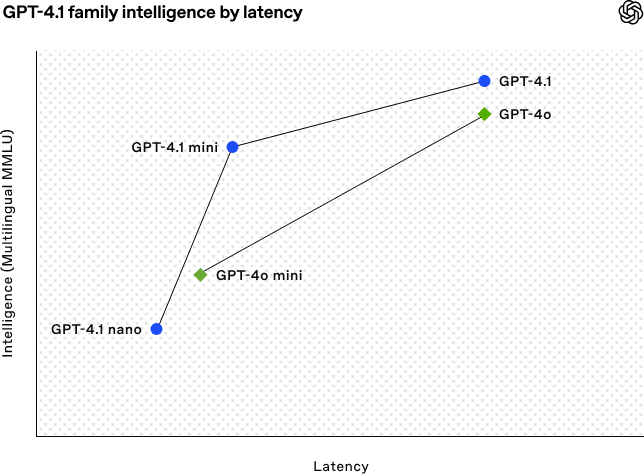
OpenAI lance la série de modèles GPT-4.1, renforçant les capacités de codage et de traitement de textes longs : OpenAI a publié le 15 avril au petit matin trois nouveaux modèles de la série GPT-4.1 : GPT-4.1 (phare), GPT-4.1 mini (haute efficacité) et GPT-4.1 nano (ultra-petit), tous disponibles uniquement via API. Cette série de modèles excelle dans le codage, le suivi des instructions et la compréhension de contextes longs, avec une fenêtre de contexte atteignant 1 million de tokens et une sortie de 32768 tokens. GPT-4.1 obtient un score de 54,6% au test SWE-bench Verified, surpassant nettement GPT-4o et le GPT-4.5 Preview qui sera bientôt obsolète. GPT-4.1 mini dépasse les performances de GPT-4o tout en réduisant la latence de moitié et les coûts de 83%. GPT-4.1 nano est actuellement le modèle le plus rapide et le moins cher, adapté aux tâches à faible latence. Ce lancement vise à offrir aux développeurs des options de modèles plus performants, plus économiques et plus rapides, favorisant la construction de systèmes intelligents complexes et d’applications d’agents intelligents. (Source : 36氪, 智东西, op7418, openai, karminski3, sama, natolambert, karminski3, karminski3, karminski3, dotey, OpenAI, GPT-4.1来了,超越GPT-4.5,SWE-Bench达到55%,开发者专属。)
Hugging Face acquiert la société de robotique open-source Pollen Robotics : La plateforme communautaire d’IA Hugging Face annonce l’acquisition de la start-up française de robotique open-source Pollen Robotics, visant à promouvoir l’open-source et la démocratisation de la robotique IA. Cette acquisition combinera les forces de Hugging Face dans les plateformes logicielles (telles que la bibliothèque LeRobot et le Hub) avec l’expertise de Pollen Robotics dans le matériel open-source (comme le robot humanoïde Reachy 2). Reachy 2 est un robot humanoïde open-source compatible VR, conçu pour la recherche, l’éducation et l’expérimentation en intelligence incarnée, vendu 70 000 $. Hugging Face considère la robotique comme la prochaine interface d’interaction importante pour l’IA et s’engage à la rendre ouverte, abordable et personnalisable. Cette acquisition est une étape clé pour réaliser cette vision, l’objectif étant de permettre à la communauté de construire et de contrôler ses propres compagnons robotiques, plutôt que de dépendre de systèmes fermés et coûteux. (Source : huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface)

🎯 Tendances
L’IA aide à résoudre un problème mathématique vieux de 50 ans : Weiguo Yin, chercheur d’origine chinoise au Brookhaven National Laboratory aux États-Unis, a utilisé le modèle de raisonnement o3-mini-high d’OpenAI pour réaliser une percée dans la résolution exacte du modèle de Potts à q états J_1-J_2 en une dimension, en particulier dans le cas q=3, où l’IA a aidé à compléter la preuve clé. Ce problème concerne un modèle fondamental de la mécanique statistique, lié à des phénomènes physiques tels que l’empilement atomique dans les matériaux en couches et la supraconductivité non conventionnelle, dont la solution exacte n’avait pas été trouvée au cours des 50 dernières années. Les chercheurs ont introduit la méthode du sous-espace de symétrie maximale (MSS) et, avec l’aide de l’IA pour traiter progressivement la matrice de transfert, ont réussi à simplifier la matrice de transfert 9×9 pour q=3 en une matrice 2×2 effective, et ont généralisé cette méthode à une valeur q arbitraire. Cette recherche résout non seulement un problème de physique mathématique de longue date, mais démontre également le potentiel énorme de l’IA pour aider à la recherche scientifique complexe et fournir de nouvelles perspectives. (Source : 刚刚,AI破解50年未解数学难题!南大校友用OpenAI模型完成首个非平凡数学证明)

Montée en puissance des assistants IA en version web, les fabricants de téléphones et de voitures déploient des expériences multi-terminaux : Des fabricants tels que Huawei (assistant Xiaoyi), Li Auto (Lixiang Tongxue) et OPPO (assistant Xiaobu) ont successivement lancé des versions web de leurs assistants IA, suscitant l’attention. Bien que ces versions web puissent être moins complètes en termes de fonctionnalités (comme l’édition de questions, la mise en page, les options de configuration) que les services de modèles professionnels comme DeepSeek, leur objectif principal n’est pas la concurrence directe, mais de servir les utilisateurs de leurs marques respectives et de boucler la boucle d’expérience entre le téléphone, la voiture et le PC. En liant les comptes utilisateurs et en synchronisant l’historique des conversations, ces versions web visent à renforcer la fidélité des utilisateurs, à offrir une expérience d’interaction cohérente sur tous les terminaux et à intégrer les assistants IA dans des scénarios d’utilisation plus larges, ce qui constitue essentiellement une stratégie axée sur les points d’entrée utilisateurs et l’écosystème de données. (Source : AI网页版扎堆上线,华为、理想、OPPO们打的什么算盘?)
Le robot Figure réalise un transfert zéro-shot de la simulation à la réalité grâce à l’apprentissage par renforcement : La société Figure a démontré que son robot humanoïde Figure 02 acquiert une démarche naturelle grâce à l’apprentissage par renforcement (RL) dans un environnement purement simulé. En utilisant un simulateur physique accéléré par GPU efficace, des années de données d’entraînement sont générées en quelques heures, formant une seule politique de réseau neuronal capable de contrôler plusieurs robots virtuels avec différents paramètres physiques et scénarios (tels que différents terrains, perturbations). En combinant la randomisation du domaine de simulation et le retour de couple à haute fréquence du robot réel, la politique entraînée peut être transférée zéro-shot au robot physique sans réglage fin. Cette méthode réduit non seulement le temps de développement et améliore la stabilité des performances dans le monde réel, mais une seule politique peut contrôler toute une flotte de robots, démontrant son potentiel pour des applications commerciales à grande échelle. (Source : 一套算法控制机器人军团!纯模拟环境强化学习,Figure学会像人一样走路)

