
Mots-clés:AI, Intelligence artificielle, Dilemme de souveraineté de l’IA, HBM et packaging avancé, Découvertes scientifiques pilotées par l’IA, Capacités de programmation de Gemini 2.5 Pro, Résolution de problèmes mathématiques par l’IA
🔥 En vedette
Le dilemme de la souveraineté en matière d’IA : comment le discours sur la sécurité nationale éclipse-t-il la valeur publique ? : Le rapport explore en profondeur le concept de “souveraineté en matière d’IA”, c’est-à-dire le contrôle d’un État sur la pile technologique de l’IA (données, puissance de calcul, talents, énergie). La tendance mondiale actuelle s’éloigne de la “souveraineté faible” dépendant des alliés pour se tourner vers une “souveraineté forte” visant une localisation complète, particulièrement sous l’impulsion de la politique américaine. Bien que ce changement vise à garantir la sécurité nationale et l’avantage militaire, il soulève également des préoccupations concernant la centralisation excessive, l’étouffement de l’innovation ouverte, l’entrave à la coopération internationale et le risque potentiel d’une course aux armements en IA. L’article soutient qu’une sécurisation excessive de l’IA pourrait sacrifier son immense potentiel au service de l’intérêt public et de la résolution des défis mondiaux. Il appelle à trouver un équilibre entre les exigences de souveraineté et la coopération ouverte, afin d’éviter que l’IA ne devienne une victime de la concurrence géopolitique plutôt qu’un outil de progrès collectif pour l’humanité. (Source: 人工智能主权困局:国家安全叙事如何吞噬AI的公共价值?)
HBM et packaging avancé : le point de friction invisible de la révolution de la puissance de calcul IA : La demande exponentielle de puissance de calcul des grands modèles d’IA met à rude épreuve les architectures de calcul traditionnelles, confrontées au goulot d’étranglement du “mur mémoire”. La mémoire à large bande passante (HBM), grâce à l’empilement 3D et à la technologie TSV, multiplie la bande passante (par exemple, plus de 1 To/s pour HBM3E), atténuant considérablement la latence de transfert de données. Parallèlement, les technologies de packaging avancé (telles que CoWoS de TSMC, EMIB d’Intel) intègrent étroitement différentes puces (CPU, GPU, HBM, etc.) via une intégration hétérogène, dépassant les limites d’une seule puce et améliorant la densité de puissance de calcul et l’efficacité énergétique. HBM et le packaging avancé sont devenus des éléments clés indispensables pour les puces IA (en particulier pour l’entraînement), leur marché étant dominé par des géants tels que SK Hynix, Samsung, Micron (HBM) et TSMC (packaging), avec des investissements massifs et des capacités de production tendues. Le développement synergique de ces deux technologies non seulement remodèle le paysage de la chaîne d’approvisionnement des semi-conducteurs (augmentation de la part de valeur du packaging), mais devient également un champ de bataille décisif pour la compétition en matière de puissance de calcul IA. (Source: HBM与先进封装:AI算力革命的隐形赛点)
Déclaration choc d’un lauréat du prix Nobel : l’IA accomplit en un an l’équivalent de 1 milliard d’années de “temps de recherche doctorale” : Demis Hassabis, lauréat du prix Nobel et PDG de Google DeepMind, a déclaré que le projet AlphaFold-2 de son équipe, en prédisant la structure des 200 millions de protéines connues sur Terre, a réalisé en un an une exploration scientifique équivalente à ce qui aurait nécessité 1 milliard d’années de temps de recherche doctorale. Il a souligné que l’IA, en particulier AlphaFold, révolutionne la vitesse et l’échelle de la découverte scientifique, démocratisant l’accès à la connaissance. Lors d’une conférence à l’Université de Cambridge, Hassabis a développé l’idée de l’avènement de l’ère de la “biologie numérique” pilotée par l’IA et a estimé que l’avenir de l’IA réside dans la construction de “modèles du monde” (tels que l’architecture JEPA) capables de comprendre le monde physique, de raisonner et de planifier, plutôt que de dépendre uniquement du traitement du langage. Il a réaffirmé son engagement envers l’IA open source, considérant que c’est la meilleure voie pour faire progresser la technologie. (Source: 诺奖得主震撼宣言:AI一年完成10亿年“博士研究时间”)

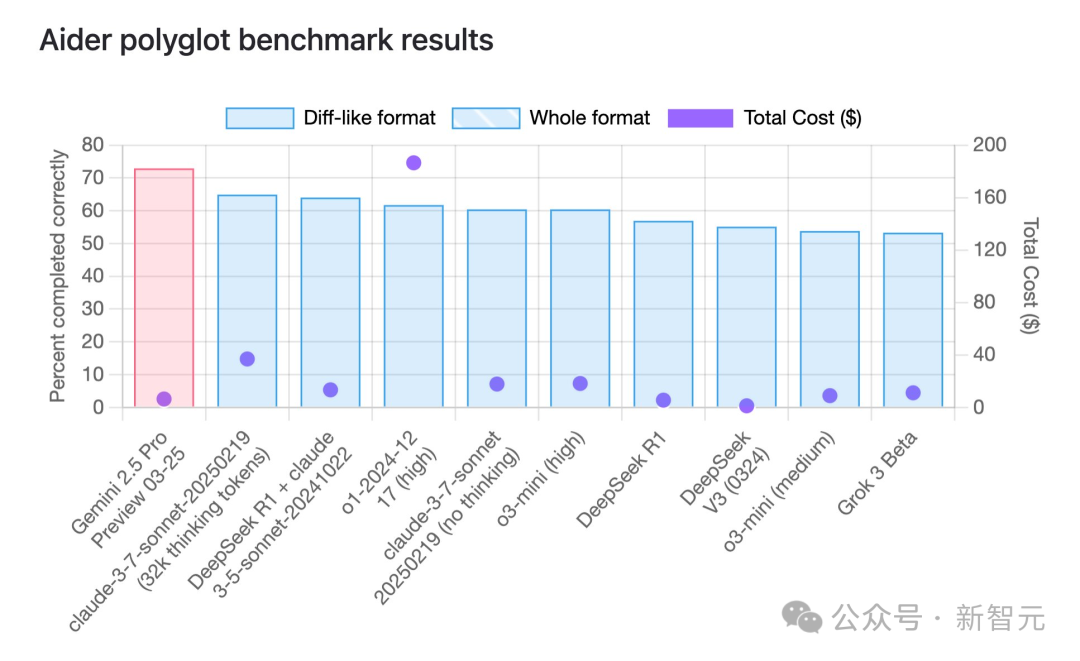
Gemini 2.5 Pro prend la tête en capacités de programmation, avec un avantage significatif en termes de rapport qualité-prix : Selon le benchmark de programmation multilingue aider, le dernier modèle Gemini 2.5 Pro de Google a dépassé Claude 3.7 Sonnet en termes de capacités de programmation, se classant premier au monde. Non seulement ses performances sont de pointe, mais son coût d’appel API est extrêmement bas (environ 6 $), bien inférieur à celui de concurrents aux performances similaires ou inférieures (comme GPT-4o, Claude 3.7 Sonnet). Jeff Dean a souligné son avantage en termes de rapport qualité-prix. De plus, un modèle Google non publié, “Dragontail”, circulant dans la communauté, a montré des performances encore meilleures que Gemini 2.5 Pro lors de tests de développement web, suggérant que Google a encore des atouts dans le domaine de la programmation IA. Gemini 2.5 Pro se classe également parmi les meilleurs dans plusieurs benchmarks généraux, défiant OpenAI et Anthropic sur tous les fronts grâce à ses hautes performances, son faible coût, sa grande fenêtre contextuelle et son accès gratuit. (Source: Gemini 2.5编程全球霸榜,谷歌重回AI王座,神秘模型曝光,奥特曼迎战)
L’IA aide avec succès à prouver un problème mathématique non résolu depuis 50 ans : Le chercheur d’origine chinoise Weiguo Yin (Brookhaven National Laboratory), avec l’aide du modèle o3-mini-high d’OpenAI, a réalisé une percée dans l’étude de la solution exacte du modèle de Potts q-state J_1-J_2 unidimensionnel, résolvant un problème vieux de 50 ans dans ce domaine. En traitant le cas spécifique q=3, le modèle IA, par analyse de symétrie, a réussi à simplifier la matrice de transfert complexe 9×9 en une matrice 2×2 effective. Cette étape clé a inspiré les chercheurs à généraliser la méthode, trouvant finalement une solution analytique applicable à n’importe quelle valeur de q. Ce résultat démontre non seulement le potentiel de l’IA dans les dérivations mathématiques complexes et les preuves non triviales, mais fournit également de nouveaux outils théoriques pour comprendre des problèmes tels que les transitions de phase en physique de la matière condensée. (Source: 刚刚,AI破解50年未解数学难题,南大校友用OpenAI模型完成首个非平凡数学证明)