DeepSeek va rendre open-source une partie des optimisations de son moteur d’inférence : DeepSeek a annoncé son intention de contribuer à la communauté une partie des optimisations et des fonctionnalités de son moteur d’inférence haute performance basé sur vLLM modifié. Ils ne publieront pas la pile d’inférence complète et hautement personnalisée, mais choisiront d’intégrer les améliorations clés (telles que la prise en charge des dernières architectures de modèles, les optimisations de performances) dans les frameworks d’inférence open-source courants comme vLLM et SGLang, l’objectif étant de permettre à la communauté d’obtenir un support de niveau SOTA pour les nouveaux modèles et technologies dès le premier jour. Cette décision a été bien accueillie par la communauté, considérée comme un véritable engagement envers la contribution open-source plutôt qu’une simple communication. (Source : Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, natolambert)
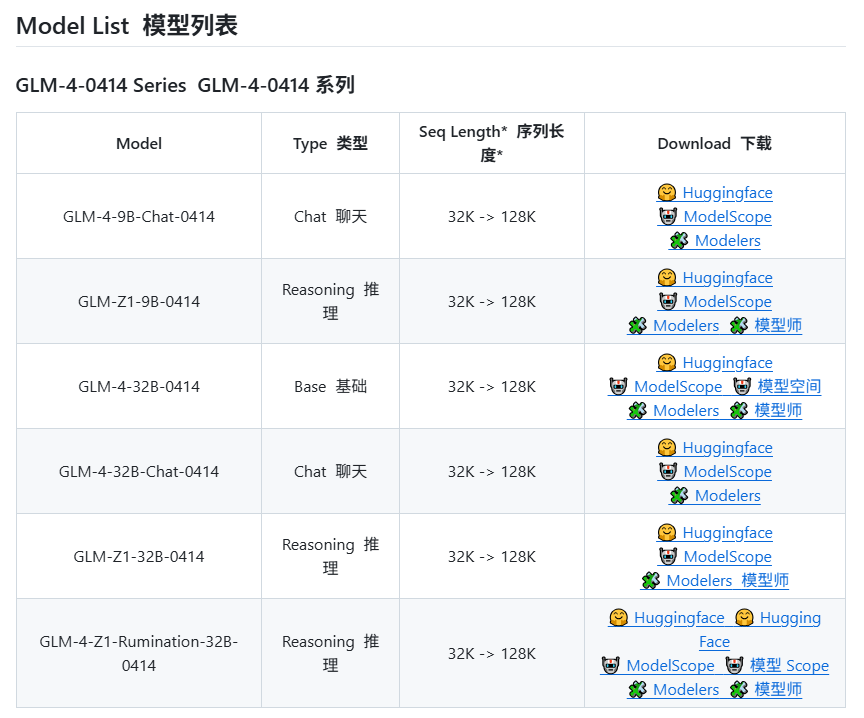
Zhipu AI s’apprêterait à lancer de nouveaux modèles de la série GLM-4 : Selon des informations divulguées sur GitHub (puis retirées), Zhipu AI semble se préparer à lancer de nouveaux modèles de la série GLM-4. Cette série pourrait inclure des versions de différentes tailles de paramètres (par exemple, 9B, 32B) et fonctionnalités, telles que des modèles de base (GLM-4-32B-0414), des modèles de dialogue (Chat), des modèles de raisonnement (GLM-Z1-32B-0414) et des modèles de “rumination” capables de réflexion plus approfondie (Rumination), potentiellement en concurrence avec Deep Research d’OpenAI. De plus, elle pourrait inclure un modèle multimodal visuel (GLM-4V-9B). Les benchmarks divulgués montrent que GLM-4-32B-0414 pourrait surpasser DeepSeek-V3 et DeepSeek-R1 sur certains indicateurs. Le code de support du moteur d’inférence associé a été fusionné dans transformers/vllm/llama.cpp. La communauté suit cela de près, attendant la sortie officielle et les évaluations. (Source : karminski3, karminski3, Reddit r/LocalLLaMA)
NVIDIA lance de nouveaux modèles de la série Nemotron : NVIDIA a publié sur Hugging Face de nouveaux modèles de base de la série Nemotron-H, comprenant trois tailles de paramètres : 56B, 47B et 8B, tous prenant en charge une fenêtre de contexte de 8K. Ces modèles sont basés sur une architecture hybride Transformer et Mamba. Actuellement, seuls les modèles de base (Base) sont publiés, aucune version affinée pour les instructions (Instruct) n’est encore disponible. La série Nemotron vise à explorer le potentiel de nouvelles architectures pour la modélisation du langage. (Source : Reddit r/LocalLLaMA)

🧰 Outils
GitHub Copilot intégré à la version Canary de Windows Terminal : Microsoft a intégré la fonctionnalité GitHub Copilot dans la version Canary de Windows Terminal, introduisant une nouvelle fonctionnalité appelée “Terminal Chat”. Cette fonction permet aux utilisateurs d’interagir directement avec l’IA dans l’environnement du terminal pour obtenir des suggestions de commandes et des explications. Les utilisateurs doivent s’abonner à GitHub Copilot et installer la dernière version Canary du terminal, puis vérifier leur compte pour l’utiliser. Cette initiative vise à intégrer directement l’assistance IA dans l’environnement de ligne de commande couramment utilisé par les développeurs, à réduire les changements de contexte, à améliorer l’efficacité lors du traitement de tâches complexes ou inconnues, à accélérer le processus d’apprentissage et à contribuer à la réduction des erreurs. (Source : GitHub Copilot 现可在 Windows 终端中运行了)

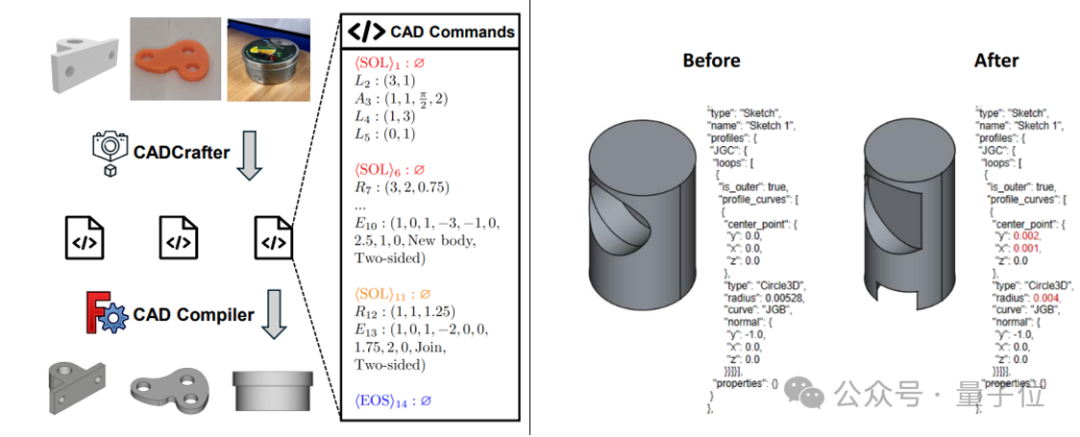
CADCrafter : Génération de fichiers CAD modifiables à partir d’une seule image : Des chercheurs de KOKONI 3D, de l’Université Technologique de Nanyang et d’autres institutions ont proposé un nouveau framework appelé CADCrafter, capable de générer directement des fichiers d’ingénierie CAD paramétriques et modifiables (représentés par une séquence d’instructions CAD) à partir d’une seule image (rendu, photo d’objet réel, etc.). Il résout les problèmes des méthodes existantes de génération 3D à partir d’images (générant des Mesh ou 3DGS) dont les modèles sont difficiles à modifier avec précision et dont la qualité de surface est médiocre. La méthode adopte une architecture de génération en deux étapes combinant VAE et Diffusion Transformer, et améliore la qualité et le taux de réussite de la génération grâce à une stratégie de distillation multi-vues vers vue unique et un mécanisme de vérification de compilabilité basé sur DPO. Les résultats de la recherche ont été acceptés à CVPR 2025, offrant un nouveau paradigme pour la conception industrielle assistée par IA. (Source : 单图直出CAD工程文件!CVPR 2025新研究解决AI生成3D模型“不可编辑”痛点|魔芯科技NTU等出品)
LangChain lance l’intégration de GraphRAG avec MongoDB Atlas : LangChain a annoncé une collaboration avec MongoDB pour lancer un système RAG basé sur des graphes (GraphRAG). Ce système utilise MongoDB Atlas pour stocker et traiter les données, implémenté via LangChain, et est capable de dépasser le RAG traditionnel basé sur la recherche par similarité pour comprendre et raisonner sur les relations entre les entités. Il prend en charge l’extraction d’entités et de relations via LLM et utilise le parcours de graphe pour obtenir des informations contextuelles connectées, visant à fournir des capacités de questions-réponses et de raisonnement plus puissantes pour les applications nécessitant une compréhension relationnelle approfondie. (Source : LangChainAI)
Hugging Face rend open-source son Inference Playground : Hugging Face a rendu open-source son outil en ligne Inference Playground, utilisé pour tester et comparer l’inférence de modèles. Il s’agit d’une interface de chat LLM basée sur le web qui permet aux utilisateurs de contrôler divers paramètres d’inférence (tels que la température, top-p, etc.), de modifier les réponses de l’IA, de comparer les performances de différents modèles et fournisseurs. Le projet est construit avec Svelte 5, Melt UI et Tailwind, et le code a été publié sur GitHub, offrant aux développeurs une plateforme d’interaction et d’évaluation de modèles locale ou en ligne personnalisable et extensible. (Source : huggingface)
La plateforme Flowith dépasse le million de dollars d’ARR, démontrant la capacité de l’AI Agent à générer des pages web : Le revenu annuel récurrent (ARR) de la plateforme d’AI Agent Flowith a dépassé 1 million de dollars, montrant une forte demande du marché pour des plateformes d’AI Agent polyvalentes capables de remplacer le travail manuel. Un utilisateur a partagé son expérience d’utilisation de la fonction Oracle de Flowith, générant rapidement un petit outil web fonctionnel avec un style précis (comme celui de Twitter) et prenant en charge l’aperçu d’images, simplement en fournissant une description en langage naturel (“Je veux créer une page web de prévisualisation de publications pour les médias sociaux…”), sans nécessiter de connexion à GitHub ni de configuration complexe, illustrant le potentiel de l’AI Agent dans la génération de pages web low-code/no-code. (Source : karminski3)
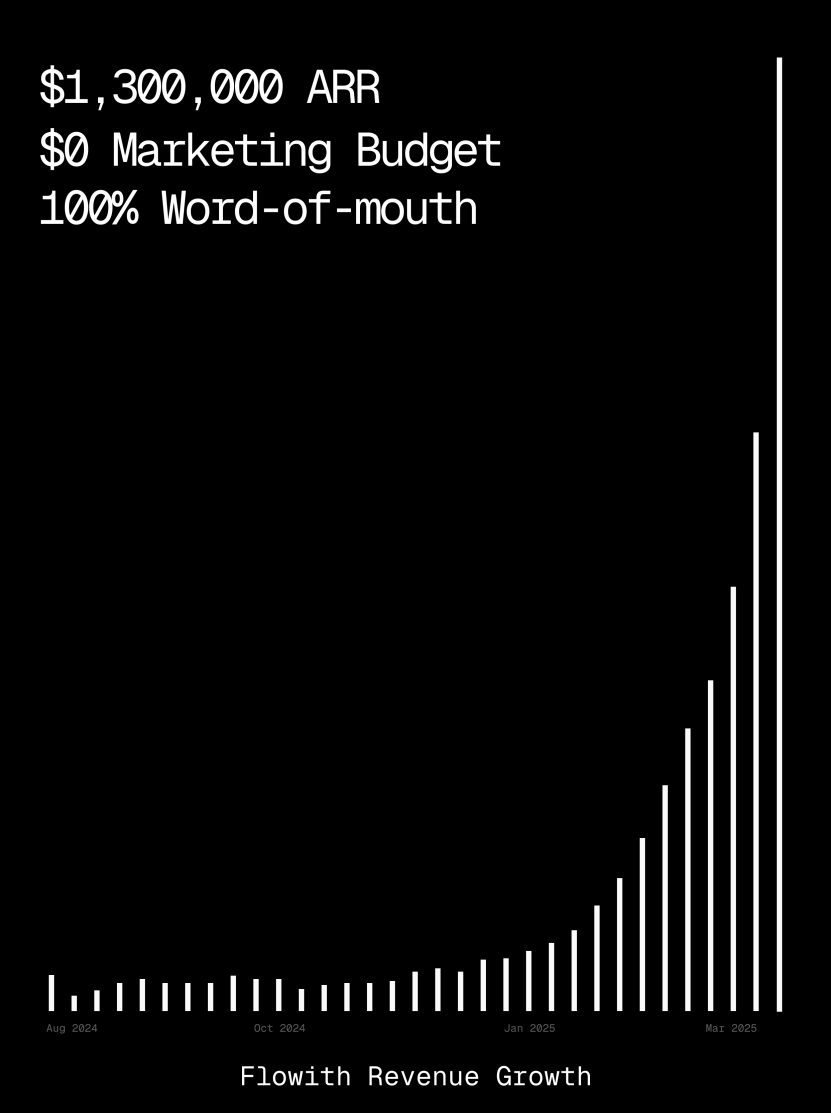
Lancement de l’agent de débogage autonome Deebo : Des chercheurs ont construit un serveur MCP d’agent de débogage autonome nommé Deebo. Il fonctionne comme un démon local auquel les agents de programmation peuvent décharger de manière asynchrone les tâches de gestion d’erreurs difficiles. Deebo génère plusieurs sous-processus avec différentes hypothèses de correction, exécute chaque scénario dans des branches git isolées, et est testé et analysé en boucle par un “agent mère”, renvoyant finalement des diagnostics et des correctifs suggérés. Lors d’un test réel sur un bug de tinygrad avec une prime de 100 $, Deebo a réussi à identifier la cause racine du problème et a proposé deux solutions de correction spécifiques qui ont passé les tests. (Source : Reddit r/MachineLearning)
![[D] We built an autonomous debugging agent. Here’s how it grokked a $100 bug](https://rebabel.net/wp-content/uploads/2025/04/81BPXr5Ywnk-6MetZBQchhgsROH341CoTk3xAdE5Jic.jpg)
📚 Apprentissage
Nabla-GFlowNet : Nouvelle méthode de réglage fin par récompense pour les modèles de diffusion, conciliant diversité et efficacité : Pour résoudre les problèmes de convergence lente de l’apprentissage par renforcement traditionnel, de surajustement facile et de perte de diversité lors de la maximisation directe de la récompense dans le réglage fin des modèles de diffusion, des chercheurs de l’Université Chinoise de Hong Kong (Shenzhen) et d’autres institutions proposent Nabla-GFlowNet. Cette méthode, basée sur le framework des réseaux de flux génératifs (GFlowNet), considère le processus de diffusion comme un système d’équilibre de flux et dérive la condition d’équilibre Nabla-DB ainsi que la fonction de perte correspondante. Grâce à une conception paramétrée, elle utilise l’estimation du débruitage en une seule étape pour estimer le gradient résiduel, évitant ainsi le besoin d’un réseau supplémentaire pour l’estimation. Les expériences montrent que lors du réglage fin de Stable Diffusion sur des fonctions de récompense telles que le score esthétique et le suivi d’instructions, Nabla-GFlowNet converge plus rapidement et est moins sujet au surajustement que des méthodes comme ReFL et DRaFT, tout en maintenant la diversité des échantillons générés. (Source : ICLR 2025 | 扩散模型奖励微调新突破!Nabla-GFlowNet让多样性与效率兼得)