🎯 Tendances
Application et évolution de l’IA dans le domaine des PNJ de jeux vidéo : L’article passe en revue l’histoire du développement de la technologie IA dans les PNJ (personnages non joueurs) de jeux vidéo, depuis les machines à états finis primitives de “Pac-Man”, en passant par les arbres de comportement, jusqu’à l’IA complexe combinant la recherche arborescente Monte-Carlo et les réseaux neuronaux profonds (comme AlphaGo). L’article souligne que bien que l’IA puisse battre les meilleurs joueurs humains dans des jeux comme “StarCraft 2” et “Dota 2”, une IA trop puissante nuit à l’expérience du joueur moyen. L’IA de jeu idéale devrait davantage se concentrer sur la simulation du comportement humain, offrir une valeur émotionnelle et une difficulté adaptative (comme le système Nemesis de “La Terre du Milieu” ou la difficulté dynamique de “Resident Evil 4”). Récemment, avec Stella de “Whispers from the Star” de Mihoyo comme exemple, l’IA générative est utilisée pour piloter les dialogues en temps réel, les réactions émotionnelles et le développement de l’intrigue des PNJ. Bien qu’elle soit confrontée à des défis tels que la latence et la mémoire, elle montre la tendance des PNJ IA à devenir plus humains et à offrir une plus grande profondeur d’interaction. (Source: AI,让游戏再次伟大)

OpenAI resserre les autorisations d’accès à l’API et introduit la vérification d’organisation : OpenAI a récemment mis en œuvre une nouvelle politique de vérification d’organisation pour son API, exigeant que les utilisateurs fournissent une pièce d’identité gouvernementale valide émise par un pays ou une région pris en charge pour accéder à ses modèles et fonctionnalités les plus avancés. Chaque pièce d’identité ne peut vérifier qu’une seule organisation tous les 90 jours. OpenAI affirme que cette mesure vise à réduire l’utilisation non sécurisée de l’IA et à préparer le lancement prochain de “nouveaux modèles passionnants” (pouvant inclure plusieurs versions comme GPT-4.1, o3, o4-mini, etc.). Ce changement de politique a suscité une large attention et des inquiétudes au sein de la communauté, en particulier pour les développeurs situés dans des pays/régions non pris en charge et les utilisateurs dépendant de services API tiers, qui pourraient être confrontés à un accès restreint ou à une augmentation des coûts. Cela a également soulevé des discussions sur l’ouverture d’OpenAI. (Source: GitHub中国IP访问崩了又复活,OpenAI API新政恐锁死GPT-5?, op7418, Reddit r/artificial)
L’arrivée d’Apple stimule le développement du “médecin IA”, défis et réglementation coexistent : Apple envisagerait d’utiliser l’IA pour améliorer les fonctionnalités de son application Santé, en lançant des services tels qu’un “coach santé IA”, ce qui a contribué à faire du “médecin IA” un sujet brûlant dans le monde entier. Cependant, les applications cliniques réelles de l’IA sont confrontées à de nombreux défis : coûts de développement élevés, dépendance à des volumes massifs de données médicales sensibles (impliquant des réglementations sur la confidentialité), difficultés d’annotation des données, etc. Actuellement, l’IA sert principalement d’outil d’aide au diagnostic. Le marché chinois est également confronté à des besoins spécifiques liés à l’inégalité des ressources médicales et à la nécessité d’une aide de l’IA pour le triage médical. Des entreprises comme Baichuan Intelligence proposent un “modèle à double médecin” (médecin IA + IA assistant le médecin humain) pour tenter de résoudre ces problèmes. L’article souligne que l’application généralisée de l’IA médicale doit reposer sur une réglementation et un système de certification stricts pour garantir l’exactitude du diagnostic, la sécurité des données et la confiance des utilisateurs, afin d’éviter les risques potentiels. (Source: 苹果入局,「AI医生」成全球热点,患者隐私保护成最大障碍?)

La tentative de Microsoft de générer directement des jeux avec l’IA donne de mauvais résultats : Microsoft a récemment présenté une démo utilisant son modèle IA “Muse” pour générer directement des images du jeu “Quake II”, dans le but de montrer la capacité de l’IA à prototyper rapidement des jeux. Cependant, la démo a donné de mauvais résultats, avec une faible résolution, un faible taux de rafraîchissement et de nombreux bugs (comportement anormal des ennemis, règles physiques non respectées, environnement incohérent), qualifiée de “rêve qui s’effondre constamment”. L’article estime que cela montre que la technologie actuelle d’IA générative (en particulier avec son problème d‘“hallucinations”) n’est pas encore suffisante pour générer directement et de manière fiable des expériences de jeu interactives complexes et jouables. En comparaison, appliquer l’IA à des étapes spécifiques du pipeline de développement de jeux (comme l’interaction des PNJ, la génération d’assets) est plus réaliste. La voie de la génération directe d’images ou de gameplay de jeu semble actuellement très difficile. (Source: 微软的AI游戏翻车,直接生成游戏或是条不归路)
Google publie le modèle open source TxGemma pour le domaine de la santé : Google a lancé la série de modèles TxGemma, basée sur ses familles de modèles Gemma et Gemini, spécifiquement optimisée pour les domaines de la santé et de la découverte de médicaments. Cette initiative vise à fournir des outils d’IA plus spécialisés pour la recherche biomédicale et le développement thérapeutique, favorisant l’innovation dans ce secteur. La publication de TxGemma fait partie de la stratégie de Google visant à proposer des modèles open source généraux et spécifiques à un domaine. (Source: JeffDean)
DeepSeek annonce son intention de rendre open source son moteur d’inférence interne : DeepSeek AI a déclaré qu’il rendrait open source son moteur d’inférence utilisé en interne. Selon la description, ce moteur est une version modifiée et optimisée du populaire framework vLLM. L’objectif de DeepSeek est de redonner à la communauté open source la technologie d’inférence optimisée, afin d’aider les développeurs à déployer plus efficacement les grands modèles. Ce plan témoigne de la volonté de DeepSeek de contribuer à la communauté open source, et le code devrait être publié sur GitHub. (Source: karminski3)
ChatGPT ajoute une fonction de mémoire pour améliorer la cohérence : OpenAI a ajouté une fonction de mémoire (Memory) à son modèle ChatGPT. Cette fonction permet à ChatGPT de se souvenir des informations, préférences ou sujets discutés précédemment par l’utilisateur au cours de plusieurs conversations. L’objectif est d’améliorer la continuité et la personnalisation de l’interaction, d’éviter que l’utilisateur ait à répéter les mêmes informations contextuelles lors de conversations ultérieures, améliorant ainsi l’expérience utilisateur. (Source: Ronald_vanLoon)

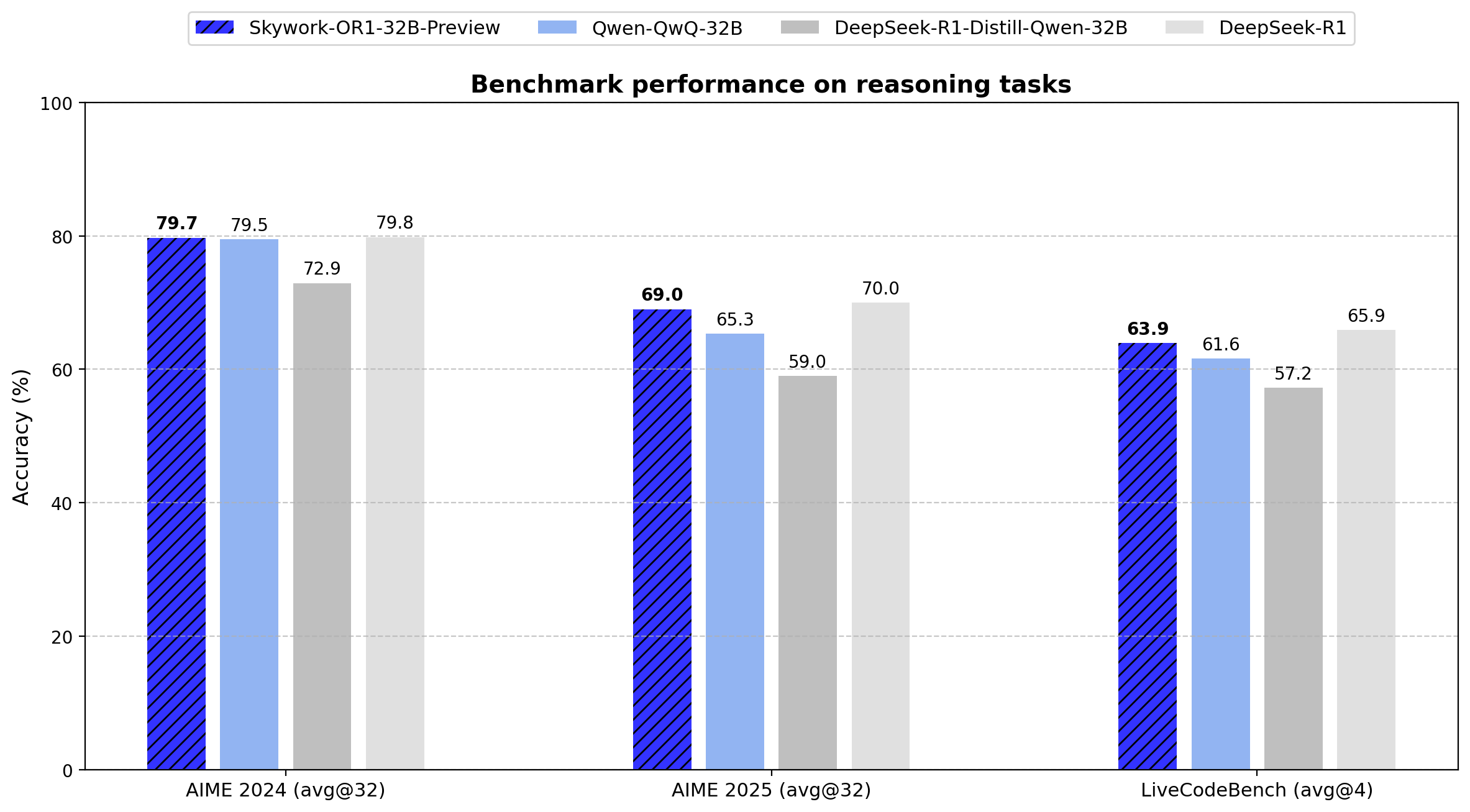
Skywork publie la série de modèles d’inférence open source OR1 : La société chinoise Skywork (Tiangong-Kunlun Wanwei) a publié une nouvelle série de modèles d’inférence open source, Skywork OR1. La série comprend OR1-Math-7B optimisé pour les mathématiques, ainsi que les versions préliminaires OR1-7B et OR1-32B qui excellent en mathématiques et en codage, la version 32B étant prétendument comparable à DeepSeek-R1 en termes de capacités mathématiques. Skywork est loué pour son ouverture, ayant publié les poids du modèle, les données d’entraînement et le code d’entraînement complet. (Source: natolambert)
Amélioration de la navigation et de la précision des opérations des robots pilotés par l’IA : Les médias sociaux montrent la capacité des robots autonomes pilotés par l’IA à naviguer avec précision dans des environnements complexes et à exécuter des tâches. Ces robots utilisent probablement des technologies d’IA telles que la vision par ordinateur, le SLAM (localisation et cartographie simultanées), l’apprentissage par renforcement, etc., pour fonctionner efficacement dans des environnements non structurés ou dynamiques, démontrant les progrès en matière de perception, de planification et de contrôle robotiques. (Source: Ronald_vanLoon)
Un exosquelette piloté par l’IA aide les utilisateurs de fauteuils roulants à marcher : Présentation d’un exosquelette avancé utilisant la technologie IA, capable d’aider les utilisateurs de fauteuils roulants à se tenir debout et à marcher à nouveau. L’IA y est potentiellement utilisée pour interpréter l’intention de l’utilisateur, maintenir l’équilibre, coordonner les mouvements et s’adapter à différents environnements, illustrant le potentiel de l’IA pour améliorer la qualité de vie des personnes handicapées et représentant une avancée importante dans la technologie des robots d’assistance. (Source: Ronald_vanLoon)
Inquiétudes concernant l’utilisation potentielle d’agents IA pour des cyberattaques : Un article de la MIT Technology Review souligne que les agents IA autonomes pourraient être utilisés pour mener des cyberattaques complexes. Ces agents IA ont le potentiel de découvrir automatiquement des vulnérabilités, de générer du code d’attaque et de lancer des attaques, potentiellement à une échelle et à une vitesse bien supérieures à celles des pirates humains, posant un défi sérieux aux systèmes de défense de cybersécurité existants. Cela suscite des inquiétudes quant à l’armement de l’IA et aux risques de sécurité. (Source: Ronald_vanLoon)

OpenAI annonce un événement en direct et pourrait lancer de nouveaux modèles : OpenAI a annoncé un événement en direct via un message énigmatique (développeur et trou noir supermassif). Parallèlement, des informations circulent sur le web concernant la mise à jour d’icônes et de fiches de modèles sur son site officiel, suggérant le lancement imminent de plusieurs nouveaux modèles, dont la série GPT-4.1 (avec les versions nano, mini), o4-mini et la version complète d’o3. Cela indique qu’OpenAI se prépare peut-être à lancer une série de nouveaux produits ou mises à jour de modèles pour faire face à une concurrence de plus en plus vive sur le marché. (Source: openai, op7418)

Le robot Figure apprend à marcher naturellement grâce à l’apprentissage par renforcement du simulé au réel : Figure AI a utilisé l’apprentissage par renforcement (RL) dans un environnement purement simulé pour entraîner avec succès son robot humanoïde Figure 02 à maîtriser une démarche naturelle. En générant une grande quantité de données via un simulateur efficace et en combinant la randomisation de domaine avec le retour de couple à haute fréquence du robot lui-même, la stratégie a été transférée du simulé au réel sans aucun échantillon (zero-shot). Cette méthode accélère non seulement le processus de développement, mais prouve également la faisabilité du contrôle de plusieurs robots par une seule stratégie de réseau neuronal, ce qui est d’une grande importance pour les futures applications commerciales des robots. (Source: 一套算法控制机器人军团!纯模拟环境强化学习,Figure学会像人一样走路)
🧰 Outils
Jimeng AI 3.0 génère des conceptions de texte stylisées et partage de Prompt : Un utilisateur partage son expérience et sa méthode pour utiliser l’outil de dessin IA chinois “Jimeng AI 3.0” afin de générer des images de texte avec un design élaboré. Comme la spécification directe des noms de police donnait de mauvais résultats, l’auteur a créé un modèle de prompt détaillé préconfiguré avec divers styles visuels (industriel, mignon, technologique, encre de Chine, etc.) et a défini des règles pour que l’IA associe ou fusionne automatiquement les styles en fonction du sens et de l’émotion du texte saisi. L’utilisateur n’a qu’à saisir le texte cible (par exemple, “garçon e-sportif”, “j’ai envie de bonbons”), et le modèle génère un prompt de dessin complet incluant le style, l’arrière-plan, la mise en page et l’ambiance, permettant d’obtenir des conceptions texte-image de haute qualité dans Jimeng AI. L’article fournit ce modèle de prompt et de nombreux exemples de génération. (Source: 即梦AI 3.0制作含字体封面,这个方案酷到封神【附:16+案例和Prompt】, AI生成字体设计我有点玩明白了,用这套Prompt提效50%。)
Utilisation de l’IA multimodale pour transformer des photos de nourriture en images de style menu : Un utilisateur des médias sociaux montre une technique utilisant des modèles d’IA multimodaux comme GPT-4o pour transformer des photos ordinaires de nourriture en images de menu raffinées. La méthode consiste à fournir la photo originale à l’IA et à la combiner avec des prompts descriptifs (par exemple, en référence aux “normes et style de menu d’hôtel cinq étoiles haut de gamme”), guidant l’IA pour styliser et éditer l’image afin de générer une présentation de plat d’aspect professionnel. Cela illustre le potentiel pratique de l’IA multimodale dans la compréhension, l’édition et le transfert de style d’images. (Source: karminski3)