MegaMath : Publication du plus grand jeu de données open-source pour le raisonnement mathématique, avec 371 milliards de Tokens : Lancé par LLM360, le jeu de données MegaMath, contenant 371 milliards de Tokens, vise à combler le manque de données de pré-entraînement à grande échelle et de haute qualité pour le raisonnement mathématique dans la communauté open-source. Ce jeu de données est divisé en trois parties : pages web à forte densité mathématique (279B), code lié aux mathématiques (28.1B) et données synthétiques de haute qualité (64B). Le processus de construction a utilisé un pipeline de traitement de données innovant, comprenant une analyse HTML optimisée pour les formules mathématiques, une extraction de texte en deux étapes, une notation dynamique de la valeur éducative, un rappel précis en plusieurs étapes des données de code et diverses méthodes de synthèse à grande échelle (Q&A, génération de code, entrelacement texte-code). Une validation de pré-entraînement de 100 milliards de Tokens sur Llama-3.2 (1B/3B) montre que MegaMath peut apporter une amélioration absolue des performances de 15 à 20% sur des benchmarks comme GSM8K et MATH. (Source : 3710亿数学Tokens!全球最大开源数学数据集MegaMath震撼发布,碾压DeepSeek-Math)
Revue des OS Agents : Étude des agents intelligents pour ordinateurs, téléphones et navigateurs basés sur des grands modèles multimodaux : L’Université du Zhejiang, en collaboration avec OPPO, 01.AI et d’autres institutions, a publié un article de synthèse sur les agents de système d’exploitation (OS Agents). L’article passe systématiquement en revue l’état actuel de la recherche sur la construction d’agents intelligents (tels que Computer Use d’Anthropic, Apple Intelligence d’Apple) capables d’accomplir automatiquement des tâches dans des environnements tels que les ordinateurs, les téléphones et les navigateurs, en utilisant de grands modèles de langage multimodaux (MLLM). Le contenu couvre les fondements des OS Agents (environnement, espace d’observation, espace d’action, capacités fondamentales), les méthodes de construction (architecture du modèle de base et stratégies d’entraînement, modules de perception/planification/mémoire/action du framework de l’agent), les protocoles d’évaluation et les benchmarks, ainsi que les produits commerciaux associés et les défis futurs (sécurité et confidentialité, personnalisation et auto-évolution). L’équipe de recherche maintient un dépôt open-source contenant plus de 250 articles pertinents, visant à promouvoir le développement dans ce domaine. (Source : 浙大、OPPO等发布最新综述:基于多模态大模型的计算机、手机与浏览器智能体研究)
NLPrompt : Méthode d’apprentissage par prompt robuste combinant la perte MAE et le transport optimal : Le YesAI Lab de l’Université ShanghaiTech propose NLPrompt dans un article Highlight de CVPR 2025, visant à résoudre le problème du bruit dans les étiquettes lors de l’apprentissage par prompt pour les modèles vision-langage. L’étude révèle que dans le scénario de l’apprentissage par prompt, l’utilisation de la perte d’erreur absolue moyenne (MAE) (PromptMAE) résiste mieux à l’influence des étiquettes bruitées que la perte d’entropie croisée (CE), et prouve sa robustesse d’un point de vue théorique de l’apprentissage des caractéristiques. De plus, elle propose une méthode de purification des données par transport optimal basée sur les prompts (PromptOT), utilisant les caractéristiques textuelles comme prototypes pour diviser l’ensemble de données en un sous-ensemble propre (entraîné avec la perte CE) et un sous-ensemble bruité (entraîné avec la perte MAE), fusionnant efficacement les avantages des deux pertes. Les expériences prouvent que NLPrompt est supérieur sur les ensembles de données bruitées synthétiques et réelles, et possède une bonne capacité de généralisation. (Source : CVPR 2025 | MAE损失+最优传输双剑合璧!上科大提出全新鲁棒提示学习方法)
Analyse du mécanisme de raisonnement de DeepSeek-R1 : Des chercheurs de l’Université McGill ont analysé le processus de raisonnement des grands modèles de raisonnement tels que DeepSeek-R1. Contrairement aux LLM qui donnent directement la réponse, les modèles de raisonnement génèrent des chaînes de raisonnement détaillées en plusieurs étapes. L’étude explore la relation entre la longueur de la chaîne de raisonnement et les performances (il existe un “point optimal”, une longueur excessive pouvant nuire aux performances), la gestion des contextes longs, les problèmes culturels et de sécurité (vulnérabilités de sécurité plus importantes par rapport aux modèles non-raisonnants), ainsi que les liens avec des phénomènes cognitifs humains (comme la persistance à examiner des problèmes déjà explorés). Cette étude révèle certaines caractéristiques et problèmes potentiels du fonctionnement des modèles de raisonnement actuels. (Source : LLM每周速递!| 涉及多模态、MoE模型、Deepseek推理、Agent安全控制、模型量化等)
C3PO : Méthode d’optimisation au moment du test pour les grands modèles MoE : L’Université Johns Hopkins a découvert que les LLM à mélange d’experts (MoE) souffrent d’un problème de chemin d’expert sous-optimal et propose la méthode d’optimisation au moment du test C3PO (Couches Critiques, Experts Clés, Optimisation du Chemin Collaboratif). Cette méthode ne dépend pas des étiquettes réelles, mais définit un objectif de substitution basé sur les “voisins réussis” dans un ensemble d’échantillons de référence pour optimiser les performances du modèle. Elle utilise des algorithmes de recherche de motifs, de régression par noyau, de perte moyenne sur des échantillons similaires, et pour réduire les coûts, n’optimise que les poids des experts clés dans les couches critiques. Appliquée aux LLM MoE, C3PO améliore la précision des modèles de base de 7 à 15% sur six benchmarks, surpassant les lignes de base d’apprentissage au moment du test courantes, et permet aux modèles MoE à petits paramètres de surpasser les LLM à plus grands paramètres, améliorant ainsi l’efficacité des MoE. (Source : LLM每周速递!| 涉及多模态、MoE模型、Deepseek推理、Agent安全控制、模型量化等)
Étude de l’impact de la quantification sur les performances des modèles de raisonnement : Une équipe de recherche de l’Université Tsinghua a exploré pour la première fois systématiquement l’impact des techniques de quantification sur les performances des modèles de langage de type raisonnement (tels que la série DeepSeek-R1, Qwen, LLaMA). L’étude a évalué les performances de différents algorithmes de quantification des poids, du cache KV et des activations à différentes largeurs de bits (W8A8, W4A16, etc.) sur des benchmarks de raisonnement en mathématiques, sciences, programmation, etc. Les résultats montrent qu’une quantification W8A8 ou W4A16 permet généralement d’obtenir des performances sans perte, mais des largeurs de bits inférieures entraînent un risque significatif de baisse de précision. La taille du modèle, sa source et la difficulté de la tâche sont des facteurs clés influençant les performances après quantification. La longueur de sortie des modèles quantifiés n’a pas augmenté de manière significative, et un ajustement raisonnable de la taille du modèle ou l’augmentation des étapes d’inférence peuvent améliorer les performances. Les modèles quantifiés et le code associés ont été rendus open-source. (Source : LLM每周速递!| 涉及多模态、MoE模型、Deepseek推理、Agent安全控制、模型量化等)
SHIELDAGENT : Garde-fou pour forcer les Agents à respecter les politiques de sécurité : L’Université de Chicago propose le framework SHIELDAGENT, visant à forcer les trajectoires d’action des AI Agents à se conformer à des politiques de sécurité explicites par le biais du raisonnement logique. Ce framework extrait d’abord des règles vérifiables à partir des documents de politique, construit un modèle de politique de sécurité (basé sur des circuits de règles probabilistes), puis, pendant l’exécution de l’Agent, récupère les règles pertinentes en fonction de sa trajectoire d’action et génère un plan de protection, utilisant une bibliothèque d’outils et du code exécutable pour une vérification formelle, garantissant que le comportement de l’Agent ne viole pas les règles de sécurité. Un jeu de données SHIELDAGENT-BENCH contenant 3K paires d’instructions et de trajectoires liées à la sécurité a également été publié. Les expériences montrent que SHIELDAGENT atteint le SOTA sur plusieurs benchmarks, améliorant considérablement le taux de conformité à la sécurité et le rappel, tout en réduisant les requêtes API et le temps d’inférence. (Source : LLM每周速递!| 涉及多模态、MoE模型、Deepseek推理、Agent安全控制、模型量化等)
MedVLM-R1 : Stimuler les capacités de raisonnement des VLM médicaux par l’apprentissage par renforcement : L’Université Technique de Munich, l’Université d’Oxford et d’autres institutions ont collaboré pour proposer MedVLM-R1, un modèle de langage visuel médical (VLM) conçu pour générer des processus de raisonnement explicites en langage naturel. Ce modèle utilise le framework d’apprentissage par renforcement GRPO (Group Relative Policy Optimization) de DeepSeek, entraîné sur des jeux de données ne contenant que la réponse finale, mais capable de découvrir de manière autonome des chemins de raisonnement interprétables par l’homme. Après avoir été entraîné sur seulement 600 échantillons VQA d’IRM, ce modèle de 2 milliards de paramètres atteint une précision de 78,22% dans les tests de référence IRM, CT et rayons X, surpassant considérablement les lignes de base et démontrant une forte capacité de généralisation hors domaine, dépassant même des modèles à plus grande échelle comme Qwen2-VL-72B. Cette recherche offre de nouvelles pistes pour la construction d’IA médicales fiables et interprétables. (Source : 小样本大能量!MedVLM-R1借力DeepSeek强化学习,重塑医疗AI推理能力)
Une étude révèle que l’entraînement par apprentissage par renforcement peut entraîner des réponses longues dans les modèles de raisonnement : Une étude de Wand AI analyse pourquoi les modèles de raisonnement (comme DeepSeek-R1) génèrent des réponses plus longues. L’étude révèle que ce comportement pourrait provenir du processus d’entraînement par apprentissage par renforcement (en particulier l’algorithme PPO), plutôt que de la nécessité d’un raisonnement plus long pour le problème lui-même. Lorsque le modèle reçoit une récompense négative pour une mauvaise réponse, la fonction de perte PPO a tendance à générer des réponses plus longues pour diluer la pénalité par token, même si le contenu supplémentaire n’aide pas à améliorer la précision. L’étude montre également qu’un raisonnement concis est souvent corrélé à une plus grande précision. En effectuant un deuxième cycle d’entraînement par apprentissage par renforcement en utilisant uniquement une partie des problèmes résolubles, il est possible de raccourcir la longueur des réponses tout en maintenant, voire en améliorant, la précision, ce qui est important pour améliorer l’efficacité du déploiement. (Source : 更长思维并不等于更强推理性能,强化学习可以很简洁)