Slideteam.net : Outil potentiel de création instantanée de diapositives piloté par l’IA : Les médias sociaux mentionnent que Slideteam.net peut créer des diapositives parfaites “instantanément”, suggérant qu’il pourrait utiliser la technologie IA pour automatiser la conception et la génération de présentations. Ces outils utilisent généralement l’IA pour la mise en page automatique, les suggestions de contenu, la correspondance de style, etc., visant à améliorer l’efficacité de la création de PPT. (Source: Ronald_vanLoon)
Démonstration d’un robot masseur IA : Une vidéo montre un robot masseur piloté par l’IA. Ce robot combine les capacités de manipulation physique d’un bras robotique avec le contrôle intelligent de l’IA. L’IA pourrait être utilisée pour comprendre les besoins de l’utilisateur, identifier les parties du corps, planifier les trajets de massage, ajuster la force et les techniques, et même percevoir les réactions de l’utilisateur via des capteurs pour optimiser l’expérience de massage, démontrant le potentiel d’application de l’IA dans les services de santé personnalisés et l’automatisation de la physiothérapie. (Source: Ronald_vanLoon)
Intégration de GitHub Copilot dans Windows Terminal : Microsoft a intégré la fonctionnalité GitHub Copilot dans la version Canary de son Windows Terminal, sous le nom de “Terminal Chat”. Les utilisateurs abonnés à Copilot peuvent interagir directement avec l’IA dans l’environnement du terminal pour obtenir des suggestions de commandes, des explications et de l’aide. Cette initiative vise à réduire le besoin pour les développeurs de changer d’application lors de la saisie de commandes, en fournissant une assistance intelligente sensible au contexte pour améliorer l’efficacité et la précision des opérations en ligne de commande, en particulier pour les tâches complexes ou peu familières. (Source: GitHub Copilot 现可在 Windows 终端中运行了)
Discussion sur les besoins matériels pour le déploiement d’OpenWebUI : Des utilisateurs de la communauté Reddit discutent de la configuration de machine virtuelle Azure nécessaire pour déployer OpenWebUI (une interface web pour LLM) pour une équipe d’environ 30 personnes. L’utilisateur prévoit d’exécuter localement le modèle d’embedding Snowflake et d’utiliser l’API OpenAI. La discussion porte sur la mise à l’échelle des ressources, l’impact de la taille du modèle d’embedding sur le CPU/RAM/stockage et l’importance du prétraitement des données. La communauté suggère qu’une forte dépendance à l’API peut réduire les besoins matériels locaux, mais que l’exécution locale de modèles (en particulier les modèles d’embedding) nécessite une configuration plus puissante. Pour les ressources limitées, il est également conseillé d’utiliser l’API pour traiter les embeddings. (Source: Reddit r/OpenWebUI)
📚 Apprentissage
Les modèles d’IA de raisonnement présentent un défaut de “réflexion excessive” en cas de prémisses manquantes : Une étude de l’Université du Maryland et d’autres institutions révèle que les modèles de raisonnement actuels (tels que DeepSeek-R1, o1), lorsqu’ils sont confrontés à des problèmes manquant d’informations nécessaires (prémisses manquantes, MiP), ont tendance à générer des réponses longues et invalides plutôt que d’identifier rapidement les défauts du problème lui-même. Ce phénomène de “réflexion excessive MiP” entraîne un gaspillage de ressources de calcul et n’est pas fortement corrélé à la capacité finale du modèle à réaliser que les prémisses sont manquantes. En comparaison, les modèles non basés sur le raisonnement s’en sortent mieux. L’étude suggère que cela expose un manque de capacité de pensée critique dans les modèles de raisonnement actuels, potentiellement dû au paradigme d’entraînement par apprentissage par renforcement ou aux problèmes du processus de distillation des connaissances. (Source: 推理AI“脑补”成瘾,废话拉满,马里兰华人学霸揭开内幕)

CVPR 2025 : CADCrafter réalise la génération de fichiers CAO modifiables à partir d’une seule image : Des chercheurs de Magic Core Technology, de l’Université Technologique de Nanyang et d’autres institutions proposent le framework CADCrafter, capable de générer directement des fichiers d’ingénierie CAO paramétrés et modifiables (représentés par une séquence d’instructions CAO) à partir d’une seule image (rendu de pièce, photo d’objet réel, etc.), plutôt que des modèles traditionnels de maillage ou de nuage de points. La méthode utilise un VAE pour encoder les instructions CAO et combine un Diffusion Transformer pour la génération conditionnée par l’image dans l’espace latent. Elle améliore les performances grâce à une stratégie de distillation multi-vues vers vue unique et utilise l’optimisation DPO pour garantir la compilabilité des instructions générées. Les fichiers CAO générés peuvent être directement utilisés pour la production et prennent en charge la modification du modèle via l’édition des instructions, améliorant considérablement la praticité et la qualité de surface des modèles 3D générés par l’IA. (Source: 单图直出CAD工程文件!CVPR 2025新研究解决AI生成3D模型“不可编辑”痛点|魔芯科技NTU等出品)
L’Université du Zhejiang, OPPO, etc. publient une revue sur les OS Agents : Cet article de revue fait le point systématiquement sur l’état actuel de la recherche sur les agents de système d’exploitation (OS Agents) basés sur des grands modèles multimodaux (MLLM). Les OS Agents désignent l’IA capable d’exécuter automatiquement des tâches sur des appareils tels que des ordinateurs et des téléphones via l’interface du système d’exploitation (GUI). L’article définit leurs éléments clés (environnement, espace d’observation, espace d’action), leurs capacités principales (compréhension, planification, exécution), passe en revue les méthodes de construction (architecture et entraînement du modèle de base, conception du framework de l’agent), et résume les protocoles d’évaluation, les benchmarks et les produits commerciaux associés. Enfin, il aborde les défis et les orientations futures tels que la sécurité et la confidentialité, la personnalisation et l’auto-évolution, fournissant une référence complète pour la recherche dans ce domaine. (Source: 浙大、OPPO等发布最新综述:基于多模态大模型的计算机、手机与浏览器智能体研究)
ICLR 2025 : Nabla-GFlowNet réalise un fine-tuning efficace et diversifié des récompenses pour les modèles de diffusion : Pour résoudre les problèmes de convergence lente (RL traditionnel) ou de perte de diversité (optimisation directe) lors du fine-tuning par récompense des modèles de diffusion, les chercheurs proposent la méthode Nabla-GFlowNet. Basée sur le framework des réseaux de flux génératifs (GFlowNet), cette méthode dérive une nouvelle condition d’équilibre de flux (Nabla-DB) et une fonction de perte associée, utilisant les informations du gradient de la récompense pour guider le fine-tuning. Grâce à une conception de paramétrage spécifique, elle atteint une vitesse de convergence plus rapide que des méthodes comme DDPO tout en maintenant la diversité des échantillons générés. Elle a été validée sur le modèle Stable Diffusion en utilisant des fonctions de récompense telles que l’esthétique et le suivi d’instructions, avec des résultats supérieurs aux méthodes existantes. (Source: ICLR 2025 | 扩散模型奖励微调新突破!Nabla-GFlowNet让多样性与效率兼得)
Analyse du mécanisme d’inférence de DeepSeek-R1 : Une étude de l’Université McGill analyse en profondeur le processus de “réflexion” des modèles de raisonnement comme DeepSeek-R1. L’étude révèle que la longueur de leur chaîne de raisonnement n’est pas positivement corrélée à la performance ; il existe un “point optimal”, et un raisonnement trop long peut même être préjudiciable. Le modèle peut s’embourber dans la répétition d’énoncés existants lorsqu’il traite des contextes longs ou des problèmes complexes. De plus, par rapport aux modèles non basés sur le raisonnement, DeepSeek-R1 pourrait présenter des vulnérabilités de sécurité plus évidentes. Cette recherche met en lumière certaines caractéristiques et limitations potentielles des mécanismes de fonctionnement des modèles de raisonnement actuels. (Source: LLM每周速递!| 涉及多模态、MoE模型、Deepseek推理、Agent安全控制、模型量化等)
Nouvelle méthode C3PO pour l’optimisation des modèles MoE lors des tests : L’Université Johns Hopkins propose la méthode C3PO (Critical Layers, Core Experts, Collaborative Path Optimization) pour optimiser les performances des grands modèles Mixture-of-Experts (MoE) au moment du test. Cette méthode rééquilibre les experts principaux dans les couches critiques, en optimisant pour chaque échantillon de test afin de résoudre le problème des chemins d’experts sous-optimaux. Les expériences montrent que C3PO peut améliorer considérablement la précision des modèles MoE (de 7 à 15 %), permettant même à des modèles MoE de plus petite taille de surpasser les modèles denses avec plus de paramètres, améliorant ainsi l’efficacité de l’architecture MoE. (Source: LLM每周速递!| 涉及多模态、MoE模型、Deepseek推理、Agent安全控制、模型量化等)
Étude systématique de l’impact de la quantification sur les performances des modèles de raisonnement : L’Université Tsinghua et d’autres institutions ont mené la première étude systématique sur l’impact de la quantification des modèles sur les performances des modèles de raisonnement (tels que DeepSeek-R1, série Qwen). Les expériences ont évalué les effets de la quantification avec différentes largeurs de bits (poids, cache KV, activations) et différents algorithmes. L’étude a révélé que la quantification W8A8 ou W4A16 permet généralement d’obtenir des performances sans perte ou quasi sans perte, mais que des largeurs de bits inférieures augmentent considérablement les risques. La taille du modèle, sa source et la difficulté de la tâche sont tous des facteurs clés influençant les performances après quantification. Les résultats de la recherche et les modèles quantifiés ont été rendus open source. (Source: LLM每周速递!| 涉及多模态、MoE模型、Deepseek推理、Agent安全控制、模型量化等)
APIGen-MT : Framework pour générer des données d’interaction multi-tours de haute qualité pour les agents : Salesforce propose le framework APIGen-MT, visant à résoudre le problème de la rareté des données de haute qualité nécessaires à l’entraînement des agents IA interactifs multi-tours. Ce framework se déroule en deux étapes : d’abord, utiliser un LLM pour examiner et itérer avec des retours afin de générer un plan de tâche détaillé, puis transformer ce plan en données de trajectoire complètes via une interaction homme-machine simulée. La série de modèles xLAM-2 entraînée sur la base de ce framework obtient d’excellents résultats sur les benchmarks d’agents multi-tours, surpassant des modèles comme GPT-4o, validant ainsi l’efficacité de cette méthode de génération de données. Les données synthétiques et les modèles ont été rendus open source. (Source: LLM每周速递!| 涉及多模态、MoE模型、Deepseek推理、Agent安全控制、模型量化等)
Une étude révèle : une chaîne de pensée plus longue n’équivaut pas à une meilleure performance de raisonnement, l’apprentissage par renforcement peut être plus concis : Une étude de Wand AI souligne que les modèles de raisonnement (en particulier ceux entraînés avec des algorithmes RL comme PPO) ont tendance à générer des réponses plus longues, non pas par nécessité de précision, mais parce que le mécanisme RL lui-même pourrait y conduire : pour les réponses incorrectes (récompense négative), allonger la réponse peut “diluer” la pénalité pour chaque token, réduisant ainsi la perte. L’étude prouve qu’un raisonnement concis est corrélé à une plus grande précision et propose une méthode d’entraînement RL en deux étapes : d’abord entraîner avec des problèmes difficiles pour améliorer la capacité (ce qui peut allonger les réponses), puis entraîner avec des problèmes de difficulté modérée pour encourager la concision tout en maintenant la précision. Cette méthode peut améliorer efficacement les performances et la robustesse, même sur des ensembles de données extrêmement petits. (Source: 更长思维并不等于更强推理性能,强化学习可以很简洁)
L’USTC et ZTE proposent Curr-ReFT : un nouveau paradigme de post-entraînement pour les VLM de petite taille : Pour résoudre les problèmes auxquels sont confrontés les petits modèles de langage visuel (VLM) après le fine-tuning supervisé, tels qu’une faible capacité de généralisation, des capacités de raisonnement limitées et une instabilité d’entraînement (phénomène du “mur de briques”), l’Université des Sciences et Technologies de Chine (USTC) et ZTE Corporation proposent le paradigme de post-entraînement Curr-ReFT. Cette méthode combine l’apprentissage par renforcement curriculaire (Curr-RL) et l’auto-amélioration basée sur l’échantillonnage par rejet. Curr-RL guide le modèle à apprendre progressivement du facile au difficile grâce à un mécanisme de récompense sensible à la difficulté ; l’échantillonnage par rejet utilise des échantillons de haute qualité pour maintenir les capacités de base du modèle. Les expériences sur les modèles Qwen2.5-VL-3B/7B montrent que Curr-ReFT améliore considérablement les performances de raisonnement et de généralisation du modèle, permettant aux petits modèles de surpasser les grands modèles sur plusieurs benchmarks. Le code, les données et les modèles ont été rendus open source. (Source: 中科大、中兴提出新后训练范式:小尺寸多模态模型,成功复现R1推理)
Tsinghua et Shanghai AI Lab proposent GenPRM : un modèle de récompense de processus génératif extensible : Pour résoudre les problèmes de manque d’interprétabilité et de capacité d’extension au moment du test des modèles traditionnels de récompense de processus (PRM) lors de la supervision du raisonnement des LLM, l’Université Tsinghua et le Shanghai AI Lab proposent GenPRM. Il évalue les étapes de raisonnement en générant une chaîne de pensée en langage naturel (CoT) et du code de vérification exécutable, fournissant un retour plus transparent. GenPRM prend en charge l’extension de calcul au moment du test, améliorant la précision en échantillonnant plusieurs chemins d’évaluation et en moyennant les récompenses. Ce modèle, entraîné avec seulement 23K données synthétiques, surpasse GPT-4o dans sa version 1.5B grâce à l’extension au moment du test, et sa version 7B surpasse les modèles de base de 72B. GenPRM peut également servir de critique au niveau de l’étape pour l’amélioration itérative des réponses. (Source: 过程奖励模型也可以测试时扩展?清华、上海AI Lab 23K数据让1.5B小模型逆袭GPT-4o)
Publication du plus grand jeu de données mathématiques open source au monde, MegaMath (371B Tokens) : LLM360 a lancé le jeu de données MegaMath, contenant 371 milliards de tokens, ce qui en fait actuellement le plus grand jeu de données de pré-entraînement open source au monde axé sur le raisonnement mathématique. Il vise à combler l’écart en termes d’échelle et de qualité entre la communauté open source et les corpus mathématiques propriétaires (comme DeepSeek-Math). Le jeu de données est composé de trois parties : données web à grande échelle liées aux mathématiques (279B, dont un sous-ensemble de haute qualité de 15B), code mathématique (28B) et données synthétiques de haute qualité (64B, incluant questions-réponses, génération de code, mélange texte-image). Après un traitement minutieux et plusieurs cycles de validation de pré-entraînement, l’utilisation de MegaMath pour le pré-entraînement sur le modèle Llama-3.2 permet d’obtenir une amélioration significative des performances de 15 à 20 % sur des benchmarks tels que GSM8K et MATH. (Source: 3710亿数学Tokens!全球最大开源数学数据集MegaMath震撼发布,碾压DeepSeek-Math)
CVPR 2025 : NLPrompt améliore la robustesse de l’apprentissage par prompt des VLM avec des étiquettes bruitées : Le YesAI Lab de l’Université ShanghaiTech propose la méthode NLPrompt, visant à résoudre le problème de la baisse de performance de l’apprentissage par prompt des modèles de langage visuel (VLM) face au bruit dans les étiquettes. L’étude révèle que dans le scénario de l’apprentissage par prompt, la perte d’erreur absolue moyenne (MAE) (PromptMAE) est plus robuste que la perte d’entropie croisée (CE). Parallèlement, elle propose la méthode de purification des données PromptOT basée sur le transport optimal, utilisant les caractéristiques textuelles générées par le prompt comme prototypes pour diviser l’ensemble de données en un ensemble propre et un ensemble bruité. NLPrompt utilise la perte CE pour l’ensemble propre et la perte MAE pour l’ensemble bruité, combinant efficacement les avantages des deux. Les expériences prouvent que cette méthode améliore considérablement la robustesse et les performances des méthodes d’apprentissage par prompt telles que CoOp sur des ensembles de données bruitées synthétiques et réelles. (Source: CVPR 2025 | MAE损失+最优传输双剑合璧!上科大提出全新鲁棒提示学习方法)
Application et discussion de la technique de distillation des connaissances dans la compression de modèles : La communauté discute de la technique de distillation des connaissances, qui consiste à utiliser un grand modèle “enseignant” pour entraîner un petit modèle “élève”, afin qu’il atteigne des performances proches de celles de l’enseignant sur une tâche spécifique, mais à un coût considérablement réduit. Un utilisateur partage son succès à distiller les capacités de GPT-4o en analyse de sentiments (précision de 92%) dans un petit modèle, réduisant le coût par 14. Les commentaires soulignent que bien que l’effet de la distillation soit significatif, il est généralement limité à un domaine spécifique, et le modèle élève manque de la capacité de généralisation du modèle enseignant. De plus, pour les scénarios professionnels nécessitant une adaptation continue aux changements de données, le coût de maintenance d’un modèle auto-entraîné peut être supérieur à l’utilisation directe d’une API de grand modèle. (Source: Reddit r/MachineLearning)