L’USTC et ZTE proposent Curr-ReFT : Améliorer les capacités de raisonnement et de généralisation des VLM de petite taille : Pour résoudre le phénomène de “mur de briques” (goulot d’étranglement de l’entraînement) et le manque de capacité de généralisation hors domaine des modèles de langage visuel (VLM) de petite taille sur des tâches complexes, l’USTC et ZTE Communications proposent le paradigme de post-entraînement par apprentissage par renforcement curriculaire (Curr-ReFT). Ce paradigme combine l’apprentissage curriculaire (CL) et l’apprentissage par renforcement (RL), conçoit un mécanisme de récompense sensible à la difficulté, permettant au modèle d’apprendre progressivement du facile au difficile (décision binaire → choix multiple → réponse ouverte). Simultanément, il adopte une stratégie d’auto-amélioration basée sur l’échantillonnage par rejet, utilisant des échantillons multimodaux et linguistiques de haute qualité pour maintenir les capacités de base du modèle. Les expériences sur les modèles Qwen2.5-VL-3B/7B montrent que Curr-ReFT améliore considérablement les performances de raisonnement et de généralisation des modèles, le modèle 7B surpassant même InternVL2.5-26B/38B sur certains benchmarks. (Source : 中科大、中兴提出新后训练范式:小尺寸多模态模型,成功复现R1推理)

GenPRM : Étendre les modèles de récompense de processus par raisonnement génératif : L’Université Tsinghua et le Shanghai AI Lab proposent le modèle de récompense de processus génératif (GenPRM), visant à résoudre les problèmes des modèles de récompense de processus (PRM) traditionnels qui dépendent de scores scalaires, manquent d’interprétabilité et ne peuvent pas être étendus au moment du test. GenPRM adopte une approche générative, combinant le raisonnement en chaîne de pensée (CoT) et la vérification de code, pour effectuer une analyse en langage naturel et une vérification par exécution de code Python à chaque étape du raisonnement, fournissant une supervision de processus plus approfondie et interprétable. De plus, GenPRM introduit un mécanisme d’extension au moment du test, améliorant la précision de l’évaluation en échantillonnant en parallèle plusieurs chemins de raisonnement et en agrégeant les valeurs de récompense. Un modèle de 1,5 milliard de paramètres entraîné avec seulement 23K données synthétiques surpasse GPT-4o sur ProcessBench grâce à l’extension au moment du test, et la version 7B surpasse Qwen2.5-Math-PRM-72B de 72 milliards de paramètres. GenPRM peut également servir de modèle critique pour guider l’optimisation du modèle de politique. (Source : 过程奖励模型也可以测试时扩展?清华、上海AI Lab 23K数据让1.5B小模型逆袭GPT-4o)
Une étude révèle le phénomène de “réflexion excessive” de l’IA de raisonnement face aux problèmes de prémisses manquantes : Une étude de l’Université du Maryland et de l’Université Lehigh révèle que les modèles de raisonnement actuels (tels que DeepSeek-R1, o1), lorsqu’ils sont confrontés à des problèmes manquant d’informations préalables nécessaires (Missing Premise, MiP), ont tendance à manifester une “réflexion excessive”. Ils génèrent des réponses 2 à 4 fois plus longues que pour les problèmes normaux, tombant dans des cycles répétitifs d’examen du problème, de spéculation sur l’intention, de doute de soi, au lieu d’identifier rapidement que le problème est insoluble et de s’arrêter. En comparaison, les modèles non-raisonnants (comme GPT-4.5) ont des réponses plus courtes aux problèmes MiP et sont plus aptes à identifier les prémisses manquantes. L’étude suggère que bien que les modèles de raisonnement puissent détecter l’absence de prémisses, ils manquent de la “pensée critique” nécessaire pour interrompre de manière décisive un raisonnement inefficace, ce schéma comportemental pouvant provenir de contraintes de longueur insuffisantes dans l’entraînement par apprentissage par renforcement et se propager par distillation. (Source : 推理AI「脑补」成瘾,废话拉满!马里兰华人学霸揭开内幕)