La définition de l’Agent IA suscite l’attention : Des cabinets de conseil comme McKinsey commencent à définir et à discuter du concept d’Agent IA, reflétant l’importance croissante des Agents IA en tant qu’entités intelligentes capables de percevoir, décider et agir de manière autonome pour atteindre des objectifs, dans les domaines commercial et technologique. Comprendre la définition, les capacités et les scénarios d’application des Agents IA devient un point d’attention pour l’industrie. (Source: Ronald_vanLoon)

💼 Affaires
Décryptage de la stratégie IA d’Alibaba : l’AGI au cœur, réinvestissement massif dans l’infrastructure pour accélérer la transformation : L’analyse indique que bien qu’Alibaba n’ait pas officiellement publié de stratégie IA, ses actions révèlent déjà une vision claire : poursuivre l’AGI comme objectif principal pour reprendre l’initiative dans la compétition. Un investissement de plus de 380 milliards de RMB est prévu au cours des trois prochaines années pour la construction d’infrastructures IA et cloud, visant principalement à répondre à la demande croissante d’inférence. La feuille de route stratégique comprend : la promotion des capacités d’Agent IA via DingTalk ; l’utilisation de la série de modèles open source Qwen pour stimuler la croissance d’Alibaba Cloud ; le développement du modèle MaaS pour l’API Tongyi. Parallèlement, Alibaba utilisera l’IA pour transformer en profondeur ses activités existantes, comme l’amélioration de l’expérience utilisateur sur Taobao, la transformation de Quark en une application IA phare (recherche + Agent), et l’exploration des applications IA de Gaode Map dans les services de la vie quotidienne. Alibaba pourrait également accélérer son déploiement IA par le biais d’investissements et d’acquisitions. (Source: 解秘阿里 AI 战略:从未发布,但已开始狂奔)
Nouvelles tendances sur le marché des talents IA : priorité à la pratique plutôt qu’aux diplômes, les compétences polyvalentes sont prisées : Basé sur l’analyse de près de 3000 postes IA à haut salaire dans les principales villes chinoises, le rapport révèle trois grandes tendances dans la demande de talents IA : 1) Forte demande d’ingénieurs en algorithmes avec des salaires attractifs, le secteur automobile devenant le principal recruteur ; 2) Les entreprises (y compris des sociétés phares comme DeepSeek) réduisent progressivement les exigences strictes en matière de diplômes, accordant plus d’importance aux compétences pratiques en ingénierie et à l’expérience dans la résolution de problèmes complexes ; 3) Demande croissante de talents polyvalents, par exemple, les chefs de produit IA doivent comprendre à la fois les utilisateurs, les modèles et l’ingénierie des prompts, car l’IA assume de plus en plus de tâches spécialisées, nécessitant une intégration et une supervision humaines à un niveau supérieur. (Source: 从近3000个招聘数据里,我找到了挖掘AI人才的三条铁律)
UBTECH enregistre des pertes continues, les défis de la commercialisation des robots humanoïdes sont importants : Le rapport financier 2024 de la société de robots humanoïdes UBTECH montre que malgré une augmentation de 23,7% du chiffre d’affaires à 1,3 milliard de yuans, elle a tout de même enregistré une perte de 1,16 milliard de yuans. La commercialisation de son activité principale de robots humanoïdes progresse lentement, avec seulement 10 unités livrées sur l’année, à un prix unitaire atteignant 3,5 millions de yuans, bien au-delà des attentes du marché et des concurrents (comme le G1 de Yushu Technology vendu à seulement 99 000 yuans). De plus, les rumeurs de problèmes de trésorerie d’une autre entreprise leader du secteur, Dataro, soulèvent des doutes sur la viabilité commerciale de l’industrie des robots humanoïdes, confirmant le point de vue prudent exprimé précédemment par l’investisseur Zhu Xiaohu. Les coûts élevés, les scénarios d’application limités et la fiabilité/sécurité sont actuellement les principaux obstacles à la commercialisation à grande échelle des robots humanoïdes. (Source: 优必选一年亏损近12亿 朱啸虎这下更有话说了)

L’IA stimule la croissance dans les secteurs des télécommunications, de la haute technologie et des médias : La discussion souligne que l’intelligence artificielle (y compris l’IA générative) devient un moteur clé de la croissance dans les secteurs des télécommunications, de la haute technologie et des médias. La technologie IA est largement utilisée pour améliorer l’expérience client, optimiser les opérations réseau, automatiser la création de contenu, accroître l’efficacité opérationnelle et développer des services innovants, aidant les entreprises de ces secteurs à acquérir un avantage concurrentiel sur des marchés en évolution rapide. (Source: Ronald_vanLoon)
Hugging Face acquiert la société de robotique open source Pollen Robotics : La célèbre plateforme de modèles et d’outils IA Hugging Face a acquis Pollen Robotics, une startup connue pour son robot humanoïde open source Reachy. Cette acquisition montre l’intention de Hugging Face d’étendre son modèle open source réussi au domaine de la robotique IA, dans le but de promouvoir la collaboration et l’innovation dans ce secteur grâce à des solutions matérielles et logicielles ouvertes, accélérant ainsi le processus de démocratisation de la technologie robotique. (Source: huggingface, huggingface, huggingface, huggingface)

🌟 Communauté
L’ère de l’IA pourrait être plus favorable au développement des diplômés en sciences humaines et sociales : Lynn Duan, fondatrice de la communauté AI+ de la Silicon Valley, estime qu’avec les outils d’IA (comme Cursor) abaissant la barrière d’entrée à la programmation, l’importance des compétences en ingénierie diminue relativement, tandis que les compétences en commercialisation, marketing, communication et autres domaines des sciences humaines et sociales deviennent plus cruciales. L’IA remplace certains postes techniques de premier niveau mais crée une demande de talents polyvalents capables de relier la technologie et le marché. Elle conseille aux diplômés d’envisager les startups pour une croissance rapide et de démontrer leurs capacités par des projets pratiques (comme le déploiement de modèles, le développement d’applications) plutôt que de se fier uniquement aux diplômes. Elle souligne également que les traits de caractère du fondateur (comme la conviction, la compréhension du secteur) sont plus importants qu’un pur bagage technique et voit d’un bon œil les opportunités d’entrepreneuriat IA dans le SaaS américain et le matériel intelligent chinois. (Source: AI反而是文科生的好时代|对话硅谷AI+创始人Lynn Duan)

Le “blocage” temporaire des IP chinoises par GitHub suscite des inquiétudes, les responsables parlent d’une erreur de manipulation : Récemment, certains utilisateurs chinois ont découvert qu’ils ne pouvaient pas accéder à GitHub sans être connectés, recevant un message indiquant que leur IP était restreinte, ce qui a suscité des inquiétudes au sein de la communauté quant à un éventuel “blocage”. Bien que GitHub ait rapidement répondu qu’il s’agissait d’une erreur de configuration qui avait été corrigée, l’incident a tout de même alimenté les discussions. Étant donné que GitHub a par le passé restreint l’accès à des régions comme l’Iran et la Russie conformément aux sanctions américaines, cet événement a été interprété par certains comme une “répétition” de mesures restrictives potentielles. L’article souligne l’importance de GitHub pour les développeurs chinois et l’écosystème open source (y compris de nombreux projets d’IA), ainsi que les impacts négatifs potentiels de telles restrictions, et liste Gitee, CODING et d’autres plateformes d’hébergement de code nationales comme alternatives. (Source: “Bug”还是“预演”?GitHub 突然“封禁”所有中国 IP,官方:只是“手滑”技术出错了)
Les performances et le service de Claude AI suscitent la controverse parmi les utilisateurs : Une discussion sur Reddit montre que certains utilisateurs expriment leur mécontentement à l’égard du modèle Claude d’Anthropic, mentionnant une baisse de performance, des modifications inutiles lors du codage, et une déception concernant les niveaux payants et les limites de débit. Certains développeurs connus ont même déclaré qu’ils se tournaient vers d’autres modèles (comme Gemini 2.5 Pro). Cependant, d’autres utilisateurs estiment que Claude (en particulier l’ancienne version Sonnet 3.5) conserve des avantages pour des tâches spécifiques (comme le codage), ou déclarent ne pas rencontrer fréquemment de limites de débit. Ce débat reflète les expériences divergentes des utilisateurs avec Claude, ainsi que les attentes élevées des utilisateurs en matière de performances et de services des modèles d’IA dans un contexte de concurrence intense. (Source: Reddit r/ClaudeAI)

L’échelle de la fonction Deep Research de Gemini fait débat : Un utilisateur partage son expérience avec la fonction Deep Research de Google Gemini Advanced, où l’IA a consulté près de 700 sites web pour répondre à une question et a généré un long rapport (par exemple, 37 pages). Cette échelle a impressionné l’utilisateur mais a également suscité des discussions sur la qualité de l’information. Les commentateurs se demandent si le traitement d’une telle quantité d’informations web peut garantir l’exactitude et la profondeur, ou s’il ne s’agit que d’une agrégation à plus grande échelle de résultats de recherche web potentiellement erronés. Cela reflète l’attention et l’examen de la communauté concernant les capacités de traitement de l’information (profondeur vs largeur) des outils de recherche IA. (Source: Reddit r/artificial)

Les capacités de programmation de Gemini 2.5 Pro reçoivent des éloges de la communauté : Plusieurs utilisateurs ont partagé dans la communauté leurs expériences positives avec Google Gemini 2.5 Pro pour la programmation, le jugeant très intelligent, capable de bien comprendre l’intention de l’utilisateur, et doté d’une capacité de traitement de contexte long de 1 million de tokens (suffisante pour analyser de grandes bases de code) tout en étant gratuit. Ses performances globales sont considérées comme supérieures à celles de concurrents comme Claude. Bien qu’il existe quelques petits défauts (comme halluciner occasionnellement des fonctions de bibliothèque inexistantes), l’évaluation globale est très élevée. Il est considéré comme l’un des modèles de codage les plus populaires actuellement, et l’attente est grande pour les modèles potentiellement plus puissants que Google pourrait lancer à l’avenir (comme Dragontail). (Source: Reddit r/ArtificialInteligence)
Les petits modèles open source évoluent rapidement, la perception des utilisateurs doit être mise à jour : Une discussion communautaire s’émerveille des progrès rapides des LLM open source. Elle souligne que des modèles comme QwQ-32B, Gemma-3-27B, qui semblent bons aujourd’hui, auraient été révolutionnaires il y a un an ou deux (lorsque GPT-4 venait de sortir). Cela rappelle à tous de ne pas négliger les capacités réelles des petits modèles open source actuels, qui ont atteint un niveau assez élevé. Les commentaires reconnaissent également que ces modèles présentent encore des lacunes par rapport aux modèles propriétaires de pointe (comme la stabilité, la vitesse, le traitement du contexte), mais soulignent leur vitesse de progression et leur potentiel, estimant que les futures percées pourraient provenir d’innovations architecturales plutôt que d’une simple accumulation de paramètres. (Source: Reddit r/LocalLLaMA)
Un membre de la communauté offre une puissance de calcul A100 gratuite pour soutenir des projets IA : Un utilisateur possédant 4 GPU Nvidia A100 a posté sur Reddit, offrant gratuitement de la puissance de calcul (environ 100 heures A100) pour des projets d’amateurs d’IA innovants, visant un impact positif et limités par les ressources de calcul. Cette initiative a reçu un accueil positif, plusieurs chercheurs et développeurs proposant des plans de projet spécifiques couvrant l’entraînement de nouvelles architectures de modèles, l’explicabilité des modèles, l’apprentissage modulaire, les applications d’interaction homme-machine, etc., reflétant le besoin de ressources de calcul de la communauté de recherche en IA ainsi que l’esprit d’entraide et de partage. (Source: Reddit r/deeplearning)
Le problème des limites de débit de Claude AI suscite un débat communautaire : Les plaintes concernant le déclenchement fréquent des limites de débit lors de l’utilisation du modèle Claude AI (par exemple, après seulement 5 messages) ont suscité un débat au sein de la communauté. Certains utilisateurs remettent fortement en question ces plaintes, les considérant comme exagérées ou résultant d’une mauvaise utilisation par l’utilisateur (comme le téléchargement systématique de contextes très longs), et demandent des preuves. Cependant, d’autres utilisateurs témoignent avoir effectivement atteint fréquemment les limites lors de tâches intensives (comme l’édition de code volumineux), ce qui affecte leur flux de travail. La discussion reflète la grande variabilité de l’expérience des utilisateurs concernant les limites de débit, potentiellement liée aux méthodes d’utilisation spécifiques et à la complexité des tâches, tout en montrant la sensibilité des utilisateurs aux restrictions des services payants. (Source: Reddit r/ClaudeAI)
💡 Autres
Conférence sur l’écosystème AIGC et des agents intelligents (Shanghai) en juin : La deuxième conférence sur l’écosystème AIGC et des agents d’intelligence artificielle se tiendra le 12 juin 2025 à Shanghai, sur le thème “Chaîner intelligemment toutes choses · Coexister sans frontières”. La conférence se concentre sur l’innovation collaborative et l’intégration écologique de l’IA générative (AIGC) et des agents intelligents (AI Agent). Le contenu couvrira l’infrastructure IA, les grands modèles de langage, le marketing AIGC et les applications sectorielles (médias, e-commerce, industrie, santé, etc.), la technologie multimodale, les cadres de décision autonomes, etc. L’objectif est de promouvoir la mise à niveau de l’IA d’un outil ponctuel vers une collaboration écosystémique, en connectant les fournisseurs de technologie, les demandeurs, les capitaux et les décideurs politiques. (Source: 6月上海|“智链万物”上海峰会:AIGC+智能体生态融合)

La conférence AI Partner de 36Kr se concentre sur la Super APP : 36Kr organisera la conférence “La Super APP est là · Conférence AI Partner 2025” le 18 avril 2025 à l’Espace Modèle de Shanghai. La conférence vise à explorer comment les applications IA remodèlent le monde des affaires et donnent naissance à des “super applications” disruptives. Elle réunira des dirigeants d’entreprises telles qu’AMD, Baidu, 360, Qualcomm, ainsi que des investisseurs, pour discuter de sujets brûlants tels que l’IA industrielle, la puissance de calcul IA, la recherche IA, l’éducation IA, etc., et annoncera des cas d’innovation d’applications natives IA ainsi que les prix de l’innovation AI Partner. Un salon sur la démocratisation de l’IA et un séminaire à huis clos sur l’exportation de l’IA seront également organisés en parallèle. (Source: Super App来了!看AI应用正如何「改写」商业世界?|2025 AI Partner大会核心看点)