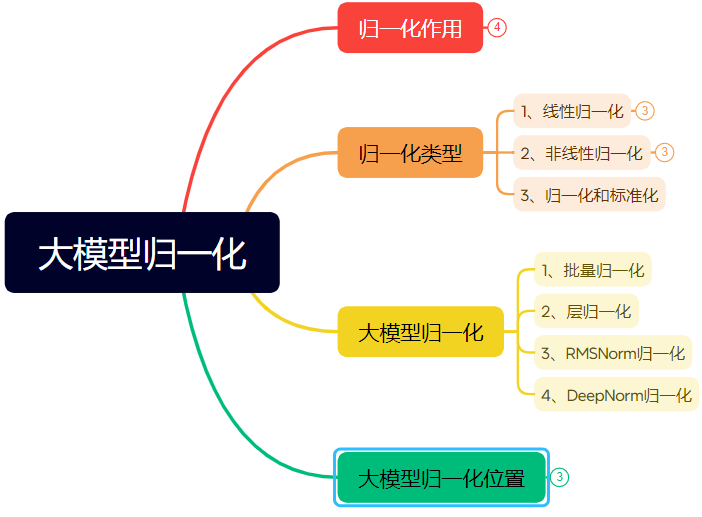
Long article de dix mille mots détaillant l’évolution de la technologie de normalisation des réseaux neuronaux : L’article passe systématiquement en revue le rôle et l’évolution de la normalisation (Normalization) dans les réseaux neuronaux, en particulier dans les Transformers et les grands modèles. La normalisation, en limitant les données à une plage fixe, résout les problèmes de comparabilité des données, améliore la vitesse d’optimisation, atténue les problèmes de zone de saturation des fonctions d’activation et de décalage de covariable interne (ICS). L’article présente les méthodes de normalisation linéaires (Min-max, Z-score, Mean) et non linéaires courantes, et expose en détail la normalisation par lots (BN), la normalisation par couche (LN), RMSNorm et DeepNorm adaptées aux modèles d’apprentissage profond, analysant leurs différences d’application dans l’architecture Transformer (pourquoi LN/RMSNorm sont plus adaptés au NLP). De plus, il discute des différents emplacements du module de normalisation au sein des couches Transformer (Post-Norm, Pre-Norm, Sandwich-Norm) et de leur impact sur la stabilité de l’entraînement et les performances. (Source : 万字长文!一文了解归一化:从Transformer归一化到主流大模型归一化的演变!)
Ingénierie de Prompt pour générer des polices de caractères de style spécifique avec l’IA : L’article partage l’expérience de l’auteur dans l’exploration de l’utilisation de Jimeng AI 3.0 pour générer des conceptions textuelles avec des styles spécifiques et des modèles de prompts. L’auteur a constaté que spécifier directement les noms de polices (comme Songti, Kaiti) donnait de mauvais résultats, la compréhension du modèle IA étant limitée à cet égard. Par conséquent, l’auteur s’est tourné vers la description des caractéristiques de style de police, de l’atmosphère émotionnelle et des effets visuels, et en combinant des exemples de référence de différents styles, a construit un modèle de Prompt “générateur de prompts de conception de style de texte avancé”. L’utilisateur n’a qu’à saisir le contenu textuel, et ce modèle peut intelligemment faire correspondre ou fusionner plusieurs styles prédéfinis (tels que lumière et ombre nocturne, brutalisme industriel, gribouillage enfantin, science-fiction métallique, etc.) en fonction de la signification du texte, générant des prompts détaillés pour les modèles texte-image, obtenant ainsi des effets de conception graphique et textuelle de qualité relativement stable. (Source : AI生成字体设计我有点玩明白了,用这套Prompt提效50%。, 即梦AI 3.0制作含字体封面,这个方案酷到封神【附:16+案例和Prompt】)

ZClip : Méthode adaptative de suppression des pics de gradient pour le pré-entraînement des LLM : Des chercheurs proposent ZClip, une méthode légère de découpage adaptatif du gradient, visant à réduire les pics de perte lors du processus d’entraînement des LLM et à améliorer la stabilité de l’entraînement. Contrairement au découpage traditionnel du gradient qui utilise un seuil fixe, ZClip utilise une méthode basée sur le z-score pour détecter et découper les pics de gradient anormaux, c’est-à-dire ceux qui s’écartent significativement de la moyenne mobile récente des gradients. Cette méthode aide à maintenir la stabilité de l’entraînement sans perturber la convergence et est facile à intégrer dans n’importe quelle boucle d’entraînement. Le code et l’article ont été publiés. (Source : Reddit r/deeplearning)
![[2504.02507] ZClip: Adaptive Spike Mitigation for LLM Pre-Training](https://rebabel.net/wp-content/uploads/2025/04/Swd9uQN43Dpl2SJyH6zjTbJAdRaXwKbmzZwM9L2rPXk.jpg)
💼 Affaires
La solution Intel Arc Graphics + processeur Xeon W favorise les appareils IA tout-en-un à faible coût : Intel, grâce à sa combinaison de cartes graphiques Arc™ et de processeurs Xeon® W, offre au marché une solution pour construire des appareils tout-en-un pour grands modèles de langage à coût maîtrisé (niveau 100 000 RMB) et aux performances pratiques. Les cartes graphiques Arc™ utilisent l’architecture Xe et le moteur d’accélération IA XMX, prennent en charge les frameworks IA courants et Ollama/vLLM, ont une faible consommation d’énergie et prennent en charge la connexion multi-cartes. Les processeurs Xeon® W offrent un nombre élevé de cœurs et une capacité d’extension de mémoire, avec la technologie d’accélération AMX intégrée. Combinée à des optimisations logicielles telles que IPEX-LLM, OpenVINO™ et oneAPI, une synergie efficace entre CPU et GPU est réalisée. Les tests montrent que cette solution tout-en-un exécutant le modèle QwQ-32B pour un seul utilisateur peut atteindre 32 tokens/s, et exécutant le modèle DeepSeek R1 de 671B (nécessite l’optimisation FlashMoE) peut atteindre près de 10 tokens/s, répondant aux besoins d’inférence hors ligne et favorisant la démocratisation de l’inférence IA. (Source : 榨干3000元显卡,跑通千亿级大模型的秘方来了)

NVIDIA fabriquera des supercalculateurs IA sur le sol américain : NVIDIA a annoncé qu’elle concevra et construira pour la première fois entièrement son supercalculateur IA sur le sol américain, en collaboration avec ses principaux partenaires de fabrication. Parallèlement, sa nouvelle génération de puces Blackwell a commencé sa production dans l’usine de TSMC en Arizona. NVIDIA prévoit de produire aux États-Unis jusqu’à cinq cents milliards de dollars d’infrastructures IA au cours des quatre prochaines années, avec des partenaires tels que TSMC, Foxconn, Wistron, Amkor et SPIL. Cette initiative vise à répondre à la demande de puces IA et de supercalculateurs, à renforcer la chaîne d’approvisionnement et à améliorer la résilience. (Source : nvidia, nvidia)

Horizon Robotics recrute des stagiaires en reconstruction/génération 3D : L’équipe d’intelligence incarnée d’Horizon Robotics recrute à Shanghai/Pékin des stagiaires en algorithmes pour la reconstruction/génération 3D. Les responsabilités incluent la participation à la conception et au développement de solutions algorithmiques Real2Sim pour robots (combinant reconstruction 3D GS, reconstruction feedforward, génération 3D/vidéo), l’optimisation des performances du simulateur Real2Sim (supportant la simulation de fluides, tactile, etc.), ainsi que le suivi de la recherche de pointe et la publication dans des conférences de premier plan. Exigences : Master ou plus, spécialisation en informatique/graphisme/IA, expérience en vision 3D/génération vidéo ou modèles multimodaux/diffusion, maîtrise de Python/Pytorch/Huggingface. Publications dans des conférences de premier plan, familiarité avec les plateformes de simulation ou expérience en projets open-source sont un plus. Opportunités de titularisation, cluster GPU et salaire compétitif offerts. (Source : 上海/北京内推 | 地平线机器人具身智能团队招聘3D重建/生成方向算法实习生)

Meituan Hotel & Travel recrute des ingénieurs algorithmes pour grands modèles L7-L8 : L’équipe d’algorithmes d’approvisionnement de Meituan Hotel & Travel recrute à Pékin des ingénieurs algorithmes pour grands modèles de niveau L7-L8 (recrutement externe). Les responsabilités incluent la construction d’un système de compréhension de l’offre hôtelière et de voyage (étiquettes de produits, identification des points chauds, découverte d’offres similaires, etc.), l’optimisation des supports d’affichage (génération de titres, textes et images, raisons recommandées), la construction de combinaisons de forfaits vacances (sélection de produits, prévision des ventes, tarification), ainsi que l’exploration et la mise en œuvre de technologies de pointe pour les grands modèles (réglage fin, RL, optimisation de Prompt). Exigences : Master ou plus, 2 ans d’expérience minimum, spécialisation en informatique/automatique/statistiques mathématiques, bases solides en algorithmes et compétences en codage. (Source : 北京内推 | 美团酒旅供给算法团队招聘L7-L8大模型算法工程师)