Horizon Robotics recrute des stagiaires en algorithmes de reconstruction/génération 3D : L’équipe d’intelligence incarnée d’Horizon Robotics recrute des stagiaires en algorithmes spécialisés dans la reconstruction/génération 3D à Shanghai et Pékin. Le poste impliquera la conception et le développement d’algorithmes Real2Sim, utilisant des technologies telles que le Gaussian Splatting 3D, la reconstruction feed-forward, la génération 3D/vidéo pour réduire les coûts d’acquisition de données robotiques et optimiser les performances du simulateur. Exige un diplôme de Master ou supérieur, avec une expérience et des compétences pertinentes. Offre des opportunités de titularisation, des ressources GPU et un encadrement professionnel. (Source: 上海/北京内推 | 地平线机器人具身智能团队招聘3D重建/生成方向算法实习生)
OceanBase organise son premier concours AI Hackathon : Le fournisseur de bases de données OceanBase, en collaboration avec Ant Open Source, Machine之心 et d’autres, organise son premier AI Hackathon sur le thème “DB+AI”, avec une cagnotte de 100 000 yuans. Le concours encourage les développeurs à explorer la combinaison d’OceanBase et des technologies IA, dans des directions telles que l’utilisation d’OceanBase comme base de données pour les applications IA, ou la construction d’applications IA (comme des systèmes de questions-réponses, de diagnostic) au sein de l’écosystème OceanBase (en combinaison avec CAMEL AI, FastGPT, etc.). Les inscriptions sont ouvertes du 10 avril au 7 mai, pour les individus et les équipes. (Source: 10万奖金×认知升级!OceanBase首届AI黑客松广发英雄帖,你敢来么?)
Meituan Hôtellerie & Voyages recrute des ingénieurs en algorithmes de grands modèles L7-L8 : L’équipe d’algorithmes d’approvisionnement de Meituan Hôtellerie & Voyages recrute à Pékin des ingénieurs en algorithmes de grands modèles de niveau L7-L8 (recrutement externe). Les responsabilités incluent l’utilisation des technologies NLP et des grands modèles pour construire un système de compréhension de l’offre hôtelière et de voyage (étiquettes, points chauds, analyse de similarité), l’optimisation du matériel d’affichage des produits (titres, images et textes), la construction de combinaisons de forfaits vacances, et l’exploration de l’application des technologies de pointe des grands modèles aux algorithmes côté offre. Exige un diplôme de Master ou supérieur, plus de 2 ans d’expérience, et de solides compétences en algorithmes et en programmation. (Source: 北京内推 | 美团酒旅供给算法团队招聘L7-L8大模型算法工程师)
Quantum Bit recrute des rédacteurs/auteurs dans le domaine de l’IA : Le média technologique IA Quantum Bit recrute des rédacteurs/auteurs à temps plein, lieu de travail à Zhongguancun, Pékin, ouvert aux recrutements externes et aux jeunes diplômés, avec des opportunités de stage menant à l’embauche. Les postes à pourvoir concernent les grands modèles d’IA, les robots d’intelligence incarnée, le matériel terminal ainsi que la rédaction pour les nouveaux médias IA (Weibo/Xiaohongshu). Exige une passion pour le domaine de l’IA, de bonnes compétences rédactionnelles et de recherche d’informations. Les atouts incluent la familiarité avec les outils IA, la capacité d’interpréter des articles de recherche, des compétences en programmation, etc. Offre un salaire et des avantages compétitifs ainsi que des opportunités de développement professionnel. (Source: 量子位招聘 | DeepSeek帮我们改的招聘启事)
Le lauréat du prix Turing LeCun parle du développement de l’IA : l’intelligence humaine n’est pas générale, la prochaine génération d’IA pourrait ne pas être générative : Lors d’une interview en podcast, Yann LeCun a estimé que la poursuite actuelle de l’AGI (Intelligence Artificielle Générale) repose sur une mauvaise compréhension, car l’intelligence humaine elle-même est hautement spécialisée et non générale. Il prédit que la prochaine percée en IA pourrait être basée sur des modèles non génératifs, comme son architecture JEPA proposée, l’accent étant mis sur la capacité de l’IA à comprendre le monde physique, à posséder des capacités de raisonnement et de planification (modèle du monde), plutôt que de simplement traiter le langage. Il estime que les LLM actuels manquent de véritables capacités de raisonnement. LeCun a également souligné l’importance de l’open source (comme LLaMA de Meta) pour faire progresser le développement de l’IA et considère les appareils tels que les lunettes intelligentes comme une direction importante pour l’application concrète de la technologie IA. (Source: 图灵奖得主LeCun:人类智能不是通用智能,下一代AI可能基于非生成式)
Sommet chinois de l’industrie AIGC à venir (16 avril, Pékin) : Le troisième sommet chinois de l’industrie AIGC se tiendra le 16 avril à Pékin. Le sommet réunira plus de 20 leaders de l’industrie issus d’entreprises et d’institutions telles que Baidu, Huawei, AWS, Microsoft Research Asia, Mianbi Intelligence, Shengshu Technology, Fenbi, NetEase Youdao, Quwan Technology, Qingsong Health, pour discuter des dernières avancées de la technologie IA, de son application dans divers secteurs, de l’infrastructure de calcul, de la sécurité et du contrôle, et d’autres sujets clés. Le sommet vise à montrer comment l’IA peut dynamiser la modernisation industrielle et annoncera des prix pertinents ainsi que la “Carte panoramique des applications AIGC en Chine”. (Source: 倒计时2天!20余位行业大佬共话AI,中国AIGC产业峰会最全攻略在此)
Exploration de solutions pour exécuter des grands modèles de plusieurs centaines de milliards de paramètres sur des cartes graphiques à faible coût : L’article explore une solution de machine IA tout-en-un à coût contrôlé (niveau 100 000 yuans) utilisant des cartes graphiques Intel Arc™ (comme A770) et des processeurs Xeon® W. Cette solution, grâce à une synergie logicielle et matérielle (IPEX-LLM, OpenVINO™, oneAPI), permet d’exécuter sur une seule machine des grands modèles tels que QwQ-32B (vitesse jusqu’à 32 tokens/s) et même DeepSeek R1 671B (avec optimisation FlashMoE, vitesse proche de 10 tokens/s). Cela offre aux entreprises une option à haut rapport qualité-prix pour déployer de grands modèles localement ou en périphérie, répondant aux besoins d’inférence hors ligne, de sécurité des données, etc. Intel a également lancé la plateforme OPEA, collaborant avec des partenaires de l’écosystème pour promouvoir la standardisation et la popularisation des applications IA d’entreprise. (Source: 榨干3000元显卡,跑通千亿级大模型的秘方来了)
Un robot chirurgical démontre une manipulation de haute précision : Une vidéo montre un robot chirurgical capable de séparer avec précision la coquille d’un œuf de caille cru de sa membrane interne, illustrant le niveau avancé des robots modernes en matière de manipulation fine et de contrôle. (Source: Ronald_vanLoon)
Aperçu des progrès de la technologie de lithographie des semi-conducteurs : Renvoi vers un article sur le contenu de la conférence SPIE Advanced Lithography + Patterning, discutant des dernières avancées dans les technologies de fabrication de puces de nouvelle génération, y compris High-NA EUV, le coût de l’EUV, le façonnage de motifs, les nouvelles résines photosensibles (oxydes métalliques, sèches) et Hyper-NA. Ces technologies sont cruciales pour soutenir le développement futur des puces IA. (Source: dylan522p)
Démonstration des compétences de précision d’un robot à roues : Une vidéo montre les compétences de mouvement ou de manipulation de haute précision d’un robot à roues, impliquant potentiellement des technologies d’IA et d’apprentissage automatique pour le contrôle et la perception. (Source: Ronald_vanLoon)