Meta utilisera les données des utilisateurs de l’UE pour entraîner son IA : Meta a annoncé se préparer à commencer à utiliser les données publiques des utilisateurs de Facebook et Instagram dans l’Union Européenne (telles que les publications, les commentaires, mais pas les messages privés) pour entraîner ses modèles d’IA, limité aux utilisateurs de 18 ans et plus. L’entreprise informera les utilisateurs via des notifications dans l’application et par e-mail, et fournira un lien pour s’opposer (opt-out). Auparavant, Meta avait suspendu ses plans d’utilisation des données des utilisateurs en Europe pour l’entraînement de l’IA suite à une demande des régulateurs irlandais. (Source : Reddit r/artificial)

Tencent Cloud lance le service hébergé MCP : Tencent Cloud propose également désormais des services hébergés MCP (Managed Cloud Platform), visant à fournir aux entreprises des solutions de gestion et d’exploitation des ressources cloud plus pratiques et efficaces. Cette décision signifie une intensification de la concurrence entre les principaux fournisseurs de cloud dans ce domaine. Les détails spécifiques du service et les “caractéristiques WeChat” n’ont pas encore été détaillés. (Source : 腾讯云也搞 MCP 托管了,还带了点“微信特色”。)
🌟 Communauté
Le lauréat du prix Turing LeCun parle du développement de l’IA : l’intelligence humaine n’est pas universelle, la prochaine percée pourrait être dans le non-génératif : Lors d’une récente interview en podcast, Yann LeCun a de nouveau souligné que le terme AGI est trompeur, arguant que l’intelligence humaine est hautement spécialisée et non universelle. Il prédit que la prochaine avancée majeure de l’IA pourrait provenir de modèles non génératifs, en se concentrant sur la capacité des machines à comprendre réellement le monde physique, à posséder des capacités de raisonnement et de planification, et une mémoire persistante, similaire à son architecture JEPA proposée. Il estime que les LLM actuels manquent de capacités de raisonnement réelles et de modélisation du monde physique, et qu’atteindre le niveau d’intelligence d’un chat serait déjà un progrès considérable. Concernant l’open-sourcing de LLaMA par Meta, il considère que c’est le bon choix pour stimuler le développement de l’ensemble de l’écosystème de l’IA, et souligne que l’innovation vient du monde entier et que l’open source est essentiel pour accélérer les percées. Il est également optimiste quant aux lunettes intelligentes en tant que support important pour les assistants IA. (Source : 图灵奖得主LeCun:人类智能不是通用智能,下一代AI可能基于非生成式)

Le “blocage” temporaire des IP chinoises par GitHub suscite l’attention, le site officiel évoque une erreur de configuration : Du 12 au 13 avril, certains utilisateurs chinois ont constaté qu’ils ne pouvaient pas accéder à GitHub, la page affichant un message indiquant que “l’adresse IP est soumise à des restrictions d’accès”, provoquant la panique et des discussions au sein de la communauté, craignant un blocage ciblé. Auparavant, GitHub avait bloqué les comptes de développeurs de pays comme la Russie et l’Iran en raison de sanctions américaines. GitHub a ensuite répondu officiellement que cet incident était dû à une erreur de modification de configuration empêchant temporairement les utilisateurs non connectés d’accéder au site, et que le problème avait été résolu le 13 avril. Bien qu’il s’agisse d’un problème technique, l’événement a de nouveau soulevé des discussions sur les risques géopolitiques des plateformes d’hébergement de code et les alternatives nationales (telles que Gitee, CODING, JiHu GitLab, etc.). (Source : “Bug”还是“预演”?GitHub 突然“封禁”所有中国 IP,官方:只是“手滑”技术出错了)

Les AI Agents suscitent des inquiétudes en matière de cybersécurité : Un article du MIT Technology Review souligne que les cyberattaques autonomes pilotées par l’IA sont imminentes. Avec l’amélioration des capacités de l’IA, des acteurs malveillants pourraient utiliser des AI Agents pour découvrir automatiquement des vulnérabilités, planifier et exécuter des cyberattaques plus complexes et à plus grande échelle, constituant une nouvelle menace pour la sécurité des individus, des entreprises et même des États. Cela exige que le domaine de la cybersécurité accélère la recherche et le déploiement de stratégies et de technologies de défense capables de contrer les attaques pilotées par l’IA. (Source : Ronald_vanLoon)

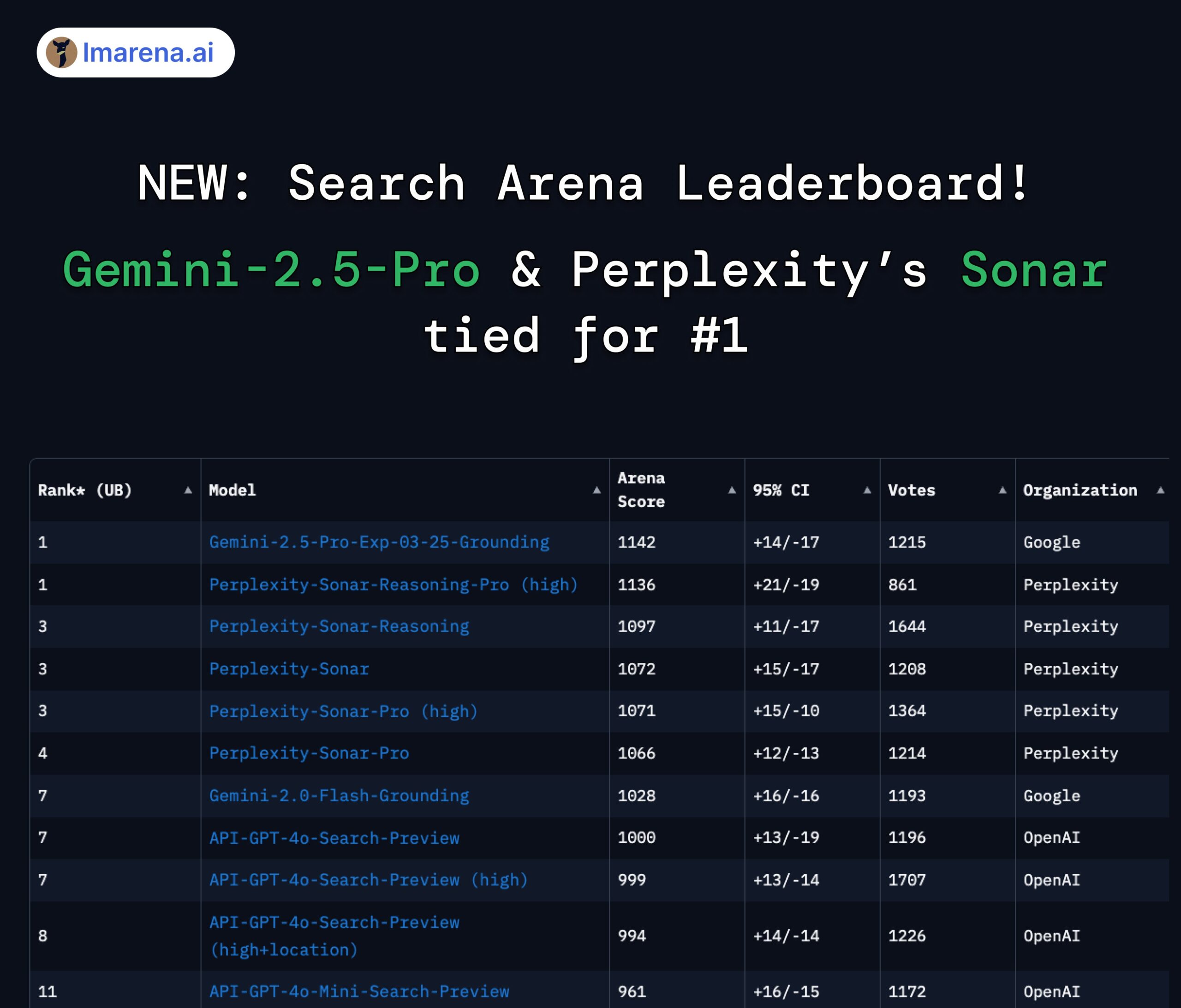
Perplexity Sonar et Gemini 2.5 Pro à égalité en tête du classement Search Arena : Dans le nouveau classement Search Arena de LMArena.ai (anciennement LMSYS), le modèle Sonar-Reasoning-Pro-High de Perplexity et Gemini-2.5-Pro-Grounding de Google sont à égalité en première position. Ce classement évalue spécifiquement la qualité des réponses des LLM basées sur la recherche web. Le PDG de Perplexity, Arav Srinivas, a exprimé ses félicitations et a souligné qu’ils continueraient à améliorer le modèle Sonar et l’index de recherche. La communauté estime que cela montre que dans le domaine des LLM améliorés par la recherche, la concurrence se joue principalement entre Google et Perplexity. (Source : AravSrinivas, lmarena_ai, lmarena_ai, AravSrinivas, lmarena_ai, AravSrinivas)
Discussion sur les limites d’utilisation du modèle Claude : Au sein de la communauté Reddit r/ClaudeAI, les utilisateurs débattent des limites d’utilisation de la version Claude Pro (telles que le plafond de messages, les limitations de capacité). Certains utilisateurs se plaignent de rencontrer fréquemment des limitations, ce qui affecte leur flux de travail, et envisagent même de changer de modèle ; d’autres affirment rencontrer rarement des limitations, suggérant que cela pourrait être dû au mode d’utilisation (comme le chargement de contextes très longs) ou à une exagération. Cela reflète les expériences et opinions divergentes des utilisateurs concernant les politiques d’utilisation et la stabilité des modèles d’Anthropic. (Source : Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)
Discussion sur l’IA et l’avenir de l’emploi : Sur Reddit r/ChatGPT, un graphique comparatif a suscité une discussion : l’IA améliorera-t-elle les capacités humaines, apportant une vie d’abondance, ou remplacera-t-elle les emplois humains, entraînant un chômage de masse ? Dans les commentaires, de nombreux utilisateurs expriment leurs inquiétudes quant au remplacement des emplois par l’IA, en particulier pour les professions créatives (programmation, art). Certains pensent que l’IA aggravera les inégalités sociales, car les bénéfices reviendront principalement aux propriétaires d’IA, tandis que la réduction de l’assiette fiscale pourrait rendre difficile la mise en œuvre de l’UBI. D’autres adoptent une attitude plus optimiste, considérant l’IA comme un outil puissant capable d’améliorer l’efficacité et de créer de nouveaux postes (comme ingénieur prompt), la clé étant de s’adapter et d’apprendre à utiliser l’IA. (Source : Reddit r/ChatGPT, Reddit r/ArtificialInteligence)

La collecte de données par l’IA soulève des préoccupations en matière de confidentialité : Une infographie comparant les types de données utilisateur collectées par différents chatbots IA (ChatGPT, Gemini, Copilot, Claude, Grok) a suscité une discussion sur les questions de confidentialité au sein de la communauté. Le graphique montre que Google Gemini collecte le plus grand nombre de types de données, tandis que Grok (nécessitant un compte) et ChatGPT (ne nécessitant pas de compte) en collectent relativement moins. Les commentaires des utilisateurs soulignent l’omniprésence de la collecte de données derrière les services gratuits (“il n’y a pas de repas gratuit”) et expriment des inquiétudes quant aux objectifs spécifiques de la collecte de données (comme la prédiction comportementale). (Source : Reddit r/artificial)

La distillation de modèles est considérée comme un moyen efficace et peu coûteux de reproduire des performances élevées : Un utilisateur de Reddit partage son expérience de l’utilisation de la technique de distillation de modèles pour entraîner des modèles plus petits et affinés à l’aide de grands modèles (comme GPT-4o), obtenant des performances proches de celles de GPT-4o (précision de 92%) dans un domaine spécifique (analyse des sentiments) pour un coût 14 fois inférieur. Les commentaires soulignent que la distillation est une technique largement utilisée, mais que les petits modèles ont généralement une capacité de généralisation inter-domaines inférieure à celle des grands modèles. Pour des domaines spécifiques et stables, la distillation est une méthode efficace pour réduire les coûts et améliorer l’efficacité, mais pour des scénarios complexes nécessitant une adaptation constante à de nouvelles données ou à plusieurs domaines, l’utilisation directe de grandes API peut être plus économique. (Source : Reddit r/MachineLearning)
![[D] Distillation is underrated. I replicated GPT-4o's capability in a 14x cheaper model](https://rebabel.net/wp-content/uploads/2025/04/zyj7as7ogque1.png)
💡 Divers
OceanBase organise son premier concours AI Hackathon : Le fournisseur de bases de données distribuées OceanBase, en collaboration avec Ant Open Source, Machine之心 et d’autres, organise son premier concours AI Hackathon. Les inscriptions ont débuté le 10 avril et se termineront le 7 mai. Le concours a pour thème “DB+AI” et propose deux axes principaux : premièrement, utiliser OceanBase comme base de données pour construire des applications IA, et deuxièmement, explorer l’intégration d’OceanBase avec l’écosystème IA (comme CAMEL AI, FastGPT, OpenDAL). Le concours offre une cagnotte totale de 100 000 RMB et est ouvert aux inscriptions individuelles et en équipe, visant à stimuler les développeurs à explorer des applications innovantes issues de l’intégration profonde des bases de données et de l’IA. (Source : 10万奖金×认知升级!OceanBase首届AI黑客松广发英雄帖,你敢来么?)

Le professeur Liu Xinjun de l’Université Tsinghua donnera une conférence en direct sur les robots parallèles : Le professeur Liu Xinjun, directeur de l’Institut de conception mécanique du département de génie mécanique de l’Université Tsinghua et président du comité chinois de l’IFToMM, donnera une conférence en ligne le soir du 15 avril sur le thème “Fondements de la cinématique des robots parallèles et innovation en matière d’équipement”. La conférence explorera la théorie fondamentale des robots parallèles et leurs applications dans l’innovation d’équipements de pointe. Le modérateur sera le professeur Liu Yingxiang de l’Université de Technologie de Harbin. (Source : 重磅直播!清华大学刘辛军教授开讲:并联机器人机构学基础与装备创新前沿)

Publication du guide du troisième sommet chinois de l’industrie AIGC : Le troisième sommet chinois de l’industrie AIGC, qui se tiendra le 16 avril à Pékin, a publié son programme détaillé et ses points forts. Le sommet se concentrera sur la technologie IA et la mise en œuvre des applications, avec des sujets couvrant l’infrastructure de calcul, les applications des grands modèles dans des scénarios verticaux tels que l’éducation, le divertissement, les services aux entreprises, l’AI4S, ainsi que la sécurité et le contrôle de l’IA. Les intervenants proviennent de Baidu, Huawei, AWS, Microsoft Research Asia, Mianbi Intelligence, Shengshu Technology, Fenbi, NetEase Youdao, Quwan Technology, Qingsong Health, Ant Group, etc. Le sommet publiera également des listes d’entreprises et de produits AIGC à surveiller en 2025, ainsi qu’une cartographie panoramique des applications AIGC en Chine. (Source : 倒计时2天!20余位行业大佬共话AI,中国AIGC产业峰会最全攻略在此)
